Go的Reactor模型的网络框架gnet介绍
文章目录
Go netpoller的问题
Go netpoller 的设计不可谓不精巧、性能也不可谓不高,配合 goroutine 开发网络应用的时候就一个字:爽。因此 Go 的网络编程模式是及其简洁高效的,然而,没有任何一种设计和架构是完美的.
goroutine-per-connection 这种模式虽然简单高效,但是在某些极端的场景下也会暴露出问题:goroutine 虽然非常轻量,它的自定义栈内存初始值仅为 2KB,后面按需扩容;海量连接的业务场景下, goroutine-per-connection ,此时 goroutine 数量以及消耗的资源就会呈线性趋势暴涨.
虽然 Go scheduler 内部做了 g 的缓存链表,可以一定程度上缓解高频创建销毁 goroutine 的压力,但是对于瞬时性暴涨的长连接场景就无能为力了,大量的 goroutines 会被不断创建出来,从而对 Go runtime scheduler 造成极大的调度压力和侵占系统资源,然后资源被侵占又反过来影响 Go scheduler 的调度,进而导致性能下降。
Reactor 网络模型
目前 Linux 平台上主流的高性能网络库/框架中,大都采用 Reactor 模式,比如 netty、libevent、libev、ACE,POE(Perl)、Twisted(Python)等。
Reactor 模式本质上指的是使用 I/O 多路复用(I/O multiplexing) + 非阻塞 I/O(non-blocking I/O) 的模式。
