前文
在你开发程序的时候,使用 LIMIT 子句做分页查询可能是非常频繁的,这是一个非常常见的业务场景。
那你在使用 limit 子句的时候有没有遇到过什么问题呢,比如说性能不好?
曾经遇到过不少由于分页查询性能差,需要优化的案例。
那常见的原因基本上也都是分页过多。
过大的分页查询为什么会慢?
下面我们先构造一个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
/**生成3百万行的测试数据**/
CREATE TABLE `limit_optimize_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`account` varchar(50) NOT NULL,
`order_id` varchar(100) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2000002 DEFAULT CHARSET=utf8
create index idx_account on limit_optimize_tbl(account);
create index idx_order_id on limit_optimize_tbl(order_id);
DELIMITER
CREATE PROCEDURE limit_optimize_test()
BEGIN
DECLARE i INT;
SET i=1000000;
WHILE i<=3000000 DO
INSERT INTO limit_optimize_tbl(account,order_id) VALUES('test_123',concat('order', i));
SET i=i+1;
END WHILE;
END
DELIMITER ;
call limit_optimize_test();
|
下面的这行 SQL 是一个常见的分页查询的语句:
1
|
mysql> select * from limit_optimize_tbl order by order_id limit 1000000,10;
|
这种写法是最简单的,但同时也是最容易出问题的。
曾经有人做过调查,用户在浏览前端页面时,假如这个页面是分页浏览的(例如淘宝),用户只会浏览前面几页,一般翻页超过 10 页很多人就开始表现的不耐烦了。
在翻页比较少的情况下,LIMIT 子句并不会表现出性能问题。
但是假如用户要直接跳到最后一页呢?
通常情况下,由于要保证所有的页面都可以正常跳转,因此可能不会使用如下这种语句:
1
|
mysql> select * from limit_optimize_tbl order by order_id desc limit 0,10;
|
而是继续采用正序顺序做分页查询:
1
|
mysql> select * from limit_optimize_tbl order by order_id limit 1000000,10;
|
采用这种 SQL 查询的话,此时从 MySQL 中取出这 10 行数据的代价是非常大的,需要先排序出前面 1000010 条记录,然后抛弃前面的 1000000 条。查询数据和排序的代价非常高。
我们再来看一下上面这个 SQL 语句的执行计划:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
mysql> explain select *from limit_optimize_tbl order by order_id limit 0,10 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: limit_optimize_tbl
partitions: NULL
type: index
possible_keys: NULL
key: idx_order_id
key_len: 302
ref: NULL
rows: 10
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
mysql> explain select* from limit_optimize_tbl order by order_id limit
1000000,10 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: limit_optimize_tbl
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1994816
filtered: 100.00
Extra: Using filesort
1 row in set, 1 warning (0.00 sec)
|
从执行计划中你可以看到,在大分页的时候,MySQL 并没有走索引扫描,而是使用了全表扫描的方式。
那这又是为什么呢?
