编码
数据结构map
json源于javascript的对象结构,golang中直接对应其数据结构,可是golang的map也是key-value结构,同时struct结构体也可以描述json。当然,对于json的数据类型,go也会有对象的结构所匹配。大致对应关系如下:
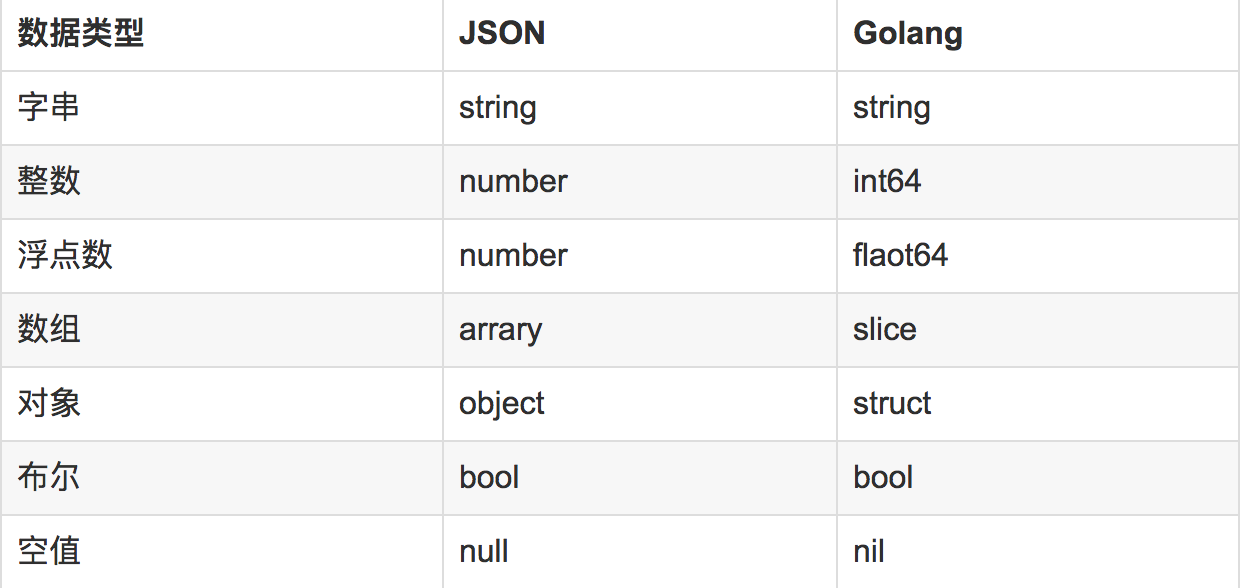
基本结构编码
golang提供了encoding/json的标准库用于编码json。大致需要两步:
- 首先定义json结构体。
- 使用 Marshal方法序列化。
定义结构体的时候,只有字段名是大写的,才会被编码到json当中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
type Account struct {
Email string
password string
Money float64
}
func main() {
account := Account{
Email: "rsj217@gmail.com",
password: "123456",
Money: 100.5,
}
rs, err := json.Marshal(account)
if err != nil{
log.Fatalln(err)
}
fmt.Println(rs)
fmt.Println(string(rs))
}
|
可以看到输出如下,Marshal方法接受一个空接口的参数,返回一个[]byte结构。小写命名的password字段没有被编码到json当中,生成的json结构字段和Account结构一致。
1
2
|
[123 34 69 109 97 105 108 34 58 34 114 115 106 50 49 55 64 103 109 97 105 108 46 99 111 109 34 44 34 77 111 110 101 121 34 58 49 48 48 46 53 125]
{"Email":"rsj217@gmail.com","Money":100.5}
|
复合结构编码
相比字符串,数字等基本数据结构,slice切片,map图则是复合结构。这些结构编码也类似。不过map的key必须是字符串,而value必须是同一类型的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
package main
import (
"encoding/json"
"fmt"
)
type User struct {
Name string
Age int
Roles []string
Skill map[string]float64
}
func main() {
skill := make(map[string]float64)
skill["python"] = 99.5
skill["elixir"] = 90
skill["ruby"] = 80.0
user := User{
Name: "rsj217",
Age: 27,
Roles: []string{"Owner", "Master"},
Skill: skill,
}
rs, err := json.Marshal(user)
if err != nil {
log.Fatalln(err)
}
fmt.Println(string(rs))
}
|
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
{
"Name":"rsj217",
"Age":27,
"Roles":[
"Owner",
"Master"
],
"Skill":{
"elixir":90,
"python":99.5,
"ruby":80
}
}
|
嵌套编码
slice和map可以匹配json的数组和对象,当前提是对象的value是同类型的情况。更通用的做法,对象的key可以是string,但是其值可以是多种结构。golang可以通过定义结构体实现这种构造:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
type Account struct {
Email string
password string
Money float64
}
type User struct {
Name string
Age int
Roles []string
Skill map[string]float64
Account Account
}
func main(){
...
user := User{
Name:"rsj217",
Age: 27,
Roles: []string{"Owner", "Master"},
Skill: skill,
Account:account,
}
...
}
|
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
{
"Name":"rsj217",
"Age":27,
"Roles":[
"Owner",
"Master"
],
"Skill":{
"elixir":90,
"python":99.5,
"ruby":80
},
"Account":{
"Email":"rsj217@gmail.com",
"Money":100.5
}
}
|
通过定义嵌套的结构体Account,实现了key与value不一样的结构。golang的数组或切片,其类型也是一样的,如果遇到不同数据类型的数组,则需要借助空结构来实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
type User struct {
...
Extra []interface{}
}
extra := []interface{}{123, "hello world"}
user := User{
...
Extra: extra,
}
|
输出:
1
2
3
4
5
6
7
|
{
...
"Extra":[
123,
"hello world"
]
}
|
使用空接口,也可以定义像结构体实现那种不同value类型的字典结构。当空接口没有初始化其值的时候,零值是 nil。编码成json就是 null
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
type User struct {
Name string
Age int
Roles []string
Skill map[string]float64
Account Account
Extra []interface{}
Level map[string]interface{}
}
func main() {
...
level := make(map[string]interface{})
level["web"] = "Good"
level["server"] = 90
level["tool"] = nil
user := User{
Name: "rsj217",
Age: 27,
Roles: []string{"Owner", "Master"},
Skill: skill,
Account: account,
Level: level,
}
...
}
|
输出:
1
2
3
4
5
6
7
8
9
|
{
...
"Extra":null,
"Level":{
"server":90,
"tool":null,
"web":"Good"
}
}
|
可以看到 Extra返回的并不是一个空的切片,而是null。同时Level字段实现了向字典的嵌套结构。
StructTag 字段重名
通过上面的例子,我们看到了Level字段中的keyserver等是小写字母,其他的都是大写字母。因为我们在定义结构的时候,只有使用大写字母开头的字段才会被导出。而通常json世界中,更盛行小写字母的方式。看起来就成了一个矛盾。其实不然,golang提供了struct tag的方式可以重命名结构字段的输出形式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
type Account struct {
Email string `json:"email"`
Password string `json:"pass_word"`
Money float64 `json:"money"`
}
func main() {
account := Account{
Email: "rsj217@gmail.com",
Password: "123456",
Money: 100.5,
}
rs, err := json.Marshal(account)
...
}
|
我们使用struct tag,重新给Aaccount结构的字段进行了重命名。其中email小写了,并且password字段还使用了下划线,输出的结果如下:
1
2
3
4
5
|
{
"email": "rsj217@gmail.com",
"pass_word": "123456",
"money": 100.5
}
|
-忽略字段
重命名这个利器还提供了更高级的选项。通常使用marshal的时候,会把结构体的所有除了私有字段都编码到json,而实际开发中,我们定义的结构可能更通用,我们需要某个字段可以导出,但是又不能编码到json中。
此时使用 struact tag的 -符号就能完美解决,我们已经知道_常用于忽略字段的占位,在tag中则使用短横线-。
1
2
3
4
5
|
type Account struct {
Email string `json:"email"`
Password string `json:"-"`
Money float64 `json:"money"`
}
|
输出:
1
2
3
4
|
{
"email": "rsj217@gmail.com",
"money": 100.5
}
|
可见即使Password不是私有字段,因为-忽略了它,因此没有被编码到json输出。
omitempty可选字段
对于另外一种字段,当其有值的时候就输出,而没有值(零值)的时候就不输出,则可以使用另外一种选项omitempty。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
type Account struct {
Email string `json:"email"`
Password string `json:"password,omitempty"`
Money float64 `json:"money"`
}
func main() {
account := Account{
Email: "rsj217@gmail.com",
Password: "",
Money: 100.5,
}
...
}
|
此时password不会被编码到json输出中。
string选项
golang是静态类型语言,对于类型定义的是不能动态修改。在json处理当中,struct tag的string可以起到部分动态类型的效果。有时候输出的json希望是数字的字符串,而定义的字段是数字类型,那么就可以使用string选项。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
type Account struct {
Email string `json:"email"`
Password string `json:"password,omitempty"`
Money float64 `json:"money,string"`
}
func main() {
account := Account{
Email: "rsj217@gmail.com",
Password: "123",
Money: 100.50,
}
...