通常设置一个主线程负责做 event-loop 事件循环和 I/O 读写,通过 select/poll/epoll_wait 等系统调用监听 I/O 事件,业务逻辑提交给其他工作线程去做。而所谓『非阻塞 I/O』的核心思想是指避免阻塞在 read() 或者 write() 或者其他的 I/O 系统调用上,这样可以最大限度的复用 event-loop 线程,让一个线程能服务于多个 sockets。在 Reactor 模式中,I/O 线程只能阻塞在 I/O multiplexing 函数上(select/poll/epoll_wait)。
Reactor 模式的基本工作流程如下:
- Server 端完成在 bind&listen 之后,将 listenfd 注册到 epollfd 中,最后进入 event-loop 事件循环。循环过程中会调用 select/poll/epoll_wait 阻塞等待,若有在 listenfd 上的新连接事件则解除阻塞返回,并调用 socket.accept 接收新连接 connfd,并将 connfd 加入到 epollfd 的 I/O 复用(监听)队列。
- 当 connfd 上发生可读/可写事件也会解除 select/poll/epoll_wait 的阻塞等待,然后进行 I/O 读写操作,这里读写 I/O 都是非阻塞 I/O,这样才不会阻塞 event-loop 的下一个循环。然而,这样容易割裂业务逻辑,不易理解和维护。
- 调用 read 读取数据之后进行解码并放入队列中,等待工作线程处理。
