设计原理
Go 语言的系统监控起到了很重要的作用,它在内部启动了一个不会中止的循环,在循环的内部会轮询网络、抢占长期运行或者处于系统调用的 Goroutine 以及触发垃圾回收,通过这些行为,它能够让系统的运行状态变得更健康。
Go程序启动时,runtime会去启动一个名为sysmon的m(一般称为监控线程),它自身通过 newm 在一个 M 上独立运行, 自身永远保持在一个循环内直到应用结束。
高优先级,在专有线程中执行 不需要绑定 P 就可以执行

负责:
- 检查是否已经没有活动线程,如果是,则崩溃
- 轮询 netpoll
- 剥离在 syscall 上阻塞的 M 的 P 发信号
- 抢占已经执行时间过⻓的 G
这里需要注意的是,在写网络应用的时候,其实并没有办法检查死锁,因为至少有一个线程等待fd ready事件
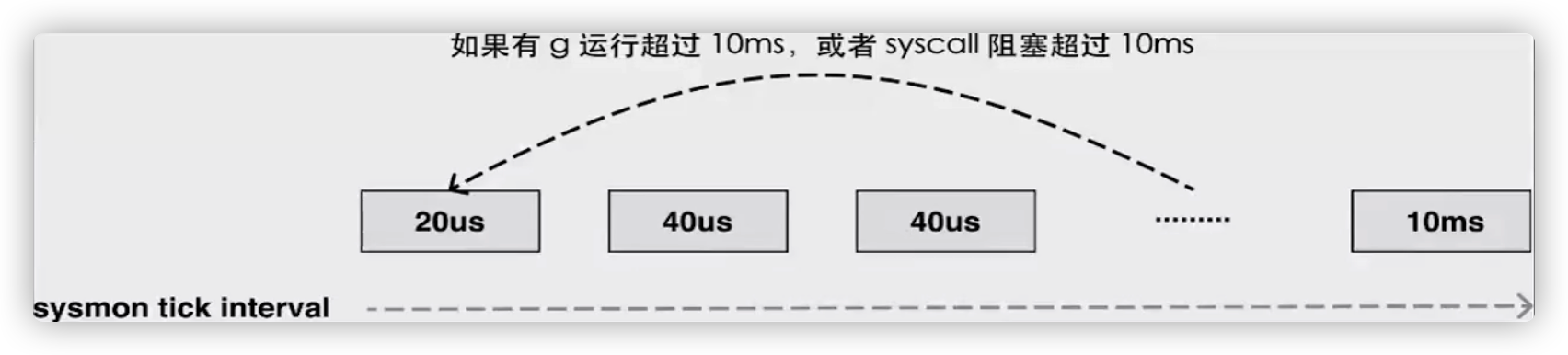
下图为sysmon执行的时间:
sysmon启动
当 Go 语言程序启动时,运行时会在第一个 Goroutine 中调用 runtime.main 启动主程序,该函数会在系统栈中创建新的线程:
1
2
3
4
5
6
7
8
9
10
|
func main() {
...
if GOARCH != "wasm" {
systemstack(func() {
// 创建监控线程,该线程独立于调度器,不需要跟 p 关联即可运行
newm(sysmon, nil)
})
}
...
}
|
runtime.newm 会创建一个存储待执行函数和处理器的新结构体 runtime.m。运行时执行系统监控不需要处理器,系统监控的 Goroutine 会直接在创建的线程上运行:
1
2
3
4
5
6
7
8
9
|
func newm(fn func(), _p_ *p) {
// 创建 m 对象
mp := allocm(_p_, fn)
// 暂存 m
mp.nextp.set(_p_)
mp.sigmask = initSigmask
...
newm1(mp)
}
|
runtime.newm1 会调用特定平台的 runtime.newsproc 通过系统调用 clone 创建一个新的线程并在新的线程中执行 runtime.mstart:
1
2
3
4
5
6
7
8
|
func newosproc(mp *m) {
stk := unsafe.Pointer(mp.g0.stack.hi)
var oset sigset
sigprocmask(_SIG_SETMASK, &sigset_all, &oset)
ret := clone(cloneFlags, stk, unsafe.Pointer(mp), unsafe.Pointer(mp.g0), unsafe.Pointer(funcPC(mstart)))
sigprocmask(_SIG_SETMASK, &oset, nil)
...
