DEFLATE压缩算法原理
文章目录
DEFLATE & INFLATE
当你键入 tar -zcf src.tar.gz src, 就可以将 src 下的所有文件打包成一个 tar.gz 格式的压缩包. 这里的 “tar” 是归档格式, 将多个文件组合成一个文件; 而 “gz” 指的就是 gzip 压缩格式, 使用 DEFLATE 算法压缩得到.
- ZIP是一种文件格式,用于存储任意数量的文件和文件夹以及无损压缩。它没有对使用的压缩方法做出严格的假设,但最常用于DEFLATE 。
- Gzip既是基于 DEFLATE 的压缩算法,又是对潜在专利等的较少阻碍,以及用于存储单个压缩文件的文件格式。它支持在与tar结合使用时压缩任意数量的文件和文件夹。生成的文件的扩展名为.tgz或.tar.gz ,通常称为tarball 。
- zlib 库提供了 Deflate 压缩和解压缩代码,供 zip,gzip, png (使用 defl 数据上的zlib 包装器 )和许多其他应用程序使用。。
DEFLATE 是同时使用了 LZ77 算法与哈夫曼编码的一个无损数据压缩算法。它最初是由 Phil Katz 为他的 PKZIP 归档工具第二版所定义的,后来定义在 RFC1951 规范中。
inflate是GZip, PNG等广泛使用的解压算法,linux也使用inflate对内核进行解压.
LZ77
J. Ziv 和 A. Lempel 在 1977 发表了一篇名为 A Universal Algorithm for Sequential Data Compression 的论文, 提出了一种顺序数据的通用压缩算法. 这个算法后来被称为 LZ77 算法. 事实上 DEFLATE 算法使用的 LZ77 跟原版有所不同, 这里我们以 DEFLATE 中的为准.
基本原理
我们平时使用的文件总是会有很多重复的部分, LZ77 压缩算法正是利用了这一点. 它会试图尽可能地找出文件中重复的内容, 然后用一个标记代替重复的部分, 这个标记能够明确地指示这部分在哪里出现过. 举个例子, 以 葛底斯堡演说 的第一段为例:
|
|
我们可以找出不少重复的片段. 我们规定, 只要有两个以上的字符与前文重复, 就使用重复标记 <d,l> 代替它. <d,l> 表示这个位置的字符串等价与 d 个字符前, 长度为 l 的字符串. 于是上面的内容就可以表示为:
|
|
呃, 你可能已经发现了这样 “压缩” 后的结果比原文还长. 别急, 这只是个演示, 稍后我们能看到如何解决这个问题.
实现这个算法最简单的方式就是遍历字符串, 对于每个字符都在前文中顺序查找是否有重复的字符, 然后求出最长重复子串. 这种做法时间复杂度为O(n^2), 效率较低, 特别是在处理大文件的时候. 为了提高效率, 我们使用哈希表和滑动窗口优化.
使用哈希表
顺序查找过于缓慢, 我们可以使用哈希表来提升效率. 我们使用一个哈希表把一个长度为三的字符串映射成一个列表, 包含这个字符串所有曾经出现过的位置. 压缩时从头到尾扫描字符串. 假设接下来的三个字符为 XYZ, 首先检查字符串 XYZ 是否在哈希表中. 如果不在, 则原样输出字符 X 并移动到下一个字符. 否则把当前位置开始的字符串与所有 XYZ 出现过的位置开始的字符串相比较, 寻找出一个长度为 N 的最长的匹配并输出重复标记, 然后向后移动 N 个字符. 无论能否在哈希表中找到匹配, 都会把当前位置插入到 XYZ 在哈希表映射的列表中.
