Go项目如何工程化
文章目录
MVC代码分层
阿里规范
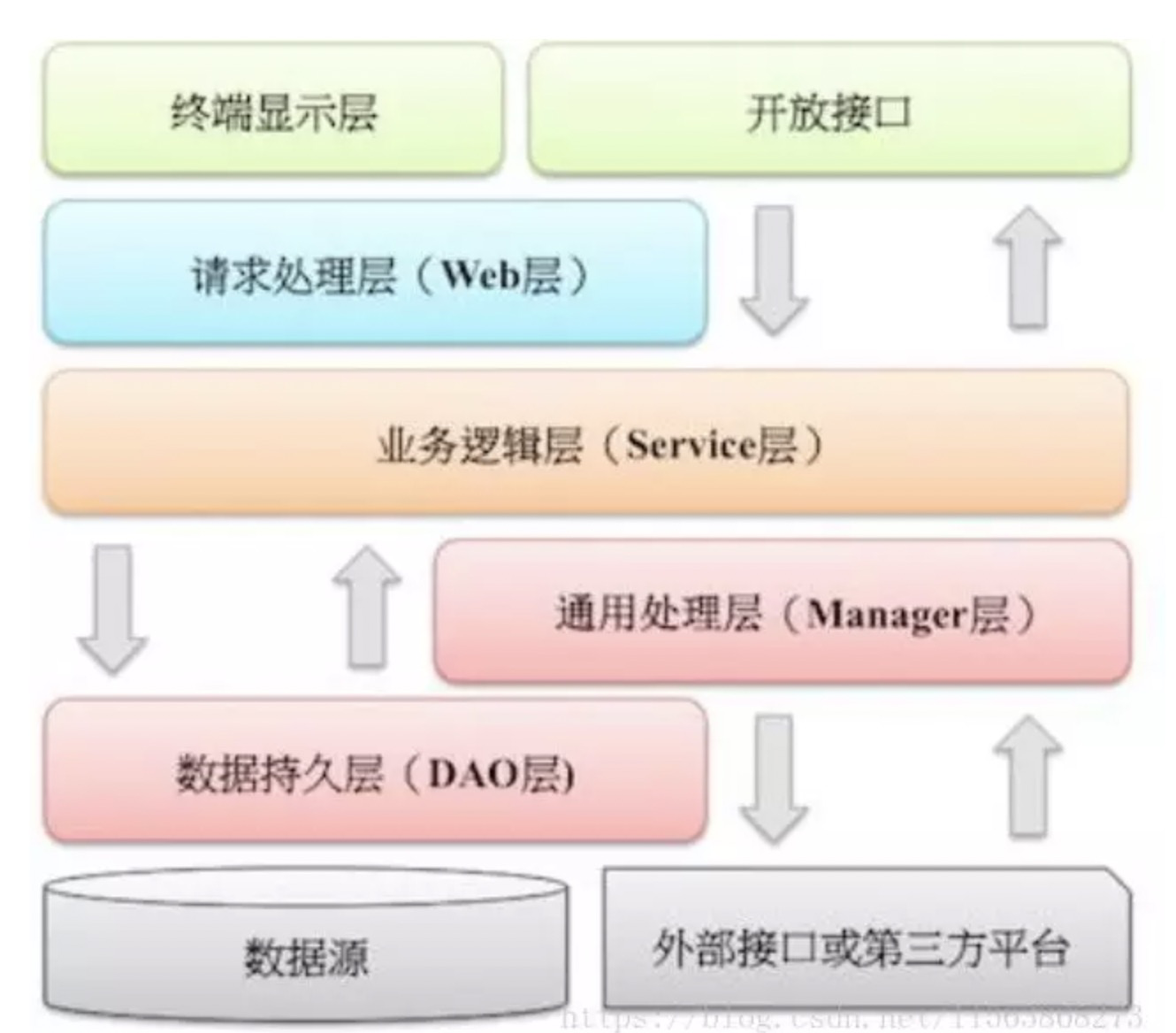
在阿里的编码规范中约束的分层如下:
-
开放接口层:可直接封装 Service 方法暴露成 RPC 接口;通过 Web 封装成 http 接口;进行 网关安全控制、流量控制等。
-
终端显示层:各个端的模板渲染并执行显示的层。当前主要是 velocity 渲染,JS 渲染, JSP 渲染,移动端展示等。
-
Web 层:主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理等。
-
Service 层:相对具体的业务逻辑服务层。
-
Manager 层:通用业务处理层,它有如下特征:1. 对第三方平台封装的层,预处理返回结果及转化异常信息;2. 对Service层通用能力的下沉,如缓存方案、中间件通用处理;3. 与DAO层交互,对多个DAO的组合复用。
-
DAO 层:数据访问层,与底层 MySQL、Oracle、Hbase 进行数据交互。
阿里巴巴规约中的分层比较清晰简单明了,但是描述得还是过于简单了,以及service层和manager层有很多同学还是有点分不清楚之间的关系,就导致了很多项目中根本没有Manager层的存在。下面介绍一下具体业务中应该如何实现分层。
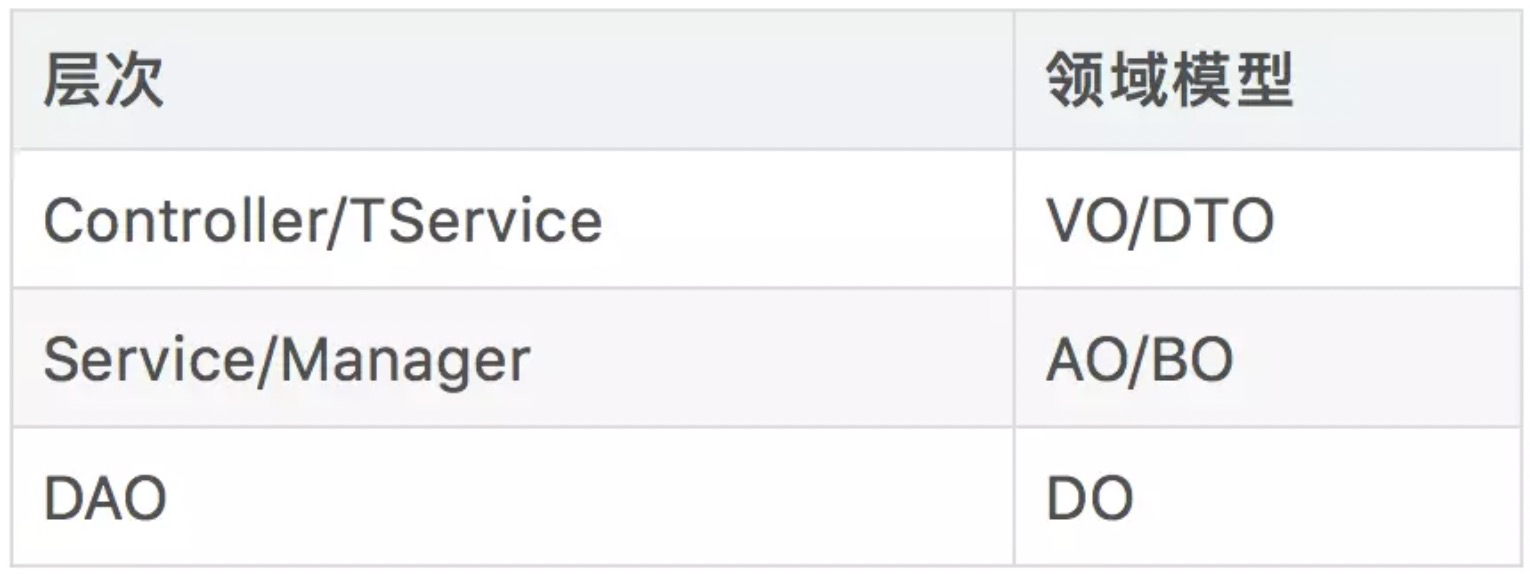
从我们的业务开发中总结了一个较为的理想模型,这里要先说明一下由于我们的rpc框架选用的是thrift可能会比其他的一些rpc框架例如dubbo会多出一层,作用和controller层类似:
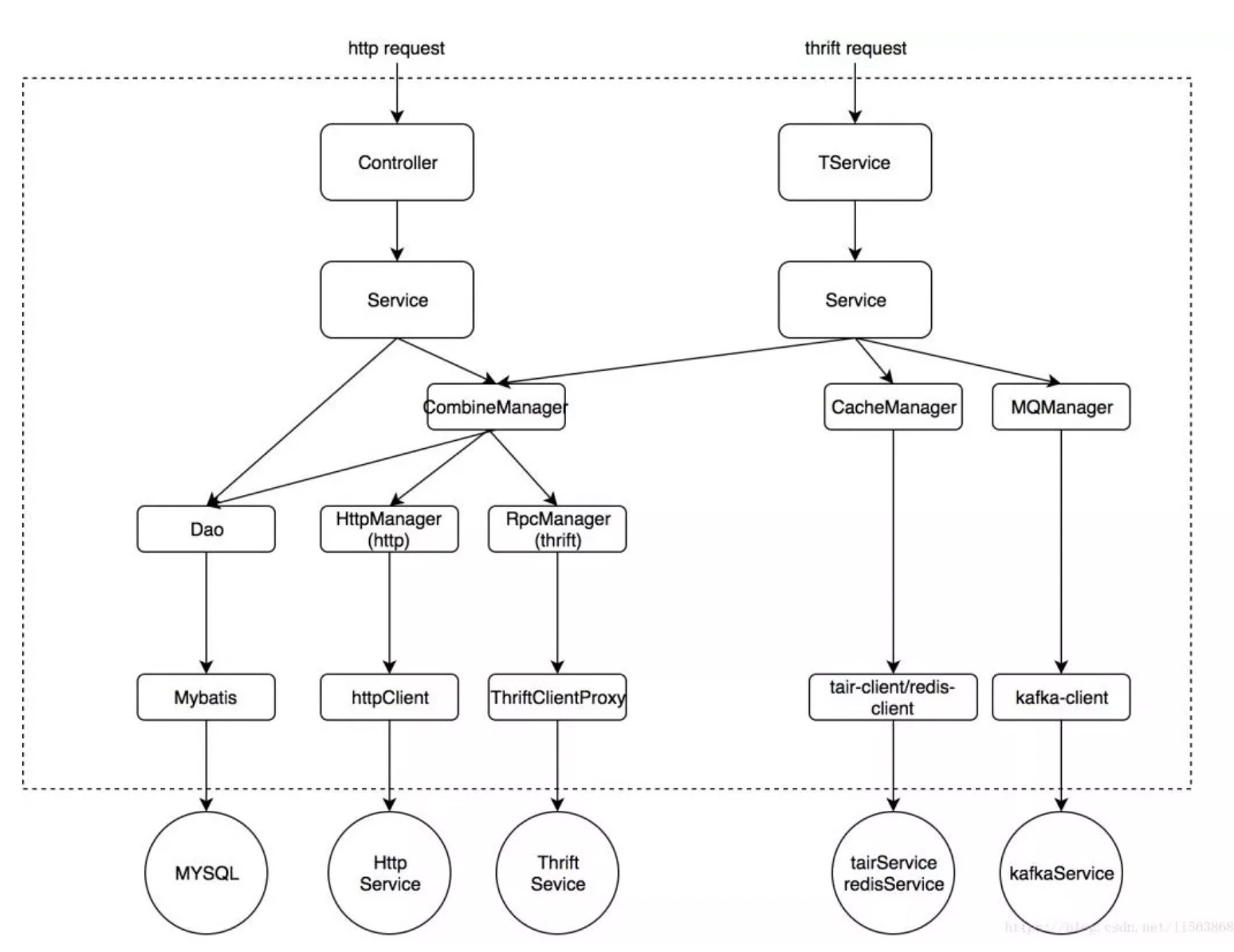
最上层controller和TService是我们阿里分层规范里面的第一层:轻业务逻辑,参数校验,异常兜底。通常这种接口可以轻易更换接口类型,所以业务逻辑必须要轻,甚至不做具体逻辑,只做参数与返回值的传递.
