简介
处理大量并发是 Go 语言的一大优势。语言内置了方便的并发语法,可以非常方便的创建很多个轻量级的 goroutine 并发处理任务。相比于创建多个线程,goroutine 更轻量、资源占用更少、切换速度更快、无线程上下文切换开销更少。但是受限于资源总量,系统中能够创建的 goroutine 数量也是受限的。默认每个 goroutine 占用 8KB 内存,一台 8GB 内存的机器满打满算也只能创建 8GB/8KB = 1000000 个 goroutine,更何况系统还需要保留一部分内存运行日常管理任务,go 运行时需要内存运行 gc、处理 goroutine 切换等。使用的内存超过机器内存容量,系统会使用交换区(swap),导致性能急速下降。我们可以简单验证一下创建过多 goroutine 会发生什么:
1
2
3
4
5
6
7
8
9
10
|
func main() {
var wg sync.WaitGroup
wg.Add(10000000)
for i := 0; i < 10000000; i++ {
go func() {
time.Sleep(1 * time.Minute)
}()
}
wg.Wait()
}
|
在我的机器上(8G内存)运行上面的程序会报errno 1455,即Out of Memory错误,这很好理解。谨慎运行。
另一方面,goroutine 的管理也是一个问题。goroutine 只能自己运行结束,外部没有任何手段可以强制j结束一个 goroutine。如果一个 goroutine 因为某种原因没有自行结束,就会出现 goroutine 泄露。此外,频繁创建 goroutine 也是一个开销。
鉴于上述原因,自然出现了与线程池一样的需求,即 goroutine 池。一般的 goroutine 池自动管理 goroutine 的生命周期,可以按需创建,动态缩容。向 goroutine 池提交一个任务,goroutine 池会自动安排某个 goroutine 来处理。
ants就是其中一个实现 goroutine 池的库。
快速使用
本文代码使用 Go Modules。
创建目录并初始化:
1
2
|
mkdir ants && cd ants
go mod init github.com/darjun/go-daily-lib/ants
|
安装ants库,使用v2版本:
1
|
go get -u github.com/panjf2000/ants/v2
|
我们接下来要实现一个计算大量整数和的程序。首先创建基础的任务结构,并实现其执行任务方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
type Task struct {
index int
nums []int
sum int
wg *sync.WaitGroup
}
func (t *Task) Do() {
for _, num := range t.nums {
t.sum += num
}
t.wg.Done()
}
|
很简单,就是将一个切片中的所有整数相加。
然后我们创建 goroutine 池,注意池使用完后需要手动关闭,这里使用defer关闭:
1
2
3
4
5
6
7
8
|
p, _ := ants.NewPoolWithFunc(10, taskFunc)
defer p.Release()
func taskFunc(data interface{}) {
task := data.(*Task)
task.Do()
fmt.Printf("task:%d sum:%d\n", task.index, task.sum)
}
|
上面调用了ants.NewPoolWithFunc()创建了一个 goroutine 池。第一个参数是池容量,即池中最多有 10 个 goroutine。第二个参数为每次执行任务的函数。当我们调用p.Invoke(data)的时候,ants池会在其管理的 goroutine 中找出一个空闲的,让它执行函数taskFunc,并将data作为参数。
接着,我们模拟数据,做数据切分,生成任务,交给 ants 处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
const (
DataSize = 10000
DataPerTask = 100
)
nums := make([]int, DataSize, DataSize)
for i := range nums {
nums[i] = rand.Intn(1000)
}
var wg sync.WaitGroup
wg.Add(DataSize / DataPerTask)
tasks := make([]*Task, 0, DataSize/DataPerTask)
for i := 0; i < DataSize/DataPerTask; i++ {
task := &Task{
index: i + 1,
nums: nums[i*DataPerTask : (i+1)*DataPerTask],
wg: &wg,
}
tasks = append(tasks, task)
p.Invoke(task)
}
wg.Wait()
fmt.Printf("running goroutines: %d\n", ants.Running())
|
随机生成 10000 个整数,将这些整数分为 100 份,每份 100 个,生成Task结构,调用p.Invoke(task)处理。wg.Wait()等待处理完成,然后输出ants正在运行的 goroutine 数量,这时应该是 0。
最后我们将结果汇总,并验证一下结果,与直接相加得到的结果做一个比较:
1
2
3
4
5
6
7
8
9
10
11
|
var sum int
for _, task := range tasks {
sum += task.sum
}
var expect int
for _, num := range nums {
expect += num
}
fmt.Printf("finish all tasks, result is %d expect:%d\n", sum, expect)
|
运行:
1
2
3
4
5
6
7
8
9
|
$ go run main.go
...
