垃圾分类
垃圾分为以下两类:
- 语义垃圾(semantic garbage): 有的被称作内存泄露 语义垃圾指的是从语法上可达(可以通过局部、全局变量引用得到)的对象,但从语义上来讲他们是垃圾,垃圾回收器对此无能为力。
- 语法垃圾(syntactic garbage): 语法垃圾是讲那些从语法上无法到达的对象,这些才是垃圾收集器主要的收集目标。
语法垃圾:
1
2
3
4
5
6
7
8
9
10
|
package main
func main() {
alloconheap()
}
func alloconheap() {
var a = make([]int, 10240)
println(a)
}
|
在 allocOnHeap 返回后, 堆上的 a 无法访问 便成为了语法垃圾.
设计理念
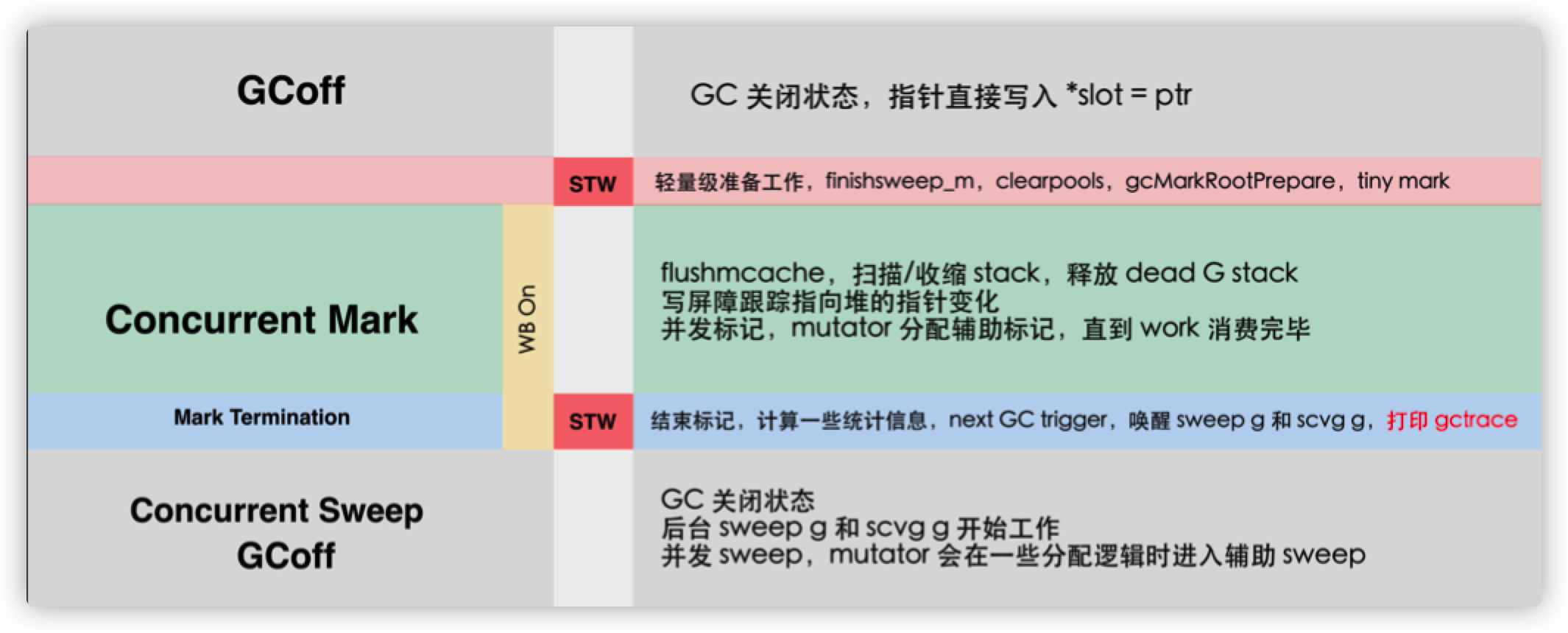
Go 实现的垃圾回收器是无分代(对象没有代际之分)、不整理(回收过程中不对对象进行移动与整理)、并发(与用户代码并发执行)的三色标记清扫算法。 从宏观的角度来看,Go 运行时的垃圾回收器主要包含五个阶段:
- 清理终止阶段(STW):对上个垃圾回收阶段进行一些收尾工作(例如清理缓存池、停止调度器等等),启动写屏障;
- 暂停程序,所有的处理器在这时会进入安全点(Safe point);
- 如果当前垃圾收集循环是强制触发的,我们还需要处理还未被清理的内存管理单元;
- 将状态切换至
_GCmark、开启写屏障、
- 标记阶段(并发):与赋值器并发执行,写屏障处于开启状态;
- 用户程序协助(Mutator Assist)并将根对象入队;
- 恢复执行程序,标记进程和用于协助的用户程序会开始并发标记内存中的对象,写屏障会将被覆盖的指针和新指针都标记成灰色,而所有新创建的对象都会被直接标记成黑色;
- 开始扫描根对象,包括所有 Goroutine 的栈、全局对象以及不在堆中的运行时数据结构,扫描 Goroutine 栈期间会暂停当前处理器;
- 依次处理灰色队列中的对象,将对象标记成黑色并将它们指向的对象标记成灰色;
- 使用分布式的终止算法检查剩余的工作,发现标记阶段完成后进入标记终止阶段;
- 标记终止阶段(STW):完成标记阶段的收尾工作,关闭写屏障,并随后对整个 GC 阶段进行的各项数据进行统计。
- 暂停程序、将状态切换至
_GCmarktermination 并关闭辅助标记的用户程序;
- 清理处理器上的线程缓存;
- 将状态切换至
_GCoff 开始清理阶段,初始化清理状态并关闭写屏障;
- 清理阶段(并发):将需要回收的内存归还到堆中,写屏障处于关闭状态;
- 恢复用户程序,所有新创建的对象会标记成白色;
- 后台并发清理所有的内存管理单元,当 Goroutine 申请新的内存管理单元时就会触发清理;
- 内存归还(并发):将过多的内存归还给操作系统,写屏障处于关闭状态
GC流程图:
对象整理的优势是解决内存碎片问题以及“允许”使用顺序内存分配器。 但 Go 运行时的分配算法基于 tcmalloc,基本上没有碎片问题。 并且顺序内存分配器在多线程的场景下并不适用。 Go 使用的是基于 tcmalloc 的现代内存分配算法,对对象进行整理不会带来实质性的性能提升。
分代 GC 依赖分代假设,即 GC 将主要的回收目标放在新创建的对象上(存活时间短,更倾向于被回收), 而非频繁检查所有对象。但 Go 的编译器会通过逃逸分析将大部分新生对象存储在栈上(栈直接被回收), 只有那些需要长期存在的对象才会被分配到需要进行垃圾回收的堆中。 也就是说,分代 GC 回收的那些存活时间短的对象在 Go 中是直接被分配到栈上, 当 goroutine 死亡后栈也会被直接回收,不需要 GC 的参与,进而分代假设并没有带来直接优势。 并且 Go 的垃圾回收器与用户代码并发执行,使得 STW 的时间与对象的代际、对象的 size 没有关系。 Go 团队更关注于如何更好地让 GC 与用户代码并发执行(使用适当的 CPU 来执行垃圾回收), 而非减少停顿时间这一单一目标上。
三色抽象
三色抽象只是一种描述追踪式回收器的方法,在实践中并没有实际含义, 它的重要作用在于从逻辑上严密推导标记清理这种垃圾回收方法的正确性。 也就是说,当我们谈及三色标记法时,通常指标记清扫的垃圾回收。
从垃圾回收器的视角来看,三色抽象规定了三种不同类型的对象,并用不同的颜色相称:
- 白色对象(可能死亡):未被回收器访问到的对象。在回收开始阶段,所有对象均为白色,当回收结束后,白色对象均不可达。
- 灰色对象(波面):已被回收器访问到的对象,但回收器需要对其中的一个或多个指针进行扫描,因为他们可能还指向白色对象。
- 黑色对象(确定存活):已被回收器访问到的对象,其中所有字段都已被扫描,黑色对象中任何一个指针都不可能直接指向白色对象。
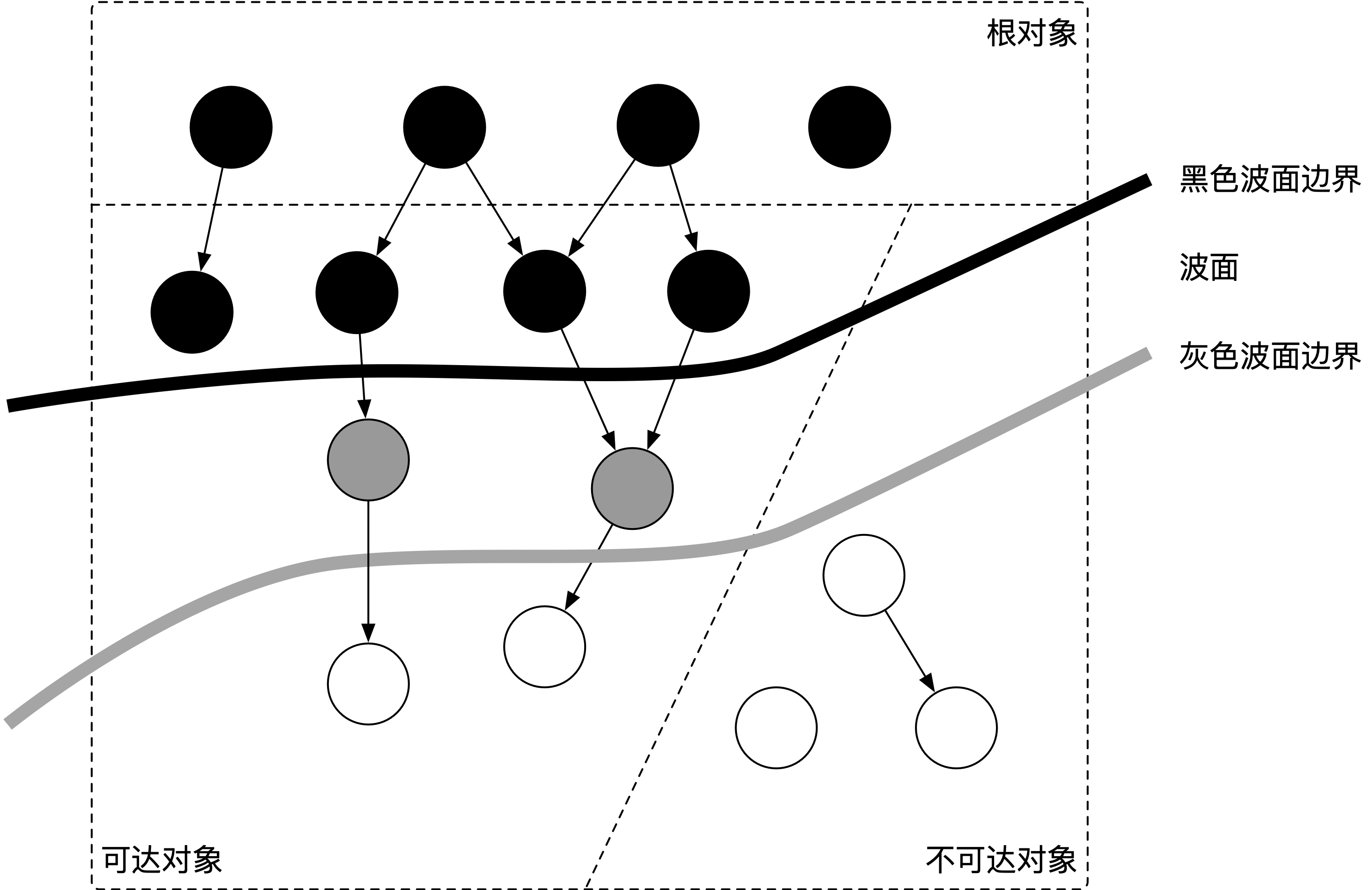
这样三种不变性所定义的回收过程其实是一个 波面(Wavefront) 不断前进的过程, 这个波面同时也是黑色对象和白色对象的边界,灰色对象就是这个波面。
当垃圾回收开始时,只有白色对象。随着标记过程开始进行时,灰色对象开始出现(着色),这时候波面便开始扩大。当一个对象的所有子节点均完成扫描时,会被着色为黑色。当整个堆遍历完成时,只剩下黑色和白色对象,这时的黑色对象为可达对象,即存活;而白色对象为不可达对象,即死亡。这个过程可以视为以灰色对象为波面,将黑色对象和白色对象分离,使波面不断向前推进,直到所有可达的灰色对象都变为黑色对象为止的过程.
对象的三种颜色可以这样来判断:
1
2
3
4
5
6
7
8
9
|
func isWhite(ref interface{}) bool {
return !isMarked(ref)
}
func isGrey(ref interface{}) bool {
return worklist.Find(ref)
}
func isBlack(ref interface{}) bool {
return isMarked(ref) && !isGrey(ref)
}
|
在垃圾收集器开始工作时,程序中不存在任何的黑色对象,垃圾收集的根对象会被标记成灰色,垃圾收集器只会从灰色对象集合中取出对象开始扫描,当灰色集合中不存在任何对象时,标记阶段就会结束。
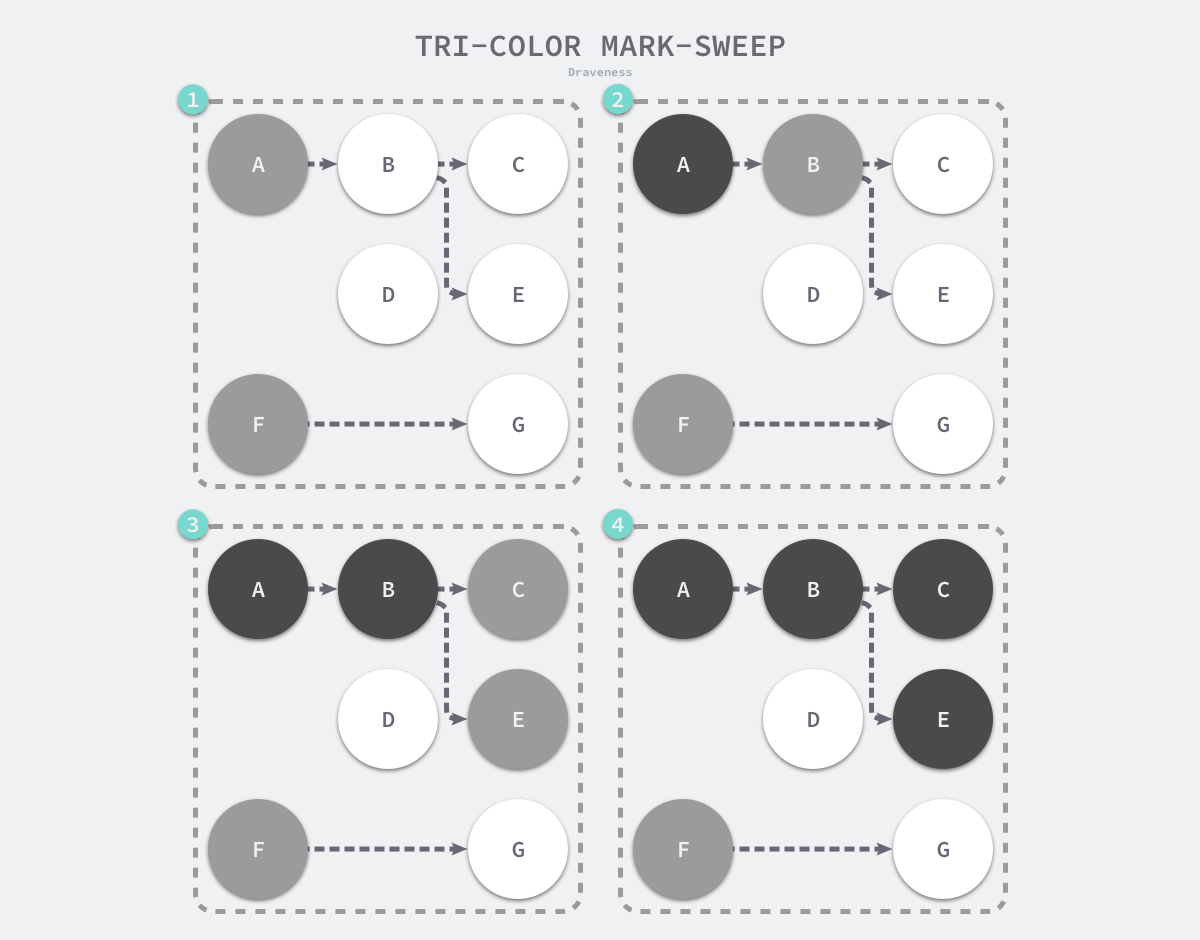
三色标记垃圾收集器的工作原理很简单,我们可以将其归纳成以下几个步骤:
- 从灰色对象的集合中选择一个灰色对象并将其标记成黑色;
- 将黑色对象指向的所有对象都标记成灰色,保证该对象和被该对象引用的对象都不会被回收;
- 重复上述两个步骤直到对象图中不存在灰色对象;
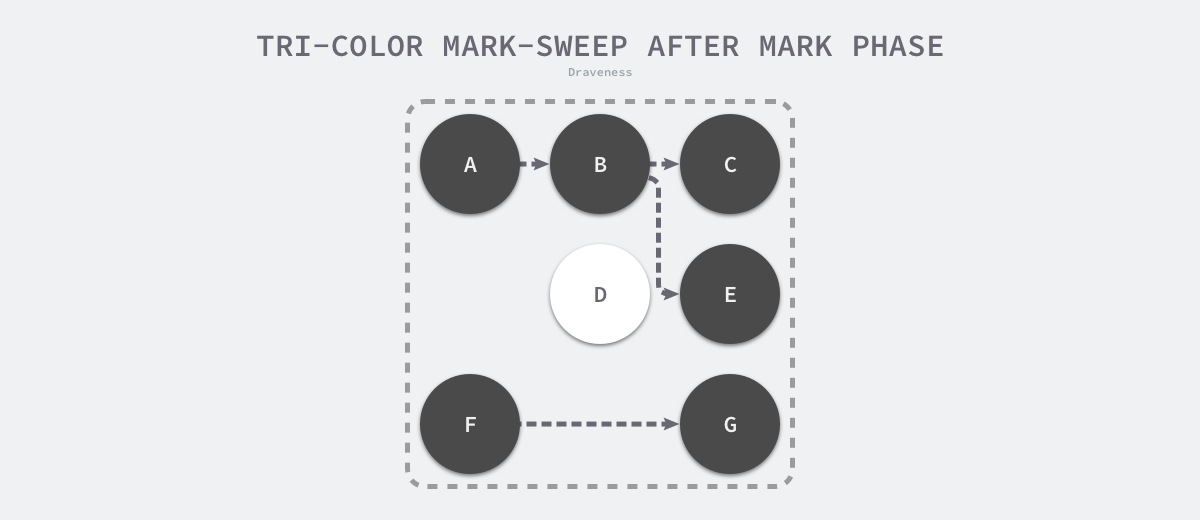
当三色的标记清除的标记阶段结束之后,应用程序的堆中就不存在任何的灰色对象,我们只能看到黑色的存活对象以及白色的垃圾对象,垃圾收集器可以回收这些白色的垃圾,下面是使用三色标记垃圾收集器执行标记后的堆内存,堆中只有对象 D 为待回收的垃圾:
因为用户程序可能在标记执行的过程中修改对象的指针,所以三色标记清除算法本身是不可以并发或者增量执行的,它仍然需要 STW,在如下所示的三色标记过程中,用户程序建立了从 A 对象到 D 对象的引用,但是因为程序中已经不存在灰色对象了,所以 D 对象会被垃圾收集器错误地回收。
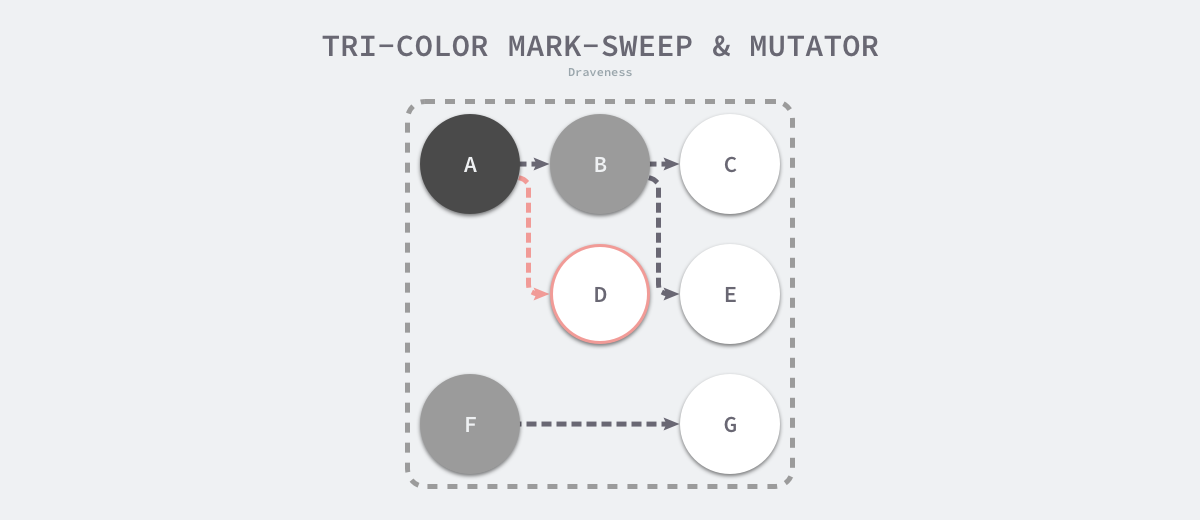
本来不应该被回收的对象却被回收了,这在内存管理中是非常严重的错误,我们将这种错误称为悬挂指针,即指针没有指向特定类型的合法对象,影响了内存的安全性,想要并发或者增量地标记对象还是需要使用屏障技术。
有黑、灰、白三个集合,每种颜色的含义:
白色:对象未被标记,gcmarkBits对应的位为0
灰色:对象已被标记,但这个对象包含的子对象未标记,gcmarkBits对应的位为1
黑色:对象已被标记,且这个对象包含的子对象也已标记,gcmarkBits对应的位为1
灰色和黑色的gcmarkBits都是1,如何区分二者呢?
标记任务有标记队列,在标记队列中的是灰色,不在标记队里中的是黑色。标记过程见下图:
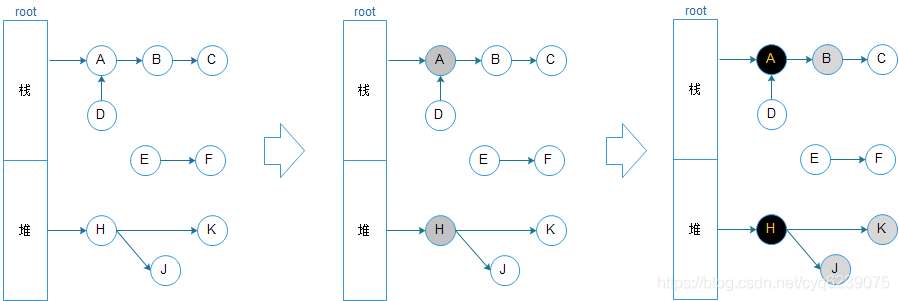
上图中根对象A是栈上分配的对象,H是堆中分配的全局变量,根对象A、H内部有分别引用了其他对象,而其他对象内部可能还引用其他对象,各个对象见的关系如上图所示。
- 初始状态下所有对象都是白色的。
- 接着开始扫描根对象,A、H是根对象所以被扫描到,A,H变为灰色对象。
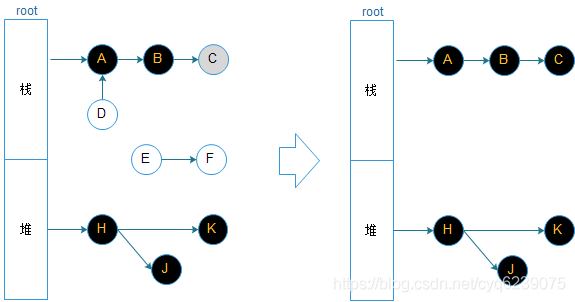
- 接下来就开始扫描灰色对象,通过A到达B,B被标注灰色,A扫描结束后被标注黑色。同理J,K都被标注灰色,H被标注黑色。
- 继续扫描灰色对象,通过B到达C,C 被标注灰色,B被标注黑色,因为J,K没有引用对象,J,K标注黑色结束
- 最终,黑色的对象会被保留下来,白色对象D,E,F会被回收掉。
屏障技术
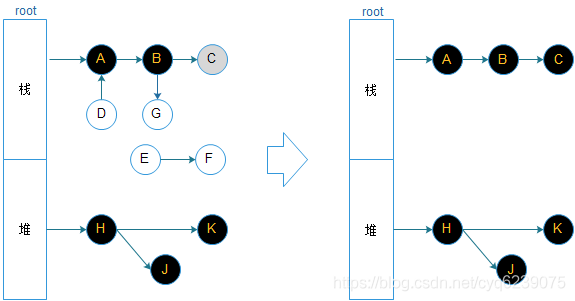
上图,假如B对象变黑后,又给B指向对象G,因为这个时候G对象已经扫描过了,所以G 对象还是白色,会被误回收。怎么解决这个问题呢?
