IP协议头详解
文章目录
IPv4
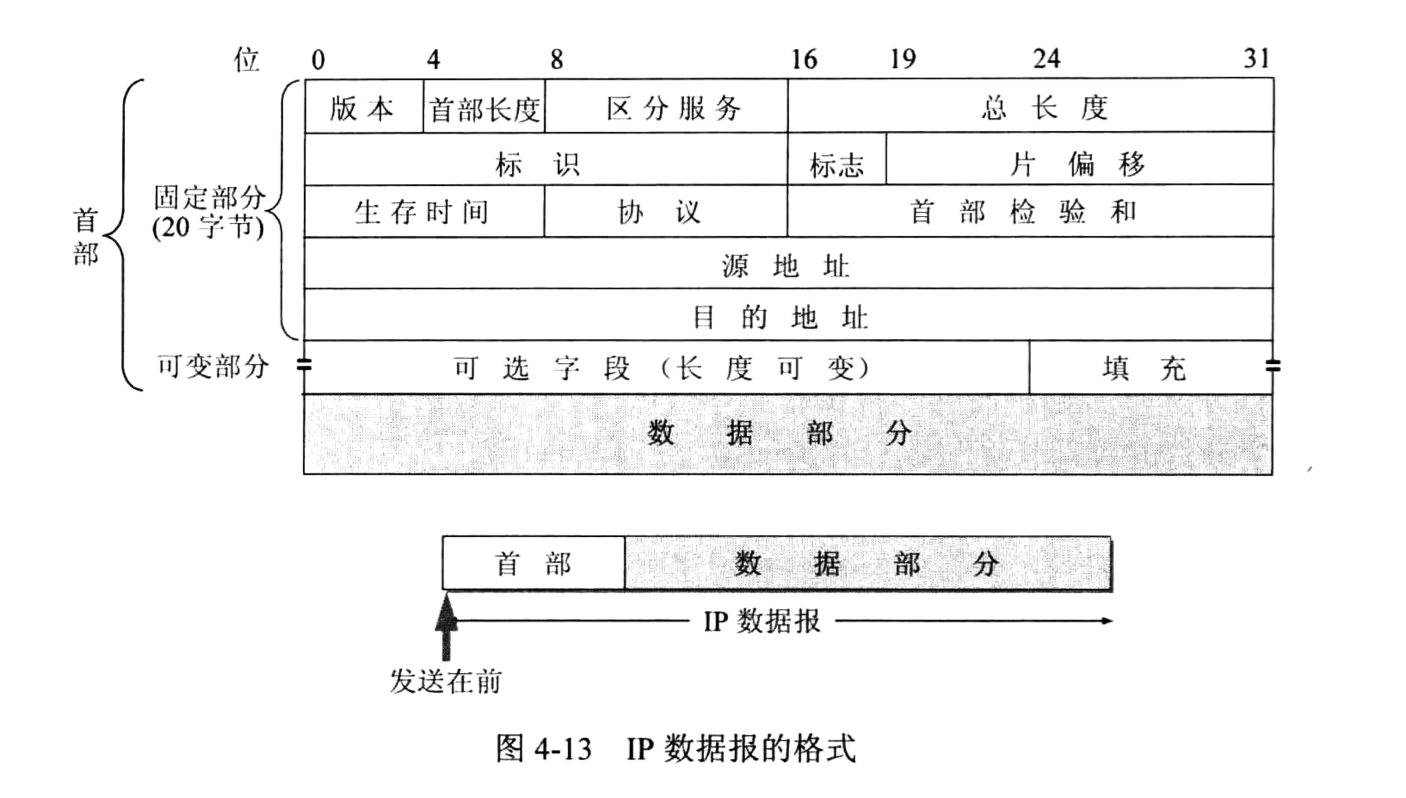
(1) 版本:占4位,指IP协议的版本。通信双方使用的IP协议的版本必须一致。目 前广泛使用的IP协议版本号为4 (即IPv4)。
(2) 首部长度:占4位,可表示的最大十进制数值是15。请注意,首部长度字段所表示数的单位是32位字(1个32位字长是4字节)。因此,首部长度字段的最小值是5 (即二 进制的0101),相当于IP首部长度为5 x 4 = 20字节。而当首部长度为1111时(即十进制 的15),首部长度就达到最大值15个32位字长,即60字节。当IP分组的首部长度不是4 字节的整数倍时,必须利用最后的填充字段加以填充。因此IP数据报的数据部分永远在4 字节的整数倍时开始,这样在实现IP协议时较为方便。首部长度限制为60字节的缺点是有时可能不够用。但这样做是希望用户尽量减少开销。最常用的首部长度就是20字节(即首 部长度为0101),这时不使用任何选项。
(3) 区分服务:占8位,用来获得更好的服务。这个字段在旧标准中叫做服务类型, 但实际上一直没有被使用过。
(4) 总长度:总长度指首部和数据之和的长度,单位为字节。总长度字段为16位,因此数据报的最大长度为2^16 - 1 = 65 535字节。然而实际上传送这样长的数据报在现实中 是极少遇到的。
我们知道,在IP层下面的每一种数据链路层协议都规定了一个数据帧中的数据字段的 最大长度,这称为最大传送单元MTU (Maximum Transfer Unit)。当一个IP数据报封装成链路层的帧时,此数据报的总长度(即首部加上数据部分)一定不能超过下面的数据链路层所 规定的MTU值。例如,最常用的以太网就规定其MTU值是1 500字节。若所传送的数据 报长度超过数据链路层的MTU值,就必须把过长的数据报进行分片处理。
