MongoDB分片集群机制及原理
文章目录
为什么要使用分片集群?
- 数据容量日益增大,访问性能日渐降低,怎么破?
- 新品上线异常火爆,如何支撑更多的并发用户?
- 单库已有10TB数据,恢复需要1一2天,如何加速?
- 数据需要服务全球用户,如何让全球的用户全部快速,低延迟地访问数据?
分片集群
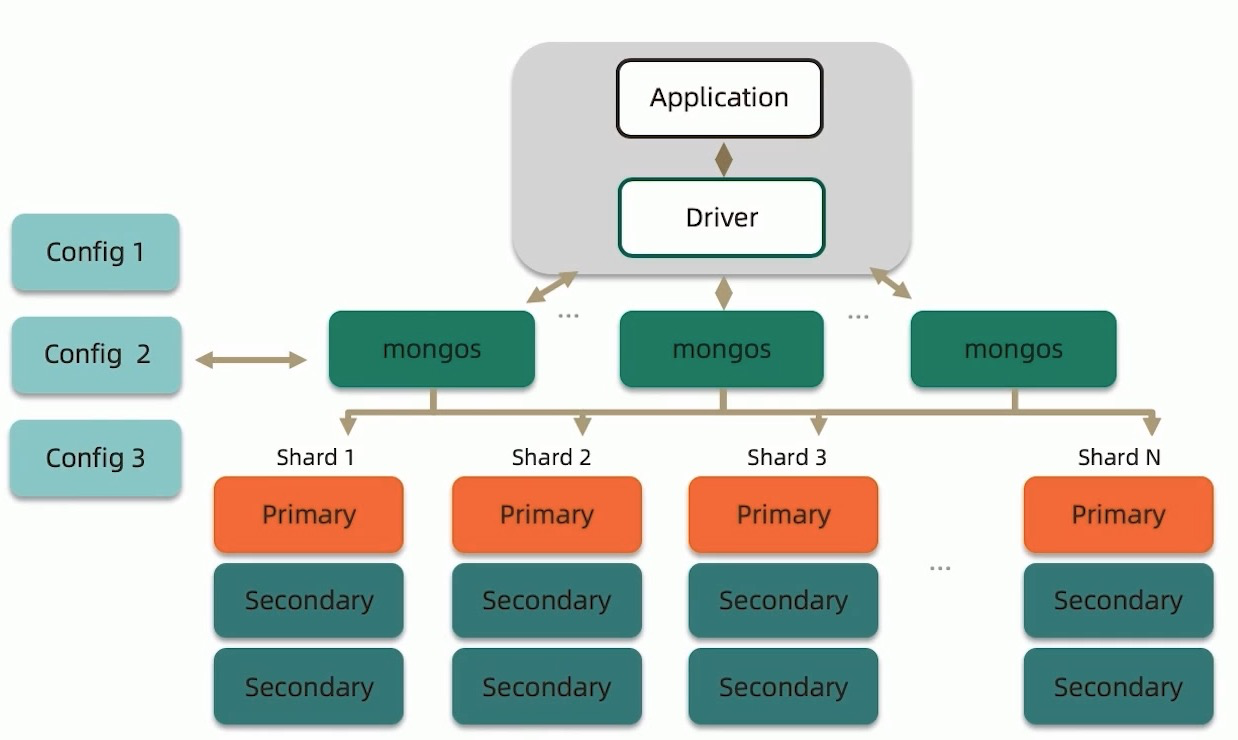
完整的分片集群包括以下几个部分:
- 路由节点(mongos):为应用程序提供集群的单一入口,转发应用端请求,选择合适的数据节点进行读写,合并多个数据节点的返回.
- 无状态
- 建议至少2个,主要是做高可用,还可以做负载均衡.
- 配置节点(config):配置节点是标准的MongoDB复制集,,这三个节点的数据相同,提供集群元数据存储,分片数据分布的映射.
- 数据节点(mongod):以复制集为单位,横向扩展,最大1024分片,分片之间数据不重复,所有分片在一起才完整工作.
