Go中的happens-before
文章目录
内存重排
如何保证在一个 goroutine 中看到在另一个 goroutine 修改的变量的值,如果程序中修改数据时有其他 goroutine 同时读取,那么必须将读取串行化。为了串行化访问,请使用 channel 或其他同步原语,例如 sync 和 sync/atomic 来保护数据。
Happen-Before
在一个 goroutine 中,读和写一定是按照程序中的顺序执行的。即编译器和处理器只有在不会改变这个 goroutine 的行为时才可能修改读和写的执行顺序。由于重排,不同的goroutine 可能会看到不同的执行顺序。例如,一个goroutine 执行 a = 1;b = 2;,另一个 goroutine 可能看到 b 在 a 之前更新。

用户写下的代码,先要编译成汇编代码,也就是各种指令,包括读写内存的指令。CPU 的设计者们,为了榨干 CPU 的性能,无所不用其极,各种手段都用上了,你可能听过不少,像流水线、分支预测等等。其中,为了提高读写内存的效率,会对读写指令进行重新排列,这就是所谓的 内存重排,英文为 MemoryReordering。 这一部分说的是 CPU 重排,其实还有编译器重排。比如:


但是,编译器无法感知到多个线程同时访问同一变量,所以编译器做的指令重排可能会带来BUG.
如果这时有另外一个线程同时干了这么一件事:

上述两段代码的输出结果就会出现不同,出现了"BUG".
在多核心场景下,没有办法轻易地判断两段程序是“等价”的。
现代 CPU 为了“抚平” 内核、内存、硬盘之间的速度差异,搞出了各种策略,例如三级缓存等。为了让 (2) 不必等待 (1) 的执行“效果”可见之后才能执行,我们可以把 (1) 的效果保存到 store buffer:
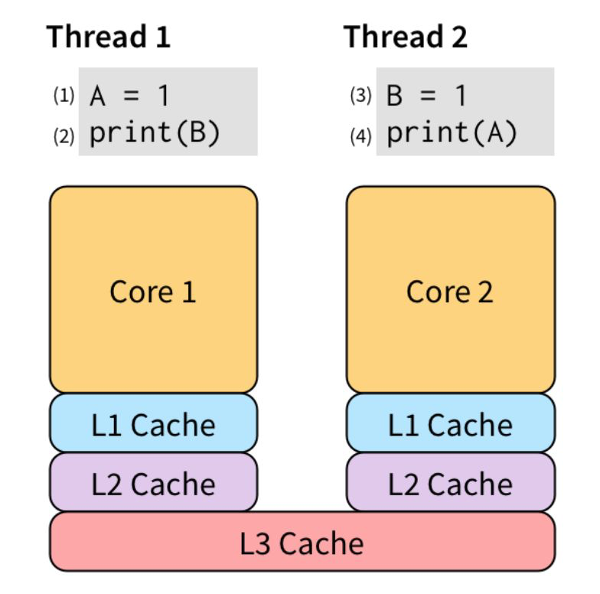
store buffer 对单线程是完美的
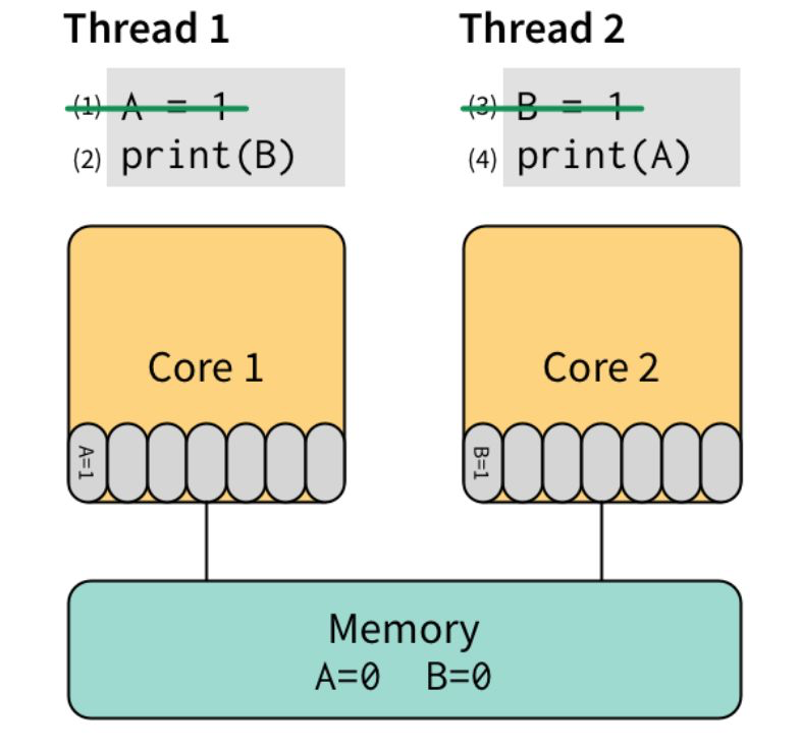
先执行 (1) 和 (3),将他们直接写入 store buffer,接着执行 (2) 和 (4)。“奇迹”要发生了:(2) 看了下 store buffer,并没有发现有 B 的值,于是从 Memory 读出了 0,(4) 同样从 Memory 读出了 0。最后,打印出了 00。
因此,对于多线程的程序,所有的 CPU 都会提供“锁”支持,称之为 barrier,或者 fence。它要求:barrier 指令要求所有对内存的操作都必须要“扩散”到 memory 之后才能继续执行其他对 memory 的操作。因此,我们可以用高级点的 atomic compare-and-swap,或者直接用更高级的锁,通常是标准库提供。
为了说明读和写的必要条件,我们定义了先行发生(Happens Before)。如果事件 e1 发生在 e2 前,我们可以说 e2 发生在 e1 后。如果 e1不发生在 e2 前也不发生在 e2 后,我们就说 e1 和 e2 是并发的。
在单一的独立的 goroutine 中先行发生的顺序即是程序中表达的顺序。
