Redis的zset为什么选择跳表
文章目录
跳表与红黑树
范围查找
在做范围查找的时候,平衡树比skiplist操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
内存占用
我们先来计算一下每个节点所包含的平均指针数目(概率期望)。节点包含的指针数目,相当于这个算法在空间上的额外开销(overhead),可以用来度量空间复杂度。 根据前面randomLevel()的伪码,我们很容易看出,产生越高的节点层数,概率越低。定量的分析如下:
- 节点层数至少为1。而大于1的节点层数,满足一个概率分布。
- 节点层数恰好等于1的概率为1-p。
- 节点层数大于等于2的概率为p,而节点层数恰好等于2的概率为p(1-p)。
- 节点层数大于等于3的概率为p2,而节点层数恰好等于3的概率为p2(1-p)。
- 节点层数大于等于4的概率为p3,而节点层数恰好等于4的概率为p3(1-p)。
- ……
因此,一个节点的平均层数(也即包含的平均指针数目),计算如下:
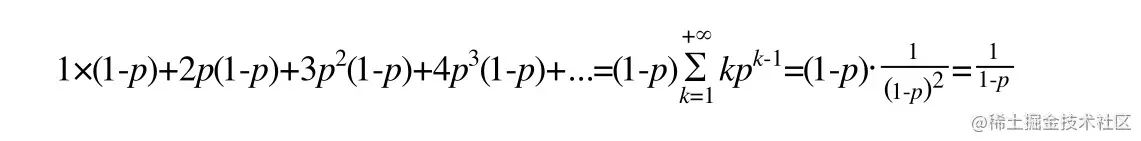
现在很容易计算出:
- 当p=1/2时,每个节点所包含的平均指针数目为2;
- 当p=1/4时,每个节点所包含的平均指针数目为1.33。这也是Redis里的skiplist实现在空间上的开销。
从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
实现难度
从算法实现难度上来比较,skiplist比平衡树要简单得多。比如平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
文章作者 Forz
上次更新 2022-01-07