Go实现层级时间轮
文章目录
引言
在软件系统中,“在一段时间后执行一个任务” 的需求比比皆是。比如:
- 客户端发起 HTTP 请求后,如果在指定时间内没有收到服务器的响应,则自动断开连接。
为了实现上述功能,通常我们会使用定时器 Timer:
- 客户端发起请求后,立即创建(启动)一个 Timer:到期间隔为 d,到期后执行 “断开连接” 的操作。
- 如果到期间隔 d 以内收到了服务器的响应,客户端就删除(停止)这个 Timer。
- 如果一直没有收到响应,则 Timer 最终会到期,然后执行 “断开连接” 的操作。
论文 Hashed and Hierarchical Timing Wheels提出了一种用于实现 Timer 的高效数据结构:时间轮。采用时间轮实现的 Timer,创建和删除的时间复杂度为 O(1)。
常见的时间轮实现有两种:
- 简单时间轮(Simple Timing Wheel)—— 比如 Netty4 的 HashedWheelTimer。
- 层级时间轮(Hierarchical Timing Wheels)—— 比如 Kafka 的 Purgatory。
下面我们来看看简单时间轮、层级时间轮、Kafka 的层级时间轮变体的实现原理,以及 Golang 实现中的一些要点。
理论
简单时间轮
一个 简单时间轮 就是一个循环列表,列表中的每一格包含一个定时任务列表(双向链表)。一个时间单位为 u、大小为 n 的简单时间轮,可以包含的定时任务的最大到期间隔为 n*u。
以 u 为 1ms、n 为 3 的简单时间轮为例,可以包含的定时任务的最大到期间隔为 3ms。
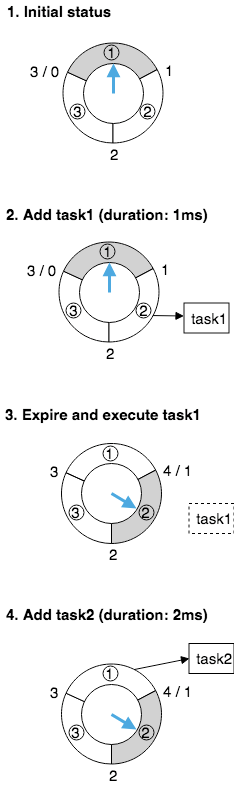
如上图所示,该简单时间轮的运行原理如下:
- 初始时,假设当前时间(蓝色箭头)指向第 1 格(此时:到期间隔为 [0ms, 1ms) 的定时任务放第 1 格,[1ms, 2ms) 的放第 2 格,[2ms, 3ms) 的放第 3 格)。
- 此时我们创建一个到期间隔为 1ms 的定时任务 task1,按规则该任务会被插入到第 2 格。
- 随着时间的流逝,过了 1ms 后当前时间指向第 2 格,这一格包含的定时任务 task1 会被删除并执行。
