Protobuf原理介绍
文章目录
序列化与反序列化
有些时候,我们希望给数据结构或对象拍个“快照”,或者保存成文件,或者传输给其他应用程序。比如,在神经网络训练过程中,我们会将不同阶段的网络权重以模型文件的形式保存下来,如果训练意外终止,可以重新载入模型文件将模型复原,继续训练。
将数据结构或对象以某种格式转化为字节流的过程,称之为序列化(Serialization),目的是把当前的状态保存下来,在需要时复原数据结构或对象(序列化时不包含与对象相关联的函数,所以后面只提数据结构)。反序列化(Deserialization),是序列化的逆过程,读取字节流,根据约定的格式协议,将数据结构复原。如下图所示,图片来自geeksforgeeks
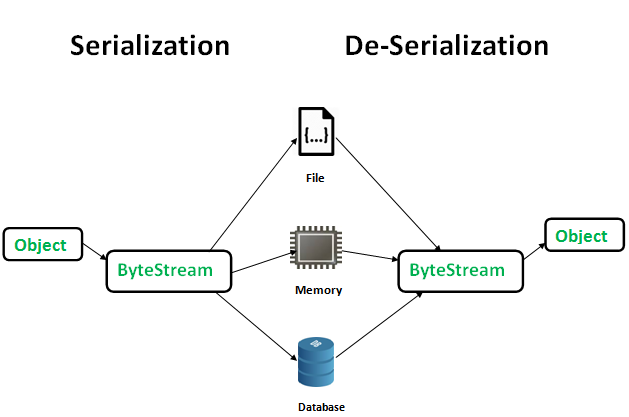
在介绍具体技术之前,我们先在脑海里分析下序列化和反序列化的过程:
- 代码运行过程中,数据结构和对象位于内存,其中的各项数据成员可能彼此紧邻,也可能分布在并不连续的各个内存区域,比如指针指向的内存块等;
- 文件中字节是顺序存储的,要想将数据结构保存成文件,就需要把所有的数据成员平铺开(flatten),然后串接在一起;
- 直接串接可能是不行的,因为字节流中没有天然的分界,所以在序列化时需要按照某种约定的格式(协议),以便在反序列化时知道“从哪里到哪里是哪个数据成员”,因此格式可能需要约定:指代数据成员的标识、起始位置、终止位置、长度、分隔符等
- 由上可见,格式协议是最重要的,它直接决定了序列化和反序列化的效率、字节流的大小和可读性等
概览
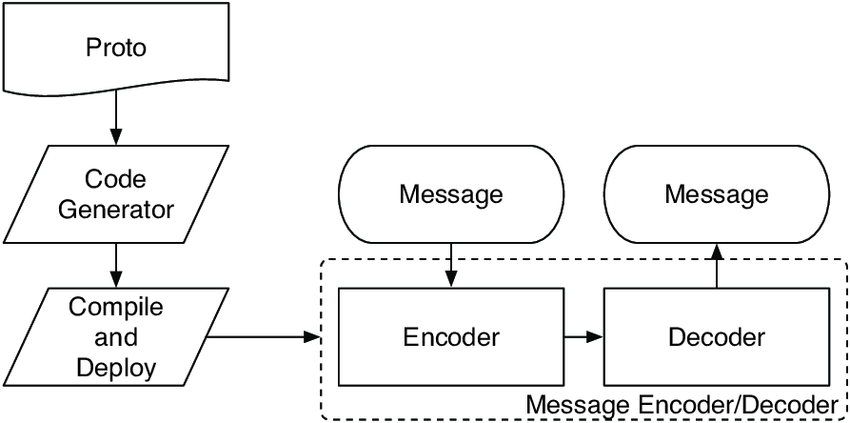
跨语言,跨平台,相比XML和JSON 更小、更快、更容易,因为XML、JSON为了可阅读、自解释被设计成字符文本形式,所以体积更大,在编码解码上也更麻烦,而Protobuf序列化为binary stream,体积更小,但是丧失了可读性——后面我们将看到可读性可以通过另一种方式得到保证。至于上面的"You define how you want your data to be structured once"该怎么理解?参看下图,图片素材来自 Protocol Buffers官网首页。

首先是proto文件,在其中定义我们想要序列化的数据结构,如上图中的message Person,通过Protobuf提供的protoc.exe生成编解码代码文件(C++语言是.cc和.h),其中定义了类Person,类的各个成员变量与proto文件中的定义保持一致。序列化时,定义Person对象,对其成员变量赋值,调用序列化成员函数,将对象保存到文件。反序列化时,读入文件,将Person对象复原,读取相应的数据成员。
proto文件仅定义了数据的结构(name、id、email),具体的数据内容(1234、“John Doe”、“jdoe@example.com”)保存在序列化生成的文件中,通过简单的思考可知,序列化后的文件里应该会存在一些辅助信息用来将数据内容与数据结构对应起来,以便在反序列化时将数据内容赋值给对应的成员。
流程如下:
varint编码
Varint 是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。
