Memchache和redis的选型对比
文章目录
memcache
memcache 提供简单的 kv cache 存储,value 大小不超过1mb。
我使用 memcache 作为大文本或者简单的 kv结构使用。
memcache 使用了slab 方式做内存管理,存在一定的浪费,如果大量接近的 item,建议调整 memcache 参数来优化每一个 slab 增长的 ratio、可以通过设置 slab_automove & slab_reassign 开启memcache 的动态/手动 move slab,防止某些 slab 热点导致内存足够的情况下引发 LRU。
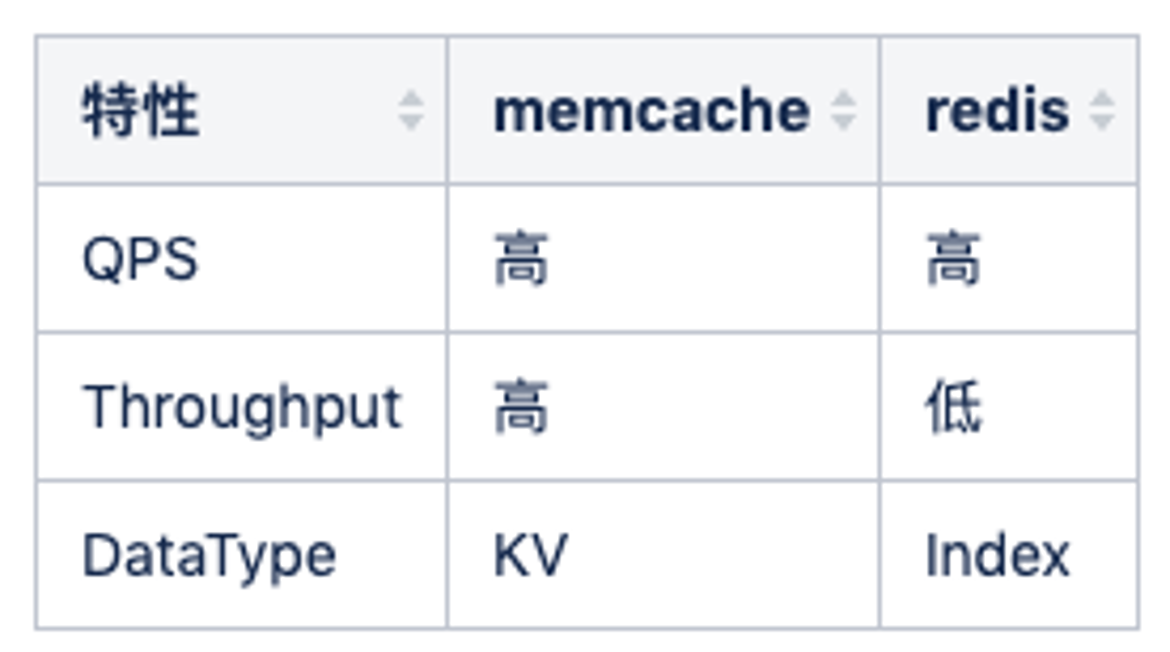
大部分情况下,简单 KV 推荐使用 Memcache,吞吐和相应都足够好。

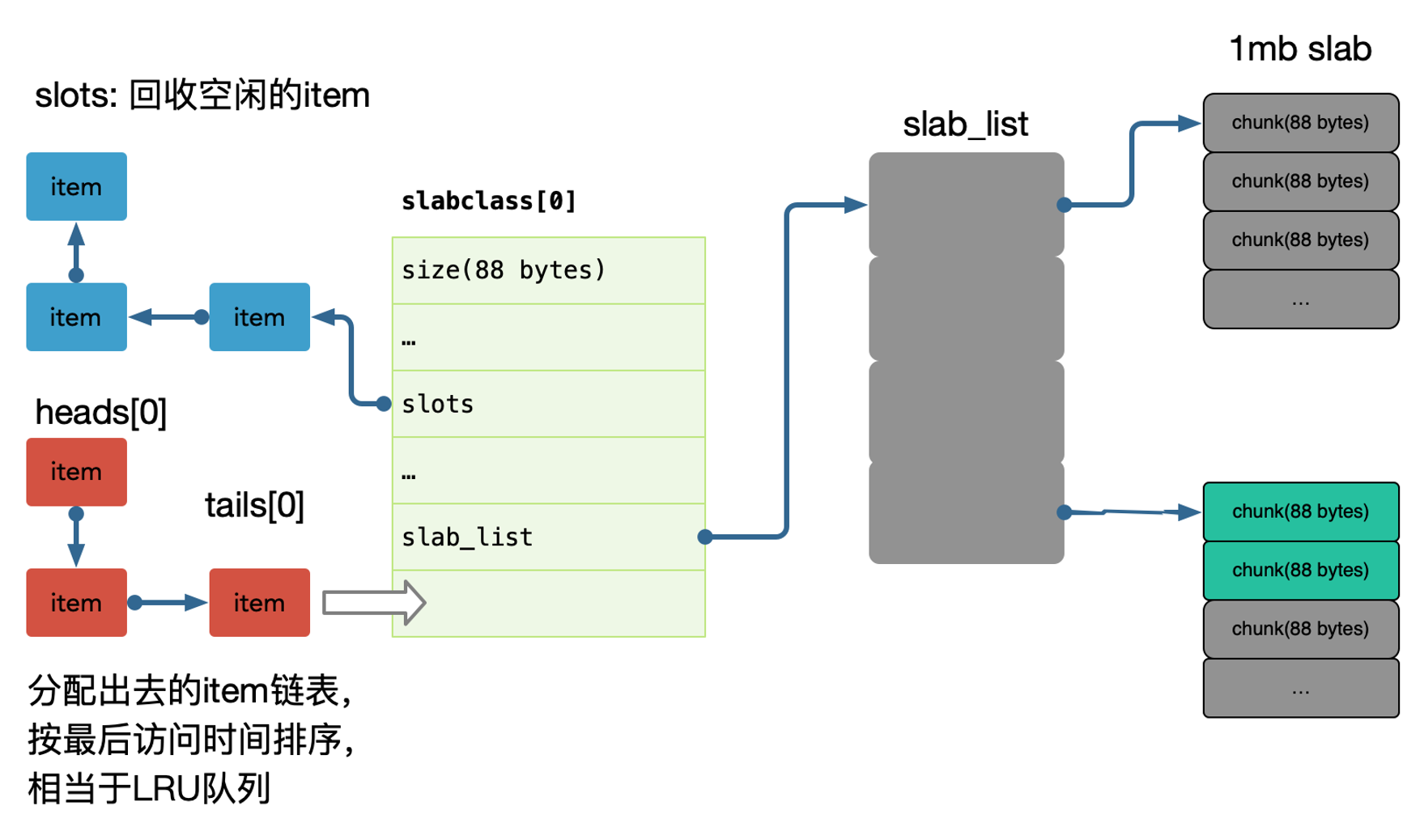
