介绍
lumberjack就是一个用来管理日志文件的利器,经常与各种日志组件配合起来使用,实现日志的老化压缩,文件分割等等功能。
清理旧的日志文件策略
每当创建新的日志文件时,旧的日志文件都可能被删除。删除会根据MaxAge和MaxBackups的参数设置
- 时间戳早于MaxAge天的文件都会被删除,如果MaxAge为0,则不会根据MaxAge删除日志文件
- MaxBackups是要保留的最大旧日志文件数,用来控制该程序日志文件的最大大小。早于MaxBackups数之前的文件都会被删除,如果MaxBackups为0,则不会根据MaxBackups进行删除日志文件
- 如果MaxAge 和 MaxBackups都为0,则不会删除日志文件
lumberjack中的代码不多,重点实现就在lumberjack.go中。
而lumberjack.go中的结构体和变量主要有这些
Logger
可以看到,外部能访问到的只有Logger对象,那我们就从Logger对象开始,看看lumberjack是怎么使用,以及怎么实现日志文件的老化功能的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
type Logger struct {
// Filename is the file to write logs to. Backup log files will be retained
// in the same directory. It uses <processname>-lumberjack.log in
// os.TempDir() if empty.
//写日志的文件名称
Filename string `json:"filename" yaml:"filename"`
// MaxSize is the maximum size in megabytes of the log file before it gets
// rotated. It defaults to 100 megabytes.
//每个日志文件长度的最大大小,默认100M。
MaxSize int `json:"maxsize" yaml:"maxsize"`
// MaxAge is the maximum number of days to retain old log files based on the
// timestamp encoded in their filename. Note that a day is defined as 24
// hours and may not exactly correspond to calendar days due to daylight
// savings, leap seconds, etc. The default is not to remove old log files
// based on age.
//日志保留的最大天数(只保留最近多少天的日志)
MaxAge int `json:"maxage" yaml:"maxage"`
// MaxBackups is the maximum number of old log files to retain. The default
// is to retain all old log files (though MaxAge may still cause them to get
// deleted.)
//只保留最近多少个日志文件,用于控制程序总日志的大小
MaxBackups int `json:"maxbackups" yaml:"maxbackups"`
// LocalTime determines if the time used for formatting the timestamps in
// backup files is the computer's local time. The default is to use UTC
// time.
//是否使用本地时间,默认使用UTC时间
LocalTime bool `json:"localtime" yaml:"localtime"`
// Compress determines if the rotated log files should be compressed
// using gzip.
// 是否压缩日志文件,压缩方法gzip
Compress bool `json:"compress" yaml:"compress"`
size int64 //记录当前日志文件的字节数
file *os.File //当前的日志文件
mu sync.Mutex
millCh chan bool
startMill sync.Once
}
|
这是Logger结构的定义,重点也先看看可导出的变量:
- Filename:顾名思义,就是日志输出的文件名,这个文件名是一个全路径,即日志文件会在Filename指定的文件的目录下,进行存储和老化。
- MaxSize:日志文件的最大占用空间,也就是日志文件达到多大时触发日志文件的分割。单位是MB。
- MaxAge:已经被分割存储的日志文件最大的留存时间,单位是天。
- MaxBackups:已经被分割存储的日志文件最多的留存个数,单位是个。这个和上面的MaxAge共同生效,满足二者中的一个条件就会触发日志文件的删除。
- LocalTime:用来指定被分割的日志文件上的时间戳是否要使用本地时间戳,默认会使用UTC时间。
- Compress:指定被分割之后的文件是否要压缩。
以上是对于可导出成员变量的定义,要使用Logger对象,还应该知道它实现了哪些接口:
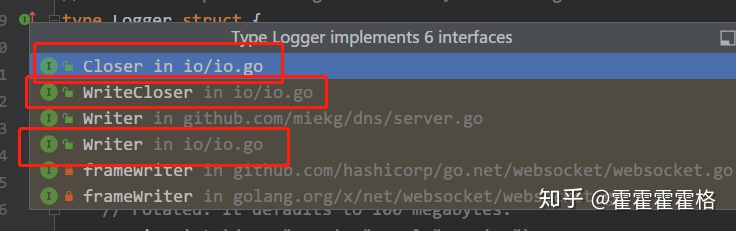
可以看到,Logger实现了标准库中的WriterCloser接口,也就是Writer和Closer接口。那么这里的Logger就可以作为一个Writer来用.