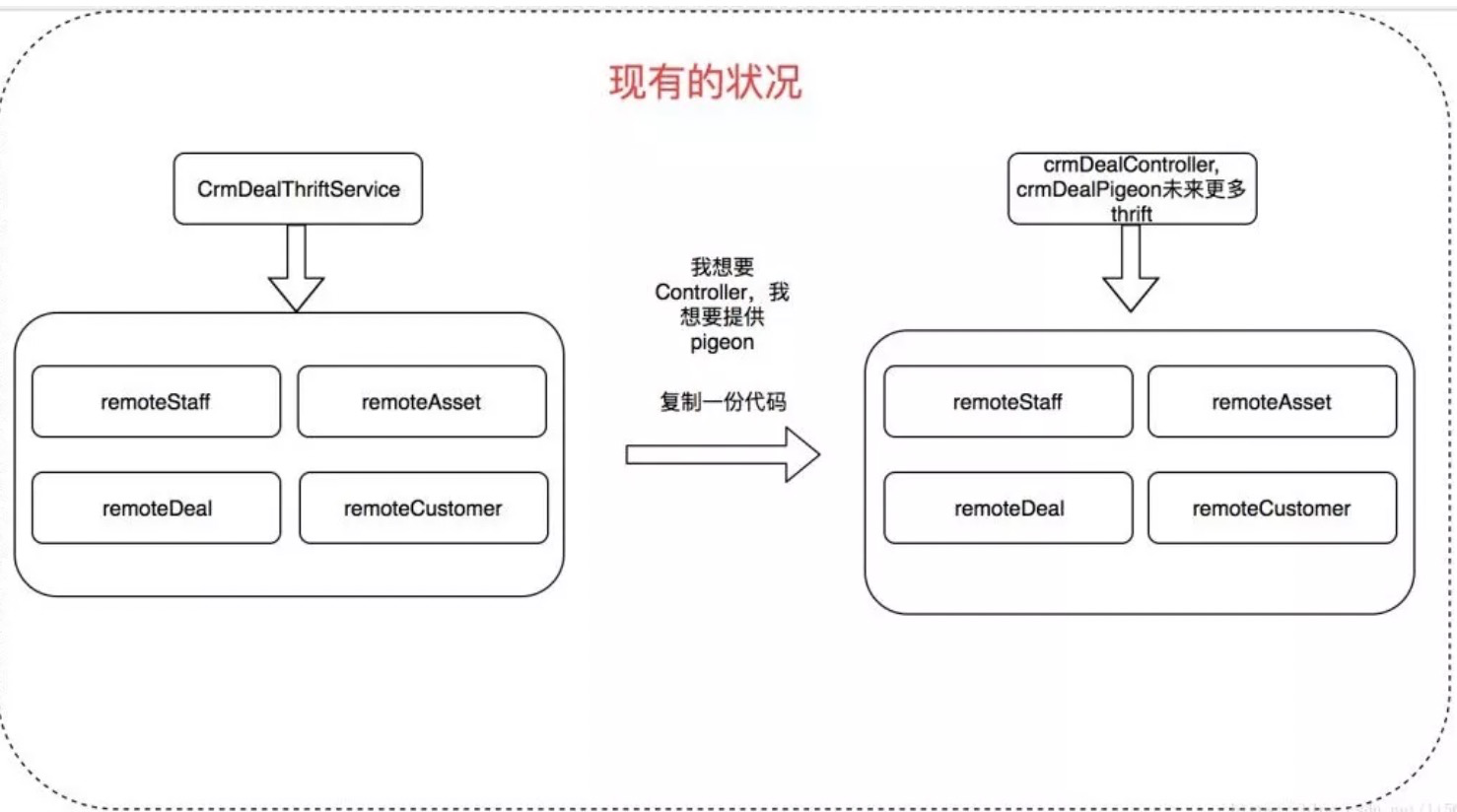
Service:业务层,复用性较低,这里推荐每一个controller方法都得对应一个service,不要把业务编排放在controller中去做,为什么呢?如果我们把业务编排放在controller层去做的话,如果以后我们要接入thrift,我们这里又需要把业务编排在做一次,这样会导致我们每接入一个入口层这个代码都得重新复制一份如下图所示:
这样大量的重复工作必定会导致我们开发效率下降,所以我们需要把业务编排逻辑都得放进service中去做:
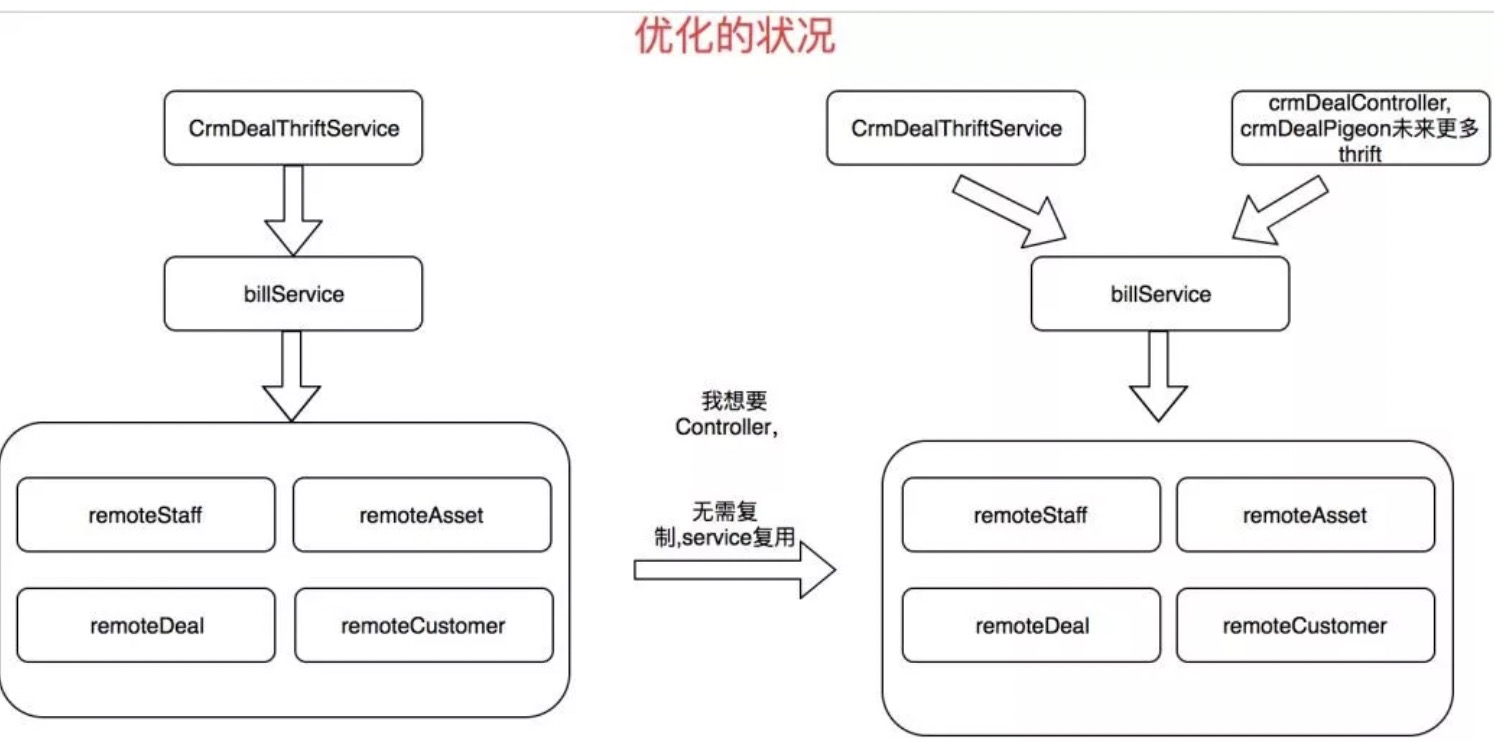
Mannager:可复用逻辑层。这里的Mannager可以是单个服务的,比如我们的cache,mq等等,当然也可以是复合的,当你需要调用多个Mannager的时候,这个可以合为一个Mannager,比如逻辑上的连表查询等。如果是httpMannager或rpcMannager需要在这一层做一些数据转换。
model层:用于内部数据处理的结构体
adapter层:只存放用于controller层用于接收,返回参数的结构体
DAO:数据库访问层。主要负责“操作数据库的某张表,映射到某个java对象”,dao应该只允许自己的Service访问,其他Service要访问我的数据必须通过对应的Service。
分层领域模型的转换
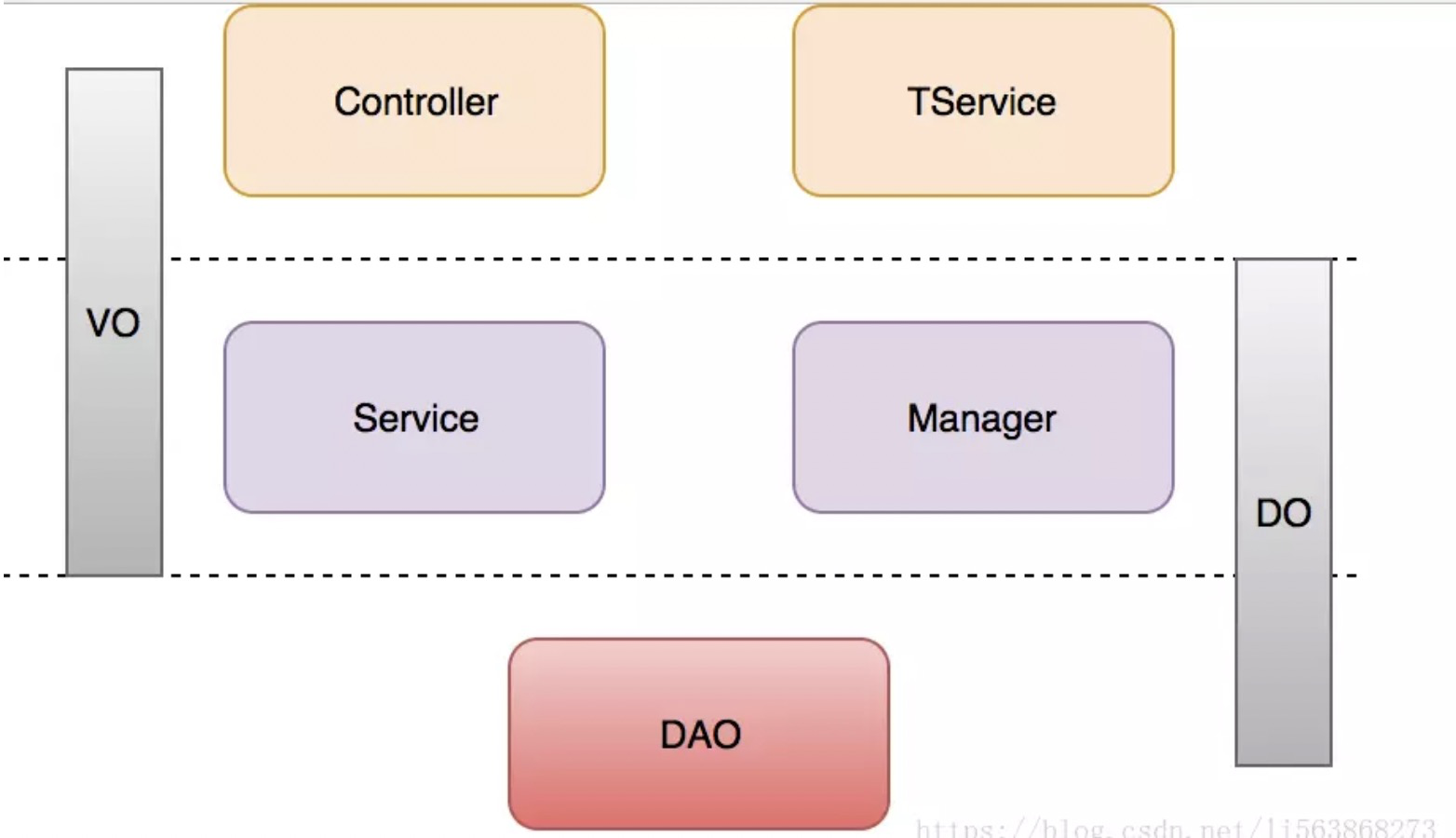
阿里巴巴编码规约中领域模型:
- DO(Data Object):与数据库表结构一一对应,通过DAO层向上传输数据源对象。
- DTO(Data Transfer Object):数据传输对象,Service或Manager向外传输的对象。
- BO(Business Object):业务对象。由Service层输出的封装业务逻辑的对象。
- AO(Application Object):应用对象。在Web层与Service层之间抽象的复用对象模型,极为贴近展示层,复用度不高。
- VO(View Object):显示层对象,通常是Web向模板渲染引擎层传输的对象。
- Query:数据查询对象,各层接收上层的查询请求。注意超过2个参数的查询封装,禁止使用Map类来传输。
每一个层基本都自己对应的领域模型,这样就导致了有些人过于追求每一层都是用自己的领域模型,这样就导致了一个对象可能会出现3次甚至4次转换在一次请求中,当返回的时候同样也会出现3-4次转换,这样有可能一次完整的请求-返回会出现很多次对象转换。如果在开发中真的按照这么来,恐怕就别写其他的了,一天就光写这个重复无用的逻辑算了吧。
- 允许Service/Manager可以操作数据领域模型,对于这个层级来说,本来自己做的工作也是做的是业务逻辑处理和数据组装
- Controller/TService层的领域模型不允许传入DAO层,这样就不符合职责划分了。
- 同理,不允许DAO层的数据传入到Controller/Service。
OBJ简述
PO:全称是persistant object持久对象
最形象的理解就是一个PO就是数据库中的一条记录。好处是可以把一条记录作为一个对象处理,可以方便的转为其它对象。
BO:全称是business object:业务对象
主要作用是把业务逻辑封装为一个对象。这个对象可以包括一个或多个其它的对象。比如一个简历,有教育经历、工作经历、社会关系等等。
我们可以把教育经历对应一个PO,工作经历对应一个PO,社会关系对应一个PO。
建立一个对应简历的BO对象处理简历,每个BO包含这些PO。这样处理业务逻辑时,我们就可以针对BO去处理。
VO :value object值对象,ViewObject表现层对象
主要对应界面显示的数据对象。对于一个WEB页面,或者SWT、SWING的一个界面,用一个VO对象对应整个界面的值。
DTO :Data Transfer Object数据传输对象
主要用于远程调用等需要大量传输对象的地方。
比如我们一张表有100个字段,那么对应的PO就有100个属性。