task:96 sum:53275
task:88 sum:50090
task:62 sum:57114
task:45 sum:48041
task:82 sum:45269
running goroutines: 0
finish all tasks, result is 5010172 expect:5010172
|
确实,任务完成之后,正在运行的 goroutine 数量变为 0。而且我们验证了,结果没有偏差。另外需要注意,goroutine 池中任务的执行顺序是随机的,与提交任务的先后没有关系。由上面运行打印的任务标识我们也能发现这一点。
函数作为任务
ants支持将一个不接受任何参数的函数作为任务提交给 goroutine 运行。由于不接受参数,我们提交的函数要么不需要外部数据,只需要处理自身逻辑,否则就必须用某种方式将需要的数据传递进去,例如闭包。
提交函数作为任务的 goroutine 池使用ants.NewPool()创建,它只接受一个参数表示池子的容量。调用池子对象的Submit()方法来提交任务,将一个不接受任何参数的函数传入。
最开始的例子可以改写一下。增加一个任务包装函数,将任务需要的参数作为包装函数的参数。包装函数返回实际的任务函数,该任务函数就可以通过闭包访问它需要的数据了:
1
2
3
4
5
6
7
8
9
10
11
12
|
type taskFunc func()
func taskFuncWrapper(nums []int, i int, sum *int, wg*sync.WaitGroup) taskFunc {
return func() {
for _, num := range nums[i*DataPerTask : (i+1)*DataPerTask] {
*sum += num
}
fmt.Printf("task:%d sum:%d\n", i+1, *sum)
wg.Done()
}
}
|
调用ants.NewPool(10)创建 goroutine 池,同样池子用完需要释放,这里使用defer:
1
2
|
p, _ := ants.NewPool(10)
defer p.Release()
|
生成模拟数据,切分任务。提交任务给ants池执行,这里使用taskFuncWrapper()包装函数生成具体的任务,然后调用p.Submit()提交:
1
2
3
4
5
6
7
8
9
10
11
12
|
nums := make([]int, DataSize, DataSize)
for i := range nums {
nums[i] = rand.Intn(1000)
}
var wg sync.WaitGroup
wg.Add(DataSize / DataPerTask)
partSums := make([]int, DataSize/DataPerTask, DataSize/DataPerTask)
for i := 0; i < DataSize/DataPerTask; i++ {
p.Submit(taskFuncWrapper(nums, i, &partSums[i], &wg))
}
wg.Wait()
|
汇总结果,验证:
1
2
3
4
5
6
7
8
9
10
11
|
var sum int
for _, partSum := range partSums {
sum += partSum
}
var expect int
for _, num := range nums {
expect += num
}
fmt.Printf("running goroutines: %d\n", ants.Running())
fmt.Printf("finish all tasks, result is %d expect is %d\n", sum, expect)
|
这个程序的功能与最开始的完全相同。
执行流程
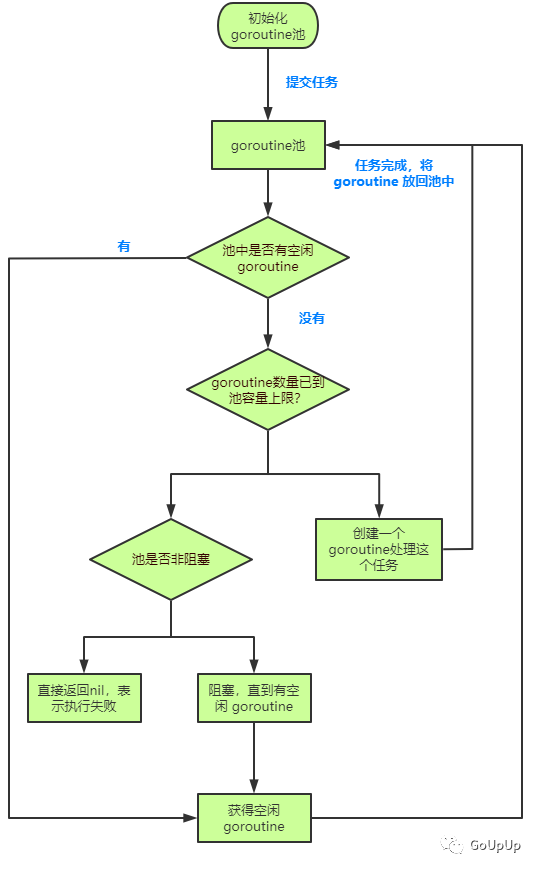
GitHub 仓库中有个执行流程图,我重新绘制了一下:
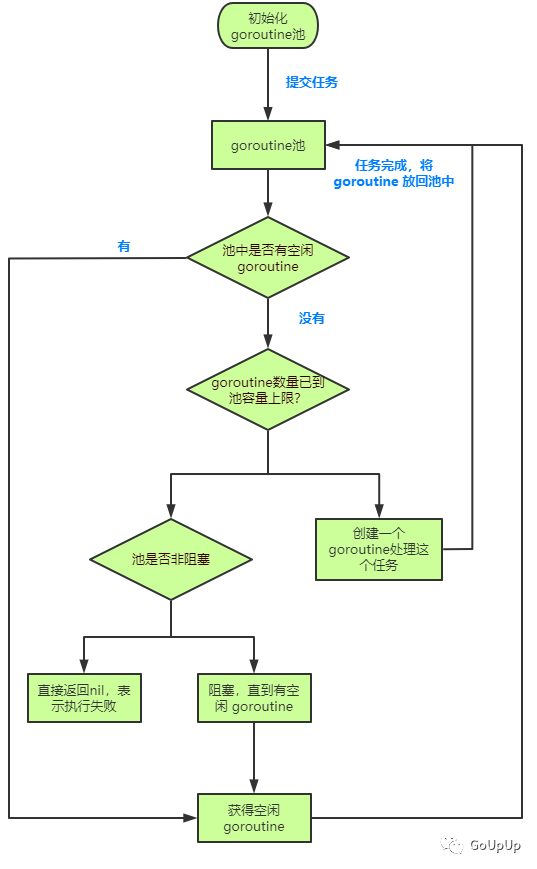
执行流程如下:
- 初始化 goroutine 池;
- 提交任务给 goroutine 池,检查是否有空闲的 goroutine:
- 已到上限,检查 goroutine 池是否是非阻塞的:
- 未到上限,创建一个新的 goroutine 处理任务
- 非阻塞,直接返回nil表示执行失败
- 阻塞,等待 goroutine 空闲
- 有,获取空闲 goroutine
- 无,检查池中的 goroutine 数量是否已到池容量上限:
- 任务处理完成,将 goroutine 交还给池,以待处理下一个任务
选项
ants提供了一些选项可以定制 goroutine 池的行为。选项使用Options结构定义:
1
2
3
4
5
6
7
8
9
|
// src/github.com/panjf2000/ants/options.go
type Options struct {
ExpiryDuration time.Duration
PreAlloc bool
MaxBlockingTasks int
Nonblocking bool
PanicHandler func(interface{})
Logger Logger
}
|
各个选项含义如下:
- ExpiryDuration:过期时间。表示 goroutine 空闲多长时间之后会被ants池回收
- PreAlloc:预分配。调用
NewPool()/NewPoolWithFunc()之后预分配worker(管理一个工作 goroutine 的结构体)切片。而且使用预分配与否会直接影响池中管理worker的结构。见下面源码
- MaxBlockingTasks:最大阻塞任务数量。即池中 goroutine 数量已到池容量,且所有 goroutine 都处理繁忙状态,这时到来的任务会在阻塞列表等待。这个选项设置的是列表的最大长度。阻塞的任务数量达到这个值后,后续任务提交直接返回失败
- Nonblocking:池是否阻塞,默认阻塞。提交任务时,如果ants池中 goroutine 已到上限且全部繁忙,阻塞的池会将任务添加的阻塞列表等待(当然受限于阻塞列表长度,见上一个选项)。非阻塞的池直接返回失败
- PanicHandler:panic 处理。遇到 panic 会调用这里设置的处理函数
- Logger:指定日志记录器
NewPool()部分源码:
1
2
3
4
5
6
7
8
|
if p.options.PreAlloc {
if size == -1 {
return nil, ErrInvalidPreAllocSize
}
p.workers = newWorkerArray(loopQueueType, size)
} else {
p.workers = newWorkerArray(stackType, 0)
}
|
使用预分配时,创建loopQueueType类型的结构,反之创建stackType类型。这是ants定义的两种管理worker的数据结构。
ants定义了一些With*函数来设置这些选项:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
func WithOptions(options Options) Option {
return func(opts *Options) {
*opts = options
}
}
func WithExpiryDuration(expiryDuration time.Duration) Option {