对于lumberjack,不用关心谁会调用它的Writer接口,只要实现好Writer内部的逻辑就好了。这种思想把职责完全分离开,互相只能看到接口,是高内聚,低耦合的一个很好的例子。
回到lumberjack中,看看Logger实现的方法:
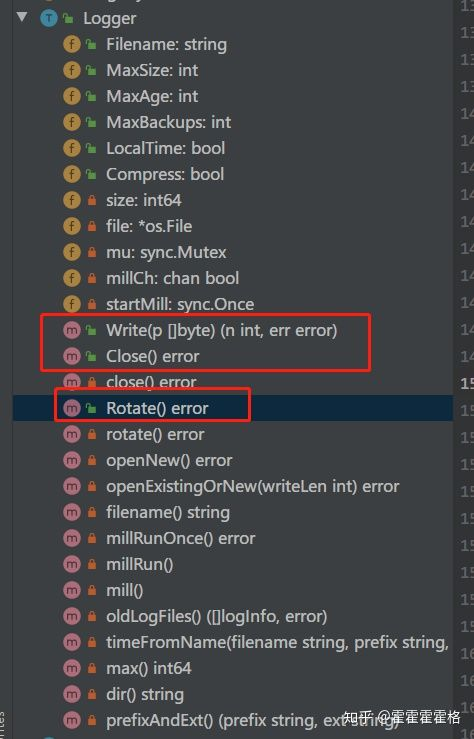
方法比较多,其中可导出方法有三个,两个是对于Writer和Closer接口的实现,Write和Close方法,还有一个用来主动触发日志分割的Rotate方法。
在这些方法当中,先看看几个和参数有关的方法:
1
2
3
4
5
6
7
8
|
// genFilename generates the name of the logfile from the current time.
func (l *Logger) filename() string {
if l.Filename != "" {
return l.Filename
}
name := filepath.Base(os.Args[0]) + "-lumberjack.log"
return filepath.Join(os.TempDir(), name)
}
|
filename方法,在内部实现中调用,用来获取待输出的文件名,如果没有设置文件名,返回的将是进程名称拼接上“-lumberjack.log”,目录在系统的临时目录下。
1
2
3
4
5
6
7
|
// max returns the maximum size in bytes of log files before rolling.
func (l *Logger) max() int64 {
if l.MaxSize == 0 {
return int64(defaultMaxSize* megabyte)
}
return int64(l.MaxSize) * int64(megabyte)
}
|
max方法,获取触发日志分割的文件大小,如果用户没有配置,默认会是100MB。
这两个方法算是对于参数的一个简单封装和校验。
Write
下来从Write方法开始,整个过程比较简单:
- 加锁
- 检查写入数据量是否超过最大文件最大大小
- 如果没有打开文件, 则打开
- 当要写入数据量加上当前已写入数据量, 大于文件最大大小时, 执行日志滚动
- 写入日志数据并更新当前已写入量的记录值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
func (l *Logger) Write(p []byte) (n int, err error) {
l.mu.Lock() // 加锁防止多个协程同时写, 将日志写乱
defer l.mu.Unlock()
writeLen := int64(len(p))
// 如果写入数据量大于设定的单个日志文件的大小, 则直接报错返回
// 这意味着我们一定要保证每次写入的量一定要小于初始化logger时设置的MaxSize
if writeLen > l.max() {
return 0, fmt.Errorf(
"write length %d exceeds maximum file size %d", writeLen, l.max(),
)
}
// 打开文件
if l.file == nil {
if err = l.openExistingOrNew(len(p)); err != nil {
return 0, err
}
}
// 当要写入数据量加上当前已写入数据量, 大于文件最大大小时, 执行日志滚动
if l.size+writeLen > l.max() {
if err := l.rotate(); err != nil {
return 0, err
}
}
n, err = l.file.Write(p) // 写入日志数据
l.size += int64(n) // 更新写入量的记录值
return n, err
}
|
Write方法实现io.Writer接口,用于向日志文件中写入信息,如果写入将导致日志文件大于MaxSize,则将当前文件关闭,将其重命名为包括当前时间的时间戳,并使用原始日志文件名创建新的日志文件。如果一次写入的长度大于MaxSize,则返回错误。
从Write方法中我们看到每次写入日志前都会检测本次的写入是否会导致当前日志文件的大小大于MaxSize,如果大于则调用rotate方法进行处理。
方法入口直接加锁,顺便看下这个锁的使用点,可以看到这个锁被所有的可导出方法共享,从对外的调用点开始保证并发安全。
