测量大小写敏感的比较
首先,我们来测量下两种字符串比较
第一种:使用比较操作符
1
2
3
4
5
|
if a == b {
return true
}else {
return false
}
|
第二种:使用 Strings.Compare
1
2
3
4
|
if strings.Compare(a, b) == 0 {
return true
}
return false
|
我们看到第一种方法相对简单点。我们不需要引入标准库的包,代码量也少一点。这看起来很好,但是哪一种更快呢?我们来验证一下。
首先,我们创建一个带有测试文件的应用。我们将使用 Go 测试工具中的 Benchmarking 实用工具。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
compare.go
package main
import (
"strings"
)
func main() {
}
// operator compare
func compareOperators(a string, b string) bool {
if a == b {
return true
} else {
return false
}
}
// strings compare
func compareString(a string, b string) bool {
if strings.Compare(a, b) == 0 {
return true
}
return false
}
|
我们还会为它创建几个测试用例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
compare_test.go
package main
import (
"testing"
)
func BenchmarkCompareOperators(b *testing.B) {
for n := 0; n < b.N; n++ {
compareOperators("This is a string", "This is a strinG")
}
}
func BenchmarkCompareString(b *testing.B) {
for n := 0; n < b.N; n++ {
compareString("This is a string", "This is a strinG")
}
}
|
我会修改示例字符串的最后一个字符,以此来确认下比较时两个方法是否都解析了整个字符串。
使用下面的命令来运行我们的基准测试:
下面是运行结果:

从上图可以看出,使用标准的比较操作符比使用 Strings 包的方法要快。2.92 纳秒比 7.39 纳秒。
重复跑了几次测试,结果都差不多:
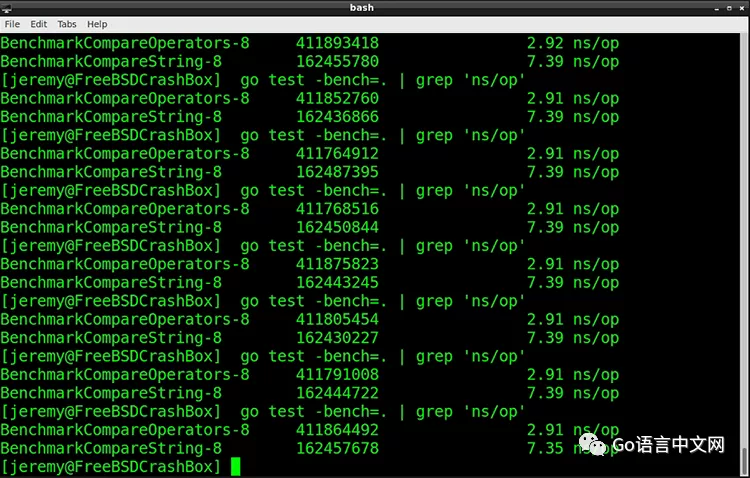
很明显第一种方式要快。如果数量级足够大,5 ns 的差别可能会非常大。
结论:在对字符串进行大小写敏感的比较时,最基本的字符串比较操作符比使用 strings 包进行比较要快。
测量大小写不敏感的比较
我们来改变一下条件。通常情况下,我做字符串比较时,我是想看下两个字符串的字母是否一样,而不关心字母的大小写。这对于我们的操作来说就增加了一些复杂性。
1
2
|
sampleString := "This is a sample string"
compareString := "this is a sample string"
|
使用标准的比较操作进行对比,由于 T 字母大写,因此两个字符串不相等。
然而,我们关心的是字母是否相同,而不关心字母的大小写。所以,我们来改一下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// operator compare
func compareOperators(a string, b string) bool {
if strings.ToLower(a) == strings.ToLower(b) {
return true
}
return false
}
// strings compare
func compareString(a string, b string) bool {
if strings.Compare(strings.ToLower(a), strings.ToLower(b)) == 0 {
return true
}
return false
}
|