虽然使用尽可能长的IP数据报会使传输效率提高(因为每一个IP数据报中首部长度占 数据报总长度的比例就会小些),但数据报短些也有好处。每一个IP数据报越短,路由器转 发的速度就越快。为此,IP协议规定,在因特网中所有的主机和路由器,必须能够接受长度不超过576字节的数据报。这是假定上层交下来的数据长度有512字节(合理的长度), 加上最长的IP首部60字节,再加上4字节的富裕量,就得到576字节。当主机需要发送长 度超过576字节的数据报时,应当先了解一下,目的主机能否接受所要发送的数据报长度。 否则,就要进行分片。
在进行分片时(见后面的“片偏移”字段),数据报首部中的“总长度”字段是指分片后的每一个分片的首部长度与该分片的的数据长度的总和。
(5) 标识(identification):占16位。IP软件在存储器中维持一个计数器,每产生一个 数据报,计数器就加1,并将此值赋给标识字段。但这个“标识”并不是序号,因为IP是 无连接服务,数据报不存在按序接收的问题。当数据报由于长度超过网络的MTU而必须分 片时,这个标识字段的值就被复制到所有的数据报片的标识字段中。相同的标识字段的值使 分片后的各数据报片最后能正确地重装成为原来的数据报。
(6) 标志(flag):占3位,但目前只有两位有意义。
标志字段中的最低位记为MF (More Fragment)。MF = 1即表示后面“还有分片” 的数据报。MF = 0表示这已是若千数据报片中的最后一个。
标志字段中间的一位记为DF (Don’t Fragment),意思是“不能分片”。只有当DF = 0 时才允许分片。