但是我们界面上只要显示10个字段,客户端用WEB service来获取数据,没有必要把整个PO对象传递到客户端,这时我们就可以用只有这10个属性的DTO来传递结果到客户端,这样也不会暴露服务端表结构.到达客户端以后,如果用这个对象来对应界面显示,那此时它的身份就转为VO
POJO :plain ordinary java object 简单java对象
个人感觉POJO是最常见最多变的对象,是一个中间对象,也是我们最常打交道的对象。
一个POJO持久化以后就是PO直接用它传递、传递过程中就是DTO直接用来对应表示层就是VO
DAO:data access object数据访问对象
这个大家最熟悉,和上面几个O区别最大,基本没有互相转化的可能性和必要.
主要用来封装对数据库的访问。通过它可以把POJO持久化为PO,用PO组装出来VO、DTO
工程项目结构
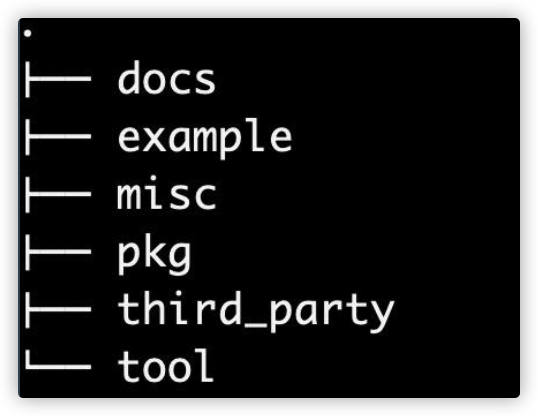
Standard Go Project Layout
https://github.com/golang-standards/project- layout/blob/master/README_zh.md
如果你尝试学习 Go,或者你正在为自己建立一个 PoC 或一 个玩具项目,这个项目布局是没啥必要的。从一些非常简单 的事情开始(一个 main.go 文件绰绰有余)。当有更多的人参 与这个项目时,你将需要更多的结构,包括需要一个 toolkit 来方便生成项目的模板,尽可能大家统一的工程目录布局。
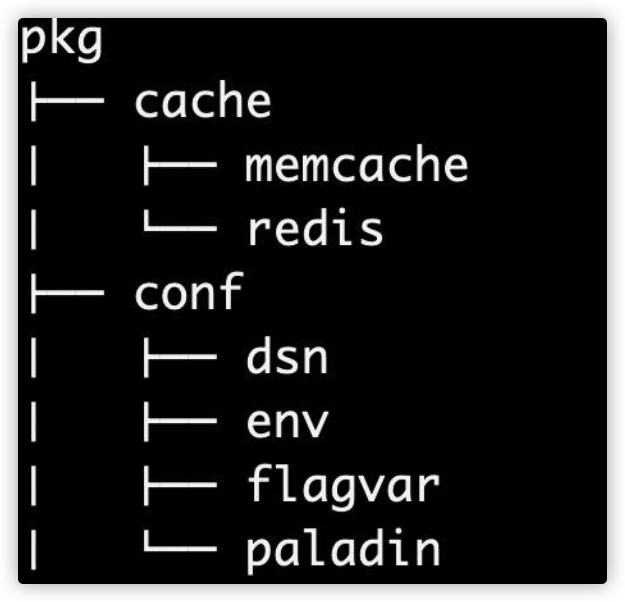
- /cmd 本项目的主干。
每个应用程序的目录名应该与你想要的可执行文件的名称相匹配(例 如,/cmd/myapp)。 不要在这个目录中放置太多代码。如果你认为代码可以导入并在其 他项目中使用,那么它应该位于 /pkg 目录中。如果代码不是可重用 的,或者你不希望其他人重用它,请将该代码放到 /internal 目录中。

- /internal
私有应用程序和库代码。这是你不希望其他人在其应用程序或库 中导入代码。请注意,这个布局模式是由 Go 编译器本身执行的。 有关更多细节,请参阅Go 1.4 release notes。注意,你并不局限于 顶级 internal 目录。在项目树的任何级别上都可以有多个内部目录。
你可以选择向 internal 包中添加一些额外的结构,以分隔共享和非 共享的内部代码。这不是必需的(特别是对于较小的项目),但是最 好有有可视化的线索来显示预期的包的用途。你的实际应用程序代 码可以放在 /internal/app 目录下(例如 /internal/app/myapp),这些 应用程序共享的代码可以放在 /internal/pkg 目录下(例如 /internal/pkg/myprivlib)。
因为我们习惯把相关的服务,比如账号服务,内部有 rpc、job、 admin 等,相关的服务整合一起后,需要区分 app。单一的服务, 可以去掉 /internal/myapp。

- /pkg
外部应用程序可以使用的库代码(例如 /pkg/mypubliclib)。其他项 目会导入这些库,所以在这里放东西之前要三思:注意,internal 目录是确保私有包不可导入的更好方法,因为它是由 Go 强制执行 的。/pkg 目录仍然是一种很好的方式,可以显式地表示该目录中的 代码对于其他人来说是安全使用的好方法。
/pkg 目录内,可以参考 go 标准库的组织方式,按照功能分类。 /internla/pkg 一般用于项目内的 跨多个应用的公共共享代码,但其 作用域仅在单个项目工程内。
由 Travis Jeffery 撰写的 I’ll take pkg over internal 博客文章提供了 pkg 和 internal 目录的一个很好的概述,以及什么时候使用它们是 有意义的。 当根目录包含大量非 Go 组件和目录时,这也是一种将 Go 代码分 组到一个位置的方法,这使得运行各种 Go 工具变得更加容易组织。
- /api
API 协议定义目录,xxapi.proto protobuf 文件,以及生成的 go 文件。我们通常把 api 文档直接在 proto 文件中描述。
- /configs
配置文件模板或默认配置。建议使用yaml.