return func(opts *Options) {
opts.ExpiryDuration = expiryDuration
}
}
func WithPreAlloc(preAlloc bool) Option {
return func(opts *Options) {
opts.PreAlloc = preAlloc
}
}
func WithMaxBlockingTasks(maxBlockingTasks int) Option {
return func(opts *Options) {
opts.MaxBlockingTasks = maxBlockingTasks
}
}
func WithNonblocking(nonblocking bool) Option {
return func(opts *Options) {
opts.Nonblocking = nonblocking
}
}
func WithPanicHandler(panicHandler func(interface{})) Option {
return func(opts *Options) {
opts.PanicHandler = panicHandler
}
}
func WithLogger(logger Logger) Option {
return func(opts *Options) {
opts.Logger = logger
}
}
|
这里使用了 Go 语言中非常常见的一种模式,我称之为选项模式,非常方便地构造有大量参数,且大部分有默认值或一般不需要显式设置的对象。
我们来验证几个选项。
最大等待队列长度
ants池设置容量之后,如果所有的 goroutine 都在处理任务。这时提交的任务默认会进入等待队列,WithMaxBlockingTasks(maxBlockingTasks int)可以设置等待队列的最大长度。超过这个长度,提交任务直接返回错误:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
func wrapper(i int, wg *sync.WaitGroup) func() {
return func() {
fmt.Printf("hello from task:%d\n", i)
time.Sleep(1* time.Second)
wg.Done()
}
}
func main() {
p, _ := ants.NewPool(4, ants.WithMaxBlockingTasks(2))
defer p.Release()
var wg sync.WaitGroup
wg.Add(8)
for i := 1; i <= 8; i++ {
go func(i int) {
err := p.Submit(wrapper(i, &wg))
if err != nil {
fmt.Printf("task:%d err:%v\n", i, err)
wg.Done()
}
}(i)
}
wg.Wait()
}
|
上面代码中,我们设置 goroutine 池的容量为 4,最大阻塞队列长度为 2。然后一个 for 提交 8 个任务,期望结果是:4 个任务在执行,2 个任务在等待,2 个任务提交失败。运行结果:
1
2
3
4
5
6
7
8
|
hello from task:8
hello from task:5
hello from task:4
hello from task:6
task:7 err:too many goroutines blocked on submit or Nonblocking is set
task:3 err:too many goroutines blocked on submit or Nonblocking is set
hello from task:1
hello from task:2
|
我们看到提交任务失败,打印too many goroutines blocked …。
代码中有 4 点需要注意:
- 提交任务必须并行进行。如果是串行提交,第 5 个任务提交时由于池中没有空闲的 goroutine 处理该任务,Submit()方法会被阻塞,后续任务就都不能提交了。也就达不到验证的目的了
- 由于任务可能提交失败,失败的任务不会实际执行,所以实际上wg.Done()次数会小于 8。因而在err != nil分支中我们需要调用一次
wg.Done()。否则wg.Wait()会永远阻塞
- 为了避免任务执行过快,空出了 goroutine,观察不到现象,每个任务中我使用time.Sleep(1 * time.Second)休眠 1s
- 由于 goroutine 之间的执行顺序未显式同步,故每次执行的顺序不确定
由于简单起见,前面的例子中Submit()方法的返回值都被我们忽略了。实际开发中一定不要忽略。
非阻塞
ants池默认是阻塞的,我们可以使用WithNonblocking(nonblocking bool)设置其为非阻塞。非阻塞的ants池中,在所有 goroutine 都在处理任务时,提交新任务会直接返回错误:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
func main() {
p, _ := ants.NewPool(2, ants.WithNonblocking(true))
defer p.Release()
var wg sync.WaitGroup
wg.Add(3)
for i := 1; i <= 3; i++ {
err := p.Submit(wrapper(i, &wg))
if err != nil {
fmt.Printf("task:%d err:%v\n", i, err)
wg.Done()
}
}
wg.Wait()
}
|
使用上个例子中的wrapper()函数,ants池容量设置为 2。连续提交 3 个任务,期望结果前两个任务正常执行,第 3 个任务提交时返回错误:
1
2
3
|
hello from task:2
task:3 err:too many goroutines blocked on submit or Nonblocking is set
hello from task:1
|
panic 处理器
一个鲁棒性强的库一定不会忽视错误的处理,特别是宕机相关的错误。在 Go 语言中就是 panic,也被称为运行时恐慌,在程序运行的过程中产生的严重性错误,例如索引越界,空指针解引用等,都会触发 panic。如果不处理 panic,程序会直接意外退出,可能造成数据丢失的严重后果。
ants中如果 goroutine 在执行任务时发生panic,会终止当前任务的执行,将发生错误的堆栈输出到os.Stderr。注意,该 goroutine 还是会被放回池中,下次可以取出执行新的任务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
func wrapper(i int, wg *sync.WaitGroup) func() {
return func() {
fmt.Printf("hello from task:%d\n", i)
if i%2 == 0 {
panic(fmt.Sprintf("panic from task:%d", i))
}
wg.Done()
}
}
func main() {
p, _ := ants.NewPool(2)
defer p.Release()
