interface和reflect源码剖析
文章目录
interface
Go 语言中的接口是一组方法的签名,它是 Go 语言的重要组成部分。使用接口能够让我们写出易于测试的代码,然而很多工程师对 Go 的接口了解都非常有限,也不清楚其底层的实现原理,这成为了开发高性能服务的阻碍。
本节会介绍使用接口时遇到的一些常见问题以及它的设计与实现,包括接口的类型转换、类型断言以及动态派发机制,帮助各位读者更好地理解接口类型。
概述
在计算机科学中,接口是计算机系统中多个组件共享的边界,不同的组件能够在边界上交换信息。如下图所示,接口的本质是引入一个新的中间层,调用方可以通过接口与具体实现分离,解除上下游的耦合,上层的模块不再需要依赖下层的具体模块,只需要依赖一个约定好的接口。
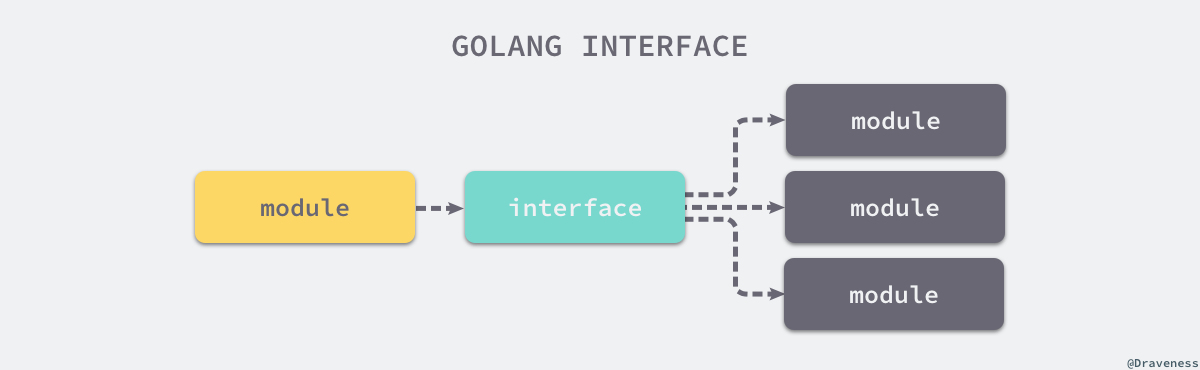
这种面向接口的编程方式有着非常强大的生命力,无论是在框架还是操作系统中我们都能够找到接口的身影。可移植操作系统接口(Portable Operating System Interface,POSIX)就是一个典型的例子,它定义了应用程序接口和命令行等标准,为计算机软件带来了可移植性 — 只要操作系统实现了 POSIX,计算机软件就可以直接在不同操作系统上运行。
除了解耦有依赖关系的上下游,接口还能够帮助我们隐藏底层实现,减少关注点。《计算机程序的构造和解释》中有这么一句话:
代码必须能够被人阅读,只是机器恰好可以执行
人能够同时处理的信息非常有限,定义良好的接口能够隔离底层的实现,让我们将重点放在当前的代码片段中。SQL 就是接口的一个例子,当我们使用 SQL 语句查询数据时,其实不需要关心底层数据库的具体实现,我们只在乎 SQL 返回的结果是否符合预期。
计算机科学中的接口是比较抽象的概念,但是编程语言中接口的概念就更加具体。Go 语言中的接口是一种内置的类型,它定义了一组方法的签名,本节会介绍 Go 语言接口的几个基本概念以及常见问题,为后面的实现原理做铺垫。
隐式接口
很多面向对象语言都有接口这一概念,例如 Java 和 C#。Java 的接口不仅可以定义方法签名,还可以定义变量,这些定义的变量可以直接在实现接口的类中使用,这里简单介绍一下 Java 中的接口:
|
|
上述代码定义了一个必须实现的方法 sayHello 和一个会注入到实现类的变量 hello。在下面的代码中,MyInterfaceImpl 实现了 MyInterface 接口:
|
|
Java 中的类必须通过上述方式显式地声明实现的接口,但是在 Go 语言中实现接口就不需要使用类似的方式。首先,我们简单了解一下在 Go 语言中如何定义接口。定义接口需要使用 interface 关键字,在接口中我们只能定义方法签名,不能包含成员变量,一个常见的 Go 语言接口是这样的:
|
|
如果一个类型需要实现 error 接口,那么它只需要实现 Error() string 方法,下面的 RPCError 结构体就是 error 接口的一个实现:
|
|
细心的读者可能会发现上述代码根本就没有 error 接口的影子,这是为什么呢?Go 语言中接口的实现都是隐式的,我们只需要实现 Error() string 方法就实现了 error 接口。Go 语言实现接口的方式与 Java 完全不同:
- 在 Java 中:实现接口需要显式地声明接口并实现所有方法;
- 在 Go 中:实现接口的所有方法就隐式地实现了接口;
我们使用上述 RPCError 结构体时并不关心它实现了哪些接口,Go 语言只会在传递参数、返回参数以及变量赋值时才会对某个类型是否实现接口进行检查,这里举几个例子来演示发生接口类型检查的时机:
|
|
Go 语言在编译期间对代码进行类型检查,上述代码总共触发了三次类型检查:
- 将
*RPCError类型的变量赋值给 error 类型的变量 rpcErr; - 将
*RPCError类型的变量 rpcErr 传递给签名中参数类型为 error 的 AsErr 函数; - 将
*RPCError类型的变量从函数签名的返回值类型为 error 的 NewRPCError 函数中返回;
从类型检查的过程来看,编译器仅在需要时才检查类型,类型实现接口时只需要实现接口中的全部方法,不需要像 Java 等编程语言中一样显式声明。
类型
接口也是 Go 语言中的一种类型,它能够出现在变量的定义、函数的入参和返回值中并对它们进行约束,不过 Go 语言中有两种略微不同的接口,一种是带有一组方法的接口,另一种是不带任何方法的 interface{}:

Go 语言使用 runtime.iface 表示第一种接口,使用 runtime.eface 表示第二种不包含任何方法的接口 interface{},两种接口虽然都使用 interface 声明,但是由于后者在 Go 语言中很常见,所以在实现时使用了特殊的类型。
需要注意的是,与 C 语言中的 void * 不同,interface{} 类型不是任意类型。如果我们将类型转换成了 interface{} 类型,变量在运行期间的类型也会发生变化,获取变量类型时会得到 interface{}。
|
|