当下面条件满足时,对变量 v 的读操作 r 是被允许看到对 v 的写操作 w 的:
- r 不先行发生于 w
- 在 w 后 r 前没有对 v 的其他写操作
为了保证对变量 v 的读操作 r 看到对 v 的写操作 w,要确保 w 是 r 允许看到的唯一写操作。即当下面条件满足时,r 被保证看到 w:
- w 先行发生于 r
- 其他对共享变量 v 的写操作要么在 w 前,要么在 r 后。
这一对条件比前面的条件更严格,需要没有其他写操作与 w 或 r 并发发生。
单个 goroutine 中没有并发,所以上面两个定义是相同的:
读操作 r 看到最近一次的写操作 w 写入 v 的值。
当多个 goroutine 访问共享变量 v 时,它们必须使用同步事件来建立先行发生这一条件来保证读操作能看到需要的写操作。
- 对变量 v 的零值初始化在内存模型中表现的与写操作相同。
- 对大于 single machine word 的变量的读写操作表现的像以不确定顺序对多个 single machine word的变量的操作。
64位机器的machine word为8byte(64位),对于小于等于single machine word 的变量的写操作是原子性的.
https://www.jianshu.com/p/5e44168f47a3
重排和可见性的问题
由于指令重排,代码并不一定会按照你写的顺序执行。
举个例子,当两个 goroutine 同时对一个数据进行读写时,假设 goroutine g1 对这个变量进行写操作 w,goroutine g2 同时对这个变量进行读操作 r,那么,如果 g2 在执行读操作 r 的时候,已经看到了 g1 写操作 w 的结果,那么,也不意味着 g2 能看到在 w 之前的其它的写操作。这是一个反直观的结果,不过的确可能会存在。
接下来,我再举几个具体的例子,带你来感受一下,重排以及多核 CPU 并发执行导致程序的运行和代码的书写顺序不一样的情况。
先看第一个例子,代码如下:
|
|
可以看到,第 9 行是要打印 b 的值。需要注意的是,即使这里打印出的值是 2,但是依然可能在打印 a 的值时,打印出初始值 0,而不是 1。这是因为,程序运行的时候,不能保证 g2 看到的 a 和 b 的赋值有先后关系。
再来看一个类似的例子。
|
|
在这段代码中,主 goroutine main 即使观察到 done 变成 true 了,最后读取到的 a 的值仍然可能为空。
更糟糕的情况是,main 根本就观察不到另一个 goroutine 对 done 的写操作,这就会导致 main 程序一直被 hang 住。甚至可能还会出现半初始化的情况,比如:
|
|
即使 main goroutine 观察到 g 不为 nil,也可能打印出空的 msg(第 17 行)。
看到这里,你可能要说了,我都运行这个程序几百万次了,怎么也没有观察到这种现象? 我可以这么告诉你,能不能观察到和提供保证(guarantee)是两码事儿。由于 CPU 架构和 Go 编译器的不同,即使你运行程序时没有遇到这些现象,也不代表 Go 可以 100% 保证不会出现这些问题。
