go test 命令参数
Go 测试工具 go test,包括各种子命令、参数之类的内容。你可以通过 go test -h 查看帮助信息。
其基本形式是:
1
|
go test [build/test flags] [packages] [build/test flags & test binary flags]
|
执行 go test 命令,它会在 *_test.go 中寻找 test 测试、benchmark 基准 和 examples 示例 函数。测试函数必须以 TestXXX 的函数名出现(XXX 为以非小写字母开头),基准函数必须以 BenchmarkXXX 的函数名出现,示例函数必须以 ExampleXXX 的形式。三种函数类似下面的签名形式:
1
2
3
4
5
6
7
8
9
10
11
12
|
// test 测试函数
func TestXXX(t *testing.T) { ... }
// benchmark 基准函数
func BenchmarkXXX(b *testing.B) { ... }
// examples 示例函数,其相关命名方式可以查看第一篇文章
func ExamplePrintln() {
Println("The output of\nthis example.")
// Output: The output of
// this example.
}
|
或
1
2
3
4
5
6
7
8
9
10
11
|
func ExamplePerm() {
for _, value := range Perm(4) {
fmt.Println(value)
}
// Unordered output: 4
// 2
// 1
// 3
// 0
}
|
更多请查看 go help testfunc。
go test 命令还会忽略 testdata 目录,该目录用来保存测试需要用到的辅助数据。
go test 有两种运行模式:
-
本地目录模式,在没有包参数(例如 go test 或 go test -v)调用时发生。在此模式下,go test 编译当前目录中找到的包和测试,然后运行测试二进制文件。在这种模式下,caching 是禁用的。在包测试完成后,go test 打印一个概要行,显示测试状态、包名和运行时间。
-
包列表模式,在使用显示包参数调用 go test 时发生(例如 go test math,go test ./... 甚至是 go test .)。在此模式下,go 测试编译并测试在命令上列出的每个包。如果一个包测试通过,go test 只打印最终的 ok 总结行。如果一个包测试失败,go test 将输出完整的测试输出。如果使用 -bench 或 -v 标志,则 go test 会输出完整的输出,甚至是通过包测试,以显示所请求的基准测试结果或详细日志记录。
下面详细说明下 go test 的具体用法,flag 的作用及一些相关例子。需要说明的是:一些 flag 支持 go test 命令和编译后的二进制测试文件。它们都能识别加 -test. 前缀的 flag,如 go test -test.v,但编译后的二进制文件必须加前缀 ./sum.test -test.bench=.。
有以下测试文件 sum.go:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
package sum
func Sum(a, b int) int {
return a + b
}
sum_test.go 内容:
package sum
import (
"flag"
"fmt"
"testing"
"time"
)
var print bool
func init() {
flag.BoolVar(&print, "p", false, "print test log")
flag.Parse()
}
func TestSum(t *testing.T) {
val := Sum(1, 2)
if print {
fmt.Println("sum=", val)
}
}
// -bench 基准测试
func BenchmarkSum(b *testing.B) {
for i := 0; i < b.N; i++ {
Sum(i, i+1)
}
}
// -timeout 测试
func TestSumLongTime(t *testing.T) {
time.Sleep(time.Second * 2)
Sum(1, 2)
}
// 子测试
func TestSumSubTest(t *testing.T) {
t.Run("1+2", func(t *testing.T) {
val := Sum(1, 2)
t.Log("1+2=", val)
})
t.Run("2+3", func(t *testing.T) {
val := Sum(2, 3)
t.Log("2+3=", val)
})
}
// 子测试,无具体子测试
func TestSumSubTest2(t *testing.T) {
val := Sum(2, 3)
t.Log("no subtest=", val)
}
// 并发测试
func TestSumParallel(t *testing.T) {
t.Parallel()
Sum(1, 2)
}
func TestSumParallel2(t *testing.T) {
t.Parallel()
Sum(1, 2)
}
|
test flag
以下 flag 可以跟被 go test 命令使用:
-args:传递命令行参数,该标志会将 -args 之后的参数作为命令行参数传递,最好作为最后一个标志。
-c:编译测试二进制文件为 [pkg].test,不运行测试。
1
|
go test -c && ./sum.test -p=true
|
-exec xprog:使用 xprog 运行测试,行为同 go run 一样,查看 go help run。
-i:安装与测试相关的包,不运行测试。
-o file:编译测试二进制文件并指定文件,同时运行测试。
test/binary flag
以下标志同时支持测试二进制文件和 go test 命令。
-bench regexp:通过正则表达式执行基准测试,默认不执行基准测试。可以使用 -bench .或-bench=.执行所有基准测试。
1
2
3
|
go test -bench=.
go test -c
./sum.test -test.bench=.
|
-benchtime t:每个基准测试运行足够迭代消耗的时间,time.Duration(如 -benchtime 1h30s),默认 1s。
1
2
|
go test -bench=. -benchtime 0.1s
./sum.test -test.bench=. -test.benchtime=1s
|
-count n:运行每个测试和基准测试的次数(默认 1),如果 -cpu 指定了,则每个 GOMAXPROCS 值执行 n 次,Examples 总是运行一次。
1
2
|
go test -bench=. -count=2
./sum.test -test.bench=. -test.count=2
|
-cover:开启覆盖分析,开启覆盖分析可能会在编译或测试失败时,代码行数不对。
1
|
go test -bench=. -cover
|
-covermode set,count,atomic:覆盖分析的模式,默认是 set,如果设置 -race,将会变为 atomic。
- set,bool,这个语句运行吗?
- count,int,该语句运行多少次?
- atomic,int,数量,在多线程正确使用,但是耗资源的aaaaaaaa
-coverpkg pkg1,pkg2,pkg3:指定分析哪个包,默认值只分析被测试的包,包为导入的路径。
1
2
|
# sum -> $GOPATH/src/test/sum
go test -coverpkg test/sum
|
-cpu 1,2,4:指定测试或基准测试的 GOMAXPROCS 值。默认为 GOMAXPROCS 的当前值。
-list regexp:列出与正则表达式匹配的测试、基准测试或 Examples。只列出顶级测试(不列出子测试),不运行测试。
-parallel n:允许并行执行通过调用 t.Parallel 的测试函数的最大次数。默认值为 GOMAXPROCS 的值。-parallel 仅适用于单个二进制测试文件,但go test命令可以通过指定 -p 并行测试不同的包。查看 go help build。
1
|
go test -run=TestSumParallel -parallel=2
|
-run regexp:只运行与正则表达式匹配的测试和Examples。我们可以通过 / 来指定测试子函数。go test Foo/A=,会先去匹配并执行 Foo 函数,再查找子函数。
1
|
go test -v -run TestSumSubTest/1+
|
-short:缩短长时间运行的测试的测试时间。默认关闭。
-timeout d:如果二进制测试文件执行时间过长,panic。默认10分钟(10m)。
1
|
go test -run TestSumLongTime -timeout 1s
|
-v:详细输出,运行期间所有测试的日志。
analyze flag
以下测试适用于 go test 和测试二进制文件:
-benchmem:打印用于基准的内存分配统计数据。
1
2
|
go test -bench=. -benchmem
./sum.test -test.bench -test.benchmem
|
-blockprofile block.out:当所有的测试都完成时,在指定的文件中写入一个 goroutine 阻塞概要文件。指定 -c,将写入测试二进制文件。
1
2
|
go test -v -cpuprofile=prof.out
go tool pprof prof.out
|
-blockprofilerate n:goroutine 阻塞时候打点的纳秒数。默认不设置就相当于 -test.blockprofilerate=1,每一纳秒都打点记录一下。
-coverprofile cover.out:在所有测试通过后,将覆盖概要文件写到文件中。设置过 -cover。
-cpuprofile cpu.out:在退出之前,将一个 CPU 概要文件写入指定的文件。
-memprofile mem.out:在所有测试通过后,将内存概要文件写到文件中。
-memprofilerate n:开启更精确的内存配置。如果为 1,将会记录所有内存分配到 profile。
1
2
|
go test -memprofile mem.out -memprofilerate 1
go tool pprof mem.out
|
-mutexprofile mutex.out:当所有的测试都完成时,在指定的文件中写入一个互斥锁争用概要文件。指定 -c,将写入测试二进制文件。
-mutexprofilefraction n:样本 1 在 n 个堆栈中,goroutines 持有 a,争用互斥锁。
-outputdir directory:在指定的目录中放置输出文件,默认情况下,go test 正在运行的目录。
-trace trace.out:在退出之前,将执行跟踪写入指定文件。
单元测试
单元测试又称为功能性测试,是为了测试函数、模块等代码的逻辑是否正确。
在 Go 中编写测试很简单,只需要在待测试功能所在文件的同级目录中创建一个以_test.go结尾的文件。在该文件中,我们可以编写一个个测试函数。测试函数名必须是TestXxxx这个形式,而且Xxxx必须以大写字母开头,另外函数带有一个*testing.T类型的参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// roman_test.go
package roman
import (
"testing"
)
func TestToRoman(t *testing.T) {
_, err1 := ToRoman(0)
if err1 != ErrOutOfRange {
t.Errorf("ToRoman(0) expect error:%v got:%v", ErrOutOfRange, err1)
}
roman2, err2 := ToRoman(1)
if err2 != nil {
t.Errorf("ToRoman(1) expect nil error, got:%v", err2)
}
if roman2 != "I" {
t.Errorf("ToRoman(1) expect:%s got:%s", "I", roman2)
}
}
|
在测试函数中编写的代码与正常的代码没有什么不同,调用相应的函数,返回结果,判断结果与预期是否一致,如果不一致则调用testing.T的Errorf()输出错误信息。运行测试时,这些错误信息会被收集起来,运行结束后统一输出。
测试编写完成之后,使用go test命令运行测试,输出结果:
1
2
3
4
5
6
|
$ go test
--- FAIL: TestToRoman (0.00s)
roman_test.go:18: ToRoman(1) expect:I got:
FAIL
exit status 1
FAIL github.com/darjun/go-daily-lib/testing 0.172s
|
我们还可以给go test命令传入-v选项,输出详细的测试信息:
1
2
3
4
5
|
$ go test -v
=== RUN TestToRoman
--- PASS: TestToRoman (0.00s)
PASS
ok github.com/darjun/go-daily-lib/testing 0.174s
|
在运行每个测试函数前,都输出一行=== RUN,运行结束之后输出--- PASS或--- FAIL信息。
函数测试,其基本签名是:
1
2
3
|
func TestName(t *testing.T){
// ...