}
|
可以看到输出为 money: "100.5", money字段的值是字符串。
编码中的html字符转义
json.Marshal生成json特殊字符<、>、&会被转义。
1
2
3
4
5
6
7
8
9
10
|
func main() {
testMap := map[string]string{
"demo": `https://xxx.xxx.com?a=1&b=2`,
}
bytes, err := json.Marshal(testMap)
if err != nil {
panic(err)
}
fmt.Println(string(bytes))
}
|
输出结果:
1
|
{"demo":"https://xxx.xxx.com?a=1\u0026b=2"}
|
查看json.Marshal源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func Marshal(v interface{}) ([]byte, error) {
e := newEncodeState()
err := e.marshal(v, encOpts{escapeHTML: true})
if err != nil {
return nil, err
}
buf := append([]byte(nil), e.Bytes()...)
e.Reset()
encodeStatePool.Put(e)
return buf, nil
}
|
json.Marshal 默认 escapeHtml 为true,会转义 <、>、&
查看官方文档:
1
2
3
4
5
6
7
|
// String values encode as JSON strings coerced to valid UTF-8,
// replacing invalid bytes with the Unicode replacement rune.
// The angle brackets "<" and ">" are escaped to "\u003c" and "\u003e"
// to keep some browsers from misinterpreting JSON output as HTML.
// Ampersand "&" is also escaped to "\u0026" for the same reason.
// This escaping can be disabled using an Encoder that had SetEscapeHTML(false)
// called on it.
|
简单的说就是,字符串在编码为JSON字符串时会被强制转换为有效的UTF-8,为了防止一些浏览器在JSON输出误解以为是HTML,“<”,“>”,“&”这类字符会被进行转义,如果不想被转义,就使用Encoder,并且SetEscapeHTML(false)即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func main() {
testMap := map[string]string{
"demo": `https://xxx.xxx.com?a=1&b=2`,
}
byteBuf := bytes.NewBuffer([]byte{})
encoder := json.NewEncoder(byteBuf)
encoder.SetEscapeHTML(false)
err := encoder.Encode(testMap)
if err != nil {
panic(err)
}
fmt.Println(byteBuf.String())
}
|
输出结果:
1
|
{"demo":"https://xxx.xxx.com?a=1&b=2"}
|
可见,& 符号没有被转义
Go结构转Json的顺序
map转json是有序的,按照ASCII码升序排列key。
源码位于encoding/json/encode.go中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
type mapEncoder struct {
elemEnc encoderFunc
}
func (me mapEncoder) encode(e *encodeState, v reflect.Value, opts encOpts) {
if v.IsNil() {//为nil时,返回null
e.WriteString("null")
return
}
e.WriteByte('{')
// Extract and sort the keys.
keys := v.MapKeys()//获取map中的所有keys
sv := make([]reflectWithString, len(keys))
for i, v := range keys {
sv[i].v = v
if err := sv[i].resolve(); err != nil {//处理key,尤其是非string(int/uint)类型的key转string
e.error(&MarshalerError{v.Type(), err})
}
}
//排序,升序,直接比较字符串
sort.Slice(sv, func(i, j int) bool { return sv[i].s < sv[j].s })
for i, kv := range sv {
if i > 0 {
e.WriteByte(',')
}
e.string(kv.s, opts.escapeHTML)
e.WriteByte(':')
me.elemEnc(e, v.MapIndex(kv.v), opts)
}
e.WriteByte('}')
}
func newMapEncoder(t reflect.Type) encoderFunc {
switch t.Key().Kind() {
case reflect.String,
reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64,
reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
default:
if !t.Key().Implements(textMarshalerType) {
return unsupportedTypeEncoder
}
}
me := mapEncoder{typeEncoder(t.Elem())}
return me.encode
}
|
struct转json的顺序与struct的顺序一致,但不排除有编译器优化重排变量的可能,不建议依赖该顺序.
末尾换行符
map 默认转换成 json 时,默认会在最后添加换行符 \n ,需要把 json字符串最后面的换行符删掉才可以。
1
2
3
4
5
6
7
8
9
10
|
byteBuf := bytes.NewBuffer([]byte{})
encoder := json.NewEncoder(byteBuf)
encoder.SetEscapeHTML(false)
err := encoder.Encode(params)
if err != nil {
panic(err)
}
data := byteBuf.String()
fmt.Printf("%q", data) // 输出结果为 "{\"domain\":\"https://www.baidu.com?name=1&id=1\",\"name\":\"test\"}\n"
fmt.Printf("%q", strings.TrimRight(data, "\n")) // 输出结果为 "{\"domain\":\"https://www.baidu.com?name=1&id=1\",\"name\":\"test\"}"
|
解码
定义结构
与编码json的Marshal类似,解析json也提供了Unmarshal方法。对于解析json,也大致分两步,首先定义结构,然后调用Unmarshal方法序列化。我们先从简单的例子开始吧
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
type Account struct {
Email string `json:"email"`
Password string `json:"password"`
Money float64 `json:"money"`
}
var jsonString string = `{
"email":"rsj217@gmail.com",
"password":"123",
"money":100.5
}`
func main() {
account := Account{}
err := json.Unmarshal([]byte(jsonString), &account)
if err != nil{
log.Fatalln(err)
}
fmt.Printf("%+v\n", account)
}
|
Unmarshal接受一个byte数组和空接口指针的参数。和sql中读取数据类似,先定义一个数据实例,然后传其指针地址。
与编码类似,golang会将json的数据结构和go的数据结构进行匹配。 匹配的原则就是寻找tag的相同的字段,然后查找字段。 查询的时候是大小写不敏感的:把 Password的tag去掉,再修改成PassWord,依然可以把json的password匹配到PassWord.
1
2
3
4
5
|
type Account struct {
Email string `json:"email"`
PassWord string
Money float64 `json:"money"`
}
|
输出
1
|
{Email:rsj217@gmail.com PassWord:123 Money:100.5}
|
但是如果结构的字段是私有的,即使tag符合,也不会被解析:
1
2
3
4
5
|
type Account struct {
Email string `json:"email"`
password string `json:"password"`
Money float64 `json:"money"`
}
|
输出
1
|
{Email:rsj217@gmail.com password: Money:100.5}
|
上面的password并不会被解析赋值json的password,大小写不敏感只是针对公有字段而言。再寻找tag或字段的时候匹配不成功,则会抛弃这个json字段的值:
1
2
3
4
|
type Account struct {
Email string `json:"email"`
Password string `json:"password"`
}
|
输出
1
|
{Email:rsj217@gmail.com Password:"123"}
|
并不会有money字段被赋值。
string tag
在编码的时候,我们使用tag string,可以把结构定义的数字类型以字符串形式编码。同样在解码的时候,只有字符串类型的数字,才能被正确解析,或者会报错:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
type Account struct {
Email string `json:"email"`
Password string `json:"password"`
Money float64 `json:"money,string"`
}
var jsonString string = `{
"email":"rsj217@gmail.com",
"password":"123",
"money":"100.5"
}`
func main() {
account := Account{}
err := json.Unmarshal([]byte(jsonString), &account)
if err != nil{
log.Fatalln(err)
}
fmt.Printf("%+v\n", account)
}
|
输出
1
|
{Email:rsj217@gmail.com Password:123 Money:100.5}
|
Money是float64类型。
如果json的money是100.5, 会得到下面的错误:
1
2
|
2016/12/23 18:12:32 json: invalid use of ,string struct tag, trying to unmarshal unquoted value into float64
exit status 1
|
- tag
与编码一样,tag的-也不会被解析,但是会初始化其零值:
1
2
3
4
5
|
type Account struct {
Email string `json:"email"`
Password string `json:"password"`
Money float64 `json:"-"`
}
|
输出:
1
|
{Email:rsj217@gmail.com Password:123 Money:0}
|
Decode
前面我们使用了简单的方法Unmarshal直接解析json字符串,下面我们使用更底层的方法NewDecode和Decode方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
type User struct {
UserName string `json:"username"`
Password string `json:"password"`
}
var jsonString string = `{
"username":"rsj217@gmail.com",
"password":"123"
}`
func Decode(r io.Reader)(u *User, err error) {
u = new(User)
err = json.NewDecoder(r).Decode(u)
if err != nil{
return
}
return
}
func main() {
user, err := Decode(strings.NewReader(jsonString))
if err !=nil{
log.Fatalln(err)
}
fmt.Printf("%#v\n",user)
}
|
我们定义了一个Decode函数,在这个函数进行json字符串的解析:调用json的NewDecoder方法构造一个Decode对象,使用这个对象的Decode方法赋值给定义好的结构对象。
对于字符串,可以使用strings.NewReader方法,让字符串变成一个Stream对象。
Unmarshal vs Decode
选择哪个要视输入而定。
json.Unmarshal 操作对象是一个 []byte,也就意味着被处理的JSON要全部加载到内存。如果有一个加载完的JSON使用json.Unmarshal会快一些。
json.Decoder 操作的是一个stream,或者其他实现了io.Reader接口的类型。意味着可以在接收或传输的同时对其进行解析。当处理一组较大数据时无需重新copy整个JSON到内存中。
最好的选择办法如下:
- 如果数据来自一个io.Reader或者需要从一个stream中读取数据,就选择json.Decoder
- 如果已经将整个JSON加载到内存中了就使用json.Unmarshal
动态解析
通常根据json的格式预先定义golang的结构进行解析是最理想的情况。可是实际开发中,理想的情况往往都存在理想的愿望之中,很多json非但格式不确定,有的还可能是动态数据类型。
例如通常登录的时候,往往既可以使用手机号做用户名,也可以使用邮件做用户名,客户端传的json可以是字符串,也可以是数字。此时服务端解析就需要技巧了。
interface
如果客户端传的username的值是一个数字类型的手机号,那么上面的解析方法将会失败。正如我们之前所介绍的动态类型行为一样,使用interface{}可以hold住这样的情景。
使用 Golang 解析 JSON 格式数据时,若以 interface{} 接收数据,则会按照下列规则进行解析:
1
2
3
4
5
6
7
8
9
10
11
|
bool, for JSON booleans
float64, for JSON numbers
