MongoDB的ReadConcern
文章目录
综述
在读取数据的过程中我们需要关注以下两个问题
- 从哪里读?关注数据节点位置
- 什么样的数据可以读?关注数据的隔离性
第一个问题是是由 readPreference 来解決 第二个问题则是由 readConcern 来解決
为了避免混淆,先简单说明下二者的区别。
- readPreference 主要控制客户端 Driver 从复制集的哪个节点读取数据,这个特性可方便的实现读写分离、就近读取等策略。
- readConcern 决定到某个读取数据时,能读到什么样的数据。
readPreference
什么是 readPreference
readpreference 决定使用哪一个节点来满足正在发起的读请求。可选值包括
- prmary:只选择主节点
- primarypreferred:优先选择主节点,如果不可用则选择从节点;
- secondary:只选择从节点
- secondarypreferred:优先选择从节点,如果从节点不可用则选择主节点
- nearest:选择最近的节点
ReadPreference 场景举例
- 用户下订单后马上将用户转到订单详情页–primary/primarypreferred。因为此时从节点可能还没复制到新订单.
- 用户查询自己下过的订单–secondary/secondarypreferred。查询历史订单对时效性通常没有太高要求.
- 生成报表–secondary.报表对时效性要求不高,但资源需求大,可以在从节点单独处理,避免对线上用户造成影响.
- 将用户上传的图片分发到全世界,让各地用户能够就近读取- nearest。每个地区的应用选择最近的节点读取数据。
Readpreference与Tag
readpreference 只能控制使用一类节点。Tag 则可以将节点选择控制到一个或几个节点。考虑以下场景:
- 一个5个节点的复制集;
- 3个节点硬件较好,专用于服务线上客户
- 2个节点硬件较差,专用于生成报表;
可以使用 Tag 来达到这样的控制目的
- 为3个较好的节点打上{purpose: “online”}
- 为2个较差的节点打上{purpose:“analyse”}
- 在线应用读取时指定online,报表读取时指定analyse
Readpreference配置
通过 Mongodb 的连接串参数:
|
|
通过 Mongodb 驱动程序 APl:
|
|
Mongo Shell:
|
|
注意事项
- 指定 readpreference 时也应注意高可用问题。例如将readpreference指定 prmary,则发生故障转移不存在prmary期间将没有节点可读。如果业务允许,则应选择 primarypreferred
- 使用 Tag 时也会遇到同样的问题,如果只有一个节点拥有一个特定 Tag,则在这个节点失效时将无节点可读。这在有时候是期望的结果,有时候不是。例如:
- 如果报表使用的节点失效,即使不生成报表,通常也不希望将报表负载转移到其他节点上,此时只有一个节点有报表 Tag 是合理的选择
- 如果线上节点失效,通常希望有替代节点,所以应该保持多个节点有同样的Tag;
- Tag 有时需要与优先级、选举权综合考虑。例如做报表的节点通常不会希望它成为主节点,则优先级应为0。
readConcern
什么是 read Concern?
在 readpreference 选择了指定的节点后,read Concern 决定这个节点上的数据哪些是可读的,类似于关系数据库的隔离级别。可选值包括
- available:读取所有可用的数据;
- local:读取所有可用且属于当前分片的数据;
- majority:读取在大多数节点上提交完成的数据;事务隔离级别相当于提交读.