}
|
测试函数的名字必须以 Test 开头,可选的后缀名必须不以小写字母开头,一般跟我们测试的函数名。
类型 testing.T 有以下方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
// 打印日志。对于测试,会在失败或指定 -test.v 标志时打印。对与基准测试,总是打印,避免因未指定 -v 带来的测试不准确
func (c *T) Log(args ...interface{})
func (c *T) Logf(format string, args ...interface{})
// 标记函数失败,继续执行该函数
func (c *T) Fail()
// 标记函数失败,调用 runtime.Goexit 退出该函数。但继续执行其它函数或基准测试。
func (c *T) FailNow()
// 返回函数是否失败
func (c *T) Failed() bool
// 等同于 t.Log + t.Fail
func (c *T) Error(args ...interface{})
// 等同于 t.Logf + t.Fail
func (c *T) Errorf(format string, args ...interface{})
// 等同于 t.Log + t.FailNow
func (c *T) Fatal(args ...interface{})
// 等同于 t.Logf + t.FailNow
func (c *T) Fatalf(format string, args ...interface{})
// 将调用函数标记标记为测试助手函数。
func (c *T) Helper()
// 返回正在运行的测试或基准测试的名称
func (c *T) Name() string
// 用于表示当前测试只会与其他带有 Parallel 方法的测试并行进行测试。
func (t *T) Parallel()
// 执行名字为 name 的子测试 f,并报告 f 在执行过程中是否失败
// Run 会阻塞到 f 的所有并行测试执行完毕。
func (t *T) Run(name string, f func(t *T)) bool
// 相当于 t.Log + t. SkipNow
func (c *T) Skip(args ...interface{})
// 将测试标记为跳过,并调用 runtime.Goexit 退出该测试。继续执行其它测试或基准测试
func (c *T) SkipNow()
// 相当于 t.Logf + t.SkipNow
func (c *T) Skipf(format string, args ...interface{})
// 报告该测试是否是忽略
func (c *T) Skipped() bool
|
子测试:Run(表格驱动测试)
table-driven(表格驱动) 测试,相比每次测试重复相同代码,减少了重复代码的数量,并且可以直接添加更多的测试用例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
func TestTime(t *testing.T) {
testCases := []struct {
gmt string
loc string
want string
}{
{"12:31", "Europe/Zuri", "13:31"}, // incorrect location name
{"12:31", "America/New_York", "7:31"}, // should be 07:31
{"08:08", "Australia/Sydney", "18:08"},
}
for _, tc := range testCases {
loc, err := time.LoadLocation(tc.loc)
if err != nil {
t.Fatalf("could not load location %q", tc.loc)
}
gmt, _ := time.Parse("15:04", tc.gmt)
if got := gmt.In(loc).Format("15:04"); got != tc.want {
t.Errorf("In(%s, %s) = %s; want %s", tc.gmt, tc.loc, got, tc.want)
}
}
}
|
我们可以利用子测试重写上面的版本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func TestTime(t *testing.T) {
testCases := []struct {
gmt string
loc string
want string
}{
{"12:31", "Europe/Zuri", "13:31"},
{"12:31", "America/New_York", "7:31"},
{"08:08", "Australia/Sydney", "18:08"},
}
for _, tc := range testCases {
t.Run(fmt.Sprintf("%s in %s", tc.gmt, tc.loc), func(t *testing.T) {
loc, err := time.LoadLocation(tc.loc)
if err != nil {
t.Fatal("could not load location")
}
gmt, _ := time.Parse("15:04", tc.gmt)
if got := gmt.In(loc).Format("15:04"); got != tc.want {
t.Errorf("got %s; want %s", got, tc.want)
}
})
}
}
|
可以看到,依次运行 3 个子测试,子测试名是父测试名和t.Run()指定的名字组合而成的,如TestToRoman/Invalid。
首先要注意的是两个实现的输出差异。原始实现打印:
1
2
|
--- FAIL: TestTime (0.00s)
time_test.go:62: could not load location "Europe/Zuri”
|
即使有两个错误,测试停止在对 Fatal 的调用上,而第二个测试不会运行。
而使用 Run 的版本两个都执行了:
1
2
3
4
5
|
--- FAIL: TestTime (0.00s)
--- FAIL: TestTime/12:31_in_Europe/Zuri (0.00s)
time_test.go:84: could not load location
--- FAIL: TestTime/12:31_in_America/New_York (0.00s)
time_test.go:88: got 07:31; want 7:31
|
Fatal 及其相关方法导致子测试被跳过,但不会跳过其父测试其他的子测试。
另一个需要注意的点是新实现版本中的错误消息较短。由于子测试名称可以唯一标识,因此无需在错误消息中再次进行标识。
每个子测试都有一个唯一的名称:由顶层测试的名称与传递给 Run 的名称组成,以斜杠分隔,并具有可选的尾随序列号,用于消除歧义。
命令行标志 -run 和 -bench 的参数是非固定的正则表达式,用于匹配测试名称。对于由斜杠分隔的测试名称,例如子测试的名称,它名称本身即可作为参数,依次匹配由斜杠分隔的每部分名称。因为参数是非固定的,一个空的表达式匹配任何字符串,所以下述例子中的 “匹配” 意味着 “顶层/子测试名称包含有”:
1
2
3
4
|
go test -run '' # 执行所有测试。
go test -run Foo # 执行匹配 "Foo" 的顶层测试,例如 "TestFooBar"。
go test -run Foo/A= # 对于匹配 "Foo" 的顶层测试,执行其匹配 "A=" 的子测试。
go test -run /A=1 # 执行所有匹配 "A=1" 的子测试。
|
看一些例子:
使用欧洲时区运行测试:
1
2
3
4
|
$ go test -run=TestTime/"in Europe"
--- FAIL: TestTime (0.00s)
--- FAIL: TestTime/12:31_in_Europe/Zuri (0.00s)
time_test.go:85: could not load location
|
仅仅运行时间在午后的测试:
1
2
3
4
5
6
7
8
9
|
$ go test -run=Time/12:[0-9] -v
=== RUN TestTime
=== RUN TestTime/12:31_in_Europe/Zuri
=== RUN TestTime/12:31_in_America/New_York
--- FAIL: TestTime (0.00s)
--- FAIL: TestTime/12:31_in_Europe/Zuri (0.00s)
time_test.go:85: could not load location
--- FAIL: TestTime/12:31_in_America/New_York (0.00s)
time_test.go:89: got 07:31; want 7:31
|
也许有点令人惊讶,使用 -run = TestTime/New_York 将不会匹配任何测试。这是因为位置名称中存在的斜线也被视为分隔符。需要这么使用:
1
2
3
4
|
$ go test -run=Time//New_York