}
|
最后执行 mstart 函数,这是在 newosproc 函数传递进来的。mstart 函数再调用 mstart1,在 mstart1 里会执行这一行:
1
2
3
4
|
// 执行启动函数。初始化过程中,fn == nil
if fn := _g_.m.mstartfn; fn != nil {
fn()
}
|
之前我们在讲初始化的时候,这里的 fn 是空,会跳过的。但在这里,fn 就是最开始在 runtime.main 里设置的 sysmon 函数,因此这里会执行 sysmon,而它又是一个无限循环,永不返回。
所以,这里不会执行到 mstart1 函数后面的 schedule 函数,也就不会进入 schedule 循环。因此这是一个不用和 p 结合的 m,它直接在后台执行,默默地执行监控任务。
sysmon
sysmon 中会进行 netpool(获取 fd 事件)、retake(抢占)、forcegc(按时间强制执行 gc),scavenge heap(释放自由列表中多余的项减少内存占用)等处理。
在新创建的线程中,我们会执行存储在 runtime.m 结构体中的 runtime.sysmon 函数启动系统监控:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
|
// Always runs without a P, so write barriers are not allowed.
//
//go:nowritebarrierrec
//首先注意,forcegcperiod是定义在sysmon函数外边的。它的含义是强制执行GC的时间间隔,默认是2分钟。
var forcegcperiod int64 = 2 * 60 * 1e9 //强制GC的时间间隔/2分钟/
func sysmon() {
lock(&sched.lock)
sched.nmsys++
checkdead()
unlock(&sched.lock)
lasttrace := int64(0)
//idle表示最近已连续有多少次系统监测任务执行但未能成功夺取P。一旦某次执行过程中成功夺取P,其值就会清零。
idle := 0 // how many cycles in succession we had not wokeup somebody
//delay表示系统监测任务具体的睡眠时间,单位为微秒。最大值为10000us,即10ms。
delay := uint32(0)
for {
if idle == 0 { // start with 20us sleep...
delay = 20
} else if idle > 50 { // start doubling the sleep after 1ms...
delay *= 2
}
if delay > 10*1000 { // up to 10ms
delay = 10 * 1000
}
usleep(delay)
now := nanotime()
next, _ := timeSleepUntil()
//STW时休眠sysmon
if debug.schedtrace <= 0 && (sched.gcwaiting != 0 || atomic.Load(&sched.npidle) == uint32(gomaxprocs)) {
lock(&sched.lock)
//如果发现有串行运行时任务等待执行,或所有P都已空闲,也就是没活干了,那么就继续睡。
if atomic.Load(&sched.gcwaiting) != 0 || atomic.Load(&sched.npidle) == uint32(gomaxprocs) {
if next > now {
//设置休眠标志,休眠(有个超时,苏醒保障)
//睡之前将调度器的sysmonwait字段设置为1,表示系统监测任务已停止。
atomic.Store(&sched.sysmonwait, 1)
unlock(&sched.lock)
// Make wake-up period small enough
// for the sampling to be correct.