MySQL 数据库采用了基于代价的查询优化器,而查询代价的估算是基于 CPU 代价和 IO 代价。由于现在机械硬盘还没有被完全淘汰掉,因此在类似这种局部扫描的动作中,随机 IO 的代价,仍然被MySQL 的查询优化器认为是非常高的。
对于局部扫描,MySQL 会根据数据量的情况和数据获取的条件,去做代价估算,决定是采用顺序扫描还是随机读取存储系统。
如果 MySQL 在查询代价估算中,认为采取顺序扫描方式比局部随机扫描的效率更高的话,就会放弃索引,转向顺序扫描的方式。
这就是为什么在大分页中 MySQL 数据库走了全表扫描的原因。
下面我们还是使用刚刚的 SQL 语句,再来实验一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
mysql> explain select *from limit_optimize_tbl order by order_id limit 5660,10
\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: limit_optimize_tbl
partitions: NULL
type: index
possible_keys: NULL
key: idx_order_id
key_len: 302
ref: NULL
rows: 5670
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
mysql> explain select* from limit_optimize_tbl order by order_id limit 5661,10
\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: limit_optimize_tbl
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1994816
filtered: 100.00
Extra: Using filesort
1 row in set, 1 warning (0.00 sec)
|
从上面的实验你可以看到2条SQL,在这个临界点上,MySQL 分别采用了索引扫描和全表扫描的查询优化方式。
你可以自行运行下这两个 SQL 语句,比较下执行时间。
由于 MySQL 的查询优化器的算法核心我们是无法人工干预的,因此我们的优化思路应该着眼于如何让分页维持在最佳的效率区间。
下面我们就来看下如何优化。
优化可以从两个角度进行分析:
SQL改写优化
索引覆盖
由于索引是有序的,因此这种优化方式的思路是直接在索引上完成排序和分页的操作。
先来说说什么是覆盖索引。
如果一个 SQL 语句,通过索引即可直接获取查询结果,而不再需要回表查询,就称这个索引覆盖了这条SQL 语句。
也就是平时所说的不需要回表操作。
在 MySQL 数据库中使用执行计划查看,如果 extra 这一列中显示 Using index ,就表示这条 SQL 语句使用了覆盖索引。
下面我们看下刚刚的那条 SQL 语句:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
mysql> explain select * from limit_optimize_tbl order by order_id limit 0,10 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: limit_optimize_tbl
partitions: NULL
type: index
possible_keys: NULL
key: idx_order_id
key_len: 302
ref: NULL
rows: 10
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
mysql> explain select order_id from limit_optimize_tbl order by order_id limit
0,10 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: limit_optimize_tbl
partitions: NULL
type: index
possible_keys: NULL
key: idx_order_id
key_len: 302
ref: NULL
rows: 10
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
mysql> explain select id from limit_optimize_tbl order by order_id limit 0,10 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: limit_optimize_tbl
