MongoDB复制集机制及原理
文章目录
复制集的作用
MongoDB复制集的主要意义在于实现服务高可用.
它的实现依赖于两个方面的功能:
- 数据写入时将数据迅速复制到另一个独立节点上.
- 在接受写入的节点发生故障时自动选举出一个新的替代节点.
在实现高可用的同时,复制集实现了其他几个附加作用:
- 数据分发:将数据从一个区域复制到另一个区域,减少另一个区域的读延迟
- 读写分离:不同类型的压力分别在不同的节点上执行
- 异地容灾:在数据中心故障时候快速切换到异地
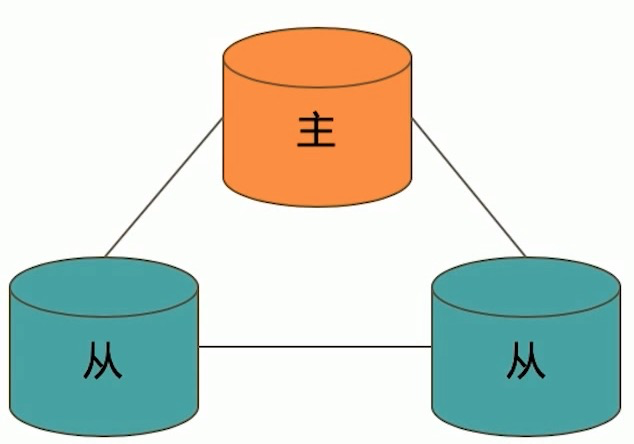
典型复制集结构
一个典型的复制集由3个以上具有投票权的节点组成,包括:
- 一个主节点(PRIMARY) :接受写入操作和选举时投票
- 两个(或多个)从节点(SECONDARY):复制主节点上的新数据和选举时投票
- 投票节点:节点并没有数据,只有投票功能.因为投票采取大多数采纳的算法,如果只有一个primary和secondry,需要增加1个投票节点,但现在不推荐使用投票节点,最好使用secondry节点.
数据如何复制
当一个修改操作,无论是插入、更新或删除,到达主节点时,它对数据的操作将被记录下来(经过一些必要的转换),这些记录称为oplog。
有一个线程专门监听oplog的变动,从节点通过在主节点上打开一个tailable游标不断获取新进入主节点的oplog,并在自己的数据上回放,以此保持跟主节点的数据一致。

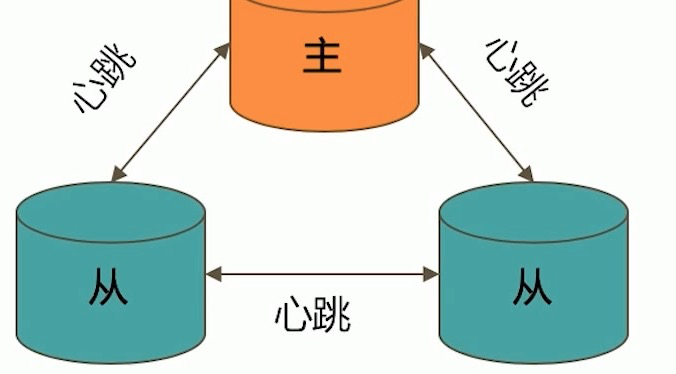
通过选举完成故障恢复
- 具有投票权的节点之间两两互相发送心跳;
- 当5次心跳未收到时判断为节点失联;
- 如果失联的是主节点,从节点会发起选举,选出新的主节点;
- 如果失联的是从节点则不会产生新的选举;
- 选举基于RAFT一致性算法实现,选举成功的必要条件是大多数投票节点存活;
- 复制集中最多可以有50个节点,但具有投票权的节点最多7个。
影响选举的因素
整个集群必须有大多数节点存活,被选举为主节点的节点必须:
- 能够与多数节点建立连接
- oplog比其他节点同等或较新.
- 具有较高的优先级(如果有配置)
常见选项
复制集节点有以下常见的选配项:
- 是否具有投票权(v参数) :有则参与投票,默认为有.
- 优先级( priority参数) :优先级越高的节点越优先成为主节点。优先级为0的节点无法成为主节点.通常在分地分中心部署时,把主数据中心的节点优先级调高,可以让主节点一直保持在主数据中心.
- 隐藏(hidden参数) :复制数据,但对应用不可见。隐藏节点可以具有投票仅,但优先级必须为0.有时可以用节点做数据库的额外备份,我们不希望在这个节点参与数据的操作和应用程序的服务,只希望多一份数据,这时可以设置为隐藏.
- 延迟(slaveDelay 参数) :复制n秒之前的数据,保持与主节点的时间差。我们有可能出现误操作,比如删表,删库.我们可以增加一个延迟较高的从节点,比如12小时,这样我们就有了12小时的恢复处理时间.
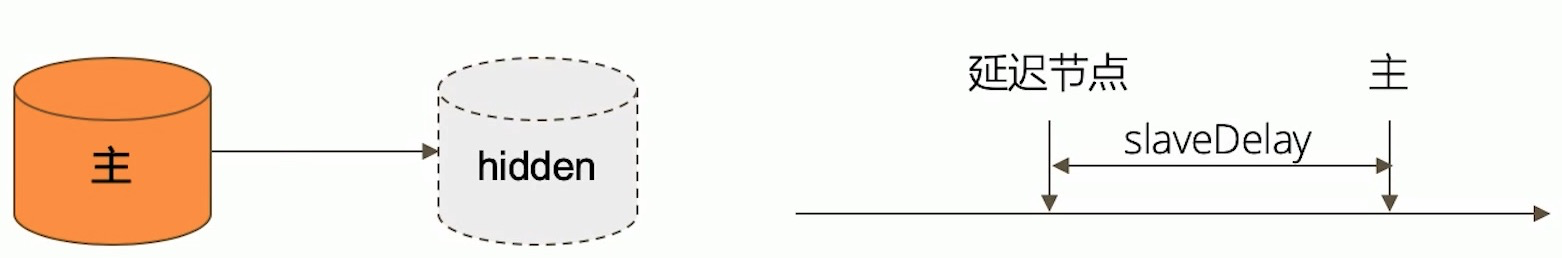
注意事项
硬件:
- 因为除了专门用于备份的节点外,正常的复制集节点都有可能成为主节点,它们的地位是一样的,因此硬件配置上必须一致;
- 为了保证节点不会同时宕机,各节点使用的硬件必须具有独立性。
软件:
- 复制集各节点软件版本必须一致,以避免出现不可预知的问题。
- 增加节点不会增加系统写性能,反而会有更大的影响.
- 增加节点能增加系统读性能,因为可以新增一些专门用于读的节点.
文章作者 Forz
上次更新 2020-03-28