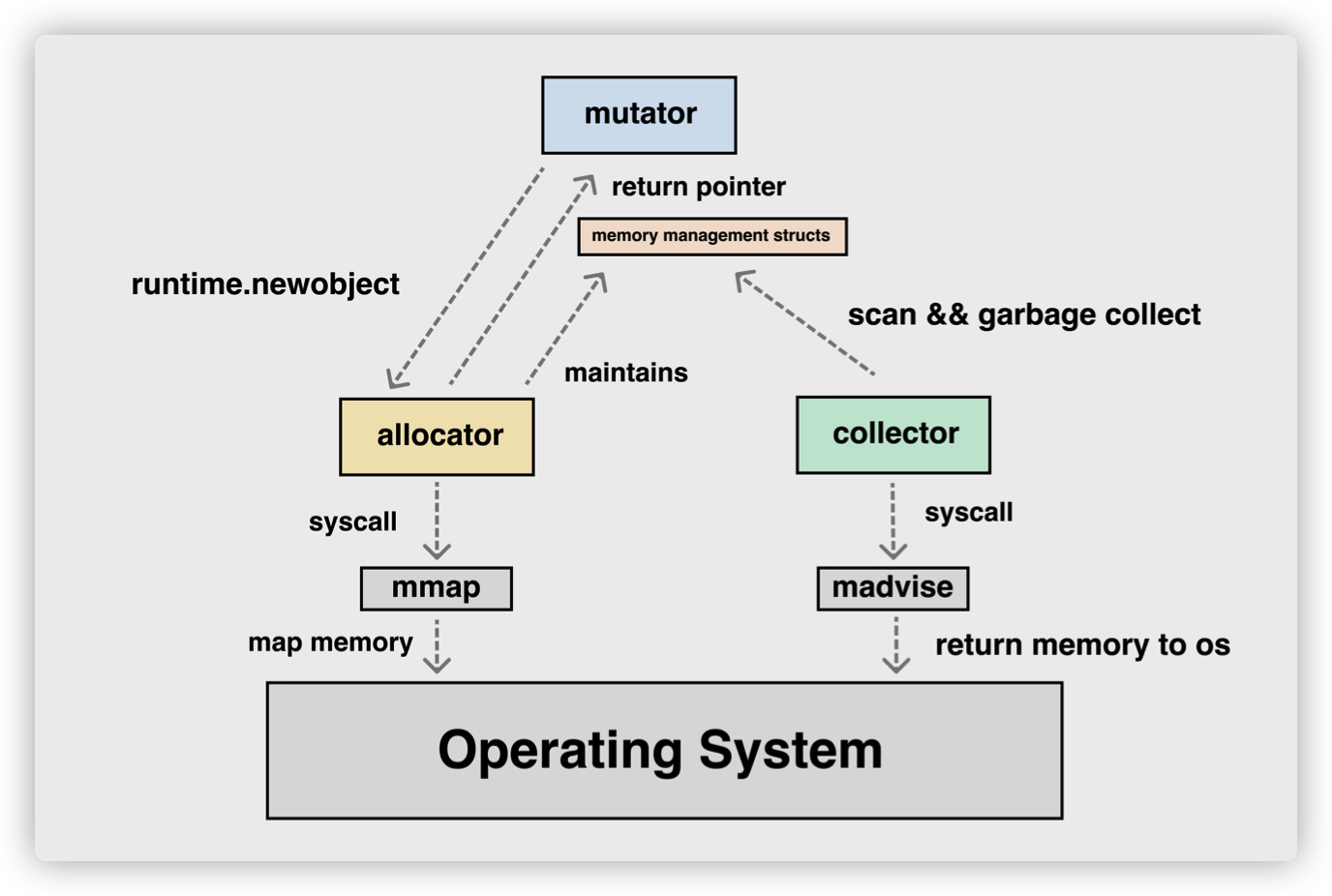
设计原理
内存管理的三个角色:
-
Mutator:fancy(花哨的) word for application,其实就是你写的应用程序,它会不断地修改对象的引用关系,即对象图。
-
Allocator:内存分配器,负责管理从操作系统中分配出的内存空间, malloc 其实底层就有一个内存分配器的实现(glibc 中),tcmalloc 是 malloc 多线程改进版。Go 中的实现类似 tcmalloc。
-
Collector:垃圾收集器,负责清理死对象,释放内存空间。
Mutator、Allocator、Collector 概览:
分级分配
线程缓存分配(Thread-Caching Malloc,TCMalloc)是用于分配内存的机制,它比 glibc 中的 malloc 函数还要快很多.Go 语言的内存分配器就借鉴了 TCMalloc 的设计实现高速的内存分配,它的核心理念是使用多级缓存将对象根据大小分类,并按照类别实施不同的分配策略。
对象大小
Go 语言的内存分配器会根据申请分配的内存大小选择不同的处理逻辑,运行时根据对象的大小将对象分成微对象、小对象和大对象三种:
| 类别 |
大小 |
| 微对象 |
(0, 16B) |
| 小对象 |
[16B, 32KB] |
| 大对象 |
(32KB, +∞) |
因为程序中的绝大多数对象的大小都在 32KB 以下,而申请的内存大小影响 Go 语言运行时分配内存的过程和开销,所以分别处理大对象和小对象有利于提高内存分配器的性能。
多级缓存
内存分配器不仅会区别对待大小不同的对象,还会将内存分成不同的级别分别管理,TCMalloc 和 Go 运行时分配器都会引入线程缓存(Thread Cache)、中心缓存(Central Cache)和页堆(Page Heap)三个组件分级管理内存:
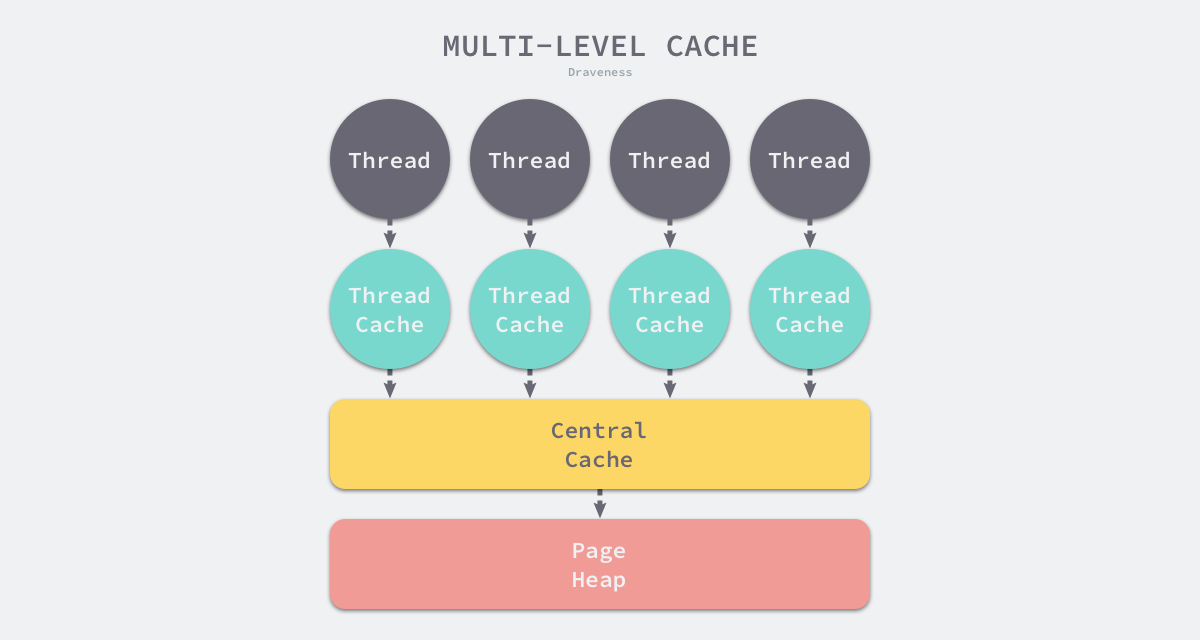
线程缓存属于每一个独立的线程,它能够满足线程上绝大多数的内存分配需求,因为不涉及多线程,所以也不需要使用互斥锁来保护内存,这能够减少锁竞争带来的性能损耗。当线程缓存不能满足需求时,就会使用中心缓存作为补充解决小对象的内存分配问题;在遇到 32KB 以上的对象时,内存分配器就会选择页堆直接分配大量的内存。
这种多层级的内存分配设计与计算机操作系统中的多级缓存也有些类似,因为多数的对象都是小对象,我们可以通过线程缓存和中心缓存提供足够的内存空间,发现资源不足时就从上一级组件中获取更多的内存资源。
虚拟内存布局
这里会介绍 Go 语言堆区内存地址空间的设计以及演进过程,在 Go 语言 1.10 以前的版本,堆区的内存空间都是连续的;但是在 1.11 版本,Go 团队使用稀疏的堆内存空间替代了连续的内存,解决了连续内存带来的限制以及在特殊场景下可能出现的问题。
线性内存
Go 语言程序的 1.10 版本在启动时会初始化整片虚拟内存区域,如下所示的三个区域 spans、bitmap 和 arena 分别预留了 512MB、16GB 以及 512GB 的内存空间,这些内存并不是真正存在的物理内存,而是虚拟内存:
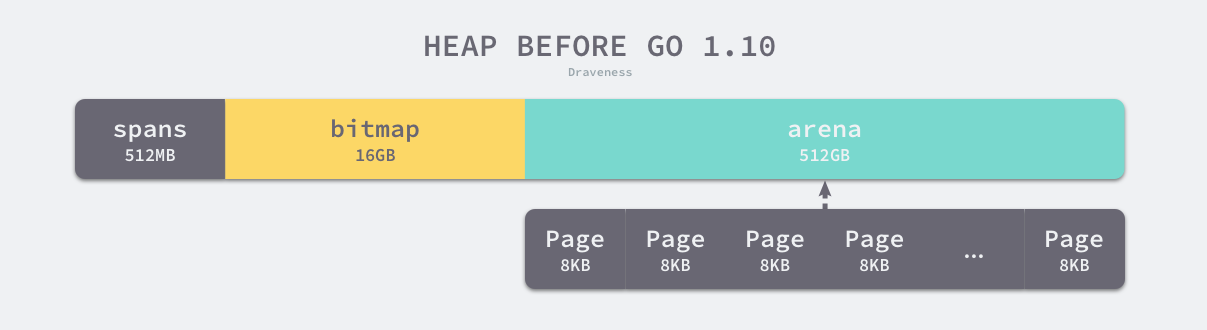
- spans 区域存储了指向mspan runtime.mspan 的指针,每个内存单元会管理几页的内存空间,每页大小为 8KB;
- bitmap 用于标识 arena 区域中的那些地址保存了对象,位图中的每个字节都会表示堆区中的 32 字节是否包含空闲;
- arena 区域是真正的堆区,运行时会将 8KB 看做一页,这些内存页中存储了所有在堆上初始化的对象;
对于任意一个地址,我们都可以根据 arena 的基地址计算该地址所在的页数并通过 spans 数组获得管理该片内存的管理单元 runtime.mspan,spans 数组中多个连续的位置可能对应同一个 runtime.mspan。
Go 语言在垃圾回收时会根据指针的地址判断对象是否在堆中,并通过上一段中介绍的过程找到管理该对象的 runtime.mspan。这些都建立在堆区的内存是连续的这一假设上。这种设计虽然简单并且方便,但是在 C 和 Go 混合使用时会导致程序崩溃:
- 分配的内存地址会发生冲突,导致堆的初始化和扩容失败;
- 没有被预留的大块内存可能会被分配给 C 语言的二进制,导致扩容后的堆不连续;
线性的堆内存需要预留大块的内存空间,但是申请大块的内存空间而不使用是不切实际的,不预留内存空间却会在特殊场景下造成程序崩溃。虽然连续内存的实现比较简单,但是这些问题我们也没有办法忽略。
稀疏内存
稀疏内存是 Go 语言在 1.11 中提出的方案,使用稀疏的内存布局不仅能移除堆大小的上限,还能解决 C 和 Go 混合使用时的地址空间冲突问题。不过因为基于稀疏内存的内存管理失去了内存的连续性这一假设,这也使内存管理变得更加复杂:
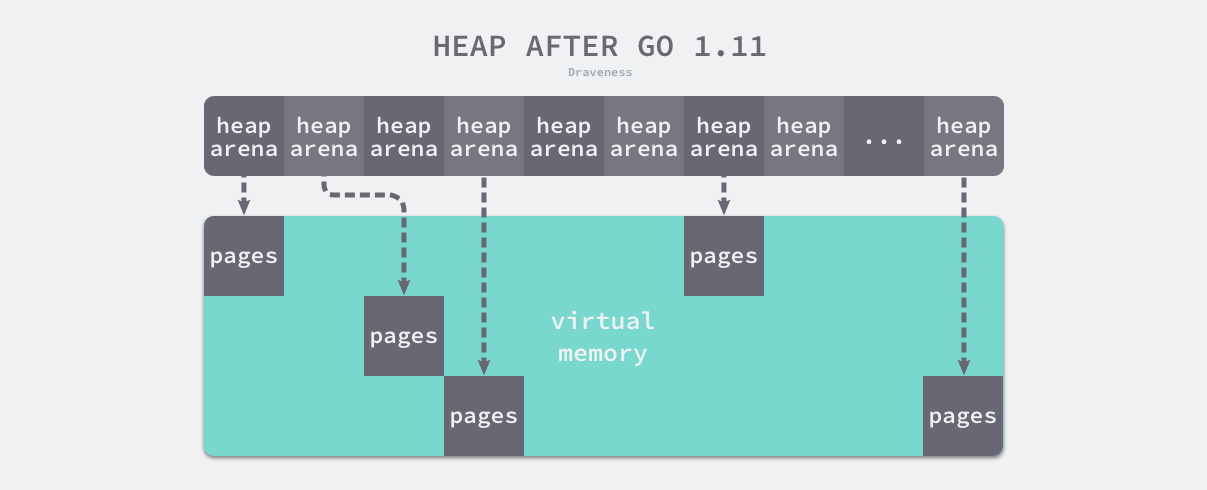
如上图所示,运行时使用二维的 runtime.heapArena 数组管理所有的内存,每个单元都会管理 64MB 的内存空间:
1
2
3
4
5
6
7
|
type heapArena struct {
bitmap [heapArenaBitmapBytes]byte
spans [pagesPerArena]*mspan
pageInUse [pagesPerArena / 8]uint8
pageMarks [pagesPerArena / 8]uint8
zeroedBase uintptr
}
|
该结构体中的 bitmap 和 spans 与线性内存中的 bitmap 和 spans 区域一一对应,zeroedBase 字段指向了该结构体管理的内存的基地址。这种设计将原有的连续大内存切分成稀疏的小内存,而用于管理这些内存的元信息也被切分成了小块。
不同平台和架构的二维数组大小可能完全不同,如果我们的 Go 语言服务在 Linux 的 x86-64 架构上运行,二维数组的一维大小会是 1,而二维大小是 4,194,304,因为每一个指针占用 8 字节的内存空间,所以元信息的总大小为 32MB。由于每个 runtime.heapArena 都会管理 64MB 的内存,整个堆区最多可以管理 256TB 的内存,这比之前的 512GB 多好几个数量级。
Go 语言团队在 1.11 版本中通过以下几个提交将线性内存变成稀疏内存,移除了 512GB 的内存上限以及堆区内存连续性的假设:
由于内存的管理变得更加复杂,上述改动对垃圾回收稍有影响,大约会增加 1% 的垃圾回收开销,不过这也是我们为了解决已有问题必须付出的成本。
系统级内存管理调用
因为所有的内存最终都是要从操作系统中申请的,所以 Go 语言的运行时构建了操作系统的内存管理抽象层,该抽象层将运行时管理的地址空间分成以下的四种状态:
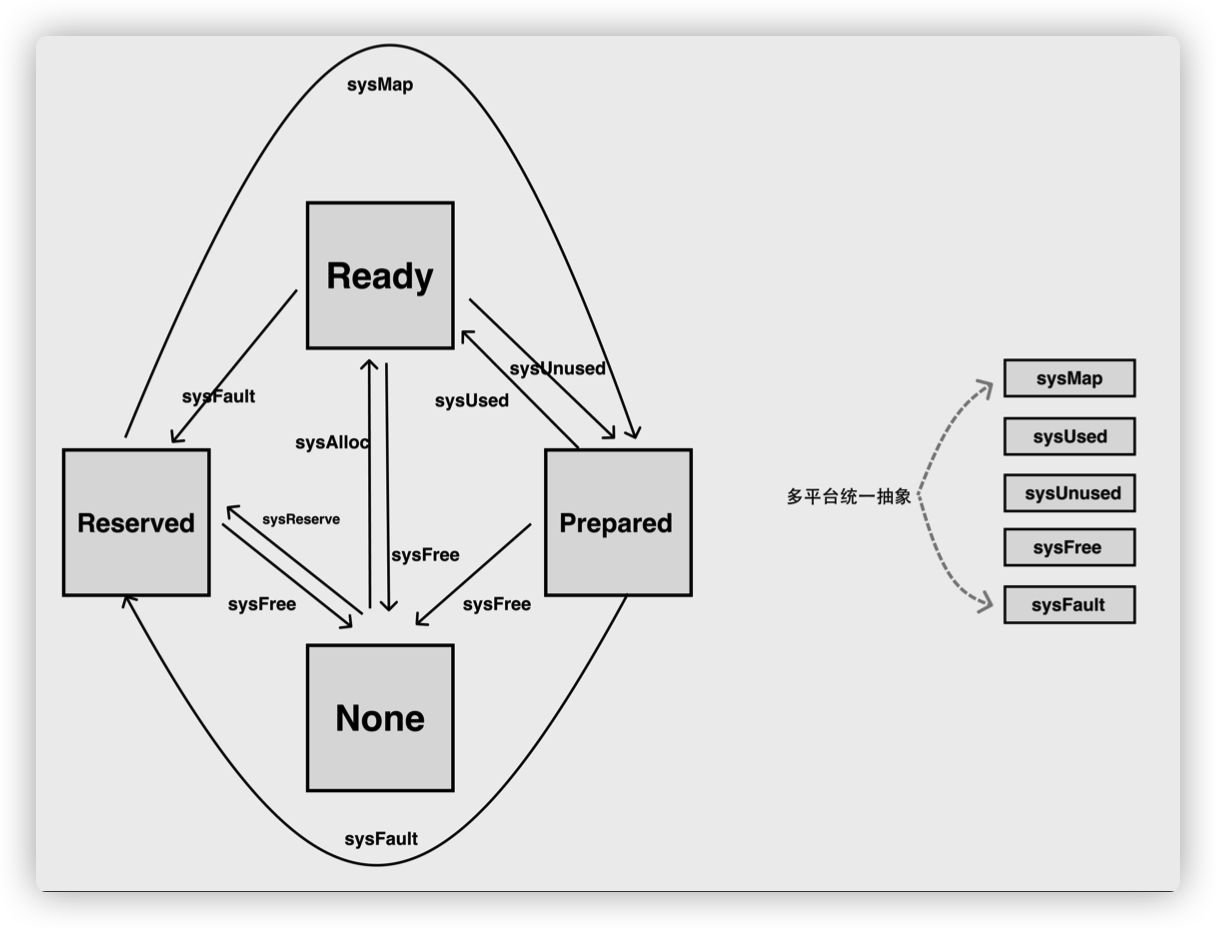
| 状态 |
解释 |
| None |
内存没有被保留或者映射,是地址空间的默认状态 |
| Reserved |
运行时持有该地址空间,但是访问该内存会导致错误 |
| Prepared |
内存被保留,一般没有对应的物理内存访问该片内存的行为是未定义的可以快速转换到 Ready 状态 |
| Ready |
可以被安全访问 |
每一个不同的操作系统都会包含一组特定的方法,这些方法可以让内存地址空间在不同的状态之间做出转换,我们可以通过下图了解不同状态之间的转换过程:
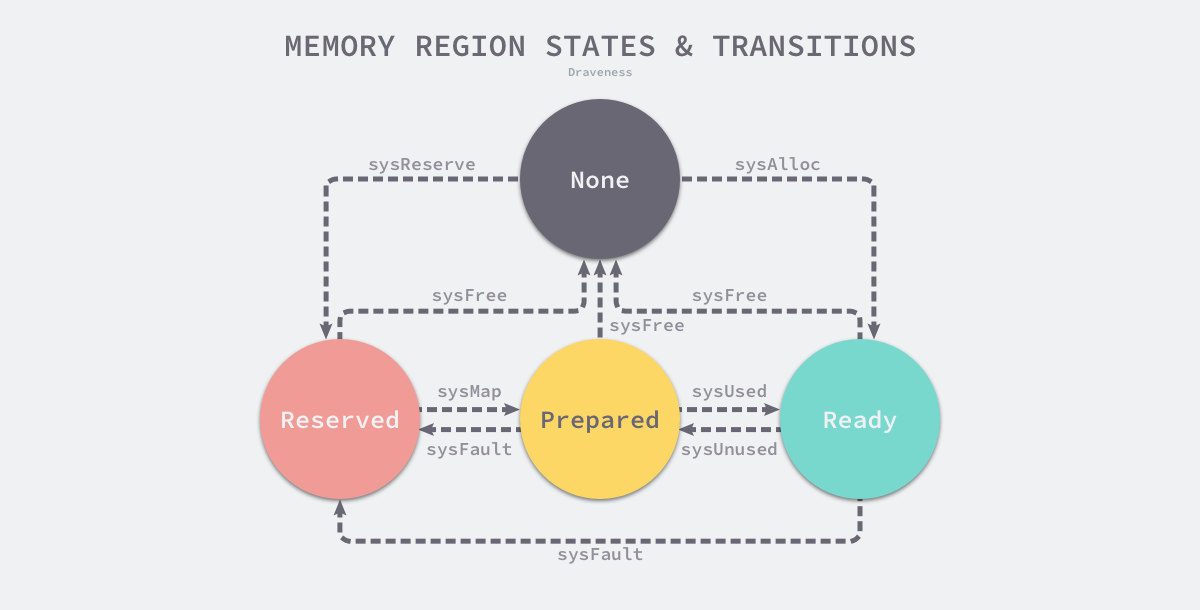
运行时中包含多个操作系统对状态转换方法的实现,所有的实现都包含在以 mem_ 开头的文件中,本节将介绍 Linux 操作系统对上图中方法的实现:
- runtime.sysAlloc 会从操作系统中获取一大块可用的内存空间,可能为几百 KB 或者几 MB;
- runtime.sysFree 会在程序发生内存不足(Out-of Memory,OOM)时调用并无条件地返回内存;
- runtime.sysReserve 会保留操作系统中的一片内存区域,对这片内存的访问会触发异常;
- runtime.sysMap 保证内存区域可以快速转换至准备就绪;
- runtime.sysUsed 通知操作系统应用程序需要使用该内存区域,需要保证内存区域可以安全访问;
- runtime.sysUnused 通知操作系统虚拟内存对应的物理内存已经不再需要了,它可以重用物理内存;
- runtime.sysFault 将内存区域转换成保留状态,主要用于运行时的调试;
其中 sysAlloc、sysReserve 和 sysMap 都是向操作系统申请内存的操作,他们均涉及关于内存分配的系统调用就是 mmap,区别在于:
- sysAlloc 是从操作系统上申请清零后的内存,调用参数是 _PROT_READ|_PROT_WRITE, _MAP_ANON|_MAP_PRIVATE;
- sysReserve 是从操作系统中保留内存的地址空间,并未直接分配内存,调用参数是 _PROT_NONE,_MAP_ANON|_MAP_PRIVATE,;
- sysMap 则是用于通知操作系统使用先前已经保留好的空间,参数是 _PROT_READ|_PROT_WRITE, _MAP_ANON|_MAP_FIXED|_MAP_PRIVATE。
不过 sysAlloc 和 sysReserve 都是操作系统对齐的内存,但堆分配器可能使用更大的对齐方式,因此这部分获得的内存都需要额外进行一些重排的工作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
// runtime/mem_linux.go
//go:nosplit
func sysAlloc(n uintptr, sysStat *uint64) unsafe.Pointer {
p, err := mmap(nil, n, _PROT_READ|_PROT_WRITE, _MAP_ANON|_MAP_PRIVATE, -1, 0)
if err != 0 {
if err == _EACCES {
print("runtime: mmap: access denied\n")
exit(2)
}
if err == _EAGAIN {
print("runtime: mmap: too much locked memory (check 'ulimit -l').\n")
exit(2)
}
return nil
}
(...)
return p
}
func sysReserve(v unsafe.Pointer, n uintptr) unsafe.Pointer {
p, err := mmap(v, n, _PROT_NONE, _MAP_ANON|_MAP_PRIVATE, -1, 0)
if err != 0 {
return nil
}
return p
}
func sysMap(v unsafe.Pointer, n uintptr, sysStat *uint64) {
(...)