举个例子, 考虑字符串 abcabcdabcde, 算法运行时有以下几步:
1.扫描到第 0 个字符 a, 哈希表为空, 原样输出字符 a, 并且将字符串 abc 插入哈希表中.
|
|
扫描到第 3 个字符 a, 哈希表指示 abc 在 0 处出现过. 最长的匹配就是 abc, 因此输出 <3,3>. 同时把当前位置插入到 abc 映射的列表中.
|
|
扫描到第 7 个字符 a, 哈希表指示 abc 在 0, 3 处出现过. 依次与当前位置匹配, 0 处只能匹配到 abc, 而 3 处能匹配到 abcd, 最长的匹配为 abcd, 于是输出 <4,4>. 同时把当前位置插入到 abc 映射的列表中.
|
|
BTW, zlib 中这个哈希表的实现非常精妙, 关于它的详细实现超出了本文的讨论范围. 对 C 语言感兴趣的同学一定要去看看这个实现.
滑动窗口
即使有了哈希表, 过长的文件仍然会导致效率问题. 为此我们使用滑动窗口, 查找重复内容时仅在窗口中查找. 窗口的长度是固定的, 通常是 32KB. 在 zlib 的实现中, 使用一个两倍窗口大小的缓冲区, 如下所示:
|
|
初始时将待压缩数据填入缓冲区, 指针位于缓冲区的开始处; 随后指针向后扫描, 对数据进行压缩. 我们把指针扫描过的的部分称为 search 区, 未扫描过的部分称为 lookahead 区. 对于每个扫描的字符, 算法都只会在 search 区中寻找匹配. 当 lookahead 区长度不足(小于一个固定值)时, 算法就会移动窗口以继续扫描更多的数据. 具体的做法时将缓冲区后半部分的数据复制到前半部分并移动指针, 然后在缓冲区的后半部分读入新数据, 接着还要更新哈希表, 因为数据的位置发生了改变.
惰性匹配(lazy matching)
有的时候这种策略并不能得到最优的压缩结果. 举个例子, 考虑字符串 abcbcdabcda, 当扫描到第 6 个字符的时候是这样的:
|
|
哈希表指示 abc 在 0 处出现过, 最长匹配为 abc, 于是输出 <6,3>; 后面的 da 没有与之重复的内容, 原样输出. 因此压缩的结果是 abcbcd<6,3>da. 然而在第 7 个字符的位置能在前文找到一个更长的匹配 bcda, 更好的压缩结果应该是 abcbcda<4,4>.
为了解决这个问题, DEFLATE 采用一叫做惰性匹配的策略优化. 每当算法找到一个长度为 N 的匹配后, 就会试图在下一个字符寻找更长的匹配. 只有当没有找到更长的匹配时, 才为当前匹配输出重复标记; 否则就会丢弃当前匹配, 使用更长的匹配. 注意惰性匹配可以连续触发, 如果一次惰性匹配发现了更长的匹配, 仍会继续进行惰性匹配, 直到无法在下一个字符找到更长匹配为止.
惰性匹配能够提高压缩率, 但是会让压缩变慢. 运行时的参数会控制惰性匹配, 只有在当前匹配不够长, i.e. 小于某个配置的值的时候, 才会触发惰性匹配. 可以根据需求是压缩率优先还是速度优先来调整这个值, 或者关闭惰性匹配.