每个 slab 包含若干大小为1M的内存页,这些内存又被分割成多个 chunk,每个 chunk存储一个 item;
在 memcache 启动初始化时,每个 slab 都预分配一个 1M 的内存页,由slabs_preallocate 完成(也可将相应代码注释掉关闭预分配功能)。
chunk 的增长因子由 -f 指定,默认1.25,起始大小为48字节。
内存池有很多种设计,可以参考下: nginx ngx_pool_t,tcmalloc 的设计等等。
redis
redis 有丰富的数据类型,支持增量方式的修改部分数据,比如排行榜,集合,数组等。
比较常用的方式是使用 redis 作为数据索引,比如评论的列表 ID,播放历史的列表 ID 集合,我们的关系链列表 ID。
redis 因为没有使用内存池,所以是存在一定的内存碎片的,一般会使用 jemalloc 来优化内存分配,需要编译时候使用 jemalloc 库代替 glib 的 malloc 使用。

redis vs memcache
Redis 和 Memcache 最大的区别其实是 redis 单线程(新版本双线程),memcache 多线程,所以 QPS 可能两者差异不大,但是吞吐会有很大的差别,比如大数据 value 返回的时候,redis qps 会抖动下降的的很厉害,因为单线程工作,其他查询进不来(新版本有不少的改善)。
所以建议纯 kv 都走 memcache,比如我们的关系链服务中用了 hashs 存储双向关系,但是我们也会使用 memcache 档一层来避免hgetall 导致的吞吐下降问题。
我们系统中多次使用 memcache + redis 双缓存设计。
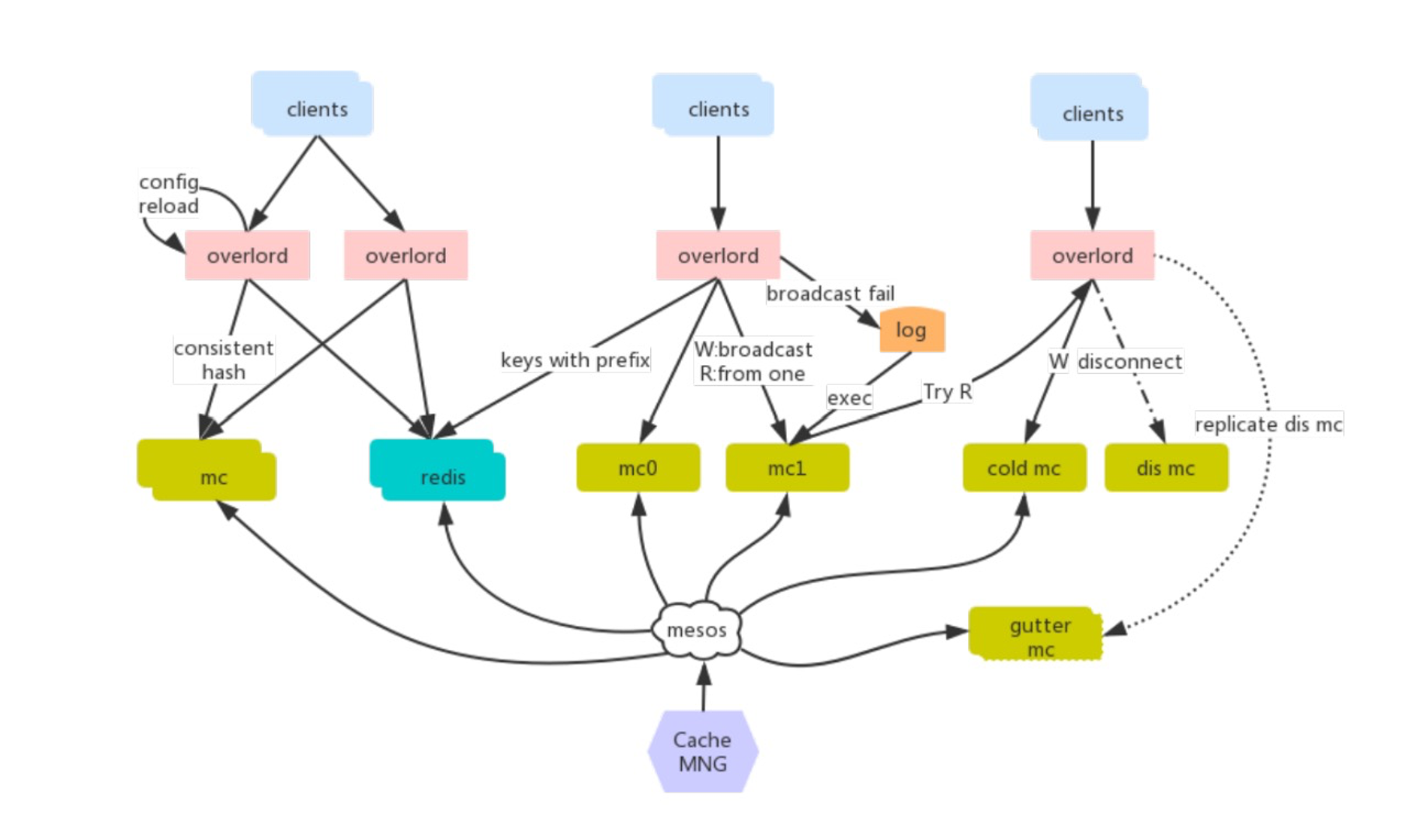
缓存选型 - Proxy
早期使用 twemproxy 作为缓存代理,但是在使用上有如下一些痛点:
- 单进程单线程模型和 redis 类似,在处理一些大 key 的时候可能出现 io 瓶颈;