我们先把字符串的字母都变成小写的,再进行比较。为了确保结果可信,我们多执行几次。看一下基准测试结果:
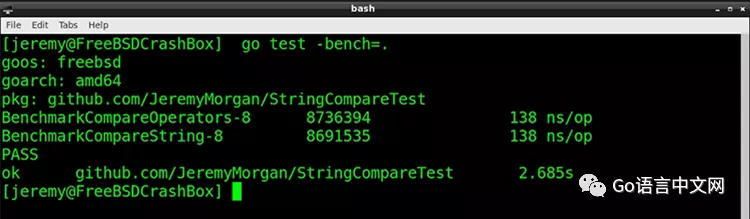
两个操作看起来耗时相同。我多跑了几次:
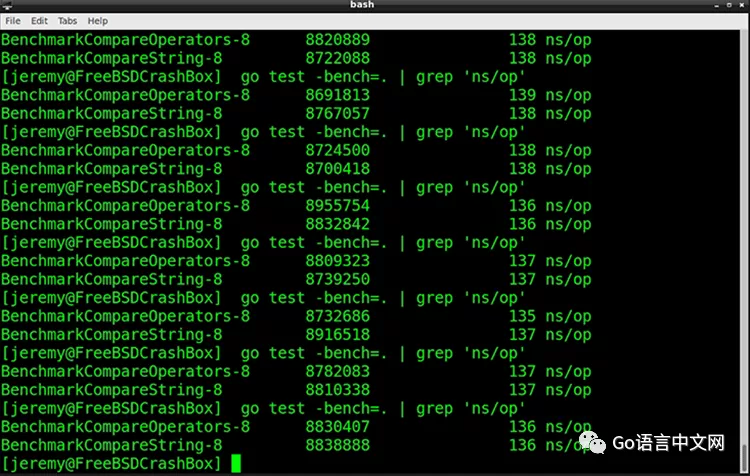
它们耗时是一样的。但是为什么呢?
其中一个原因是,我们在每一次执行过程中都加入了 Strings.ToLower[3]。这会影响整体的性能。字符串就是 rune 字符的集合,ToLower() 方法会遍历每个 rune 字符,把每个字符转换成小写,然后再进行比较。而这段额外的时间掩盖了测量中的两种方式的差别。
EqualFold 是一种用来对字符串进行大小写不敏感的比较操作的方法。我们认为 Equalfold 是三种方法中最快的。我们来看看基准测试结果是否与我们的结论吻合。
向 compare.go 添加下面的代码:
1
2
3
4
5
6
7
8
|
// EqualFold compare
func compareEF(a string, b string) bool {
if strings.EqualFold(sampleString, compareString) {
return true
} else {
return false
}
}
|
向 compare_test.go 文件添加下面的测试代码
1
2
3
4
5
|
func BenchmarkEqualFold(b *testing.B) {
for n := 0; n < b.N; n++ {
compareEF("This is a string", "This is a strinG")
}
}
|
现在基于这个方法,我们运行基准测试:

哇!EqualFold 很明显地比另外两个快。我运行了几次,结果都一样。
它为什么会快呢?因为虽然 Equalfold 也会逐个字符进行解析,但是当它解析到两个字符串中不同的字符时,就会“提前下车”。
结论:对于大小写不敏感的比较,EqualFold(Strings 包)比较快。
进行更深入的测试
我们现在了解了几个方法运行基准测试后的不同结果。现在再加入一些复杂性进行测试。
上篇文章中,我们用这个 20 万行的列表[4]来进行比较。我们会修改代码中的方法,改成打开文件后进行字符串比较,直到找到想找的字符串。

这个文件中,我把想找的名字加到了最后一行,因此这个测试过程会在找到匹配的结果之前遍历前面的 199000 个单词。
修改下代码:
compare.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
// operator compare
func compareOperators(a string) bool {
file, err := os.Open("names.txt")
result := false;
if err != nil {
log.Fatalf("failed opening file: %s", err)
}
scanner := bufio.NewScanner(file)
scanner.Split(bufio.ScanLines)
for scanner.Scan() {
if strings.ToLower(a) == strings.ToLower(scanner.Text()) {
result = true
}else {
result = false
}
}
file.Close()
return result
}
// strings compare
func compareString(a string) bool {
file, err := os.Open("names.txt")
result := false;
if err != nil {
log.Fatalf("failed opening file: %s", err)
}
scanner := bufio.NewScanner(file)
scanner.Split(bufio.ScanLines)
for scanner.Scan() {
if strings.Compare(strings.ToLower(a), strings.ToLower(scanner.Text())) == 0 {
result = true
}else {
result = false
}
}
file.Close()
return result
}
// EqualFold compare