刚刚说了,程序在运行的时候,两个操作的顺序可能不会得到保证,那该怎么办呢?接下来,我要带你了解一下 Go 内存模型中很重要的一个概念:happens-before,这是用来描述两个时间的顺序关系的。如果某些操作能提供 happens-before 关系,那么,我们就可以 100% 保证它们之间的顺序。
在并发编程中的 memory barrier 和 GC 中的 barrier 不是一回 事。
Memory barrier 是为了防止各种类型的读写重排:
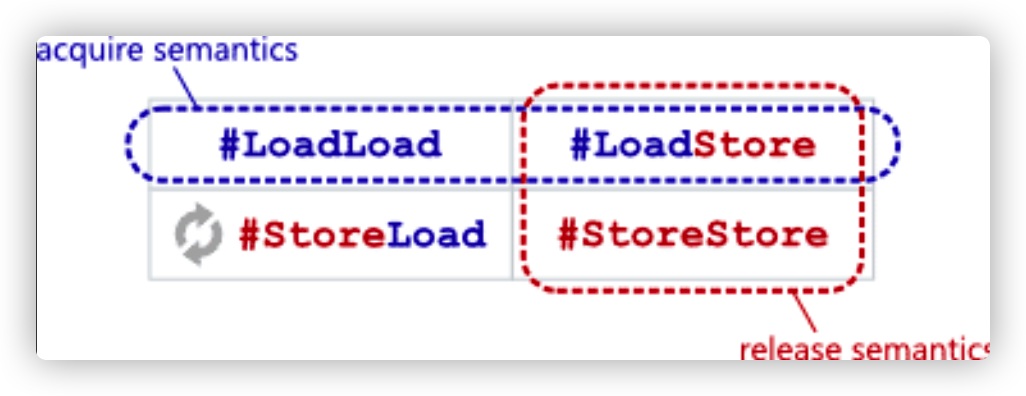
而 GC 中的 read/write barrier 则是指堆上指针修改之前插入 的一小段代码。
happens-before
在一个 goroutine 内部,程序的执行顺序和它们的代码指定的顺序是一样的,即使编译器或者 CPU 重排了读写顺序,从行为上来看,也和代码指定的顺序一样。
这是一个非常重要的保证,我们一定要记住。
我们来看一个例子。在下面的代码中,即使编译器或者 CPU 对 a、b、c 的初始化进行了重排,但是打印结果依然能保证是 1、2、3,而不会出现 1、0、0 或 1、0、1 等情况。
|
|
但是,对于另一个 goroutine 来说,重排却会产生非常大的影响。因为 Go 只保证 goroutine 内部重排对读写的顺序没有影响,比如刚刚我们在讲“可见性”问题时提到的三个例子,那该怎么办呢?这就要用到 happens-before 关系了。
如果两个 action(read 或者 write)有明确的 happens-before 关系,你就可以确定它们之间的执行顺序(或者是行为表现上的顺序)。
Go 内存模型通过 happens-before 定义两个事件(读、写 action)的顺序:如果事件 e1 happens before 事件 e2,那么,我们就可以说事件 e2 在事件 e1 之后发生(happens after)。如果 e1 不是 happens before e2, 同时也不 happens after e2,那么,我们就可以说事件 e1 和 e2 是同时发生的。
如果要保证对“变量 v 的读操作 r”能够观察到一个对“变量 v 的写操作 w”,并且 r 只能观察到 w 对变量 v 的写,没有其它对 v 的写操作,也就是说,我们要保证 r 绝对能观察到 w 操作的结果,那么就需要同时满足两个条件:
- w happens before r;
- 其它对 v 的写操作(w2、w3、w4, …) 要么 happens before w,要么 happens after r,绝对不会和 w、r 同时发生,或者是在它们之间发生。
你可能会说,这是很显然的事情啊,但我要和你说的是,这是一个非常严格、严谨的数学定义。
对于单个的 goroutine 来说,它有一个特殊的 happens-before 关系,Go 内存模型中是这么讲的:
Within a single goroutine, the happens-before order is the order expressed by the program.