(7) 片偏移 占13位。片偏移指出:较长的分组在分片后,某片在原分组中的相对 位置。也就是说,相对于用户数据字段的起点,该片从何处开始。片偏移以8个字节为偏移 单位。这就是说,每个分片的长度一定是8字节(64位)的整数倍。
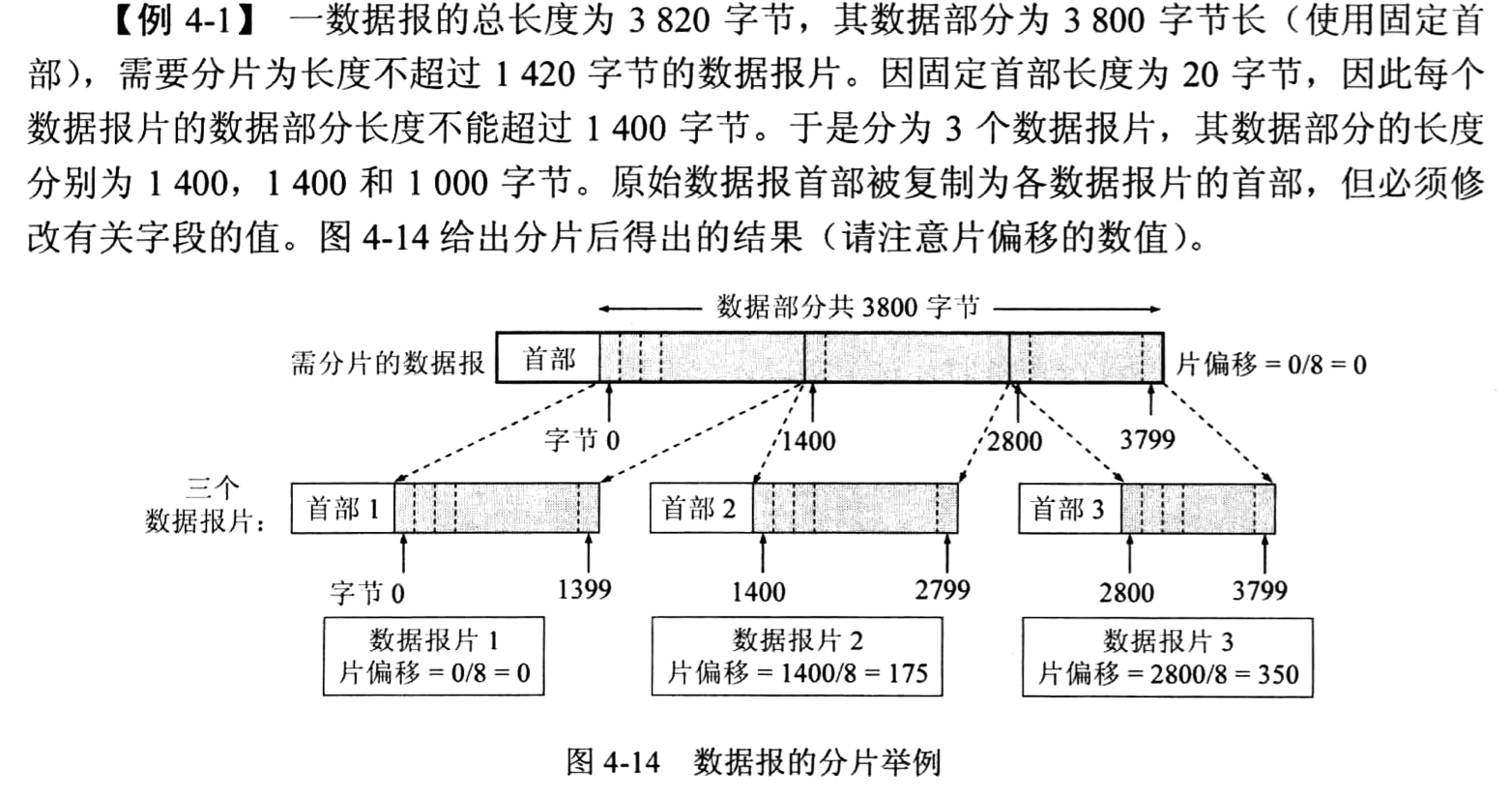

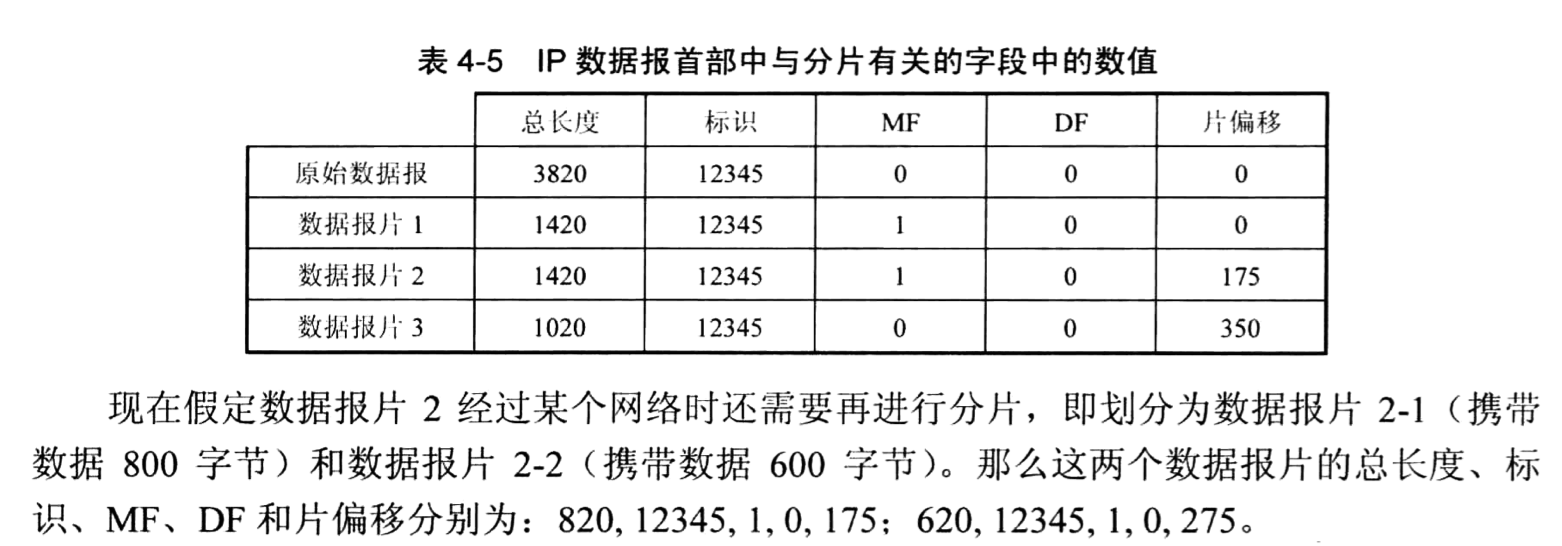
(8) 生存时间:占8位,生存时间字段常用的英文缩写是TTL (Time To Live),表明 是数据报在网络中的寿命。由发出数据报的源点设置这个字段。其目的是防止无法交付的数 据报无限制地在因特网中兜圈子(例如从路由器心转发到R2,再转发到心,然后又转发到 R,),因而白白消耗网络资源。最初的设计是以秒作为TTL值的单位。每经过一个路由器时,就把TTL减去数据报在路由器所消耗掉的一段时间。若数据报在路由器消耗的时间小 于1秒,就把TTL值减1。当TTL值减为零时,就丢弃这个数据报。
然而,随着技术的进步,路由器处理数据报所需的时间不断在缩短,一般都远远小于 1秒钟,后来就把TTL字段的功能改为“跳数限制”(但名称不变)。路由器在转发数据报 之前就把TTL值减1。若TTL值减小到零,就丢弃这个数据报,不再转发。因此,现在 TTL的单位不再是秒,而是跳数。TTL的意义是指明数据报在因特网中至多可经过多少个 路由器。显然,数据报能在因特网中经过的路由器的最大数值是255。若把TTL的初始值 设置为1,就表示这个数据报只能在本局域网中传送。因为这个数据报一传送到局域网上的 某个路由器,在被转发之前TTL值就减小到零,因而就会被这个路由器丢弃。