- linearizable:可线性化读取文档;
- snapshot:读取最近快照中的数据;
local和available
在复制集中{oalL 和 available 是没有区别的。两者的区别主要体现在分片集上。考虑以下场景
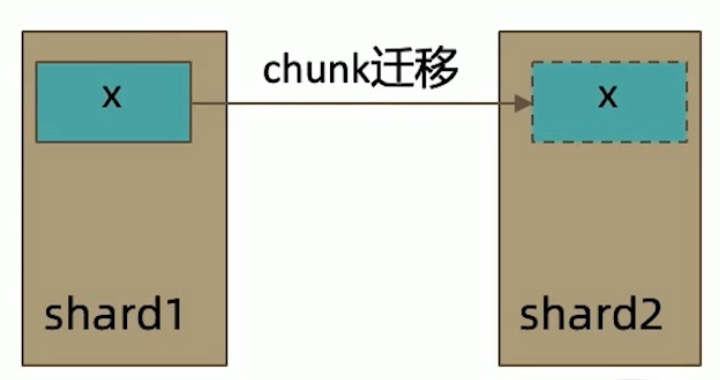
- 一个 chunk x 正在从 shard1 向 shard2 迁移
- 整个迁移过程中 chunk x 中的部分数据会在 shard1 和 shard2 中同时存在,但源分片 shard1 仍然是 chunk X 的负责方:
- 所有对 chunk x 的读写操作仍然进入 shard1
- config 中记录的信息 chunk x 仍然属于 shard1
- 此时如果读 shard2, 则会体现出 local 和 available 的区别
- local:只取应该由 shard2 负责的数据(不包括 x)
- available: shard2 上有什么就读什么(包括 x)
注意事项:
- 虽然看上去总是应该选择local,但毕竟对结果集进行过滤会造成额外消耗。在一些无关紧要的场景(例如统计)下,也可以考虑 available
- Mongodb <=3.6 不支持对从节点使用{readConcern:“local”}
- 从主节点读取数据时默认 read Concern 是 local,从从节点读取数据时默认 readConcern是available(向前兼容原因)
majority
只读取大多数据节点上都提交了的数据。考虑如下场景:
- 集合中原有文档{x:0}
- 将x值更新为 1
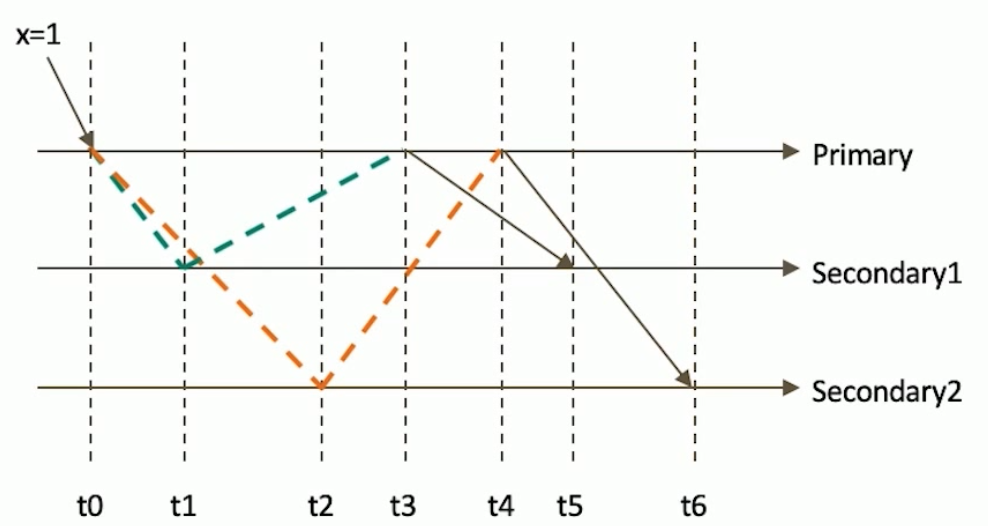
如果在各节点上应用{readConcern: “majority”}来读取数据
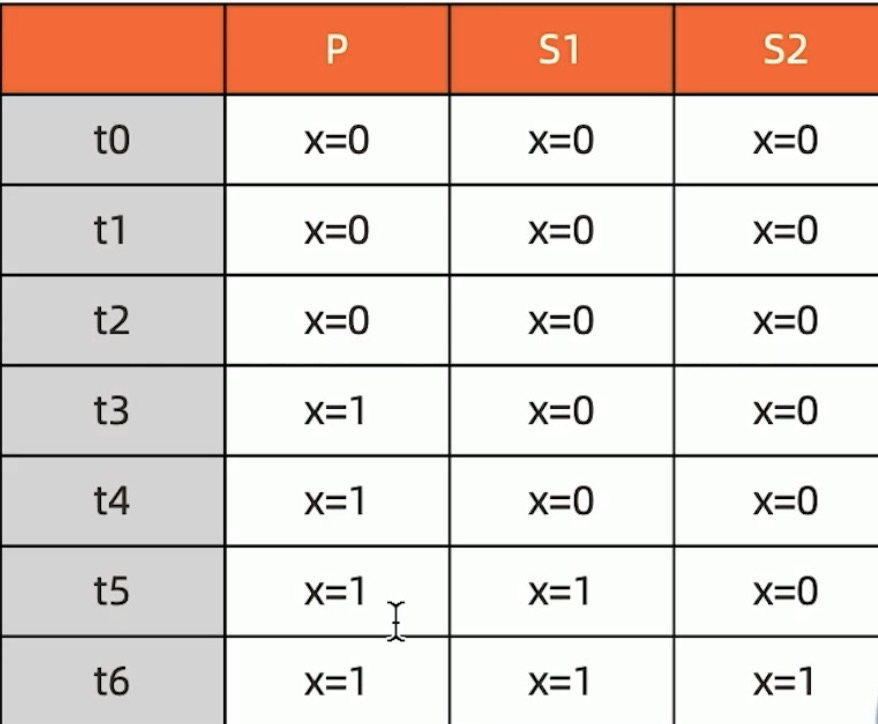
majority的实现方式
考虑 t3 时刻的 Secondary1, 此时:
- 对于要求 majority 的读操作,它将返回 X=0
- 对于不要求 majoity 的读操作,它将返回 x=1
如何实现?
节点上维护多个x版本,MVCC机制.Mongodb通过维护多个快照来链接不同的版本:
- 每个被大多数节点确认过的版本都将是一个快照
- 快照持续到没有人使用为止才被删除;
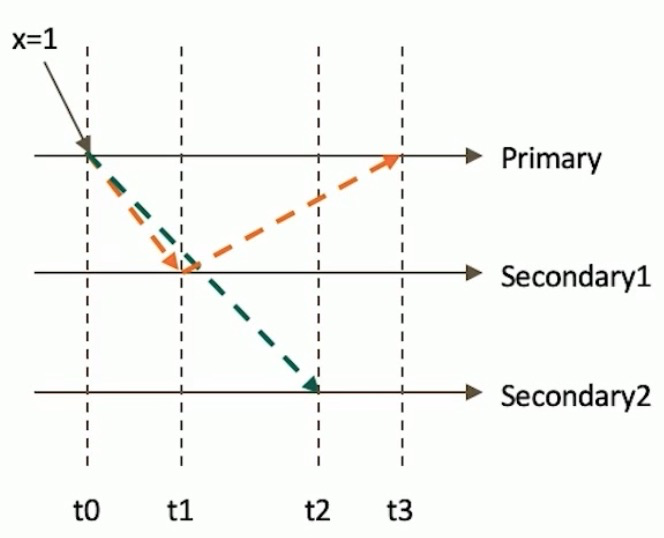
majority与脏读
readConcern 的初衷在于解决『脏读』的问题,比如用户从 MongoDB 的 primary 上读取了某一条数据,但这条数据并没有同步到大多数节点,然后 primary 就故障了,重新恢复后 这个primary节点会将未同步到大多数节点的数据回滚掉,导致用户读到了『脏数据』。
当指定 readConcern 级别为 majority 时,能保证用户读到的数据『已经写入到大多数节点』,而这样的数据肯定不会发生回滚,避免了脏读的问题。
需要注意的是,readConcern 能保证读到的数据『不会发生回滚』,但并不能保证读到的数据是最新的.