var wg sync.WaitGroup
wg.Add(3)
for i := 1; i <= 2; i++ {
p.Submit(wrapper(i, &wg))
}
time.Sleep(1 * time.Second)
p.Submit(wrapper(3, &wg))
p.Submit(wrapper(5, &wg))
wg.Wait()
}
|
我们让偶数个任务触发panic。提交两个任务,第二个任务一定会触发panic。触发panic之后,我们还可以继续提交任务 3、5。注意这里没有 4,提交任务 4 还是会触发panic。
上面的程序需要注意 2 点:
- 任务函数中wg.Done()是在panic方法之后,如果触发了panic,函数中的其他正常逻辑就不会再继续执行了。所以我们虽然wg.Add(3),但是一共提交了 4 个任务,其中一个任务触发了panic,wg.Done()没有正确执行。实际开发中,我们一般使用defer语句来确保wg.Done()一定会执行
- 在 for 循环之后,我添加了一行代码time.Sleep(1 * time.Second)。如果没有这一行,后续的两条Submit()方法可以直接执行,可能会导致任务很快就完成了,wg.Wait()直接返回了,这时panic的堆栈还没有输出。你可以尝试注释掉这行代码运行看看结果
除了ants提供的默认 panic 处理器,我们还可以使用WithPanicHandler(paincHandler func(interface{}))指定我们自己编写的 panic 处理器。处理器的参数就是传给panic的值:
1
2
3
4
5
6
|
func panicHandler(err interface{}) {
fmt.Fprintln(os.Stderr, err)
}
p, _ := ants.NewPool(2, ants.WithPanicHandler(panicHandler))
defer p.Release()
|
其余代码与上面的完全相同,指定了panicHandler后触发panic就会执行它。运行:
1
2
3
4
5
|
hello from task:2
panic from task:2
hello from task:1
hello from task:5
hello from task:3
|
看到输出了传给panic函数的字符串(第二行输出)。
默认池
为了方便使用,很多 Go 库都喜欢提供其核心功能类型的一个默认实现。可以直接通过库提供的接口调用。例如net/http,例如ants。ants库中定义了一个默认的池,默认容量为MaxInt32。goroutine 池的各个方法都可以直接通过ants包直接访问:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// src/github.com/panjf2000/ants/ants.go
defaultAntsPool, _ = NewPool(DefaultAntsPoolSize)
func Submit(task func()) error {
return defaultAntsPool.Submit(task)
}
func Running() int {
return defaultAntsPool.Running()
}
func Cap() int {
return defaultAntsPool.Cap()
}
func Free() int {
return defaultAntsPool.Free()
}
func Release() {
defaultAntsPool.Release()
}
func Reboot() {
defaultAntsPool.Reboot()
}
|
直接使用:
1
2
3
4
5
6
7
8
9
10
|
func main() {
defer ants.Release()
var wg sync.WaitGroup
wg.Add(2)
for i := 1; i <= 2; i++ {
ants.Submit(wrapper(i, &wg))
}
wg.Wait()
}
|
默认池也需要Release()。
源码剖析
Pool
通过上篇文章,我们知道ants池有两种创建方式:
p, _:= ants.NewPool(cap):这种方式创建的池子对象需要调用p.Submit(task)提交任务,任务是一个无参数无返回值的函数;p,_ := ants.NewPoolWithFunc(cap, func(interface{})):这种方式创建的池子对象需要指定池函数,并且使用p.Invoke(arg)调用池函数。arg就是传给池函数func(interface{})的参数。
在ants中这两种池子使用不同的结构来表示:ants.Pool和ants.PoolWithFunc。我们先来介绍Pool。PoolWithFunc结构也是类似的,介绍完Pool之后,我们再简单比较一下它们。
Pool结构定义在文件pool.go中:
1
2
3
4
5
6
7
8
9
10
11
12
|
// src/github.com/panjf2000/ants/pool.go
type Pool struct {
capacity int32
running int32
workers workerArray
state int32
lock sync.Locker
cond *sync.Cond
workerCache sync.Pool
blockingNum int
options *Options
}
|
各个字段含义如下:
- capacity:池容量,表示ants最多能创建的 goroutine 数量。如果为负数,表示容量无限制;
- running:已经创建的 worker goroutine 的数量;
- workers:存放一组 worker 对象,workerArray只是一个接口,表示一个 worker 容器,后面详述;
- state:记录池子当前的状态,是否已关闭(CLOSED);
- lock:锁。ants自己实现了一个自旋锁。用于同步并发操作;
- cond:条件变量。处理任务等待和唤醒;
- workerCache:使用sync.Pool对象池管理和创建worker对象,提升性能;
- blockingNum:阻塞等待的任务数量;
- options:选项。上一篇文章已经详细介绍过了。
这里明确一个概念,ants中为每个任务都是由 worker 对象来处理的,每个 worker 对象会对应创建一个 goroutine 来处理任务。ants中使用goWorker表示 worker:
1
2
3
4
5
6
|
// src/github.com/panjf2000/ants/worker.go
type goWorker struct {
pool *Pool
task chan func()
recycleTime time.Time
}
|
后文详细介绍这一块内容,现在我们只需要知道Pool.workers字段就是存放goWorker对象的容器。
Pool创建
创建Pool对象需调用ants.NewPool(size, options)函数。省略了一些处理选项的代码,最终代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
// src/github.com/panjf2000/ants/pool.go
func NewPool(size int, options ...Option) (*Pool, error) {
// ...