- 当前时间指向第 2 格(此时:到期间隔为 [0ms, 1ms) 的定时任务放第 2 格,[1ms, 2ms) 的放第 3 格,[2ms, 3ms) 的放第 1 格),我们继续创建一个到期间隔为 2ms 的定时任务 task2,按规则该任务被插入到第 1 格。
简单时间轮的优点是实现简单,缺点是:
- 一旦选定 n,就不能包含到期间隔超过 n*u 的定时任务。
- 如果定时任务的到期时间跨度较大,就会选择较大的 n,在定时任务较少时会造成很大的空间浪费。
有一些简单时间轮的变体实现,它们通过在定时任务中增加记录 round 轮次信息,可以有效弥补上述两个缺点。同样以上面 u 为 1ms、n 为 3 的简单时间轮为例,初始时间指向第 1 格;此时如果要创建到期时间为 4ms 的定时任务,可以在该任务中设置 round 为 1(4/3 取整),剩余到期时间用 4ms 减去 round*3ms 等于 1ms,因此放到第 2 格;等到当前时间指向第 2 格时,判断任务中的 round 大于 0,所以不会删除并执行该任务,而是对其 round 减一(于是 round 变为 0);等到再过 3ms 后,当前时间再次指向第 2 格,判断任务中的 round 为 0,进而删除并执行该任务。
然而,这些变体实现因为只使用了一个时间轮,所以仍然存在一个缺点:处理每一格的定时任务列表的时间复杂度是 O(n),如果定时任务数量很大,分摊到每一格的定时任务列表就会很长,这样的处理性能显然是让人无法接受的。
层级时间轮
层级时间轮 通过使用多个时间轮,并且对每个时间轮采用不同的 u,可以有效地解决简单时间轮及其变体实现的问题。
参考 Kafka 的 Purgatory中的层级时间轮实现:
- 每一层时间轮的大小都固定为 n,第一层时间轮的时间单位为 u,那么第二层时间轮(我们称之为第一层时间轮的溢出时间轮 Overflow Wheel)的时间单位就为 n*u,以此类推。
- 除了第一层时间轮是固定创建的,其他层的时间轮(均为溢出时间轮)都是按需创建的。
- 原先插入到高层时间轮(溢出时间轮)的定时任务,随着时间的流逝,会被降级重新插入到低层时间轮中。
以 u 为 1ms、n 为 3 的层级时间轮为例,第一层时间轮的时间单位为 1ms、大小为 3,第二层时间轮的时间单位为 3ms、大小为 3,以此类推。
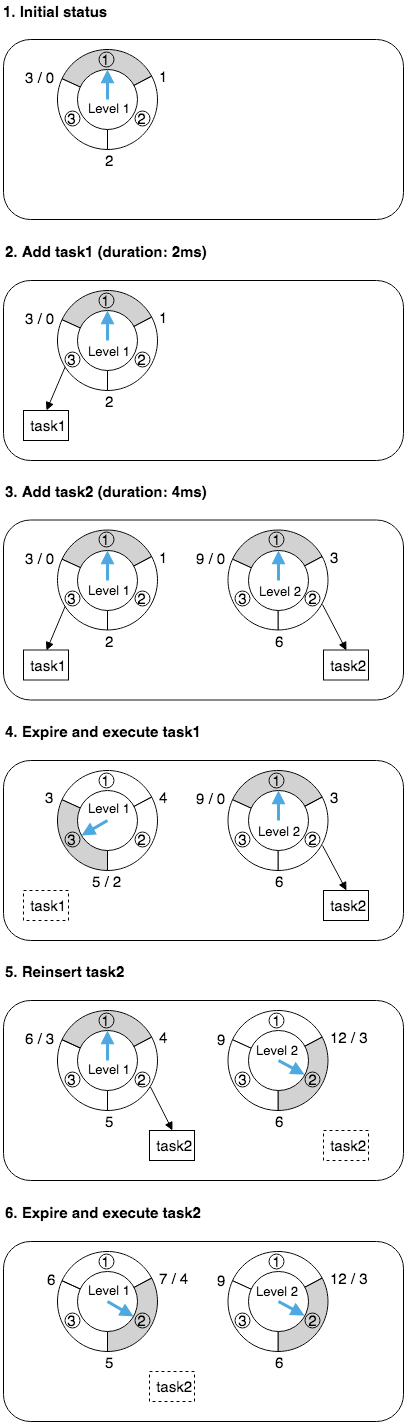
如上图所示,该层级时间轮的运行原理如下:
- 初始时,只有第一层(Level 1)时间轮,假设当前时间(蓝色箭头)指向第 1 格(此时:到期间隔为 [0ms, 1ms) 的定时任务放第 1 格,[1ms, 2ms) 的放第 2 格,[2ms, 3ms) 的放第 3 格)。
- 此时我们创建一个到期间隔为 2ms 的定时任务 task1,按规则该任务会被插入到第一层时间轮的第 3 格。
- 同一时刻,我们再次创建一个到期间隔为 4ms 的定时任务 task2,因为到期间隔超过了第一层时间轮的间隔范围,所以会创建第二层(Level 2)时间轮;第二层时间轮中的当前时间(蓝色箭头)也指向第 1 格,按规则该任务会被插入到第二层时间轮的第 2 格。
- 随着时间的流逝,过了 2ms 后,第一层时间轮中的当前时间指向第 3 格,这一格包含的任务 task1 会被删除并执行;此时,第二层时间轮的当前时间没有变化,依然指向第 1 格。
- 随着时间的流逝,又过了 1ms 后,第一层时间轮中的当期时间指向第 1 格,这一格中没有任务;此时,第二层当前时间指向第 2 格,这一格包含的任务 task2 会被删除并重新插入时间轮,因为剩余到期时间为 1ms,所以 task2 会被插入到第一层时间轮的第 2 格。
- 随着时间的流逝,又过了 1ms 后,第一层时间轮中的当前时间指向第 2 格,这一格包含的定时任务 task2 会被删除并执行;此时,第二层时间轮的当前时间没有变化,依然指向第 2 格。
Kafka 的变体实现
在具体实现层面 Kafka Timer 实现源码,Kafka 的层级时间轮与上面描述的原理有一些差别。
时间轮表示
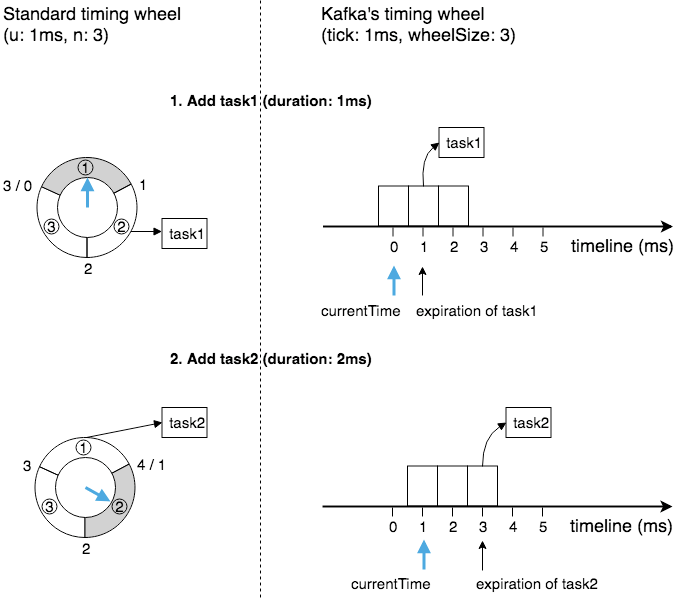
如上图所示,在时间轮的表示上面:
- 使用大小为 wheelSize 的数组来表示一层时间轮,其中每一格是一个 bucket,每个 bucket 的时间单位为 tick。
- 这个时间轮数组并没有模拟循环列表的行为(如图左所示),而是模拟了哈希表的行为。
我们用数组模拟时间轮(数组的每个元素是一个列表头,添加任务就是往列表头后面挂任务而已),数组的大小代表时间的格子数,添加过程中我们会通过 过期时间/时间轮格子代表时间 % 时间轮格子总数 算出的格子位置,然后通过挂链的方法添加到时间轮格子当中。
