Go调试器:GODEBUG
文章目录
介绍
让 Go 更强大的原因之一莫过于它的 GODEBUG 工具,GODEBUG 的设置可以让 Go 程序在运行时输出调试信息,可以根据你的要求很直观的看到你想要的调度器或垃圾回收等详细信息,并且还不需要加装其它的插件,非常方便,今天我们将先讲解 GODEBUG 的调度器相关内容,希望对你有所帮助。
GODEBUG 变量可以控制运行时内的调试变量,参数以逗号分隔,格式为:name=val。
调度器观察
本节重点在调度器观察上,将会使用如下两个参数:
- schedtrace:设置 schedtrace=X 参数可以使运行时在每 X 毫秒发出一行调度器的摘要信息到标准 err 输出中。
- scheddetail:设置 schedtrace=X 和 scheddetail=1 可以使运行时在每 X 毫秒发出一次详细的多行信息,信息内容主要包括调度程序、处理器、OS 线程 和 Goroutine 的状态。
演示代码
|
|
列表1的第12行使用一个for循环创建10个goroutine,第16行main函数中等待所有的goroutine完成任务。第22行的work函数先sleep 1秒,然后计数 10亿次。一旦计数完成,调用waitGroup的Done方法然后返回。
首先go build程序,然后运行时设置GODEBUG环境变量。这个变量会被运行时读取,所以Go命令也会产生跟踪信息。如果在运行go run命令的时候设置了GODEBUG变量,在程序运行之前就会看到跟踪信息。