p, err := mmap(v, n, _PROT_READ|_PROT_WRITE, _MAP_ANON|_MAP_FIXED|_MAP_PRIVATE, -1, 0)
if err == _ENOMEM {
throw("runtime: out of memory")
}
if p != v || err != 0 {
throw("runtime: cannot map pages in arena address space")
}
}
|
进程虚拟内存分布:
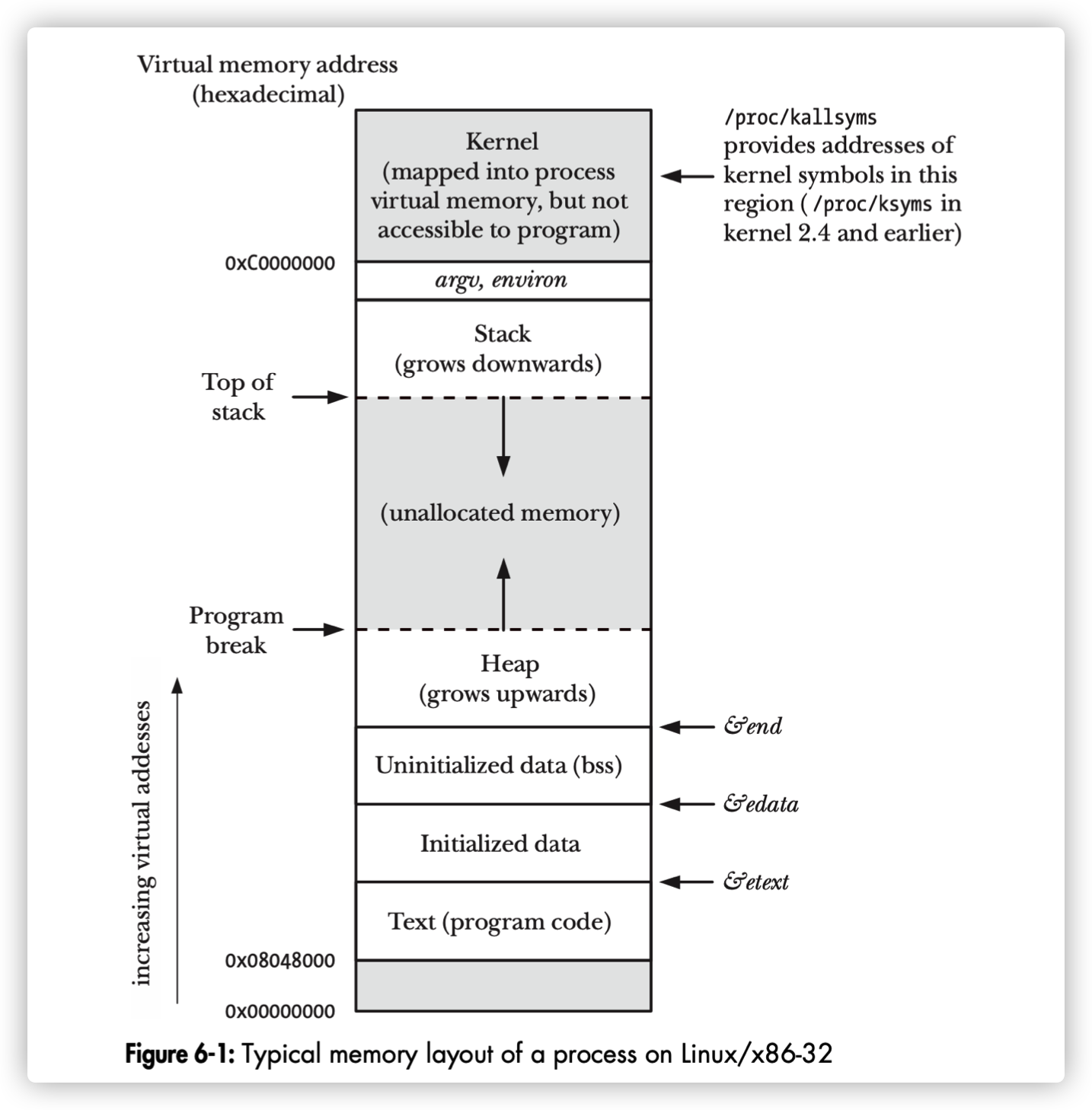
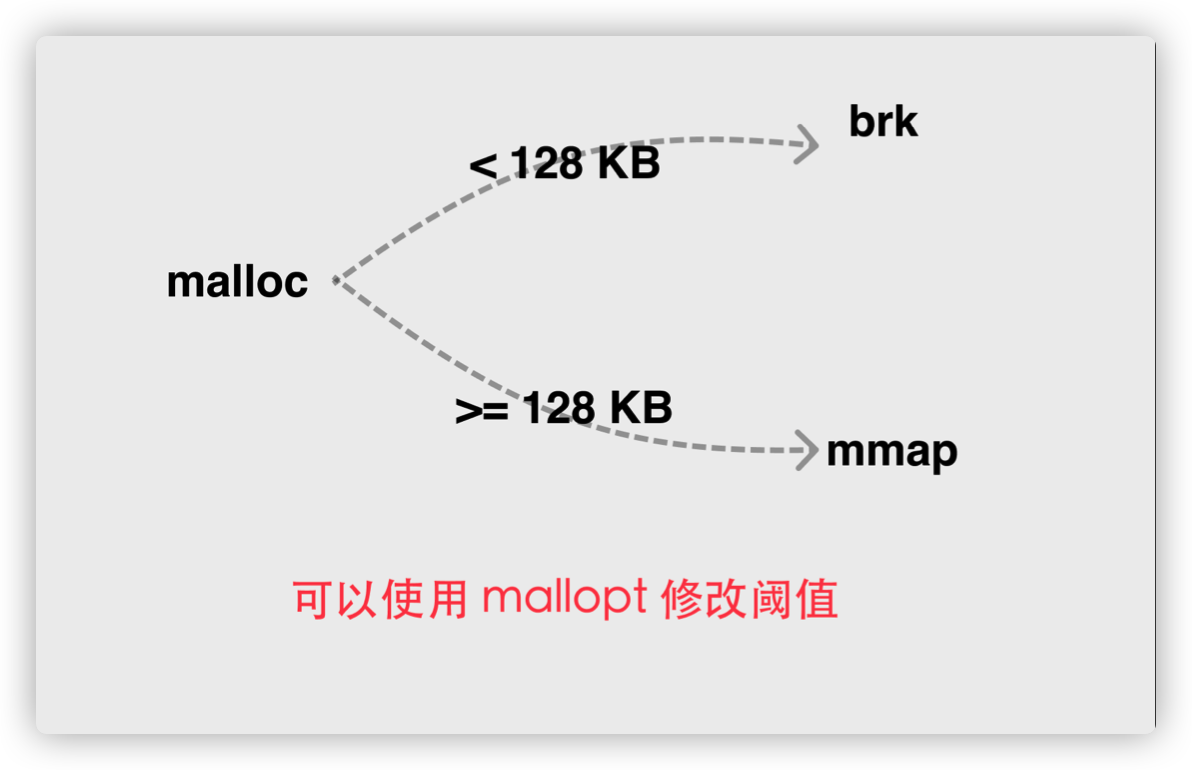
Linux 下内存分配调用有多个:
- brk: 可以让进程的堆指针增长,从逻辑上消耗一块虚拟地址空间,只能通过调整 program break位置推动堆增⻓.
- mmap: 可以让进程的虚拟地址空间切分出一块指定大小的虚拟地址空间,mmap 映射返回的地址也是从逻辑上被消耗的,需要通过 unmap 进行回收。可以从任意未分配位置映射内存
熟悉 C 语言的读者应该知道 malloc,它只是 C 语言的标准库函数,本质上是通过上述两个系统调用完成, 当分配内存较小时调用 brk,反之则会调用 mmap。不过 64 位系统上的 Go 运行时并没有使用 brk,目的很明显, 是为了能够更加灵活的控制虚拟地址空间。
而对于 unmap 操作,它被封装在了 sysFree 中:
1
2
3
4
5
|
//go:nosplit
func sysFree(v unsafe.Pointer, n uintptr, sysStat *uint64) {
(...)
munmap(v, n)
}
|
sysUnused、sysUsed 是 madvice 的封装,我们知道 madvice 用于向操作系统通知某段内存区域是否被应用所使用。sysFault 用于将 sysAlloc 获得的内存区域标记为故障,只用于运行时调试。
最后我们来理一下这些系统级调用的关系:
- 当开始保留内存地址时,调用 sysReserve;
- 当需要使用或不适用保留的内存区域时通知操作系统,调用 sysUnused、sysUsed;
- 正式使用保留的地址,使用 sysMap;
- 释放时使用 sysFree 以及调试时使用 sysFault;
- 非用户态的调试、堆外内存则使用 sysAlloc 直接向操作系统获得清零的内存。
运行时使用 Linux 提供的 mmap、munmap 和 madvise 等系统调用实现了操作系统的内存管理抽象层,抹平了不同操作系统的差异,为运行时提供了更加方便的接口,除了 Linux 之外,运行时还实现了 BSD、Darwin、Plan9 以及 Windows 等平台上抽象层。
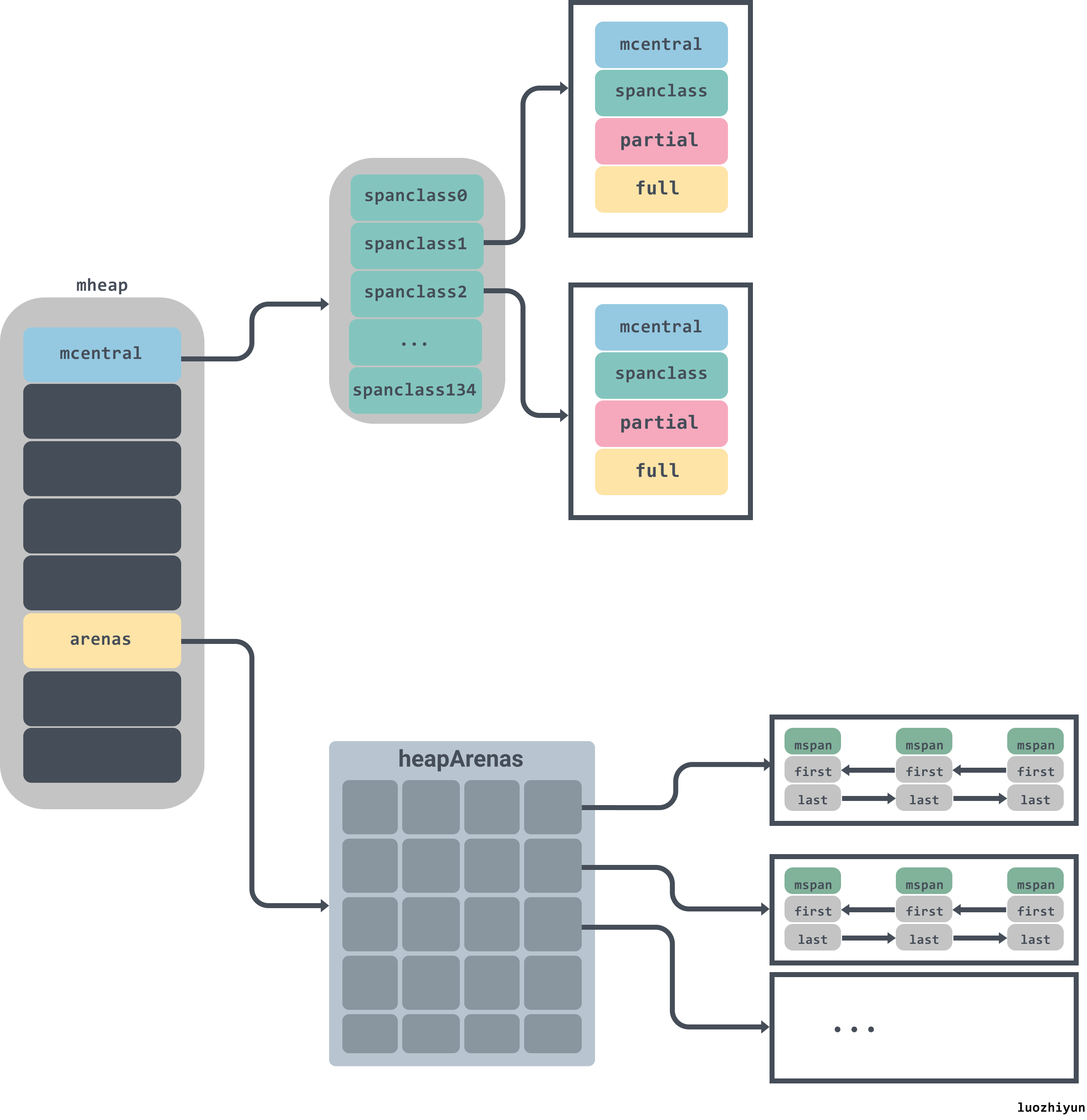
整体架构
Go 的内存分配器主要包含以下几个核心组件:
- heapArena: 保留整个虚拟地址空间
- mheap:分配的堆,在页大小为 8KB 的粒度上进行管理
- mspan:是 mheap 上管理的一连串的页
- mcentral:收集了给定大小等级的所有 span
- mcache:为 per-P 的缓存。
其中页是向操作系统申请内存的最小单位,目前设计为 8KB。
传统意义上的栈被 Go 的运行时霸占,不开放给用户态代码;而传统意义上的堆内存,又被 Go 运行时划分为了两个部分, 一个是 Go 运行时自身所需的堆内存,即堆外内存;另一部分则用于 Go 用户态代码所使用的堆内存,也叫做 Go 堆。 Go 堆负责了用户态对象的存放以及 goroutine 的执行栈。
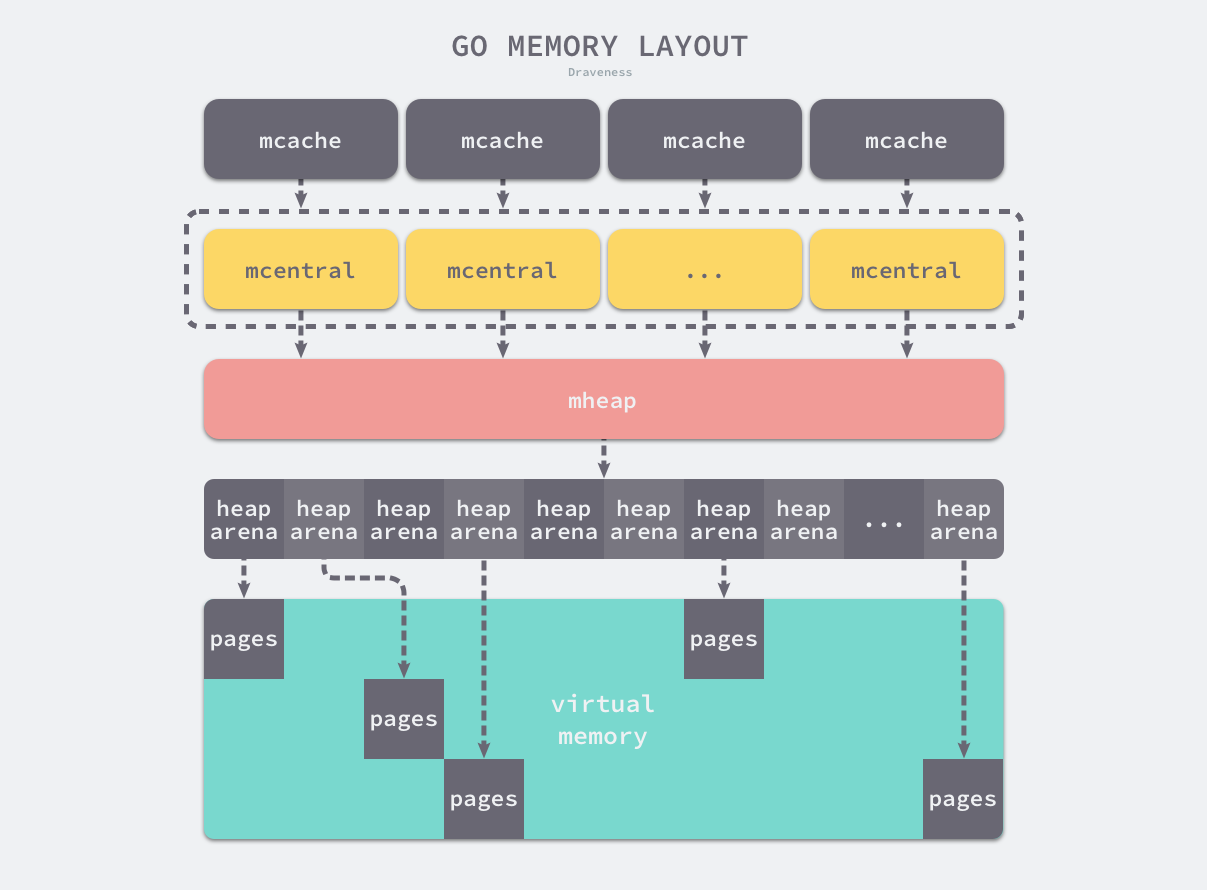
所有的 Go 语言程序都会在启动时初始化如上图所示的内存布局,每一个处理器都会被分配一个线程缓存 runtime.mcache 用于处理微对象和小对象的分配,它们会持有runtime.mspan。
每个类型的mspan都会管理特定大小的对象,当mspan中不存在空闲对象时,它们会从 runtime.mheap 持有的 134 个中心缓存 runtime.mcentral 中获取新的内存单元,中心缓存属于全局的堆结构体 runtime.mheap,它会从操作系统中申请内存。
在 amd64 的 Linux 操作系统上,runtime.mheap 会持有 4,194,304 runtime.heapArena,每一个 runtime.heapArena 都会管理 64MB 的内存,单个 Go 语言程序的内存上限也就是 256TB。
虚拟地址空间:heapArena
Go 堆被视为由多个 arena 组成,每个 arena 在 64 位机器上为 64MB,且起始地址与 arena 的大小对齐, 所有的 arena 覆盖了整个 Go 堆的地址空间。
Go语言中对于heapArena有精准的管理,精准到每一个指针大小的内存信息,每一个page对应的mspan信息都有记录。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
const (
pageSize = 8192 // 8KB
heapArenaBytes = 67108864 // 64MB
heapArenaBitmapBytes = heapArenaBytes / 32 // 2097152
pagesPerArena = heapArenaBytes / pageSize // 8192
)
//go:notinheap
type heapArena struct {
// heapArena中bitmap用每2个bit记录一个指针大小(8byte)的内存信息,主要用于gc
bitmap [heapArenaBitmapBytes]byte
// spans 将 page ID 对应到 arena 里的 mspan
spans [pagesPerArena]*mspan
pageInUse [pagesPerArena / 8]uint8
pageMarks [pagesPerArena / 8]uint8
zeroedBase uintptr
}
|
arenaHint
结构比较简单,是 arenaHint 链表的节点结构,保存了 arena 的起始地址、是否为最后一个 arena,以及下一个 arenaHint 指针。
1
2
3
4
5
6
|
//go:notinheap
type arenaHint struct {
addr uintptr
down bool
next *arenaHint
}
|
内存基本单元:mspan
runtime.mspan 是 Go 语言内存管理的基本单元.
管理 arena 如此粒度的内存并不符合实践,相反,所有的堆对象都通过 span 按照预先设定好的 大小等级分别分配,小于 32KB 的小对象则分配在固定大小等级的 span 上,否则直接从 mheap 上进行分配。
mspan 是相同大小等级的 span 的双向链表的一个节点,每个节点还记录了自己的起始地址、 指向的 span 中页的数量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
|
//go:notinheap
// 双向链表
type mspan struct {
// 链表中的下一个 span,如果为空则为 nil
next *mspan // next span in list, or nil if none
// 链表中的前一个 span,如果为空则为 nil
prev *mspan // previous span in list, or nil if none
list *mSpanList // For debugging. TODO: Remove.
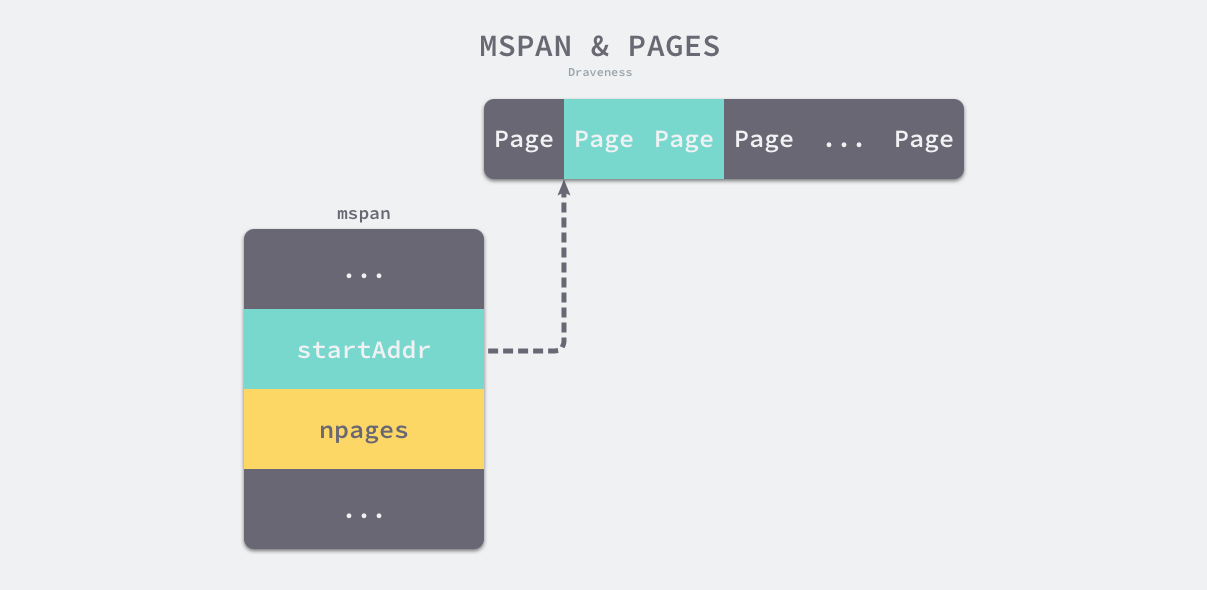
// startAddr 和 npages 确定该结构体管理的多个页所在的内存,每个页的大小都是 8KB;
// span 的第一个字节的地址,即 s.base()
startAddr uintptr // address of first byte of span aka s.base()
// 一个 span 中的 page 数量
npages uintptr // number of pages in span
// mSpanManual span 的释放对象链表
manualFreeList gclinkptr // list of free objects in mSpanManual spans
// freeindex is the slot index between 0 and nelems at which to begin scanning
// for the next free object in this span.
// Each allocation scans allocBits starting at freeindex until it encounters a 0
// indicating a free object. freeindex is then adjusted so that subsequent scans begin
// just past the newly discovered free object.
//
// If freeindex == nelem, this span has no free objects.
//
// allocBits is a bitmap of objects in this span.
// If n >= freeindex and allocBits[n/8] & (1<<(n%8)) is 0
// then object n is free;
// otherwise, object n is allocated. Bits starting at nelem are
// undefined and should never be referenced.
//
// Object n starts at address n*elemsize + (start << pageShift).
//扫描页中空闲对象的初始索引
freeindex uintptr
// TODO: Look up nelems from sizeclass and remove this field if it
// helps performance.
// span 中对象的数量
nelems uintptr // number of object in the span.
// Cache of the allocBits at freeindex. allocCache is shifted
// such that the lowest bit corresponds to the bit freeindex.
// allocCache holds the complement of allocBits, thus allowing
// ctz (count trailing zero) to use it directly.
// allocCache may contain bits beyond s.nelems; the caller must ignore
// these.
//allocBits 的补码,可以用于快速查找内存中未被使用的内存;
allocCache uint64
// allocBits and gcmarkBits hold pointers to a span's mark and
// allocation bits. The pointers are 8 byte aligned.
// There are three arenas where this data is held.
// free: Dirty arenas that are no longer accessed
// and can be reused.
// next: Holds information to be used in the next GC cycle.
// current: Information being used during this GC cycle.
// previous: Information being used during the last GC cycle.
// A new GC cycle starts with the call to finishsweep_m.
// finishsweep_m moves the previous arena to the free arena,
// the current arena to the previous arena, and
// the next arena to the current arena.
// The next arena is populated as the spans request
// memory to hold gcmarkBits for the next GC cycle as well
// as allocBits for newly allocated spans.
//
// The pointer arithmetic is done "by hand" instead of using
// arrays to avoid bounds checks along critical performance
// paths.
// The sweep will free the old allocBits and set allocBits to the
// gcmarkBits. The gcmarkBits are replaced with a fresh zeroed
// out memory.
//分别用于标记内存的占用和回收情况;
allocBits *gcBits
gcmarkBits *gcBits
// sweep generation:
// if sweepgen == h->sweepgen - 2, the span needs sweeping
// if sweepgen == h->sweepgen - 1, the span is currently being swept
// if sweepgen == h->sweepgen, the span is swept and ready to use
// if sweepgen == h->sweepgen + 1, the span was cached before sweep began and is still cached, and needs sweeping
// if sweepgen == h->sweepgen + 3, the span was swept and then cached and is still cached
// h->sweepgen is incremented by 2 after every GC
sweepgen uint32
divMul uint16 // for divide by elemsize - divMagic.mul
baseMask uint16 // if non-0, elemsize is a power of 2, & this will get object allocation base
// 分配对象的数量
allocCount uint16 // number of allocated objects
// 大小等级与 noscan (uint8)
spanclass spanClass // size class and noscan (uint8)
// mspaninuse 等等信息
// mspan状态,共有四种状态
// _MSpanDead、_MSpanInUse、_MSpanManual、_MSpanFree
state mSpanStateBox // mSpanInUse etc; accessed atomically (get/set methods)
// 从当前mspan分配对象时,是否需要将对象的内存空间初始化为0
needzero uint8 // needs to be zeroed before allocation
divShift uint8 // for divide by elemsize - divMagic.shift
divShift2 uint8 // for divide by elemsize - divMagic.shift2
// mspan能分配的对象大小
elemsize uintptr // computed from sizeclass or from npages
// 当前mspan指向空间的结束为止+1字节
limit uintptr // end of data in span
speciallock mutex // guards specials list
specials *special // linked list of special records sorted by offset.