- /test
额外的外部测试应用程序和测试数据。你可以随时根据需求构造 /test 目录。对于较大的项目,有一个数据子目录是有意义的。例如, 你可以使用 /test/data 或 /test/testdata (如果你需要忽略目录中的内 容)。请注意,Go 还会忽略以“.”或“_”开头的目录或文件,因此在如 何命名测试数据目录方面有更大的灵活性。
- 不应该包含:/src
有些 Go 项目确实有一个 src 文件夹,但这通常发生在开发人员有 Java 背景,在那里它是一种常见的模式。不要将项目级别 src 目录 与 Go 用于其工作空间的 src 目录。
Kit Project Layout
每个公司都应当为不同的微服务建立一个统一的 kit 工具包项目(基 础库/框架) 和 app 项目。
基础库 kit 为独立项目,公司级建议只有一个,按照功能目录来拆 分会带来不少的管理工作,因此建议合并整合。
by Package Oriented Design
“To this end, the Kit project is not allowed to have a vendor folder. If any of packages are dependent on 3rd party packages, they must always build against the latest version of those dependences.”
kit 项目必须具备的特点:
- 统一
- 标准库方式布局
- 高度抽象
- 支持插件
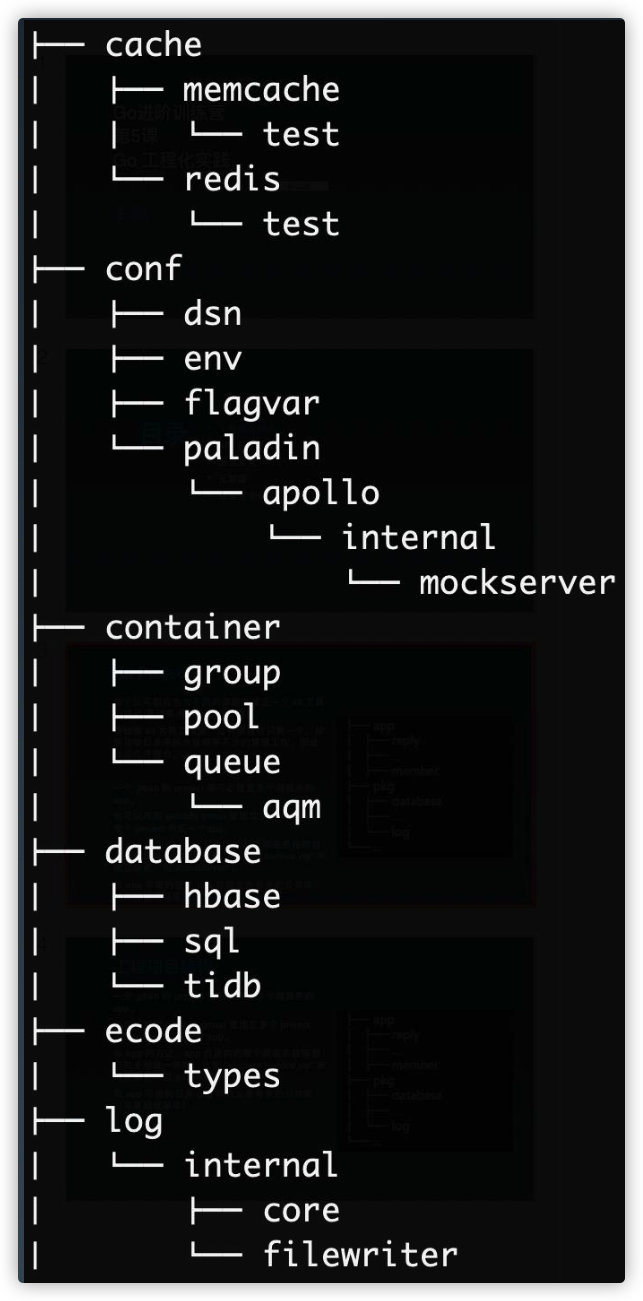
Service Application Project
一个 gitlab 的 project 里可以放置多个微服务的 app(类似 monorepo)。也可以按照 gitlab 的 group 里建立多个 project,每个 project 对应一个 app。
-
多app的方式,app目录内的每个微服务按照自己 的全局唯一名称,比如 “account.service.vip” 来建立 目录,如: account/vip/*。
- account:业务
- service:服务
- vip:子服务
- 不建议用部门组织结构命名,因为项目可能会迁移,服务名是不能改变的.
-
和app平级的目录pkg存放业务有关的公共库(非 基础框架库)。如果应用不希望导出这些目录,可以 放置到 myapp/internal/pkg 中。
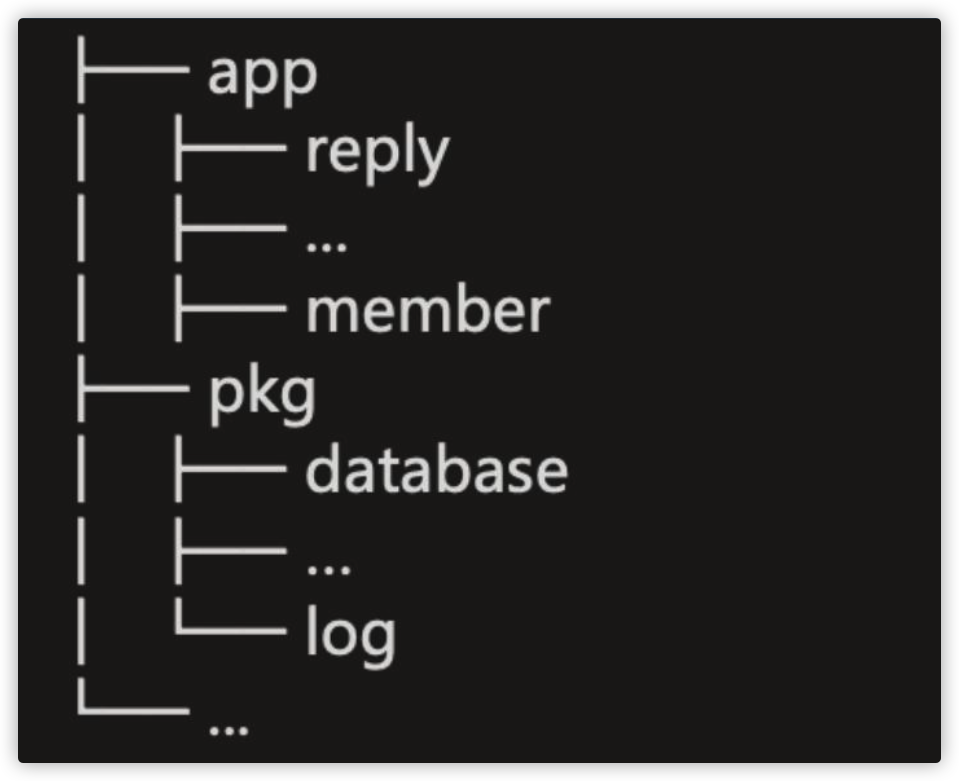
微服务中的 app 服务类型分为4类:interface、 service、job、admin。
- interface:对外的BFF服务,接受来自用户的请求, 比如暴露了 HTTP/gRPC 接口。
- service:对内的微服务,仅接受来自内部其他服务或 者网关的请求,比如暴露了gRPC 接口只对内服务。
- admin:区别于service,更多是面向运营侧的服务, 通常数据权限更高,隔离带来更好的代码级别安全。
- job:流式任务处理的服务,上游一般依赖message broker。
- task:定时任务,类似cronjob,部署到task托管平 台中。
cmd 应用目录负责程序的: 启动、关闭、配置初始化等。

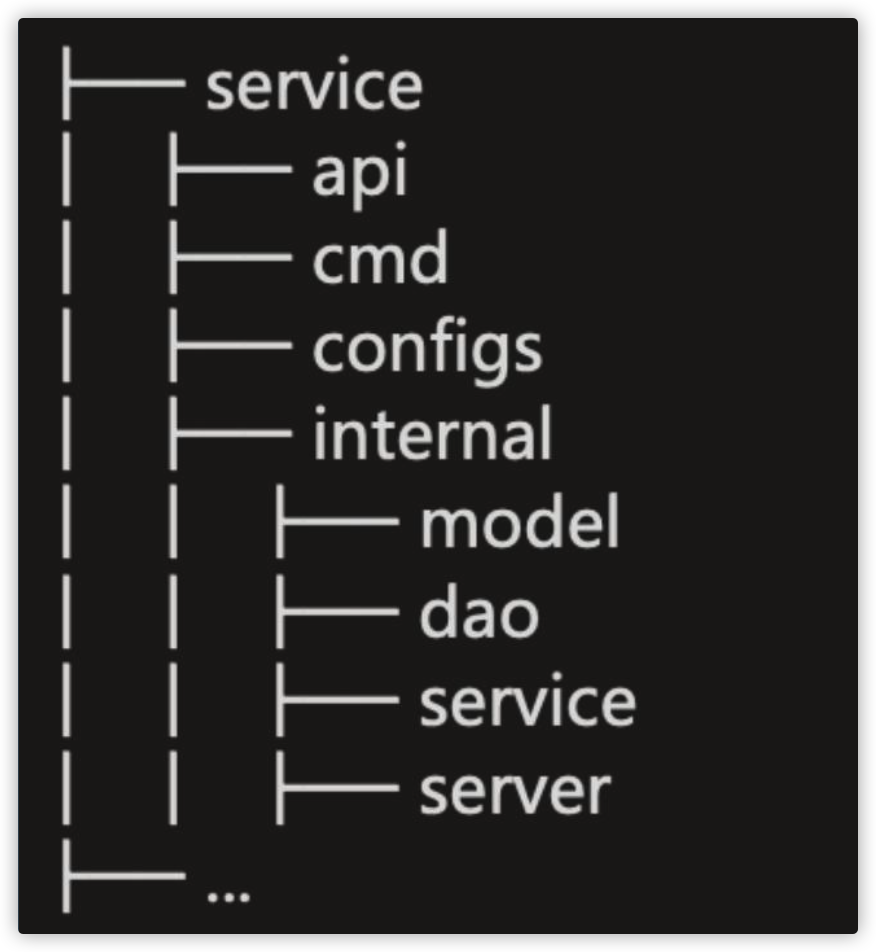
Service Application Project - v1
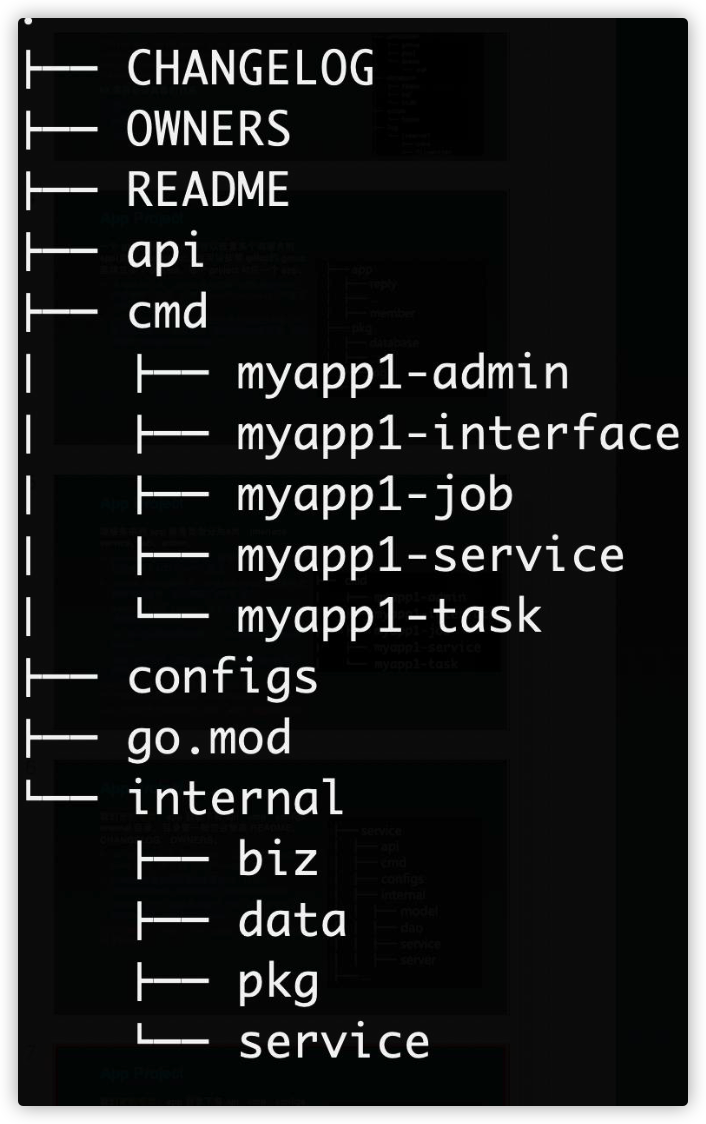
我们老的布局,app 目录下有 api、cmd、configs、 internal 目录,目录里一般还会放置 README、 CHANGELOG、OWNERS。