所以还是让我们先编译程序:
|
|
schedtrace
schedtrace参数告诉运行时打印一行调度器的摘要信息到标准err输出中,时间间隔可以指定,单位毫秒,如下所示:
|
|
- sched:每一行都代表调度器的调试信息,后面提示的毫秒数表示启动到现在的运行时间,输出的时间间隔受 schedtrace 的值影响。
- gomaxprocs:当前的 CPU 核心数(GOMAXPROCS 的当前值)。
- idleprocs:空闲的处理器数量,后面的数字表示当前的空闲数量。
- threads:OS 线程数量,后面的数字表示当前正在运行的线程数量。
- spinningthreads:自旋状态的 OS 线程数量。
- idlethreads:空闲的线程数量。
- runqueue:全局队列中中的 Goroutine 数量,而后面的 [0 0 1 1] 则分别代表这 4 个 P 的本地队列正在运行的 Goroutine 数量。
自旋线程的这个说法,是因为 Go Scheduler 的设计者在考虑了 “OS 的资源利用率” 以及 “频繁的线程抢占给 OS 带来的负载” 之后,提出了 “Spinning Thread” 的概念。也就是当 “自旋线程” 没有找到可供其调度执行的 Goroutine 时,并不会销毁该线程 ,而是采取 “自旋” 的操作保存了下来。虽然看起来这是浪费了一些资源,但是考虑一下 syscall 的情景就可以知道,比起 “自旋",线程间频繁的抢占以及频繁的创建和销毁操作可能带来的危害会更大。
