SQL语句:DML语句-数据查询
文章目录
介绍
数据查询是数据库的核心操作。SQL提供了 SELECT语句进行数据查询,该语句具有 灵活的使用方式和丰富的功能。其一般格式为
SELECT [ALL丨DISTINCT]〈目标列表达式>[,<目标列表达式>]…
FROM<表名或视图名> [,<表名或视图名>•••] |(<SELECT语句>>[AS]<别名>
[WHERE <条件表达式>]
[GROUP BY<列名 1> [HAVING <条件表达式>]]
[ORDER BY<列名 2> [ASC| DESC]];
整个SELECT语句的含义是,根据WHERE子句的条件表达式从FROM子句指定的基本表、视图或派生表中找出满足条件的元组,再按SELECT子句中的目标列表达式选出元组中的属性值形成结果表。
如果有GROUP BY子句,则将结果按<列名1>的值进行分组,该属性列值相等的元组为一个组。通常会在每组中作用聚集函数。如果GROUP BY子句带HAVING短语,则只有满足指定条件的组才予以输出。
如果有ORDER BY子句,则结果表还要按<列名2>的值的升序或降序排序。SELECT语句既可以完成简单的单表查询,也可以完成复杂的连接查询和嵌套查询。
单表查询
单表査询是指仅涉及一个表的查询。
1. 选择表中的若干列
选择表中的全部或部分列即关系代数的投影运算。
(1) 查询指定列
在很多情况下,用户只对表中的一部分属性列感兴趣,这时可以通过在SELECT子句 的< 目标列表达式> 中指定要查询的属性列。
例:查询全体学生的学号与姓名。
SELECT Sno,Sname
FROM Student;
该语句的执行过程可以是这样的:从Student表中取出一个元组,取出该元组在属性 Sno和Sname上的值,形成一个新的元组作为输出。对Student表中的所有元组做相同的 处理,最后形成一个结果关系作为输出。
<目标列表达式>中各个列的先后顺序可以与表中的顺序不一致。用户可以根据应用的 需要改变列的显示顺序。本例中先列出姓名,再列出学号和所在系。
(2) 查询全部列
将表中的所有属性列都选出来有两种方法,一种方法就是在SELECT关键字后列出所 有列名;如果列的显示顺序与其在基表中的顺序相同,也可以简单地将<目标列表达式>指 定为*。
例:查询全体学生的详细记录。
SELECT *
FROM Student;
(3) 查询经过计算的值
SELECT子句的<目标列表达式>不仅可以是表中的属性列,也可以是表达式。
例:查询全体学生的姓名及其出生年份。
SELECT Sname,2014-Sage /\*查询结果的第2列是一个算术表达式*/
FROM Student;
查询结果中第2列不是列名而是一个计算表达式,是用当时的年份(假设为2014年)减去学生的年龄。这样所得的即是学生的出生年份。
<目标列表达式 >不仅可以是算术表达式,还可以是字符串常量、函数等
例:查询全体学生的姓名、出生年份和所在的院系,要求用小写字母表示系名。
SELECT Sname,'Year of Birth: ',2014-Sage,LOWER(Sdept)
FROM Student;
结果为:

用户可以通过指定别名来改变查询结果的列标题,这对于含算术表达式、常量、函数 名的目标列表达式尤为有用。可以定义如下列别名:
SELECT Sname NAME,'Year of Birth:' BIRTH,2014-Sage BIRTHDAY,
LOWER(Sdept) DEPARTMENT
FROM Student;
结果为:

2. 选择表中的若干元组
(1) 消除取值重复的行
两个本来并不完全相同的元组在投影到指定的某些列上后,可能会变成相同的行。可以用DISTINCT消除它们。
例:查询选修了课程的学生学号。该查询结果里包含了许多重复的行。如想去掉结果表中的重复行,必须指定DISTINCT.
