设计原理
栈区的内存一般由编译器自动进行分配和释放,其中存储着函数的入参以及局部变量,这些参数会随着函数的创建而创建,函数的返回而消亡,一般不会在程序中长期存在,这种线性的内存分配策略有着极高地效率,但是工程师也往往不能控制栈内存的分配,这部分工作基本都是由编译器自动完成的。
寄存器
寄存器是中央处理器(CPU)中的稀缺资源,它的存储能力非常有限,但是能提供最快的读写速度,充分利用寄存器的效率可以构建高性能的应用程序。寄存器在物理机上非常有限,然而栈区的操作就会使用到两个以上的寄存器,这足以说明栈内存在应用程序的重要性。
栈寄存器在是 CPU 寄存器中的一种,它的主要作用是跟踪函数的调用栈,Go 语言的汇编代码中包含 BP 和 SP 两个栈寄存器,它们分别存储了栈的基址指针和栈顶的地址,栈内存与函数调用的关系非常紧密,BP 和 SP 之间的内存就是当前函数的调用栈。
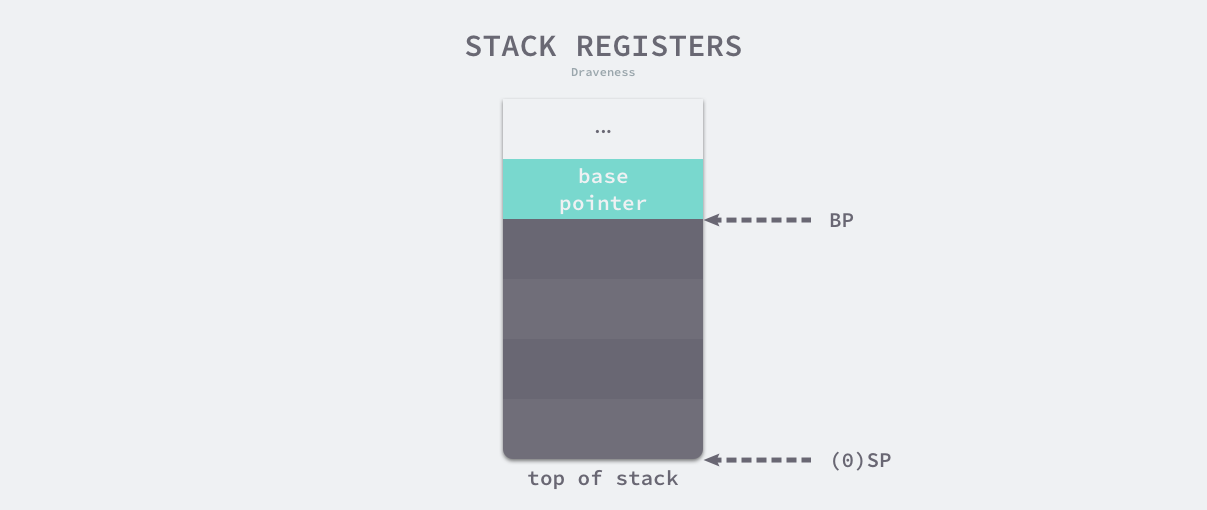
由于历史的设计问题,目前的栈区内存都是从高地址向低地址扩展的,当应用程序申请或者释放栈内存时只需要修改 SP 寄存器的值,这种线性的内存分配方式与堆内存相比更加快速,占用极少的额外开销。
线程栈
如果我们在 Linux 操作系统中执行 pthread_create 系统调用,进程会启动一个新的线程,如果用户没有通过软资源限制 RLIMIT_STACK 指定线程栈的大小,那么操作系统会根据架构选择不同的默认栈大小。
| 架构 |
默认栈大小 |
| i386 |
2 MB |
| IA-64 |
32 MB |
| PowerPC |
4 MB |
| … |
… |
| x86_64 |
2 MB |
多数架构上默认栈大小都在 2 ~ 4 MB 左右,极少数架构会使用 32 MB 作为默认大小,用户程序可以在分配的栈上存储函数参数和局部变量。然而这个固定的栈大小在某些场景下可能不是一个合适的值,如果一个程序需要同时运行几百个甚至上千个线程,那么这些线程中的绝大部分都只会用到很少的栈空间,而如果函数的调用栈非常深,固定的栈大小也无法满足用户程序的需求。
线程和进程都是代码执行的上下文(Context of Execution),但是如果一个应用程序中包含成百上千个执行上下文并且每个上下文都是线程,就会占用大量的内存空间并带来其他的额外开销,Go 语言在设计时认为执行上下文应该是轻量级的,所以在它实现了用户级的 Goroutine 作为执行上下文。
栈内存空间
Go 语言使用用户态线程 Goroutine 作为执行上下文,它的额外开销和默认栈大小都比线程小很多,然而 Goroutine 的栈内存空间和栈结构也在早期几个版本中发生过一些变化:
- v1.0 ~ v1.1 — 最小栈内存空间为 4KB;
- v1.2 — 将最小栈内存提升到了 8KB;
- v1.3 — 使用连续栈替换之前版本的分段栈;
- v1.4 — 将最小栈内存降低到了 2KB;
Goroutine 的初始栈内存在最初的几个版本中多次修改,从 4KB 提升到 8KB 是临时的解决方案,其目的是为了减轻分段栈的栈分裂问题对程序造成的性能影响;在 v1.3 版本引入连续栈之后,Goroutine 的初始栈大小降低到了 2KB,进一步减少了 Goroutine 占用的内存空间。
分段栈
分段栈是 Go 语言在 v1.3 版本之前的实现,所有 Goroutine 在初始化时都会调用 runtime.stackalloc#go1.2 分配一块固定大小的内存空间,这块内存的大小由 StackMin#go1.2 表示,在 v1.2 版本中为 8KB:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
void*runtime·stackalloc(uint32 n) {
uint32 pos;
void*v;
if(n == FixedStack || m->mallocing || m->gcing) {
if(m->stackcachecnt == 0)
stackcacherefill();
pos = m->stackcachepos;
pos = (pos - 1) % StackCacheSize;
v = m->stackcache[pos];
m->stackcachepos = pos;
m->stackcachecnt--;
m->stackinuse++;
return v;
}
return runtime·mallocgc(n, 0, FlagNoProfiling|FlagNoGC|FlagNoZero|FlagNoInvokeGC);
}
|
如果通过该方法申请的内存大小为固定的 8KB 或者满足其他的条件,运行时会在全局的栈缓存链表中找到空闲的内存块并作为新 Goroutine 的栈空间返回;在其余情况下,栈内存空间会从堆上申请一块合适的内存。
当 Goroutine 调用的函数层级或者局部变量需要的越来越多时,运行时会调用 runtime.morestack#go1.2 和 runtime.newstack#go1.2 创建一个新的栈空间,这些栈空间虽然不连续,但是当前 Goroutine 的多个栈空间会以链表的形式串联起来,运行时会通过指针找到连续的栈片段:
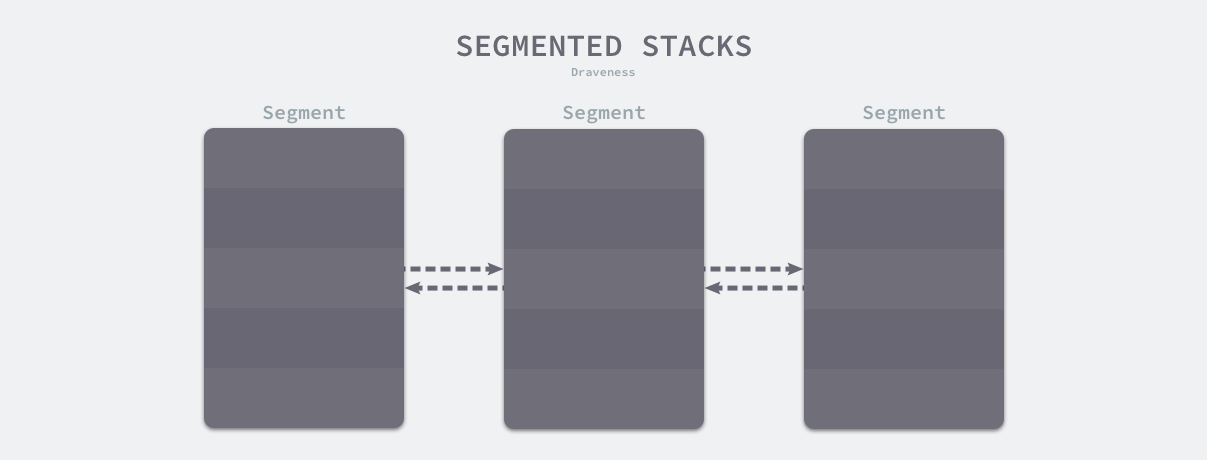
一旦 Goroutine 申请的栈空间不再被需要,运行时会调用 runtime.lessstack#go1.2 和 runtime.oldstack#go1.2 释放不再使用的内存空间。
分段栈机制虽然能够按需为当前 Goroutine 分配内存并且及时减少内存的占用,但是它也存在两个比较大的问题:
- 如果当前 Goroutine 的栈几乎充满,那么任意的函数调用都会触发栈的扩容,当函数返回后又会触发栈的收缩,如果在一个循环中调用函数,栈的分配和释放就会造成巨大的额外开销,这被称为热分裂问题(Hot split);
- 一旦 Goroutine 使用的内存越过了分段栈的扩缩容阈值,运行时就会触发栈的扩容和缩容,带来额外的工作量;
连续栈
连续栈可以解决分段栈中存在的两个问题,其核心原理就是每当程序的栈空间不足时,初始化一片更大的栈空间并将原栈中的所有值都迁移到新的栈中,新的局部变量或者函数调用就有了充足的内存空间。使用连续栈机制时,栈空间不足导致的扩容会经历以下几个步骤:
- 在内存空间中分配更大的栈内存空间;
- 将旧栈中的所有内容复制到新的栈中;
- 将指向旧栈对应变量的指针重新指向新栈;
- 销毁并回收旧栈的内存空间;
在扩容的过程中,最重要的是调整指针的第三步,这一步能够保证指向栈的指针的正确性,因为栈中的所有变量内存都会发生变化,所以原本指向栈中变量的指针也需要调整。我们在前面提到过经过逃逸分析的 Go 语言程序的遵循以下不变性 —— 指向栈对象的指针不能存在于堆中,所以指向栈中变量的指针只能在栈上,我们只需要调整栈中的所有变量就可以保证内存的安全了。
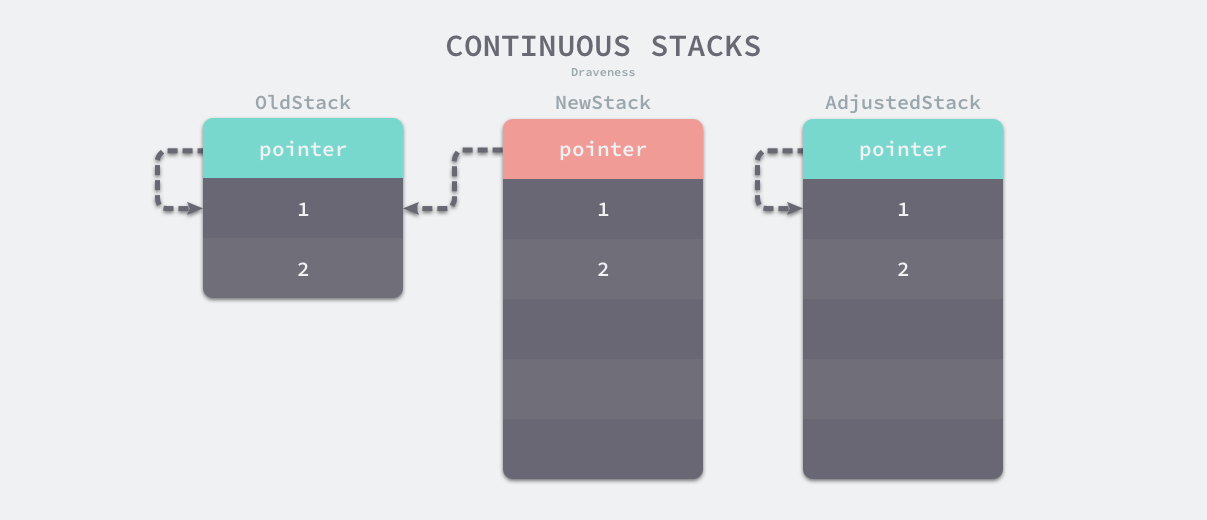
因为需要拷贝变量和调整指针,连续栈增加了栈扩容时的额外开销,但是通过合理栈缩容机制就能避免热分裂带来的性能问题,在 GC 期间如果 Goroutine 使用了栈内存的四分之一,那就将其内存减少一半,这样在栈内存几乎充满时也只会扩容一次,不会因为函数调用频繁扩缩容。
协程栈
Go 语言中的执行栈由 runtime.stack 结构体表示,该结构体中只包含两个字段,分别表示栈的顶部和栈的底部,每个栈结构体都表示范围 [lo, hi) 的内存空间:
1
2
3
4
|
type stack struct {
lo uintptr
hi uintptr
}
|
每个goroutine都维护着自己的栈区,栈结构是连续栈,是一块连续的内存,在goroutine的类型定义的源码里我们可以找到标记着栈区边界的stack信息,stack里记录着栈区边界的高位内存地址和低位内存地址:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
type g struct {
// Stack parameters.