压缩
让我们用这个例子来看看它是如何工作的:
|
|
首先能想到的最简单做法就是直接替换第二次出现的 O为指向第一次出现的 O 的一个标记,或者替换第二次出现的RTO为指向第一次出现的RTO。 下面更具体地描述一下这个过程,假定我们设置的缓冲区大小是 4,把这 4 个长度的缓冲区看成是一个滑动窗口沿着正文文本向右滑动:
|
|
滑动窗口随着随着编码的迭代一步步向右移动,前面 4 步中滑动窗口内的字母都没有发现重复。
到了第 5 步,滑动窗口内字母 O 已经出现重复了,然后查看字母 O 右侧的R 发现在滑动窗口中匹配字母 O 右侧相邻的字母并非 R ,便不再继续向右进行匹配,将第 2 个 O 替换成 (1, 1) (表示:滑动窗口中匹配的字母离当前字母偏移距离为 1,匹配上的连续字母长度为 1)。
在第 6 步中,滑动窗口中字母 R 与其左边第 4 个字母匹配上了,继续检查下一个字母 T 的匹配情况,然后发现滑动窗口中 RT 也匹配上了。然后继续下一个字母 O ,在滑动窗口中匹配 RTO 也匹配上了,并且到此为止,因为下一个字母匹配上了。滑动窗口中匹配上的字母与当前字母的偏移距离为 4,同时有连续 3 个字母匹配上了,所以这里将匹配上的 3 个字母替换成 (4, 3) 。
接着在第 7 步中,字母 R 与偏移距离 3 处的字母匹配上,但是接下来的 RR 并未匹配上,在第 8 步中发现最近的匹配上的 R 的偏移距离为 1。最终整段文本经过编码的结果如下:
|
|
解压
压缩过的文本其实是由一系列的这种 (d, 1) 标记对和字母组成,标记对无法直接找到相匹配的字母。在解压过程中,字母保持不变,这种标记对转换为其指向位置的字母。下面看一个解压的例子:
|
|
字母 abc 保持不变,标记对 (3, 2) 表示从当前位置向左移动 3 个单位,然后取出 2 个字母,因此其转换为 ab。现在原始文本变成了这样 abcab(1, 1),最后的一个标记对表示从当前位置向左移动 1 个单位,然后取出 1 个字母,因此转换为 b。最终解压完成的文本为 abcabb。
哈夫曼编码
如果我们真的使用 <d,l> 这样的格式表示重复的内容, 那就太愚蠢了. 首先是这样的格式太占空间了, 2.1 节中使用这种方式 “压缩” 的 葛底斯堡演说 比甚至原文还长. 其次这种格式让尖括号变成了特殊字符, 还得设法转义它们. 那么应该如何表示重复部分距离和长度呢? DEFLATE 的做法是打破旧秩序, 建立新秩序,使用 Huffman 编码对数据重新编码.
Huffman 编码由美国计算机科学家 David A. Huffman 于 1952 年提出, 它是根据字符出现频率构造而成的前缀编码. 与我们平时常用的固定位编码(每个字符占 8 位)不同, Huffman 编码中每个字符的编码的位数都可能不同, 却能够明确地区分每个字符, 不会有任何歧义.
压缩
为什么每个字符占的位数都不同却能明确地区分它们呢? 这就是前缀编码的作用. 为了说明什么是前缀编码, 试想我们在打电话. 电话号码的长度是不一样的: 有三位的, 如 110, 119; 有五位的, 如 10086, 10010; 有 7 位或 8 位的固定电话, 又有 11 位的手机号码等等. 然而拨号的时候依次输入号码, 总能正确识别 (固定电话摘机拨号无需按呼叫键). 这是因为除了匪警 110 之外不会有任何一个电话号码以 110 开头, 任何一个固定电话号都不可能是某个手机号的前缀. 电话号码就是一种前缀编码. 所以, 虽然 Huffman 编码中每个字符的编码位数都不同, 但是短的编码不会是长的编码的前缀. 这样就保证了 Huffman 编码没有歧义.