string, for JSON strings
[]interface{}, for JSON arrays
map[string]interface{}, for JSON objects
nil for JSON null
|
1
2
3
4
|
type User struct {
UserName interface{} `json:"username"`
Password string `json:"password"`
}
|
先统一解组到interface{} 然后判断关键字段再进行后续处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
type Data struct {
Type string `json:"type"`
Id interface{} `json:"id"`
}
func decode(t string) {
var x Data
err := json.Unmarshal([]byte(t), &x)
if err != nil {
panic(err)
}
if x.Type == "a" {
fmt.Println(x.Id.(string))
} else {
fmt.Println(x.Id.(float64)) //json解析中number默认作为float64解析
}
}
func main() {
t1 := `{"type":"a", "id":"aaa"}`
t2 := `{"type":"b", "id":22222}`
decode(t1)
decode(t2)
}
|
延迟解析
因为UserName字段,实际上是在使用的时候,才会用到他的具体类型,因此我们可以延迟解析。使用json.RawMessage方式,将json的字符串继续以byte数组方式存在。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
type User struct {
UserName json.RawMessage `json:"username"`
Password string `json:"password"`
Email string
Phone int64
}
var jsonString string = `{
"username":"18512341234@qq.com",
"password":"123"
}`
func Decode(r io.Reader) (u *User, err error) {
u = new(User)
if err = json.NewDecoder(r).Decode(u); err != nil{
return
}
var email string
if err = json.Unmarshal(u.UserName, &email); err == nil{
u.Email = email
return
}
var phone int64
if err = json.Unmarshal(u.UserName, &phone); err == nil{
u.Phone = phone
}
return
}
func main() {
user, err := Decode(strings.NewReader(jsonString))
if err != nil {
log.Fatalln(err)
}
fmt.Printf("%#v\n", user)
}
|
总体而言,延迟解析和使用空接口的方式类似。需要再次调用Unmarshal方法,对json.RawMessage进行解析。原理和解析到接口的形式类似。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
type Resp struct {
Type string `json:"type"`
Data json.RawMessage `json:"data"`
}
type Data struct {
Id json.Number `json:"id"` //处理大数
}
func main() {
t := `{"type": "a", "data":{"id": 1234567890123456789012345}}`
var x Resp
var y Data
json.Unmarshal([]byte(t), &x)
//进一步解组
if "a" == x.Type {
json.Unmarshal(x.Data, &y)
}
fmt.Println(y.Id)
r, _ := json.Marshal(x)
fmt.Println(string(r))
}
|
不定字段解析
对于未知json结构的解析,不同的数据类型可以映射到接口或者使用延迟解析。有时候,会遇到json的数据字段都不一样的情况。例如需要解析下面一个json字符串:
接口配合断言
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
var jsonString string = `{
"things": [
{
"name": "Alice",
"age": 37
},
{
"city": "Ipoh",
"country": "Malaysia"
},
{
"name": "Bob",
"age": 36
},
{
"city": "Northampton",
"country": "England"
}
]
}`
|
json字符串的是一个对象,其中一个key things的值是一个数组,这个数组的每一个item都未必一样,大致是两种数据结构,可以抽象为person和place。即,定义下面的结构体:
1
2
3
4
5
6
7
8
9
|
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
}
type Place struct {
City string `json:"city"`
Country string `json:"country"`
}
|
接下来我们Unmarshal json字符串到一个map结构,然后迭代item并使用type断言的方式解析数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
func decode(jsonStr []byte) (persons []Person, places []Place) {
var data map[string][]map[string]interface{}
err := json.Unmarshal(jsonStr, &data)
if err != nil {
fmt.Println(err)
return
}
for i := range data["things"] {
item := data["things"][i]
if item["name"] != nil {
persons = addPerson(persons, item)
} else {
places = addPlace(places, item)
}
}
return
}
|
迭代的时候会判断item是否是person还是place,然后调用对应的解析方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func addPerson(persons []Person, item map[string]interface{}) []Person {
name := item["name"].(string)
age := item["age"].(float64)
person := Person{name, int(age)}
persons = append(persons, person)
return persons
}
func addPlace(places []Place, item map[string]interface{})([]Place){
city := item["city"].(string)
country := item["country"].(string)
place := Place{City:city, Country:country}
places = append(places, place)
return places
}
|
最后调用如下:
1
2
3
4
5
|
func main() {
personsA, placesA := decode([]byte(jsonString))
fmt.Printf("%+v\n", personsA)
fmt.Printf("%+v\n", placesA)
}
|
输出如下:
1
2
|
[{Name:Alice Age:37} {Name:Bob Age:36}]
[{City:Ipoh Country:Malaysia} {City:Northampton Country:England}]
|
混合结构
混合结构很好理解,如同我们前面解析username为 email和phone两种情况,就在结构中定义好这两种结构即可。
1
2
3
4
5
6
|
type Mixed struct {
Name string `json:"name"`
Age int `json:"age"`
city string `json:"city"`
Country string `json:"country"`
}
|
混合结构的思路很简单,借助golang会初始化没有匹配的json和抛弃没有匹配的json,给特定的字段赋值。比如每一个item都具有四个字段,只不过有的会匹配person的json数据,有的则是匹配place。没有匹配的字段则是零值。接下来在根据item的具体情况,分别赋值到对于的Person或Place结构。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func decode(jsonStr []byte) (persons []Person, places []Place) {
var data map[string][]Mixed
err := json.Unmarshal(jsonStr, &data)
if err != nil {
fmt.Println(err)
return
}
fmt.Printf("%+v\n", data["things"])
for i := range data["things"] {
item := data["things"][i]
if item.Name != "" {
persons = append(persons, Person{Name: item.Name, Age: item.Age})
} else {
places = append(places, Place{City: item.city, Country: item.Country})
}
}
return
}
|
混合结构的解析方式也很不错。思路还是借助了解析json中抛弃不要的字段,借助零值处理。
json.RawMessage
json.RawMessage非常有用,延迟解析也可以使用这个样例。我们已经介绍过类似的技巧,下面就贴代码了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
func addPerson(item json.RawMessage, persons []Person)([]Person){
person := Person{}
if err := json.Unmarshal(item, &person); err != nil{
fmt.Println(err)
}else{
if person != *new(Person){
persons = append(persons, person)
}
}
return persons
}
func addPlace(item json.RawMessage, places []Place)([]Place){
place :=Place{}
if err := json.Unmarshal(item, &place); err != nil{
fmt.Println(err)
}else{
if place != *new(Place){
places = append(places, place)
}
}
return places
}
func decode(jsonStr []byte)(persons []Person, places []Place){
var data map[string][]json.RawMessage
err := json.Unmarshal(jsonStr, &data)
if err != nil{
fmt.Println(err)
return
}
for _, item := range data["things"]{
persons = addPerson(item, persons)
places = addPlace(item, places)
}
return
}
|
把things的item数组解析成一个json.RawMessage,然后再定义其他结构逐步解析。上述这些例子其实在真实的开发环境下,应该尽量避免。像person或是place这样的数据,可以定义两个数组分别存储他们,这样就方便很多。不管怎么样,通过这个略傻的例子,我们也知道了如何解析json数据。
数字的解析
float64与int64
JSON的规范中,对于数字类型,并不区分是整型还是浮点型。
对于如下JSON文本:
1
2
3
4
|
{
"name": "ethancai",
"fansCount": 9223372036854775807
}
|
如果反序列化的时候指定明确的结构体和变量类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
package main
import (
"encoding/json"
"fmt"
)
type User struct {
Name string
FansCount int64
}
func main() {
const jsonStream = `
{"name":"ethancai", "fansCount": 9223372036854775807}
`
var user User // 类型为User
err := json.Unmarshal([]byte(jsonStream), &user)
if err != nil {
fmt.Println("error:", err)
}
fmt.Printf("%+v \n", user)
}
// Output:
// {Name:ethancai FansCount:9223372036854775807}
|
如果反序列化不指定结构体类型或者变量类型,则JSON中的数字类型,默认被反序列化成float64类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package main
import (
"encoding/json"
"fmt"
"reflect"
)
func main() {
const jsonStream = `
{"name":"ethancai", "fansCount": 9223372036854775807}
`
var user interface{} // 不指定反序列化的类型
err := json.Unmarshal([]byte(jsonStream), &user)
if err != nil {
fmt.Println("error:", err)
}
m := user.(map[string]interface{})
fansCount := m["fansCount"]
fmt.Printf("%+v \n", reflect.TypeOf(fansCount).Name())
fmt.Printf("%+v \n", fansCount.(float64))
}
// Output:
// float64
// 9.223372036854776e+18
|
我们看一下源码,encoding/json/decode.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
|
// literalStore decodes a literal stored in item into v.