上述函数不接受任意类型的参数,只接受 interface{} 类型的值,在调用 Print 函数时会对参数 v 进行类型转换,将原来的 Test 类型转换成 interface{} 类型,本节会在后面介绍类型转换的实现原理。
指针和接口
在 Go 语言中同时使用指针和接口时会发生一些让人困惑的问题,接口在定义一组方法时没有对实现的接收者做限制,所以我们会看到某个类型实现接口的两种方式:

这是因为结构体类型和指针类型是不同的,就像我们不能向一个接受指针的函数传递结构体一样,在实现接口时这两种类型也不能划等号。虽然两种类型不同,但是上图中的两种实现不可以同时存在,Go 语言的编译器会在结构体类型和指针类型都实现一个方法时报错 “method redeclared”。
对 Cat 结构体来说,它在实现接口时可以选择接受者的类型,即结构体或者结构体指针,在初始化时也可以初始化成结构体或者指针。下面的代码总结了如何使用结构体、结构体指针实现接口,以及如何使用结构体、结构体指针初始化变量。
|
|
实现接口的类型和初始化返回的类型两个维度共组成了四种情况,然而这四种情况不是都能通过编译器的检查:
| 结构体实现接口 | 结构体指针实现接口 | |
|---|---|---|
| 结构体初始化变量 | 通过 | 不通过 |
| 结构体指针初始化变量 | 通过 | 通过 |
四种中只有使用指针实现接口,使用结构体初始化变量无法通过编译,其他的三种情况都可以正常执行。当实现接口的类型和初始化变量时返回的类型时相同时,代码通过编译是理所应当的:
- 方法接受者和初始化类型都是结构体;
- 方法接受者和初始化类型都是结构体指针;
而剩下的两种方式为什么一种能够通过编译,另一种无法通过编译呢?我们先来看一下能够通过编译的情况,即方法的接受者是结构体,而初始化的变量是结构体指针:
|
|
作为指针的 &Cat{} 变量能够隐式地获取到指向的结构体,所以能在结构体上调用 Walk 和 Quack 方法。我们可以将这里的调用理解成 C 语言中的 d->Walk() 和 d->Speak(),它们都会先获取指向的结构体再执行对应的方法。
但是如果我们将上述代码中方法的接受者和初始化的类型进行交换,代码就无法通过编译了:
|
|
|
|
编译器会提醒我们:Cat 类型没有实现 Duck 接口,Quack 方法的接受者是指针。这两个报错对于刚刚接触 Go 语言的开发者比较难以理解,如果我们想要搞清楚这个问题,首先要知道 Go 语言在传递参数时都是传值的。
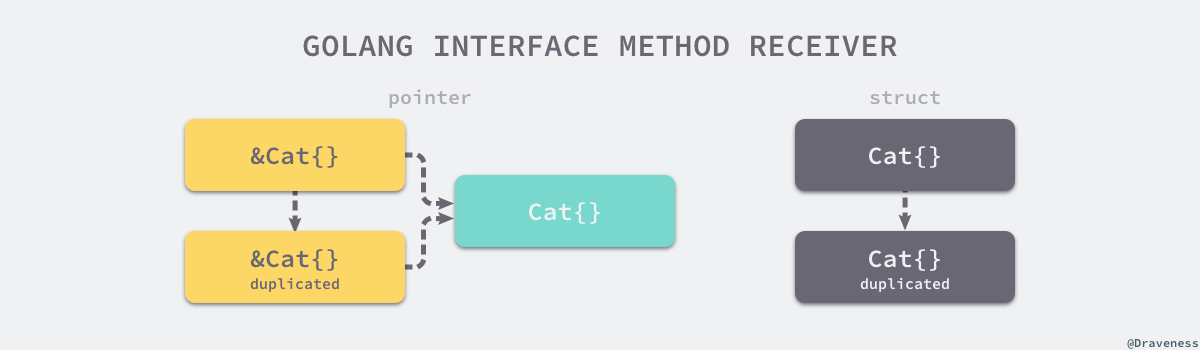
如上图所示,无论上述代码中初始化的变量 c 是 Cat{} 还是 &Cat{},使用 c.Quack() 调用方法时都会发生值拷贝:
- 如上图左侧,对于
&Cat{}来说,这意味着拷贝一个新的&Cat{}指针,这个指针与原来的指针指向一个相同并且唯一的结构体,所以编译器可以隐式的对变量解引用(dereference)获取指针指向的结构体; - 如上图右侧,对于
Cat{}来说,这意味着 Quack 方法会接受一个全新的Cat{},因为方法的参数是*Cat,编译器不会无中生有创建一个新的指针;即使编译器可以创建新指针,这个指针指向的也不是最初调用该方法的结构体;
上面的分析解释了指针类型的现象,当我们使用指针实现接口时,只有指针类型的变量才会实现该接口;当我们使用结构体实现接口时,指针类型和结构体类型都会实现该接口。当然这并不意味着我们应该一律使用结构体实现接口,这个问题在实际工程中也没那么重要,在这里我们只想解释现象背后的原因。
nil 和 non-nil
我们可以通过一个例子理解Go 语言的接口类型不是任意类型这一句话,下面的代码在 main 函数中初始化了一个 *TestStruct 类型的变量,由于指针的零值是 nil,所以变量 s 在初始化之后也是 nil:
|
|
|
|
我们简单总结一下上述代码执行的结果:
- 将上述变量与 nil 比较会返回 true;
- 将上述变量传入 NilOrNot 方法并与 nil 比较会返回 false;
出现上述现象的原因是 —— 调用 NilOrNot 函数时发生了隐式的类型转换,除了向方法传入参数之外,变量的赋值也会触发隐式类型转换。在类型转换时,*TestStruct 类型会转换成 interface{}类型,转换后的变量不仅包含转换前的变量,还包含变量的类型信息 TestStruct,所以转换后的变量与 nil 不相等。
数据结构
相信各位读者已经对 Go 语言的接口有了一些的了解,接下来我们从源代码和汇编指令层面介绍接口的底层数据结构。
Go 语言根据接口类型是否包含一组方法将接口类型分成了两类:
- 使用 runtime.iface 结构体表示包含方法的接口
- 使用 runtime.eface 结构体表示不包含任何方法的
interface{}类型;
runtime.eface 结构体在 Go 语言中的定义是这样的:
|
|
由于 interface{} 类型不包含任何方法,所以它的结构也相对来说比较简单,只包含指向底层数据和类型的两个指针。从上述结构我们也能推断出 — Go 语言的任意类型都可以转换成 interface{}。