}
|
串联后的上述结构体会构成如下双向链表,运行时会使用 runtime.mSpanList 存储双向链表的头结点和尾节点并在线程缓存以及中心缓存中使用。
1
2
3
4
|
type mSpanList struct {
first *mspan // first span in list, or nil if none
last *mspan // last span in list, or nil if none
}
|
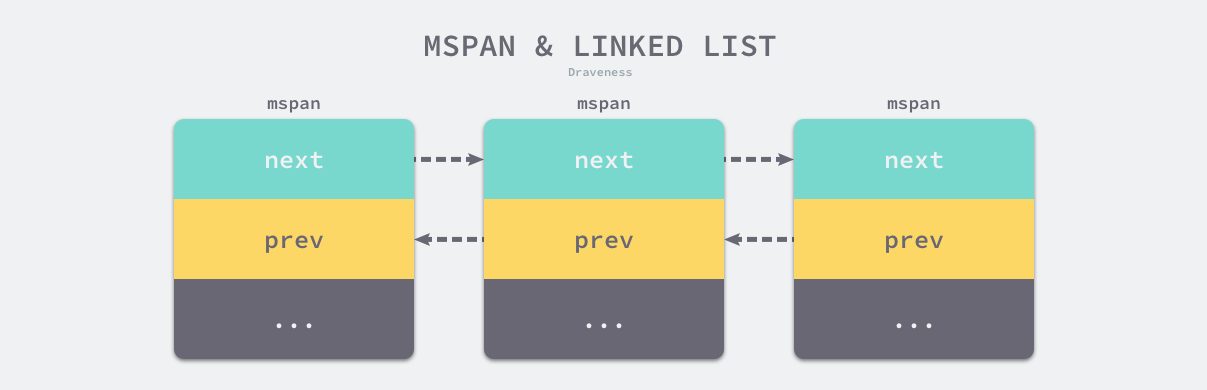
因为相邻的管理单元会互相引用,所以我们可以从任意一个结构体访问双向链表中的其他节点。
每个 runtime.mspan 都管理 npages 个大小为 8KB 的页,这里的页不是操作系统中的内存页,它们是操作系统内存页的整数倍
1
2
|
_PageShift = 13
_PageSize = 1 << _PageShift
|
该结构体会使用下面的这些字段来管理内存页的分配和回收:
- startAddr 和 npages — 确定该结构体管理的多个页所在的内存,每个页的大小都是 8KB;
- freeindex — 扫描页中空闲对象的初始索引;
- allocBits 和 gcmarkBits — 分别用于标记内存的占用和回收情况;
- allocCache — allocBits 的补码,可以用于快速查找内存中未被使用的内存;
runtime.mspan 会以两种不同的视角看待管理的内存,当结构体管理的内存不足时,运行时会以页为单位向堆申请内存:
-
nelems代表这个mspan中可以存放多少对象,等于(npages * pageSize)/elemsize;
-
elemsize表示一个对象会占用多个个bytes,等于class_to_size[sizeclass],需要注意的是sizeclass每次获取的时候会sizeclass方法,将sizeclass»1;
-
limit表示span结束的地址值,等于startAddr+ npages*pageSize;
当用户程序或者线程向 runtime.mspan 申请内存时,该结构会使用 allocCache 字段以对象为单位在管理的内存中快速查找待分配的空间:
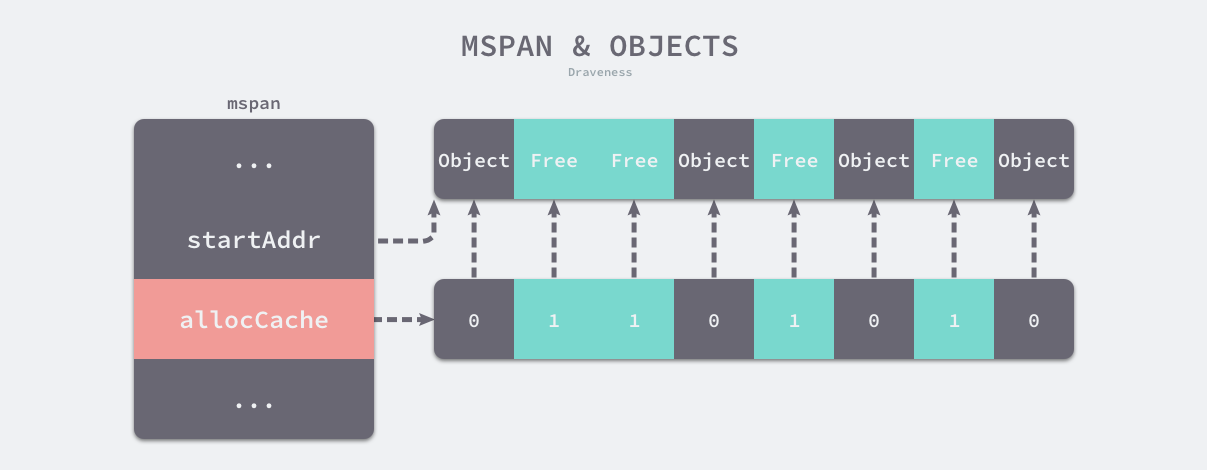
堆中无论是空闲还是使用中的内存,都使用mspan对象来表达。mspan中持有系统页整数倍的内存空间。通过state状态标记来标识当前mspan是被使用中还是空闲中。
mspan中持有的空间,可用来分配一个或多个相同类型的对象空间,elemsize表明了对象类型占用的空间大小。nelems表明了当前mspan下可以分配对象的最大数量。
mspan在mheap、mcentral、mcache中都有缓存。
区别在于,在mheap中缓存的mspan对象是以page为单位的,npages表明了mheap中的mspan对象所持有的系统页数量。mheap分配空间时,根据需求的page数量,分配合适的mspan给使用者。mheap不会分配半个mspan给使用者。
而在mcentral、mcache中的mspan,是以spanclass来划分的,spanclass可以理解为一个限定的对象大小。一个mspan被分配到mcentral或mcache后,它的spanclass是固定的,意味着在这个mspan上,只能分配大小固定的对象。详见spanclass。
spanClass
runtime.spanClass 是 runtime.mspan 结构体的跨度类,它决定了mspan中存储的对象大小和个数:
Go 语言的内存管理模块中一共包含 67 种跨度类,每一个跨度类都会存储特定大小的对象并且包含特定数量的页数以及对象,所有的数据都会被预选计算好并存储在 runtime.class_to_size 和 runtime.class_to_allocnpages 等变量中:
1
|
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
|
| class |
bytes/obj |
bytes/span |
objects |
tail waste |
max waste |
| 1 |
8 |
8192 |
1024 |
0 |
87.50% |
| 2 |
16 |
8192 |
512 |
0 |
43.75% |
| 3 |
32 |
8192 |
256 |
0 |
46.88% |
| 4 |
48 |
8192 |
170 |
32 |
31.52% |
| 5 |
64 |
8192 |
128 |
0 |
23.44% |
| 6 |
80 |
8192 |
102 |
32 |
19.07% |
| … |
… |
… |
… |
… |
… |
| 66 |
32768 |
32768 |
1 |
0 |
12.50% |
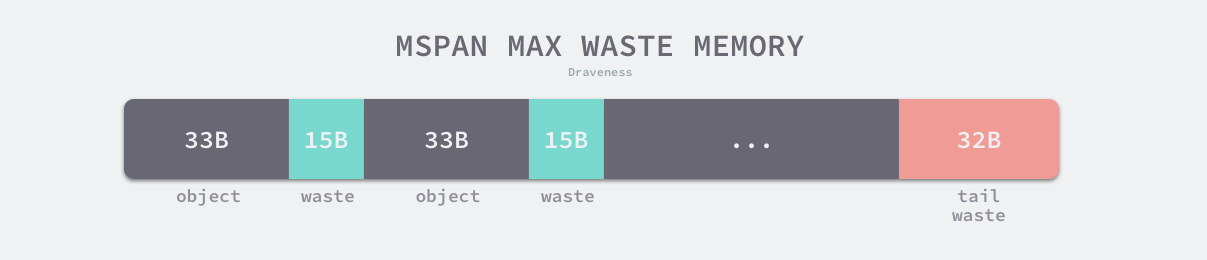
上表展示了对象大小从 8B 到 32KB,总共 66 种跨度类的大小、存储的对象数以及浪费的内存空间,以表中的第四个跨度类为例,跨度类为 4 的 runtime.mspan 中对象的大小上限为 48 字节、管理 1 个页、最多可以存储 170 个对象。因为内存需要按照页进行管理,所以在尾部会浪费 32 字节的内存,当页中存储的对象都是 33 字节时,最多会浪费 31.52% 的资源:
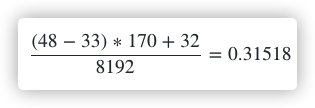
除了上述 66 个跨度类之外,运行时中还包含 ID 为 0 的特殊跨度类,它能够管理大于 32KB 的特殊对象,我们会在后面详细介绍大对象的分配过程,在这里就不展开说明了。
跨度类中除了存储类别的 ID 之外,它还会存储一个 noscan 标记位,该标记位表示对象是否包含指针,垃圾回收会对包含指针的 runtime.mspan 结构体进行扫描。我们可以通过下面的几个函数和方法了解 ID 和标记位的底层存储方式:
1
2
3
4
5
6
7
8
9
10
11
|
func makeSpanClass(sizeclass uint8, noscan bool) spanClass {
return spanClass(sizeclass<<1) | spanClass(bool2int(noscan))
}
func (sc spanClass) sizeclass() int8 {
return int8(sc >> 1)
}
func (sc spanClass) noscan() bool {
return sc&1 != 0
}
|
runtime.spanClass 是一个 uint8 类型的整数,它的前 7 位存储着跨度类的 ID,最后一位表示是否包含指针,该类型提供的两个方法能够帮我们快速获取对应的字段。
我们如何判定一个span占用几页呢? 实际上占用的页数与我们刚才选定的切分的大小是一一对应的,在sizeclasses.go中还有一个长度为67的数组。
1
|
var class_to_allocnpages = [_NumSizeClasses]uint8{0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 2, 1, 2, 1, 3, 2, 3, 1, 3, 2, 3, 4, 5, 6, 1, 7, 6, 5, 4, 3, 5, 7, 2, 9, 7, 5, 8, 3, 10, 7, 4}
|
比如说,当我们选定spanclass为3时,我们要切分的大小为32字节,那么我们分配span的页数就是1。
状态
运行时会使用 runtime.mSpanStateBox 结构体存储mspan的状态 runtime.mSpanState:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
const (
// 当mspan被创建和初始化时,状态为dead
_MSpanDead mSpanState = iota
// 无论是在mcentral、mcache中缓存的mspan,还是通过largeAlloc分配的大
// 内存mspan,只要是存在于mheap的busy列表中的mspan,都会被置为inuse状态
_MSpanInUse
// Manual申请的内存,会被标记为Manual,这部分内存不会通过GC来归还,需要
// 使用者显式调用freeManual归还到堆缓存
// 此外allocSpanLocked中堆返回内存量大于请求量时,归还部分内存会暂时把
// 两个连续mspan的状态置为Manual,避免free合并刚申请的空间。
_MSpanManual
// 处于堆缓存free列表和mtreap的mspan会被置为free状态。
_MSpanFree
)
|
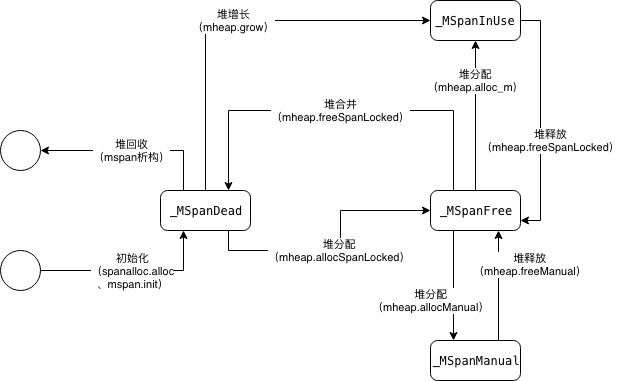
该状态可能处于 mSpanDead、mSpanInUse、mSpanManual 和 mSpanFree 四种情况。当 runtime.mspan 在空闲堆中,它会处于 mSpanFree 状态;当 runtime.mspan 已经被分配时,它会处于 mSpanInUse、mSpanManual 状态,这些状态会在遵循以下规则发生转换:
- 在垃圾回收的任意阶段,可能从 mSpanFree 转换到 mSpanInUse 和 mSpanManual;
- 在垃圾回收的清除阶段,可能从 mSpanInUse 和 mSpanManual 转换到 mSpanFree;
- 在垃圾回收的标记阶段,不能从 mSpanInUse 和 mSpanManual 转换到 mSpanFree;
设置 runtime.mspan 结构体状态的读写操作必须是原子性的避免垃圾回收造成的线程竞争问题。
allocCache
mspan中拥有allocCache字段,其作为一个位图,用于标记span元素中的大小。由于allocCache元素为uint64大小,因此其最多一次缓存64位的大小。
allocCache使用从后往前的方式与span中元素对应起来。例如allocCache中最后一个bit位对应的是span元素中最前的一个元素。
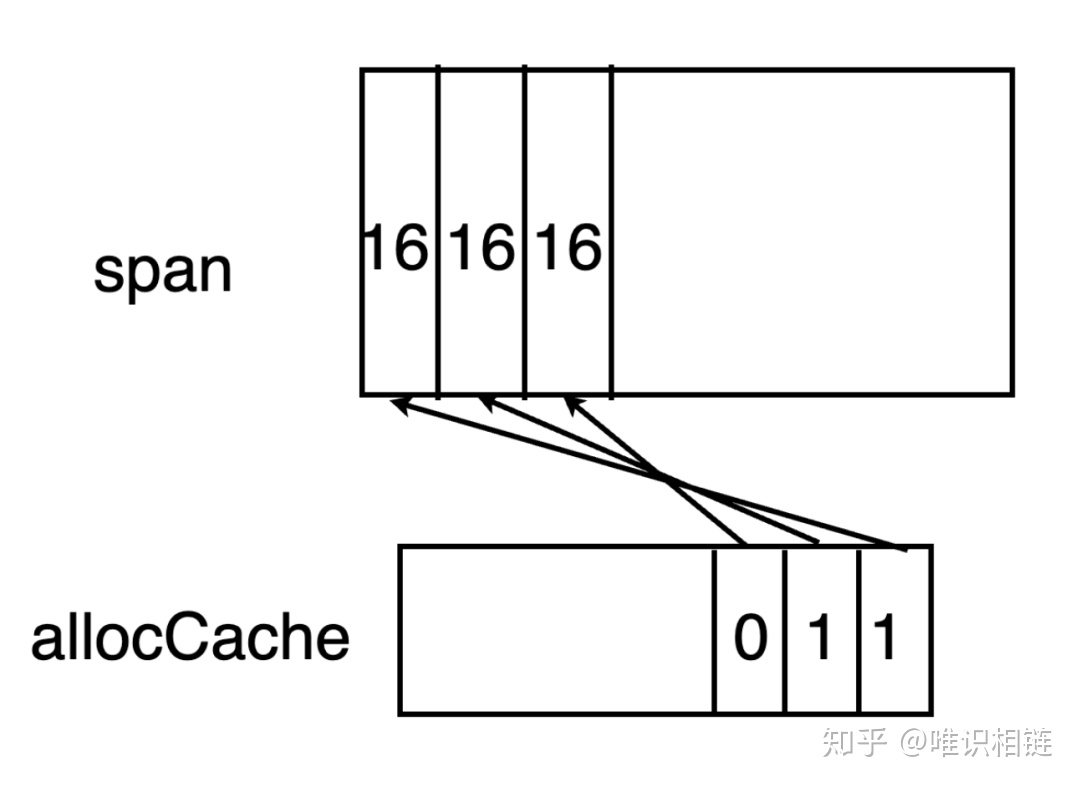
有时候,span中元素的个数大于64个,因此需要专门有一个字段freeindex来标识当前span中元素分配到了哪里。在span中小于freeindex序号的元素意味着都已经分配了,将从freeindex开始继续分配。
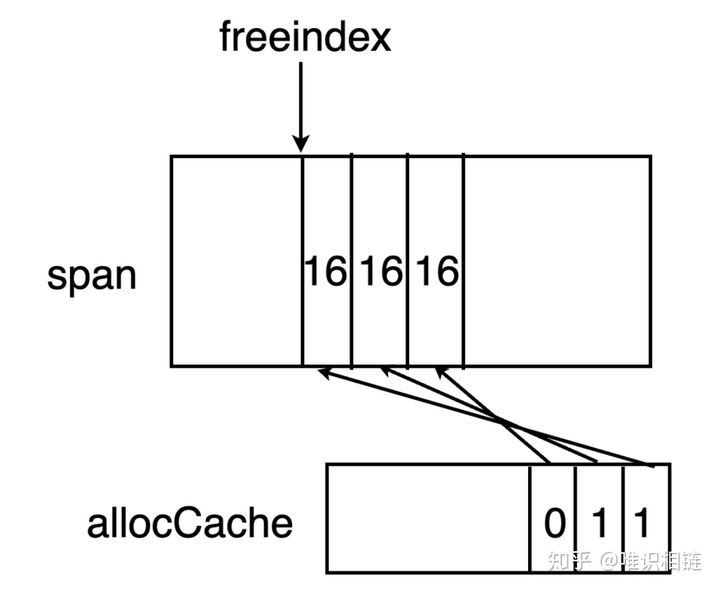
因此,只要从acclocCache开始找到哪一位为0即可。假如找到了X位为0,那么X + freeindex 为当前span中可用的元素序号。当allocCache中全部都已经标记为1后,就需要移动freeindex ,并更新allocCache。一直到达span元素末尾为止。
微小对象分配器:mcache
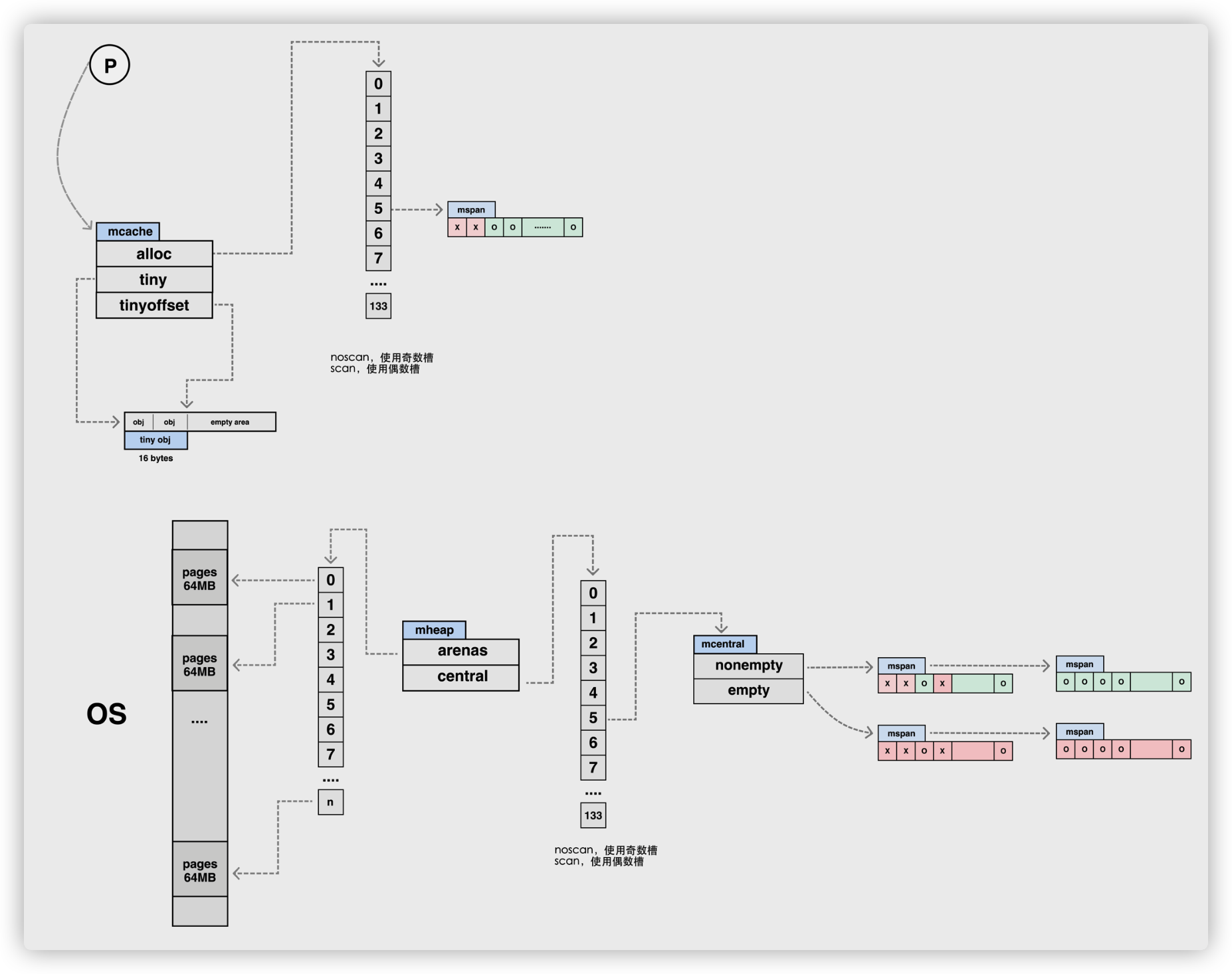
runtime.mcache 是 Go 语言中的线程缓存,它会与线程上的处理器一一绑定,是一个 per-P 的缓存,主要用来缓存用户程序申请的微小对象。每一个线程缓存都持有 67 * 2 个 runtime.mspan,这些mspan都存储在结构体的 alloc 字段中:
mcache 是一个 per-P 的缓存,因此每个线程都只访问自身的 mcache,因此也就不会出现并发,也就省去了对其进行加锁步骤。
它是一个包含不同大小等级的 span 链表的数组,其中 mcache.alloc 的每一个数组元素 都是某一个特定大小的 mspan 的链表头指针。
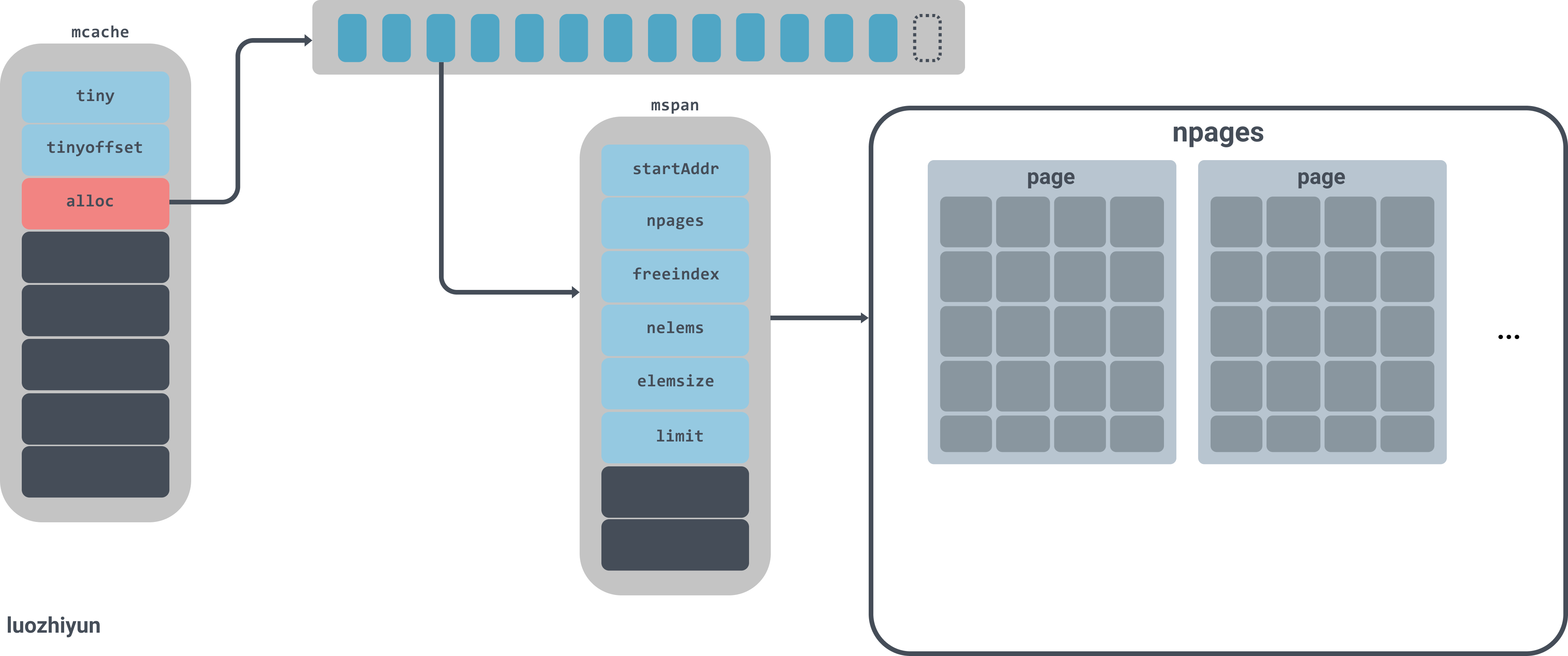
图中alloc是一个拥有134个元素的mspan数组,mspan数组管理数个page大小的内存,每个page是8k,page的数量由spanclass规格决定。
线程缓存在刚刚被初始化时是不包含 runtime.mspan 的,只有当用户程序申请内存时才会从上一级组件获取新的 runtime.mspan 满足内存分配的需求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
// Per-thread (in Go, per-P) cache for small objects.