- api:放置API定义(protobuf),以及对应的生成的client代 码,基于 pb 生成的 swagger.json。
- configs:放服务所需要的配置文件,比如database.yaml、 redis.yaml、application.yaml。
- internal:是为了避免有同业务下有人跨目录引用了内部的 model、dao 等内部 struct。
- server:放置HTTP/gRPC的路由代码,以及DTO转换的 代码。
DTO(Data Transfer Object):数据传输对象,这个概念来源于 J2EE 的设计模式。但在这里,泛指用于展示层/API 层与服务层(业务逻辑层)之间的数据传输对象。
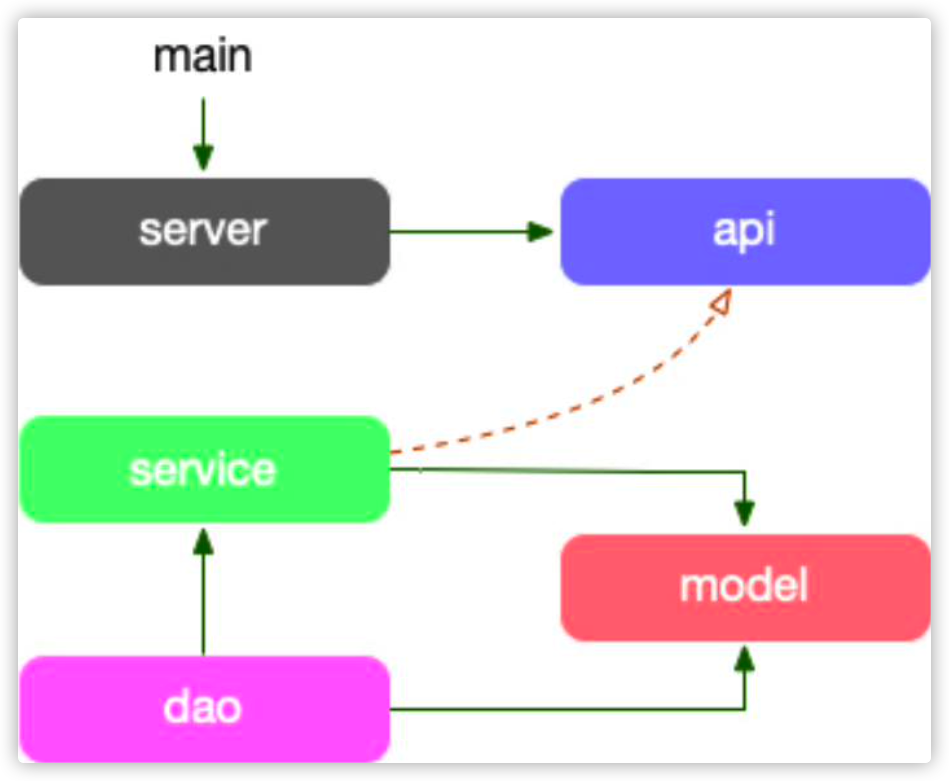
项目的依赖路径为: model -> dao -> service -> api, model struct 串联各个层,直到 api 需要做 DTO 对象 转换。
- model:放对应“存储层”的结构体,是对存储的一一映射。
- dao:数据读写层,数据库和缓存全部在这层统一处理,包括 cache miss 处理。
- service:组合各种数据访问来构建业务逻辑。
- server:依赖proto定义的服务作为入参,提供快捷的启动服务全局方法。
- api:定义了APIproto文件,和生成的stub代码,它生成 的 interface,其实现者在 service 中。
service 的方法签名因为实现了 API 的 接口定义,DTO 直接在业务逻辑层直接使用了,更有 dao 直接使用,最简化代码。
DO(Domain Object): 领域对象,就是从现实世界中抽象出来 的有形或无形的业务实体。缺乏 DTO -> DO 的对象转换。
Service Application Project - v2
app 目录下有 api、cmd、configs、internal 目录,目录里一般还会 放置 README、CHANGELOG、OWNERS。
- internal: 是为了避免有同业务下有人跨目录引用了内部的 biz、 data、service 等内部 struct。
- biz:业务逻辑的组装层,类似DDD的domain层,data类似DDD 的 repo,repo 接口在这里定义,使用依赖倒置的原则。
- data:业务数据访问,包含cache、db等封装,实现了biz的repo 接口。我们可能会把 data 与 dao 混淆在一起,data 偏重业务的含义, 它所要做的是将领域对象重新拿出来,我们去掉了 DDD 的 infra层。
- service:实现了api定义的服务层,类似DDD的application层,处理 DTO 到 biz 领域实体的转换(DTO -> DO),同时协同各类 biz 交互, 但是不应处理复杂逻辑。
PO(Persistent Object): 持久化对象,它跟持久层(通常是关系型数据库) 的数据结构形成一一对应的映射关系,如果持久层是关系型数据库,那 么数据表中的每个字段(或若干个)就对应 PO 的一个(或若干个)属 性。https://github.com/facebook/ent
Lifecycle
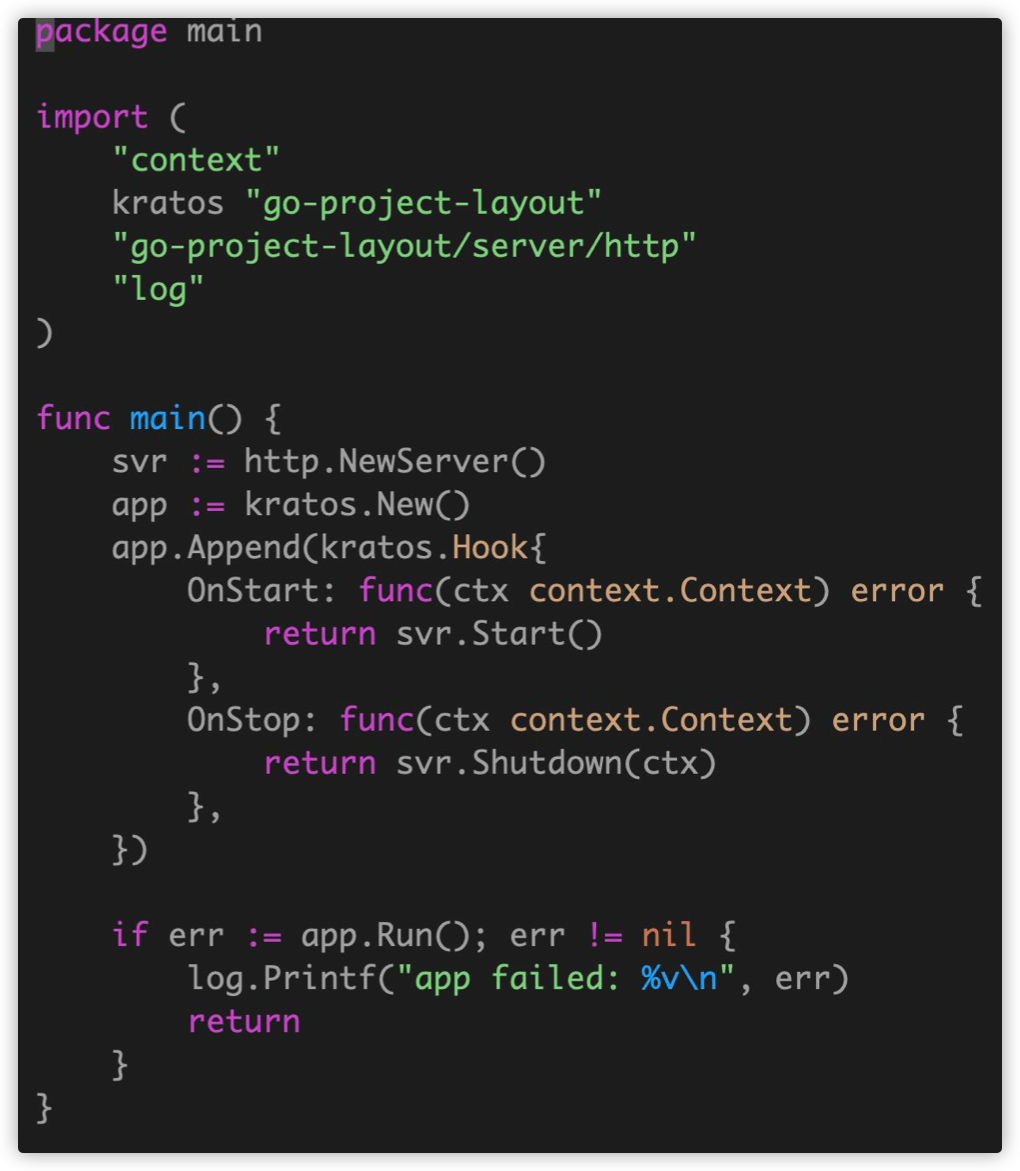
Lifecycle 需要考虑服务应用的对象初始化以及生命周期的 管理,所有 HTTP/gRPC 依赖的前置资源初始化,包括 data、biz、service,之后再启动监听服务。我们使用 https://github.com/google/wire ,来管理所有资源的依赖 注入。为何需要依赖注入?