在这个过程中我们需要注意的是任务首先需要判断当前时间轮是否放的下,判断放得下的标准就是时间轮当前时间 + 一圈时间轮时间是否大于任务过期时间,如果大于就代表放的下,如果小于就代表无法放置那么就需要往上一层时间轮放置。
时钟驱动方式
常规的时间轮实现中,会在一个线程中每隔一个时间单位 tick 就醒来一次,并驱动时钟走向下一格,然后检查这一格中是否包含定时任务。如果时间单位 tick 很小(比如 Kafka 中 tick 为 1ms)并且(在最低层时间轮的)定时任务很少,那么这种驱动方式将会非常低效。
Kafka 的层级时间轮实现中,利用了 Java 内置的 DelayQueue 结构,将每一层时间轮中所有 “包含有定时任务的 bucket” 都加入到同一个 DelayQueue 中,然后 等到有 bucket 到期后再驱动时钟往前走,并逐个处理该 bucket 中的定时任务。
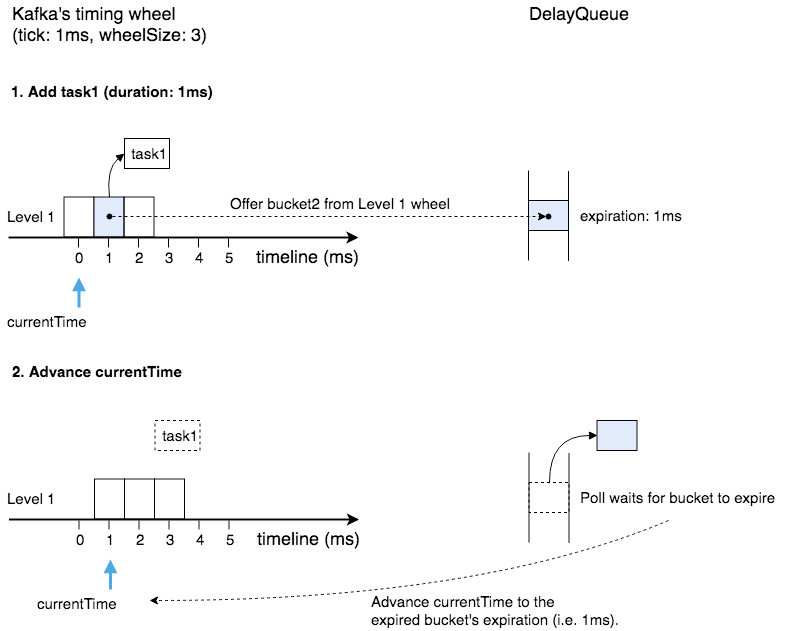
如上图所示:
- 往层级时间轮中添加一个定时任务 task1 后,会将该任务所属的 bucket2 的到期时间设置为 task1 的到期时间 expiration(= 当前时间 currentTime + 定时任务到期间隔 duration),并将这个 bucket2 添加(Offer)到 DelayQueue 中。
- DelayQueue(内部有一个线程)会等待 “到期时间最早(earliest)的 bucket” 到期,图中等到的是排在队首的 bucket2,于是经由 poll 返回并删除这个 bucket2;随后,时间轮会将当前时间 currentTime 往前移动到 bucket2 的 expiration 所指向的时间(图中是 1ms 所在的位置);最后,bucket2 中包含的 task1 会被删除并执行。
上述 Kafka 层级时间轮的驱动方式是非常高效的。虽然 DelayQueue 中 offer(添加)和 poll(获取并删除)操作的时间复杂度为 O(log n),但是相比定时任务的个数而言,bucket 的个数其实是非常小的(也就是 O(log n) 中的 n 很小),因此性能也是没有问题的。
源码分析
因为我们这个Go语言版本的时间轮代码是仿照Kafka写的,所以在具体实现时间轮 TimingWheel 时还有一些小细节:
- 时间轮的时间格中每个链表会有一个root节点用于简化边界条件。它是一个附加的链表节点,该节点作为第一个节点,它的值域中并不存储任何东西,只是为了操作的方便而引入的;
- 除了第一层时间轮,其余高层时间轮的起始时间(startMs)都设置为创建此层时间轮时前面第一轮的 currentTime。每一层的 currentTime 都必须是 tickMs 的整数倍,如果不满足则会将 currentTime 修剪为 tickMs 的整数倍。修剪方法为:currentTime = startMs – (startMs % tickMs);
- Kafka 中的定时器只需持有 TimingWheel 的第一层时间轮的引用,并不会直接持有其他高层的时间轮,但每一层时间轮都会有一个引用(overflowWheel)指向更高一层的应用;
- Kafka 中的定时器使用了 DelayQueue 来协助推进时间轮。在操作中会将每个使用到的时间格中每个链表都加入 DelayQueue,DelayQueue 会根据时间轮对应的过期时间 expiration 来排序,最短 expiration 的任务会被排在 DelayQueue 的队头,通过单独线程来获取 DelayQueue 中到期的任务;
结构体
|
|
tick、wheelSize、interval、currentTime都比较好理解,buckets字段代表的是时间格列表,queue是一个延迟队列,所有的任务都是通过延迟队列来进行触发,overflowWheel是上层时间轮的引用。
|
|
bucket里面实际上封装的是时间格里面的任务队列,里面放入的是相同过期时间的任务,到期后会将队列timers拿出来进行处理。这里有个有意思的地方是由于会有多个线程并发的访问bucket,所以需要用到原子类来获取int64位的值,为了保证32位系统上面读取64位数据的一致性,需要进行64位对齐。
|
|
Timer是时间轮的最小执行单元,是定时任务的封装,到期后会调用task来执行任务。
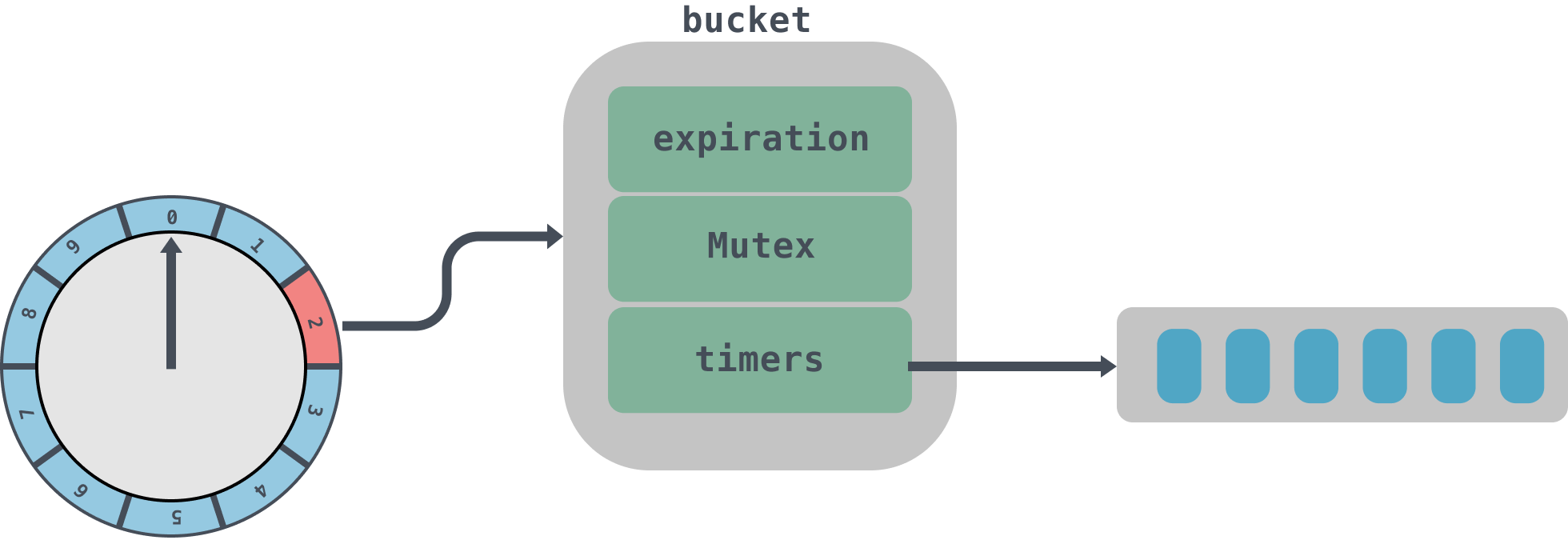
初始化时间轮
例如现在初始化一个tick是1s,wheelSize是10的时间轮:
|
|
初始化十分简单,大家可以看看上面的代码注释即可。
启动时间轮
下面我们看看start方法:
|
|
这里使用了util封装的一个Wrap方法,这个方法会起一个goroutines异步执行传入的函数.