p := &Pool{
capacity: int32(size),
lock: internal.NewSpinLock(),
options: opts,
}
p.workerCache.New = func() interface{} {
return &goWorker{
pool: p,
task: make(chan func(), workerChanCap),
}
}
if p.options.PreAlloc {
if size == -1 {
return nil, ErrInvalidPreAllocSize
}
p.workers = newWorkerArray(loopQueueType, size)
} else {
p.workers = newWorkerArray(stackType, 0)
}
p.cond = sync.NewCond(p.lock)
go p.purgePeriodically()
return p, nil
}
|
代码不难理解:
- 创建Pool对象,设置容量,创建一个自旋锁来初始化lock字段,设置选项;
- 设置workerCache这个sync.Pool对象的New方法,在调用sync.Pool对象的Get()方法时,如果它没有缓存的 worker 对象了,则调用这个方法创建一个;
- 根据是否设置了预分配选项,创建不同类型的 workers;
- 使用p.lock锁创建一个条件变量;
- 最后启动一个 goroutine 用于定期清理过期的 worker。
Pool.workers字段为workerArray类型,这实际上是一个接口,表示一个 worker 容器:
1
2
3
4
5
6
7
8
|
type workerArray interface {
len() int
isEmpty() bool
insert(worker *goWorker) error
detach()*goWorker
retrieveExpiry(duration time.Duration) []*goWorker
reset()
}
|
每个方法从名字上很好理解含义:
- len() int:worker 数量;
- isEmpty() bool:worker 数量是否为 0;
- insert(worker *goWorker) error:goroutine 任务执行结束后,将相应的 worker 放回workerArray中;
- detach()*goWorker:从workerArray中取出一个 worker;
- retrieveExpiry(duration time.Duration) []*goWorker:取出所有的过期 worker;
- reset():重置容器。
workerArray在ants中有两种实现,即workerStack和loopQueue。
workerStack
我们先来介绍一下workerStack,它位于文件worker_stack.go中:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// src/github.com/panjf2000/ants/worker_stack.go
type workerStack struct {
items []*goWorker
expiry []*goWorker
size int
}
func newWorkerStack(size int) *workerStack {
return &workerStack{
items: make([]*goWorker, 0, size),
size: size,
}
}
|
- items:空闲的worker;
- expiry:过期的worker。
goroutine 完成任务之后,Pool池会将相应的 worker 放回workerStack,调用workerStack.insert()直接append到items中即可:
1
2
3
4
|
func (wq *workerStack) insert(worker*goWorker) error {
wq.items = append(wq.items, worker)
return nil
}
|
新任务到来时,会调用workerStack.detach()从容器中取出一个空闲的 worker:
1
2
3
4
5
6
7
8
9
10
11
12
|
func (wq *workerStack) detach()*goWorker {
l := wq.len()
if l == 0 {
return nil
}
w := wq.items[l-1]
wq.items[l-1] = nil // avoid memory leaks
wq.items = wq.items[:l-1]
return w
}
|
这里总是返回最后一个 worker,每次insert()也是append到最后,符合栈后进先出的特点,故称为workerStack。
这里有一个细节,由于切片的底层结构是数组,只要有引用数组的指针,数组中的元素就不会释放。这里取出切片最后一个元素后,将对应数组元素的指针设置为nil,主动释放这个引用。
上面说过新建Pool对象时会创建一个 goroutine 定期检查和清理过期的 worker。通过调用workerArray.retrieveExpiry()获取过期的 worker 列表。workerStack实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func (wq *workerStack) retrieveExpiry(duration time.Duration) []*goWorker {
n := wq.len()
if n == 0 {
return nil
}
expiryTime := time.Now().Add(-duration)
index := wq.binarySearch(0, n-1, expiryTime)
wq.expiry = wq.expiry[:0]
if index != -1 {
wq.expiry = append(wq.expiry, wq.items[:index+1]...)
m := copy(wq.items, wq.items[index+1:])
for i := m; i < n; i++ {
wq.items[i] = nil
}
wq.items = wq.items[:m]
}
return wq.expiry
}
|
实现使用二分查找法找到已过期的最近一个 worker。由于过期时间是按照 goroutine 执行任务后的空闲时间计算的,而workerStack.insert()入队顺序决定了,它们的过期时间是从早到晚的。所以可以使用二分查找:
1
2
3
4
5
6
7
8
9
10
11
12
|
func (wq *workerStack) binarySearch(l, r int, expiryTime time.Time) int {
var mid int
for l <= r {
mid = (l + r) / 2
if expiryTime.Before(wq.items[mid].recycleTime) {
r = mid - 1
} else {
l = mid + 1
}
}
return r
}
|
二分查找的是最近过期的 worker,即将过期的 worker 的前一个。它和在它之前的 worker 已经全部过期了。
如果找到索引index,将items从开头到index(包括)的所有 worker 复制到expiry字段中。然后将index之后的所有未过期 worker 复制到切片头部,这里使用了copy函数。copy返回实际复制的数量,即未过期的 worker 数量m。然后将切片items从m开始所有的元素置为nil,避免内存泄漏,因为它们已经被复制到头部了。最后裁剪items切片,返回过期 worker 切片。
loopQueue
loopQueue实现基于循环队列,结构定义在文件worker_loop_queue中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
type loopQueue struct {
items []*goWorker
expiry []*goWorker
head int
tail int
size int
isFull bool
}
func newWorkerLoopQueue(size int) *loopQueue {
return &loopQueue{
items: make([]*goWorker, size),
size: size,
}
}
|
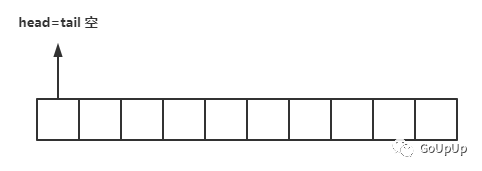
由于是循环队列,这里先创建好了一个长度为size的切片。循环队列有一个队列头指针head,指向第一个有元素的位置,一个队列尾指针tail,指向下一个可以存放元素的位置。所以一开始状态如下:
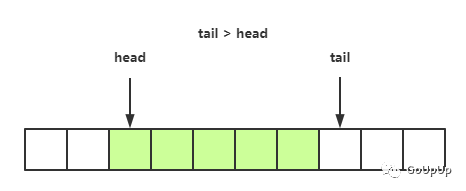
在tail处添加元素,添加后tail指针后移。在head处取出元素,取出后head指针也后移。进行一段时间操作后,队列状态如下:
head或tail指针到队列尾了,需要回绕。所以可能出现这种情况:
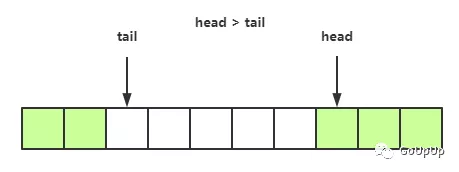