//
// fromQuoted indicates whether this literal came from unwrapping a
// string from the ",string" struct tag option. this is used only to
// produce more helpful error messages.
func (d *decodeState) literalStore(item []byte, v reflect.Value, fromQuoted bool) error {
// Check for unmarshaler.
if len(item) == 0 {
//Empty string given
d.saveError(fmt.Errorf("json: invalid use of ,string struct tag, trying to unmarshal %q into %v", item, v.Type()))
return nil
}
isNull := item[0] == 'n' // null
u, ut, pv := indirect(v, isNull)
if u != nil {
return u.UnmarshalJSON(item)
}
if ut != nil {
if item[0] != '"' {
if fromQuoted {
d.saveError(fmt.Errorf("json: invalid use of ,string struct tag, trying to unmarshal %q into %v", item, v.Type()))
return nil
}
val := "number"
switch item[0] {
case 'n':
val = "null"
case 't', 'f':
val = "bool"
}
d.saveError(&UnmarshalTypeError{Value: val, Type: v.Type(), Offset: int64(d.readIndex())})
return nil
}
s, ok := unquoteBytes(item)
if !ok {
if fromQuoted {
return fmt.Errorf("json: invalid use of ,string struct tag, trying to unmarshal %q into %v", item, v.Type())
}
panic(phasePanicMsg)
}
return ut.UnmarshalText(s)
}
v = pv
switch c := item[0]; c {
case 'n': // null
// The main parser checks that only true and false can reach here,
// but if this was a quoted string input, it could be anything.
if fromQuoted && string(item) != "null" {
d.saveError(fmt.Errorf("json: invalid use of ,string struct tag, trying to unmarshal %q into %v", item, v.Type()))
break
}
switch v.Kind() {
case reflect.Interface, reflect.Ptr, reflect.Map, reflect.Slice:
v.Set(reflect.Zero(v.Type()))
// otherwise, ignore null for primitives/string
}
case 't', 'f': // true, false
value := item[0] == 't'
// The main parser checks that only true and false can reach here,
// but if this was a quoted string input, it could be anything.
if fromQuoted && string(item) != "true" && string(item) != "false" {
d.saveError(fmt.Errorf("json: invalid use of ,string struct tag, trying to unmarshal %q into %v", item, v.Type()))
break
}
switch v.Kind() {
default:
if fromQuoted {
d.saveError(fmt.Errorf("json: invalid use of ,string struct tag, trying to unmarshal %q into %v", item, v.Type()))
} else {
d.saveError(&UnmarshalTypeError{Value: "bool", Type: v.Type(), Offset: int64(d.readIndex())})
}
case reflect.Bool:
v.SetBool(value)
case reflect.Interface:
if v.NumMethod() == 0 {
v.Set(reflect.ValueOf(value))
} else {
d.saveError(&UnmarshalTypeError{Value: "bool", Type: v.Type(), Offset: int64(d.readIndex())})
}
}
case '"': // string
s, ok := unquoteBytes(item)
if !ok {
if fromQuoted {
return fmt.Errorf("json: invalid use of ,string struct tag, trying to unmarshal %q into %v", item, v.Type())
}
panic(phasePanicMsg)
}
switch v.Kind() {
default:
d.saveError(&UnmarshalTypeError{Value: "string", Type: v.Type(), Offset: int64(d.readIndex())})
case reflect.Slice:
if v.Type().Elem().Kind() != reflect.Uint8 {
d.saveError(&UnmarshalTypeError{Value: "string", Type: v.Type(), Offset: int64(d.readIndex())})
break
}
b := make([]byte, base64.StdEncoding.DecodedLen(len(s)))
n, err := base64.StdEncoding.Decode(b, s)
if err != nil {
d.saveError(err)
break
}
v.SetBytes(b[:n])
case reflect.String:
v.SetString(string(s))
case reflect.Interface:
if v.NumMethod() == 0 {
v.Set(reflect.ValueOf(string(s)))
} else {
d.saveError(&UnmarshalTypeError{Value: "string", Type: v.Type(), Offset: int64(d.readIndex())})
}
}
default: // number
if c != '-' && (c < '0' || c > '9') {
if fromQuoted {
return fmt.Errorf("json: invalid use of ,string struct tag, trying to unmarshal %q into %v", item, v.Type())
}
panic(phasePanicMsg)
}
s := string(item)
switch v.Kind() {
default:
if v.Kind() == reflect.String && v.Type() == numberType {
v.SetString(s)
if !isValidNumber(s) {
return fmt.Errorf("json: invalid number literal, trying to unmarshal %q into Number", item)
}
break
}
if fromQuoted {
return fmt.Errorf("json: invalid use of ,string struct tag, trying to unmarshal %q into %v", item, v.Type())
}
d.saveError(&UnmarshalTypeError{Value: "number", Type: v.Type(), Offset: int64(d.readIndex())})
case reflect.Interface:
n, err := d.convertNumber(s)
if err != nil {
d.saveError(err)
break
}
if v.NumMethod() != 0 {
d.saveError(&UnmarshalTypeError{Value: "number", Type: v.Type(), Offset: int64(d.readIndex())})
break
}
v.Set(reflect.ValueOf(n))
case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
n, err := strconv.ParseInt(s, 10, 64)
if err != nil || v.OverflowInt(n) {
d.saveError(&UnmarshalTypeError{Value: "number " + s, Type: v.Type(), Offset: int64(d.readIndex())})
break
}
v.SetInt(n)
case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
n, err := strconv.ParseUint(s, 10, 64)
if err != nil || v.OverflowUint(n) {
d.saveError(&UnmarshalTypeError{Value: "number " + s, Type: v.Type(), Offset: int64(d.readIndex())})
break
}
v.SetUint(n)
case reflect.Float32, reflect.Float64:
n, err := strconv.ParseFloat(s, v.Type().Bits())
if err != nil || v.OverflowFloat(n) {
d.saveError(&UnmarshalTypeError{Value: "number " + s, Type: v.Type(), Offset: int64(d.readIndex())})
break
}
v.SetFloat(n)
}
}
return nil
}
// convertNumber converts the number literal s to a float64 or a Number
// depending on the setting of d.useNumber.
func (d *decodeState) convertNumber(s string) (interface{}, error) {
if d.useNumber {
return Number(s), nil
}
f, err := strconv.ParseFloat(s, 64)
if err != nil {
return nil, &UnmarshalTypeError{Value: "number " + s, Type: reflect.TypeOf(0.0), Offset: int64(d.off)}
}
return f, nil
}
|
可以看出来,Json解析实现的时候通过反射来判断要生成的具体的类型。如果是interface{}类型,通过converNumber方法转成float64(里面是通过strconv.ParseFloat实现),如果类型是整型相关,通过strconv.ParseInt方法转换。无符号整型是通过strconv.ParseUint实现。
int64的科学计数法
如果对一个 map[string]interface{} 赋值整数,转换为JSON再直接输出为string,超过6位就会使用科学记数法,而若在Struct中明确是一个整数int64类型,始终都是整数int64的输出格式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
package main
import (
"encoding/json"
"fmt"
)
type T struct {
Int int64
Map map[string]interface{}
}
func main() {
var v1, v2 int64 = 123456, 1234567
test(v1)
test(v2)
}
func test(val int64) {
t, t2 := T{Map: make(map[string]interface{})}, T{Map: make(map[string]interface{})}
t.Int = val
t.Map["val"] = val
fmt.Println(fmt.Sprintf("before: %v", t))
jsonBytes, _ := json.Marshal(t)
json.Unmarshal(jsonBytes, &t2)
fmt.Println(fmt.Sprintf("after: %v", t2))
}
|
1
2
3
4
|
before: {123456 map[val:123456]}
after: {123456 map[val:123456]}
before: {1234567 map[val:1234567]}
after: {1234567 map[val:1.234567e+06]}
|
只要在打印时指定打印格式,或者转换为整数打印,更好的方法是下面的json.Number
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
package main
import (
"encoding/json"
"fmt"
)
type T struct {
Int int64
Map map[string]interface{}
}
func main() {
var v1, v2 int64 = 123456, 1234567
test(v1)
test(v2)
}
func test(val int64) {
t, t2 := T{Map: make(map[string]interface{})}, T{Map: make(map[string]interface{})}
t.Int = val
t.Map["val"] = val
fmt.Println(fmt.Sprintf("before: %v", t))
jsonBytes, _ := json.Marshal(t)
json.Unmarshal(jsonBytes, &t2)
fmt.Println(fmt.Sprintf("after: %v", int64(t2.Map["val"].(float64))))
}
|
1
2
3
4
|
before: {123456 map[val:123456]}
after: 123456
before: {1234567 map[val:1234567]}
after: 1234567
|
如前面所说,json的Unmarshal会把数字解析为float64格式,那么变成科学计数法的原因应该在于Marshal编码float64格式的数字上,进入golang的源码包,发现在encoding/json/encode.go是这样处理float类型的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
type floatEncoder int // number of bits
func (bits floatEncoder) encode(e *encodeState, v reflect.Value, opts encOpts) {
f := v.Float()
if math.IsInf(f, 0) || math.IsNaN(f) {
e.error(&UnsupportedValueError{v, strconv.FormatFloat(f, 'g', -1, int(bits))})
}
// Convert as if by ES6 number to string conversion.
// This matches most other JSON generators.
// See golang.org/issue/6384 and golang.org/issue/14135.
