runtime
Go 语言是一⻔有 runtime 的语言,那么 runtime 是什么?
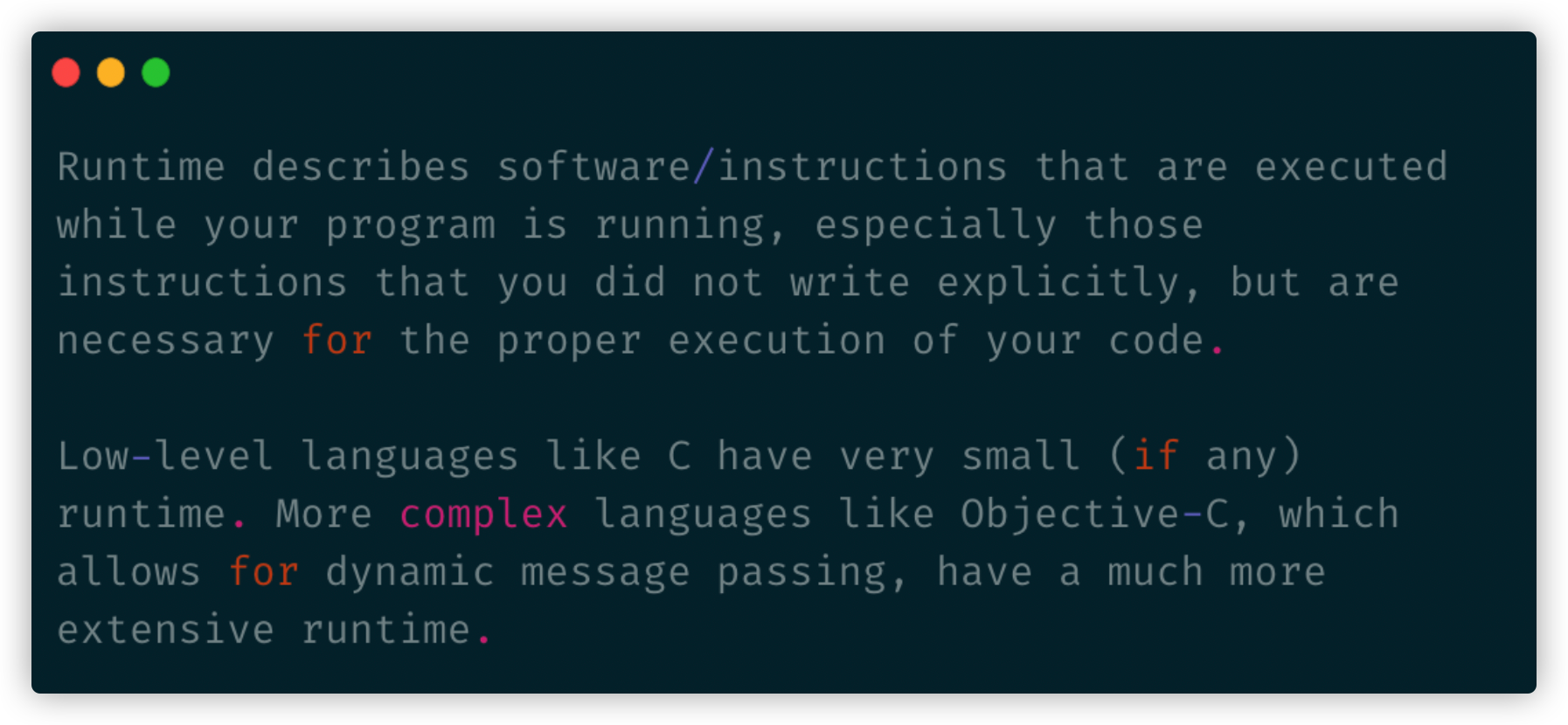
可以认为 runtime 是为了实现额外的功能,而在程序运行时自动 加载/运行的一些模块。
Go 语言的 runtime 包括:

这些模块中,最核心的就是 Scheduler,它负责串联所有的 runtime 流程.
调度器的生命周期
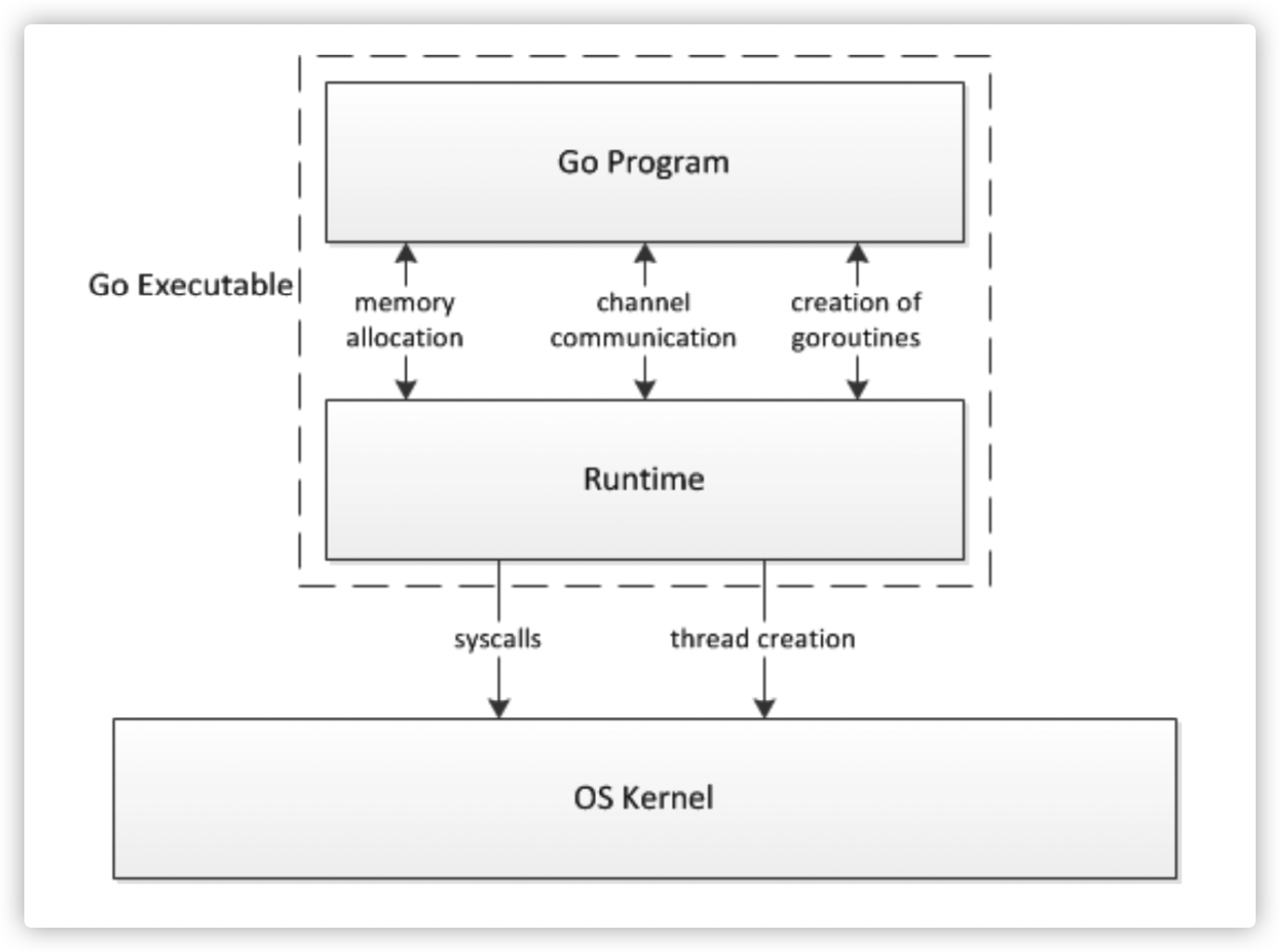
所有的Go程序运行都会经过一个完整的调度器生命周期:从创建到结束。
即使下面这段简单的代码:
1
2
3
4
5
6
7
8
|
package main
import "fmt"
// main.main
func main() {
fmt.Println("Hello scheduler")
}
|
也会经历如上图所示的过程:
- runtime创建最初的线程m0和goroutine g0,并把2者关联。
- 调度器初始化:初始化m0、栈、垃圾回收,以及创建和初始化由GOMAXPROCS个P构成的P列表。
- 示例代码中的main函数是main.main,runtime中也有1个main函数——runtime.main,代码经过编译后,runtime.main会调用main.main,程序启动时会为runtime.main创建goroutine,称它为main goroutine吧,然后把main goroutine加入到P的本地队列。
- 启动m0,m0已经绑定了P,会从P的本地队列获取G,获取到main goroutine。
- G拥有栈,M根据G中的栈信息和调度信息设置运行环境
- M运行G
- G退出,再次回到M获取可运行的G,这样重复下去,直到main.main退出,runtime.main执行Defer和Panic处理,或调用runtime.exit退出程序。
调度器的生命周期几乎占满了一个Go程序的一生,runtime.main的goroutine执行之前都是为调度器做准备工作,runtime.main的goroutine运行,才是调度器的真正开始,直到runtime.main结束而结束。
M0 是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量 runtime.m0 中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了。
G0 是每次启动一个 M 都会第一个创建的 gourtine,G0 仅用于负责调度的 G,G0 不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0 的栈空间,全局变量的 G0 是 M0 的 G0。
Go进程的执行入口
在 proc.go 和 runtime2.go 文件中,有一些很重要全局的变量,我们先列出来:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// 所有 g 的长度
allglen uintptr
// 保存所有的 g
allgs []*g
// 保存所有的 m
allm *m
// 保存所有的 p,_MaxGomaxprocs = 1024
allp [_MaxGomaxprocs + 1]*p