(9) 协议:占8位,协议字段指出此数据报携带的数据是使用何种协议,以便使目的 主机的IP层知道应将数据部分上交给哪个处理过程。

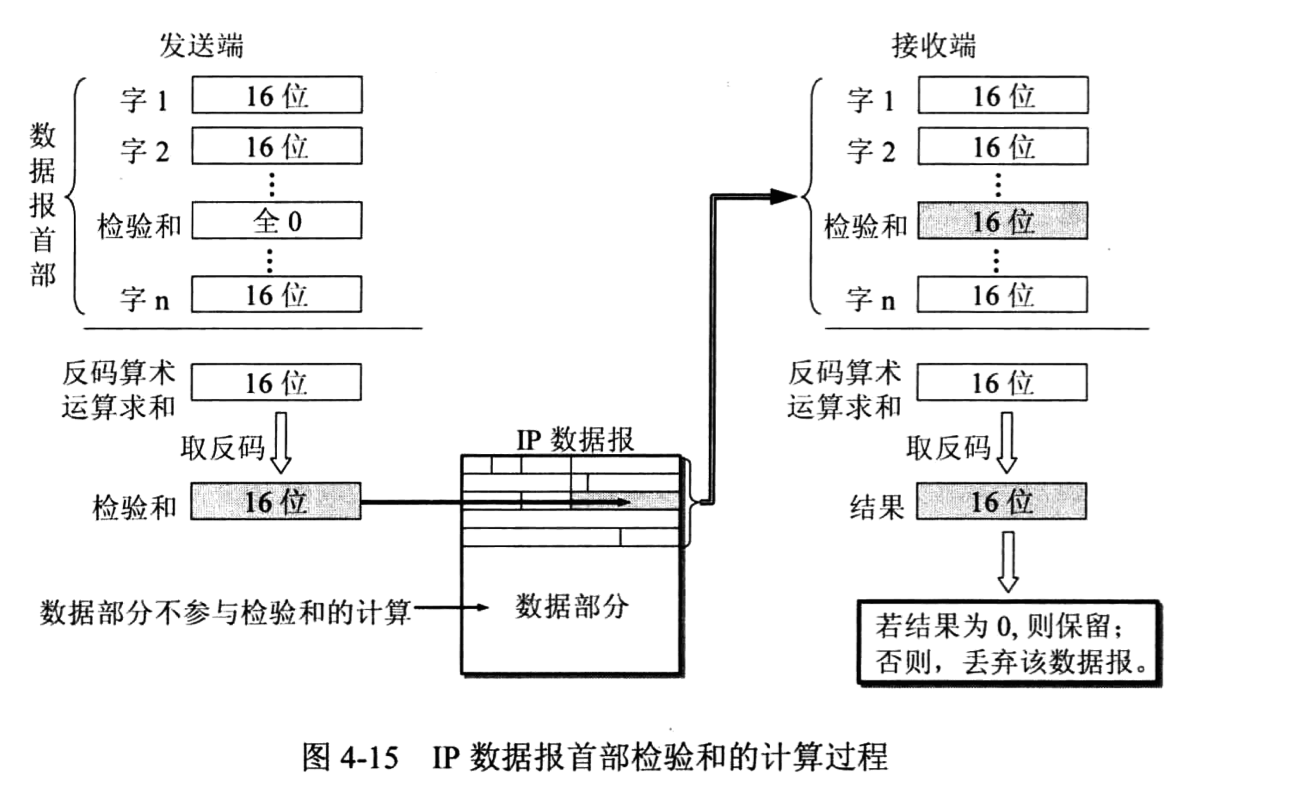
(10)首部检验和 占16位。这个字段只检验数据报的首部,但不包括数据部分。这是因为数据报每经过一个路由器,路由器都要重新计算一下首部检验和(一些字段,如生存 时间、标志、片偏移等都可能发生变化)。不检验数据部分可减少计算的工作量。
IP首部的检验和采用下面的简单计算方法:在发送方,先把IP数据报首部划分为许多16位字的序列,并把检验和字段置 零。用反码算术运算把所有16位字相加后,将得到的和的反码写入检验和字段。接收方收到数据报后,将首部的所有16位字再使用反码算术运算相加一次。将得到的和取反码, 即得出接收方检验和的计算结果。若首部未发生任何变化,则此结果必为0,于是就保留这个数据报。否则即认为出差错,并将此数据报丢弃。图4-15说明了 IP数据报首部检验和的 计算过程。

(11)源地址:将IP地址看作是32位数值则需要将网络字节顺序转化位主机字节顺序。转化的方法是:将每4个字节首尾互换,将2、3字节互换。
(12)目的地址:转换方法和来源IP地址一样。在网络协议中,IP是面向非连接的,所谓的非连接就是传递数据的时候,不检测网络是否连通。所以是不可靠的数据报协议,IP协议主要负责在主机之间寻址和选择数据包路由。
(13)IP首部的可变部分就是一个选项字段。选项字段用来支持排错、测量以及安全等措施,内容很丰富。此字段的长度可变,从1个字节到40个字节不等,取决于所选择的项目。某些选项项目只需要1个字节,它只包括1个字节的选项代码。但还有些选项需要多个 字节,这些选项一个个拼接起来,中间不需要有分隔符,最后用全0的填充字段补齐成为4 字节的整数倍。