SELECT DISTINCT Sno
FROM SC;
如果没有指定DISTINCT关键词,则默认为ALL,即保留结果表中取值重复的行。
SELECT Sno
FROM SC;
等价于
SELECT ALL Sno
FROM SC;
(2) 查询满足条件的元组
查询满足指定条件的元组可以通过WHERE子句实现。

1. 比较大小
査询计算机科学系全体学生的名单。
SELECT Sname
FROM Student
WHERE Sdept='CS';
关系数据库管理系统执行该查询的一种可能过程是:对Student表进行全表扫描,取 出一个元组,检查该元组在Sdept列的值是否等于’CS’,如果相等,则取出Sname列的值 形成一个新的元组输出;否则跳过该元组,取下一个元组。重复该过程,直到处理完Student表的所有元组。
査询考试成绩不及格的学生的学号。
SELECT DISTINCT Sno
FROM SC
WHERE Grade<60;
这里使用了 DISTINCT短语,当一个学生有多门课程不及格,他的学号也只列一次。
2. 确定范围
谓词BETWEEN…AND…和NOT BETWEEN—AND…可以用来查找属性值在(或不在)指定范围内的元组,其中BETWEEN后是范围的下限(即低值),AND后是范围的上限(即高值)。
查询年龄在20〜23岁(包括20岁和23岁)之间的学生的姓名、系别和年龄。
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage BETWEEN 20 AND 23;
查询年龄不在20〜23岁之间的学生姓名、系别和年龄。
SELECT Sname’Sdept, Sage
FROM Student
WHERE Sage NOT BETWEEN 20 AND 23;
3. 确定集合
谓词IN可以用来查找属性值属于指定集合的元组。
例:査询计算机科学系(CS)、数学系(MA)和信息系(IS)学生的姓名和性别。
SELECT Sname,Ssex
FROM Student
WHERE Sdept IN ('CS','MA','IS');
与IN相对的谓词是NOT IN,用于查找属性值不属于指定集合的元组。
4. 字符匹配
谓词LIKE可以用来进行字符串的匹配。其一般语法格式如下:
[NOT] LIKE '<匹配串>'[ESCAPE'<换码字符>']
其含义是查找指定的属性列值与 < 匹配串 > 相匹配的元组。< 匹配串 >可以是一个完整的字符串,也可以含有通配符%和_
-
% (百分号)代表任意长度(长度可以为0)的字符串。
例如a%b表示以a开头,以b结尾的任意长度的字符串。如acb、addgb、ab等都满足该匹配串。
-
_ (下横线)代表任意单个字符。
例如a_b表示以a开头,以b结尾的长度为3的任意字符串。如acb、afb等都满足该 匹配串。 查询学号为201215121的学生的详细情况。
SELECT * FROM Student WHERE Sno LIKE ‘201215121’;
等价于
SELECT *
FROM Student
WHERE Snc='201215121';
如果LIKE后面的匹配串中不含通配符,则可以用=(等于)运算符取代LIKE谓词,用!=或<> (不等于)运算符取代NOTLIKE谓词。
查询所有姓刘的学生的姓名、学号和性别。
SELECT Sname,Sno,Ssex
FROM Student
WHERE Sname LIKE,'刘%';
查询姓“欧阳”且全名为三个汉字的学生的姓名。
SELECT Sname
FROM Student
WHERE Sname LIKE '欧阳_';
如果用户要查询的字符串本身就含有通配符%或这时就要使用ESCAPE’<换码字符>’短语对通配符进行转义了。
查询DB_DeSign课程的课程号和学分。
SELECT Cno,Ccredit
FROM Course
WHERE Cname LIKE ’DB \_Design' ESCAPE '\';
ESCAPE ‘' 表示’'为换码字符.这样匹配串中紧跟在“ \ ”后面的字符转为普通字符.