Start方法会启动两个goroutines。第一个goroutines用来调用延迟队列的queue的Poll方法,这个方法会一直循环获取队列里面的数据,然后将到期的数据放入到queue的C管道中;第二个goroutines会无限循环获取queue中C的数据,如果C中有数据表示已经到期,那么会先调用advanceClock方法将当前时间 currentTime 往前移动到 bucket的到期时间,然后再调用Flush方法取出bucket中的队列,并调用addOrRun方法执行。
|
|
advanceClock方法会根据到期时间来从新设置currentTime,从而推进时间轮前进。
|
|
Flush方法会根据bucket里面timers列表进行遍历插入到ts数组中,然后调用reinsert方法,这里是调用的addOrRun方法。
|
|
addOrRun会调用add方法检查传入的定时任务Timer是否已经到期,如果到期那么异步调用task方法直接执行。add方法我们下面会接着分析。
整个start执行流程如图:
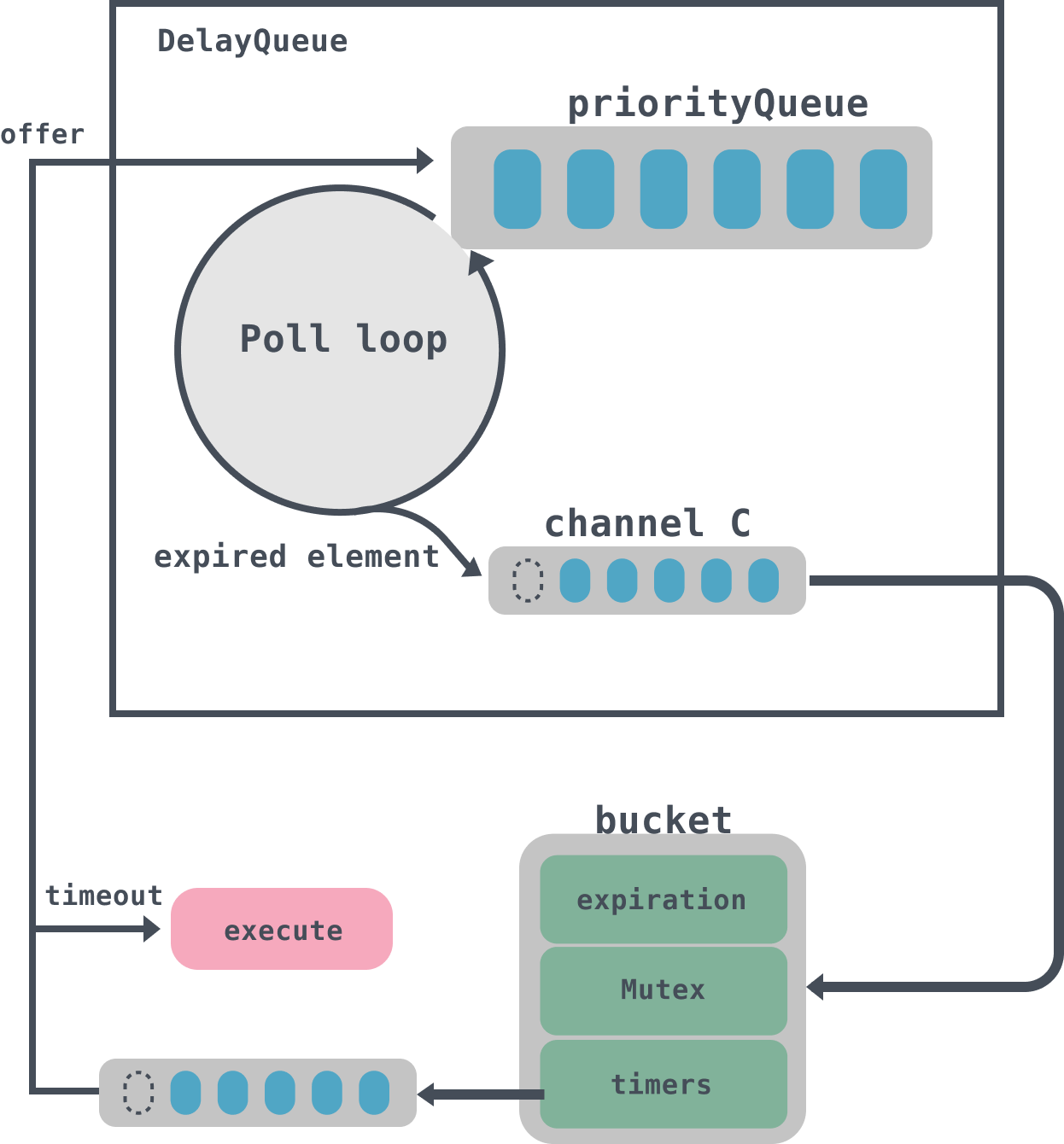
- start方法回启动一个goroutines调用poll来处理DelayQueue中到期的数据,并将数据放入到管道C中;
- start方法启动第二个goroutines方法会循环获取DelayQueue中管道C的数据,管道C中实际上存放的是一个bucket,然后遍历bucket的timers列表,如果任务已经到期,那么异步执行,没有到期则重新放入到DelayQueue中。
add task
|
|
我们通过AfterFunc方法添加一个15s的定时任务,如果到期了,那么执行传入的函数。
|
|