最简单的方法就是STW(stop the world)。也就是说,停止所有的协程。这个方法比较暴力会引起程序的卡顿,并不友好。让GC回收器,满足下面两种情况之一时,可保对象不丢失. 所以引出强-弱三色不变性:
内存屏障技术是一种屏障指令,它可以让 CPU 或者编译器在执行内存相关操作时遵循特定的约束,目前的多数的现代处理器都会乱序执行指令以最大化性能,但是该技术能够保证代码对内存操作的顺序性,在内存屏障前执行的操作一定会先于内存屏障后执行的操作。
想要在并发或者增量的标记算法中保证正确性,我们需要达成以下两种三色不变性(Tri-color invariant)中的任意一种:
- 强三色不变性 — 黑色对象不会指向白色对象,只会指向灰色对象或者黑色对象;
- 弱三色不变性 — 黑色对象指向的白色对象必须包含一条从灰色对象经由多个白色对象的可达路径;
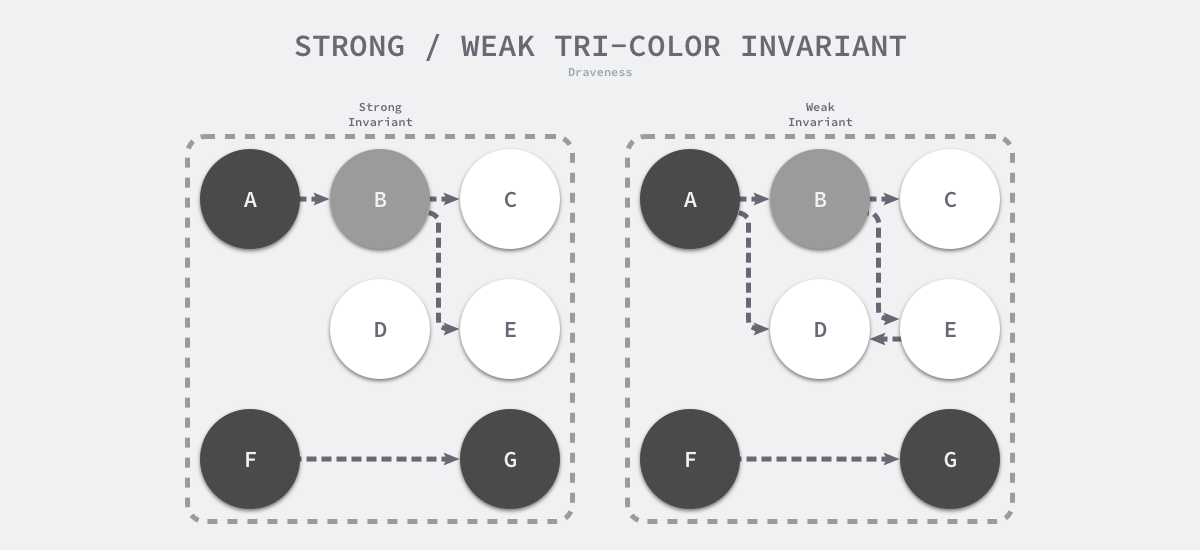
上图分别展示了遵循强三色不变性和弱三色不变性的堆内存,遵循上述两个不变性中的任意一个,我们都能保证垃圾收集算法的正确性,而屏障技术就是在并发或者增量标记过程中保证三色不变性的重要技术。
垃圾收集中的屏障技术更像是一个钩子方法,它是在用户程序读取对象、创建新对象以及更新对象指针时执行的一段代码,根据操作类型的不同,我们可以将它们分成读屏障(Read barrier)和写屏障(Write barrier)两种,因为读屏障需要在读操作中加入代码片段,对用户程序的性能影响很大,所以编程语言往往都会采用写屏障保证三色不变性。
我们在这里想要介绍的是 Go 语言中使用的两种写屏障技术,分别是 Dijkstra 提出的插入写屏障和 Yuasa 提出的删除写屏障,这里会分析它们如何保证三色不变性和垃圾收集器的正确性。
插入写屏障
Dijkstra 在 1978 年提出了插入写屏障,通过如下所示的写屏障,用户程序和垃圾收集器可以在交替工作的情况下保证程序执行的正确性:
1
2
3
4
5
|
// 灰色赋值器 Dijkstra 插入屏障
func DijkstraWritePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) {
shade(ptr)
*slot = ptr
}
|
- Slot 是 Go 代码里的被修改的指针对象
- Ptr 是 Slot 要修改成的值
上述插入写屏障的伪代码非常好理解,每当我们执行类似 *slot = ptr 的表达式时,我们会执行上述写屏障通过 shade 函数尝试改变指针的颜色。如果 ptr 指针是白色的,那么该函数会将该对象设置成灰色,其他情况则保持不变。
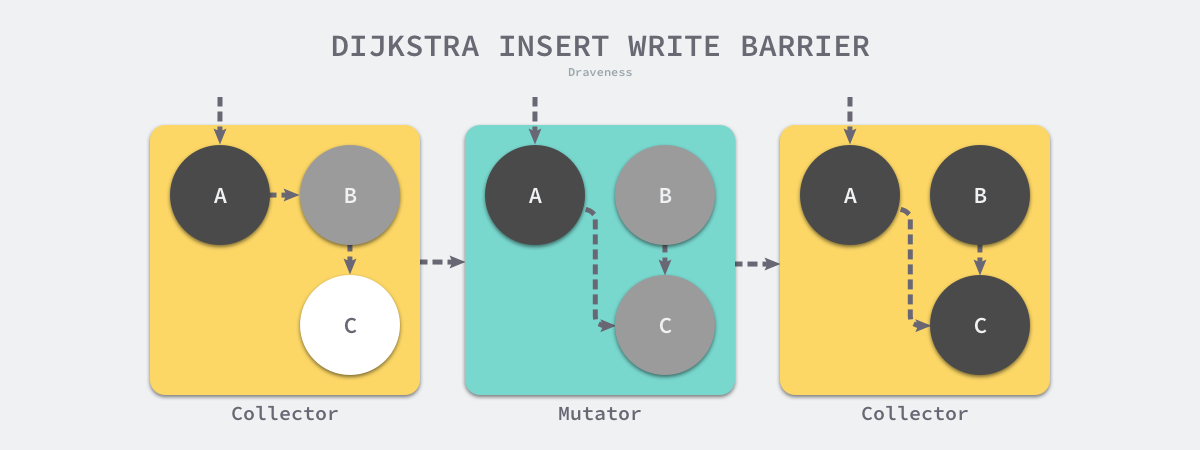
假设我们在应用程序中使用 Dijkstra 提出的插入写屏障,在一个垃圾收集器和用户程序交替运行的场景中会出现如上图所示的标记过程:
- 垃圾收集器将根对象指向 A 对象标记成黑色并将 A 对象指向的对象 B 标记成灰色;
- 用户程序修改 A 对象的指针,将原本指向 B 对象的指针指向 C 对象,这时触发写屏障将 C 对象标记成灰色;
- 垃圾收集器依次遍历程序中的其他灰色对象,将它们分别标记成黑色;
Dijkstra 的插入写屏障是一种相对保守的屏障技术,它会将有存活可能的对象都标记成灰色以满足强三色不变性。在如上所示的垃圾收集过程中,实际上不再存活的 B 对象最后没有被回收;而如果我们在第二和第三步之间将指向 C 对象的指针改回指向 B,垃圾收集器仍然认为 C 对象是存活的,这些被错误标记的垃圾对象只有在下一个循环才会被回收。
在 Go 语言 v1.7 版本之前,运行时会使用 Dijkstra 插入写屏障保证强三色不变性,但是运行时并没有在所有的垃圾收集根对象上开启插入写屏障。因为 Go 语言的应用程序可能包含成百上千的 Goroutine,而垃圾收集的根对象一般包括全局变量和栈对象,如果运行时需要在几百个 Goroutine 的栈上都开启写屏障,会带来巨大的额外开销,所以 Go 团队在实现上选择了在标记阶段完成时暂停程序、将所有栈对象标记为灰色并重新扫描,在活跃 Goroutine 非常多的程序中,重新扫描的过程需要占用 10 ~ 100ms 的时间。
插入式的 Dijkstra 写屏障虽然实现非常简单并且也能保证强三色不变性,但是它也有很明显的缺点。因为栈上的对象在垃圾收集中也会被认为是根对象,所以为了保证内存的安全,Dijkstra 在标记阶段完成重新对栈上的对象进行扫描,重新扫描栈对象时需要暂停程序,这个自然就会导致整个进程的赋值器卡顿,
删除写屏障
删除写屏障也叫基于快照的写屏障方案,必须在起始时,STW 扫描整个栈(注意了,是所有的 goroutine 栈),保证所有堆上在用的对象都处于灰色保护下,保证的是弱三色不变式;
该算法会使用如下所示的写屏障保证增量或者并发执行垃圾收集时程序的正确性:
1
2
3
4
5
|
// 黑色赋值器 Yuasa 屏障
func YuasaWritePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) {
shade(*slot)
*slot = ptr
}
|
上述代码会在老对象的引用被删除时,将白色的老对象涂成灰色,这样删除写屏障就可以保证弱三色不变性,老对象引用的下游对象一定可以被灰色对象引用。
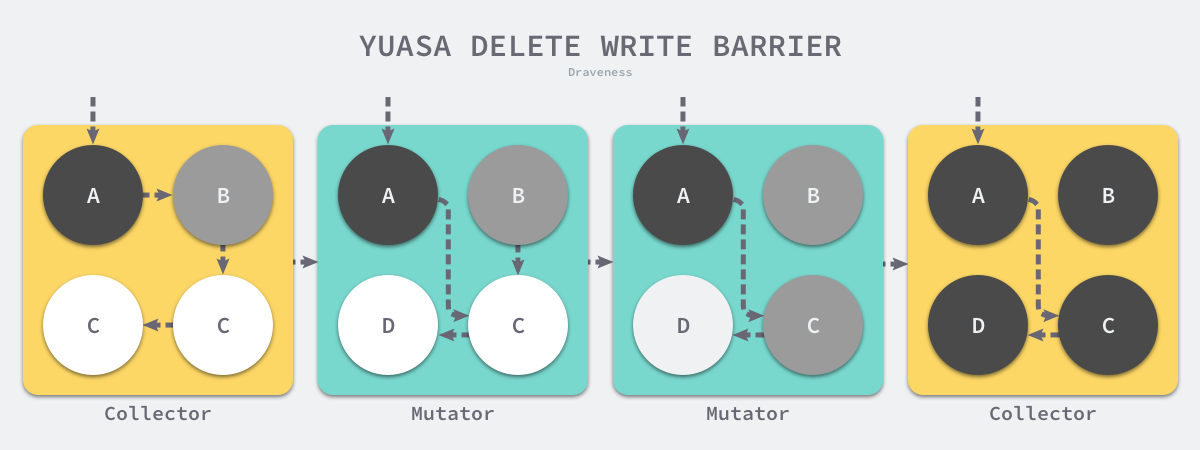
假设我们在应用程序中使用 Yuasa 提出的删除写屏障,在一个垃圾收集器和用户程序交替运行的场景中会出现如上图所示的标记过程:
- 垃圾收集器将根对象指向 A 对象标记成黑色并将 A 对象指向的对象 B 标记成灰色;
- 用户程序将 A 对象原本指向 B 的指针指向 C,触发删除写屏障,但是因为 B 对象已经是灰色的,所以不做改变;
- 用户程序将 B 对象原本指向 C 的指针删除,触发删除写屏障,白色的 C 对象被涂成灰色;
- 垃圾收集器依次遍历程序中的其他灰色对象,将它们分别标记成黑色;
上述过程中的第三步触发了 Yuasa 删除写屏障的着色,因为用户程序删除了 B 指向 C 对象的指针,所以 C 和 D 两个对象会分别违反强三色不变性和弱三色不变性:
- 强三色不变性 — 黑色的 A 对象直接指向白色的 C 对象;
- 弱三色不变性 — 垃圾收集器无法从某个灰色对象出发,经过几个连续的白色对象访问白色的 C 和 D 两个对象;
Yuasa 删除写屏障通过对 C 对象的着色,保证了 C 对象和下游的 D 对象能够在这一次垃圾收集的循环中存活,避免发生悬挂指针以保证用户程序的正确性。
由于起始快照的原因,起始也是执行 STW,删除写屏障不适用于栈特别大的场景,栈越大,STW 扫描时间越长,对于现代服务器上的程序来说,栈地址空间都很大,所以删除写屏障都不适用.
删除写屏障会导致扫描进度(波面)的后退,所以扫描精度不如插入写屏障.
写屏障对比
Dijkstra insertion barrier
优点:
- 能够保证堆上对象的强三色不变性(无栈对象参与时)
- 能防止指针从栈被隐藏进堆(因为堆上新建的连接都会被着色)
缺点:
- 不能防止栈上的黑色对象指向堆上的白色对象(这个白色对象之前是被堆上的黑/灰指着的),所以在mark结束后需要stw重新扫描所有 goroutine 栈
Yuasa deletion barrier
优点:
- 能够保证堆上的弱三色不变性(无栈对象参与时)
- 能防止指针从堆被隐藏进栈(因为堆上断开的连接都会被着色)
缺点:
- 不能防止堆上的黑色对象指向堆上的白色对象(这个白色对象之前是由栈的黑/灰色对象指着的),所以需要 GC 开始时 STW 对栈做快照
混合写屏障
在删除写屏障下,如果我不 STW 所有的栈,而是一个栈一个栈的快照,有什么问题?举例:如果没有把栈完全扫黑,那么可能出现丢数据,如下:
初始状态:
- A 是 g1 栈的一个对象,g1栈已经扫描完了,并且 C 也是扫黑了的对象;
- B 是 g2 栈的对象,指向了 C 和 D,g2 完全还没扫描,B 是一个灰色对象,D 是白色对象;
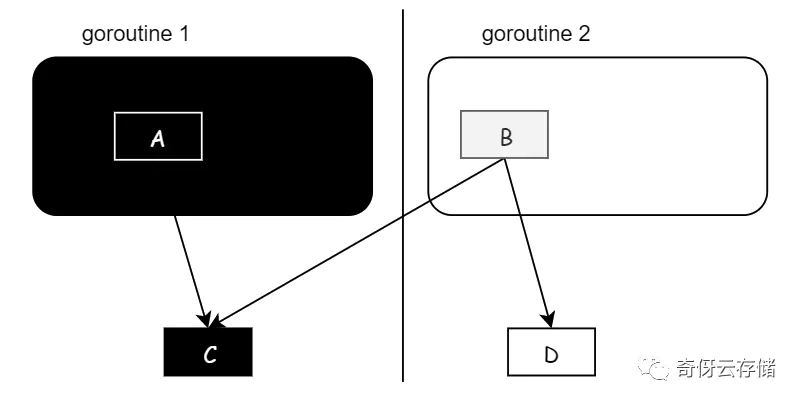
步骤一:g2 进行赋值变更,把 C 指向 D 对象,这个时候黑色的 C 就指向了白色的 D(由于是删除屏障,这里是不会触发hook的)
步骤二:把 B 指向 C 的引用删除,由于是栈对象操作,不会触发删除写屏障;
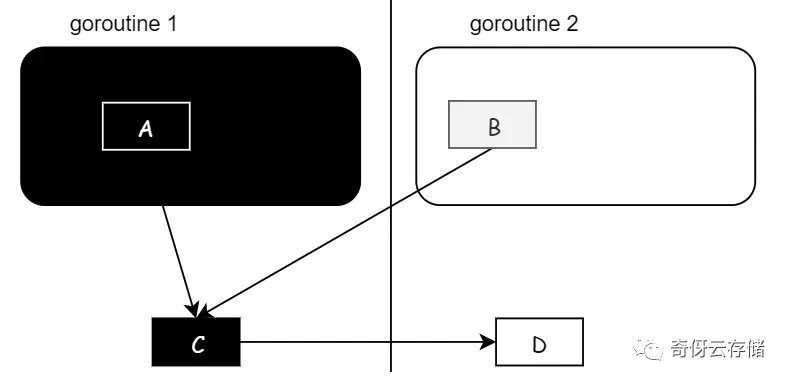
步骤三:清理,因为 C 已经是黑色对象了,所以不会再扫描,所以 D 就会被错误的清理掉。
解决办法:加入插入写屏障的逻辑,C 指向 D 的时候,把 D 置灰,这样扫描也没问题。这样就能去掉起始 STW 扫描,从而可以并发,一个一个栈扫描。这就成了当前在用的混合写屏障了
Go 语言在 v1.8 组合 Dijkstra 插入写屏障和 Yuasa 删除写屏障构成了如下所示的混合写屏障,该写屏障会将被覆盖的对象标记成灰色并在当前栈没有扫描时将新对象也标记成灰色:
1
2
3
4
5
|
writePointer(slot, ptr):
shade(*slot)
if current stack is grey:
shade(ptr)
*slot = ptr
|
后来Go语言团队认为 stack check 成本太高,至少要进行一次atomic操作,实际上在Go语言是如此实现的:
1
2
3
4
|
writePointer(slot, ptr):
shade(*slot)
shade(ptr)
*slot = ptr
|
混合写屏障具体操作:
-
GC开始后逐一将栈上的对象全部扫描并标记为黑色(无需STW),
-
GC期间,任何在栈上创建的新对象,均为黑色。防止新分配的栈内存和堆内存中的对象被错误地回收,因为栈内存在标记阶段最终都会变为黑色,所以不再需要重新扫描栈空间。
-
被删除的对象标记为灰色。
-
被添加的对象标记为灰色。
满足: 变形的弱三色不变式.
采用混合屏障后可以大幅压缩1.7版本插入写屏障带来的的第二次STW的时间。
总结:
- 混合写屏障继承了插入写屏障的优点,起始无需 STW 打快照,直接并发扫描垃圾即可;
- 混合写屏障继承了删除写屏障的优点,消除了插入写屏障时期最后 STW 的重新扫描栈;
- 混合写屏障扫描栈虽然没有 STW,但是扫描某一个具体的栈的时候,还是要停止这个 goroutine 赋值器的工作.
增量和并发
传统的垃圾收集算法会在垃圾收集的执行期间暂停应用程序,一旦触发垃圾收集,垃圾收集器就会抢占 CPU 的使用权占据大量的计算资源以完成标记和清除工作,然而很多追求实时的应用程序无法接受长时间的 STW。
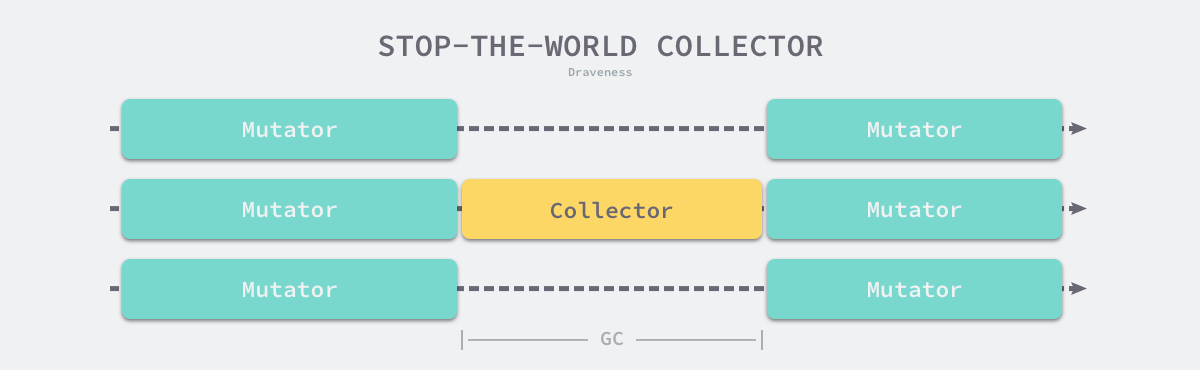
远古时代的计算资源还没有今天这么丰富,今天的计算机往往都是多核的处理器,垃圾收集器一旦开始执行就会浪费大量的计算资源,为了减少应用程序暂停的最长时间和垃圾收集的总暂停时间,我们会使用下面的策略优化现代的垃圾收集器:
- 增量垃圾收集 — 增量地标记和清除垃圾,降低应用程序暂停的最长时间;
- 并发垃圾收集 — 利用多核的计算资源,在用户程序执行时并发标记和清除垃圾;
因为增量和并发两种方式都可以与用户程序交替运行,所以我们需要使用屏障技术保证垃圾收集的正确性;与此同时,应用程序也不能等到内存溢出时触发垃圾收集,因为当内存不足时,应用程序已经无法分配内存,这与直接暂停程序没有什么区别,增量和并发的垃圾收集需要提前触发并在内存不足前完成整个循环,避免程序的长时间暂停。
增量收集器
增量式(Incremental)的垃圾收集是减少程序最长暂停时间的一种方案,它可以将原本时间较长的暂停时间切分成多个更小的 GC 时间片,虽然从垃圾收集开始到结束的时间更长了,但是这也减少了应用程序暂停的最大时间:
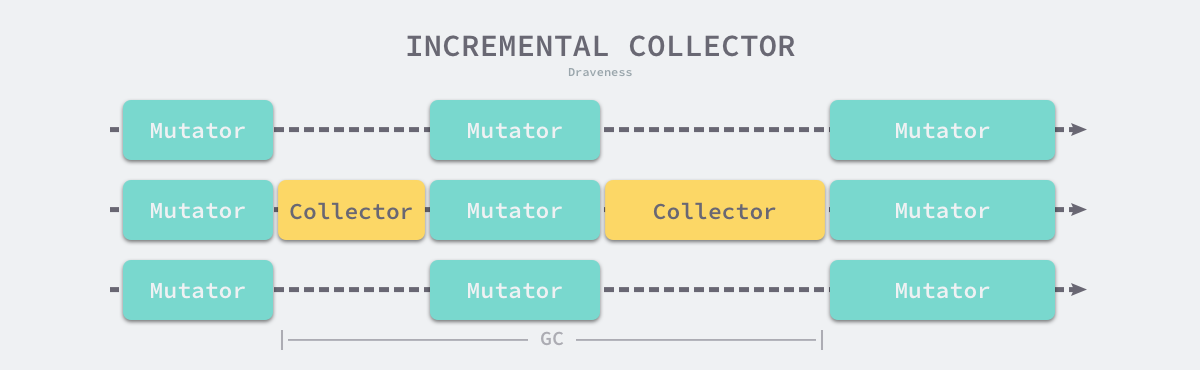
需要注意的是,增量式的垃圾收集需要与三色标记法一起使用,为了保证垃圾收集的正确性,我们需要在垃圾收集开始前打开写屏障,这样用户程序对内存的修改都会先经过写屏障的处理,保证了堆内存中对象关系的强三色不变性或者弱三色不变性。虽然增量式的垃圾收集能够减少最大的程序暂停时间,但是增量式收集也会增加一次 GC 循环的总时间,在垃圾收集期间,因为写屏障的影响用户程序也需要承担额外的计算开销,所以增量式的垃圾收集也不是只有优点的。
并发收集器
并发(Concurrent)的垃圾收集不仅能够减少程序的最长暂停时间,还能减少整个垃圾收集阶段的时间,通过开启读写屏障、利用多核优势与用户程序并行执行,并发垃圾收集器确实能够减少垃圾收集对应用程序的影响:
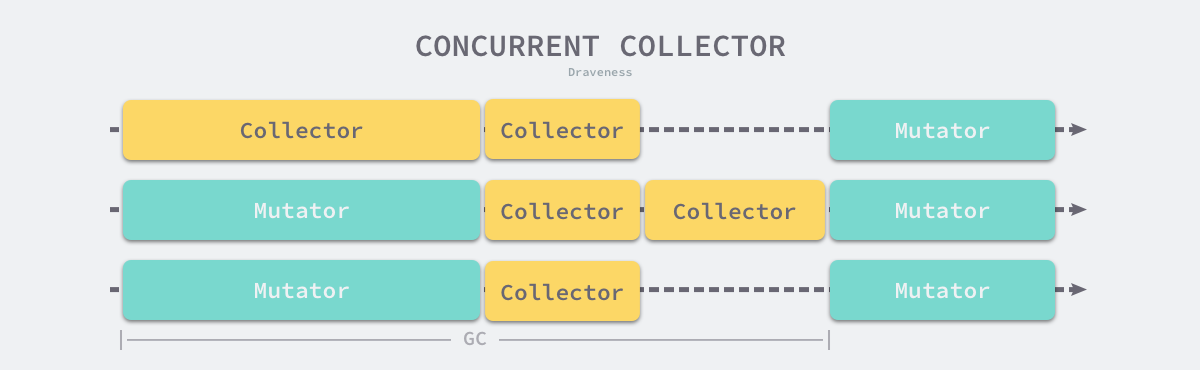
虽然并发收集器能够与用户程序一起运行,但是并不是所有阶段都可以与用户程序一起运行,部分阶段还是需要暂停用户程序的,不过与传统的算法相比,并发的垃圾收集可以将能够并发执行的工作尽量并发执行;当然,因为读写屏障的引入,并发的垃圾收集器也一定会带来额外开销,不仅会增加垃圾收集的总时间,还会影响用户程序,这是我们在设计垃圾收集策略时必须要注意的。
Go 语言在 v1.5 中引入了并发的垃圾收集器,该垃圾收集器使用了我们上面提到的三色抽象和写屏障技术保证垃圾收集器执行的正确性,如何实现并发的垃圾收集器在这里就不展开介绍了,我们来了解一些并发垃圾收集器的工作流程。
首先,并发垃圾收集器必须在合适的时间点触发垃圾收集循环,假设我们的 Go 语言程序运行在一台 4 核的物理机上,那么在垃圾收集开始后,收集器会占用 25% 计算资源在后台来扫描并标记内存中的对象:
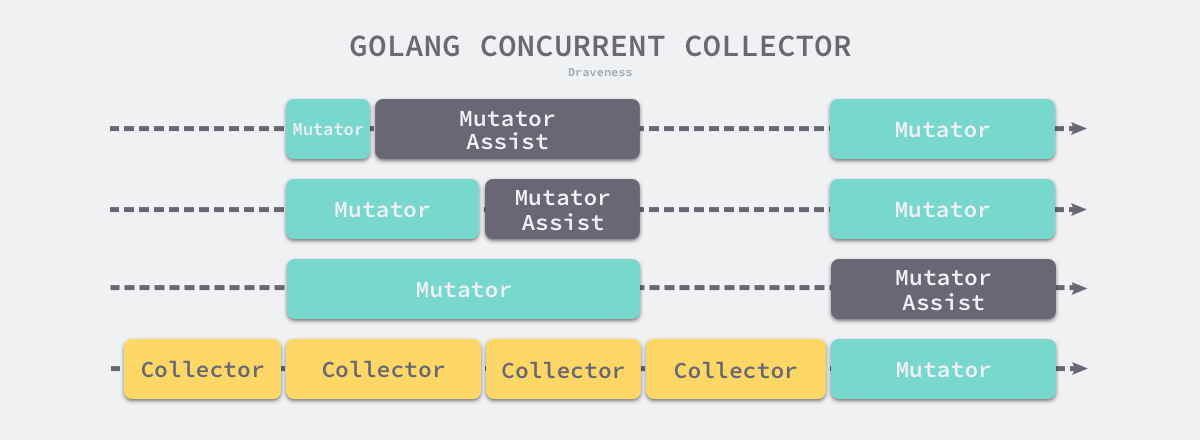
Go 语言的并发垃圾收集器会在扫描对象之前暂停程序做一些标记对象的准备工作,其中包括启动后台标记的垃圾收集器以及开启写屏障,如果在后台执行的垃圾收集器不够快,应用程序申请内存的速度超过预期,运行时就会让申请内存的应用程序辅助完成垃圾收集的扫描阶段,在标记和标记终止阶段结束之后就会进入异步的清理阶段,将不用的内存增量回收。
v1.5 版本实现的并发垃圾收集策略由专门的 Goroutine 负责在处理器之间同步和协调垃圾收集的状态。当其他的 Goroutine 发现需要触发垃圾收集时,它们需要将该信息通知给负责修改状态的主 Goroutine,然而这个通知的过程会带来一定的延迟,这个延迟的时间窗口很可能是不可控的,用户程序会在这段时间分配界面很多内存空间。
v1.6 引入了去中心化的垃圾收集协调机制,将垃圾收集器变成一个显式的状态机,任意的 Goroutine 都可以调用方法触发状态的迁移,常见的状态迁移方法包括以下几个
- runtime.gcStart — 从
_GCoff 转换至_GCmark 阶段,进入并发标记阶段并打开写屏障;
- runtime.gcMarkDone — 如果所有可达对象都已经完成扫描,调用
runtime.gcMarkTermination;
- runtime.gcMarkTermination — 从
_GCmark 转换_GCmarktermination 阶段,进入标记终止阶段并在完成后进入 _GCoff;
调步算法
STW 的垃圾收集器虽然需要暂停程序,但是它能够有效地控制堆内存的大小,Go 语言运行时的默认配置会在堆内存达到上一次垃圾收集的 2 倍时,触发新一轮的垃圾收集,这个行为可以通过环境变量 GOGC 调整,在默认情况下它的值为 100,即增长 100% 的堆内存才会触发 GC。

因为并发垃圾收集器会与程序一起运行,所以它无法准确的控制堆内存的大小,并发收集器需要在达到目标前触发垃圾收集,这样才能够保证内存大小的可控,并发收集器需要尽可能保证垃圾收集结束时的堆内存与用户配置的 GOGC 一致。

Go 语言 v1.5 引入并发垃圾收集器的同时使用垃圾收集调步(Pacing)算法计算触发的垃圾收集的最佳时间,确保触发的时间既不会浪费计算资源,也不会超出预期的堆大小。如上图所示,其中黑色的部分是上一次垃圾收集后标记的堆大小,绿色部分是上次垃圾收集结束后新分配的内存,因为我们使用并发垃圾收集,所以黄色的部分就是在垃圾收集期间分配的内存,最后的红色部分是垃圾收集结束时与目标的差值,我们希望尽可能减少红色部分内存,降低垃圾收集带来的额外开销以及程序的暂停时间。
垃圾收集调步算法是跟随 v1.5 一同引入的,该算法的目标是优化堆的增长速度和垃圾收集器的 CPU 利用率,而在 v1.10 版本中又对该算法进行了优化,将原有的目的堆大小拆分成了软硬两个目标.
调步算法包含四个部分:
- GC 周期所需的扫描估计器
- 为用户代码根据堆分配到目标堆大小的时间估计扫描工作量的机制
- 用户代码为未充分利用 CPU 预算时进行后台扫描的调度程序
- GC 触发比率的控制器
现在我们从两个不同的视角来对这个问题进行建模。

Ht的时候开始GC,Ha的时候结束GC,Ha非常接近Hg。
如何保证在Ht开始gc时所有的span都被清扫完?
除了有一个后台清扫协程外,用户在分配内存时也需要辅助清扫来保证在开启下一轮的gc时span都被清扫完毕。假设有k page的span需要sweep,那么距离下一次gc还有Ht-Hm(n-1)的内存可供分配,那么平均每申请1byte内存需要清扫k/ Ht-Hm(n-1) page 的span。(k值会根据sweep进度更改)
辅助清扫申请新span时才会检查,辅助清扫的触发可以看cacheSpan函数, 触发时G会帮助回收"工作量"页的对象.
1
|
spanBytes * sweepPagesPerByte
|
意思是分配的大小乘以系数sweepPagesPerByte, sweepPagesPerByte的计算在函数gcSetTriggerRatio中.
如何保证在Ha时gc都被mark完?
Gc在Ht开始,在到达Hg时尽量标记完所有的对象,除了后台的标记协程外还需要在分配内存是进行辅助mark。从Ht到Hg的内存可以分配,这个时候还有scanWorkExpected的对象需要scan,那么平均分配1byte内存需要辅助mark量:scanWorkExpected/(Hg-Ht) 个对象,scanWorkExpected会根据mark进度更改。
辅助标记的触发可以查看上面的mallocgc函数, 触发时G会帮助扫描"工作量"个对象, 工作量的计算公式是:
1
|
debtBytes * assistWorkPerByte
|
意思是分配的大小乘以系数assistWorkPerByte, assistWorkPerByte的计算在函数revise中.