partitions: NULL
type: index
possible_keys: NULL
key: idx_order_id
key_len: 302
ref: NULL
rows: 10
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
|
从这个实验中可以看到,除了 select * 的那条 SQL 语句,其他两个都使用了覆盖索引。
你也可以对比一下使用了覆盖索引的大分页和和没有使用覆盖索引的性能差异。
在我的环境中执行实验中的 “LIMIT 1000000,10” 的分页查询,
没有使用覆盖索引的 SQL 语句执行时间是 2.51s
使用了覆盖索引的 SQL 语句执行时间是 0.16s
优化效果还是非常明显的。
子查询优化
由于在 SELECT 语句中我们很少会只查询某一两个列,因此上述覆盖索引的适用范围就比较有限。
可以通过将分页的 SQL 语句改写成子查询的方法获得性能的提升。
示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
mysql> select * from limit_optimize_tbl where id >= (select id from limit_optimize_tbl order by order_id limit 1000000,1) limit 10;
+
| id | account | order_id |
+
| 1000001 | test_123 | order2000000 |
| 1000002 | test_123 | order2000001 |
| 1000003 | test_123 | order2000002 |
| 1000004 | test_123 | order2000003 |
| 1000005 | test_123 | order2000004 |
| 1000006 | test_123 | order2000005 |
| 1000007 | test_123 | order2000006 |
| 1000008 | test_123 | order2000007 |
| 1000009 | test_123 | order2000008 |
| 1000010 | test_123 | order2000009 |
+
10 rows in set (0.16 sec)
|
执行时间和上一节的使用了覆盖索引的 SQL 语句基本一致。
不知道你有没有观察到,这种优化方法也有其局限性:
- 首先,分页的数据必须是连续的
- 其次,WHERE 子句里面不能再添加别的条件
延迟关联
和上述子查询的做法类似,我们也可以使用 JOIN 的语法,先在索引上完成分页的操作,然后再回表获取
需要的数据列。
示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
mysql> select a.* from limit_optimize_tbl a
inner join (select id from limit_optimize_tbl order by order_id limit 1000000,10) b on a.id=b.id;
+
| id | account | order_id |
+
| 1000001 | test_123 | order2000000 |
| 1000002 | test_123 | order2000001 |
| 1000003 | test_123 | order2000002 |
| 1000004 | test_123 | order2000003 |
| 1000005 | test_123 | order2000004 |
| 1000006 | test_123 | order2000005 |
| 1000007 | test_123 | order2000006 |
| 1000008 | test_123 | order2000007 |
| 1000009 | test_123 | order2000008 |
| 1000010 | test_123 | order2000009 |
+
10 rows in set (0.15 sec)
|
你可以和上一小节的子查询优化的方式做个对比,在采用了 JOIN 语法改写之后,上面的两个限制都解除了,并且 SQL 的执行效率没有损失
记录书签
和上述使用覆盖索引的思路不同,记录书签的优化思路是使用书签记录上一页数据的位置,下次分页时直接从这个书签的位置开始扫描,从而避免 MySQL 扫描大量的数据行再丢弃的操作。
示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