增加首部的可变部分是为了增加IP数据报的功能,但这同时也使得IP数据报的首部长度成为可变的。这就增加了每一个路由器处理数据报的开销。实际上这些选项很少被使用。 很多路由器都不考虑IP首部的选项字段,因此新的IP版本IPv6就把IP数据报的首部长度做成固定的。这里就不讨论这些选项的细节。
IPv6
基本首部
IPv6仍支持无连接的传送,但将协议数据单元PDU称为分组,而不是IPv4的数据报。
(1)IPv6数据报的首部和IPv4的并不兼容。IPv6定义了许多可选的 扩展首部,不仅可提供比IPv4更多的功能,而且还可提高路由器的处理效率,这是因为路 由器对扩展首部不进行处理(除逐跳扩展首部外)。
(2) 改进的选项。IPv6允许数据报包含有选项的控制信息,因而可以包含一些新的选 项。但IPv6的首部长度是固定的,其选项放在有效载荷中。我们知道,IPv4所规定的选项 是固定不变的,其选项放在首部的可变部分。
(3) 允许协议继续扩充。这一点很重要,因为技术总是在不断地发展(如网络硬件的更新)而新的应用也还会出现。但我们知道,IPv4的功能是固定不变的。
(4) 支持即插即用(即自动配置)。
(5) 支持资源的预分配。IPv6支持实时视像等要求保证一定的带宽和时延的应用。
(6) IPv6首部改为8字节对齐(即首部长度必须是8字节的整数倍)。原来的IPv4首部是4字节对齐。
IPv6数据报在基本首部(base header)的后面允许有零个或多个扩展首部(extension header),再后面是数据(图10-1)。但请注意,所有的扩展首部并不算是IPv6数据报的首部。所有的扩展首部和数据合起来叫做数据报的有效载荷(payload)或净负荷。