// p 的最大值,默认等于 ncpu
gomaxprocs int32
// 程序启动时,会调用 osinit 函数获得此值
ncpu int32
// 调度器结构体对象,记录了调度器的工作状态
sched schedt
// 代表进程的主线程
m0 m
// m0 的 g0,即 m0.g0 = &g0
g0 g
|
在程序初始化时,这些全局变量都会被初始化为零值:指针被初始化为 nil 指针,切片被初始化为 nil 切片,int 被初始化为 0,结构体的所有成员变量按其类型被初始化为对应的零值。
因此程序刚启动时 allgs,allm 和allp 都不包含任何 g,m 和 p。
不仅是 Go 程序,系统加载可执行文件大概都会经过这几个阶段:
- 从磁盘上读取可执行文件,加载到内存
- 创建进程和主线程
- 为主线程分配栈空间
- 把由用户在命令行输入的参数拷贝到主线程的栈
- 把主线程放入操作系统的运行队列等待被调度
我们从一个 Hello World 的例子来回顾一下 Go 程序初始化的过程:
1
2
3
4
5
6
7
|
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
|
在项目根目录下执行:
1
|
go build -gcflags "-N -l" -o hello src/main.go
|
-gcflags “-N -l” 是为了关闭编译器优化和函数内联,防止后面在设置断点的时候找不到相对应的代码位置。
得到了可执行文件 hello,执行:
进入 gdb 调试模式,执行 info files,得到可执行文件的文件头,列出了各种段:
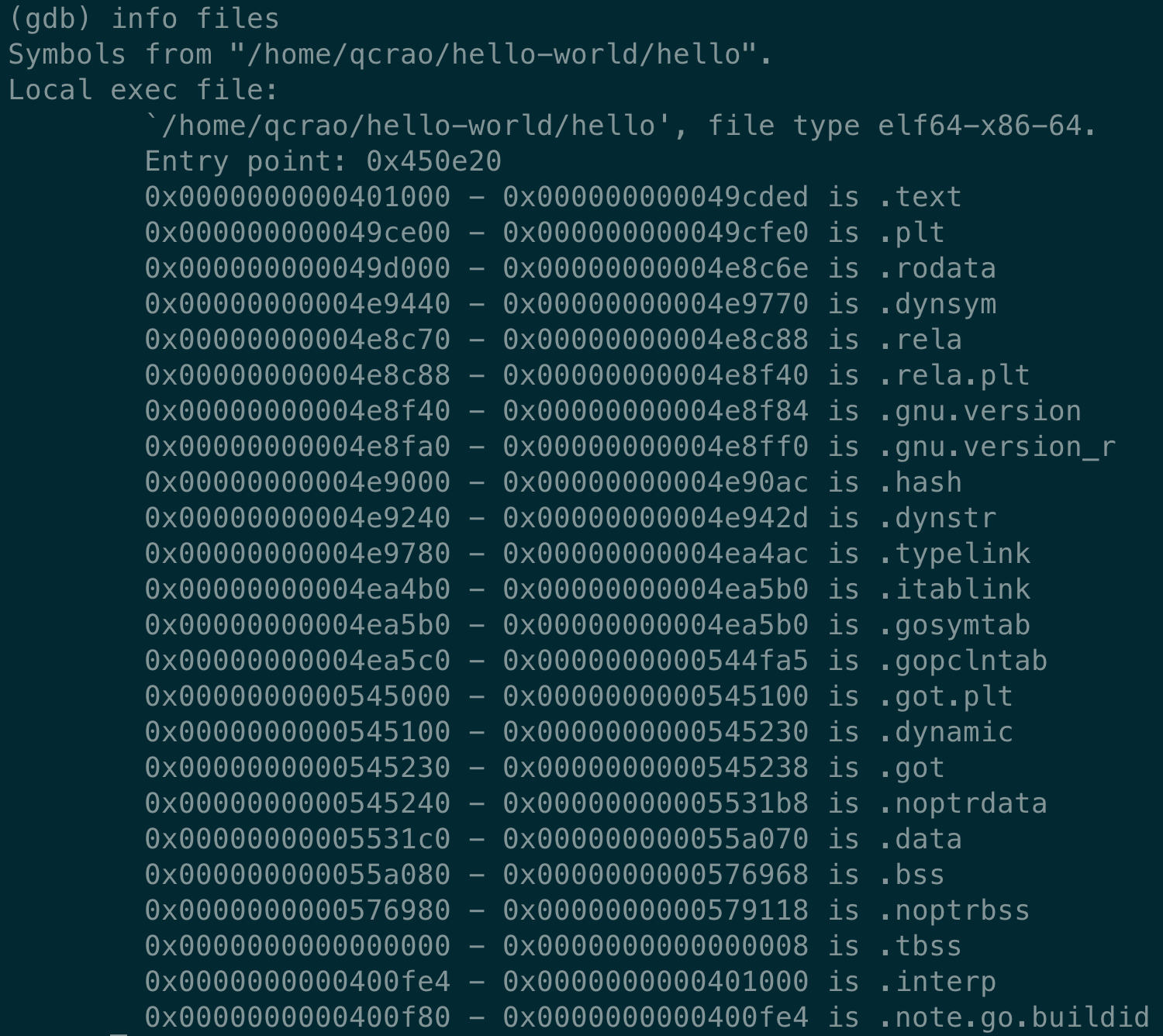
同时,我们也得到了入口地址:0x450e20。
1
2
|
(gdb) b *0x450e20
Breakpoint 1 at 0x450e20: file /usr/local/go/src/runtime/rt0_linux_amd64.s, line 8.
|
这就是 Go 程序的入口地址,我是在 linux 上运行的,所以入口文件为 src/runtime/rt0_linux_amd64.s,runtime 目录下有各种不同名称的程序入口文件,支持各种操作系统和架构,代码为:
1
2
3
4
5
|
TEXT _rt0_amd64_linux(SB),NOSPLIT,$-8
LEAQ 8(SP), SI // argv
MOVQ 0(SP), DI // argc
MOVQ $main(SB), AX
JMP AX
|
主要是把 argc,argv 从内存拉到了寄存器。这里 LEAQ 是计算内存地址,然后把内存地址本身放进寄存器里,也就是把 argv 的地址放到了 SI 寄存器中。最后跳转到:
1
2
3
|
TEXT main(SB),NOSPLIT,$-8
MOVQ $runtime·rt0_go(SB), AX
JMP AX
|
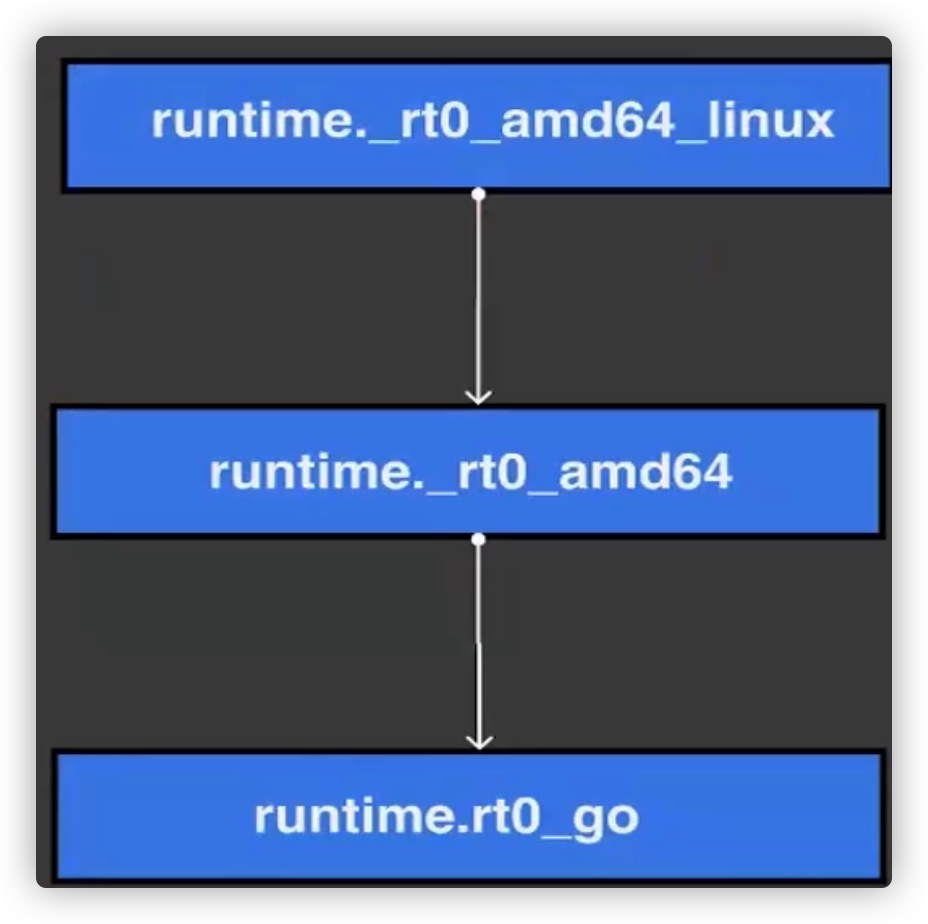
继续跳转到 runtime·rt0_go(SB),完成 go 启动时所有的初始化工作。位于 /usr/local/go/src/runtime/asm_amd64.s.
或者使用开源反编译工具cutter.