- 工作线程处理完数据之后,返回到 event-loop 线程,由这个线程负责调用 write 把数据写回 client。
accept 连接以及 conn 上的读写操作若是在主线程完成,则要求是非阻塞 I/O,因为 Reactor 模式一条最重要的原则就是:I/O 操作不能阻塞 event-loop 事件循环。实际上 event loop 可能也可以是多线程的,只是一个线程里只有一个 select/poll/epoll_wait。
上面提到了 Go netpoller 在某些场景下可能因为创建太多的 goroutine 而过多地消耗系统资源,而在现实世界的网络业务中,服务器持有的海量连接中在极短的时间窗口内只有极少数是 active 而大多数则是 idle,就像这样(非真实数据,仅仅是为了比喻):
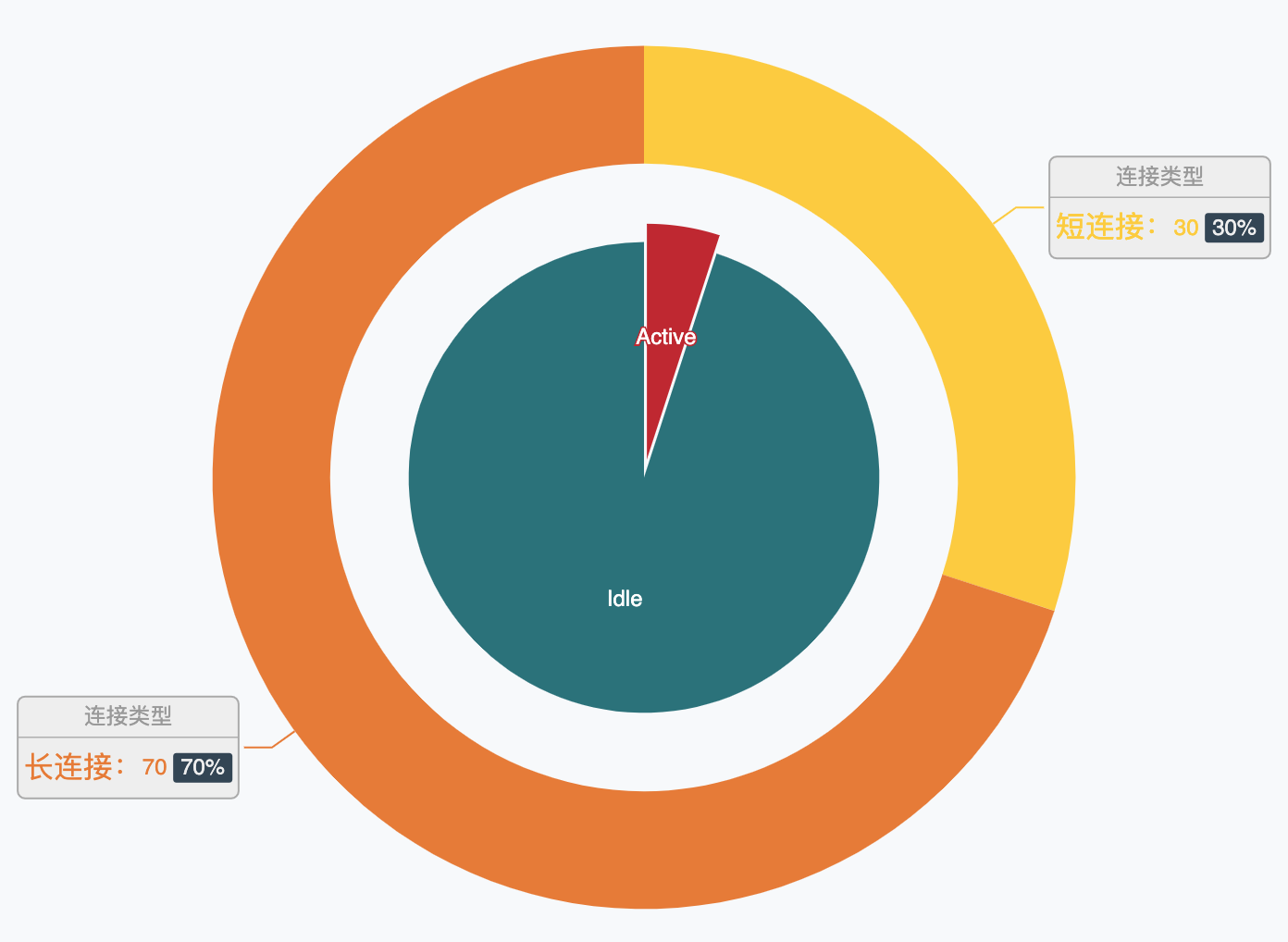
那么为每一个连接指派一个 goroutine 就显得太过奢侈了,而 Reactor 模式这种利用 I/O 多路复用进而只需要使用少量线程即可管理海量连接的设计就可以在这样网络业务中大显身手了:
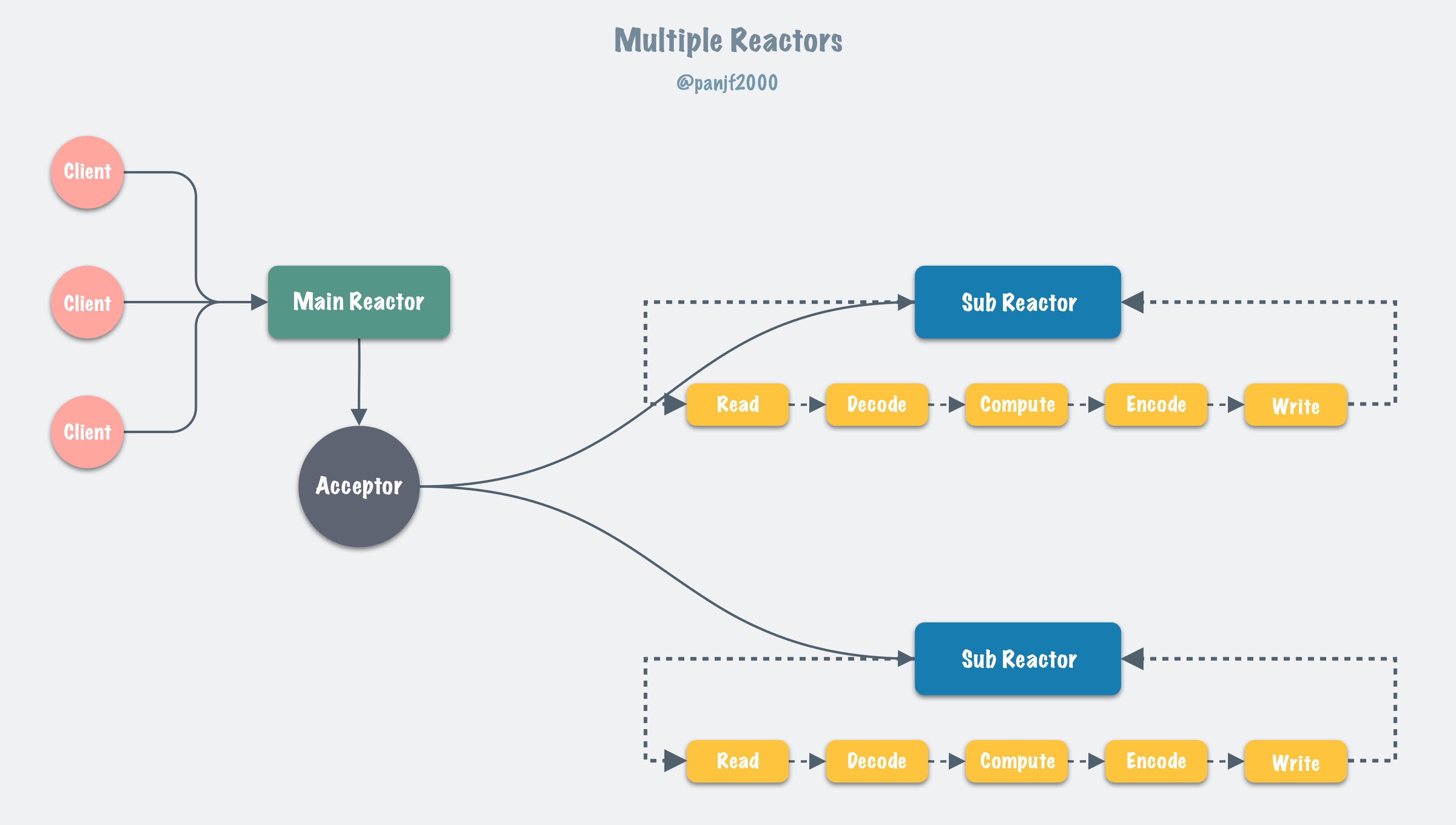
在绝大部分应用场景下,我推荐大家还是遵循 Go 的 best practices,使用原生的 Go 网络库来构建自己的网络应用。然而,在某些极度追求性能、压榨系统资源以及技术栈必须是原生 Go (不考虑 C/C++ 写中间层而 Go 写业务层)的业务场景下,我们可以考虑自己构建 Reactor 网络模型。
文章作者 Forz
上次更新 2021-08-09