// stack describes the actual stack memory: [stack.lo, stack.hi).
// stackguard0 is the stack pointer compared in the Go stack growth prologue.
// It is stack.lo+StackGuard normally, but can be StackPreempt to trigger a preemption.
// stackguard1 is the stack pointer compared in the C stack growth prologue.
// It is stack.lo+StackGuard on g0 and gsignal stacks.
// It is ~0 on other goroutine stacks, to trigger a call to morestackc (and crash).
stack stack // offset known to runtime/cgo
// stackguard0 用于跟函数的 sp 进行比较,通常等于 stack.lo+StackGuard,但是在需要触发抢占调度时,会被赋值为 StackPreempt
stackguard0 uintptr // offset known to liblink
// stackguard1 用于跟系统线程的 sp 进行比较,在 g0 和 gsignal 上等于 stack.lo+StackGuard,在其他 goroutine 上等于 ~0,用于触发栈扩容和崩溃
stackguard1 uintptr // offset known to liblink
......
}
|
栈的结构虽然非常简单,但是想要理解 Goroutine 栈的实现原理,还是需要我们从编译期间和运行时两个阶段入手:
-
编译器会在编译阶段会通过 cmd/internal/obj/x86.stacksplit 在调用函数前插入 runtime.morestack 或者 runtime.morestack_noctxt 函数;
-
运行时在创建新的 Goroutine 时会在 runtime.malg 函数中调用 runtime.stackalloc 申请新的栈内存,并在编译器插入的 runtime.morestack 中检查栈空间是否充足;
需要注意的是,Go 语言的编译器不会为所有的函数插入 runtime.morestack,它只会在必要时插入指令以减少运行时的额外开销,编译指令 nosplit 可以跳过栈溢出的检查,虽然这能降低一些开销,不过固定大小的栈也存在溢出的风险。本节将分别分析栈的初始化、创建 Goroutine 时栈的分配、编译器和运行时协作完成的栈扩容以及当栈空间利用率不足时的缩容过程。
栈初始化
栈空间在运行时中包含两个重要的全局变量,分别是 runtime.stackpool 和 runtime.stackLarge,这两个变量分别表示全局的栈缓存和大栈缓存,前者可以分配小于 32KB 的内存,后者用来分配大于 32KB 的栈空间:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
var stackpool [_NumStackOrders]struct {
item stackpoolItem
_ [cpu.CacheLinePadSize - unsafe.Sizeof(stackpoolItem{})%cpu.CacheLinePadSize]byte
}
type stackpoolItem struct {
mu mutex
span mSpanList
}
//大空间内存池
var stackLarge struct {
//由于是全局共享变量,所以使用时会加锁
lock mutex
//heapAddrBits,
//pageShift=13,go的内存管理中一页的大小为8kb,此值代表log2(8*1024) = 13
//索引其实是从2开始才可能有空闲内存
//2 => 全为2^2 * page大小的mspan (注:page大小为8KB)
//3 => 全为2^3 * page大小的mspan
//...
free [heapAddrBits - pageShift]mSpanList
}
//mspan结构中有三个指针next、prev、list(指向mSpanList)
type mSpanList struct {
first *mspan // first span in list, or nil if none
last *mspan // last span in list, or nil if none
}
|
stackcache的结构图示:
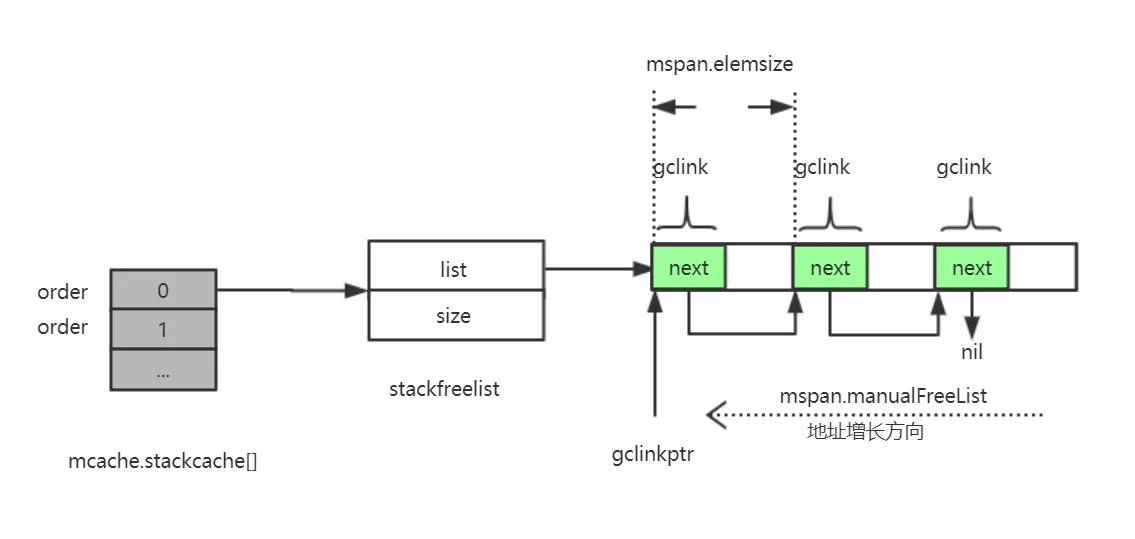
这两个用于分配空间的全局变量都与内存管理单元 runtime.mspan 有关,我们可以认为 Go 语言的栈内存都是分配在堆上的,运行时初始化时调用的 runtime.stackinit 函数会在初始化这些全局变量:
1
2
3
4
5
6
7
8
|
func stackinit() {
for i := range stackpool {
stackpool[i].item.span.init()
}
for i := range stackLarge.free {
stackLarge.free[i].init()
}
}
|
从调度器和内存分配的经验来看,如果运行时只使用全局变量来分配内存的话,势必会造成线程之间的锁竞争进而影响程序的执行效率,栈内存由于与线程关系比较密切,所以我们在每一个线程缓存 runtime.mcache 中都加入了栈缓存减少锁竞争影响。
1
2
3
4
5
6
7
8
|
type mcache struct {
stackcache [_NumStackOrders]stackfreelist
}
type stackfreelist struct {
list gclinkptr
size uintptr
}
|
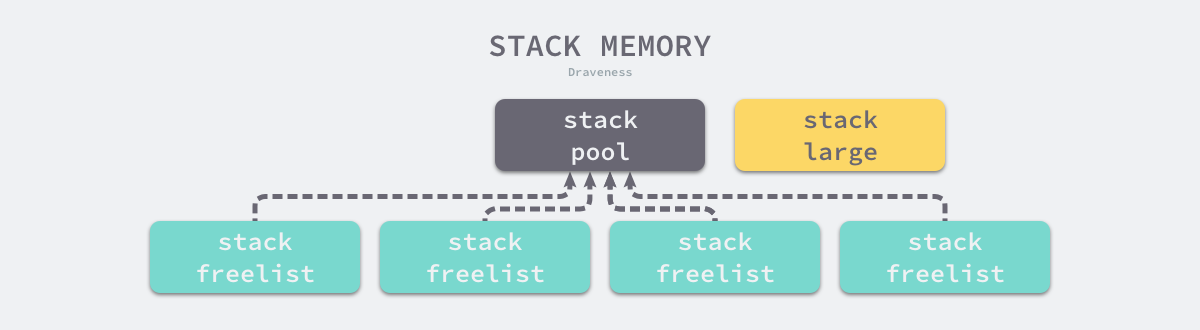
运行时使用全局的 runtime.stackpool 和线程缓存中的空闲链表分配 32KB 以下的栈内存,使用全局的 runtime.stackLarge 和堆内存分配 32KB 以上的栈内存,提高本地分配栈内存的性能。
栈分配
运行时会在 Goroutine 的初始化函数 runtime.malg 中调用 runtime.stackalloc 分配一个大小足够栈内存空间,根据线程缓存和申请栈的大小,
我们在这里会按照栈的大小分两部分介绍运行时对栈空间的分配。在 Linux 上,_FixedStack = 2048、_NumStackOrders = 4、_StackCacheSize = 32768,也就是如果申请的栈空间小于 32KB 时,我们会在全局栈缓存池或者线程的栈缓存中初始化内存:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
|
// stackalloc allocates an n byte stack.
//
// stackalloc must run on the system stack because it uses per-P
// resources and must not split the stack.
//
//go:systemstack
stackNoCache = 0 // disable per-P small stack caches
func stackalloc(n uint32) stack {
// Stackalloc must be called on scheduler stack, so that we
// never try to grow the stack during the code that stackalloc runs.
// Doing so would cause a deadlock (issue 1547).
//必须在调度程序堆栈上调用Stackalloc,
//以防止在正在执行此动作时发送栈扩导致的死锁
// 因为是在 systemstack 上执行的,当前 g 必须是 g0
thisg := getg()
if thisg != thisg.m.g0 {
throw("stackalloc not on scheduler stack")
}
if n&(n-1) != 0 {
throw("stack size not a power of 2")
}
if stackDebug >= 1 {
print("stackalloc ", n, "\n")
}
if debug.efence != 0 || stackFromSystem != 0 {
n = uint32(alignUp(uintptr(n), physPageSize))
v := sysAlloc(uintptr(n), &memstats.stacks_sys)
if v == nil {
throw("out of memory (stackalloc)")
}
return stack{uintptr(v), uintptr(v) + uintptr(n)}
}
// Small stacks are allocated with a fixed-size free-list allocator.
// If we need a stack of a bigger size, we fall back on allocating
// a dedicated span.
//需要小堆栈在固定大小空闲列表中分配,大堆栈则到专用span中申请分配
//_StackCacheSize 是一个常量32*1024 即32KB
var v unsafe.Pointer
//如果栈空间较小,使用全局栈缓存或者线程缓存上固定大小的空闲链表分配内存;
if n < _FixedStack<<_NumStackOrders && n < _StackCacheSize {
// 需要分配的栈空间比较小
// order 用于索引对应大小的栈空间
order := uint8(0)
n2 := n
//order 代表: n是_FixedStack的几倍
// 0: _FixedStack大小,1:代表2倍_FixedStack大小;2代表四倍
for n2 > _FixedStack {
order++
n2 >>= 1
}
var x gclinkptr
// 如果
// 1. 不使用 P 的空闲栈空间缓存
// 2. 当前 m 没有关联的P,也就没有 mcache
// 3. thisg.m.preemptoff 不为空
// 则从全局的空闲栈空间池子中分配
if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" {
// thisg.m.p == 0 can happen in the guts of exitsyscall
// or procresize. Just get a stack from the global pool.
// Also don't touch stackcache during gc
// as it's flushed concurrently.
lock(&stackpool[order].item.mu)
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
//本地内存缓存mcache.stackcache中获取可用内存
//如果本地缓存中存在,则直接获取,并更新链表
//如果不存在则 调用stackpoolalloc 向mheap去申请
c := thisg.m.p.ptr().mcache
x = c.stackcache[order].list
if x.ptr() == nil {
//stackcacherefill会调用stackpoolalloc然后把申请到的内存填充到c.stackcache 中
stackcacherefill(c, order)
x = c.stackcache[order].list
}
c.stackcache[order].list = x.ptr().next
c.stackcache[order].size -= uintptr(n)
}
v = unsafe.Pointer(x)
} else {
//如果栈空间较大,从全局的大栈缓存 runtime.stackLarge 中获取内存空间;
//如果是大空间(大于等于32KB)
//则先到stackLarge的数组中获取,如果对应下标的数组为空则向mheap申请
var s *mspan
npage := uintptr(n) >> _PageShift
// stacklog2 返回 log_2(n)
log2npage := stacklog2(npage)
// Try to get a stack from the large stack cache.