//这次睡的时间是forcegcperiod和scavengelimit中较小值的一半。
//也就是说,是强制GC时间间隔和清扫堆时间间隔中较短时间间隔的一半。
sleep := forcegcperiod / 2
if next-now < sleep {
sleep = next - now
}
shouldRelax := sleep >= osRelaxMinNS
if shouldRelax {
osRelax(true)
}
//runtime.notesleep 会使用信号量同步系统监控即将进入休眠的状态。
notetsleep(&sched.sysmonnote, sleep)
if shouldRelax {
osRelax(false)
}
now = nanotime()
next, _ = timeSleepUntil()
lock(&sched.lock)
//睡完之后调度器的sysmonwait字段要清零
atomic.Store(&sched.sysmonwait, 0)
//调用 runtime.noteclear 通知系统监控被唤醒并重置休眠的间隔。
noteclear(&sched.sysmonnote)
}
//把idle清零,并将delay设为初始值20。
idle = 0
delay = 20
}
unlock(&sched.lock)
}
lock(&sched.sysmonlock)
{
// If we spent a long time blocked on sysmonlock
// then we want to update now and next since it's
// likely stale.
now1 := nanotime()
if now1-now > 50*1000 /* 50µs */ {
next, _ = timeSleepUntil()
}
now = now1
}
// trigger libc interceptors if needed
// 需要时触发 libc interceptor
if *cgo_yield != nil {
asmcgocall(*cgo_yield, nil)
}
//接下来就是抢夺P和G的过程。
//首先如果网络I/O轮询器已经初始化,并且距上次通过网络轮询器获取G的时间已超过10ms,那么就记录此次获取的时间并通过网络I/O轮询器获取一个可运行G,否则跳过此步。
// poll network if not polled for more than 10ms
//从网络I/O轮询器获取一个可运行G
//上次从网络轮询器获取G的时间
lastpoll := int64(atomic.Load64(&sched.lastpoll))
//获取超过10ms的netpoll结果
if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now {
//更新调度器的lastpoll值
atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now))
// 非阻塞 - 返回一个goroutine列表
list := netpoll(0) // non-blocking - returns list of goroutines
if !list.empty() {
// Need to decrement number of idle locked M's
// (pretending that one more is running) before injectglist.
// Otherwise it can lead to the following situation:
// injectglist grabs all P's but before it starts M's to run the P's,
// another M returns from syscall, finishes running its G,
// observes that there is no work to do and no other running M's
// and reports deadlock.
//incidlelocked是”inc idle locked “这三个单词组合而成,意思是增加因锁定而空闲的M的数量。这个数量其实是调度器的nmidlelocked字段
//在通过网络轮询器获得G之后,将这些G放入调度器的全局G队列前后两次调用incidlelocked函数到底有什么用呢?
//想象一下,如果在injectglist函数在完成它的工作之前,某个M从系统调用返回并执行完了它的G,此时它掐指一算,系统中没有工作可做了,也没有运行的M了,于是死锁就发生了。然而这时的injectglist函数就是有冤无处述,有苦说不出了。就因为送货(G)慢了点,人家就关门了,也不等等它。所以现在你应该知道了incidlelockd(-1)的作用就是为了避免这种死锁的情况。将nmidlelocked减一后,run的值怎么都是大于等于1,不会小于0。从而避免从网络轮询器获得的G在运行之前发生死锁。也就是说假装还有一个M在运行,但是真实的情况肯定不是这样,所以等到injectglist函数完成它的工作后,就要再次调用incidlelocked(1)来恢复系统真实的样子。
incidlelocked(-1)
//它会把G都加入到调度器的可运行G队列,并启动一个空闲的P来运行G。
injectglist(&list)
incidlelocked(1)
}
}
//如果在这之后,我们发现下一个计时器需要触发的时间小于当前时间,这也就说明所有的线程可能正在忙于运行 Goroutine,系统监控会启动新的线程来触发计时器,避免计时器的到期时间有较大的偏差。
if next < now {
// There are timers that should have already run,
// perhaps because there is an unpreemptible P.
// Try to start an M to run them.
startm(nil, false)
}
if atomic.Load(&scavenge.sysmonWake) != 0 {
// Kick the scavenger awake if someone requested it.
wakeScavenger()
}
// retake P's blocked in syscalls
// and preempt long running G's
//其次是从调度器那里抢夺符合条件的P和G,这一步由retake函数完成,抢夺成功则idle会清零,失败则idle自加一.