// No locking needed because it is per-thread (per-P).
//
// mcaches are allocated from non-GC'd memory, so any heap pointers
// must be specially handled.
//
//go:notinheap
type mcache struct {
// The following members are accessed on every malloc,
// so they are grouped here for better caching.
// 分配这么多字节后触发堆样本
next_sample uintptr // trigger heap sample after allocating this many bytes
// 分配的可扫描堆的字节数
local_scan uintptr // bytes of scannable heap allocated
// Allocator cache for tiny objects w/o pointers.
// See "Tiny allocator" comment in malloc.go.
// tiny points to the beginning of the current tiny block, or
// nil if there is no current tiny block.
//
// tiny is a heap pointer. Since mcache is in non-GC'd memory,
// we handle it by clearing it in releaseAll during mark
// termination.
// 没有指针的微小对象的分配器缓存。
// tiny 指向当前 tiny 块的起始位置,或当没有 tiny 块时候为 nil
// tiny 是一个堆指针。由于 mcache 在非 GC 内存中,我们通过在
// mark termination 期间在 releaseAll 中清除它来处理它。
tiny uintptr
// tinyOffset 是下一个空闲内存所在的偏移量
tinyoffset uintptr
// 不计入其他统计的极小分配的数量
//已经分配的对象个数
local_tinyallocs uintptr // number of tiny allocs not counted in other stats
// The rest is not accessed on every malloc.
// 用来分配的 spans,由 spanClass 索引
// 申请的134个span
alloc [numSpanClasses]*mspan // spans to allocate from, indexed by spanClass
// 栈链表
stackcache [_NumStackOrders]stackfreelist
// 本地分配器统计,在 GC 期间被刷新
// Local allocator stats, flushed during GC.
local_largefree uintptr // bytes freed for large objects (>maxsmallsize)
local_nlargefree uintptr // number of frees for large objects (>maxsmallsize)
local_nsmallfree [_NumSizeClasses]uintptr // number of frees for small objects (<=maxsmallsize)
// flushGen indicates the sweepgen during which this mcache
// was last flushed. If flushGen != mheap_.sweepgen, the spans
// in this mcache are stale and need to the flushed so they
// can be swept. This is done in acquirep.
flushGen uint32
}
|
当 mcache 中 span 的数量不够使用时,会向 mcentral 的 nonempty 列表中获得新的 span。
线程缓存中还包含几个用于分配微对象的字段,下面的这三个字段组成了微对象分配器,专门为 16 字节以下的对象申请和管理内存:
1
2
3
4
5
|
type mcache struct {
tiny uintptr
tinyoffset uintptr
local_tinyallocs uintptr
}
|
微分配器只会用于分配非指针类型的内存,上述三个字段中 tiny 会指向堆中的一片内存,tinyOffset 是下一个空闲内存所在的偏移量,最后的 local_tinyallocs 会记录内存分配器中分配的对象个数。
Go 语言运行时将小于 16 字节的对象划分为微对象,它会使用线程缓存上的微分配器提高微对象分配的性能,我们主要使用它来分配较小的字符串以及逃逸的临时变量。微分配器可以将多个较小的内存分配请求合入同一个内存块中,只有当内存块中的所有对象都需要被回收时,整片内存才可能被回收。
微分配器管理的对象不可以是指针类型,管理多个对象的内存块大小 maxTinySize 是可以调整的,在默认情况下,内存块的大小为 16 字节。maxTinySize 的值越大,组合多个对象的可能性就越高,内存浪费也就越严重;maxTinySize 越小,内存浪费就会越少,不过无论如何调整,8 的倍数都是一个很好的选择。
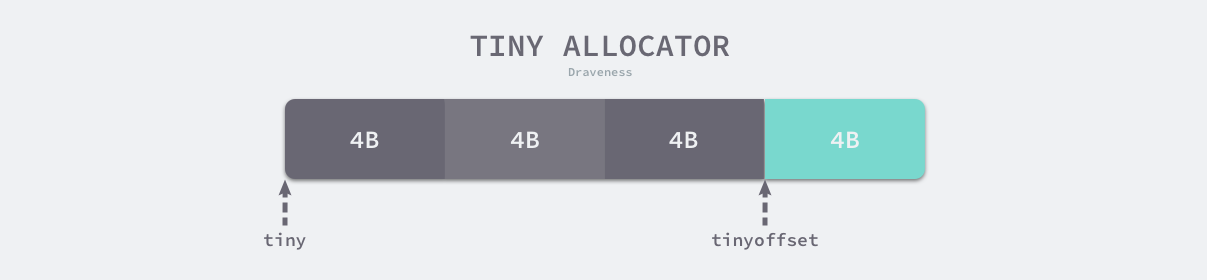
如上图所示,微分配器已经在 16 字节的内存块中分配了 12 字节的对象,如果下一个待分配的对象小于 4 字节,它就会直接使用上述内存块的剩余部分,减少内存碎片,不过该内存块只有在 3 个对象都被标记为垃圾时才会被回收。
寻找 span 的过程其实与小对象分配完全一致,区别在于微对象分配只寻找 tinySpanClass 大小等级的 span。 而且不会对这部分内存进行清零。
小对象是指大小为 16 字节到 32,768 字节的对象以及所有小于 16 字节的指针类型的对象.
当对一个小对象(<32KB)分配内存时,会将该对象所需的内存大小调整到某个能够容纳该对象的大小等级(size class), 并查看 mcache 中对应等级的 mspan,通过扫描 mspan 的 freeindex 来确定是否能够进行分配。
当没有可分配的 mspan 时,会从 mcentral 中获取一个所需大小空间的新的 mspan,从 mcentral 中分配会对其进行加锁, 但一次性获取整个 span 的过程均摊了对 mcentral 加锁的成本。
如果 mcentral 的 mspan 也为空时,则它也会发生增长,从而从 mheap 中获取一连串的页,作为一个新的 mspan 进行提供。 而如果 mheap 仍然为空,或者没有足够大的对象来进行分配时,则会从操作系统中分配一组新的页(至少 1MB), 从而均摊与操作系统沟通的成本。
初始化
运行时在初始化处理器时会调用 runtime.allocmcache 初始化线程缓存,该函数会在系统栈中使用 runtime.mheap 中的线程缓存分配器初始化新的 runtime.mcache 结构体:
由于 mheap 是全局的,因此在分配期必须对其进行加锁,而分配通过 fixAlloc 组件完成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// 虚拟的MSpan,不包含任何对象。
var emptymspan mspan
func allocmcache() *mcache {
var c *mcache
systemstack(func() {
lock(&mheap_.lock)
c = (*mcache)(mheap_.cachealloc.alloc())
c.flushGen = mheap_.sweepgen
unlock(&mheap_.lock)
})
for i := range c.alloc {
// 暂时指向虚拟的 mspan 中
c.alloc[i] = &emptymspan
}
// 返回下一个采样点,是服从泊松过程的随机数
c.next_sample = nextSample()
return c
}
|
就像我们在上面提到的,初始化后的 runtime.mcache 中的所有 runtime.mspan 都是空的占位符 emptymspan。
由于运行时提供了采样过程堆分析的支持, 由于我们的采样的目标是平均每个 MemProfileRate 字节对分配进行采样, 显然,在整个时间线上的分配情况应该是完全随机分布的,这是一个泊松过程。 因此最佳的采样点应该是服从指数分布 exp(MemProfileRate) 的随机数,其中 MemProfileRate 为均值。
1
2
3
4
5
6
7
8
9
10
|
func nextSample() uintptr {
if GOOS == "plan9" {
// Plan 9 doesn't support floating point in note handler.
if g := getg(); g == g.m.gsignal {
return nextSampleNoFP()
}
}
return uintptr(fastexprand(MemProfileRate))
}
|
MemProfileRate 是一个公共变量,可以在用户态代码进行修改:
1
|
var MemProfileRate int = 512 * 1024
|
refill
runtime.mcache.refill 方法会为线程缓存获取一个指定跨度类的mspan,被替换的单元不能包含空闲的内存空间,而获取的单元中需要至少包含一个空闲对象用于分配内存:
可以看到 refill 其实是从 mcentral 调用 cacheSpan 方法来获得 span:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
// refill acquires a new span of span class spc for c. This span will
// have at least one free object. The current span in c must be full.
//
// Must run in a non-preemptible context since otherwise the owner of
// c could change.
func (c *mcache) refill(spc spanClass) {
// Return the current cached span to the central lists.
s := c.alloc[spc]
if uintptr(s.allocCount) != s.nelems {
throw("refill of span with free space remaining")
}
if s != &emptymspan {
// Mark this span as no longer cached.
if s.sweepgen != mheap_.sweepgen+3 {
throw("bad sweepgen in refill")
}
mheap_.central[spc].mcentral.uncacheSpan(s)
}
// Get a new cached span from the central lists.
// 向central进行申请
s = mheap_.central[spc].mcentral.cacheSpan()
if s == nil {
throw("out of memory")
}
if uintptr(s.allocCount) == s.nelems {
throw("span has no free space")
}
// Indicate that this span is cached and prevent asynchronous
// sweeping in the next sweep phase.
s.sweepgen = mheap_.sweepgen + 3
// Assume all objects from this span will be allocated in the
// mcache. If it gets uncached, we'll adjust this.
stats := memstats.heapStats.acquire()
atomic.Xadduintptr(&stats.smallAllocCount[spc.sizeclass()], uintptr(s.nelems)-uintptr(s.allocCount))
memstats.heapStats.release()
// Update heap_live with the same assumption.
usedBytes := uintptr(s.allocCount) * s.elemsize
atomic.Xadd64(&memstats.heap_live, int64(s.npages*pageSize)-int64(usedBytes))
// Flush tinyAllocs.
if spc == tinySpanClass {
atomic.Xadd64(&memstats.tinyallocs, int64(c.tinyAllocs))
c.tinyAllocs = 0
}
// While we're here, flush scanAlloc, since we have to call
// revise anyway.
atomic.Xadd64(&memstats.heap_scan, int64(c.scanAlloc))
c.scanAlloc = 0
if trace.enabled {
// heap_live changed.
traceHeapAlloc()
}
if gcBlackenEnabled != 0 {
// heap_live and heap_scan changed.
gcController.revise()
}
c.alloc[spc] = s
}
|
如上述代码所示,该函数会从中心缓存中申请新的 runtime.mspan 存储到线程缓存中,这也是向线程缓存中插入mspan的唯一方法。
releaseAll
由于 mcache 从非 GC 内存上进行分配,因此出现的任何堆指针都必须进行特殊处理。 所以在释放前,需要调用 mcache.releaseAll 将堆指针进行处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func (c *mcache) releaseAll() {
for i := range c.alloc {
s := c.alloc[i]
if s != &emptymspan {
// 将 span 归还
mheap_.central[i].mcentral.uncacheSpan(s)
c.alloc[i] = &emptymspan
}
}
// 清空 tinyalloc 池.
c.tiny = 0
c.tinyoffset = 0
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func freemcache(c *mcache) {
systemstack(func() {
// 归还 span
c.releaseAll()
// 释放 stack
stackcache_clear(c)
lock(&mheap_.lock)
// 记录局部统计
purgecachedstats(c)
// 将 mcache 释放
mheap_.cachealloc.free(unsafe.Pointer(c))
unlock(&mheap_.lock)
})
}
|
per-P
首先,mcache 是一个 per-P 的 mcache,我们很自然的疑问就是,这个 mcache 在 p/m 这两个结构体上都有成员:
1
2
3
4
5
6
7
8
9
10
|
type p struct {
(...)
mcache *mcache
(...)
}
type m struct {
(...)
mcache *mcache
(...)
}
|
那么 mcache 是跟着谁跑的?结合调度器的知识不难发现,m 在执行时需要持有一个 p 才具备执行能力。 有利的证据是,当调用 runtime.procresize 时,初始化新的 P 时,mcache 是直接分配到 p 的; 回收 p 时,mcache 是直接从 p 上获取:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
func procresize(nprocs int32) *p {
(...)
// 初始化新的 P
for i := int32(0); i < nprocs; i++ {
pp := allp[i]
(...)
// 为 P 分配 cache 对象
if pp.mcache == nil {
if old == 0 && i == 0 {
if getg().m.mcache == nil {
throw("missing mcache?")
}
pp.mcache = getg().m.mcache
} else {
// 创建 cache
pp.mcache = allocmcache()
}
}
(...)
}
// 释放未使用的 P
for i := nprocs; i < old; i++ {
p := allp[i]
(...)
// 释放当前 P 绑定的 cache
freemcache(p.mcache)
p.mcache = nil
(...)
}
(...)
}
|
因而我们可以明确:
- mcache 会被 P 持有,当 M 和 P 绑定时,M 同样会保留 mcache 的指针
- mcache 直接向操作系统申请内存,且常驻运行时
- P 通过 make 命令进行分配,会分配在 Go 堆上
中心缓存:mcentral
runtime.mcentral 是内存分配器的中心缓存,与线程缓存不同,访问中心缓存中的mspan需要使用互斥锁:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
// Central list of free objects of a given size.
//
//go:notinheap
type mcentral struct {
lock mutex
spanclass spanClass
// For !go115NewMCentralImpl.
// 不包含空闲对象的链表
nonempty mSpanList // list of spans with a free object, ie a nonempty free list
// 包含空闲对象的列表
empty mSpanList // list of spans with no free objects (or cached in an mcache)
// partial and full contain two mspan sets: one of swept in-use
// spans, and one of unswept in-use spans. These two trade
// roles on each GC cycle. The unswept set is drained either by
// allocation or by the background sweeper in every GC cycle,
// so only two roles are necessary.
//
// sweepgen is increased by 2 on each GC cycle, so the swept
// spans are in partial[sweepgen/2%2] and the unswept spans are in
// partial[1-sweepgen/2%2]. Sweeping pops spans from the
// unswept set and pushes spans that are still in-use on the
// swept set. Likewise, allocating an in-use span pushes it
// on the swept set.
//
// Some parts of the sweeper can sweep arbitrary spans, and hence
// can't remove them from the unswept set, but will add the span
// to the appropriate swept list. As a result, the parts of the
// sweeper and mcentral that do consume from the unswept list may
// encounter swept spans, and these should be ignored.
// 空闲的span列表
partial [2]spanSet // list of spans with a free object
// 已经被使用的span列表
full [2]spanSet // list of spans with no free objects
// nmalloc is the cumulative count of objects allocated from
// this mcentral, assuming all spans in mcaches are
// fully-allocated. Written atomically, read under STW.
// nmalloc 字段也记录了该结构体中分配的对象个数
nmalloc uint64
}
|
每一个中心缓存都会管理某个跨度类的mspan,它会同时持有两个 runtime.mSpanList,分别存储包含空闲对象的列表和不包含空闲对象的链表:
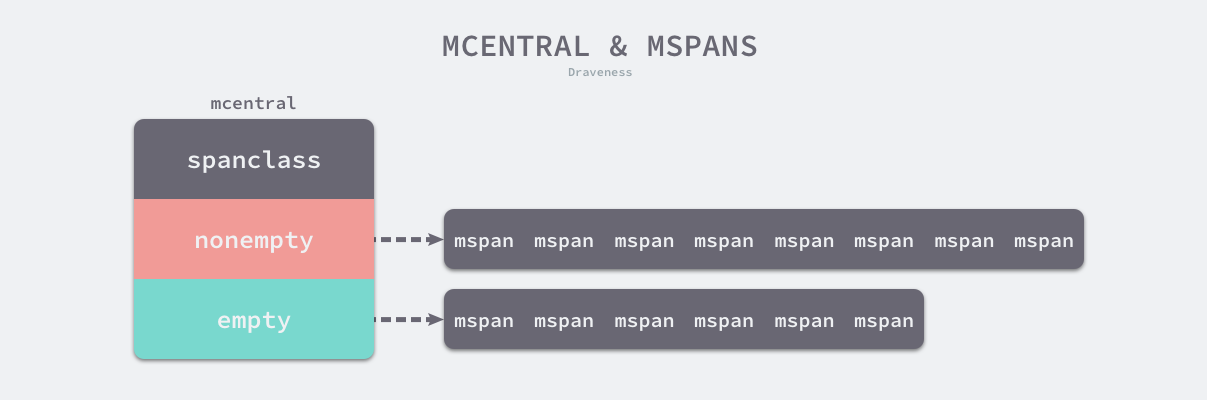
既然是没有空闲元素的nonempty列表,怎么还需要去遍历呢?这是由于有些span可能已经被垃圾回收器标记为空闲了,只是还没有来得及清理。这些Span在清扫后仍然是可以使用的,因此需要遍历。
当 mcentral 中 nonempty 列表中也没有可分配的 span 时,则会向 mheap 提出请求,从而获得 新的 span,并进而交给 mcache。
该结构体在初始化时,两个链表都不包含任何内存,程序运行时会扩容结构体持有的两个链表,nmalloc 字段也记录了该结构体中分配的对象个数。
runtime.mcentral的数据会由两个spanSet托管,partial负责空闲的列表,full负责已被使用的列表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
type headTailIndex uint64
// A spanSet is a set of *mspans.
//
// spanSet is safe for concurrent push and pop operations.
type spanSet struct {
// A spanSet is a two-level data structure consisting of a
// growable spine that points to fixed-sized blocks. The spine
// can be accessed without locks, but adding a block or
// growing it requires taking the spine lock.
//
// Because each mspan covers at least 8K of heap and takes at
// most 8 bytes in the spanSet, the growth of the spine is
// quite limited.
//
// The spine and all blocks are allocated off-heap, which
// allows this to be used in the memory manager and avoids the
// need for write barriers on all of these. spanSetBlocks are
// managed in a pool, though never freed back to the operating
// system. We never release spine memory because there could be
// concurrent lock-free access and we're likely to reuse it
// anyway. (In principle, we could do this during STW.)
spineLock mutex
// 数据块的指针
spine unsafe.Pointer // *[N]*spanSetBlock, accessed atomically
spineLen uintptr // Spine array length, accessed atomically
spineCap uintptr // Spine array cap, accessed under lock
// index is the head and tail of the spanSet in a single field.
// The head and the tail both represent an index into the logical
// concatenation of all blocks, with the head always behind or
// equal to the tail (indicating an empty set). This field is
// always accessed atomically.
//
// The head and the tail are only 32 bits wide, which means we
// can only support up to 2^32 pushes before a reset. If every
// span in the heap were stored in this set, and each span were
// the minimum size (1 runtime page, 8 KiB), then roughly the
// smallest heap which would be unrepresentable is 32 TiB in size.
// 头尾的指针,前32位是头指针,后32位是尾指针
index headTailIndex
}
|
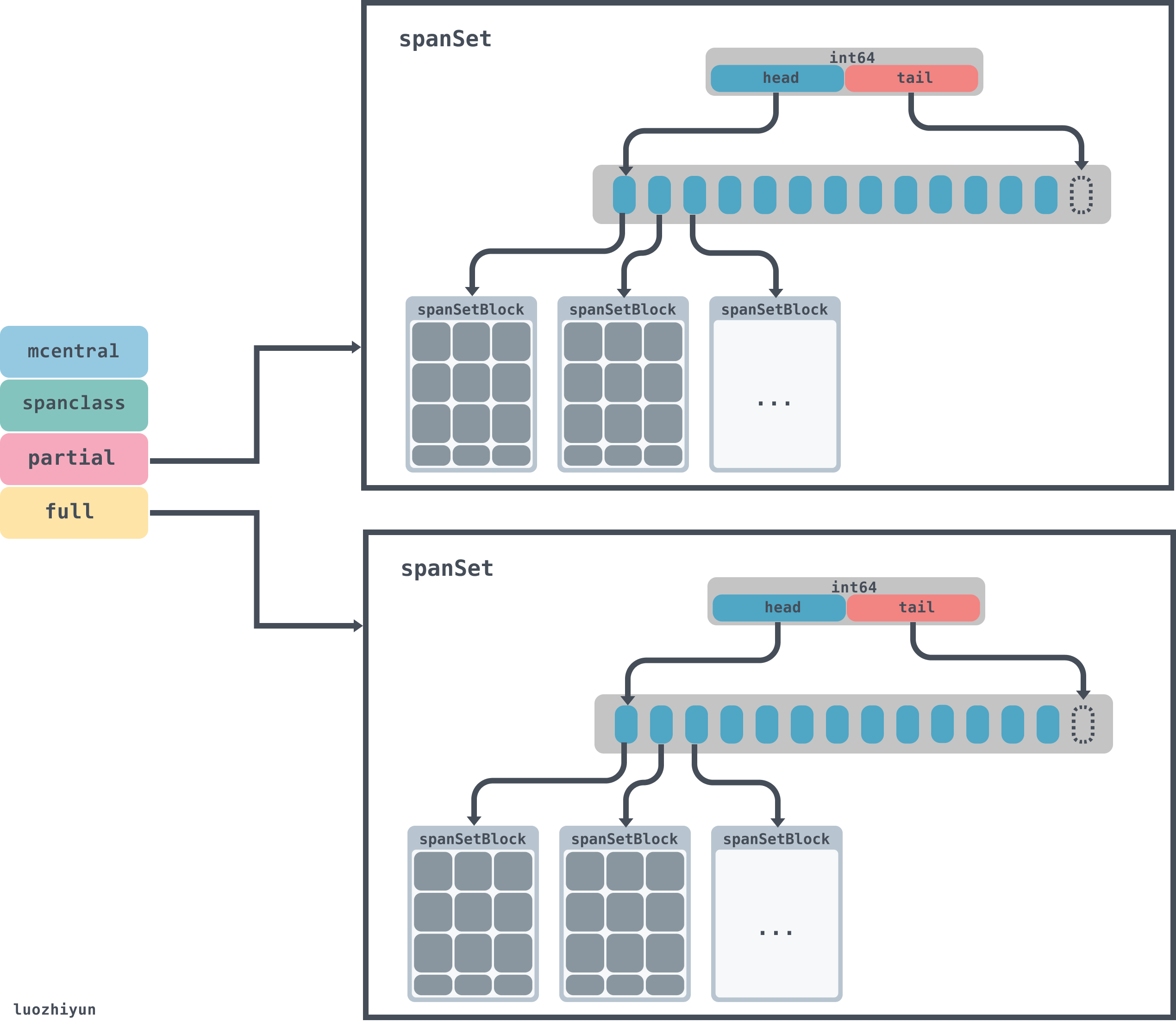
spanSet这个数据结构里面有一个由index组成的头尾指针,pop数据的时候会从头获取,push数据的时候从tail放入,spine相当于数据块的指针,通过head和tail的位置可以算出每个数据块的具体位置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// partialUnswept returns the spanSet which holds partially-filled
// unswept spans for this sweepgen.
func (c *mcentral) partialUnswept(sweepgen uint32) *spanSet {
return &c.partial[1-sweepgen/2%2]
}
// partialSwept returns the spanSet which holds partially-filled
// swept spans for this sweepgen.
func (c *mcentral) partialSwept(sweepgen uint32) *spanSet {
return &c.partial[sweepgen/2%2]
}
// fullUnswept returns the spanSet which holds unswept spans without any
// free slots for this sweepgen.
func (c *mcentral) fullUnswept(sweepgen uint32) *spanSet {
return &c.full[1-sweepgen/2%2]
}
// fullSwept returns the spanSet which holds swept spans without any
// free slots for this sweepgen.
func (c *mcentral) fullSwept(sweepgen uint32) *spanSet {
return &c.full[sweepgen/2%2]
}
|
数据块由spanSetBlock表示:
1
2
3
4
5
|
const spanSetBlockEntries = 512
type spanSetBlock struct {
...
spans [spanSetBlockEntries]*mspan
}
|
spanSetBlock是一个存放mspan的数据块,里面会包含一个存放512个mspan的数据指针。所以mcentral的总体数据结构如下:
cacheSpan
线程缓存会通过中心缓存的 runtime.mcentral.cacheSpan 方法获取新的mspan,该方法的实现比较复杂,我们可以将其分成以下几个部分:
- 从有空闲对象的 runtime.mspan 链表中查找可以使用的mspan;
- 从没有空闲对象的 runtime.mspan 链表中查找可以使用的mspan;
- 调用 runtime.mcentral.grow 从堆中申请新的mspan;
- 更新mspan的 allocCache 等字段帮助快速分配内存;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
|
// Allocate a span to use in an mcache.
func (c *mcentral) cacheSpan() *mspan {
if !go115NewMCentralImpl {
return c.oldCacheSpan()
}
....