AfterFunc方法回根据传入的任务到期时间,以及到期需要执行的函数封装成Timer,调用addOrRun方法。addOrRun方法我们上面已经看过了,会根据到期时间来决定是否需要执行定时任务。
下面我们来看一下add方法:
|
|
add方法根据到期时间来分成了三部分,第一部分是小于当前时间+tick,表示已经到期,那么返回false执行任务即可;
第二部分的判断会根据expiration是否小于时间轮的跨度,如果小于的话表示该定时任务可以放入到当前时间轮中,通过取模找到buckets对应的时间格并放入到bucket队列中,SetExpiration方法会根据传入的参数来判断是否已经执行过延迟队列的Offer方法,防止重复插入;
第三部分表示该定时任务的时间跨度超过了当前时间轮,需要升级到上一层的时间轮中。需要注意的是,上一层的时间轮的tick是当前时间轮的interval,延迟队列还是同一个,然后设置为指针overflowWheel,并调用add方法往上层递归。
到这里时间轮已经讲完了,不过还有需要注意的地方,我们在用上面的时间轮实现中,使用了DelayQueue加环形队列的方式实现了时间轮。对定时任务项的插入和删除操作而言,TimingWheel时间复杂度为 O(1),在DelayQueue中的队列使用的是优先队列,时间复杂度是O(log n),但是由于buckets列表实际上是非常小的,所以并不会影响性能。
与标准库比较
自己就时间轮和 timer 也做了个 benchmark:
|
|
从上面可以直接看出,在添加了一千万个定时器后,时间轮的单次调用时间有明显的上涨,但是 timer 却依然很稳。
从官方的一个数据显示:
|
|
在很多项测试中,性能确实得到了很大的增强。
参考
文章作者 Forz
上次更新 2019-10-23