当tail指针赶上head指针了,说明队列就满了:
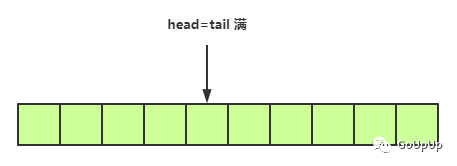 当head指针赶上tail指针了,队列再次为空:
当head指针赶上tail指针了,队列再次为空:
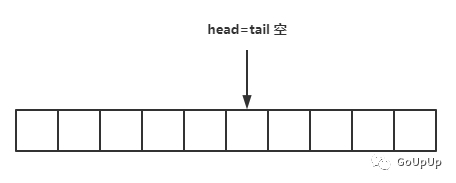
根据示意图,我们再来看loopQueue的操作方法就很简单了。
由于head和tail相等的情况有可能是队列空,也有可能是队列满,所以loopQueue中增加一个isFull字段以示区分。goroutine 完成任务之后,会将对应的 worker 对象放回loopQueue,执行的是insert()方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func (wq *loopQueue) insert(worker*goWorker) error {
if wq.size == 0 {
return errQueueIsReleased
}
if wq.isFull {
return errQueueIsFull
}
wq.items[wq.tail] = worker
wq.tail++
if wq.tail == wq.size {
wq.tail = 0
}
if wq.tail == wq.head {
wq.isFull = true
}
return nil
}
|
这个方法执行的就是循环队列的入队流程,注意如果插入后tail==head了,说明队列满了,设置isFull字段。
新任务到来调用loopQueeue.detach()方法获取一个空闲的 worker 结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func (wq *loopQueue) detach()*goWorker {
if wq.isEmpty() {
return nil
}
w := wq.items[wq.head]
wq.items[wq.head] = nil
wq.head++
if wq.head == wq.size {
wq.head = 0
}
wq.isFull = false
return w
}
|
这个方法对应的是循环队列的出队流程,注意每次出队后,队列肯定不满了,isFull要重置为false。
与workerStack结构一样,先入的 worker 对象过期时间早,后入的晚,获取过期 worker 的方法与workerStack中类似,只是没有使用二分查找了。这里就不赘述了。
再看Pool创建
介绍完两种workerArray的实现之后,再来看Pool的创建函数中workers字段的设置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
if p.options.PreAlloc {
if size == -1 {
return nil, ErrInvalidPreAllocSize
}
p.workers = newWorkerArray(loopQueueType, size)
} else {
p.workers = newWorkerArray(stackType, 0)
}
newWorkerArray()定义在文件worker_array.go中:
type arrayType int
const (
stackType arrayType = 1 << iota
loopQueueType
)
func newWorkerArray(aType arrayType, size int) workerArray {
switch aType {
case stackType:
return newWorkerStack(size)
case loopQueueType:
return newWorkerLoopQueue(size)
default:
return newWorkerStack(size)
}
}
|
即如果设置了预分配选项,就采用loopQueue结构。否则就采用stack的结构。
worker 结构
介绍完Pool的创建和结构,我们来看看 worker 的结构。在ants中 worker 用结构体goWorker表示,定义在文件worker.go中。它的结构非常简单:
1
2
3
4
5
6
|
// src/github.com/panjf2000/ants/worker.go
type goWorker struct {
pool *Pool
task chan func()
recycleTime time.Time
}
|
具体字段含义很明显:
- pool:持有 goroutine 池的引用;
- task:任务通道,通过这个通道将类型为func ()的函数作为任务发送给goWorker;
- recyleTime:这个字段记录goWorker什么时候被放回池中(即什么时候开始空闲)。其完成任务后,在将其放回 goroutine 池的时候设置。
goWorker创建时会调用run()方法,run()方法中启动一个新 goroutine 处理任务。run()主体流程非常简单:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func (w *goWorker) run() {
go func() {
for f := range w.task {
if f == nil {
return
}
f()
if ok := w.pool.revertWorker(w); !ok {
return
}
}
}()
}
|
这个方法启动一个新的 goroutine,然后不停地从task通道中接收任务,然后执行任务,任务执行完成之后调用池对象的revertWorker()方法将该goWorker对象放回池中,以便下次取出处理新的任务。revertWorker()方法后面会详细分析。
这里注意,实际上for f := range w.task这个循环直到通道task关闭或取出为nil的任务才会终止。所以这个 goroutine 一直在运行,这正是ants高性能的关键所在。每个goWorker只会启动一次 goroutine, 后续重复利用这个 goroutine。goroutine 每次只执行一个任务就会被放回池中。
还有一个细节,如果放回操作失败,则会调用return,这会让 goroutine 运行结束,防止 goroutine 泄漏。
这里f == nil为 true 时return,也是一个细节点,我们后面讲池关闭的时候会详细介绍。
下面我们看看run()方法的异常处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
defer func() {
w.pool.workerCache.Put(w)
if p := recover(); p != nil {
if ph := w.pool.options.PanicHandler; ph != nil {
ph(p)
} else {
w.pool.options.Logger.Printf("worker exits from a panic: %v\n", p)
var buf [4096]byte
n := runtime.Stack(buf[:], false)
w.pool.options.Logger.Printf("worker exits from panic: %s\n", string(buf[:n]))
}
}
w.pool.cond.Signal()
}()
|
简单来说,就是在defer中通过recover()函数捕获任务执行过程中抛出的panic。这时任务执行失败,goroutine 也结束了。但是goWorker对象还是可以重复利用,所以defer函数一开始调用w.pool.workerCache.Put(w)将goWorker对象放回sync.Pool池中。
接着就是处理panic,如果选项中指定了panic处理器,直接调用这个处理器。否则,ants调用选项中设置的Logger记录一些日志,如堆栈,panic信息等。
最后需要调用w.pool.cond.Signal()通知现在有空闲的goWorker了。因为我们实际运行的goWorker数量由于panic少了一个,而池中可能有其他任务在等待处理。
提交任务
接下来,通过提交任务就可以串起整个流程。由上一篇文章我们知道,可以调用池对象的Submit()方法提交任务:
1
2
3
4
5
6
7
8
9
10
11
|
func (p *Pool) Submit(task func()) error {
if p.IsClosed() {
return ErrPoolClosed
}
var w*goWorker
if w = p.retrieveWorker(); w == nil {
return ErrPoolOverload
}
w.task <- task
return nil
}
|
首先判断池是否已关闭,然后调用retrieveWorker()方法获取一个空闲的 worker,然后将任务task发送到 worker 的任务通道。下面是retrieveWorker()实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
func (p *Pool) retrieveWorker() (w*goWorker) {