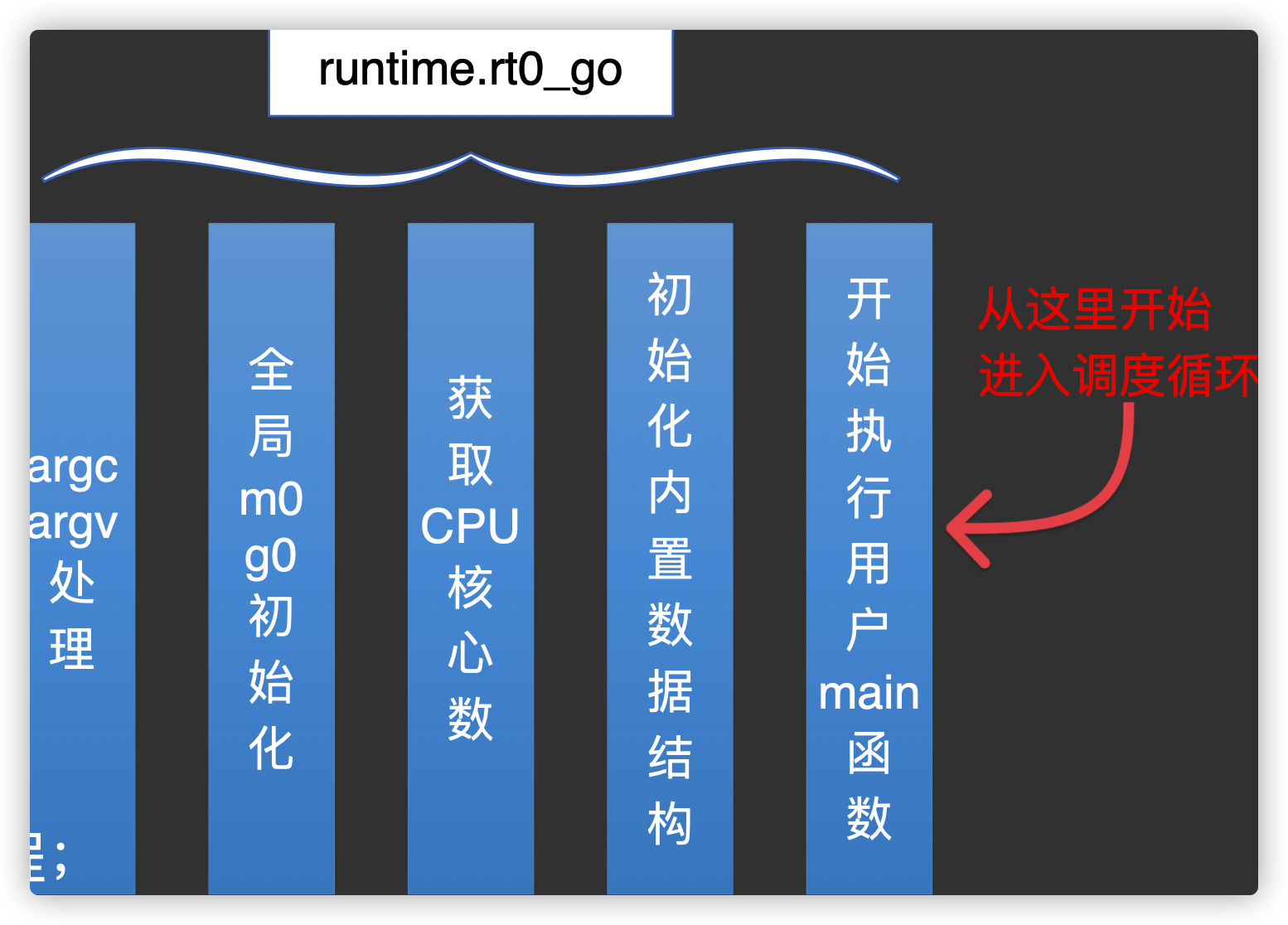
Go启动的初始化工作
rt0_go完成 go 启动时所有的初始化工作.请注意这里的用户mian函数是通过执行runtime.main函数来执行的.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
|
TEXT runtime·rt0_go(SB),NOSPLIT,$0
// copy arguments forward on an even stack
MOVQ DI, AX // argc
MOVQ SI, BX // argv
SUBQ $(4*8+7), SP // 2args 2auto
// 调整栈顶寄存器使其按 16 字节对齐
ANDQ $~15, SP
// argc 放在 SP+16 字节处
MOVQ AX, 16(SP)
// argv 放在 SP+24 字节处
MOVQ BX, 24(SP)
// create istack out of the given (operating system) stack.
// _cgo_init may update stackguard.
// 给 g0 分配栈空间
// 把 g0 的地址存入 DI
MOVQ $runtime·g0(SB), DI
// BX = SP - 64*1024 + 104
LEAQ (-64*1024+104)(SP), BX
// g0.stackguard0 = SP - 64*1024 + 104
MOVQ BX, g_stackguard0(DI)
// g0.stackguard1 = SP - 64*1024 + 104
MOVQ BX, g_stackguard1(DI)
// g0.stack.lo = SP - 64*1024 + 104
MOVQ BX, (g_stack+stack_lo)(DI)
// g0.stack.hi = SP
MOVQ SP, (g_stack+stack_hi)(DI)
// ……………………
// 省略了很多检测 CPU 信息的代码
// ……………………
// 初始化 m 的 tls
// DI = &m0.tls,取 m0 的 tls 成员的地址到 DI 寄存器
LEAQ runtime·m0+m_tls(SB), DI
// 调用 settls 设置线程本地存储,settls 函数的参数在 DI 寄存器中
// 之后,可通过 fs 段寄存器找到 m.tls
CALL runtime·settls(SB)
// store through it, to make sure it works
// 获取 fs 段基址并放入 BX 寄存器,其实就是 m0.tls[1] 的地址,get_tls 的代码由编译器生成
get_tls(BX)
MOVQ $0x123, g(BX)
MOVQ runtime·m0+m_tls(SB), AX
CMPQ AX, $0x123
JEQ 2(PC)
MOVL AX, 0 // abort
ok:
// set the per-goroutine and per-mach "registers"
// 获取 fs 段基址到 BX 寄存器
get_tls(BX)
// 将 g0 的地址存储到 CX,CX = &g0
LEAQ runtime·g0(SB), CX
// 把 g0 的地址保存在线程本地存储里面,也就是 m0.tls[0]=&g0
MOVQ CX, g(BX)
// 将 m0 的地址存储到 AX,AX = &m0
LEAQ runtime·m0(SB), AX
// save m->g0 = g0
// m0.g0 = &g0
MOVQ CX, m_g0(AX)
// save m0 to g0->m
// g0.m = &m0
MOVQ AX, g_m(CX)
CLD // convention is D is always left cleared
CALL runtime·check(SB)
MOVL 16(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 24(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
// 初始化系统核心数
CALL runtime·osinit(SB)
// 调度器初始化
CALL runtime·schedinit(SB)
// create a new goroutine to start program
// 创建一个新的 goroutine 来启动程序
MOVQ $runtime·mainPC(SB), AX // entry
// newproc 的第二个参数入栈,也就是新的 goroutine 需要执行的函数
// AX = &funcval{runtime·main},
PUSHQ AX
// newproc 的第一个参数入栈,该参数表示 runtime.main 函数需要的参数大小,
// 因为 runtime.main 没有参数,所以这里是 0
PUSHQ $0 // arg size
// 创建 main goroutine
CALL runtime·newproc(SB)
POPQ AX
POPQ AX
// start this M
// 主线程进入调度循环,运行刚刚创建的 goroutine
CALL runtime·mstart(SB)
// 永远不会返回,万一返回了,crash 掉
MOVL $0xf1, 0xf1 // crash
RET
|
这段代码完成之后,整个 Go 程序就可以跑起来了。
调度器初始化函数:schedinit 返回后,调度器的相关参数都已经初始化好了.
argc和argv处理
第一段代码,将 SP 调整到了一个地址是 16 的倍数的位置:
1
2
3
|
SUBQ $(4*8+7), SP // 2args 2auto
// 调整栈顶寄存器使其按 16 个字节对齐
ANDQ $~15, SP
|
先是将 SP 减掉 39,也就是向下移动了 39 个 Byte,再进行与运算。
15 的二进制低四位是全 1:1111,其他位都是 0;取反后,变成了 0000,高位则是全 1。这样,与 SP 进行了与运算后,低 4 位变成了全 0,高位则不变。因此 SP 继续向下移动,并且这回是在一个地址值为 16 的倍数的地方,16 字节对齐的地方。
为什么要这么做?画一张图就明白了。不过先得说明一点,前面 _rt0_amd64_linux 函数里讲过,DI 里存的是 argc 的值,8 个字节,而 SI 里则存的是 argv 的地址,8 个字节。
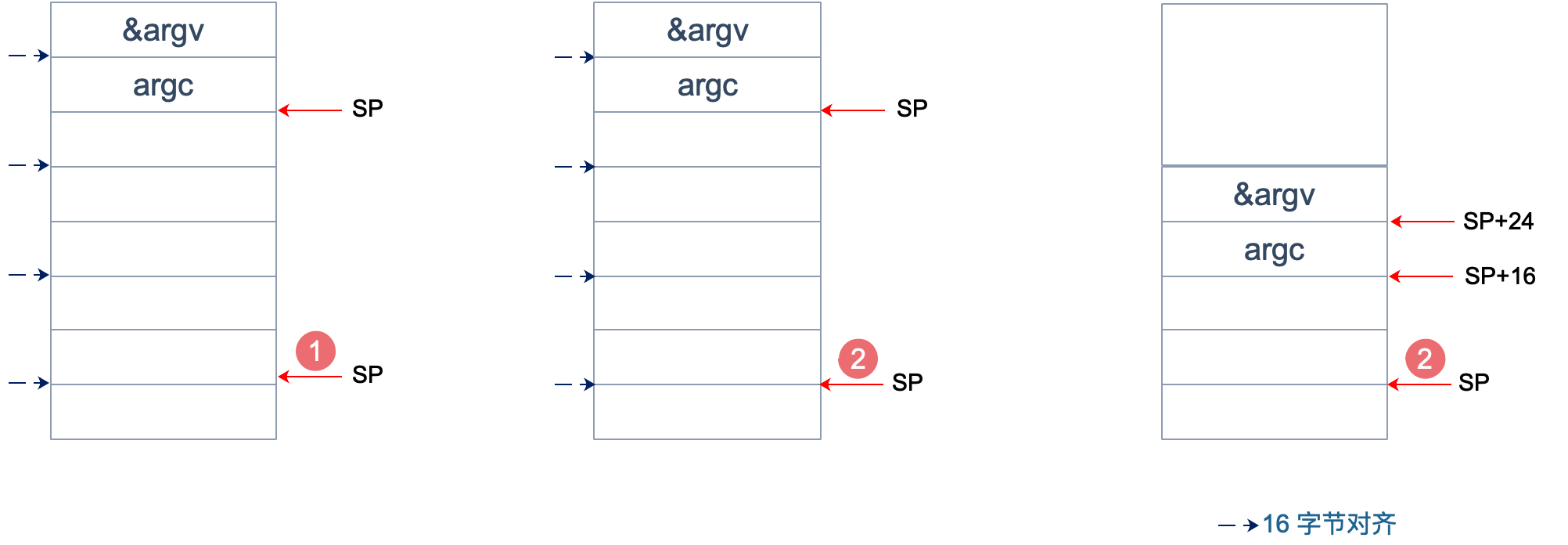
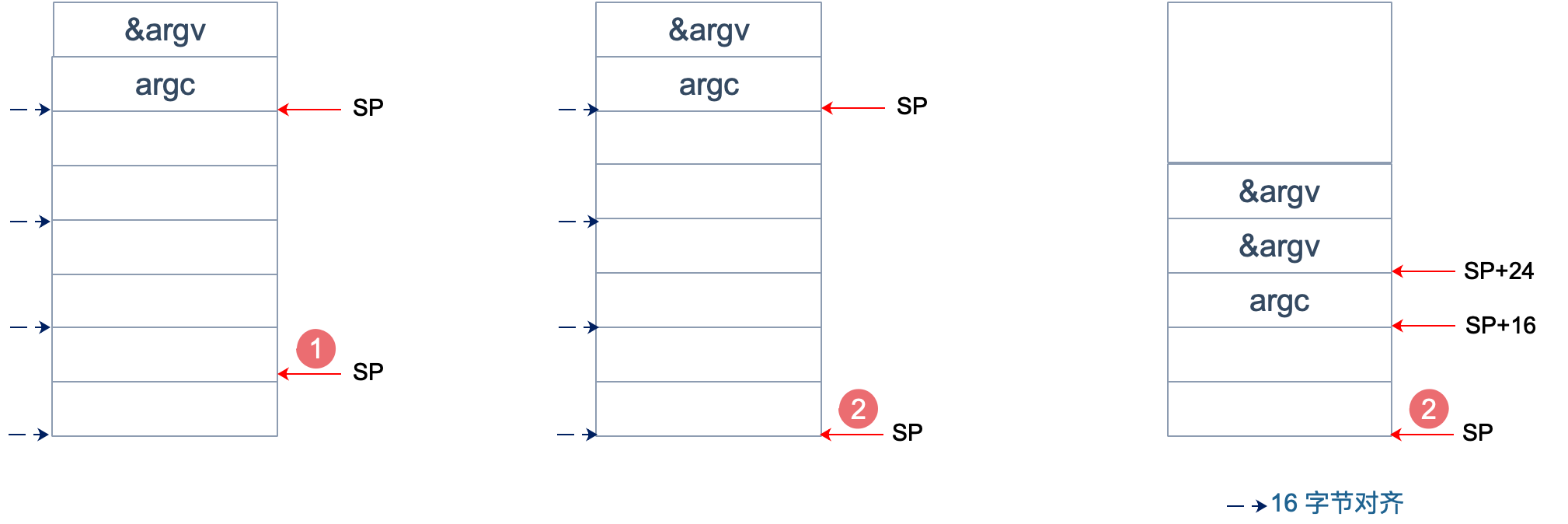
上面两张图中,左侧用箭头标注了 16 字节对齐的位置。第一步表示向下移动 39 B,第二步表示与 ~15 相与。
存在两种情况,这也是第一步将 SP 下移的时候,多移了 7 个 Byte 的原因。第一张图里,与 ~15 相与的时候,SP 值减少了 1,第二张图则减少了 9。最后都是移位到了 16 字节对齐的位置。