//抢夺syscall长时间阻塞的P
//向长时间运行的G发出抢占调度
//从调度器那里抢夺符合条件的P和G
if retake(now) != 0 {
idle = 0
} else {
idle++
}
// check if we need to force a GC
//在最后,系统监控还会决定是否需要触发强制垃圾回收,runtime.sysmon 会构建 runtime.gcTrigger 结构体并调用 runtime.gcTrigger.test 函数判断是否需要触发垃圾回收
//如果当前GC未执行,且距上一次执行已超过GC最大时间间隔,系统监测程序就会恢复专用于强制GC的G,并把它放入调度器的可运行G队列。GC最大时间间隔就是forcegcperiod的值,初始值为2分钟,
//用于强制GC的G是一个专用G,它在调度器初始化时就开始运行了,只不过一般处于暂停状态,只有系统监测程序可以恢复它。
if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && atomic.Load(&forcegc.idle) != 0 {
lock(&forcegc.lock)
forcegc.idle = 0
var list gList
list.push(forcegc.g)
injectglist(&list)
//forcegc就是强制GC的专用G。它在runtime2.go中定义,类型是forcegcstate。
//forcegcstate是一个结构体类型,其中封装了一个G。
unlock(&forcegc.lock)
}
//如果程序运行之前设置了GODEBUG环境变量,并且包含schedtrace=x,那么系统监测程序就会每过x毫秒打印一次调度器跟踪信息。这的x就是打印周期。
if debug.schedtrace > 0 && lasttrace+int64(debug.schedtrace)*1000000 <= now {
lasttrace = now
schedtrace(debug.scheddetail > 0)
}
unlock(&sched.sysmonlock)
}
}
|
当运行时刚刚调用上述函数时,会先通过 runtime.checkdead 检查是否存在死锁,然后进入核心的监控循环;系统监控在每次循环开始时都会通过 usleep 挂起当前线程,该函数的参数是微秒,运行时会遵循以下的规则决定休眠时间:
- 初始的休眠时间是 20μs;
- 最长的休眠时间是 10ms;
- 当系统监控在 50 个循环中都没有唤醒 Goroutine 时,休眠时间在每个循环都会倍增;
当程序趋于稳定之后,系统监控的触发时间就会稳定在 10ms。它除了会检查死锁之外,还会在循环中完成以下的工作:
- 运行计时器 — 获取下一个需要被触发的计时器;
- 轮询网络 — 获取需要处理的到期文件描述符;
- 抢占处理器 — 抢占运行时间较长的或者处于系统调用的 Goroutine;
- 垃圾回收 — 在满足条件时触发垃圾收集回收内存;
我们在这一节中会依次介绍系统监控是如何处理五种不同工作的。
checkdead
系统监控通过 runtime.checkdead 检查运行时是否发生了死锁,我们可以将检查死锁的过程分成以下三个步骤:
- 检查是否存在正在运行的线程;
- 检查是否存在正在运行的 Goroutine;
- 检查处理器上是否存在计时器;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
|
// Check for deadlock situation.
// The check is based on number of running M's, if 0 -> deadlock.
// sched.lock must be held.
func checkdead() {
// For -buildmode=c-shared or -buildmode=c-archive it's OK if
// there are no running goroutines. The calling program is
// assumed to be running.
if islibrary || isarchive {
return
}
// If we are dying because of a signal caught on an already idle thread,
// freezetheworld will cause all running threads to block.
// And runtime will essentially enter into deadlock state,
// except that there is a thread that will call exit soon.
if panicking > 0 {
return
}
// If we are not running under cgo, but we have an extra M then account
// for it. (It is possible to have an extra M on Windows without cgo to
// accommodate callbacks created by syscall.NewCallback. See issue #6751
// for details.)
