Go如何优化GC触发频率
文章目录
观察GC
我们以下面的程序为例,先使用四种不同的方式来介绍如何观察 GC,并在后面的问题中通过几个详细的例子再来讨论如何优化 GC。
|
|
go tool prof
Go 基础性能分析工具,pprof的用法和启动方式参考go pprof性能分析,其中的heap即为内存分配分析,go tool默认是查看正在使用的内存(inuse_heap),如果要看其它数据,使用go tool pprof –alloc_space|inuse_objects|alloc_objects。
需要注意的是,go pprof本质是数据采样分析,其中的值并不是精确值,适用于性能热点优化,而非真实数据统计。
go tool trace
go tool trace 的主要功能是将统计而来的信息以一种可视化的方式展示给用户。要使用此工具,可以通过调用 trace API:
|
|
并通过执行以下命令,来启动可视化界面:
|
|
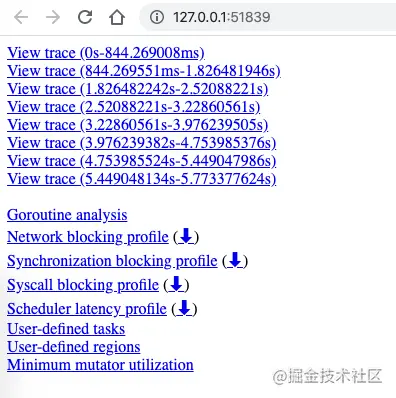
选择第一个链接可以获得如下图示:
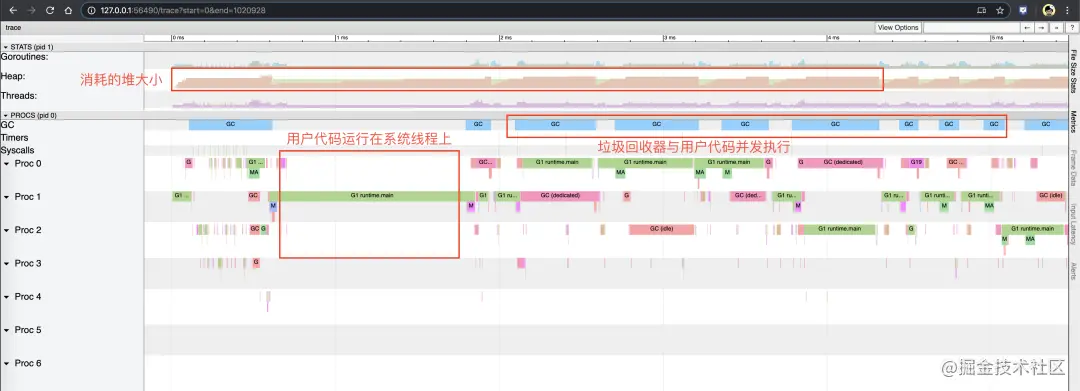
右上角的问号可以打开帮助菜单,包含的信息量比较广,横轴为时间线,各行为各种维度的度量,通过A/D左右移动,W/S放大放小。以下是各行的意义:
- Goroutines: 包含GCWaiting,Runnable,Running三种状态的Goroutine数量统计
- Heap: 包含当前堆使用量(Allocated)和下次GC阈值(NextGC)统计
- Threads: 包含正在运行和正在执行系统调用的Threads数量
- GC: 哪个时间段在执行GC
- ProcN: 各个P上面的goroutine调度情况
除了View trace之外,trace目录的第二个Goroutine analysis也比较有用,它能够直观统计Goroutine的数量和执行状态:
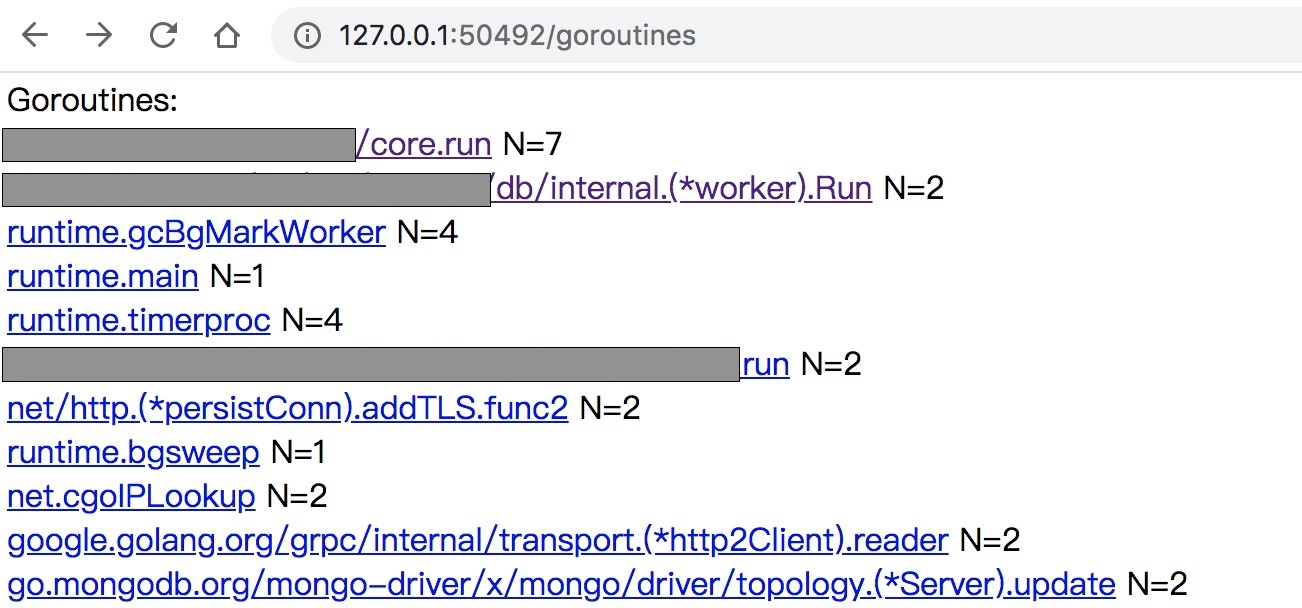
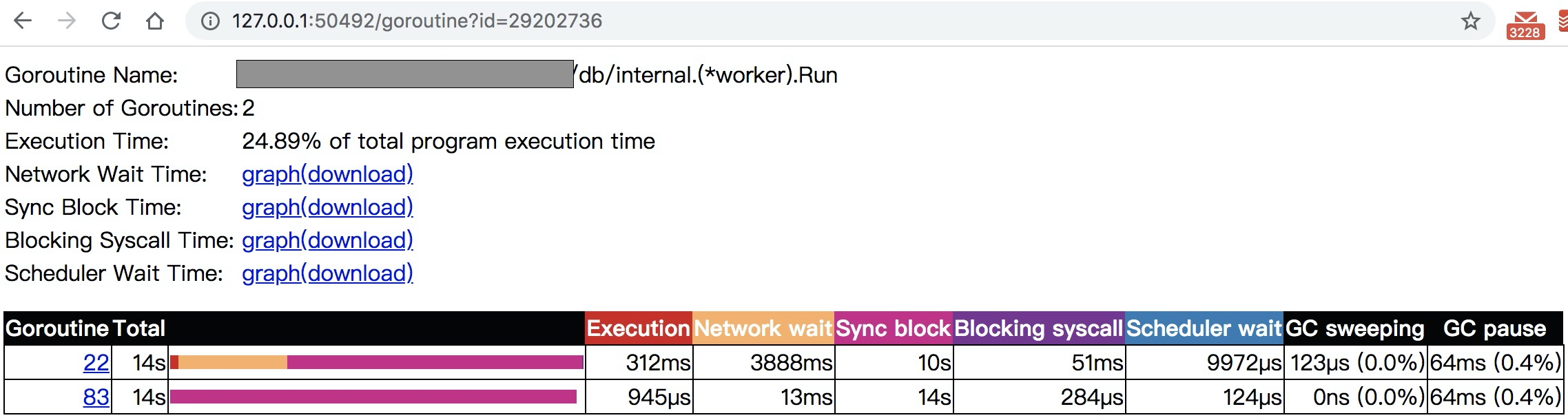
通过它可以对各个goroutine进行健康诊断,各种network,syscall的采样数据下载下来之后可以直接通过go tool pprof分析,因此,实际上pprof和trace两套工具是相辅相成的。
GODEBUG=gctrace=1
GC Trace是Golang提供的非侵入式查看GC信息的方案,用法很简单,设置GCDEBUG=gctrace=1环境变量即可.
我们首先可以通过命令:GODEBUG=gctrace=1 ./main 来查看,如下所示:
|
|
在这个日志中可以观察到两类不同的信息:
|
|
另外还有:
|
|
对于用户代码向运行时申请内存产生的垃圾回收:
|
|
含义由下表所示:
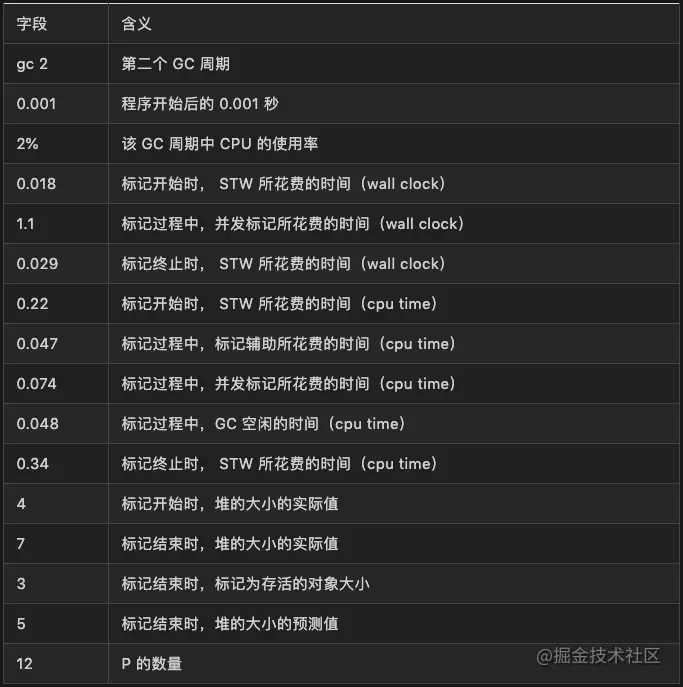
wall clock 是指开始执行到完成所经历的实际时间,包括其他程序和本程序所消耗的时间;cpu time 是指特定程序使用 CPU 的时间;他们存在以下关系:
- wall clock < cpu time: 充分利用多核
- wall clock ≈ cpu time: 未并行执行
- wall clock > cpu time: 多核优势不明显
对于运行时向操作系统申请内存产生的垃圾回收(向操作系统归还多余的内存):
|
|
含义由下表所示:

runtime.ReadMemStats
runtime.MemStats记录了内存分配的一些统计信息,通过runtime.ReadMemStats(&ms)获取,它是runtime.mstats的对外版(再次可见Go单一访问控制的弊端),MemStats字段比较多,其中比较重要的有:
|
|
程序可以通过定期调用runtime.ReadMemStatsAPI来获取内存分配信息发往时序数据库进行监控。另外,该API是会STW的,但是很短,Google内部也在用,用他们的话说:”STW不可怕,长时间STW才可怕”,该API通常一分钟调用一次即可。
除了使用 debug 包提供的方法外,还可以直接通过运行时的内存相关的 API 进行监控:
|
|
|
|
当然,后两种方式能够监控的指标很多,大家可以自行查看 debug.GCStats 和 runtime.MemStats 的字段,这里不再赘述了。
debug.ReadGCStats
debug.ReadGCStats用于获取最近的GC统计信息,主要是GC造成的延迟信息:
|
|
此方式可以通过代码的方式来直接实现对感兴趣指标的监控,例如我们希望每隔一秒钟监控一次 GC 的状态:
|
|
我们能够看到如下输出:
|
|
优化方式
SetGCPercent
SetGCPercent设置垃圾收集目标百分比:当新分配的数据与上次收集后剩余的实时数据的比率达到此百分比时,就会触发收集。SetGCPercent返回之前的设置。初始设置是启动时GOGC环境变量的值,如果没有设置变量,则为100。负百分比禁用垃圾收集
|
|
我们都知道 GO 的 GC 是标记-清除方式,当 GC 会触发时全量遍历变量进行标记,当标记结束后执行清除,把标记为白色的对象执行垃圾回收。值得注意的是,这里的回收仅仅是标记内存可以返回给操作系统,并不是立即回收,这就是你看到 Go 应用 RSS 一直居高不下的原因。在整个垃圾回收过程中会暂停整个 Go 程序(STW),Go 垃圾回收的耗时还是主要取决于标记花费的时间的长短,清除过程是非常快的。
弊端
GOGC 设置比率的方式不精确
设置 GOGC 基本上我们比较常用的 Go GC 调优的方式,大部分情况下其实我们并不需要调整 GOGC 就可以,一方面是不涉及内存密集型的程序本身对内存敏感程度太低,另外就是 GOGC 这种设置比率的方式不精确,我们很难精确的控制我们想要的触发的垃圾回收的阈值。
GOGC 设置过小
GOGC 设置的非常小,会频繁触发 GC 导致太多无效的 CPU 浪费,反应到程序的表现就会特别明显。举个例子,对于 API 接口来说,导致的结果的就是接口周期性的耗时变化。这个时候你抓取 CPU profile 来看,大部分的耗时都集中在 GC 的相关处理上。