流程图
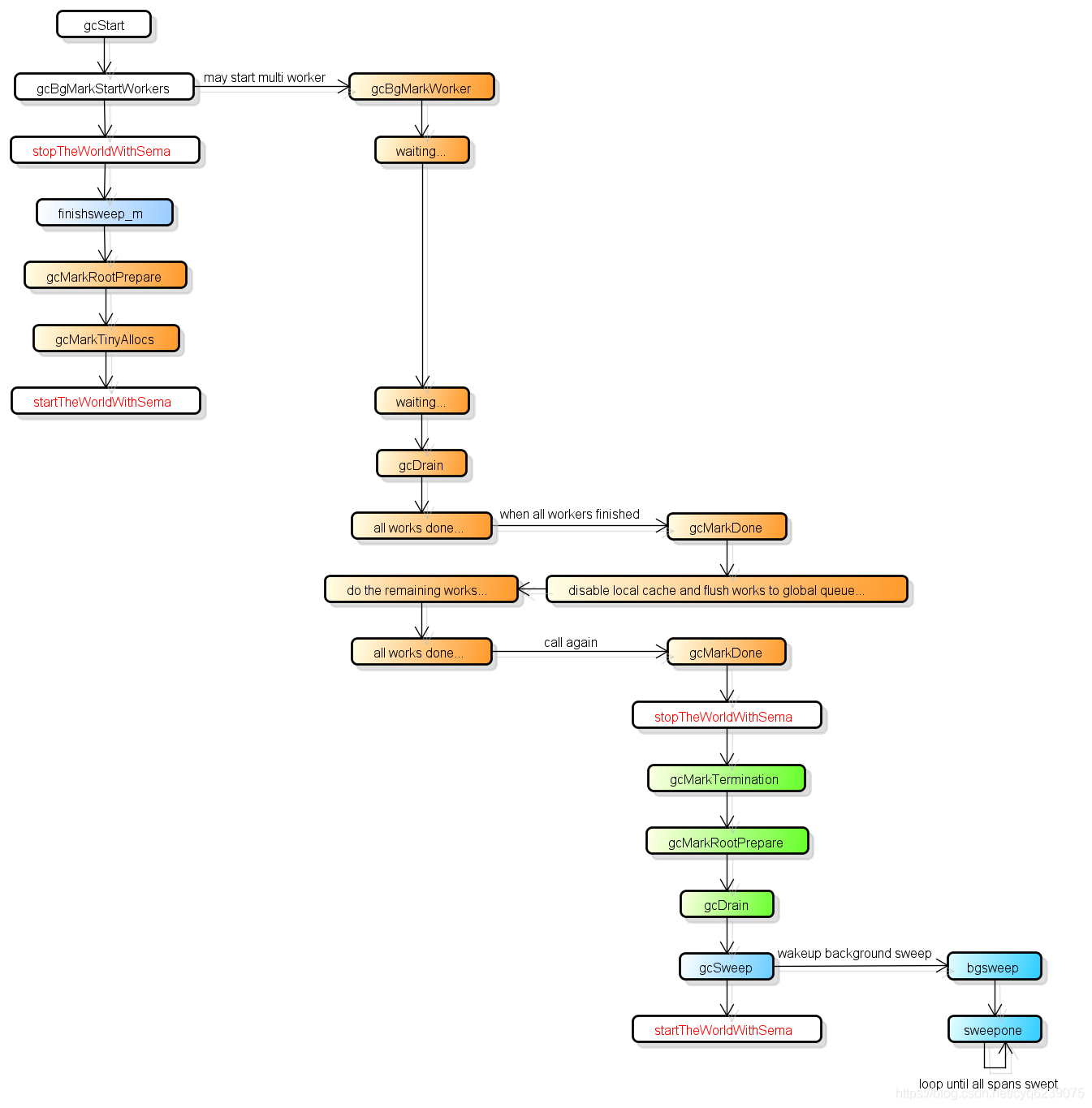
垃圾回收代码流程
- gcStart -> gcBgMarkWorker && gcRootPrepare,这时 gcBgMarkWorker 在休眠中
- schedule -> findRunnableGCWorker 唤醒适宜数量的 gcBgMarkWorker
- gcBgMarkWorker -> gcDrain -> scanobject -> greyobject(set mark bit and put to gcw)
- 在 gcBgMarkWorker 中调用 gcMarkDone 排空各种 wbBuf 后,使用分布式 termination 检查算法,进入 gcMarkTermination -> gcSweep 唤醒后台沉睡的 sweepg 和 scvg -> sweep -> wake bgsweep && bgscavenge
全局变量
在垃圾收集中有一些比较重要的全局变量,在分析其过程之前,我们会先逐一介绍这些重要的变量,这些变量在垃圾收集的各个阶段中会反复出现,所以理解他们的功能是非常重要的,我们先介绍一些比较简单的变量:
- runtime.gcphase 是垃圾收集器当前处于的阶段,可能处于 _GCoff、_GCmark 和 _GCmarktermination,Goroutine 在读取或者修改该阶段时需要保证原子性;
- runtime.gcBlackenEnabled 是一个布尔值,当垃圾收集处于标记阶段时,该变量会被置为 1,在这里辅助垃圾收集的用户程序和后台标记的任务可以将对象涂黑;
- runtime.gcController 实现了垃圾收集的调步算法,它能够决定触发并行垃圾收集的时间和待处理的工作;
- runtime.gcpercent 是触发垃圾收集的内存增长百分比,默认情况下为 100,即堆内存相比上次垃圾收集增长 100% 时应该触发 GC,并行的垃圾收集器会在到达该目标前完成垃圾收集;
- runtime.writeBarrier 是一个包含写屏障状态的结构体,其中的 enabled 字段表示写屏障的开启与关闭;
- runtime.worldsema 是全局的信号量,获取该信号量的线程有权利暂停当前应用程序;
除了上述全局的变量之外,我们在这里还需要简单了解一下 runtime.work 变量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
|
var work struct {
full lfstack // lock-free list of full blocks workbuf
empty lfstack // lock-free list of empty blocks workbuf
pad0 cpu.CacheLinePad // prevents false-sharing between full/empty and nproc/nwait
wbufSpans struct {
lock mutex
// free is a list of spans dedicated to workbufs, but
// that don't currently contain any workbufs.
free mSpanList
// busy is a list of all spans containing workbufs on
// one of the workbuf lists.
busy mSpanList
}
// Restore 64-bit alignment on 32-bit.
_ uint32
// bytesMarked is the number of bytes marked this cycle. This
// includes bytes blackened in scanned objects, noscan objects
// that go straight to black, and permagrey objects scanned by
// markroot during the concurrent scan phase. This is updated
// atomically during the cycle. Updates may be batched
// arbitrarily, since the value is only read at the end of the
// cycle.
//
// Because of benign races during marking, this number may not
// be the exact number of marked bytes, but it should be very
// close.
//
// Put this field here because it needs 64-bit atomic access
// (and thus 8-byte alignment even on 32-bit architectures).
bytesMarked uint64
markrootNext uint32 // next markroot job
markrootJobs uint32 // number of markroot jobs
nproc uint32
tstart int64
nwait uint32
ndone uint32
// Number of roots of various root types. Set by gcMarkRootPrepare.
nFlushCacheRoots int
nDataRoots, nBSSRoots, nSpanRoots, nStackRoots int
// Each type of GC state transition is protected by a lock.
// Since multiple threads can simultaneously detect the state
// transition condition, any thread that detects a transition
// condition must acquire the appropriate transition lock,
// re-check the transition condition and return if it no
// longer holds or perform the transition if it does.
// Likewise, any transition must invalidate the transition
// condition before releasing the lock. This ensures that each
// transition is performed by exactly one thread and threads
// that need the transition to happen block until it has
// happened.
//
// startSema protects the transition from "off" to mark or
// mark termination.
startSema uint32
// markDoneSema protects transitions from mark to mark termination.
markDoneSema uint32
bgMarkReady note // signal background mark worker has started
bgMarkDone uint32 // cas to 1 when at a background mark completion point
// Background mark completion signaling
// mode is the concurrency mode of the current GC cycle.
mode gcMode
// userForced indicates the current GC cycle was forced by an
// explicit user call.
userForced bool
// totaltime is the CPU nanoseconds spent in GC since the
// program started if debug.gctrace > 0.
totaltime int64
// initialHeapLive is the value of memstats.heap_live at the
// beginning of this GC cycle.
initialHeapLive uint64
// assistQueue is a queue of assists that are blocked because
// there was neither enough credit to steal or enough work to
// do.
assistQueue struct {
lock mutex
q gQueue
}
// sweepWaiters is a list of blocked goroutines to wake when
// we transition from mark termination to sweep.
sweepWaiters struct {
lock mutex
list gList
}
// cycles is the number of completed GC cycles, where a GC
// cycle is sweep termination, mark, mark termination, and
// sweep. This differs from memstats.numgc, which is
// incremented at mark termination.
cycles uint32
// Timing/utilization stats for this cycle.
stwprocs, maxprocs int32
tSweepTerm, tMark, tMarkTerm, tEnd int64 // nanotime() of phase start
pauseNS int64 // total STW time this cycle
pauseStart int64 // nanotime() of last STW
// debug.gctrace heap sizes for this cycle.
heap0, heap1, heap2, heapGoal uint64
}
|
该结构体中包含大量垃圾收集的相关字段,例如:表示完成的垃圾收集循环的次数、当前循环时间和 CPU 的利用率、垃圾收集的模式等等,我们会在后面的小节中见到该结构体中的更多的字段。
根对象
在GC的标记阶段首先需要标记的就是"根对象", 从根对象开始可到达的所有对象都会被认为是存活的.
根对象包含了全局变量, 各个G的栈上的变量等, GC会先扫描根对象然后再扫描根对象可到达的所有对象.
- Fixed Roots: 特殊的扫描工作 :
- fixedRootFinalizers: 扫描析构器队列
- fixedRootFreeGStacks: 释放已中止的G的栈
- Flush Cache Roots: 释放mcache中的所有span, 要求STW
- Data Roots: 扫描可读写的全局变量
- BSS Roots: 扫描只读的全局变量
- Span Roots: 扫描各个span中特殊对象(析构器列表)
- Stack Roots: 扫描各个G的栈
标记阶段(Mark)会做其中的"Fixed Roots", “Data Roots”, “BSS Roots”, “Span Roots”, “Stack Roots”.
完成标记阶段(Mark Termination)会做其中的"Fixed Roots", “Flush Cache Roots”.
触发时机
gcTrigger
运行时会通过如下所示的 runtime.gcTrigger.test 方法决定是否需要触发垃圾收集,当满足触发垃圾收集的基本条件时 — 允许垃圾收集、程序没有崩溃并且没有处于垃圾收集循环,该方法会根据三种不同的方式触发进行不同的检查:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
// gcTrigger 是一个 GC 周期开始的谓词。具体而言,它是一个 _GCoff 阶段的退出条件
type gcTrigger struct {
kind gcTriggerKind
now int64 // gcTriggerTime: 当前时间
n uint32 // gcTriggerCycle: 开始的周期数
}
type gcTriggerKind int
const (
// gcTriggerHeap 表示当堆大小达到控制器计算的触发堆大小时开始一个周期
gcTriggerHeap gcTriggerKind = iota
// gcTriggerTime 表示自上一个 GC 周期后当循环超过
// forcegcperiod 纳秒时应开始一个周期。
gcTriggerTime
// gcTriggerCycle 表示如果我们还没有启动第 gcTrigger.n 个周期
// (相对于 work.cycles)时应开始一个周期。
gcTriggerCycle
)
// test 报告当前出发条件是否满足,换句话说 _GCoff 阶段的退出条件已满足。
// 退出条件应该在分配阶段已完成测试。
func (t gcTrigger) test() bool {
// 如果已禁用 GC
if !memstats.enablegc || panicking != 0 || gcphase != _GCoff {
return false
}
// 根据类别做不同判断
switch t.kind {
case gcTriggerHeap:
// 上个周期结束时剩余的加上到目前为止分配的内存 超过 触发标记阶段标准的内存
// 考虑性能问题,对非原子操作访问 heap_live 。如果我们需要触发该条件,
// 则所在线程一定会原子的写入 heap_live,从而我们会观察到我们的写入。
return memstats.heap_live >= memstats.gc_trigger
case gcTriggerTime:
// 因为允许在运行时动态调整 gcpercent,因此需要额外再检查一遍
if gcpercent < 0 {
return false
}
// 计算上次 gc 开始时间是否大于强制执行 GC 周期的时间
lastgc := int64(atomic.Load64(&memstats.last_gc_nanotime))
return lastgc != 0 && t.now-lastgc > forcegcperiod// 两分钟
case gcTriggerCycle:
// 进行测试的周期 t.n 大于实际触发的,需要进行 GC 则通过测试
return int32(t.n-work.cycles) > 0
}
return true
}
|
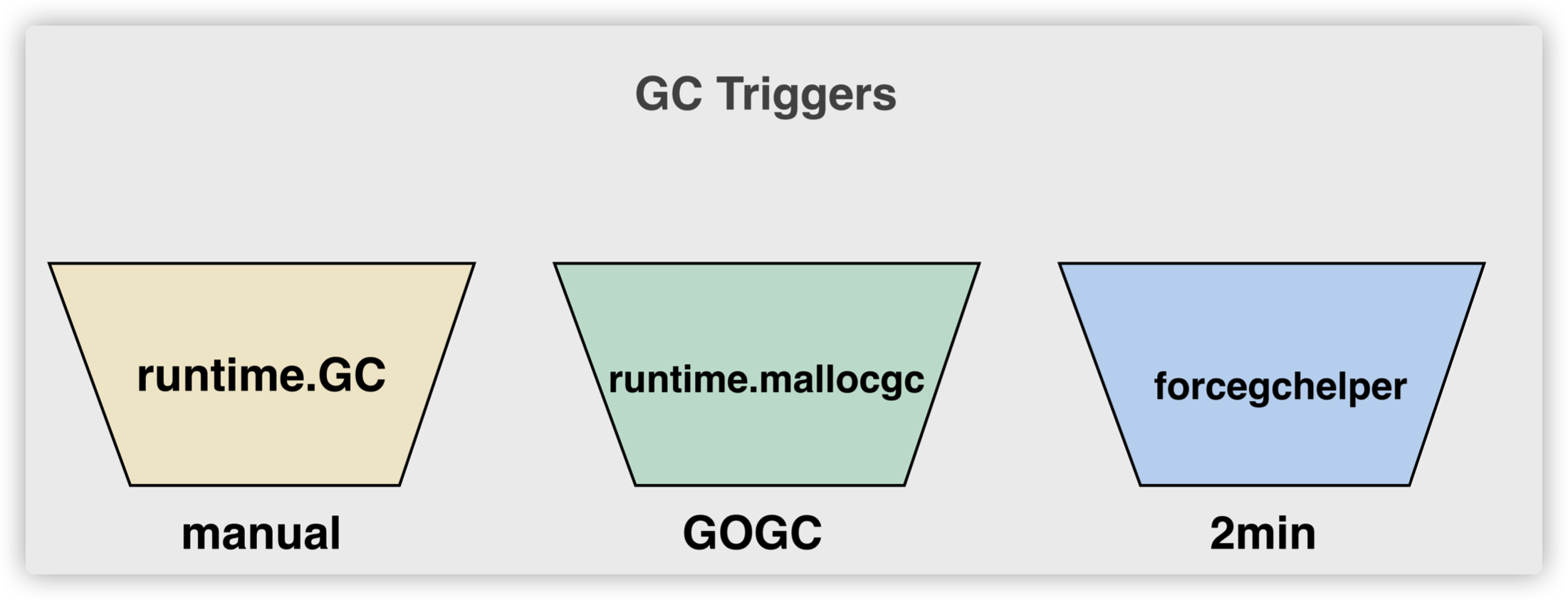
- gcTriggerHeap — 堆内存的分配达到控制器计算的触发堆大小;
- gcTriggerTime — 如果一定时间内没有触发,就会触发新的循环,该出发条件由 runtime.forcegcperiod 变量控制,默认为 2 分钟;
- gcTriggerCycle — 如果当前没有开启垃圾收集,则触发新的循环;
用于开启垃圾收集的方法 runtime.gcStart 会接收一个 runtime.gcTrigger 类型的谓词,我们可以根据这个触发_GCoff 退出的结构体找到所有触发的垃圾收集的代码:
- runtime.sysmon 和 runtime.forcegchelper — 后台运行定时检查和垃圾收集;
- runtime.GC — 用户程序手动触发垃圾收集;
- runtime.mallocgc — 申请内存时根据堆大小触发垃圾收集;
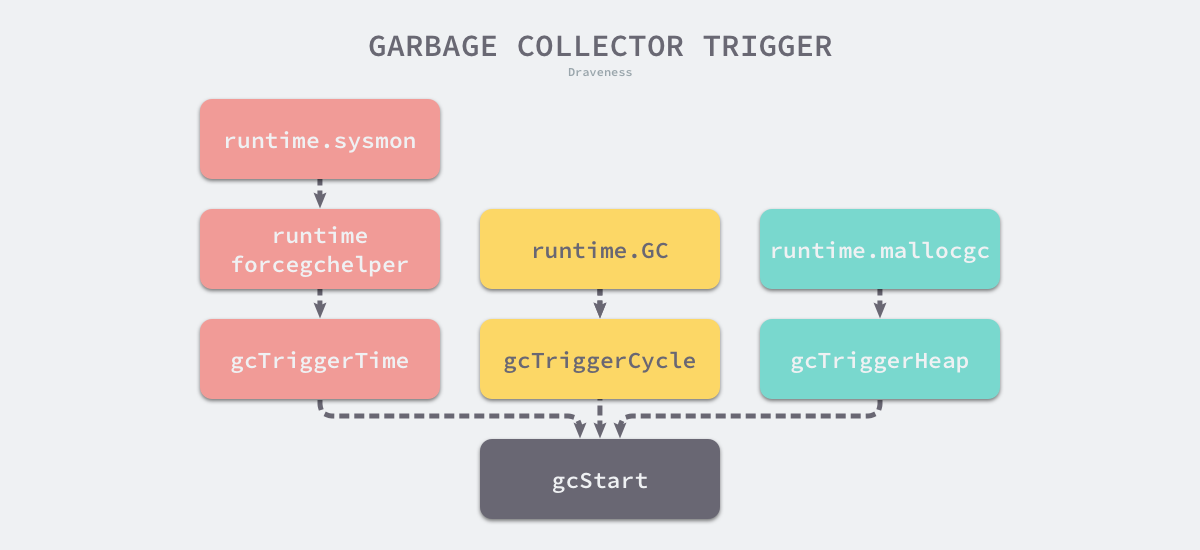
通过堆内存触发垃圾收集需要比较 runtime.mstats 中的两个字段:
- heap_live:表示垃圾收集中存活对象的字节数
- gc_trigger:表示触发标记的堆内存的大小
当内存中存活的对象字节数大于触发垃圾收集的堆大小时,新一轮的垃圾收集就会开始。
在这里,我们将分别介绍这两个值的计算过程:
- heap_live — 为了减少锁竞争,运行时只会在中心缓存分配或者释放内存管理单元以及在堆上分配大对象时才会更新;
- gc_trigger — 在标记终止阶段调用 runtime.gcSetTriggerRatio 更新触发下一次垃圾收集的堆大小;
runtime.gcController 会在每个循环结束后计算触发比例并通过 runtime.gcSetTriggerRatio 设置 gc_trigger,它能够决定触发垃圾收集的时间以及用户程序和后台处理的标记任务的多少,利用反馈控制的算法根据堆的增长情况和垃圾收集 CPU 利用率确定触发垃圾收集的时机。
后台触发
运行时会在应用程序启动时在后台开启一个用于强制触发垃圾收集的 Goroutine,该 Goroutine 的职责非常简单 — 调用 runtime.gcStart 方法尝试启动新一轮的垃圾收集:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
func init() {
go forcegchelper()
}
func forcegchelper() {
forcegc.g = getg()
lockInit(&forcegc.lock, lockRankForcegc)
for {
lock(&forcegc.lock)
if forcegc.idle != 0 {
throw("forcegc: phase error")
}
atomic.Store(&forcegc.idle, 1)
goparkunlock(&forcegc.lock, waitReasonForceGCIdle, traceEvGoBlock, 1)
// this goroutine is explicitly resumed by sysmon
if debug.gctrace > 0 {
println("GC forced")
}
// Time-triggered, fully concurrent.
gcStart(gcTrigger{kind: gcTriggerTime, now: nanotime()})
}
}
|
为了减少对计算资源的占用,该 Goroutine 会在循环中调用 runtime.goparkunlock 主动陷入休眠等待其他 Goroutine 的唤醒,runtime.forcegchelper 在大多数时间都是陷入休眠的,但是它会被系统监控器 runtime.sysmon 在满足垃圾收集条件时唤醒:
1
2
3
4
5
|
// Puts the current goroutine into a waiting state and unlocks the lock.
// The goroutine can be made runnable again by calling goready(gp).
func goparkunlock(lock *mutex, reason waitReason, traceEv byte, traceskip int) {
gopark(parkunlock_c, unsafe.Pointer(lock), reason, traceEv, traceskip)
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func sysmon() {
...
for {
...
if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && atomic.Load(&forcegc.idle) != 0 {
lock(&forcegc.lock)
forcegc.idle = 0
var list gList
list.push(forcegc.g)
injectglist(&list)
unlock(&forcegc.lock)
}
}
}
|
系统监控在每个循环中都会主动构建一个 runtime.gcTrigger 并检查垃圾收集的触发条件是否满足,如果满足条件,系统监控会将 runtime.forcegc 状态中持有的 Goroutine 加入全局队列等待调度器的调度。
手动触发
用户程序会通过 runtime.GC 函数在程序运行期间主动通知运行时执行,该方法在调用时会阻塞调用方直到当前垃圾收集循环完成,在垃圾收集期间也可能会通过 STW 暂停整个程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
|
// GC runs a garbage collection and blocks the caller until the
// garbage collection is complete. It may also block the entire
// program.
func GC() {
// We consider a cycle to be: sweep termination, mark, mark
// termination, and sweep. This function shouldn't return
// until a full cycle has been completed, from beginning to
// end. Hence, we always want to finish up the current cycle
// and start a new one. That means:
//
// 1. In sweep termination, mark, or mark termination of cycle
// N, wait until mark termination N completes and transitions
// to sweep N.
//
// 2. In sweep N, help with sweep N.
//
// At this point we can begin a full cycle N+1.
//
// 3. Trigger cycle N+1 by starting sweep termination N+1.
//
// 4. Wait for mark termination N+1 to complete.
//
// 5. Help with sweep N+1 until it's done.
//
// This all has to be written to deal with the fact that the
// GC may move ahead on its own. For example, when we block
// until mark termination N, we may wake up in cycle N+2.
// Wait until the current sweep termination, mark, and mark
// termination complete.
n := atomic.Load(&work.cycles)
//在正式开始垃圾收集前,运行时需要通过 runtime.gcWaitOnMark 函数等待上一个循环的标记终止、标记和标记终止阶段完成;
gcWaitOnMark(n)
// We're now in sweep N or later. Trigger GC cycle N+1, which
// will first finish sweep N if necessary and then enter sweep
// termination N+1.
//调用 runtime.gcStart 触发新一轮的垃圾收集
gcStart(gcTrigger{kind: gcTriggerCycle, n: n + 1})
// Wait for mark termination N+1 to complete.
//通过 runtime.gcWaitOnMark 等待该轮垃圾收集的标记终止阶段正常结束;
gcWaitOnMark(n + 1)
// Finish sweep N+1 before returning. We do this both to
// complete the cycle and because runtime.GC() is often used
// as part of tests and benchmarks to get the system into a
// relatively stable and isolated state.
//持续调用 runtime.sweepone 清理全部待处理的内存管理单元并等待所有的清理工作完成,等待期间会调用 runtime.Gosched 让出处理器;
for atomic.Load(&work.cycles) == n+1 && sweepone() != ^uintptr(0) {
sweep.nbgsweep++
Gosched()
}
// Callers may assume that the heap profile reflects the
// just-completed cycle when this returns (historically this
// happened because this was a STW GC), but right now the
// profile still reflects mark termination N, not N+1.
//
// As soon as all of the sweep frees from cycle N+1 are done,
// we can go ahead and publish the heap profile.
//
// First, wait for sweeping to finish. (We know there are no
// more spans on the sweep queue, but we may be concurrently
// sweeping spans, so we have to wait.)
for atomic.Load(&work.cycles) == n+1 && atomic.Load(&mheap_.sweepers) != 0 {
Gosched()
}
// Now we're really done with sweeping, so we can publish the
// stable heap profile. Only do this if we haven't already hit
// another mark termination.
mp := acquirem()
cycle := atomic.Load(&work.cycles)
//完成本轮垃圾收集的清理工作后,通过 runtime.mProf_PostSweep 将该阶段的堆内存状态快照发布出来,我们可以获取这时的内存状态;
if cycle == n+1 || (gcphase == _GCmark && cycle == n+2) {
mProf_PostSweep()
}
releasem(mp)
}
|
手动触发垃圾收集的过程不是特别常见,一般只会在运行时的测试代码中才会出现,不过如果我们认为触发主动垃圾收集是有必要的,我们也可以直接调用该方法,但是作者并不认为这是一种推荐的做法。
申请内存
最后一个可能会触发垃圾收集的就是 runtime.mallocgc 函数了,我们在内存分配器中曾经介绍过运行时会将堆上的对象按大小分成微对象、小对象和大对象三类,这三类对象的创建都可能会触发新的垃圾收集循环:
- 当前线程的内存管理单元中不存在空闲空间时,创建微对象和小对象需要调用
runtime.mcache.nextFree 方法从中心缓存或者页堆中获取新的管理单元,在这时就可能触发垃圾收集;
- 当用户程序申请分配 32KB 以上的大对象时,一定会构建 runtime.gcTrigger 结构体尝试触发 垃圾收集;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
shouldhelpgc := false
...
if size <= maxSmallSize {
if noscan && size < maxTinySize {
...
v := nextFreeFast(span)
if v == 0 {
v, _, shouldhelpgc = c.nextFree(tinySpanClass)
}
...
} else {
...
v := nextFreeFast(span)
if v == 0 {
v, span, shouldhelpgc = c.nextFree(spc)
}
...
}
} else {
shouldhelpgc = true
...
}
...
if shouldhelpgc {
if t := (gcTrigger{kind: gcTriggerHeap}); t.test() {
gcStart(t)
}
}
return x
}
|
垃圾收集启动:gcStart
垃圾收集在启动过程一定会调用 runtime.gcStart 函数,虽然该函数的实现比较复杂,但是它的主要职责就是修改全局的垃圾收集状态到 _GCmark 并做一些准备工作,我们会分以下几个阶段介绍该函数的实现:
- 两次调用 runtime.gcTrigger.test 方法检查是否满足垃圾收集条件;
- 暂停程序、在后台启动用于处理标记任务的工作 Goroutine、确定所有内存管理单元都被清理以及其他标记阶段开始前的准备工作;
- 进入标记阶段、准备后台的标记工作、根对象的标记工作以及微对象、恢复用户程序,进入并发扫描和标记阶段;
验证垃圾收集条件的同时,该方法还会在循环中不断调用 runtime.sweepone 清理已经被标记的内存单元,完成上一个垃圾收集循环的收尾工作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
|
// gcStart starts the GC. It transitions from _GCoff to _GCmark (if
// debug.gcstoptheworld == 0) or performs all of GC (if
// debug.gcstoptheworld != 0).
//
// This may return without performing this transition in some cases,
// such as when called on a system stack or with locks held.
func gcStart(trigger gcTrigger) {
// 判断当前G是否可抢占, 不可抢占时不触发GC
// Since this is called from malloc and malloc is called in
// the guts of a number of libraries that might be holding
// locks, don't attempt to start GC in non-preemptible or
// potentially unstable situations.
mp := acquirem()
if gp := getg(); gp == mp.g0 || mp.locks > 1 || mp.preemptoff != "" {
releasem(mp)
return
}
releasem(mp)
mp = nil
// Pick up the remaining unswept/not being swept spans concurrently
//
// This shouldn't happen if we're being invoked in background
// mode since proportional sweep should have just finished
// sweeping everything, but rounding errors, etc, may leave a
// few spans unswept. In forced mode, this is necessary since
// GC can be forced at any point in the sweeping cycle.
//
// We check the transition condition continuously here in case
// this G gets delayed in to the next GC cycle.
//验证垃圾收集条件的同时,该方法还会在循环中不断调用 runtime.sweepone 清理已经被标记的内存单元,完成上一个垃圾收集循环的收尾工作:
for trigger.test() && sweepone() != ^uintptr(0) {
sweep.nbgsweep++
}
//在验证了垃圾收集的条件并完成了收尾工作后,该方法会通过 semacquire 获取全局的 worldsema 信号量
// Perform GC initialization and the sweep termination
// transition.
semacquire(&work.startSema)
// Re-check transition condition under transition lock.
//重新检查gcTrigger的条件是否成立, 不成立时不触发GC
if !trigger.test() {
semrelease(&work.startSema)
return
}
// For stats, check if this GC was forced by the user.
// 记录是否强制触发, gcTriggerCycle是runtime.GC用的
work.userForced = trigger.kind == gcTriggerCycle
// In gcstoptheworld debug mode, upgrade the mode accordingly.
// We do this after re-checking the transition condition so
// that multiple goroutines that detect the heap trigger don't
// start multiple STW GCs.
// 判断是否指定了禁止并行GC的参数
mode := gcBackgroundMode
if debug.gcstoptheworld == 1 {
mode = gcForceMode
} else if debug.gcstoptheworld == 2 {
mode = gcForceBlockMode
}
// Ok, we're doing it! Stop everybody else
semacquire(&gcsema)
semacquire(&worldsema)
// 跟踪处理
if trace.enabled {
traceGCStart()
}
// Check that all Ps have finished deferred mcache flushes.
for _, p := range allp {
if fg := atomic.Load(&p.mcache.flushGen); fg != mheap_.sweepgen {
println("runtime: p", p.id, "flushGen", fg, "!= sweepgen", mheap_.sweepgen)
throw("p mcache not flushed")
}
}
//调用 runtime.gcBgMarkStartWorkers 启动后台标记任务
gcBgMarkStartWorkers()
// 重置标记相关的状态
systemstack(gcResetMarkState)
//修改全局变量 runtime.work 持有的状态,包括垃圾收集需要的 Goroutine 数量以及已完成的循环数。
work.stwprocs, work.maxprocs = gomaxprocs, gomaxprocs
if work.stwprocs > ncpu {
// This is used to compute CPU time of the STW phases,
// so it can't be more than ncpu, even if GOMAXPROCS is.
work.stwprocs = ncpu
}
work.heap0 = atomic.Load64(&memstats.heap_live)
work.pauseNS = 0
work.mode = mode
// 记录开始时间
now := nanotime()
work.tSweepTerm = now
work.pauseStart = now
if trace.enabled {
traceGCSTWStart(1)
}
//在系统栈中调用 runtime.stopTheWorldWithSema 停止世界
systemstack(stopTheWorldWithSema)
// Finish sweep before we start concurrent scan.
// 清扫上一轮GC未清扫的span, 确保上一轮GC已完成
systemstack(func() {
finishsweep_m()
})
// clearpools before we start the GC. If we wait they memory will not be
// reclaimed until the next GC cycle.