5. 涉及空值的查询
查询缺少成绩的学生的学号和相应的课程号。
SELECT Sno,Cno
FROM SC
WHERE Grade IS NULL; /* 分数 Grade 是空值*/
注意这里的“is”不能用等号(=)代替。
6. 多重条件查询
逻辑运算符AND和OR可用来连接多个查询条件。AND的优先级高于OR,但用户可以用括号改变优先级。
查询计算机科学系年龄在20岁以下的学生姓名。
SELECT Sname
FROM Student
WHERE Sdept='CS' AND Sage<20;
IN谓词实际上是多个OR运算符的缩写:
SELECT Sname,Ssex
FROM Student
WHERE Sdept='CS ' OR Sdept='MA' OR Sdept='IS';
3. ORDER BY 子句
用户可以用ORDER BY子句对查询结果按照一个或多个属性列的升序(ASC)或降序 (DESC)排列,默认值为升序。
对于空值,排序时显示的次序由具体系统实现来决定。例如按升序排,含空值的元组最 后显示;按降序排,空值的元组则最先显示。各个系统的实现可以不同,只要保持一致就行。
查询全体学生情况,查询结果按所在系的系号升序排列,同一系中的学生按年龄降序排列。
SELECT *
FROM Student
ORDER BY Sdept,Sage DESC; //Sdept默认ASC
4. 聚集函数

如果指定DISTINCT短语,则表示在计算时要取消指定列中的重复值。如果不指定DISTINCT短语或指定ALL短语(ALL为默认值),则表示不取消重复值。
注意:聚集函数无复合功能,不能写成
MAX(AVG(x))
查询学生总人数。
SELECT COUNT(*)
FROM Student;
查询选修了课程的学生人数。
SELECT COUNT(DISTINCT Sno)
FROM SC;
计算选修1号课程的学生平均成绩。
SELECT AVG(Grade)
FROM SC
WHERE Cno='1';
查询选修1号课程的学生最高分数。
SELECT MAX(Grade)
FROM SC
WHERE Cno='1';
当聚集函数遇到空值时,除COUNT (*)外,都跳过空值而只处理非空值。COUNT (*)是对元组进行计数,某个元组的一个或部分列取空值不影响COUNT的统计结果。
注意,WHERE子句中是不能用聚集函数作为条件表达式的。聚集函数只能用于SELECT子句和GROUP BY中的HAVING子句。
5. GROUP BY 子句
GROUP BY子句将查询结果按某一列或多列的值分组,值相等的为一组。
对査询结果分组的目的是为了细化聚集函数的作用对象。如果未对查询结果分组,聚集函数将作用于整个查询结果,分组后聚集函数将作用于每一个组,即每一组都有一个函数值。
求各个课程号及相应的选课人数。
SELECT Cno,COUNT(Sno)
FROM SC
GROUP BY Cno;
如果分组后还要求按一定的条件对这些组进行筛选,最终只输出满足指定条件的组,则可以使用HAVING短语指定筛选条件。
査询选修了三门以上课程的学生学号。
SELECT Sno
FROM SC
GROUP BY Sno
HAVING COUNT(*) >3;
这里先用GROUP BY子句按Sno进行分组,再用聚集函数COUNT对每一组计数;HAVING短语给出了选择组的条件,只有满足条件(即元组个数>3,表示此学生选修的课超过3门)的组才会被选出来。
WHERE子句与HAVING短语的区别在于作用对象不同。WHERE子句作用于基本表或视图,从中选择满足条件的元组。HAVING短语作用于组,从中选择满足条件的组。
查询平均成绩大于等于90分的学生学号和平均成绩。
下面的语句是不对的:
SELECT Sno,AVG(Grade)
FROM SC
WHERE AVG(Grade)>=90
GROUP BY Sno;