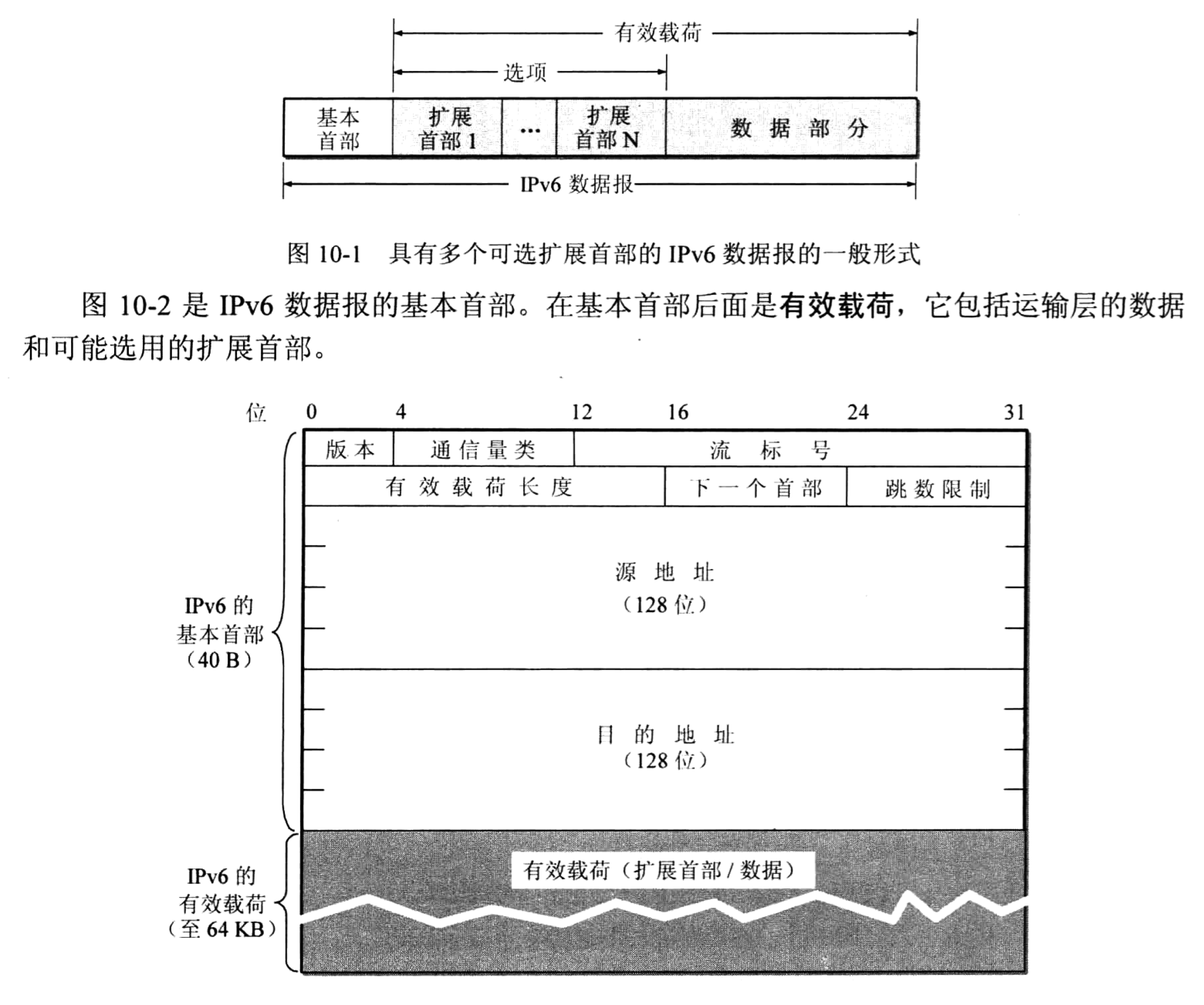
与IPv4相比,IPv6对首部中的某些字段进行了如下的更改:
-
取消了首部长度字段,因为它的首部长度是固定的(40字节)。
-
取消了服务类型字段,因为优先级和流标号字段合起来实现了服务类型字段的功 能。
-
取消了总长度字段,改用有效载荷长度字段。
-
取消了标识、标志和片偏移字段,因为这些功能己包含在分片扩展首部中。
-
把TTL字段改称为跳数限制字段,但作用是一样的(名称与作用更加一致)。
-
取消了协议字段,改用下一个首部字段。
-
取消了检验和字段,这样就加快了路由器处理数据报的速度。我们知道,在数据链路层对检测出有差错的帧就丢弃。在运输层,当使用UDP时,若检测出有差错的 用户数据报就丢弃。当使用TCP时,对检测出有差错的报文段就重传,直到正确 传送到目的进程为止。因此在网络层的差错检测可以精简掉。
-
取消了选项字段,而用扩展首部来实现选项功能。由于把首部中不必要的功能取消了,使得IPv6首部的字段数减少到只有8个(虽然首部长度增大了一倍)。
下面解释IPv6基本首部中各字段的作用。
(1) 版本(version):占4位。它指明了协议的版本,对IPv6该字段是6。
(2) 通信量类(traffic class):占8位。这是为了区分不同的IPv6数据报的类别或优先级。目前正在进行不同的通信量类性能的实验。
