连接与连接池
database/sql
database/sql是golang的标准库之一,它提供了一系列接口方法,用于访问关系数据库。它并不会提供数据库特有的方法,那些特有的方法交给数据库驱动去实现。
database/sql库提供了一些type。这些类型对掌握它的用法非常重要。
- DB 数据库对象。 sql.DB类型代表了数据库。和其他语言不一样,它并是数据库连接。golang中的连接来自内部实现的连接池,连接的建立是惰性的,当你需要连接的时候,连接池会自动帮你创建。通常你不需要操作连接池。一切都有go来帮你完成。
- Results 结果集。数据库查询的时候,都会有结果集。sql.Rows类型表示查询返回多行数据的结果集。sql.Row则表示单行查询结果的结果集。当然,对于插入更新和删除,返回的结果集类型为sql.Result。
- Statements 语句。sql.Stmt类型表示sql查询语句,例如DDL,DML等类似的sql语句。可以把当成prepare语句构造查询,也可以直接使用sql.DB的函数对其操作。
快速开始
下面就开始我们的sql数据库之旅,我们使用mysql数据库为例子,驱动使用go-sql-driver/mysql。
对于其他语言,查询数据的时候需要创建一个连接,对于go而言则是需要创建一个数据库抽象对象。连接将会在查询需要的时候,由连接池创建并维护。使用sql.Open函数创建数据库对象。它的第一个参数是数据库驱动名,第二个参数是一个连接字串(符合DSN风格,可以是一个tcp连接,一个unix socket等)。
构建连接, 格式是:“用户名:密码@tcp(IP:端口)/数据库?charset=utf8”
打开数据库,前者是驱动名,所以要导入: _ “github.com/go-sql-driver/mysql”
设置数据库最大连接数和设置上数据库最大闲置连接数
验证连接:使用Ping()函数
代码参考如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
//数据库配置
const (
userName = "root"
password = "123456"
ip = "127.0.0.1"
port = "3306"
dbName = "loginserver"
)
//Db数据库连接池
var DB *sql.DB
//注意方法名大写,就是public
func InitDB() {
//构建连接:"用户名:密码@tcp(IP:端口)/数据库?charset=utf8"
path := strings.Join([]string{userName, ":", password, "@tcp(",ip, ":", port, ")/", dbName, "?charset=utf8"}, "")
//打开数据库,前者是驱动名,所以要导入: _ "github.com/go-sql-driver/mysql"
DB, _ = sql.Open("mysql", path)
//设置数据库最大连接数
DB.SetConnMaxLifetime(100)
//设置上数据库最大闲置连接数
DB.SetMaxIdleConns(10)
//验证连接
if err := DB.Ping(); err != nil{
fmt.Println("opon database fail")
return
}
fmt.Println("connnect success")
}
|
创建了数据库对象之后,在函数退出的时候,需要释放连接,即调用sql.Close方法。例子使用了defer语句设置释放连接。
接下来进行一些基本的数据库操作,首先我们使用Exec方法执行一条sql,创建一个数据表:
1
2
3
4
5
6
7
8
9
10
11
12
|
func main() {
db, err := sql.Open("mysql", "root:@tcp(127.0.0.1:3306)/test?parseTime=true")
if err != nil{
log.Fatal(err)
}
defer db.Close()
_, err = db.Exec("CREATE TABLE IF NOT EXISTS test.hello(world varchar(50))")
if err != nil{
log.Fatalln(err)
}
}
|
此时可以看见,数据库生成了一个新的表。接下来再插入一些数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func main() {
db, err := sql.Open("mysql", "root:@tcp(127.0.0.1:3306)/test?parseTime=true")
...
rs, err := db.Exec("INSERT INTO test.hello(world) VALUES ('hello world')")
if err != nil{
log.Fatalln(err)
}
rowCount, err := rs.RowsAffected()
if err != nil{
log.Fatalln(err)
}
log.Printf("inserted %d rows", rowCount)
}
|
同样使用Exec方法即可插入数据,返回的结果集对象是是一个sql.Result类型,它有一个LastInsertId方法,返回插入数据后的id。当然此例的数据表并没有id字段,就返回一个0.