有用户误以为,readConcern 指定为 majority 时,客户端会从大多数的节点读取数据,然后返回最新的数据。实际上并不是这样,无论何种级别的 readConcern,客户端都只会从『某一个确定的节点』(具体是哪个节点由 readPreference 决定)读取数据,该节点根据自己看到的同步状态视图,只会返回已经同步到大多数节点的数据。
MONGODB中的回滚:
- 写操作到达大多数节点之前都是不安全的,一旦主节点崩溃,而从节还没复制到该次操作,刚才的写操作就丢失了
- 把一次写操作视为一个事务,从事务的角度,可以认为事务被回滚了。
所以从分布式系统的角度来看,事务的提交被提升到了分布式集群的多个节点级别的"提交",而不再是单个节点上的“提交”。
在可能发生回滚的前提下考虑脏读问题:
- 如果在一次写操作到达大多数节点前读取了这个写操作,然后因为系统故障该操作回滚了,则发生了脏读问题;
使用{readConcern:"majority"}可以有效避免脏读
majority实现安全的读写分离
考虑如下场景:
- 向主节点写入一条数据;
- 立即从从节点读取这条数据。
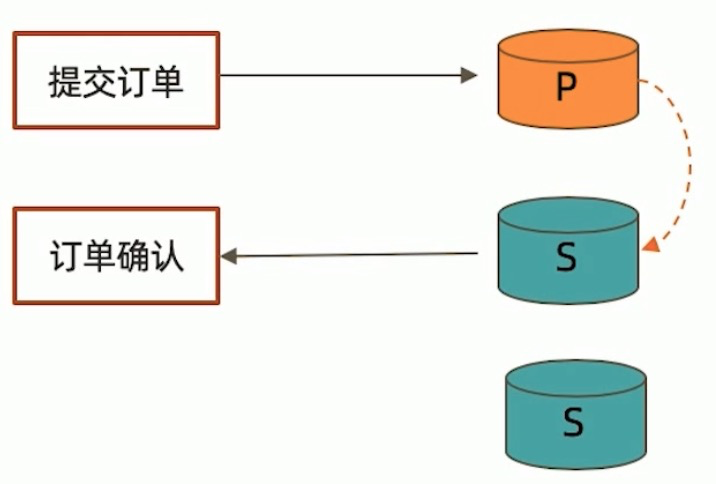
如何保证自己能够读到刚刚写入的数据?
下述方式有可能读不到刚写入的订单:
|
|
使用 writeConcern+readConcern majority 来解決:
|
|
readConcern 实现原理
MongoDB 要支持 majority 的 readConcern 级别,必须设置replication.enableMajorityReadConcern参数,加上这个参数后,MongoDB 会起一个单独的snapshot 线程,会周期性的对当前的数据集进行 snapshot,并记录 snapshot 时最新 oplog的时间戳,得到一个映射表。
| 最新oplog时间戳 | snapshot | 状态 |
|---|---|---|
| t0 | snapshot0 | committed |
| t1 | snapshot1 | uncommitted |
| t2 | snapshot2 | uncommitted |
| t3 | snapshot3 | uncommitted |
只有确保 oplog 已经同步到大多数节点时,对应的 snapshot 才会标记为 commmited,用户读取时,从最新的 commited 状态的 snapshot 读取数据,就能保证读到的数据一定已经同步到的大多数节点。
关键的问题就是如何确定『oplog 已经同步到大多数节点』?
primary 节点
secondary 节点在自身oplog发生变化时,会通过 replSetUpdatePosition 命令来将 oplog 进度立即通知给 primary,另外心跳的消息里也会包含最新 oplog 的信息;通过上述方式,primary 节点能很快知道 oplog 同步情况,知道『最新一条已经同步到大多数节点的 oplog』,并更新 snapshot 的状态。比如当t2已经写入到大多数据节点时,snapshot1、snapshot2都可以更新为 commited 状态。(不必要的 snapshot也会定期被清理掉)
secondary 节点
secondary 节点拉取 oplog 时,primary 节点会将『最新一条已经同步到大多数节点的 oplog』的信息返回给 secondary 节点,secondary 节点通过这个oplog时间戳来更新自身的 snapshot 状态。
linearizable
只读取大多数节点确认过的数据。和majority最大差别是保证绝对的操作线性顺序一在写操作自然时间后面的发生的读,一定可以读到之前的写.