}
// Allocate a span to use in an mcache.
//
// For !go115NewMCentralImpl.
func (c *mcentral) oldCacheSpan() *mspan {
// Deduct credit for this span allocation and sweep if necessary.
spanBytes := uintptr(class_to_allocnpages[c.spanclass.sizeclass()]) * _PageSize
deductSweepCredit(spanBytes, 0)
lock(&c.lock)
traceDone := false
if trace.enabled {
traceGCSweepStart()
}
sg := mheap_.sweepgen
retry:
var s *mspan
//首先我们会在中心缓存的非空链表中查找可用的 runtime.mspan,根据 sweepgen 字段分别进行不同的处理:
// 从nonempty链表查找空闲span
for s = c.nonempty.first; s != nil; s = s.next {
//1. 当内存单元等待回收时,将其插入 empty 链表、调用 runtime.mspan.sweep 清理该单元并返回;
if s.sweepgen == sg-2 && atomic.Cas(&s.sweepgen, sg-2, sg-1) {// 等待回收
// 在nonempty链表删除该span
c.nonempty.remove(s)
// 在empty链表增加该span
c.empty.insertBack(s)
unlock(&c.lock)
s.sweep(true)
goto havespan
//2. 当内存单元正在被后台回收时,跳过该内存单元;
if s.sweepgen == sg-1 {// 正在回收
// the span is being swept by background sweeper, skip
continue
}
//3. 当内存单元已经被回收时,将内存单元插入 empty 链表并返回;
// we have a nonempty span that does not require sweeping, allocate from it
c.nonempty.remove(s)// 已经回收
c.empty.insertBack(s)
unlock(&c.lock)
goto havespan
}
//如果中心缓存没有在 nonempty 中找到可用的mspan,就会继续遍历其持有的 empty 链表,我们在这里的处理与包含空闲对象的链表几乎完全相同。当找到需要回收的内存单元时,我们也会触发 runtime.mspan.sweep 进行清理,如果清理后的内存单元仍然不包含空闲对象,就会重新执行相应的代码:
// 在empty链表查找是否有可用的span,是因为某些span可能被垃圾回收标记为空闲但是还没清理
for s = c.empty.first; s != nil; s = s.next {
if s.sweepgen == sg-2 && atomic.Cas(&s.sweepgen, sg-2, sg-1) {
// we have an empty span that requires sweeping,
// sweep it and see if we can free some space in it
c.empty.remove(s)
// swept spans are at the end of the list
c.empty.insertBack(s)
unlock(&c.lock)
s.sweep(true)
freeIndex := s.nextFreeIndex()
if freeIndex != s.nelems {
s.freeindex = freeIndex
goto havespan
}
lock(&c.lock)
// the span is still empty after sweep
// it is already in the empty list, so just retry
goto retry// 不包含空闲对象
}
if s.sweepgen == sg-1 {
// the span is being swept by background sweeper, skip
continue
}
// already swept empty span,
// all subsequent ones must also be either swept or in process of sweeping
break
}
if trace.enabled {
traceGCSweepDone()
traceDone = true
}
unlock(&c.lock)
//如果 runtime.mcentral 在两个链表中都没有找到可用的内存单元,它会调用 runtime.mcentral.grow 触发扩容操作从堆中申请新的内存:
// Replenish central list if empty.
s = c.grow()
if s == nil {
return nil
}
lock(&c.lock)
c.empty.insertBack(s)
unlock(&c.lock)
// At this point s is a non-empty span, queued at the end of the empty list,
// c is unlocked.
havespan:
if trace.enabled && !traceDone {
traceGCSweepDone()
}
n := int(s.nelems) - int(s.allocCount)
if n == 0 || s.freeindex == s.nelems || uintptr(s.allocCount) == s.nelems {
throw("span has no free objects")
}
// Assume all objects from this span will be allocated in the
// mcache. If it gets uncached, we'll adjust this.
atomic.Xadd64(&c.nmalloc, int64(n))
usedBytes := uintptr(s.allocCount) * s.elemsize
atomic.Xadd64(&memstats.heap_live, int64(spanBytes)-int64(usedBytes))
if trace.enabled {
// heap_live changed.
traceHeapAlloc()
}
if gcBlackenEnabled != 0 {
// heap_live changed.
gcController.revise()
}
freeByteBase := s.freeindex &^ (64 - 1)
whichByte := freeByteBase / 8
// Init alloc bits cache.
s.refillAllocCache(whichByte)
// Adjust the allocCache so that s.freeindex corresponds to the low bit in
// s.allocCache.
s.allocCache >>= s.freeindex % 64
return s
}
|
无论通过哪种方法获取到了内存单元,该方法的最后都会对内存单元的 allocBits 和 allocCache 等字段进行更新,让运行时在分配内存时能够快速找到空闲的对象。
grow
中心缓存的扩容方法 runtime.mcentral.grow 会根据预先计算的 class_to_allocnpages 和 class_to_size 获取待分配的页数以及跨度类并调用 runtime.mheap.alloc 获取新的 runtime.mspan 结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// grow allocates a new empty span from the heap and initializes it for c's size class.
func (c *mcentral) grow() *mspan {
//查表获取其需要多少页
npages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()])
size := uintptr(class_to_size[c.spanclass.sizeclass()])
s := mheap_.alloc(npages, c.spanclass, true)
if s == nil {
return nil
}
// Use division by multiplication and shifts to quickly compute:
// n := (npages << _PageShift) / size
// 计算object数量
n := (npages << _PageShift) >> s.divShift * uintptr(s.divMul) >> s.divShift2
s.limit = s.base() + size*n
heapBitsForAddr(s.base()).initSpan(s)
return s
}
|
获取了 runtime.mspan 之后,我们会在上述方法中初始化 limit 字段并清除该结构在堆上对应的位图。
页堆:mheap
运行时对于大于 32KB 的大对象会单独处理,我们不会从线程缓存或者中心缓存中获取mspan,而是直接在系统的栈中调用 runtime.largeAlloc 函数分配大片的内存:
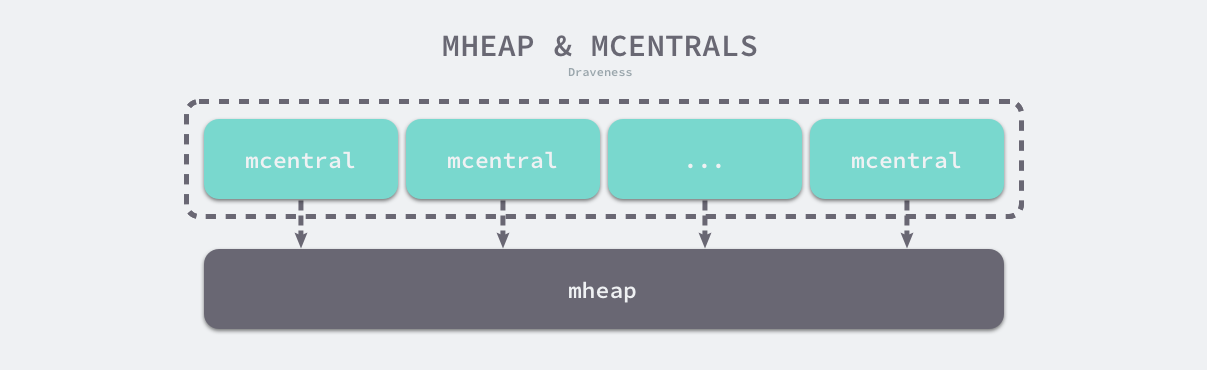
runtime.mheap 是内存分配的核心结构体,Go 语言程序只会存在一个全局的结构,而堆上初始化的所有对象都由该结构体统一管理,该结构体中包含两组非常重要的字段,其中一个是全局的中心缓存列表 central,另一个是管理堆区内存区域的 arenas 以及相关字段。
页堆中包含一个长度为 134 的 runtime.mcentral 数组,其中 67 个为跨度类需要 scan 的中心缓存,另外的 67 个是 noscan 的中心缓存:
Go 语言所有的内存空间都由如下所示的二维矩阵 runtime.heapArena 管理的,这个二维矩阵管理的内存可以是不连续的:
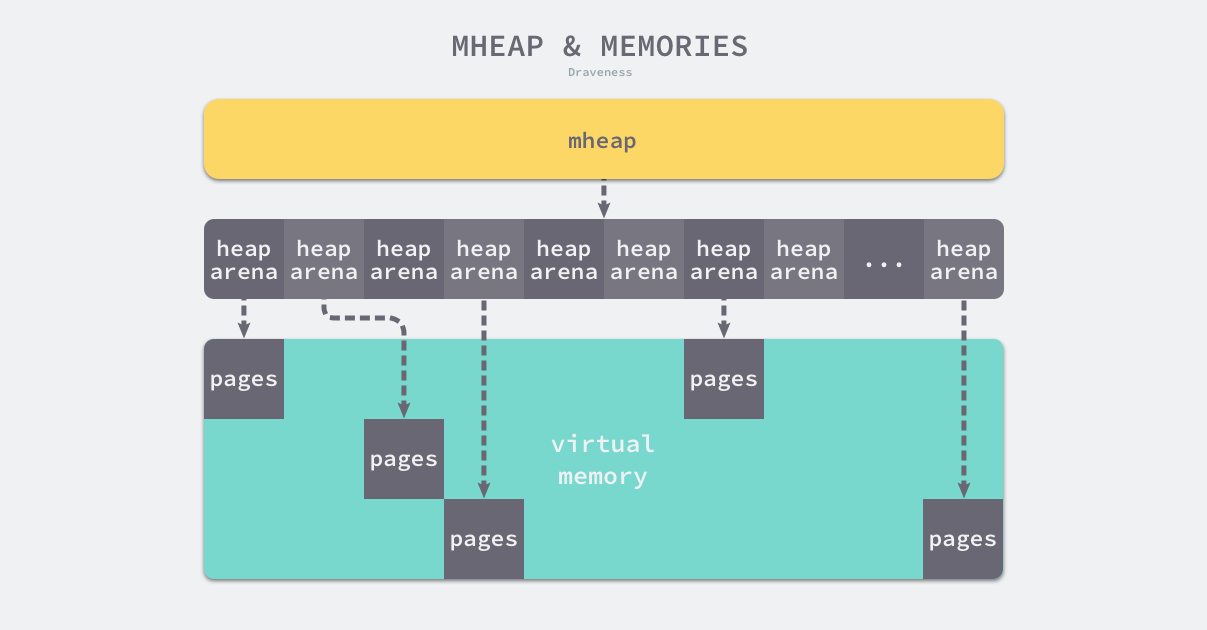
在除了 Windows 以外的 64 位操作系统中,每一个 runtime.heapArena 都会管理 64MB 的内存空间,如下所示的表格展示了不同平台上 Go 语言程序管理的堆区大小以及 runtime.heapArena 占用的内存空间:
| 平台 |
地址位数 |
Arena 大小 |
一维大小 |
二维大小 |
| */64-bit |
48 |
64MB |
1 |
4M (32MB) |
| windows/64-bit |
48 |
4MB |
64 |
1M (8MB) |
| */32-bit |
32 |
4MB |
1 |
1024 (4KB) |
| */mips(le) |
31 |
4MB |
1 |
512 (2KB) |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
|
// Main malloc heap.
// The heap itself is the "free" and "scav" treaps,
// but all the other global data is here too.
//
// mheap must not be heap-allocated because it contains mSpanLists,
// which must not be heap-allocated.
//
//go:notinheap
type mheap struct {
// lock must only be acquired on the system stack, otherwise a g
// could self-deadlock if its stack grows with the lock held.
// 互斥锁
lock mutex
pages pageAlloc // page allocation data structure
// GC相关
sweepgen uint32 // sweep generation, see comment in mspan; written during STW
// GC相关
sweepdone uint32 // all spans are swept
// GC相关
sweepers uint32 // number of active sweepone calls
// allspans is a slice of all mspans ever created. Each mspan
// appears exactly once.
//
// The memory for allspans is manually managed and can be
// reallocated and move as the heap grows.
//
// In general, allspans is protected by mheap_.lock, which
// prevents concurrent access as well as freeing the backing
// store. Accesses during STW might not hold the lock, but
// must ensure that allocation cannot happen around the
// access (since that may free the backing store).
// 所有 spans 从这里分配出去
allspans []*mspan // all spans out there
// sweepSpans contains two mspan stacks: one of swept in-use
// spans, and one of unswept in-use spans. These two trade
// roles on each GC cycle. Since the sweepgen increases by 2
// on each cycle, this means the swept spans are in
// sweepSpans[sweepgen/2%2] and the unswept spans are in
// sweepSpans[1-sweepgen/2%2]. Sweeping pops spans from the
// unswept stack and pushes spans that are still in-use on the
// swept stack. Likewise, allocating an in-use span pushes it
// on the swept stack.
//
// For !go115NewMCentralImpl.
sweepSpans [2]gcSweepBuf
_ uint32 // align uint64 fields on 32-bit for atomics
// Proportional sweep
//
// These parameters represent a linear function from heap_live
// to page sweep count. The proportional sweep system works to
// stay in the black by keeping the current page sweep count
// above this line at the current heap_live.
//
// The line has slope sweepPagesPerByte and passes through a
// basis point at (sweepHeapLiveBasis, pagesSweptBasis). At
// any given time, the system is at (memstats.heap_live,
// pagesSwept) in this space.
//
// It's important that the line pass through a point we
// control rather than simply starting at a (0,0) origin
// because that lets us adjust sweep pacing at any time while
// accounting for current progress. If we could only adjust
// the slope, it would create a discontinuity in debt if any
// progress has already been made.
pagesInUse uint64 // pages of spans in stats mSpanInUse; updated atomically
pagesSwept uint64 // pages swept this cycle; updated atomically
pagesSweptBasis uint64 // pagesSwept to use as the origin of the sweep ratio; updated atomically
sweepHeapLiveBasis uint64 // value of heap_live to use as the origin of sweep ratio; written with lock, read without
sweepPagesPerByte float64 // proportional sweep ratio; written with lock, read without
// TODO(austin): pagesInUse should be a uintptr, but the 386
// compiler can't 8-byte align fields.
// scavengeGoal is the amount of total retained heap memory (measured by
// heapRetained) that the runtime will try to maintain by returning memory
// to the OS.
scavengeGoal uint64
// Page reclaimer state
// reclaimIndex is the page index in allArenas of next page to
// reclaim. Specifically, it refers to page (i %
// pagesPerArena) of arena allArenas[i / pagesPerArena].
//
// If this is >= 1<<63, the page reclaimer is done scanning
// the page marks.
//
// This is accessed atomically.
reclaimIndex uint64
// reclaimCredit is spare credit for extra pages swept. Since
// the page reclaimer works in large chunks, it may reclaim
// more than requested. Any spare pages released go to this
// credit pool.
//
// This is accessed atomically.
reclaimCredit uintptr
// Malloc stats.
largealloc uint64 // bytes allocated for large objects
nlargealloc uint64 // number of large object allocations
largefree uint64 // bytes freed for large objects (>maxsmallsize)
nlargefree uint64 // number of frees for large objects (>maxsmallsize)
nsmallfree [_NumSizeClasses]uint64 // number of frees for small objects (<=maxsmallsize)
// arenas is the heap arena map. It points to the metadata for
// the heap for every arena frame of the entire usable virtual
// address space.
//
// Use arenaIndex to compute indexes into this array.
//
// For regions of the address space that are not backed by the
// Go heap, the arena map contains nil.
//
// Modifications are protected by mheap_.lock. Reads can be
// performed without locking; however, a given entry can
// transition from nil to non-nil at any time when the lock
// isn't held. (Entries never transitions back to nil.)
//
// In general, this is a two-level mapping consisting of an L1
// map and possibly many L2 maps. This saves space when there
// are a huge number of arena frames. However, on many
// platforms (even 64-bit), arenaL1Bits is 0, making this
// effectively a single-level map. In this case, arenas[0]
// will never be nil.
// arenas数组集合,一个二维数组
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
// heapArenaAlloc is pre-reserved space for allocating heapArena
// objects. This is only used on 32-bit, where we pre-reserve
// this space to avoid interleaving it with the heap itself.
heapArenaAlloc linearAlloc
// arenaHints is a list of addresses at which to attempt to
// add more heap arenas. This is initially populated with a
// set of general hint addresses, and grown with the bounds of
// actual heap arena ranges.
arenaHints *arenaHint
// arena is a pre-reserved space for allocating heap arenas
// (the actual arenas). This is only used on 32-bit.
arena linearAlloc
// allArenas is the arenaIndex of every mapped arena. This can
// be used to iterate through the address space.
//
// Access is protected by mheap_.lock. However, since this is
// append-only and old backing arrays are never freed, it is
// safe to acquire mheap_.lock, copy the slice header, and
// then release mheap_.lock.
allArenas []arenaIdx
// sweepArenas is a snapshot of allArenas taken at the
// beginning of the sweep cycle. This can be read safely by
// simply blocking GC (by disabling preemption).
sweepArenas []arenaIdx
// markArenas is a snapshot of allArenas taken at the beginning
// of the mark cycle. Because allArenas is append-only, neither
// this slice nor its contents will change during the mark, so
// it can be read safely.
markArenas []arenaIdx
// curArena is the arena that the heap is currently growing
// into. This should always be physPageSize-aligned.
curArena struct {
base, end uintptr
}
// _ uint32 // ensure 64-bit alignment of central
// central free lists for small size classes.
// the padding makes sure that the mcentrals are
// spaced CacheLinePadSize bytes apart, so that each mcentral.lock
// gets its own cache line.
// central is indexed by spanClass.
// mcentral 内存分配中心,mcache没有足够的内存分配的时候,会从mcentral分配
// mcentral 是mheap在管理
central [numSpanClasses]struct {
mcentral mcentral
pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte
}
// span* 分配器
spanalloc fixalloc // allocator for span*
// mcache* 分配器
cachealloc fixalloc // allocator for mcache*
// specialfinalizer* 分配器
specialfinalizeralloc fixalloc // allocator for specialfinalizer*
// specialprofile* 分配器
specialprofilealloc fixalloc // allocator for specialprofile*
// 特殊记录分配器的锁
speciallock mutex // lock for special record allocators.
// arenaHints 分配器
arenaHintAlloc fixalloc // allocator for arenaHints
unused *specialfinalizer // never set, just here to force the specialfinalizer type into DWARF
}
|
init
堆区的初始化会使用 runtime.mheap.init 方法,我们能看到该方法初始化了非常多的结构体和字段,不过其中初始化的两类变量比较重要:
- spanalloc、cachealloc 以及 arenaHintAlloc 等 runtime.fixalloc 类型的空闲链表分配器;
- central 切片中 runtime.mcentral 类型的中心缓存;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
// Initialize the heap.
// 堆初始化
func (h *mheap) init() {
// 初始化堆中各个组件的分配器
lockInit(&h.lock, lockRankMheap)
lockInit(&h.sweepSpans[0].spineLock, lockRankSpine)
lockInit(&h.sweepSpans[1].spineLock, lockRankSpine)
lockInit(&h.speciallock, lockRankMheapSpecial)
h.spanalloc.init(unsafe.Sizeof(mspan{}), recordspan, unsafe.Pointer(h), &memstats.mspan_sys)
h.cachealloc.init(unsafe.Sizeof(mcache{}), nil, nil, &memstats.mcache_sys)
h.specialfinalizeralloc.init(unsafe.Sizeof(specialfinalizer{}), nil, nil, &memstats.other_sys)
h.specialprofilealloc.init(unsafe.Sizeof(specialprofile{}), nil, nil, &memstats.other_sys)
h.arenaHintAlloc.init(unsafe.Sizeof(arenaHint{}), nil, nil, &memstats.other_sys)
// Don't zero mspan allocations. Background sweeping can
// inspect a span concurrently with allocating it, so it's
// important that the span's sweepgen survive across freeing
// and re-allocating a span to prevent background sweeping
// from improperly cas'ing it from 0.
//
// This is safe because mspan contains no heap pointers.
// 不对 mspan 的分配清零,后台扫描可以通过分配它来并发的检查一个 span
// 因此 span 的 sweepgen 在释放和重新分配时候能存活,从而可以防止后台扫描
// 不正确的将其从 0 进行 CAS。
//
// 因为 mspan 不包含堆指针,因此它是安全的
h.spanalloc.zero = false
// h->mapcache needs no init
// h->mapcache 不需要初始化
for i := range h.central {
h.central[i].mcentral.init(spanClass(i))
}
h.pages.init(&h.lock, &memstats.gc_sys)
}
|
堆中初始化的多个空闲链表分配器与我们在设计原理一节中提到的分配器没有太多区别,当我们调用 runtime.fixalloc.init 初始化分配器时,需要传入待初始化的结构体大小等信息,这会帮助分配器分割待分配的内存,该分配器提供了以下两个用于分配和释放内存的方法:
- runtime.fixalloc.alloc — 获取下一个空闲的内存空间;
- runtime.fixalloc.free — 释放指针指向的内存空间;
除了这些空闲链表分配器之外,我们还会在该方法中初始化所有的中心缓存,这些中心缓存会维护全局的mspan,各个线程会通过中心缓存获取新的内存单元。
fixalloc
fixalloc 是一个基于自由列表的固定大小的分配器。其核心原理是将若干未分配的内存块连接起来, 将未分配的区域的第一个字为指向下一个未分配区域的指针使用。
Go 的主分配堆中 malloc(span、cache、treap、finalizer、profile、arena hint 等) 均 围绕它为实体进行固定分配和回收。
fixalloc 作为抽象,非常简洁,只包含三个基本操作:初始化、分配、回收
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// fixalloc 是一个简单的固定大小对象的自由表内存分配器。
// Malloc 使用围绕 sysAlloc 的 fixalloc 来管理其 MCache 和 MSpan 对象。
//
// fixalloc.alloc 返回的内存默认为零,但调用者可以通过将 zero 标志设置为 false
// 来自行负责将分配归零。如果这部分内存永远不包含堆指针,则这样的操作是安全的。
//
// 调用方负责锁定 fixalloc 调用。调用方可以在对象中保持状态,
// 但当释放和重新分配时第一个字会被破坏。
//
// 考虑使 fixalloc 的类型变为 go:notinheap.
type fixalloc struct {
size uintptr
first func(arg, p unsafe.Pointer) // 首次调用时返回 p
arg unsafe.Pointer
list *mlink
chunk uintptr // 使用 uintptr 而非 unsafe.Pointer 来避免 write barrier
nchunk uint32
inuse uintptr // 正在使用的字节
stat *uint64
zero bool // 归零的分配
}
|
初始化
Go 语言对于零值有自己的规定,自然也就体现在内存分配器上。而 fixalloc 作为内存分配器内部组件的来源于 操作系统的内存,自然需要自行初始化,因此,fixalloc 的初始化也就不可避免的需要将自身的各个字段归零:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// 初始化 f 来分配给定大小的对象。
// 使用分配器来按 chunk 获取
func (f *fixalloc) init(size uintptr, first func(arg, p unsafe.Pointer), arg unsafe.Pointer, stat *uint64) {
f.size = size
f.first = first
f.arg = arg
f.list = nil
f.chunk = 0
f.nchunk = 0
f.inuse = 0
f.stat = stat
f.zero = true
}
|
分配
fixalloc 基于自由表策略进行实现,分为两种情况:
- 存在被释放、可复用的内存
- 不存在可复用的内存
对于第一种情况,也就是在运行时内存被释放,但这部分内存并不会被立即回收给操作系统, 我们直接从自由表中获得即可,但需要注意按需将这部分内存进行清零操作。
对于第二种情况,我们直接向操作系统申请固定大小的内存,然后扣除分配的大小即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
const _FixAllocChunk = 16 << 10 // FixAlloc 一个 Chunk 的大小
func (f *fixalloc) alloc() unsafe.Pointer {
// fixalloc 的个字段必须先被 init
if f.size == 0 {
print("runtime: use of FixAlloc_Alloc before FixAlloc_Init\n")
throw("runtime: internal error")
}
// 如果 f.list 不是 nil, 则说明还存在已经释放、可复用的内存,直接将其分配
if f.list != nil {
// 取出 f.list
v := unsafe.Pointer(f.list)
// 并将其指向下一段区域
f.list = f.list.next
// 增加使用的(分配)大小
f.inuse += f.size
// 如果需要对内存清零,则对取出的内存执行初始化
if f.zero {
memclrNoHeapPointers(v, f.size)
}
// 返回分配的内存
return v
}
// f.list 中没有可复用的内存
// 如果此时 nchunk 不足以分配一个 size
if uintptr(f.nchunk) < f.size {
// 则向操作系统申请内存,大小为 16 << 10 pow(2,14)
f.chunk = uintptr(persistentalloc(_FixAllocChunk, 0, f.stat))
f.nchunk = _FixAllocChunk
}
// 指向申请好的内存
v := unsafe.Pointer(f.chunk)
if f.first != nil { // first 只有在 fixalloc 作为 spanalloc 时候,才会被设置为 recordspan
f.first(f.arg, v) // 用于为 heap.allspans 添加新的 span
}
// 扣除并保留 size 大小的空间
f.chunk = f.chunk + f.size
f.nchunk -= uint32(f.size)
f.inuse += f.size // 记录已经使用的大小
return v
}
|
回收
回收就更加简单了,直接将回收的地址指针放回到自由表中即可:
1
2
3
4
5
6
7
8
|
func (f *fixalloc) free(p unsafe.Pointer) {
// 减少使用的字节数
f.inuse -= f.size
// 将要释放的内存地址作为 mlink 指针插入到 f.list 内,完成回收
v := (*mlink)(p)
v.next = f.list
f.list = v
}
|
alloc
runtime.mheap 是内存分配器中的核心组件,运行时会通过它的 runtime.mheap.alloc 方法在系统栈中获取新的 runtime.mspan:
在分配内存的时候是按页来进行分配的,每个页的大小是_PageSize(8K),然后需要根据传入的size来判断需要分多少页,最后调用alloc从堆上分配。
这个方法需要指明要分配的页数、span 的大小等级、是否为大对象、是否清零:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// alloc allocates a new span of npage pages from the GC'd heap.