//stackLarge数组所指向的空闲内存空间全部是通过栈回收来获得的。
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
if s == nil {
//如果栈空间较大并且 runtime.stackLarge 空间不足,在堆上申请一片大小足够内存空间;
//向mheap申请npage大小的内存空间用于栈
// Allocate a new stack from the heap.
s = mheap_.allocManual(npage, &memstats.stacks_inuse)
if s == nil {
throw("out of memory")
}
osStackAlloc(s)
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}
if raceenabled {
racemalloc(v, uintptr(n))
}
if msanenabled {
msanmalloc(v, uintptr(n))
}
if stackDebug >= 1 {
print(" allocated ", v, "\n")
}
return stack{uintptr(v), uintptr(v) + uintptr(n)}
}
|
到空闲池stackpoolalloc中获取内存,并缓存到mcache的stackcache数组中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
// stackcacherefill/stackcacherelease implement a global pool of stack segments.
// The pool is required to prevent unlimited growth of per-thread caches.
//
//go:systemstack
func stackcacherefill(c *mcache, order uint8) {
if stackDebug >= 1 {
print("stackcacherefill order=", order, "\n")
}
// Grab some stacks from the global cache.
// Grab half of the allowed capacity (to prevent thrashing).
var list gclinkptr
var size uintptr
lock(&stackpool[order].item.mu)
//这里有一个循环获取的方法,看起来是获取的大小要超过_StackCacheSize的一半,官方给出的解释是防止系统颠簸
for size < _StackCacheSize/2 {
x := stackpoolalloc(order)
x.ptr().next = list
list = x
size += _FixedStack << order
}
unlock(&stackpool[order].item.mu)
c.stackcache[order].list = list
c.stackcache[order].size = size
}
|
runtime.stackpoolalloc 函数会在全局的栈缓存池 runtime.stackpool 中获取新的内存,如果栈缓存池中不包含剩余的内存,运行时会从堆上申请一片内存空间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
// Allocates a stack from the free pool. Must be called with
// stackpool[order].item.mu held.
func stackpoolalloc(order uint8) gclinkptr {
//我们有一个全局的缓存池,stackpool,存储的就是不同规格的spanlist,首先我们获取对应规格的spanlist
list := &stackpool[order].item.span
//s为指向span的指针
s := list.first
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
//如果list是空的,我们就调用allocManual申请新的span
if s == nil {
// no free stacks. Allocate another span worth.
//一次申请32KB内存即4页
s = mheap_.allocManual(_StackCacheSize>>_PageShift, &memstats.stacks_inuse)
if s == nil {
throw("out of memory")
}
if s.allocCount != 0 {
throw("bad allocCount")
}
if s.manualFreeList.ptr() != nil {
throw("bad manualFreeList")
}
//对新申请的内存,在使用之前先初始化系统栈
osStackAlloc(s)
s.elemsize = _FixedStack << order
for i := uintptr(0); i < _StackCacheSize; i += s.elemsize {
//gclinkptr 也是一个指针类型
//作用是屏蔽gc扫描
x := gclinkptr(s.base() + i)
//链表头插法
x.ptr().next = s.manualFreeList
s.manualFreeList = x
}
list.insert(s)
}
x := s.manualFreeList
if x.ptr() == nil {
throw("span has no free stacks")
}
//获取到list后,我们读取第一个span,然后分配manualFreeList的第一个单元给栈即可,如果manualFreeList用完了,则直接移除该span即可。
s.manualFreeList = x.ptr().next
s.allocCount++
if s.manualFreeList.ptr() == nil {
// all stacks in s are allocated.
//所有内存已经分配完毕,删除节点s
list.remove(s)
}
return x
}
|
无论是小栈分配还是大栈的分配,在分配失败时都会从 mheap 上分配重新分配新的缓存,使用 allocManual
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
|
// allocManual allocates a manually-managed span of npage pages.
// allocManual returns nil if allocation fails.
//
// allocManual adds the bytes used to *stat, which should be a
// memstats in-use field. Unlike allocations in the GC'd heap, the
// allocation does *not* count toward heap_inuse or heap_sys.
//
// The memory backing the returned span may not be zeroed if
// span.needzero is set.
//
// allocManual must be called on the system stack because it may
// acquire the heap lock via allocSpan. See mheap for details.
//
//go:systemstack
func (h *mheap) allocManual(npages uintptr, stat *uint64) *mspan {
return h.allocSpan(npages, true, 0, stat)
}
// allocSpan allocates an mspan which owns npages worth of memory.
//
// If manual == false, allocSpan allocates a heap span of class spanclass
// and updates heap accounting. If manual == true, allocSpan allocates a
// manually-managed span (spanclass is ignored), and the caller is
// responsible for any accounting related to its use of the span. Either
// way, allocSpan will atomically add the bytes in the newly allocated
// span to *sysStat.
//
// The returned span is fully initialized.
//
// h must not be locked.
//
// allocSpan must be called on the system stack both because it acquires
// the heap lock and because it must block GC transitions.
//
//go:systemstack
func (h *mheap) allocSpan(npages uintptr, manual bool, spanclass spanClass, sysStat *uint64) (s *mspan) {
// Function-global state.
gp := getg()
base, scav := uintptr(0), uintptr(0)
// If the allocation is small enough, try the page cache!
pp := gp.m.p.ptr()
if pp != nil && npages < pageCachePages/4 {
c := &pp.pcache
// If the cache is empty, refill it.
if c.empty() {
lock(&h.lock)
*c = h.pages.allocToCache()
unlock(&h.lock)
}
// Try to allocate from the cache.
base, scav = c.alloc(npages)
if base != 0 {
s = h.tryAllocMSpan()
if s != nil && gcBlackenEnabled == 0 && (manual || spanclass.sizeclass() != 0) {
goto HaveSpan
}
// We're either running duing GC, failed to acquire a mspan,
// or the allocation is for a large object. This means we
// have to lock the heap and do a bunch of extra work,
// so go down the HaveBaseLocked path.
//
// We must do this during GC to avoid skew with heap_scan
// since we flush mcache stats whenever we lock.
//
// TODO(mknyszek): It would be nice to not have to
// lock the heap if it's a large allocation, but
// it's fine for now. The critical section here is
// short and large object allocations are relatively
// infrequent.
}
}
// For one reason or another, we couldn't get the
// whole job done without the heap lock.
lock(&h.lock)
if base == 0 {
// Try to acquire a base address.
base, scav = h.pages.alloc(npages)
if base == 0 {
if !h.grow(npages) {
unlock(&h.lock)
return nil
}
base, scav = h.pages.alloc(npages)
if base == 0 {
throw("grew heap, but no adequate free space found")
}
}
}
if s == nil {
// We failed to get an mspan earlier, so grab
// one now that we have the heap lock.
s = h.allocMSpanLocked()
}
if !manual {
// This is a heap span, so we should do some additional accounting
// which may only be done with the heap locked.
// Transfer stats from mcache to global.
var c *mcache
if gp.m.p != 0 {
c = gp.m.p.ptr().mcache
} else {
// This case occurs while bootstrapping.
// See the similar code in mallocgc.
c = mcache0
if c == nil {
throw("mheap.allocSpan called with no P")
}
}
memstats.heap_scan += uint64(c.local_scan)
c.local_scan = 0
memstats.tinyallocs += uint64(c.local_tinyallocs)
c.local_tinyallocs = 0
// Do some additional accounting if it's a large allocation.
if spanclass.sizeclass() == 0 {
mheap_.largealloc += uint64(npages * pageSize)
mheap_.nlargealloc++
atomic.Xadd64(&memstats.heap_live, int64(npages*pageSize))
}
// Either heap_live or heap_scan could have been updated.
if gcBlackenEnabled != 0 {
gcController.revise()
}
}
unlock(&h.lock)
HaveSpan:
// At this point, both s != nil and base != 0, and the heap
// lock is no longer held. Initialize the span.
s.init(base, npages)
if h.allocNeedsZero(base, npages) {
s.needzero = 1
}
nbytes := npages * pageSize
if manual {
s.manualFreeList = 0
s.nelems = 0
s.limit = s.base() + s.npages*pageSize
// Manually managed memory doesn't count toward heap_sys.
mSysStatDec(&memstats.heap_sys, s.npages*pageSize)
s.state.set(mSpanManual)
} else {
// We must set span properties before the span is published anywhere
// since we're not holding the heap lock.
s.spanclass = spanclass
if sizeclass := spanclass.sizeclass(); sizeclass == 0 {
s.elemsize = nbytes
s.nelems = 1
s.divShift = 0
s.divMul = 0
s.divShift2 = 0
s.baseMask = 0
} else {
s.elemsize = uintptr(class_to_size[sizeclass])
s.nelems = nbytes / s.elemsize
m := &class_to_divmagic[sizeclass]
s.divShift = m.shift
s.divMul = m.mul
s.divShift2 = m.shift2
s.baseMask = m.baseMask
}
// Initialize mark and allocation structures.
s.freeindex = 0
s.allocCache = ^uint64(0) // all 1s indicating all free.
s.gcmarkBits = newMarkBits(s.nelems)
s.allocBits = newAllocBits(s.nelems)
// It's safe to access h.sweepgen without the heap lock because it's
// only ever updated with the world stopped and we run on the
// systemstack which blocks a STW transition.
atomic.Store(&s.sweepgen, h.sweepgen)
// Now that the span is filled in, set its state. This
// is a publication barrier for the other fields in
// the span. While valid pointers into this span
// should never be visible until the span is returned,
// if the garbage collector finds an invalid pointer,
// access to the span may race with initialization of
// the span. We resolve this race by atomically
// setting the state after the span is fully
// initialized, and atomically checking the state in
// any situation where a pointer is suspect.
s.state.set(mSpanInUse)
}
// Commit and account for any scavenged memory that the span now owns.
if scav != 0 {
// sysUsed all the pages that are actually available
// in the span since some of them might be scavenged.
sysUsed(unsafe.Pointer(base), nbytes)
mSysStatDec(&memstats.heap_released, scav)
}
// Update stats.
mSysStatInc(sysStat, nbytes)
mSysStatDec(&memstats.heap_idle, nbytes)
// Publish the span in various locations.
// This is safe to call without the lock held because the slots
// related to this span will only ever be read or modified by
// this thread until pointers into the span are published (and
// we execute a publication barrier at the end of this function
// before that happens) or pageInUse is updated.
h.setSpans(s.base(), npages, s)
if !manual {
if !go115NewMCentralImpl {
// Add to swept in-use list.
//
// This publishes the span to root marking.
//
// h.sweepgen is guaranteed to only change during STW,
// and preemption is disabled in the page allocator.
h.sweepSpans[h.sweepgen/2%2].push(s)
}
// Mark in-use span in arena page bitmap.
//
// This publishes the span to the page sweeper, so
// it's imperative that the span be completely initialized
// prior to this line.
arena, pageIdx, pageMask := pageIndexOf(s.base())
atomic.Or8(&arena.pageInUse[pageIdx], pageMask)
// Update related page sweeper stats.
atomic.Xadd64(&h.pagesInUse, int64(npages))
if trace.enabled {
// Trace that a heap alloc occurred.
traceHeapAlloc()
}
}
// Make sure the newly allocated span will be observed
// by the GC before pointers into the span are published.