Go运行时给了我们很多有用的摘要信息。当我们看第一秒的跟踪数据时,我们看到一个goroutine正在运行,而其它9个都在等待:
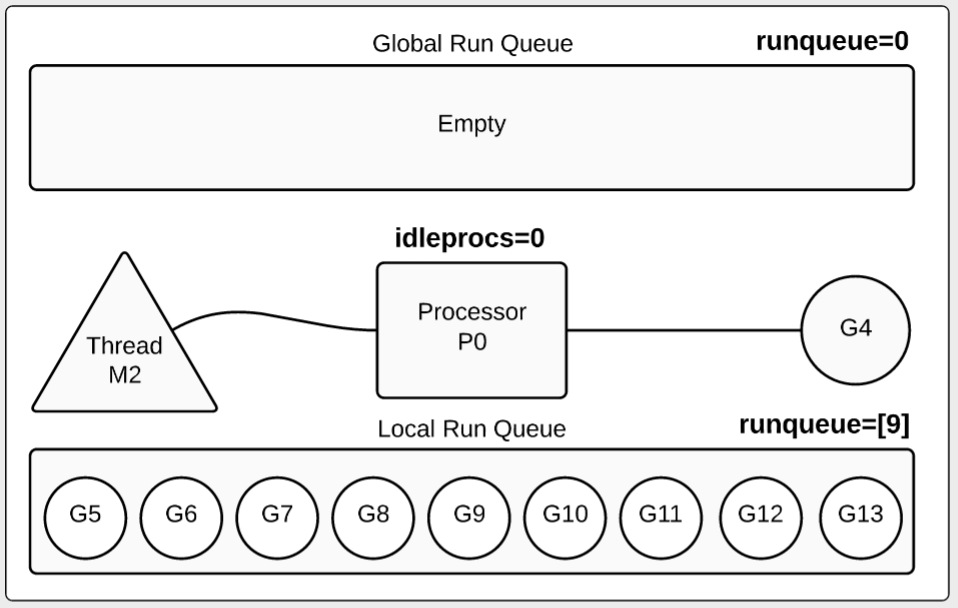
图1中处理器由字符P代表,线程由M代表,goroutine由G代表。我们看到全局run队列为空,处理器正在执行一个goroutine。其余9在本地队列中等待。
如果我们配置多个处理器会怎样呢?让我们增加GOMAXPROCS 看看输出结果:
|
|
让我们将视线放在第二秒:
|
|
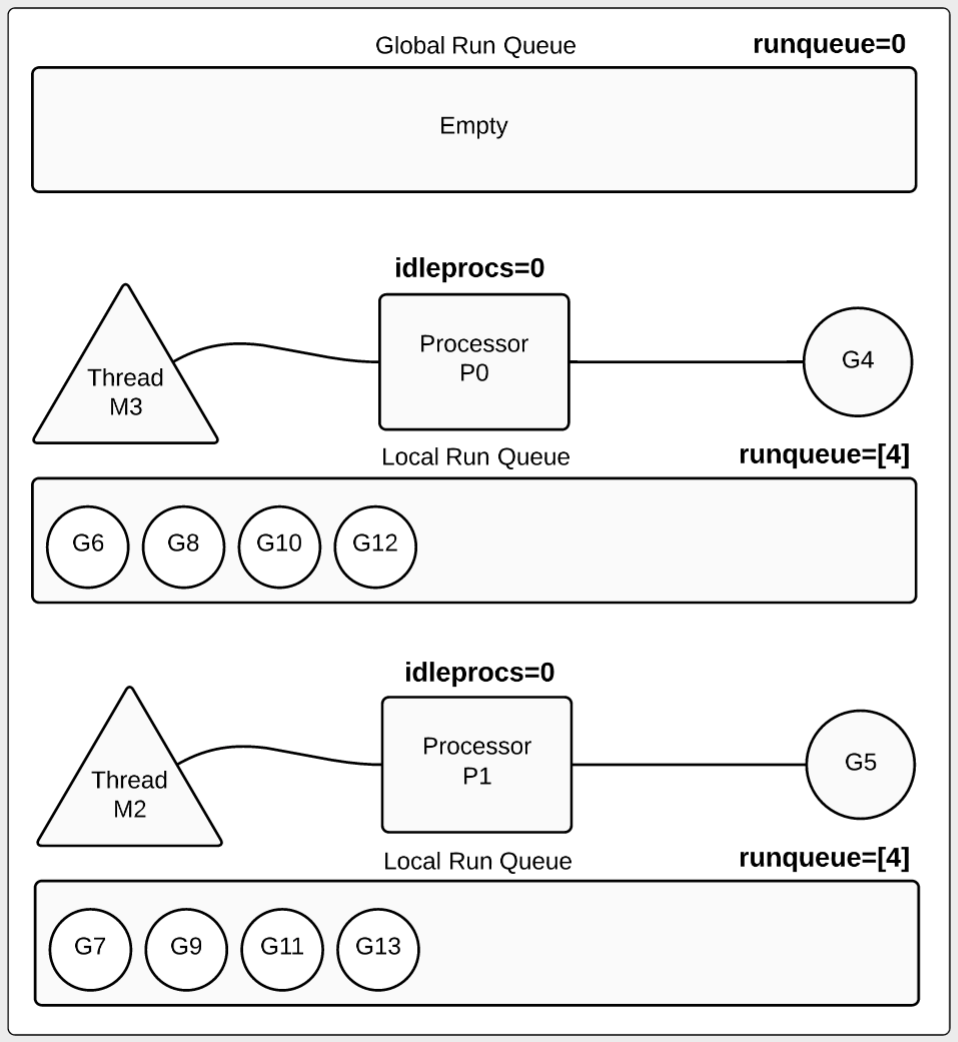
让我们看第二秒的信息,可以看到goroutine是如何被处理器运行的。我们也可以看到有8个goroutine在本地run队列中等待,每个本地run队列包含4个等待的goroutine。
让我们再来看第6秒的信息:
|
|
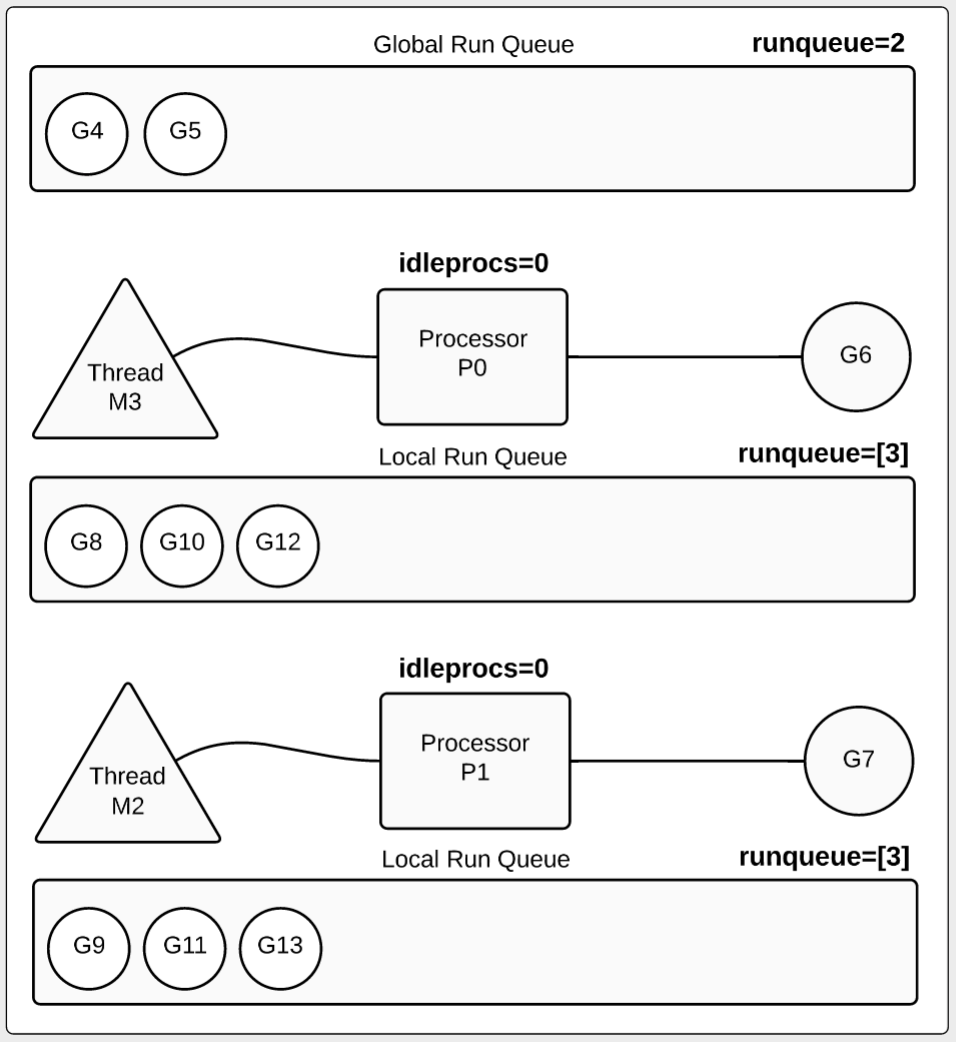
第6秒数据有些变化,如图3所示,两个goroutine完成了它们的任务,放回到全局run队列中。当然我们还是有两个goruntine在运行(G6,G7),每个P运行一个。每个本地run队列中还有3个goroutine在等待。
注意:
在很多情况下goroutine在终止前并没有被放回到全局run队列。本文中的例子比较特殊,它的方法体是一个for循环,并没有调用其它函数,而且运行时间超过10ms。10毫秒是调度器的调度标杆,过了10毫秒的执行时间,调度器就会尝试占用(preempt)这个goroutine。本例中的goroutine没有被占用是因为它们没有调用其它函数。本例中一旦goroutine执行到wg.Done调用,它们立即被占用,然后移动到全局run队列等待终止。
在17秒我们看到只有两个goroutine还在运行:
|
|
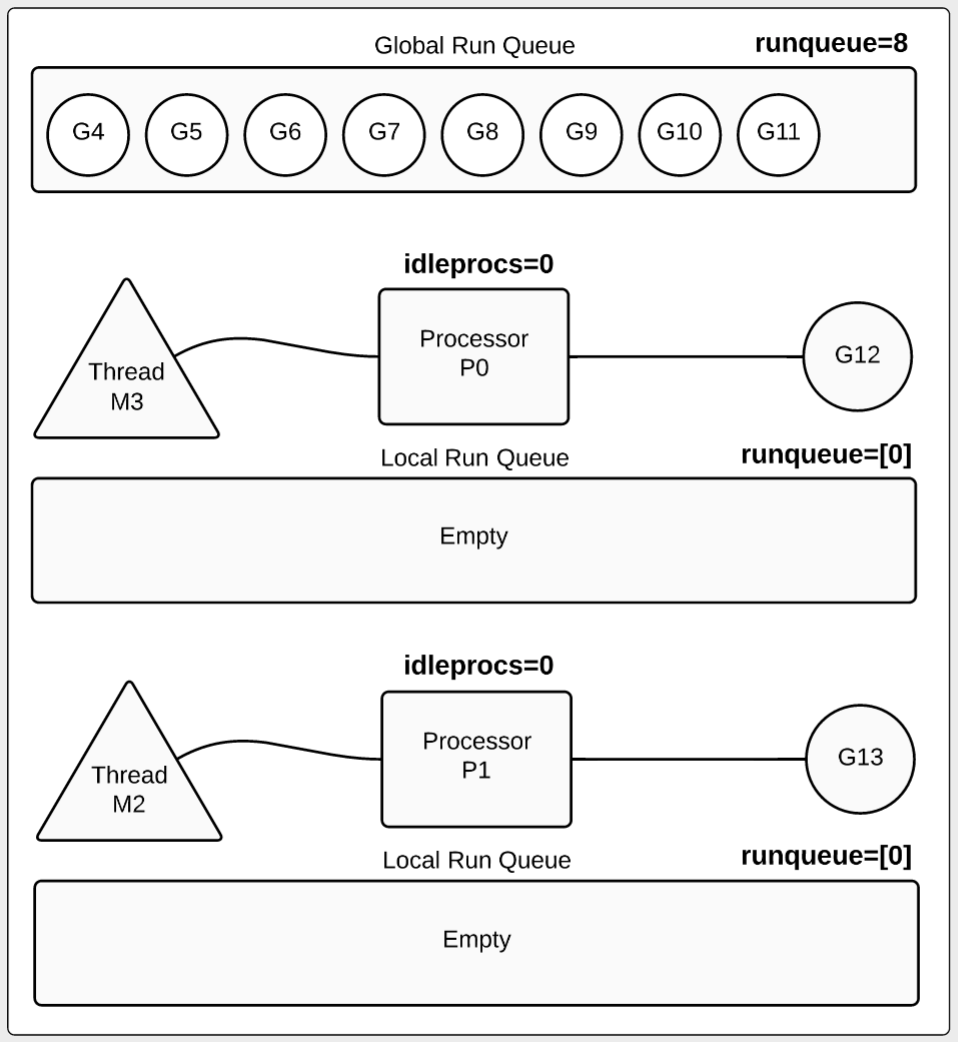
从图4可以看出,8个goroutine被移动到全局run队列等待终止。两个goroutine(G12和G13)还在运行,本地run队列都为空。
最后在第21秒:
|
|
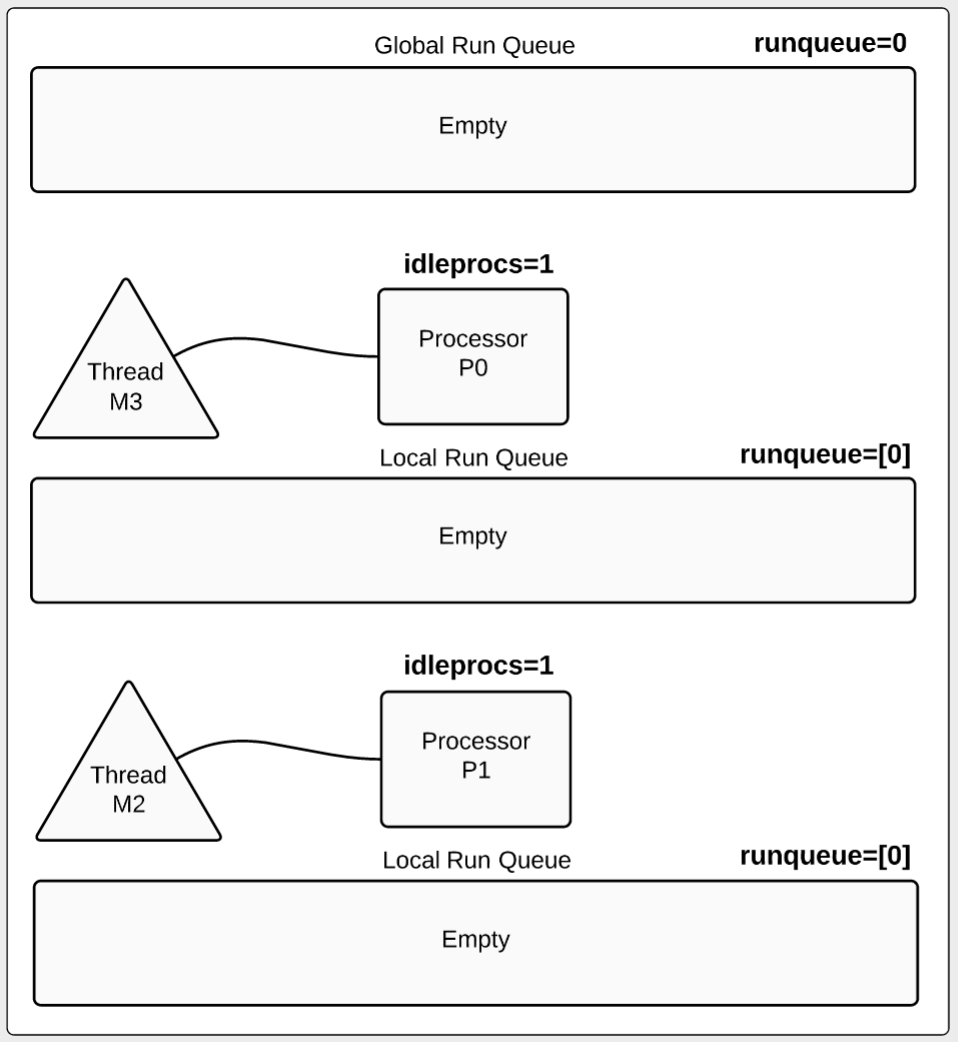
如图5所示,这时那10个goroutine都已经完成任务被终止。
scheddetail
如果我们想要更详细的看到调度器的完整信息时,我们可以增加 scheddetail 参数,就能够更进一步的查看调度的细节逻辑,如下:
|
|
在这里我们抽取了 1000ms 时的调试信息来查看,信息量比较大,我们先从每一个字段开始了解。如下:
G
- status:G 的运行状态。
- m:隶属哪一个 M。-1表示未分配.