插入了一些数据,接下来再简单的查询一下数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func main() {
db, err := sql.Open("mysql", "root:@tcp(127.0.0.1:3306)/test?parseTime=true")
...
rows, err := db.Query("SELECT world FROM test.hello")
if err != nil{
log.Fatalln(err)
}
for rows.Next(){
var s string
err = rows.Scan(&s)
if err !=nil{
log.Fatalln(err)
}
log.Printf("found row containing %q", s)
}
rows.Close()
}
|
我们使用了Query方法执行select查询语句,返回的是一个sql.Rows类型的结果集。迭代后者的Next方法,然后使用Scan方法给变量s赋值,以便取出结果。最后再把结果集关闭(释放连接)。
通过上面一个简单的例子,介绍了database/sql的基本数据查询操作。而对于开篇所说的几个结构类型尚未进行详细的介绍。下面我们再针对database/sql库的类型和数据库交互做更深的探究。
连接池
正如上文所言,sql.DB是数据库的抽象,虽然通常它容易被误以为是数据库连接。它提供了一些跟数据库交互的函数,同时管理维护一个数据库连接池,帮你处理了单调而重复的管理工作,并且在多个goroutines也是十分安全。
虽然在完成数据库之后Close()数据库是惯用的,但是sql.DB对象被设计为长连接。不要经常Open()和Close()数据库。相反,为你需要访问的每个不同的数据存储创建一个sql.DB对象,并保留它,直到程序访问数据存储完毕。在需要时传递它,或在全局范围内使其可用,但要保持开放。并且不要从短暂的函数中Open()和Close()。相反,通过sql.DB作为参数传递给该短暂的函数。
如果你不把sql.DB视为长期存在的对象,则可能会遇到诸如重复使用和连接共享不足,耗尽可用的网络资源以及由于TIME_WAIT中剩余大量TCP连接而导致的零星故障的状态。这些问题表明你没有像设计的那样使用database/sql的迹象。
创建数据库对象需要引入标准库database/sql,同时还需要引入驱动go-sql-driver/mysql。使用_表示引入驱动的变量,这样做的目的是为了在你的代码中不至于和标注库的函数变量namespace冲突。
连接池的工作原理相当简单。当你的函数(例如Exec,Query)调用需要访问底层数据库的时候,函数首先会向连接池请求一个连接。如果连接池有空闲的连接,则返回给函数。否则连接池将会创建一个新的连接给函数。一旦连接给了函数,连接则归属于函数。函数执行完毕后,要不把连接所属权归还给连接池,要么传递给下一个需要连接的(Rows)对象,最后使用完连接的对象也会把连接释放回到连接池。
database/sql包中有一个基本的连接池。没有很多的控制或检查能力,但这里有一些你可能会发现有用的知识:
- 连接池意味着在单个数据库上执行两个连续的语句可能会打开两个链接并单独执行它们。对于程序员来说,为什么它们的代码行为不当,这是相当普遍的。例如,后面跟着INSERT的LOCK TABLES可能会被阻塞,因为INSERT位于不具有表锁定的连接上。
- 连接是在需要时创建的,池中没有空闲连接。
- 默认情况下,连接数量没有限制。如果你尝试同时执行很多操作,可以创建任意数量的连接。这可能导致数据库返回错误,例如“连接太多”。
- 在Golang1.1或更新版本中,你可以使用db.SetMaxIdleConns(N)来限制池中的空闲连接数。这并不限制池的大小。
- 在Golang1.2.1或更新版本中,可以使用db.SetMaxOpenConns(N)来限制于数据库的总打开连接数。不幸的是,一个死锁bug(修复)阻止db.SetMaxOpenConns(N)在1.2中安全使用。
- 连接回收相当快。使用db.SetMaxIdleConns(N)设置大量空闲连接可以减少此流失,并有助于保持连接以重新使用。
- 长期保持连接空闲可能会导致问题(例如在微软azure上的这个问题)。尝试db.SetMaxIdleConns(0)如果你连接超时,因为连接空闲时间太长。
请求一个连接的函数有好几种,执行完毕处理连接的方式稍有差别,大致如下:
- db.Ping() 调用完毕后会马上把连接返回给连接池。
- db.Exec() 调用完毕后会马上把连接返回给连接池,但是它返回的Result对象还保留这连接的引用,当后面的代码需要处理结果集的时候连接将会被重用。
- db.Query() 调用完毕后会将连接传递给sql.Rows类型,当然后者迭代完毕或者显示的调用.Close()方法后,连接将会被释放回到连接池。
- db.QueryRow()调用完毕后会将连接传递给sql.Row类型,当.Scan()方法调用之后把连接释放回到连接池。
- db.Begin() 调用完毕后将连接传递给sql.Tx类型对象,当.Commit()或.Rollback()方法调用后释放连接。
因为每一个连接都是惰性创建的,如何验证sql.Open调用之后,sql.DB对象可用呢?通常使用db.Ping()方法初始化:
1
2
3
4
5
6
7
8
9
10
11
|
db, err := sql.Open("driverName", "dataSourceName")
if err != nil{
log.Fatalln(err)
}
defer db.Close()
err = db.Ping()
if err != nil{
log.Fatalln(err)
}
|
调用了Ping之后,连接池一定会初始化一个数据库连接。当然,实际上对于失败的处理,应该定义一个符合自己需要的方式,现在为了演示,简单的使用log.Fatalln(err)表示了。
连接失败