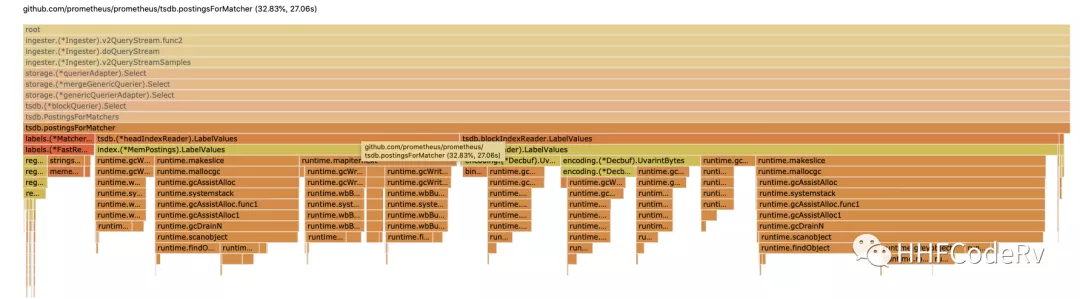 如上图,这是一次 prometheus 的查询操作,我们看到大部分的 CPU 都消耗在 GC 的操作上。这也是生产环境遇到的,由于 GOGC 设置的过小,导致过多的消耗都耗费在 GC 上。
如上图,这是一次 prometheus 的查询操作,我们看到大部分的 CPU 都消耗在 GC 的操作上。这也是生产环境遇到的,由于 GOGC 设置的过小,导致过多的消耗都耗费在 GC 上。
对某些程序本身占用内存就低,容易触发 GC
对 API 接口耗时比较敏感的业务,如果 GOGC 置默认值的时候,也可能也会遇到接口的周期性的耗时波动。这是为什么呢?
因为这种接口本身占用内存比较低,每次 GC 之后本身占的内存比较低,如果按照上次 GC 后的 heap 的一倍的 GC 步调来设置 GOGC 的话,这个阈值其实是很容易就能够触发,于是就很容易出现接口因为 GC 的触发导致额外的消耗。
GOGC 设置很大,有的时候又容易触发 OOM
那如何调整呢?是不是把 GOGC 设置的越大越好呢?这样确实能够降低 GC 的触发频率,但是这个值需要设置特别大才有效果。这样带来的问题,GOGC 设置的过大,如果这些接口突然接受到一大波流量,由于长时间无法触发 GC 可能导致 OOM。
GO 内存 ballast
刷新风暴
我们在Twitch有一个名为Visage的服务,它充当我们的API前端。Visage 是所有外部发起的 API 流量的中心网关。它负责很多事情,从授权到请求路由,再到(最近)服务器端 GraphQL。因此,它必须扩展以处理我们无法控制的用户流量模式。
例如,我们看到的一种常见的流量模式是"刷新风暴"。当一个受欢迎的广播公司的流媒体由于其互联网连接的短暂出现而下降时,就会发生这种情况。作为响应,广播公司将重新启动流。这通常会导致查看者反复刷新他们的页面,突然之间,我们有更多的API流量需要处理。
Visage 是一个 Go 应用程序(在此更改时使用 Go 1.11 构建),在负载均衡器后面的 EC2 上运行。在大多数情况下,在EC2上,它可以很好地水平扩展。
但是,即使使用 EC2 和 Auto Scaling 组的魔力,我们仍然会遇到处理非常大的流量峰值的问题。在刷新风暴期间,我们经常在几秒钟内出现数百万个请求的激增,大约是正常负载的 20 倍。最重要的是,当我们的前端服务器负载过重时,我们将看到API延迟显着降低。
处理此问题的一种方法是保持您的车队永久过度扩展,但这是浪费和昂贵的。为了降低这种不断增长的成本,我们决定花一些时间寻找一些低垂的果实,这些果实可以提高每个主机的吞吐量,并在主机处于负载状态时提供更可靠的每个请求处理。
问题原因
幸运的是,我们在生产环境中运行pprof,因此获取实际的生产流量配置文件变得非常微不足道。如果你不运行pprof,我强烈建议你这样做。在大多数情况下,探查器具有非常小的 CPU 开销。执行跟踪程序的开销可能很小,但仍然足够小,以至于我们很乐意在生产环境中每小时运行几秒钟。
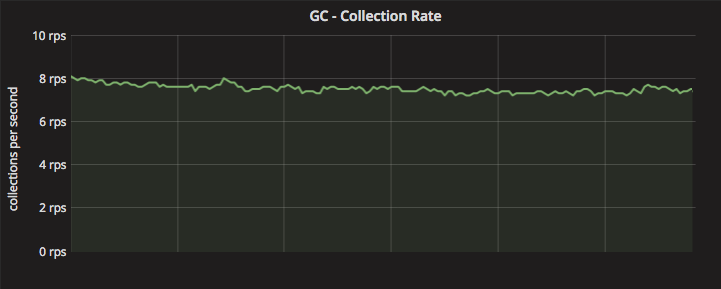
