Go中unsafe使用实践
文章目录
指针类型
在正式介绍 unsafe 包之前,需要着重介绍 Go 语言中的指针类型。
举一个例子:
|
|
非常简单,我想在 double 函数里将 a 翻倍,但是例子中的函数却做不到。为什么?因为 Go 语言的函数传参都是值传递。double 函数里的 x 只是实参 a 的一个拷贝,在函数内部对 x 的操作不能反馈到实参 a。
如果这时,有一个指针就可以解决问题了!这也是我们常用的“伎俩”。
|
|
很常规的操作,不用多解释。唯一可能有些疑惑的在这一句:
|
|
这得稍微思考一下,才能得出这一行代码根本不影响的结论。因为是值传递,所以 x 也只是对 &a 的一个拷贝。
|
|
这一句把 x 指向的值(也就是 &a 指向的值,即变量 a)变为原来的 2 倍。但是对 x 本身(一个指针)的操作却不会影响外层的 a,所以 x = nil 掀不起任何大风大浪。
下面的这张图可以“自证清白”:
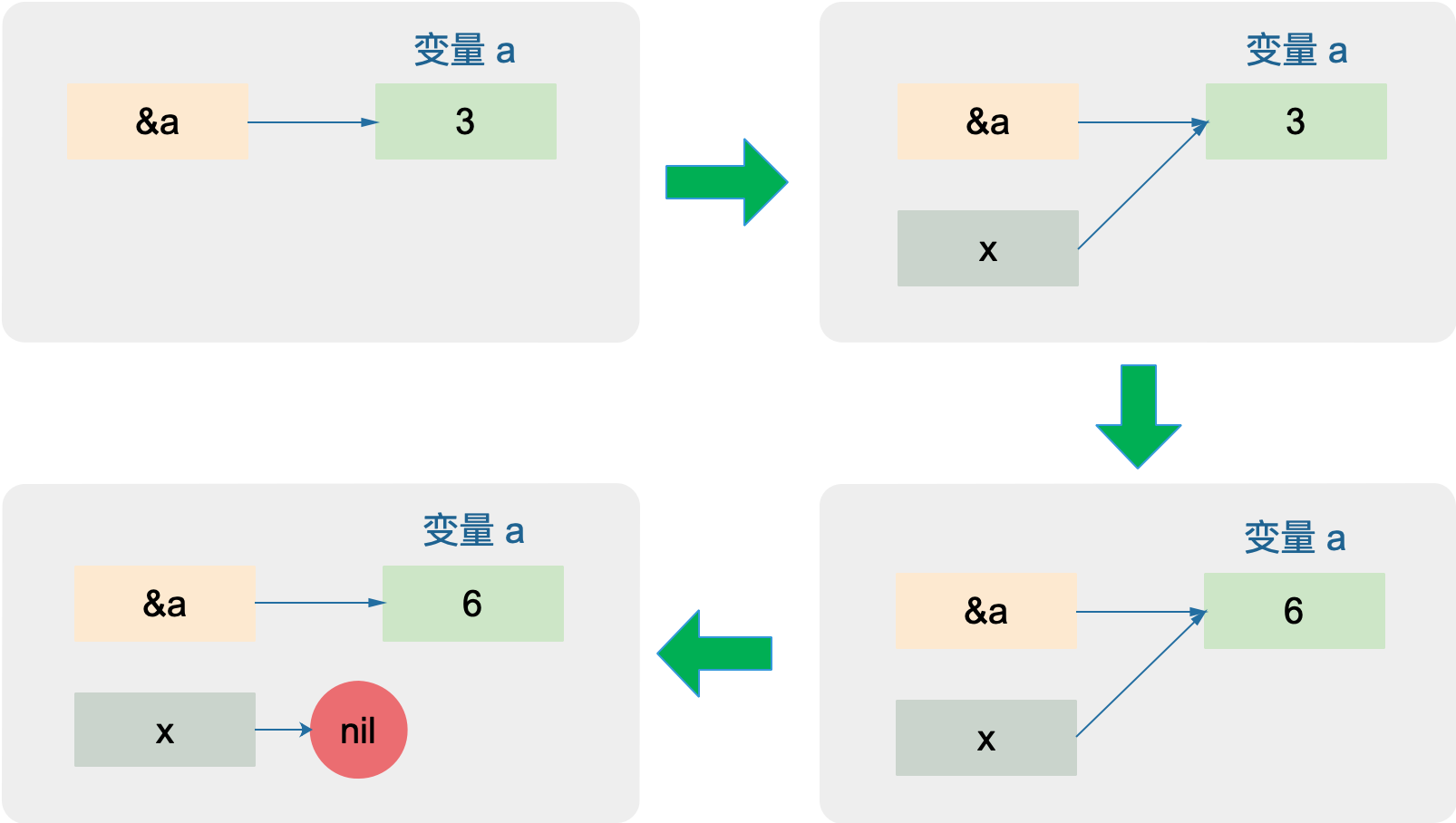
然而,相比于 C 语言中指针的灵活,Go 的指针多了一些限制。但这也算是 Go 的成功之处:既可以享受指针带来的便利,又避免了指针的危险性。
限制一:Go 的指针不能进行数学运算。
来看一个简单的例子:
|
|
上面的代码将不能通过编译,会报编译错误:invalid operation,也就是说不能对指针做数学运算。
限制二:不同类型的指针不能相互转换。
例如下面这个简短的例子:
|
|
也会报编译错误:
|
|
限制三:不同类型的指针不能使用 == 或 != 比较。
只有在两个指针类型相同或者可以相互转换的情况下,才可以对两者进行比较。另外,指针可以通过 == 和 != 直接和 nil 作比较。
限制四:不同类型的指针变量不能相互赋值。
这一点同限制三。
什么是 unsafe
前面所说的指针是类型安全的,但它有很多限制。Go 还有非类型安全的指针,这就是 unsafe 包提供的 unsafe.Pointer。在某些情况下,它会使代码更高效,当然,也更危险。
unsafe 包用于 Go 编译器,在编译阶段使用。从名字就可以看出来,它是不安全的,官方并不建议使用。我在用 unsafe 包的时候会有一种不舒服的感觉,可能这也是语言设计者的意图吧。
但是高阶的 Gopher,怎么能不会使用 unsafe 包呢?它可以绕过 Go 语言的类型系统,直接操作内存。例如,一般我们不能操作一个结构体的未导出成员,但是通过 unsafe 包就能做到。unsafe 包让我可以直接读写内存,还管你什么导出还是未导出。
为什么有 unsafe
Go 语言类型系统是为了安全和效率设计的,有时,安全会导致效率低下。有了 unsafe 包,高阶的程序员就可以利用它绕过类型系统的低效。因此,它就有了存在的意义,阅读 Go 源码,会发现有大量使用 unsafe 包的例子。