--- FAIL: TestTime (0.00s)
--- FAIL: TestTime/12:31_in_America/New_York (0.00s)
time_test.go:88: got 07:31; want 7:31
|
注意 // 在传递给 -run 的字符串中,在时区名称 America/New_York 中的 / 被处理了,就好像它是一个子测试分隔符。模式(TestTime)的第一个正则表达式匹配顶级测试。 第二个正则表达式(空字符串)匹配任何内容,在这 case 中,是时间和位置的洲部分。 第三个正则表达式(New_York)匹配位置的城市部分。
将名称中的斜杠视为分隔符可以让用户重构测试的层次结构,而无需更改命名。它也简化了转义规则。用户应避免在名称中使用斜扛,如果出现问题,请使用反斜杠替换它们。
唯一的序列号附加到不唯一的测试名称。因此,如果没有更好的子测试命名方案,则可以将空字符串传递给 Run,并且可以通过序列号轻松识别子测试。
子测试和子基准测试可用于管理常见的 setup 和 tear-down 代码:
1
2
3
4
5
6
7
8
9
10
11
|
func TestFoo(t *testing.T) {
// <setup code>
t.Run("A=1", func(t *testing.T) { ... })
t.Run("A=2", func(t *testing.T) { ... })
t.Run("B=1", func(t *testing.T) {
if !test(foo{B:1}) {
t.Fail()
}
})
// <tear-down code>
}
|
当运行测试时,Setup 和 Tear-down 代码运行且最多运行一次。即使任何一个子测试调用了 Skip,Fail 或 Fatal,也适用。
并发Parallel
子测试允许对并行性进行细粒度控制。为了理解如何使用子测试进行并行控制,得先理解并行测试的语义。
每个测试都与一个测试函数相关联。如果测试函数调用了其 testing.T 实例上的 Parallel 方法,则测试称为并行测试。并行测试从不与顺序测试同时运行,直到顺序测试返回,并行测试才继续运行。-parallel 标志定义可并行运行的最大并行测试数。
一个测试被堵塞,直到其所有的子测试都已完成。这意味着在一个测试中(TestXXX 函数中),在并行测试完成后,顺序测试才会执行。
对于由 Run 和 顶级测试 创建的测试,此行为是相同的。实际上,顶级测试是隐式的主测试 (master test) 的子测试。
上述语义允许并行地运行一组测试,但不允许其他并行测试:
1
2
3
4
5
6
7
8
9
10
11
12
|
func TestGroupedParallel(t *testing.T) {
for _, tc := range testCases {
tc := tc // capture range variable
t.Run(tc.Name, func(t *testing.T) {
t.Parallel()
if got := foo(tc.in); got != tc.out {
t.Errorf("got %v; want %v", got, tc.out)
}
...
})
}
}
|
在由 Run 启动的所有并行测试完成之前,外部测试将不会完成。因此,没有其他并行测试可以并行地运行这些并行测试。
请注意,我们需要复制 range 变量以确保 tc 绑定到正确的实例。(因为 range 会重用 tc)
有一些控制并行执行的测试标志。例如,-parallel标志指定其中的多少可以并行运行。如果使用go test -parallel=1执行它,输出将再次变为顺序的,但是顺序将是Test3,Test1和Test2。
前面提到的多个子测试共享setup和teardown有一个前提是子测试没有并发,如果子测试使用t.Parallel()指定并发,那么就没办法共享teardown了,因为执行顺序很可能是setup->子测试1->teardown->子测试2…。
如果子测试可能并发,则可以把子测试通过Run()再嵌套一层,Run()可以保证其下的所有子测试执行结束后再返回。
为便于说明,我们创建文件subparallel_test.go用于说明:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
package gotest_test
import (
"fmt"
"testing"
"time"
)
// 并发子测试,无实际测试工作,仅用于演示
func parallelTest1(t *testing.T) {
t.Parallel()
time.Sleep(3 * time.Second)
fmt.Println("parallel test 1")
}
// 并发子测试,无实际测试工作,仅用于演示
func parallelTest2(t *testing.T) {
t.Parallel()
time.Sleep(2 * time.Second)
fmt.Println("parallel test 2")
}
// 并发子测试,无实际测试工作,仅用于演示
func parallelTest3(t *testing.T) {
t.Parallel()
time.Sleep(1 * time.Second)
fmt.Println("parallel test 3")
}
// TestSubParallel 通过把多个子测试放到一个组中并发执行,同时多个子测试可以共享setup和tear-down
func TestSubParallel(t *testing.T) {
// setup
t.Logf("Setup")
t.Run("group", func(t *testing.T) {
t.Run("Test1", parallelTest1)
t.Run("Test2", parallelTest2)
t.Run("Test3", parallelTest3)
})
// tear down
t.Logf("teardown")
}
|
上面三个子测试中分别sleep了3s、2s、1s用于观察并发执行顺序。通过Run()将多个子测试“封装”到一个组中,可以保证所有子测试全部执行结束后再执行tear-down。
输出如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
=== RUN TestSubParallel
/Users/forz/Code/go/src/example/main_test.go:33: Setup
=== RUN TestSubParallel/group
=== RUN TestSubParallel/group/Test1
=== PAUSE TestSubParallel/group/Test1
=== RUN TestSubParallel/group/Test2
=== PAUSE TestSubParallel/group/Test2
=== RUN TestSubParallel/group/Test3
=== PAUSE TestSubParallel/group/Test3
=== CONT TestSubParallel/group/Test1
=== CONT TestSubParallel/group/Test2
=== CONT TestSubParallel/group/Test3
parallel test 3
parallel test 2
parallel test 1
=== CONT TestSubParallel
/Users/forz/Code/go/src/example/main_test.go:42: teardown
--- PASS: TestSubParallel (3.01s)
--- PASS: TestSubParallel/group (0.00s)
--- PASS: TestSubParallel/group/Test3 (1.01s)
--- PASS: TestSubParallel/group/Test2 (2.01s)
--- PASS: TestSubParallel/group/Test1 (3.01s)
PASS
coverage: 0.0% of statements
ok example 3.012s coverage: 0.0% of statements
|
通过该输出可以看出:
- 子测试是并发执行的(Test1最先被执行却最后结束)
- tear-down在所有子测试结束后才执行
基准测试
基准测试和普通单元测试类似。 唯一的区别是基准测试接收的参数是*testing.B 而不是 *testing.T。 这两种类型都实现了 testing.TB 接口,这个接口提供了一些比较常用的方法 Errorf(), Fatalf(), and FailNow()。
测试函数的名字必须以 Benchmark 开头,可选的后缀名必须不以小写字母开头,一般跟我们测试的函数名。
比如你有一个简单的函数:
1
2
3
4
5
6
7
8
9
10
11
|
// 此函数计算斐波那契数列中第 N 个数字
func Fib(n int) int {
switch n {
case 0:
return 0
case 1:
return 1
default:
return Fib(n-1) + Fib(n-2)
}
}
|
我们可以使用 testing 包以如下形式为此函数写一个基准测试。基准测试函数也写在以 _test.go 结尾的文件里,它和test函数共存.