// Like fmt %g, but the exponent cutoffs are different
// and exponents themselves are not padded to two digits.
b := e.scratch[:0]
abs := math.Abs(f)
fmt := byte('f')
// Note: Must use float32 comparisons for underlying float32 value to get precise cutoffs right.
if abs != 0 {
if bits == 64 && (abs < 1e-6 || abs >= 1e21) || bits == 32 && (float32(abs) < 1e-6 || float32(abs) >= 1e21) {
fmt = 'e'
}
}
b = strconv.AppendFloat(b, f, fmt, -1, int(bits))
if fmt == 'e' {
// clean up e-09 to e-9
n := len(b)
if n >= 4 && b[n-4] == 'e' && b[n-3] == '-' && b[n-2] == '0' {
b[n-2] = b[n-1]
b = b[:n-1]
}
}
if opts.quoted {
e.WriteByte('"')
}
e.Write(b)
if opts.quoted {
e.WriteByte('"')
}
}
|
可以看到处理float的是这个函数b = strconv.AppendFloat(b, f, fmt, -1, int(bits)),这个函数在注释中,可以看到格式化参数的说明:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
// FormatFloat converts the floating-point number f to a string,
// according to the format fmt and precision prec. It rounds the
// result assuming that the original was obtained from a floating-point
// value of bitSize bits (32 for float32, 64 for float64).
//
// The format fmt is one of
// 'b' (-ddddp±ddd, a binary exponent),
// 'e' (-d.dddde±dd, a decimal exponent),
// 'E' (-d.ddddE±dd, a decimal exponent),
// 'f' (-ddd.dddd, no exponent),
// 'g' ('e' for large exponents, 'f' otherwise), or
// 'G' ('E' for large exponents, 'f' otherwise).
//
// The precision prec controls the number of digits (excluding the exponent)
// printed by the 'e', 'E', 'f', 'g', and 'G' formats.
// For 'e', 'E', and 'f' it is the number of digits after the decimal point.
// For 'g' and 'G' it is the maximum number of significant digits (trailing
// zeros are removed).
// The special precision -1 uses the smallest number of digits
// necessary such that ParseFloat will return f exactly.
func FormatFloat(f float64, fmt byte, prec, bitSize int) string {
return string(genericFtoa(make([]byte, 0, max(prec+4, 24)), f, fmt, prec, bitSize))
}
// AppendFloat appends the string form of the floating-point number f,
// as generated by FormatFloat, to dst and returns the extended buffer.
func AppendFloat(dst []byte, f float64, fmt byte, prec, bitSize int) []byte {
return genericFtoa(dst, f, fmt, prec, bitSize)
}
|
g对于大的数使用e即科学计数法表示,其他使用的正常方式表示。
那么,为什么7位就变成科学计数了呢?原来在b = strconv.AppendFloat(b, f, fmt, -1, int(bits))中,有个控制精度的参数被赋值为-1,AppendFloat函数包装了genericFtoa函数,在genericFtoa函数中,如果精度参数为-1,表示的只要数据准确,就可以尽可能的短,进而在formatDigits函数中根据这个结果把位数设置为6。
json.Number
解析大数
如果fansCount精度比较高,反序列化成float64类型的数值时存在丢失精度的问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
package main
import (
"encoding/json"
"fmt"
)
type User struct {
Name string
FansCount interface{} // 不指定FansCount变量的类型
}
func main() {
const jsonStream = `
{"name":"ethancai", "fansCount": 9223372036854775807}
`
var user User
err := json.Unmarshal([]byte(jsonStream), &user)
if err != nil {
fmt.Println("error:", err)
}
fmt.Printf("%+v \n", user)
}
// Output:
// {Name:ethancai FansCount:9.223372036854776e+18}
|
解决办法有以下两种形式:
- 可以直接使用json.Number类型存放json中对应的高精度数值
- 有时候我们想偷懒,并不想自己定义结构体,还是想使用
map[string]interface{}来解析 JSON,可以使用UseNumber方法,UseNumber方法告诉反序列化JSON的数字类型的时候,不直接转换成float64,而是转换成json.Number类型.
Unmarshal
1
2
3
4
5
6
7
8
|
val := `{"id": 100010001000100010001000 }` //26位数字
var y map[string]json.Number
json.Unmarshal([]byte(val), &y)
fmt.Println(y) //map[id:100010001000100010001000]
z, _ := json.Marshal(struct {
Id json.Number `json:"id"`
}{y["id"]})
fmt.Println(string(z)) //{"id":100010001000100010001000}
|
Decode
1
2
3
4
5
6
7
8
9
10
11
|
val := `{"id": 100010001000100010001000 }` //26位数字
val2 := strings.NewReader(val) //先转成io.Reader
d := json.NewDecoder(val2)
d.UseNumber() //标记使用josn.Number
var x map[string]interface{}
if err := d.Decode(&x); err != nil {
panic(err)
}
fmt.Printf("%#v\n", x) //相应值的Go语法表示
newJson, _ := json.Marshal(x)
fmt.Println(string(newJson)) //json.Number编组结果
|
输出结果:
1
2
|
map[string]interface {}{"id":"100010001000100010001000"}
{"id":100010001000100010001000}
|
解析整型和字符串
定义了两个 JSON 串,一个是整型,一个是字符串。如何将这两个数据解析到同一种类型中呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
package main
import (
"encoding/json"
"log"
)
func main() {
var raw = []byte(`{"a":1}`)
var raw_string = []byte(`{"a":"2"}`)
type S3 struct {
A json.Number `json:"a"`
}
s3 := new(S3)
err := json.Unmarshal(raw, s3)
log.Println(err, s3.A)
s31 := new(S3)
err = json.Unmarshal(raw_string, s31)
log.Println(err, s31.A)
}
|
将对象a的类型定义成json.Number就可以实现对两种数据类型的解析。
解析固定位数的浮点数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
package main
import (
"encoding/json"
"fmt"
)
type Record struct {
A json.Number `json:"a"`
B json.Number `json:"b"`
}
func main() {
var (
data = `{ "a": 0.000, "b": 0.000 }`
record Record
)
_ = json.Unmarshal([]byte(data), &record)
fmt.Printf("a(%s) b(%s)\n", record.A, record.B)
}
|
或者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
type Record map[string]interface{}
var jsonstr = `
{
"a": 0.000,
"b": 0.000
}
`
func main() {
var record Record
dec := json.NewDecoder(strings.NewReader(jsonstr))
dec.UseNumber()
dec.Decode(&record)
fmt.Println(record)
}
|
原理
我们知道,解析 JSON 的时候其实是对 JSON 串的遍历,其实所有遍历出来的值都是[]byte类型,然后根据识别目标解析对象字段类型,或者识别[]byte数据的内容转换格式。比如,如果数据被解析到int上,把[]byte转换为int;如果被解析到interface{}上,就只能通过[]byte的类型来转换了,数字会被统一处理能float64,这个有个问题,就是会丢精度。而通过Number解析时,值会被直接保存为字符串类型。
json.Number内部实现机制是什么,我们来看看源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// A Number represents a JSON number literal.
type Number string
// String returns the literal text of the number.
func (n Number) String() string { return string(n) }
// Float64 returns the number as a float64.
func (n Number) Float64() (float64, error) {
return strconv.ParseFloat(string(n), 64)
}
// Int64 returns the number as an int64.
func (n Number) Int64() (int64, error) {
return strconv.ParseInt(string(n), 10, 64)
}
|
json.Number本质是字符串,反序列化的时候将JSON的数值先转成json.Number,其实是一种延迟处理的手段,待后续逻辑需要时候,再把json.Number转成float64或者int64。
使用Int64还是float64就可以通过用户自己的情况选择了。
区分空值和没传
由于golang的特性,结构体基础数据类型没有赋值会默认零值(int默认0,string默认"“等),所以require不能校验出基础类型是默认零值,还是被赋为了零值。比如:
1
|
CommType int64 `json:"comm_type"`
|
这样无法判断是传入了0表示某种商品类型,还是根本就没传,一种解决办法是:
1
|
CommType *int64 `json:"comm_type"`
|
改成指针类型,这样没传就是nil,传了0就不是nil,这样就区分开了,如果没传就不能通过校验。
time.time的编解码
对于 json 格式,是没有时间类型的,日期和时间以 json 格式存储时,需要转换为字符串类型。这就带来了一个问题,日期时间的字符串表示有多种多样,go 的 json 包支持的是哪一种呢?
使用下面的代码来输出 json.Marshal 方法将 Time 类型转换为字符串后的格式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
type Person struct {
Name string
Birth time.Time
}
func main() {
person := Person{
Name: "Wang Wu",
Birth: time.Now(),
}
jsonBytes, _ := json.Marshal(person)
fmt.Println(string(jsonBytes)) // {"Name":"Wang Wu","Birth":"2018-12-20T16:22:02.00287617+08:00"}
}
|
根据输出可以判断,go 的 json 包使用的是 RFC3339 标准中定义的格式。接下来测试一下 json.Unmarshal 方法所支持的日期时间格式。
1
2
3
4
5
6
7
|
dateStr := "2018-10-12"
var person Person
jsonStr := fmt.Sprintf("{\"name\":\"Wang Wu\", \"Birth\": \"%s\"}", dateStr)
json.Unmarshal([]byte(jsonStr), &person)
fmt.Println(person.Birth) // 0001-01-01 00:00:00 +0000 UTC
|
对于形如 2018-10-12 的字符串,json 包并没有成功将其解析,接下来我们把 time 包中支持的所有格式都试一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
const (
ANSIC = "Mon Jan _2 15:04:05 2006"
UnixDate = "Mon Jan _2 15:04:05 MST 2006"
RubyDate = "Mon Jan 02 15:04:05 -0700 2006"
RFC822 = "02 Jan 06 15:04 MST"
RFC822Z = "02 Jan 06 15:04 -0700" // RFC822 with numeric zone
RFC850 = "Monday, 02-Jan-06 15:04:05 MST"
RFC1123 = "Mon, 02 Jan 2006 15:04:05 MST"
RFC1123Z = "Mon, 02 Jan 2006 15:04:05 -0700" // RFC1123 with numeric zone
RFC3339 = "2006-01-02T15:04:05Z07:00"
RFC3339Nano = "2006-01-02T15:04:05.999999999Z07:00"
Kitchen = "3:04PM"
// Handy time stamps.