接下来判断了输入参数的长度,如果输入的长度大于触发文件分割的阈值,直接返回错误。否则,判断持有的file对象,也就是真正的文件句柄是否为空,如果为空,调用openExistingOrNew方法,打开或者新建日志文件,这个方法内部逻辑稍后再了解。总之,调用过这个方法后,文件句柄已经不为空了。size用来记录当前文件已写入的大小,所以下来会判断这次写进去后,会不会超过分割的阈值,如果会超过,先调用rotate方法触发一次分割,同样,rotate方法的内部实现稍后了解。(在rotate方法内部,会保证完成文件句柄的切换,size记录的重置)经过这些检查,下来就可以调用file的Write方法,将日志内容真正写入文件了,同时给size变量加上本次写入的长度。
Write的逻辑很简单,对于入参做必要的校验,然后根据文件句柄的情况和已写入大小,做不同的处理,最终调用写文件的方法,真正写入文件。下来需要看看刚刚遗留的openExistingOrNew方法和rotate方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
func (l *Logger) openExistingOrNew(writeLen int) error {
l.mill()
filename := l.filename()
info, err := os_Stat(filename)
if os.IsNotExist(err) {
return l.openNew()
}
if err != nil {
return fmt.Errorf("error getting log file info: %s", err)
}
if info.Size()+int64(writeLen) >= l.max() {
return l.rotate()
}
file, err := os.OpenFile(filename, os.O_APPEND|os.O_WRONLY, 0644)
if err != nil {
// if we fail to open the old log file for some reason, just ignore
// it and open a new log file.
return l.openNew()
}
l.file = file
l.size = info.Size()
return nil
}
|
openExistingOrNew从方法名上可以看到,是打开存在的文件或者新建文件,在满足以下条件时会新建文件:
- 老文件不存在
- 老文件大小加上本次要写入的达到阈值
- 老文件打开失败
下来检查是否已经存在待输出的文件,如果不存在,调用openNew方法新创建文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
// openNew opens a new log file for writing, moving any old log file out of the
// way. This methods assumes the file has already been closed.
func (l *Logger) openNew() error {
err := os.MkdirAll(l.dir(), 0744)
if err != nil {
return fmt.Errorf("can't make directories for new logfile: %s", err)
}
name := l.filename()
mode := os.FileMode(0644)
info, err := os_Stat(name)
if err == nil {
// Copy the mode off the old logfile.
mode = info.Mode()
// move the existing file
newname := backupName(name, l.LocalTime)
if err := os.Rename(name, newname); err != nil {
return fmt.Errorf("can't rename log file: %s", err)
}
// this is a no-op anywhere but linux
if err := chown(name, info); err != nil {
return err
}
}
// we use truncate here because this should only get called when we've moved
// the file ourselves. if someone else creates the file in the meantime,
// just wipe out the contents.
