Zstd压缩算法介绍
文章目录
介绍
我们称 Zstandard 或 Zstd 是一种快速的无损压缩算法,是针对 zlib 级别的实时压缩方案,以及更好的压缩比。它由一个非常快的熵阶段,由 Huff0 和 FSE 库提供。这个项目是作为开源的 BSD 许可收费的库,以及一个生成和解码 .zst 格式。
性能测试对比
| Compressor name | Ratio | Compression | Decompress |
|---|---|---|---|
| zstd 1.4.4 -1 | 2.884 | 520 MB/s | 1600 MB/s |
| zlib 1.2.11 -1 | 2.743 | 110 MB/s | 440 MB/s |
| brotli 1.0.7 -0 | 2.701 | 430 MB/s | 470 MB/s |
| quicklz 1.5.0 -1 | 2.238 | 600 MB/s | 800 MB/s |
| lzo1x 2.09 -1 | 2.106 | 680 MB/s | 950 MB/s |
| lz4 1.8.3 | 2.101 | 800 MB/s | 4220 MB/s |
| snappy 1.1.4 | 2.073 | 580 MB/s | 2020 MB/s |
| lzf 3.6 -1 | 2.077 | 440 MB/s | 930 MB/s |
Zstd 还可以压缩速度为代价提供更强的压缩比,Speed vs Rtrade 可以通过小增量进行配置。在所有设置中,解压速度保持不变,并在所有 LZ压缩算法( 比如 zlib 或者lzma) 共享的属性中保持不变。
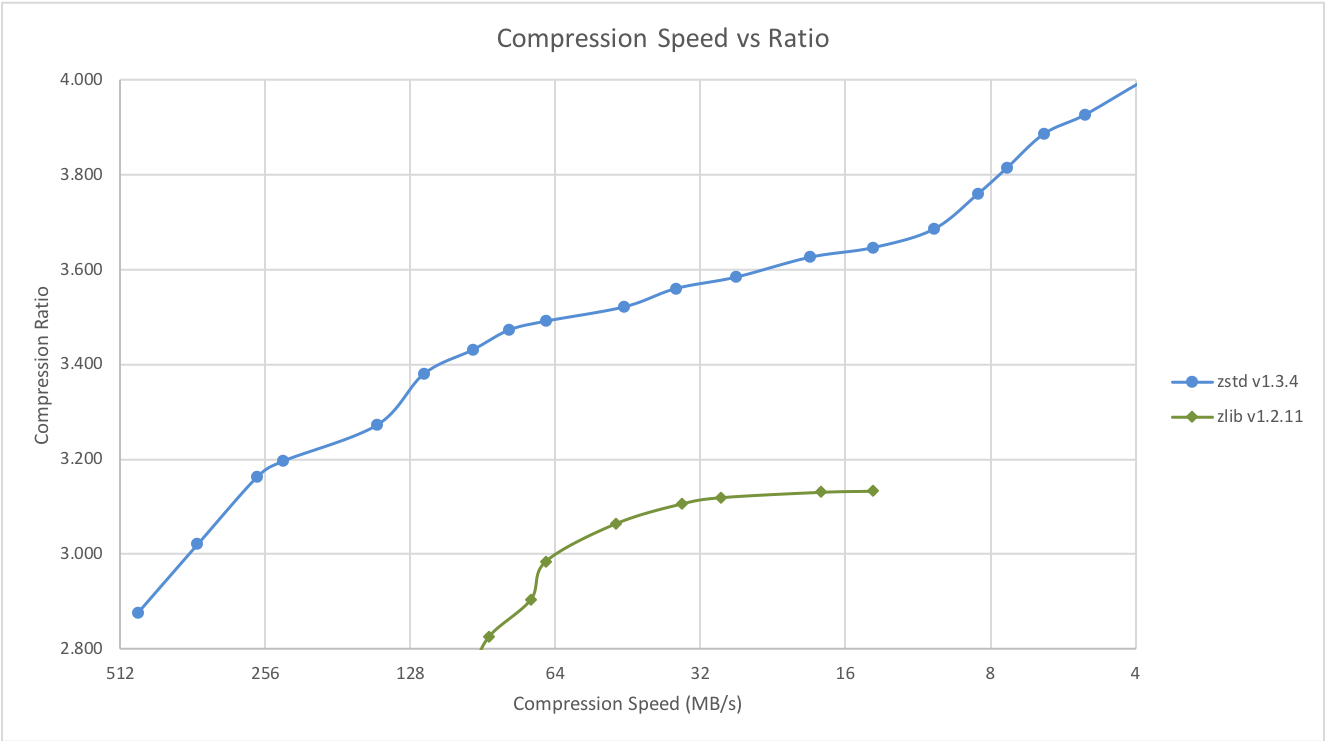
以前的压缩方式,都是适用于典型文件和二进制的压缩方案( MB/GB)的情况。然而,要压缩的数据量越小,压缩就越困难。这是所有压缩算法都存在的问题,原因是压缩算法从过去的数据中学习如何压缩未来的数据。但是在一个新的数据集的开始,没有“过去”可以参考。