- lockedm:是否有锁定 M。-1表示否.
在第一点中我们有提到 G 的运行状态,这对于分析内部流转非常的有用,共涉及如下 9 种状态:
| 状态 | 值 | 含义 |
|---|---|---|
| _Gidle | 0 | 刚刚被分配,还没有进行初始化。 |
| _Grunnable | 1 | 已经在运行队列中,还没有执行用户代码。 |
| _Grunning | 2 | 不在运行队列里中,已经可以执行用户代码,此时已经分配了 M 和 P。 |
| _Gsyscall | 3 | 正在执行系统调用,此时分配了 M。 |
| _Gwaiting | 4 | 在运行时被阻止,没有执行用户代码,也不在运行队列中,此时它正在某处阻塞等待中。 |
| _Gmoribund_unused | 5 | 尚未使用,但是在 gdb 中进行了硬编码。 |
| _Gdead | 6 | 尚未使用,这个状态可能是刚退出或是刚被初始化,此时它并没有执行用户代码,有可能有也有可能没有分配堆栈。 |
| _Genqueue_unused | 7 | 尚未使用。 |
| _Gcopystack | 8 | 正在复制堆栈,并没有执行用户代码,也不在运行队列中。 |
| 在理解了各类的状态的意思后,我们结合上述案例看看,如下: |
|
|
在这个片段中,G1 的运行状态为 _Gwaiting,并没有分配 M 和锁定。这时候你可能好奇在片段中括号里的是什么东西呢,其实是因为该 status=4 是表示 Goroutine 在运行时时被阻止,而阻止它的事件就是 semacquire 事件,是因为 semacquire 会检查信号量的情况,在合适的时机就调用 goparkunlock 函数,把当前 Goroutine 放进等待队列,并把它设为_Gwaiting 状态。
那么在实际运行中还有什么原因会导致这种现象呢,我们一起看看,如下:
|
|
我们通过以上 waitReason 可以了解到 Goroutine 会被暂停运行的原因要素,也就是会出现在括号中的事件。
M
- p:隶属哪一个 P。
- curg:当前正在使用哪个 G。
- runqsize:运行队列中的 G 数量。
- gfreecnt:可用的G(状态为 Gdead)。
- mallocing:是否正在分配内存。
- throwing:是否抛出异常。
- preemptoff:不等于空字符串的话,保持 curg 在这个 m 上运行。
P
- status:P 的运行状态。
- schedtick:P 的调度次数。
- syscalltick:P 的系统调用次数。
- m:隶属哪一个 M。
- runqsize:运行队列中的 G 数量。
- gfreecnt:可用的G(状态为 Gdead)。
| 状态 | 值 | 含义 |
|---|---|---|
| _Pidle | 0 | 刚刚被分配,还没有进行进行初始化。 |
| _Prunning | 1 | 当 M 与 P 绑定调用 acquirep 时,P 的状态会改变为 _Prunning。 |