两张图的共同点是 SP 与 argc 中间多出了 16 个字节的空位。这个后面应该会用到,我们接着探索。
至于为什么进行 16 个字节对齐,就比较好理解了:因为 CPU 有一组 SSE 指令,这些指令中出现的内存地址必须是 16 的倍数。
全局g0和m0初始化
接着往后看,开始初始化 g0 的栈了。g0 栈的作用就是为运行 runtime 代码提供一个“环境”。
1
2
3
4
5
6
7
8
9
10
11
12
|
// 把 g0 的地址存入 DI
MOVQ $runtime·g0(SB), DI
// BX = SP - 64*1024 + 104
LEAQ (-64*1024+104)(SP), BX
// g0.stackguard0 = SP - 64*1024 + 104
MOVQ BX, g_stackguard0(DI)
// g0.stackguard1 = SP - 64*1024 + 104
MOVQ BX, g_stackguard1(DI)
// g0.stack.lo = SP - 64*1024 + 104
MOVQ BX, (g_stack+stack_lo)(DI)
// g0.stack.hi = SP
MOVQ SP, (g_stack+stack_hi)(DI)
|
代码 L2 把 g0 的地址存入 DI 寄存器;L4 将 SP 下移 (64K-104)B,并将地址存入 BX 寄存器;L6 将 BX 里存储的地址赋给 g0.stackguard0;L8,L10,L12 分别 将 BX 里存储的地址赋给 g0.stackguard1, g0.stack.lo, g0.stack.hi。
这部分完成之后,g0 栈空间如下图:
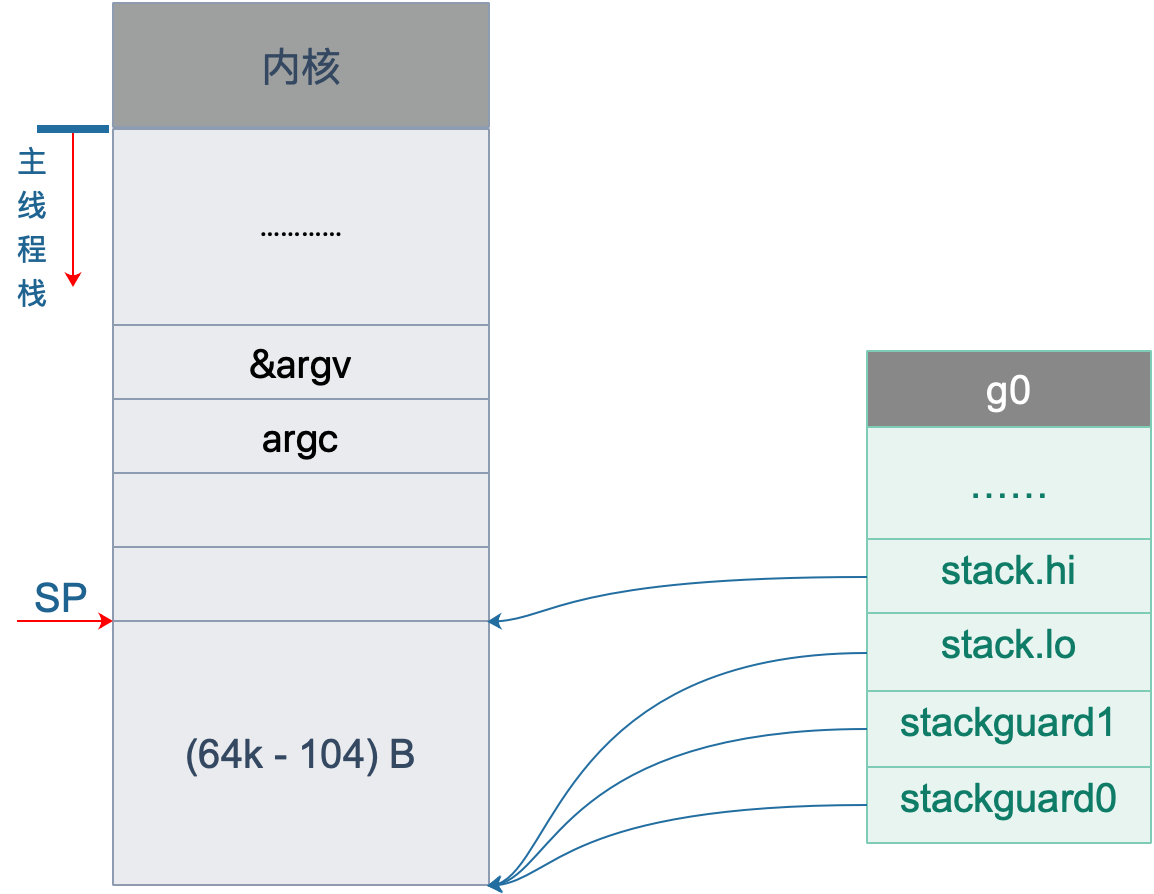
m0: Go 程序启动后创建的第一个线程
接着往下看,中间我们省略了很多检查 CPU 相关的代码,直接看主线程绑定 m0 的部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// 初始化 m 的 tls
// DI = &m0.tls,取 m0 的 tls 成员的地址到 DI 寄存器
LEAQ runtime·m0+m_tls(SB), DI
// 调用 settls 设置线程本地存储,settls 函数的参数在 DI 寄存器中
// 之后,可通过 fs 段寄存器找到 m.tls
CALL runtime·settls(SB)
// store through it, to make sure it works
// 获取 fs 段基地址并放入 BX 寄存器,其实就是 m0.tls[1] 的地址,get_tls 的代码由编译器生成
get_tls(BX)
MOVQ $0x123, g(BX)
MOVQ runtime·m0+m_tls(SB), AX
CMPQ AX, $0x123
JEQ 2(PC)
MOVL AX, 0 // abort
|
因为 m0 是全局变量,而 m0 又要绑定到工作线程才能执行。我们又知道,runtime 会启动多个工作线程,每个线程都会绑定一个 m0。而且,代码里还得保持一致,都是用 m0 来表示。这就要用到线程本地存储的知识了,也就是常说的 TLS(Thread Local Storage)。简单来说,TLS 就是线程本地的私有的全局变量。
一般而言,全局变量对进程中的多个线程同时可见。进程中的全局变量与函数内定义的静态(static)变量,是各个线程都可以访问的共享变量。一个线程修改了,其他线程就会“看见”。要想搞出一个线程私有的变量,就需要用到 TLS 技术。
如果需要在一个线程内部的各个函数调用都能访问、但其它线程不能访问的变量(被称为 static memory local to a thread,线程局部静态变量),就需要新的机制来实现。这就是 TLS。
继续来看源码,L3 将 m0.tls 地址存储到 DI 寄存器,再调用 settls 完成 tls 的设置,tls 是 m 结构体中的一个数组。
1
2
|
// thread-local storage (for x86 extern register)
tls [6]uintptr
|
设置 tls 的函数 runtime·settls(SB) 位于源码 src/runtime/sys_linux_amd64.s 处,主要内容就是通过一个系统调用将 fs 段基址设置成 m.tls[1] 的地址,而 fs 段基址又可以通过 CPU 里的寄存器 fs 来获取。
而每个线程都有自己的一组 CPU 寄存器值,操作系统在把线程调离 CPU 时会帮我们把所有寄存器中的值保存在内存中,调度线程来运行时又会从内存中把这些寄存器的值恢复到 CPU。
这样,工作线程代码就可以通过 fs 寄存器来找到 m.tls。
设置完 tls 之后,又来了一段验证上面 settls 是否能正常工作。如果不能,会直接 crash。
1
2
3
4
5
6
|
get_tls(BX)
MOVQ $0x123, g(BX)
MOVQ runtime·m0+m_tls(SB), AX
CMPQ AX, $0x123
JEQ 2(PC)
MOVL AX, 0 // abort
|
第一行代码,获取 tls,get_tls(BX) 的代码由编译器生成,源码中并没有看到,可以理解为将 m.tls 的地址存入 BX 寄存器。
L2 将一个数 0x123 放入 m.tls[0] 处,L3 则将 m.tls[0] 处的数据取出来放到 AX 寄存器,L4 则比较两者是否相等。如果相等,则跳过 L6 行的代码,否则执行 L6,程序 crash。
继续看代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// set the per-goroutine and per-mach "registers"
// 获取 fs 段基址到 BX 寄存器
get_tls(BX)
// 将 g0 的地址存储到 CX,CX = &g0
LEAQ runtime·g0(SB), CX
// 把 g0 的地址保存在线程本地存储里面,也就是 m0.tls[0]=&g0
MOVQ CX, g(BX)
// 将 m0 的地址存储到 AX,AX = &m0
LEAQ runtime·m0(SB), AX
// save m->g0 = g0
// m0.g0 = &g0
MOVQ CX, m_g0(AX)
// save m0 to g0->m
// g0.m = &m0
MOVQ AX, g_m(CX)
|
L3 将 m.tls 地址存入 BX;L5 将 g0 的地址存入 CX;L7 将 CX,也就是 g0 的地址存入 m.tls[0];L9 将 m0 的地址存入 AX;L13 将 g0 的地址存入 m0.g0;L16 将 m0 存入 g0.m。也就是:
1
2
3
|
tls[0] = g0
m0.g0 = &g0
g0.m = &m0
|
代码中寄存器前面的符号看着比较奇怪,其实它们最后会被链接器转化为偏移量。
这种写法在标准 plan9 汇编中只是个 symbol,没有任何偏移量的意思,但这里却用名字来代替了其偏移量,这是怎么回事呢?