Varint 中的每个字节(最后一个字节除外)都设置了最高有效位(msb),这一位表示还会有更多字节出现。每个字节的低 7 位用于以 7 位组的形式存储数字的二进制补码表示,最低有效组首位。
varint是一种可变长编码,使用1个或多个字节对整数进行编码,可编码任意大的整数,小整数占用的字节少,大整数占用的字节多,如果小整数更频繁出现,则通过varint可实现压缩存储。
varint中每个字节的最高位bit称之为most significant bit (MSB),如果该bit为0意味着这个字节为表示当前整数的最后一个字节,如果为1则表示后面还有至少1个字节,可见,varint的终止位置其实是自解释的。
在Protobuf中,tag和length都是使用varint编码的。length和tag中的field_number都是正整数int32,这里提一下tag,它的低3位bit为wire type,如果只用1个字节表示的话,最高位bit为0,则留给field_number只有4个bit位,1到15,如果field_number大于等于16,就需要用2个字节,所以对于频繁使用的field其field_number应设置为1到15。
如果用不到 1 个字节,那么最高有效位设为 0 ,如下面这个例子,1 用一个字节就可以表示,所以 msb 为 0.
|
|
如果需要多个字节表示,msb 就应该设置为 1 。例如 300,如果用 Varint 表示的话:
|
|
如果按照正常的二进制计算的话,这个表示的是 88068(65536 + 16384 + 4096 + 2048 + 4)。
那 Varint 是怎么编码的呢?
下面代码是 Varint int 32 的编码计算方法。
|
|
|
|
由于 300 超过了 7 位(Varint 一个字节只有 7 位能用来表示数字,最高位 msb 用来表示后面是否有更多字节),所以 300 需要用 2 个字节来表示。
Varint 的编码,以 300 举例:
|
|
- 100101100 | 10000000 = 1 1010 1100
- 110101100 取出末尾 7 位 = 010 1100
- 100101100 » 7 = 10 = 0000 0010
- 1010 1100 0000 0010 (最终 Varint 结果)
Varint 的解码算法应该是这样的:(实际就是编码的逆过程)
- 如果是多个字节,先去掉每个字节的 msb(通过逻辑或运算),每个字节只留下 7 位。
- 逆序整个结果,最多是 5 个字节,排序是 1-2-3-4-5,逆序之后就是 5-4-3-2-1,字节内部的二进制位的顺序不变,变的是字节的相对位置。
解码过程调用 GetVarint32Ptr 函数,如果是大于一个字节的情况,会调用 GetVarint32PtrFallback 来处理。
|
|
至此,Varint 处理过程读者应该都熟悉了。上面列举出了 Varint 32 的算法,64 位的同理,只不过不再用 10 个分支来写代码了,太丑了。(32位 是 5 个 字节,64位 是 10 个字节)
64 位 Varint 编码实现:
|
|
原理不变,只不过用循环来解决了。
64 位 Varint 解码实现:
|
|
读到这里可能有读者会问了,Varint 不是为了紧凑 int 的么?那 300 本来可以用 2 个字节表示,现在还是 2 个字节了,哪里紧凑了,花费的空间没有变啊?!