| _Psyscall | 2 | 正在执行系统调用。 |
| _Pgcstop | 3 | 暂停运行,此时系统正在进行 GC,直至 GC 结束后才会转变到下一个状态阶段。 |
| _Pdead | 4 | 废弃,不再使用。 |
实战
GC观察
本节着重点在 GC 的观察上,主要涉及 gctrace 参数,我们通过设置 gctrace=1 后就可以使得垃圾收集器向标准错误流发出 GC 运行信息。
涉及术语
- mark:标记阶段。
- markTermination:标记结束阶段。
- mutator assist:辅助 GC,是指在 GC 过程中 mutator 线程会并发运行,而 mutator assist 机制会协助 GC 做一部分的工作。
- heap_live:在 Go 的内存管理中,span 是内存页的基本单元,每页大小为 8kb,同时 Go 会根据对象的大小不同而分配不同页数的 span,而 heap_live 就代表着所有 span 的总大小。
- dedicated / fractional / idle:在标记阶段会分为三种不同的 mark worker 模式,分别是 * dedicated、fractional 和 idle,它们代表着不同的专注程度,其中 dedicated 模式最专注,是完整的 GC 回收行为,fractional 只会干部分的 GC 行为,idle 最轻松。这里你只需要了解它是不同专注程度的 mark worker 就好了。
| 行为 | 会不会 STW | 为什么 |
|---|---|---|
| 标记开始 | 会 | 在开始标记时,准备根对象的扫描,会打开写屏障(Write Barrier) 和 辅助GC(mutator assist),而回收器和应用程序是并发运行的,因此会暂停当前正在运行的所有 Goroutine。 |
| 并发标记中 | 不会 | 标记阶段,主要目的是标记堆内存中仍在使用的值。 |
| 标记结束 | 会 | 在完成标记任务后,将重新扫描部分根对象,这时候会禁用写屏障(Write Barrier)和辅助GC(mutator assist),而标记阶段和应用程序是并发运行的,所以在标记阶段可能会有新的对象产生,因此在重新扫描时需要进行 STW。 |
演示代码
|
|
gctrace
|
|
格式
|
|
- gc #:GC 执行次数的编号,每次叠加。
- @#s:自程序启动后到当前的具体秒数。
- #%:自程序启动以来在GC中花费的时间百分比。
- #+…+#:GC 的标记工作共使用的 CPU 时间占总 CPU 时间的百分比。
- #->#-># MB:分别表示开始mark阶段前的heap_live大小;开始markTermination阶段前的heap_live大小和被标记对象的大小(当前活跃堆内存的大小)。444->444->0 MB, 表示垃圾回收器已经把444M的内存标记为非活跃的内存。注意:垃圾回收器回收了应用层的内存后,并不会立即将内存归还给系统。
- #MB goal:下一次触发 GC 的内存占用阈值。
