SRE自适应熔断算法实现
文章目录
前言
断路器(Circuit Breakers): 为了限制操作的持续时间,我们可以使用超时,超时可以防止挂起操作并保证系统可以响应。因为我们处于高度动态的环境中,几乎不可能确定在每种情况下都能正常工作的准确的时间限制。断路器以现实世界的电子元件命名,因为它们的行为是都是相同的。断路器在分布式系统中非常有用,因为重复的故障可能会导致雪球效应,并使整个系统崩溃。
- 服务依赖的资源出现大量错误。
- 某个用户超过资源配额时,后端任务会快速拒绝请求,返回“配额不足”的错误,但是拒绝回复仍然会消耗一定资源。有可能后端忙着不停发送拒绝请求,导致过载。
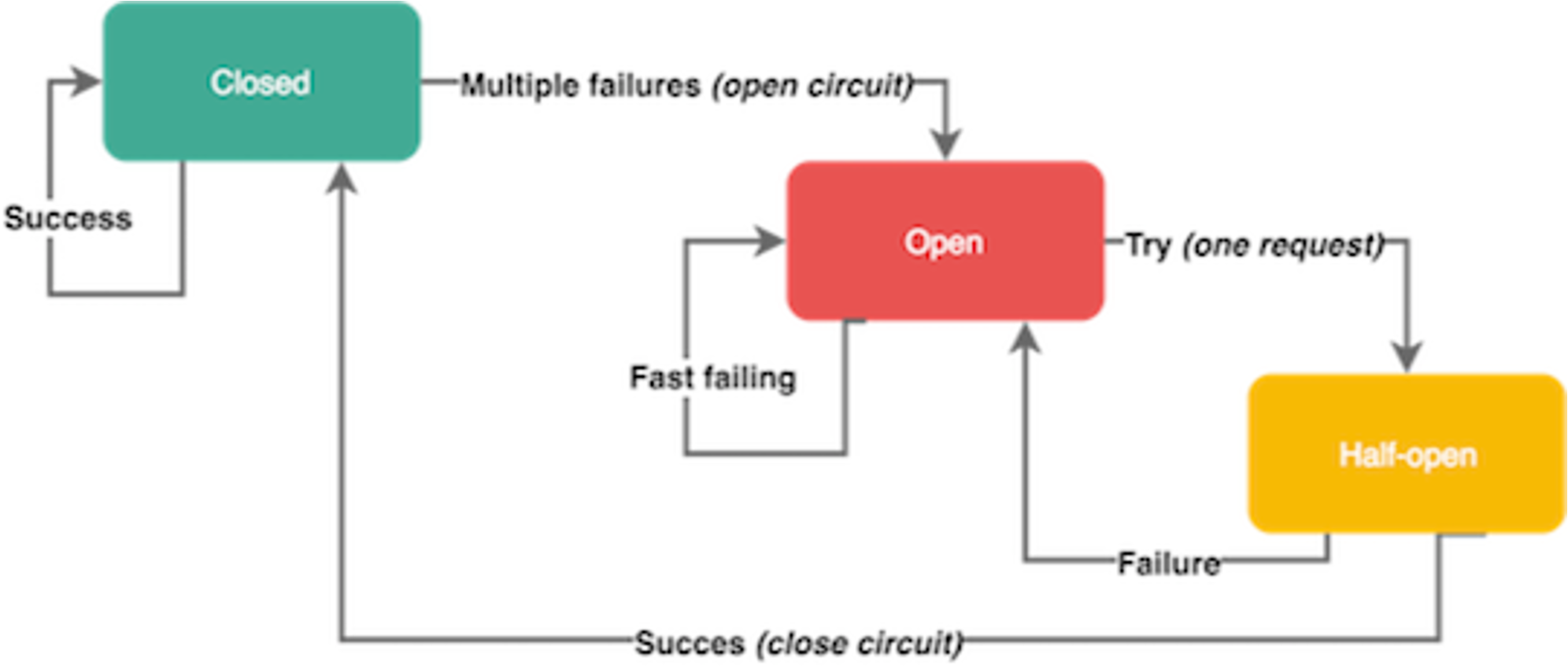
这类熔断算法的算法核心是:当请求失败比率达到一定阈值之后,熔断器开启,并休眠一段时间(由配置决定),这段休眠期过后,熔断器将处于半开状态,在此状态下将试探性的放过一部分流量,如果这部分流量调用成功后,再次将熔断器关闭,否则熔断器继续保持开启并进入下一轮休眠周期。
但这个熔断算法有一个问题,过于一刀切。是否可以做到在熔断器开启状态下(但是后端未 Shutdown)仍然可以放行少部分流量呢?当然,这里有个前提,需要看后端此时还能够接受多少流量。下一步我们来看看 Google 的策略实现。
算法原理
We implemented client-side throttling through a technique we call adaptive throttling:该算法称为(客户端)自适应限流。
现实中,过载是极易发生的异常状态: 一方面,当客户端检测到最近的请求出现错误都是 “out of quota(配额不足)”,说明可能这个客户端超过了资源配额,后端任务会快速拒绝请求,返回 “配额不足” 的错误,有可能后端忙着不停发送拒绝请求,导致过载; 另一方面,当依赖的资源出现大量错误,处于对下游的保护,也需要在客户端本地进行限流操作
解决的办法就是客户端自行限制请求速度,限制生成请求的数量, 超过这个数量的请求直接在本地回复失败,而不会真是发送到服务端
该算法统计的指标依赖如下两种,每个客户端记录过去两分钟内的以下信息(一般代码中以滑动窗口实现):
-
requests(客户端尝试的请求数): The number of requests attempted by the application layer(at the client, on top of the adaptive throttling system)
-
accepts 后端接受的请求数(客户端发送的请求数-后端拒绝的请求数量): The number of requests accepted by the backend
该算法的通用描述如下:
- 在通常情况下(无错误发生时) requests==accepts
- 当后端出现异常情况时,accepts 的数量会逐渐小于 requests
- 当后端持续异常时,客户端可以继续发送请求直到 requests=K×accepts,一旦超过这个值,客户端就启动自适应限流机制,新产生的请求在本地会以 p 概率(下面描述的 Client request rejection probability 定义)被拒绝
- 当客户端主动丢弃请求时,requests 值会一直增大,在某个时间点会超过 K×accepts,使概率 p 计算出来的值大于 0,此时客户端会以此概率对请求做主动丢弃。
- 当后端逐渐恢复时,accepts 增加,(同时 requests 值也会增加,但是由于 K 的关系,K×accepts 的放大倍数更快),使得
(requests−K×accepts)/(requests+1)变为负数,从而概率 p==0,客户端自适应限流结束
客户端请求拒绝的概率(Client request rejection probability)基于如下公式计算(其中 K 为倍率 - multiplier,常用的值为 2):