p.lock.Lock()
w = p.workers.detach()
if w != nil {
p.lock.Unlock()
} else if capacity := p.Cap(); capacity == -1 || capacity > p.Running() {
p.lock.Unlock()
spawnWorker()
} else {
if p.options.Nonblocking {
p.lock.Unlock()
return
}
Reentry:
if p.options.MaxBlockingTasks != 0 && p.blockingNum >= p.options.MaxBlockingTasks {
p.lock.Unlock()
return
}
p.blockingNum++
p.cond.Wait()
p.blockingNum--
var nw int
if nw = p.Running(); nw == 0 {
p.lock.Unlock()
if !p.IsClosed() {
spawnWorker()
}
return
}
if w = p.workers.detach(); w == nil {
if nw < capacity {
p.lock.Unlock()
spawnWorker()
return
}
goto Reentry
}
p.lock.Unlock()
}
return
}
|
这个方法稍微有点复杂,我们一点点来看。首先调用p.workers.detach()获取goWorker对象。p.workers是loopQueue或者workerStack对象,它们都实现了detach()方法,前面已经介绍过了。
如果返回了一个goWorker对象,说明有空闲 goroutine,直接返回。
否则,池容量还没用完(即容量大于正在工作的goWorker数量),则调用spawnWorker()新建一个goWorker,执行其run()方法:
1
2
3
4
|
spawnWorker := func() {
w = p.workerCache.Get().(*goWorker)
w.run()
}
|
否则,池容量已用完。如果设置了非阻塞选项,则直接返回。否则,如果设置了最大阻塞队列长度上限,且当前阻塞等待的任务数量已经达到这个上限,直接返回。否则,阻塞等待数量 +1,调用p.cond.Wait()等待。
然后goWorker.run()完成一个任务后,调用池的revertWorker()方法放回goWorker:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
func (p *Pool) revertWorker(worker*goWorker) bool {
if capacity := p.Cap(); (capacity > 0 && p.Running() > capacity) || p.IsClosed() {
return false
}
worker.recycleTime = time.Now()
p.lock.Lock()
if p.IsClosed() {
p.lock.Unlock()
return false
}
err := p.workers.insert(worker)
if err != nil {
p.lock.Unlock()
return false
}
p.cond.Signal()
p.lock.Unlock()
return true
}
|
这里设置了goWorker的recycleTime字段,用于判定过期。然后将goWorker放回池。workers的insert()方法前面也已经分析过了。
接着调用p.cond.Signal()唤醒之前retrieveWorker()方法中的等待。retrieveWorker()方法继续执行,阻塞等待数量 -1,这里判断当前goWorker的数量(也即 goroutine 数量)。如果数量等于 0,很有可能池子刚刚执行了Release()关闭,这时需要判断池是否处于关闭状态,如果是则直接返回。否则,调用spawnWorker()创建一个新的goWorker并执行其run()方法。
如果当前goWorker数量不为 0,则调用p.workers.detach()取出一个空闲的goWorker返回。这个操作有可能失败,因为可能同时有多个 goroutine 在等待,唤醒的时候只有部分 goroutine 能获取到goWorker。如果失败了,其容量还未用完,直接创建新的goWorker,反之重新执行阻塞等待逻辑。
这里有很多加锁和解锁的逻辑,再加上和信号量混在一起很难看明白。其实只需要知道一点就很简单了,那就是p.cond.Wait()内部会将当前 goroutine 挂起,然后解开它持有的锁,即会调用p.lock.Unlock()。这也是为什么revertWorker()中p.lock.Lock()加锁能成功的原因。然后p.cond.Signal()或p.cond.Broadcast()会唤醒因为p.cond.Wait()而挂起的 goroutine,但是需要Signal()/Broadcast()所在 goroutine 调用解锁方法。
最后,放上整体流程图:
清理过期goWorker
在NewPool()函数中会启动一个 goroutine 定期清理过期的goWorker:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func (p *Pool) purgePeriodically() {
heartbeat := time.NewTicker(p.options.ExpiryDuration)
defer heartbeat.Stop()
for range heartbeat.C {
if p.IsClosed() {
break
}
p.lock.Lock()
expiredWorkers := p.workers.retrieveExpiry(p.options.ExpiryDuration)
p.lock.Unlock()
for i := range expiredWorkers {
expiredWorkers[i].task <- nil
expiredWorkers[i] = nil
}
if p.Running() == 0 {
p.cond.Broadcast()
}
}
}
|
如果池子已关闭,直接退出 goroutine。由选项ExpiryDuration来设置清理的间隔,如果没有设置该选项,采用默认值 1s:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// src/github.com/panjf2000/ants/pool.go
func NewPool(size int, options ...Option) (*Pool, error) {
if expiry := opts.ExpiryDuration; expiry < 0 {
return nil, ErrInvalidPoolExpiry
} else if expiry == 0 {
opts.ExpiryDuration = DefaultCleanIntervalTime
}
}
// src/github.com/panjf2000/ants/pool.go
const (
DefaultCleanIntervalTime = time.Second
)
|
然后就是每个清理周期,调用p.workers.retrieveExpiry()方法,取出过期的goWorker。因为由这些goWorker启动的 goroutine 还阻塞在通道task上,所以要向该通道发送一个nil值,而goWorker.run()方法中接收到一个值为nil的任务会return,结束 goroutine,避免了 goroutine 泄漏。
如果所有goWorker都被清理掉了,可能这时还有 goroutine 阻塞在retrieveWorker()方法中的p.cond.Wait()上,所以这里需要调用p.cond.Broadcast()唤醒这些 goroutine。
容量动态修改
在运行过程中,可以动态修改池的容量。调用p.Tune(size int)方法:
1
2
3
4
5
6
|
func (p *Pool) Tune(size int) {
if capacity := p.Cap(); capacity == -1 || size <= 0 || size == capacity || p.options.PreAlloc {
return
}
atomic.StoreInt32(&p.capacity, int32(size))
}
|
这里只是简单设置了一下新的容量,不影响当前正在执行的goWorker,而且如果设置了预分配选项,容量不能再次设置。
下次执行revertWorker()的时候就会以新的容量判断是否能放回,下次执行retrieveWorker()的时候也会以新容量判断是否能创建新goWorker。
关闭和重新启动Pool
使用完成之后,需要关闭Pool,避免 goroutine 泄漏。调用池对象的Release()方法关闭:
1
2
3
4
5
6
7
|
func (p *Pool) Release() {
atomic.StoreInt32(&p.state, CLOSED)
