HTTP协议中的Content-Encoding
文章目录
Content-Encoding & Accept-Encoding
Accept-Encoding 和 Content-Encoding 是 HTTP 中用来对「采用何种编码格式传输正文」进行协定的一对头部字段。它的工作原理是这样:浏览器发送请求时,通过 Accept-Encoding 带上自己支持的内容编码格式列表;服务端从中挑选一种用来对正文进行编码,并通过 Content-Encoding 响应头指明选定的格式;浏览器拿到响应正文后,依据 Content-Encoding 进行解压。当然,服务端也可以返回未压缩的正文,但这种情况不允许返回 Content-Encoding。这个过程就是 HTTP 的内容编码机制。
内容编码目的是优化传输内容大小,通俗地讲就是进行压缩。一般经过 gzip 压缩过的文本响应,只有原始大小的 1/4。对于文本类响应是否开启了内容压缩,是我们做性能优化时首先要检查的重要项目;而对于 JPG / PNG 这类本身已经高度压缩过的二进制文件,不推荐开启内容压缩,效果微乎其微还浪费 CPU。
内容编码针对的只是传输正文。在 HTTP/1 中,头部始终是以 ASCII 文本传输,没有经过任何压缩。这个问题在 HTTP/2 中得以解决,详见:HTTP/2 头部压缩技术介绍。
内容编码使用特别广泛,理解起来也很简单,随手打开一个网页抓包看下请求响应就能明白。唯一要注意的是不要把它与 HTTP 中的另外一个概念:传输编码(Transfer-Encoding)搞混即可。
有关 HTTP 内容编码机制我打算只介绍这么多,下面重点介绍两种具体的内容编码格式:gzip 和 deflate,具体会涉及到两个问题:1)gzip 和 deflate 分别是什么编码?2)为什么很少见到 Content-Encoding: deflate?
开始之前,先来介绍三种数据压缩格式:
- DEFLATE,是一种使用 Lempel-Ziv 压缩算法(LZ77)和哈夫曼编码的数据压缩格式。定义于 RFC 1951 : DEFLATE Compressed Data Format Specification;
- ZLIB,是一种使用 DEFLATE 的数据压缩格式。定义于 RFC 1950 : ZLIB Compressed Data Format Specification;
- GZIP,是一种使用 DEFLATE 的文件格式。定义于 RFC 1952 : GZIP file format specification;
这三个名词有太多的含义,很容易让人晕菜。所以本文有如下约定:
- DEFLATE、ZLIB、GZIP 这种大写字符,表示数据压缩格式;
- deflate、gzip 这种小写字符,表示 HTTP 中 Content-Encoding 的取值;
- Gzip 特指 GUN zip 文件压缩程序,Zlib 特指 Zlib 库;
在 HTTP/1.1 的初始规范 RFC 2616 的「3.5 Content Codings」这一节中,这样定义了 Content-Encoding 中的 gzip 和 deflate:
- gzip,一种由文件压缩程序「Gzip,GUN zip」产生的编码格式,描述于 RFC 1952。这种编码格式是一种具有 32 位 CRC 的 Lempel-Ziv 编码(LZ77);
- deflate,由定义于 RFC 1950 的「ZLIB」编码格式与 RFC 1951 中描述的「DEFLATE」压缩机制组合而成的产物;
RFC 2616 对 Content-Encoding 中的 gzip 的定义很清晰,它就是指在 RFC 1952 中定义的 GZIP 编码格式;但对 deflate 的定义含糊不清,实际上它指的是 RFC 1950 中定义的 ZLIB 编码格式,但 deflate 这个名字特别容易产生误会。
在 Zlib 库的官方网站,有这么一条 FAQ:What’s the difference between the “gzip” and “deflate” HTTP 1.1 encodings? 就是在讨论 HTTP/1.1 对 deflate 的错误命名:
Q:在 HTTP/1.1 的 Content-Encoding 中,gzip 和 deflate 的区别是什么?