分片集群特点:
- 应用全透明,无特殊处理:分片集群的应用程序和单复制集的应用程序相同,不需要进行代码修改.
- 数据自动均衡:自动检测各节点数据分布情况,如果不平衡,MongoDB自动将一分片的数据搬到另一分片.
- 动态扩容,无须下线:不用一开始就构建分片集群,可以是复制集.当需要的时候,可以动态在线上增加新的复制集.
数据分布方式
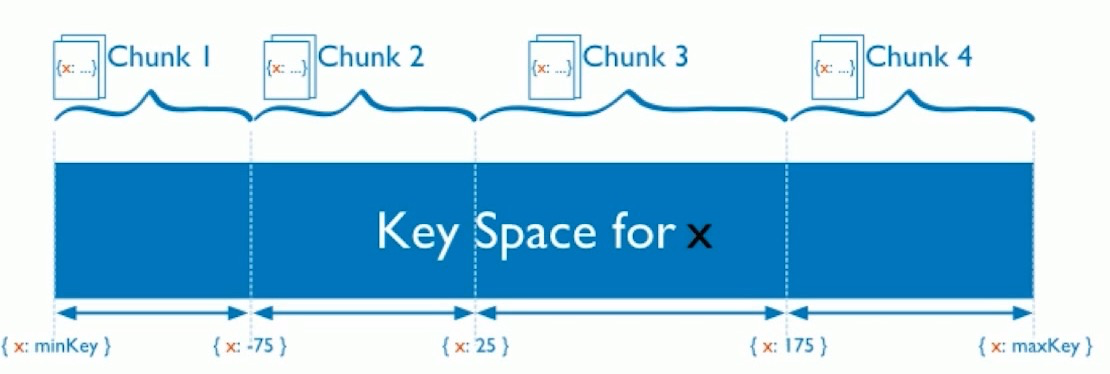
基于范围
选一个或几个组合字段,把字段的值的范围分成多个范围块,如chunk1,chunk2….将这些chunk分配到不同的分片中.
优点:
- 片键范围查询性能好.相邻的数据保存在同一节点中.读性能提高
缺点:
- 数据分布可能不均匀,容易有热点.比如以自增主键为片键,写操作总是最新的分片中.
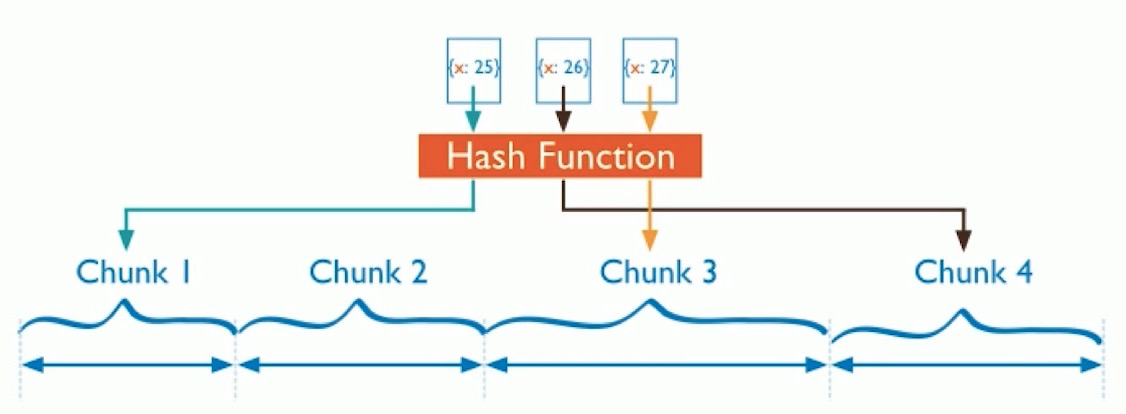
基于哈希
如果不希望有热分片,热点写的话,可以使用哈希方式.
将某个字段直接求哈希,放到对应的分片中.写操作可以随机分布到各个分片中.
优点:
- 数据分布均匀,写优化.