var run0 int32
if !iscgo && cgoHasExtraM {
mp := lockextra(true)
haveExtraM := extraMCount > 0
unlockextra(mp)
if haveExtraM {
run0 = 1
}
}
//首先会检查 Go 语言运行时中正在运行的线程数量,我们通过调度器中的多个字段计算该值的结果:
//1. runtime.mcount返回的是目前系统中存在的M的数量:根据下一个待创建的线程 id 和释放的线程数得到系统中存在的线程数;
//2. nmidle 是处于空闲状态的线程数量;
//3. nmidlelocked 是处于锁定状态的线程数量;
//4. nmsys 是处于系统调用的线程数量;
//run代表的就是还在运行的M的数量。如果线程数量大于 0,说明当前程序不存在死锁;如果线程数小于 0,说明当前程序的状态不一致;如果线程数等于 0,我们需要进一步检查程序的运行状态
run := mcount() - sched.nmidle - sched.nmidlelocked - sched.nmsys
if run > run0 {
return
}
if run < 0 {
print("runtime: checkdead: nmidle=", sched.nmidle, " nmidlelocked=", sched.nmidlelocked, " mcount=", mcount(), " nmsys=", sched.nmsys, "\n")
throw("checkdead: inconsistent counts")
}
//当存在 Goroutine 处于 _Grunnable、_Grunning 和 _Gsyscall 状态时,意味着程序发生了死锁;
//当所有的 Goroutine 都处于 _Gidle、_Gdead 和 _Gcopystack 状态时,意味着主程序调用了 runtime.goexit;
grunning := 0
lock(&allglock)
for i := 0; i < len(allgs); i++ {
gp := allgs[i]
if isSystemGoroutine(gp, false) {
continue
}
s := readgstatus(gp)
switch s &^ _Gscan {
case _Gwaiting,
_Gpreempted:
grunning++
case _Grunnable,
_Grunning,
_Gsyscall:
unlock(&allglock)
print("runtime: checkdead: find g ", gp.goid, " in status ", s, "\n")
throw("checkdead: runnable g")
}
}
unlock(&allglock)
if grunning == 0 { // possible if main goroutine calls runtime·Goexit()
unlock(&sched.lock) // unlock so that GODEBUG=scheddetail=1 doesn't hang
throw("no goroutines (main called runtime.Goexit) - deadlock!")
}
// Maybe jump time forward for playground.
if faketime != 0 {
when, _p_ := timeSleepUntil()
if _p_ != nil {
faketime = when
for pp := &sched.pidle; *pp != 0; pp = &(*pp).ptr().link {
if (*pp).ptr() == _p_ {
*pp = _p_.link
break
}
}
mp := mget()
if mp == nil {
// There should always be a free M since
// nothing is running.
throw("checkdead: no m for timer")
}
mp.nextp.set(_p_)
notewakeup(&mp.park)
return
}
}
//当运行时存在等待的 Goroutine 并且不存在正在运行的 Goroutine 时,我们会检查处理器中存在的计时器:
//如果处理器中存在等待的计时器,那么所有的 Goroutine 陷入休眠状态是合理的,不过如果不存在等待的计时器,运行时就会直接报错并退出程序。
// There are no goroutines running, so we can look at the P's.
for _, _p_ := range allp {
if len(_p_.timers) > 0 {
return
}
}
getg().m.throwing = -1 // do not dump full stacks
unlock(&sched.lock) // unlock so that GODEBUG=scheddetail=1 doesn't hang
throw("all goroutines are asleep - deadlock!")