为了解决这种情况,Zstd 提供了一种新的训练模式,可以使用这种模式对所选数据类型的算法进行调优。 训练 Zstandard 是通过提供一些样本(每个样本一个文件)来实现的,训练的结果存储在称为“字典”的文件中,该文件必须在压缩和解压缩之前加载。使用此字典,可以在小数据上实现的压缩率大大提高。
以下示例,使用由 github 公共 API 创建的 github 用户示例集。它由大约 10K 条记录组成,每条记录 1KB 左右。
小数据压缩的案例
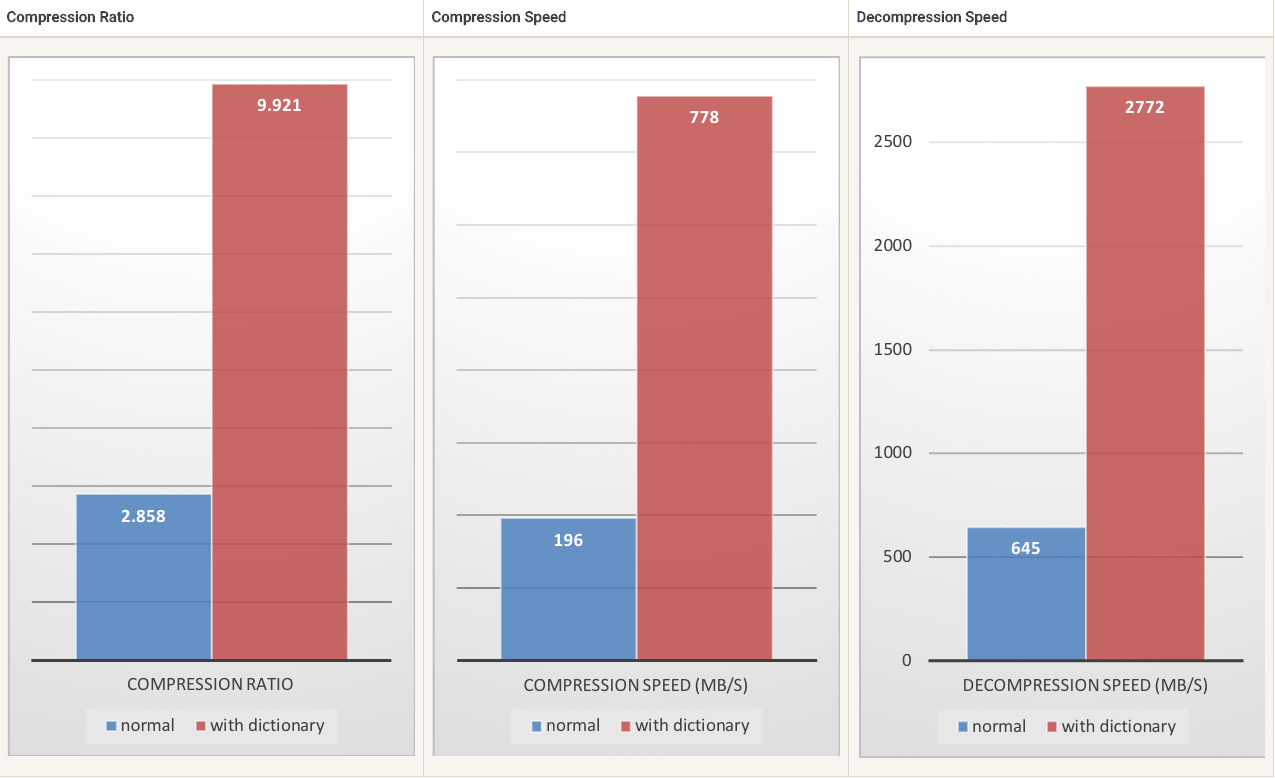
如果在一组小的数据样本中存在某种相关性,那么训练就是有效的。一个字典的数据越具体,它的效率就越高(没有通用字典)。因此,为每种类型的数据部署一个字典将带来最大的好处。字典增益在前几个 KB 中最有效。然后,压缩算法将逐步使用先前解码的内容,以更好地压缩文件的其余部分。
字典压缩使用示例
|
|
二进制工具
主要介绍 zstd 工具的安装和全部的参数命令
安装方式
|
|
参数
|
|
使用方式 :
|
|
参数选项 :
|
|
高级选项 :
|
|
字典生成器 :
|
|
性能测试参数 :
|
|
使用技巧
主要介绍一些关于 zstd 工具的使用示例和参数解释
简单使用
|
|
高级用法
|
|
日志文件测试
大文件压缩
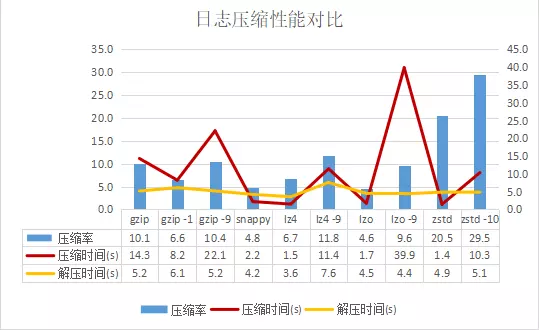
从上面可以看出:
- 解压时间各种算法差别不大
- 压缩时间(越小越好):lz4, zstd < lzo < snappy « gzip-1 < lz4-9 < gzip < gzip-9 < lzo-9
- 压缩率(越大越好):zstd-10 > zstd » lz4-9 > gzip-9 > gzip, lzo-9 » lz4, gzip-1 > snappy, lzo