缺点:
- 范围查询效率低.每次范围查询都需要跨大量分片.
基于哈希的分片方式适合日志,物联网等高并发写入场景.
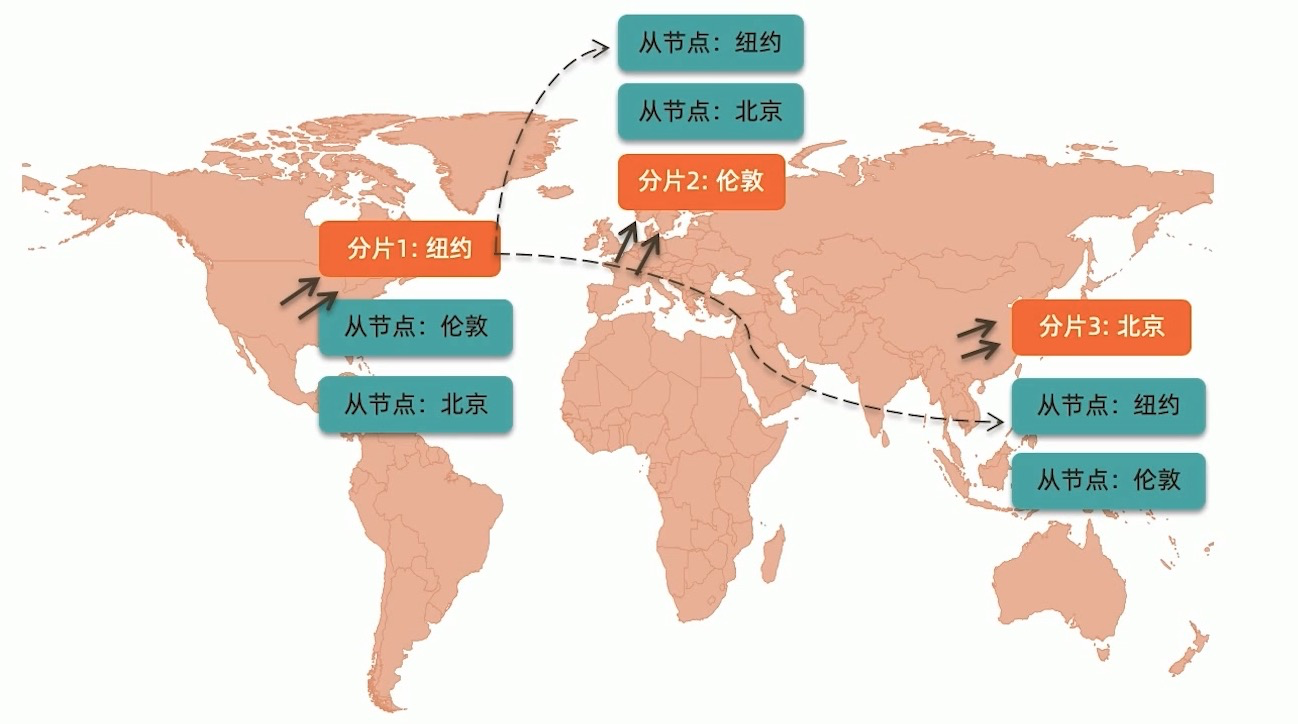
自定义Zone
如果数据有天然的地域性,某个区域的数据只用于某个区域的用户.这时可以给数据进行地域标签化.可以根据这些地域进行分片.
小结
分片集群可以有效解决性能瓶颈及系统扩容问题. 分片额外消耗较多,管理复杂,尽量不要分片,最好是在复制集中进行优化,实在无法支持再进行分片.
分片集群设计
如何用好分片集群

需要多少分片
分片的基本标准:
- 关于数据:数据量不超过3TB,尽可能保持在2TB一个片;
- 关于索引:常用索引必须容纳进内存;
按照以上标准初步确定分片后,还需要考虑业务压力,随着压力增大,CPU、RAM、磁盘中的任何一项出现瓶颈时,都可以通过添加更多分片来解决。
下面有个公式可以简单计算分片的数量:

工作集包括热数据和索引所占的空间:
- 索引通过index.stats可以得到
- 热数据和应用场景有关.新闻的热数据是最近几天的新闻,电商的热数据是商品详情.