1
2
3
4
5
|
func BenchmarkFib20(b *testing.B) {
for n := 0; n < b.N; n++ {
Fib(20) // 运行 Fib 函数 N 次
}
}
|
这是一个基准测试的例子,从中我们可以看出以下规则:
- 基准测试的代码文件必须以_test.go结尾
- 基准测试的函数必须以Benchmark开头,必须是可导出的
- 基准测试函数必须接受一个指向Benchmark类型的指针作为唯一参数
- 基准测试函数不能有返回值
- 最后的for循环很重要,被测试的代码要放到循环里
- b.N是基准测试框架提供的,表示循环的次数,因为需要反复调用测试的代码,才可以评估性能
因为基准测试使用testing 包,它们同样通过 go test 命令执行。但是,默认情况下,当你调用go test时,基准测试是不执行的。
要显式地执行基准测试请使用 -bench 标识。 -bench 接收一个与待运行的基准测试名称相匹配的正则表达式,因此,如果要运行包中所有的基准测试,最常见的方法是这样写 -bench=.。-bench选项的值是一个简单的模式,.表示匹配所有的,Fib表示运行名字中有Fib的。例如:
1
2
3
4
5
6
|
% go test -bench=. ./examples/fib/
goos: darwin
goarch: amd64
BenchmarkFib20-8 30000 44514 ns/op
PASS
ok _/Users/dfc/devel/gophercon2018-performance-tuning-workshop/2-benchmarking/examples/fib 1.795s
|
注意: go test 会在运行基准测试之前之前执行包里所有的单元测试,所有如果你的包里有很多单元测试,或者它们会运行很长时间,你也可以通过 go test 的-run 标识排除这些单元测试,不让它们执行; 比如: go test -run=^$。
基准测试函数会被一直调用直到b.N无效,它是基准测试循环的次数
b.N 从 1 开始,如果基准测试函数在1秒内就完成 (默认值),则 b.N 增加,并再次运行基准测试函数。
b.N 在近似这样的序列中不断增加;1, 2, 3, 5, 10, 20, 30, 50, 100 等等。 基准框架试图变得聪明,如果它看到当b.N较小而且测试很快就完成的时候,它将让序列增加地更快。
看上面的例子, BenchmarkFib20-8 发现约 30000 次迭代只需要1秒钟。 From there the benchmark framework computed that
注意: The -8 后缀和用于运行次测试的 GOMAXPROCS 值有关。 与GOMAXPROCS一样,此数字默认为启动时Go进程可见的CPU数。 你可以使用-cpu标识更改此值,可以传入多个值以列表形式来运行基准测试。
1
2
3
4
5
6
7
|
% go test -bench=. -cpu=1,2,4 ./examples/fib/
goos: darwin
goarch: amd64
BenchmarkFib20 30000 44644 ns/op
BenchmarkFib20-2 30000 44504 ns/op
BenchmarkFib20-4 30000 44848 ns/op
PASS
|
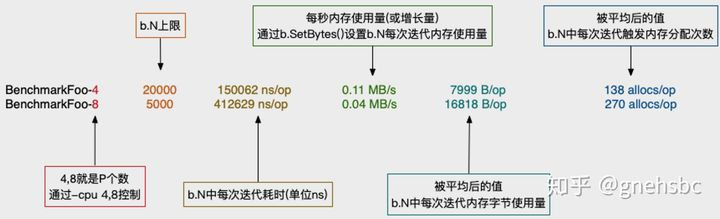
B 类型有一个参数 N,它可以用来只是基准测试的迭代运行的次数。基准测试与测试,基准测试总是会输出日志。
1
2
3
4
|
type B struct {
N int
// contains filtered or unexported fields
}
|
基准测试较测试多了些函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
func (c *B) Log(args ...interface{})
func (c *B) Logf(format string, args ...interface{})
func (c *B) Fail()
func (c *B) FailNow()
func (c *B) Failed() bool
func (c *B) Error(args ...interface{})
func (c *B) Errorf(format string, args ...interface{})
func (c *B) Fatal(args ...interface{})
func (c *B) Fatalf(format string, args ...interface{})
func (c *B) Helper()
func (c *B) Name() string
func (b *B) Run(name string, f func(b *B)) bool
func (c *B) Skip(args ...interface{})
func (c *B) SkipNow()
func (c *B) Skipf(format string, args ...interface{})
func (c *B) Skipped() bool
// 打开当前基准测试的内存统计功能,与使用 -test.benchmem 设置类似,
// 但 ReportAllocs 只影响那些调用了该函数的基准测试。
func (b *B) ReportAllocs()
// 对已经逝去的基准测试时间以及内存分配计数器进行清零。对于正在运行中的计时器,这个方法不会产生任何效果。
func (b *B) ResetTimer()
例:
func BenchmarkBigLen(b *testing.B) {
big := NewBig()
b.ResetTimer()
for i := 0; i < b.N; i++ {
big.Len()
}
}
// 以并行的方式执行给定的基准测试。RunParallel 会创建出多个 goroutine,并将 b.N 个迭代分配给这些 goroutine 执行,
// 其中 goroutine 数量的默认值为 GOMAXPROCS。用户如果想要增加非CPU受限(non-CPU-bound)基准测试的并行性,
// 那么可以在 RunParallel 之前调用 SetParallelism。RunParallel 通常会与 -cpu 标志一同使用。
// body 函数将在每个 goroutine 中执行,这个函数需要设置所有 goroutine 本地的状态,
// 并迭代直到 pb.Next 返回 false 值为止。因为 StartTimer、StopTimer 和 ResetTimer 这三个函数都带有全局作用,所以 body函数不应该调用这些函数;
// 除此之外,body 函数也不应该调用 Run 函数。
func (b *B) RunParallel(body func(*PB))
例:
func BenchmarkTemplateParallel(b *testing.B) {
templ := template.Must(template.New("test").Parse("Hello, {{.}}!"))
b.RunParallel(func(pb *testing.PB) {
var buf bytes.Buffer
for pb.Next() {
buf.Reset()
templ.Execute(&buf, "World")
}
})
}
// 记录在单个操作中处理的字节数量。 在调用了这个方法之后, 基准测试将会报告 ns/op 以及 MB/s
func (b *B) SetBytes(n int64)
// 将 RunParallel 使用的 goroutine 数量设置为 p*GOMAXPROCS,如果 p 小于 1,那么调用将不产生任何效果。
// CPU受限(CPU-bound)的基准测试通常不需要调用这个方法。
func (b *B) SetParallelism(p int)
// 开始对测试进行计时。
// 这个函数在基准测试开始时会自动被调用,它也可以在调用 StopTimer 之后恢复进行计时。
func (b *B) StartTimer()
// 停止对测试进行计时。
func (b *B) StopTimer()
|
子测试:Run(表格驱动测试)
Run的作用就是生成一个subbenchmark,每一个subbenchmark都被当成一个普通的Benchmark执行。
在 Go 1.7 之前,不可能使用相同的 table-driven 方法进行基准测试。 基准测试对整个函数的性能进行测试,因此迭代基准测试只是将它们整体作为一个基准测试。
常见的解决方法是定义单独的顶级基准,每个基准用不同的参数调用共同的函数。 例如,在 1.7 之前,strconv 包的 AppendFloat 的基准测试看起来像这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
func benchmarkAppendFloat(b *testing.B, f float64, fmt byte, prec, bitSize int) {
dst := make([]byte, 30)
b.ResetTimer() // Overkill here, but for illustrative purposes.
for i := 0; i < b.N; i++ {
AppendFloat(dst[:0], f, fmt, prec, bitSize)
}
}
func BenchmarkAppendFloatDecimal(b *testing.B) {
benchmarkAppendFloat(b, 33909, 'g', -1, 64)
}
func BenchmarkAppendFloat(b *testing.B) {
benchmarkAppendFloat(b, 339.7784, 'g', -1, 64)
}
func BenchmarkAppendFloatExp(b *testing.B) {
benchmarkAppendFloat(b, -5.09e75, 'g', -1, 64)
}
func BenchmarkAppendFloatNegExp(b *testing.B) {
benchmarkAppendFloat(b, -5.11e-95, 'g', -1, 64)
}
func BenchmarkAppendFloatBig(b *testing.B) {
benchmarkAppendFloat(b, 123456789123456789123456789, 'g', -1, 64)
}
|
使用 Go 1.7 中提供的 Run 方法,现在将同一组基准表示为单个顶级基准:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func BenchmarkAppendFloat(b *testing.B) {
benchmarks := []struct {
name string
float float64
fmt byte
prec int
bitSize int
}{
{"Decimal", 33909, 'g', -1, 64},
{"Float", 339.7784, 'g', -1, 64},
{"Exp", -5.09e75, 'g', -1, 64},
{"NegExp", -5.11e-95, 'g', -1, 64},
{"Big", 123456789123456789123456789, 'g', -1, 64},
}
dst := make([]byte, 30)
for _, bm := range benchmarks {
b.Run(bm.name, func(b *testing.B) {
for i := 0; i < b.N; i++ {
AppendFloat(dst[:0], bm.float, bm.fmt, bm.prec, bm.bitSize)
}
})
}
}
|
每次调用 Run 方法创建一个单独的基准测试。调用 Run 方法的基准函数只运行一次,不进行性能度量。
新代码行数更多,但是更可维护,更易读,并且与通常用于测试的 table-driven 方法一致。 此外,共同的 setup 代码现在在 Run 之间共享,而不需要重置定时器。
并发:RunParallel
1
2
3
4
5
6
7
|
func BenchmarkFoo(b *testing.B) {
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
dosomething()
}
})
}
|
如果代码只是像上例这样写,那么并行的goroutine个数是默认等于runtime.GOMAXPROCS(0)。
创建P个goroutine之后,再把b.N打散到每个goroutine上执行。所以并行用法就比较适合IO型的测试对象。
SetParallelism 将 RunParallel 使用的 goroutine 数量设置为 p * GOMAXPROCS ,如果 p 小于 1 ,那么调用将不产生任何效果。