另一个用于表示接口的结构体是 runtime.iface,这个结构体中有指向原始数据的指针 data,不过更重要的是 runtime.itab 类型的 tab 字段。
|
|
接下来我们将详细分析 Go 语言接口中的这两个类型,即 runtime._type 和 runtime.itab。
_type
runtime._type 是 Go 语言类型的运行时表示。下面是运行时包中的结构体,其中包含了很多类型的元信息,例如:类型的大小、哈希、对齐以及种类等。
|
|
- size 字段存储了类型占用的内存空间,为内存空间的分配提供信息;
- hash 字段能够帮助我们快速确定类型是否相等;
- equal 字段用于判断当前类型的多个对象是否相等,该字段是为了减少 Go 语言二进制包大小从 typeAlg 结构体中迁移过来的;
我们只需要对 runtime._type 结构体中的字段有一个大体的概念,不需要详细理解所有字段的作用和意义。
itab
runtime.itab 结构体是接口类型的核心组成部分,每一个 runtime.itab 都占 32 字节,我们可以将其看成接口类型和具体类型的组合,它们分别用 inter 和 _type 两个字段表示:
|
|
除了 inter 和 _type 两个用于表示类型的字段之外,上述结构体中的另外两个字段也有自己的作用:
- hash 是对
_type.hash的拷贝,当我们想将 interface 类型转换成具体类型时,可以使用该字段快速判断目标类型和具体类型runtime._type是否一致; - fun 是一个动态大小的数组,它是一个用于动态派发的虚函数表,存储了一组函数指针。虽然该变量被声明成大小固定的数组,但是在使用时会通过原始指针获取其中的数据,所以 fun 数组中保存的元素数量是不确定的;
我们会在类型断言中介绍 hash 字段的使用,在动态派发一节中介绍 fun 数组中存储的函数指针是如何被使用的。
类型转换
既然我们已经了解了接口在运行时的数据结构,接下来会通过几个例子来深入理解接口类型是如何初始化和传递的,本节会介绍在实现接口时使用指针类型和结构体类型的区别。这两种不同的接口实现方式会导致 Go 语言编译器生成不同的汇编代码,进而影响最终的处理过程。
指针类型
首先回到这一节开头提到的 Duck 接口的例子,我们使用 //go:noinline指令禁止 Quack 方法的内联编译:
|
|
我们使用编译器将上述代码编译成汇编语言、删掉一些对理解接口原理无用的指令并保留与赋值语句 var c Duck = &Cat{Name: "draven"} 相关的代码,这里将生成的汇编指令拆分成三部分分析:
- 结构体 Cat 的初始化;
- 赋值触发的类型转换过程;
- 调用接口的方法 Quack();
我们先来分析结构体 Cat 的初始化过程:
|
|
- 获取 Cat 结构体类型指针并将其作为参数放到栈上;
- 通过 CALL 指定调用
runtime.newobject函数,这个函数会以 Cat 结构体类型指针作为入参,分配一片新的内存空间并将指向这片内存空间的指针返回到 SP+8 上; - SP+8 现在存储了一个指向 Cat 结构体的指针,我们将栈上的指针拷贝到寄存器 DI 上方便操作;
- 由于 Cat 中只包含一个字符串类型的 Name 变量,所以在这里会分别将字符串地址
&"draven"和字符串长度 6 设置到结构体上,最后三行汇编指令等价于cat.Name = "draven";
字符串在运行时的表示是指针加上字符串长度,在前面的章节字符串已经介绍过它的底层表示和实现原理,但是这里要看一下初始化之后的 Cat 结构体在内存中的表示是什么样的:
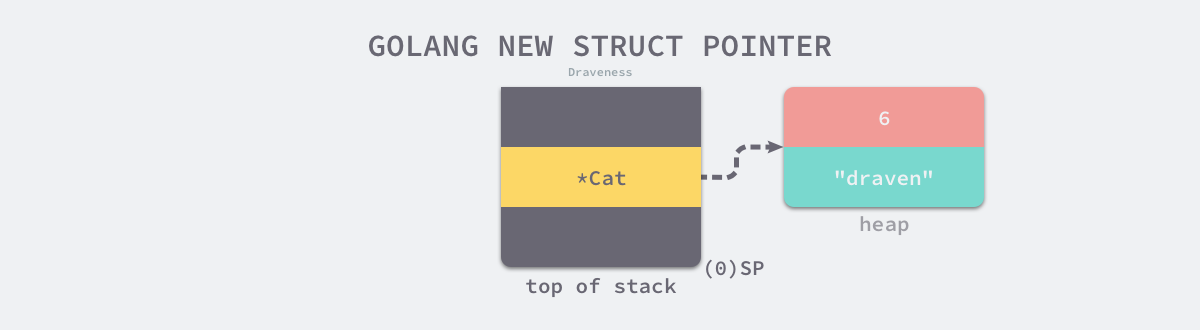
因为 Cat 结构体的定义中只包含一个字符串,而字符串在 Go 语言中总共占 16 字节,所以每一个 Cat 结构体的大小都是 16 字节。初始化 Cat 结构体之后就进入了将 *Cat 转换成 Duck 类型的过程了:
|
|
类型转换的过程比较简单,Duck 作为一个包含方法的接口,它在底层使用 runtime.iface 结构体表示。runtime.iface 结构体包含两个字段,其中一个是指向数据的指针,另一个是表示接口和结构体关系的 tab 字段,我们已经通过上一段代码 SP+8 初始化了 Cat 结构体指针,这段代码只是将编译期间生成的 runtime.itab 结构体指针复制到 SP 上:
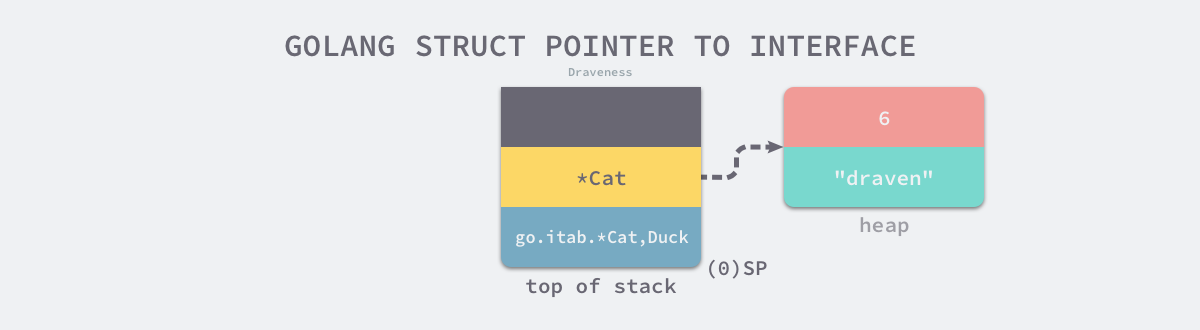
到这里,我们会发现 SP ~ SP+16 共同组成了 runtime.iface 结构体,而栈上的这个 runtime.iface 也是 Quack 方法的第一个入参。
|
|
上述代码会直接通过 CALL 指令完成方法的调用,细心的读者可能会发现一个问题 —— 为什么在代码中我们调用的是 Duck.Quack 但生成的汇编是*Cat.Quack 呢?Go 语言的编译器会在编译期间将一些需要动态派发的方法调用改写成对目标方法的直接调用,以减少性能的额外开销。如果在这里禁用编译器优化,就会看到动态派发的过程,我们会在后面分析接口的动态派发以及性能上的额外开销。
结构体类型