Stamp = "Jan _2 15:04:05"
StampMilli = "Jan _2 15:04:05.000"
StampMicro = "Jan _2 15:04:05.000000"
StampNano = "Jan _2 15:04:05.000000000"
)
|
经过试验,发现 json.Unmarshal 方法只支持 RFC3339 和 RFC3339Nano 两种格式的转换。还有一个需要注意的地方,使用 time.Now() 生成的时间是带有一个 Monotonic Time 的,经过 json.Marshal 转换时候,由于 RFC3339 规范里没有存放 Monotonic Time 的位置,会丢掉这一部分。
nil的编码解码
官方文档:
1
2
3
|
a nil slice encodes as the null JSON value.
A nil pointer encodes as the null JSON value.
A nil interface value encodes as the null JSON value.
|
举个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package main
import (
"fmt"
"encoding/json"
)
func main() {
// map
var sm map[string]interface{}
sb, err := json.Marshal(sm)
fmt.Printf("%s, %v, err: %v\n", string(sb), sb, err)
// slice
var ss []string
sb, err = json.Marshal(ss)
fmt.Printf("%s, %v, err: %v\n", string(sb), sb, err)
var sbs []byte
sb, err = json.Marshal(sbs)
fmt.Printf("%s, %v, err: %v\n", string(sb), sb, err)
// pointer
var sp *string
sb, err = json.Marshal(sp)
fmt.Printf("%s, %v, err: %v\n", string(sb), sb, err)
// interface
var si interface{}
sb, err = json.Marshal(si)
fmt.Printf("%s, %v, err: %v\n", string(sb), sb, err)
}
|
输出:
1
2
3
4
5
|
null, [110 117 108 108], err: <nil>
null, [110 117 108 108], err: <nil>
null, [110 117 108 108], err: <nil>
null, [110 117 108 108], err: <nil>
null, [110 117 108 108], err: <nil>
|
注意哦,这里序列化得到的结果并不是大小为0的byte切片,而是字符串null!!!当然,如果不想输出字符串null,那么可以修改为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
package main
import (
"fmt"
"encoding/json"
)
func main() {
// map
sm := make(map[string]interface{}, 0)
sb, err := json.Marshal(sm)
fmt.Printf("%s, %v, err: %v\n", string(sb), sb, err)
// slice
ss := make([]string, 0)
sb, err = json.Marshal(ss)
fmt.Printf("%s, %v, err: %v\n", string(sb), sb, err)
// bytes
sbs := make([]byte, 0)
sb, err = json.Marshal(sbs)
fmt.Printf("%s, %v, err: %v\n", string(sb), sb, err)
}
|
输出:
1
2
3
|
{}, [123 125], err: <nil>
[], [91 93], err: <nil>
"", [34 34], err: <nil>
|
此时,输出分别是对应类型的零值的字符串表示。例如,空 Map 的序列化值为字符串{}
所以,如果你只是希望在空的情况下,序列化得出空的结果,那么最好在序列化之前进行一次判空。
Json多次转义
编码
我们在对外提供API接口,返回响应的时候,很多时候需要使用如下的数据结构
1
2
3
4
5
|
type Response struct {
Code int `json:"code"`
Msg string `json:"msg"`
Data interface{} `json:"data"`
}
|
该API接口返回一个状态码,状态信息,以及具体的值。但是具体的值可能根据各个接口的不同而不同。
在实际的开发过程中我们可能会得到一个实际的数据值,并将这个值赋值给data,然后json序列化返回给调用方。
这时如果你得到的data是一个经过json序列化之后的字符串,类似于{“Name”:“happy”},然后再将这个字符串赋值给data,此时将response序列化得到的string,如下
1
|
{“code”:1,”msg”:”success”,”data”:”{\”Name\”:\”Happy\”}”}
|
我们会发现之前已经序列化好的字符串,每一个都多了\,这是因为转义引起的问题。
解决方案
直接将未序列化的data赋值给data:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
package main
import (
"encoding/json"
"fmt"
)
type Response struct {
Code int `json:"code"`
Msg string `json:"msg"`
Data interface{} `json:"data"`
}
type People struct {
Name string
}
func main() {
data := People{Name: "happy"}
response := &Response{
Code: 1,
Msg: "success",
Data: data,
}
b, err := json.Marshal(&response)
if err != nil {
fmt.Println("err", err)
}
fmt.Println(string(b))
}
|
使用json 的RawMessage 将转义后的string,赋值给data:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
package main
import (
"encoding/json"
"fmt"
)
type Response struct {
Code int `json:"code"`
Msg string `json:"msg"`
Data interface{} `json:"data"`
}
type People struct {
Name string
}
func main() {
data := `{"Name":"Happy"}`
response := &Response{
Code: 1,
Msg: "success",
Data: json.RawMessage(data),
}
b, err := json.Marshal(&response)
if err != nil {
fmt.Println("err", err)
}
fmt.Println(string(b))
}
|
通过使用json的json.RawMessage(data)函数将其转换一下,这样也能保证不存在转义符。
解码
利用strconv.Unquote做一次转义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
package main
import (
"encoding/json"
"fmt"
"strconv"
)
type Msg struct {
Channel string
Name string
Msg string
}
func main() {
var msg Msg
var val []byte = []byte(`"{\"channel\":\"buu\",\"name\":\"john\", \"msg\":\"doe\"}"`)
s, _ := strconv.Unquote(string(val))
err := json.Unmarshal([]byte(s), &msg)
fmt.Println(s)
fmt.Println(err)
fmt.Println(msg.Channel, msg.Name, msg.Msg)
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
// 将带有单引号、双引号、反引号的字符串转为常规字符串
// 函数假设s是一个单引号、双引号、反引号包围的go语法字符串,解析它并返回它表示的值。(如果是单引号括起来的,函数会认为s是go字符字面值,返回一个单字符的字符串)
func Unquote(s string) (t string, err error)
// 将带引号字符串(不包含首尾的引号)中的第一个字符“取消转义”并解码
// 1) value,表示一个rune值或者一个byte值
// 2) multibyte,表示value是否是一个多字节的utf-8字符
// 3) tail,表示字符串剩余的部分
// 4) err,表示可能存在的语法错误
// 参数 quote 定义“引号符”语法规范
// 如果设置为单引号,则认为单引号是语法字符, s 中允许出现 \'、" 字符,不允许出现单独的 ' 字符
// 如果设置为双引号,则认为双引号是语法字符, s 中允许出现 \"、' 字符,不允许出现单独的 " 字符
// 如果设置为 0,函数把单引号和双引号当成普通字符,则可以出现单独的 ' 或 " 字符,但不允许出现 \' 或 \" 字符,
func UnquoteChar(s string, quote byte) (value rune, multibyte bool, tail string, err error)
// 示例
fmt.Println(strconv.Unquote("`or backquoted.`")) // or backquoted. <nil>
fmt.Println(strconv.Unquote("\"The string must be either double-quoted\"")) // The string must be either double-quoted <nil>
fmt.Println(strconv.Unquote("'\u2639'")) // ☹ <nil>
value, mb, tail ,err := strconv.UnquoteChar(`\"Test *&^$ Test Func\"`, '"')
fmt.Println(value, mb, tail ,err)// 34 false Test *&^$ Test Func\" <nil>
fmt.Println(string(value), mb, tail ,err)// " false Test *&^$ Test Func\" <nil>
|
struct的编解码控制
减少struct字段
假设您有以下结构:
1
2
3
4
5
|
type User struct {
Email string `json:"email"`
Password string `json:"password"`
// many more fields…
}
|
您想要的是编码User,但没有password字段。使用struct composition做到这一点的一种简单方法是将其包装在另一个struct中:
1
2
3
4
5
6
7
8
9
10
11
|
type omit *struct{}
type PublicUser struct {
*User
Password omit `json:"password,omitempty"`
}
// when you want to encode your user:
json.Marshal(PublicUser{
User: user,
})
|
这里的窍门是,我们从不设置的Password属性 PublicUser,并且由于它是指针类型,因此它将默认设置为nil,并且将被省略(因为omitempty)。
注意,不需要声明omit类型,我们可以简单地使用 *struct{}甚至bool,int,但是声明类型可以使我们明确地从输出中忽略该字段。我们使用哪种内置类型都没有关系,只要它具有omitempty 标签可以识别的零值即可。
我们本可以只使用匿名值:
1
2
3
4
5
6
|
json.Marshal(struct {
*User
Password bool `json:"password,omitempty"`
}{
User: user,
})
|
尝试一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
package main
import (
"encoding/json"
"os"
)
type omit bool
type User struct {
Email string `json:"email"`
Password string `json:"password"`
}
func NewUser() (*User, error) {
u := &User{}
return u, json.Unmarshal([]byte(`{
"email": "test@example.com",
"password": "secret"
}`), u)
}
func main() {
u, _ := NewUser()
// Omit the password:
json.NewEncoder(os.Stdout).Encode(struct {
*User
Password omit `json:"password,omitempty"`
}{
User: u,
})
}
|
还要注意,我们User在包装器结构中仅包含指向原始结构的指针。这种间接方式避免了必须分配的新副本 User。
增加struct字段
添加字段甚至比省略更为简单。继续前面的示例,让我们隐藏密码,但公开一个附加token属性:
1
2
3
4
5
6
7
8
9
10
11
12
|
type omit *struct{}
type PublicUser struct {
*User
Token string `json:"token"`
Password omit `json:"password,omitempty"`
}
json.Marshal(PublicUser{
User: user,
Token: token,
})
|
尝试一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
package main
import (
"encoding/json"
"os"
)
type omit bool
type User struct {
Email string `json:"email"`
Password string `json:"password"`
}
func NewUser() (*User, error) {
u := &User{}
return u, json.Unmarshal([]byte(`{
"email": "test@example.com",