1
|
func (b *B) SetParallelism(p int)
|
CPU受限(CPU-bound)的基准测试通常不需要调用这个方法。
1
2
|
// 最终goroutine个数 = 形参p的值 *runtime.GOMAXPROCS(0)
numProcs := b.parallelism * runtime.GOMAXPROCS(0)
|
要注意,b.SetParallelism()的调用一定要放在b.RunParallel()之前。
并行用法带来一些启示,注意到b.N是被RunParallel()接管的。意味着,开发者可以自己写一个RunParallel()方法,goroutine个数和b.N的打散机制自己控制。或接管b.N之后,定制自己的策略。
要注意b.N会递增,这次b.N执行完,不满足终止条件,就会递增b.N,逼近上限,直至满足终止条件。
1
2
3
|
// 终止策略: 执行过程中没有竟态问题 & 时间没超出 & 次数没达到上限
// d := b.benchTime
if !b.failed && b.duration < d && n < 1e9 {}
|
benchtime & count
fib 函数是一个模拟的例子 — 除非你编写 TechPower 服务器基准测试来验证,否则你的业务不太可能是你计算斐波那契数列中第20个数字的速度。 但是,基准确实展现了我认为有效的基准。
具体来说,当你的基准测试运行几千次迭代的时候,我们可以认为获得了一个每次运行的平均值,而如果基准测试只运行几十次,那么这个平均值很可能不稳定,也就不能说明问题。
要增加迭代次数,可以使用-benchtime标识增加运行时间,例如
1
2
3
4
|
% go test -bench=. -benchtime=10s ./examples/fib/
goos: darwin
goarch: amd64
BenchmarkFib20-8 300000 44616 ns/op
|
运行一个相同的基准测试,直到它到达b.N的值,运行时间超过10秒。当我们运行时间是10倍的时候,迭代次数也会增加到10倍。然而每一次执行的结果却没有什么变化,这正是我们所预期的。
如果你有一个基准测试,它运行数百万次或数十亿次迭代,每次操作的时间都在微秒或纳秒级,那么你可能会发现基准测试结果不稳定,因为热缩放、内存局部性、后台处理、gc活动等等。
对于每次操作是以10或个位数纳秒为单位计算的函数来说,指令重新排序和代码对齐的相对效应都将对结果产生影响。
可以使用-count 标识多次运行基准测试来解决这个问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
% go test -bench=Fib1 -count=10 ./examples/fib/
goos: darwin
goarch: amd64
BenchmarkFib1-8 2000000000 1.99 ns/op
BenchmarkFib1-8 1000000000 1.95 ns/op
BenchmarkFib1-8 2000000000 1.99 ns/op
BenchmarkFib1-8 2000000000 1.97 ns/op
BenchmarkFib1-8 2000000000 1.99 ns/op
BenchmarkFib1-8 2000000000 1.96 ns/op
BenchmarkFib1-8 2000000000 1.99 ns/op
BenchmarkFib1-8 2000000000 2.01 ns/op
BenchmarkFib1-8 2000000000 1.99 ns/op
BenchmarkFib1-8 1000000000 2.00 ns/op
|
得出Fib(1)的基准测试在2纳秒左右,方差为正负2%.
提示: 如果你发现需要针对特定的包调整不同的默认值,我建议使用Makefile中完成这些设定,这样每个想要运行基准测试的人都可以使用相同的配置进行编码。
结果对比:benchstat
先前的Fib函数对斐波纳契数列中的第0和第1个数字进行了硬编码。 之后,代码以递归方式调用自身。 我们将在后边讨论递归的代价,但目前,假设它有代价,特别当我们的算法是指数级复杂度的时候。
要解决这个问题,最简单的方法就是硬编码斐波那契数列中的另一个数字,将每次调用的深度减少一个。
1
2
3
4
5
6
7
8
9
10
11
12
|
func Fib(n int) int {
switch n {
case 0:
return 0
case 1:
return 1
case 2:
return 1
default:
return Fib(n-1) + Fib(n-2)
}
}
|
为了比较我们的新版本,我们编译了一个新的测试二进制文件并对它们都进行了基准测试,并使用benchstat对输出进行比较。
1
2
3
4
5
6
|
% go test -c
% ./fib.golden -test.bench=. -test.count=10 > old.txt
% ./fib.test -test.bench=. -test.count=10 > new.txt
% benchstat old.txt new.txt
name old time/op new time/op delta
Fib20-8 44.3µs ± 6% 25.6µs ± 2% -42.31% (p=0.000 n=10+10)
|
比较基准测试时需要检查三件事
- 新老两次的方差。1-2% 是不错的, 3-5% 也还行,但是大于5%的话,可能不太可靠。 在比较一方具有高差异的基准时要小心,您可能看不到改进。
- p值。p值低于0.05是比较好的情况,大于0.05则意味着基准测试结果可能没有统计学意义。
- 样本不足。benchstat将报告它认为有效的新旧样本的数量,有时你可能只发现9个报告,即使你设置了
-count=10。拒绝率小于10%一般是没问题的,而高于10%可能表明你的设置是不稳定的,也可能是比较的样本太少了。
Start/Stop/ResetTimer
benchmark中难免有一些初始化的工作,这些工作耗时不希望被计算进benchmark结果中。
通常做法是
1
2
3
4
5
6
7
8
9
|
// 串行情况在for循环之前调用
init() // 初始化工作
b.ResetTimer()
for i:=0; i<b.N; i++ { dosomething() }
// 并行情况在b.RunParallel()之前调用
init() // 初始化工作
b.ResetTimer()
b.RunParallel(func(pb *testing.PB) { dosomething() })
|
剩下的StopTimer()和ResetTimer()呢?可以这样用:
1
2
3
4
5
6
7
|
init(); // 初始化工作
b.ResetTimer()
for i:=0; i<b.N; i++ { dosomething1() }
b.StopTimer()
otherWork(); // 例如做一些转换工作
b.StartTimer()
for i:=0; i<b.N; i++ { dosomething2() }
|
也可以这样用:
1
2
3
4
5
6
7
8
9
10
|
init(); // 初始化工作
b.ResetTimer()
for i:=0; i<b.N; i++ {
flag := dosomething()
if flag {
b.StopTimer()
} else {
b.StartTimer()
}
}
|
理解好这三个方法本质后灵活运用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
func (b *B) StartTimer() {
if !b.timerOn {
// 记录当前时间为开始时间 和 内存分配情况
b.timerOn = true
}
}
func (b *B) StopTimer() {
if b.timerOn {
// 累计记录执行的时间(当前时间 - 记录的开始时间)
// 累计记录内存分配次数和分配字节数
b.timerOn = false
}
}
func (b *B) ResetTimer() {
if b.timerOn {
// 记录当前时间为开始时间 和 内存分配情况
}
// 清空所有的累计变量
}
|
ReportAllocs & benchmem
分配计数和大小与基准测试的执行时间密切相关。 你可以告诉测试框架记录被测代码所做的分配数量。
1
2
3
4
5
6
|
func BenchmarkRead(b *testing.B) {
b.ReportAllocs()
for n := 0; n < b.N; n++ {
// 被测试的功能
}
}
|
ReportAllocs打开当前基准测试的内存统计功能,与使用 -test.benchmem 设置类似,但 ReportAllocs 只影响那些调用了该函数的基准测试。
以下是使用bufio软件包基准测试的示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
% go test -run=^$ -bench=. bufio
goos: darwin
goarch: amd64
pkg: bufio
BenchmarkReaderCopyOptimal-8 20000000 103 ns/op
BenchmarkReaderCopyUnoptimal-8 10000000 159 ns/op
BenchmarkReaderCopyNoWriteTo-8 500000 3644 ns/op
BenchmarkReaderWriteToOptimal-8 5000000 344 ns/op
BenchmarkWriterCopyOptimal-8 20000000 98.6 ns/op
BenchmarkWriterCopyUnoptimal-8 10000000 131 ns/op
BenchmarkWriterCopyNoReadFrom-8 300000 3955 ns/op
BenchmarkReaderEmpty-8 2000000 789 ns/op 4224 B/op 3 allocs/op
BenchmarkWriterEmpty-8 2000000 683 ns/op 4096 B/op 1 allocs/op
BenchmarkWriterFlush-8 100000000 17.0 ns/op 0 B/op 0 allocs/op
|
想对所有基准测试都生效,你也可以使用go test -benchmem标识。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
% go test -run=^$ -bench=. -benchmem bufio
goos: darwin
goarch: amd64
pkg: bufio
BenchmarkReaderCopyOptimal-8 20000000 93.5 ns/op 16 B/op 1 allocs/op
BenchmarkReaderCopyUnoptimal-8 10000000 155 ns/op 32 B/op 2 allocs/op
BenchmarkReaderCopyNoWriteTo-8 500000 3238 ns/op 32800 B/op 3 allocs/op
BenchmarkReaderWriteToOptimal-8 5000000 335 ns/op 16 B/op 1 allocs/op
BenchmarkWriterCopyOptimal-8 20000000 96.7 ns/op 16 B/op 1 allocs/op
BenchmarkWriterCopyUnoptimal-8 10000000 124 ns/op 32 B/op 2 allocs/op
BenchmarkWriterCopyNoReadFrom-8 500000 3219 ns/op 32800 B/op 3 allocs/op
BenchmarkReaderEmpty-8 2000000 748 ns/op 4224 B/op 3 allocs/op
BenchmarkWriterEmpty-8 2000000 662 ns/op 4096 B/op 1 allocs/op
BenchmarkWriterFlush-8 100000000 16.9 ns/op 0 B/op 0 allocs/op
PASS
ok bufio 20.366s
|
profile
testing包内置了支持生成CPU,内存和阻塞情况的 profile 文件。
-cpuprofile=$FILE 将 CPU 分析结果写入 $FILE.-memprofile=$FILE 将内存分析结果写入 $FILE-memprofilerate=N 调整记录速率为 1/N.-blockprofile=$FILE, 将阻塞分析结果写入 $FILE.-mutexprofile=$FILE 将锁分析结果写入$FILE.