在这里我们继续修改上一节中的代码,使用结构体类型实现 Duck 接口并初始化结构体类型的变量:
|
|
如果我们在初始化变量时使用指针类型 &Cat{Name: "draven"} 也能够通过编译,不过生成的汇编代码和上一节中的几乎完全相同,所以这里也就不分析这个情况了。
编译上述代码会得到如下所示的汇编指令,需要注意的是为了代码更容易理解和分析,这里的汇编指令依然经过了删减,不过不影响具体的执行过程。与上一节一样,我们将汇编代码的执行过程分成以下几个部分:
- 初始化 Cat 结构体;
- 完成从 Cat 到 Duck 接口的类型转换;
- 调用接口的 Quack 方法; 我们先来看一下上述汇编代码中用于初始化 Cat 结构体的部分:
|
|
这段汇编指令会在栈上初始化 Cat 结构体,而上一节的代码在堆上申请了 16 字节的内存空间,栈上只有一个指向 Cat 的指针。
初始化结构体后会进入类型转换的阶段,编译器会将 go.itab."".Cat,"".Duck 的地址和指向 Cat 结构体的指针作为参数一并传入 runtime.convT2I 函数:
|
|
这个函数会获取 runtime.itab 中存储的类型,根据类型的大小申请一片内存空间并将 elem 指针中的内容拷贝到目标的内存中:
|
|
runtime.convT2I 会返回一个 runtime.iface,其中包含 runtime.itab 指针和 Cat 变量。当前函数返回之后,main 函数的栈上会包含以下数据:
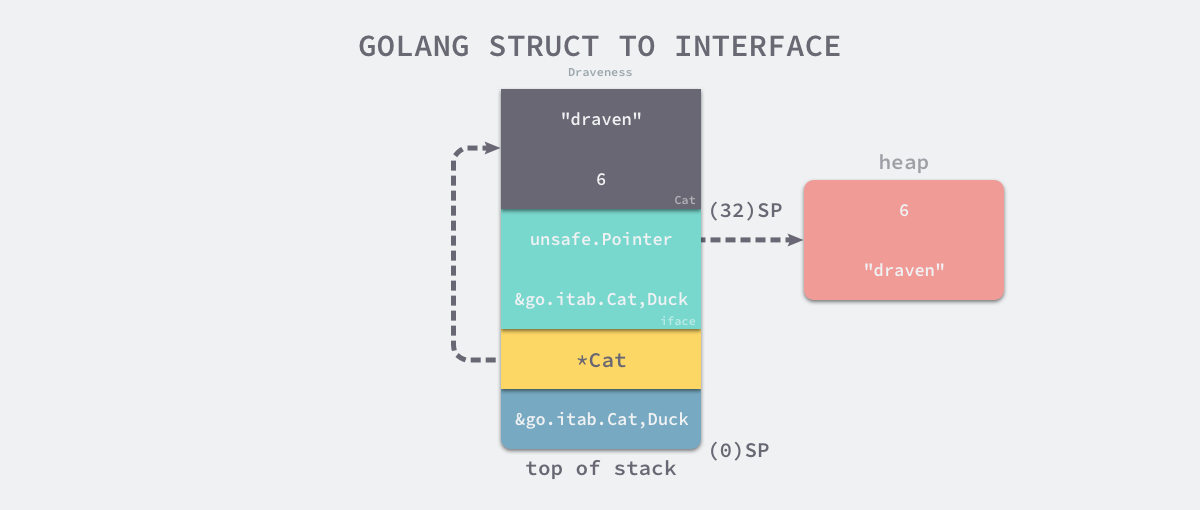
SP 和 SP+8 中存储的 runtime.itab 和 Cat 指针是 runtime.convT2I 函数的入参,这个函数的返回值位于 SP+16,是一个占 16 字节内存空间的 runtime.iface 结构体,SP+32 存储的是在栈上的 Cat 结构体,它会在 runtime.convT2I 执行的过程中拷贝到堆上。
在最后,我们会通过以下的指令调用 Cat 实现的接口方法 Quack():
|
|
这几个汇编指令还是非常好理解的,MOVQ 24(AX), AX 是最关键的指令,它从 runtime.itab 结构体中取出 Cat.Quack 方法指针作为 CALL 指令调用时的参数。接口变量的第 24 字节是 itab.fun 数组开始的位置,由于 Duck 接口只包含一个方法,所以 itab.fun[0] 中存储的就是指向 Quack 方法的指针了。
类型断言
上一节介绍是如何把具体类型转换成接口类型,而这一节介绍的是如何将一个接口类型转换成具体类型。本节会根据接口中是否存在方法分两种情况介绍类型断言的执行过程。
非空接口
首先分析接口中包含方法的情况,Duck 接口是一个非空的接口,我们来分析从 Duck 转换回 Cat 结构体的过程:
|
|
我们将编译得到的汇编指令分成两部分分析,第一部分是变量的初始化,第二部分是类型断言,第一部分的代码如下:
|
|
0037 ~ 0049 三个指令初始化了 Duck 变量,Cat 结构体初始化在 SP+8 ~ SP+24 上。因为 Go 语言的编译器做了一些优化,所以代码中没有runtime.iface 的构建过程,不过对于这一节要介绍的类型断言和转换没有太多的影响。下面进入类型转换的部分:
|
|
switch语句生成的汇编指令会将目标类型的 hash 与接口变量中的 itab.hash 进行比较:
- 如果两者相等意味着变量的具体类型是 Cat,我们会跳转到 0080 所在的分支完成类型转换。
- 获取 SP+8 存储的 Cat 结构体指针;
- 将结构体指针拷贝到栈顶;
- 调用 Quack 方法;
- 恢复函数的栈并返回;
- 如果接口中存在的具体类型不是 Cat,就会直接恢复栈指针并返回到调用方;
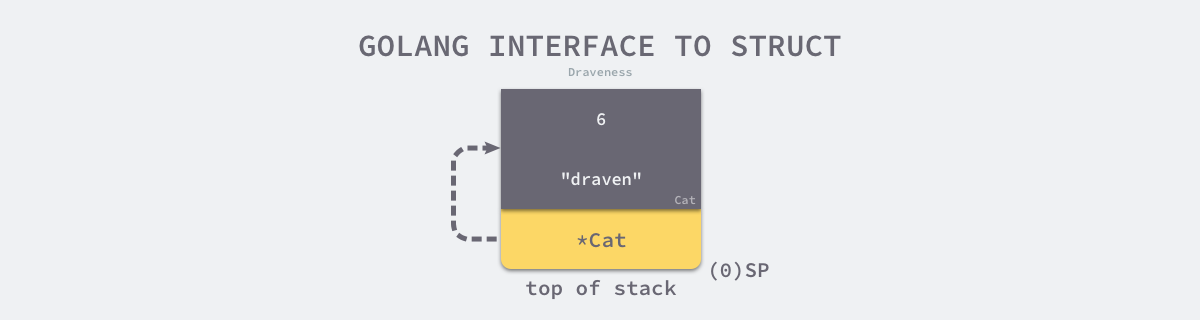
上图展示了调用 Quack 方法时的堆栈情况,其中 Cat 结构体存储在 SP+8 ~ SP+24 上,Cat 指针存储在栈顶并指向上述结构体。
空接口
当我们使用空接口类型 interface{} 进行类型断言时,如果不关闭 Go 语言编译器的优化选项,生成的汇编指令是差不多的。编译器会省略将 Cat 结构体转换成 runtime.eface 的过程:
|
|
如果禁用编译器优化,上述代码会在类型断言时就不是直接获取变量中具体类型的 runtime._type,而是从 eface._type 中获取,汇编指令仍然会使用目标类型的 hash 与变量的类型比较。
动态派发
动态派发(Dynamic dispatch)是在运行期间选择具体多态操作(方法或者函数)执行的过程,它是面向对象语言中的常见特性。Go 语言虽然不是严格意义上的面向对象语言,但是接口的引入为它带来了动态派发这一特性,调用接口类型的方法时,如果编译期间不能确认接口的类型,Go 语言会在运行期间决定具体调用该方法的哪个实现。
在如下所示的代码中,main 函数调用了两次 Quack 方法:
- 第一次以
Duck接口类型的身份调用,调用时需要经过运行时的动态派发; - 第二次以
*Cat具体类型的身份调用,编译期就会确定调用的函数:
|
|