}
|
incidlelocked
incidlelocked函数十分简单,它就做了两件事:
- 将参数加到调度器的nmidlelocked字段上
- 如果参数大于0,就调用checkdead函数检查是否发生死锁。
1
2
3
4
5
6
7
8
|
func incidlelocked(v int32) {
lock(&sched.lock)//加锁
sched.nmidlelocked += v
if v > 0 {
checkdead()//检查死锁
}
unlock(&sched.lock)//解锁
}
|
那么为什么只在参数大于0的情况下才去检查死锁呢?因为参数大于0时,nmidlelocked值会增大,这时就有可能使run的值变成负数。也就是说这个M的锁定可能使系统中没有运行的M而发生死锁,当然有必要查看一下是否发生了死锁。如果incidlelocked函数的参数小于0,那么nmidlelocked的值会变小,而run的值只会更大,如果run本来就大于0,那么更不可能因此而发生死锁了,当然也就没必要检查了。
injectglist
injectglist函数会非阻塞地调用 runtime.netpoll 检查待执行的文件描述符并通过 runtime.injectglist 将所有处于就绪状态的 Goroutine 加入全局运行队列中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
func injectglist(glist *gList) {
if glist.empty() {
return
}
lock(&sched.lock)
var n int
for n = 0; !glist.empty(); n++ {
gp := glist.pop()
casgstatus(gp, _Gwaiting, _Grunnable)
globrunqput(gp)
}
unlock(&sched.lock)
for ; n != 0 && sched.npidle != 0; n-- {
startm(nil, false)
}
*glist = gList{}
}
|
该函数会将所有 Goroutine 的状态从 _Gwaiting 切换至_Grunnable 并加入全局运行队列等待运行,如果当前程序中存在空闲的处理器,就会通过 runtime.startm 函数启动线程来执行这些任务。
retake
系统监控通过在循环中抢占处理器来避免同一个 Goroutine 占用线程太长时间造成饥饿问题。
系统监控在循环中调用 runtime.retake 函数抢占处于运行或者系统调用中的处理器,该函数会遍历运行时的全局处理器,
runtime.retake 中的循环包含了两种不同的抢占逻辑:
- 当处理器处于 Prunning 或 Psyscall 状态时,如果上一次触发调度的时间已经过去了 10ms,我们就会通过 runtime.preemptone 抢占当前处理器;
- 当处理器处于 _Psyscall 状态时,在满足以下两种情况下会调用 runtime.handoffp 让出处理器的使用权:
- P的可运行G队列不为空.
- 没有自旋的M或者有休息的P.
- 距离上一次系统调用的时间超过10ms.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
|
func retake(now int64) uint32 {
// 在retake函数开始处,首先初始化了一个变量n := 0,它用来记录成功抢夺到P的次数
// 而最后retake函数的返回值也是这个n,所以在sysmon函数中我们能够用retake函数的返回值是否大于0来判断抢夺P是否成功。
n := 0
// Prevent allp slice changes. This lock will be completely
// uncontended unless we're already stopping the world.
// 防止 allp 数组发生变化,除非我们已经 STW,此锁将完全没有人竞争
lock(&allpLock)
// We can't use a range loop over allp because we may
// temporarily drop the allpLock. Hence, we need to re-fetch
// allp each time around the loop.
//接下来是对全局P列表中所有P进行迭代,并在可以抢夺的时候将P抢过来。不过在这之前,首先要初始化一些变量。
for i := 0; i < len(allp); i++ {
_p_ := allp[i]
//为什么从全局P列表取出的P还要进行为空判断呢?这是为了防止此时调用了procresize函数增加了P的最大数量,虽然数量已经涨上去了,但实际上P还没有被创建出来,导致获取的P为空。
if _p_ == nil {
// This can happen if procresize has grown
// allp but not yet created new Ps.
continue
}
// 用于 sysmon 线程记录被监控 p 的系统调用时间和运行时间
pd := &_p_.sysmontick
// p 的状态
s := _p_.status
sysretake := false
if s == _Prunning || s == _Psyscall {
// 如果 G 运行时时间太长则进行抢占
// Preempt G if it's running for too long.