我来解释下这句话。它的意思是,在单个的 goroutine 内部, happens-before 的关系和代码编写的顺序是一致的。
我再具体解释下。
在 goroutine 内部对一个局部变量 v 的读,一定能观察到最近一次对这个局部变量 v 的写。如果要保证多个 goroutine 之间对一个共享变量的读写顺序,在 Go 语言中,可以使用并发原语为读写操作建立 happens-before 关系,这样就可以保证顺序了。
说到这儿,我想先给你补充三个 Go 语言中和内存模型有关的小知识,掌握了这些,你就能更好地理解下面的内容。
- 在 Go 语言中,对变量进行零值的初始化就是一个写操作。
- 如果对超过机器 word(64bit、32bit 或者其它)大小的值进行读写,那么,就可以看作是对拆成 word 大小的几个读写无序进行。
- Go 并不提供直接的 CPU 屏障(CPU fence)来提示编译器或者 CPU 保证顺序性,而是使用不同架构的内存屏障指令来实现统一的并发原语。
接下来,我就带你学习下 Go 语言中提供的 happens-before 关系保证。
Happen-before 到底是什么?
本质是在用户不知道 memory barrier 概念和具体实现的前提 下,能够按照官方提供的 happen-before 正确进行并发编 程。
Go 语言中保证的 happens-before 关系
除了单个 goroutine 内部提供的 happens-before 保证,Go 语言中还提供了一些其它的 happens-before 关系的保证,下面我来一个一个介绍下。
init 函数
应用程序的初始化是在单一的 goroutine 执行的。如果包 p 导入了包 q,那么,q 的 init 函数的执行一定 happens before p 的任何初始化代码。
这里有一个特殊情况需要你记住:main 函数一定在导入的包的 init 函数之后执行。
包级别的变量在同一个文件中是按照声明顺序逐个初始化的,除非初始化它的时候依赖其它的变量。同一个包下的多个文件,会按照文件名的排列顺序进行初始化。这个顺序被定义在Go 语言规范中,而不是 Go 的内存模型规范中。你可以看看下面的例子中各个变量的值:
|
|
具体怎么对这些变量进行初始化呢?Go 采用的是依赖分析技术。不过,依赖分析技术保证的顺序只是针对同一包下的变量,而且,只有引用关系是本包变量、函数和非接口的方法,才能保证它们的顺序性。
同一个包下可以有多个 init 函数,但是每个文件最多只能有一个 init 函数,多个 init 函数按照它们的文件名顺序逐个初始化。
刚刚讲的这些都是不同包的 init 函数执行顺序,下面我举一个具体的例子,把这些内容串起来,你一看就明白了。
这个例子是一个 main 程序,它依赖包 p1,包 p1 依赖包 p2,包 p2 依赖 p3。
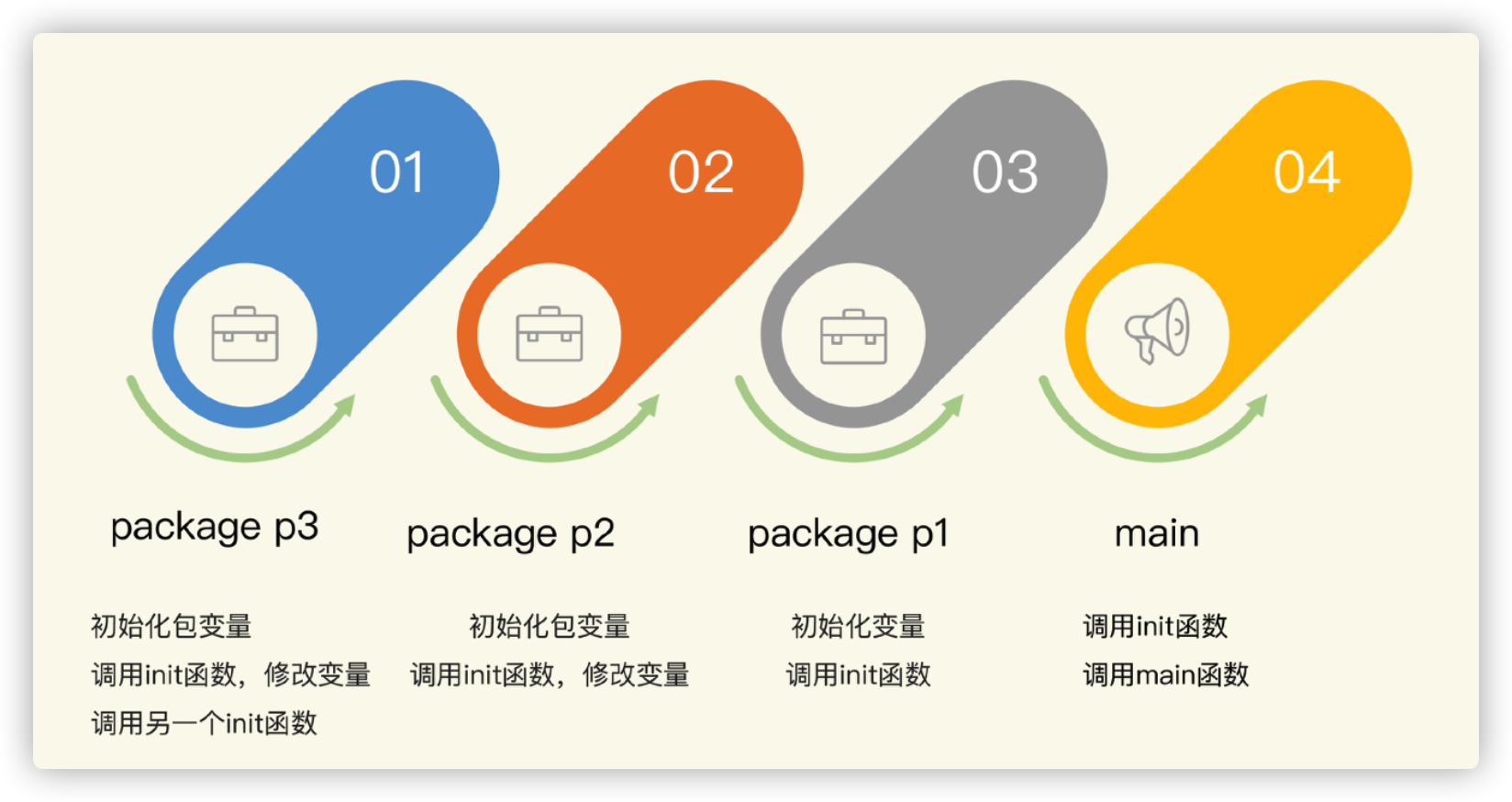