|
|
这个例子中,我们希望能无损地压缩这段文本。通常一个字母占用 8 字节,所以这段文本总长度有 200 字节。在这段本文中,我们发现其中字母 F 只出现了 1 次,而字母 E 出现了 7 次。哈夫曼编码正是利用了这一特性,通过减少出现频率高的字母本身的字节长度,来减少整个文本所占的总长度。 要采用哈夫曼编码压缩文章,首先需要统计各个文本中各个字母的出现频率,上述例子中的字母频率如下:
|
|
我们需要使用文本中的字母作为叶子节点来构建一颗二叉树,通过这颗二叉树来编码文本中的每一个字母。从出现频率最小的字母:P 和 F 开始,让其作为底层的叶子节点,将其频率相加的值作为父节点,这样便得到了如下的二叉树:
|
|
重复上面的步骤,依次使用频率最小的字母:U 和 O 以及 R 和 T,最后剩下频率最高的字母 E 先单独放着。
|
|
接下来使用上面得到的 4 个二叉树作为子节点来创建一颗更大的二叉树,将上面的二叉树的根节点的频率值递增排序,优先使用根节点频率值小的二叉树作为新的二叉树子节点。这里使用 U 和 O、R 和 T 这两组二叉树组成了如下的一颗二叉树:
|
|
这时候还有 3 颗二叉树,根节点分别为:9、9、7(第一个 9 是上一步创建的二叉树),同样的,将根节点频率值最小的两个作为子节点创建新的二叉树如下:
|
|
现在剩下一颗将根节点值为 16 的大二叉树和根节点值为 9 叶子节点为 R、T 的二叉树,将其作为子节点创建一颗新的二叉树如下:
|
|
现在我们要做的就是根据这棵二叉树来对文本进行编码。依次从跟节点访问各个字母,遇到左分支当成 0,遇到右分支当成 1,按照字母沿着二叉树访问路径的顺序所将这些 0、1 连接起来。比如,从根节点到字母 E 先后需要经过 1 次左分支和 1 次右分支,所以字母 E 的编码为 10 。字母 U 需要经过 4 次左分支,其编码为 1111;F 需要经过 2 次左分支和 2 次右分支,其编码为 1100 。可以发现,在这里例子中出现频率非常高的字母 E 编码后位数比出现频率较少的字母 F 编码后位数要少。经过这样的编码处理,最终压缩过的文本如下:
|
|
这段压缩后的文本长度只有 68 位,远比原始的 200 位长度小。
解压
假如收到这样一段压缩过的文本,我们希望能够解压它让其变得可以理解。我们都知道一段未压缩过的文本中的一个字符占用 8 位,上面说过经过哈夫曼编码压缩后一个字符的位数并不是固定 8 位的,所以并不清楚一段数据(比如:011)是表示 1 个字符、2 个字符或者 3 个字符,因此这段压缩过的文本将如何解压呢?
这一步不存在任何奇迹,要准确解压还需要上面编码中构建的二叉树。得到这个用于编码的二叉树有两种方案,第一种是其和压缩后的文本放一起作为原始文本的压缩结果,这可能会导致压缩后的文本比原始文本还要大;第二种方案是使用预先定义好的二叉树。我们知道各个字母在英语中的使用频率,完全可以根据这个频率来构建上述的二叉树。使用这种预先定义的公共字母频率二叉树压缩部分文本的结果可能比根据文本内容字母频率二叉树压缩的效果差一些,但是这样不再需要将字母频率二叉树保存到压缩后的文件中。总而言之,这两种方案各有优缺点。
对距离和长度进行编码
一个字节有 8 位, 因此我们需要 0 至 255 一共 256 个 Huffman 编码. 统计文件各个字符的使用频率, 构造出 Huffman 树即可计算出这 256 个编码. 那么如何用 Huffman 编码表示重复标记中的距离和长度呢? DEFLATE 算法是这样做的:
对于距离, 它有 0 至 29 一共 30 个编码. 距离编码的含义如下表所示:
| code | extra | distance | code | extra | distance | code | extra | distance |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 10 | 4 | 33-48 | 20 | 9 | 1025-1536 |
| 1 | 0 | 2 | 11 | 4 | 49-64 | 21 | 9 | 1537-2048 |
| 2 | 0 | 3 | 12 | 5 | 65-96 | 22 | 10 | 2049-3072 |
| 3 | 0 | 4 | 13 | 5 | 97-128 | 23 | 10 | 3073-4096 |
| 4 | 1 | 5,6 | 14 | 6 | 129-192 | 24 | 11 | 4097-6144 |
| 5 | 1 | 7,8 | 15 | 6 | 193-256 | 25 | 11 | 6145-8192 |
| 6 | 2 | 9-12 | 16 | 7 | 257-384 | 26 | 12 | 8193-12288 |
| 7 | 2 | 13-16 | 17 | 7 | 385-512 | 27 | 12 | 12289-16384 |
| 8 | 3 | 17-24 | 18 | 8 | 513-768 | 28 | 13 | 16385-24576 |
| 9 | 3 | 25-32 | 19 | 8 | 769-1024 | 29 | 13 | 24577-32768 |
每个编码都表示一个或多个距离. 当它表示多个距离时, 意味着接下来会有 extra 位表示具体的距离是多少. 例如假设编码 14 接下来的 6 位为 011010, 则表示距离为 129 + 0b011010 = 129 + 26 = 155. 这样距离编码能表示的距离范围为 1 至 32768.