- 只对读取单个文档时有效;
- 可能导致非常慢的读,因此总是建议配合使用maxTimeMS;
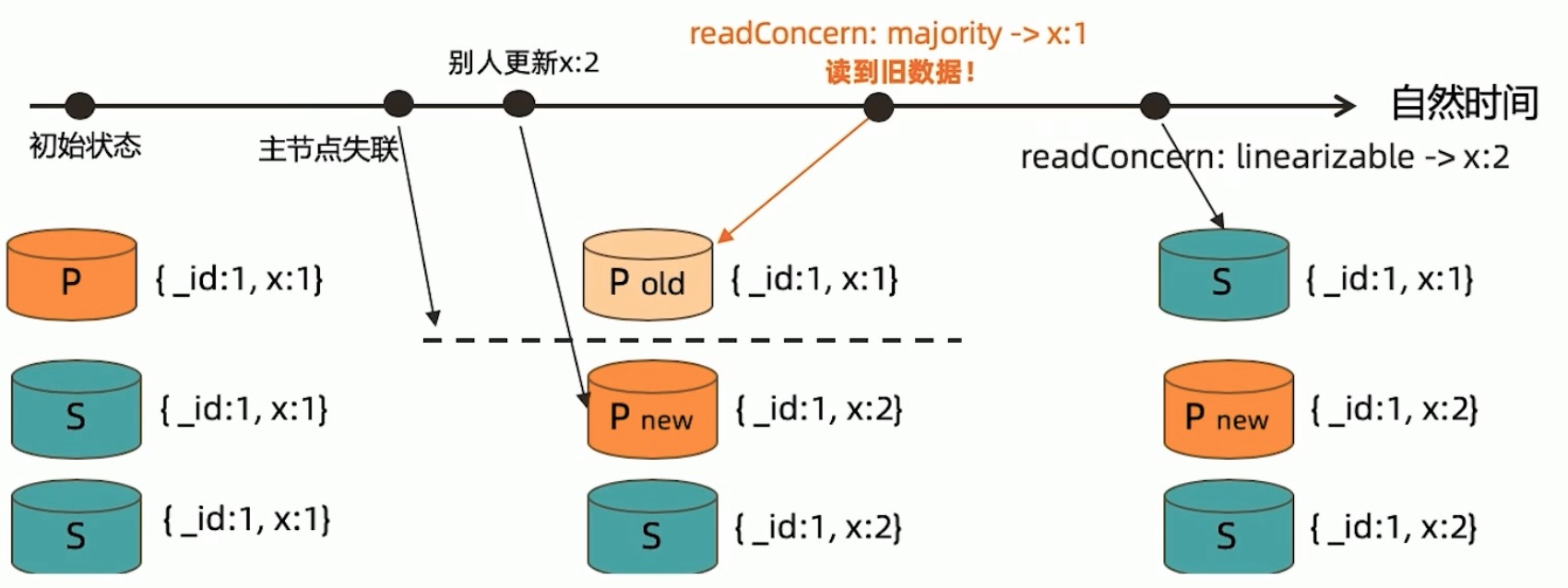
即使用了majority,在极少数情况下依然会有脏读存在:
- 初始状态,x=1更新到3个节点.
- 主节点没有宕机,但因为网络问题与从节点失联,其他两节点与主节点失联后会进行选举,产生新的primary.
- 收到x=2更新请求,新的主节点和从节点对x更新.
- 旧的主节点在自检过程中,且还没发现自身失联时,客户端请求,会读取到旧数据x=1.
在这种情况下,需要使用linearizable.如果设置linearizable,在读取单个文档时,数据库会检查所有节点,只有多个节点响应数据为最新值,才会返回.如果旧的主节点和其他节点失联,会在检查中发现,不会读取到旧数据x=1.
因为linearizable的性能非常低,一般情况下用不到这个级别.
snapshot
snapshot只在多文档事务中生效。将一个事务的readConcern设置为snapshot,将保证在事务中的读:
- 不出现脏读;
- 不出现不可重复读;
- 不出现幻读。
因为所有的读都将使用同一个快照,直到事务提交为止该快照才被释放。
注意事项
- 目前 readConcern 主要用于跟 mongos 与 config server 的交互上,参考MongoDB Sharded Cluster 路由策略
- 使用 readConcern 需要配置replication.enableMajorityReadConcern选项
- 只有支持 readCommited 隔离级别的存储引擎才能支持 readConcern,比如 wiredtiger 引擎,而 mmapv1引擎则不能支持。
文章作者 Forz
上次更新 2020-03-26