zstd无论从处理时间还是压缩率来看都占优。snappy, lz4, lzo的压缩率较低,但压缩速度都很快,而zstd甚至比这些算法更快。Gzip的压缩率比lz4等高不少,而zstd的压缩率比gzip还提升一倍。
如果从上面的比较还不是特别直观的话,我们再引入一个创造性的指标(从网上其他压缩算法对比没有见过使用这项指标):
压缩效率 = 权重系数 * 压缩去掉的冗余数据大小 / 压缩时间
代表单位处理时间可以压缩去掉多少冗余数据。其中权重系数用来指定压缩率和压缩速度哪个更重要,这里我们认为在我们的使用场景里两者同样重要,取系数为1。
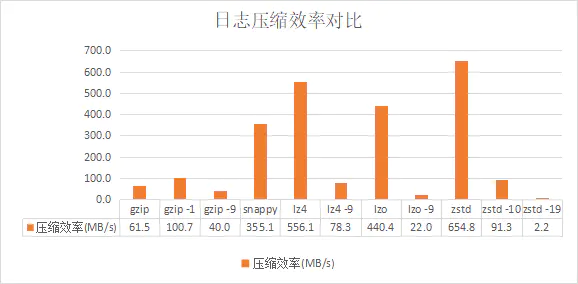
从这里我们可以明显看出,zstd > lz4 > lzo > snappy » 其他。
小数据量压缩
对1000行、大小约为1MB的文件进行压缩测试,各种算法的压缩率跟1GB大文件的压缩率几乎一样。
下面再对更小的数据量——10行日志数据的压缩率进行对比。虽然我们的使用场景里没有对小数据量的压缩处理,但还是比较好奇zstd字典模式的效果。
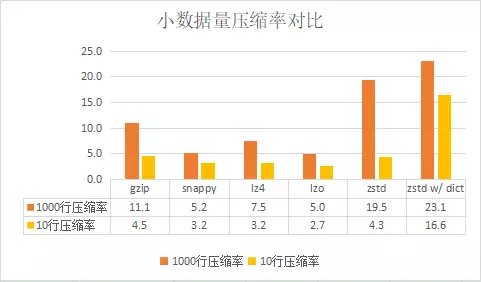
其中最后一组数据为zstd使用10000行日志进行训练生成字典文件,并利用字典文件辅助压缩测试数据。
可以看出来,除了zstd字典模式外,各种压缩算法在处理更小的数据量时压缩率都下降很多。而zstd字典模式对压缩率带来帮助非常明显,与gzip对比,压缩率从1000行时相差1倍,到10行时变为了相差接近3倍。
结论
- 对大数据量的文本压缩场景,zstd是综合考虑压缩率和压缩性能最优的选择,其次是lz4。
- 对小数据量的压缩场景,如果能使用zstd的字典方式,压缩效果更为突出。
kafka测试