因为WHERE子句中是不能用聚集函数作为条件表达式的,正确的査询语句应该是:
SELECT Sno, AVG(Grade)
FROM SC
GROUP BY Sno
HAVING AVG(Grade)>=90;
连接查询
前面的查询都是针对一个表进行的。若一个査询同时涉及两个以上的表,则称之为连 接查询。
从大类上分,表连接分为内连接和外连接,它们之间的最主要区别是內连接仅选出两张表中 互相匹配的记录,而外连接会选出其他不匹配的记录。
1. 内连接
连接查询的WHERE子句中用来连接两个表的条件称为连接条件或连接谓词,其一般 格式为
[<表名1>.] <列名1><比较运算符> [<表名2>.] <列名2>
其中比较运算符主要有=、>、<、>=、<=、!=(或◊)等。
此外连接谓词还可以使用下面形式:
[<表名1>.] <列名1> BETWEEN [<表名2>.] <列名2> AND [<表名2>.] <列名3>
当连接运算符为=时,称为等值连接。使用其他运算符称为非等值连接。
连接谓词中的列名称为连接字段。连接条件中的各连接字段类型必须是可比的,但名字不必相同。
查询每个学生及其选修课程的情况
学生情况存放在Student表中,学生选课情况存放在SC表中,所以本查询实际上涉及 Student与SC两个表。这两个表之间的联系是通过公共属性Sno实现的。
SELECT Student.*,SC *
FROM Student,SC
WHERE Student.Sno=SC.Sno;/*将Student与SC中同一学生的元组连接起来*/
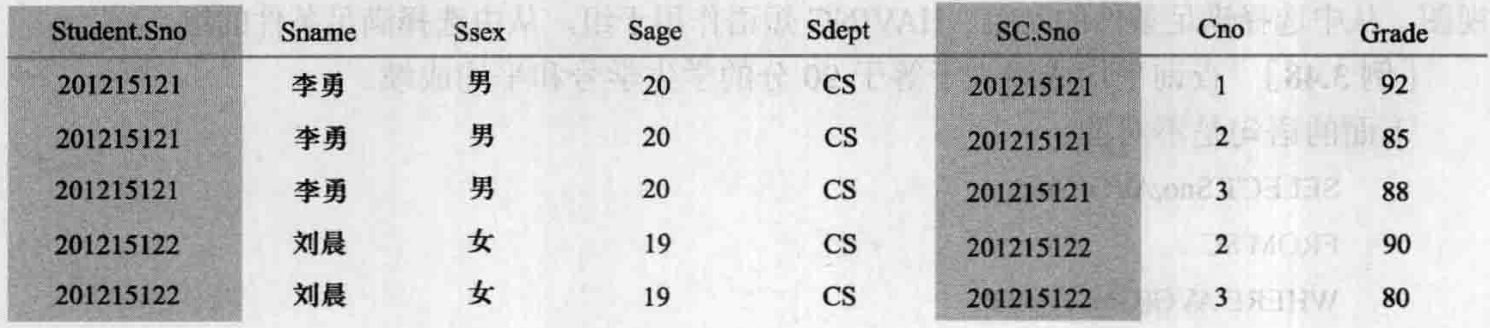
本例中,SELECT子句与WHERE子句中的属性名前都加上了表名前缀,这是为了避免混淆。如果属性名在参加连接的各表中是唯一的,则可以省略表名前缀。
若在等值连接中把目标列中重复的属性列去掉则为自然连接。
2. 自身连接
连接操作不仅可以在两个表之间进行,也可以是一个表与其自己进行连接,称为表的自身连接。
例:查询每一门课的间接先修课(即先修课的先修课)。
在Course表中只有每门课的直接先修课信息,而没有先修课的先修课。要得到这个信息,必须先对一门课找到其先修课,再按此先修课的课程号查找它的先修课程。这就要将Course表与其自身连接。
为此,要为Course表取两个别名,一个是FIRST,另一个是SECOND。
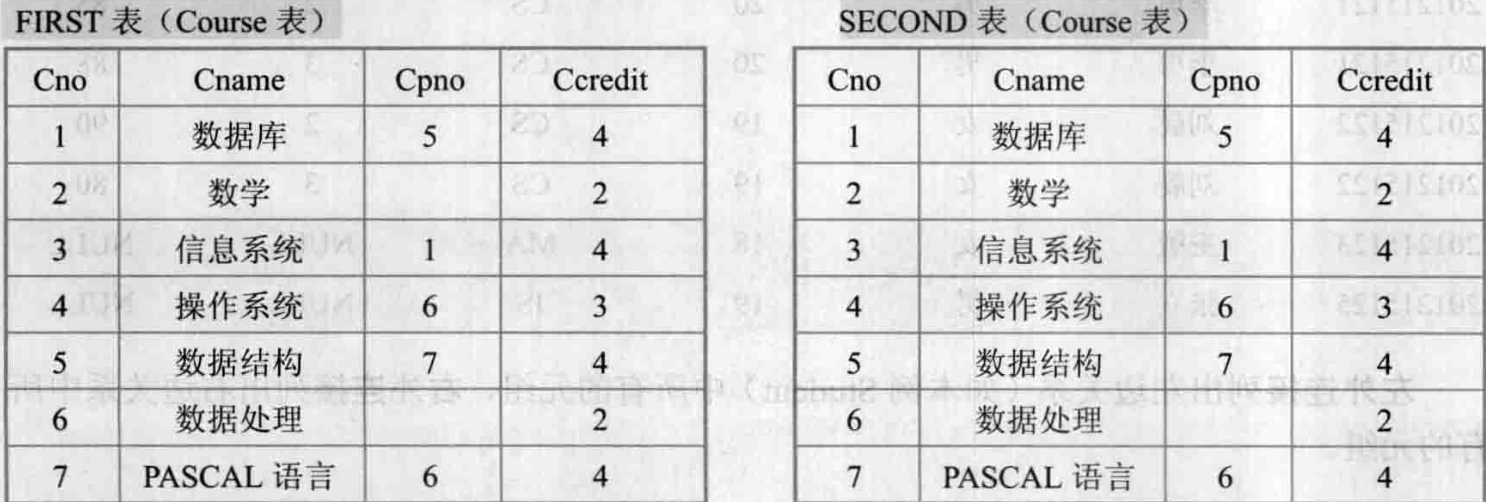
完成该査询的SQL语句为
SELECT FIRST.Cno,SECOND.Cpno
FROM Course FIRST,Course SECOND
WHERE FIRST.Cpno=SECOND.Cno;
3. 外连接
两个关系R和S在做自然连接时,选择两个关系在公共属性上值相等的元组构成新的关系。此时,关系R中某些元组有可能在S中不存在公共属性上值相等的元组,从而造成R中这些元组在操作时被舍弃了,同样,S中某些元组也可能被舍弃。这些被舍弃的元组称为悬浮元组。
如果把悬浮元组也保存在结果关系中,而在其他属性上填空值(NULL),那么这种连接就叫做外连接,如果只保留左边关系中的悬浮元组就叫做左外连接.如果只保留右边关系S中的悬浮元组就叫做右外连接.
例:
SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
FROM Student LEFT OUTER JOIN SC ON (Student.Sno=SC.Sno);
4. 多表连接
连接操作除了可以是两表连接、一个表与其自身连接外,还可以是两个以上的表进行连接,后者通常称为多表连接。
例:查询每个学生的学号、姓名、选修的课程名及成绩。
本查询涉及三个表,完成该查询的SQL语句如下:
SELECT Student. Sno,Sname,Cname,Grade
FROM Student,SC,Course