publicationBarrier()
return s
}
|
我们用一个流程图来归纳下栈空间分配的流程
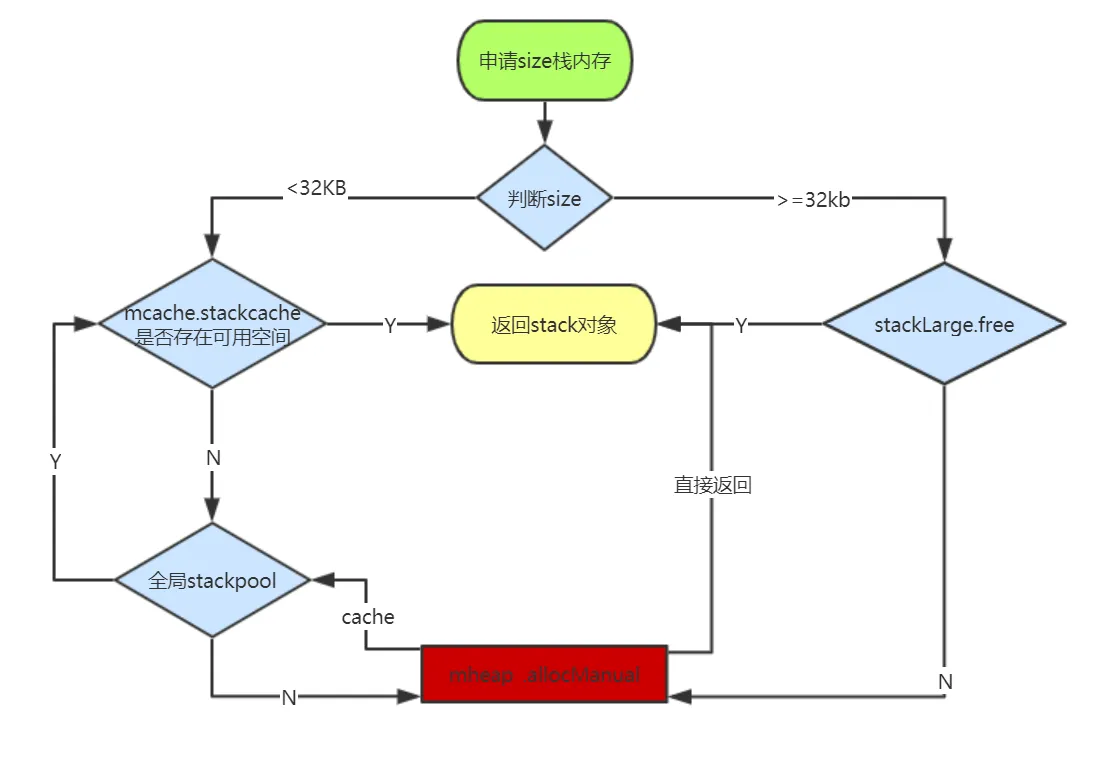
执行栈的伸缩
早年的 Go 运行时使用分段栈的机制,即当一个 Goroutine 的执行栈溢出时, 栈的扩张操作是在另一个栈上进行的,这两个栈彼此没有连续。 这种设计的缺陷很容易破坏缓存的局部性原理,从而降低程序的运行时性能。 因此现在 Go 运行时开始使用连续栈机制,当一个执行栈发生溢出时, 新建一个两倍于原栈大小的新栈,再将原栈整个拷贝到新栈上。 从而整个栈总是连续的。栈的拷贝并非想象中的那样简单,因为一个栈上可能保留指向被拷贝栈的指针, 从而当栈发生拷贝后,这个指针可能还指向原栈,从而造成错误。 此外,Goroutine 上原本的 gobuf 也需要被更新,这也是使用连续栈的难点之一。
分段标记
分段标记是编译器的机制,涉及栈帧大小的计算。这个过程比较复杂,我们暂时假设编译器已经计算好了栈帧的大小, 这时,编译的预处理阶段,会为没有标记为 go:nosplit 的函数插入栈的分段检查:
1
2
3
4
5
6
7
8
9
10
11
12
|
// cmd/internal/obj/x86/obj6.go
func preprocess(ctxt *obj.Link, cursym *obj.LSym, newprog obj.ProgAlloc) {
...
p := cursym.Func.Text
autoffset := int32(p.To.Offset) // 栈帧大小
// 一些额外的栈帧大小计算
...
if !cursym.Func.Text.From.Sym.NoSplit() {
p = stacksplit(ctxt, cursym, p, newprog, autoffset, int32(textarg)) // 触发分段检查
}
...
}
|
与处理阶段将栈帧大小传入 stacksplit,用于针对不同大小的栈进行不同的分段检查, 具体的代码相当繁琐,这里直接给出的是汇编的伪代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
func stacksplit(ctxt *obj.Link, cursym *obj.LSym, p *obj.Prog, newprog obj.ProgAlloc, framesize int32, textarg int32) *obj.Prog {
...
var q1 *obj.Prog
if framesize <= objabi.StackSmall {
// 小栈: SP <= stackguard,直接比较 SP 和 stackguard
// CMPQ SP, stackguard
...
} else if framesize <= objabi.StackBig {
// 大栈: SP-framesize <= stackguard-StackSmall
// LEAQ -xxx(SP), AX
// CMPQ AX, stackguard
...
} else {
// 更大的栈需要防止 wraparound
// 如果 SP 接近于零:
// SP-stackguard+StackGuard <= framesize + (StackGuard-StackSmall)
// 两端的 +StackGuard 是为了保证左侧大于零。
// SP 允许位于 stackguard 下面一点点
//
// 抢占设置了 stackguard 为 StackPreempt,一个大到能够打破上面的数学计算的值,
// 因此必须显式的进行检查:
// MOVQ stackguard, CX
// CMPQ CX, $StackPreempt
// JEQ label-of-call-to-morestack
// LEAQ StackGuard(SP), AX
// SUBQ CX, AX
// CMPQ AX, $(framesize+(StackGuard-StackSmall))
...
}
...
// 函数的尾声
morestack := "runtime.morestack"
switch {
case cursym.CFunc():
morestack = "runtime.morestackc" // morestackc 会 panic,因为此时是系统栈上的 C 函数
case !cursym.Func.Text.From.Sym.NeedCtxt():
morestack = "runtime.morestack_noctxt"
}
call.To.Sym = ctxt.Lookup(morestack)
...
return jls
}
|
总而言之,没有被 go:nosplit 标记的函数的序言部分会插入分段检查,从而在发生栈溢出的情况下, 触发 runtime.morestack 调用,如果函数不需要 ctxt,则会调用 runtime.morestack_noctxt 从而抛弃 ctxt 再调用 morestack:
1
2
3
|
TEXT runtime·morestack_noctxt(SB),NOSPLIT,$0
MOVL $0, DX
JMP runtime·morestack(SB)
|
栈扩容
每一个函数执行都要占用栈空间,用于保存变量,参数等。运行在协程里的函数自然是占用运行它的协程栈。但协程的栈是有限的,如果发现不够用,会调用stackalloc分配一块新的栈,大小比原来大一倍。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
TEXT runtime·morestack(SB),NOSPLIT,$0-0
// 无法增长调度器的栈(m->g0)
get_tls(CX)
MOVQ g(CX), BX
MOVQ g_m(BX), BX
MOVQ m_g0(BX), SI
CMPQ g(CX), SI
JNE 3(PC)
CALL runtime·badmorestackg0(SB)
CALL runtime·abort(SB)
// 无法增长信号栈 (m->gsignal)
MOVQ m_gsignal(BX), SI
CMPQ g(CX), SI
JNE 3(PC)
CALL runtime·badmorestackgsignal(SB)
CALL runtime·abort(SB)
// 从 f 调用
// 将 m->morebuf 设置为 f 的调用方
MOVQ 8(SP), AX // f 的调用方 PC
MOVQ AX, (m_morebuf+gobuf_pc)(BX)
LEAQ 16(SP), AX // f 的调用方 SP
MOVQ AX, (m_morebuf+gobuf_sp)(BX)
get_tls(CX)
MOVQ g(CX), SI
MOVQ SI, (m_morebuf+gobuf_g)(BX)
// 将 g->sched 设置为 f 的 context
MOVQ 0(SP), AX // f 的 PC
MOVQ AX, (g_sched+gobuf_pc)(SI)
MOVQ SI, (g_sched+gobuf_g)(SI)
LEAQ 8(SP), AX // f 的 SP
MOVQ AX, (g_sched+gobuf_sp)(SI)
MOVQ BP, (g_sched+gobuf_bp)(SI)
MOVQ DX, (g_sched+gobuf_ctxt)(SI)
// 在 m->g0 栈上调用 newstack.
MOVQ m_g0(BX), BX
MOVQ BX, g(CX)
MOVQ (g_sched+gobuf_sp)(BX), SP
CALL runtime·newstack(SB)
CALL runtime·abort(SB) // 如果 newstack 返回则崩溃
RET
|
编译器会在 cmd/internal/obj/x86.stacksplit 函数中为函数调用插入 runtime.morestack 运行时检查,它会在几乎所有的函数调用之前检查当前 Goroutine 的栈内存是否充足,如果当前栈需要扩容,我们会保存一些栈的相关信息并调用 runtime.newstack 创建新的栈:
newstack 在前半部分承担了对 Goroutine 进行抢占的任务, 而在后半部分则是真正的栈扩张。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
|
// Called from runtime·morestack when more stack is needed.
// Allocate larger stack and relocate to new stack.
// Stack growth is multiplicative, for constant amortized cost.
//
// g->atomicstatus will be Grunning or Gscanrunning upon entry.
// If the scheduler is trying to stop this g, then it will set preemptStop.
//
// This must be nowritebarrierrec because it can be called as part of
// stack growth from other nowritebarrierrec functions, but the
// compiler doesn't check this.
//
//go:nowritebarrierrec
func newstack() {
//先做一些准备工作
thisg := getg()
// TODO: double check all gp. shouldn't be getg().
if thisg.m.morebuf.g.ptr().stackguard0 == stackFork {
throw("stack growth after fork")
}
if thisg.m.morebuf.g.ptr() != thisg.m.curg {
print("runtime: newstack called from g=", hex(thisg.m.morebuf.g), "\n"+"\tm=", thisg.m, " m->curg=", thisg.m.curg, " m->g0=", thisg.m.g0, " m->gsignal=", thisg.m.gsignal, "\n")
morebuf := thisg.m.morebuf
traceback(morebuf.pc, morebuf.sp, morebuf.lr, morebuf.g.ptr())
throw("runtime: wrong goroutine in newstack")
}
gp := thisg.m.curg
if thisg.m.curg.throwsplit {
// Update syscallsp, syscallpc in case traceback uses them.
morebuf := thisg.m.morebuf
gp.syscallsp = morebuf.sp
gp.syscallpc = morebuf.pc
pcname, pcoff := "(unknown)", uintptr(0)
f := findfunc(gp.sched.pc)
if f.valid() {
pcname = funcname(f)
pcoff = gp.sched.pc - f.entry
}
print("runtime: newstack at ", pcname, "+", hex(pcoff),
" sp=", hex(gp.sched.sp), " stack=[", hex(gp.stack.lo), ", ", hex(gp.stack.hi), "]\n",
"\tmorebuf={pc:", hex(morebuf.pc), " sp:", hex(morebuf.sp), " lr:", hex(morebuf.lr), "}\n",
"\tsched={pc:", hex(gp.sched.pc), " sp:", hex(gp.sched.sp), " lr:", hex(gp.sched.lr), " ctxt:", gp.sched.ctxt, "}\n")
thisg.m.traceback = 2 // Include runtime frames
traceback(morebuf.pc, morebuf.sp, morebuf.lr, gp)
throw("runtime: stack split at bad time")
}
morebuf := thisg.m.morebuf
thisg.m.morebuf.pc = 0
thisg.m.morebuf.lr = 0
thisg.m.morebuf.sp = 0
thisg.m.morebuf.g = 0
// NOTE: stackguard0 may change underfoot, if another thread
// is about to try to preempt gp. Read it just once and use that same
// value now and below.
preempt := atomic.Loaduintptr(&gp.stackguard0) == stackPreempt
// Be conservative about where we preempt.
// We are interested in preempting user Go code, not runtime code.
// If we're holding locks, mallocing, or preemption is disabled, don't
// preempt.
// This check is very early in newstack so that even the status change
// from Grunning to Gwaiting and back doesn't happen in this case.
// That status change by itself can be viewed as a small preemption,
// because the GC might change Gwaiting to Gscanwaiting, and then
// this goroutine has to wait for the GC to finish before continuing.
// If the GC is in some way dependent on this goroutine (for example,
// it needs a lock held by the goroutine), that small preemption turns
// into a real deadlock.
//检查当前 Goroutine 是否发出了抢占请求,如果发出了抢占请求:
if preempt {
//当前线程可以被抢占时,直接调用 runtime.gogo 触发调度器的调度;
if !canPreemptM(thisg.m) {
// Let the goroutine keep running for now.
// gp->preempt is set, so it will be preempted next time.
gp.stackguard0 = gp.stack.lo + _StackGuard
gogo(&gp.sched) // never return
}
}
if gp.stack.lo == 0 {
throw("missing stack in newstack")
}
sp := gp.sched.sp
if sys.ArchFamily == sys.AMD64 || sys.ArchFamily == sys.I386 || sys.ArchFamily == sys.WASM {
// The call to morestack cost a word.
// 到 morestack 的调用会消耗一个字
sp -= sys.PtrSize
}
if stackDebug >= 1 || sp < gp.stack.lo {
print("runtime: newstack sp=", hex(sp), " stack=[", hex(gp.stack.lo), ", ", hex(gp.stack.hi), "]\n",
"\tmorebuf={pc:", hex(morebuf.pc), " sp:", hex(morebuf.sp), " lr:", hex(morebuf.lr), "}\n",
"\tsched={pc:", hex(gp.sched.pc), " sp:", hex(gp.sched.sp), " lr:", hex(gp.sched.lr), " ctxt:", gp.sched.ctxt, "}\n")
}
if sp < gp.stack.lo {
print("runtime: gp=", gp, ", goid=", gp.goid, ", gp->status=", hex(readgstatus(gp)), "\n ")
print("runtime: split stack overflow: ", hex(sp), " < ", hex(gp.stack.lo), "\n")
throw("runtime: split stack overflow")
}
//检查当前 Goroutine 是否发出了抢占请求,如果发出了抢占请求:
if preempt {
if gp == thisg.m.g0 {
throw("runtime: preempt g0")
}
if thisg.m.p == 0 && thisg.m.locks == 0 {
throw("runtime: g is running but p is not")
}
//如果当前 Goroutine 在垃圾回收被 runtime.scanstack 函数标记成了需要收缩栈,调用 runtime.shrinkstack;
if gp.preemptShrink {
// We're at a synchronous safe point now, so
// do the pending stack shrink.
gp.preemptShrink = false
shrinkstack(gp)
}
//如果当前 Goroutine 被 runtime.suspendG 函数挂起,调用 runtime.preemptPark 被动让出当前处理器的控制权并将 Goroutine 的状态修改至 _Gpreempted
if gp.preemptStop {
preemptPark(gp) // never returns
}
// Act like goroutine called runtime.Gosched.