Varint 确实是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。比如对于 int32 类型的数字,一般需要 4 个 byte 来表示。但是采用 Varint,对于很小的 int32 类型的数字,则可以用 1 个 byte 来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个 byte 来表示。从统计的角度来说,一般不会所有的消息中的数字都是大数,因此大多数情况下,采用 Varint 后,可以用更少的字节数来表示数字信息。
300 如果用 int32 表示,需要 4 个字节,现在用 Varint 表示,只需要 2 个字节了。缩小了一半!
Message Structure 编码
protocol buffer 中 message 是一系列键值对。message 的二进制版本只是使用字段号(field’s number 和 wire_type)作为 key。每个字段的名称和声明类型只能在解码端通过引用消息类型的定义(即 .proto 文件)来确定。这一点也是人们常常说的 protocol buffer 比 JSON,XML 安全一点的原因,如果没有数据结构描述 .proto 文件,拿到数据以后是无法解释成正常的数据的。
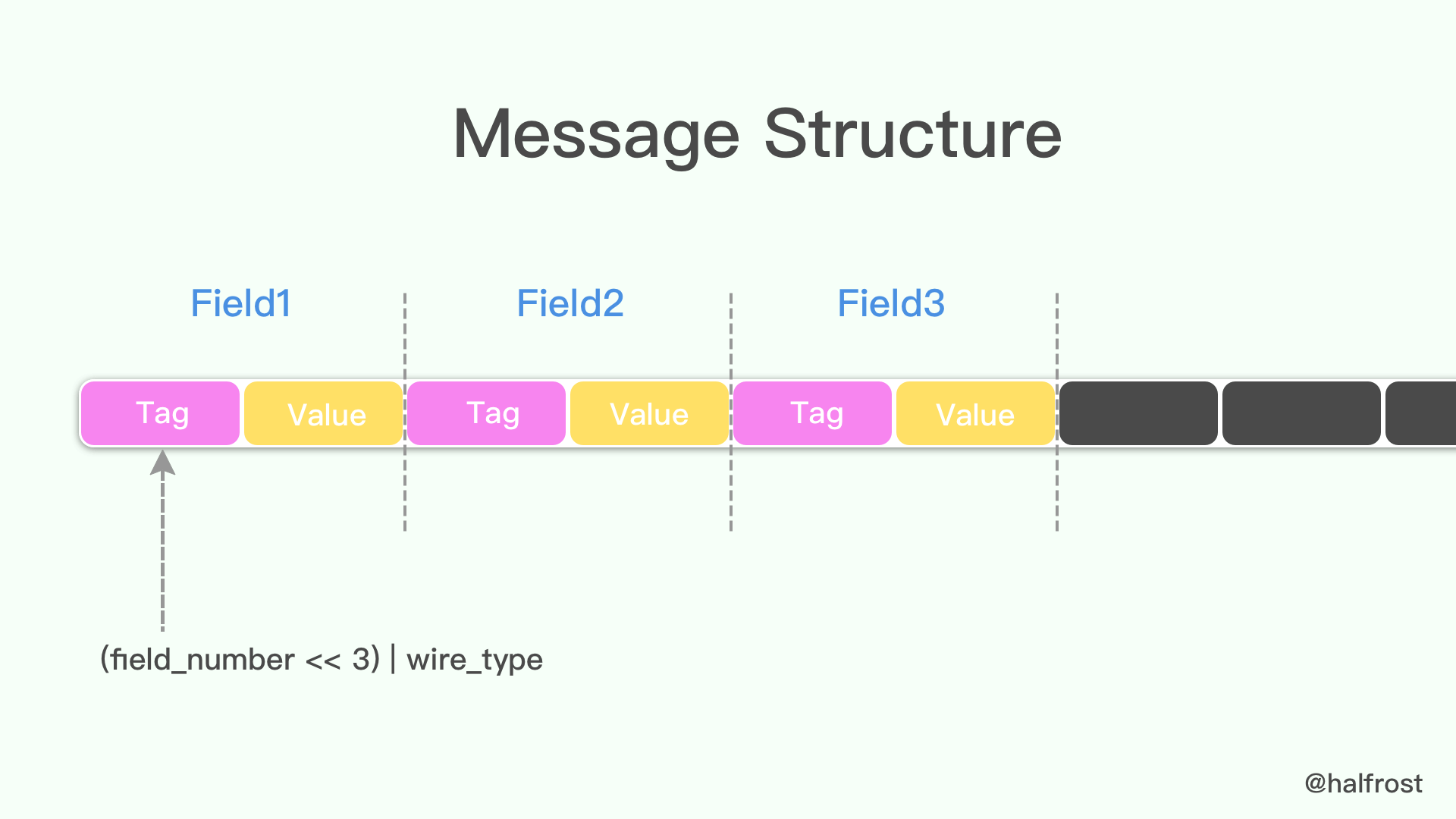
由于采用了 tag-value 的形式,所以 option 的 field 如果有,就存在在这个 message buffer 中,如果没有,就不会在这里,这一点也算是压缩了 message 的大小了。
当消息编码时,键和值被连接成一个字节流。当消息被解码时,解析器需要能够跳过它无法识别的字段。这样,可以将新字段添加到消息中,而不会破坏不知道它们的旧程序。这就是所谓的 “向后”兼容性。