使用这些标识中的任何一个同时都会保留二进制文件。
1
2
|
% go test -run=XXX -bench=. -cpuprofile=c.p
% go tool pprof c.p
|
SetBytes
1
|
func (b *B) SetBytes(n int64)
|
记录在单个操作中处理的字节数量。在调用了这个方法之后,基准测试将会报告 ns/op 以及 MB/s。形参n表示在b.N次循环中,每一次循环用到了多少字节内存。
最后在benchmark输出结果中会多出MB/s这一项信息。MB/s取值公式如下:
1
|
(float64(r.Bytes) * float64(r.N) / 1e6) / r.T.Seconds()
|
意思是这次benchmark每秒大约用了多少MB的内存。
这玩意儿有啥用?个人理解,它可以大概估算堆内存增长趋势来判断GC被触发频率。
例如下面例子,dAtA这种返回值变量一般是被分配在堆上的。最后通过b.SetBytes(int64(total / b.N))来估算下每秒分配多少MB内存。
MB/s值大小的影响要结合GOGC的值来理解,默认GOGC是100,即堆内存增长一倍就被触发GC。如果MB/s值比较小,可以大概认为GC被触发频率较低;反之较高;
1
2
3
4
5
6
7
8
|
for i := 0; i < b.N; i++ {
dAtA, err := github_com_gogo_protobuf_proto.Marshal(pops[i%10000])
if err != nil {
panic(err)
}
total += len(dAtA)
}
b.SetBytes(int64(total / b.N))
|
编译优化
这个例子来自 issue 14813。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
const m1 = 0x5555555555555555
const m2 = 0x3333333333333333
const m4 = 0x0f0f0f0f0f0f0f0f
const h01 = 0x0101010101010101
func popcnt(x uint64) uint64 {
x -= (x >> 1) & m1
x = (x & m2) + ((x >> 2) & m2)
x = (x + (x >> 4)) & m4
return (x * h01) >> 56
}
func BenchmarkPopcnt(b *testing.B) {
for i := 0; i < b.N; i++ {
popcnt(uint64(i))
}
}
|
你觉得这个基准测试会有多快?让我们来看看。
1
2
3
4
5
|
% go test -bench=. ./examples/popcnt/
goos: darwin
goarch: amd64
BenchmarkPopcnt-8 2000000000 0.30 ns/op
PASS
|
0.3 纳秒,这基本上是一个时钟周期。即使假设CPU每个时钟周期内会执行多条指令,这个数字似乎也不合理地低。 发生了什么?
要了解发生了什么,我们必须看看benchmark下的函数popcnt。 popcnt是一个叶子函数 - 它不调用任何其他函数 - 因此编译器可以内联它。
因为函数是内联的,所以编译器现在可以看到它没有副作用。 popcnt不会影响任何全局变量的状态。 这样,调用就被消除了。 这是编译器看到的:
1
2
3
4
5
|
func BenchmarkPopcnt(b *testing.B) {
for i := 0; i < b.N; i++ {
// 优化了
}
}
|
在所有版本的Go编译器上,仍然会生成循环。 但是英特尔CPU非常擅长优化循环,尤其是空循环。
原理介绍
以单个Benchmark举例串起流程分析下原理。
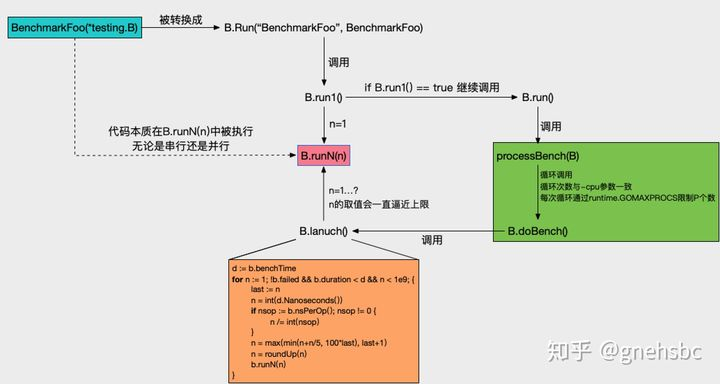
如上图,浅蓝色部分就是开发者自行编写的benchmark方法,调用逻辑按箭头方向依次递进。
B.run1()的作用是先尝试跑一次,在这次尝试中要做 竞态检查 和 当前benchmark是否被skip了。目的检查当前benchmark是否有必要继续执行。
go test 命令有-cpu参数,用于控制benchmark分别在不同的P数量下执行。这里就对应上图绿色部分,每次通过runtime.GOMAXPROCS(n)更新P个数,然后调用B.doBench()。
核心方法是红色部分的B.runN(n)。形参n值就是b.N值,由外部传进。n不断被逼近上限,逼近策略不能过快,过快可能引起benchmark执行超时。
橙色部分就是逼近策略。先通过n/=int(nsop)来估算b.N的上限,然后再通过n=max(min(n+n/5, 100*last), last+1)计算最后的b.N。benchmark可能是CPU型或IO型,若直接使用第一次估算的b.N值会过于粗暴,可能使结果不准确,所以需要做进一步的约束来逼近。
示例测试
示例测试用于演示模块或函数的使用。同样地,示例测试也在文件_test.go中编写,并且示例测试函数名必须是ExampleXxx的形式。在Example*函数中编写代码,然后在注释中编写期望的输出,go test会运行该函数,然后将实际输出与期望的做比较。下面摘取自 Go 源码net/url/example_test.go文件中的代码演示了url.Values的用法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func ExampleValuesGet() {
v := url.Values{}
v.Set("name", "Ava")
v.Add("friend", "Jess")
v.Add("friend", "Sarah")
v.Add("friend", "Zoe")
fmt.Println(v.Get("name"))
fmt.Println(v.Get("friend"))
fmt.Println(v["friend"])
// Output:
// Ava
// Jess
// [Jess Sarah Zoe]
}
|
注释中Output:后是期望的输出结果,go test会运行这些函数并与期望的结果做比较,比较会忽略空格。
有时候我们输出的顺序是不确定的,这时就需要使用Unordered Output。我们知道url.Values底层类型为map[string][]string,所以可以遍历输出所有的键值,但是输出顺序不确定:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func ExampleValuesAll() {
v := url.Values{}
v.Set("name", "Ava")
v.Add("friend", "Jess")
v.Add("friend", "Sarah")
v.Add("friend", "Zoe")
for key, values := range v {
fmt.Println(key, values)
}
// Unordered Output:
// name [Ava]
// friend [Jess Sarah Zoe]
}
|
运行:
1
2
3
4
5
6
7
8
|
$ go test -v
$ go test -v
=== RUN ExampleValuesGet
--- PASS: ExampleValuesGet (0.00s)
=== RUN ExampleValuesAll
--- PASS: ExampleValuesAll (0.00s)
PASS
ok github.com/darjun/url 0.172s
|
没有注释,或注释中无Output/Unordered Output的函数会被忽略。
关于示例函数我们需要知道:
- 函数的签名需要以 Example 开头
- 输出的对比有有序(Output)和无序(Unordered output)两种
- 如果函数没有输出注释,将不会被执行
官方给我们的命名的规则是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// 一个包的 example
func Example() { ... }
// 一个函数 F 的 example
func ExampleF() { ... }
// 一个类型 T 的 example
func ExampleT() { ... }
// 一个类型 T 的方法 M 的 example
func ExampleT_M() { ... }
// 如果以上四种类型需要提供多个示例,可以通过添加后缀的方式
// 后缀必须小写
func Example_suffix() { ... }
func ExampleF_suffix() { ... }
func ExampleT_suffix() { ... }
func ExampleT_M_suffix() { ... }
|
主测试
有一种特殊的测试函数,函数名为TestMain(),接受一个*testing.M类型的参数。这个函数一般用于在运行所有测试前执行一些初始化逻辑(如创建数据库链接),或所有测试都运行结束之后执行一些清理逻辑(释放数据库链接)。如果测试文件中定义了这个函数,则go test命令会直接运行这个函数,否者go test会创建一个默认的TestMain()函数。这个函数的默认行为就是运行文件中定义的测试。我们自定义TestMain()函数时,也需要手动调用m.Run()方法运行测试函数,否则测试函数不会运行。默认的TestMain()类似下面代码:
1
2
3
|
func TestMain(m *testing.M) {
os.Exit(m.Run())
}
|
下面自定义一个TestMain()函数,打印go test支持的选项:
1
2
3
4
5
6
7
|
func TestMain(m *testing.M) {
flag.Parse()
flag.VisitAll(func(f*flag.Flag) {
fmt.Printf("name:%s usage:%s value:%v\n", f.Name, f.Usage, f.Value)
})
os.Exit(m.Run())
}
|
运行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
$ go test -v
name:test.bench usage:run only benchmarks matching `regexp` value:
name:test.benchmem usage:print memory allocations for benchmarks value:false
name:test.benchtime usage:run each benchmark for duration `d` value:1s