为了追踪初始化过程,并输出有意义的日志,我定义了一个辅助方法,打印出日志并返回一个用来初始化的整数值:
|
|
包 p3 包含两个文件,分别定义了一个 init 函数。第一个文件中定义了两个变量,这两个变量的值还会在 init 函数中进行修改。
我们来分别看下包 p3 的这两个文件:
|
|
|
|
下面再来看看包 p2。包 p2 定义了变量和 init 函数。第一个变量初始化为 2,并在 init 函数中更改为 200。第二个变量是复制的 p3.V2_p3。
|
|
包 p1 定义了变量和 init 函数。它的两个变量的值是复制的 p2 对应的两个变量值。
|
|
main 定义了 init 函数和 main 函数。
|
|
运行 main 函数会依次输出 p3、p2、p1、main 的初始化变量时的日志(变量初始化时的日志和 init 函数调用时的日志):
|
|
下面,我们再来看看 goroutine 对 happens-before 关系的保证情况。
goroutine
首先,我们需要明确一个规则:启动 goroutine 的 go 语句的执行,一定 happens before 此 goroutine 内的代码执行。
根据这个规则,我们就可以知道,如果 go 语句传入的参数是一个函数执行的结果,那么,这个函数一定先于 goroutine 内部的代码被执行。
同一个 goroutine 内的逻辑有依赖的语句执行,满足顺序关系。
编译器/CPU 可能对同一个 goroutine 中的语句执行进行打 乱,以提高性能,但不能破坏其应用原有的逻辑。
不同的 goroutine 观察到的共享变量的修改顺序可能不一样。
Goroutine 的创建(creation)一定先于 goroutine 的执行 (execution)
我们来看一个例子。在下面的代码中,第 8 行 a 的赋值和第 9 行的 go 语句是在同一个 goroutine 中执行的,所以,在主 goroutine 看来,第 8 行肯定 happens before 第 9 行,又由于刚才的保证,第 9 行子 goroutine 的启动 happens before 第 4 行的变量输出,那么,我们就可以推断出,第 8 行 happens before 第 4 行。也就是说,在第 4 行打印 a 的值的时候,肯定会打印出“hello world”。
|
|
刚刚说的是启动 goroutine 的情况,goroutine 退出的时候,是没有任何 happensbefore 保证的。所以,如果你想观察某个 goroutine 的执行效果,你需要使用同步机制建立 happens-before 关系,比如 Mutex 或者 Channel。接下来,我会讲 Channel 的 happens-before 的关系保证。
在没有显式同步的情况下,goroutine 的结束没有任何保证, 可能被执行,也可能不被执行
Channel