关于连接池另外一个知识点就是你不必检查或者尝试处理连接失败的情况。当你进行数据库操作的时候,如果连接失败了,database/sql会帮你处理。实际上,当从连接池取出的连接断开的时候,database/sql会自动尝试重连10次。仍然无法重连的情况下会自动从连接池再获取一个或者新建另外一个。
连接池配置
无论哪一个版本的go都不会提供很多控制连接池的接口。知道1.2版本以后才有一些简单的配置。可是1.2版本的连接池有一个bug,请升级更高的版本。
配置连接池有两个的方法:
- db.SetMaxOpenConns(n int) 设置打开数据库的最大连接数。包含正在使用的连接和连接池的连接。如果你的函数调用需要申请一个连接,并且连接池已经没有了连接或者连接数达到了最大连接数。此时的函数调用将会被block,直到有可用的连接才会返回。设置这个值可以避免并发太高导致连接mysql出现too many connections的错误。该函数的默认设置是0,表示无限制。
- db.SetMaxIdleConns(n int) 设置连接池中的保持连接的最大连接数。默认也是0,表示连接池不会保持释放会连接池中的连接的连接状态:即当连接释放回到连接池的时候,连接将会被关闭。这会导致连接再连接池中频繁的关闭和创建。
对于连接池的使用依赖于你是如何配置连接池,如果使用不当会导致下面问题:
- 大量的连接空闲,导致额外的工作和延迟。
- 连接数据库的连接过多导致错误。
- 连接阻塞。
- 连接池有超过十个或者更多的死连接,限制就是10次重连。
大多数时候,如何使用sql.DB对连接的影响大过连接池配置的影响。这些具体问题我们会在使用sql.DB的时候逐一介绍。
MaxOpenConns 应该和实际的打开的连接数的监测值相关。然后按照 MaxOpenConns 的一定比值设置 MaxIdleConns,比方说 50%,这个值取决于你对业务的预估。每维持一个闲散连接,会造成 1MB 左右的客户端内存开销和 2MB 左右的数据库内存开销,CPU 开销相对小一点。
掌握了database/sql关于数据库连接池管理内容,下一步则是使用这些连接,进行数据的交互操作啦。
源码分析
数据结构
sql.DB:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
// DB is a database handle representing a pool of zero or more
// underlying connections. It's safe for concurrent use by multiple
// goroutines.
//
// The sql package creates and frees connections automatically; it
// also maintains a free pool of idle connections. If the database has
// a concept of per-connection state, such state can be reliably observed
// within a transaction (Tx) or connection (Conn). Once DB.Begin is called, the
// returned Tx is bound to a single connection. Once Commit or
// Rollback is called on the transaction, that transaction's
// connection is returned to DB's idle connection pool. The pool size
// can be controlled with SetMaxIdleConns.
type DB struct {
// Atomic access only. At top of struct to prevent mis-alignment
// on 32-bit platforms. Of type time.Duration.
waitDuration int64 // Total time waited for new connections.
//数据库实现驱动
connector driver.Connector
// numClosed is an atomic counter which represents a total number of
// closed connections. Stmt.openStmt checks it before cleaning closed
// connections in Stmt.css.
numClosed uint64
// 锁
mu sync.Mutex // protects following fields
// 空闲连接
freeConn []*driverConn
// 阻塞请求队列,等连接数达到最大限制时,后续请求将插入此队列等待可用连接
connRequests map[uint64]chan connRequest
// 记录下一个key用于connRequests map的key
nextRequest uint64 // Next key to use in connRequests.
// 已经打开的和将要打开的连接的总数
numOpen int // number of opened and pending open connections
// Used to signal the need for new connections
// a goroutine running connectionOpener() reads on this chan and
// maybeOpenNewConnections sends on the chan (one send per needed connection)
// It is closed during db.Close(). The close tells the connectionOpener
// goroutine to exit.