该公式的解释如下: 当 requests−K×accepts>=0 时,概率 p==0,客户端不会主动丢弃请求;反之,则概率 p,会随着 accepts 值的变小而增加,即成功接受的请求数越少,本地丢弃请求的概率就越高。通俗点说,Client 可以发送请求直到 requests=K×accepts,一旦超过限制,按照概率进行截流。
从 Google 的文档描述中,该算法在实际中使用效果极为良好,可以使整体上保持一个非常稳定的请求速率。对于后端而言,调整 K 值可以使得自适应限流算法适配不同的后端。关于 K 值的意义,原文描述如下:
- Reducing the multiplier will make adaptive throttling behave more aggressively
- Increasing the multiplier will make adaptive throttling behave less aggressively
翻译上面两句话就是:
- 降低 K 值会使自适应限流算法更加激进(允许客户端在算法启动时拒绝更多本地请求)
- 增加 K 值会使自适应限流算法不再那么激进(允许服务端在算法启动时尝试接收更多的请求,与上面相反)
通过修改算法中的K(倍值),可以调节熔断器的敏感度,当降低该倍值会使自适应熔断算法更敏感,当增加该倍值会使得自适应熔断算法降低敏感度,举例来说,假设将调用方的请求上限从 requests = 2 * acceptst 调整为 requests = 1.1 * accepts 那么就意味着调用方每十个请求之中就有一个请求会触发熔断
全局变量
在 breaker.go) 中定义了 3 个全局变量:
|
|
熔断器: breaker
熔断器 breaker 的公共部分封装 在此,包含了熔断器的实现接口、熔断器组的定义,以及配置等等。
单个熔断器的接口定义如下:
- Allow 方法:每次 RPC、接口调用时均会调用,用来判断是否在熔断状态,根据结果(error)来决定后续动作
- MarkSuccess:每次 RPC 接口完成后,上报 Succ 状态(Kratos 中用 RollingPolicy 结构)
- MarkFailed:每次 RPC 接口完成后,上报 Failed 状态
MarkSuccess 和 MarkFailed 都是用来完成熔断器状态检测的计算依据,所以针对何种错误下进行标记十分重要。
|
|
熔断器的配置 Config:
|
|
newBreaker 方法,生成一个 breaker 对象,其中 newSRE 是创建对应的熔断器对象:
|
|
熔断器组: Group
熔断器组的定义如下,注意 brks 是一个 map,以不通的 key 标识不同的熔断器,比如在 gRPC 中,我们可能对每个不同的 RPC 方法创建熔断器,那么使用 RPC 的名字作为 key 就非常合适。此外 Breaker 是 interface{} 类型,这里会被实例化为用户实现的熔断器类型,比如 Kratos 中的 SREBreaker:
|
|
和 Group 有关的操作如下:
|
|
|
|
Reload 方法,重新(按照传入的 conf 配置)初始化熔断器组:
|
|
Go 方法:
|
|
此外,Breaker 还暴露了一个使用默认熔断器(全局变量)配置的 Go 方法,应用程序可以直接调用,就像 hystix-Go 的 Go 方法那样:
|
|
sreBreaker
SRE-Breaker 是 Breaker 的实现(的一种),按照 Breaker 定义的接口描述实现了具体的功能。
首先看下 sreBreaker 的定义,它使用了 metric.RollingCounter 作为统计结构,这也比较好理解,对于熔断器的判定指标,只需要关注一段时间内,正确响应和失败响应这两个指标的数量即可。另外,使用 rand.Rand 生成一个随机数,用来与 客户端请求拒绝的概率 做比较.