// 清扫sched.sudogcache和sched.deferpool
clearpools()
// 增加GC计数
work.cycles++
// 标记新一轮GC已开始
gcController.startCycle()
work.heapGoal = memstats.next_gc
// In STW mode, disable scheduling of user Gs. This may also
// disable scheduling of this goroutine, so it may block as
// soon as we start the world again.
if mode != gcBackgroundMode {
schedEnableUser(false)
}
// Enter concurrent mark phase and enable
// write barriers.
//
// Because the world is stopped, all Ps will
// observe that write barriers are enabled by
// the time we start the world and begin
// scanning.
//
// Write barriers must be enabled before assists are
// enabled because they must be enabled before
// any non-leaf heap objects are marked. Since
// allocations are blocked until assists can
// happen, we want enable assists as early as
// possible.
//在完成全部的准备工作后,该方法就进入了执行的最后阶段。在该阶段中,我们会修改全局的垃圾收集状态到 _GCmark 并依次执行下面的步骤:
setGCPhase(_GCmark)
//调用 runtime.gcBgMarkPrepare 函数初始化后台扫描需要的状态;
gcBgMarkPrepare() // Must happen before assist enable.
//调用 runtime.gcMarkRootPrepare 函数扫描栈上、全局变量等根对象并将它们加入队列;
gcMarkRootPrepare()
// Mark all active tinyalloc blocks. Since we're
// allocating from these, they need to be black like
// other allocations. The alternative is to blacken
// the tiny block on every allocation from it, which
// would slow down the tiny allocator.
// 标记所有tiny alloc等待合并的对象
gcMarkTinyAllocs()
// At this point all Ps have enabled the write
// barrier, thus maintaining the no white to
// black invariant. Enable mutator assists to
// put back-pressure on fast allocating
// mutators.
//设置全局变量 runtime.gcBlackenEnabled,用户程序和标记任务可以将对象涂黑;
// 启用辅助GC
atomic.Store(&gcBlackenEnabled, 1)
// Assists and workers can start the moment we start
// the world.
// 记录标记开始的时间
gcController.markStartTime = now
// In STW mode, we could block the instant systemstack
// returns, so make sure we're not preemptible.
mp = acquirem()
// Concurrent mark.
// 调用 runtime.startTheWorldWithSema 启动程序,后台任务也会开始标记堆中的对象;
// 重新启动世界
// 前面创建的后台标记任务会开始工作, 所有后台标记任务都完成工作后, 进入完成标记阶段
systemstack(func() {
now = startTheWorldWithSema(trace.enabled)
// 记录停止了多久, 和标记阶段开始的时间
work.pauseNS += now - work.pauseStart
work.tMark = now
})
// Release the world sema before Gosched() in STW mode
// because we will need to reacquire it later but before
// this goroutine becomes runnable again, and we could
// self-deadlock otherwise.
semrelease(&worldsema)
releasem(mp)
// Make sure we block instead of returning to user code
// in STW mode.
if mode != gcBackgroundMode {
Gosched()
}
semrelease(&work.startSema)
}
|
在分析垃圾收集的启动过程中,我们省略了几个关键的过程,其中包括暂停和恢复应用程序和后台任务的启动,下面将详细分析这几个过程的实现原理。
gcBgMarkStartWorkers
在垃圾收集启动期间,运行时会调用 runtime.gcBgMarkStartWorkers 为全局每个处理器创建用于执行后台标记任务的 Goroutine,这些 Goroutine 都会运行 runtime.gcBgMarkWorker,所有运行 runtime.gcBgMarkWorker 的 Goroutine 在启动后都会陷入休眠等待调度器的唤醒:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// gcBgMarkStartWorkers prepares background mark worker goroutines.
// These goroutines will not run until the mark phase, but they must
// be started while the work is not stopped and from a regular G
// stack. The caller must hold worldsema.
func gcBgMarkStartWorkers() {
// Background marking is performed by per-P G's. Ensure that
// each P has a background GC G.
for _, p := range allp {
// 如果已启动则不重复启动
if p.gcBgMarkWorker == 0 {
go gcBgMarkWorker(p)
// 启动后等待该任务通知信号量bgMarkReady再继续
notetsleepg(&work.bgMarkReady, -1)
noteclear(&work.bgMarkReady)
}
}
//zhouyunjia
}
|
这些 Goroutine 与处理器是一一对应的关系
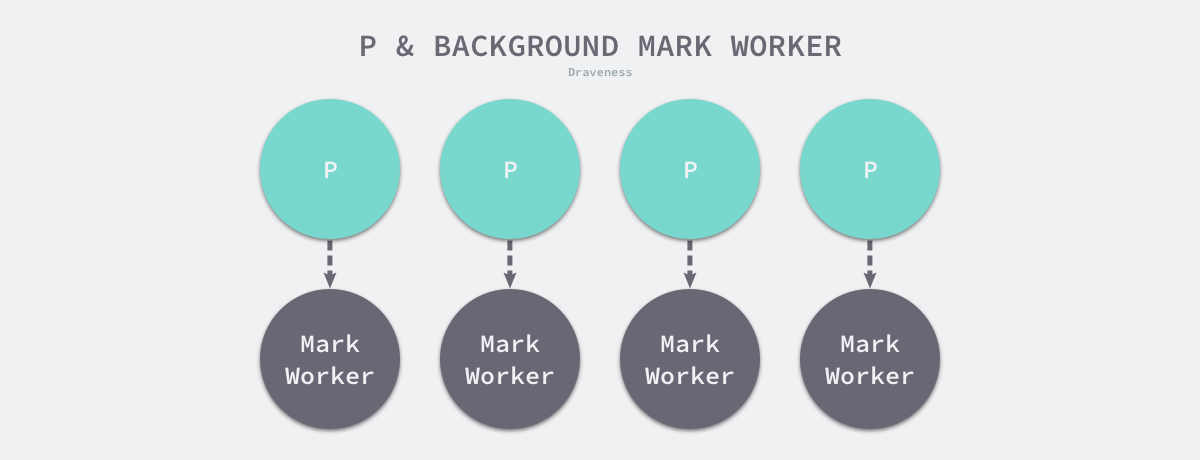
gcResetMarkState
gcResetMarkState函数会重置标记相关的状态:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
// gcResetMarkState resets global state prior to marking (concurrent
// or STW) and resets the stack scan state of all Gs.
//
// This is safe to do without the world stopped because any Gs created
// during or after this will start out in the reset state.
//
// gcResetMarkState must be called on the system stack because it acquires
// the heap lock. See mheap for details.
//
//go:systemstack
func gcResetMarkState() {
// This may be called during a concurrent phase, so make sure
// allgs doesn't change.
lock(&allglock)
for _, gp := range allgs {
gp.gcscandone = false // set to true in gcphasework
gp.gcAssistBytes = 0
}
unlock(&allglock)
// Clear page marks. This is just 1MB per 64GB of heap, so the
// time here is pretty trivial.
lock(&mheap_.lock)
arenas := mheap_.allArenas
unlock(&mheap_.lock)
for _, ai := range arenas {
ha := mheap_.arenas[ai.l1()][ai.l2()]
for i := range ha.pageMarks {
ha.pageMarks[i] = 0
}
}
work.bytesMarked = 0
work.initialHeapLive = atomic.Load64(&memstats.heap_live)
}
|
stopTheWorldWithSema
函数会停止整个世界, 这个函数必须在g0中运行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
|
// stopTheWorldWithSema is the core implementation of stopTheWorld.
// The caller is responsible for acquiring worldsema and disabling
// preemption first and then should stopTheWorldWithSema on the system
// stack:
//
// semacquire(&worldsema, 0)
// m.preemptoff = "reason"
// systemstack(stopTheWorldWithSema)
//
// When finished, the caller must either call startTheWorld or undo
// these three operations separately:
//
// m.preemptoff = ""
// systemstack(startTheWorldWithSema)
// semrelease(&worldsema)
//
// It is allowed to acquire worldsema once and then execute multiple
// startTheWorldWithSema/stopTheWorldWithSema pairs.
// Other P's are able to execute between successive calls to
// startTheWorldWithSema and stopTheWorldWithSema.
// Holding worldsema causes any other goroutines invoking
// stopTheWorld to block.
func stopTheWorldWithSema() {
_g_ := getg()
// If we hold a lock, then we won't be able to stop another M
// that is blocked trying to acquire the lock.
if _g_.m.locks > 0 {
throw("stopTheWorld: holding locks")
}
lock(&sched.lock)
//因为程序中活跃的最大处理数为 gomaxprocs,所以在每次发现停止的处理器时都会对该变量减一,直到所有的处理器都停止运行。
// 设置stopwait的初始值为最大的 p 的个数
sched.stopwait = gomaxprocs
// 设置gc等待标记, 调度时看见此标记会进入等待
atomic.Store(&sched.gcwaiting, 1)
// 给所有的 p 发送抢占信号,如果成功,则对应的 p 进入 idle 状态
// 抢占所有运行中的G
preemptall()
//依次停止当前处理器、等待处于系统调用的处理器以及获取并抢占空闲的处理器,处理器的状态在该函数返回时都会被更新至_Pgcstop,等待垃圾收集器的重新唤醒。
// stop current P
_g_.m.p.ptr().status = _Pgcstop // Pgcstop is only diagnostic.
// 减少需要停止的P数量(当前的P算一个)
sched.stopwait--
// try to retake all P's in Psyscall status
// 抢占所有在Psyscall状态的P, 防止它们重新参与调度
// 遍历所有的 p 如果满足条件(p的状态为 _Psyscall)则释放这个 p , 并且把 p 的状态都设置成 _Pgcstop ; 然后stopwait--
for _, p := range allp {
s := p.status
if s == _Psyscall && atomic.Cas(&p.status, s, _Pgcstop) {
if trace.enabled {
traceGoSysBlock(p)
traceProcStop(p)
}
p.syscalltick++
sched.stopwait--
}
}
// stop idle P's
// 防止所有空闲的P重新参与调度
for {
//获取idle 状态的 p, 从 _Pidle list 获取
p := pidleget()
if p == nil {
break
}
// 把 p 状态设置为 _Pgcstop
p.status = _Pgcstop
// 计数 stopwait --
sched.stopwait--
}
wait := sched.stopwait > 0
unlock(&sched.lock)
// 如果仍有需要停止的P, 则等待它们停止
// wait for remaining P's to stop voluntarily
if wait {
for {
// wait for 100us, then try to re-preempt in case of any races
// 循环等待 + 抢占所有运行中的G
//notetsleep函数内部每隔一段时间就会返回:
if notetsleep(&sched.stopnote, 100*1000) {
noteclear(&sched.stopnote)
break
}
preemptall()
}
}
// sanity checks
// 逻辑正确性检查
bad := ""
if sched.stopwait != 0 {
bad = "stopTheWorld: not stopped (stopwait != 0)"
} else {
for _, p := range allp {
if p.status != _Pgcstop {
bad = "stopTheWorld: not stopped (status != _Pgcstop)"
}
}
}
if atomic.Load(&freezing) != 0 {
// Some other thread is panicking. This can cause the
// sanity checks above to fail if the panic happens in
// the signal handler on a stopped thread. Either way,
// we should halt this thread.
lock(&deadlock)
lock(&deadlock)
}
if bad != "" {
throw(bad)
}
// 到这里所有运行中的G都会变为待运行, 并且所有的P都不能被M获取
// 也就是说所有的go代码(除了当前的)都会停止运行, 并且不能运行新的go代码
}
func notetsleep(n *note, ns int64) bool {
gp := getg()
if gp != gp.m.g0 {
throw("notetsleep not on g0")
}
semacreate(gp.m)
return notetsleep_internal(n, ns, nil, 0)
}
|
暂停程序主要使用了 runtime.preemptall 函数,该函数会调用我们runtime.preemptone.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// Tell all goroutines that they have been preempted and they should stop.
// This function is purely best-effort. It can fail to inform a goroutine if a
// processor just started running it.
// No locks need to be held.
// Returns true if preemption request was issued to at least one goroutine.
func preemptall() bool {
res := false
for _, _p_ := range allp {
if _p_.status != _Prunning {
continue
}
if preemptone(_p_) {
res = true
}
}
return res
}
|
notetsleep函数内部每隔一段时间就会返回:
1
|
return atomic.Load(key32(&n.key)) != 0 // n.key 为参数 &shced.stopnote.key的值
|
如果要想让返回值为 true 就需要满足上面的条件。 stopnote.key的值有两个函数可以控制:
- notewakeup 把 stopnote 设置为 1
- noteclear 把stopnote设置为 0
所以我们需要调用notewakeup才行。而这个函数我们可以看到是在gcstopm()有调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// Stops the current m for stopTheWorld.
// Returns when the world is restarted.
func gcstopm() {
...
lock(&sched.lock)
_p_.status = _Pgcstop
sched.stopwait--
if sched.stopwait == 0 {
notewakeup(&sched.stopnote)
}
unlock(&sched.lock)
stopm()
}
|
当sched.stopwait为0时,会唤醒notetsleep,继续执行下面的操作.
finishsweep_m
finishsweep_m函数会清扫上一轮GC未清扫的span, 确保上一轮GC已完成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
// finishsweep_m ensures that all spans are swept.
//
// The world must be stopped. This ensures there are no sweeps in
// progress.
//
//go:nowritebarrier
func finishsweep_m() {
// sweepone会取出一个未sweep的span然后执行sweep
// Sweeping must be complete before marking commences, so
// sweep any unswept spans. If this is a concurrent GC, there
// shouldn't be any spans left to sweep, so this should finish
// instantly. If GC was forced before the concurrent sweep
// finished, there may be spans to sweep.
for sweepone() != ^uintptr(0) {
sweep.npausesweep++
}
if go115NewMCentralImpl {
// Reset all the unswept buffers, which should be empty.
// Do this in sweep termination as opposed to mark termination
// so that we can catch unswept spans and reclaim blocks as
// soon as possible.
sg := mheap_.sweepgen
for i := range mheap_.central {
c := &mheap_.central[i].mcentral
c.partialUnswept(sg).reset()
c.fullUnswept(sg).reset()
}
}
// Sweeping is done, so if the scavenger isn't already awake,
// wake it up. There's definitely work for it to do at this
// point.
wakeScavenger()
// 所有span都sweep完成后, 启动一个新的markbit时代
// 这个函数是实现span的gcmarkBits和allocBits的分配和复用的关键, 流程如下
// - span分配gcmarkBits和allocBits
// - span完成sweep
// - 原allocBits不再被使用
// - gcmarkBits变为allocBits
// - 分配新的gcmarkBits
// - 开启新的markbit时代
// - span完成sweep, 同上
// - 开启新的markbit时代
// - 2个时代之前的bitmap将不再被使用, 可以复用这些bitmap
nextMarkBitArenaEpoch()
}
|
clearpools
clearpools函数会清理sched.sudogcache和sched.deferpool, 让它们的内存可以被回收:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
func clearpools() {
// clear sync.Pools
if poolcleanup != nil {
poolcleanup()
}
// Clear central sudog cache.
// Leave per-P caches alone, they have strictly bounded size.
// Disconnect cached list before dropping it on the floor,
// so that a dangling ref to one entry does not pin all of them.
lock(&sched.sudoglock)
var sg, sgnext *sudog
for sg = sched.sudogcache; sg != nil; sg = sgnext {
sgnext = sg.next
sg.next = nil
}
sched.sudogcache = nil
unlock(&sched.sudoglock)
// Clear central defer pools.
// Leave per-P pools alone, they have strictly bounded size.
lock(&sched.deferlock)
for i := range sched.deferpool {
// disconnect cached list before dropping it on the floor,
// so that a dangling ref to one entry does not pin all of them.
var d, dlink *_defer
for d = sched.deferpool[i]; d != nil; d = dlink {
dlink = d.link
d.link = nil
}
sched.deferpool[i] = nil
}
unlock(&sched.deferlock)
}
|
startCycle
用于并发扫描对象的工作协程 Goroutine 总共有三种不同的模式 runtime.gcMarkWorkerMode,这三种不同模式的 Goroutine 在标记对象时使用完全不同的策略,垃圾收集控制器会按照需要执行不同类型的工作协程:
- gcMarkWorkerDedicatedMode — 处理器专门负责标记对象,不会被调度器抢占;
- gcMarkWorkerFractionalMode — 当垃圾收集的后台 CPU 使用率达不到预期时(默认为 25%),启动该类型的工作协程帮助垃圾收集达到利用率的目标,因为它只占用同一个 CPU 的部分资源,所以可以被调度;
- gcMarkWorkerIdleMode — 当处理器没有可以执行的 Goroutine 时,它会运行垃圾收集的标记任务直到被抢占;
runtime.gcControllerState.startCycle 会根据全局处理器的个数以及垃圾收集的 CPU 利用率计算出 dedicatedMarkWorkersNeeded 和 fractionalUtilizationGoal 以决定不同模式的工作协程的数量。
因为后台标记任务的 CPU 利用率为 25%,如果主机是 4 核或者 8 核,那么垃圾收集需要 1 个或者 2 个专门处理相关任务的 Goroutine;不过如果主机是 3 核或者 6 核,因为无法被 4 整除,所以这时需要 0 个或者 1 个专门处理垃圾收集的 Goroutine,运行时需要占用某个 CPU 的部分时间,使用 gcMarkWorkerFractionalMode 模式的协程保证 CPU 的利用率。
正常情况下gc的CPU占用会被约束在25%,超过25%的话,应用协程经常被征用去做mark assist,应用延迟会变高

三种不同模式的工作协程会相互协同保证垃圾收集的 CPU 利用率达到期望的阈值,在到达目标堆大小前完成标记任务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
// startCycle resets the GC controller's state and computes estimates
// for a new GC cycle. The caller must hold worldsema.
func (c *gcControllerState) startCycle() {
c.scanWork = 0
c.bgScanCredit = 0
c.assistTime = 0
c.dedicatedMarkTime = 0
c.fractionalMarkTime = 0
c.idleMarkTime = 0
// 确保next_gc和heap_live之间最少有1MB
// Ensure that the heap goal is at least a little larger than
// the current live heap size. This may not be the case if GC
// start is delayed or if the allocation that pushed heap_live
// over gc_trigger is large or if the trigger is really close to
// GOGC. Assist is proportional to this distance, so enforce a
// minimum distance, even if it means going over the GOGC goal
// by a tiny bit.
if memstats.next_gc < memstats.heap_live+1024*1024 {
memstats.next_gc = memstats.heap_live + 1024*1024
}
// 计算可以同时执行的后台标记任务的数量
// dedicatedMarkWorkersNeeded等于P的数量的25%去除小数点
// 如果可以整除则fractionalMarkWorkersNeeded等于0否则等于1
// totalUtilizationGoal是GC所占的P的目标值(例如P一共有5个时目标是1.25个P)
// fractionalUtilizationGoal是Fractiona模式的任务所占的P的目标值(例如P一共有5个时目标是0.25个P)
// Compute the background mark utilization goal. In general,
// this may not come out exactly. We round the number of
// dedicated workers so that the utilization is closest to
// 25%. For small GOMAXPROCS, this would introduce too much
// error, so we add fractional workers in that case.
totalUtilizationGoal := float64(gomaxprocs) * gcBackgroundUtilization
c.dedicatedMarkWorkersNeeded = int64(totalUtilizationGoal + 0.5)
utilError := float64(c.dedicatedMarkWorkersNeeded)/totalUtilizationGoal - 1
const maxUtilError = 0.3
if utilError < -maxUtilError || utilError > maxUtilError {
// Rounding put us more than 30% off our goal. With
// gcBackgroundUtilization of 25%, this happens for
// GOMAXPROCS<=3 or GOMAXPROCS=6. Enable fractional
// workers to compensate.
if float64(c.dedicatedMarkWorkersNeeded) > totalUtilizationGoal {
// Too many dedicated workers.
c.dedicatedMarkWorkersNeeded--
}
c.fractionalUtilizationGoal = (totalUtilizationGoal - float64(c.dedicatedMarkWorkersNeeded)) / float64(gomaxprocs)
} else {
c.fractionalUtilizationGoal = 0
}
// In STW mode, we just want dedicated workers.
if debug.gcstoptheworld > 0 {
c.dedicatedMarkWorkersNeeded = int64(gomaxprocs)
c.fractionalUtilizationGoal = 0
}
// 重置P中的辅助GC所用的时间统计
// Clear per-P state
for _, p := range allp {
p.gcAssistTime = 0
p.gcFractionalMarkTime = 0
}
// 计算辅助GC的参数
// 参考上面对计算assistWorkPerByte的公式的分析
// Compute initial values for controls that are updated
// throughout the cycle.
c.revise()
if debug.gcpacertrace > 0 {
print("pacer: assist ratio=", c.assistWorkPerByte,
" (scan ", memstats.heap_scan>>20, " MB in ",
work.initialHeapLive>>20, "->",
memstats.next_gc>>20, " MB)",
" workers=", c.dedicatedMarkWorkersNeeded,
"+", c.fractionalUtilizationGoal, "\n")
}
}
|
setGCPhase
setGCPhase函数会修改表示当前GC阶段的全局变量和是否开启写屏障的全局变量:
1
2
3
4
5
6
|
//go:nosplit
func setGCPhase(x uint32) {
atomic.Store(&gcphase, x)
writeBarrier.needed = gcphase == _GCmark || gcphase == _GCmarktermination
writeBarrier.enabled = writeBarrier.needed || writeBarrier.cgo
}
|
写屏障是保证 Go 语言并发标记安全不可或缺的技术,我们需要使用混合写屏障维护对象图的弱三色不变性,然而写屏障的实现需要编译器和运行时的共同协作。在 SSA 中间代码生成阶段,编译器会使用 cmd/compile/internal/ssa.writebarrier 函数在 Store、Move 和 Zero 操作中加入写屏障,生成如下所示的代码:
1
2
3
4
5
|
if writeBarrier.enabled {
gcWriteBarrier(ptr, val)
} else {
*ptr = val
}
|
当 Go 语言进入垃圾收集阶段时,全局变量 runtime.writeBarrier 中的 enabled 字段会被置成开启,所有的写操作都会调用 runtime.gcWriteBarrier:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
TEXT runtime·gcWriteBarrier(SB),NOSPLIT,$28
...
get_tls(BX)
MOVL g(BX), BX
MOVL g_m(BX), BX
MOVL m_p(BX), BX
MOVL (p_wbBuf+wbBuf_next)(BX), CX
LEAL 8(CX), CX
MOVL CX, (p_wbBuf+wbBuf_next)(BX)
CMPL CX, (p_wbBuf+wbBuf_end)(BX)
MOVL AX, -8(CX) // 记录值
MOVL (DI), BX
MOVL BX, -4(CX) // 记录 *slot
JEQ flush
ret:
MOVL 20(SP), CX
MOVL 24(SP), BX
MOVL AX, (DI) // 触发写操作
RET
flush:
...
CALL runtime·wbBufFlush(SB)
...
JMP ret
|
在上述汇编函数中,DI 寄存器是写操作的目的地址,AX 寄存器中存储了被覆盖的值,该函数会覆盖原来的值并通过 runtime.wbBufFlush 通知垃圾收集器将原值和新值加入当前处理器的工作队列,因为该写屏障的实现比较复杂,所以写屏障对程序的性能还是有比较大的影响,之前只需要一条指令完成的工作,现在需要几十条指令。
我们在上面提到过 Dijkstra 和 Yuasa 写屏障组成的混合写屏障在开启后,所有新创建的对象都需要被直接涂成黑色,这里的标记过程是由 runtime.gcmarknewobject 完成的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
if gcphase != _GCoff {
gcmarknewobject(uintptr(x), size, scanSize)
}
...
}
func gcmarknewobject(obj, size, scanSize uintptr) {
markBitsForAddr(obj).setMarked()
gcw := &getg().m.p.ptr().gcw
gcw.bytesMarked += uint64(size)
gcw.scanWork += int64(scanSize)
}
|
runtime.mallocgc 会在垃圾收集开始后调用该函数,获取对象对应的内存单元以及标记位 runtime.markBits 并调用 runtime.markBits.setMarked 直接将新的对象涂成黑色。
gcBgMarkPrepare
gcBgMarkPrepare函数会重置后台标记任务的计数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// gcBgMarkPrepare sets up state for background marking.
// Mutator assists must not yet be enabled.
func gcBgMarkPrepare() {
// Background marking will stop when the work queues are empty
// and there are no more workers (note that, since this is
// concurrent, this may be a transient state, but mark
// termination will clean it up). Between background workers
// and assists, we don't really know how many workers there
// will be, so we pretend to have an arbitrarily large number
// of workers, almost all of which are "waiting". While a
// worker is working it decrements nwait. If nproc == nwait,
// there are no workers.
work.nproc = ^uint32(0)
work.nwait = ^uint32(0)
}
|
gcMarkRootPrepare
gcMarkRootPrepare函数会计算扫描根对象的任务数量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
// gcMarkRootPrepare queues root scanning jobs (stacks, globals, and
// some miscellany) and initializes scanning-related state.
//
// The world must be stopped.
func gcMarkRootPrepare() {
work.nFlushCacheRoots = 0
// 计算block数量的函数, rootBlockBytes是256KB
// Compute how many data and BSS root blocks there are.
nBlocks := func(bytes uintptr) int {
return int(divRoundUp(bytes, rootBlockBytes))
}
work.nDataRoots = 0
work.nBSSRoots = 0
// Scan globals.
// 计算扫描可读写的全局变量的任务数量
for _, datap := range activeModules() {
nDataRoots := nBlocks(datap.edata - datap.data)
if nDataRoots > work.nDataRoots {
work.nDataRoots = nDataRoots
}
}
// 计算扫描只读的全局变量的任务数量
for _, datap := range activeModules() {
nBSSRoots := nBlocks(datap.ebss - datap.bss)
if nBSSRoots > work.nBSSRoots {
work.nBSSRoots = nBSSRoots
}
}
// Scan span roots for finalizer specials.
//
// We depend on addfinalizer to mark objects that get
// finalizers after root marking.
if go115NewMarkrootSpans {
// We're going to scan the whole heap (that was available at the time the
// mark phase started, i.e. markArenas) for in-use spans which have specials.
//
// Break up the work into arenas, and further into chunks.
//
// Snapshot allArenas as markArenas. This snapshot is safe because allArenas
// is append-only.
mheap_.markArenas = mheap_.allArenas[:len(mheap_.allArenas):len(mheap_.allArenas)]
work.nSpanRoots = len(mheap_.markArenas) * (pagesPerArena / pagesPerSpanRoot)
} else {
// We're only interested in scanning the in-use spans,
// which will all be swept at this point. More spans
// may be added to this list during concurrent GC, but
// we only care about spans that were allocated before
// this mark phase.
work.nSpanRoots = mheap_.sweepSpans[mheap_.sweepgen/2%2].numBlocks()
}
// Scan stacks.
//
// Gs may be created after this point, but it's okay that we
// ignore them because they begin life without any roots, so
// there's nothing to scan, and any roots they create during
// the concurrent phase will be scanned during mark
// termination.
work.nStackRoots = int(atomic.Loaduintptr(&allglen))
// 计算总任务数量
// 后台标记任务会对markrootNext进行原子递增, 来决定做哪个任务
// 这种用数值来实现锁自由队列的办法挺聪明的, 尽管google工程师觉得不好(看后面markroot函数的分析)
work.markrootNext = 0
work.markrootJobs = uint32(fixedRootCount + work.nFlushCacheRoots + work.nDataRoots + work.nBSSRoots + work.nSpanRoots + work.nStackRoots)
}
|
gcMarkTinyAllocs
gcMarkTinyAllocs函数会标记所有tiny alloc等待合并的对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// gcMarkTinyAllocs greys all active tiny alloc blocks.
//
// The world must be stopped.
func gcMarkTinyAllocs() {
for _, p := range allp {
c := p.mcache
if c == nil || c.tiny == 0 {
continue
}
// 标记各个P中的mcache中的tiny
// 在上面的mallocgc函数中可以看到tiny是当前等待合并的对象
_, span, objIndex := findObject(c.tiny, 0, 0)
gcw := &p.gcw
// 标记一个对象存活, 并把它加到标记队列(该对象变为灰色)
greyobject(c.tiny, 0, 0, span, gcw, objIndex)
}
}
|
startTheWorldWithSema
startTheWorldWithSema函数会重新启动世界:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
func startTheWorldWithSema(emitTraceEvent bool) int64 {
mp := acquirem() // disable preemption because it can be holding p in a local var
// 调用 runtime.netpoll 从网络轮询器中获取待处理的任务并加入全局队列;
// 判断收到的网络事件(fd可读可写或错误)并添加对应的G到待运行队列
if netpollinited() {
list := netpoll(0) // non-blocking
injectglist(&list)
}
lock(&sched.lock)
// 如果要求改变gomaxprocs则调整P的数量
// procresize会返回有可运行任务的P的链表
procs := gomaxprocs
if newprocs != 0 {
procs = newprocs
newprocs = 0
}
//调用 runtime.procresize 扩容或者缩容全局的处理器;
p1 := procresize(procs)
// 取消GC等待标记
sched.gcwaiting = 0
// 如果sysmon在等待则唤醒它
if sched.sysmonwait != 0 {
sched.sysmonwait = 0
notewakeup(&sched.sysmonnote)
}
unlock(&sched.lock)
// 唤醒有可运行任务的P
//调用 runtime.notewakeup 或者 runtime.newm 依次唤醒处理器或者为处理器创建新的线程;
for p1 != nil {
p := p1
p1 = p1.link.ptr()
if p.m != 0 {
mp := p.m.ptr()
p.m = 0
if mp.nextp != 0 {
throw("startTheWorld: inconsistent mp->nextp")
}
mp.nextp.set(p)
notewakeup(&mp.park)
} else {
// Start M to run P. Do not start another M below.
newm(nil, p, -1)
}
}
// Capture start-the-world time before doing clean-up tasks.
startTime := nanotime()
if emitTraceEvent {
traceGCSTWDone()
}
// Wakeup an additional proc in case we have excessive runnable goroutines
// in local queues or in the global queue. If we don't, the proc will park itself.