"password": "secret"
}`), u)
}
func main() {
u, _ := NewUser()
// Add a token, omit the password:
json.NewEncoder(os.Stdout).Encode(struct {
*User
Token string `json:"token"`
Password omit `json:"password,omitempty"`
}{
User: u,
Token: "nerdfighters",
})
}
|
struct组合
当合并来自不同服务的数据时,这非常方便。例如,下面的BlogPost结构还包含分析数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
type BlogPost struct {
URL string `json:"url"`
Title string `json:"title"`
}
type Analytics struct {
Visitors int `json:"visitors"`
PageViews int `json:"page_views"`
}
json.Marshal(struct{
*BlogPost
*Analytics
}{post, analytics})
|
尝试一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
package main
import (
"encoding/json"
"os"
)
type BlogPost struct {
URL string `json:"url"`
Title string `json:"title"`
}
type Analytics struct {
Visitors int `json:"visitors"`
PageViews int `json:"page_views"`
}
func NewBlogPost() (*BlogPost, error) {
b := &BlogPost{}
return b, json.Unmarshal([]byte(`{
"url": "attila@attilaolah.eu",
"title": "Attila's Blog"
}`), b)
}
func NewAnalytics() (*Analytics, error) {
a := &Analytics{}
return a, json.Unmarshal([]byte(`{
"visitors": 6,
"page_views": 14
}`), a)
}
func main() {
post, _ := NewBlogPost()
analytics, _ := NewAnalytics()
json.NewEncoder(os.Stdout).Encode(struct {
*BlogPost
*Analytics
}{post, analytics})
}
|
struct分割
这与构成结构相反。就像对组合结构进行编码时一样,我们可以解码为组合结构并分别使用值:
1
2
3
4
5
6
7
8
9
|
json.Unmarshal([]byte(`{
"url": "attila@attilaolah.eu",
"title": "Attila's Blog",
"visitors": 6,
"page_views": 14
}`), &struct {
*BlogPost
*Analytics
}{&post, &analytics})
|
尝试一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
package main
import (
"encoding/json"
"fmt"
)
type BlogPost struct {
URL string `json:"url"`
Title string `json:"title"`
}
type Analytics struct {
Visitors int `json:"visitors"`
PageViews int `json:"page_views"`
}
func main() {
post, analytics := BlogPost{}, Analytics{}
json.Unmarshal([]byte(`{
"url": "attila@attilaolah.eu",
"title": "Attila's Blog",
"visitors": 6,
"page_views": 14
}`), &struct {
*BlogPost
*Analytics
}{&post, &analytics})
fmt.Printf("%+v\n%+v\n", post, analytics)
}
|
重命名struct字段
这是删除字段和添加额外字段的组合:我们只需删除字段并使用其他json:标签添加即可。可以使用指针间接完成此操作,以避免分配内存,尽管对于较小的数据类型,间接开销所花费的内存量与创建字段副本所花费的内存量相同,外加运行时开销。
这是一个示例,其中我们重命名两个结构字段,对嵌套结构使用间接寻址并复制整数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
type CacheItem struct {
Key string `json:"key"`
MaxAge int `json:"cacheAge"`
Value Value `json:"cacheValue"`
}
json.Marshal(struct{
*CacheItem
// Omit bad keys
OmitMaxAge omit `json:"cacheAge,omitempty"`
OmitValue omit `json:"cacheValue,omitempty"`
// Add nice keys
MaxAge int `json:"max_age"`
Value *Value `json:"value"`
}{
CacheItem: item,
// Set the int by value:
MaxAge: item.MaxAge,
// Set the nested struct by reference, avoid making a copy:
Value: &item.Value,
})
|
尝试一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
package main
import (
"encoding/json"
"os"
)
type omit bool
type Value interface{}
type CacheItem struct {
Key string `json:"key"`
MaxAge int `json:"cacheAge"`
Value Value `json:"cacheValue"`
}
func NewCacheItem() (*CacheItem, error) {
i := &CacheItem{}
return i, json.Unmarshal([]byte(`{
"key": "foo",
"cacheAge": 1234,
"cacheValue": {
"nested": true
}
}`), i)
}
func main() {
item, _ := NewCacheItem()
json.NewEncoder(os.Stdout).Encode(struct {
*CacheItem
// Omit bad keys
OmitMaxAge omit `json:"cacheAge,omitempty"`
OmitValue omit `json:"cacheValue,omitempty"`
// Add nice keys
MaxAge int `json:"max_age"`
Value *Value `json:"value"`
}{
CacheItem: item,
// Set the int by value:
MaxAge: item.MaxAge,
// Set the nested struct by reference, avoid making a copy:
Value: &item.Value,
})
}
|
请注意,这仅在您要重命名大型结构中的一个或两个字段时才是实际的。重命名所有字段时,仅创建一个新对象(即序列化器)并避免结构组合通常更简单(更简洁)。
复用旧struct
如果你为类型实现了MarshalJSON() ([]byte, error)和UnmarshalJSON(b []byte) error方法,那么这个类型在序列化反序列化时将采用你定制的方法。
这些都是我们常用的设置技巧。
如果临时想为一个struct增加一个字段的话,可以采用本译文的技巧,临时创建一个类型,通过嵌入原类型的方式来实现。通过嵌入的方式创建一个新的类型,你序列化和反序列化的时候需要使用这个新类型,而本译文中的方法是无痛改变原类型的MarshalJSON方式,采用Alias方式避免递归解析,确实是一种非常巧妙的方法。
Go的 encoding/json序列化strcut到JSON数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
package main
import (
"encoding/json"
"os"
"time"
)
type MyUser struct {
ID int64 `json:"id"`
Name string `json:"name"`
LastSeen time.Time `json:"lastSeen"`
}
func main() {
_ = json.NewEncoder(os.Stdout).Encode(
&MyUser{1, "Ken", time.Now()},
)
}
|
序列化的结果:
1
|
{"id":1,"name":"Ken","lastSeen":"2009-11-10T23:00:00Z"}
|
但是如果我们想改变一个字段的显示结果我们要怎么做呢?例如,我们想把LastSeen显示为unix时间戳。
最简单的方式是引入另外一个辅助struct,在MarshalJSON中使用它进行正确的格式化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
package main
import (
"encoding/json"
"os"
"time"
)
type MyUser struct {
ID int64 `json:"id"`
Name string `json:"name"`
LastSeen time.Time `json:"lastSeen"`
}
func (u *MyUser) MarshalJSON() ([]byte, error) {
return json.Marshal(&struct {
ID int64 `json:"id"`
Name string `json:"name"`
LastSeen int64 `json:"lastSeen"`
}{
ID: u.ID,
Name: u.Name,
LastSeen: u.LastSeen.Unix(),
})
}
func main() {
_ = json.NewEncoder(os.Stdout).Encode(
&MyUser{1, "Ken", time.Now()},
)
}
|
这样做当然没有问题,但是如果有很多字段的话就会很麻烦,如果我们能把原始struct嵌入到新的struct中,并让它继承所有不需要改变的字段就太好了:
1
2
3
4
5
6
7
8
9
|
func (u *MyUser) MarshalJSON() ([]byte, error) {
return json.Marshal(&struct {
LastSeen int64 `json:"lastSeen"`
*MyUser
}{
LastSeen: u.LastSeen.Unix(),
MyUser: u,
})
}
|
但是等等,问题是这个辅助struct也会继承原始struct的MarshalJSON方法.这会导致这个方法进入无限循环中,最后堆栈溢出。
解决办法就是为原始类型起一个别名,别名会有原始struct所有的字段,但是不会继承它的方法:
1
2
3
4
5
6
7
8
9
10
|
func (u *MyUser) MarshalJSON() ([]byte, error) {
type Alias MyUser
return json.Marshal(&struct {
LastSeen int64 `json:"lastSeen"`
*Alias
}{
LastSeen: u.LastSeen.Unix(),
Alias: (*Alias)(u),
})
}
|
同样的技术也可以应用于UnmarshalJSON方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func (u *MyUser) UnmarshalJSON(data []byte) error {
type Alias MyUser
aux := &struct {
LastSeen int64 `json:"lastSeen"`
*Alias
}{
Alias: (*Alias)(u),
}
if err := json.Unmarshal(data, &aux); err != nil {
return err
}
u.LastSeen = time.Unix(aux.LastSeen, 0)
return nil
|
自定义 marshal/unmarshal
Go 语言标准库 encoding/json 提供了操作 JSON 的方法,一般可以使用 json.Marshal 和 json.Unmarshal 来序列化和解析 JSON 字符串。当你想实现自定义的 Unmarshal 方法,就要实现 Unmarshaler 接口。
发现问题
一位老哥在 golang/go 项目下提了一个类似的 issue:https://github.com/golang/go/issues/39470 , 无意间点进去发现这个问题还挺有意思的,自己经过实践后才发现,这应该是 golang 中的一个大坑。
先来看一下这位仁兄遇到了什么问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
package main
import (
"encoding/json"
"fmt"
"time"
)
var testJSON = `{"num":5,"duration":"5s"}`
type Nested struct {
Dur time.Duration `json:"duration"`
}
func (n *Nested) UnmarshalJSON(data []byte) error {
*n = Nested{}
tmp := struct {
Dur string `json:"duration"`
}{}
fmt.Printf("parsing nested json %s \n", string(data))
if err := json.Unmarshal(data, &tmp); err != nil {
fmt.Printf("failed to parse nested: %v", err)
return err
}
tmpDur, err := time.ParseDuration(tmp.Dur)
if err != nil {
fmt.Printf("failed to parse duration: %v", err)
return err
}
(*n).Dur = tmpDur
return nil
}
type Object struct {
Nested
Num int `json:"num"`
}
//uncommenting this method still doesnt help.