//调用 runtime.gopreempt_m 主动让出当前处理器的控制权;
gopreempt_m(gp) // never return
}
//如果当前 Goroutine 不需要被抢占,也就意味着我们需要新的栈空间来支持函数调用和本地变量的初始化,运行时会先检查目标大小的栈是否会溢出:
// Allocate a bigger segment and move the stack.
// 分配一个更大的段,并对栈进行移动
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2 // 比原来大一倍
// Make sure we grow at least as much as needed to fit the new frame.
// (This is just an optimization - the caller of morestack will
// recheck the bounds on return.)
if f := findfunc(gp.sched.pc); f.valid() {
max := uintptr(funcMaxSPDelta(f))
for newsize-oldsize < max+_StackGuard {
newsize *= 2
}
}
// 需要的栈太大,直接溢出
if newsize > maxstacksize {
print("runtime: goroutine stack exceeds ", maxstacksize, "-byte limit\n")
print("runtime: sp=", hex(sp), " stack=[", hex(gp.stack.lo), ", ", hex(gp.stack.hi), "]\n")
throw("stack overflow")
}
//如果目标栈的大小没有超出程序的限制,我们会将 Goroutine 切换至 _Gcopystack 状态并调用 runtime.copystack 开始栈的拷贝
//处于_Gcopystack 状态时 GC不会扫描栈空间
// The goroutine must be executing in order to call newstack,
// so it must be Grunning (or Gscanrunning).
casgstatus(gp, _Grunning, _Gcopystack)
// The concurrent GC will not scan the stack while we are doing the copy since
// the gp is in a Gcopystack status.
copystack(gp, newsize) //修改协程状态
if stackDebug >= 1 {
print("stack grow done\n")
}
casgstatus(gp, _Gcopystack, _Grunning)
gogo(&gp.sched)
}
|
栈缩容
栈的缩容主要是发生在GC期间。一个协程变成常驻状态,繁忙时需要占用很大的内存,但空闲时占用很少,这样会浪费很多内存,为了避免浪费Go在GC时对协程的栈进行了缩容,缩容也是分配一块新的内存替换原来的,大小只有原来的1/2。
runtime.shrinkstack 是用于栈缩容的函数,该函数的实现原理非常简单,其中大部分都是检查是否满足缩容前置条件的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
// Maybe shrink the stack being used by gp.
//
// gp must be stopped and we must own its stack. It may be in
// _Grunning, but only if this is our own user G.
func shrinkstack(gp *g) {
if gp.stack.lo == 0 {
throw("missing stack in shrinkstack")
}
if s := readgstatus(gp); s&_Gscan == 0 {
// We don't own the stack via _Gscan. We could still
// own it if this is our own user G and we're on the
// system stack.
if !(gp == getg().m.curg && getg() != getg().m.curg && s == _Grunning) {
// We don't own the stack.
throw("bad status in shrinkstack")
}
}
if !isShrinkStackSafe(gp) {
throw("shrinkstack at bad time")
}
// Check for self-shrinks while in a libcall. These may have
// pointers into the stack disguised as uintptrs, but these
// code paths should all be nosplit.
if gp == getg().m.curg && gp.m.libcallsp != 0 {
throw("shrinking stack in libcall")
}
if debug.gcshrinkstackoff > 0 {
return
}
f := findfunc(gp.startpc)
if f.valid() && f.funcID == funcID_gcBgMarkWorker {
// We're not allowed to shrink the gcBgMarkWorker
// stack (see gcBgMarkWorker for explanation).
return
}
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize / 2
// Don't shrink the allocation below the minimum-sized stack
// allocation.
if newsize < _FixedStack {
return
}
// Compute how much of the stack is currently in use and only
// shrink the stack if gp is using less than a quarter of its
// current stack. The currently used stack includes everything
// down to the SP plus the stack guard space that ensures
// there's room for nosplit functions.
//当所有的已使用的空间小于栈总空间的1/4时,栈收缩为原来的一半
//gp.sched.sp 为栈顶指针kongjian
//_StackLimit 在不扩容情况下执行被调函数所能用的最大空间
avail := gp.stack.hi - gp.stack.lo
//当已使用的栈占不到总栈的1/4 进行缩容
if used := gp.stack.hi - gp.sched.sp + _StackLimit; used >= avail/4 {
return
}
if stackDebug > 0 {
print("shrinking stack ", oldsize, "->", newsize, "\n")
}
copystack(gp, newsize)
}
|
如果要触发栈的缩容,新栈的大小会是原始栈的一半,不过如果新栈的大小低于程序的最低限制 2KB,那么缩容的过程就会停止。
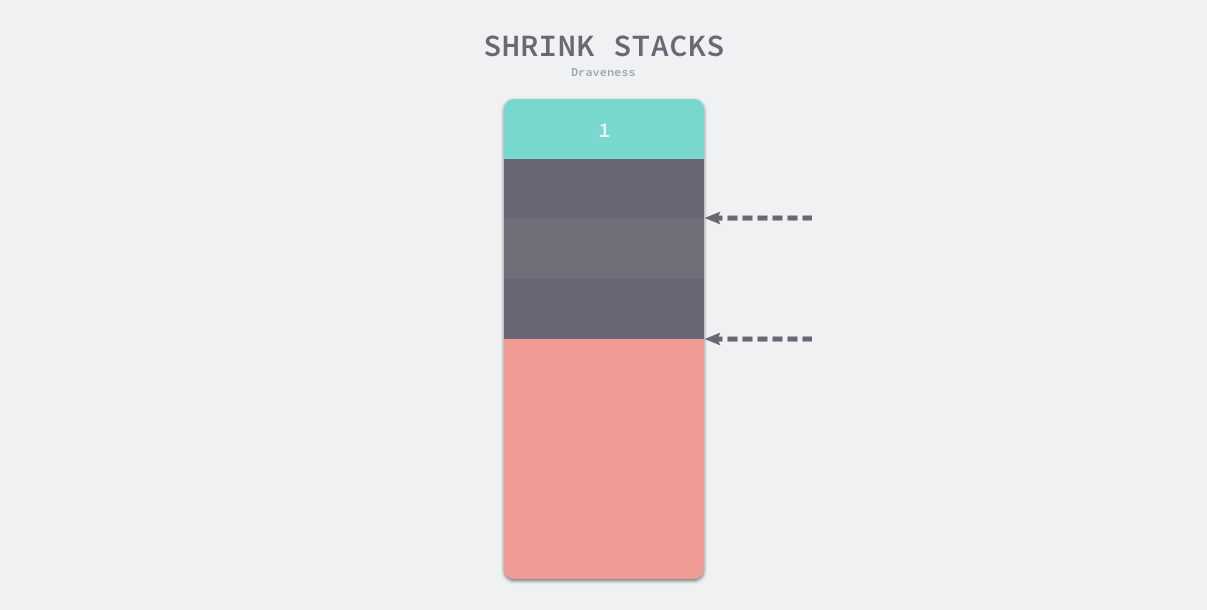
运行时只会在栈内存使用不足 1/4 时进行缩容,缩容也会调用扩容时使用的 runtime.copystack 函数开辟新的栈空间。
栈拷贝
前面我们已经提到了,栈拷贝的其中一个难点就是 Go 中栈上的变量会包含自己的地址, 当我们拷贝了一个指向原栈的指针时,拷贝后的指针会变为无效指针。 不难发现,只有栈上分配的指针才能指向栈上的地址,否则这个指针指向的对象会重新在堆中进行分配(逃逸)。在这期间我们需要分别调整以下的指针:
- 调用 runtime.adjustsudogs 或者 runtime.syncadjustsudogs 调整 runtime.sudog 结构体的指针;
- 调用 runtime.memmove 将源栈中的整片内存拷贝到新的栈中;
- 调用 runtime.adjustctxt、runtime.adjustdefers 和 runtime.adjustpanics 调整剩余 Goroutine 相关数据结构的指针;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
|
// Copies gp's stack to a new stack of a different size.
// Caller must have changed gp status to Gcopystack.
func copystack(gp *g, newsize uintptr) {
if gp.syscallsp != 0 {
throw("stack growth not allowed in system call")
}
old := gp.stack
if old.lo == 0 {
throw("nil stackbase")
}
used := old.hi - gp.sched.sp
// allocate new stack
//在拷贝栈的内存之前,运行时会通过 runtime.stackalloc 函数分配新的栈空间
new := stackalloc(uint32(newsize))
if stackPoisonCopy != 0 {
fillstack(new, 0xfd)
}
if stackDebug >= 1 {
print("copystack gp=", gp, " [", hex(old.lo), " ", hex(old.hi-used), " ", hex(old.hi), "]", " -> [", hex(new.lo), " ", hex(new.hi-used), " ", hex(new.hi), "]/", newsize, "\n")
}
// Compute adjustment.
// 这里主要调整g的一些调度相关参数
// 如果它们存储在老的栈上面,需要将它们拷贝到新栈上
var adjinfo adjustinfo
adjinfo.old = old
adjinfo.delta = new.hi - old.hi // 计算新栈和旧栈之间内存地址差
// Adjust sudogs, synchronizing with channel ops if necessary.
ncopy := used
if !gp.activeStackChans {
if newsize < old.hi-old.lo && atomic.Load8(&gp.parkingOnChan) != 0 {
// It's not safe for someone to shrink this stack while we're actively
// parking on a channel, but it is safe to grow since we do that
// ourselves and explicitly don't want to synchronize with channels
// since we could self-deadlock.
throw("racy sudog adjustment due to parking on channel")
}
adjustsudogs(gp, &adjinfo)
} else {
// sudogs may be pointing in to the stack and gp has
// released channel locks, so other goroutines could
// be writing to gp's stack. Find the highest such
// pointer so we can handle everything there and below
// carefully. (This shouldn't be far from the bottom
// of the stack, so there's little cost in handling
// everything below it carefully.)
adjinfo.sghi = findsghi(gp, old)
// Synchronize with channel ops and copy the part of
// the stack they may interact with.
ncopy -= syncadjustsudogs(gp, used, &adjinfo)
}
// Copy the stack (or the rest of it) to the new location
//把旧栈数据复制到新栈
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
// Adjust remaining structures that have pointers into stacks.
// We have to do most of these before we traceback the new
// stack because gentraceback uses them.
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
if adjinfo.sghi != 0 {
adjinfo.sghi += adjinfo.delta
}
// Swap out old stack for new one
// 切换到新堆栈上工作
gp.stack = new
gp.stackguard0 = new.lo + _StackGuard // NOTE: might clobber a preempt request
gp.sched.sp = new.hi - used
gp.stktopsp += adjinfo.delta
// Adjust pointers in the new stack.
// 在新栈重调整指针
gentraceback(^uintptr(0), ^uintptr(0), 0, gp, 0, nil, 0x7fffffff, adjustframe, noescape(unsafe.Pointer(&adjinfo)), 0)
// free old stack
// 释放老的堆栈
if stackPoisonCopy != 0 {
fillstack(old, 0xfc)
}
//调用runtime.stackfree销毁并回收旧栈的内存空间;
stackfree(old)
}
func fillstack(stk stack, b byte) {
for p := stk.lo; p < stk.hi; p++ {
*(*byte)(unsafe.Pointer(p)) = b
}
}
func findsghi(gp *g, stk stack) uintptr {
var sghi uintptr
for sg := gp.waiting; sg != nil; sg = sg.waitlink {
p := uintptr(sg.elem) + uintptr(sg.c.elemsize)
if stk.lo <= p && p < stk.hi && p > sghi {
sghi = p
}
}
return sghi
}
func syncadjustsudogs(gp *g, used uintptr, adjinfo *adjustinfo) uintptr {
if gp.waiting == nil {
return 0
}
// Lock channels to prevent concurrent send/receive.