核心是为了:1、方便测试;2、单次初始化和复用;
Wire
手撸资源的初始化和关闭是非常繁琐,容易出错的。上面 提到我们使用依赖注入的思路 DI,结合 google wire,静 态的 go generate 生成静态的代码,可以在很方便诊断和 查看,不是在运行时利用 reflection 实现。
API 设计
GRPC
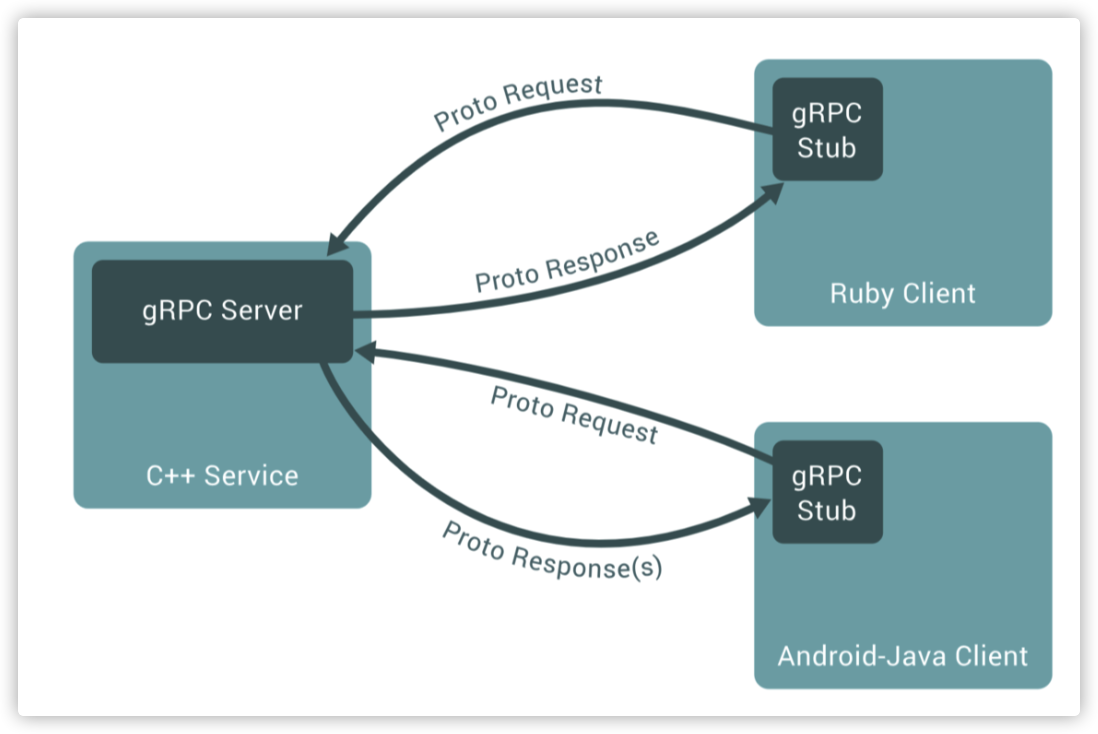
gRPC是什么可以用官网的一句话来概括
“A high-performance, open-source universal RPC framework”
-
多语言:语言中立,支持多种语言。
-
轻量级、高性能:序列化支持 PB(Protocol Buffer)和 JSON,PB 是一种语言无关的高性能序列化框架。
-
可插拔
-
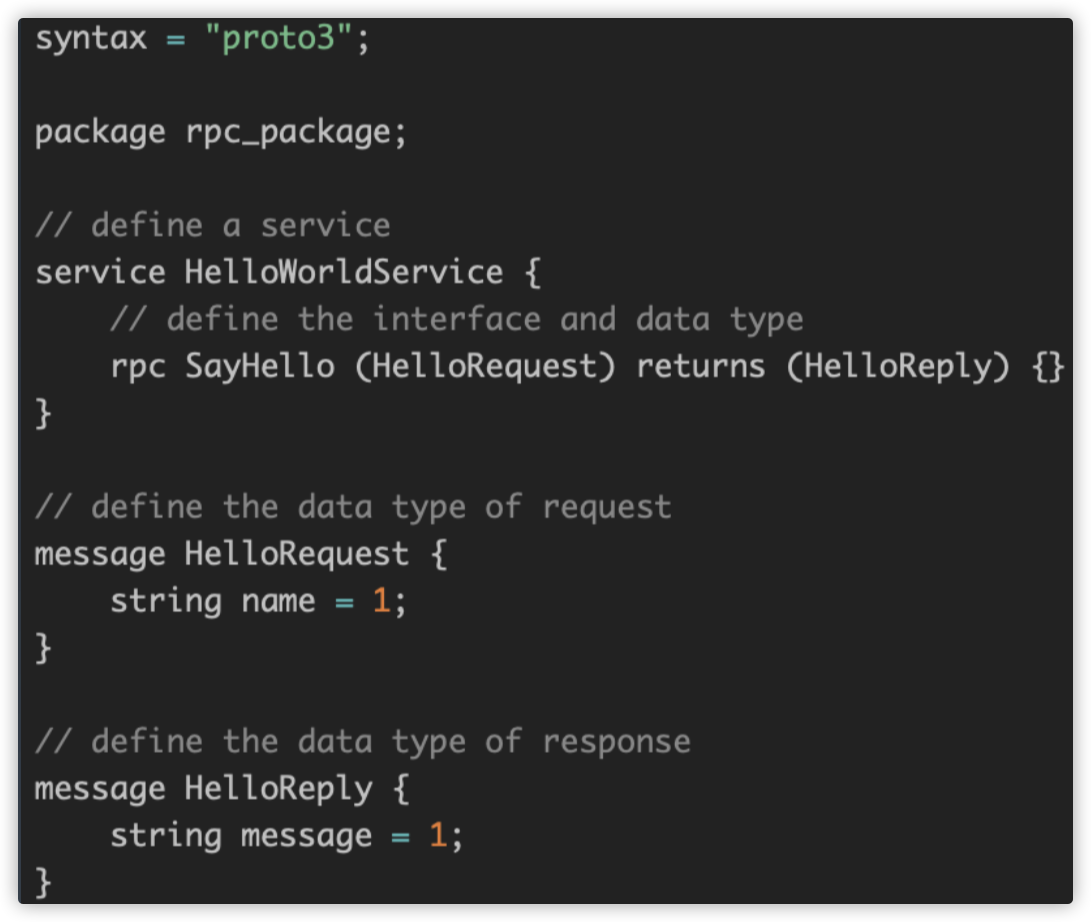
IDL:基于文件定义服务,通过proto3工具生成指定语言的数据结构、服务端接口以及客户端 Stub。
-
设计理念
-
移动端:基于标准的HTTP2设计,支持双向流、消息 头压缩、单TCP的多路复用、服务端推送等特性,这些特性使得 gRPC在移动端设备上更加省电和节省网络流量。
-
服务而非对象、消息而非引用:促进微服务的系统间 粗粒度消息交互设计理念。
- 服务指的是service,消息指的是message
-
负载无关的:不同的服务需要使用不同的消息类型和 编码,例如protocol buffers、JSON、XML和Thrift。
-
流:Streaming API。
-
阻塞式和非阻塞式:支持异步和同步处理在客户端和服务端间交互的消息序列。
-
元数据交换:常见的横切关注点,如认证或跟踪,依 赖数据交换。
-
标准化状态码:客户端通常以有限的方式响应API调 用返回的错误。
不要过早关注性能问题,先标准化。
API Project
https://github.com/googleapis/googleapis
https://github.com/envoyproxy/data-plane-api
为了统一检索和规范 API,我们内部建立了一个统一的 bapis 仓库,整合所有对内对外 API。
- API 仓库,方便跨部门协作。
- 版本管理,基于 git 控制。
- 规范化检查,API lint。
- API design review,变更 diff。
- 权限管理,目录 OWNERS。
- 在每个目录里面定义一个api文件,定义谁对此负责.
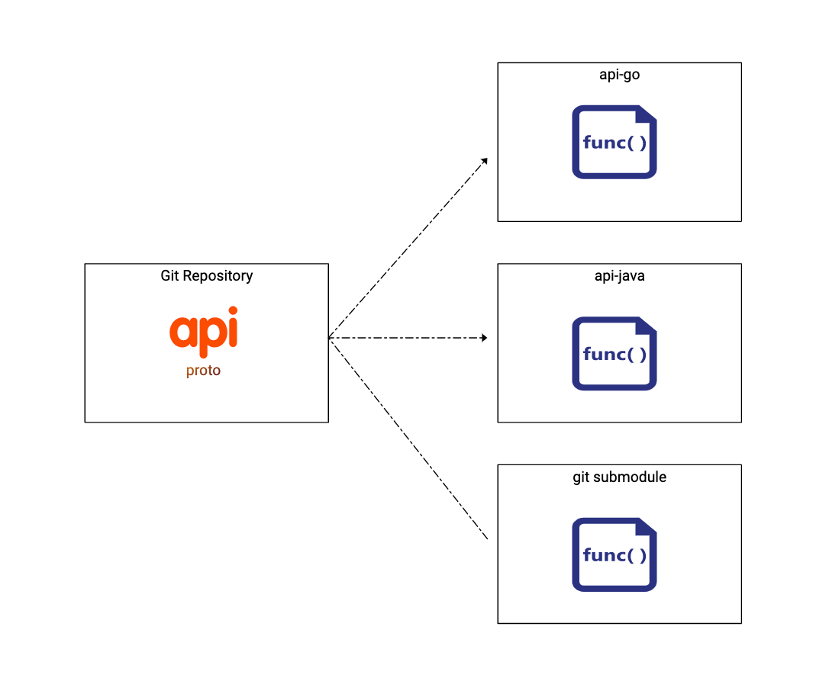
API Project Layout
项目中定义 proto,以 api 为包名根目录:

在统一仓库中管理 proto ,以仓库为包名根目录:


API Compatibility
向后兼容(非破坏性)的修改:
- 给 API 服务定义添加 API 接口 从协议的角度来看,这始终是安全的。
- 给请求消息添加字段 只要客户端在新版和旧版中对该字段的处理不保持一致,添加请求字段就是兼容的。
- 给响应消息添加字段 在不改变其他响应字段的行为的前提下,非资源(例如,ListBooksResponse)的响应消息可以扩展而不必破坏客户端的兼容性。即使会引入冗余,先前在响应中填充的任何字段应继续使用相同的语义填充。
向后不兼容(破坏性)的修改:
- 删除或重命名服务,字段,方法或枚举值 从根本上说,如果客户端代码可以引用某些东西,那么删除或重命名它都是不兼容的变化,这时必须修改major 版本号。
- 修改字段的类型 即使新类型是传输格式兼容的,这也可能会导致客户端库生成的代码发生变化,因此必须增加major版本号。 对于编译型静态语言来说,会容易引入编译错误。
- 修改现有请求的可见行为 客户端通常依赖于 API 行为和语义,即使这样的行为没有被明确支持或记录。 因此,在大多数情况下,修改 API 数据的行为或语义将被消费者视为是破坏性的。如果行为没有加密隐藏,您应该假设用户已经发现它,并将依赖于它。
- 给资源消息添加 读取/写入 字段
- 比如有一个update接口,新接口对数据库的写入是否影响旧接口的写入.