// 用来接收创建新连接的信号
// connectionOpener方法会读取该channel的信号,而当需要创建连接的时候,maybeOpenNewConnections就会往该channel发信号。
// 当调用db.Close()的时候,该channel就会被关闭
openerCh chan struct{}
closed bool
dep map[finalCloser]depSet
lastPut map[*driverConn]string // stacktrace of last conn's put; debug only
maxIdleCount int // zero means defaultMaxIdleConns; negative means 0
// 最大打开连接数
maxOpen int // <= 0 means unlimited
// 连接最大存活时间
maxLifetime time.Duration // maximum amount of time a connection may be reused
maxIdleTime time.Duration // maximum amount of time a connection may be idle before being closed
cleanerCh chan struct{}
waitCount int64 // Total number of connections waited for.
maxIdleClosed int64 // Total number of connections closed due to idle count.
maxIdleTimeClosed int64 // Total number of connections closed due to idle time.
// 因为超过存活时间而被关闭的连接总数
maxLifetimeClosed int64 // Total number of connections closed due to max connection lifetime limit.
stop func() // stop cancels the connection opener and the session resetter.
}
|
driverConn代表了一个具体的数据库连接,每一条sql的执行最终都会落实到一个具体的driverConn
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// driverConn wraps a driver.Conn with a mutex, to
// be held during all calls into the Conn. (including any calls onto
// interfaces returned via that Conn, such as calls on Tx, Stmt,
// Result, Rows)
type driverConn struct {
db *DB // 数据库句柄
createdAt time.Time
sync.Mutex // guards following // 锁
ci driver.Conn// 对应具体的连接
needReset bool // The connection session should be reset before use if true.
closed bool // 是否标记关闭
finalClosed bool // ci.Close has been called // 是否最终关闭
openStmt map[*driverStmt]bool // 在这个连接上打开的状态
// guarded by db.mu
inUse bool// 连接是否占用
returnedAt time.Time // Time the connection was created or returned.
// 连接归还时要运行的函数,在 noteUnusedDriverStatement 添加
onPut []func() // code (with db.mu held) run when conn is next returned
// 和 closed 状态一致,但是由锁保护,用于 removeClosedStmtLocked
dbmuClosed bool // same as closed, but guarded by db.mu, for removeClosedStmtLocked
}
|
sql.Open
该方法返回的DB对象是线程安全的,可以放心使用,它自己会保持一个空闲的连接池。所以,Open方法在程序里应该只被调用一次,通常情况是不需要去关闭的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
// Open opens a database specified by its database driver name and a
// driver-specific data source name, usually consisting of at least a
// database name and connection information.
//
// Most users will open a database via a driver-specific connection
// helper function that returns a *DB. No database drivers are included
// in the Go standard library. See https://golang.org/s/sqldrivers for
// a list of third-party drivers.
//
// Open may just validate its arguments without creating a connection
// to the database. To verify that the data source name is valid, call
// Ping.
//
// The returned DB is safe for concurrent use by multiple goroutines
// and maintains its own pool of idle connections. Thus, the Open
// function should be called just once. It is rarely necessary to
// close a DB.
func Open(driverName, dataSourceName string) (*DB, error) {
driversMu.RLock()
driveri, ok := drivers[driverName]
driversMu.RUnlock()
if !ok {
return nil, fmt.Errorf("sql: unknown driver %q (forgotten import?)", driverName)
}
if driverCtx, ok := driveri.(driver.DriverContext); ok {
connector, err := driverCtx.OpenConnector(dataSourceName)
if err != nil {
return nil, err
}
return OpenDB(connector), nil
}
return OpenDB(dsnConnector{dsn: dataSourceName, driver: driveri}), nil
}
// OpenDB opens a database using a Connector, allowing drivers to
// bypass a string based data source name.
//
// Most users will open a database via a driver-specific connection
// helper function that returns a *DB. No database drivers are included
// in the Go standard library. See https://golang.org/s/sqldrivers for
// a list of third-party drivers.
//
// OpenDB may just validate its arguments without creating a connection
// to the database. To verify that the data source name is valid, call
// Ping.