f, err := os.OpenFile(name, os.O_CREATE|os.O_WRONLY|os.O_TRUNC, mode)
if err != nil {
return fmt.Errorf("can't open new logfile: %s", err)
}
l.file = f
l.size = 0
return nil
}
|
openNew方法逻辑相对简单,只是把创建文件的过程用代码写出来。首先创建全目录,下来再判断老文件是否存在(这个方法不止在不存在老文件是调用,需要保证兼容);如果存在,调用backupName函数,生成老的日志文件被分割后的文件名,调用Rename方法重命名旧文件。无论是否存在老文件,下来都要创建新文件,并重置Logger对象的文件句柄和已输出大小。
回到刚才接着看openExistingOrNew方法,如果老文件已经存在,那就不会调用到openNew方法,往下走,会判断老文件的大小加上当前写入的会不会大于分割阈值,如果会,直接调用rotate方法触发一次分割。
Rotate
Rotate方法是对外提供手动切换日志文件的功能,同步调用rotate方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
func (l *Logger) Rotate() error {
l.mu.Lock()
defer l.mu.Unlock()
return l.rotate()
}
func (l *Logger) rotate() error {
//关闭当前日志文件
if err := l.close(); err != nil {
return err
}
//把当前日志文件进行重命名,并创建一个新的日志文件用于写入日志
if err := l.openNew(); err != nil {
return err
}
l.mill()
return nil
}
func (l *Logger) close() error {
if l.file == nil {
return nil
}
err := l.file.Close()
l.file = nil
return err
}
|
rotate方法中,做了三件事,关闭原有的文件句柄,调用上述的openNew创建新文件,之后调用mill进行日志文件的压缩删除。
接下来,既然这些条件都不满足,那就说明可以向老文件中直接写入,使用APPEND和WRONLY模式打开文件,如果打开失败,直接调用openNew创建新文件。打开成功的话,将文件句柄和size变量刷新就好。
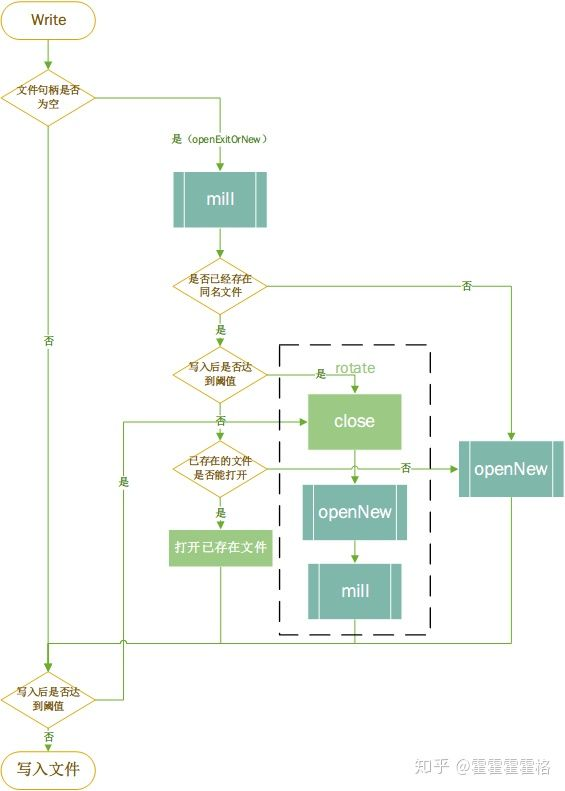
到这里,我们已经把lumberjack对日志文件管理的大概流程理清楚了。用流程图画出来是这样一个逻辑:
mill
openExistingOrNew方法中首先调用了mill方法,mill方法会开启一个goroutine进行处理,处理的核心方法是millRunOnce, millRunOnce方法会根据配置判断是否需要删除的历史日志文件,如果有则删除。如果配置的压缩,则会对未压缩的历史文件进行压缩。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
|
func (l *Logger) mill() {
l.startMill.Do(func() {
l.millCh = make(chan bool, 1)
go l.millRun()
})
select {
case l.millCh <- true:
default:
}
}
func (l *Logger) millRun() {
for _ = range l.millCh {
// what am I going to do, log this?
_ = l.millRunOnce()
}
}
func (l *Logger) millRunOnce() error {
if l.MaxBackups == 0 && l.MaxAge == 0 && !l.Compress {
return nil
}
//获取老的日志文件
files, err := l.oldLogFiles()
if err != nil {
return err
}
var compress, remove []logInfo
//MaxBackups大于0 并且 当前的文件数大于MaxBackups,说明有需要删除的日志文件
if l.MaxBackups > 0 && l.MaxBackups < len(files) {
preserved := make(map[string]bool)
var remaining []logInfo
for _, f := range files { //遍历每一个文件
// Only count the uncompressed log file or the
// compressed log file, not both.