- #P:当前使用的处理器 P 的数量。
如果信息以"(forced)“结尾,那么这次GC是被runtime.GC()调用所触发。
如果gctrace设置了任何大于0的值,还会在垃圾回收器将内存归还给系统时打印一条汇总信息。
这个将内存归还给系统的操作叫做scavenging。
这个汇总信息的格式以后可能会发生变化。
目前它的格式:
|
|
各字段的含义:
- scvg# scavenge次数的变化,每次scavenge时递增
- inuse: # MB 垃圾回收器中使用的大小
- idle: # MB 垃圾回收器中空闲等待归还的大小
- sys: # MB 垃圾回收器中系统映射内存的大小
- released: # MB 归还给系统的大小
- consumed: # MB 从系统申请的大小
gcvis
gcvis 的原理很简单, 就是逐行解析目标程序的 GC 输出,然后用正则匹配相关的数据,然后生成 JSON 数据,另外也会起一个协程开启 HTTP 服务,用于图表展示。
Installation
|
|
gcvis 主要有两种用法:
直接运行:
|
|
管道重定向方式(standard error)
|
|
gcvis 的图标输出效果如下:
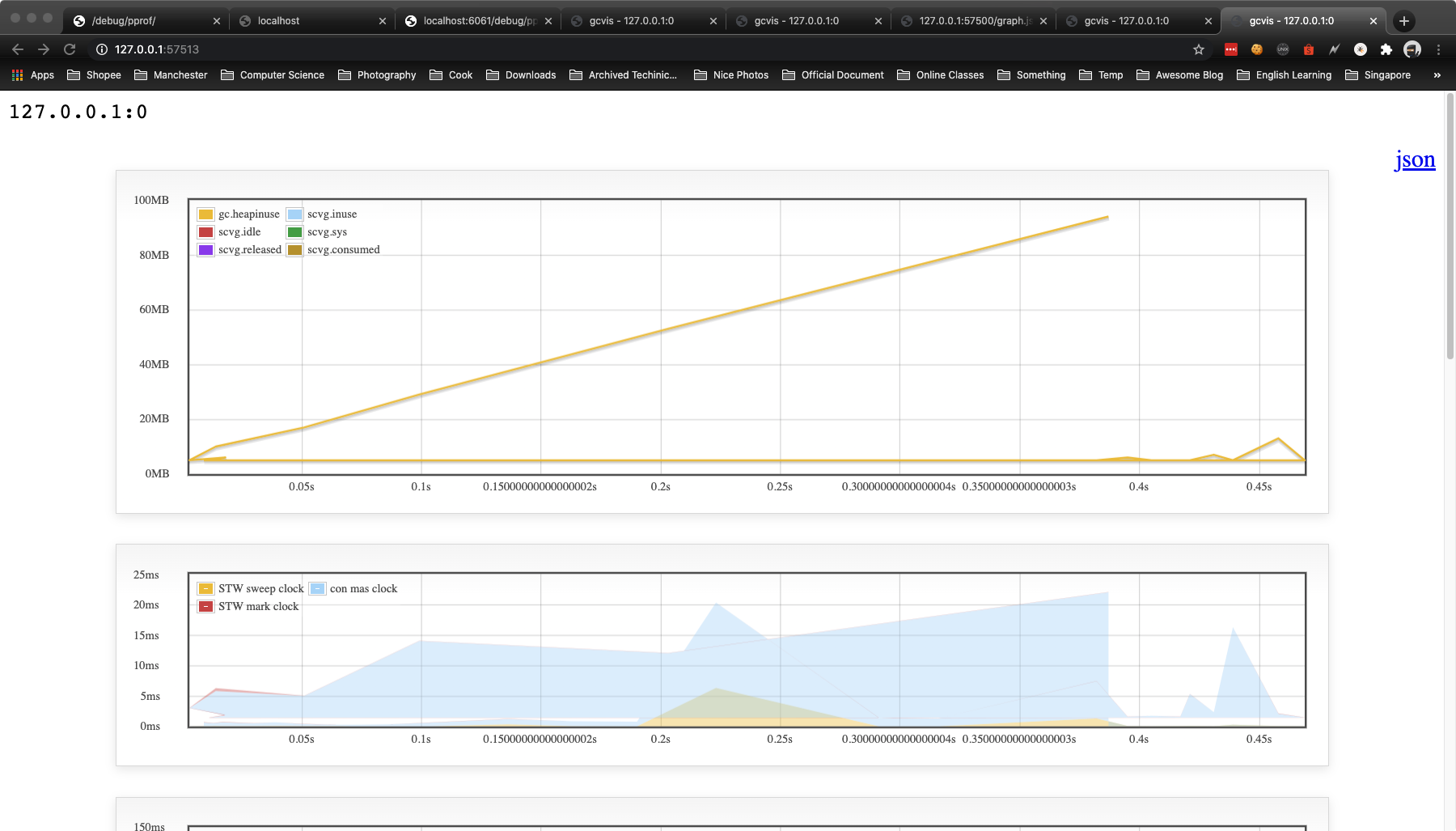
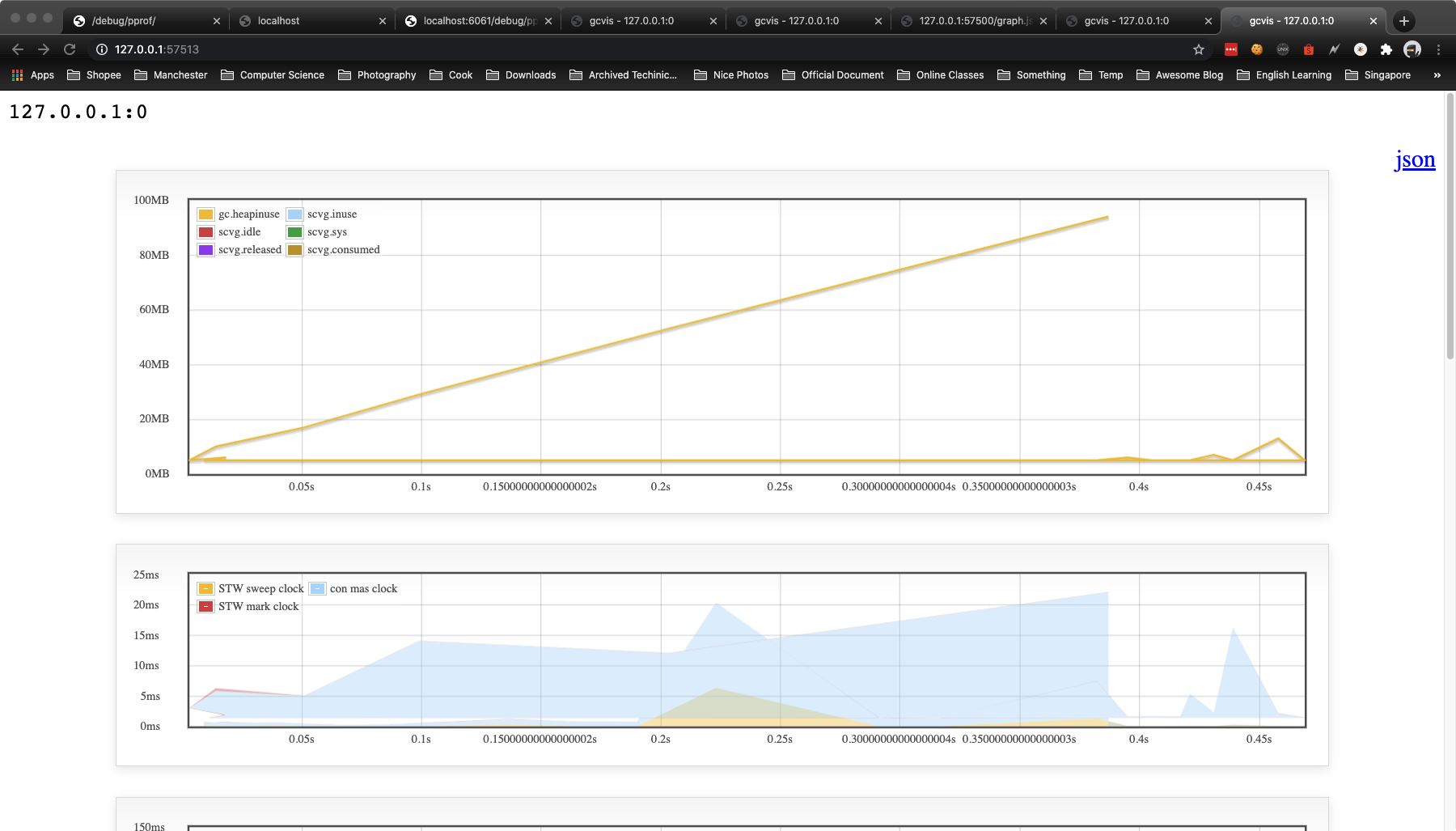
案例
|
|
- gc 7:第 7 次 GC。
- @0.140s:当前是程序启动后的 0.140s。
- 1%:程序启动后到现在共花费 1% 的时间在 GC 上。
- 0.031+2.0+0.042 ms clock:
- 0.031:表示单个 P 在 mark 阶段的 STW 时间。
- 2.0:表示所有 P 的 mark concurrent(并发标记)所使用的时间。
- 0.042:表示单个 P 的 markTermination 阶段的 STW 时间。
- 0.12+0.43/1.8/0.049+0.17 ms cpu:
- 0.12:表示整个进程在 mark 阶段 STW 停顿的时间。
- 0.43/1.8/0.049:0.43 表示 mutator assist 占用的时间,1.8 表示 dedicated + fractional 占用的时间,0.049 表示 idle 占用的时间。
- 0.17ms:0.17 表示整个进程在 markTermination 阶段 STW 时间。
- 4->4->1 MB:
- 4:表示开始 mark 阶段前的 heap_live 大小。
- 4:表示开始 markTermination 阶段前的 heap_live 大小。
- 1:表示被标记对象的大小。
- 5 MB goal:表示下一次触发 GC 回收的阈值是 5 MB。
- 4 P:本次 GC 一共涉及多少个 P。
副作用:runtime调度阻塞
当你开启GODEBUG=gctrace=1,并且日志是重定向到文件,那么有概率会造成runtime调度阻塞。