Apache Kafka 2.1.0正式支持ZStandard —— ZStandard是Facebook开源的压缩算法,旨在提供超高的压缩比(compression ratio),具体细节参见https://facebook.github.io/zstd/。本文对Kafka支持的这几种压缩算法(GZIP、Snappy、LZ4、ZStandard)做了一下基本的性能测试,希望能够以不同维度去衡量不同压缩算法在Kafka>中的表现。
测试producer端
使用kafka-producer-perf-test.sh脚本依次为4个topic发送60,000,000条消息,每条消息1KB大小,去计算各种压缩算法的TPS以及其他指标。结果如下:
1、客户端CPU使用率统计图
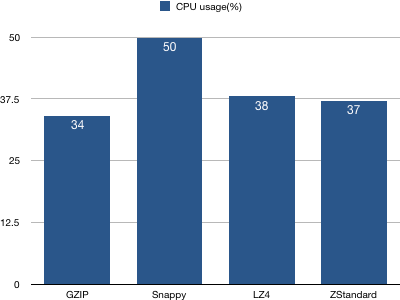
结论:Snappy算法使用的CPU资源最多,其他3种压缩算法相差不多。
2、Broker服务器带宽统计
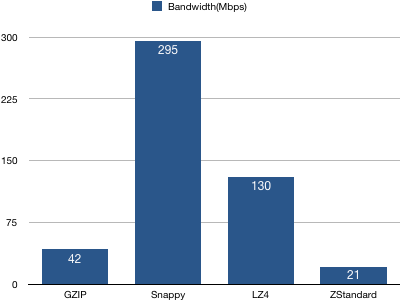
结论:Snappy算法占用的带宽最多且遥遥领先,LZ4次之,而新引入的ZStandard使用的带宽最少。一个可能的原因是ZStandard有较高的压缩比,减少了总体的网络IO传输量。
3、producer吞吐量(TPS)统计
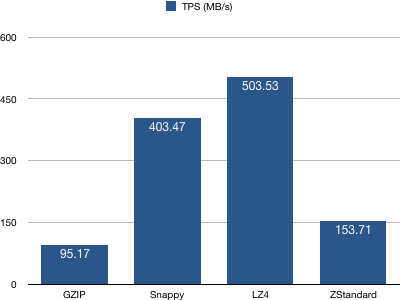
结论:配置LZ4的producer TPS最高——LZ4算法有着最快的压缩时间(至少是top3),故整体TPS最高也不令人惊讶。Snappy次之,ZStandard位居第三位。说明ZStandard不是一个很快的压缩算法。
4、producer延时分布统计
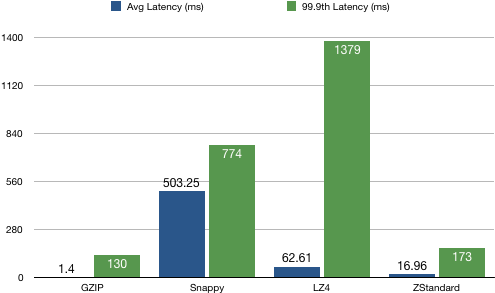
结论:GZIP算法的延时最低,ZStandard次之。有意思的是,Snappy算法的平均值和99.9分位均值比较接近,而LZ4算法方差较大(当然也可能因为异常点导致)。总之从延时角度来看GZIP最优。