//
// The returned DB is safe for concurrent use by multiple goroutines
// and maintains its own pool of idle connections. Thus, the OpenDB
// function should be called just once. It is rarely necessary to
// close a DB.
func OpenDB(c driver.Connector) *DB {
ctx, cancel := context.WithCancel(context.Background())
db := &DB{
connector: c,
openerCh: make(chan struct{}, connectionRequestQueueSize),
lastPut: make(map[*driverConn]string),
connRequests: make(map[uint64]chan connRequest),
stop: cancel,
}
go db.connectionOpener(ctx)
return db
}
|
用sql.Open函数创建连接池,可是此时只是初始化了连接池,并没有创建任何连接。连接创建都是惰性的,只有当你真正使用到连接的时候,连接池才会创建连接。连接池很重要,它直接影响着你的程序行为。
db.Close
关闭数据库,并释放所有相关资源。
再次强调:通常不需要执行该操作。DB句柄应该是长期生存的,可以安全的共享于众多的协程中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
func (db *DB) Close() error {
db.mu.Lock()
if db.closed { // Make DB.Close idempotent
db.mu.Unlock()
return nil
}
close(db.openerCh)
if db.cleanerCh != nil {
close(db.cleanerCh)
}
var err error
fns := make([]func() error, 0, len(db.freeConn))
for _, dc := range db.freeConn {
fns = append(fns, dc.closeDBLocked())
}
db.freeConn = nil
db.closed = true
for _, req := range db.connRequests {
close(req)
}
db.mu.Unlock()
for _, fn := range fns {
err1 := fn()
if err1 != nil {
err = err1
}
}
return err
}
|
连接池
这个连接池有几个特征参数:
- maxLifetime
maximum amount of time a connection may be reused
- maxIdle
允许的最大空闲连接数
- maxOpen
允许的打开的最大连接数
连接池中的连接数最大会增长到maxOpen,当请求高峰过后,连接池的可用连接数又会慢慢缩回到maxIdle
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
func (db *DB) Query(query string, args ...interface{}) (*Rows, error) {
return db.QueryContext(context.Background(), query, args...)
}
func (db *DB) QueryContext(ctx context.Context, query string, args ...interface{}) (*Rows, error) {
var rows *Rows
var err error
// 优先用池子里的连接
// maxBadConnRetries是一个常量,值为2
for i := 0; i < maxBadConnRetries; i++ {
// cacheOrNewConn: 是获取连接策略常量,优先从连接池中获取一个可用的连接,如果没有可用连接,此时如果连接数已经达到上限,则等待,否则则直接创建一个新连接。
rows, err = db.query(ctx, query, args, cachedOrNewConn)
// 如果连接异常,则重试
if err != driver.ErrBadConn {
break
}
}
// 当然池子里的连接有可能会过期,如果重试两次还取不到可以用的连接
// 那就从数据库请求一个新的
if err == driver.ErrBadConn {
// 再重试一遍,使用创建连接的策略
return db.query(ctx, query, args, alwaysNewConn)
}
return rows, err
}
func (db *DB) query(ctx context.Context, query string, args []interface{}, strategy connReuseStrategy) (*Rows, error) {
dc, err := db.conn(ctx, strategy)
if err != nil {
return nil, err
}
return db.queryDC(ctx, nil, dc, dc.releaseConn, query, args)
}
|
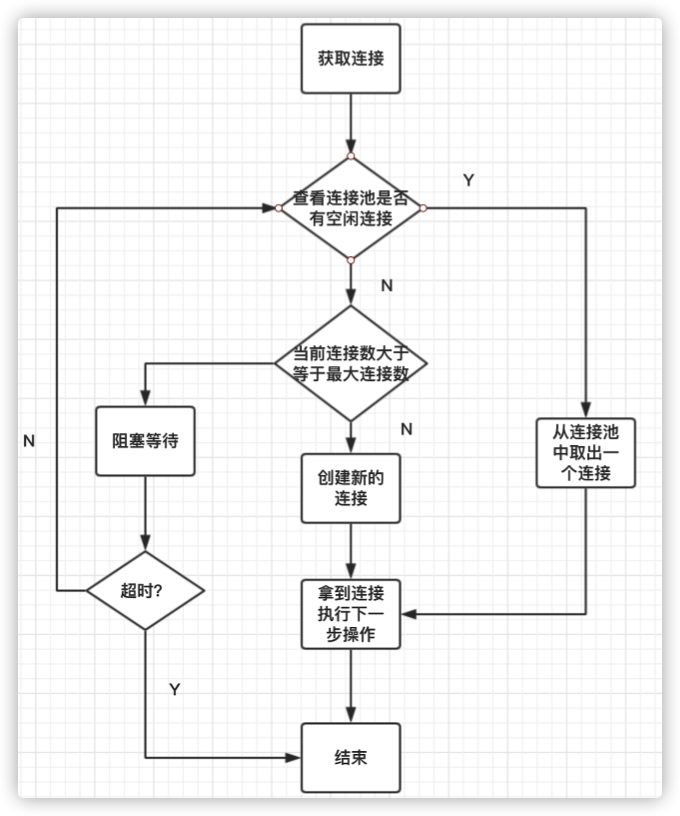
获取连接
下面就是获取连接的逻辑了,流程如下:
- 如果策略是优先使用缓存连接且连接池中还有空闲连接,则直接从连接池中取一个连接返回
- 如果连接池里当前已打开的连接数已超出maxOpen限制,则阻塞一直等待有连接归还到连接池后再取用
- 否则就新建一个连接返回
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
|
// conn returns a newly-opened or cached *driverConn.