unsafe 实现原理
我们来看源码:
|
|
从命名来看,Arbitrary 是任意的意思,也就是说 Pointer 可以指向任意类型,实际上它类似于 C 语言里的 void*。
unsafe 包还有其他三个函数:
|
|
- Sizeof 返回类型 x 所占据的字节数,但不包含 x 所指向的内容的大小。例如,对于一个指针,函数返回的大小为 8 字节(64位机上),一个 slice 的大小则为 slice header 的大小。
- Offsetof 返回结构体成员在内存中的位置离结构体起始处的字节数,所传参数必须是结构体的成员。
- Alignof 返回 m,m 是指当类型进行内存对齐时,它分配到的内存地址能整除 m。
uintptr与unsafe.Pointer
注意到以上三个函数返回的结果都是 uintptr 类型,这和 unsafe.Pointer 可以相互转换。三个函数都是在编译期间执行,它们的结果可以直接赋给 const 型变量。另外,因为三个函数执行的结果和操作系统、编译器相关,所以是不可移植的。
综上所述,unsafe 包提供了 2 点重要的能力:
- 任何类型的指针和 unsafe.Pointer 可以相互转换。
- uintptr 类型和 unsafe.Pointer 可以相互转换。

pointer 不能直接进行数学运算,但可以把它转换成 uintptr,对 uintptr 类型进行数学运算,再转换成 pointer 类型。
|
|
unsafe.Pointer在Golang中是用于各种类型转化的桥梁,Pointer代表了一个指向任意类型的指针。uintptr是Golang的内置类型,是能存储指针的整型,uintptr的底层类型是int,它和unsafe.Pointer可相互转换。
Pointer与uintptr的区别在于:
- unsafe.Pointer只是一个指针的类型,但是不能像C中的指针那样作计算,而只能用于转化不同类型的指针;如果unsafe.Pointer变量仍然有效,则由unsafe.Pointer变量表示的地址处的数据不会被GC回收;
- uintptr是可以用于指针运算的,但是无法持有对象,GC并不把uintptr当做指针,所以uintptr类型的目标会被回收。
在Golang中出于安全的原因,不允许两个不同指针类型的值去直接转换;也不允许指针类型和uintptr的值去直接转换。但是借助unsafe.Pointer,我们
- 任何类型的指针值都可以转换为unsafe.Pointer;
- unsafe.Pointer可以转换为任何类型的指针值;
- uintptr可以转换为unsafe.Pointer;
- unsafe.Pointer可以转换为uintptr。