// 每发生一次调度,调度器 ++ 该值
t := int64(_p_.schedtick)
//pd.schedtick == t 说明(pd.schedwhen ~ now)这段时间未发生过调度
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
//如果没超过10ms,则忽略
//forcepreemptNS,它是有” force preempt NS “组成,意思是强制抢占P的纳秒数,NS是单位,纳秒。它在retake函数外面定义,是一个常量。这一步是说距上次系统调用的时间间隔不足强制抢占P的时间间隔,就放弃抢占P。换句话说,当这个条件不满足时,说明这个P(准确的说是这个P当前运行的G)已经运行太长时间了,应该把它停止,并把运行机会让给其他G,以保证公平。
// 这段时间是同一个goroutine一直在运行,检查是否连续运行超过了 10 毫秒
// 连续运行超过 10 毫秒了,发起抢占请求
// 对于 syscall 的情况,因为 M 没有与 P 绑定,
// preemptone() 不工作
preemptone(_p_)
// In case of syscall, preemptone() doesn't
// work, because there is no M wired to P.
sysretake = true
}
}
// 对阻塞在系统调用上的 P 进行抢占
if s == _Psyscall {
// Retake P from syscall if it's there for more than 1 sysmon tick (at least 20us).
//第一小步:判断当前P的系统调用计数和备份的系统调用计数是否相等。如果相等就继续后面的小步骤,如果不相等,要更新备份,并更新最近一次系统调用的时刻。
t := int64(_p_.syscalltick)
// _p_.syscalltick 用于记录系统调用的次数,在完成系统调用之后加 1
if !sysretake && int64(pd.syscalltick) != t {
// pd.syscalltick != _p_.syscalltick,说明已经不是上次观察到的系统调用了,
// 而是另外一次系统调用,所以需要重新记录 tick 和 when 值
pd.syscalltick = uint32(t)
pd.syscallwhen = now
continue
}
//这个条件中用到的上次系统调用时间正是备份中的syscallwhen字段,因为如果P的系统调用计数和备份中的不同步,说明在此次系统调用之前,已经有人捷足先登进行过系统调用了,那么最新的系统调用的时间也就必定不是备份中syscallwhen字段记录的时刻,这就会导致这里我们用备份中的syscallwhen字段来判断距离上次系统调用的时间间隔是否大于10ms是不准确的。
//所以在第一小步中一旦发现P的系统调用计数和备份中的不同步,就应该更新备份,并且忽略后面的步骤。
// On the one hand we don't want to retake Ps if there is no other work to do,
// but on the other hand we want to retake them eventually
// because they can prevent the sysmon thread from deep sleep.
//检查是否有其他任务需要P,是否超出时间限制,是否有必要抢夺P
// 一方面,在没有其他 work 的情况下,我们不希望抢夺 P
// 另一方面,因为它可能阻止 sysmon 线程从深度睡眠中唤醒,所以最终我们仍希望抢夺 P
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
// Drop allpLock so we can take sched.lock.
// 解除 allpLock,从而可以获取 sched.lock
unlock(&allpLock)
//抢夺P的过程就是将P转手。
//抢夺过程包裹在incidlelocked函数调用之间。然后要将P的状态转换为空闲状态(Pidle),并自增记录成功抢夺P次数的变量n以及P系统调用计数,最后通过handoffp函数转手这个P。
// 在 CAS 之前需要减少空闲 M 的数量(假装某个还在运行)
// 否则发生抢夺的 M 可能退出 syscall 然后再增加 nmidle ,进而发生死锁
// 这个过程发生在 stoplockedm 中
// Need to decrement number of idle locked M's
// (pretending that one more is running) before the CAS.
// Otherwise the M from which we retake can exit the syscall,
// increment nmidle and report deadlock.