p.lock.Lock()
p.workers.reset()
p.lock.Unlock()
p.cond.Broadcast()
}
|
调用p.workers.reset()结束loopQueue或wokerStack中的 goroutine,做一些清理工作,同时为了防止有 goroutine 阻塞在p.cond.Wait()上,执行一次p.cond.Broadcast()。
workerStack与loopQueue的reset()基本相同,即发送nil到task通道从而结束 goroutine,然后重置各个字段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
// loopQueue 版本
func (wq *loopQueue) reset() {
if wq.isEmpty() {
return
}
Releasing:
if w := wq.detach(); w != nil {
w.task <- nil
goto Releasing
}
wq.items = wq.items[:0]
wq.size = 0
wq.head = 0
wq.tail = 0
}
// stack 版本
func (wq *workerStack) reset() {
for i := 0; i < wq.len(); i++ {
wq.items[i].task <- nil
wq.items[i] = nil
}
wq.items = wq.items[:0]
}
|
池关闭后还可以调用Reboot()重启:
1
2
3
4
5
|
func (p *Pool) Reboot() {
if atomic.CompareAndSwapInt32(&p.state, CLOSED, OPENED) {
go p.purgePeriodically()
}
}
|
由于p.purgePeriodically()在p.Release()之后检测到池关闭就直接退出了,这里需要重新开启一个 goroutine 定期清理。
PoolWithFunc和WorkWithFunc
上一篇文章中我们还介绍了另一种方式创建Pool,即NewPoolWithFunc(),指定一个函数。后面提交任务时调用p.Invoke()提供参数就可以执行该函数了。这种方式创建的 Pool 和 Woker 结构如下:
1
2
3
4
5
6
7
8
9
10
|
type PoolWithFunc struct {
workers []*goWorkerWithFunc
poolFunc func(interface{})
}
type goWorkerWithFunc struct {
pool *PoolWithFunc
args chan interface{}
recycleTime time.Time
}
|
与前面介绍的Pool和goWorker大体相似,只是PoolWithFunc保存了传入的函数对象,使用数组保存 worker。goWorkerWithFunc以interface{}为args通道的数据类型,其实也好理解,因为已经有函数了,只需要传入数据作为参数就可以运行了:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func (w *goWorkerWithFunc) run() {
go func() {
for args := range w.args {
if args == nil {
return
}
w.pool.poolFunc(args)
if ok := w.pool.revertWorker(w); !ok {
return
}
}
}()
}
|
从通道接收函数参数,执行池中保存的函数对象。
其他细节
task缓冲通道
还记得创建p.workerCache这个sync.Pool对象的代码么:
1
2
3
4
5
6
|
p.workerCache.New = func() interface{} {
return &goWorker{
pool: p,
task: make(chan func(), workerChanCap),
}
}
|
在sync.Pool中没有goWorker对象时,调用New()方法创建一个,注意到这里创建的task通道使用workerChanCap作为容量。这个变量定义在ants.go文件中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
var (
// workerChanCap determines whether the channel of a worker should be a buffered channel
// to get the best performance. Inspired by fasthttp at
// <https://github.com/valyala/fasthttp/blob/master/workerpool.go#L139>
workerChanCap = func() int {
// Use blocking channel if GOMAXPROCS=1.
// This switches context from sender to receiver immediately,
// which results in higher performance (under go1.5 at least).
if runtime.GOMAXPROCS(0) == 1 {
return 0
}
// Use non-blocking workerChan if GOMAXPROCS>1,
// since otherwise the sender might be dragged down if the receiver is CPU-bound.
return 1
}()
)
|
为了方便对照,我把注释也放上来了。ants参考了著名的 Web 框架fasthttp的实现。当GOMAXPROCS为 1 时(即操作系统线程数为 1),向通道task发送会挂起发送 goroutine,将执行流程转向接收 goroutine,这能提升接收处理性能。如果GOMAXPROCS大于 1,ants使用带缓冲的通道,为了防止接收 goroutine 是 CPU 密集的,导致发送 goroutine 被阻塞。下面是fasthttp中的相关代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// src/github.com/valyala/fasthttp/workerpool.go
var workerChanCap = func() int {
// Use blocking workerChan if GOMAXPROCS=1.
// This immediately switches Serve to WorkerFunc, which results
// in higher performance (under go1.5 at least).
if runtime.GOMAXPROCS(0) == 1 {
return 0
}
// Use non-blocking workerChan if GOMAXPROCS>1,
// since otherwise the Serve caller (Acceptor) may lag accepting
// new connections if WorkerFunc is CPU-bound.
return 1
}()
|
自旋锁
ants利用atomic.CompareAndSwapUint32()这个原子操作实现了一个自旋锁。与其他类型的锁不同,自旋锁在加锁失败之后不会立刻进入等待,而是会继续尝试。这对于很快就能获得锁的应用来说能极大提升性能,因为能避免加锁和解锁导致的线程切换:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
type spinLock uint32
func (sl *spinLock) Lock() {
backoff := 1
for !atomic.CompareAndSwapUint32((*uint32)(sl), 0, 1) {
for i := 0; i < backoff; i++ {
runtime.Gosched()
}
backoff <<= 1
}
}
func (sl *spinLock) Unlock() {
atomic.StoreUint32((*uint32)(sl), 0)
}
// NewSpinLock instantiates a spin-lock.
func NewSpinLock() sync.Locker {
return new(spinLock)
}
|
另外这里使用了指数退避,先等 1 个循环周期,通过runtime.Gosched()告诉运行时切换其他 goroutine 运行。如果还是获取不到锁,就再等 2 个周期。如果还是不行,再等 4,8,16…以此类推。这可以防止短时间内获取不到锁,导致 CPU 时间的浪费。
总结
ants源码短小精悍,没有引用其他任何第三方库。各种细节处理,各种性能优化的点都是值得我们细细品味的。强烈建议大家读一读源码。阅读优秀的源码,能极大地提高自身的编码素养。
转载
Go 每日一库之 ants
Go 每日一库之 ants 源码赏析