WHERE Student.Sno=SC.Sno AND SC.Cno=Course.Cno;
嵌套查询
在SQL语言中,一个SELECT-FROM-WHERE语句称为一个查询块。将一个查询块嵌套在另一个查询块的WHERE子句或HAVING短语的条件中的查询称为嵌套查询.
例如:
SELECT Sname /*外层查询或父査询*/
FROM Student
WHERE Sno IN
(SELECT Sno /*内层査询或子査询*/
FROM SC
WHERE Cno='2');
上层的查询块称为外层查询或父查询,下层查询块称为内层查询或子查询。
需要特别指出的是,子查询的SELECT语句中不能使用ORDER BY子句,ORDER BY子句只能对最终查询结果排序。
1.带有IN谓词的子查询
在嵌套查询中,子査询的结果往往是一个集合,所以谓词IN是嵌套查询中最经常使用的谓词。
例:查询与“刘晨”在同一个系学习的学生。
先分步来完成此查询,然后再构造嵌套查询。
-
确定“刘晨”所在系名
SELECT Sdept FROM Student WHERE Sname=’刘晨’;结果为cs。
-
查找所有在cs系学习的学生。
SELECT Sno,Sname,Sdept FROM Student WHERE Sdept='CS'; -
将第一步查询嵌入到第二步查询的条件中,构造嵌套查询如下:
SELECT Sno,Sname,Sdept FROM Student WHERE Sdept IN (SELECT Sdept FROM Student WHERE Sname='刘晨');
本例中,子查询的查询条件不依赖于父查询,称为不相关子查询。
本例中的查询也可以用自身连接来完成:
SELECT S1.Sno,S1.Sname,S1.Sdept
FROM Student S1,Student S2
WHERE S1.Sdept=S2.Sdept AND S2.Sname='刘晨';
有些嵌套查询可以用连接运算替代,有些是不能替代的。查询涉及多个关系时,用嵌套查询逐步求解层次清楚,易于构造,具有结构化程序设计的优点。但是相比于连接运算,目前商用关系数据库管理系统对嵌套查询的优化做得还不够完善,所以在实际应用中,能够用连接运算表达的查询尽可能采用连接运算。
2.带有比较运算符的子查询
带有比较运算符的子査询是指父查询与子查询之间用比较运算符进行连接。当用户能确切知道内层查询返回的是单个值时,可以用>、<、=、>=、<=、!=或<>等比较运算符。
例:找出每个学生超过他自己选修课程平均成绩的课程号。
SELECT Sno,Cno
FROM SC x
WHERE Grade >=(SELECT AVG(Grade) /*某学生的平均成绩•/
FROM SC y
WHERE y.Sno=x.Sno);
内层查询是求一个学生所有选修课程平均成绩的,至于是哪个学生的平均成绩要看参数x.Siio的值,而该值是与父查询相关的,因此这类查询称为相关子查询。
求解相关子查询不能像求解不相关子查询那样一次将子查询求解出来,然后求解父查 询。内层查询由于与外层查询有关,因此必须反复求值。
3. 带有ANY (SOME)或ALL谓词的子查询
子查询返回单值时可以用比较运算符,但返回多值时要用ANY (有的系统用SOME)或ALL谓词修饰符。而使用ANY或ALL谓词时则必须同时使用比较运算符。其语义如下所示:

查询非计算机科学系中比计算机科学系任意一个学生年龄小的学生姓名和 年龄。
SELECT Sname,Sage
FROM Student
WHERE Sage<ANY (SELECT Sage
FROM Student
WHERE Sdept=' CS')
AND Sdept<>'CS; /*注意这是父查询块中的条件*/
本查询也可以用聚集函数来实现,首先用子查询找出CS系中最大年龄(20),然后在 父查询中查所有非CS系且年龄小于20岁的学生。SQL语句如下:
SELECT Sname, Sage
FROM Student
WHERE Sage <
(SELECT MAX(Sage)
FROM Student
WHERE Sdept='CS')
AND Sdept <> 'CS';
事实上,用聚集函数实现子查询通常比直接用ANY或ALL查询效率要高。ANY、ALL与聚集函数的对应关系如下:

4. 带有EXISTS谓词的子查询
EXISTS代表存在量词。带有EXISTS谓词的子查询不返回任何数据,只产生逻辑真值“true”或逻辑假值“false”。
例:查询所有选修了1号课程的学生姓名。
本査询涉及Student和SC表。可以在Student中依次取每个元组的Sno值,用此值去 检查SC表。若SC中存在这样的元组,其Sno值等于此Student.Sno值,并且其Cno=‘1’, 则取此Student.Sname送入结果表。将此想法写成SQL语句是
SELECT Sname
FROM Student
WHERE EXISTS
(SELECT *
FROM SC
WHERE Sno=Student.Sno AND Cno='1');
使用存在量词EXISTS后,若内层查询结果非空,则外层的WHERE子句返回真值,否则返回假值。
由EXISTS引出的子查询,其目标列表达式通常都用*,因为带EXISTS的子查询只返回真值或假值,给出列名无实际意义。
本例中子查询的查询条件依赖于外层父查询的某个属性值(Student的Sno值),因此 也是相关子查询。
这个相关子查询的处理过程是:首先取外层查询中Student表的第一个元组,根据它与内层查询相关的属性值(Sno值)处理内层查询,若WHERE子句返回值为真,则取外层查询中该元组的Sname放入结果表;然后再取Student表的下一个元组;重复这一过程,直至外层Student表全部检查完为止。
与EXISTS谓词相对应的是NOT EXISTS谓词。使用存在量词NOT EXISTS后,若内层查询结果为空,则外层的WHERE子句返回真值,否则返回假值。
例:査询没有选修1号课程的学生姓名。
SELECT Sname
FROM Student
WHERE NOT EXISTS
(SELECT *
FROM SC
WHERE Sno=Student.Sno AND Cno='1');
一些带EXISTS或NOT EXISTS谓词的子查询不能被其他形式的子查询等价替换,但所有带IN谓词、比较运算符、ANY和ALL谓词的子查询都能用带EXISTS谓词的子查询等价替换。
由于带EXISTS量词的相关子查询只关心内层查询是否有返回值,并不需要查具体值,因此其效率并不一定低于不相关子查询,有时是高效的方法。
例:查询选修了全部课程的学生姓名
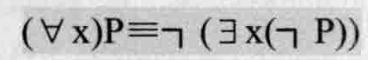
由于没有全称量词,可将题目的意思转换成等价的用存在量词的形式:查询这样的学 生,没有一门课程是他不选修的。其SQL语句如下:
SELECT Sname //任选一学生
FROM Student
WHERE NOT EXISTS
(SELECT * //任选一课程
FROM Course
WHERE NOT EXISTS
(SELECT * //表示其已选的课程
FROM SCWHERE Sno=Student.Sno
AND Cno=Course.Cno));
从而用EXIST/NOT EXIST来实现带全称量词的查询。
例:查询至少选修了学生201215122选修的全部课程的学生号码。
本查询可以用逻辑蕴涵来表达:查询学号为x的学生,对所有的课程y,只要201215122学生选修了课程y,则x也选修了 y。形式化表示如下:
用p表示谓词“学生201215122选修了课程y”
用q表示谓词“学生x选修了课程y”
则上述查询为

注:学生x没有选y,可以转化为不存在选了y课的学生.