name:test.blockprofile usage:write a goroutine blocking profile to `file` value:
name:test.blockprofilerate usage:set blocking profile `rate` (see runtime.SetBlockProfileRate) value:1
name:test.count usage:run tests and benchmarks `n` times value:1
name:test.coverprofile usage:write a coverage profile to `file` value:
name:test.cpu usage:comma-separated `list` of cpu counts to run each test with value:
name:test.cpuprofile usage:write a cpu profile to `file` value:
name:test.failfast usage:do not start new tests after the first test failure value:false
name:test.list usage:list tests, examples, and benchmarks matching `regexp` then exit value:
name:test.memprofile usage:write an allocation profile to `file` value:
name:test.memprofilerate usage:set memory allocation profiling `rate` (see runtime.MemProfileRate) value:0
name:test.mutexprofile usage:write a mutex contention profile to the named file after execution value:
name:test.mutexprofilefraction usage:if >= 0, calls runtime.SetMutexProfileFraction() value:1
name:test.outputdir usage:write profiles to `dir` value:
name:test.paniconexit0 usage:panic on call to os.Exit(0) value:true
name:test.parallel usage:run at most `n` tests in parallel value:8
name:test.run usage:run only tests and examples matching `regexp` value:
name:test.short usage:run smaller test suite to save time value:false
name:test.testlogfile usage:write test action log to `file` (for use only by cmd/go) value:
name:test.timeout usage:panic test binary after duration `d` (default 0, timeout disabled) value:10m0s
name:test.trace usage:write an execution trace to `file` value:
name:test.v usage:verbose: print additional output value:tru
|
这些选项也可以通过go help testflag查看。
TestMain 会在主 goroutine 中运行,并做一些 setup 和 teardown,主测试需要调用os.Exit(m.Run())
给一个例子吧: example_test.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
package example
import (
"testing"
"os"
)
var s string
func TestA(t *testing.T) {
t.Logf("%s", s)
}
func TestMain(m *testing.M) {
s = "1"
os.Exit(m.Run())
}
func TestB(t *testing.T) {
t.Logf("%s", s)
}
|
go test -v $(go list ./...) 输出:
1
2
3
4
5
6
7
|
=== RUN TestA
--- PASS: TestA (0.00s)
a_test.go:11: 1
=== RUN TestB
--- PASS: TestB (0.00s)
a_test.go:20: 1
PASS
|
可以看到TestMain初始化了变量 s,然后函数TestMain上面和下面的函数获取到的都是字符串 1
帮助函数(helpers)
对一些重复的逻辑,抽取出来作为公共的帮助函数(helpers),可以增加测试代码的可读性和可维护性。 借助帮助函数,可以让测试用例的主逻辑看起来更清晰。
例如,我们可以将创建子测试的逻辑抽取出来:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
// calc_test.go
package main
import "testing"
type calcCase struct{ A, B, Expected int }
func Mul(a int, b int) int {
return a * b
}
func createMulTestCase(t *testing.T, c *calcCase) {
// t.Helper()
if ans := Mul(c.A, c.B); ans != c.Expected {
t.Fatalf("%d * %d expected %d, but %d got",
c.A, c.B, c.Expected, ans)
}
}
func TestMul(t *testing.T) {
createMulTestCase(t, &calcCase{2, 3, 6})
createMulTestCase(t, &calcCase{2, -3, -6})
createMulTestCase(t, &calcCase{2, 0, 1}) // wrong case
}
|
在这里,我们故意创建了一个错误的测试用例,运行 go test,用例失败,会报告错误发生的文件和行号信息:
1
2
3
4
5
6
|
=== RUN TestMul
/Users/forz/Code/go/src/example/main_test.go:15: 2 * 0 expected 1, but 0 got
--- FAIL: TestMul (0.00s)
FAIL
coverage: 0.0% of statements
FAIL example 0.004s
|
可以看到,错误发生在第15行,也就是帮助函数 createMulTestCase 内部。18, 19, 20行都调用了该方法,我们第一时间并不能够确定是哪一行发生了错误。有些帮助函数还可能在不同的函数中被调用,报错信息都在同一处,不方便问题定位。因此,Go 语言在 1.9 版本中引入了 t.Helper(),用于标注该函数是帮助函数,报错时将输出帮助函数调用者的信息,而不是帮助函数的内部信息。
修改 createMulTestCase,调用 t.Helper()
1
2
3
4
5
6
7
|
func createMulTestCase(t *testing.T, c *calcCase) {
t.Helper()
if ans := Mul(c.A, c.B); ans != c.Expected {
t.Fatalf("%d * %d expected %d, but %d got",
c.A, c.B, c.Expected, ans)
}
}
|
运行 go test,报错信息如下,可以非常清晰地知道,错误发生在第 23 行。
1
2
3
4
5
6
|
=== RUN TestMul
/Users/forz/Code/go/src/example/main_test.go:23: 2 * 0 expected 1, but 0 got
--- FAIL: TestMul (0.00s)
FAIL
coverage: 0.0% of statements
FAIL example 0.004s
|
关于 helper 函数的 2 个建议:
- 不要返回错误, 帮助函数内部直接使用 t.Error 或 t.Fatal 即可,在用例主逻辑中不会因为太多的错误处理代码,影响可读性。
- 调用 t.Helper() 让报错信息更准确,有助于定位。
禁用测试缓存
项目开发在做单元测试, 发现跑测试 cases 的时候,每一个跑完,日志后都带有一个 (cached) 的标志。尽管代码的实现已经做了修改(比如返回不同数据), 但是发现再次执行 go test -v case_test.go ,返回跟上一次的结果居然一致,实际上这样的测试是没多少意义的。
问题分析
Go 官方文档详细说明了 test 包的工作原理:在执行 go test 时会编译每个包和所有后缀匹配 *_test.go 命名的文件(这些测试文件包括一些单元测试和基准测试),链接和执行生成的二进制程序, 然后打印每一个测试函数的输出日志。
Go test 支持两种模式:
- Local directory mode, 在调用 go test 时,没有加参数 (比如 go test 或 go test -v)。在这种模式下,缓存会被禁用。 会编译当前目录下的代码和测试,然后运行测试二进制程序。
- Package list mode,执行 go test时,指定文件路径 (比如 go test math, go test ./…)。在这种模式下,会编译并测试路径列出的每个测试文件。go test 会缓存成功的测试结果,以避免不必要的重复运行测试。当再次执行测试时,会检查缓存中对应的测试结果是否 OK, 如果 OK 会重新显示之前的输出,而不会运行测试二进制文件。此时 go test 会打印 ‘(cached)’ 标识。
回过头来再看下项目的测试脚本:
1
|
CGO_ENABLED=1 go test -v --mod=vendor ./pkg/...
|
运行在 Package list mode, 所以单测通过后的二次测试, 会走 cache。
解决方案
有以下三种方式, 在测试中禁用缓存:
-
执行 go test添加 –count=1 参数(推荐,效率高),以上面 例子:
1
|
CGO_ENABLED=1 go test -v --count=1 --mod=vendor ./pkg/...