(3) 流标号(flow label) 占20位。IPv6的一个新的机制是支持资源预分配,并且允许 路由器把每一个数据报与一个给定的资源分配相联系。IPv6提出流(flow)的抽象概念。所谓“流”就是互联网络上从特定源点到特定终点(单播或多播)的一系列数据报(如实时音频 或视频传输),而在这个“流”所经过的路径上的路由器都保证指明的服务质量。所有属于 同一个流的数据报都具有同样的流标号。因此,流标号对实时音频/视频数据的传送特别有 用。对于传统的电子邮件或非实时数据,流标号则没有用处,把它置为0即可。
(4) 有效载荷长度(payload length) 占16位。它指明IPv6数据报除基本首部以外的字节数(所有扩展首部都算在有效载荷之内)。这个字段的最大值是64 KB (65535字节)。
(5) 下一个首部(next header):占8位。它相当于IPv4的协议字段或可选字段。当IPv6数据报没有扩展首部时,下一个首部字段的作用和IPv4的协议字段一样, 它的值指出了基本首部后面的数据应交付IP层上面的哪一个高层协议(例如:6 或17分别表示应交付运输层的TCP或UDP)。当出现扩展首部时,下一个首部字段的值就标识后面第一个扩展首部的类型。
(6) 跳数限制(hop limit) 占8位。用来防止数据报在网络中无限期地存在。源点在每 个数据报发出时即设定某个跳数限制(最大为255跳)。每个路由器在转发数据报时,要先 把跳数限制字段中的值减1。当跳数限制的值为零时,就要把这个数据报丢弃。
(7) 源地址 占128位。是数据报的发送端的IP地址。
(8)目的地址 占128位。是数据报的接收端的IP地址。
扩展首部