Channel 是 goroutine 同步交流的主要方法。往一个 Channel 中发送一条数据,通常对应着另一个 goroutine 从这个 Channel 中接收一条数据。
通用的 Channel happens-before 关系保证有 4 条规则,我分别来介绍下。
第 1 条规则是,往 Channel 中的发送操作,happens before 从该 Channel 接收相应数据的动作完成之前,即第 n 个 send 一定 happens before 第 n 个 receive 的完成。
|
|
在这个例子中,s 的初始化(第 5 行)happens before 往 ch 中发送数据, 往 ch 发送数据 happens before 从 ch 中读取出一条数据(第 11 行),第 12 行打印 s 的值 happens after 第 11 行,所以,打印的结果肯定是初始化后的 s 的值“hello world”。
第 2 条规则是,close 一个 Channel 的调用,肯定 happens before 从关闭的 Channel 中读取出一个零值。
还是拿刚刚的这个例子来说,如果你把第 6 行替换成 close(ch),也能保证同样的执行顺序。因为第 11 行从关闭的 ch 中读取出零值后,第 6 行肯定被调用了。
第 3 条规则是,对于 unbuffered 的 Channel,也就是容量是 0 的 Channel,从此 Channel 中读取数据的调用一定 happens before 往此 Channel 发送数据的调用完成。
所以,在上面的这个例子中呢,如果想保持同样的执行顺序,也可以写成这样:
|
|
如果第 11 行发送语句执行成功(完毕),那么根据这个规则,第 6 行(接收)的调用肯定发生了(执行完成不完成不重要,重要的是这一句“肯定执行了”),那么 s 也肯定初始化了,所以一定会打印出“hello world”。
这一条比较晦涩,但是,因为 Channel 是 unbuffered 的 Channel,所以这个规则也成立。
第 4 条规则是,如果 Channel 的容量是 m(m>0),那么,第 n 个 receive 一定 happens before 第 n+m 个 send 的完成。
前一条规则是针对 unbuffered channel 的,这里给出了更广泛的针对 buffered channel 的保证。利用这个规则,我们可以实现信号量(Semaphore)的并发原语。Channel 的容量相当于可用的资源,发送一条数据相当于请求信号量,接收一条数据相当于释放信号。
Mutex/RWMutex
对于互斥锁 Mutex m 或者读写锁 RWMutex m,有 3 条 happens-before 关系的保证。
- 第 n 次的 l.Unlock,那么,和这个 RLock 相对应的 l.RUnlock 一定 happens 第 n 次的 m.Unlock 一定 happens before 第 n+1 m.Lock 方法的返回; 1.