// It's important that we *only* do this for async
// copystack; otherwise, gp may be in the middle of
// putting itself on wait queues and this would
// self-deadlock.
var lastc *hchan
for sg := gp.waiting; sg != nil; sg = sg.waitlink {
if sg.c != lastc {
lock(&sg.c.lock)
}
lastc = sg.c
}
// Adjust sudogs.
adjustsudogs(gp, adjinfo)
// Copy the part of the stack the sudogs point in to
// while holding the lock to prevent races on
// send/receive slots.
var sgsize uintptr
if adjinfo.sghi != 0 {
oldBot := adjinfo.old.hi - used
newBot := oldBot + adjinfo.delta
sgsize = adjinfo.sghi - oldBot
memmove(unsafe.Pointer(newBot), unsafe.Pointer(oldBot), sgsize)
}
// Unlock channels.
lastc = nil
for sg := gp.waiting; sg != nil; sg = sg.waitlink {
if sg.c != lastc {
unlock(&sg.c.lock)
}
lastc = sg.c
}
return sgsize
}
|
在扩容和缩容这个过程中,做了很多调整。从连续栈的实现方式上我们了解到,不管是扩容还是缩容,都重新申请一块新栈,然后把旧栈的数据复制到新栈。协程占用的物理内存完全被替换了,而Go在运行时会把指针保存到内存里面,例如:gp.sched.ctxt ,gp._defer ,gp._panic,包括函数里的指针。这部分指针值会被转换成整数型uintptr,然后 + delta进行调整。
调整指向栈内存的指针都会调用 runtime.adjustpointer,该函数会利用 runtime.adjustinfo 计算的新栈和旧栈之间的内存地址差来调整指针。所有的指针都被调整后,我们就可以更新 Goroutine 的几个变量并通过 runtime.stackfree 释放原始栈的内存空间了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
//栈空间调整信息
type adjustinfo struct {
old stack //旧的栈空间,stack.hi, stack.lo
delta uintptr //旧栈栈底到新栈栈底的偏移量
cache pcvalueCache //调整栈帧时会用到
//sudog.elem 在栈上的最高位置
sghi uintptr
}
// Adjustpointer checks whether *vpp is in the old stack described by adjinfo.
// If so, it rewrites *vpp to point into the new stack.
func adjustpointer(adjinfo *adjustinfo, vpp unsafe.Pointer) {
pp := (*uintptr)(vpp)
p := *pp
if stackDebug >= 4 {
print(" ", pp, ":", hex(p), "\n")
}
//如果这个整数型数字在旧栈的范围,就调整
if adjinfo.old.lo <= p && p < adjinfo.old.hi {
*pp = p + adjinfo.delta
if stackDebug >= 3 {
print(" adjust ptr ", pp, ":", hex(p), " -> ", hex(*pp), "\n")
}
}
}
|
我们主要看下函数调用gentraceback进行新栈上的指针的调整,我们就不把这个函数贴出来了,太复杂(感兴趣的同学可以看源码runtime.stack.go),我们看到它传进去的一个函数adjustframe,看函数名字,它应该就是我们要找的函数。
2.我们来看下adjustframe
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
|
// Note: the argument/return area is adjusted by the callee.
func adjustframe(frame *stkframe, arg unsafe.Pointer) bool {
adjinfo := (*adjustinfo)(arg)
if frame.continpc == 0 {
// Frame is dead.
return true
}
f := frame.fn
if stackDebug >= 2 {
print(" adjusting ", funcname(f), " frame=[", hex(frame.sp), ",", hex(frame.fp), "] pc=", hex(frame.pc), " continpc=", hex(frame.continpc), "\n")
}
if f.funcID == funcID_systemstack_switch {
// A special routine at the bottom of stack of a goroutine that does a systemstack call.
// We will allow it to be copied even though we don't
// have full GC info for it (because it is written in asm).
return true
}
locals, args, objs := getStackMap(frame, &adjinfo.cache, true)
// Adjust local variables if stack frame has been allocated.
if locals.n > 0 {
size := uintptr(locals.n) * sys.PtrSize
adjustpointers(unsafe.Pointer(frame.varp-size), &locals, adjinfo, f)
}
// Adjust saved base pointer if there is one.
if sys.ArchFamily == sys.AMD64 && frame.argp-frame.varp == 2*sys.RegSize {
if !framepointer_enabled {
print("runtime: found space for saved base pointer, but no framepointer experiment\n")
print("argp=", hex(frame.argp), " varp=", hex(frame.varp), "\n")
throw("bad frame layout")
}
if stackDebug >= 3 {
print(" saved bp\n")
}
if debugCheckBP {
// Frame pointers should always point to the next higher frame on
// the Go stack (or be nil, for the top frame on the stack).
bp := *(*uintptr)(unsafe.Pointer(frame.varp))
if bp != 0 && (bp < adjinfo.old.lo || bp >= adjinfo.old.hi) {
println("runtime: found invalid frame pointer")
print("bp=", hex(bp), " min=", hex(adjinfo.old.lo), " max=", hex(adjinfo.old.hi), "\n")
throw("bad frame pointer")
}
}
adjustpointer(adjinfo, unsafe.Pointer(frame.varp))
}
// Adjust arguments.
if args.n > 0 {
if stackDebug >= 3 {
print(" args\n")
}
adjustpointers(unsafe.Pointer(frame.argp), &args, adjinfo, funcInfo{})
}
// Adjust pointers in all stack objects (whether they are live or not).
// See comments in mgcmark.go:scanframeworker.
if frame.varp != 0 {
for _, obj := range objs {
off := obj.off
base := frame.varp // locals base pointer
if off >= 0 {
base = frame.argp // arguments and return values base pointer
}
p := base + uintptr(off)
if p < frame.sp {
// Object hasn't been allocated in the frame yet.
// (Happens when the stack bounds check fails and
// we call into morestack.)
continue
}
t := obj.typ
gcdata := t.gcdata
var s *mspan
if t.kind&kindGCProg != 0 {
// See comments in mgcmark.go:scanstack
s = materializeGCProg(t.ptrdata, gcdata)
gcdata = (*byte)(unsafe.Pointer(s.startAddr))
}
for i := uintptr(0); i < t.ptrdata; i += sys.PtrSize {
if *addb(gcdata, i/(8*sys.PtrSize))>>(i/sys.PtrSize&7)&1 != 0 {
adjustpointer(adjinfo, unsafe.Pointer(p+i))
}
}
if s != nil {
dematerializeGCProg(s)
}
}
}
return true
}
|
栈扩容的示意图
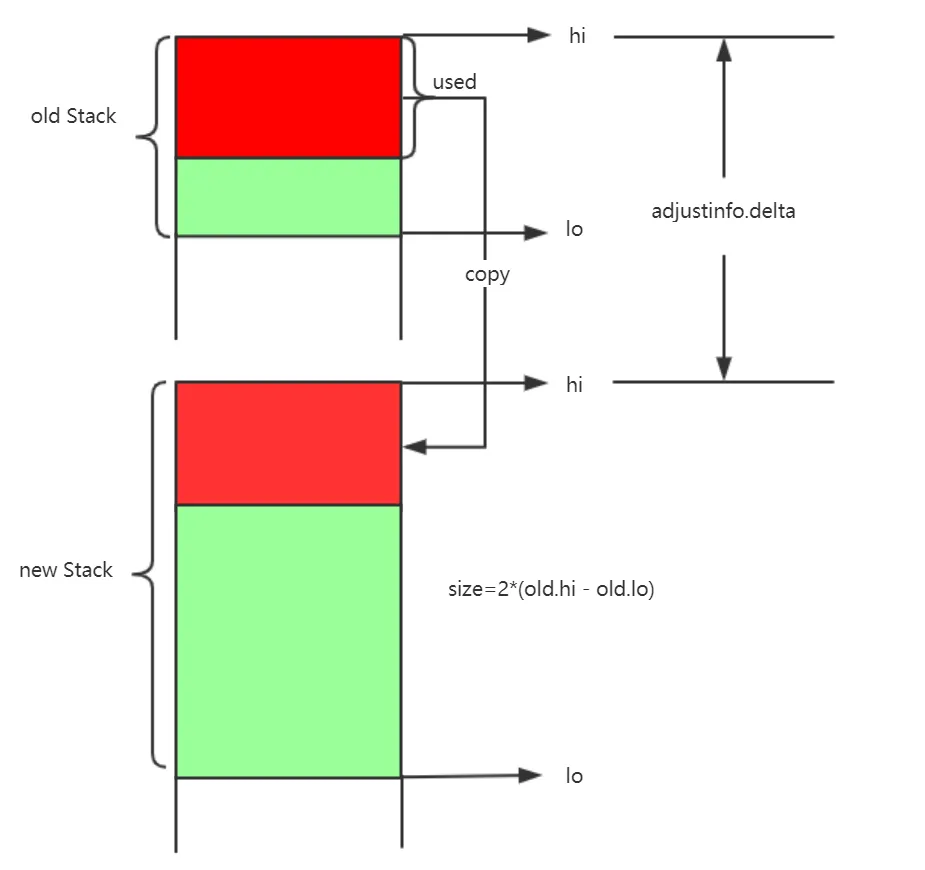
栈释放
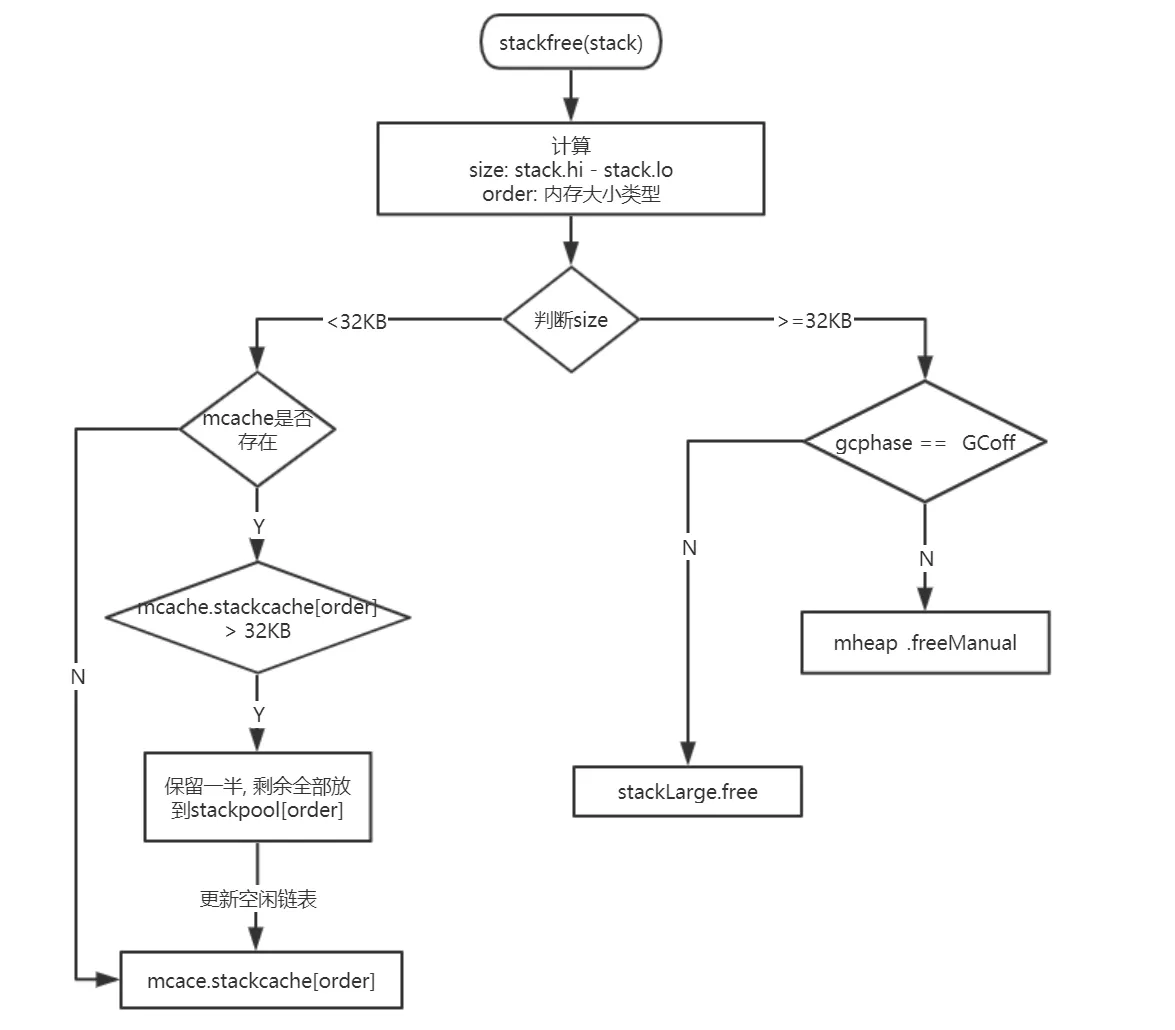
stackfree 就是栈申请空间的逆向操作,我们用图示表示其过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
|
// stackfree frees an n byte stack allocation at stk.
//
// stackfree must run on the system stack because it uses per-P
// resources and must not split the stack.