// conn 获取一个缓存中的或者新打开的连接
func (db *DB) conn(ctx context.Context, strategy connReuseStrategy) (*driverConn, error) {
//从连接池中获取连接时首先要对整个连接池加锁,如果连接池已经事先被关掉了,直接返回 errDBClosed 错误。如果连接池无恙,将会评估连接请求是否取消或过期。
db.mu.Lock()
if db.closed {
db.mu.Unlock()
// 如果数据库已经关闭,会直接返回错误,而且外部不会对这个错误做处理
return nil, errDBClosed
}
// Check if the context is expired.
// 检查是否已被取消
select {
default:
case <-ctx.Done():
db.mu.Unlock()
return nil, ctx.Err()
}
// 一个连接的最大生命周期
lifetime := db.maxLifetime
//尽可能优先使用空闲的连接而不是新建一条连接(这也是连接池存在的意义)。看一下是否还剩下空闲连接,如果还有,就取第 0 条连接出来,然后左移所有连接填补空位。这里对连接本身操作都会上锁。
// Prefer a free connection, if possible.
// 查看是否有空闲的连接 如果有则直接使用空闲连接
// 获取空闲的连接,判断是否超时,无超时返回调用方,超时返回err, 调用方会重试,默认是重试2次
numFree := len(db.freeConn)
if strategy == cachedOrNewConn && numFree > 0 {
// 取第一个空闲连接,并生成新的空闲连接列表
conn := db.freeConn[0]
// 复制数组,去除第一个连接
// 这是在更新空闲的数据库连接数组,最开始的那个连接现在已经要被占用了
copy(db.freeConn, db.freeConn[1:])
// 移除掉末尾那个无用的元素
db.freeConn = db.freeConn[:numFree-1]
// 通过以上两步,成功从freeConn中删掉了开头的第一个连接
conn.inUse = true
// 检查连接是否已经过期
// 注意如果过期并没有尝试取下一个,而是直接返回了错误
// 由上层来继续发起连接,我理解这样会保持不同层之间逻辑的干净
if conn.expired(lifetime) {
// 如果超时了,则关闭该连接,返回该错误时,外部会重试
db.maxLifetimeClosed++
db.mu.Unlock()
conn.Close()
return nil, driver.ErrBadConn
}
db.mu.Unlock()
// Reset the session if required.
if err := conn.resetSession(ctx); err == driver.ErrBadConn {
conn.Close()
return nil, driver.ErrBadConn
}
return conn, nil
}
// Out of free connections or we were asked not to use one. If we're not
// allowed to open any more connections, make a request and wait.
// 如果当前打开的连接数已经超过了db.maxOpen
//如果没有空闲连接了,而且已打开的 + 即将打开的连接数超过了限定的最大打开的连接数,就要发送一条连接请求然后排队(不会新建连接)。等待排队期间同时监听连接请求是否取消或过期,如果此时连接被取消很不巧正好有连接来了,就将连接放回连接池中;如果等着等着连接来了,会先检查这个连接的上一次会话是否被重置,确认没问题就用这条连接。
if db.maxOpen > 0 && db.numOpen >= db.maxOpen {
// Make the connRequest channel. It's buffered so that the
// connectionOpener doesn't block while waiting for the req to be read.