为此,线性的格式消息中每对的“key”实际上是两个值,其中一个是来自.proto文件的字段编号,加上提供正好足够的信息来查找下一个值的长度。在大多数语言实现中,这个 key 被称为 tag。
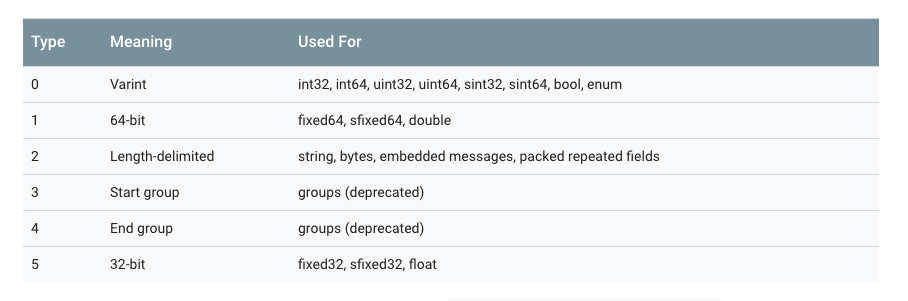
注意上图中,3 和 4 已经被废弃了,所以 wire_type 取值目前只有 0、1、2、5。
key 的计算方法是 (field_number << 3) | wire_type,换句话说,key 的最后 3 位表示的就是 wire_type。
举例,一般 message 的字段号都是 1 开始的,所以对应的 tag 可能是这样的:
|
|
末尾 3 位表示的是 value 的类型,这里是 000,即 0 ,代表的是 varint 值。右移 3 位,即 0001,这代表的就是字段号(field number)。tag 的例子就举这么多,接下来举一个 value 的例子,还是用 varint 来举例:
|
|
可以 96 01 代表的数据就是 150 。
|
|
如果存在上面这样的一个 message 的结构,如果存入 150,在 Protocol Buffer 中显示的二进制应该为 08 96 01 。
额外说一句,type 需要注意的是 type = 2 的情况,tag 里面除了包含 field number 和 wire_type ,还需要再包含一个 length,决定 value 从那一段取出来。(具体原因见 Protocol Buffer 字符串 这一章节)
Signed Integers 编码
从上面的表格里面可以看到 wire_type = 0 中包含了无符号的 varints,但是如果是一个无符号数呢?