// If we have lots of excessive work, resetspinning will unpark additional procs as necessary.
//如果当前待处理的 Goroutine 数量过多,创建额外的处理器辅助完成任务;
wakep()
releasem(mp)
return startTime
}
// Tries to add one more P to execute G's.
// Called when a G is made runnable (newproc, ready).
func wakep() {
if atomic.Load(&sched.npidle) == 0 {
return
}
// be conservative about spinning threads
if atomic.Load(&sched.nmspinning) != 0 || !atomic.Cas(&sched.nmspinning, 0, 1) {
return
}
startm(nil, true)
}
|
重启世界后各个M会重新开始调度, 调度时会优先使用findRunnableGCWorker函数查找任务, 之后就有大约25%的P运行后台标记任务.
并发扫描与标记辅助
标记对象从哪里来?
- gcMarkWorker
- Markassist
- mutatorwrite/deleteheappointers
标记对象到哪里去?
- Workbuffer
- 本地workbuffer=>p.gcw
- 全局workbuffer=>runtime.work.full • Write barrier buffer
- 本地writebarrierbuffer=>p.wbBuf
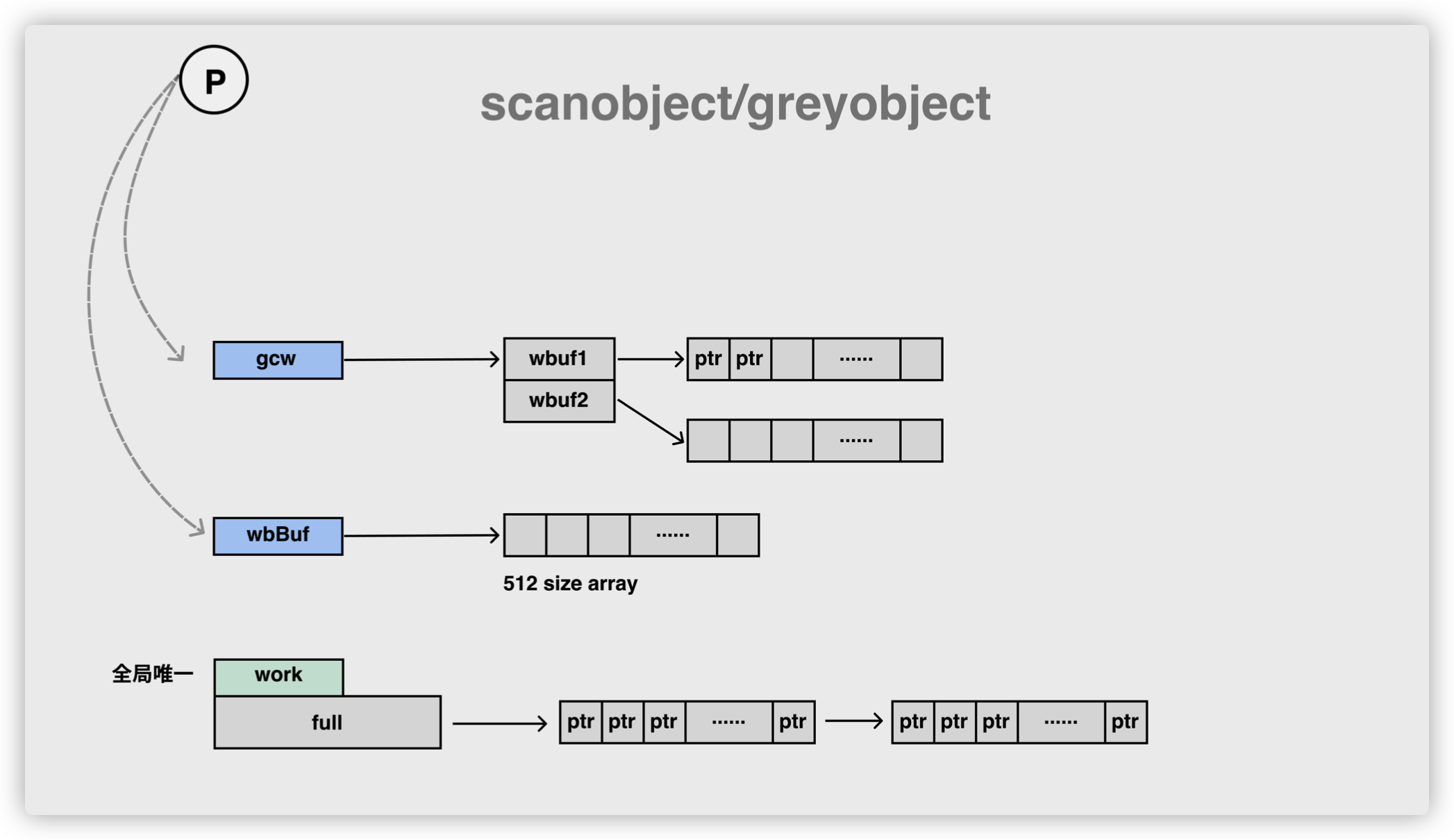
在调用 runtime.gcDrain 函数时,运行时会传入处理器上的 runtime.gcWork,这个结构体是垃圾收集器中工作池的抽象,它实现了一个生产者和消费者的模型,我们可以以该结构体为起点从整体理解标记工作:
写屏障、根对象扫描和栈扫描都会向工作池中增加额外的灰色对象等待处理,而对象的扫描过程会将灰色对象标记成黑色,同时也可能发现新的灰色对象,当工作队列中不包含灰色对象时,整个扫描过程就会结束。
为了减少锁竞争,运行时在每个处理器上会保存独立的待扫描工作,然而这会遇到与调度器一样的问题 — 不同处理器的资源不平均,导致部分处理器无事可做,调度器引入了工作窃取来解决这个问题,垃圾收集器也使用了差不多的机制平衡不同处理器上的待处理任务。
runtime.gcWork.balance 方法会将处理器本地一部分工作放回全局队列中,让其他的处理器处理,保证不同处理器负载的平衡。
runtime.gcWork 为垃圾收集器提供了生产和消费任务的抽象,该结构体持有了两个重要的工作缓冲区 wbuf1 和 wbuf2,这两个缓冲区分别是主缓冲区和备缓冲区:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
type gcWork struct {
wbuf1, wbuf2 *workbuf
...
}
type workbufhdr struct {
node lfnode // must be first
nobj int
}
type workbuf struct {
workbufhdr
obj [(_WorkbufSize - unsafe.Sizeof(workbufhdr{})) / sys.PtrSize]uintptr
}
|
当我们向该结构体中增加或者删除对象时,它总会先操作主缓冲区,一旦主缓冲区空间不足或者没有对象,就会触发主备缓冲区的切换;而当两个缓冲区空间都不足或者都为空时,会从全局的工作缓冲区中插入或者获取对象,该结构体相关方法的实现都非常简单,这里就不展开分析了。
运行时会使用 runtime.gcDrain 函数扫描工作缓冲区中的灰色对象,它会根据传入 gcDrainFlags 的不同选择不同的策略:
gcDrain 这个函数就是从队列里不断获取,处理这些对象,最重要的一个就是调用 scanobject 继续扫描对象。
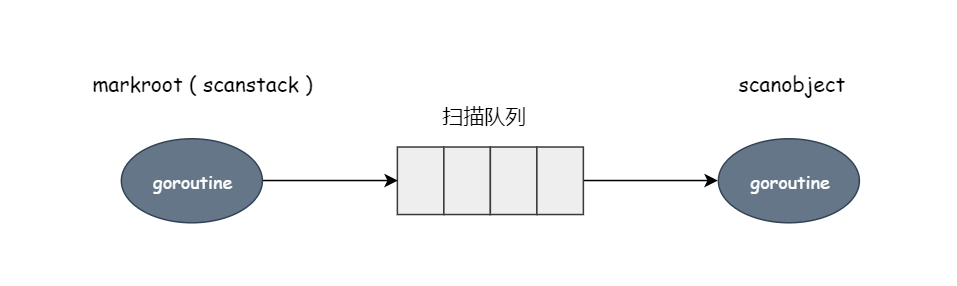
markroot 从根(栈)扫描,把扫描到的对象投入扫描队列。gcDrain 等函数从里面不断获取,不断处理,并且扫描这些对象,进一步挖掘引用关系,当扫描结束之后,那些没有扫描到的就是垃圾了。
findRunnableGCWorker
调度器在调度循环 runtime.schedule 中可以通过垃圾收集控制器的 findRunnableGCWorker 方法获取并执行用于后台标记的任务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
// 执行一轮调度器的工作:找到一个 runnable 的 goroutine,并且执行它
// 永不返回
func schedule() {
...
top:
//如果GC处于等待状态,停止M,等待GC完成被唤醒
//准备进入GC STW,休眠
//判断是否有串行运行时任务正在等待执行,判断依据就是调度器的gcwaiting字段是否为0。如果
//gcwaiting不为0,则停止并阻塞当前M直到串行运行时任务结束,才继续执行后面的调度动作。
//串行运行时任务执行时需要停止Go的调度器,官方称此操作为Stop the world,简称STW。
if sched.gcwaiting != 0 {
gcstopm()
goto top
}
if _g_.m.p.ptr().runSafePointFn != 0 {
runSafePointFn()
}
//接下来就是寻找可运行G的过程。首先试图获取执行踪迹读取任务的G。
var gp *g
//当从P.next提取G时,inheritTime = true
//不累加P.schedtick计数,使得它延长本地队列处理时间
var inheritTime bool
if trace.enabled || trace.shutdown {
gp = traceReader()
if gp != nil {
casgstatus(gp, _Gwaiting, _Grunnable)
traceGoUnpark(gp, 0)
}
}
//未果,试图获取执行GC标记任务的G。
//进入GC MarkWorker工作模式
if gp == nil && gcBlackenEnabled != 0 {
gp = gcController.findRunnableGCWorker(_g_.m.p.ptr())
}
...
}
|
垃圾收集控制器会在 runtime.gcControllerState.findRunnableGCWorker 方法中设置处理器的 gcMarkWorkerMode:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
// findRunnableGCWorker returns the background mark worker for _p_ if it
// should be run. This must only be called when gcBlackenEnabled != 0.
func (c *gcControllerState) findRunnableGCWorker(_p_ *p) *g {
if gcBlackenEnabled == 0 {
throw("gcControllerState.findRunnable: blackening not enabled")
}
if _p_.gcBgMarkWorker == 0 {
// The mark worker associated with this P is blocked
// performing a mark transition. We can't run it
// because it may be on some other run or wait queue.
return nil
}
if !gcMarkWorkAvailable(_p_) {
// No work to be done right now. This can happen at
// the end of the mark phase when there are still
// assists tapering off. Don't bother running a worker
// now because it'll just return immediately.
return nil
}
// 原子减少对应的值, 如果减少后大于等于0则返回true, 否则返回false
decIfPositive := func(ptr *int64) bool {
if *ptr > 0 {
if atomic.Xaddint64(ptr, -1) >= 0 {
return true
}
// We lost a race
atomic.Xaddint64(ptr, +1)
}
return false
}
// 减少dedicatedMarkWorkersNeeded, 成功时后台标记任务的模式是Dedicated
// dedicatedMarkWorkersNeeded是当前P的数量的25%去除小数点
// 详见startCycle函数
if decIfPositive(&c.dedicatedMarkWorkersNeeded) {
// This P is now dedicated to marking until the end of
// the concurrent mark phase.
_p_.gcMarkWorkerMode = gcMarkWorkerDedicatedMode
} else if c.fractionalUtilizationGoal == 0 {
// No need for fractional workers.
return nil
} else {
// Is this P behind on the fractional utilization
// goal?
//
// This should be kept in sync with pollFractionalWorkerExit.
// 减少fractionalMarkWorkersNeeded, 成功是后台标记任务的模式是Fractional
// 上面的计算如果小数点后有数值(不能够整除)则fractionalMarkWorkersNeeded为1, 否则为0
// 详见startCycle函数
// 举例来说, 4个P时会执行1个Dedicated模式的任务, 5个P时会执行1个Dedicated模式和1个Fractional模式的任务
delta := nanotime() - gcController.markStartTime
if delta > 0 && float64(_p_.gcFractionalMarkTime)/float64(delta) > c.fractionalUtilizationGoal {
// Nope. No need to run a fractional worker.
return nil
}
// Run a fractional worker.
_p_.gcMarkWorkerMode = gcMarkWorkerFractionalMode
}
// 安排后台标记任务执行
// Run the background mark worker
gp := _p_.gcBgMarkWorker.ptr()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp
}
|
控制器通过 dedicatedMarkWorkersNeeded 决定专门执行标记任务的 Goroutine 数量并根据执行标记任务的时间和总时间决定是否启动 gcMarkWorkerFractionalMode 模式的 Goroutine.
findrunnable
除了这两种控制器要求的工作协程之外,调度器还会在 findrunnable 函数中利用空闲的处理器执行垃圾收集以加速该过程:
当垃圾收集处于标记阶段并且当前处理器不需要做任何任务时,runtime.findrunnable 函数会在当前处理器上执行该 Goroutine 辅助并发的对象标记:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
// Finds a runnable goroutine to execute.
// Tries to steal from other P's, get g from global queue, poll network.
// 寻找一个可运行的 Goroutine 来执行。
// 尝试从其他的 P 偷取、从全局队列中获取、poll 网络
func findrunnable() (gp *g, inheritTime bool) {
top:
//1. 获取执行GC标记任务的G。如果恰巧正处于GC标记阶段,且本地P可用于GC标记任务。
//那么调度器会把本地P持有的GC标记专用G置为Grunnable状态并返回这个G。
//检查GC MarkWorker
// We have nothing to do. If we're in the GC mark phase, can
// safely scan and blacken objects, and have work to do, run
// idle-time marking rather than give up the P.
if gcBlackenEnabled != 0 && _p_.gcBgMarkWorker != 0 && gcMarkWorkAvailable(_p_) {
_p_.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := _p_.gcBgMarkWorker.ptr() //获取用于GC标记的专用G
casgstatus(gp, _Gwaiting, _Grunnable)//将gp并发安全的从Gwaiting状态转为Grunnable状态
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
...
//4. 再次获取执行GC标记任务的G。如果正好处于GC标记阶段,且GC标记任务相关的全局资源可用。调度器就从空闲P列表中取出一个P,如果这个P持有GC标记专用G,就将该P与当前M关联,并从第二阶段开始继续执行。否则该P会被重新放回空闲P列表。
// Check for idle-priority GC work again.
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(nil) {
lock(&sched.lock)
_p_ = pidleget()
if _p_ != nil && _p_.gcBgMarkWorker == 0 {
pidleput(_p_)
_p_ = nil
}
unlock(&sched.lock)
if _p_ != nil {
acquirep(_p_)
if wasSpinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
// Go back to idle GC check.
goto stop
}
}
...
goto top
}
func gcMarkWorkAvailable(p *p) bool {
if p != nil && !p.gcw.empty() {
return true
}
if !work.full.empty() {
return true // global work available
}
if work.markrootNext < work.markrootJobs {
return true // root scan work available
}
return false
}
|
gcBgMarkWorker
runtime.gcBgMarkWorker 是后台的标记任务执行的函数,该函数的循环中执行了对内存中对象图的扫描和标记,我们分三个部分介绍该函数的实现原理:
- 获取当前处理器以及 Goroutine 打包成 parkInfo 类型的结构体并主动陷入休眠等待唤醒;
- 根据处理器上的 gcMarkWorkerMode 模式决定扫描任务的策略;
- 所有标记任务都完成后,调用 runtime.gcMarkDone 方法完成标记阶段;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
|
const (
gcDrainUntilPreempt gcDrainFlags = 1 << iota
gcDrainFlushBgCredit
gcDrainIdle
gcDrainFractional
)
func gcBgMarkWorker(_p_ *p) {
gp := getg()
//首先我们来看后台标记任务的准备工作,运行时在这里创建了一个 parkInfo 结构体,该结构体会预先存储处理器和当前 Goroutine,
// 用于休眠后重新获取P的构造体
type parkInfo struct {
m muintptr // Release this m on park.
attach puintptr // If non-nil, attach to this p on park.
}
// We pass park to a gopark unlock function, so it can't be on
// the stack (see gopark). Prevent deadlock from recursively
// starting GC by disabling preemption.
gp.m.preemptoff = "GC worker init"
park := new(parkInfo)
gp.m.preemptoff = ""
// 设置当前的M并禁止抢占
park.m.set(acquirem())
// 设置当前的P(需要关联到的P)
park.attach.set(_p_)
// Inform gcBgMarkStartWorkers that this worker is ready.
// After this point, the background mark worker is scheduled
// cooperatively by gcController.findRunnable. Hence, it must
// never be preempted, as this would put it into _Grunnable
// and put it on a run queue. Instead, when the preempt flag
// is set, this puts itself into _Gwaiting to be woken up by
// gcController.findRunnable at the appropriate time.
// 通知gcBgMarkStartWorkers可以继续处理
notewakeup(&work.bgMarkReady)
for {
// 让当前G进入休眠
// Go to sleep until woken by gcController.findRunnable.
// We can't releasem yet since even the call to gopark
// may be preempted.
//当我们调用 runtime.gopark 触发休眠时,运行时会在系统栈中安全地建立处理器和后台标记任务的绑定关系
gopark(func(g *g, parkp unsafe.Pointer) bool {
park := (*parkInfo)(parkp)
// The worker G is no longer running, so it's
// now safe to allow preemption.
// 允许G被抢占
releasem(park.m.ptr())
// 设置关联的P
// 把当前的G设到P的gcBgMarkWorker成员, 下次findRunnableGCWorker会使用
// 设置失败时不休眠
// If the worker isn't attached to its P,
// attach now. During initialization and after
// a phase change, the worker may have been
// running on a different P. As soon as we
// attach, the owner P may schedule the
// worker, so this must be done after the G is
// stopped.
if park.attach != 0 {
p := park.attach.ptr()
park.attach.set(nil)
// cas the worker because we may be
// racing with a new worker starting
// on this P.
if !p.gcBgMarkWorker.cas(0, guintptr(unsafe.Pointer(g))) {
// The P got a new worker.
// Exit this worker.
return false
}
}
return true
}, unsafe.Pointer(park), waitReasonGCWorkerIdle, traceEvGoBlock, 0)
//通过 runtime.gopark 陷入休眠的 Goroutine 不会进入运行队列,它只会等待垃圾收集控制器或者调度器的直接唤醒;在休眠后,我们会根据处理器 gcMarkWorkerMode 选择不同的标记执行策略,不同的执行策略都会调用 runtime.gcDrain 扫描工作缓冲区 runtime.gcWork:
// Loop until the P dies and disassociates this
// worker (the P may later be reused, in which case
// it will get a new worker) or we failed to associate.
// 检查P的gcBgMarkWorker是否和当前的G一致, 不一致时结束当前的任务
if _p_.gcBgMarkWorker.ptr() != gp {
break
}
// 禁止M被抢占
// Disable preemption so we can use the gcw. If the
// scheduler wants to preempt us, we'll stop draining,
// dispose the gcw, and then preempt.
park.m.set(acquirem())
if gcBlackenEnabled == 0 {
throw("gcBgMarkWorker: blackening not enabled")
}
// 记录开始时间
startTime := nanotime()
_p_.gcMarkWorkerStartTime = startTime
decnwait := atomic.Xadd(&work.nwait, -1)
if decnwait == work.nproc {
println("runtime: work.nwait=", decnwait, "work.nproc=", work.nproc)
throw("work.nwait was > work.nproc")
}
// 切换到g0运行
systemstack(func() {
// Mark our goroutine preemptible so its stack
// can be scanned. This lets two mark workers
// scan each other (otherwise, they would
// deadlock). We must not modify anything on
// the G stack. However, stack shrinking is
// disabled for mark workers, so it is safe to
// read from the G stack.
// 设置G的状态为等待中这样它的栈可以被扫描(两个后台标记任务可以互相扫描对方的栈)
casgstatus(gp, _Grunning, _Gwaiting)
// 判断后台标记任务的模式
switch _p_.gcMarkWorkerMode {
default:
throw("gcBgMarkWorker: unexpected gcMarkWorkerMode")
case gcMarkWorkerDedicatedMode:
//需要注意的是,gcMarkWorkerDedicatedMode 模式的任务是不能被抢占的,为了减少额外开销,第一次调用 runtime.gcDrain 方法时是允许抢占的,但是一旦处理器被抢占,当前 Goroutine会将处理器上的所有可运行的 Goroutine 转移至全局队列中,保证垃圾收集占用的 CPU 资源。
// 这个模式下P应该专心执行标记
// 执行标记, 直到被抢占, 并且需要计算后台的扫描量来减少辅助GC和唤醒等待中的G
gcDrain(&_p_.gcw, gcDrainUntilPreempt|gcDrainFlushBgCredit)
// 被抢占时把本地运行队列中的所有G都踢到全局运行队列
if gp.preempt {
// We were preempted. This is
// a useful signal to kick
// everything out of the run
// queue so it can run
// somewhere else.
lock(&sched.lock)
for {
gp, _ := runqget(_p_)
if gp == nil {
break
}
globrunqput(gp)
}
unlock(&sched.lock)
}
// Go back to draining, this time
// without preemption.
// 继续执行标记, 直到无更多任务, 并且需要计算后台的扫描量来减少辅助GC和唤醒等待中的G
gcDrain(&_p_.gcw, gcDrainFlushBgCredit)
case gcMarkWorkerFractionalMode:
// 这个模式下P应该适当执行标记
// 执行标记, 直到被抢占, 并且需要计算后台的扫描量来减少辅助GC和唤醒等待中的G
gcDrain(&_p_.gcw, gcDrainFractional|gcDrainUntilPreempt|gcDrainFlushBgCredit)
case gcMarkWorkerIdleMode:
// 这个模式下P只在空闲时执行标记
// 执行标记, 直到被抢占或者达到一定的量, 并且需要计算后台的扫描量来减少辅助GC和唤醒等待中的G
gcDrain(&_p_.gcw, gcDrainIdle|gcDrainUntilPreempt|gcDrainFlushBgCredit)
}
// 恢复G的状态到运行中
casgstatus(gp, _Gwaiting, _Grunning)
})
// 累加所用时间
// Account for time.
duration := nanotime() - startTime
switch _p_.gcMarkWorkerMode {
case gcMarkWorkerDedicatedMode:
atomic.Xaddint64(&gcController.dedicatedMarkTime, duration)
atomic.Xaddint64(&gcController.dedicatedMarkWorkersNeeded, 1)
case gcMarkWorkerFractionalMode:
atomic.Xaddint64(&gcController.fractionalMarkTime, duration)
atomic.Xaddint64(&_p_.gcFractionalMarkTime, duration)
case gcMarkWorkerIdleMode:
atomic.Xaddint64(&gcController.idleMarkTime, duration)
}
// Was this the last worker and did we run out
// of work?
incnwait := atomic.Xadd(&work.nwait, +1)
// 判断是否所有后台标记任务都完成, 并且没有更多的任务
if incnwait > work.nproc {
println("runtime: p.gcMarkWorkerMode=", _p_.gcMarkWorkerMode,
"work.nwait=", incnwait, "work.nproc=", work.nproc)
throw("work.nwait > work.nproc")
}
// If this worker reached a background mark completion
// point, signal the main GC goroutine.
// 当所有的后台工作任务都陷入等待并且没有剩余工作时,我们就认为该轮垃圾收集的标记阶段结束了,这时我们会调用 runtime.gcMarkDone 函数:
if incnwait == work.nproc && !gcMarkWorkAvailable(nil) {
// Make this G preemptible and disassociate it
// as the worker for this P so
// findRunnableGCWorker doesn't try to
// schedule it.
// 取消和P的关联
_p_.gcBgMarkWorker.set(nil)
// 允许G被抢占
releasem(park.m.ptr())
// 准备进入完成标记阶段
gcMarkDone()
// Disable preemption and prepare to reattach
// to the P.
//
// We may be running on a different P at this
// point, so we can't reattach until this G is
// parked.
// 休眠之前会重新关联P
// 因为上面允许被抢占, 到这里的时候可能就会变成其他P
// 如果重新关联P失败则这个任务会结束
park.m.set(acquirem())
park.attach.set(_p_)
}
}
}
|
runtime.gcDrain 是用于扫描和标记堆内存中对象的核心方法.
gcDrain
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
|
// gcDrain scans roots and objects in work buffers, blackening grey
// objects until it is unable to get more work. It may return before
// GC is done; it's the caller's responsibility to balance work from
// other Ps.
//
// If flags&gcDrainUntilPreempt != 0, gcDrain returns when g.preempt
// is set.
//
// If flags&gcDrainIdle != 0, gcDrain returns when there is other work
// to do.
//
// If flags&gcDrainFractional != 0, gcDrain self-preempts when
// pollFractionalWorkerExit() returns true. This implies
// gcDrainNoBlock.
//
// If flags&gcDrainFlushBgCredit != 0, gcDrain flushes scan work
// credit to gcController.bgScanCredit every gcCreditSlack units of
// scan work.
//
// gcDrain will always return if there is a pending STW.
//
//go:nowritebarrier
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
if !writeBarrier.needed {
throw("gcDrain phase incorrect")
}
gp := getg().m.curg
// 看到抢占标志时是否要返回
// gcDrainUntilPreempt — 当 Goroutine 的 preempt 字段被设置成 true 时返回;
preemptible := flags&gcDrainUntilPreempt != 0
// gcDrainFlushBgCredit — 调用 runtime.gcFlushBgCredit 计算后台完成的标记任务量以减少并发标记期间的辅助垃圾收集的用户程序的工作量;
// 是否计算后台的扫描量来减少辅助GC和唤醒等待中的G
flushBgCredit := flags&gcDrainFlushBgCredit != 0
// 是否只执行一定量的工作
// gcDrainIdle — 调用 runtime.pollWork 函数,当处理器上包含其他待执行 Goroutine 时返回;
idle := flags&gcDrainIdle != 0
// 记录初始的已扫描数量
initScanWork := gcw.scanWork
// checkWork is the scan work before performing the next
// self-preempt check.
checkWork := int64(1<<63 - 1)
// 运行时会使用本地变量中的 check 函数检查当前是否应该退出标记任务并让出该处理器。
var check func() bool
// gcDrainFractional — 调用 runtime.pollFractionalWorkerExit 函数,当 CPU 的占用率超过 fractionalUtilizationGoal 的 20% 时返回;
if flags&(gcDrainIdle|gcDrainFractional) != 0 {
checkWork = initScanWork + drainCheckThreshold
if idle {
check = pollWork
} else if flags&gcDrainFractional != 0 {
check = pollFractionalWorkerExit
}
}
// 当我们做完准备工作后,就可以开始扫描全局变量中的根对象了,这也是标记阶段中需要最先被执行的任务:
// 如果根对象未扫描完, 则先扫描根对象
// Drain root marking jobs.
if work.markrootNext < work.markrootJobs {
// Stop if we're preemptible or if someone wants to STW.
// 如果标记了preemptible, 循环直到被抢占
for !(gp.preempt && (preemptible || atomic.Load(&sched.gcwaiting) != 0)) {
// 从根对象扫描队列取出一个值(原子递增)
job := atomic.Xadd(&work.markrootNext, +1) - 1
if job >= work.markrootJobs {
break
}
//扫描根对象需要使用 runtime.markroot 函数,该函数会扫描缓存、数据段、存放全局变量和静态变量的 BSS 段以及 Goroutine 的栈内存;
// 执行根对象扫描工作
markroot(gcw, job)
// 如果是idle模式并且有其他工作, 则返回
if check != nil && check() {
goto done
}
}
}
// 一旦完成了对根对象的扫描,当前 Goroutine 会开始从本地和全局的工作缓存池中获取待执行的任务:
// 根对象已经在标记队列中, 消费标记队列
// 如果标记了preemptible, 循环直到被抢占
// Drain heap marking jobs.
// Stop if we're preemptible or if someone wants to STW.
for !(gp.preempt && (preemptible || atomic.Load(&sched.gcwaiting) != 0)) {
// Try to keep work available on the global queue. We used to
// check if there were waiting workers, but it's better to
// just keep work available than to make workers wait. In the
// worst case, we'll do O(log(_WorkbufSize)) unnecessary
// balances.
// 如果全局标记队列为空, 把本地标记队列的一部分工作分过去
// (如果wbuf2不为空则移动wbuf2过去, 否则移动wbuf1的一半过去)
if work.full == 0 {
gcw.balance()
}
// 从本地标记队列中获取对象, 获取不到则从全局标记队列获取
b := gcw.tryGetFast()
if b == 0 {
// 非阻塞获取
b = gcw.tryGet()
if b == 0 {
// Flush the write barrier
// buffer; this may create
// more work.
wbBufFlush(nil, 0)
b = gcw.tryGet()
}
}
if b == 0 {
// Unable to get work.
break
}
// 扫描获取到的对象
scanobject(b, gcw)
//扫描对象会使用 runtime.scanobject,该函数会从传入的位置开始扫描,扫描期间会调用 runtime.greyobject 为找到的活跃对象上色。
// Flush background scan work credit to the global
// account if we've accumulated enough locally so
// mutator assists can draw on it.
// 如果已经扫描了一定数量的对象(gcCreditSlack的值是2000)
if gcw.scanWork >= gcCreditSlack {
// 把扫描的对象数量添加到全局
atomic.Xaddint64(&gcController.scanWork, gcw.scanWork)
// 减少辅助GC的工作量和唤醒等待中的G
if flushBgCredit {
gcFlushBgCredit(gcw.scanWork - initScanWork)
initScanWork = 0
}
checkWork -= gcw.scanWork
gcw.scanWork = 0
// 如果达到了检查的扫描量, 则检查是否有其他任务(G), 如果有则跳出循环
if checkWork <= 0 {
checkWork += drainCheckThreshold
if check != nil && check() {
break
}
}
}
}
done:
// Flush remaining scan work credit.