mysql> select * from limit_optimize_tbl where id>=1000001 limit 0,10;
+
| id | account | order_id |
+
| 1000001 | test_123 | order2000000 |
| 1000002 | test_123 | order2000001 |
| 1000003 | test_123 | order2000002 |
| 1000004 | test_123 | order2000003 |
| 1000005 | test_123 | order2000004 |
| 1000006 | test_123 | order2000005 |
| 1000007 | test_123 | order2000006 |
| 1000008 | test_123 | order2000007 |
| 1000009 | test_123 | order2000008 |
| 1000010 | test_123 | order2000009 |
+
10 rows in set (0.00 sec)
|
从上面的 SQL 语句你可以看到,由于使用了主键索引来做分页的操作,SQL 语句的性能是极佳的。
使用其他列做书签也是可以的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
mysql> select * from limit_optimize_tbl where order_id>='order2000000' limit 0,10;
+
| id | account | order_id |
+
| 1000001 | test_123 | order2000000 |
| 1000002 | test_123 | order2000001 |
| 1000003 | test_123 | order2000002 |
| 1000004 | test_123 | order2000003 |
| 1000005 | test_123 | order2000004 |
| 1000006 | test_123 | order2000005 |
| 1000007 | test_123 | order2000006 |
| 1000008 | test_123 | order2000007 |
| 1000009 | test_123 | order2000008 |
| 1000010 | test_123 | order2000009 |
+
10 rows in set (0.01 sec)
|
这里要给你提个醒,如果没有使用主键索引或唯一索引做这个书签,排序的字段有大量重复值的情况下,输出的结果不一定是准确的,不适合使用这种写法。
反向查找
反向查找即我们在本文的开头提到的例子:
1
|
mysql> select * from limit_optimize_tbl order by order_id desc limit 0,10;
|
这种优化的思路来自于二分查找,也就是说,当偏移量超过记录数的一半时,就可以使用这种写法来获得性能的提升
不过这种方法需要在分页前知道符合条件的总的记录条数,但是在 InnoDB 存储引擎中,COUNT (*) 的开销其实也不小。
因此建议你仅在一些特殊情况下选用,例如直接跳到尾页。
业务角度优化
下面我们一起来看看从业务角度如何优化大分页查询。
其实这个优化思路要看具体的业务内容,业务是千变万化的,因此本文中提到的这几个案例,不一定就适合你们公司的业务类型,只是起个抛砖引玉的作用。
翻页限制
不允许翻过多的页 , 一言以蔽之,就是不给你查了。
把 LIMIT 分页的偏移量做一个限制,超过某个阈值就停止。
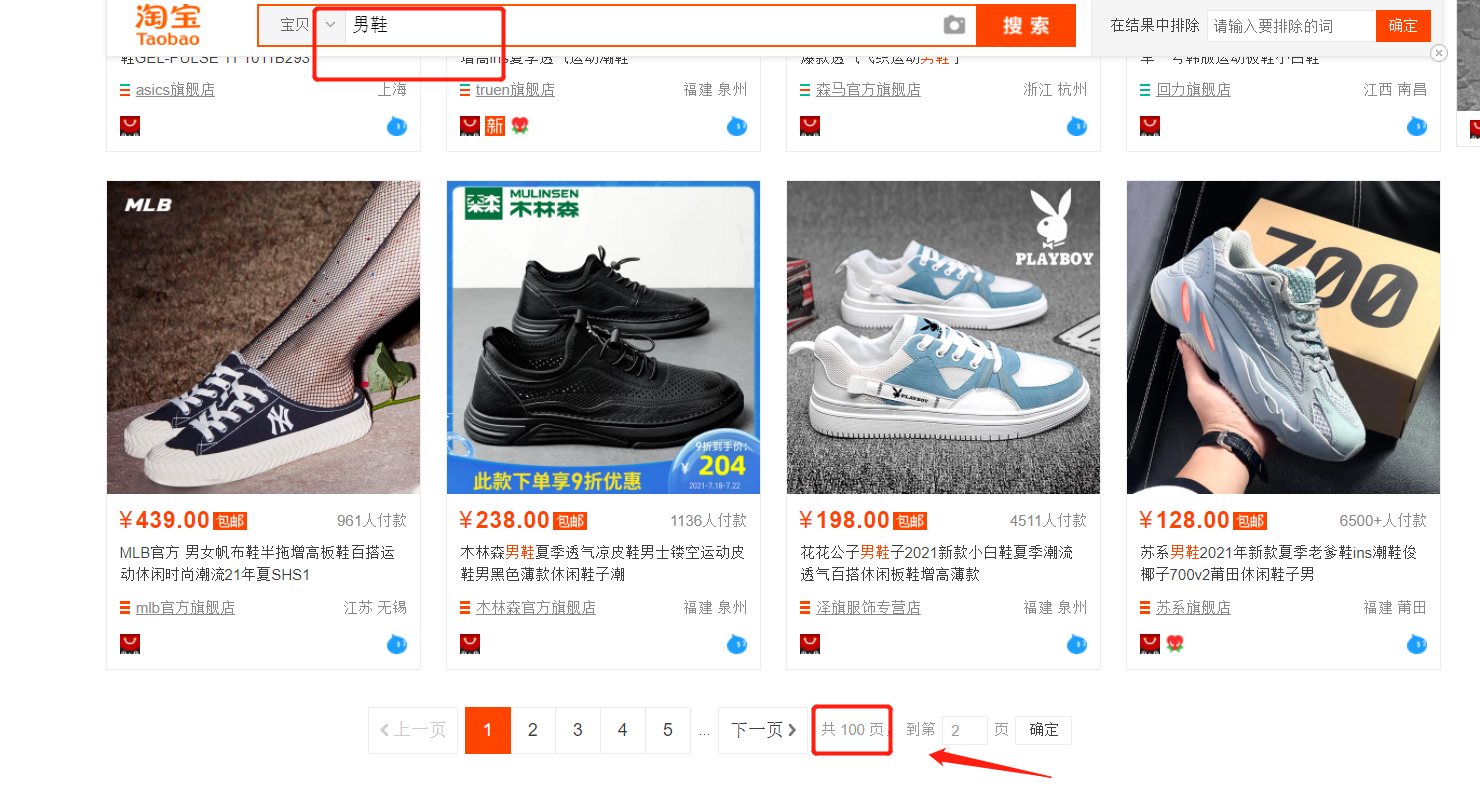
我们以淘宝网为例,使用比较热门的 “男鞋” 的关键词进行搜索,网站仅仅提供了 100 个数据
页。
很多大型互联网公司由于数据量巨大,都有使用这种方法。
流式分页
这种分页方式比较适用于移动端,即只能一页一页的向前或向后加载,不提供跳转的功能。
可以在上一级入口中提供业务列表给用户选择,从而减少分页。
这种分页方式在电商和新闻类 APP 上应用的非常广泛,你也可以试试。
总结
总的来说,大分页的优化思路就是让分页的SQL语句尽量在最佳的性能区间内执行,不要触发全表顺序扫描,也不要扫描太多的数据行。
SQL 的优化有两个方向,一个是 SQL 语义的优化,另一个是从业务角度对 SQL 语句进行优化。
SQL 语义的优化所能发挥的功力有限,在 SQL 优化的工作中大概只有3成的SQL 能通过 SQL 的改写完成优化;而从业务角度的调优占了有 7 成。
因此在对 SQL 语句进行优化时,不妨多从业务角度入手,想想看有没有好的解决方案。
转载
MySQL如何优化超大的分页查询?