对于长度, 它与普通字符共用同一编码空间. 这个编码空间一共有 286 个编码, 范围是从 0 至 285. 其中 0 至 255 为普通字符编码, 256 表示压缩块的结束; 而 257 至 285 则表示长度. 长度编码的含义如下表所示:
| code | extra | length(s) | code | extra | length(s) | code | extra | length(s) |
|---|---|---|---|---|---|---|---|---|
| 257 | 0 | 3 | 267 | 1 | 15,16 | 277 | 4 | 67-82 |
| 258 | 0 | 4 | 268 | 1 | 17,18 | 278 | 4 | 83-98 |
| 259 | 0 | 5 | 269 | 2 | 19-22 | 279 | 4 | 99-114 |
| 260 | 0 | 6 | 270 | 2 | 23-26 | 280 | 4 | 115-130 |
| 261 | 0 | 7 | 271 | 2 | 27-30 | 281 | 5 | 131-162 |
| 262 | 0 | 8 | 272 | 2 | 31-34 | 282 | 5 | 163-194 |
| 263 | 0 | 9 | 273 | 3 | 35-42 | 283 | 5 | 195-226 |
| 264 | 0 | 10 | 274 | 3 | 43-50 | 284 | 5 | 227-257 |
| 265 | 1 | 11,12 | 275 | 3 | 51-58 | 285 | 0 | 258 |
| 266 | 1 | 13,14 | 276 | 3 | 59-66 |
与距离编码类似, 每个编码都表示一个或多个长度, 表示多个长度时后面会有 extra 位指示具体的长度. 长度编码能表示的长度范围为 3 至 258.
解压时, 当读到编码小于等于 255, 则认为这是个普通字符, 原样输出即可; 若在 257 至 285 之间, 则说明遇到了一个重复标记, 这意味着当前编码表示的是长度, 且下一个编码表示的是距离. 解码得到长度和距离, 再在解压缓冲区中找到相应的部分输出即可; 若为 256, 则说明压缩块结束了.
哈夫曼表的存储
我们知道, Huffman 编码是根据字符的出现频率构造的. 不同的文件字符出现的频率都不同, 因此 Huffman 编码也不同. 为了能够正确地解压, 压缩块中还必须存储 Huffman 编码表. 这一节我们来讨论如何用最小的空间存储这个 Huffman 编码表.
3.2.1 将 Huffman 编码表表示为长度序列 为了高效地存储 Huffman 编码表, DEFLATE 算法规定, Huffman 树的每一层的叶子节点必须从这一层的最左侧开始, 按照 Huffman 编码的数值大小从小到大依次排列; 内部节点排列在随后. 此外同一层的字符应该按照字符表(如 ASCII 码表)的顺序依次排列. 这样 3.1 节中的 Huffman 树就应该调整为:
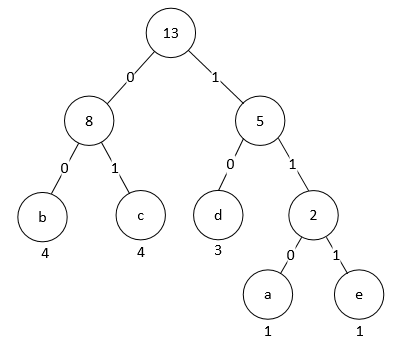
调整后的 Huffman 编码表就是:
| character | code |
|---|---|
| a | 110 |
| b | 00 |
| c | 01 |
| d | 10 |
| e | 111 |
注意调整后的 Huffman 编码并不影响压缩率: 各个字符编码的长度不变, 最常用的字符的编码仍是最短的. 不难发现, 相同长度的编码都是依次递增的, 且某个长度的编码的最小值取决于上个长度的编码的最小值和数量. 现设长度为i的编码的最小值为mi, 有ni个; 又设长度为 0 的编码的最小值为 0, 有 0 个. 那么易得
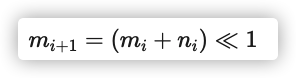 这里的 “≪” 表示左移. 这样, 我们只需要知道每个字符的 Huffman 编码长度, 即可推算出所有字符的 Huffman 编码了. 对如上面的例子, 我们只需存储长度序列<3,1,4,1,4>即可. 解压时扫描这个序列, 得到各个长度的编码的数量, 即可求算出各个长度的编码的最小值; 相同长度的编码都是依次递增的, 所以依次加一, 即可得出所有字符的 Huffman 编码. 特别地, 长度 0 表示这个字符没有在压缩块中出现过, 构造 Huffman 编码的时候会排除它.