//当本轮的扫描因为外部条件变化而中断时,该函数会通过 runtime.gcFlushBgCredit 记录这次扫描的内存字节数用于减少辅助标记的工作量。
// 把扫描的对象数量添加到全局
if gcw.scanWork > 0 {
atomic.Xaddint64(&gcController.scanWork, gcw.scanWork)
// 减少辅助GC的工作量和唤醒等待中的G
if flushBgCredit {
gcFlushBgCredit(gcw.scanWork - initScanWork)
}
gcw.scanWork = 0
}
}
|
markroot
扫描以 markroot 开始,从栈,全局变量,寄存器等根对象开始扫描,创建一个有向引用图,把根对象投入到队列中.
markroot函数用于执行根对象扫描工作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
|
// markroot scans the i'th root.
//
// Preemption must be disabled (because this uses a gcWork).
//
// nowritebarrier is only advisory here.
//
//go:nowritebarrier
func markroot(gcw *gcWork, i uint32) {
// 判断取出的数值对应哪种任务
// (google的工程师觉得这种办法可笑)
// TODO(austin): This is a bit ridiculous. Compute and store
// the bases in gcMarkRootPrepare instead of the counts.
baseFlushCache := uint32(fixedRootCount)
baseData := baseFlushCache + uint32(work.nFlushCacheRoots)
baseBSS := baseData + uint32(work.nDataRoots)
baseSpans := baseBSS + uint32(work.nBSSRoots)
baseStacks := baseSpans + uint32(work.nSpanRoots)
end := baseStacks + uint32(work.nStackRoots)
// Note: if you add a case here, please also update heapdump.go:dumproots.
switch {
// 释放mcache中的所有span, 要求STW
case baseFlushCache <= i && i < baseData:
flushmcache(int(i - baseFlushCache))
// 扫描可读写的全局变量
// 这里只会扫描i对应的block, 扫描时传入包含哪里有指针的bitmap数据
case baseData <= i && i < baseBSS:
for _, datap := range activeModules() {
markrootBlock(datap.data, datap.edata-datap.data, datap.gcdatamask.bytedata, gcw, int(i-baseData))
}
// 扫描只读的全局变量
// 这里只会扫描i对应的block, 扫描时传入包含哪里有指针的bitmap数据
case baseBSS <= i && i < baseSpans:
for _, datap := range activeModules() {
markrootBlock(datap.bss, datap.ebss-datap.bss, datap.gcbssmask.bytedata, gcw, int(i-baseBSS))
}
// 扫描析构器队列
case i == fixedRootFinalizers:
for fb := allfin; fb != nil; fb = fb.alllink {
cnt := uintptr(atomic.Load(&fb.cnt))
scanblock(uintptr(unsafe.Pointer(&fb.fin[0])), cnt*unsafe.Sizeof(fb.fin[0]), &finptrmask[0], gcw, nil)
}
// 释放已中止的G的栈
case i == fixedRootFreeGStacks:
// Switch to the system stack so we can call
// stackfree.
systemstack(markrootFreeGStacks)
// 扫描各个span中特殊对象(析构器列表)
case baseSpans <= i && i < baseStacks:
// mark mspan.specials
markrootSpans(gcw, int(i-baseSpans))
// 扫描各个G的栈
default:
// the rest is scanning goroutine stacks
// 获取需要扫描的G
var gp *g
if baseStacks <= i && i < end {
gp = allgs[i-baseStacks]
} else {
throw("markroot: bad index")
}
// 记录等待开始的时间
// remember when we've first observed the G blocked
// needed only to output in traceback
status := readgstatus(gp) // We are not in a scan state
if (status == _Gwaiting || status == _Gsyscall) && gp.waitsince == 0 {
gp.waitsince = work.tstart
}
// 切换到g0运行(有可能会扫到自己的栈)
// scanstack must be done on the system stack in case
// we're trying to scan our own stack.
systemstack(func() {
// If this is a self-scan, put the user G in
// _Gwaiting to prevent self-deadlock. It may
// already be in _Gwaiting if this is a mark
// worker or we're in mark termination.
// 判断扫描的栈是否自己的
userG := getg().m.curg
// 如果正在扫描自己的栈则切换状态到等待中防止死锁
selfScan := gp == userG && readgstatus(userG) == _Grunning
if selfScan {
casgstatus(userG, _Grunning, _Gwaiting)
userG.waitreason = waitReasonGarbageCollectionScan
}
// TODO: suspendG blocks (and spins) until gp
// stops, which may take a while for
// running goroutines. Consider doing this in
// two phases where the first is non-blocking:
// we scan the stacks we can and ask running
// goroutines to scan themselves; and the
// second blocks.
stopped := suspendG(gp)
if stopped.dead {
gp.gcscandone = true
return
}
if gp.gcscandone {
throw("g already scanned")
}
scanstack(gp, gcw)
gp.gcscandone = true
resumeG(stopped)
// 如果正在扫描自己的栈则把状态切换回运行中
if selfScan {
casgstatus(userG, _Gwaiting, _Grunning)
}
})
}
}
|
suspendG
函数负责扫描G的栈:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
|
// suspendG suspends goroutine gp at a safe-point and returns the
// state of the suspended goroutine. The caller gets read access to
// the goroutine until it calls resumeG.
//
// It is safe for multiple callers to attempt to suspend the same
// goroutine at the same time. The goroutine may execute between
// subsequent successful suspend operations. The current
// implementation grants exclusive access to the goroutine, and hence
// multiple callers will serialize. However, the intent is to grant
// shared read access, so please don't depend on exclusive access.
//
// This must be called from the system stack and the user goroutine on
// the current M (if any) must be in a preemptible state. This
// prevents deadlocks where two goroutines attempt to suspend each
// other and both are in non-preemptible states. There are other ways
// to resolve this deadlock, but this seems simplest.
//
// TODO(austin): What if we instead required this to be called from a
// user goroutine? Then we could deschedule the goroutine while
// waiting instead of blocking the thread. If two goroutines tried to
// suspend each other, one of them would win and the other wouldn't
// complete the suspend until it was resumed. We would have to be
// careful that they couldn't actually queue up suspend for each other
// and then both be suspended. This would also avoid the need for a
// kernel context switch in the synchronous case because we could just
// directly schedule the waiter. The context switch is unavoidable in
// the signal case.
//
//go:systemstack
func suspendG(gp *g) suspendGState {
if mp := getg().m; mp.curg != nil && readgstatus(mp.curg) == _Grunning {
// Since we're on the system stack of this M, the user
// G is stuck at an unsafe point. If another goroutine
// were to try to preempt m.curg, it could deadlock.
throw("suspendG from non-preemptible goroutine")
}
// See https://golang.org/cl/21503 for justification of the yield delay.
const yieldDelay = 10 * 1000
var nextYield int64
// Drive the goroutine to a preemption point.
stopped := false
var asyncM *m
var asyncGen uint32
var nextPreemptM int64
// 循环直到扫描完成
for i := 0; ; i++ {
// 判断G的当前状态
switch s := readgstatus(gp); s {
default:
if s&_Gscan != 0 {
// Someone else is suspending it. Wait
// for them to finish.
//
// TODO: It would be nicer if we could
// coalesce suspends.
break
}
dumpgstatus(gp)
throw("invalid g status")
// G已中止, 不需要扫描它
case _Gdead:
// Nothing to suspend.
//
// preemptStop may need to be cleared, but
// doing that here could race with goroutine
// reuse. Instead, goexit0 clears it.
return suspendGState{dead: true}
// G的栈正在扩展, 下一轮重试
case _Gcopystack:
// The stack is being copied. We need to wait
// until this is done.
case _Gpreempted:
// We (or someone else) suspended the G. Claim
// ownership of it by transitioning it to
// _Gwaiting.
if !casGFromPreempted(gp, _Gpreempted, _Gwaiting) {
break
}
// We stopped the G, so we have to ready it later.
stopped = true
s = _Gwaiting
fallthrough
// G不是运行中, 首先需要防止它运行
case _Grunnable, _Gsyscall, _Gwaiting:
// Claim goroutine by setting scan bit.
// This may race with execution or readying of gp.
// The scan bit keeps it from transition state.
if !castogscanstatus(gp, s, s|_Gscan) {
// 跳出循环
break
}
// Clear the preemption request. It's safe to
// reset the stack guard because we hold the
// _Gscan bit and thus own the stack.
gp.preemptStop = false
gp.preempt = false
gp.stackguard0 = gp.stack.lo + _StackGuard
// The goroutine was already at a safe-point
// and we've now locked that in.
//
// TODO: It would be much better if we didn't
// leave it in _Gscan, but instead gently
// prevented its scheduling until resumption.
// Maybe we only use this to bump a suspended
// count and the scheduler skips suspended
// goroutines? That wouldn't be enough for
// {_Gsyscall,_Gwaiting} -> _Grunning. Maybe
// for all those transitions we need to check
// suspended and deschedule?
return suspendGState{g: gp, stopped: stopped}
// G正在运行
case _Grunning:
// Optimization: if there is already a pending preemption request
// (from the previous loop iteration), don't bother with the atomics.
// 如果已经有抢占请求, 则抢占成功时会帮我们处理
if gp.preemptStop && gp.preempt && gp.stackguard0 == stackPreempt && asyncM == gp.m && atomic.Load(&asyncM.preemptGen) == asyncGen {
break
}
// 抢占G, 抢占成功时会帮我们处理
// Temporarily block state transitions.
if !castogscanstatus(gp, _Grunning, _Gscanrunning) {
break
}
// Request synchronous preemption.
gp.preemptStop = true
gp.preempt = true
gp.stackguard0 = stackPreempt
// Prepare for asynchronous preemption.
asyncM2 := gp.m
asyncGen2 := atomic.Load(&asyncM2.preemptGen)
needAsync := asyncM != asyncM2 || asyncGen != asyncGen2
asyncM = asyncM2
asyncGen = asyncGen2
casfrom_Gscanstatus(gp, _Gscanrunning, _Grunning)
// Send asynchronous preemption. We do this
// after CASing the G back to _Grunning
// because preemptM may be synchronous and we
// don't want to catch the G just spinning on
// its status.
if preemptMSupported && debug.asyncpreemptoff == 0 && needAsync {
// Rate limit preemptM calls. This is
// particularly important on Windows
// where preemptM is actually
// synchronous and the spin loop here
// can lead to live-lock.
now := nanotime()
if now >= nextPreemptM {
nextPreemptM = now + yieldDelay/2
preemptM(asyncM)
}
}
}
// TODO: Don't busy wait. This loop should really only
// be a simple read/decide/CAS loop that only fails if
// there's an active race. Once the CAS succeeds, we
// should queue up the preemption (which will require
// it to be reliable in the _Grunning case, not
// best-effort) and then sleep until we're notified
// that the goroutine is suspended.
// 第一轮休眠10毫秒, 第二轮休眠5毫秒
if i == 0 {
nextYield = nanotime() + yieldDelay
}
if nanotime() < nextYield {
procyield(10)
} else {
osyield()
nextYield = nanotime() + yieldDelay/2
}
}
}
|
设置preemptscan后, 在抢占G成功时会调用scanstack扫描它自己的栈, 具体代码在这里.
scanstack
这个函数是起点函数( 起始最原始的还是 markroot,但是我们这里梳理主线 ),该扫描栈上所有可达对象,因为栈是一个根,因为你做事情总要有个开始的地方,那么“栈”就是 golang 的起点。
- 找到这个 goroutine 栈上的内存对象(一个个找,一个个处理);
- 找到对象之后,获取到这个对象的 type 结构,然后取出 type.ptrdata, type.gcdata ,从而我们就知道扫描的内存范围,和内存块上指针的所在位置;
- 调用 scanblock 扫描这个内存块;
扫描栈用的函数是scanstack
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
|
// scanstack scans gp's stack, greying all pointers found on the stack.
//
// scanstack will also shrink the stack if it is safe to do so. If it
// is not, it schedules a stack shrink for the next synchronous safe
// point.
//
// scanstack is marked go:systemstack because it must not be preempted
// while using a workbuf.
//
//go:nowritebarrier
//go:systemstack
func scanstack(gp *g, gcw *gcWork) {
if readgstatus(gp)&_Gscan == 0 {
print("runtime:scanstack: gp=", gp, ", goid=", gp.goid, ", gp->atomicstatus=", hex(readgstatus(gp)), "\n")
throw("scanstack - bad status")
}
switch readgstatus(gp) &^ _Gscan {
default:
print("runtime: gp=", gp, ", goid=", gp.goid, ", gp->atomicstatus=", readgstatus(gp), "\n")
throw("mark - bad status")
case _Gdead:
return
case _Grunning:
print("runtime: gp=", gp, ", goid=", gp.goid, ", gp->atomicstatus=", readgstatus(gp), "\n")
throw("scanstack: goroutine not stopped")
case _Grunnable, _Gsyscall, _Gwaiting:
// ok
}
if gp == getg() {
throw("can't scan our own stack")
}
if isShrinkStackSafe(gp) {
// Shrink the stack if not much of it is being used.
shrinkstack(gp)
} else {
// Otherwise, shrink the stack at the next sync safe point.
gp.preemptShrink = true
}
var state stackScanState
state.stack = gp.stack
if stackTraceDebug {
println("stack trace goroutine", gp.goid)
}
if debugScanConservative && gp.asyncSafePoint {
print("scanning async preempted goroutine ", gp.goid, " stack [", hex(gp.stack.lo), ",", hex(gp.stack.hi), ")\n")
}
// Scan the saved context register. This is effectively a live
// register that gets moved back and forth between the
// register and sched.ctxt without a write barrier.
if gp.sched.ctxt != nil {
scanblock(uintptr(unsafe.Pointer(&gp.sched.ctxt)), sys.PtrSize, &oneptrmask[0], gcw, &state)
}
// scanframeworker会根据代码地址(pc)获取函数信息
// 然后找到函数信息中的stackmap.bytedata, 它保存了函数的栈上哪些地方有指针
// 再调用scanblock来扫描函数的栈空间, 同时函数的参数也会这样扫描
// Scan the stack. Accumulate a list of stack objects.
scanframe := func(frame *stkframe, unused unsafe.Pointer) bool {
scanframeworker(frame, &state, gcw)
return true
}
// 枚举所有调用帧, 分别调用scanframe函数
gentraceback(^uintptr(0), ^uintptr(0), 0, gp, 0, nil, 0x7fffffff, scanframe, nil, 0)
// Find additional pointers that point into the stack from the heap.
// Currently this includes defers and panics. See also function copystack.
// Find and trace all defer arguments.
// 枚举所有defer的调用帧, 分别调用scanframe函数
tracebackdefers(gp, scanframe, nil)
// Find and trace other pointers in defer records.
for d := gp._defer; d != nil; d = d.link {
if d.fn != nil {
// tracebackdefers above does not scan the func value, which could
// be a stack allocated closure. See issue 30453.
scanblock(uintptr(unsafe.Pointer(&d.fn)), sys.PtrSize, &oneptrmask[0], gcw, &state)
}
if d.link != nil {
// The link field of a stack-allocated defer record might point
// to a heap-allocated defer record. Keep that heap record live.
scanblock(uintptr(unsafe.Pointer(&d.link)), sys.PtrSize, &oneptrmask[0], gcw, &state)
}
// Retain defers records themselves.
// Defer records might not be reachable from the G through regular heap
// tracing because the defer linked list might weave between the stack and the heap.
if d.heap {
scanblock(uintptr(unsafe.Pointer(&d)), sys.PtrSize, &oneptrmask[0], gcw, &state)
}
}
if gp._panic != nil {
// Panics are always stack allocated.
state.putPtr(uintptr(unsafe.Pointer(gp._panic)), false)
}
// Find and scan all reachable stack objects.
//
// The state's pointer queue prioritizes precise pointers over
// conservative pointers so that we'll prefer scanning stack
// objects precisely.
state.buildIndex()
for {
p, conservative := state.getPtr()
if p == 0 {
break
}
obj := state.findObject(p)
if obj == nil {
continue
}
t := obj.typ
if t == nil {
// We've already scanned this object.
continue
}
obj.setType(nil) // Don't scan it again.
if stackTraceDebug {
printlock()
print(" live stkobj at", hex(state.stack.lo+uintptr(obj.off)), "of type", t.string())
if conservative {
print(" (conservative)")
}
println()
printunlock()
}
gcdata := t.gcdata
var s *mspan
if t.kind&kindGCProg != 0 {
// This path is pretty unlikely, an object large enough
// to have a GC program allocated on the stack.
// We need some space to unpack the program into a straight
// bitmask, which we allocate/free here.
// TODO: it would be nice if there were a way to run a GC
// program without having to store all its bits. We'd have
// to change from a Lempel-Ziv style program to something else.
// Or we can forbid putting objects on stacks if they require
// a gc program (see issue 27447).
s = materializeGCProg(t.ptrdata, gcdata)
gcdata = (*byte)(unsafe.Pointer(s.startAddr))
}
b := state.stack.lo + uintptr(obj.off)
if conservative {
scanConservative(b, t.ptrdata, gcdata, gcw, &state)
} else {
scanblock(b, t.ptrdata, gcdata, gcw, &state)
}
if s != nil {
dematerializeGCProg(s)
}
}
// Deallocate object buffers.
// (Pointer buffers were all deallocated in the loop above.)
for state.head != nil {
x := state.head
state.head = x.next
if stackTraceDebug {
for i := 0; i < x.nobj; i++ {
obj := &x.obj[i]
if obj.typ == nil { // reachable
continue
}
println(" dead stkobj at", hex(gp.stack.lo+uintptr(obj.off)), "of type", obj.typ.string())
// Note: not necessarily really dead - only reachable-from-ptr dead.
}
}
x.nobj = 0
putempty((*workbuf)(unsafe.Pointer(x)))
}
if state.buf != nil || state.cbuf != nil || state.freeBuf != nil {
throw("remaining pointer buffers")
}
}
|
scanblock
scanblock函数是一个通用的扫描函数, 扫描全局变量和栈空间都会用它, 和scanobject不同的是bitmap需要手动传入,他的一切参数都是传入的,这个函数作为一个基础函数被很多地方调用:
- scanblock 这个函数非常简单,只扫描给定的一段内存块;
- 大循环每次递进 64 个字节,小循环每次递进 8 字节;
- 是否作为指针扫描是由 ptrmask 指定的;
- 只要长度和地址是对齐的,指针类型按 8 字节对齐,那么我们按照 8 字节递进扫描一定是全方位覆盖,不会漏掉一个对象的;
- 再次提醒下,uintptr 是数值类型,编译器不会标识成指针类型,所以不受扫描保护;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
// scanblock scans b as scanobject would, but using an explicit
// pointer bitmap instead of the heap bitmap.
//
// This is used to scan non-heap roots, so it does not update
// gcw.bytesMarked or gcw.scanWork.
//
// If stk != nil, possible stack pointers are also reported to stk.putPtr.
//go:nowritebarrier
func scanblock(b0, n0 uintptr, ptrmask *uint8, gcw *gcWork, stk *stackScanState) {
// Use local copies of original parameters, so that a stack trace
// due to one of the throws below shows the original block
// base and extent.
b := b0
n := n0
// 枚举扫描的地址
for i := uintptr(0); i < n; {
// Find bits for the next word.
// 找到bitmap中对应的byte
bits := uint32(*addb(ptrmask, i/(sys.PtrSize*8)))
if bits == 0 {
i += sys.PtrSize * 8
continue
}
// 枚举byte
for j := 0; j < 8 && i < n; j++ {
// 如果该地址包含指针
if bits&1 != 0 {
// 标记在该地址的对象存活, 并把它加到标记队列(该对象变为灰色)
// Same work as in scanobject; see comments there.
p := *(*uintptr)(unsafe.Pointer(b + i))
if p != 0 {
// 找到该对象对应的span和bitmap
if obj, span, objIndex := findObject(p, b, i); obj != 0 {
// 标记一个对象存活, 并把它加到标记队列(该对象变为灰色)
greyobject(obj, b, i, span, gcw, objIndex)
} else if stk != nil && p >= stk.stack.lo && p < stk.stack.hi {
stk.putPtr(p, false)
}
}
}
// 处理下一个指针下一个bit
bits >>= 1
i += sys.PtrSize
}
}
}
|
greyobject用于标记一个对象存活, 并把它加到标记队列(该对象变为灰色):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
// obj is the start of an object with mark mbits.
// If it isn't already marked, mark it and enqueue into gcw.
// base and off are for debugging only and could be removed.
//
// See also wbBufFlush1, which partially duplicates this logic.
//
//go:nowritebarrierrec
func greyobject(obj, base, off uintptr, span *mspan, gcw *gcWork, objIndex uintptr) {
// obj should be start of allocation, and so must be at least pointer-aligned.
if obj&(sys.PtrSize-1) != 0 {
throw("greyobject: obj not pointer-aligned")
}
mbits := span.markBitsForIndex(objIndex)
if useCheckmark {
// checkmark是用于检查是否所有可到达的对象都被正确标记的机制, 仅除错使用
if !mbits.isMarked() {
printlock()
print("runtime:greyobject: checkmarks finds unexpected unmarked object obj=", hex(obj), "\n")
print("runtime: found obj at *(", hex(base), "+", hex(off), ")\n")
// Dump the source (base) object
gcDumpObject("base", base, off)
// Dump the object
gcDumpObject("obj", obj, ^uintptr(0))
getg().m.traceback = 2
throw("checkmark found unmarked object")
}
hbits := heapBitsForAddr(obj)
if hbits.isCheckmarked(span.elemsize) {
return
}
hbits.setCheckmarked(span.elemsize)
if !hbits.isCheckmarked(span.elemsize) {
throw("setCheckmarked and isCheckmarked disagree")
}
} else {
if debug.gccheckmark > 0 && span.isFree(objIndex) {
print("runtime: marking free object ", hex(obj), " found at *(", hex(base), "+", hex(off), ")\n")
gcDumpObject("base", base, off)
gcDumpObject("obj", obj, ^uintptr(0))
getg().m.traceback = 2
throw("marking free object")
}
// 如果对象所在的span中的gcmarkBits对应的bit已经设置为1则可以跳过处理
// If marked we have nothing to do.
if mbits.isMarked() {
return
}
mbits.setMarked()
// Mark span.
arena, pageIdx, pageMask := pageIndexOf(span.base())
if arena.pageMarks[pageIdx]&pageMask == 0 {
// 设置对象所在的span中的gcmarkBits对应的bit为1
atomic.Or8(&arena.pageMarks[pageIdx], pageMask)
}
// If this is a noscan object, fast-track it to black
// instead of greying it.
// 如果确定对象不包含指针(所在span的类型是noscan), 则不需要把对象放入标记队列
if span.spanclass.noscan() {
gcw.bytesMarked += uint64(span.elemsize)
return
}
}
// Queue the obj for scanning. The PREFETCH(obj) logic has been removed but
// seems like a nice optimization that can be added back in.
// There needs to be time between the PREFETCH and the use.
// Previously we put the obj in an 8 element buffer that is drained at a rate
// to give the PREFETCH time to do its work.
// Use of PREFETCHNTA might be more appropriate than PREFETCH
// 把对象放入标记队列
// 先放入本地标记队列, 失败时把本地标记队列中的部分工作转移到全局标记队列, 再放入本地标记队列
if !gcw.putFast(obj) {
gcw.put(obj)
}
}
|
scanobject
gcDrain函数扫描完根对象, 就会开始消费标记队列, 对从标记队列中取出的对象调用scanobject函数.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
|
// scanobject scans the object starting at b, adding pointers to gcw.
// b must point to the beginning of a heap object or an oblet.
// scanobject consults the GC bitmap for the pointer mask and the
// spans for the size of the object.
//
//go:nowritebarrier
func scanobject(b uintptr, gcw *gcWork) {
// Find the bits for b and the size of the object at b.
//
// b is either the beginning of an object, in which case this
// is the size of the object to scan, or it points to an
// oblet, in which case we compute the size to scan below.
// 获取对象对应的bitmap
hbits := heapBitsForAddr(b)
// 获取对象所在的span
s := spanOfUnchecked(b)
// 获取对象的大小
n := s.elemsize
if n == 0 {
throw("scanobject n == 0")
}
// 对象大小过大时(maxObletBytes是128KB)需要分割扫描
// 每次最多只扫描128KB
if n > maxObletBytes {
// Large object. Break into oblets for better
// parallelism and lower latency.
if b == s.base() {
// It's possible this is a noscan object (not
// from greyobject, but from other code
// paths), in which case we must *not* enqueue
// oblets since their bitmaps will be
// uninitialized.
if s.spanclass.noscan() {
// Bypass the whole scan.
gcw.bytesMarked += uint64(n)
return
}
// Enqueue the other oblets to scan later.
// Some oblets may be in b's scalar tail, but
// these will be marked as "no more pointers",
// so we'll drop out immediately when we go to
// scan those.
for oblet := b + maxObletBytes; oblet < s.base()+s.elemsize; oblet += maxObletBytes {
if !gcw.putFast(oblet) {
gcw.put(oblet)
}
}
}
// Compute the size of the oblet. Since this object
// must be a large object, s.base() is the beginning
// of the object.
n = s.base() + s.elemsize - b
if n > maxObletBytes {
n = maxObletBytes
}
}
// 扫描对象中的指针
var i uintptr
for i = 0; i < n; i += sys.PtrSize {
// Find bits for this word.
// 获取对应的bit
if i != 0 {
// Avoid needless hbits.next() on last iteration.
hbits = hbits.next()
}
// Load bits once. See CL 22712 and issue 16973 for discussion.
bits := hbits.bits()
// 检查scan bit判断是否继续扫描, 注意第二个scan bit是checkmark
// During checkmarking, 1-word objects store the checkmark
// in the type bit for the one word. The only one-word objects
// are pointers, or else they'd be merged with other non-pointer
// data into larger allocations.
if i != 1*sys.PtrSize && bits&bitScan == 0 {
break // no more pointers in this object
}
// 检查pointer bit, 不是指针则继续
if bits&bitPointer == 0 {
continue // not a pointer
}
// Work here is duplicated in scanblock and above.
// If you make changes here, make changes there too.
// 取出指针的值
obj := *(*uintptr)(unsafe.Pointer(b + i))
// At this point we have extracted the next potential pointer.
// Quickly filter out nil and pointers back to the current object.
// 如果指针在arena区域中, 则调用greyobject标记对象并把对象放到标记队列中
if obj != 0 && obj-b >= n {
// Test if obj points into the Go heap and, if so,
// mark the object.
//
// Note that it's possible for findObject to
// fail if obj points to a just-allocated heap
// object because of a race with growing the
// heap. In this case, we know the object was
// just allocated and hence will be marked by
// allocation itself.
if obj, span, objIndex := findObject(obj, b, i); obj != 0 {
greyobject(obj, b, i, span, gcw, objIndex)
}
}
}
// 统计扫描过的大小和对象数量
gcw.bytesMarked += uint64(n)
gcw.scanWork += int64(i)
}
|
gcAssistAlloc
为了保证用户程序分配内存的速度不会超出后台任务的标记速度,运行时还引入了标记辅助技术,它遵循一条非常简单并且朴实的原则,分配多少内存就需要完成多少标记任务。每一个 Goroutine 都持有 gcAssistBytes 字段,这个字段存储了当前 Goroutine 辅助标记的对象字节数。在并发标记阶段期间,当 Goroutine 调用 runtime.mallocgc 分配新的对象时,该函数会检查申请内存的 Goroutine 是否处于入不敷出的状态:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
var assistG*g
if gcBlackenEnabled != 0 {
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
gcAssistAlloc(assistG)
}
}
...
return x
}
|
申请内存时调用的 runtime.gcAssistAlloc 和扫描内存时调用的 runtime.gcFlushBgCredit 分别负责『借债』和『还债』,通过这套债务管理系统,我们能够保证 Goroutine 在正常运行的同时不会为垃圾收集造成太多的压力,保证在达到堆大小目标时完成标记阶段。
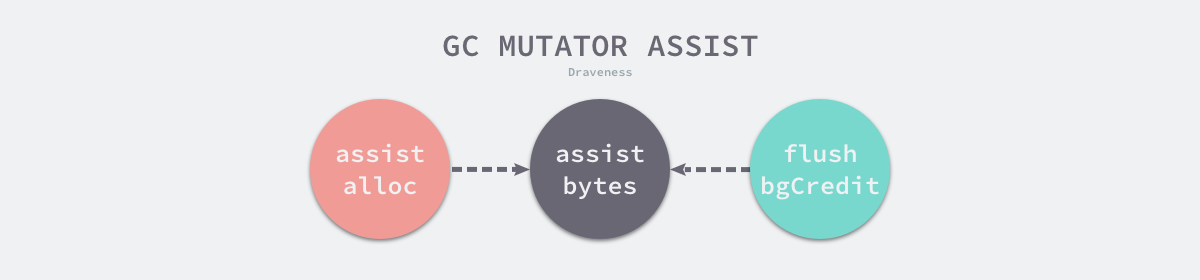
每个 Goroutine 持有的 gcAssistBytes 表示当前协程辅助标记的字节数,全局垃圾收集控制器持有的 bgScanCredit 表示后台协程辅助标记的字节数,当本地 Goroutine 分配了较多的对象时,可以使用公用的信用 bgScanCredit 偿还。我们先来分析 runtime.gcAssistAlloc 函数的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
|
// gcAssistAlloc performs GC work to make gp's assist debt positive.
// gp must be the calling user gorountine.