func compareEF(a string) bool {
file, err := os.Open("names.txt")
result := false;
if err != nil {
log.Fatalf("failed opening file: %s", err)
}
scanner := bufio.NewScanner(file)
scanner.Split(bufio.ScanLines)
for scanner.Scan() {
if strings.EqualFold(a, scanner.Text()) {
result = true
}else {
result = false
}
}
file.Close()
return result
}
|
每个方法的逻辑都是:
- 打开一个文件文件
- 逐行解析
- 查找字符
我们把测试方法改成只有一个入参:
compare_test.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func BenchmarkCompareOperators(b *testing.B) {
for n := 0; n < b.N; n++ {
compareOperators("Immanuel1234")
}
}
func BenchmarkCompareString(b*testing.B) {
for n := 0; n < b.N; n++ {
compareString("Immanuel1234")
}
}
func BenchmarkEqualFold(b *testing.B) {
for n := 0; n < b.N; n++ {
compareEF("Immanuel1234")
}
}
|
现在我们可以让测试运行的时间长一点,基准测试工具的重复用例也会少一点。下面是测试结果:
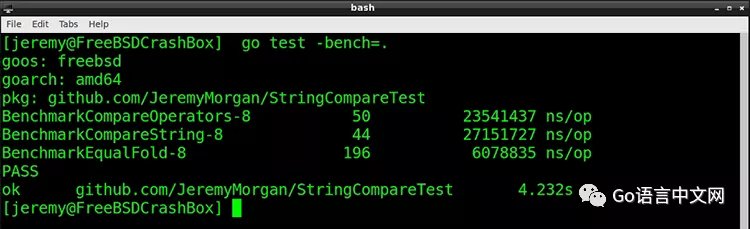
EqualFold 仍以相当大的优势领先。
添加了这个复杂性,有好处也有坏处。
好处:读取文本文件并进行序列化的测试更接近真实的生产环境
好处:我们可以用不同的字符串进行多种多样的测试
坏处:我们引入了多个因素(如读取文件),可能会影响最终结果的真实性
结论:对于大小写不敏感的比较,EqualFold(Strings 包)仍然比较快。
等一下,还没完呢
我们还能让比较操作更快点吗?当然。我决定统计下字符串的字符个数。如果字符个数不一样,它们肯定不相等,我们就可以提前结束比较过程。
但是在字符串长度相同而字符不同时,我们仍然需要引入 EqualFold。后面加上的长度的检查使整个操作更繁琐,它会更快吗?我们来看看。
compare.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func compareByCount(a string) bool {
file, err := os.Open("names.txt")
result := false;
if err != nil {
log.Fatalf("failed opening file: %s", err)
}
scanner := bufio.NewScanner(file)
scanner.Split(bufio.ScanLines)
for scanner.Scan() {
if len(a) == len(scanner.Text()) && strings.EqualFold(a, scanner.Text()){
result = true
}else {
result = false
}
}
file.Close()
return result
}
|
compare_test.go
1
2
3
4
5
|
func BenchmarkCompareByCount(b *testing.B){
for n := 0; n < b.N; n++ {
compareByCount("Immanuel1234")
}
}
|
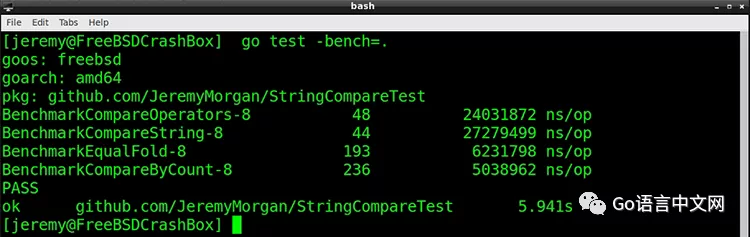
它确实更快!每个小小的改动都很重要。
结论:使用 EqualFold 时先进行字符数量对比,速度会更快。
总结
本文中,我们研究了几种比较字符串的方法以及哪种方法比较快。
- 对于大小写敏感的比较,使用基本的比较操作,
- 对于大小写不敏感的比较,使用字符数量对比 + EqualFold。
转载
Go 中优化字符串的比较操作