因此,在查看了Go应用程序的配置文件后,我们进行了以下观察:
- 在稳定状态下,我们的应用程序每秒触发大约 8–10 个垃圾回收 (GC) 周期(每分钟 400–600 个)。
- 30% 的 CPU 周期用于与 GC 相关的函数调用
- 在流量高峰期间,GC 周期数将增加
- 我们的堆大小平均相当小(<450Mib)
面像应用 GC 每秒周期数
应用程序 MiB 的 heap in use
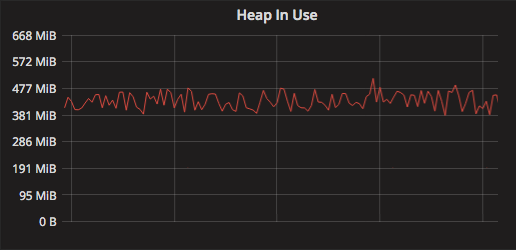
正如我们之前所指出的,Visage应用程序在自己的VM上运行,具有64GiB的物理内存,在仅使用约400MiB的物理内存的情况下,GC非常频繁。
Go GC 使用调步算法来确定何时触发下一个 GC 周期。步调建模类似于控制问题,它试图找到触发 GC 周期的正确时间,以便达到目标堆大小目标。Go 的默认调步算法将在堆大小加倍时尝试触发 GC 周期。它通过在当前 GC 周期的标记终止阶段设置下一个堆触发器大小来实现此目的。因此,在标记所有活动内存后,当总堆大小是当前活动集的2倍时,它可以决定触发下一个GC。2x 值来自运行时用于设置触发比率的变量 GOGC。
在我们的例子中,调步算法在将堆上的垃圾保持在最低限度方面做得非常出色,但这是以不必要的工作为代价的,因为我们只使用了系统内存的约0.6%。
ballast
这就需要 Go ballast 出场了。什么是 Go ballast,其实很简单就是初始化一个生命周期贯穿整个 Go 应用生命周期的超大 slice。
|
|
上面的代码就初始化了一个 ballast,利用 runtime.KeepAlive 来保证 ballast 不会被 GC 给回收掉。
如前所述,每次堆大小加倍时,GC 都会触发。堆大小是堆上分配的总大小。因此,如果分配了 10 GiB 的ballast,则只有在堆大小增长到 20 GiB 时才会触发下一个 GC。届时,将有大约 10 GiB 的ballast + 10 GiB 的其他分配。
当GC运行时,ballast不会作为垃圾扫描,因为我们仍然在主函数中保存对它的引用,因此它被认为是实时内存的一部分。由于我们应用程序中的大多数分配只存在于 API 请求的短暂生存期内,因此 10 GiB 的分配中的大部分将被扫描,从而再次将堆减少到略高于约 10 GiB(即,10GiB 的ballast加上飞行请求中的任何内容都有分配,并被视为实时内存)。现在,当堆大小(当前仅大于 10 GiB)再次翻倍时,将发生下一个 GC 周期。
因此,总而言之,镇流器增加了堆的基本大小,因此我们的GC触发器被延迟,并且随着时间的推移减少了GC周期的数量。
如果您想知道为什么我们使用字节数组作为镇流器,这是为了确保我们只在标记阶段添加一个额外的对象。由于字节数组没有任何指针(对象本身除外),GC 可以在 O(1) 时间内标记整个对象。
推出此更改按预期工作 - 我们看到GC周期减少了约99%:
显示每分钟 GC 周期的对数基数 2 刻度图:
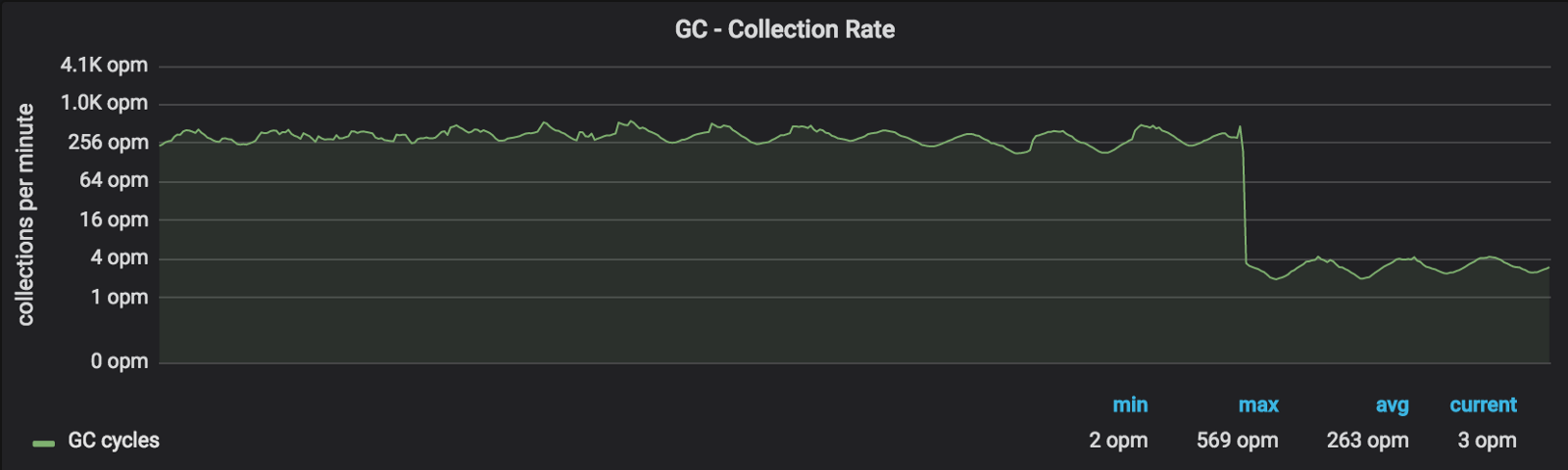
所以这看起来不错,CPU利用率呢?