A:gzip 是指 GZIP 格式,deflate 是指 ZLIB 格式。HTTP/1.1 的作者或许应该将后者称之为 zlib,从而避免与原始的 DEFLATE 数据格式产生混淆。虽然 HTTP/1.1 RFC 2016 正确指出,Content-Encoding 中的 deflate 就是 RFC 1950 描述的 ZLIB,但仍然有报告显示部分服务器及浏览器错误地生成或期望收到原始的 DEFLATE 格式,特别是微软。所以虽然使用 ZLIB 更为高效(实际上这正是 ZLIB 的设计目标),但使用 GZIP 格式可能更为可靠,这一切都是因为 HTTP/1.1 的作者不幸地选择了错误的命名。
结论:在 HTTP/1.1 的 Content-Encoding 中,请使用 gzip。
在 HTTP/1.1 的修订版 RFC 7230 的 4.2 Compression Codings 这一节中,彻底明确了 deflate 的含义,对 gzip 也做了补充:
-
deflate,包含「使用 Lempel-Ziv 压缩算法(LZ77)和哈夫曼编码的 DEFLATE 压缩数据流(RFC 1951)」的 ZLIB 数据格式(RFC 1950)。注:一些不符合规范的实现会发送没有经过 ZLIB 包装的 DEFLATE 压缩数据;
-
gzip,具有 32 位循环冗余检查(CRC)的 LZ77 编码,通常由 Gzip 文件压缩程序(RFC 1952)产生。接受方应该将 x-gzip 视为 gzip;
总结一下,HTTP 标准中定义的 Content-Encoding: deflate,实际上指的是 ZLIB 编码(RFC 1950)。但由于 RFC 2616 中含糊不清的定义,导致 IE 错误地实现为只接受原始 DEFLATE(RFC 1951)。为了兼容 IE,我们只能用 Content-Encoding: gzip 进行内容编码,它指的是 GZIP 编码(RFC 1952)。
其实上,ZLIB 和 DEFLATE 的差别很小:ZLIB 数据去掉 2 字节的 ZLIB 头,再忽略最后 4 字节的校验和,就变成了 DEFLATE 数据。在 Fiddler 增加以下处理,就可以让 IE 支持标准的 Content-Encoding: deflate(ZLIB 编码),很好奇为啥微软一直不改。
|
|
由于其它浏览器也能解析原始 DEFLATE,所以有些 WEB 应用干脆为了迁就 IE 直接输出原始 DEFLATE,个人觉得这种不遵守标准的做法不值得推荐,还是推荐直接用 GZIP 编码来获得更好的兼容性。
如何压缩 HTTP 请求正文