实际上这是 runtime 的特权,是需要链接器配合完成的,再来看看 gobuf 在 runtime 中的 struct 定义开头部分的注释:
1
|
// The offsets of sp, pc, and g are known to (hard-coded in) libmach.
|
对于我们而言,这种写法读起来比较容易。
这一段执行完之后,就把 m0,g0,m.tls[0] 串联起来了。通过 m.tls[0] 可以找到 g0,通过 g0 可以找到 m0(通过 g 结构体的 m 字段)。并且,通过 m 的字段 g0,m0 也可以找到 g0。于是,主线程和 m0,g0 就关联起来了。
从这里还可以看到,保存在主线程本地存储中的值是 g0 的地址,也就是说工作线程的私有全局变量其实是一个指向 g 的指针而不是指向 m 的指针。
目前这个指针指向g0,表示代码正运行在 g0 栈。
于是,前面的图又增加了新的玩伴 m0:
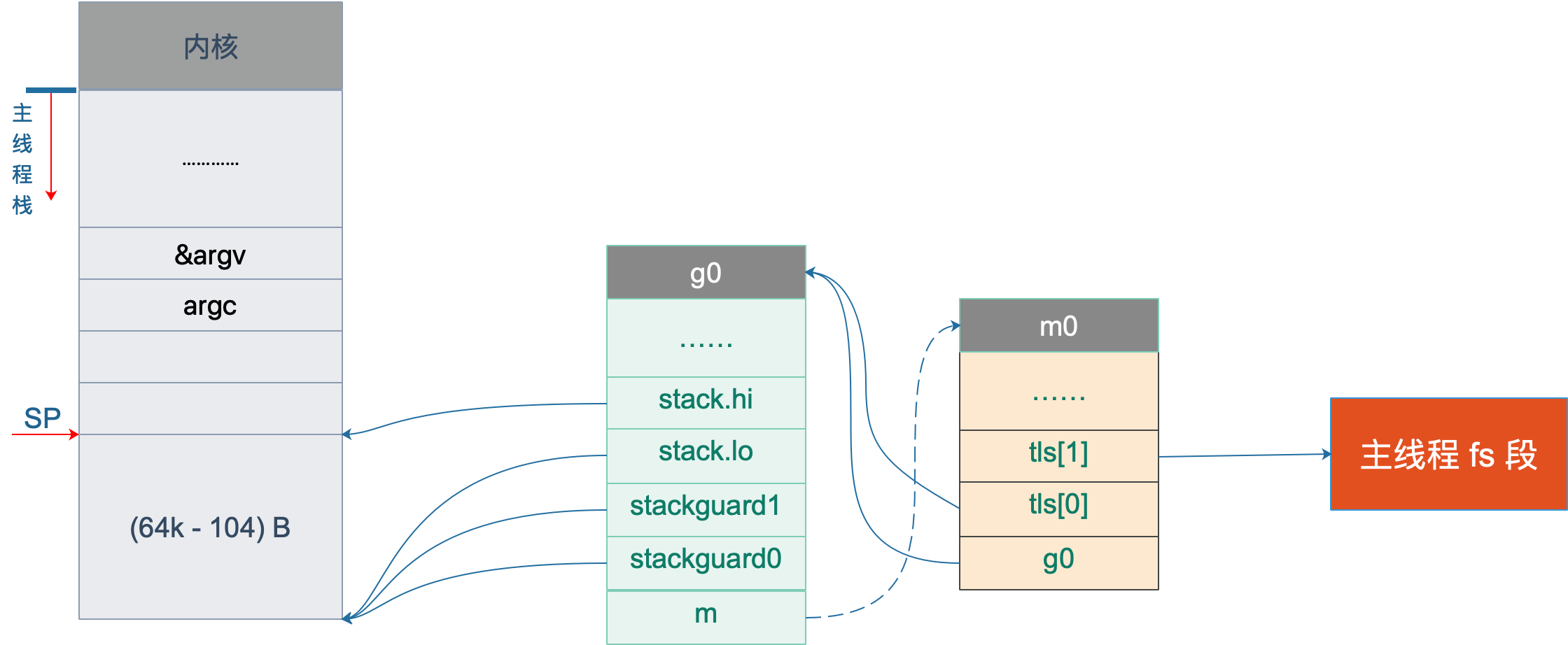
初始化系统核心数与调度器
1
2
3
4
5
6
7
8
9
|
MOVL 16(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 24(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
// 初始化系统核心数
CALL runtime·osinit(SB)
// 调度器初始化
CALL runtime·schedinit(SB)
|
L1-L2 将 16(SP) 处的内容移动到 0(SP),也就是栈顶,通过前面的图,16(SP) 处的内容为 argc;L3-L4 将 argv 存入 8(SP),接下来调用 runtime·args 函数,处理命令行参数。
接着,连续调用了两个 runtime 函数。osinit 函数初始化系统核心数,将全局变量 ncpu 初始化的核心数,schedinit 则是调度器的初始化。
创建runtime main goroutine
继续看代码,前面我们完成了 schedinit 函数,这是 runtime·rt0_go 函数里的一步,接着往后看:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// 创建一个新的 goroutine 来启动程序
MOVQ $runtime·mainPC(SB), AX // entry
// newproc 的第二个参数入栈,也就是新的 goroutine 需要执行的函数
// AX = &funcval{runtime·main},
PUSHQ AX
// newproc 的第一个参数入栈,该参数表示 runtime.main 函数需要的参数大小,
// 因为 runtime.main 没有参数,所以这里是 0
PUSHQ $0 // arg size
// 创建 main goroutine
CALL runtime·newproc(SB)
POPQ AX
POPQ AX
// start this M
// 主线程进入调度循环,运行刚刚创建的 goroutine
CALL runtime·mstart(SB)
// 永远不会返回,万一返回了,crash 掉
MOVL $0xf1, 0xf1 // crash
RET
|
代码前面几行是在为调用 newproc 函数构“造栈”,执行完 runtime·newproc(SB) 后,就会以一个新的 goroutine 来执行 mainPC 也就是 runtime.main() 函数。runtime.main() 函数最终会执行到我们写的 main 函数。
重点来看 newproc 函数:
1
2
3
4
5
6
7
|
// src/runtime/proc.go
// 创建一个新的 g,运行 fn 函数,需要 siz byte 的参数
// 将其放至 G 队列等待运行
// 编译器会将 go 关键字的语句转化成此函数
//go:nosplit
func newproc(siz int32, fn *funcval)
|
每个 goroutine 都有自己的栈空间,newproc 函数会新创建一个新的 goroutine 来执行 fn 函数.
当前代码在 g0 栈上执行,因此执行完_g_ := getg() 之后,无论是在什么情况下都可以得到 _g_ = g0。之后通过 g0 找到其绑定的 P,也就是 p0。
接着,尝试从 p0 上找一个空闲的 G.