//
// spanclass indicates the span's size class and scannability.
//
// If needzero is true, the memory for the returned span will be zeroed.
func (h *mheap) alloc(npages uintptr, spanclass spanClass, needzero bool) *mspan {
// Don't do any operations that lock the heap on the G stack.
// It might trigger stack growth, and the stack growth code needs
// to be able to allocate heap.
var s *mspan
systemstack(func() {
// To prevent excessive heap growth, before allocating n pages
// we need to sweep and reclaim at least n pages.
//为了阻止内存的大量占用和堆的增长,我们在分配对应页数的内存前需要先调用 runtime.mheap.reclaim 方法回收一部分内存
if h.sweepdone == 0 {
h.reclaim(npages)
}
//接下来我们将通过 runtime.mheap.allocSpan 分配新的mspan,
s = h.allocSpan(npages, false, spanclass, &memstats.heap_inuse)
})
if s != nil {
// 需要清零时,对分配的 span 进行清零
if needzero && s.needzero != 0 {
memclrNoHeapPointers(unsafe.Pointer(s.base()), s.npages<<_PageShift)
}
// 标记已经清零
s.needzero = 0
}
return s
}
|
allocSpan
我们会将mheap.allocSpan的执行过程拆分成两个部分:
- 从堆上分配新的内存页和mspan runtime.mspan;
- 初始化mspan并将其加入 runtime.mheap 持有内存单元列表;
allocSpan方法会通过处理器的页缓存 runtime.pageCache 或者全局的页分配器 runtime.pageAlloc 两种途径从堆中申请内存:
- 如果申请的内存比较小,获取申请内存的处理器并尝试调用 runtime.pageCache.alloc 获取内存区域的基地址和大小;
- 如果申请的内存比较大或者线程的页缓存中内存不足,会通过 runtime.pageAlloc.alloc 在页堆上申请内存;
- 如果发现页堆上的内存不足,会尝试通过 runtime.mheap.grow 进行扩容并重新调用 runtime.pageAlloc.alloc 申请内存;
- 如果申请到内存,意味着扩容成功;
- 如果没有申请到内存,意味着扩容失败,宿主机可能不存在空闲内存,运行时会直接中止当前程序;
无论通过哪种方式获得内存页,我们都会在该函数中分配新的 runtime.mspan 结构体;该方法的剩余部分会通过页数、内存空间以及跨度类等参数初始化它的多个字段:
在allocSpan中,我们通过调用 runtime.mspan.init 方法以及设置参数初始化刚刚分配的 runtime.mspan 结构并通过 runtime.mheaps.setSpans 方法建立页堆与内存单元的联系。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
|
// allocSpan allocates an mspan which owns npages worth of memory.
//
// If manual == false, allocSpan allocates a heap span of class spanclass
// and updates heap accounting. If manual == true, allocSpan allocates a
// manually-managed span (spanclass is ignored), and the caller is
// responsible for any accounting related to its use of the span. Either
// way, allocSpan will atomically add the bytes in the newly allocated
// span to *sysStat.
//
// The returned span is fully initialized.
//
// h must not be locked.
//
// allocSpan must be called on the system stack both because it acquires
// the heap lock and because it must block GC transitions.
//
//go:systemstack
func (h *mheap) allocSpan(npages uintptr, manual bool, spanclass spanClass, sysStat *uint64) (s *mspan) {
// Function-global state.
gp := getg() // 获取当前协程
base, scav := uintptr(0), uintptr(0) // 基址,回收地址(bit位)
// If the allocation is small enough, try the page cache!
// 当申请页数小于 8*64/4=128时从P的pageCache申请
// 注意pageCache是连续的
pp := gp.m.p.ptr()
// 申请的内存比较小,尝试从pcache申请内存
if pp != nil && npages < pageCachePages/4 {
c := &pp.pcache
// p对应的pageCache为空,则申请cache内存
// If the cache is empty, refill it.
if c.empty() {
lock(&h.lock)
// 填充本地的pageCache
*c = h.pages.allocToCache()
unlock(&h.lock)
}
// Try to allocate from the cache.
// 1、先从p的页缓存获取内存区域的基地址和大小
base, scav = c.alloc(npages)
// 申请成功
if base != 0 {
// 对应span
s = h.tryAllocMSpan()
if s != nil && gcBlackenEnabled == 0 && (manual || spanclass.sizeclass() != 0) {
goto HaveSpan
}
// We're either running duing GC, failed to acquire a mspan,
// or the allocation is for a large object. This means we
// have to lock the heap and do a bunch of extra work,
// so go down the HaveBaseLocked path.
//
// We must do this during GC to avoid skew with heap_scan
// since we flush mcache stats whenever we lock.
//
// TODO(mknyszek): It would be nice to not have to
// lock the heap if it's a large allocation, but
// it's fine for now. The critical section here is
// short and large object allocations are relatively
// infrequent.
}
}
// For one reason or another, we couldn't get the
// whole job done without the heap lock.
lock(&h.lock)
// 2、P的页缓存没有足够的内存,则在页堆上申请内存
// 内存比较大或者线程的页缓存中内存不足,从mheap的pages上获取内存
if base == 0 {
// Try to acquire a base address.
// mheap全局堆区
base, scav = h.pages.alloc(npages)
// 内存也不够,那么进行扩容
if base == 0 {
if !h.grow(npages) {
// 从系统申请固定页数大小的内存区域
unlock(&h.lock)
return nil
}
// 重新申请内存
base, scav = h.pages.alloc(npages) //重新从mheap获取
// 内存不足,抛出异常
if base == 0 {
throw("grew heap, but no adequate free space found")
}
}
}
if s == nil {
// We failed to get an mspan earlier, so grab
// one now that we have the heap lock.
// 分配一个mspan对象
s = h.allocMSpanLocked()
}
if !manual {
// This is a heap span, so we should do some additional accounting
// which may only be done with the heap locked.
// Transfer stats from mcache to global.
var c *mcache
if gp.m.p != 0 {
c = gp.m.p.ptr().mcache
} else {
// This case occurs while bootstrapping.
// See the similar code in mallocgc.
c = mcache0
if c == nil {
throw("mheap.allocSpan called with no P")
}
}
memstats.heap_scan += uint64(c.local_scan)
c.local_scan = 0
memstats.tinyallocs += uint64(c.local_tinyallocs)
c.local_tinyallocs = 0
// Do some additional accounting if it's a large allocation.
if spanclass.sizeclass() == 0 {
mheap_.largealloc += uint64(npages * pageSize)
mheap_.nlargealloc++
atomic.Xadd64(&memstats.heap_live, int64(npages*pageSize))
}
// Either heap_live or heap_scan could have been updated.
if gcBlackenEnabled != 0 {
gcController.revise()
}
}
unlock(&h.lock)
HaveSpan:
// At this point, both s != nil and base != 0, and the heap
// lock is no longer held. Initialize the span.
s.init(base, npages)
if h.allocNeedsZero(base, npages) {
s.needzero = 1
}
nbytes := npages * pageSize
if manual {
s.manualFreeList = 0
s.nelems = 0
s.limit = s.base() + s.npages*pageSize
// Manually managed memory doesn't count toward heap_sys.
mSysStatDec(&memstats.heap_sys, s.npages*pageSize)
s.state.set(mSpanManual)
} else {
// We must set span properties before the span is published anywhere
// since we're not holding the heap lock.
s.spanclass = spanclass
if sizeclass := spanclass.sizeclass(); sizeclass == 0 {
s.elemsize = nbytes
s.nelems = 1
s.divShift = 0
s.divMul = 0
s.divShift2 = 0
s.baseMask = 0
} else {
s.elemsize = uintptr(class_to_size[sizeclass])
s.nelems = nbytes / s.elemsize
m := &class_to_divmagic[sizeclass]
s.divShift = m.shift
s.divMul = m.mul
s.divShift2 = m.shift2
s.baseMask = m.baseMask
}
// Initialize mark and allocation structures.
s.freeindex = 0
s.allocCache = ^uint64(0) // all 1s indicating all free.
s.gcmarkBits = newMarkBits(s.nelems)
s.allocBits = newAllocBits(s.nelems)
// It's safe to access h.sweepgen without the heap lock because it's
// only ever updated with the world stopped and we run on the
// systemstack which blocks a STW transition.
atomic.Store(&s.sweepgen, h.sweepgen)
// Now that the span is filled in, set its state. This
// is a publication barrier for the other fields in
// the span. While valid pointers into this span
// should never be visible until the span is returned,
// if the garbage collector finds an invalid pointer,
// access to the span may race with initialization of
// the span. We resolve this race by atomically
// setting the state after the span is fully
// initialized, and atomically checking the state in
// any situation where a pointer is suspect.
s.state.set(mSpanInUse)
}
// Commit and account for any scavenged memory that the span now owns.
if scav != 0 {
// sysUsed all the pages that are actually available
// in the span since some of them might be scavenged.
sysUsed(unsafe.Pointer(base), nbytes)
mSysStatDec(&memstats.heap_released, scav)
}
// Update stats.
mSysStatInc(sysStat, nbytes)
mSysStatDec(&memstats.heap_idle, nbytes)
// Publish the span in various locations.
// This is safe to call without the lock held because the slots
// related to this span will only ever be read or modified by
// this thread until pointers into the span are published (and
// we execute a publication barrier at the end of this function
// before that happens) or pageInUse is updated.
h.setSpans(s.base(), npages, s)
if !manual {
if !go115NewMCentralImpl {
// Add to swept in-use list.
//
// This publishes the span to root marking.
//
// h.sweepgen is guaranteed to only change during STW,
// and preemption is disabled in the page allocator.
h.sweepSpans[h.sweepgen/2%2].push(s)
}
// Mark in-use span in arena page bitmap.
//
// This publishes the span to the page sweeper, so
// it's imperative that the span be completely initialized
// prior to this line.
arena, pageIdx, pageMask := pageIndexOf(s.base())
atomic.Or8(&arena.pageInUse[pageIdx], pageMask)
// Update related page sweeper stats.
atomic.Xadd64(&h.pagesInUse, int64(npages))
if trace.enabled {
// Trace that a heap alloc occurred.
traceHeapAlloc()
}
}
// Make sure the newly allocated span will be observed
// by the GC before pointers into the span are published.
publicationBarrier()
return s
}
|
pageCache
在Go1.12的时候,Go语言采用了Treap 进行内存的管理,Treap 是一种引入了随机数的二叉树搜索树,其实现简单,并且引入的随机数以及必要时的旋转保证了比较好的平衡特性。Michael Knyszek 提出这种方式具有扩展性的问题,由于这棵树是mheap管理,当操作此二叉树的时候都需要维持一个lock。这在密集的对象分配以及逻辑处理器P过多的时候,会导致更长的等待时间。Michael Knyszek 提出用bitmap来管理内存页,并在每个P中维护一份page cache。这就是现在Go语言实现的方式。因此在go1.14之后,我们会看到在每个逻辑处理器P内部都有一个cache。
1
2
3
4
5
|
type pageCache struct {
base uintptr // 虚拟内存的基址 base address of the chunk
cache uint64 // bit位标记内存是否被分配
scav uint64 // bit位标记内存是否被回收
}
|

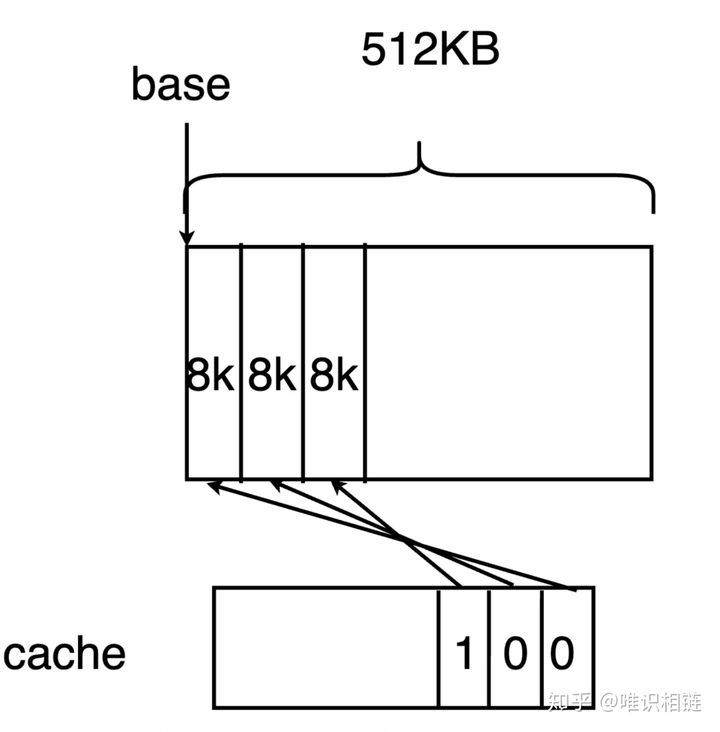
一位表示一页(8KB),所以最大表示8KB*64=512KB缓存。当需要分配的页数小于 512/4=128KB时,需要首先从cache中分配
若页缓存没有足够的页,则向虚拟内存申请页
mheap会首先查找在每个逻辑处理器P中pageCache字段的cache。cache也是一个位图,其每一位都代表了一个page(8 KB) 因此,由于cache为uint64类型,其一共可以存储64*8=512KB的缓存。这512KB是连续的虚拟内存。在cache中,1代表未分配的内存,而0代表已分配的内存。base代表该虚拟内存的基地址。当需要分配的页数小于 512/4=128KB时,需要首先从cache中分配。
例如,假如要分配n pages,就需要查找cache中是否有连续n个1位。如果存在,则说明在缓存中查找到了合适的内存,用于初始化span。
从页缓存申请,只能申请连续个页,若不能连续则返回失败
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
// alloc allocates npages from the page cache and is the main entry
// point for allocation.
//
// Returns a base address and the amount of scavenged memory in the
// allocated region in bytes.
//
// Returns a base address of zero on failure, in which case the
// amount of scavenged memory should be ignored.
// 申请pageCache
func (c *pageCache) alloc(npages uintptr) (uintptr, uintptr) {
if c.cache == 0 {
return 0, 0
}
// 页数为1
if npages == 1 {
i := uintptr(sys.TrailingZeros64(c.cache))
scav := (c.scav >> i) & 1
// 把使用的页数对应的bit位置为0 set bit to mark in-use
c.cache &^= 1 << i // set bit to mark in-use
c.scav &^= 1 << i // clear bit to mark unscavenged
return c.base + i*pageSize, uintptr(scav) * pageSize
}
// 申请连续的n页
return c.allocN(npages)
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// allocN is a helper which attempts to allocate npages worth of pages
// from the cache. It represents the general case for allocating from
// the page cache.
//
// Returns a base address and the amount of scavenged memory in the
// allocated region in bytes.
func (c *pageCache) allocN(npages uintptr) (uintptr, uintptr) {
i := findBitRange64(c.cache, uint(npages))
if i >= 64 {
return 0, 0
}
mask := ((uint64(1) << npages) - 1) << i
scav := sys.OnesCount64(c.scav & mask)
// 把使用的页数对应的bit位置为0 mark in-use bits 例如1110&^10=1100
c.cache &^= mask // mark in-use bits
c.scav &^= mask // clear scavenged bits
return c.base + uintptr(i*pageSize), uintptr(scav) * pageSize
}
|
pageAlloc
当要分配的page过大或者在逻辑处理器P的cache中没有找到可用的页数时,就需要对mheap加锁,并在整个mheap管理的虚拟地址空间的位图中查找是否有可用的pages。而且其在本质上涉及到Go语言是如何对线性的地址空间进行位图管理的。
管理线性的地址空间的位图结构叫做基数树(radix tree), 他和一般的基数树结构有点不太一样,这个名字很大一部分是由于父节点包含了子节点的若干信息。
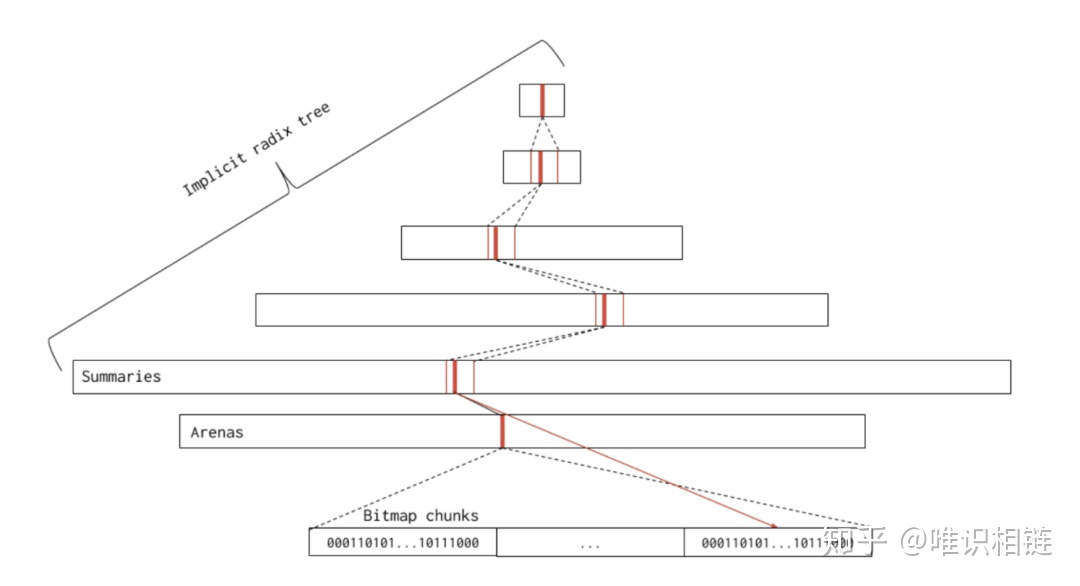
在该树中的每一个节点对应一个pallocSum结构。其中最底层的叶子节点对应的一个pallocSum结构包含了一个chunk的信息(512 8 KB),而除了叶子节点外的节点都包含了连续8个子节点的内存信息。例如,倒数第二层的节点包含了8个叶子节点(即8chunk)的连续内存信息。因此,越上层的节点,其对应的内存就越多。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
// pallocSum is a packed summary type which packs three numbers: start, max,
// and end into a single 8-byte value. Each of these values are a summary of
// a bitmap and are thus counts, each of which may have a maximum value of
// 2^21 - 1, or all three may be equal to 2^21. The latter case is represented
// by just setting the 64th bit.
type pallocSum uint64
// packPallocSum takes a start, max, and end value and produces a pallocSum.
func packPallocSum(start, max, end uint) pallocSum {
if max == maxPackedValue {
return pallocSum(uint64(1 << 63))
}
return pallocSum((uint64(start) & (maxPackedValue - 1)) |
((uint64(max) & (maxPackedValue - 1)) << logMaxPackedValue) |
((uint64(end) & (maxPackedValue - 1)) << (2 * logMaxPackedValue)))
}
// start extracts the start value from a packed sum.
func (p pallocSum) start() uint {
if uint64(p)&uint64(1<<63) != 0 {
return maxPackedValue
}
return uint(uint64(p) & (maxPackedValue - 1))
}
// max extracts the max value from a packed sum.
func (p pallocSum) max() uint {
if uint64(p)&uint64(1<<63) != 0 {
return maxPackedValue
}
return uint((uint64(p) >> logMaxPackedValue) & (maxPackedValue - 1))
}
// end extracts the end value from a packed sum.
func (p pallocSum) end() uint {
if uint64(p)&uint64(1<<63) != 0 {
return maxPackedValue
}
return uint((uint64(p) >> (2 * logMaxPackedValue)) & (maxPackedValue - 1))
}
|
pallocSum虽然是一个简单的uint64类型,但是分成了开头、中间、末尾3个部分,开头语末尾部分占据了21bit,中间部分占据了22bit。它们分别包含了在这个区域中连续空闲内存页的信息。包括了在开头有多少连续内存页,最大有多少连续内存页,在末尾有多少连续内存页。对于最顶层的节点,由于其中间的max位为22bit,因此一颗完整的基数树最多代表2^21 pages=16G内存。
Go语言并不是一开始就直接从根节点往下查找的,而是首先做了一定的优化,类似于又一级别的缓存。在Go语言中,存储了一个特别的字段searchAddr,看名字就可以猜想到是用于搜索可用内存时使用的。searchAddr有一个重要的设定是在searchAddr地址之前一定是已经分配过的。因此在查找时,只需要往searchAddr地址的后方查找即可跳过查找的节点,减少查找的时间。
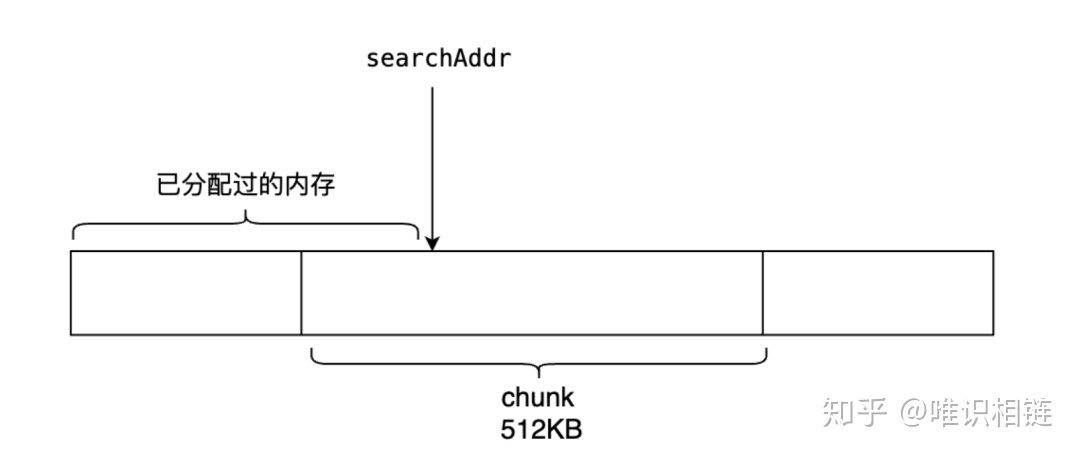
在第一次查找时,会首先从当前searchAddr的chunk块中查找是否有对应大小的连续空间。这种优化主要是针对比较小的内存分配(至少小于512KB)时使用的。Go语言对于内存有非常精细化的管理,chunk块的每一个page(8 KB)都有位图表明其是否已经被分配。
每一个chunk都有一个pallocData结构,其中pallocBits管理其分配的位图。pallocBits是一个uint64的大小为8的数组。由于每一位对应着一个page,因此pallocBits总共对应着64*8=512KB,恰好是一个chunk块的大小。位图的对应方式和之前是一样的。
1
2
3
4
5
6
7
8
9
10
11
|
// pallocData encapsulates pallocBits and a bitmap for
// whether or not a given page is scavenged in a single
// structure. It's effectively a pallocBits with
// additional functionality.
//
// Update the comment on (*pageAlloc).chunks should this
// structure change.
type pallocData struct {
pallocBits
scavenged pageBits
}
|
而所有的chunk pallocData都在pageAlloc结构中进行管理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
|
type pageAlloc struct {
// Radix tree of summaries.
//
// Each slice's cap represents the whole memory reservation.
// Each slice's len reflects the allocator's maximum known
// mapped heap address for that level.
//
// The backing store of each summary level is reserved in init
// and may or may not be committed in grow (small address spaces
// may commit all the memory in init).
//
// The purpose of keeping len <= cap is to enforce bounds checks
// on the top end of the slice so that instead of an unknown
// runtime segmentation fault, we get a much friendlier out-of-bounds
// error.
//
// To iterate over a summary level, use inUse to determine which ranges
// are currently available. Otherwise one might try to access
// memory which is only Reserved which may result in a hard fault.
//
// We may still get segmentation faults < len since some of that
// memory may not be committed yet.
summary [summaryLevels][]pallocSum
// chunks is a slice of bitmap chunks.
//
// The total size of chunks is quite large on most 64-bit platforms
// (O(GiB) or more) if flattened, so rather than making one large mapping
// (which has problems on some platforms, even when PROT_NONE) we use a
// two-level sparse array approach similar to the arena index in mheap.