一个负数一般会被表示为一个很大的整数,因为计算机定义负数的符号位为数字的最高位。如果采用 Varint 表示一个负数,那么一定需要 10 个 byte 长度。
为何 32 位和 64 位的负数都需要 10 个 byte 长度呢?
|
|
因为源码里面是这么规定的。32 位的有符号数都会转换成 64 位无符号来处理。至于源码为什么要这么规定呢,猜想可能是怕 32 位的负数转换会有溢出的可能。(只是猜想)
在网络传输和数据存储场景中,需要对数据进行压缩。数据压缩的算法非常多,但大部分的数据压缩算法的原理是通过某种编码方式不存储数据中的0比特位,因此0比特位越多,数据压缩的效果越好。ZigZag编码就是一种增加0比例位的编码方式。
可以看到varint对于有符号数,由于最高位是是符号位,如果是负数,那最高位就是1,这种情况下varint就会使用5个字节存储,会比原来更加浪费空间。zigzag编码就是为了解决负数问题的,同时其对正数也没有很大的影响。
为此 Google Protocol Buffer 定义了 sint32 这种类型,采用 zigzag 编码。将所有整数映射成无符号整数,然后再采用 varint 编码方式编码,这样,绝对值小的整数,编码后也会有一个较小的 varint 编码值。
ZigZag是将有符号数统一映射到无符号数的一种编码方案,对于无符号数0 1 2 3 4,映射前的有符号数分别为0 -1 1 -2 2,负数以及对应的正数来回映射到从0变大的数字序列里,这也是”zig-zag”的名字来源。
为了便于后面的分析,我们先回顾下几个概念:
- 原码:最高位为符号位,剩余位表示绝对值;
- 反码:除符号位外,对原码剩余位依次取反;
- 补码:对于正数,补码为其自身;对于负数,除符号位外对原码剩余位依次取反然后+1。
补码解决了原码中0存在两种编码的问题:
0=[00000000]原=[10000000]原0=[00000000]原=[10000000]原
补码[10000001]补[10000001]补 表示−127−127;
此外,原码中还存在加法错误的问题:
1+(−1)=[00000001]原+[10000001]原=[10000010]原=−21+(−1)=[00000001]原+[10000001]原=[10000010]原=−2
若用补码,则可得到正确结果:
1+(−1)=[00000001]补+[11111111]补=[00000000]补=01+(−1)=[00000001]补+[11111111]补=[00000000]补=0
因此,在计算机存储整数时,采用的是补码。此外,整数的补码有一些有趣的性质:
- 左移1位(n « 1),无论正数还是负数,相当于乘以2;对于正数,若大于
Integer.MAX_VALUE/2(1076741823),则会发生溢出,导致左移1位后为负数 - 右移31位(n » 31),对于正数,则返回
0x00000000;对于负数,则返回0xffffffff
这些性质正好在ZigZag编码中用到了。
Zigzag 映射函数为:
|
|
正数
假设数据类型为byte的正数11,其二进制表示为:00001011
数据左移一位:00010110
符号位(正数的符号为0)放到最后一位:00010110
负数
假设数据类型为byte的负数-11,其二进制在计算机中是用补码表示的,计算过程如下。
正数原码:00001011。
反码:11110100
补码(反码加1):11110101
处理过程:
左移一位:11101010
符号位放到最后一位:11101011
除最后一位外全部取反:00010101
正数经过处理后,前导0和后置0的个数不变。但是负数经过处理后,增加了三个前导0,可以用于压缩。