fn := f.Name() //获取文件名称
//如果文件名以.gz结尾,则从文件名称删除.gz
if strings.HasSuffix(fn, compressSuffix) {
fn = fn[:len(fn)-len(compressSuffix)]
}
preserved[fn] = true
if len(preserved) > l.MaxBackups {
remove = append(remove, f) //需要删除的文件列表
} else {
remaining = append(remaining, f) //保留的文件列表
}
}
files = remaining
}
if l.MaxAge > 0 {
diff := time.Duration(int64(24*time.Hour) * int64(l.MaxAge))
cutoff := currentTime().Add(-1 * diff) //需要删除的时间节点
var remaining []logInfo
for _, f := range files { //遍历保留的日志文件
if f.timestamp.Before(cutoff) { //需要删除的日志文件(超过了保留时间)
remove = append(remove, f) //需要删除的文件列表
} else {
remaining = append(remaining, f)
}
}
files = remaining
}
if l.Compress { //获取需要压缩的文件列表
for _, f := range files {
if !strings.HasSuffix(f.Name(), compressSuffix) {
compress = append(compress, f)
}
}
}
for _, f := range remove { //需要删除的文件列表
errRemove := os.Remove(filepath.Join(l.dir(), f.Name()))
if err == nil && errRemove != nil {
err = errRemove
}
}
for _, f := range compress { //压缩每一个需要删除的日志文件
fn := filepath.Join(l.dir(), f.Name())
errCompress := compressLogFile(fn, fn+compressSuffix)
if err == nil && errCompress != nil {
err = errCompress
}
}
return err
}
|
startMill是一个once对象,用来控制这里的通道只初始化一次,以及协程只启动一次。millCh用来传递进行日志压缩删除的信号。可以看到在millRun方法中,使用range关键字不断的从millCh通道中读取信号,每读到一次,就调用一次millRunOnce来真正实现压缩删除。而向millCh通道写入信息的就在mill方法中,使用了select关键字尝试写入。这里很好的利用了select关键字的特性做了任务去重,如果millCh中没有元素,自然可以写入,并使得millRun读到,开始调用millRunOnce方法;如果有元素,不能写入,那么就说明在millRun方法中还在执行millRunOnce方法,那也就没必要写入了,直接走default分支结束就好。这里的思路和go的timer中的通道类似,使用容量为1的通道做通知以及去重。至于millRunOnce方法,稍后我们再看,这里知道调用了mill方法,会尝试触发日志压缩删除就可以了。
分清楚其中子流程的职责就可以了,其中mill的职责是对历史日志文件的压缩和删除;openNew的职责是重命名旧文件并创建新文件;rotate其实是mill和openNew的组合。
最后再来分析下millRunOnce的实现:首先根据老化的参数做一些判断,如果最多数量和最长时间都没有配置以及不需要压缩,直接返回即可。否则,获取到日志目录下的除过当前正在打印的文件之外的所有文件列表,对于这个文件列表,判断文件个数,以及文件名的时间戳是否符合配置的要求。生成出来待删除的文件列表和待压缩的文件列表,调用删除和压缩的函数分别对其进行处理。
代码逻辑不算复杂,直接读代码就能看懂,唯一需要提的就是,在获取文件列表时,有一次排序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
func (l *Logger) oldLogFiles() ([]logInfo, error) {
files, err := ioutil.ReadDir(l.dir())
if err != nil {
return nil, fmt.Errorf("can't read log file directory: %s", err)
}
logFiles := []logInfo{}
prefix, ext := l.prefixAndExt()
for _, f := range files {
if f.IsDir() {
continue
}
if t, err := l.timeFromName(f.Name(), prefix, ext); err == nil {
logFiles = append(logFiles, logInfo{t, f})
continue
}
if t, err := l.timeFromName(f.Name(), prefix, ext+compressSuffix); err == nil {
logFiles = append(logFiles, logInfo{t, f})
continue
}
// error parsing means that the suffix at the end was not generated
// by lumberjack, and therefore it's not a backup file.
}
sort.Sort(byFormatTime(logFiles))
return logFiles, nil
}
// byFormatTime sorts by newest time formatted in the name.
type byFormatTime []logInfo
func (b byFormatTime) Less(i, j int) bool {
return b[i].timestamp.After(b[j].timestamp)
}
func (b byFormatTime) Swap(i, j int) {
b[i], b[j] = b[j], b[i]
}
func (b byFormatTime) Len() int {
return len(b)
}
|
byFormatTime类型是对[]logInfo类型的重命名,实现了sort包中的Interface接口,有三个方法,Less,Swap,Len方法,其中比较重要的是Less方法,实现了自定义的比较规则。这样当调用sort.Sort(byFormatTime(logFiles))时,会按照自定义的比较方法进行比较排序。这也是go中对于自定义排序规则的一种实现方式。
参考
Golang优秀源码走读—lumberjack
Golang日志框架lumberjack包源码分析