单服务器内存容量:MongoDB默认用来做缓存的内存是物理内存的60%.
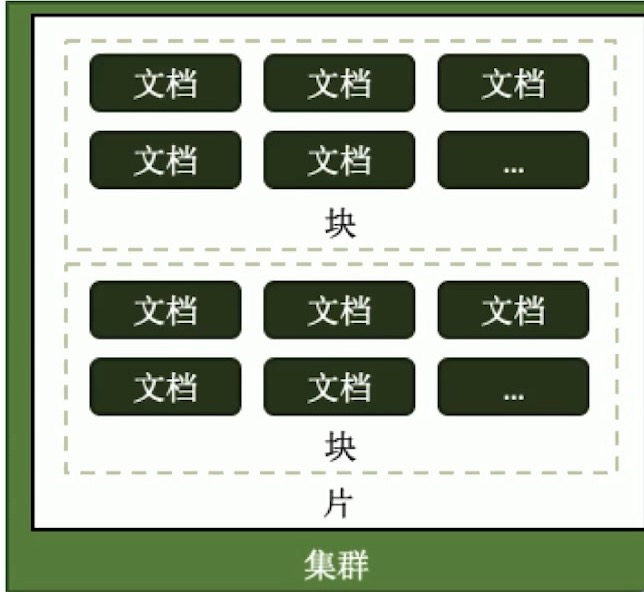
分片概念
各种概念由小到大:
- 片键shard key:文档中的一个字段或多个组合字段,是分片的准则.
- 文档doc:包含shardkey的一行数据.MongoDB存储的基本单位.
- 块Chunk :包含n个文档,通常为64MB.包含文档数量取决于文档的大小.分片集群的均衡以块为单位.
- 分片Shard:包含n个chunk
- 集群Cluster:包含n个分片
选择合适片键
影响片键效率的主要因素:
- 取值基数(Cardinality)
- 取值分布
- 分散写,集中读
- 被尽可能多的业务场景用到
- 避免单调递增或递减的片键
选择基数大的片键
对于小基数的片键:
- 因为备选值有限,那么块的总数量就有限;
- 随着数据增多,块的大小会越来越大;
- 太大的块,会导致水平扩展时移动块会非常困难。因为MongoDB以块为单位进行分片均衡.如果块过大,分片均衡困难.
例如:存储一个高中的师生数据,以年龄( 假设年龄范围为15~65岁)作为片键,那么
- 15<=年龄<=65,且只为整数
- 最多只会有51个chunk
结论:取值基数要大!
选择分布均匀的片键
对于分布不均匀的片键:
- 造成某些块的数据量急剧增大
- 这些块压力随之增大
- 数据均衡以chunk为单位,所以系统无能为力
例如:存储一个学校的师生数据,以年龄(假设年龄范围为15~65岁)作为片键,那么:
- 15<=年龄<=65,且只为整数
- 大部分人的年龄范围为15~18岁(学生)
- 15、16、17、18四个chunk的数据量、访问压力远大于其他chunk
结论:取值分布应尽可能均匀
定向性好
考虑:
4个分片的集群,你希望读某条特定的数据.如果你用片键作为条件查询,mongos可以直接定位到具体的分片如果你不用片键, mongos需要把查询发到4个分片等最后的一个分片响应,mongos才能响应应用端。
结论:对主要查询要具有定向能力
足够的资源
mongos与config通常消耗很少的资源,可以选择低规格虚拟机;
资源的重点在于shard服务器:
- 需要足以容纳热数据索引的内存;
- 正确创建索引后CPU通常不会成为瓶颈,除非涉及非常多的计算;
- 磁盘尽量选用SSD。
最后,实际测试是最好的检验,来看你的资源配置是否完备。
文章作者 Forz
上次更新 2020-03-29