//
//go:systemstack
func stackfree(stk stack) {
gp := getg()
v := unsafe.Pointer(stk.lo)
n := stk.hi - stk.lo
if n&(n-1) != 0 {
throw("stack not a power of 2")
}
if stk.lo+n < stk.hi {
throw("bad stack size")
}
if stackDebug >= 1 {
println("stackfree", v, n)
memclrNoHeapPointers(v, n) // for testing, clobber stack data
}
if debug.efence != 0 || stackFromSystem != 0 {
if debug.efence != 0 || stackFaultOnFree != 0 {
sysFault(v, n)
} else {
sysFree(v, n, &memstats.stacks_sys)
}
return
}
if msanenabled {
msanfree(v, n)
}
//如果是小的栈,则直接放回缓存,看起来跟分配的时候很相似
if n < _FixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > _FixedStack {
order++
n2 >>= 1
}
x := gclinkptr(v)
//如果没有对应规格的缓存,则放回全局队列
if stackNoCache != 0 || gp.m.p == 0 || gp.m.preemptoff != "" {
lock(&stackpool[order].item.mu)
stackpoolfree(x, order)
unlock(&stackpool[order].item.mu)
} else {
c := gp.m.p.ptr().mcache
//如果缓存满了,则调用stackcacherelease放回一部分到全局队列
if c.stackcache[order].size >= _StackCacheSize {
stackcacherelease(c, order)
}
//放到我们的本地缓存中
x.ptr().next = c.stackcache[order].list
c.stackcache[order].list = x
c.stackcache[order].size += n
}
} else {
//大的栈内存释放,还给mheap
s := spanOfUnchecked(uintptr(v))
if s.state.get() != mSpanManual {
println(hex(s.base()), v)
throw("bad span state")
}
if gcphase == _GCoff {
// Free the stack immediately if we're
// sweeping.
osStackFree(s)
mheap_.freeManual(s, &memstats.stacks_inuse)
} else {
//如果正在GC,则直接放到全局的stackLarge中去
// If the GC is running, we can't return a
// stack span to the heap because it could be
// reused as a heap span, and this state
// change would race with GC. Add it to the
// large stack cache instead.
log2npage := stacklog2(s.npages)
lock(&stackLarge.lock)
stackLarge.free[log2npage].insert(s)
unlock(&stackLarge.lock)
}
}
}
|
我们来分析下代码:
1.首先我们判断要回收的栈的大小,如果是小栈,则直接返回缓存中即可,如果是大的栈则首先是否正在进行GC,如果是就放入到stackLarge中等待GC处理,否则直接返还给mheap
2.我们看下放回缓存的操作,如果无本地的该规格的缓存,则直接返回给全局缓存,调用stackpoolfree
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
// Adds stack x to the free pool. Must be called with stackpool[order].item.mu held.
func stackpoolfree(x gclinkptr, order uint8) {
s := spanOfUnchecked(uintptr(x))
if s.state.get() != mSpanManual {
throw("freeing stack not in a stack span")
}
if s.manualFreeList.ptr() == nil {
// s will now have a free stack
stackpool[order].item.span.insert(s)
}
x.ptr().next = s.manualFreeList
s.manualFreeList = x
s.allocCount--
if gcphase == _GCoff && s.allocCount == 0 {
// Span is completely free. Return it to the heap
// immediately if we're sweeping.
//
// If GC is active, we delay the free until the end of
// GC to avoid the following type of situation:
//
// 1) GC starts, scans a SudoG but does not yet mark the SudoG.elem pointer
// 2) The stack that pointer points to is copied
// 3) The old stack is freed
// 4) The containing span is marked free
// 5) GC attempts to mark the SudoG.elem pointer. The
// marking fails because the pointer looks like a
// pointer into a free span.
//
// By not freeing, we prevent step #4 until GC is done.
stackpool[order].item.span.remove(s)
s.manualFreeList = 0
osStackFree(s)
mheap_.freeManual(s, &memstats.stacks_inuse)
}
}
|
我们看到,返还给全局的缓存后,会检测下该span是否还有已经分配的内容,如果没有并且GC结束,则返还mheap
3.如果本地有对应规格的缓存,则首先判断本地的缓存是否满了(大于_StackCacheSize),如果满了,则释放一些。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
//go:systemstack
func stackcacherelease(c *mcache, order uint8) {
if stackDebug >= 1 {
print("stackcacherelease order=", order, "\n")
}
x := c.stackcache[order].list
size := c.stackcache[order].size
lock(&stackpool[order].item.mu)
for size > _StackCacheSize/2 {
y := x.ptr().next
stackpoolfree(x, order)
x = y
size -= _FixedStack << order
}
unlock(&stackpool[order].item.mu)
c.stackcache[order].list = x
c.stackcache[order].size = size
}
|
我们看到释放的方式是,首先通过调用stackpoolfree释放一半给mheap,然后再还给全局的缓存
4.如果本地还没满,则直接放入本地队列即可
其他触发时机
垃圾回收期间也会触发栈的释放。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func markroot(gcw *gcWork, i uint32) {
....
switch {
case baseFlushCache <= i && i < baseData:
//这里会对该p所对应的栈缓存清掉
flushmcache(int(i - baseFlushCache))
....
case i == fixedRootFinalizers:
if work.markrootDone {
break
}
......
case i == fixedRootFreeGStacks:
if !work.markrootDone {
//此处调用了栈收缩
systemstack(markrootFreeGStacks)
}
}
}
|
我们来看下flushmcacheh会释放掉当前P上的缓存,我们看下这个函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// flushmcache flushes the mcache of allp[i].
//
// The world must be stopped.
//
//go:nowritebarrier
func flushmcache(i int) {
p := allp[i]
c := p.mcache
if c == nil {
return
}
c.releaseAll()
stackcache_clear(c)
}
|
看到没有,释放的就是那个mcache,释放栈的是stackcache_clear(c),我们来看下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
//go:systemstack
func stackcache_clear(c *mcache) {
if stackDebug >= 1 {
print("stackcache clear\n")
}
for order := uint8(0); order < _NumStackOrders; order++ {
lock(&stackpool[order].item.mu)
x := c.stackcache[order].list
for x.ptr() != nil {
y := x.ptr().next
stackpoolfree(x, order)
x = y
}
c.stackcache[order].list = 0
c.stackcache[order].size = 0
unlock(&stackpool[order].item.mu)
}
}
|
调用的就是stackpoolfree释放的。 继续看markroot,里面还有一个操作systemstack(markrootFreeGStacks),这个函数实际上调用的是shrinkstack,我们直接追过去
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
func shrinkstack(gp *g) {
gstatus := readgstatus(gp)
if gstatus&^_Gscan == _Gdead {
if gp.stack.lo != 0 {
// Free whole stack - it will get reallocated
// if G is used again.
stackfree(gp.stack)
gp.stack.lo = 0
gp.stack.hi = 0
}
return
}
....
oldsize := gp.stack.hi - gp.stack.lo
//缩小为原来的1/2
newsize := oldsize / 2
if newsize < _FixedStack {
return
}
avail := gp.stack.hi - gp.stack.lo
//判断使用是否超过了1/4
if used := gp.stack.hi - gp.sched.sp + _StackLimit; used >= avail/4 {
return
}
if gp.syscallsp != 0 {
return
}
if sys.GoosWindows != 0 && gp.m != nil && gp.m.libcallsp != 0 {
return
}
if stackDebug > 0 {
print("shrinking stack ", oldsize, "->", newsize, "\n")
}
//栈拷贝
copystack(gp, newsize, false)
}
|
ok,看下这里的逻辑,如果当前栈的使用量超过1/4则不进行收缩,否则缩为原来的1/2释放空间,并进行栈拷贝。到这里栈的管理结束了。
栈内存的申请与堆内存的申请
我们看到貌似栈内存的申请与堆内存的申请很相似,并且到最后都是用的mheap_这个全局的heap,那么我们知道垃圾回收的时候,只会回收堆上的内存,而我们的golang的虚拟地址实际上没有堆区与栈区的概念,他们的内存都是在arena区域,那么垃圾回收的时候怎么判断哪些span是堆哪些是栈的呢?堆申请span的时候调用的是cacheSpan函数,该函数最终调用的mcentral的grow函数,函数内部有一个更新bitmap的操作:
1
|
heapBitsForSpan(s.base()).initSpan(s)
|
但是栈的申请实际上是直接调用的mheap的grow函数,它并不会标记bitmap.
另外一个是我们知道golang的垃圾回收是三色标记法,需要提前知道根对象,而且根对象是从协程栈上拿到的,那么我们怎么知道协程栈上哪些是指针呢? 首先,我们要理清楚以下几点:
-
我们看起来堆内存的申请与栈内存的申请很相似,但是实际上二者有些地方还是不同的,最重要的一点,我们的堆是为单个对象或者变量申请内存的,而我们的分配栈是为整个协程的栈申请的内存,并非为单个变量。
-
既然我们栈内存的申请并非为单个变量申请的,所以我们在这也发现不了哪些地方存储了指针。
golang是根据在adjustframe函数中的一个stackmap类型找到栈內的指针了,那么谁来更新它呢?猜测应该是创建变量的时候入栈操作,会相应的更新这个类似bigmap的东西吧。 到此,栈内存的分配基本结束了。
逃逸分析
在 C 语言和 C++ 这类需要手动管理内存的编程语言中,将对象或者结构体分配到栈上或者堆上是由工程师自主决定的,这也为工程师的工作带来的挑战,如果工程师能够精准地为每一个变量分配最合理的空间,那么整个程序的运行效率和内存使用效率一定是最高的,但是手动分配内存会导致如下的两个问题:
- 不需要分配到堆上的对象分配到了堆上 — 浪费内存空间;
- 需要分配到堆上的对象分配到了栈上 — 悬挂指针、影响内存安全;
与悬挂指针相比,浪费的内存空间反而是小问题。在 C 语言中,栈上的变量被函数作为返回值返回给调用方是一个常见的错误,在如下所示的代码中,栈上的变量 i 被错误地返回:
1
2
3
4
|
int *dangling_pointer() {
int i = 2;
return &i;
}
|
当 dangling_pointer 函数返回后,它的本地变量就会被编译器直接回收,调用方获取的是危险的悬挂指针,我们不确定当前指针指向的值是否合法,这种问题在大型项目中是比较难以发现和定位的。
在编译器优化中,逃逸分析(Escape analysis)是用来决定指针动态作用域的方法。Go 语言的编译器使用逃逸分析决定哪些变量应该在栈上分配,哪些变量应该在堆上分配,其中包括使用 new、make 和字面量等方法隐式分配的内存,Go 语言的逃逸分析遵循以下两个不变性:
- 指向栈对象的指针不能存在于堆中;
- 指向栈对象的指针不能在栈对象回收后存活;
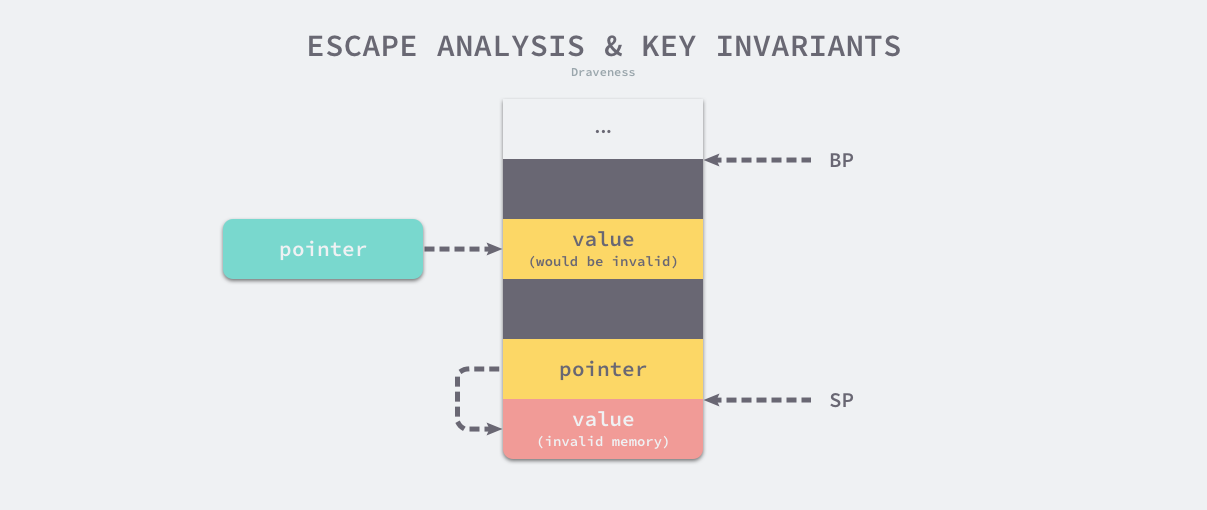
我们通过上图展示两条不变性存在的意义,当我们违反了第一条不变性,堆上的绿色指针指向了栈中的黄色内存,一旦当前函数返回函数栈被回收,该绿色指针指向的值就不再合法;如果我们违反了第二条不变性,因为寄存器 SP 下面的内存由于函数返回已经被释放掉,所以黄色指针指向的内存已经不再合法。