//
// This must be called with preemption enabled.
func gcAssistAlloc(gp *g) {
//该函数会先根据 Goroutine 的 gcAssistBytes 和垃圾收集控制器的配置计算需要完成的标记任务数量,如果全局信用 bgScanCredit 中有可用的点数,那么就会减去该点数,因为并发执行没有加锁,所以全局信用可能会被更新成负值,然而在长期来看这不是一个比较重要的问题。
// Don't assist in non-preemptible contexts. These are
// generally fragile and won't allow the assist to block.
if getg() == gp.m.g0 {
return
}
if mp := getg().m; mp.locks > 0 || mp.preemptoff != "" {
return
}
traced := false
retry:
// Compute the amount of scan work we need to do to make the
// balance positive. When the required amount of work is low,
// we over-assist to build up credit for future allocations
// and amortize the cost of assisting.
debtBytes := -gp.gcAssistBytes
scanWork := int64(gcController.assistWorkPerByte * float64(debtBytes))
if scanWork < gcOverAssistWork {
scanWork = gcOverAssistWork
debtBytes = int64(gcController.assistBytesPerWork * float64(scanWork))
}
// Steal as much credit as we can from the background GC's
// scan credit. This is racy and may drop the background
// credit below 0 if two mutators steal at the same time. This
// will just cause steals to fail until credit is accumulated
// again, so in the long run it doesn't really matter, but we
// do have to handle the negative credit case.
bgScanCredit := atomic.Loadint64(&gcController.bgScanCredit)
stolen := int64(0)
if bgScanCredit > 0 {
if bgScanCredit < scanWork {
stolen = bgScanCredit
gp.gcAssistBytes += 1 + int64(gcController.assistBytesPerWork*float64(stolen))
} else {
stolen = scanWork
gp.gcAssistBytes += debtBytes
}
atomic.Xaddint64(&gcController.bgScanCredit, -stolen)
scanWork -= stolen
if scanWork == 0 {
// We were able to steal all of the credit we
// needed.
if traced {
traceGCMarkAssistDone()
}
return
}
}
if trace.enabled && !traced {
traced = true
traceGCMarkAssistStart()
}
//如果全局信用不足以覆盖本地的债务,运行时会在系统栈中调用 runtime.gcAssistAlloc1 执行标记任务,该函数会直接调用 runtime.gcDrainN 完成指定数量的标记任务并返回:
// Perform assist work
systemstack(func() {
gcAssistAlloc1(gp, scanWork)
// The user stack may have moved, so this can't touch
// anything on it until it returns from systemstack.
})
completed := gp.param != nil
gp.param = nil
if completed {
gcMarkDone()
}
//如果在完成标记辅助任务后,当前 Goroutine 仍然入不敷出并且 Goroutine 没有被抢占,那么运行时会执行 runtime.gcParkAssist;在该函数中,如果全局信用依然不足,runtime.gcParkAssist 会将当前 Goroutine 陷入休眠、加入全局的辅助标记队列并等待后台标记任务的唤醒。
if gp.gcAssistBytes < 0 {
// We were unable steal enough credit or perform
// enough work to pay off the assist debt. We need to
// do one of these before letting the mutator allocate
// more to prevent over-allocation.
//
// If this is because we were preempted, reschedule
// and try some more.
if gp.preempt {
Gosched()
goto retry
}
// Add this G to an assist queue and park. When the GC
// has more background credit, it will satisfy queued
// assists before flushing to the global credit pool.
//
// Note that this does *not* get woken up when more
// work is added to the work list. The theory is that
// there wasn't enough work to do anyway, so we might
// as well let background marking take care of the
// work that is available.
if !gcParkAssist() {
goto retry
}
// At this point either background GC has satisfied
// this G's assist debt, or the GC cycle is over.
}
if traced {
traceGCMarkAssistDone()
}
}
// gcAssistAlloc1 is the part of gcAssistAlloc that runs on the system
// stack. This is a separate function to make it easier to see that
// we're not capturing anything from the user stack, since the user
// stack may move while we're in this function.
//
// gcAssistAlloc1 indicates whether this assist completed the mark
// phase by setting gp.param to non-nil. This can't be communicated on
// the stack since it may move.
//
//go:systemstack
func gcAssistAlloc1(gp *g, scanWork int64) {
// Clear the flag indicating that this assist completed the
// mark phase.
gp.param = nil
if atomic.Load(&gcBlackenEnabled) == 0 {
// The gcBlackenEnabled check in malloc races with the
// store that clears it but an atomic check in every malloc
// would be a performance hit.
// Instead we recheck it here on the non-preemptable system
// stack to determine if we should perform an assist.
// GC is done, so ignore any remaining debt.
gp.gcAssistBytes = 0
return
}
// Track time spent in this assist. Since we're on the
// system stack, this is non-preemptible, so we can
// just measure start and end time.
startTime := nanotime()
decnwait := atomic.Xadd(&work.nwait, -1)
if decnwait == work.nproc {
println("runtime: work.nwait =", decnwait, "work.nproc=", work.nproc)
throw("nwait > work.nprocs")
}
// gcDrainN requires the caller to be preemptible.
casgstatus(gp, _Grunning, _Gwaiting)
gp.waitreason = waitReasonGCAssistMarking
// drain own cached work first in the hopes that it
// will be more cache friendly.
gcw := &getg().m.p.ptr().gcw
workDone := gcDrainN(gcw, scanWork)
casgstatus(gp, _Gwaiting, _Grunning)
// Record that we did this much scan work.
//
// Back out the number of bytes of assist credit that
// this scan work counts for. The "1+" is a poor man's
// round-up, to ensure this adds credit even if
// assistBytesPerWork is very low.
gp.gcAssistBytes += 1 + int64(gcController.assistBytesPerWork*float64(workDone))
// If this is the last worker and we ran out of work,
// signal a completion point.
incnwait := atomic.Xadd(&work.nwait, +1)
if incnwait > work.nproc {
println("runtime: work.nwait=", incnwait,
"work.nproc=", work.nproc)
throw("work.nwait > work.nproc")
}
if incnwait == work.nproc && !gcMarkWorkAvailable(nil) {
// This has reached a background completion point. Set
// gp.param to a non-nil value to indicate this. It
// doesn't matter what we set it to (it just has to be
// a valid pointer).
gp.param = unsafe.Pointer(gp)
}
duration := nanotime() - startTime
_p_ := gp.m.p.ptr()
_p_.gcAssistTime += duration
if _p_.gcAssistTime > gcAssistTimeSlack {
atomic.Xaddint64(&gcController.assistTime, _p_.gcAssistTime)
_p_.gcAssistTime = 0
}
}
// gcParkAssist puts the current goroutine on the assist queue and parks.
//
// gcParkAssist reports whether the assist is now satisfied. If it
// returns false, the caller must retry the assist.
//
//go:nowritebarrier
func gcParkAssist() bool {
lock(&work.assistQueue.lock)
// If the GC cycle finished while we were getting the lock,
// exit the assist. The cycle can't finish while we hold the
// lock.
if atomic.Load(&gcBlackenEnabled) == 0 {
unlock(&work.assistQueue.lock)
return true
}
gp := getg()
oldList := work.assistQueue.q
work.assistQueue.q.pushBack(gp)
// Recheck for background credit now that this G is in
// the queue, but can still back out. This avoids a
// race in case background marking has flushed more
// credit since we checked above.
if atomic.Loadint64(&gcController.bgScanCredit) > 0 {
work.assistQueue.q = oldList
if oldList.tail != 0 {
oldList.tail.ptr().schedlink.set(nil)
}
unlock(&work.assistQueue.lock)
return false
}
// Park.
goparkunlock(&work.assistQueue.lock, waitReasonGCAssistWait, traceEvGoBlockGC, 2)
return true
}
|
用于还债的 runtime.gcFlushBgCredit 实现比较简单,如果辅助队列中不存在等待的 Goroutine,那么当前的信用会直接加到全局信用 bgScanCredit 中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
// gcFlushBgCredit flushes scanWork units of background scan work
// credit. This first satisfies blocked assists on the
// work.assistQueue and then flushes any remaining credit to
// gcController.bgScanCredit.
//
// Write barriers are disallowed because this is used by gcDrain after
// it has ensured that all work is drained and this must preserve that
// condition.
//
//go:nowritebarrierrec
func gcFlushBgCredit(scanWork int64) {
if work.assistQueue.q.empty() {
// Fast path; there are no blocked assists. There's a
// small window here where an assist may add itself to
// the blocked queue and park. If that happens, we'll
// just get it on the next flush.
atomic.Xaddint64(&gcController.bgScanCredit, scanWork)
return
}
scanBytes := int64(float64(scanWork) * gcController.assistBytesPerWork)
lock(&work.assistQueue.lock)
for !work.assistQueue.q.empty() && scanBytes > 0 {
gp := work.assistQueue.q.pop()
// Note that gp.gcAssistBytes is negative because gp
// is in debt. Think carefully about the signs below.
if scanBytes+gp.gcAssistBytes >= 0 {
// Satisfy this entire assist debt.
scanBytes += gp.gcAssistBytes
gp.gcAssistBytes = 0
// It's important that we *not* put gp in
// runnext. Otherwise, it's possible for user
// code to exploit the GC worker's high
// scheduler priority to get itself always run
// before other goroutines and always in the
// fresh quantum started by GC.
ready(gp, 0, false)
} else {
// Partially satisfy this assist.
gp.gcAssistBytes += scanBytes
scanBytes = 0
// As a heuristic, we move this assist to the
// back of the queue so that large assists
// can't clog up the assist queue and
// substantially delay small assists.
work.assistQueue.q.pushBack(gp)
break
}
}
if scanBytes > 0 {
// Convert from scan bytes back to work.
scanWork = int64(float64(scanBytes) * gcController.assistWorkPerByte)
atomic.Xaddint64(&gcController.bgScanCredit, scanWork)
}
unlock(&work.assistQueue.lock)
}
|
如果辅助队列不为空,上述函数会根据每个 Goroutine 的债务数量和已完成的工作决定是否唤醒这些陷入休眠的 Goroutine;如果唤醒所有的 Goroutine 后,标记任务量仍然有剩余,这些标记任务都会加入全局信用中。
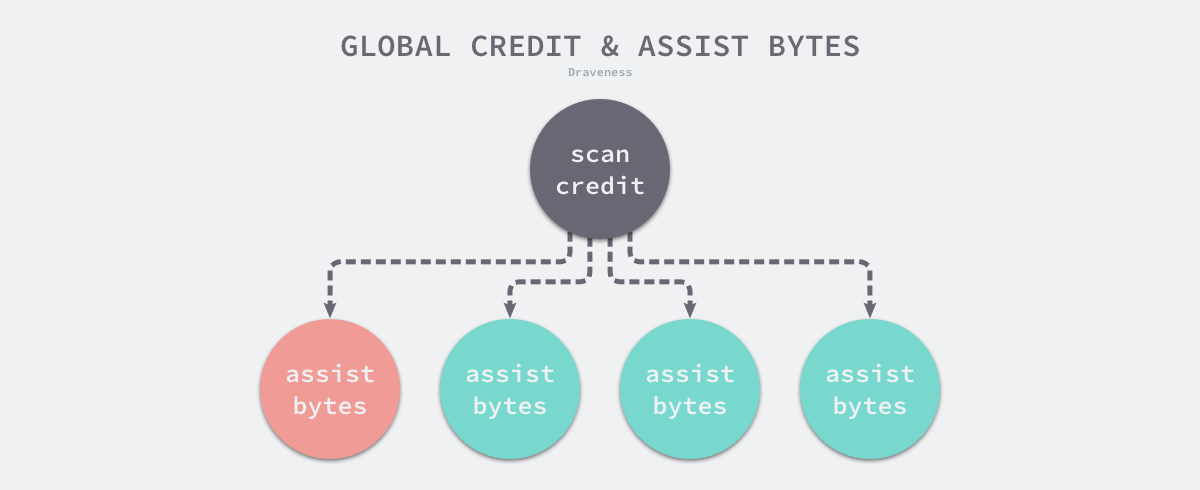
用户程序辅助标记的核心目的就是避免用户程序分配内存影响垃圾收集器完成标记工作的期望时间,它通过维护账户体系保证用户程序不会对垃圾收集造成过多的负担,一旦用户程序分配了大量的内存,该用户程序就会通过辅助标记的方式平衡账本,这个过程会在最后达到相对平衡,保证标记任务在到达期望堆大小时完成。
标记终止: gcMarkDone
当所有处理器的本地任务都完成并且不存在剩余的工作 Goroutine 时,会执行gcMarkDone函数准备进入完成标记阶段(mark termination):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
|
// gcMarkDone transitions the GC from mark to mark termination if all
// reachable objects have been marked (that is, there are no grey
// objects and can be no more in the future). Otherwise, it flushes
// all local work to the global queues where it can be discovered by
// other workers.
//
// This should be called when all local mark work has been drained and
// there are no remaining workers. Specifically, when
//
// work.nwait == work.nproc && !gcMarkWorkAvailable(p)
//
// The calling context must be preemptible.
//
// Flushing local work is important because idle Ps may have local
// work queued. This is the only way to make that work visible and
// drive GC to completion.
//
// It is explicitly okay to have write barriers in this function. If
// it does transition to mark termination, then all reachable objects
// have been marked, so the write barrier cannot shade any more
// objects.
func gcMarkDone() {
// Ensure only one thread is running the ragged barrier at a
// time.
semacquire(&work.markDoneSema)
top:
// Re-check transition condition under transition lock.
//
// It's critical that this checks the global work queues are
// empty before performing the ragged barrier. Otherwise,
// there could be global work that a P could take after the P
// has passed the ragged barrier.
//当所有可达对象都被标记后,该函数会将垃圾收集的状态切换至 _GCmarktermination;如果本地队列中仍然存在待处理的任务,当前方法会将所有的任务加入全局队列并等待其他 Goroutine 完成处理:
if !(gcphase == _GCmark && work.nwait == work.nproc && !gcMarkWorkAvailable(nil)) {
semrelease(&work.markDoneSema)
return
}
// forEachP needs worldsema to execute, and we'll need it to
// stop the world later, so acquire worldsema now.
semacquire(&worldsema)
// Flush all local buffers and collect flushedWork flags.
gcMarkDoneFlushed = 0
// 把所有本地标记队列中的对象都推到全局标记队列
systemstack(func() {
gp := getg().m.curg
// Mark the user stack as preemptible so that it may be scanned.
// Otherwise, our attempt to force all P's to a safepoint could
// result in a deadlock as we attempt to preempt a worker that's
// trying to preempt us (e.g. for a stack scan).
casgstatus(gp, _Grunning, _Gwaiting)
forEachP(func(_p_ *p) {
// Flush the write barrier buffer, since this may add
// work to the gcWork.
wbBufFlush1(_p_)
// For debugging, shrink the write barrier
// buffer so it flushes immediately.
// wbBuf.reset will keep it at this size as
// long as throwOnGCWork is set.
if debugCachedWork {
b := &_p_.wbBuf
b.end = uintptr(unsafe.Pointer(&b.buf[wbBufEntryPointers]))
b.debugGen = gcWorkPauseGen
}
// Flush the gcWork, since this may create global work
// and set the flushedWork flag.
//
// TODO(austin): Break up these workbufs to
// better distribute work.
_p_.gcw.dispose()
// Collect the flushedWork flag.
if _p_.gcw.flushedWork {
atomic.Xadd(&gcMarkDoneFlushed, 1)
_p_.gcw.flushedWork = false
} else if debugCachedWork {
// For debugging, freeze the gcWork
// until we know whether we've reached
// completion or not. If we think
// we've reached completion, but
// there's a paused gcWork, then
// that's a bug.
_p_.gcw.pauseGen = gcWorkPauseGen
// Capture the G's stack.
for i := range _p_.gcw.pauseStack {
_p_.gcw.pauseStack[i] = 0
}
callers(1, _p_.gcw.pauseStack[:])
}
})
casgstatus(gp, _Gwaiting, _Grunning)
})
if gcMarkDoneFlushed != 0 {
if debugCachedWork {
// Release paused gcWorks.
atomic.Xadd(&gcWorkPauseGen, 1)
}
// More grey objects were discovered since the
// previous termination check, so there may be more
// work to do. Keep going. It's possible the
// transition condition became true again during the
// ragged barrier, so re-check it.
semrelease(&worldsema)
goto top
}
if debugCachedWork {
throwOnGCWork = true
// Release paused gcWorks. If there are any, they
// should now observe throwOnGCWork and panic.
atomic.Xadd(&gcWorkPauseGen, 1)
}
// There was no global work, no local work, and no Ps
// communicated work since we took markDoneSema. Therefore
// there are no grey objects and no more objects can be
// shaded. Transition to mark termination.
now := nanotime()
work.tMarkTerm = now
work.pauseStart = now
//如果运行时中不包含全局任务、处理器中也不存在本地任务,那么当前垃圾收集循环中的灰色对象也就都标记成了黑色,我们就可以开始触发垃圾收集的阶段迁移了:
getg().m.preemptoff = "gcing"
if trace.enabled {
traceGCSTWStart(0)
}
// 停止所有运行中的G, 并禁止它们运行
systemstack(stopTheWorldWithSema)
// The gcphase is _GCmark, it will transition to _GCmarktermination
// below. The important thing is that the wb remains active until
// all marking is complete. This includes writes made by the GC.
if debugCachedWork {
// For debugging, double check that no work was added after we
// went around above and disable write barrier buffering.
for _, p := range allp {
gcw := &p.gcw
if !gcw.empty() {
printlock()
print("runtime: P ", p.id, " flushedWork ", gcw.flushedWork)
if gcw.wbuf1 == nil {
print(" wbuf1=<nil>")
} else {
print(" wbuf1.n=", gcw.wbuf1.nobj)
}
if gcw.wbuf2 == nil {
print(" wbuf2=<nil>")
} else {
print(" wbuf2.n=", gcw.wbuf2.nobj)
}
print("\n")
if gcw.pauseGen == gcw.putGen {
println("runtime: checkPut already failed at this generation")
}
throw("throwOnGCWork")
}
}
} else {
// For unknown reasons (see issue #27993), there is
// sometimes work left over when we enter mark
// termination. Detect this and resume concurrent
// mark. This is obviously unfortunate.
//
// Switch to the system stack to call wbBufFlush1,
// though in this case it doesn't matter because we're
// non-preemptible anyway.
restart := false
systemstack(func() {
for _, p := range allp {
wbBufFlush1(p)
if !p.gcw.empty() {
restart = true
break
}
}
})
if restart {
getg().m.preemptoff = ""
systemstack(func() {
now := startTheWorldWithSema(true)
work.pauseNS += now - work.pauseStart
})
semrelease(&worldsema)
goto top
}
}
//函数在最后会关闭混合写屏障、唤醒所有协助垃圾收集的用户程序、恢复用户 Goroutine 的调度并调用 runtime.gcMarkTermination 进入标记终止阶段:
// Disable assists and background workers. We must do
// this before waking blocked assists.
// 禁止辅助GC和后台标记任务的运行
atomic.Store(&gcBlackenEnabled, 0)
// Wake all blocked assists. These will run when we
// start the world again.
// 唤醒所有因为辅助GC而休眠的G
gcWakeAllAssists()
// Likewise, release the transition lock. Blocked
// workers and assists will run when we start the
// world again.
semrelease(&work.markDoneSema)
// In STW mode, re-enable user goroutines. These will be
// queued to run after we start the world.
schedEnableUser(true)
// 计算下一次触发gc需要的heap大小
// endCycle depends on all gcWork cache stats being flushed.
// The termination algorithm above ensured that up to
// allocations since the ragged barrier.
nextTriggerRatio := gcController.endCycle()
// Perform mark termination. This will restart the world.
// 进入完成标记阶段, 会重新启动世界
gcMarkTermination(nextTriggerRatio)
}
// gcWakeAllAssists wakes all currently blocked assists. This is used
// at the end of a GC cycle. gcBlackenEnabled must be false to prevent
// new assists from going to sleep after this point.
func gcWakeAllAssists() {
lock(&work.assistQueue.lock)
list := work.assistQueue.q.popList()
injectglist(&list)
unlock(&work.assistQueue.lock)
}
|
gcMarkTermination
gcMarkTermination函数会进入完成标记阶段:
函数中很多数据统计的代码,包括正在使用的内存大小、本轮垃圾收集的暂停时间、CPU 的利用率等数据,这些数据能够帮助控制器决定下一轮触发垃圾收集的堆大小.
除了数据统计之外该函数还会调用 runtime.gcSweep 重置清理阶段的相关状态并在需要时阻塞清理所有的内存管理单元;_GCmarktermination 状态在垃圾收集中并不会持续太久,它会迅速转换至_GCoff 并恢复应用程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
|
func gcMarkTermination(nextTriggerRatio float64) {
// World is stopped.
// Start marktermination which includes enabling the write barrier.
// 禁止辅助GC和后台标记任务的运行
atomic.Store(&gcBlackenEnabled, 0)
// 设置当前GC阶段到完成标记阶段, 并启用写屏障
setGCPhase(_GCmarktermination)
// 记录开始时间
work.heap1 = memstats.heap_live
startTime := nanotime()
// 禁止G被抢占
mp := acquirem()
mp.preemptoff = "gcing"
_g_ := getg()
_g_.m.traceback = 2
// 设置G的状态为等待中这样它的栈可以被扫描
gp := _g_.m.curg
casgstatus(gp, _Grunning, _Gwaiting)
gp.waitreason = waitReasonGarbageCollection
// Run gc on the g0 stack. We do this so that the g stack
// we're currently running on will no longer change. Cuts
// the root set down a bit (g0 stacks are not scanned, and
// we don't need to scan gc's internal state). We also
// need to switch to g0 so we can shrink the stack.
// 切换到g0运行
systemstack(func() {
// 开始STW中的标记
gcMark(startTime)
// 必须立刻返回, 因为外面的G的栈有可能被移动, 不能在这之后访问外面的变量
// Must return immediately.
// The outer function's stack may have moved
// during gcMark (it shrinks stacks, including the
// outer function's stack), so we must not refer
// to any of its variables. Return back to the
// non-system stack to pick up the new addresses
// before continuing.
})
// 重新切换到g0运行
systemstack(func() {
work.heap2 = work.bytesMarked
// 如果启用了checkmark则执行检查, 检查是否所有可到达的对象都有标记
if debug.gccheckmark > 0 {
// Run a full non-parallel, stop-the-world
// mark using checkmark bits, to check that we
// didn't forget to mark anything during the
// concurrent mark process.
gcResetMarkState()
initCheckmarks()
gcw := &getg().m.p.ptr().gcw
gcDrain(gcw, 0)
wbBufFlush1(getg().m.p.ptr())
gcw.dispose()
clearCheckmarks()
}
// marking is complete so we can turn the write barrier off
//标记终止结束后,会进入 GCoff 阶段,并调用 gcSweep 来并发的使后台清扫器 Goroutine 与赋值器并发执行。
// 设置当前GC阶段到关闭, 并禁用写屏障
setGCPhase(_GCoff)
// 唤醒后台清扫任务, 将在STW结束后开始运行
gcSweep(work.mode)
})
// 设置G的状态为运行中
_g_.m.traceback = 0
casgstatus(gp, _Gwaiting, _Grunning)
// 跟踪处理
if trace.enabled {
traceGCDone()
}
// all done
mp.preemptoff = ""
if gcphase != _GCoff {
throw("gc done but gcphase != _GCoff")
}
// Record next_gc and heap_inuse for scavenger.
memstats.last_next_gc = memstats.next_gc
memstats.last_heap_inuse = memstats.heap_inuse
// Update GC trigger and pacing for the next cycle.
// 更新下一次触发gc需要的heap大小(gc_trigger)
gcSetTriggerRatio(nextTriggerRatio)
// 更新用时记录
// Update timing memstats
now := nanotime()
sec, nsec, _ := time_now()
unixNow := sec*1e9 + int64(nsec)
work.pauseNS += now - work.pauseStart
work.tEnd = now
atomic.Store64(&memstats.last_gc_unix, uint64(unixNow)) // must be Unix time to make sense to user
atomic.Store64(&memstats.last_gc_nanotime, uint64(now)) // monotonic time for us
memstats.pause_ns[memstats.numgc%uint32(len(memstats.pause_ns))] = uint64(work.pauseNS)
memstats.pause_end[memstats.numgc%uint32(len(memstats.pause_end))] = uint64(unixNow)
memstats.pause_total_ns += uint64(work.pauseNS)
// Update work.totaltime.
// 更新所用cpu记录
sweepTermCpu := int64(work.stwprocs) * (work.tMark - work.tSweepTerm)
// We report idle marking time below, but omit it from the
// overall utilization here since it's "free".
markCpu := gcController.assistTime + gcController.dedicatedMarkTime + gcController.fractionalMarkTime
markTermCpu := int64(work.stwprocs) * (work.tEnd - work.tMarkTerm)
cycleCpu := sweepTermCpu + markCpu + markTermCpu
work.totaltime += cycleCpu
// Compute overall GC CPU utilization.
totalCpu := sched.totaltime + (now-sched.procresizetime)*int64(gomaxprocs)
memstats.gc_cpu_fraction = float64(work.totaltime) / float64(totalCpu)
// Reset sweep state.
// 重置清扫状态
sweep.nbgsweep = 0
sweep.npausesweep = 0
// 统计强制开始GC的次数
if work.userForced {
memstats.numforcedgc++
}
// 统计执行GC的次数然后唤醒等待清扫的G
// Bump GC cycle count and wake goroutines waiting on sweep.
lock(&work.sweepWaiters.lock)
memstats.numgc++
injectglist(&work.sweepWaiters.list)
unlock(&work.sweepWaiters.lock)
// Finish the current heap profiling cycle and start a new
// heap profiling cycle. We do this before starting the world
// so events don't leak into the wrong cycle.
// 性能统计用
mProf_NextCycle()
// 重新启动世界
systemstack(func() { startTheWorldWithSema(true) })
// Flush the heap profile so we can start a new cycle next GC.
// This is relatively expensive, so we don't do it with the
// world stopped.
// 性能统计用
mProf_Flush()
// Prepare workbufs for freeing by the sweeper. We do this
// asynchronously because it can take non-trivial time.
// 移动标记队列使用的缓冲区到自由列表, 使得它们可以被回收
prepareFreeWorkbufs()
// Free stack spans. This must be done between GC cycles.
// 释放未使用的栈
systemstack(freeStackSpans)
// Ensure all mcaches are flushed. Each P will flush its own
// mcache before allocating, but idle Ps may not. Since this
// is necessary to sweep all spans, we need to ensure all
// mcaches are flushed before we start the next GC cycle.
systemstack(func() {
forEachP(func(_p_ *p) {
_p_.mcache.prepareForSweep()
})
})
// Print gctrace before dropping worldsema. As soon as we drop
// worldsema another cycle could start and smash the stats
// we're trying to print.
// 除错用
if debug.gctrace > 0 {
util := int(memstats.gc_cpu_fraction * 100)
var sbuf [24]byte
printlock()
print("gc ", memstats.numgc,
" @", string(itoaDiv(sbuf[:], uint64(work.tSweepTerm-runtimeInitTime)/1e6, 3)), "s ",
util, "%: ")
prev := work.tSweepTerm
for i, ns := range []int64{work.tMark, work.tMarkTerm, work.tEnd} {
if i != 0 {
print("+")
}
print(string(fmtNSAsMS(sbuf[:], uint64(ns-prev))))
prev = ns
}
print(" ms clock, ")
for i, ns := range []int64{sweepTermCpu, gcController.assistTime, gcController.dedicatedMarkTime + gcController.fractionalMarkTime, gcController.idleMarkTime, markTermCpu} {
if i == 2 || i == 3 {
// Separate mark time components with /.
print("/")
} else if i != 0 {
print("+")
}
print(string(fmtNSAsMS(sbuf[:], uint64(ns))))
}
print(" ms cpu, ",
work.heap0>>20, "->", work.heap1>>20, "->", work.heap2>>20, " MB, ",
work.heapGoal>>20, " MB goal, ",
work.maxprocs, " P")
if work.userForced {
print(" (forced)")
}
print("\n")
printunlock()
}
semrelease(&worldsema)
semrelease(&gcsema)
// Careful: another GC cycle may start now.
// 重新允许当前的G被抢占
releasem(mp)
mp = nil
// now that gc is done, kick off finalizer thread if needed
// 如果是并行GC, 让当前M继续运行(会回到gcBgMarkWorker然后休眠)
// 如果不是并行GC, 则让当前M开始调度
if !concurrentSweep {
// give the queued finalizers, if any, a chance to run
Gosched()
}
}
|
gcMark
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
|
// gcMark runs the mark (or, for concurrent GC, mark termination)
// All gcWork caches must be empty.
// STW is in effect at this point.
func gcMark(start_time int64) {
if debug.allocfreetrace > 0 {
tracegc()
}
if gcphase != _GCmarktermination {
throw("in gcMark expecting to see gcphase as _GCmarktermination")
}
work.tstart = start_time
// Check that there's no marking work remaining.
if work.full != 0 || work.markrootNext < work.markrootJobs {
print("runtime: full=", hex(work.full), " next=", work.markrootNext, " jobs=", work.markrootJobs, " nDataRoots=", work.nDataRoots, " nBSSRoots=", work.nBSSRoots, " nSpanRoots=", work.nSpanRoots, " nStackRoots=", work.nStackRoots, "\n")
panic("non-empty mark queue after concurrent mark")
}
if debug.gccheckmark > 0 {
// This is expensive when there's a large number of
// Gs, so only do it if checkmark is also enabled.
gcMarkRootCheck()
}
if work.full != 0 {
throw("work.full != 0")
}
// Clear out buffers and double-check that all gcWork caches
// are empty. This should be ensured by gcMarkDone before we
// enter mark termination.