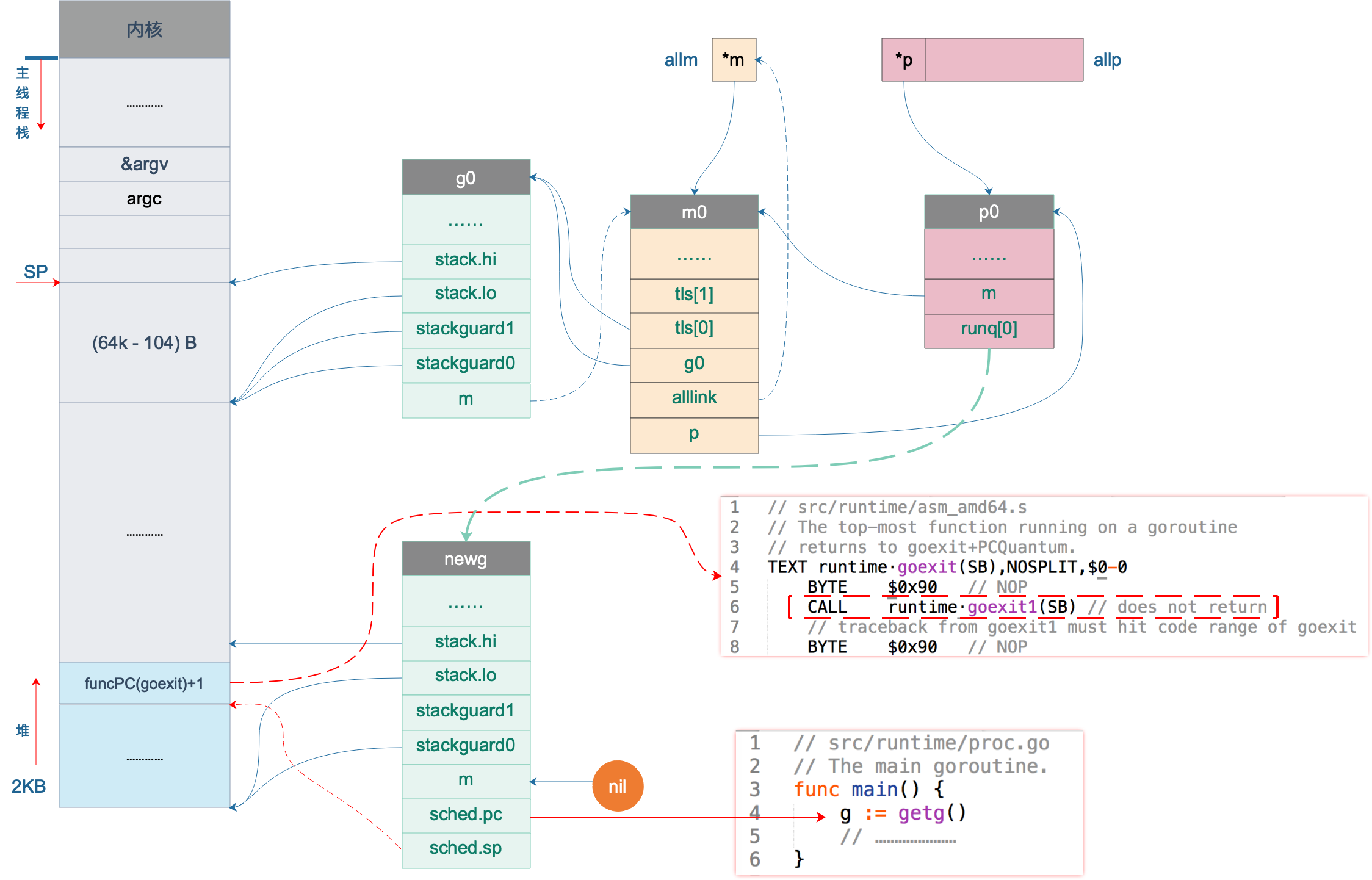
如果拿不到,则会在堆上创建一个新的 G,为其分配 2KB 大小的栈,并设置好新 goroutine 的 stack 成员,设置其状态为 _Gdead,并将其添加到全局变量 allgs 中。创建完成之后,我们就在堆上有了一个 2K 大小的栈。于是,我们的图再次丰富:
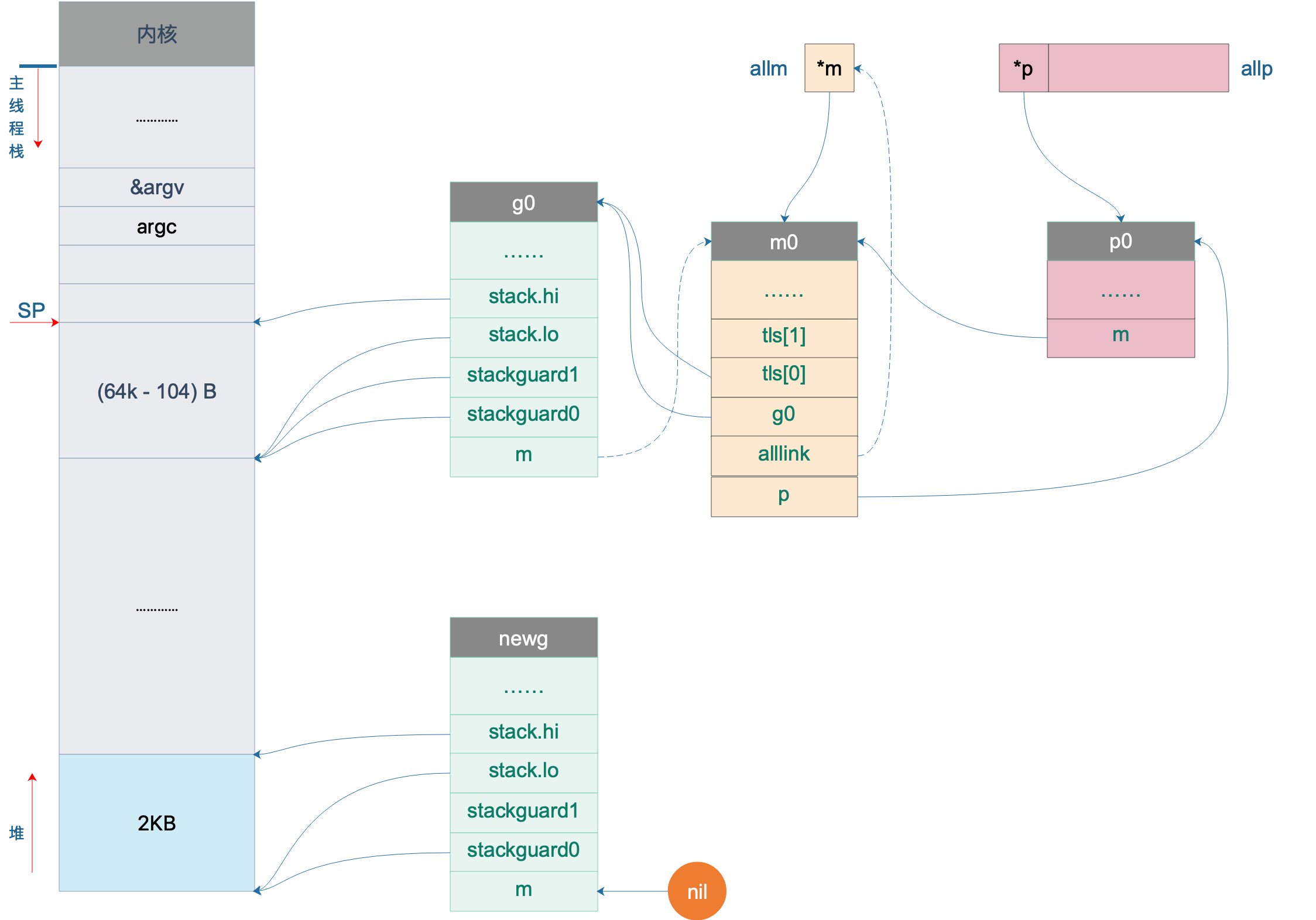
g0 栈用于执行调度器的代码,执行完之后,要跳转到执行用户代码的地方,如何跳转?这中间涉及到栈和寄存器的切换。
将 fn 的参数从 g0 栈上拷贝到 newg 的栈上,memmove 函数需要传入源地址、目的地址、参数大小。由于 main 函数在这里没有参数需要拷贝,因此这里相当于没做什么。
接着,初始化 newg 的各种字段,而且涉及到最重要的 pc,sp 等字段:
而 goexit 函数也通过“偷天换日”将自己的地址“强行”放到 newg 的栈顶,达到自己不可告人的目的:每个 goroutine 执行完之后,都要经过我的一些清理工作,才能“放行”。这样一说,goexit 函数还真是无私,默默地做一些“扫尾”的工作。
设置完 newg.sched 这后,我们的图又可以前进一步:
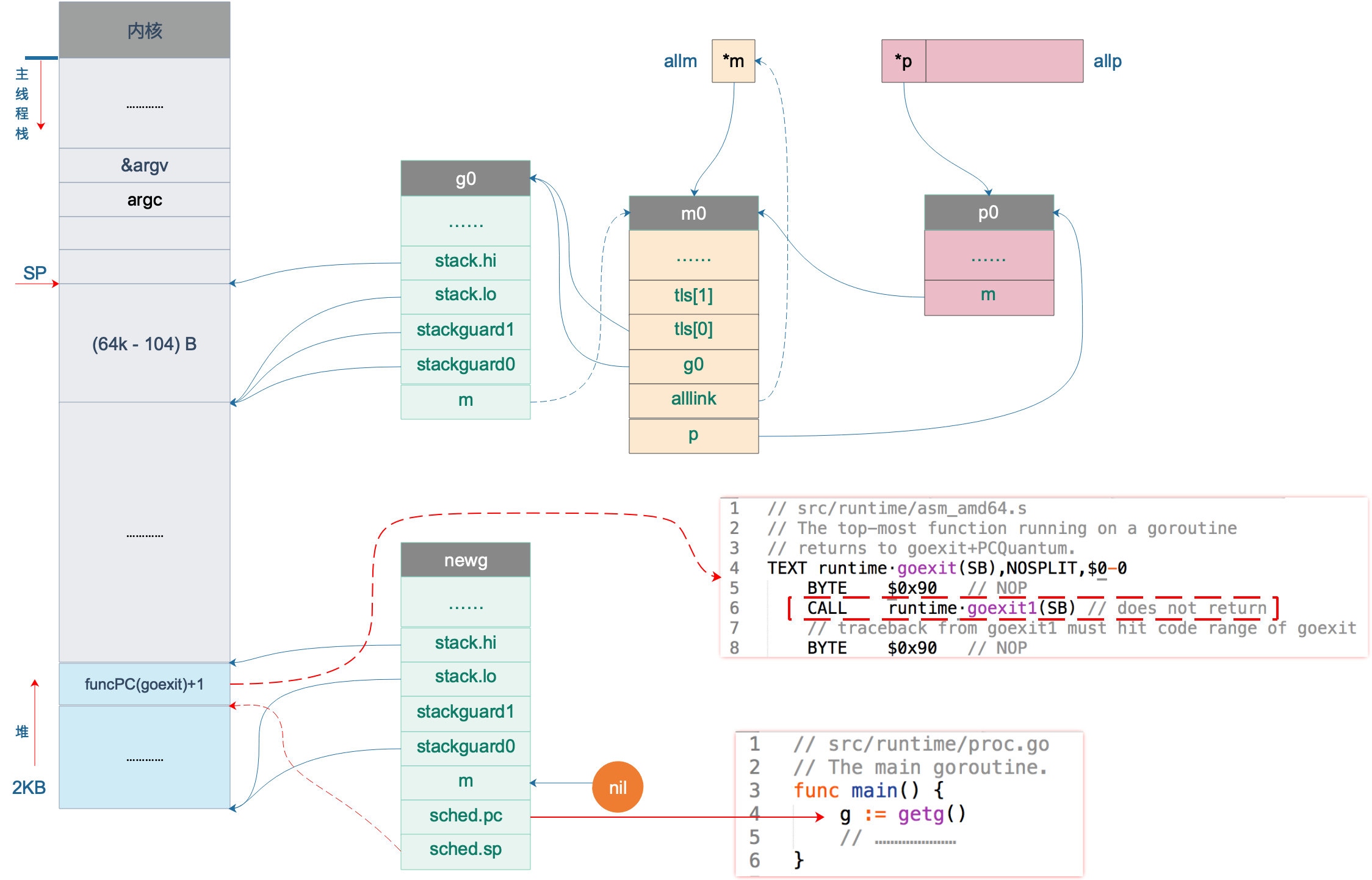
上图中,newg 新增了 sched.pc 指向 runtime.main 函数,当它被调度起来执行时,就从这里开始;新增了 sched.sp 指向了 newg 栈顶位置,同时,newg 栈顶位置的内容是一个跳转地址,指向 runtime.goexit 的第二条指令,当 goroutine 退出时,这条地址会载入 CPU 的 PC 寄存器,跳转到这里执行“扫尾”工作。
newg 的状态变成可执行后(Runnable),就可以将它加入到 P 的本地运行队列里,等待调度。所以,goroutine 何时被执行,用户代码决定不了。
主线程开始 schedule 循环
在 runtime·rt0_go 函数里,执行完 runtime·newproc(SB) 后,两条 POP 指令将之前为调用它构建的参数弹出栈。只剩下一个函数了:
1
2
3
|
// start this M
// 主线程进入调度循环,运行刚刚创建的 goroutine
CALL runtime·mstart(SB)
|
mstart 函数设置了 stackguard0 和 stackguard1 字段后,就直接调用 mstart1() 函数:
调用 gosave 函数来保存调度信息到 g0.sched 结构体.
主要是设置了 g0.sched.sp 和 g0.sched.pc,前者指向 mstart1 函数栈上参数的位置,后者则指向 gosave 函数返回后的下一条指令。如下图:
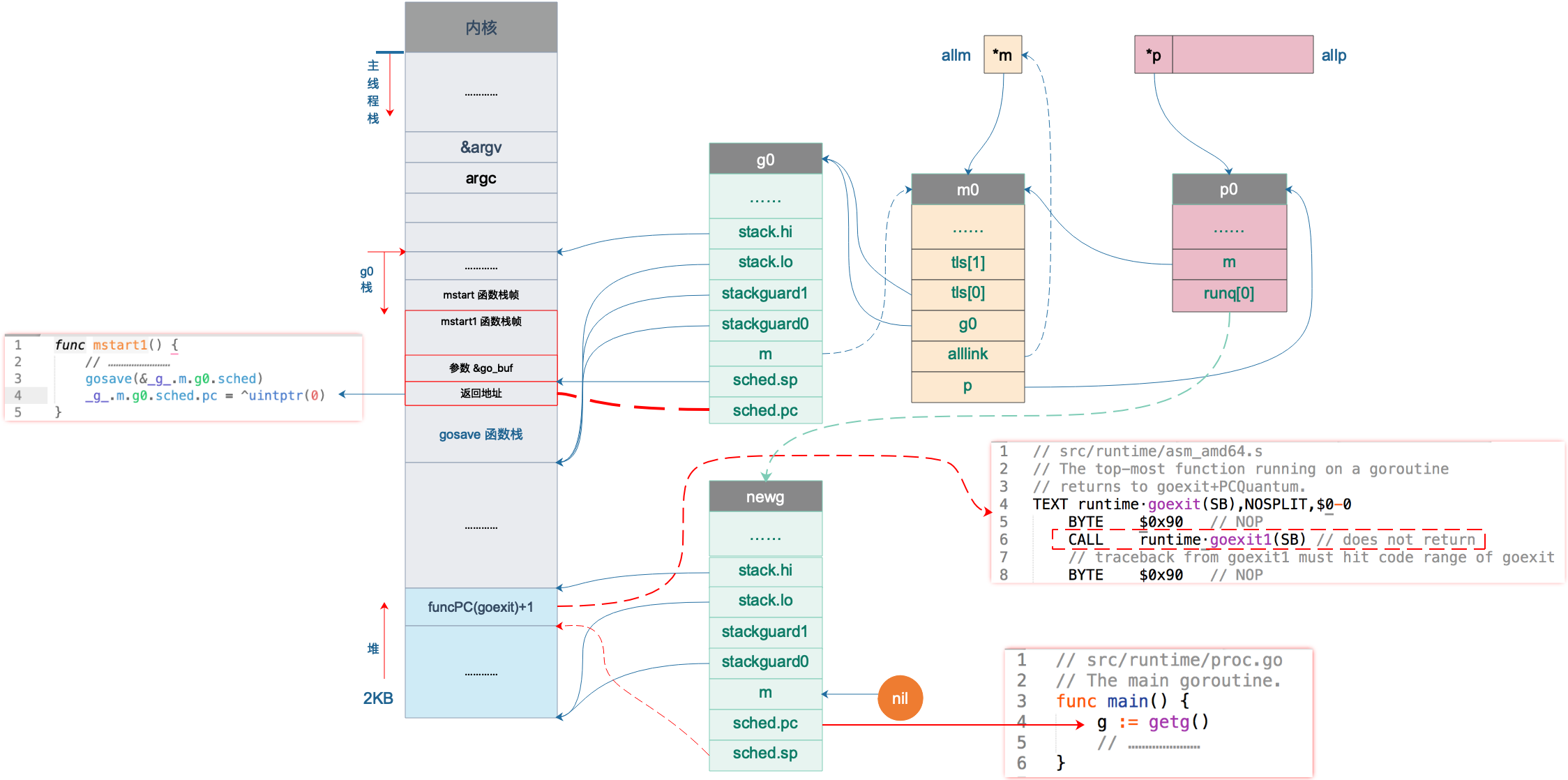
图中 sched.pc 并不直接指向返回地址,所以图中的虚线并没有箭头。
接下来,进入 schedule 函数,找到了可以运行的 runtime.main goroutine,调用 execute(gp, inheritTime) 将 gp 的状态改为 _Grunning,将 m 和 gp 相互关联起来。最后,调用 gogo 完成从 g0 到 gp 的切换,CPU 的执行权将从 g0 转让到 gp。开始执行 runtime.main 函数。
main goroutine 退出后直接调用 exit(0) 使得整个进程退出,而普通 goroutine 退出后,则进行了一系列的调用,最终又切到 g0 栈,执行 schedule 函数。
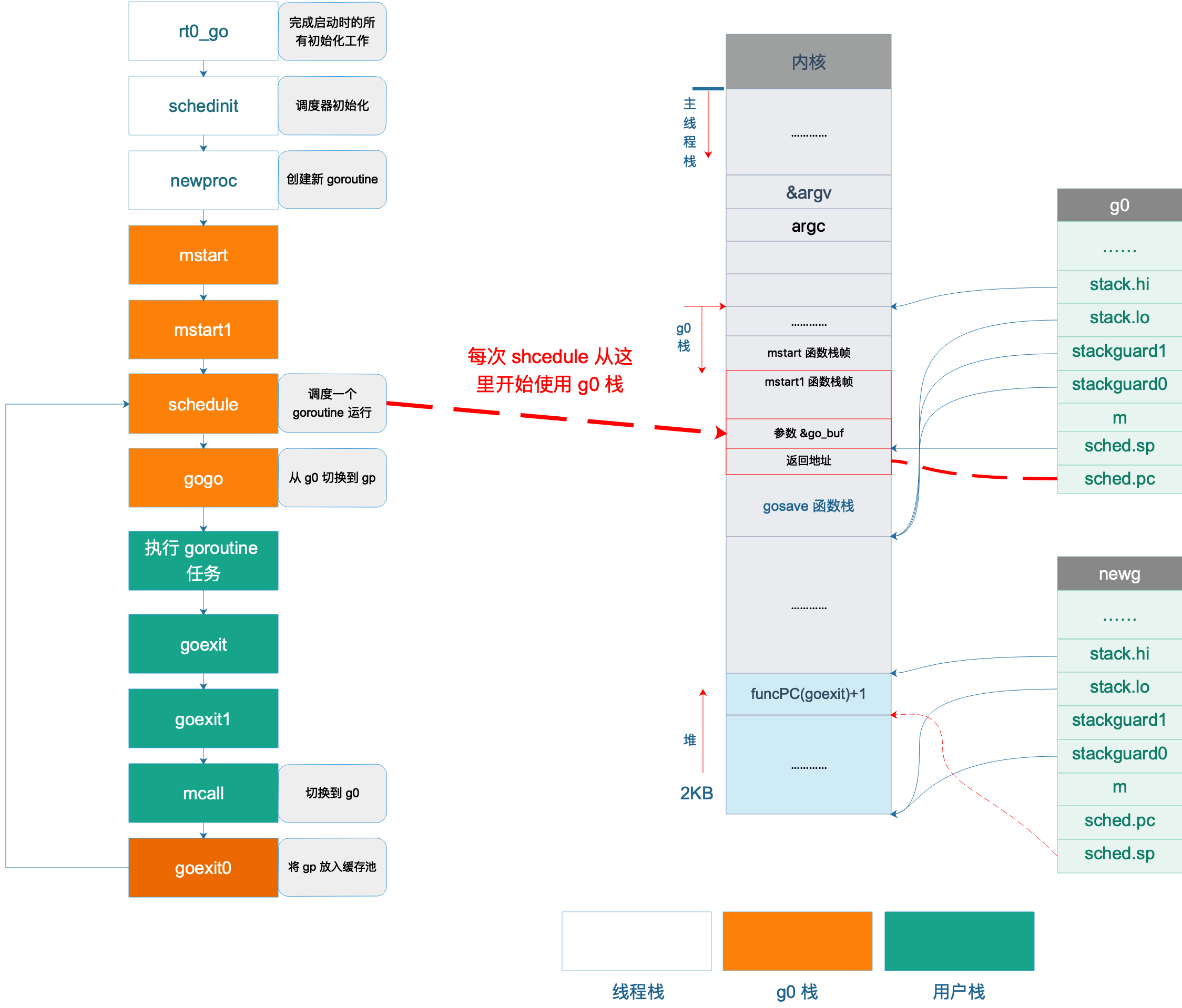
如图所示,rt0_go 负责 Go 程序启动的所有初始化,中间进行了很多初始化工作,调用 mstart 之前,已经切换到了 g0 栈,图中不同色块表示使用不同的栈空间。
接着调用 gogo 函数,完成从 g0 栈到用户 goroutine 栈的切换,包括 main goroutine 和普通 goroutine。
之后,执行 main 函数或者用户自定义的 goroutine 任务。
执行完成后,main goroutine 直接调用 eixt(0) 退出,普通 goroutine 则调用 goexit -> goexit1 -> mcall,完成普通 goroutine 退出后的清理工作,然后切换到 g0 栈,调用 goexit0 函数,将普通 goroutine 添加到缓存池中,再调用 schedule 函数进行新一轮的调度。
1
|
schedule() -> execute() -> gogo() -> goroutine 任务 -> goexit() -> goexit1() -> mcall() -> goexit0() -> schedule()
|
可以看出,一轮调度从调用 schedule 函数开始,经过一系列过程再次调用 schedule 函数来进行新一轮的调度,从一轮调度到新一轮调度的过程称之为一个调度循环。
这里说的调度循环是指某一个工作线程的调度循环,而同一个Go 程序中存在多个工作线程,每个工作线程都在进行着自己的调度循环。