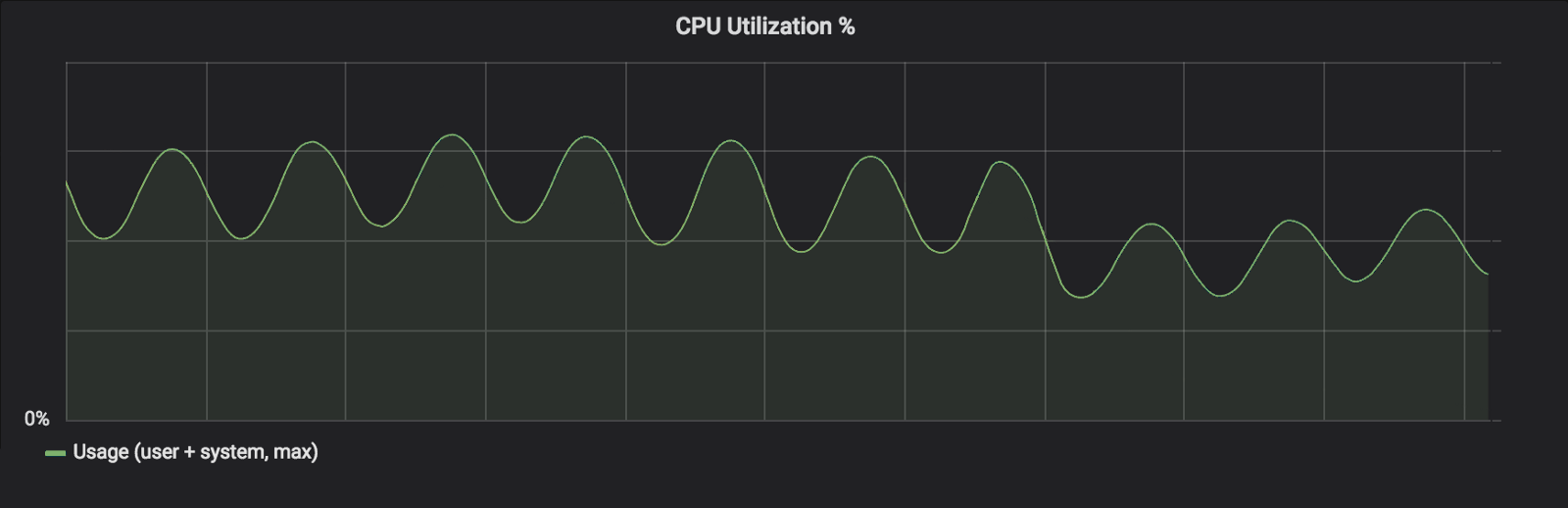
绿色正弦 CPU 利用率指标是由于流量的每日振荡。人们可以看到更改后的台阶。
每箱CPU减少约30%意味着无需进一步考虑,我们可以将机队规模缩小30%,但我们也关心的是API延迟.
这不会耗尽我宝贵的RAM的10Gib吗?我会让你放心。答案是:不,它不会,除非你故意这样做。linux系统中的内存实际上由操作系统通过页表进行寻址和映射。当上述代码运行时,镇流器切片指向的数组将在程序的虚拟地址空间中分配。仅当我们尝试读取或写入切片时,才会发生页面错误,从而导致支持虚拟地址的物理 RAM 被分配。
|
|
|
|
这个结果是在 CentOS Linux release 7.9 验证的,我们看到占用的 RSS 真实的物理内存只有 344M,但是 VSZ 虚拟内存确实有 10G 的占用。
正如预期的那样,字节数组的一半现在位于占用物理内存的 RSS 中。VSZ 保持不变,因为两个程序中都存在相同大小的虚拟分配。
因此,只要我们不读取或写入镇流器,我们就可以放心,它将仅作为虚拟分配保留在堆中。
延伸一点,当怀疑我们的接口的耗时是由于 GC 的频繁触发引起的,我们需要怎么确定呢?首先你会想到周期性的抓取 pprof 的来分析,这种方案其实也可以,但是太麻烦了。其实可以根据 GC 的触发时间绘制这个曲线图,GC 的触发时间可以利用 runtime.Memstats 的 LastGC 来获取。
改善API延迟
如上所述,由于GC运行频率较低,我们看到API延迟有所改善(特别是在高负载期间)。最初,我们认为这可能是由于GC暂停时间的减少 - 这是GC在GC周期中实际停止世界的时间量。但是,更改前后的 GC 暂停时间没有显著差异。此外,我们的暂停时间大约是个位数毫秒,而不是我们在峰值负载时看到的100毫秒的改进。要了解这种延迟改进的来源,我们需要谈谈Go GC的一个称为assists.
GC 辅助将 GC 周期期间内存分配的负担放在负责分配的 goroutine 上。如果没有此机制,运行时将无法防止堆在 GC 周期内未绑定地增长。
由于 Go 已经有一个后台 GC 工作者,因此术语"协助"是指我们的 goroutines 协助背景工作者。专门协助标记工作。
为了进一步理解这一点,让我们举个例子:
|
|
当执行此代码时,通过一系列符号转换和类型检查,goroutine 对 runtime.makeslice 进行调用,最终调用 runtime.mallocgc 为我们的切片分配一些内存。
查看 runtime.mallocgc 函数内部,可以向我们显示有趣的代码路径。
请注意,我已经删除了大部分功能,只显示了下面的相关部分:
|
|
在上面的代码中,if assistG.gcAssistBytes < 0行正在检查我们的 goroutine 是否处于分配债务中。分配债务是一种花哨的说法,即这个goroutine在GC周期中分配的比做GC工作更多。
您可以将此视为您的goroutine必须在GC周期内为分配支付的税款,除了必须在实际分配之前预先支付此税。此外,税收与goroutine试图分配的金额成正比。这提供了一定程度的公平性,使得分配很多的goroutines将为这些分配付出代价。
因此,假设这是我们的goroutine在当前GC周期中第一次分配,它将被迫进行GC辅助工作。这里有趣的一句话是对gcAssistAlloc调用
此函数负责一些内务管理,并最终调用 gcAssistAlloc1 以执行实际的 GC 辅助工作。我不会详细介绍 gcAssistAlloc 函数,但本质上它执行以下操作:
- 检查goroutine是否没有做一些不可抢占的事情(即系统goroutine)
- 执行 GC 标记工作
- 检查goroutine是否仍有分配债务,否则返回
- 执行第二步.