结合两种情况得出byte类型数据的编码公式:
|
|
-11的处理过程如下:
- 11110101 » 7 = 11111111
- 11110101 « 1 = 11101010
- 11111111^11101010 = 00010101
ZigZag的逆函数:
|
|
负数00010101的解码过程:
- n»>1:00001010
- n&1:00000001
- -(n&1):11111111
- 1111111^0000101=11110101
需要注意的是,第二个转换 (n » 31) 部分,是一个算术转换。所以,换句话说,移位的结果要么是一个全为0(如果n是正数),要么是全部1(如果n是负数)。
- 编码时,先使用zigzag编码,后使用varint编码
- 解码时,先使用varint解码,后使用zigzag解码
当 sint32 或 sint64 被解析时,它的值被解码回原始的带符号的版本。
Non-varint Numbers
Non-varint 数字比较简单,double 、fixed64 的 wire_type 为 1,在解析时告诉解析器,该类型的数据需要一个 64 位大小的数据块即可。同理,float 和 fixed32 的 wire_type 为5,给其 32 位数据块即可。两种情况下,都是高位在后,低位在前。
说 Protocol Buffer 压缩数据没有到极限,原因就在这里,因为并没有压缩 float、double 这些浮点类型。
字符串
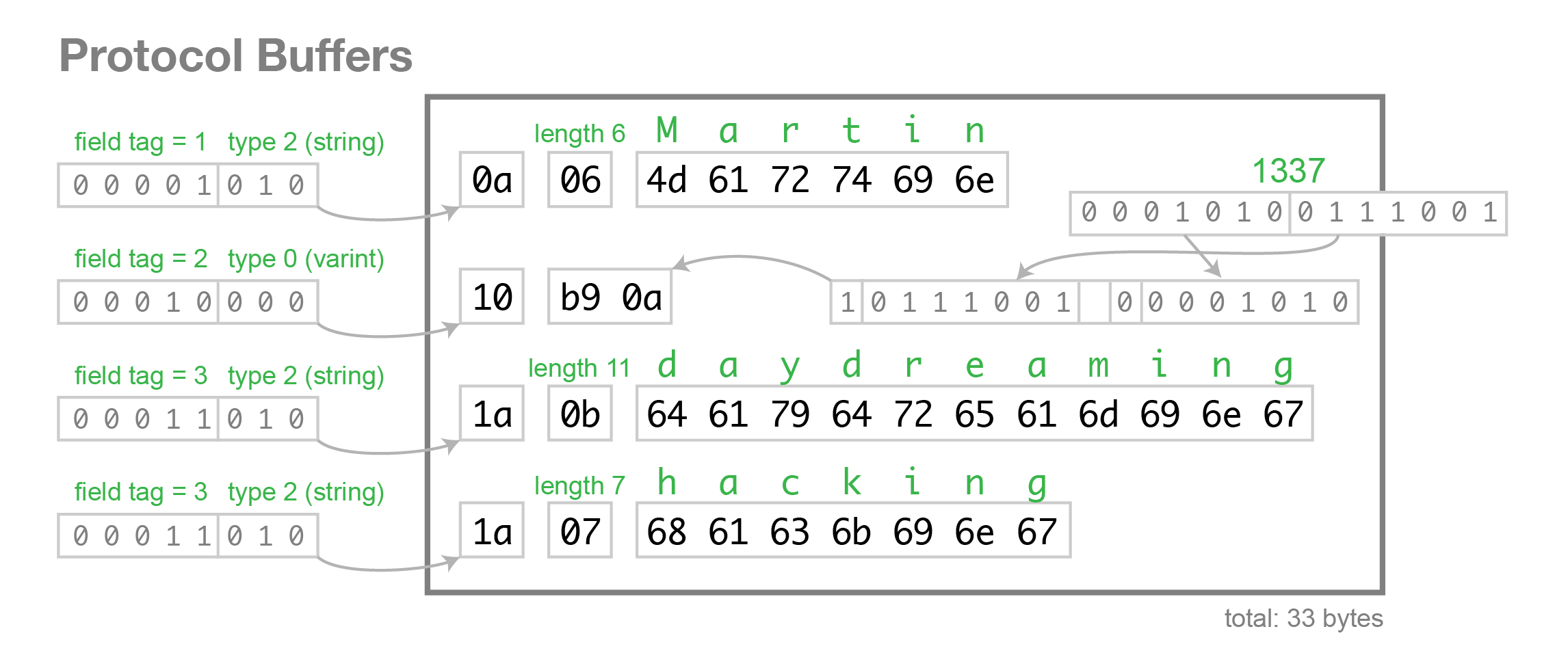
wire_type 类型为 2 的数据,是一种指定长度的编码方式:key + length + content,key 的编码方式是统一的,length 采用 varints 编码方式,content 就是由 length 指定长度的 Bytes。
举例,假设定义如下的 message 格式:
|
|
设置该值为"testing",二进制格式查看:
|
|
74 65 73 74 69 6e 67 是“testing”的 UTF8 代码。
此处,key 是16进制表示的,所以展开是:
12 -> 0001 0010,后三位 010 为 wire type = 2,0001 0010 右移三位为 0000 0010,即 tag = 2。
length 此处为 7,后边跟着 7 个bytes,即我们的字符串"testing"。
所以 wire_type 类型为 2 的数据,编码的时候会默认转换为 T-L-V (Tag - Length - Value)的形式。
嵌入式 message
假设,定义如下嵌套消息:
|
|
设置字段为整数150,编码后的字节为:
|
|
08 96 01 这三个代表的是 150,上面讲解过,这里就不再赘述了。
1a -> 0001 1010,后三位 010 为 wire type = 2,0001 1010 右移三位为 0000 0011,即 tag = 3。
length 为 3,代表后面有 3 个字节,即 08 96 01 。
需要转变为 T - L - V 形式的还有 string, bytes, embedded messages, packed repeated fields (即 wire_type 为 2 的形式都会转变成 T - L - V 形式)
Optional 和 Repeated 的编码