- 对于读写锁 RWMutex m,如果它的第 n 个 m.Lock 方法的调用已返回,那么它的第 n 个 m.Unlock 的方法调用一定 happens before 任何一个 m.RLock 方法调用的返回, 只要这些 m.RLock 方法调用 happens after 第 n 次 m.Lock 的调用的返回。这就可以保证,只有释放了持有的写锁,那些等待的读请求才能请求到读锁。
- 对于读写锁 RWMutex m,如果它的第 n 个 m.RLock 方法的调用已返回,那么它的第 k (k<=n)个成功的 m.RUnlock 方法的返回一定 happens before 任意的 m.RUnlockLock 方法调用,只要这些 m.Lock 方法调用 happens after 第 n 次 m.RLock。
读写锁的保证有点绕,我再带你看看官方的描述:
对于读写锁 l 的 l.RLock 方法调用,如果存在一个 n,这次的 l.RLock 调用 happens after第 n 次的 l.Unlock,那么,和这个 RLock 相对应的 l.RUnlock 一定 happens before 第 n+1 次 l.Lock。意思是,读写锁的 Lock 必须等待既有的读锁释放后才能获取到。
我再举个例子。在下面的代码中,第 6 行第一次的 Unlock 一定 happens before 第二次的 Lock(第 12 行),所以这也能保证正确地打印出“hello world”。
|
|
WaitGroup
接下来是 WaitGroup 的保证。
对于一个 WaitGroup 实例 wg,在某个时刻 t0 时,它的计数值已经不是零了,假如 t0 时刻之后调用了一系列的 wg.Add(n) 或者 wg.Done(),并且只有最后一次调用 wg 的计数值变为了 0,那么,可以保证这些 wg.Add 或者 wg.Done() 一定 happens before t0 时刻之后调用的 wg.Wait 方法的返回。
这个保证的通俗说法,就是 Wait 方法等到计数值归零之后才返回。
Once
它提供的保证是:对于 once.Do(f) 调用,f 函数的那个单次调用一定 happens before 任何 once.Do(f) 调用的返回。换句话说,就是函数 f 一定会在 Do 方法返回之前执行。
还是以 hello world 的例子为例,这次我们使用 Once 并发原语实现,可以看下下面的代码:
|
|
第 5 行的执行一定 happens before 第 9 行的返回,所以执行到第 10 行的时候,sd 已经初始化了,所以会正确地打印“hello world”。
最后,我再来说说 atomic 的保证。
atomic
其实,Go 内存模型的官方文档并没有明确给出 atomic 的保证,有一个相关的 issue go# 5045记录了相关的讨论。光看 issue 号,就知道这个讨论由来已久了。Russ Cox 想让 atomic 有一个弱保证,这样可以为以后留下充足的可扩展空间,所以,Go 内存模型规范上并没有严格的定义。
对于 Go 1.15 的官方实现来说,可以保证使用 atomic 的 Load/Store 的变量之间的顺序性。
在下面的例子中,打印出的 a 的结果总是 1,但是官方并没有做任何文档上的说明和保证。
依照 Ian Lance Taylor 的说法,Go 核心开发组的成员几乎没有关注这个方向上的研究, 因为这个问题太复杂,有很多问题需要去研究,所以,现阶段还是不要使用 atomic 来保证顺序性。
|
|
Ian Lance Taylor曾经在论坛中说:
In C++ memory model terms I believe that the sync/atomic Load operations are memory_order_acquire, and I believe that the sync/atomic Store operations are memory_order_release. It’s possible that if we ever document it we will go for stronger memory ordering, but I believe that these operations must at least carry those guarantees.
I’m somewhat less certain of the memory order guarantees of the Swap, CompareAndSwap, and Add functions. I guess that Swap and CompareAndSwap are probably at least memory_order_acq_rel, but Add may be memory_order_relaxed.
Russ Cox曾经回答过问题,他把go的atomic 操作定位sequential consistency的,这是一个更严格的memory ordering。它们之前的读写操作,不会重排在Load/Store之后, 它们之后的读写操作也不会重排在Load/Store之前,所以建立了一个内存屏障(Memory barrier)。
rsc 2019年7月16日上午9:12:01
Although there’s been no official resolution to the issue, I think the actual path forward is what I posted a while back: “Go’s atomics guarantee sequential consistency among the atomic variables (behave like C/C++’s seqconst atomics), and that you shouldn’t mix atomic and non-atomic accesses for a given memory word.”
至少目前,我们可以按照他们的解答进行理解。
总结
Go 的内存模型规范中,一开始有这么一段话:
If you must read the rest of this document to understand the behavior of your program, you are being too clever.
Don’t be clever.
理解你的程序的行为是聪明的,但是, 不要自作聪明。
谨慎地使用这些保证,能够让你的程序按照设想的 happens-before 关系执行,但是不要以为完全理解这些概念和保证,就可以随意地制造所谓的各种技巧,否则就很容易掉进“坑”里,而且会给代码埋下了很多的“定时炸弹”。
比如,Go 里面已经有值得信赖的互斥锁了,如果没有额外的需求,就不要使用 Channel 创造出自己的互斥锁。
当然,我也不希望你畏手畏脚地把思想局限住,我还是建议你去做一些有意义的尝试,比如使用 Channel 实现信号量等扩展并发原语。
文章作者 Forz
上次更新 2021-05-23