这里的 “≪” 表示左移. 这样, 我们只需要知道每个字符的 Huffman 编码长度, 即可推算出所有字符的 Huffman 编码了. 对如上面的例子, 我们只需存储长度序列<3,1,4,1,4>即可. 解压时扫描这个序列, 得到各个长度的编码的数量, 即可求算出各个长度的编码的最小值; 相同长度的编码都是依次递增的, 所以依次加一, 即可得出所有字符的 Huffman 编码. 特别地, 长度 0 表示这个字符没有在压缩块中出现过, 构造 Huffman 编码的时候会排除它.
对长度序列编码
长度序列中很容易出现连续重复的值; 并且由于文件中可能有很多未使用的字符, 也会出现很多 0. 因此 DEFLATE 会对这个长度序列编码, 如下所示:
| code | meaning |
|---|---|
| 0-15 | 表示长度 0 至 15 |
| 16 | 前面的长度重复 3 到 6 次. 接下来的两位指示具体重复多少次, 这与 3.2 节中的长度和距离编码类似. |
| 17 | 长度 0 重复 3 至 10 次. 接下来的 3 位指示具体重复多少次. |
| 18 | 长度 0 重复 11 至 138 次. 接下来的 7 位指示具体重复多少次. |
使用 Huffman 编码压缩 Huffman 编码表
将 Huffman 编码表表示成编码后的长度序列已经比较精简了, 但是 DEFLATE 算法认为这还不够. 它决定对这个编码后的长度序列再次使用 Huffman 编码压缩. 这一步就有一点点绕了. 为了做到这一点, 我们需要为长度序列的编码,0 至 18, 构造 Huffman 编码表(然而这个长度序列表示的就是一个 Huffman 编码表, 等于我们是在为一个 Huffman 编码表构造 Huffman 编码表). 问题来了, 怎么表示这个 Huffman 编码表的 Huffman 编码表呢? 首先, DEFLATE 算法定义了一个神秘数组:
|
|
因为有可能不是所有的长度都能用上, 因此我们会先用一个数字标识使用这个数组中的前 k 个编码. 例如长度序列编码只使用了 2, 3, 4, 16, 17, 则 k = 16. 接下来会有 k 个数字, 第i个数字表示长度序列编码A[i]的 Huffman 编码的长度, 0 表示相应的编码未使用. 因为只要知道了每个字符的 Huffman 编码长度, 就能推算出所有字符的 Huffman 编码. 这样我们就得到了编码后的长度序列的 Huffman 编码表.
在压缩数据中先存储编码后的长度序列的 Huffman 编码表, 紧接着再存储编码后的长度序列的 Huffman 编码数据. 这样我们就在压缩块中用较小的空间存储了压缩数据的 Huffman 编码表.