|
|
初始化 SRE
通过 newSRE 来创建一个 SreBreaker:
|
|
MarkSuccess & MarkFailed
在 SreBreaker 中简单封装了RollingCounter 的 Add 操作:
|
|
熔断判定: Allow
Allow 方法是 Breaker 判定的核心方法,在每次服务端执行真正的 RPC 请求前都需要调用 Allow 方法来进行熔断状态判定,Allow 方法的大致流程如下:
- 通过 summary() 方法拿到当前滑动窗口 metric.RollingCounter 中统计的(滑动窗口)成功量 success 和请求总量 total
- 根据 GoogleSRE 算法来进行熔断状态判定:
|
|
进行统计的方法 summary 实现如下,调用 RollingCounter.Reduce 方法,累加滑动窗口 Bucket 中的 bucket.Count 和 bucket.Points:
|
|
而 trueOnProba 方法就是产生一个 0-1 之间的浮点数,和 proba 进行比较,间接实现了比较大小得出某个概率的方法,其中 b.r.Float64() 的 r 为 *rand.Rand 类型,此方法返回一个取值范围在 [0.0, 1.0) 的伪随机 Float64 值。 当 proba 越大时,truth 为真的概率就越大。有个细节是 b.r.Float64() 是非线程安全的,所以加了 Lock:
|
|
一般使用
客户端场景可以使用熔断器来进行服务保护:
|
|
降级策略
配置自动熔断降级前,首先我们需要识别出可能出现不稳定的服务,然后判断其是否可降级。降级处理通常是快速失败,当然我们业可以自定义降级处理结果(Fallback),例如:尝试包装返回默认结果(兜底降级),返回上一次请求的缓存结果(时效性降级),包装返回处理失败的提示结果等。
对弱依赖和次要功能的降级通常是人工推送开关来完成的,而Sentinel的熔断降级主要是在“调用端”自动判断并执行的,Sentinel基于规则中配置的时间窗口内的平均响应时间、错误比例、错误数等统计指标来执行自动熔断降级。
举个例子:我们系统同时支持“余额支付”和“银行卡支付”,这两个功能对应的接口默认在相同应用的同一线程池中,任何一方出现RT抖动和大量超时都可能请求积压并导致线程池被耗尽。假设从业务角度来看“余额支付”的比例更高,保障的优先级也更高。那么我们可以在检查到 “银行卡支付”接口(依赖第三方,不稳定)中RT持续上升或者发生大量异常时对其执行“自动熔断降级”(前提是不能导致数据不一致等影响业务流程的问题),这样优先保证“余额支付”的功能可以继续正常使用。
通过降级回复来减少工作量,或者丢弃不重要的请求。而且需要了解哪些流量可以降级,并且有能力区分不同的请求。我们通常提供降低回复的质量来答复减少所需的计算量或者时间。我们自动降级通常需要考虑几个点:
- 确定具体采用哪个指标作为流量评估和优雅降级的决定性指标(如,CPU、延迟、队列长度、线程数量、错误等)。
- 当服务进入降级模式时,需要执行什么动作?
- 从远程缓存返回数据
- 从本地缓存返回数据
- 返回空回复
- 流量抛弃或者优雅降级应该在服务的哪一层实现?是否需要在整个服务的每一层都实现,还是可以选择某个高层面的关键节点来实现?
同时我们要考虑一下几点:
- 优雅降级不应该被经常触发 - 通常触发条件显示了容量规划的失误,或者是意外的负载。
- 演练,代码平时不会触发和使用,需要定期针对一小部分的流量进行演练,保证模式的正常。
- 应该足够简单。
降级方案
降级本质为: 提供有损服务。
- UI 模块化,非核心模块降级。
- BFF 层聚合 API,模块降级。
- 页面上一次缓存副本。
- 默认值、热门推荐等。
- 流量拦截 + 定期数据缓存(过期副本策略)。 处理策略
- 页面降级、延迟服务、写/读降级、缓存降级
- 抛异常、返回约定协议、Mock 数据、Fallback 处理
降级 - Case Study
- 客户端解析协议失败,app 奔溃。
- 客户端部分协议不兼容,导致页面失败。
- local cache 数据源缓存,发版失效 + 依赖接口故障,引起的白屏。
- local cache 在 remote cache缓存一份,双保险.
- 没有 playbook,导致的 MTTR 上升。
参考
文章作者 Forz
上次更新 2021-03-21