- 二次开发成本难度高,难以于公司运维平台进行深度集成;
- 不支持自动伸缩,不支持 autorebalance 增删节点需要重启才能生效;
- 运维不友好,没有控制面板;
业界开源的的其他代理工具:
- codis: 只支持 redis 协议,且需要使用 patch版本的 redis;
- mcrouter: 只支持 memcache 协议,C 开发,与运维集成开发难度高;
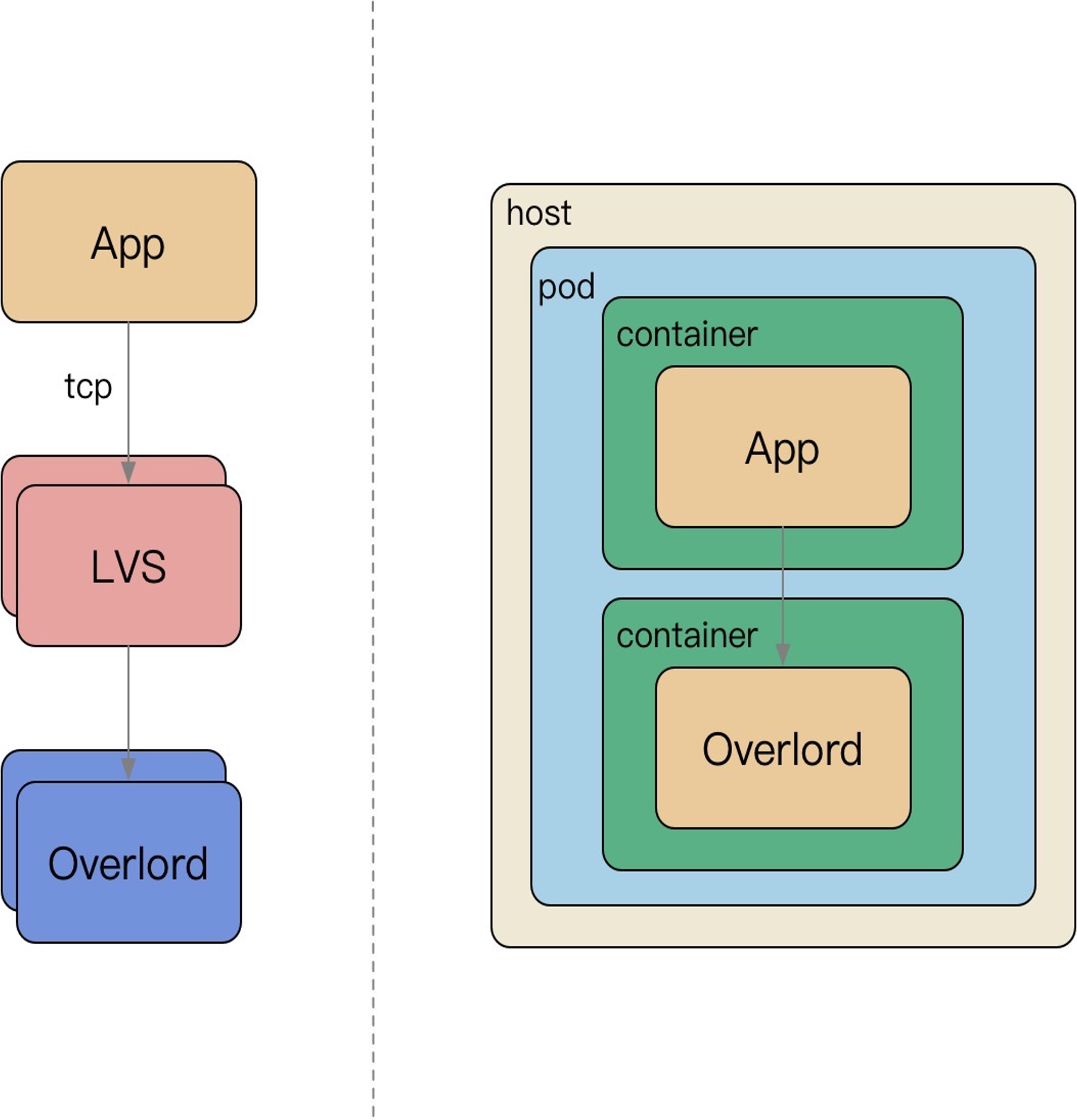
从集中式访问缓存到 Sidecar 访问缓存:
- 微服务强调去中心化;
- LVS 运维困难,容易流量热点,随下游扩容而扩容,连接不均衡等问题;
- Sidecar 伴生容器随 App 容器启动而启动,配置简化;
缓存选型 - Hash
数据分片的 hash 方式也是这个思想,即按照数据的某一特征(key)来计算哈希值,并将哈希值与系统中的节点建立映射关系,从而将哈希值不同的数据分布到不同的节点上。