IPv4的数据报如果在其首部中使用了选项,那么沿着数据报传送路径上的 每一个路由器都必须对这些选项一一进行检查,这就降低了路由器处理数据报的速度。然而 实际上很多的选项在途中的路由器上是不需要检查的(因为不需要使用这些选项的信息)。 IPv6把原来IPv4首部中选项的功能都放在扩展首部中,并把扩展首部留给路径两端的源点 和终点的主机来处理,而数据报途中经过的路由器都不处理这些扩展首部(只有一个首部例 外,即逐跳选项扩展首部),这样就大大提高了路由器的处理效率。
在RFC 2460中定义了以下六种扩展首部:
- 逐跳选项。
- 路由选择。
- 分片。
- 鉴别。
- 封装安全有效载荷。
- 目的站选项。
每一个扩展首部都由若干个字段组成,它们的长度也各不同。但所有扩展首部的第一 个字段都是8位的“下一个首部”字段。此字段的值指出了在该扩展首部后面的字段是什么。当使用多个扩展首部时,应按以上的先后顺序出现。高层首部总是放在最后面。
图10-3(a)表示当数据报不包含扩展首部时,固定首部中的下一个首部字段就相当于IPv4 首部中的协议字段,此字段的值指出后面的有效载荷应当交付上一层的哪一个进程。例如, 当有效载荷是TCP报文段时(固定首部中下一个首部字段的值就是6,这个数值和IPv4中 协议字段填入的值一样),后面的有效载荷就被交付运输层的TCP进程。
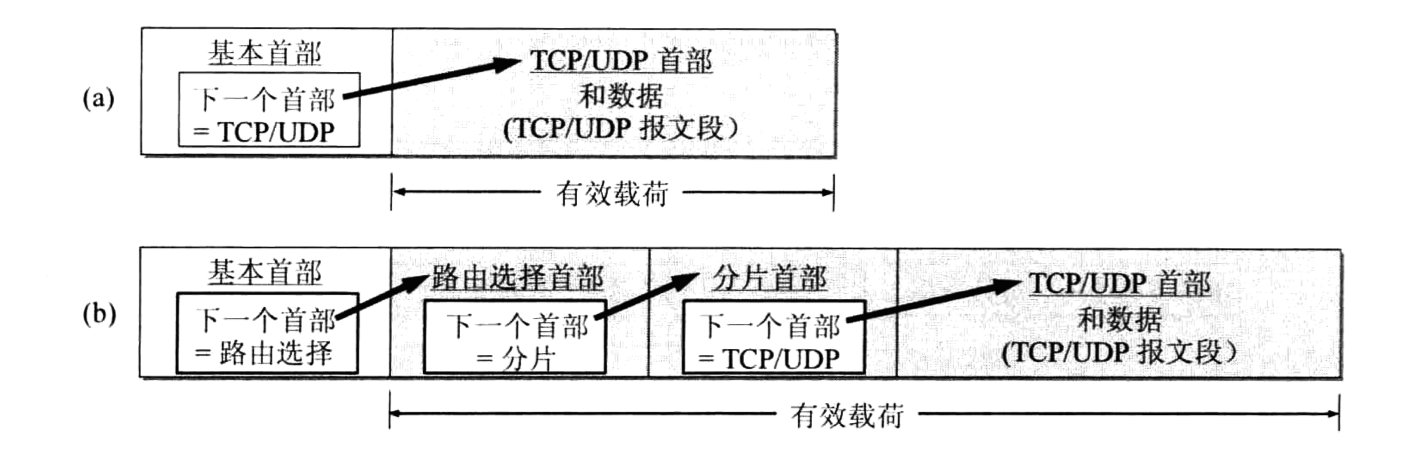
图10-3(b)表示在基本首部后面有两个扩展首部的情况。所有扩展首部中的第一个字段 “下一个首部”的值都是指出了跟随在此扩展首部后面的是何种首部。例如,第一个扩展首 部是路由选择首部,其“下一个首部字段”的值就指出后面的扩展首部是分片扩展首部,而 分片扩展首部的“下一个首部字段”的值又指出再后面的首部是TCP/UDP的首部。
文章作者 Forz
上次更新 2017-07-30