从前面的代码分析可以得知,上面调度循环中的每一个函数调用都没有返回,虽然 goroutine 任务-> goexit() -> goexit1() -> mcall() 是在 g2 的栈空间执行的,但剩下的函数都是在 g0 的栈空间执行的。
runtime main goroutine 执行与退出
我们探索 main goroutine 以及普通 goroutine 从执行到退出的整个过程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
|
// The main goroutine.
func main() {
// g = main goroutine,不再是 g0 了
g := getg()
// Racectx of m0->g0 is used only as the parent of the main goroutine.
// It must not be used for anything else.
g.m.g0.racectx = 0
// Max stack size is 1 GB on 64-bit, 250 MB on 32-bit.
// Using decimal instead of binary GB and MB because
// they look nicer in the stack overflow failure message.
if sys.PtrSize == 8 {
maxstacksize = 1000000000
} else {
maxstacksize = 250000000
}
// Allow newproc to start new Ms.
mainStarted = true
if GOARCH != "wasm" { // no threads on wasm yet, so no sysmon
systemstack(func() {
// 创建监控线程,该线程独立于调度器,不需要跟 p 关联即可运行
newm(sysmon, nil, -1)
})
}
// Lock the main goroutine onto this, the main OS thread,
// during initialization. Most programs won't care, but a few
// do require certain calls to be made by the main thread.
// Those can arrange for main.main to run in the main thread
// by calling runtime.LockOSThread during initialization
// to preserve the lock.
lockOSThread()
if g.m != &m0 {
throw("runtime.main not on m0")
}
// 调用 runtime 包的初始化函数,由编译器实现
doInit(&runtime_inittask) // must be before defer
if nanotime() == 0 {
throw("nanotime returning zero")
}
// Defer unlock so that runtime.Goexit during init does the unlock too.
needUnlock := true
defer func() {
if needUnlock {
unlockOSThread()
}
}()
// Record when the world started.
runtimeInitTime = nanotime()
// 开启垃圾回收器
gcenable()
main_init_done = make(chan bool)
if iscgo {
if _cgo_thread_start == nil {
throw("_cgo_thread_start missing")
}
if GOOS != "windows" {
if _cgo_setenv == nil {
throw("_cgo_setenv missing")
}
if _cgo_unsetenv == nil {
throw("_cgo_unsetenv missing")
}
}
if _cgo_notify_runtime_init_done == nil {
throw("_cgo_notify_runtime_init_done missing")
}
// Start the template thread in case we enter Go from
// a C-created thread and need to create a new thread.
startTemplateThread()
cgocall(_cgo_notify_runtime_init_done, nil)
}
// main 包的初始化,递归的调用我们 import 进来的包的初始化函数