按照 hash 方式做数据分片,映射关系非常简单;需要管理的元数据也非常之少,只需要记录节点的数目以及 hash 方式就行了。
当加入或者删除一个节点的时候,大量的数据需要移动。比如在这里增加一个节点 N3,因此 hash 方式变为了 mod 4。
均衡问题:原始数据的特征值分布不均匀,导致大量的数据集中到一个物理节点上;第二,对于可修改的记录数据,单条记录的数据变大。
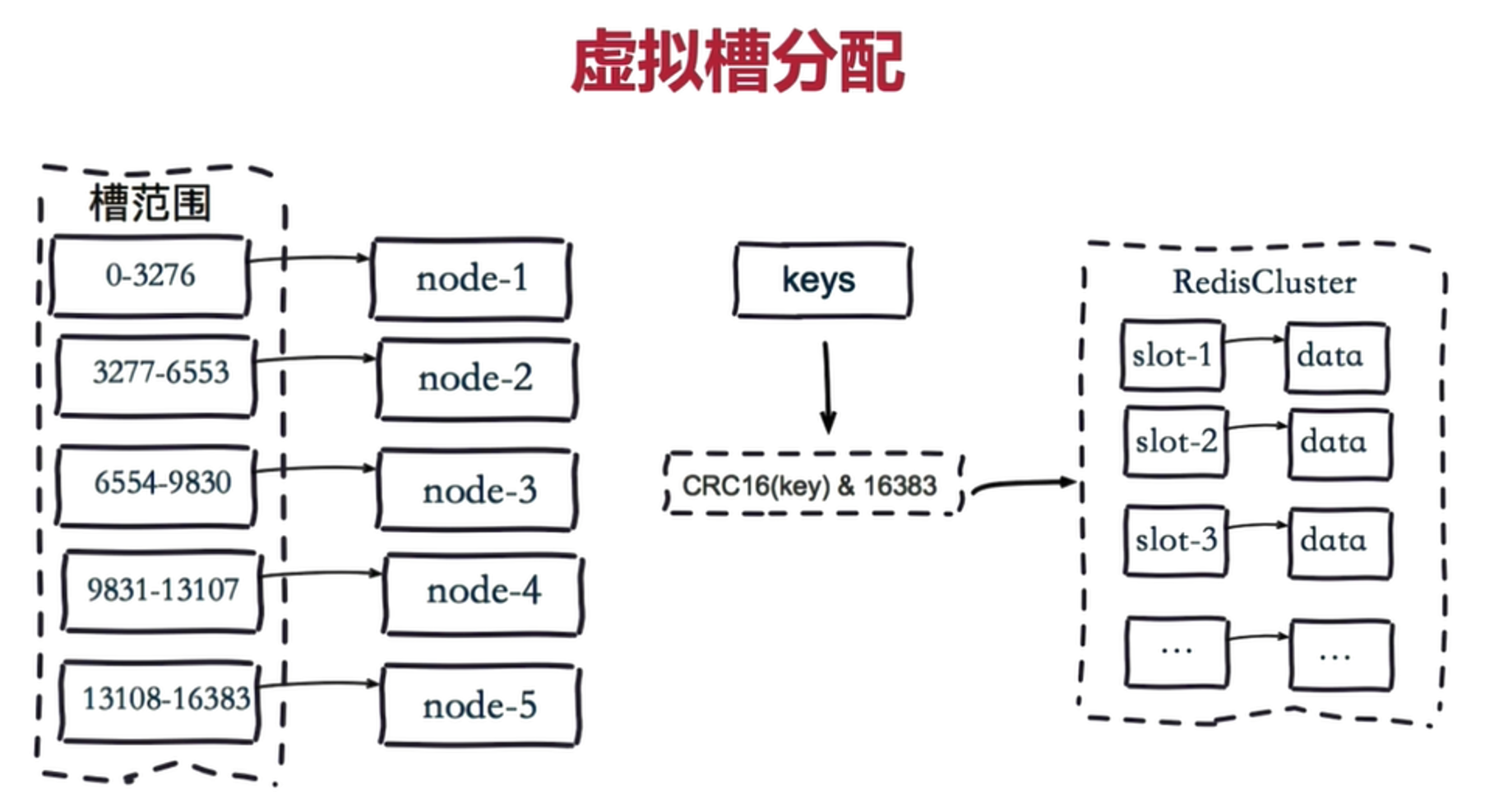
高级玩法是抽象 slot,基于 Hash 的 Slot Sharding,例如 Redis-Cluster。
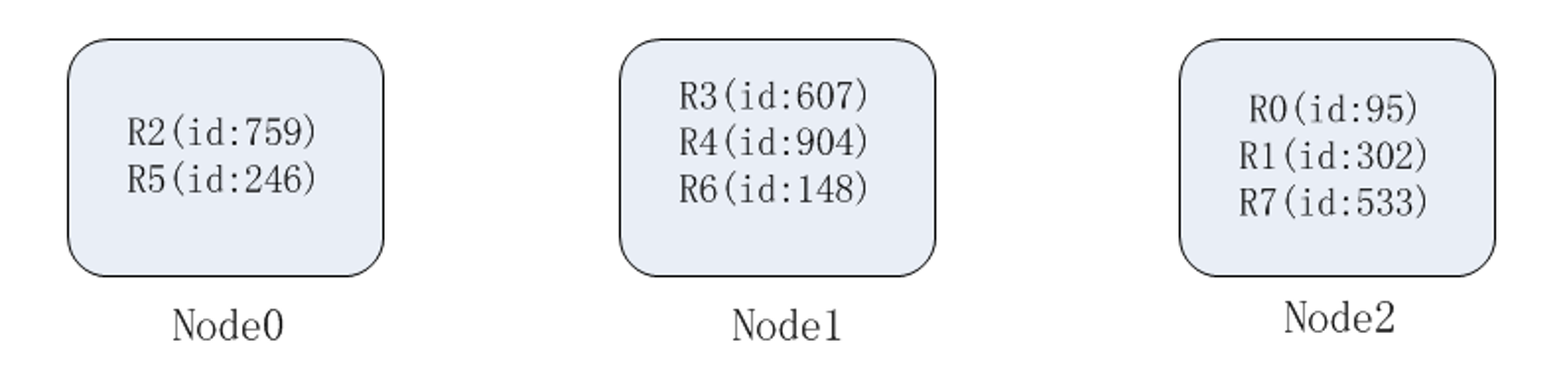
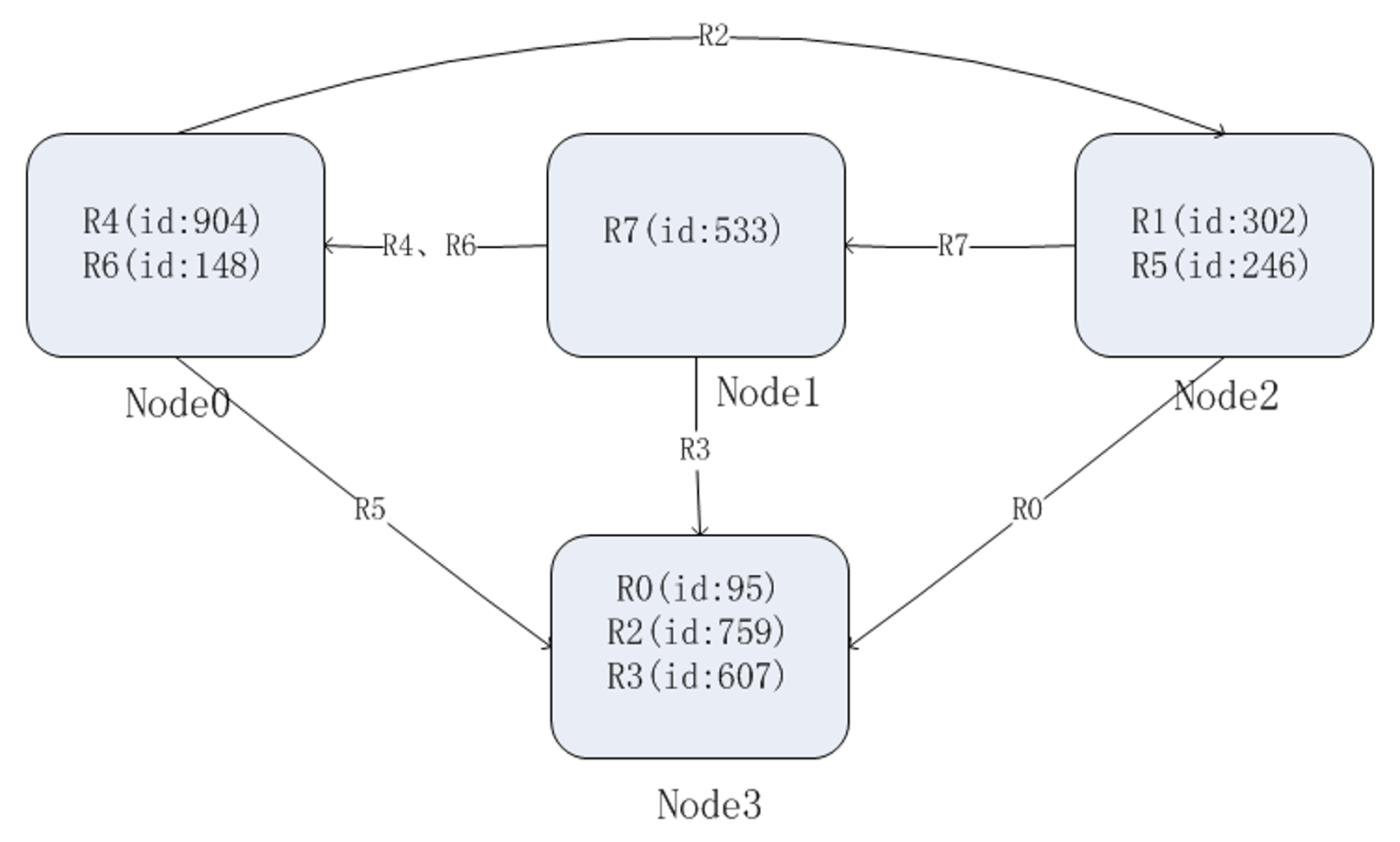
缓存选型 - Slot