现在应该清楚的是,任何从事涉及分配的工作的goroutine都将在GC周期内引起GCAssist处罚。由于工作必须在分配之前完成,因此这将显示为goroutine打算做的实际有用工作的延迟或缓慢。
在我们的 API 前端中,这意味着 API 响应在 GC 周期期间的延迟会增加。如前所述,随着每个服务器的负载增加,内存分配速率将增加,这反过来又会增加 GC 周期的速率(通常为 10 秒或 20 秒/秒)。我们现在知道,更多的GC周期意味着为API服务的goroutines提供更多的GC辅助工作,因此,更多的API延迟。
您可以从我们应用程序的执行跟踪中清楚地看到这一点。以下是来自Visage的同一执行轨迹的两个切片;一个在GC循环运行时,一个在运行时。
GC 周期内的执行跟踪

该跟踪显示哪些 goroutines 在哪个处理器上运行。任何标记为app-code的内容都是为我们的应用程序运行有用代码的 goroutine(例如,为 API 请求提供服务的逻辑)。请注意,除了运行GC代码的四个专用过程之外,我们的其他goroutines如何被延迟并被迫执行MARK ASSIST(即runtime.gcAssistAlloc)工作。

来自与上述相同应用程序的配置文件,而不是在GC周期内
与此配置文件进行对比,该配置文件来自同一正在运行的应用程序,而不是在 GC 周期内。在这里,我们的 goroutines 花费了大部分时间按预期运行我们的应用程序代码。
因此,通过简单地降低GC频率,我们看到标记辅助工作减少了近99%,这意味着在峰值流量下第99百分位API延迟提高了约45%。
你可能想知道为什么Go会选择如此奇怪的设计(使用辅助)作为其GC,但它实际上很有意义。GC的主要功能是确保我们将堆保持在合理的大小,并且不会让它不受垃圾的约束而增长。这在停止世界(STW)GC中很容易,但在并发GC中,我们需要一种机制来确保GC周期中发生的分配不会无限制地增长。在我看来,让每个goroutine支付与它在GC周期中想要分配的分配成比例的分配税是一个非常优雅的设计。
生产环境验证
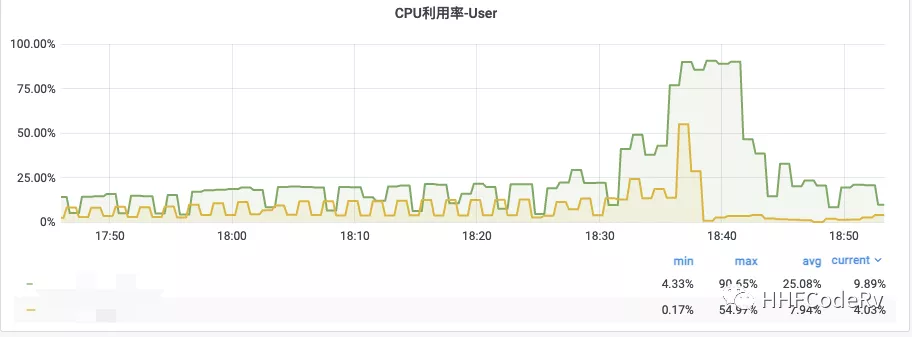
绿线 调整前 GOGC = 30
黄线 调整后 GOGC 默认值,ballast = 50G
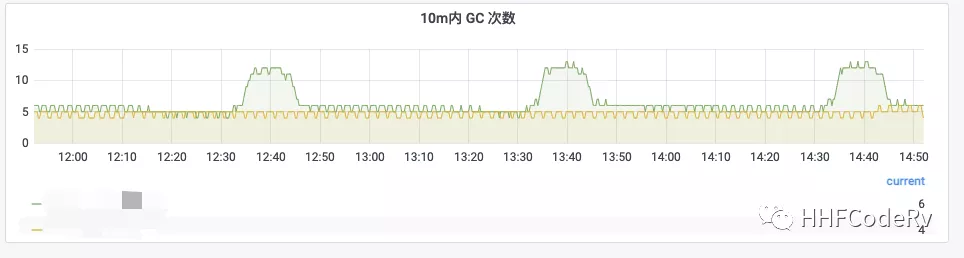
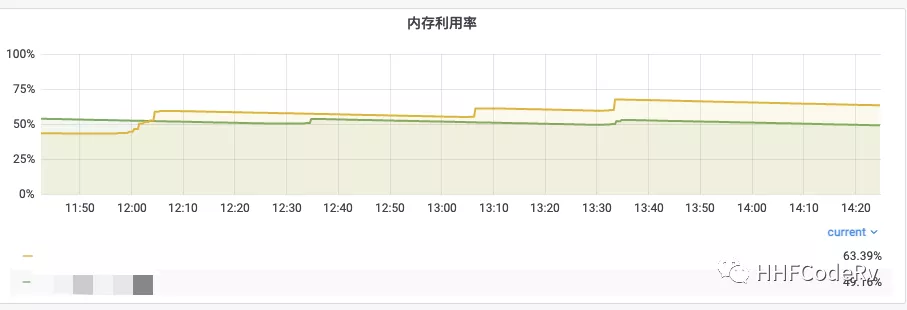
这张图相同的流量压力下,ballast 的表现明显偏好
 。
。
自动调整GOGC
Uber 最近发了一篇文章,主要讲的是在核心服务上动态调整 GOGC 来降低 GC 的 mark 阶段 CPU 占用。基本可以做到有效果,低风险,可扩展,半自动化。
Uber 当前的服务规模大概是几千微服务,基于云上的调度基础设施来进行部署。大部分服务是 GO 写的,这篇文章的作者是做 Maps Production Engineering,这个组之前帮一些 Java 系统调整过 GC 参数(这应该就是他们帮 Go 做优化想的也是怎么调整参数的出发点吧)。
总之经过一段时间的线上 profile 采集发现 GC 是很多核心服务的一个很大的 CPU 消耗点,比如 runtime.scanobject 方法消耗了很大比例的计算资源:
Service #1

Service #2

有了这样的发现,团队开始想办法能不能想出一些方案来进行优化。
GOGC Tuner