上篇文章中,我介绍了 HTTP 协议中的 Accept-Encoding/Content-Encoding 机制。这套机制可以很好地用于文本类响应正文的压缩,可以大幅减少网络传输,从而一直被广泛使用。但 HTTP 请求的发起方(例如浏览器),无法事先知晓要访问的服务端是否支持解压,所以现阶段的浏览器没有压缩请求正文。
有一些通讯协议基于 HTTP 做了扩展,他们的客户端和服务端是专用的,可以放心大胆地压缩请求正文。例如 WebDAV 客户端就是这样。
实际的 Web 项目中,会存在请求正文非常大的场景,例如发表长篇博客,上报用于调试的网络数据等等。这些数据如果能在本地压缩后再提交,就可以节省网络流量、减少传输时间。本文介绍如何对 HTTP 请求正文进行压缩,包含如何在服务端解压、如何在客户端压缩两个部分。
开始之前,先来介绍本文涉及的三种数据压缩格式:
- DEFLATE,是一种使用 Lempel-Ziv 压缩算法(LZ77)和哈夫曼编码的压缩格式。详见 RFC 1951;
- ZLIB,是一种使用 DEFLATE 的压缩格式,对应 HTTP 中的 Content-Encoding: deflate。详见 RFC 1950;
- GZIP,也是一种使用 DEFLATE 的压缩格式,对应 HTTP 中的 Content-Encoding: gzip。详见 RFC 1952;
Content-Encoding 中的 deflate,实际上是 ZLIB。为了清晰,本文将 DEFLATE 称之为 RAW DEFLATE,ZLIB 和 GZIP 都是 RAW DEFLATE 的不同 Wrapper。
解压请求正文
服务端收到请求正文后,需要分析请求头中的 Content-Encoding 字段,才能知道正文采用了哪种压缩格式。本文规定用 gzip、deflate 和 deflate-raw 分别表示请求正文采用 GZIP、ZLIB 和 RAW DEFLATE 压缩格式。
Nginx
Nginx 没有类似于 Apache 的 SetInputFilter 指令,不能直接给请求添加处理逻辑,还好有 OpenResty。OpenResty 通过集成 Lua 及大量 Lua 库,极大地提升了 Nginx 的功能丰富度和可扩展性。而 LuaJIT 中的 FFI 库,允许纯 Lua 代码调用外部 C 函数,使用 C 数据结构。
把这一切结合起来,就能方便地实现这个需求:首先安装 OpenResty;下载并解压 Zlib 库的 FFI 版;然后在 Nginx 的配置中,通过 lua_package_path 指令将这个库引入;再新建一个 lua 文件,如 request-compress.lua,调用 Zlib 库实现解压功能:
|
|