因为编译器优化影响了我们对原始汇编指令的理解,所以需要使用编译参数 -N 关闭编译器优化。如果不指定这个参数,编译器会对代码进行重写,与最初生成的执行过程有一些偏差,例如:
- 因为接口类型中的 tab 参数并没有被使用,所以优化从 Cat 转换到 Duck 的过程;
- 因为变量的具体类型是确定的,所以删除从 Duck 接口类型转换到 *Cat 具体类型时可能会发生崩溃的分支;
在具体分析调用 Quack 方法的两种姿势之前,我们要先了解 Cat 结构体究竟是如何初始化的,以及初始化后的栈上有哪些数据:
|
|
这段代码的初始化过程其实和上两节中的过程没有太多的差别,它先初始化了 Cat 结构体指针,再将 Cat 和 tab 打包成了一个 runtime.iface 类型的结构体,我们直接来看初始化结束后的栈情况:
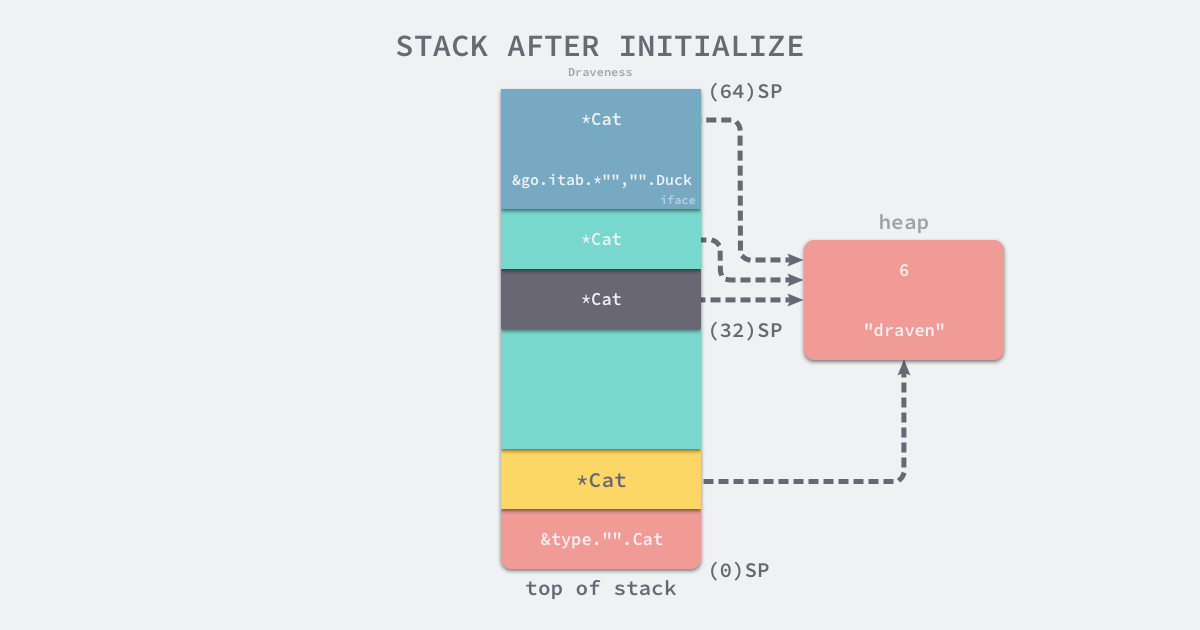
- SP 是 Cat 类型,它也是运行时
runtime.newobject方法的参数; - SP+8 是
runtime.newobject方法的返回值,即指向堆上的 Cat 结构体的指针; - SP+32、SP+40 是对 SP+8 的拷贝,这两个指针都会指向堆上的 Cat 结构体;
- SP+48 ~ SP+64 是接口变量 runtime.iface 结构体,其中包含了 tab 结构体指针和 *Cat 指针;
初始化过程结束后,就进入到了动态派发的过程,c.Quack() 语句展开的汇编指令会在运行时确定函数指针。
|
|
这段代码的执行过程可以分成以下三个步骤:
- 从接口变量中获取保存
Cat.Quack方法指针的tab.func[0]; - 接口变量在
runtime.iface中的数据会被拷贝到栈顶; - 方法指针会被拷贝到寄存器中并通过汇编指令 CALL 触发:
另一个调用 Quack 方法的语句 c.(*Cat).Quack() 生成的汇编指令看起来会有一些复杂,但是代码前半部分都是在做类型转换,将接口类型转换成*Cat 类型,只有最后两行代码才是函数调用相关的指令:
|
|
下面的几行代码只是将 Cat 指针拷贝到了栈顶并调用 Quack 方法。这一次调用的函数指针在编译期就已经确定了,所以运行时就不需要动态查找方法的实现:
|
|
两次方法调用对应的汇编指令差异就是动态派发带来的额外开销,这些额外开销在有低延时、高吞吐量需求的服务中是不能被忽视的,我们来详细分析一下产生的额外汇编指令对性能造成的影响。
基准测试
下面代码中的两个方法 BenchmarkDirectCall 和 BenchmarkDynamicDispatch 分别会调用结构体方法和接口方法,在接口上调用方法时会使用动态派发机制,我们以直接调用作为基准分析动态派发带来了多少额外开销:
|
|
我们直接运行下面的命令,使用 1 个 CPU 运行上述代码,每一个基准测试都会被执行 3 次:
|
|
- 调用结构体方法时,每一次调用需要 ~3.03ns;
- 使用动态派发时,每一调用需要 ~3.58ns;
在关闭编译器优化的情况下,从上面的数据来看,动态派发生成的指令会带来 ~18% 左右的额外性能开销。
这些性能开销在一个复杂的系统中不会带来太多的影响。一个项目不可能只使用动态派发,而且如果我们开启编译器优化后,动态派发的额外开销会降低至 ~5%,这对应用性能的整体影响就更小了,所以与使用接口带来的好处相比,动态派发的额外开销往往可以忽略。
上面的性能测试建立在实现和调用方法的都是结构体指针上,当我们将结构体指针换成结构体又会有比较大的差异:
|
|
当我们重新执行相同的基准测试时,会得到如下所示的结果:
|
|
直接调用方法需要消耗时间的平均值和使用指针实现接口时差不多,约为 ~3.09ns,而使用动态派发调用方法却需要 ~6.98ns 相比直接调用额外消耗了 ~125% 的时间,从生成的汇编指令我们也能看出后者的额外开销会高很多。
| 直接调用 | 动态派发 | |
|---|---|---|
| 指针 | ~3.03ns | ~3.58ns |
| 结构体 | ~3.09ns | ~6.98ns |
从上述表格我们可以看到使用结构体实现接口带来的开销会大于使用指针实现,而动态派发在结构体上的表现非常差,这也提醒我们应当尽量避免使用结构体类型实现接口。
使用结构体带来的巨大性能差异不只是接口带来的问题,带来性能问题主要因为 Go 语言在函数调用时是传值的,动态派发的过程只是放大了参数拷贝带来的影响。
小结
重新回顾一下本节介绍的内容,我们在开头简单介绍了使用 Go 语言接口的常见问题,例如使用不同类型实现接口带来的差异、函数调用时发生的隐式类型转换;我们还分析了接口的类型转换、类型断言以及动态派发机制,相信这一节的内容能够帮助各位深入理解 Go 语言的接口。
reflect
虽然在大多数的应用和服务中并不常见,但是很多框架都依赖 Go 语言的反射机制简化代码。因为 Go 语言的语法元素很少、设计简单,所以它没有特别强的表达能力,但是 Go 语言的 reflect 包能够弥补它在语法上reflect.Type的一些劣势。
reflect 实现了运行时的反射能力,能够让程序操作不同类型的对象。反射包中有两对非常重要的函数和类型,两个函数分别是:
- reflect.TypeOf 能获取类型信息;
- reflect.ValueOf 能获取数据的运行时表示;
两个类型是 reflect.Type 和 reflect.Value,它们与函数是一一对应的关系:
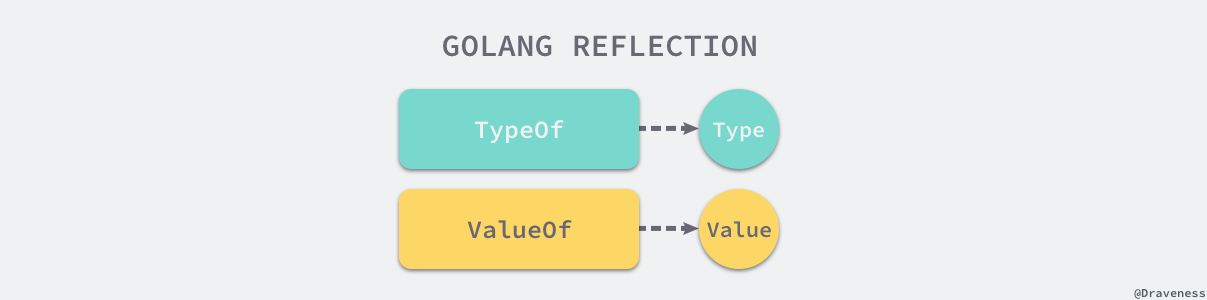
类型 reflect.Type 是反射包定义的一个接口,我们可以使用 reflect.TypeOf 函数获取任意变量的类型,reflect.Type 接口中定义了一些有趣的方法,MethodByName 可以获取当前类型对应方法的引用、Implements 可以判断当前类型是否实现了某个接口:
|
|
反射包中 reflect.Value 的类型与 reflect.Type 不同,它被声明成了结构体。这个结构体没有对外暴露的字段,但是提供了获取或者写入数据的方法:
|
|
反射包中的所有方法基本都是围绕着 reflect.Type 和 reflect.Value 两个类型设计的。我们通过 reflect.TypeOf、reflect.ValueOf 可以将一个普通的变量转换成反射包中提供的 reflect.Type 和 reflect.Value,随后就可以使用反射包中的方法对它们进行复杂的操作。
三大法则
运行时反射是程序在运行期间检查其自身结构的一种方式。反射带来的灵活性是一把双刃剑,反射作为一种元编程方式可以减少重复代码,但是过量的使用反射会使我们的程序逻辑变得难以理解并且运行缓慢。我们在这一节中会介绍 Go 语言反射的三大法则,其中包括:
- 从
interface{}变量可以反射出反射对象; - 从反射对象可以获取
interface{}变量; - 要修改反射对象,其值必须可设置;
第一法则
反射的第一法则是我们能将 Go 语言的 interface{} 变量转换成反射对象。很多读者可能会对这以法则产生困惑 — 为什么是从 interface{} 变量到反射对象?当我们执行 reflect.ValueOf(1) 时,虽然看起来是获取了基本类型 int 对应的反射类型,但是由于 reflect.TypeOf、reflect.ValueOf 两个方法的入参都是 interface{} 类型,所以在方法执行的过程中发生了类型转换。
因为Go 语言的函数调用都是值传递的,所以变量会在函数调用时进行类型转换。基本类型 int 会转换成 interface{} 类型,这也就是为什么第一条法则是从接口到反射对象。
上面提到的 reflect.TypeOf 和 reflect.ValueOf 函数就能完成这里的转换,如果我们认为 Go 语言的类型和反射类型处于两个不同的世界,那么这两个函数就是连接这两个世界的桥梁。
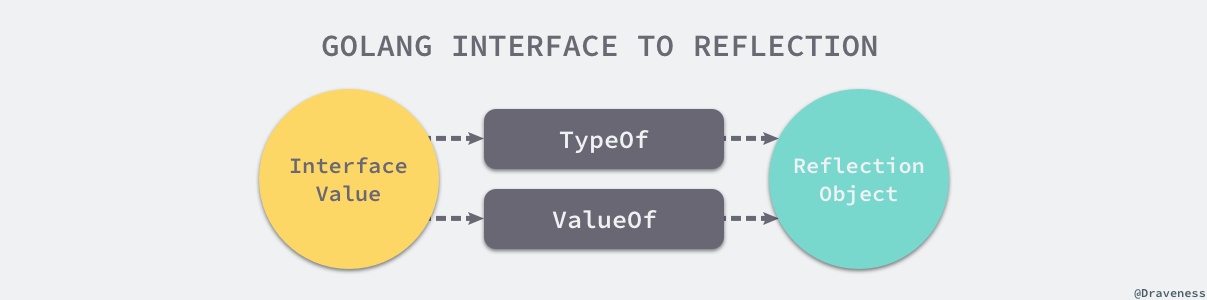
我们可以通过以下例子简单介绍它们的作用,reflect.TypeOf 获取了变量 author 的类型,reflect.ValueOf 获取了变量的值 draven。如果我们知道了一个变量的类型和值,那么就意味着我们知道了这个变量的全部信息。
|
|
|
|
有了变量的类型之后,我们可以通过 Method 方法获得类型实现的方法,通过 Field 获取类型包含的全部字段。对于不同的类型,我们也可以调用不同的方法获取相关信息:
- 结构体:获取字段的数量并通过下标和字段名获取字段 StructField;
- 哈希表:获取哈希表的 Key 类型;
- 函数或方法:获取入参和返回值的类型;
总而言之,使用 reflect.TypeOf 和 reflect.ValueOf 能够获取 Go 语言中的变量对应的反射对象。一旦获取了反射对象,我们就能得到跟当前类型相关数据和操作,并可以使用这些运行时获取的结构执行方法。
第二法则
反射的第二法则是我们可以从反射对象可以获取 interface{} 变量。既然能够将接口类型的变量转换成反射对象,那么一定需要其他方法将反射对象还原成接口类型的变量,reflect 中的reflect.Value.Interface 就能完成这项工作:
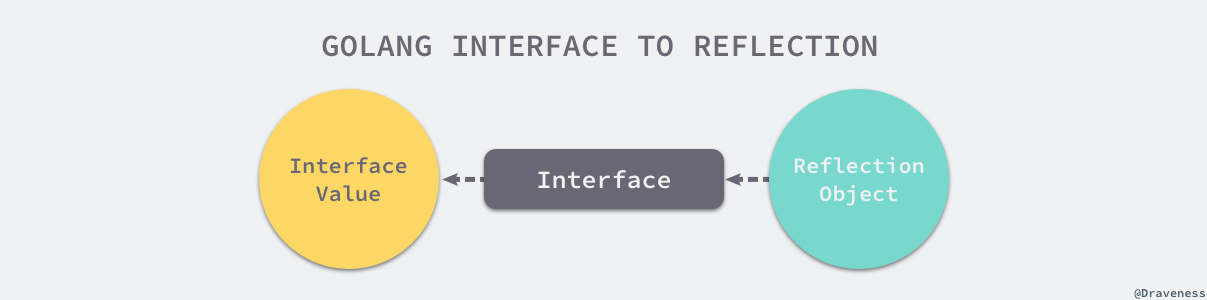
不过调用 reflect.Value.Interface 方法只能获得 interface{} 类型的变量,如果想要将其还原成最原始的状态还需要经过如下所示的显式类型转换:
|
|
从反射对象到接口值的过程是从接口值到反射对象的镜面过程,两个过程都需要经历两次转换:
- 从接口值到反射对象:
- 从基本类型到接口类型的类型转换;
- 从接口类型到反射对象的转换;
- 从反射对象到接口值:
- 反射对象转换成接口类型;
- 通过显式类型转换变成原始类型;
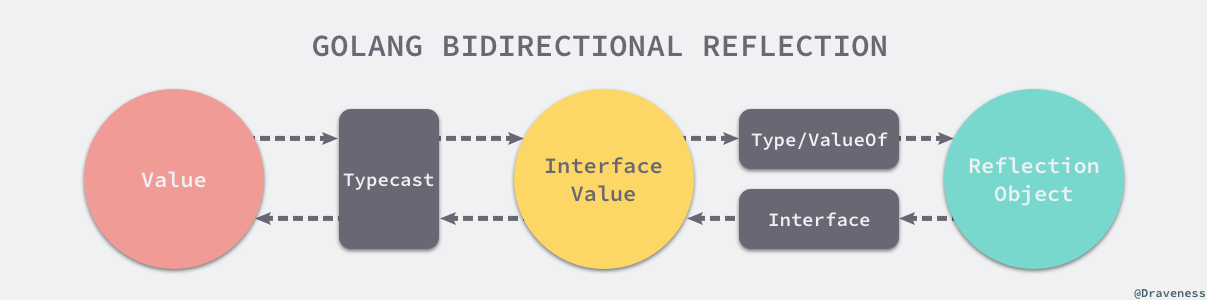
当然不是所有的变量都需要类型转换这一过程。如果变量本身就是 interface{} 类型的,那么它不需要类型转换,因为类型转换这一过程一般都是隐式的,所以我不太需要关心它,只有在我们需要将反射对象转换回基本类型时才需要显式的转换操作。
第三法则
Go 语言反射的最后一条法则是与值是否可以被更改有关,如果我们想要更新一个 reflect.Value,那么它持有的值一定是可以被更新的,假设我们有以下代码:
|
|
|
|
运行上述代码会导致程序崩溃并报出 “reflect: reflect.flag.mustBeAssignable using unaddressable value” 错误,仔细思考一下就能够发现出错的原因:由于 Go 语言的函数调用都是传值的,所以我们得到的反射对象跟最开始的变量没有任何关系,那么直接修改反射对象无法改变原始变量,程序为了防止错误就会崩溃。
想要修改原变量只能使用如下的方法:
|
|
|
|
- 调用
reflect.ValueOf获取变量指针; - 调用
reflect.Value.Elem获取指针指向的变量; - 调用
reflect.Value.SetInt更新变量的值:
由于 Go 语言的函数调用都是值传递的,所以我们只能只能用迂回的方式改变原变量:先获取指针对应的 reflect.Value,再通过 reflect.Value.Elem 方法得到可以被设置的变量,我们可以通过下面的代码理解这个过程:
|
|
如果不能直接操作 i 变量修改其持有的值,我们就只能获取 i 变量所在地址并使用*v 修改所在地址中存储的整数。
TypeOf&ValueOf
Go 语言的 interface{} 类型在语言内部是通过 reflect.emptyInterface 结体表示的,其中的 rtype 字段用于表示变量的类型,另一个 word 字段指向内部封装的数据:
|
|
用于获取变量类型的 reflect.TypeOf 函数将传入的变量隐式转换成 reflect.emptyInterface 类型并获取其中存储的类型信息 reflect.rtype:
|
|
reflect.rtype 是一个实现了 reflect.Type 接口的结构体,该结构体实现的 reflect.rtype.String 方法可以帮助我们获取当前类型的名称:
|
|
reflect.TypeOf 的实现原理其实并不复杂,它只是将一个 interface{} 变量转换成了内部的 reflect.emptyInterface 表示,然后从中获取相应的类型信息。
用于获取接口值 reflect.Value 的函数 reflect.ValueOf 实现也非常简单,在该函数中我们先调用了 reflect.escapes 保证当前值逃逸到堆上,然后通过 reflect.unpackEface 从接口中获取 reflect.Value 结构体:
|
|
reflect.unpackEface 会将传入的接口转换成 reflect.emptyInterface,然后将具体类型和指针包装成 reflect.Value 结构体后返回。
reflect.TypeOf 和 reflect.ValueOf 的实现都很简单。我们已经分析了这两个函数的实现,现在需要了解编译器在调用函数之前做了哪些工作:
|
|
|
|
从上面这段截取的汇编语言,我们可以发现在函数调用之前已经发生了类型转换,上述指令将 int 类型的变量转换成了占用 16 字节 autotmp_19+280(SP) ~ autotmp_19+288(SP) 的接口,两个 LEAQ 指令分别获取了类型的指针 type.int(SB) 以及变量 i 所在的地址。
当我们想要将一个变量转换成反射对象时,Go 语言会在编译期间完成类型转换,将变量的类型和值转换成了 interface{} 并等待运行期间使用 reflect 包获取接口中存储的信息。
Value.Set
当我们想要更新 reflect.Value 时,就需要调用 reflect.Value.Set 更新反射对象,该方法会调用 reflect.flag.mustBeAssignable 和 reflect.flag.mustBeExported 分别检查当前反射对象是否是可以被设置的以及字段是否是对外公开的:
|
|
reflect.Value.Set 会调用 reflect.Value.assignTo 并返回一个新的反射对象,这个返回的反射对象指针会直接覆盖原反射变量。
|
|
reflect.Value.assignTo 会根据当前和被设置的反射对象类型创建一个新的 reflect.Value 结构体:
- 如果两个反射对象的类型是可以被直接替换,就会直接返回目标反射对象;
- 如果当前反射对象是接口并且目标对象实现了接口,就会把目标对象简单包装成接口值;
在变量更新的过程中,reflect.Value.assignTo 返回的 reflect.Value 中的指针会覆盖当前反射对象中的指针实现变量的更新。
实现协议
reflect 包还为我们提供了 reflect.rtype.Implements 方法可以用于判断某些类型是否遵循特定的接口。在 Go 语言中获取结构体的反射类型 reflect.Type 还是比较容易的,但是想要获得接口类型需要通过以下方式:
|
|
我们通过一个例子在介绍如何判断一个类型是否实现了某个接口。假设我们需要判断如下代码中的 CustomError 是否实现了 Go 语言标准库中的 error 接口:
|
|
上述代码的运行结果正如我们在接口一节中介绍的:
- CustomError 类型并没有实现 error 接口;