// 创建一个chan
req := make(chan connRequest, 1)
// 获取下一个request 作为map 中的key
reqKey := db.nextRequestKeyLocked()
db.connRequests[reqKey] = req
db.waitCount++
db.mu.Unlock()
waitStart := nowFunc()
// Timeout the connection request with the context.
select {
//下面就是select+ctx判断请求有没有超时,还有等待队列是否接收到数据
// 注意这个select没有default分支,所以会一直阻塞在这两个分支上
// 直到任何一个分支的条件满足,即:1. query被取消了 2. 有free连接可用了
case <-ctx.Done():
// Remove the connection request and ensure no value has been sent
// on it after removing.
db.mu.Lock()
delete(db.connRequests, reqKey)
db.mu.Unlock()
atomic.AddInt64(&db.waitDuration, int64(time.Since(waitStart)))
select {
default:
case ret, ok := <-req:
if ok && ret.conn != nil {
db.putConn(ret.conn, ret.err, false)
}
}
return nil, ctx.Err()
// 如果没有取消则从req chan中获取数据 阻塞主一直等待有conn数据传入
case ret, ok := <-req:
atomic.AddInt64(&db.waitDuration, int64(time.Since(waitStart)))
if !ok {// 连接被关闭
return nil, errDBClosed// 说明 DB 已经关闭了
}
// Only check if the connection is expired if the strategy is cachedOrNewConns.
// If we require a new connection, just re-use the connection without looking
// at the expiry time. If it is expired, it will be checked when it is placed
// back into the connection pool.
// This prioritizes giving a valid connection to a client over the exact connection
// lifetime, which could expire exactly after this point anyway.
// 判断超时
if strategy == cachedOrNewConn && ret.err == nil && ret.conn.expired(lifetime) {
db.mu.Lock()
db.maxLifetimeClosed++
db.mu.Unlock()
ret.conn.Close()
return nil, driver.ErrBadConn
}
if ret.conn == nil {
return nil, ret.err
}
// Reset the session if required.
if err := ret.conn.resetSession(ctx); err == driver.ErrBadConn {
ret.conn.Close()
return nil, driver.ErrBadConn
}
return ret.conn, ret.err
}
}
// 如果还没到限定的最大打开的连接数,新建一条
// 如果没有空闲连接且尚未达到最大连接数的限制
// 那就开一个新连接
db.numOpen++ // optimistically
db.mu.Unlock()
// 调用connector的Connect方法建立连接
ci, err := db.connector.Connect(ctx)
if err != nil {
db.mu.Lock()
db.numOpen-- // correct for earlier optimism
db.maybeOpenNewConnections()
db.mu.Unlock()
return nil, err
}
db.mu.Lock()
dc := &driverConn{
db: db,
createdAt: nowFunc(),
returnedAt: nowFunc(),
ci: ci,
inUse: true,
}
db.addDepLocked(dc, dc)
db.mu.Unlock()
return dc, nil
}
|
释放连接
下面是归还连接的逻辑:
- 如果有connRequests,那么优先满足它
- 否则就要准备归还到池子中了,但这里还有一个check,如果当前空闲连接书freeConn大于允许的最大空闲连接限制的话就不归还了,会把连接直接关闭掉
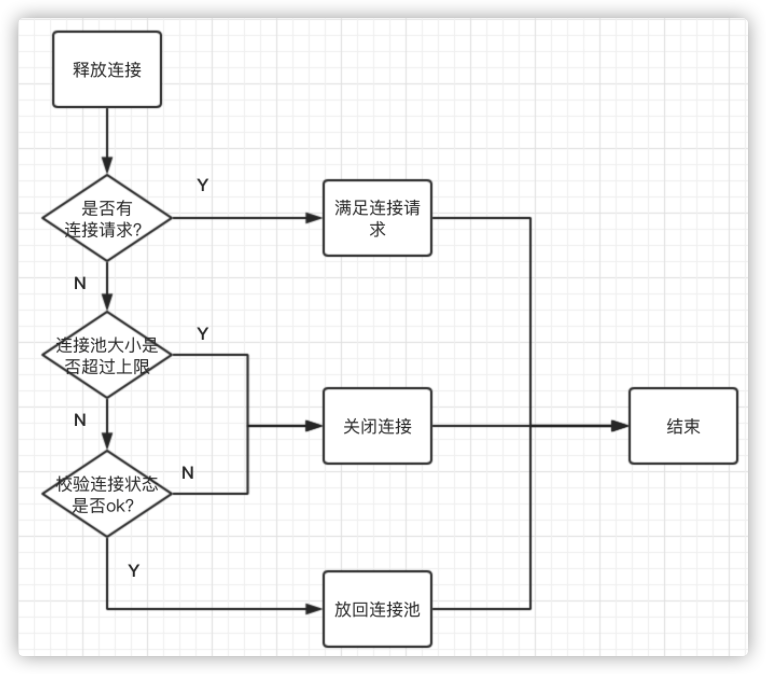
当归还连接到连接池的时候,发现当前的连接数已经大于我们自己配置的maxOpen,那么就直接close连接。如果正常连接池,那么观察下db.connRequests是否有人等待连接。
如果在等待,那么就把连接通过channel传递过去。如果没有人正在等待获取sql连接,那么就把连接放到db.freeConn里。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
|
func (dc *driverConn) releaseConn(err error) {
dc.db.putConn(dc, err, true)
}
// putConn adds a connection to the db's free pool.