我们的 Nginx 一般都是挡在最前面,背后还有 PHP、Node.js 等实际服务。这段代码从 Content-Encoding 请求头中获取请求压缩格式,并在解压后移除了这个头部。这样对于 Nginx 背后的服务来说,完全感知不到跟平常有什么不一样。
现在还差最后一步,找到 Nginx 中配置 xxx_pass(proxy_pass、uwsgi_pass、fastcgi_pass 等)的地方,加入 lua 处理逻辑:
|
|
这个配置目的是让这个 lua 逻辑工作在 Nginx 的 Access 阶段。
到此为止,基于 OpenResty 的解压方案已经写好。它能否按预期正常工作呢?我决定先放一放,后面再验证。
Node.js
Node.js 内置了对 Zlib 库的封装。使用 Node.js 也可以轻松应对压缩内容。直接上代码:
|
|
这段代码将请求正文解压之后,直接做为输出返回,它可以正常工作,但仅作示意。实际项目中,这些通用逻辑应该放在框架层统一处理,业务层代码无需关心。
PHP
PHP 也内置了处理这些压缩格式的函数,以下是实例代码:
|
|
可以看到,ZLIB 格式的压缩数据去掉头尾,就是 RAW DEFLATE,可以直接用 gzinflate 解压。跟前面一样,如果采用 PHP 解压方案,也应该在框架层统一处理。
小结一下:在 Nginx 统一解压的好处是无论后端挂接什么服务,都可以做到无感知,坏处是需要替换为 OpenResty;在 Web 框架中处理更灵活,但不同语言不同项目需要分别处理,性能方面应该也有差别。如何选择,要看各自实际情况。
压缩请求正文
浏览器
通过 pako 这个 JS 库,可以在浏览器中使用 Zlib 库的大部分功能。它也能用于 Node.js 环境,但 Node.js 中一般用官方的 Zlib 就可以了。
pako 的浏览器版可以在这里下载,我们只需要压缩功能,使用 pako_deflate.min.js 即可。这个文件有 27.3KB,gzip 后 9.1KB,算很小的了。它同时支持 GZIP、ZLIB 和 RAW DEFLATE 三种压缩格式,如果只保留一种应该还能更小。
下面是使用 pako 库在浏览器中实现压缩请求正文的示例代码:
|
|
这段代码本身没什么好多说的,十分简单。这里有一个最终的 DEMO 页面,大家可以实际体验下。在这个 DEMO 中,针对 Zepto 源码压缩后能够减少 70% 的体积,十分可观。这个 DEMO 服务端使用的是前面介绍的 Node.js 解压方案。
Gzip + Curl
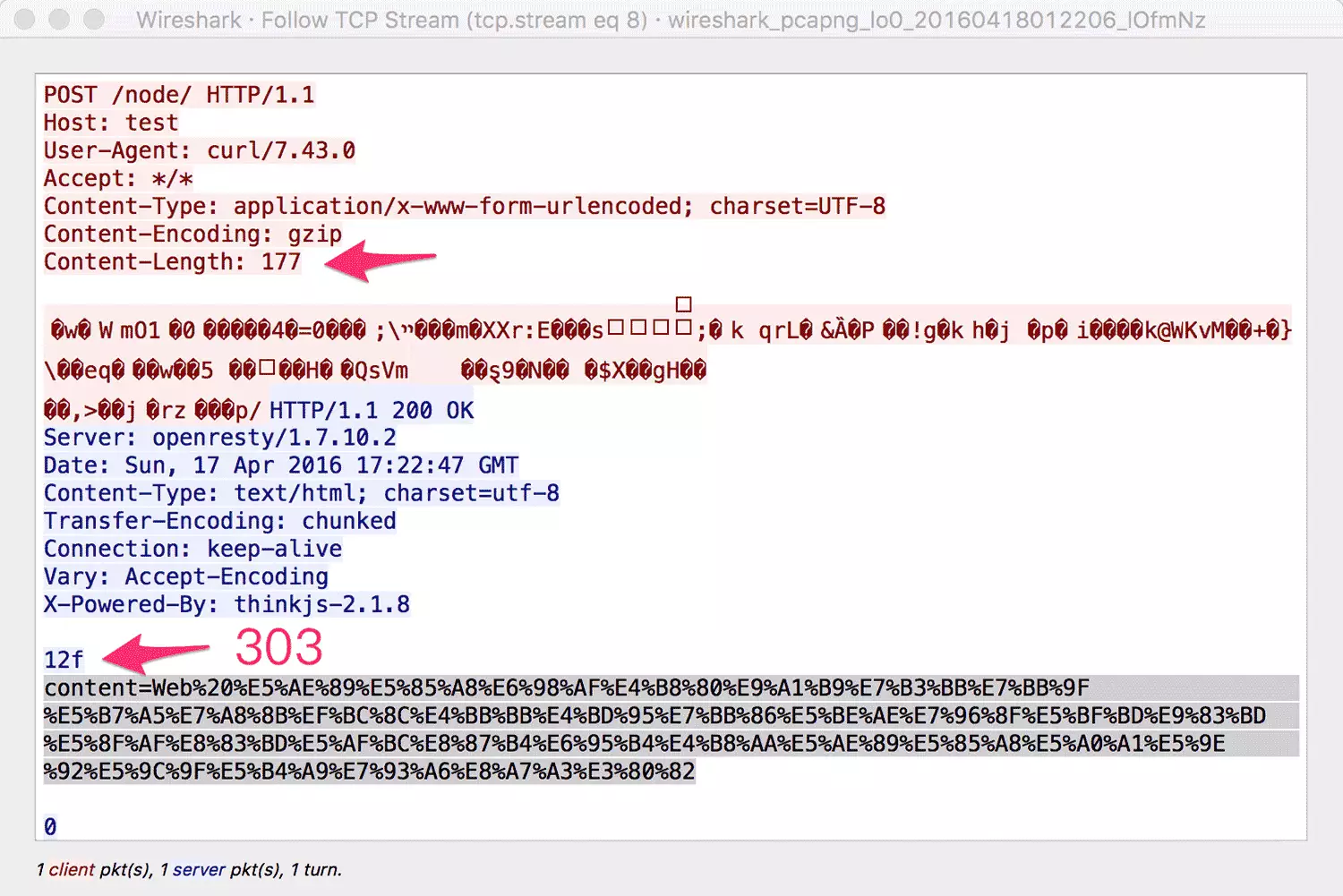
使用 Curl 命令,可以将 Gzip 程序生成的 GZIP 压缩数据 POST 给服务端。例如:
|
|
通过下图可以清晰的看到整个数据传输过程:
参考
文章作者 Forz
上次更新 2021-04-28