unsafe 包中的几个函数都是在编译期间执行完毕,毕竟,编译器对内存分配这些操作“了然于胸”。在 /usr/local/go/src/cmd/compile/internal/gc/unsafe.go 路径下,可以看到编译期间 Go 对 unsafe 包中函数的处理。
强制类型转换
在此之前提示一下这里我们说的类型的转化,是转化前后变量为同一变量,而不是这样为两个变量:
|
|
如果我们要来做一个强制的转化的话,a = float64(a),Golang会报错:cannot use float64(a) (type float64) as type int64 in assignment。
使用unsafe.Pointer来将T1转化为T2,一个大致的语法为*(*T2)(unsafe.Pointer(&t1))
|
|
这个例子虽然没有实际的意义,但是绕过了Golang类型系统和内存安全,将一个变量的类型作了转化。
修改结构体私有成员
我们知道在Golang中指针是不能用来计算的,但是借助uintptr我们可以作计算:
|
|
对于一个结构体,通过 offset 函数可以获取结构体成员的偏移量,进而获取成员的地址,读写该地址的内存,就可以达到改变成员值的目的。
这里有一个内存分配相关的事实:结构体会被分配一块连续的内存,结构体的地址也代表了第一个成员的地址。
我们来看一个例子:
|
|
运行代码,输出:
|
|
name 是结构体的第一个成员,因此可以直接将 &p 解析成 *string。这一点,在前面获取 map 的 count 成员时,用的是同样的原理。
对于结构体的私有成员,现在有办法可以通过 unsafe.Pointer 改变它的值了。
我把 Programmer 结构体升级,多加一个字段:
|
|
并且放在其他包,这样在 main 函数中,它的三个字段都是私有成员变量,不能直接修改。但我通过 unsafe.Sizeof() 函数可以获取成员大小,进而计算出成员的地址,直接修改内存。
|
|
输出:
|
|
string与[]byte相互转换
我们在写程序的时候会经常遇到string与[]byte相互转换的情况,这种转化其实代价很高,因为string与[]byte的内存空间不共享,所以每次转换都伴随着内存的分配与底层字节的拷贝。而我们使用unsafe就可以避开这些,从而提升性能。
|
|
这样的转化过程依赖于二者的数据结构:
|
|
注意,这样虽然可以实现,但强烈推荐不要使用这种方法来转换类型,因为这样会导致修改转化过后的值会影响之前的变量。
修改私有成员变量
在Golang中对于不在同一个package里面的对象的私有变量(小写的)是不能直接修改的,但是使用unsafe可以做到:
|
|
我们在mian里面实现来直接修改i,j的值:
|
|
其实在上面用uintptr计算偏移量介绍的那样,这样可以达到修改私有变量的目的。虽然达到了目的,但是在开发中其实并不建议这么干。
在反射中使用