SELECT DISTINCT Sno //任选一学生x
FROM SC SCX
WHERE NOT EXISTS //不存在这样的学生
(SELECT * //学生201215122选修的课程y
FROM SC SCY
WHERE SCY.Sno='201215122' AND
NOT EXISTS //不存在这样的课程
(SELECT *
FROM SC SCZ
WHERE SCZ.Sno=SCX.Sno AND //满足x选中该课
SCZ.Cno=SCY.Cno)); //满足y选中该课
集合查询
SELECT语句的査询结果是元组的集合,所以多个SELECT语句的结果可进行集合操作。集合操作主要包括并操作UNION、交操作INTERSECT和差操作EXCEPT。
注意,参加集合操作的各查询结果的列数必须相同;对应项的数据类型也必须相同。
例:查询计算机科学系的学生及年龄不大于19岁的学生。
SELECT *
FROM Student
WHERE Sdept='CS'
UNION
SELECT *
FROM Student
WHERE Sage<=19;
本查询实际上是求计算机科学系的所有学生与年龄不大于19岁的学生的并集。使用UNION将多个查询结果合并起来时,系统会自动去掉重复元组。如果要保留重复元组则用UNION ALL操作符。
例:查询计算机科学系的学生与年龄不大于19岁的学生的交集。
SELECT *
FROM Student
WHERE Sdept='CS'
INTERSECT
SELECT *
FROM Student
WHERE Sage<= 19;
例:查询计算机科学系的学生与年龄不大于19岁的学生的差集。
SELECT *
FROM Student
WHERE Sdept='CS'
EXCEPT
SELECT *
FROM Student
WHERE Sage <=19;
基于派生表的查询
子查询不仅可以出现在WHERE子句中,还可以出现在FROM子句中,这时子查询生成的临时派生表(derived table)成为主查询的查询对象。
例:找出每个学生超过他自己选修课程平均成绩的课程号.
SELECT Sno, Cno
FROM SC, (SELECT Sno, Avg(Grade) FROM SC GROUP BY Sno)
AS Avg_sc(avg_sno,avg_grade)
WHERE SC.Sno = Avg_sc.avg_sno and SC.Grade >= Avg_sc.avg_grade
这里FROM子句中的子查询将生成一个派生表Avg_sc。该表由avg_sno和avg grade 两个属性组成,记录了每个学生的学号及平均成绩。主查询将SC表与Avg_sc按学号相等 进行连接,选出修课成绩大于其平均成绩的课程号。
如果子查询中没有聚集函数,派生表可以不指定属性列,子査询SELECT子句后面的列 名为其默认属性。
例:查询所有选修了1号课程的学生姓名.
SELECT Sname
FROM Student, (SELECT Sno FROM SC WHERE Cno='1') AS SCI
WHERE Student.Sno=SCl.Sno;
需要说明的是,通过FROM子句生成派生表时,AS关键字可以省略,但必须为派生关系指定一个别名。而对于基本表,别名是可选择项。
文章作者 Forz
上次更新 2017-08-13