Go 的 runtime 会间隙性地调用垃圾收集器来并发进行垃圾回收。这个启动是由内存的压力反馈来决定何时启动 GC 的。所以 Go 的服务可以通过增加内存的用量来降低 GC 的频率以降低 GC 的总 CPU 占用,Uber 内部的服务大多实例配比是 1C5G,而实际的 Go 服务 CPU : 内存占比大约是 1:1 或者 1:2 左右,即占用 1c 的 CPU 时同时占用 1G 或 2G 的内存。所以这里确实存在参数调整的空间。
Go 的 GC 触发算法可以简化成下面这样的公式:
|
|
由 pacer 算法来计算每次最合适触发的 heap 内存占用。
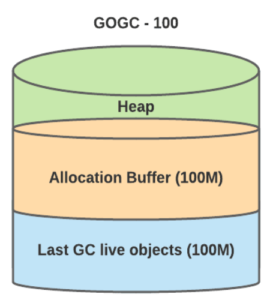
固定的 GOGC 值没法满足 Uber 内部所有的服务。具体的挑战包括:
- 对于容器内的可用最大内存并没有进行考虑,理论上存在 OOM 的可能性。
- 不同的微服务对内存的使用情况完全不同。比如,比如有些系统只使用 100MB 内存,而内存占用 99 分位的服务则使用 1G 的内存,而 100MB 那个服务,GC 使用的 CPU 非常高。
Uber 内部搞了一个叫 GOGCTuner 的库。这个库简化了 Go 的 GOGC 参数调整流程,并且能够可靠地自动对其进行调整。
这个工具会根据容器的 memory limit (应用 owner 也可以自己指定)使用 Go 的 runtime API ,动态地调整 GOGC 参数:
- 默认的 GOGC 参数是 100%,这个值对于 GO 的开发者来说并不明确,其本身还是依赖于活跃的堆内存。GOGCTuner 会限制应用使用 70% 的内存。并且能够将内存用量严格限制住。
- 可以保护应用不发生 OOM:该库会读取 cgroup 下的应用内存限制,并且强制限制只能使用 70% 的内存,从我们的经验来看这样还是比较安全的。
- 这种保护当然也是有限制的。这个 tuner 只能对 buffer 的分配进行自适应,所以如果你的堆上活跃对象比 tuner 工具限制的内存量还要高,那这个工具会设置为你的活跃对象容量 * 1.25。
- 在一些特殊情况下,容许 GOGC 的值更高一些,比如:
- 我们提到默认的 GOGC 是不明确的。尽管我们做了自适应,但我们依然依赖于当前活跃的对象的大小。如果当前的活跃对象大小比我们之前最大值的两倍还要大会发生啥?GOGCTuner 会将总内存限制住,使得应用消耗更多的 CPU。如果是手动地调 GOGC 为固定值,这里可能会直接发生 OOM。不过一般应用 owner 会给这种场景提供额外的 buffer 量,参考后文的一些例子。
Normal traffic (live dataset is 150M)
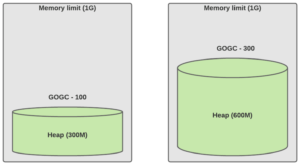
左边用默认值,右边是手动调整了 GOGC 为固定值
Traffic increased 2X (live dataset is 300M)
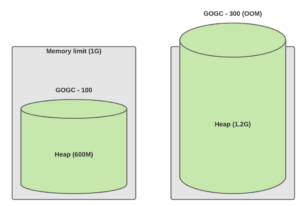
load 翻倍。左边的是默认值,右边是手动调整的固定值
Traffic increased 2X with GOGCTuner at 70% (live dataset is 300M)
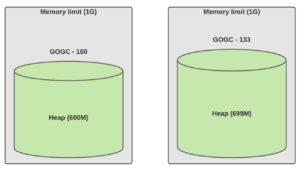
load 翻倍。左边的是默认值,右边的是用 GOGCTuner 动态调整的值.
Observability
为了提升可观测性,我们还对垃圾回收的一些关键指标进行了监控。
垃圾回收触发的时间间隔:可以知道是否还需要进一步的优化。比如 Go 每两分钟强制触发一次垃圾回收。如果你的服务还有 GC 方面的问题,但是你在这张图上看到的值都是120s,那说明你已经没法通过调整 GOGC 进行优化了。这种情况下你该从应用着手去做这些对象分配的优化。