在 proto2 中定义成 repeated 的字段,(没有加上 [packed=true] option ),编码后的 message 有一个或者多个包含相同 tag 数字的 key-value 对。这些重复的 value 不需要连续的出现;他们可能与其他的字段间隔的出现。尽管他们是无序的,但是在解析时,他们是需要有序的。在 proto3 中 repeated 字段默认采用 packed 编码(具体原因见 Packed Repeated Fields 这一章节)
对于 proto3 中的任何非重复字段或 proto2 中的可选字段,编码的 message 可能有也可能没有包含该字段号的键值对。
通常,编码后的 message,其 required 字段和 optional 字段最多只有一个实例。但是解析器却需要处理多对一的情况。对于数字类型和 string 类型,如果同一值出现多次,解析器接受最后一个它收到的值。对于内嵌字段,解析器合并(merge)它接收到的同一字段的多个实例。就如 MergeFrom 方法一样,所有单数的字段,后来的会替换先前的,所有单数的内嵌 message 都会被合并(merge),所有的 repeated 字段,都会串联起来。这样的规则的结果是,解析两个串联的编码后的 message,与分别解析两个 message 然后 merge,结果是一样的。例如:
|
|
等价于
|
|
这种方法有时是非常有用的。比如,即使不知道 message 的类型,也能够将其合并。
Packed Repeated Fields
在 2.1.0 版本以后,protocol buffers 引入了该种类型,其与 repeated 字段一样,只是在末尾声明了 [packed=true]。类似 repeated 字段却又不同。在 proto3 中 Repeated 字段默认就是以这种方式处理。对于 packed repeated 字段,如果 message 中没有赋值,则不会出现在编码后的数据中。否则的话,该字段所有的元素会被打包到单一一个 key-value 对中,且它的 wire_type=2,长度确定。每个元素正常编码,只不过其前没有标签 tag。例如有如下 message 类型:
|
|
构造一个 Test4 字段,并且设置 repeated 字段 d 3个值:3,270和86942,编码后:
|
|
形成了 Tag - Length - Value - Value - Value …… 对。
只有原始数字类型(使用varint,32位或64位)的重复字段才可以声明为“packed”。
有一点需要注意,对于 packed 的 repeated 字段,尽管通常没有理由将其编码为多个 key-value 对,编码器必须有接收多个 key-pair 对的准备。这种情况下,payload 必须是串联的,每个 pair 必须包含完整的元素。
Protocol Buffer 解析器必须能够解析被重新编译为 packed 的字段,就像它们未被 packed 一样,反之亦然。这允许以正向和反向兼容的方式将[packed = true]添加到现有字段。
Field Order
编码/解码与字段顺序无关,这一点由 key-value 机制保证。
如果消息具有未知字段,则当前的 Java 和 C++ 实现在按顺序排序的已知字段之后以任意顺序写入它们。当前的 Python 实现不会跟踪未知字段。
优缺点
protocol buffers 在序列化方面,与 XML 相比,有诸多优点:
- 更加简单
- 数据体积小 3- 10 倍
- 更快的反序列化速度,提高 20 - 100 倍
- 可以自动化生成更易于编码方式使用的数据访问类
举个例子:
如果要编码一个用户的名字和 email 信息,用 XML 的方式如下:
|
|
相同需求,如果换成 protocol buffers 来实现,定义文件如下:
|
|