逃逸分析是静态分析的一种,在编译器解析了 Go 语言源文件后,它可以获得整个程序的抽象语法树(Abstract syntax tree,AST),编译器可以根据抽象语法树分析静态的数据流,我们会通过以下几个步骤实现静态分析的全过程:
- 构建带权重的有向图,其中顶点 cmd/compile/internal/gc.EscLocation 表示被分配的变量,边 cmd/compile/internal/gc.EscEdge 表示变量之间的分配关系,权重表示寻址和取地址的次数;
- 遍历对象分配图并查找违反两条不变性的变量分配关系,如果堆上的指针指向了栈上的变量,那么栈上的变量就需要分配在堆上;
- 记录从函数的调用参数到堆以及返回值的数据流,增强函数参数的逃逸分析;
决定变量是在栈上还是堆上虽然重要,但是这是一个定义相对清晰的问题,我们可以通过编译器在统一作出决策。为了保证内存的绝对安全,编译器可能会将一些变量错误地分配到堆上,但是因为这些对也会被垃圾收集器处理,所以不会造成内存泄露以及悬挂指针等安全问题,解放了工程师的生产力。
逃逸机制的优点:
- 减少了gc压力。如果变量都分配到堆上,堆不像栈可以自动清理。它会引起Go频繁地进行垃圾回收,而垃圾回收会占用比较大的系统开销(占用CPU容量的25%),甚至会导致STW(stop the world)。
- 提高效率。堆和栈相比,堆适合不可预知大小的内存分配。但是为此付出的代价是分配速度较慢,而且会形成内存碎片。栈内存分配则会非常快。栈分配内存只需要两个CPU指令:“PUSH”和“RELEASE”,分配和释放;而堆分配内存首先需要去找到一块大小合适的内存块,之后要通过垃圾回收才能释放。
- 同步消除。如果你定义的对象的方法上有同步锁,但在运行时,却只有一个线程在访问,此时逃逸分析后的机器码,会去掉同步锁运行。
逃逸日志分析
开启逃逸分析日志很简单,只要在编译的时候加上-gcflags '-m',但是我们为了不让编译时自动内联函数,一般会加-l参数,最终为-gcflags '-m -l'
Example:
1
2
3
4
5
6
7
8
9
10
|
package main
import (
"fmt"
)
func main() {
s := "hello"
fmt.Println(s)
}
|
1
|
go run -gcflags '-m -l' escape.go
|
Output:
1
2
3
4
|
### command-line-arguments
escape_analysis/main.go:9: s escapes to heap
escape_analysis/main.go:9: main ... argument does not escape
hello
|
关于-gcflags “-m -l"的输出,有两种情况:
- moved to heap:xxx
- xxx escapes to heap
根据我个人的实验结果,二者都表示发生逃逸,当 xxx 变量类型为指针时,出现下一种;当 xxx 变量为值类型时,为上一种。
逃逸情景
全部逃逸情景参考: https://github.com/golang/go/tree/master/test 下的escape相关文件
- 在方法内把局部变量指针返回并被引用。 局部变量原本应该在栈中分配,在栈中回收。但是由于返回时被外部引用,因此其生命周期大于栈,则溢出,因此要分配到堆上。
- 发送指针或带有指针的值到 channel 中。 在编译时,是没有办法知道哪个 goroutine 会在 channel 上接收数据的。所以编译器没法知道变量什么时候才会被释放,一般都会逃逸到堆上分配。
- 在一个切片上存储指针或带指针的值。 一个典型的例子就是
[]*string 。这会导致切片的内容逃逸。尽管其后面的数组可能是在栈上分配的,但其引用的值一定是在堆上。
- slice 的背后数组被重新分配了,因为 append 时可能会超出其容量( cap )。 slice 初始化的地方在编译时是可以知道的,它最开始会在栈上分配。如果切片背后的存储要基于运行时的数据进行扩充,就会在堆上分配。
- 在 interface 类型上调用方法。 在 interface 类型上调用方法都是动态调度的 —— 方法的真正实现只能在运行时知道。想像一个 io.Reader 类型的变量 r , 调用 r.Read(b) 会使得 r 的值和切片b 的背后存储都逃逸掉,所以会在堆上分配。
- 闭包引用对象,也会发生逃逸
- 尽管能够符合分配到栈的场景,但是其大小不能够在在编译时候确定的情况,也会分配到堆上.
函数返回局部指针变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
package main
type User struct {
Name string
}
func foo(s string) *User {
u := new(User)
u.Name = s
return u // 1.方法内局部变量返回,逃逸
}
func main() {
user := foo("hui")
user.Name = "dev"
}
/*逃逸分析日志
# command-line-arguments
./main.go:11:6: can inline foo
./main.go:17:6: can inline main
./main.go:18:13: inlining call to foo
./main.go:11:10: leaking param: s
./main.go:12:10: new(User) escapes to heap # 逃逸
./main.go:18:13: new(User) does not escape
*/
|
interface类型逃逸
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
package main
import "fmt"
func main() {
name := "devhui"
fmt.Println(name)
}
/*逃逸分析日志
# command-line-arguments
./main.go:7:13: inlining call to fmt.Println
./main.go:7:13: name escapes to heap # 逃逸
./main.go:7:13: []interface {} literal does not escape
*/
|
很多函数的参数为interface{} 空接口类型,这些都会造成逃逸。比如
1
2
3
4
5
|
func Printf(format string, a ...interface{}) (n int, err error)
func Sprintf(format string, a ...interface{}) string
func Fprint(w io.Writer, a ...interface{}) (n int, err error)
func Print(a ...interface{}) (n int, err error)
func Println(a ...interface{}) (n int, err error)
|
编译期间很难确定其参数的具体类型,也能产生逃逸
1
2
3
4
5
6
7
8
9
|
func main() {
fmt.Println("hello 逃逸")
}
/*逃逸日志分析
./main.go:5:6: can inline main
./main.go:6:13: inlining call to fmt.Println
./main.go:6:14: "hello 逃逸" escapes to heap
./main.go:6:13: []interface {} literal does not escape
*/
|
闭包产生的逃逸
1
2
3
4
5
6
7
8
9
10
11
12
|
func Increase() func() int {
n := 0
return func() int {
n++
return n
}
}
func main() {
in := Increase()
fmt.Println(in()) // 1
}
|
查看逃逸分析结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
go build -gcflags="-m -m -l" ./test3.go
# command-line-arguments
./test3.go:10:3: Increase.func1 capturing by ref: n (addr=true assign=true width=8)
./test3.go:9:9: func literal escapes to heap
./test3.go:9:9: from ~r0 (assigned) at ./test3.go:7:17
./test3.go:9:9: func literal escapes to heap
./test3.go:9:9: from &(func literal) (address-of) at ./test3.go:9:9
./test3.go:9:9: from ~r0 (assigned) at ./test3.go:7:17
./test3.go:10:3: &n escapes to heap
./test3.go:10:3: from func literal (captured by a closure) at ./test3.go:9:9
./test3.go:10:3: from &(func literal) (address-of) at ./test3.go:9:9
./test3.go:10:3: from ~r0 (assigned) at ./test3.go:7:17
./test3.go:8:2: moved to heap: n
./test3.go:17:16: in() escapes to heap
./test3.go:17:16: from ... argument (arg to ...) at ./test3.go:17:13
./test3.go:17:16: from *(... argument) (indirection) at ./test3.go:17:13
./test3.go:17:16: from ... argument (passed to call[argument content escapes]) at ./test3.go:17:13
./test3.go:17:13: main ... argument does not escape
|
因为函数也是一个指针类型,所以匿名函数当作返回值时也发生了逃逸,在匿名函数中使用外部变量n,这个变量n会一直存在直到in被销毁,所以n变量逃逸到了堆上。
变量大小不确定及栈空间不足引发逃逸
我们先使用ulimit -a查看操作系统的栈空间:
1
2
3
4
5
6
7
8
9
10
|
ulimit -a
-t: cpu time (seconds) unlimited
-f: file size (blocks) unlimited
-d: data seg size (kbytes) unlimited
-s: stack size (kbytes) 8192
-c: core file size (blocks) 0
-v: address space (kbytes) unlimited
-l: locked-in-memory size (kbytes) unlimited
-u: processes 2784
-n: file descriptors 256
|
我的电脑的栈空间大小是8192,所以根据这个我们写一个测试用例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
package main
import (
"math/rand"
)
func LessThan8192() {
nums := make([]int, 100) // = 64KB
for i := 0; i < len(nums); i++ {
nums[i] = rand.Int()
}
}
func MoreThan8192(){
nums := make([]int, 1000000) // = 64KB
for i := 0; i < len(nums); i++ {
nums[i] = rand.Int()
}
}
func NonConstant() {
number := 10
s := make([]int, number)
for i := 0; i < len(s); i++ {
s[i] = i
}
}
func main() {
NonConstant()
MoreThan8192()
LessThan8192()
}
|
查看逃逸分析结果:
1
2
3
4
5
6
7
8
9
|
go build -gcflags="-m -m -l" ./test4.go
# command-line-arguments
./test4.go:8:14: LessThan8192 make([]int, 100) does not escape
./test4.go:16:14: make([]int, 1000000) escapes to heap
./test4.go:16:14: from make([]int, 1000000) (non-constant size) at ./test4.go:16:14
./test4.go:25:11: make([]int, number) escapes to heap
./test4.go:25:11: from make([]int, number) (non-constant size) at ./test4.go:25:11
|
我们可以看到,当栈空间足够时,不会发生逃逸,但是当变量过大时,已经完全超过栈空间的大小时,将会发生逃逸到堆上分配内存。
同样当我们初始化切片时,没有直接指定大小,而是填入的变量,这种情况为了保证内存的安全,编译器也会触发逃逸,在堆上进行分配内存。
在 slice 或 map 中存储指针
在 slice 或 map 中存储指针。比如 []*string,其后面的数组可能是在栈上分配的,但其引用的值还是在堆上。
1
2
3
4
5
6
7
|
package main
func main() {
var x int
x = 10
var ls []*int
ls = append(ls, &x) // x发生逃逸,ls存储的是指针,所以ls底层的数组虽然在栈存储,但x本身却是逃逸到堆上
}
|
向 channel 发送指针数据
向 channel 发送指针数据。因为在编译时,不知道channel中的数据会被哪个 goroutine 接收,因此编译器没法知道变量什么时候才会被释放,因此只能放入堆中。
1
2
3
4
5
6
7
8
9
10
|
package main
func main() {
ch := make(chan int, 1)
x := 5
ch <- x // x不发生逃逸,因为只是复制的值
ch1 := make(chan *int, 1)
y := 5
py := &y
ch1 <- py // y逃逸,因为y地址传入了chan中,编译时无法确定什么时候会被接收,所以也无法在函数返回后回收y
}
|
内存逃逸的弊端
我们知道传递指针可以减少底层值的拷贝,可以提高效率,但是如果拷贝的数据量小,由于指针传递会产生逃逸,可能会使用堆,也可能会增加GC的负担,所以传递指针不一定是高效的。
如何得知变量是分配在栈(stack)上还是堆(heap)上?
准确地说,你并不需要知道。Golang 中的变量只要被引用就一直会存活,存储在堆上还是栈上由内部实现决定而和具体的语法没有关系。
知道变量的存储位置确实和效率编程有关系。如果可能,Golang 编译器会将函数的局部变量分配到函数栈帧(stack frame)上。 然而,如果编译器不能确保变量在函数 return之后不再被引用,编译器就会将变量分配到堆上。而且,如果一个局部变量非常大,那么它也应该被分配到堆上而不是栈上。
当前情况下,如果一个变量被取地址,那么它就有可能被分配到堆上。然而,还要对这些变量做逃逸分析,如果函数return之后,变量不再被引用,则将其分配到栈上。
避免内存逃逸的办法
- 对于小型的数据,使用传值而不是传指针,避免内存逃逸。
- 避免使用长度不固定的slice切片,在编译期无法确定切片长度,只能将切片使用堆分配。
- interface调用方法会发生内存逃逸,在热点代码片段,谨慎使用。
参考
7.3 栈空间管理
栈内存管理
6.7 执行栈管理
从垃圾回收解开Golang内存管理的面纱之二Golang的堆栈分析
Go语言的内存逃逸分析
简单聊聊内存逃逸 | 剑指 offer - golang