5、磁盘占用统计
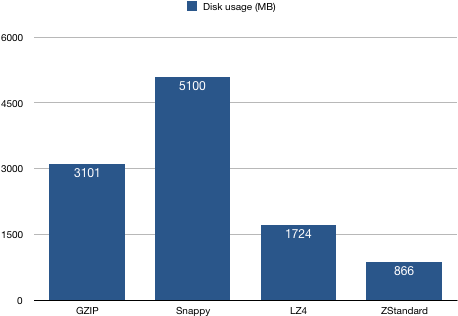
结论:配置ZStandard算法producer生产的消息有着最高的压缩比,这符合ZStandard算法官方的定位:“Zstd can trade compression speed for stronger compression ratios.” —— 即该算法牺牲一部分压缩速度去换取更高的压缩比。
测试consumer端
使用kafka-consumer-perf-test.sh脚本依次消费4个topic,每个topic消费60,000,000条消息,去计算consumer端解压缩性能以及其他核心指标,结果如下:
1、客户端CPU使用率统计
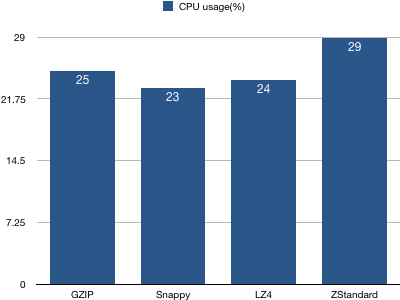
结论:基本上4种压缩算法的客户端CPU使用率基本持平,ZStandard算法略高一些
2、Broker端带宽占用统计
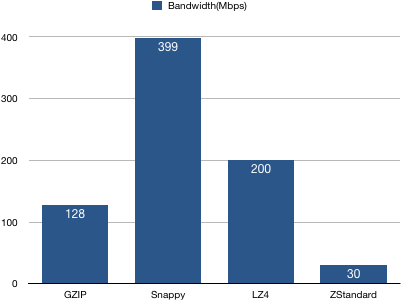
结论:Snappy占用带宽最多,ZStandard最少——同理,这是因为ZStandard有最高的压缩比,极大地降低了网络IO传输量。
3、consumer吞吐量(TPS)统计
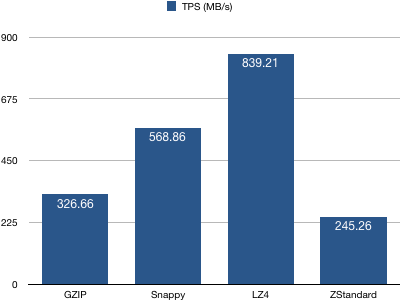
结论:配置LZ4算法的consumer有着最高的TPS,而ZStandard算法最低。
总结
相比于其他压缩算法,ZStandard有着最高的压缩比,相同的消息量占用最少的磁盘容量,因此带宽的占用也是比较少的,但是在TPS方面的表现并不抢眼,因此对于那些在乎磁盘和带宽资源的用户而言,配置ZStandard算法似乎是个不错的选择,但如果追求应用TPS,就目前的Kafka而言LZ4依然是最好的选择。
参考
文章作者 Forz
上次更新 2021-04-28