protocol buffers 通过编码以后,以二进制的方式进行数据传输,最多只需要 28 bytes 空间和 100-200 ns 的反序列化时间。但是 XML 则至少需要 69 bytes 空间(经过压缩以后,去掉所有空格)和 5000-10000 的反序列化时间。
上面说的是性能方面的优势。接下来说说编码方面的优势。
protocol buffers 自带代码生成工具,可以生成友好的数据访问存储接口。从而开发人员使用它来编码更加方便。例如上面的例子,如果用 C++ 的方式去读取用户的名字和 email,直接调用对应的 get 方法即可(所有属性的 get 和 set 方法的代码都自动生成好了,只需要调用即可)
|
|
而 XML 读取数据会麻烦一些:
|
|
Protobuf 语义更清晰,无需类似 XML 解析器的东西(因为 Protobuf 编译器会将 .proto 文件编译生成对应的数据访问类以对 Protobuf 数据进行序列化、反序列化操作)。
使用 Protobuf 无需学习复杂的文档对象模型,Protobuf 的编程模式比较友好,简单易学,同时它拥有良好的文档和示例,对于喜欢简单事物的人们而言,Protobuf 比其他的技术更加有吸引力。
protocol buffers 最后一个非常棒的特性是,即“向后”兼容性好,人们不必破坏已部署的、依靠“老”数据格式的程序就可以对数据结构进行升级。这样您的程序就可以不必担心因为消息结构的改变而造成的大规模的代码重构或者迁移的问题。因为添加新的消息中的 field 并不会引起已经发布的程序的任何改变(因为存储方式本来就是无序的,k-v 形式)。
当然 protocol buffers 也并不是完美的,在使用上存在一些局限性。
由于文本并不适合用来描述数据结构,所以 Protobuf 也不适合用来对基于文本的标记文档(如 HTML)建模。另外,由于 XML 具有某种程度上的自解释性,它可以被人直接读取编辑,在这一点上 Protobuf 不行,它以二进制的方式存储,除非你有 .proto 定义,否则你没法直接读出 Protobuf 的任何内容。
总结
读完本篇 Protocol Buffer 编码原理以后,读者应该能明白以下几点:
- Protocol Buffer 利用 varint 原理压缩数据以后,二进制数据非常紧凑,option 也算是压缩体积的一个举措。所以 pb 体积更小,如果选用它作为网络数据传输,势必相同数据,消耗的网络流量更少。但是并没有压缩到极限,float、double 浮点型都没有压缩。
- Protocol Buffer 比 JSON 和 XML 少了 {、}、: 这些符号,体积也减少一些。再加上 varint 压缩,gzip 压缩以后体积更小!
- Protocol Buffer 是 Tag - Value (Tag - Length - Value)的编码方式的实现,减少了分隔符的使用,数据存储更加紧凑。
- Protocol Buffer 另外一个核心价值在于提供了一套工具,一个编译工具,自动化生成 get/set 代码。简化了多语言交互的复杂度,使得编码解码工作有了生产力。
- Protocol Buffer 不是自我描述的,离开了数据描述 .proto 文件,就无法理解二进制数据流。这点即是优点,使数据具有一定的“加密性”,也是缺点,数据可读性极差。所以 Protocol Buffer 非常适合内部服务之间 RPC 调用和传递数据。
- Protocol Buffer 具有向后兼容的特性,更新数据结构以后,老版本依旧可以兼容,这也是 Protocol Buffer 诞生之初被寄予解决的问题。因为编译器对不识别的新增字段会跳过不处理。
参考
文章作者 Forz
上次更新 2021-04-20