zlib & gzip & zip
zlib是一种数据压缩程序库,它的设计目标是处理单纯的数据(而不管数据的来源是什么)。
gzip是一种文件压缩工具(或该压缩工具产生的压缩文件格式),它的设计目标是处理单个的文件。gzip在压缩文件中的数据时使用的就是zlib。为了保存与文件属性有关的信息,gzip需要在压缩文件(.gz)中保存更多的头信息内容,而zlib不用考虑这一点。但gzip只适用于单个文件,所以我们在UNIX/Linux上经常看到的压缩包后缀都是.tar.gz或*.tgz,也就是先用tar把多个文件打包成单个文件,再用gzip压缩的结果。
zip是适用于压缩多个文件的格式(相应的工具有PkZip和WinZip等),因此,zip文件还要进一步包含文件目录结构的信息,比gzip的头信息更多。但需要注意,zip格式可采用多种压缩算法,我们常见的zip文件大多不是用zlib的算法压缩的,其压缩数据的格式与gzip大不一样。
Java SDK提供了对上述三种压缩技术的支持:Inflater类和Deflater类直接用zlib库对数据压缩/解压缩,GZIPInputStream类和GZIPOutputStream类提供了对gzip格式的支持,ZipFile、ZipInputStream、ZipOutputStream则用于处理zip格式的文件。
所以,你应当根据你的具体需求,选择不同的压缩技术:如果只需要压缩/解压缩数据,你可以直接用zlib实现,如果需要生成gzip格式的文件或解压其他工具的压缩结果,你就必须用gzip或zip等相关的类来处理了。
Gzip 格式
最后我们再简单描述下 gzip 的格式.
Gzip 格式由头部信息, 压缩主体和尾部信息组成. 头部包括文件基本信息, 时间, 压缩方法, 操作系统等; 尾部则包含校验和与原始大小. 这些信息与压缩算法无关, 这里就不深入讨论了, 需要了解的同学可直接参阅 RFC1952.
压缩主体由一个或多个区块(block)组成. 每个区块的长度不固定, 都有自己的压缩和编码方式. 区块可能起始或结束于任何一个比特, 不必对齐字节. 需要说明的是, 重复标记指示的距离有可能跨越区块.
上文阐述的都是使用动态 Huffman 编码压缩. 事实上一个区块还有可能使用静态 Huffman 编码压缩或者不压缩. 使用静态 Huffman 编码压缩的区块会使用算法预设的 Huffman 编码进行压缩和解压, 不需要存储 Huffman 编码表.
所有的区块都以一个 3 位的头部开始, 包含以下数据:
| name | length | description |
|---|---|---|
| BFINAL | 1 位 | 标识是否是最后一个区块 |
| BTYPE | 2 位 | 标识类型. 00: 未压缩; 01: 静态 Huffman 编码压缩; 10: 动态 Huffman 编码压缩; 11: 保留 |
未压缩区块
未压缩区块包含以下数据(紧接着头部):
| name | length | description | | —- | ——– | | LEN | 2 位 | 区块数据长度 | | NLEN | 2 位 | LEN 的补码 | | DATA | LEN 字节 | 有效数据 |
压缩区块
动态 Huffman 编码压缩区块包含以下数据(紧接着头部):
| name | length | description |
|---|---|---|
| HLIT | 5 位 | 长度/字符编码的最大值减 257. 因为并不是所有的长度编码都被使用, 因此这里标记最大的长度/字符编码(长度与普通字符共用同一编码空间). |
| HDIST | 5 位 | 距离编码最大值减 1. 原理同上. |
| HCLEN | 4 位 | 3.2.3 节中的 k 减 4. 标识使用了神秘数组中的前几个编码. |
| 编码后的长度序列的 Huffman 编码表 | (HCLEN + 4) * 3 位 | 如 3.2.3 节所述的 “k 个数字”. 因为长度序列编码只有 19 个, 因此每个数字 3 位就够了. |
| 长度/字符编码的 Huffman 编码表 | 变长 | 根据上述 Huffman 编码表编码的长度序列, 用于表示长度/字符编码的 Huffman 编码表. |
| 距离编码的 Huffman 编码表 | 变长 | 根据上述 Huffman 编码表编码的长度序列, 用于表示距离编码的 Huffman 编码表. |
| DATA | 变长 | 有效压缩数据 |
| 256 结束标记 | 变长 | 标识区块的结束 |
静态压缩区块比较简单, 头部后紧接着就是有效压缩数据, 最后在加一个 256 结束标记.
参考
[译] 理解 zip 和 gzip 压缩格式背后的压缩算法 Gzip 格式和 DEFLATE 压缩算法 zlib,gzip,zip,7z压缩的区别
文章作者 Forz
上次更新 2021-04-27