redis-cluster 把16384 槽按照节点数量进行平均分配,由节点进行管理。
对每个 key 按照 CRC16 规则进行 hash 运算,把 hash 结果对16383进行取余,把余数发送给 Redis 节点。
需要注意的是:Redis Cluster 的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽
memcache 小技巧
flag 使用:标识 compress、encoding、large value 等;
memcache 支持 gets,尽量读取,尽可能的 pipeline,减少网络往返;
使用二进制协议,支持 pipeline delete,UDP 读取、TCP 更新;
redis 小技巧
增量更新一致性:EXPIRE、ZADD/HSET 等,保证索引结构体务必存在的情况下去操作新增数据;
BITSET: 存储每日登陆用户,单个标记位置(boolean),为了避免单个 BITSET 过大或者热点,需要使用 region sharding,比如按照mid求余 %和/ 10000,商为 KEY、余数作为offset;
List:抽奖的奖池、顶弹幕,用于类似 Stack PUSH/POP操作;
Sortedset: 翻页、排序、有序的集合,杜绝 zrange 或者 zrevrange 返回的集合过大;
Hashs: 过小的时候会使用压缩列表、过大的情况容易导致 rehash 内存浪费,也杜绝返回hgetall,对于小结构体,建议直接使用 memcache KV;
String: SET 的 EX/NX 等 KV 扩展指令,SETNX 可以用于分布式锁、SETEX 聚合了SET + EXPIRE;
Sets: 类似 Hashs,无 Value,去重等;
尽可能的 PIPELINE 指令,但是避免集合过大;
避免超大 Value;
文章作者 Forz
上次更新 2021-11-28