查找问题
开始业务方说我们的grpc sidecar时不时发生高时延抖动,我对比了监控上的性能数据,貌似是磁盘io引起的,我迅速调高了日志级别及修改日志库为异步写入模式。接口的时延抖动问题确实减少了,但依旧还是出现。
通过项目代码变更得知,一同事在部署脚本里加入了gctrace监控。开始不觉得是这个问题引起的,但近一段时间也就这一个commit提交,我就尝试回滚代码,问题居然就这么解决了。
我们先来分析下golang gc gctrace相关的代码,我们知道go 1.12的stop the world会发生mark的两个阶段,一个是mark setup开始阶段,另一个就是mark termination收尾阶段。gc在进行到gcMarkTermination时,会stop the world,然后判断是否需要输出gctrace的调试日志。
简单说,这个打印输出的过程是在stop the world里。默认是打印到pts伪终端上,这个过程是纯内存操作,理论是很快的。
但如果在开启gctrace时进行文件重定向,那么他的操作就是文件io操作了。如果这时候你的服务里有大量的磁盘io的操作,本来写page buffer的操作,会触发阻塞flush磁盘。那么这时候go gctrace打印日志是在开启stop the world之后操作的,因为磁盘繁忙,只能是等待磁盘io操作完,这里的stw会影响runtime对其他协程的调度。
|
|
解决方法
线上就不应该长期的去监控gctrace的日志。另外需要把较为频繁的业务日志进行采样输出。前面有说,我们第一个解决方法就修改日志的写入模式,当几千个协程写日志时,不利于磁盘的高效使用和性能,可以借助disruptor做日志缓存,然后由独立的协程来写入日志。
除此之外,还发现一个问题,开始时整个golang进程开了几百个线程,这是由于过多的写操作超过磁盘瓶颈,继而触发了disk io阻塞。这时候golang runtime sysmon检测到syscall超时,继而解绑mp,接着实例化新的m线程进行绑定p。
我们可以想到如果函数gcMarkTermination输出日志放在关闭stop the world后面,这样就不会影响runtime调度。当然,这个在线上重定向go gctrace的问题本来就很奇葩。
参考: https://book.eddycjy.com/golang/tools/godebug-sched.html https://book.eddycjy.com/golang/tools/godebug-gc.html http://xiaorui.cc/2019/12/13/go-gctrace%E6%97%A5%E5%BF%97%E5%BC%95%E8%B5%B7runtime%E8%B0%83%E5%BA%A6%E9%98%BB%E5%A1%9E/ https://colobu.com/2016/04/19/Scheduler-Tracing-In-Go/
文章作者 Forz
上次更新 2020-02-11