incidlelocked(-1)
//抢夺P
// 将 P 设为 idle,从而交于其他 M 使用
if atomic.Cas(&_p_.status, s, _Pidle) {
if trace.enabled {
traceGoSysBlock(_p_)
traceProcStop(_p_)
}
n++
_p_.syscalltick++
// 寻找一新的 m 接管 p
handoffp(_p_)
}
incidlelocked(1)
lock(&allpLock)
}
}
unlock(&allpLock)
return uint32(n)
}
|
抢占进行系统调用的 P
我们先来看抢占阻塞在系统调用上的 G 这种情况。这种抢占的实现方法非常的自然,因为 Goroutine 已经阻塞在了系统调用上,我们可以非常安全的将 M 与 P 进行解绑,即便是 Goroutine 从阻塞中恢复,也会检查自身所在的 M 是否仍然持有 P,如果没有 P 则重新考虑 与可用的 P 进行绑定。这种异步抢占的本质是:抢占 P。
当 P 处于 _Psyscall 状态时,表明对应的 goroutine 正在进行系统调用。如果抢占 p,需要满足几个条件:
- p 的本地运行队列里面有等待运行的 goroutine。这时 p 绑定的 g 正在进行系统调用,无法去执行其他的 g,因此需要接管 p 来执行其他的 g。
- 没有“无所事事”的 p。sched.nmspinning 和 sched.npidle 都为 0,这就意味着没有“找工作”的 m,也没有空闲的 p,大家都在“忙”,可能有很多工作要做。因此要抢占当前的 p,让它来承担一部分工作。
- 从上一次监控线程观察到 p 对应的 m 处于系统调用之中到现在已经超过 10 毫秒。这说明系统调用所花费的时间较长,需要对其进行抢占,以此来使得 retake 函数返回值不为 0,这样,会保持 sysmon 线程 20 us 的检查周期,提高 sysmon 监控的实时性。
注意,原代码是用的三个与条件,三者都要满足才会执行下面的 continue,也就是不进行抢占。因此要想进行抢占的话,只需要三个条件有一个不满足就行了。于是就有了上述三种情况。
确定要抢占当前 p 后,先使用原子操作将 p 的状态修改为 _Pidle,最后调用 handoffp 进行抢占。
handoffp 再次进行场景判断,以调用 startm 启动一个工作线程来绑定 p,使得整体工作继续推进。
在抢占 P 的过程中,有两个非常小心的处理方式:
- 如果此时队列为空,那么完全没有必要进行抢占,这时候似乎可以继续遍历其他的 P, 但必须在调度器中自旋的 M 和 空闲的 P 同时存在时、且系统调用阻塞时间非常长的情况下 才能这么做。否则,这个 retake 过程可能返回 0,进而系统监控可能看起来像是什么事情 也没做的情况下调整自己的步调进入深度睡眠。
- 在将 P 设置为空闲状态前,必须先将 M 的数量减少,否则当 M 退出系统调用时, 会在 exitsyscall0 中调用 stoplockedm 从而增加空闲 M 的数量,进而发生死锁。
抢占长时间运行的M
在检查 P 的状态时,P 如果是运行状态会调用 preemptone,来通过系统信号来完成抢占.之所以没有在之前提及的原因在于该调用 在 M 不与 P 绑定的情况下是不起任何作用直接返回的。这种异步抢占的本质是:抢占 M。
接下来我们就来分析当 P 处于 _Prunning 状态的情况。sysmon 扫描每个 p 时,都会记录下当前调度器调度的次数和当前时间,数据记录在结构体:
1
2
3
4
5
6
|
type sysmontick struct {
schedtick uint32//调度计数
schedwhen int64//调度时刻
syscalltick uint32//系统调用计数
syscallwhen int64//系统调用时刻
}
|
前面两个字段记录调度器调度的次数和时间,后面两个字段记录系统调用的次数和时间。
其实sysmontick结构中的syscalltick字段和syscallwhen字段在P结构体中也有,那么为什么这里还要重复存一份呢?目的就是为了备份,当发现sysmontick中的syscalltick值与P中的不一样是,就说明新的系统调用发生了,此时就可以更新syscallwhen字段为当前时间,记录下此次系统调用的时刻了。
在下一次扫描时,对比 sysmon 记录下的 p 的调度次数和时间,与当前 p 自己记录下的调度次数和时间对比,如果一致。说明 P 在这一段时间内一直在运行同一个 goroutine。那就来计算一下运行时间是否太长了。
如果发现运行时间超过了 10 ms,则要调用 preemptone(_p_) 发起抢占的请求
参考
地鼠宝宝的秩事异闻之调度器
6.7 系统监控
sysmon 后台监控线程做了什么