API Naming Conventions
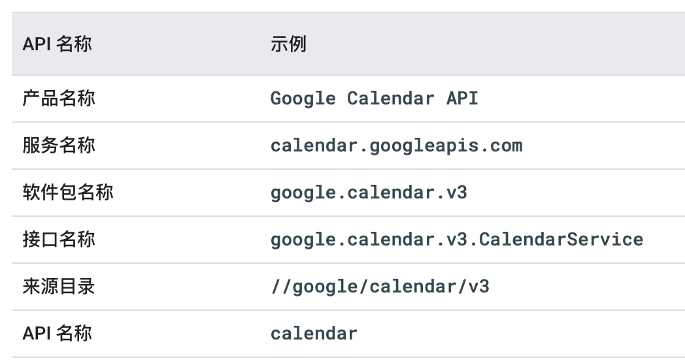
包名为应用的标识(APP_ID),用于生成 gRPC 请求路径,或者 proto 之间进行引用 Message。文件中声明的包名称应该与产品和服务名称保持一致。带有版本的 API 的软件包名称必须以此版本结尾。
my.package.v1,为 API 目录,定义service相关接口,用于提供业务使用。
|
|
为所有的输入和输出都定义对象,方便后期扩展,不建议使用google.protobuf.empty.
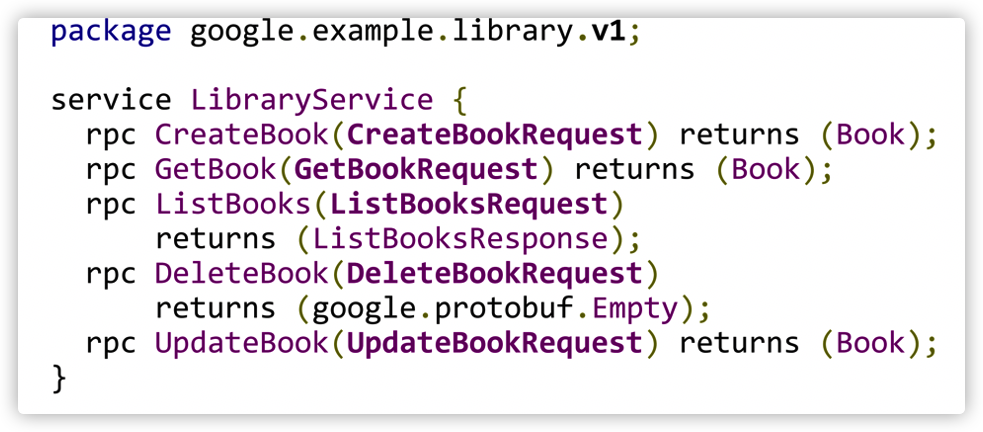
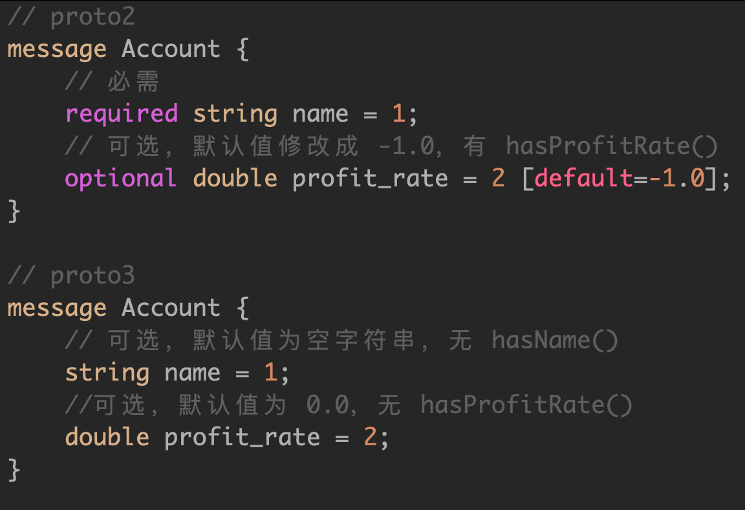
API Primitive Fields
gRPC 默认使用 Protobuf v3 格式,因为去除了 required 和 optional 关键字,默认全部都是 optional 字段。如果没有赋值的字段,默认会基础类型字段的默认值,比如 0 或者 “”。
Protobuf v3 中,建议使用:
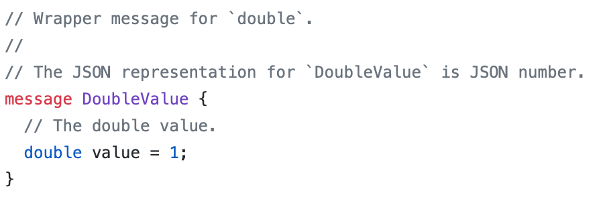
https://github.com/protocolbuffers/protobuf/blob/master/src/google/protobuf/wrappers.proto
Warpper 类型的字段,即包装一个 message,使用时变为指针。可以通过这个包判断某个字段是否为空
Protobuf 作为强 schema 的描述文件,也可以方便扩展,是不是用于配置文件定义也可?

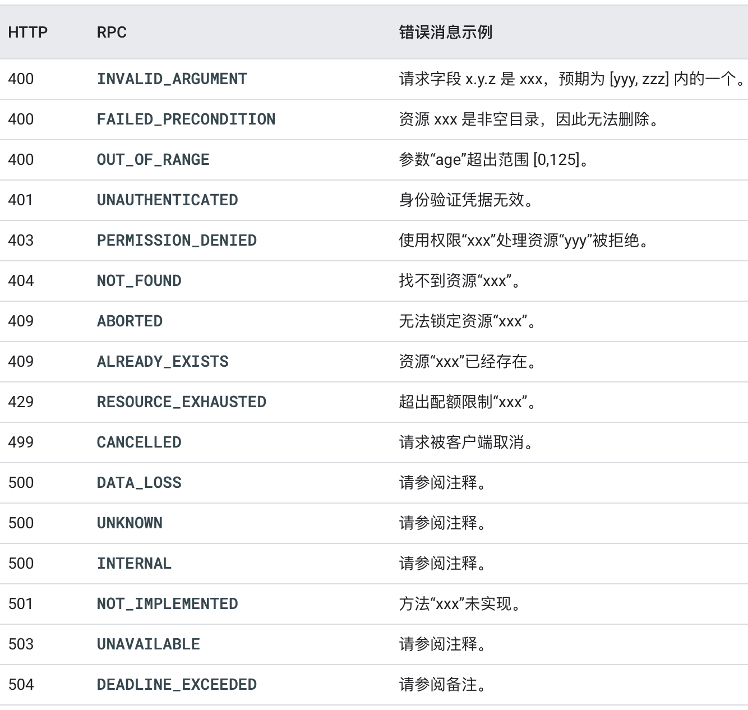
API Errors
使用一小组标准错误配合大量资源
- 例如,服务器没有定义不同类型的“找不到”错误,而是使用一个标准 google.rpc.Code.NOT_FOUND 错误代码并告诉客户端找不到哪个特定资源。状态空间变小降低了文档的复杂性,在客户端库中提供了更好的惯用映射,并降低了客户端的逻辑复杂性,同时不限制是否包含可操作信息(/google/rpc/error_details)。 错误传播
- 鼓励使用HTTP与GRPC标准错误码,比如HTTP不应该全部返回200,而是应该使用HTTP标准错误码,这样方便运维在七层负载上进行接口健康监控.
- 通常建议采用大错误+小错误的方案,大错误是HTTP或GRPC的标准错误码,小错误是服务内部业务的错误.