//
// To find the chunk containing a memory address `a`, do:
// chunkOf(chunkIndex(a))
//
// Below is a table describing the configuration for chunks for various
// heapAddrBits supported by the runtime.
//
// heapAddrBits | L1 Bits | L2 Bits | L2 Entry Size
// ------------------------------------------------
// 32 | 0 | 10 | 128 KiB
// 33 (iOS) | 0 | 11 | 256 KiB
// 48 | 13 | 13 | 1 MiB
//
// There's no reason to use the L1 part of chunks on 32-bit, the
// address space is small so the L2 is small. For platforms with a
// 48-bit address space, we pick the L1 such that the L2 is 1 MiB
// in size, which is a good balance between low granularity without
// making the impact on BSS too high (note the L1 is stored directly
// in pageAlloc).
//
// To iterate over the bitmap, use inUse to determine which ranges
// are currently available. Otherwise one might iterate over unused
// ranges.
//
// TODO(mknyszek): Consider changing the definition of the bitmap
// such that 1 means free and 0 means in-use so that summaries and
// the bitmaps align better on zero-values.
chunks [1 << pallocChunksL1Bits]*[1 << pallocChunksL2Bits]pallocData
// The address to start an allocation search with. It must never
// point to any memory that is not contained in inUse, i.e.
// inUse.contains(searchAddr.addr()) must always be true. The one
// exception to this rule is that it may take on the value of
// maxOffAddr to indicate that the heap is exhausted.
//
// We guarantee that all valid heap addresses below this value
// are allocated and not worth searching.
searchAddr offAddr
// start and end represent the chunk indices
// which pageAlloc knows about. It assumes
// chunks in the range [start, end) are
// currently ready to use.
start, end chunkIdx
// inUse is a slice of ranges of address space which are
// known by the page allocator to be currently in-use (passed
// to grow).
//
// This field is currently unused on 32-bit architectures but
// is harmless to track. We care much more about having a
// contiguous heap in these cases and take additional measures
// to ensure that, so in nearly all cases this should have just
// 1 element.
//
// All access is protected by the mheapLock.
inUse addrRanges
// scav stores the scavenger state.
//
// All fields are protected by mheapLock.
scav struct {
// inUse is a slice of ranges of address space which have not
// yet been looked at by the scavenger.
inUse addrRanges
// gen is the scavenge generation number.
gen uint32
// reservationBytes is how large of a reservation should be made
// in bytes of address space for each scavenge iteration.
reservationBytes uintptr
// released is the amount of memory released this generation.
released uintptr
// scavLWM is the lowest (offset) address that the scavenger reached this
// scavenge generation.
scavLWM offAddr
// freeHWM is the highest (offset) address of a page that was freed to
// the page allocator this scavenge generation.
freeHWM offAddr
}
// mheap_.lock. This level of indirection makes it possible
// to test pageAlloc indepedently of the runtime allocator.
mheapLock *mutex
// sysStat is the runtime memstat to update when new system
// memory is committed by the pageAlloc for allocation metadata.
sysStat *sysMemStat
// Whether or not this struct is being used in tests.
test bool
}
|
当所有的内存分配过大或者当前chunk块没有连续的npages空间时,就需要到基数树中从上到下进行查找。基数树有一个特性,即当要分配的内存越大时,它能够越快的查找到当前的基数树中是否有连续的空间能够满足。
在查找基数树的过程中,从上到下,从左到右的查找每一个节点是否符合要求。首先计算
pallocSum字段的开头start有多少连续的内存空间。如果start大于npages,说明我们已经查找到了可用的空间和地址。没有找到时,会计算pallocSum字段的max,即中间有多少连续的内存空间。如果max大于npages,我们需要继续往基数树当前节点对应的下一级继续查找。原因在于,max大于npages,表明当前一定有连续的空间满足npages,但是我们并不知道具体在哪一个位置,必须要继续往下一级查找时才能找到具体可用的地址。如果max也不满足,是不是就不满足了呢?不一定,因为有可能两个节点可以合并起来组成一个更大的连续空间。因此还需要将当前pallocSum计算的end与后一个节点的start加起来查看是否能够组合成大于npages的连续空间。
每一次从基数树中查找到内存,或者事后从操作系统分配内存的时候,都需要更新基数树中每一个节点的pallocSum。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
// alloc allocates npages worth of memory from the page heap, returning the base
// address for the allocation and the amount of scavenged memory in bytes
// contained in the region [base address, base address + npages*pageSize).
//
// Returns a 0 base address on failure, in which case other returned values
// should be ignored.
//
// p.mheapLock must be held.
//
// Must run on the system stack because p.mheapLock must be held.
//
//go:systemstack
func (p *pageAlloc) alloc(npages uintptr) (addr uintptr, scav uintptr) {
assertLockHeld(p.mheapLock)
// If the searchAddr refers to a region which has a higher address than
// any known chunk, then we know we're out of memory.
if chunkIndex(p.searchAddr.addr()) >= p.end {
return 0, 0
}
// If npages has a chance of fitting in the chunk where the searchAddr is,
// search it directly.
searchAddr := minOffAddr
// chunkPages总页数-当前使用页数>=需要申请的页数 说明chunk满足申请的页数
if pallocChunkPages-chunkPageIndex(p.searchAddr.addr()) >= uint(npages) {
// npages is guaranteed to be no greater than pallocChunkPages here.
i := chunkIndex(p.searchAddr.addr())
if max := p.summary[len(p.summary)-1][i].max(); max >= uint(npages) {
j, searchIdx := p.chunkOf(i).find(npages, chunkPageIndex(p.searchAddr.addr()))
if j == ^uint(0) {
print("runtime: max = ", max, ", npages = ", npages, "\n")
print("runtime: searchIdx = ", chunkPageIndex(p.searchAddr.addr()), ", p.searchAddr = ", hex(p.searchAddr.addr()), "\n")
throw("bad summary data")
}
addr = chunkBase(i) + uintptr(j)*pageSize
searchAddr = offAddr{chunkBase(i) + uintptr(searchIdx)*pageSize}
goto Found
}
}
// We failed to use a searchAddr for one reason or another, so try
// the slow path.
addr, searchAddr = p.find(npages)
if addr == 0 {
if npages == 1 {
// We failed to find a single free page, the smallest unit
// of allocation. This means we know the heap is completely
// exhausted. Otherwise, the heap still might have free
// space in it, just not enough contiguous space to
// accommodate npages.
p.searchAddr = maxSearchAddr
}
return 0, 0
}
Found:
// Go ahead and actually mark the bits now that we have an address.
scav = p.allocRange(addr, npages)
// If we found a higher searchAddr, we know that all the
// heap memory before that searchAddr in an offset address space is
// allocated, so bump p.searchAddr up to the new one.
if p.searchAddr.lessThan(searchAddr) {
p.searchAddr = searchAddr
}
return addr, scav
}
|
grow
当在基数树都查找不到可用的连续内存时,就需要从操作系统中索取内存。
每一次向操作系统申请内存时,Go语言规定必须为heapArena 大小的倍数。heapArena是和平台有关的内存大小,在unix 64位系统中,其大小为64M。这意味着即便需要的内存大小很少,最终也至少向操作系统申请64M。多申请的内存可以用于下次分配使用。
runtime.mheap.grow 方法会向操作系统申请更多的内存空间,传入的页数经过对齐可以得到期望的内存大小,我们可以将该方法的执行过程分成以下几个部分:
- 通过传入的页数从已经保留的arena中获取期望分配的内存空间大小以及内存的基地址;
- 如果 arena 区域没有足够的空间,调用 runtime.mheap.sysAlloc 从操作系统中申请更多的内存;
- 扩容 runtime.mheap 持有的 arena 区域并更新页分配器的元信息;
- 在某些场景下,调用 runtime.pageAlloc.scavenge 回收不再使用的空闲内存页;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
|
// Try to add at least npage pages of memory to the heap,
// returning whether it worked.
//
// h.lock must be held.
func (h *mheap) grow(npage uintptr) bool {
assertLockHeld(&h.lock)
// We must grow the heap in whole palloc chunks.
ask := alignUp(npage, pallocChunkPages) * pageSize
totalGrowth := uintptr(0)
// This may overflow because ask could be very large
// and is otherwise unrelated to h.curArena.base.
end := h.curArena.base + ask
nBase := alignUp(end, physPageSize)
// 内存不够则调用sysAlloc申请内存
if nBase > h.curArena.end || /* overflow */ end < h.curArena.base {
// Not enough room in the current arena. Allocate more
// arena space. This may not be contiguous with the
// current arena, so we have to request the full ask.
av, asize := h.sysAlloc(ask)
if av == nil {
print("runtime: out of memory: cannot allocate ", ask, "-byte block (", memstats.heap_sys, " in use)\n")
return false
}
// 重新设置curArena的值
if uintptr(av) == h.curArena.end {
// The new space is contiguous with the old
// space, so just extend the current space.
h.curArena.end = uintptr(av) + asize
} else {
// The new space is discontiguous. Track what
// remains of the current space and switch to
// the new space. This should be rare.
if size := h.curArena.end - h.curArena.base; size != 0 {
h.pages.grow(h.curArena.base, size)
totalGrowth += size
}
// Switch to the new space.
h.curArena.base = uintptr(av)
h.curArena.end = uintptr(av) + asize
}
// The memory just allocated counts as both released
// and idle, even though it's not yet backed by spans.
//
// The allocation is always aligned to the heap arena
// size which is always > physPageSize, so its safe to
// just add directly to heap_released.
atomic.Xadd64(&memstats.heap_released, int64(asize))
stats := memstats.heapStats.acquire()
atomic.Xaddint64(&stats.released, int64(asize))
memstats.heapStats.release()
// Recalculate nBase.
// We know this won't overflow, because sysAlloc returned
// a valid region starting at h.curArena.base which is at
// least ask bytes in size.
nBase = alignUp(h.curArena.base+ask, physPageSize)
}
// Grow into the current arena.
v := h.curArena.base
h.curArena.base = nBase
h.pages.grow(v, nBase-v)
totalGrowth += nBase - v
// We just caused a heap growth, so scavenge down what will soon be used.
// By scavenging inline we deal with the failure to allocate out of
// memory fragments by scavenging the memory fragments that are least
// likely to be re-used.
if retained := heapRetained(); retained+uint64(totalGrowth) > h.scavengeGoal {
todo := totalGrowth
if overage := uintptr(retained + uint64(totalGrowth) - h.scavengeGoal); todo > overage {
todo = overage
}
h.pages.scavenge(todo, false)
}
return true
}
|
grow会通过curArena的end值来判断是不是需要从系统申请内存;如果end小于nBase那么会调用runtime.mheap.sysAlloc方法从操作系统中申请更多的内存;
在页堆扩容的过程中,runtime.mheap.sysAlloc 是页堆用来申请虚拟内存的方法.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
|
// sysAlloc allocates heap arena space for at least n bytes. The
// returned pointer is always heapArenaBytes-aligned and backed by
// h.arenas metadata. The returned size is always a multiple of
// heapArenaBytes. sysAlloc returns nil on failure.
// There is no corresponding free function.
//
// sysAlloc returns a memory region in the Prepared state. This region must
// be transitioned to Ready before use.
//
// h must be locked.
func (h *mheap) sysAlloc(n uintptr) (v unsafe.Pointer, size uintptr) {
n = alignUp(n, heapArenaBytes)
//首先,该方法会尝试在预保留的区域申请内存:
// First, try the arena pre-reservation.
//调用线性分配器的 runtime.linearAlloc.alloc 方法在预先保留的内存中申请一块可以使用的空间。
// 在预先保留的内存中申请一块可以使用的空间
v = h.arena.alloc(n, heapArenaBytes, &memstats.heap_sys)
if v != nil {
size = n
goto mapped
}
// Try to grow the heap at a hint address.
// 如果获取不到,再尝试增长 arena hint
//如果没有可用的空间,我们会根据页堆的 arenaHints 在目标地址上尝试扩容:
//runtime.sysReserve 和 runtime.sysMap 是代码的核心部分,它们会从操作系统中申请内存并将内存转换至 Prepared 状态。
for h.arenaHints != nil {
hint := h.arenaHints
p := hint.addr
if hint.down {
p -= n
}
if p+n < p {// 溢出
// We can't use this, so don't ask.
v = nil
} else if arenaIndex(p+n-1) >= 1<<arenaBits {// 溢出
// Outside addressable heap. Can't use.
v = nil
} else {
v = sysReserve(unsafe.Pointer(p), n)
}
if p == uintptr(v) {
// 获取成功,更新 arena hint
// Success. Update the hint.
if !hint.down {
p += n
}
hint.addr = p
size = n
break
}
// Failed. Discard this hint and try the next.
//
// TODO: This would be cleaner if sysReserve could be
// told to only return the requested address. In
// particular, this is already how Windows behaves, so
// it would simplify things there.
// 失败,丢弃并重新尝试
if v != nil {
sysFree(v, n, nil)
}
h.arenaHints = hint.next
h.arenaHintAlloc.free(unsafe.Pointer(hint))
}
if size == 0 {
if raceenabled {
// The race detector assumes the heap lives in
// [0x00c000000000, 0x00e000000000), but we
// just ran out of hints in this region. Give
// a nice failure.
throw("too many address space collisions for -race mode")
}
// All of the hints failed, so we'll take any
// (sufficiently aligned) address the kernel will give
// us.
v, size = sysReserveAligned(nil, n, heapArenaBytes)
if v == nil {
return nil, 0
}
// Create new hints for extending this region.
// 创建新的 hint 来增长此区域
hint := (*arenaHint)(h.arenaHintAlloc.alloc())
hint.addr, hint.down = uintptr(v), true
hint.next, mheap_.arenaHints = mheap_.arenaHints, hint
hint = (*arenaHint)(h.arenaHintAlloc.alloc())
hint.addr = uintptr(v) + size
hint.next, mheap_.arenaHints = mheap_.arenaHints, hint
}
// Check for bad pointers or pointers we can't use.
// 检查不能使用的指针
{
var bad string
p := uintptr(v)
if p+size < p {
bad = "region exceeds uintptr range"
} else if arenaIndex(p) >= 1<<arenaBits {
bad = "base outside usable address space"
} else if arenaIndex(p+size-1) >= 1<<arenaBits {
bad = "end outside usable address space"
}
if bad != "" {
// This should be impossible on most architectures,
// but it would be really confusing to debug.
print("runtime: memory allocated by OS [", hex(p), ", ", hex(p+size), ") not in usable address space: ", bad, "\n")
throw("memory reservation exceeds address space limit")
}
}
if uintptr(v)&(heapArenaBytes-1) != 0 {
throw("misrounded allocation in sysAlloc")
}
// Transition from Reserved to Prepared.
// 正式开始使用保留的内存
sysMap(v, size, &memstats.heap_sys)
mapped:
// Create arena metadata.
//runtime.mheap.sysAlloc 方法在最后会初始化一个新的 runtime.heapArena 结构体来管理刚刚申请的内存空间,该结构体会被加入页堆的二维矩阵中。
// 创建 arena 的 metadata
for ri := arenaIndex(uintptr(v)); ri <= arenaIndex(uintptr(v)+size-1); ri++ {
l2 := h.arenas[ri.l1()]
if l2 == nil {
// Allocate an L2 arena map.
// 分配 L2 arena map
l2 = (*[1 << arenaL2Bits]*heapArena)(persistentalloc(unsafe.Sizeof(*l2), sys.PtrSize, nil))
if l2 == nil {
throw("out of memory allocating heap arena map")
}
atomic.StorepNoWB(unsafe.Pointer(&h.arenas[ri.l1()]), unsafe.Pointer(l2))
}
if l2[ri.l2()] != nil {
throw("arena already initialized")
}
var r *heapArena
r = (*heapArena)(h.heapArenaAlloc.alloc(unsafe.Sizeof(*r), sys.PtrSize, &memstats.gc_sys))
if r == nil {
r = (*heapArena)(persistentalloc(unsafe.Sizeof(*r), sys.PtrSize, &memstats.gc_sys))
if r == nil {
throw("out of memory allocating heap arena metadata")
}
}
// Add the arena to the arenas list.
// 将 arena 添加到 arena 列表中
if len(h.allArenas) == cap(h.allArenas) {
size := 2 * uintptr(cap(h.allArenas)) * sys.PtrSize
if size == 0 {
size = physPageSize
}
newArray := (*notInHeap)(persistentalloc(size, sys.PtrSize, &memstats.gc_sys))
if newArray == nil {
throw("out of memory allocating allArenas")
}
oldSlice := h.allArenas
*(*notInHeapSlice)(unsafe.Pointer(&h.allArenas)) = notInHeapSlice{newArray, len(h.allArenas), int(size / sys.PtrSize)}
copy(h.allArenas, oldSlice)
// Do not free the old backing array because
// there may be concurrent readers. Since we
// double the array each time, this can lead
// to at most 2x waste.
}
h.allArenas = h.allArenas[:len(h.allArenas)+1]
h.allArenas[len(h.allArenas)-1] = ri
// Store atomically just in case an object from the
// new heap arena becomes visible before the heap lock
// is released (which shouldn't happen, but there's
// little downside to this).
atomic.StorepNoWB(unsafe.Pointer(&l2[ri.l2()]), unsafe.Pointer(r))
}
// Tell the race detector about the new heap memory.
if raceenabled {
racemapshadow(v, size)
}
return
}
|
这个过程略显复杂:
- 首先会通过现有的 arena 中获得已经保留的内存区域,如果能获取到,则直接对 arena 进行初始化;
- 如果没有,则会通过 sysReserve 为 arena 保留新的内存区域,并通过 sysReserveAligned 对操作系统对齐的区域进行重排,而后使用 sysMap 正式使用所在区块的内存。
- 在 arena 初始化阶段,本质上是为 arena 创建 metadata,这部分内存属于堆外内存,即不会被 GC 所追踪的内存,因而通过 persistentalloc 进行分配。
persistentalloc 是 sysAlloc 之上的一层封装,它分配到的内存用于不能被释放。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
|
// Wrapper around sysAlloc that can allocate small chunks.
// There is no associated free operation.
// Intended for things like function/type/debug-related persistent data.
// If align is 0, uses default align (currently 8).
// The returned memory will be zeroed.
//
// Consider marking persistentalloc'd types go:notinheap.
func persistentalloc(size, align uintptr, sysStat *uint64) unsafe.Pointer {
var p *notInHeap
systemstack(func() {
p = persistentalloc1(size, align, sysStat)
})
return unsafe.Pointer(p)
}
// Must run on system stack because stack growth can (re)invoke it.
// See issue 9174.
//go:systemstack
func persistentalloc1(size, align uintptr, sysStat *uint64) *notInHeap {
const (
maxBlock = 64 << 10 // VM reservation granularity is 64K on windows
)
// 不允许分配大小为 0 的空间
if size == 0 {
throw("persistentalloc: size == 0")
}
// 对齐数必须为 2 的指数、且不大于 PageSize
if align != 0 {
if align&(align-1) != 0 {
throw("persistentalloc: align is not a power of 2")
}
if align > _PageSize {
throw("persistentalloc: align is too large")
}
} else {
// 若未指定则默认为 8
align = 8
}
// 分配大内存:分配的大小如果超过最大的 block 大小,则直接调用 sysAlloc 进行分配
if size >= maxBlock {
return (*notInHeap)(sysAlloc(size, sysStat))
}
// 分配小内存:在 m 上进行
// 先获取 m
mp := acquirem()
var persistent *persistentAlloc
if mp != nil && mp.p != 0 {
// 如果能够获取到 m 且同时持有 p,则直接分配到 p 的 palloc 上
persistent = &mp.p.ptr().palloc
} else {
// 否则就分配到全局的 globalAlloc.persistentAlloc 上
lock(&globalAlloc.mutex)
persistent = &globalAlloc.persistentAlloc
}
// 四舍五入 off 到 align 的倍数
persistent.off = alignUp(persistent.off, align)
if persistent.off+size > persistentChunkSize || persistent.base == nil {
persistent.base = (*notInHeap)(sysAlloc(persistentChunkSize, &memstats.other_sys))
if persistent.base == nil {
if persistent == &globalAlloc.persistentAlloc {
unlock(&globalAlloc.mutex)
}
throw("runtime: cannot allocate memory")
}
// Add the new chunk to the persistentChunks list.
for {
chunks := uintptr(unsafe.Pointer(persistentChunks))
*(*uintptr)(unsafe.Pointer(persistent.base)) = chunks
if atomic.Casuintptr((*uintptr)(unsafe.Pointer(&persistentChunks)), chunks, uintptr(unsafe.Pointer(persistent.base))) {
break
}
}
persistent.off = alignUp(sys.PtrSize, align)
}
p := persistent.base.add(persistent.off)
persistent.off += size
releasem(mp)
if persistent == &globalAlloc.persistentAlloc {
unlock(&globalAlloc.mutex)
}
if sysStat != &memstats.other_sys {
mSysStatInc(sysStat, size)
mSysStatDec(&memstats.other_sys, size)
}
return p
}
|
可以看到,这里申请到的内存会被记录到 globalAlloc 中:
1
2
3
4
5
6
7
8
|
var globalAlloc struct {
mutex
persistentAlloc
}
type persistentAlloc struct {
base *notInHeap // 空结构,内存首地址
off uintptr // 偏移量
}
|
linearAlloc
linearAlloc 是一个基于线性分配策略的分配器,但由于它只作为 mheap_.heapArenaAlloc 和 mheap_.arena 在 32 位系统上使用,这里不做详细分析。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// linearAlloc 是一个简单的线性分配器,它预留一块内存区域并按需将其映射到 Ready 状态。
// 调用方有责任对齐进行加锁。
type linearAlloc struct {
next uintptr // 下一个可用的字节
mapped uintptr // 映射空间后的一个字节
end uintptr // 保留空间的末尾
}
func (l *linearAlloc) init(base, size uintptr) {
l.next, l.mapped = base, base
l.end = base + size
}
func (l *linearAlloc) alloc(size, align uintptr, sysStat *uint64) unsafe.Pointer {
p := round(l.next, align)
if p+size > l.end {
return nil
}
l.next = p + size
if pEnd := round(l.next-1, physPageSize); pEnd > l.mapped {
// We need to map more of the reserved space.
sysMap(unsafe.Pointer(l.mapped), pEnd-l.mapped, sysStat)
l.mapped = pEnd
}
return unsafe.Pointer(p)
}
|
堆内存释放
堆内存的分配释放主要通过allocSpanLocked和freeSpanLocked完成。
- allocSpanLocked优先从已分配堆内存中进行分配,如果没有合适的堆内存块(mspan),则触发堆增长,并再次申请。
- freeSpanLocked将内存块归还到已分配堆内存队列中。一个额外动作是,通过检查当前mspan空间的和其连续空间的前后mspan是否均处于_MSpanFree状态,来决定是否要合并这些mspan。
注意这两个方法的命名。Locked表示对这两个方法的调用需要使用mheap.lock加锁,因为其内部操作了mheap的缓存队列或mTreap。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
func (h *mheap) allocSpanLocked(npage uintptr, stat *uint64) *mspan {
var list *mSpanList
var s *mspan
// 如果需求page数量小于128,则优先从mheap.free中获取满足npage数量的mspan
for i := int(npage); i < len(h.free); i++ {
list = &h.free[i]
if !list.isEmpty() {
s = list.first
list.remove(s)
goto HaveSpan
}
}
// 如果npage大于128,则从mheap.freelarge树堆中分配满足npage数量的mspan
s = h.allocLarge(npage)
if s == nil {
// mheap.freelarge树堆中没有满足条件可用的mspan,则扩张堆空间。
if !h.grow(npage) {
return nil
}
// 再次尝试从堆中申请
s = h.allocLarge(npage)
if s == nil {
return nil
}
}
HaveSpan:
// ...
if s.npages > npage {
// 从mtreap中获得mspan为最小的满足npage需求的mspan,其实际空间可能大于需求量
// 如果实际分配的空间大于需求的空间,则使用多余出来的空间构造出一个新的mspan
// 将新的mspan归还给堆缓存
t := (*mspan)(h.spanalloc.alloc())
t.init(s.base()+npage<<_PageShift, s.npages-npage)
s.npages = npage
h.setSpan(t.base()-1, s)
h.setSpan(t.base(), t)
h.setSpan(t.base()+t.npages*pageSize-1, t)
t.needzero = s.needzero
s.state = _MSpanManual // s是最终要返回的mspan对象,由于其与t是连续的,为了避免free t时发生合并,暂时将s状态置为非_MSpanFree
t.state = _MSpanManual
h.freeSpanLocked(t, false, false, s.unusedsince)
s.state = _MSpanFree
}
s.unusedsince = 0
// 更新heapArena
h.setSpans(s.base(), npage, s)
// ...
return s
}
|
allocSpanLocked仅会返回满足需求页数量的内存空间,如果查找到堆中的mspan拥有的系统页数量超过需求量,多余的系统页将被额外新创建的mspan持有,并写回堆缓存中。
allocSpanLocked主要完成空闲mspan从free、freelarge的脱链,返回的mspan处于_MSpanFree状态。
查找mheap.free时时间复杂度最大为O(N)
freeSpanLocked
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
func (h *mheap) freeSpanLocked(s*mspan, acctinuse, acctidle bool, unusedsince int64) {
// ...