reflect包中Value类型的方法中名称为Pointer和UnsafeAddr的方法的返回值类型是uintptr而不是unsafe.Pointer,目的是为了使调用者可以将结果转为任意类型而不用导入unsafe包。然而,这意味着调用结果必须马上再调用完成后转为Pointer,并且是在同一个表达式中完成;如下:
|
|
获取 slice 长度
通过前面关于 slice 的文章,我们知道了 slice header 的结构体定义:
|
|
调用 make 函数新建一个 slice,底层调用的是 makeslice 函数,返回的是 slice 结构体:
|
|
因此我们可以通过 unsafe.Pointer 和 uintptr 进行转换,得到 slice 的字段值。
|
|
Len,cap 的转换流程如下:
|
|
获取 map 长度
再来看一下我们讲到的 map:
|
|
和 slice 不同的是,makemap 函数返回的是 hmap 的指针,注意是指针:
|
|
我们依然能通过 unsafe.Pointer 和 uintptr 进行转换,得到 hamp 字段的值,只不过,现在 count 变成二级指针了:
|
|
count 的转换过程:
|
|
在 map 源码中,mapaccess1、mapassign、mapdelete 函数中,需要定位 key 的位置,会先对 key 做哈希运算。
例如:
|
|
h.buckets 是一个 unsafe.Pointer,将它转换成 uintptr,然后加上 (hash&m)*uintptr(t.bucketsize),二者相加的结果再次转换成 unsafe.Pointer,最后,转换成 bmap 指针,得到 key 所落入的 bucket 位置。
上面举的例子相对简单,来看一个关于赋值的更难一点的例子:
|
|
这段代码是在找到了 key 要插入的位置后,进行“赋值”操作。insertk 和 val 分别表示 key 和 value 所要“放置”的地址。如果 t.indirectkey 为真,说明 bucket 中存储的是 key 的指针,因此需要将 insertk 看成指针的指针,这样才能将 bucket 中的相应位置的值设置成指向真实 key 的地址值,也就是说 key 存放的是指针。
下面这张图展示了设置 key 的全部操作:
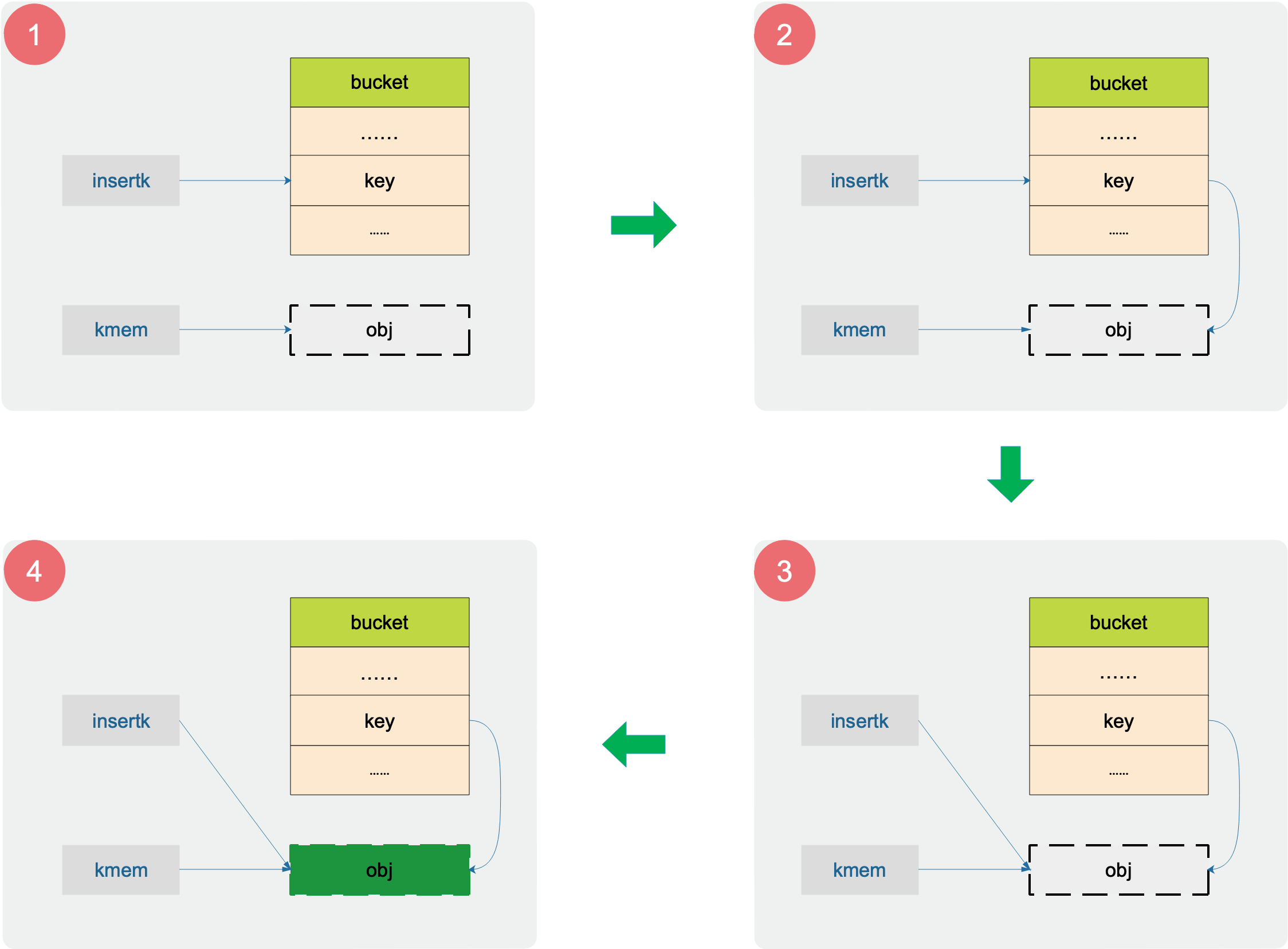
obj 是真实的 key 存放的地方。第 4 号图,obj 表示执行完 typedmemmove 函数后,被成功赋值。
总结
其实说了这么多,大部分使用在日常的开发中都不怎么会用到。所以文中有不止一处说了“不建议”,那是因为用的时候的确有很多需要注意的地方,但是如果你可以很准确地控制,那么使用"unsafe"则可能成为一把利剑。
参考
文章作者 Forz
上次更新 2018-11-27