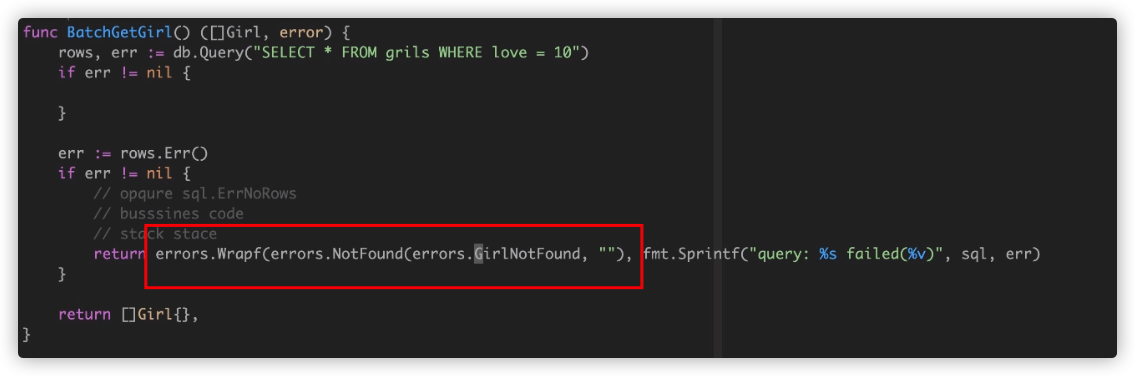
如果您的 API 服务依赖于其他服务,则不应盲目地将这些服务的错误传播到您的客户端。在翻译错误时,我们建议执行以下操作:
- 隐藏实现详细信息和机密信息。
- 调整负责该错误的一方。例如,从另一个服务接收 INVALID_ARGUMENT 错误的服务器应该将 INTERNAL 传播给它自己的调用者。
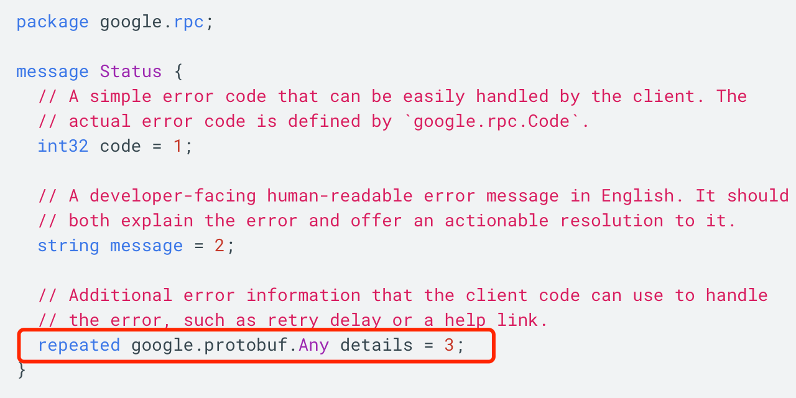
全局错误码
全局错误码,是松散、易被破坏契约的,基于我们上述讨论的,在每个服务传播错误的时候,做一次翻译,这样保证每个服务 + 错误枚举,应该是唯一的,而且在 proto 定义中是可以写出来文档的。

API Design
Update行为,只提供一个接口


FieldMask 部分更新的方案:
客户端可以执行需要更新的字段信息:
- paths: “author”
- paths: “submessage.submessage.field”
空 FieldMask 默认应用到 “所有字段”

配置管理
- 环境变量(配置) Region(华北,华中)、Zone(空间)、Cluster(集群)、Environment(测试,生产)、Color(染色)、Discovery(服务发现)、AppID、Host,等之类的环境信息,都是通过在线运行时平台打入到容器或者物理机,供 kit 库读取使用。
- 静态配置 资源需要初始化的配置信息,比如 http/gRPC server、redis、mysql 等,这类资源在线变更配置的风险非常大,我通常不鼓励 on-the-fly 变更,很可能会导致业务出现不可预期的事故,变更静态配置和发布 bianry app 没有区别,应该走一次迭代发布的流程。
- 动态配置 应用程序可能需要一些在线的开关,来控制业务的一些简单策略,会频繁的调整和使用,我们把这类是基础类型(int, bool)等配置,用于可以动态变更业务流的收归一起,同时可以考虑结合类似 https://pkg.go.dev/expvar 来结合使用。
- 全局配置 通常,我们依赖的各类组件、中间件都有大量的默认配置或者指定配置,在各个项目里大量拷贝复制,容易出现意外,所以我们使用全局配置模板来定制化常用的组件,然后再特化的应用里进行局部替换。
Redis client example
|
|
“我要自定义超时时间!” “我要设定 Database!” “我要控制连接池的策略!” “我要安全使用 Redis,让我填一下 Password!” “可以提供一下慢查询请求记录,并且可以设置 slowlog 时间?”
Add Features
|
|
net/http
net/http是搞一个结构体,然后在里面填各种字段,最后再执行.
|
|
坏处:
- 字段是自己定义,需要在里面写很复杂的文档供大家阅读.
- 如果字段没填,需要写文档标清楚
- 无法判断是可选还是必选
|
|
|
|
“I believe that we, as Go programmers, should work hard to ensure that nil is never a parameter that needs to be passed to any public function.” – Dave Cheney
作为一个公共函数,我们要尽量保证不要传入nil.
Functional options
Self-referential functions and the design of options – Rob Pike
Functional options for friendly APIs – Dave Cheney
|
|
通过选项模式,可以解决对象初始化和默认值的问题.
|
|
|
|
GRPC是如何做的?
|
|
Hybrid APIs
“JSON/YAML 配置怎么加载,无法映射 DialOption 啊!” “嗯,不依赖配置的走 options,配置加载走config”
|
|
“For example, both your infrastructure and interface might use plain JSON. However, avoid tight coupling between the data format you use as the interface and the data format you use internally. For example, you may use a data structure internally that contains the data structure consumed from configuration. The internal data structure might also contain completely implementation-specific data that never needs to be surfaced outside of the system.”
– the-site-reliability-workbook 2
尽量避免数据操作和配置操作强耦合.
|
|
- 仅保留 options API;
- config file 和 options struct 解耦;
配置工具的实践:
- 语义验证
- 高亮
- Lint
- 格式化
YAML + Protobuf
|
|
|
|
|
|
|
|
|
|
Configuration Best Pratice
代码更改系统功能是一个冗长且复杂的过程,往往还涉及Review、测试等流程,但更改单个配置选项可能会对功能产生重大影响,通常配置还未经测试。配置的目标:
- 避免复杂
- 多样的配置
- 简单化努力
- 以基础设施 -> 面向用户进行转变
- 配置的必选项和可选项
- pb的wrap
- option模式
- 配置的防御编程
- 配置文件的校验
- 权限和变更跟踪
- 权限控制和变更记录
- 配置的版本和应用对齐
- 配置文件的版本和二进制文件的版本必须是一一映射
- 安全的配置变更:逐步部署、回滚更改、自动回滚
包管理
go mod
可以用下面的包进行私有仓库和共有仓库的转换. https://github.com/gomods/athens
这是proxy
https://blog.golang.org/modules2019 https://blog.golang.org/using-go-modules https://blog.golang.org/migrating-to-go-modules https://blog.golang.org/module-mirror-launch https://blog.golang.org/publishing-go-modules https://blog.golang.org/v2-go-modules https://blog.golang.org/module-compatibility
测试
Unittest
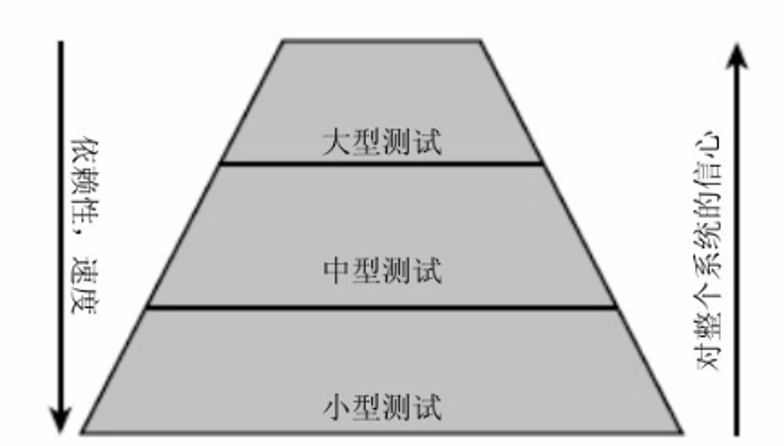
小型测试带来优秀的代码质量、良好的异常处理、优雅的错误报告;大中型测试会带来整体产品质量和数据验证。
不同类型的项目,对测试的需求不同,总体上有一个经验法则,即70/20/10原则:70%是小型测试,20%是中型测试,10%是大型测试。
如果一个项目是面向用户的,拥有较高的集成度,或者用户接口比较复杂,他们就应该有更多的中型和大型测试;如果是基础平台或者面向数据的项目,例如索引或网络爬虫,则最好有大量的小型测试,中型测试和大型测试的数量要求会少很多。
业务开发一定要保证API测试,基础库开发要写大量的单元测试.
“自动化实现的,用于验证一个单独函数或独立功能模块的代码是否按照预期工作,着重于典型功能性问题、数据损坏、错误条件和大小差一错误(译注:大小差一(off-by-one)错误是一类常见的程序设计错误)等方面的验证” - 《Google软件测试之道》
单元测试的基本要求:
- 快速
- 环境一致
- 任意顺序
- 并行(go test -parallel)
subtest 子测试
docker
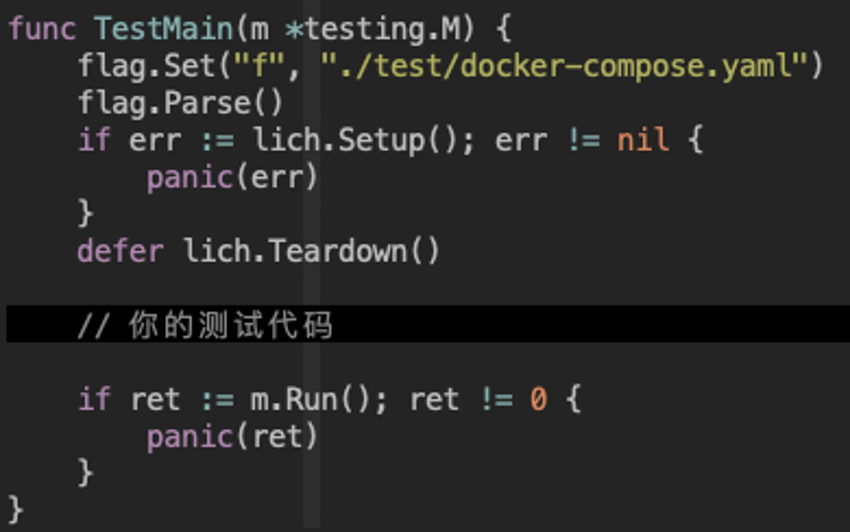
基于 docker-compose 实现跨平台跨语言环境的容器依赖管理方案,以解决运行 unittest 场景下的(mysql, redis, mc)容器依赖问题:
- 本地安装 Docker。
- 无侵入式的环境初始化。
- 快速重置环境。
- 随时随地运行(不依赖外部服务)。
- 语义式 API 声明资源。
- 真实外部依赖,而非 in-process 模拟。
- 在单元测试开始前,导入封装好的 testing 库,方便启动和销毁容器。
- 对于 service 的单元测试,使用 gomock 等库把 dao mock 掉,所以在设计包的时候,应该面向抽象编程。
- 在本地执行依赖 Docker,在 CI 环境里执行Unittest,需要考虑在物理机里的 Docker 网络,或者在 Docker 里再次启动一个 Docker
利用 go 官方提供的: Subtests + Gomock 完成整个单元测试。
- /api 比较适合进行集成测试,直接测试 API,使用 API 测试框架(例如: yapi),维护大量业务测试 case。
- /data docker compose 把底层基础设施真实模拟,因此可以去掉 infra 的抽象层。
- /biz 依赖 repo、rpc client,利用 gomock 模拟 interface 的实现,来进行业务单元测试。
- /service 依赖 biz 的实现,构建 biz 的实现类传入,进行单元测试。
基于 git branch 进行 feature 开发,本地进行 unittest,之后提交 gitlab merge request 进行 CI 的单元测试,基于 feature branch 进行构建,完成功能测试,之后合并 master,基于master发布到稳定的集成环境中,进行集成测试,先灰度回归测试,再放量回归测试,上线后进行回归测试。
参考
文章作者 Forz
上次更新 2019-06-03