//
// TODO: We could clear out buffers just before mark if this
// has a non-negligible impact on STW time.
for _, p := range allp {
// The write barrier may have buffered pointers since
// the gcMarkDone barrier. However, since the barrier
// ensured all reachable objects were marked, all of
// these must be pointers to black objects. Hence we
// can just discard the write barrier buffer.
if debug.gccheckmark > 0 {
// For debugging, flush the buffer and make
// sure it really was all marked.
wbBufFlush1(p)
} else {
p.wbBuf.reset()
}
gcw := &p.gcw
if !gcw.empty() {
printlock()
print("runtime: P ", p.id, " flushedWork ", gcw.flushedWork)
if gcw.wbuf1 == nil {
print(" wbuf1=<nil>")
} else {
print(" wbuf1.n=", gcw.wbuf1.nobj)
}
if gcw.wbuf2 == nil {
print(" wbuf2=<nil>")
} else {
print(" wbuf2.n=", gcw.wbuf2.nobj)
}
print("\n")
throw("P has cached GC work at end of mark termination")
}
// There may still be cached empty buffers, which we
// need to flush since we're going to free them. Also,
// there may be non-zero stats because we allocated
// black after the gcMarkDone barrier.
gcw.dispose()
}
// Update the marked heap stat.
memstats.heap_marked = work.bytesMarked
// Flush scanAlloc from each mcache since we're about to modify
// heap_scan directly. If we were to flush this later, then scanAlloc
// might have incorrect information.
for _, p := range allp {
c := p.mcache
if c == nil {
continue
}
memstats.heap_scan += uint64(c.scanAlloc)
c.scanAlloc = 0
}
// Update other GC heap size stats. This must happen after
// cachestats (which flushes local statistics to these) and
// flushallmcaches (which modifies heap_live).
memstats.heap_live = work.bytesMarked
memstats.heap_scan = uint64(gcController.scanWork)
if trace.enabled {
traceHeapAlloc()
}
}
|
gcSetTriggerRatio
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
|
// gcSetTriggerRatio sets the trigger ratio and updates everything
// derived from it: the absolute trigger, the heap goal, mark pacing,
// and sweep pacing.
//
// This can be called any time. If GC is the in the middle of a
// concurrent phase, it will adjust the pacing of that phase.
//
// This depends on gcpercent, memstats.heap_marked, and
// memstats.heap_live. These must be up to date.
//
// mheap_.lock must be held or the world must be stopped.
func gcSetTriggerRatio(triggerRatio float64) {
// Compute the next GC goal, which is when the allocated heap
// has grown by GOGC/100 over the heap marked by the last
// cycle.
goal := ^uint64(0)
if gcpercent >= 0 {
goal = memstats.heap_marked + memstats.heap_marked*uint64(gcpercent)/100
}
// Set the trigger ratio, capped to reasonable bounds.
if gcpercent >= 0 {
scalingFactor := float64(gcpercent) / 100
// Ensure there's always a little margin so that the
// mutator assist ratio isn't infinity.
maxTriggerRatio := 0.95 * scalingFactor
if triggerRatio > maxTriggerRatio {
triggerRatio = maxTriggerRatio
}
// If we let triggerRatio go too low, then if the application
// is allocating very rapidly we might end up in a situation
// where we're allocating black during a nearly always-on GC.
// The result of this is a growing heap and ultimately an
// increase in RSS. By capping us at a point >0, we're essentially
// saying that we're OK using more CPU during the GC to prevent
// this growth in RSS.
//
// The current constant was chosen empirically: given a sufficiently
// fast/scalable allocator with 48 Ps that could drive the trigger ratio
// to <0.05, this constant causes applications to retain the same peak
// RSS compared to not having this allocator.
minTriggerRatio := 0.6 * scalingFactor
if triggerRatio < minTriggerRatio {
triggerRatio = minTriggerRatio
}
} else if triggerRatio < 0 {
// gcpercent < 0, so just make sure we're not getting a negative
// triggerRatio. This case isn't expected to happen in practice,
// and doesn't really matter because if gcpercent < 0 then we won't
// ever consume triggerRatio further on in this function, but let's
// just be defensive here; the triggerRatio being negative is almost
// certainly undesirable.
triggerRatio = 0
}
memstats.triggerRatio = triggerRatio
// Compute the absolute GC trigger from the trigger ratio.
//
// We trigger the next GC cycle when the allocated heap has
// grown by the trigger ratio over the marked heap size.
trigger := ^uint64(0)
if gcpercent >= 0 {
trigger = uint64(float64(memstats.heap_marked) * (1 + triggerRatio))
// Don't trigger below the minimum heap size.
minTrigger := heapminimum
if !isSweepDone() {
// Concurrent sweep happens in the heap growth
// from heap_live to gc_trigger, so ensure
// that concurrent sweep has some heap growth
// in which to perform sweeping before we
// start the next GC cycle.
sweepMin := atomic.Load64(&memstats.heap_live) + sweepMinHeapDistance
if sweepMin > minTrigger {
minTrigger = sweepMin
}
}
if trigger < minTrigger {
trigger = minTrigger
}
if int64(trigger) < 0 {
print("runtime: next_gc=", memstats.next_gc, " heap_marked=", memstats.heap_marked, " heap_live=", memstats.heap_live, " initialHeapLive=", work.initialHeapLive, "triggerRatio=", triggerRatio, " minTrigger=", minTrigger, "\n")
throw("gc_trigger underflow")
}
if trigger > goal {
// The trigger ratio is always less than GOGC/100, but
// other bounds on the trigger may have raised it.
// Push up the goal, too.
goal = trigger
}
}
// Commit to the trigger and goal.
memstats.gc_trigger = trigger
memstats.next_gc = goal
if trace.enabled {
traceNextGC()
}
// Update mark pacing.
if gcphase != _GCoff {
gcController.revise()
}
// Update sweep pacing.
if isSweepDone() {
mheap_.sweepPagesPerByte = 0
} else {
// Concurrent sweep needs to sweep all of the in-use
// pages by the time the allocated heap reaches the GC
// trigger. Compute the ratio of in-use pages to sweep
// per byte allocated, accounting for the fact that
// some might already be swept.
// 当前的Heap大小
heapLiveBasis := atomic.Load64(&memstats.heap_live)
// 距离触发GC的Heap大小 = 下次触发GC的Heap大小 - 当前的Heap大小
heapDistance := int64(trigger) - int64(heapLiveBasis)
// Add a little margin so rounding errors and
// concurrent sweep are less likely to leave pages
// unswept when GC starts.
heapDistance -= 1024 * 1024
if heapDistance < _PageSize {
// Avoid setting the sweep ratio extremely high
heapDistance = _PageSize
}
// 已清扫的页数
pagesSwept := atomic.Load64(&mheap_.pagesSwept)
pagesInUse := atomic.Load64(&mheap_.pagesInUse)
// 未清扫的页数 = 使用中的页数 - 已清扫的页数
sweepDistancePages := int64(pagesInUse) - int64(pagesSwept)
if sweepDistancePages <= 0 {
mheap_.sweepPagesPerByte = 0
} else {
// 每分配1 byte(的span)需要辅助清扫的页数 = 未清扫的页数 / 距离触发GC的Heap大小
mheap_.sweepPagesPerByte = float64(sweepDistancePages) / float64(heapDistance)
mheap_.sweepHeapLiveBasis = heapLiveBasis
// Write pagesSweptBasis last, since this
// signals concurrent sweeps to recompute
// their debt.
atomic.Store64(&mheap_.pagesSweptBasis, pagesSwept)
}
}
gcPaceScavenger()
}
|
内存清理
gcSweep
gcSweep实现非常简单,只需要将 mheap_ 相关的标志位清零,并唤醒后台清扫器 Goroutine 即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
// gcSweep must be called on the system stack because it acquires the heap
// lock. See mheap for details.
//
// The world must be stopped.
//
//go:systemstack
func gcSweep(mode gcMode) {
// 此时为 GCoff 阶段
if gcphase != _GCoff {
throw("gcSweep being done but phase is not GCoff")
}
// 增加sweepgen, 这样sweepSpans中两个队列角色会交换, 所有span都会变为"待清扫"的span
lock(&mheap_.lock)
mheap_.sweepgen += 2
mheap_.sweepdone = 0
if !go115NewMCentralImpl && mheap_.sweepSpans[mheap_.sweepgen/2%2].index != 0 {
// We should have drained this list during the last
// sweep phase. We certainly need to start this phase
// with an empty swept list.
throw("non-empty swept list")
}
mheap_.pagesSwept = 0
mheap_.sweepArenas = mheap_.allArenas
mheap_.reclaimIndex = 0
mheap_.reclaimCredit = 0
unlock(&mheap_.lock)
if go115NewMCentralImpl {
sweep.centralIndex.clear()
}
// 如果非并行GC则在这里完成所有工作(STW中)
if !_ConcurrentSweep || mode == gcForceBlockMode {
// Special case synchronous sweep.
// Record that no proportional sweeping has to happen.
lock(&mheap_.lock)
mheap_.sweepPagesPerByte = 0
unlock(&mheap_.lock)
// Sweep all spans eagerly.
for sweepone() != ^uintptr(0) {
sweep.npausesweep++
}
// Free workbufs eagerly.
// freeSomeWbufs 释放一些 workbufs 回到堆中,如果需要再次调用则返回 true
prepareFreeWorkbufs()
for freeSomeWbufs(false) {
}
// All "free" events for this mark/sweep cycle have
// now happened, so we can make this profile cycle
// available immediately.
mProf_NextCycle()
mProf_Flush()
return
}
// 并发清扫(唤醒后台 Goroutine)
// Background sweep.
lock(&sweep.lock)
if sweep.parked {
sweep.parked = false
ready(sweep.g, 0, true)
}
unlock(&sweep.lock)
}
|
bgsweep
后台清扫任务会在程序启动时调用的gcenable函数中启动.
清扫过程依赖下面的结构:
1
2
3
4
5
6
7
8
9
10
11
|
var sweep sweepdata
type sweepdata struct {
lock mutex
g *g
parked bool
started bool
nbgsweep uint32
npausesweep uint32
}
|
该结构通过:
- mutex 保证清扫过程的原子性
- g 指针来保存所在的 Goroutine
- started 判断是否开始
- nbgsweep 和 npausesweep 来统计清扫过程
当一个后台 sweeper 从应用程序启动时休眠后,再重新唤醒时,会进入如下循环,并一直在次循环中反复休眠与被唤醒:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
// The main goroutine.
func main() {
...
gcenable()
...
}
// gcenable is called after the bulk of the runtime initialization,
// just before we're about to start letting user code run.
// It kicks off the background sweeper goroutine, the background
// scavenger goroutine, and enables GC.
func gcenable() {
// Kick off sweeping and scavenging.
c := make(chan int, 2)
go bgsweep(c)
go bgscavenge(c)
<-c
<-c
memstats.enablegc = true // now that runtime is initialized, GC is okay
}
func bgsweep(c chan int) {
sweep.g = getg()
lockInit(&sweep.lock, lockRankSweep)
lock(&sweep.lock)
sweep.parked = true
c <- 1
goparkunlock(&sweep.lock, waitReasonGCSweepWait, traceEvGoBlock, 1)
// 循环清扫
for {
// 清扫 span,如果清扫了一部分 span,则记录 bgsweep 的次数
// 清扫一个span, 然后进入调度(一次只做少量工作)
for sweepone() != ^uintptr(0) {
sweep.nbgsweep++
Gosched()
}
// 可抢占的释放一些 workbufs 到堆中
// 释放一些未使用的标记队列缓冲区到heap
for freeSomeWbufs(true) {
Gosched()
}
// 在 mheap_ 上判断是否完成清扫,若未完成,则继续进行清扫
lock(&sweep.lock)
if !isSweepDone() {// 即 mheap_.sweepdone != 0
// This can happen if a GC runs between
// gosweepone returning ^0 above
// and the lock being acquired.
unlock(&sweep.lock)
continue
}
// 否则让 Goroutine 进行 park
// 否则让后台清扫任务进入休眠, 当前M继续调度
sweep.parked = true
goparkunlock(&sweep.lock, waitReasonGCSweepWait, traceEvGoBlock, 1)
}
}
|
垃圾收集的清理中包含对象回收器(Reclaimer)和内存单元回收器,这两种回收器使用不同的算法清理堆内存:
- 对象回收器在内存管理单元中查找并释放未被标记的对象,但是如果 runtime.mspan 中的所有对象都没有被标记,整个单元就会被直接回收,该过程会被 runtime.mcentral.cacheSpan 或者 runtime.sweepone 异步触发;
- 内存单元回收器会在内存中查找所有的对象都未被标记的 runtime.mspan,该过程会被 runtime.mheap.reclaim 触发;
sweepone
runtime.sweepone 是我们在垃圾收集过程中经常会见到的函数,该函数会在堆内存中查找待清理的内存管理单元:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
|
// sweepone sweeps some unswept heap span and returns the number of pages returned
// to the heap, or ^uintptr(0) if there was nothing to sweep.
func sweepone() uintptr {
_g_ := getg()
sweepRatio := mheap_.sweepPagesPerByte // For debugging
// increment locks to ensure that the goroutine is not preempted
// in the middle of sweep thus leaving the span in an inconsistent state for next GC
// 增加锁的数量确保 Goroutine 在 sweep 中不会被抢占,进而不会将 span 留到下个 GC 产生不一致
// 禁止G被抢占
_g_.m.locks++
// 检查是否已完成清扫
if atomic.Load(&mheap_.sweepdone) != 0 {
_g_.m.locks--
return ^uintptr(0)
}
// 记录 sweeper 的数量
// 更新同时执行sweep的任务数量
atomic.Xadd(&mheap_.sweepers, +1)
// Find a span to sweep.
// 寻找需要 sweep 的 span
var s *mspan
sg := mheap_.sweepgen
for {
// 从sweepSpans中取出一个span
if go115NewMCentralImpl {
s = mheap_.nextSpanForSweep()
} else {
s = mheap_.sweepSpans[1-sg/2%2].pop()
}
// 全部清扫完毕时跳出循环
if s == nil {
atomic.Store(&mheap_.sweepdone, 1)
break
}
// 其他M已经在清扫这个span时跳过
if state := s.state.get(); state != mSpanInUse {
// This can happen if direct sweeping already
// swept this span, but in that case the sweep
// generation should always be up-to-date.
if !(s.sweepgen == sg || s.sweepgen == sg+3) {
print("runtime: bad span s.state=", state, " s.sweepgen=", s.sweepgen, " sweepgen=", sg, "\n")
throw("non in-use span in unswept list")
}
continue
}
// 原子增加span的sweepgen, 失败表示其他M已经开始清扫这个span, 跳过
if s.sweepgen == sg-2 && atomic.Cas(&s.sweepgen, sg-2, sg-1) {
break
}
}
// Sweep the span we found.
// sweep 找到的 span
npages := ^uintptr(0)
if s != nil {
// 清扫这个span, 然后跳出循环
npages = s.npages
if s.sweep(false) {
// false 表示将其归还到 heap 中
// Whole span was freed. Count it toward the
// page reclaimer credit since these pages can
// now be used for span allocation.
// 整个 span 都已被释放,记录释放的额度,因为整个页都能用作 span 分配了
atomic.Xadduintptr(&mheap_.reclaimCredit, npages)
} else {
// Span is still in-use, so this returned no
// pages to the heap and the span needs to
// move to the swept in-use list.
// span 还在被使用,因此返回零
// 并需要 span 移动到已经 sweep 的 in-use 列表中。
npages = 0
}
}
// Decrement the number of active sweepers and if this is the
// last one print trace information.
// 减少 sweeper 的数量并确保最后一个运行的 sweeper 正常标记了 mheap.sweepdone
// 更新同时执行sweep的任务数量
if atomic.Xadd(&mheap_.sweepers, -1) == 0 && atomic.Load(&mheap_.sweepdone) != 0 {
// Since the sweeper is done, move the scavenge gen forward (signalling
// that there's new work to do) and wake the scavenger.
//
// The scavenger is signaled by the last sweeper because once
// sweeping is done, we will definitely have useful work for
// the scavenger to do, since the scavenger only runs over the
// heap once per GC cyle. This update is not done during sweep
// termination because in some cases there may be a long delay
// between sweep done and sweep termination (e.g. not enough
// allocations to trigger a GC) which would be nice to fill in
// with scavenging work.
systemstack(func() {
lock(&mheap_.lock)
mheap_.pages.scavengeStartGen()
unlock(&mheap_.lock)
})
// Since we might sweep in an allocation path, it's not possible
// for us to wake the scavenger directly via wakeScavenger, since
// it could allocate. Ask sysmon to do it for us instead.
readyForScavenger()
if debug.gcpacertrace > 0 {
print("pacer: sweep done at heap size ", memstats.heap_live>>20, "MB; allocated ", (memstats.heap_live-mheap_.sweepHeapLiveBasis)>>20, "MB during sweep; swept ", mheap_.pagesSwept, " pages at ", sweepRatio, " pages/byte\n")
}
}
// 允许G被抢占
_g_.m.locks--
// 返回清扫的页数
return npages
}
|
查找内存管理单元时会通过 state 和 sweepgen 两个字段判断当前单元是否需要处理。如果内存单元的 sweepgen 等于 mheap.sweepgen - 2,那么就意味着当前单元需要被清理,如果等于 mheap.sweepgen - 1,那么当前管理单元就正在被清理。
sweep
所有的回收工作最终都是靠 runtime.mspan.sweep 完成的,该函数会根据并发标记阶段回收内存单元中的垃圾并清除标记以免影响下一轮垃圾收集。
span的sweep函数用于清扫单个span:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
|
// Sweep frees or collects finalizers for blocks not marked in the mark phase.
// It clears the mark bits in preparation for the next GC round.
// Returns true if the span was returned to heap.
// If preserve=true, don't return it to heap nor relink in mcentral lists;
// caller takes care of it.
func (s *mspan) sweep(preserve bool) bool {
if !go115NewMCentralImpl {
return s.oldSweep(preserve)
}
// It's critical that we enter this function with preemption disabled,
// GC must not start while we are in the middle of this function.
_g_ := getg()
if _g_.m.locks == 0 && _g_.m.mallocing == 0 && _g_ != _g_.m.g0 {
throw("mspan.sweep: m is not locked")
}
sweepgen := mheap_.sweepgen
if state := s.state.get(); state != mSpanInUse || s.sweepgen != sweepgen-1 {
print("mspan.sweep: state=", state, " sweepgen=", s.sweepgen, " mheap.sweepgen=", sweepgen, "\n")
throw("mspan.sweep: bad span state")
}
if trace.enabled {
traceGCSweepSpan(s.npages * _PageSize)
}
// 统计已清理的页数
atomic.Xadd64(&mheap_.pagesSwept, int64(s.npages))
spc := s.spanclass
size := s.elemsize
c := _g_.m.p.ptr().mcache
// The allocBits indicate which unmarked objects don't need to be
// processed since they were free at the end of the last GC cycle
// and were not allocated since then.
// If the allocBits index is >= s.freeindex and the bit
// is not marked then the object remains unallocated
// since the last GC.
// This situation is analogous to being on a freelist.
// 判断在special中的析构器, 如果对应的对象已经不再存活则标记对象存活防止回收, 然后把析构器移到运行队列
// Unlink & free special records for any objects we're about to free.
// Two complications here:
// 1. An object can have both finalizer and profile special records.
// In such case we need to queue finalizer for execution,
// mark the object as live and preserve the profile special.
// 2. A tiny object can have several finalizers setup for different offsets.
// If such object is not marked, we need to queue all finalizers at once.
// Both 1 and 2 are possible at the same time.
hadSpecials := s.specials != nil
specialp := &s.specials
special := *specialp
for special != nil {
// A finalizer can be set for an inner byte of an object, find object beginning.
objIndex := uintptr(special.offset) / size
p := s.base() + objIndex*size
mbits := s.markBitsForIndex(objIndex)
if !mbits.isMarked() {
// This object is not marked and has at least one special record.
// Pass 1: see if it has at least one finalizer.
hasFin := false
endOffset := p - s.base() + size
for tmp := special; tmp != nil && uintptr(tmp.offset) < endOffset; tmp = tmp.next {
if tmp.kind == _KindSpecialFinalizer {
// Stop freeing of object if it has a finalizer.
mbits.setMarkedNonAtomic()
hasFin = true
break
}
}
// Pass 2: queue all finalizers _or_ handle profile record.
for special != nil && uintptr(special.offset) < endOffset {
// Find the exact byte for which the special was setup
// (as opposed to object beginning).
p := s.base() + uintptr(special.offset)
if special.kind == _KindSpecialFinalizer || !hasFin {
// Splice out special record.
y := special
special = special.next
*specialp = special
freespecial(y, unsafe.Pointer(p), size)
} else {
// This is profile record, but the object has finalizers (so kept alive).
// Keep special record.
specialp = &special.next
special = *specialp
}
}
} else {
// object is still live: keep special record
specialp = &special.next
special = *specialp
}
}
if hadSpecials && s.specials == nil {
spanHasNoSpecials(s)
}
if debug.allocfreetrace != 0 || debug.clobberfree != 0 || raceenabled || msanenabled {
// Find all newly freed objects. This doesn't have to
// efficient; allocfreetrace has massive overhead.
mbits := s.markBitsForBase()
abits := s.allocBitsForIndex(0)
for i := uintptr(0); i < s.nelems; i++ {
if !mbits.isMarked() && (abits.index < s.freeindex || abits.isMarked()) {
x := s.base() + i*s.elemsize
if debug.allocfreetrace != 0 {
tracefree(unsafe.Pointer(x), size)
}
if debug.clobberfree != 0 {
clobberfree(unsafe.Pointer(x), size)
}
if raceenabled {
racefree(unsafe.Pointer(x), size)
}
if msanenabled {
msanfree(unsafe.Pointer(x), size)
}
}
mbits.advance()
abits.advance()
}
}
// Check for zombie objects.
if s.freeindex < s.nelems {
// Everything < freeindex is allocated and hence
// cannot be zombies.
//
// Check the first bitmap byte, where we have to be
// careful with freeindex.
obj := s.freeindex
if (*s.gcmarkBits.bytep(obj / 8)&^*s.allocBits.bytep(obj / 8))>>(obj%8) != 0 {
s.reportZombies()
}
// Check remaining bytes.
for i := obj/8 + 1; i < divRoundUp(s.nelems, 8); i++ {
if *s.gcmarkBits.bytep(i)&^*s.allocBits.bytep(i) != 0 {
s.reportZombies()
}
}
}
// 计算释放的对象数量
// Count the number of free objects in this span.
nalloc := uint16(s.countAlloc())
nfreed := s.allocCount - nalloc
if nalloc > s.allocCount {
// The zombie check above should have caught this in
// more detail.
print("runtime: nelems=", s.nelems, " nalloc=", nalloc, " previous allocCount=", s.allocCount, " nfreed=", nfreed, "\n")
throw("sweep increased allocation count")
}
// 设置新的allocCount
s.allocCount = nalloc
// 重置freeindex, 下次分配从0开始搜索
s.freeindex = 0 // reset allocation index to start of span.
if trace.enabled {
getg().m.p.ptr().traceReclaimed += uintptr(nfreed) * s.elemsize
}
// gcmarkBits变为新的allocBits
// 然后重新分配一块全部为0的gcmarkBits
// 下次分配对象时可以根据allocBits得知哪些元素是未分配的
// gcmarkBits becomes the allocBits.
// get a fresh cleared gcmarkBits in preparation for next GC
s.allocBits = s.gcmarkBits
s.gcmarkBits = newMarkBits(s.nelems)
// 更新freeindex开始的allocCache
// Initialize alloc bits cache.
s.refillAllocCache(0)
// The span must be in our exclusive ownership until we update sweepgen,
// check for potential races.
if state := s.state.get(); state != mSpanInUse || s.sweepgen != sweepgen-1 {
print("mspan.sweep: state=", state, " sweepgen=", s.sweepgen, " mheap.sweepgen=", sweepgen, "\n")
throw("mspan.sweep: bad span state after sweep")
}
if s.sweepgen == sweepgen+1 || s.sweepgen == sweepgen+3 {
throw("swept cached span")
}
// We need to set s.sweepgen = h.sweepgen only when all blocks are swept,
// because of the potential for a concurrent free/SetFinalizer.
//
// But we need to set it before we make the span available for allocation
// (return it to heap or mcentral), because allocation code assumes that a
// span is already swept if available for allocation.
//
// Serialization point.
// At this point the mark bits are cleared and allocation ready
// to go so release the span.
atomic.Store(&s.sweepgen, sweepgen)
if spc.sizeclass() != 0 {
// Handle spans for small objects.
// 把span加到mcentral, res等于是否添加成功
if nfreed > 0 {
// Only mark the span as needing zeroing if we've freed any
// objects, because a fresh span that had been allocated into,
// wasn't totally filled, but then swept, still has all of its
// free slots zeroed.
s.needzero = 1
c.local_nsmallfree[spc.sizeclass()] += uintptr(nfreed)
}
if !preserve {
// The caller may not have removed this span from whatever
// unswept set its on but taken ownership of the span for
// sweeping by updating sweepgen. If this span still is in
// an unswept set, then the mcentral will pop it off the
// set, check its sweepgen, and ignore it.
if nalloc == 0 {
// Free totally free span directly back to the heap.
mheap_.freeSpan(s)
return true
}
// Return span back to the right mcentral list.
if uintptr(nalloc) == s.nelems {
mheap_.central[spc].mcentral.fullSwept(sweepgen).push(s)
} else {
mheap_.central[spc].mcentral.partialSwept(sweepgen).push(s)
}
}
} else if !preserve {
// Handle spans for large objects.
if nfreed != 0 {
// Free large object span to heap.
// NOTE(rsc,dvyukov): The original implementation of efence
// in CL 22060046 used sysFree instead of sysFault, so that
// the operating system would eventually give the memory
// back to us again, so that an efence program could run
// longer without running out of memory. Unfortunately,
// calling sysFree here without any kind of adjustment of the
// heap data structures means that when the memory does
// come back to us, we have the wrong metadata for it, either in
// the mspan structures or in the garbage collection bitmap.
// Using sysFault here means that the program will run out of
// memory fairly quickly in efence mode, but at least it won't
// have mysterious crashes due to confused memory reuse.
// It should be possible to switch back to sysFree if we also
// implement and then call some kind of mheap.deleteSpan.
if debug.efence > 0 {
s.limit = 0 // prevent mlookup from finding this span
sysFault(unsafe.Pointer(s.base()), size)
} else {
mheap_.freeSpan(s)
}
c.local_nlargefree++
c.local_largefree += size
return true
}
// Add a large span directly onto the full+swept list.
mheap_.central[spc].mcentral.fullSwept(sweepgen).push(s)
}
return false
}
|
从bgsweep和前面的分配器可以看出扫描阶段的工作是十分懒惰(lazy)的,实际可能会出现前一阶段的扫描还未完成, 就需要开始新一轮的GC的情况,所以每一轮GC开始之前都需要完成前一轮GC的扫描工作(Sweep Termination阶段).
freeSomeWbufs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
// freeSomeWbufs 释放一些 workbufs 回到堆中,如果需要再次调用则返回 true
func freeSomeWbufs(preemptible bool) bool {
const batchSize = 64 // 每个 span 需要 ~1–2 µs
lock(&work.wbufSpans.lock)
// 如果此时在标记阶段、或者 wbufSpans 为空,则不需要进行释放
// 因为标记阶段 workbufs 需要被标记,而 workbufs 为空则更不需要释放
if gcphase != _GCoff || work.wbufSpans.free.isEmpty() {
unlock(&work.wbufSpans.lock)
return false
}
systemstack(func() {
gp := getg().m.curg
// 清扫一批 span,64 个,大约 ~1–2 µs
// 在需要被抢占时停止、在清扫完毕后停止
for i := 0; i < batchSize && !(preemptible && gp.preempt); i++ {
span := work.wbufSpans.free.first
if span == nil {
break
}
// 将 span 移除 wbufSpans 的空闲链表中
work.wbufSpans.free.remove(span)
// 将 span 归还到 mheap 中
mheap_.freeManual(span, &memstats.gc_sys)
}
})
// workbufs 的空闲 span 列表尚未清空,还需要更多清扫
more := !work.wbufSpans.free.isEmpty()
unlock(&work.wbufSpans.lock)
return more
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
//go:systemstack
func (h *mheap) freeManual(s *mspan, stat *uint64) {
s.needzero = 1 // span 在下次被分配走时需要对该段内存进行清零
lock(&h.lock)
*stat -= uint64(s.npages << _PageShift)
memstats.heap_sys += uint64(s.npages << _PageShift) // 记录并增加堆中的剩余空间
h.freeSpanLocked(s, false, true) // 将其释放会堆中
unlock(&h.lock)
}
func (h *mheap) freeSpanLocked(s *mspan, acctinuse, acctidle bool) {
switch s.state {
case mSpanManual:
... // panic
case mSpanInUse:
...
h.pagesInUse -= uint64(s.npages)
// 清除 arena page bitmap 正在使用的二进制位
arena, pageIdx, pageMask := pageIndexOf(s.base())
arena.pageInUse[pageIdx] &^= pageMask
default:
... // panic
}
if acctinuse {
memstats.heap_inuse -= uint64(s.npages << _PageShift)
}
if acctidle {
memstats.heap_idle += uint64(s.npages << _PageShift)
}
s.state = mSpanFree
// 与邻居进行结合
h.coalesce(s)
// 插入回 treap
h.free.insert(s)
}
|
参考
7.2 垃圾收集器
深入理解GO语言:GC原理及源码分析
golang 混合写屏障深入剖析。
Golang GC核心要点和度量方法