// 将mspan从使用中列表脱链,修改状态为空闲状态
s.state = _MSpanFree
if s.inList() {
h.busyList(s.npages).remove(s)
}
// 如果与s连续内存的低地址方向也是一个已分配的空闲的mspan,则合并s和before
// 两个mspan
if before := spanOf(s.base() - 1); before != nil && before.state == _MSpanFree {
s.startAddr = before.startAddr
s.npages += before.npages
s.npreleased = before.npreleased
s.needzero |= before.needzero
h.setSpan(before.base(), s)
// 从空闲列表中移除before mspan
if h.isLargeSpan(before.npages) {
h.freelarge.removeSpan(before)
} else {
h.freeList(before.npages).remove(before)
}
// 释放before mspan对象,归还到spanalloc固定对象分配器中
before.state = _MSpanDead
h.spanalloc.free(unsafe.Pointer(before))
}
// 与before一样
if after := spanOf(s.base() + s.npages*pageSize); after != nil && after.state == _MSpanFree {
s.npages += after.npages
s.npreleased += after.npreleased
s.needzero |= after.needzero
h.setSpan(s.base()+s.npages*pageSize-1, s)
if h.isLargeSpan(after.npages) {
h.freelarge.removeSpan(after)
} else {
h.freeList(after.npages).remove(after)
}
// 释放after mspan对象,归还到spanalloc固定对象分配器中,固定对象分配器
// 要求传入的mspan状态必须为_MSpanDead
after.state = _MSpanDead
h.spanalloc.free(unsafe.Pointer(after))
}
// 将前后合并后的s放到空闲mspan列表中。
if h.isLargeSpan(s.npages) {
// 如果是大于1MB的mspan,则插入到树堆中
h.freelarge.insert(s)
} else {
// 如果是小于1MB的mspan,则插入到指定page数量的mspan链表中
h.freeList(s.npages).insert(s)
}
}
|
在busy列表中查找使用中的mspan,时间复杂度为常数级。
alloc/alloc_m
alloc通过调用alloc_m方法实现mspan的分配,并对分配空间进行了必要的清零工作。
实际内存分配的过程在alloc_m中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
// alloc
func (h *mheap) alloc(npage uintptr, spanclass spanClass, large bool, needzero bool)*mspan
// alloc_m
func (h *mheap) alloc_m(npage uintptr, spanclass spanClass, large bool) *mspan {
//...
lock(&h.lock)
//...
// 向堆中申请持有npage数量的mspan
s := h.allocSpanLocked(npage, &memstats.heap_inuse)
if s != nil {
//...
// 初始化mspan成员
s.state = _MSpanInUse
s.allocCount = 0
s.spanclass = spanclass
if sizeclass := spanclass.sizeclass(); sizeclass == 0 {
s.elemsize = s.npages << _PageShift
s.divShift = 0
s.divMul = 0
s.divShift2 = 0
s.baseMask = 0
} else {
s.elemsize = uintptr(class_to_size[sizeclass])
m := &class_to_divmagic[sizeclass]
s.divShift = m.shift
s.divMul = m.mul
s.divShift2 = m.shift2
s.baseMask = m.baseMask
}
// 记录大内存使用量,并将mspan添加到busy链表
h.pagesInUse += uint64(npage)
if large {
memstats.heap_objects++
mheap_.largealloc += uint64(s.elemsize)
mheap_.nlargealloc++
atomic.Xadd64(&memstats.heap_live, int64(npage<<_PageShift))
//
if s.npages < uintptr(len(h.busy)) {
h.busy[s.npages].insertBack(s)
} else {
h.busylarge.insertBack(s)
}
}
}
//...
unlock(&h.lock)
return s
}
|
alloc_m调用allocSpanLocked分配了合适的mspan,完成了mspan的初始化,修改mspan状态为_MSpanInUse,并将mspan追加到mheap的busy链表中。
此外,由于allocSpanLocked/freeSpanLocked是对堆缓存的主要操作方法,所以在调用这两个方法的位置需要加锁,使用的是mheap.lock对象。
分配内存:newobject
堆上所有的对象都会通过调用 runtime.newobject 函数分配内存.
1
2
3
4
5
6
7
|
// implementation of new builtin
// compiler (both frontend and SSA backend) knows the signature
// of this function
// 创建一个新的对象
func newobject(typ *_type) unsafe.Pointer {
return mallocgc(typ.size, typ, true)// true 内存清零
}
|
其中 _type 为 Go 类型的实现,通过其 size 属性能够获得该类型所需要的大小。
mallocgc
该函数会调用 runtime.mallocgc 分配指定大小的内存空间,这也是用户程序向堆上申请内存空间的必经函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
|
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
if gcphase == _GCmarktermination {
throw("mallocgc called with gcphase == _GCmarktermination")
}
// 创建大小为零的对象,例如空结构体
if size == 0 {
return unsafe.Pointer(&zerobase)
}
if debug.sbrk != 0 {
align := uintptr(16)
if typ != nil {
// TODO(austin): This should be just
// align = uintptr(typ.align)
// but that's only 4 on 32-bit platforms,
// even if there's a uint64 field in typ (see #599).
// This causes 64-bit atomic accesses to panic.
// Hence, we use stricter alignment that matches
// the normal allocator better.
if size&7 == 0 {
align = 8
} else if size&3 == 0 {
align = 4
} else if size&1 == 0 {
align = 2
} else {
align = 1
}
}
return persistentalloc(size, align, &memstats.other_sys)
}
// assistG is the G to charge for this allocation, or nil if
// GC is not currently active.
var assistG *g
if gcBlackenEnabled != 0 {
// Charge the current user G for this allocation.
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// Charge the allocation against the G. We'll account
// for internal fragmentation at the end of mallocgc.
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
// This G is in debt. Assist the GC to correct
// this before allocating. This must happen
// before disabling preemption.
gcAssistAlloc(assistG)
}
}
// Set mp.mallocing to keep from being preempted by GC.
mp := acquirem()
if mp.mallocing != 0 {
throw("malloc deadlock")
}
if mp.gsignal == getg() {
throw("malloc during signal")
}
mp.mallocing = 1
shouldhelpgc := false
dataSize := size
var c *mcache
// 获取当前 g 所在 M 所绑定 P 的 mcache
if mp.p != 0 {
c = mp.p.ptr().mcache
} else {
// We will be called without a P while bootstrapping,
// in which case we use mcache0, which is set in mallocinit.
// mcache0 is cleared when bootstrapping is complete,
// by procresize.
c = mcache0
if c == nil {
throw("malloc called with no P")
}
}
var span *mspan
var x unsafe.Pointer
noscan := typ == nil || typ.ptrdata == 0
// size <= 32KB
if size <= maxSmallSize {
// 小于16B的时候Tiny对象申请
if noscan && size < maxTinySize {
// tiny对象的内存分配
// 微对象分配
// Tiny allocator.
//
// Tiny allocator combines several tiny allocation requests
// into a single memory block. The resulting memory block
// is freed when all subobjects are unreachable. The subobjects
// must be noscan (don't have pointers), this ensures that
// the amount of potentially wasted memory is bounded.
//
// Size of the memory block used for combining (maxTinySize) is tunable.
// Current setting is 16 bytes, which relates to 2x worst case memory
// wastage (when all but one subobjects are unreachable).
// 8 bytes would result in no wastage at all, but provides less
// opportunities for combining.
// 32 bytes provides more opportunities for combining,
// but can lead to 4x worst case wastage.
// The best case winning is 8x regardless of block size.
//
// Objects obtained from tiny allocator must not be freed explicitly.
// So when an object will be freed explicitly, we ensure that
// its size >= maxTinySize.
//
// SetFinalizer has a special case for objects potentially coming
// from tiny allocator, it such case it allows to set finalizers
// for an inner byte of a memory block.
//
// The main targets of tiny allocator are small strings and
// standalone escaping variables. On a json benchmark
// the allocator reduces number of allocations by ~12% and
// reduces heap size by ~20%.
//线程缓存 runtime.mcache 中的 tiny 字段指向了 maxTinySize 大小的块,如果当前块中还包含大小合适的空闲内存,运行时会通过基地址和偏移量获取并返回这块内存:
off := c.tinyoffset
// Align tiny pointer for required (conservative) alignment.
// 将微型指针对齐以进行所需(保守)对齐。
// 对齐 调整偏移量
if size&7 == 0 {
off = alignUp(off, 8)
} else if size&3 == 0 {
off = alignUp(off, 4)
} else if size&1 == 0 {
off = alignUp(off, 2)
}
// 若偏移量+size小于16B 则进行微对象分配
if off+size <= maxTinySize && c.tiny != 0 {
// 能直接被当前的内存块容纳
// The object fits into existing tiny block.
x = unsafe.Pointer(c.tiny + off)
// 增加 offset
c.tinyoffset = off + size
// 统计数量
c.local_tinyallocs++
// 完成分配,释放 m
mp.mallocing = 0
releasem(mp)
return x
}
// Allocate a new maxTinySize block.
//当内存块中不包含空闲的内存时,下面的这段代码会先从线程缓存找到跨度类对应的mspan runtime.mspan,调用 runtime.nextFreeFast 获取空闲的内存;当不存在空闲内存时,我们会调用 runtime.mcache.nextFree 从中心缓存或者页堆中获取可分配的内存块:
// 根据 tinySpan 的大小等级获得对应的 span 链表
// 从而用于分配一个新的 maxTinySize 块,与小对象分配的过程一致
// 当前tiny 块内存空间不足,向mache申请一个span
span = c.alloc[tinySpanClass]
// 尝试从当前的span 获取内存,获取不到返回0,也就是我需要大小为16B的span
v := nextFreeFast(span)
if v == 0 {
// 没有从 allocCache 获取到内存,netxtFree函数
// 尝试从 mcentral获取一个新的对应规格的span内存
// 替换原先内存空间不足的内存块,并分配内存
v, span, shouldhelpgc = c.nextFree(tinySpanClass)
}
x = unsafe.Pointer(v)
//将申请的内存块全置为 0
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
// See if we need to replace the existing tiny block with the new one
// based on amount of remaining free space.
// 看看我们是否需要根据剩余可用空间量替换现有的小块
// 如果申请的内存块用不完,则将剩下的给 tiny,用 tinyoffset 记录分配了多少。
if size < c.tinyoffset || c.tiny == 0 {
c.tiny = uintptr(x)
c.tinyoffset = size
}
//获取新的空闲内存块之后,上述代码会清空空闲内存中的数据、更新构成微对象分配器的几个字段 tiny 和 tinyoffset 并返回新的空闲内存。
size = maxTinySize
} else {
// 小对象分配
//1. 确定分配对象的大小以及跨度类 runtime.spanClass;
// 这里将所有级别分为2类
// 1) size <= 1024-8
// 首先会先计算sizeclass 大小,计算 sizeclass 是通过预先定义两个数组:size_to_class8 和 size_to_class128。小于 1024 - 8 = 1016 (smallSizeMax=1024),使用 size_to_class8,否则使用数组 size_to_class128。
// 举个例子,比如要分配 20 byte 的内存,那么sizeclass = size_to_calss8[(20+7)/8] = size_to_class8[3] = 3。然后通过class_to_size[3]获取到对应的值32,表示应该要分配32bytes的内存值。
var sizeclass uint8
if size <= smallSizeMax-8 {
// eg: size =700 (size+smallSizeDiv-1)/smallSizeDiv = (700+8-1/8)= 88 sizeclass=28 =>704
// 获取size对应的sizeclass
sizeclass = size_to_class8[divRoundUp(size, smallSizeDiv)]
} else {
// 2) size >1024-8
// 获取size对应的sizeclass
sizeclass = size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]
}
//2. 从线程缓存、中心缓存或者堆中获取mspan并从mspan找到空闲的内存空间;
// sizeclass对应的size,也就是span的大小
size = uintptr(class_to_size[sizeclass])
spc := makeSpanClass(sizeclass, noscan)
// 找到对应的span
span = c.alloc[spc]
//尝试从 allocCache 获取内存,获取不到返回0
v := nextFreeFast(span)
if v == 0 {
v, span, shouldhelpgc = c.nextFree(spc)
}
x = unsafe.Pointer(v)
//3. 调用 runtime.memclrNoHeapPointers 清空空闲内存中的所有数据;
if needzero && span.needzero != 0 {
memclrNoHeapPointers(unsafe.Pointer(v), size)
}
}
} else {
// 大对象分配
shouldhelpgc = true
systemstack(func() {
span = largeAlloc(size, needzero, noscan)
})
span.freeindex = 1
span.allocCount = 1
x = unsafe.Pointer(span.base())
size = span.elemsize
}
var scanSize uintptr
if !noscan {
// If allocating a defer+arg block, now that we've picked a malloc size
// large enough to hold everything, cut the "asked for" size down to
// just the defer header, so that the GC bitmap will record the arg block
// as containing nothing at all (as if it were unused space at the end of
// a malloc block caused by size rounding).
// The defer arg areas are scanned as part of scanstack.
if typ == deferType {
dataSize = unsafe.Sizeof(_defer{})
}
heapBitsSetType(uintptr(x), size, dataSize, typ)
if dataSize > typ.size {
// Array allocation. If there are any
// pointers, GC has to scan to the last
// element.
if typ.ptrdata != 0 {
scanSize = dataSize - typ.size + typ.ptrdata
}
} else {
scanSize = typ.ptrdata
}
c.local_scan += scanSize
}
// Ensure that the stores above that initialize x to
// type-safe memory and set the heap bits occur before
// the caller can make x observable to the garbage
// collector. Otherwise, on weakly ordered machines,
// the garbage collector could follow a pointer to x,
// but see uninitialized memory or stale heap bits.
publicationBarrier()
// Allocate black during GC.
// All slots hold nil so no scanning is needed.
// This may be racing with GC so do it atomically if there can be
// a race marking the bit.
if gcphase != _GCoff {
gcmarknewobject(span, uintptr(x), size, scanSize)
}
if raceenabled {
racemalloc(x, size)
}
if msanenabled {
msanmalloc(x, size)
}
mp.mallocing = 0
releasem(mp)
if debug.allocfreetrace != 0 {
tracealloc(x, size, typ)
}
if rate := MemProfileRate; rate > 0 {
if rate != 1 && size < c.next_sample {
c.next_sample -= size
} else {
mp := acquirem()
profilealloc(mp, x, size)
releasem(mp)
}
}
if assistG != nil {
// Account for internal fragmentation in the assist
// debt now that we know it.
assistG.gcAssistBytes -= int64(size - dataSize)
}
if shouldhelpgc {
if t := (gcTrigger{kind: gcTriggerHeap}); t.test() {
gcStart(t)
}
}
return x
}
|
上述代码使用 runtime.gomcache 获取了线程缓存并通过类型判断类型是否为指针类型。我们从这个代码片段可以看出 runtime.mallocgc 会根据对象的大小执行不同的分配逻辑,在前面的章节也曾经介绍过运行时根据对象大小将它们分成微对象、小对象和大对象,这里会根据大小选择不同的分配逻辑:
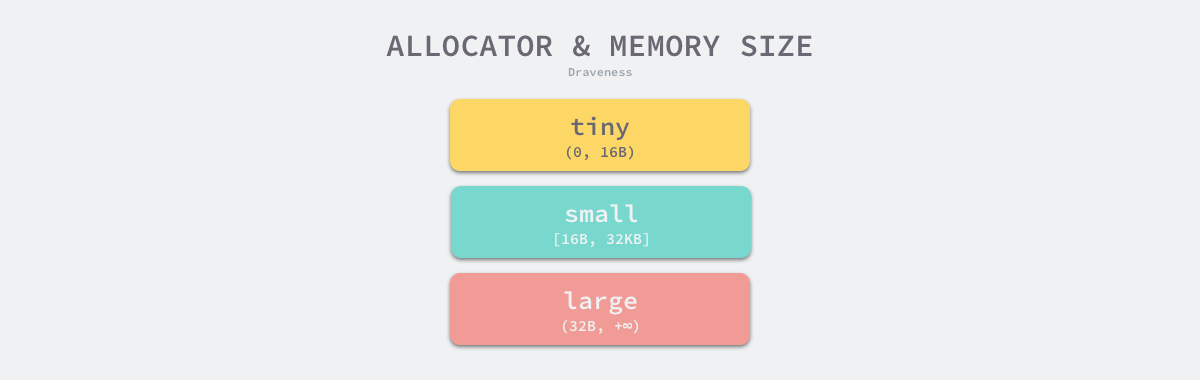
- 微对象 (0, 16B) — 先使用微型分配器,再依次尝试线程缓存、中心缓存和堆分配内存;
- 小对象 [16B, 32KB] — 依次尝试使用线程缓存、中心缓存和堆分配内存;
- 大对象 (32KB, +∞) — 直接在堆上分配内存;
在分配过程中,我们会发现需要持有 M 才可进行分配,这是因为分配不仅可能涉及 mcache,还需要将正在分配的 M 标记为 mallocing,用于记录当前 M 的分配状态。
nextFreeFast
nextFreeFast 不涉及正式的分配过程,只是简单的寻找一个能够容纳当前微对象的 span
runtime.nextFreeFast 会利用mspan中的 allocCache 字段,快速找到该字段中为 1 的位数,我们在上面介绍过1表示该位对应的内存空间是空闲的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// nextFreeFast returns the next free object if one is quickly available.
// Otherwise it returns 0.
func nextFreeFast(s *mspan) gclinkptr {
theBit := sys.Ctz64(s.allocCache) // Is there a free object in the allocCache?
// 如果小于 64 则说明可以直接使用
if theBit < 64 {
result := s.freeindex + uintptr(theBit)
if result < s.nelems {
freeidx := result + 1
if freeidx%64 == 0 && freeidx != s.nelems {
return 0
}
s.allocCache >>= uint(theBit + 1)
s.freeindex = freeidx
s.allocCount++
return gclinkptr(result*s.elemsize + s.base())
}
}
return 0
}
|
allocCache 字段用于计算 freeindex 上的 allocBits 缓存,allocCache 进行了移位使其最低位对应于 freeindex 位。allocCache 保存 allocBits 的补码,从而尾零计数可以直接使用它。
找到了空闲的对象后,我们就可以更新mspan的 allocCache、freeindex 等字段并返回该片内存了
nextFree
如果我们没有找到空闲的内存,运行时会通过 runtime.mcache.nextFree 找到新的mspan:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
// nextFree returns the next free object from the cached span if one is available.
// Otherwise it refills the cache with a span with an available object and
// returns that object along with a flag indicating that this was a heavy
// weight allocation. If it is a heavy weight allocation the caller must
// determine whether a new GC cycle needs to be started or if the GC is active
// whether this goroutine needs to assist the GC.
//
// Must run in a non-preemptible context since otherwise the owner of
// c could change.
func (c *mcache) nextFree(spc spanClass) (v gclinkptr, s *mspan, shouldhelpgc bool) {
s = c.alloc[spc]
shouldhelpgc = false
// 获得 s.freeindex 中或之后 s 中下一个空闲对象的索引
freeIndex := s.nextFreeIndex()
if freeIndex == s.nelems {
// span 已满,进行填充
// The span is full.
if uintptr(s.allocCount) != s.nelems {
println("runtime: s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount != s.nelems && freeIndex == s.nelems")
}
// 这个地方 mcache 向 mcentral 申请
c.refill(spc)
shouldhelpgc = true
s = c.alloc[spc]
// mcache 向 mcentral 申请完之后,再次从 mcache 申请
freeIndex = s.nextFreeIndex()
}
if freeIndex >= s.nelems {
throw("freeIndex is not valid")
}
// 这部分内容需要被 gc 接管,因此需要计算位置
v = gclinkptr(freeIndex*s.elemsize + s.base())
s.allocCount++// 分配计数
if uintptr(s.allocCount) > s.nelems {
println("s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount > s.nelems")
}
return
}
|
在上述方法中,如果我们在线程缓存中没有找到可用的mspan,会通过前面介绍的 runtime.mcache.refill 使用中心缓存中的mspan替换已经不存在可用对象的结构体,该方法会调用新结构体的 runtime.mspan.nextFreeIndex 获取空闲的内存并返回。
largeAlloc
runtime.largeAlloc 函数会计算分配该对象所需要的页数,它会按照 8KB 的倍数为对象在堆上申请内存:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
func largeAlloc(size uintptr, needzero bool, noscan bool) *mspan {
// print("largeAlloc size=", size, "\n")
// 对象太大,溢出
// _PageSize=8k,也就是表明对象太大,溢出
if size+_PageSize < size {
throw("out of memory")
}
// _PageShift==13,计算需要分配的页数
// 计算出对象所需的页数 对于大于32K的大内存分配都是整数页
// 根据分配的大小计算需要分配的页数
npages := size >> _PageShift
// 如果不是整数,多出来一些,需要加1
if size&_PageMask != 0 {
npages++
}
// Deduct credit for this span allocation and sweep if
// necessary. mHeap_Alloc will also sweep npages, so this only
// pays the debt down to npage pages.
deductSweepCredit(npages*_PageSize, npages)
spc := makeSpanClass(0, noscan)
// 从堆上分配
// 分配函数的具体实现,使用span->sizeclass=0
s := mheap_.alloc(npages, spc, needzero)
if s == nil {
throw("out of memory")
}
if go115NewMCentralImpl {
// Put the large span in the mcentral swept list so that it's
// visible to the background sweeper.
mheap_.central[spc].mcentral.fullSwept(mheap_.sweepgen).push(s)
}
s.limit = s.base() + size
// bitmap 记录分配的span
heapBitsForAddr(s.base()).initSpan(s)
return s
}
|
申请内存时会创建一个跨度类为 0 的 runtime.spanClass 并调用 runtime.mheap.alloc 分配一个管理对应内存的管理单元。
memclrNoHeapPointers
memclrNoHeapPointers 用于清理不包含堆指针的内存区块:
1
2
3
4
5
6
7
8
9
|
// memclrNoHeapPointers 清除从 ptr 开始的 n 个字节
// 通常情况下你应该使用 typedmemclr,而 memclrNoHeapPointers 应该仅在调用方知道 *ptr
// 不包含堆指针的情况下使用,因为 *ptr 只能是下面两种情况:
// 1. *ptr 是初始化过的内存,且其类型不是指针。
// 2. *ptr 是未初始化的内存(例如刚被新分配时使用的内存),则指包含 "junk" 垃圾内存
// 见 memclr_*.s
//
//go:noescape
func memclrNoHeapPointers(ptr unsafe.Pointer, n uintptr)
|
清理过程是汇编实现的,就是一些内存的归零工作,简单浏览一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
TEXT runtime·memclrNoHeapPointers(SB), NOSPLIT, $0-8
MOVL ptr+0(FP), DI
MOVL n+4(FP), BX
XORL AX, AX
// MOVOU 好像总是比 REP STOSL 快
tail:
(...)
loop:
MOVOU X0, 0(DI)
MOVOU X0, 16(DI)
MOVOU X0, 32(DI)
MOVOU X0, 48(DI)
MOVOU X0, 64(DI)
MOVOU X0, 80(DI)
MOVOU X0, 96(DI)
(...)
|
程序初始化:mallocinit
除去执行栈外,内存分配器是最先完成初始化的,我们先来看这个初始化的过程。 内存分配器的初始化除去一些例行的检查之外,就是对堆的初始化了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
func mallocinit() {
// 一些涉及内存分配器的常量的检查,包括
// heapArenaBitmapBytes, physPageSize 等等
...
// 初始化堆
mheap_.init()
_g_ := getg()
_g_.m.mcache = allocmcache()
// 创建初始的 arena 增长 hint
if sys.PtrSize == 8 && GOARCH != "wasm" {
for i := 0x7f; i >= 0; i-- {
var p uintptr
switch {
case GOARCH == "arm64" && GOOS == "darwin":
p = uintptr(i)<<40 | uintptrMask&(0x0013<<28)
(...)
default:
p = uintptr(i)<<40 | uintptrMask&(0x00c0<<32)
}
hint := (*arenaHint)(mheap_.arenaHintAlloc.alloc())
hint.addr = p
hint.next, mheap_.arenaHints = mheap_.arenaHints, hint
}
} else {
// 32 位机器,不关心
(...)
}
}
|
在这个过程中还包含对 mcache 初始化 allocmcache(),这个 mcache 会在 procresize 中将 mcache 转移到 P 的门下,而并非属于 M.
小结
展示了所有结构的关系。
heap 最中间的灰色区域 arena 覆盖了 Go 程序的整个虚拟内存, 每个 arena 包括一段 bitmap 和一段指向连续 span 的指针; 每个 span 由一串连续的页组成;每个 arena 的起始位置通过 arenaHint 进行记录。
分配的顺序从右向左,代价也就越来越大。 小对象和微对象优先从白色区域 per-P 的 mcache 分配 span,这个过程不需要加锁(白色); 若失败则会从 mheap 持有的 mcentral 加锁获得新的 span,这个过程需要加锁,但只是局部(灰色); 若仍失败则会从右侧的 free 或 scav 进行分配,这个过程需要对整个 heap 进行加锁,代价最大(黑色)。
参考
7.1 内存分配器
7.1 设计原则
Go内存管理三部曲[1]- 内存分配
详解Go中内存分配源码实现