doInit(&main_inittask)
close(main_init_done)
needUnlock = false
unlockOSThread()
if isarchive || islibrary {
// A program compiled with -buildmode=c-archive or c-shared
// has a main, but it is not executed.
return
}
// 调用 main.main 函数
fn := main_main // make an indirect call, as the linker doesn't know the address of the main package when laying down the runtime
fn()
if raceenabled {
racefini()
}
// Make racy client program work: if panicking on
// another goroutine at the same time as main returns,
// let the other goroutine finish printing the panic trace.
// Once it does, it will exit. See issues 3934 and 20018.
if atomic.Load(&runningPanicDefers) != 0 {
// Running deferred functions should not take long.
for c := 0; c < 1000; c++ {
if atomic.Load(&runningPanicDefers) == 0 {
break
}
Gosched()
}
}
if atomic.Load(&panicking) != 0 {
gopark(nil, nil, waitReasonPanicWait, traceEvGoStop, 1)
}
// 进入系统调用,退出进程,可以看出 main goroutine 并未返回,而是直接进入系统调用退出进程了
exit(0)
// 保护性代码,如果 exit 意外返回,下面的代码会让该进程 crash 死掉
for {
var x *int32
*x = 0
}
}
|
main 函数执行流程如下图:
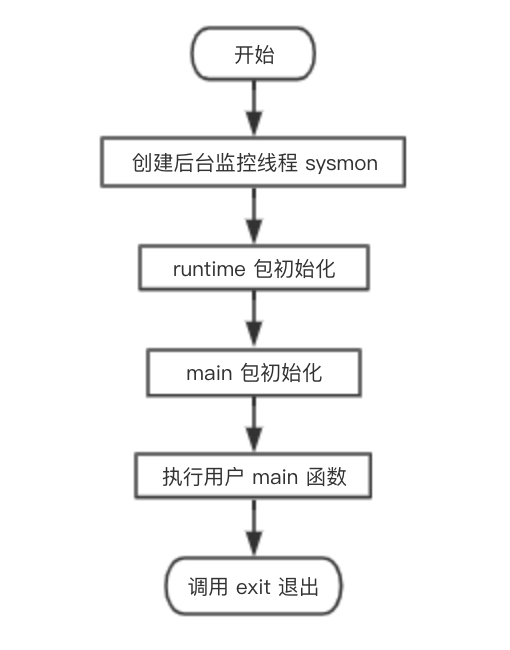
从流程图可知,main goroutine 执行完之后就直接调用 exit(0) 退出了,这会导致整个进程退出,太粗暴了。
不过,main goroutine 实际上就是代表用户的 main 函数,它都执行完了,肯定是用户的任务都执行完了,直接退出就可以了,就算有其他的 goroutine 没执行完,同样会直接退出。
1
2
3
4
5
6
7
|
package main
import "fmt"
func main() {
go func() {fmt.Println("hello qcrao.com")}()
}
|
在这个例子中,main gorutine 退出时,还来不及执行 go 出去 的函数,整个进程就直接退出了,打印语句不会执行。因此,main goroutine 不会等待其他 goroutine 执行完再退出,知道这个有时能解释一些现象,比如上面那个例子。
这时,心中可能会跳出疑问,我们在新创建 goroutine 的时候,不是整出了个“偷天换日”,风风火火地设置了 goroutine 退出时应该跳到 runtime.goexit 函数吗,怎么这会不用了,闲得慌?
回顾一下跳转到 main 函数的两行代码:
1
2
3
4
|
// 把 sched.pc 值放入 BX 寄存器
MOVQ gobuf_pc(BX), BX
// JMP 把 BX 寄存器的包含的地址值放入 CPU 的 IP 寄存器,于是,CPU 跳转到该地址继续执行指令
JMP BX
|
直接使用了一个跳转,并没有使用 CALL 指令,而 runtime.main 函数中确实也没有 RET 返回的指令。所以,main goroutine 执行完后,直接调用 exit(0) 退出整个进程。
那之前整地“偷天换日”还有用吗?有的!这是针对非 main goroutine 起作用。
main goroutine 和普通 goroutine 的退出过程:
- 对于 main goroutine,在执行完用户定义的 main 函数的所有代码后,直接调用 exit(0) 退出整个进程,非常霸道。
- 对于普通 goroutine 则没这么“舒服”,需要经历一系列的过程。先是跳转到提前设置好的 goexit 函数的第二条指令,然后调用 runtime.goexit1,接着调用 mcall(goexit0),而 mcall 函数会切换到 g0 栈,运行 goexit0 函数,清理 goroutine 的一些字段,并将其添加到 goroutine 缓存池里,然后进入 schedule 调度循环。到这里,普通 goroutine 才算完成使命。
转载
Asciidoc 笔记