|
-
Go 官方提供 clean工具,来删除对象文件和缓存文件, 不过这种方式相对麻烦:
1
|
go clean -testcache // Delete all cached test results
|
-
设置 GOCACHE 环境变量。GOCACHE 指定了 go 命令执行时缓存的路径,以便之后被复用。 设置 GOCACHE=off 即可禁用缓存。
子进程测试
最近在写 logger 的单元测试的时候遇到了一个问题,如果直接执行 logger.Fatal,由于这个函数底层调用了 os.Exit(1) ,进程会直接终止,testing 包会认为 test failed.虽然这是个简单的函数,而且几乎用不上,但是迫于强迫症,必须给他安排一个单元测试。
后来意外找到了Andrew Gerrand(Golang的开发者之一) 在 Google I/O 2014 上一篇关于测试技巧的slide(见附录),里面有讲到 subporcess tests, 也就是子进程测试,内容如下:
1
|
Sometimes you need to test the behavior of a process, not just a function.
|
1
2
3
4
|
func Crasher() {
fmt.Println("Going down in flames!")
os.Exit(1)
}
|
To test this code, we invoke the test binary itself as a subprocess:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func TestCrasher(t *testing.T) {
if os.Getenv("BE_CRASHER") == "1" {
Crasher()
return
}
cmd := exec.Command(os.Args[0], "-test.run=TestCrasher")
cmd.Env = append(os.Environ(), "BE_CRASHER=1")
err := cmd.Run()
if e, ok := err.(*exec.ExitError); ok && !e.Success() {
return
}
t.Fatalf("process ran with err %v, want exit status 1", err)
}
|
这里讲到如果我们要测试进程的行为,而不仅仅是函数,那么我们可以通过单元测试的二进制文件创建一个子进程来测试。所以回过头来,从测试的角度出发,我们需要测试Fatal函数的这两个行为:
所以我们单元测试就需要覆盖函数的这两个行为,Andrew Gerrand 讲的子进程测试的技巧,正好适用这种情况。所以可以参考这个例子,给Fatal写一个单元测试
假设我们的Fatal函数是基于标准库的log包的封装
1
2
3
4
5
|
package logger
func Fatal(v ...interface{}){
log.Fatal(v...)
}
|
这里我们可以先看下标准库log包的实现(事实上 zap/logrus 等log包的Fatal函数也是类似的,最终都调用了os.Exit(1))
1
2
3
4
|
func Fatal(v ...interface{}) {
std.Output(2, fmt.Sprint(v...)) //输出到标准输出/标准错误输出
os.Exit(1) // 有错误地退出进程
}
|
先按正常的思路写一个单元测试
1
2
3
|
func TestFatal(t *testing.T) {
Fatal("fatal log")
}
|
执行单元测试的结果如下,如我之前所说,结果是FAIL
1
2
3
4
5
|
go test -v
=== RUN TestFatal
2020/01/11 11:39:24 fatal log
exit status 1
FAIL github.com/YouEclipse/mytest/log 0.001
|
我们照猫画虎,尝试写一个子进程测试,这里我把标准输出和标准错误输出都打印出来了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func TestFatal(t*testing.T) {
if os.Getenv("SUB_PROCESS") == "1" {
Fatal("fatal log")
return
}
var outb, errb bytes.Buffer
cmd := exec.Command(os.Args[0], "-test.run=TestFatal")
cmd.Env = append(os.Environ(), "SUB_PROCESS=1")
cmd.Stdout = &outb
cmd.Stderr = &errb
err := cmd.Run()
if e, ok := err.(*exec.ExitError); ok && !e.Success() {
fmt.Print(cmd.Stderr)
fmt.Print(cmd.Stdout)
return
}
t.Fatalf("process ran with err %v, want exit status 1", err)
}
|
执行单元测试,结果果然是成功的,达到了我们的预期
1
2
3
4
5
6
|
go test -v
=== RUN TestFatal
2020/01/11 11:40:38 fatal log
--- PASS: TestFatal (0.00s)
PASS
ok github.com/YouEclipse/mytest/log 0.002s
|
当然,我们不仅要知其然,更要知其所以然。我们分析一下子进程测试代码为什么是这样写
-
通过os.Getenv获取环境变量,这里值为空,所以Fatal并不会执行
-
定义了outb,errb,这里是为了后续捕捉标准输出和标准错误输出
-
调用exec.Command 根据传入的参数构造一个Cmd的结构体
exec 是标准库中专门用于执行命令的的包,这里不做太多赘述
我们可以看到,exec.Cmmand 第一个参数是要执行的命令或者二进制文件的名字,第二个参数是不定参数,是我们需要执行的命令的参数
这里我们第一个参数传入了os.Args[0], os.Args[0]是程序启动时的程序的二进制文件的路径,第二个参数是执行二进制文件时的参数。至于为什么是os.Args[0]而不是os.Args[1]或者os.Args[2]呢,我们执行一下go test -n,你会看到输出了一堆东西(省略了大部分无关内容)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
mkdir -p $WORK/b001/
#
# internal/cpu
#
...
/usr/local/go/pkg/tool/linux_amd64/compile -o ./_pkg_.a -trimpath "$WORK/b001=>" -p main -complete -buildid 5WmoKx2_LnkcztVfW1Bj/5WmoKx2_LnkcztVfW1Bj -dwarf=false -goversion go1.13.5 -D "" -importcfg ./importcfg -pack -c=4 ./_testmain.go
...
/usr/local/go/pkg/tool/linux_amd64/link -o $WORK/b001/log.test -importcfg $WORK/b001/importcfg.link -s -w -buildmode=exe -buildid=o8I_q2gkkk-Xda8yeh2G/5WmoKx2_LnkcztVfW1Bj/5WmoKx2_LnkcztVfW1Bj/o8I_q2gkkk-Xda8yeh2G -extld=gcc $WORK/b001/_pkg_.a
...
cd /home/yoyo/go/src/github.com/YouEclipse/mytest/log
TERM='dumb' /usr/local/go/pkg/tool/linux_amd64/vet -atomic -bool -buildtags -errorsas -nilfunc -printf $WORK/b052/vet.cfg
$WORK/b001/log.test -test.timeout=10m0s
|
从输出的内容我们可以知道go test最终是将源码文件编译链接成二进制文件(当然还有govet静态检查)执行的。实际上go test和go run最终调用的是同一个函数,这篇文章对此也不做过多讨论,具体可以查看源码中cmd/go/internal/test/test.go和cmd/go/internal/work/build.go这两个文件的内容。
而-n 参数,可以打印go test或者go run 执行过程中用到的所有命令,所以我们在输出的最后一行,执行了最终的二进制文件并且带上了-test.timeout=10m0s默认超时的flag。而os.Args是os包的一个常量,在进程启动时,就会把执行的命令和flag写入
1
2
|
// Args hold the command-line arguments, starting with the program name.
var Args []string
|
所以 os.Args[0]自然获取的就是编译后的二进制文件的完整文件名。
第二个参数-test.run=TestFatal 是执行二进制文件的flag,test.runflag 指定的test的函数名。
当我们执行go test -run TestFatal时,实际上最终就是执行成$WORK/b001/log.test -run=TestFatal
其他flag可以执行go help testflag查看,或者参考 cmd/go/internal/test/testflag.go文件中的testFlagDefn传入,具体定义和说明都在源码中。
- cmd.Env 设置子进程运行的环境变量
os.Environ() 获取当前环境变量的拷贝,我们添加一个SUB_PROCESS环境变量用户判断是否是子进程。
- cmd.Stdout = &outb
- cmd.Stderr = &errb 捕获子进程运行时的标注输出和标准错误,因为我们需要测试是否输出
- cmd.Run() 启动子进程,等待返回结果 如果退出,可能会返回exec.ExitError,可以拿到退出的statusCode,而我们的目的就是测试进程是否退出
- 在子进程中,此时环境变量SUB_PROCESS的值为1,这时候会执行Fatal函数,主进程收到exit code,打印子进程的输出
至此,这段测试代码的原理我们也清楚了。
但是,美中不足的是,在执行go test -cover进行测试覆盖率统计的时候,通过子进程运行的单元测试的函数,并不会被统计上。
参考
go test 禁用测试缓存
https://github.com/sxs2473/go-performane-tuning
go benchmark实践与原理
Go 每日一库之 testing
【译】子测试和子基准测试的使用
golang 中的 testing 包介绍
Go测试–子测试
Go 单元测试,基准测试,http 测试
Go 测试,go test 工具的具体指令 flag
Go Test 单元测试简明教程
理解 Golang 子进程测试