//tmp is parsed with the completed json at Nested
//which doesnt take care of Num field, so Num is zero value.
func (o *Object) UnmarshalJSON(data []byte) error {
*o = Object{}
tmp := struct {
Nested
Num int `json:"num"`
}{}
fmt.Printf("parsing object json %s \n", string(data))
if err := json.Unmarshal(data, &tmp); err != nil {
fmt.Printf("failed to parse object: %v", err)
return err
}
fmt.Printf("tmp object: %+v \n", tmp)
(*o).Num = tmp.Num
(*o).Nested = tmp.Nested
return nil
}
func main() {
obj := Object{}
if err := json.Unmarshal([]byte(testJSON), &obj); err != nil {
fmt.Printf("failed to parse result: %v", err)
return
}
fmt.Printf("result: %+v \n", obj)
}
|
代码看起来是要实现一个带有自定义功能的 unmarshal ,Object 结构体内嵌了 Nested 结构体,并且带有一个 Num 字段,想要把 json string {"num":5,"duration":"5s"} unmarshal 到结构体 Object 中。代码看上去没什么问题,Object 中嵌入了 Nested,都实现了 UnmarshalJSON, 符合了 json 包中 Unmarshaler 接口。
1
2
3
4
5
6
7
|
package json
..........
/ By convention, to approximate the behavior of Unmarshal itself,
// Unmarshalers implement UnmarshalJSON([]byte("null")) as a no-op.
type Unmarshaler interface {
UnmarshalJSON([]byte) error
}
|
当一切准备就绪的时候,让我们执行代码。
1
2
3
4
|
parsing object json {"num":5,"duration":"5s"}
parsing nested json {"num":5,"duration":"5s"}
tmp object: {Nested:{Dur:5s} Num:0}
result: {Nested:{Dur:5s} Num:0}
|
现象是,Num 字段并没有被解析成功。
分析问题
代码看起来并没有什么问题,用回归本质的方式解释起来就是,结构体嵌入并实现接口方法。那先让我们来看一段回归本质的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
package main
import "fmt"
type Funer interface{
Name()string
PrintName()
}
type A struct {
}
func (a *A) Name() string {
return "a"
}
func (a *A) PrintName() {
fmt.Println(a.Name())
}
type B struct {
A
}
func (b *B) Name() string {
return "b"
}
func getBer() Funer {
return &B{}
}
func main() {
b := getBer()
b.PrintName()
}
|
这段代码的输出应该是什么?考虑 20s 说出你的答案。
这个实现中,正确的输出的是 a,而通常在 C++,Java,Python 中这种思想下,我们给出的答案往往是 b,受到之前的语言思维习惯影响,那么 go 的这个实现就会导致很多意想不到的事情。比如上面这位老哥遇到的诡异事情。
这个问题的本质和这位老哥遇到的问题一样,因为 Object 中嵌入了 Nested,所以有了 UnmarshalJSON, 符合了 json 包中 Unmarshaler 接口,所以内部用接口去处理的时候,Object 是满足的,但实际处理的是 Nested,也就是以 Nested 作为实体来进行 UnmarshalJSON,导致了诡异的错误信息。
简单解释下就是嵌入字段 Nested 的方法被提升了,导致 Object 的方法不会被执行,所以 Num 字段不会被 Unmarshal。
解决方案1
解决这个问题的方式有很多种,这里给出一种比较稳妥的思路:将嵌入字段的处理与其余字段分开,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
package main
import (
"encoding/json"
"fmt"
"time"
)
var testJSON = `{"num":5,"duration":"5s"}`
type Nested struct {
Dur time.Duration `json:"duration"`
}
func (n *Nested) UnmarshalJSON(data []byte) error {
*n = Nested{}
tmp := struct {
Dur string `json:"duration"`
}{}
fmt.Printf("parsing nested json %s \n", string(data))
if err := json.Unmarshal(data, &tmp); err != nil {
fmt.Printf("failed to parse nested: %v", err)
return err
}
tmpDur, err := time.ParseDuration(tmp.Dur)
if err != nil {
fmt.Printf("failed to parse duration: %v", err)
return err
}
(*n).Dur = tmpDur
fmt.Printf("tmp object: %+v \n", tmp)
return nil
}
type Object struct {
Nested
Num int `json:"num"`
}
//uncommenting this method still doesnt help.
//tmp is parsed with the completed json at Nested
//which doesnt take care of Num field, so Num is zero value.
func (o *Object) UnmarshalJSON(data []byte) error {
tmp := struct {
//Nested
Num int `json:"num"`
}{}
// unmarshal Nested alone
tmpNest := struct {
Nested
}{}
fmt.Printf("parsing object json %s \n", string(data))
if err := json.Unmarshal(data, &tmp); err != nil {
fmt.Printf("failed to parse object: %v", err)
return err
}
// the Nested impl UnmarshalJSON, so it should be unmarshaled alone
if err := json.Unmarshal(data, &tmpNest); err != nil {
fmt.Printf("failed to parse object: %v", err)
return err
}
fmt.Printf("tmp object: %+v \n", tmp)
(o).Num = tmp.Num
(o).Nested = tmpNest.Nested
return nil
}
func main() {
obj := Object{}
if err := json.Unmarshal([]byte(testJSON), &obj); err != nil {
fmt.Printf("failed to parse result: %v", err)
return
}
fmt.Printf("result: %+v \n", obj)
}
|
解决方案2
另一个办法是将两个结构体合并成一个.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
package main
import (
"encoding/json"
"fmt"
"time"
)
var testJSON = `{"num":5,"duration":"5s"}`
type Nested struct {
Dur time.Duration `json:"duration"`
}
func (obj *Object) UnmarshalJSON(data []byte) error {
tmp := struct {
Dur string `json:"duration"`
Num int `json:"num"`
}{}
if err := json.Unmarshal(data, &tmp); err != nil {
return err
}
dur, err := time.ParseDuration(tmp.Dur)
if err != nil {
return err
}
obj.Dur = dur
obj.Num = tmp.Num
return nil
}
type Object struct {
Nested
Num int `json:"num"`
}
var _ json.Unmarshaler = (*Object)(nil)
func main() {
obj := Object{}
_ = json.Unmarshal([]byte(testJSON), &obj)
fmt.Printf("result: %+v \n", obj)
}
|
随后这位老哥补充到,在嵌入字段都实现了接口方法的情况下,The type assertion will be a nice guide, 添加该类型的断言是一个好的实践,可以帮助你快速捕捉到潜在的 bug。
解决方案3
第三种办法是将time.Duration起一个别名,并实现 custom time unmarshaller。
这样嵌入字段 Nested 就没有unmarshal方法,也就不会有unmarshal方法被提升到Object中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
package main
import (
"encoding/json"
"fmt"
"time"
)
var testJSON = `{"num":5,"duration":"5s"}`
type customTimeDuration time.Duration
type Nested struct {
Dur customTimeDuration `json:"duration"`
}
func (ctd *customTimeDuration) UnmarshalJSON(b []byte) error {
var durStr string
if err := json.Unmarshal(b, &durStr); err != nil {
return err
}
dur, err := time.ParseDuration(durStr)
if err == nil {
*ctd = customTimeDuration(dur)
}
return err
}
type Object struct {
Nested
Num int `json:"num"`
}
func main() {
obj := Object{}
_ = json.Unmarshal([]byte(testJSON), &obj)
fmt.Printf("result: %+v \n", obj)
}
|
参考:
https://www.jianshu.com/p/40d5556842f1
https://www.jianshu.com/p/31757e530144
https://ethancai.github.io/2016/06/23/bad-parts-about-json-serialization-in-Golang/
https://blog.csdn.net/hatlonely/article/details/79187676
https://blog.cyeam.com/golang/2016/05/02/jsonnumber
https://hackcv.com/index.php/archives/97/
https://www.simpleapples.com/2018/12/24/practice-in-json-with-go/
https://ictar.xyz/2017/11/29/golang%E7%9A%84%E8%B8%A9%E5%9D%91%E4%B8%8D%E5%AE%8C%E5%85%A8%E8%AE%B0%E5%BD%95%E4%B9%8Bjson/
https://blog.csdn.net/linhenk/article/details/89636192
https://blog.csdn.net/suiban7403/article/details/79175583
JSON 的填坑之旅:官方给的解答
[译]自定义Go Json的序列化方法
golang map转json的顺序问题
go map 转 json 小记