- *CustomError 指针类型实现了 error 接口;
抛开上述的执行结果不谈,我们来分析一下 reflect.rtype.Implements 方法的工作原理:
|
|
reflect.rtype.Implements 会检查传入的类型是不是接口,如果不是接口或者是空值就会直接崩溃并中止当前程序。在参数没有问题的情况下,上述方法会调用私有函数 reflect.implements 判断类型之间是否有实现关系:
|
|
如果接口中不包含任何方法,就意味着这是一个空的接口,任意类型都自动实现该接口,这时会直接返回 true。
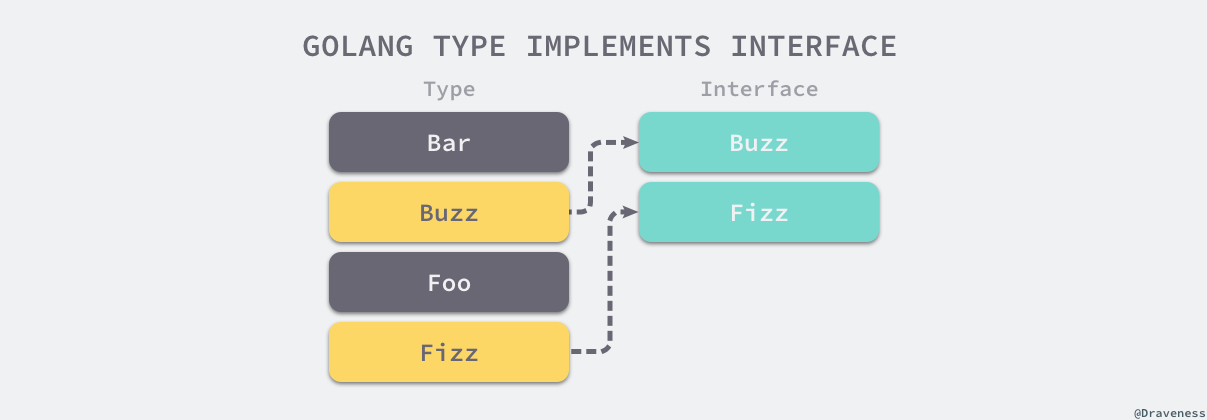
在其他情况下,由于方法都是按照字母序存储的,reflect.implements 会维护两个用于遍历接口和类型方法的索引 i 和 j 判断类型是否实现了接口,因为最多只会进行 n 次比较(类型的方法数量),所以整个过程的时间复杂度是 𝑂(𝑛)。
方法调用
作为一门静态语言,如果我们想要通过 reflect 包利用反射在运行期间执行方法不是一件容易的事情,下面的十几行代码就使用反射来执行 Add(0, 1) 函数:
|
|
- 通过 reflect.ValueOf 获取函数 Add 对应的反射对象;
- 调用 reflect.rtype.NumIn 获取函数的入参个数;
- 多次调用 reflect.ValueOf 函数逐一设置 argv 数组中的各个参数;
- 调用反射对象 Add 的 reflect.Value.Call 方法并传入参数列表;
- 获取返回值数组、验证数组的长度以及类型并打印其中的数据;
使用反射来调用方法非常复杂,原本只需要一行代码就能完成的工作,现在需要十几行代码才能完成,但这也是在静态语言中使用动态特性需要付出的成本。
|
|
reflect.Value.Call 是运行时调用方法的入口,它通过两个 MustBe 开头的方法确定了当前反射对象的类型是函数以及可见性,随后调用 reflect.Value.call 完成方法调用,这个私有方法的执行过程会分成以下的几个部分:
- 检查输入参数以及类型的合法性;
- 将传入的 reflect.Value 参数数组设置到栈上;
- 通过函数指针和输入参数调用函数;
- 从栈上获取函数的返回值;
我们将按照上面的顺序分析使用 reflect 进行函数调用的几个过程。
参数检查
参数检查是通过反射调用方法的第一步,在参数检查期间我们会从反射对象中取出当前的函数指针 unsafe.Pointer,如果该函数指针是方法,那么我们会通过 reflect.methodReceiver 获取方法的接收者和函数指针。
|
|
上述方法还会检查传入参数的个数以及参数的类型与函数签名中的类型是否可以匹配,任何参数的不匹配都会导致整个程序的崩溃中止。
准备参数
当我们已经对当前方法的参数完成验证后,就会进入函数调用的下一个阶段,为函数调用准备参数,在前面函数调用一节中,我们已经介绍过 Go 语言的函数调用惯例,函数或者方法在调用时,所有的参数都会被依次放到栈上。
|
|
- 通过
reflect.funcLayout计算当前函数需要的参数和返回值的栈布局,也就是每一个参数和返回值所占的空间大小; - 如果当前函数有返回值,需要为当前函数的参数和返回值分配一片内存空间 args;
- 如果当前函数是方法,需要向将方法的接收接收者者拷贝到 args 内存中;
- 将所有函数的参数按照顺序依次拷贝到对应 args 内存中
- 使用 reflect.funcLayout 返回的参数计算参数在内存中的位置;
- 将参数拷贝到内存空间中;
准备参数是计算各个参数和返回值占用的内存空间并将所有的参数都拷贝内存空间对应位置的过程,该过程会考虑函数和方法、返回值数量以及参数类型带来的差异。
调用函数
准备好调用函数需要的全部参数后,就会通过下面的代码执行函数指针了。我们会向该函数传入栈类型、函数指针、参数和返回值的内存空间、栈的大小以及返回值的偏移量:
|
|
上述函数实际上并不存在,它会在编译期间链接到 reflect.reflectcall 这个用汇编实现的函数上,我们在这里不会分析该函数的具体实现,感兴趣的读者可以自行了解其实现原理。
处理返回值
当函数调用结束之后,就会开始处理函数的返回值:
- 如果函数没有任何返回值,会直接清空 args 中的全部内容来释放内存空间;
- 如果当前函数有返回值;
- 将 args 中与输入参数有关的内存空间清空;
- 创建一个 nout 长度的切片用于保存由反射对象构成的返回值数组;
- 从函数对象中获取返回值的类型和内存大小,将 args 内存中的数据转换成 reflect.Value 类型并存储到切片中;
|
|
由 reflect.Value 构成的 ret 数组会被返回到调用方,到这里为止使用反射实现函数调用的过程就结束了。
小结
Go 语言的 reflect 包为我们提供了多种能力,包括如何使用反射来动态修改变量、判断类型是否实现了某些接口以及动态调用方法等功能,通过分析反射包中方法的原理能帮助我们理解之前看起来比较怪异、令人困惑的现象。
转载
文章作者 Forz
上次更新 2021-06-28