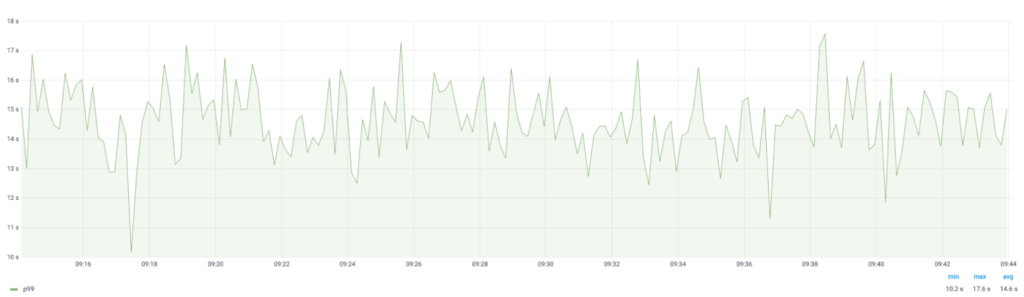
GC 的 CPU 使用量: 使我们能知道哪些服务受 GC 影响最大。
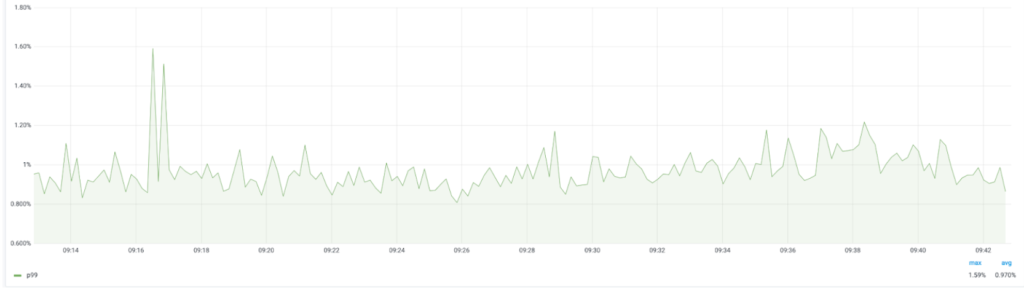
活跃的对象大小: 帮我们来诊断内存泄露。在使用 GOGCTuner 之前,应用的 owner 是通过内存总用量来判断是否发生内存泄露的,现在我们需要把活跃的对象内存用量监控起来帮他们进行这个判断。
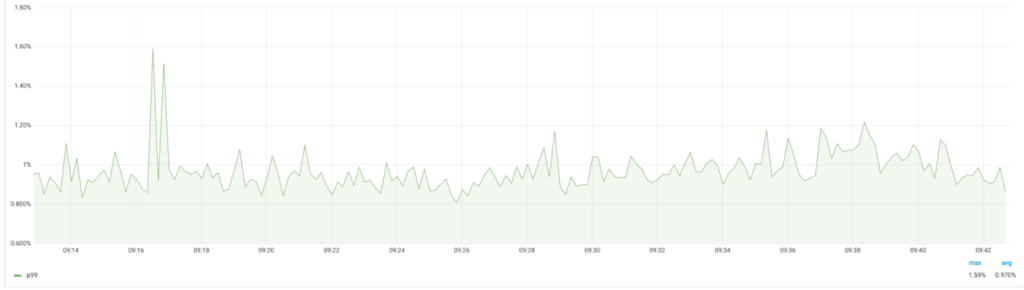
GOGC 的动态值: 能知道 tuner 是不是在干活。
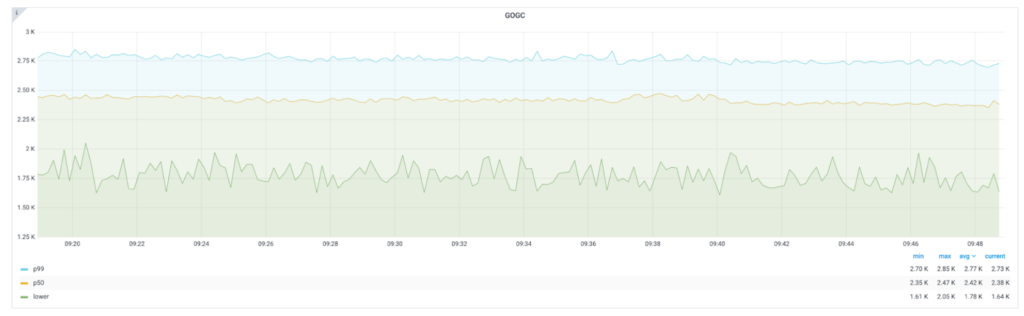
实现
最初的实现方式是每秒运行一个ticker 来监控堆的指标,然后来按指标调整 GOGC 的值。这种方法的缺点显而易见,读取 Memstats 需要 STW 并且这个值也不精确,因为每秒种可能会触发多次 GC。
我们还有更好的办法,Go 有一个 finalizer 机制,在对象被 GC 时可以触发用户的回调方法。 Uber 实现了一个自引用的 finalizer 能够在每次 GC 的时候进行 reset,这样也可以降低这个内存检测的 CPU 消耗。比如:

在 finalizerHandler 里调用 runtime.SetFinalizer(f, finalizerHandler) 能让这个 handler 在每次 GC 期间被执行;这样就不会让引用真的被干掉了,这样使该对象存活也并不需要太高的成本,只是一个指针而已。
影响
在一些服务中部署了 GOGCTuner 之后,我们看到了这个工具对一些服务的性能影响很大,有些服务甚至会有百分之几十的性能提升。我们大约节省了 70k 的 CPU 核心的成本。
下面是两个例子:
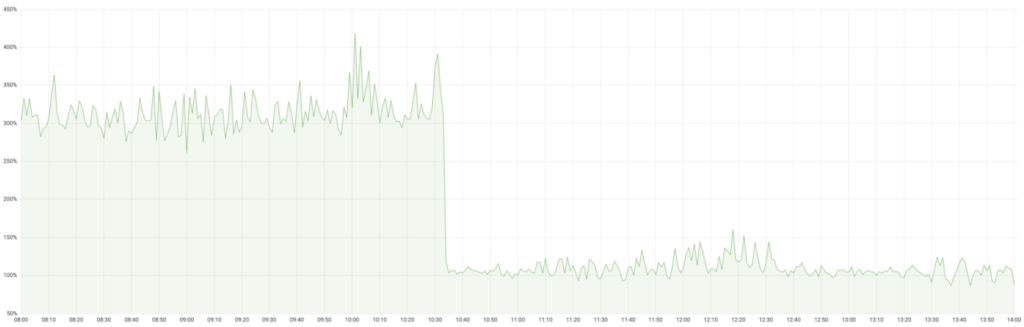 Figure 13: Mission critical Uber eats service that operates on thousands of compute cores, showed ~30% reduction in p99 CPU utilization.
Figure 13: Mission critical Uber eats service that operates on thousands of compute cores, showed ~30% reduction in p99 CPU utilization.
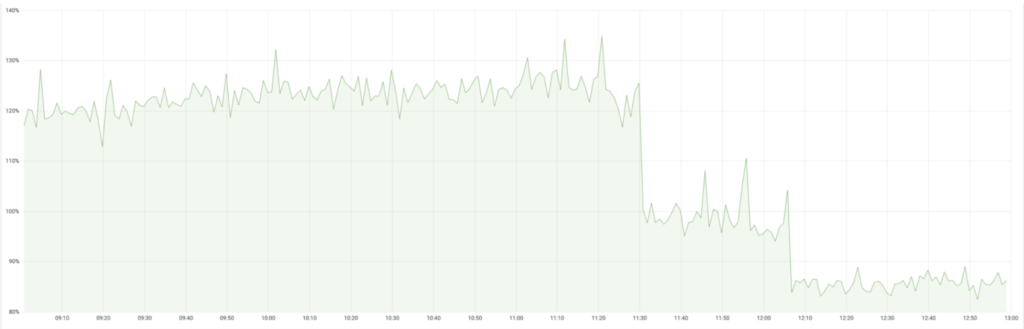
CPU 使用的降低使得 P99 延迟也大幅改进(相应的 SLA,用户体验也同样),也降低了应用需要扩容的成本消耗(因为扩容是按照 SLA 指标来的)。
垃圾回收是最难搞明白的语言特性,其对应用的性能影响也经常被低估。Go 的 GC 策略以及简易的 tuning 方法,我们内部多样的,大规模的 Go 服务特性,以及内部的稳定的 Go 可观测性平台对于我们能够做出这样的改进功不可没。随着 Go 的 GC 的迭代,我们也能继续进行改进,提升公司在技术领域的竞争力。
这里再强调一下引言中的观点:没有银弹,没有一统天下的优化方案。我们认为 GC 优化在云原生场景下依然是个很难的问题。当前 CNCF 中大量的项目使用 Go 编写,希望我们的实践也能够帮助到外部的这些项目。
参考
Go memory ballast: How I learnt to stop worrying and love the heap
文章作者 Forz
上次更新 2022-02-16