// err is optionally the last error that occurred on this connection.
// 释放连接
func (db *DB) putConn(dc *driverConn, err error, resetSession bool) {
if err != driver.ErrBadConn {
if !dc.validateConnection(resetSession) {
err = driver.ErrBadConn
}
}
db.mu.Lock()
// 检查连接是否在使用中
if !dc.inUse {
db.mu.Unlock()
if debugGetPut {
fmt.Printf("putConn(%v) DUPLICATE was: %s\n\nPREVIOUS was: %s", dc, stack(), db.lastPut[dc])
}
panic("sql: connection returned that was never out")
}
if err != driver.ErrBadConn && dc.expired(db.maxLifetime) {// 连接有问题
db.maxLifetimeClosed++
err = driver.ErrBadConn
}
if debugGetPut {
db.lastPut[dc] = stack()
}
// 设置已经在使用中
dc.inUse = false
dc.returnedAt = nowFunc()
for _, fn := range dc.onPut {
fn()
}
dc.onPut = nil
// 判断连接是否有错误
if err == driver.ErrBadConn {
// Don't reuse bad connections.
// Since the conn is considered bad and is being discarded, treat it
// as closed. Don't decrement the open count here, finalClose will
// take care of that.
db.maybeOpenNewConnections()
db.mu.Unlock()
dc.Close()
return
}
if putConnHook != nil {
putConnHook(db, dc)
}
// 调用方法 释放连接
// 函数名带 Locked 表示已经加过锁
added := db.putConnDBLocked(dc, nil)
db.mu.Unlock()
// 判断如果没有加到了空闲列表中 dc关闭
if !added {
// 回池出现问题,强行关闭连接
dc.Close()
return
}
}
// Satisfy a connRequest or put the driverConn in the idle pool and return true
// or return false.
// putConnDBLocked will satisfy a connRequest if there is one, or it will
// return the *driverConn to the freeConn list if err == nil and the idle
// connection limit will not be exceeded.
// If err != nil, the value of dc is ignored.
// If err == nil, then dc must not equal nil.
// If a connRequest was fulfilled or the *driverConn was placed in the
// freeConn list, then true is returned, otherwise false is returned.
func (db *DB) putConnDBLocked(dc *driverConn, err error) bool {
if db.closed {
return false
}
// 即将打开 + 已打开的连接数超过了最大打开的连接数
if db.maxOpen > 0 && db.numOpen > db.maxOpen {
return false
}
// 如果等待chan列表大于0
// 判断有没有等待队列
// 如果有connRequests(连接需求),优先满足它
if c := len(db.connRequests); c > 0 {
var req chan connRequest
var reqKey uint64
// 获取map 中chan和key
for reqKey, req = range db.connRequests {
// 从表中随便拿一个
break
}
// 从列表中删除chan
delete(db.connRequests, reqKey) // Remove from pending requests.
if err == nil {
dc.inUse = true
}
// 把连接传入chan中 让之前获取连接被阻塞的获取函数继续
// 将连接发送给连接请求
req <- connRequest{
conn: dc,
err: err,
}
return true
} else if err == nil && !db.closed {
// 判断是否超过最大空闲连接数
// 如果连接池 < 最大闲散连接数,放回连接池
if db.maxIdleConnsLocked() > len(db.freeConn) {
// 如果没有等待列表,则把连接放到空闲列表中
// 将连接放回池子
db.freeConn = append(db.freeConn, dc)
db.startCleanerLocked()
return true
}
// 为啥直接增加了maxIdleClosed而没有做什么呢?
// 因为这种情况下本函数会返回false,进而导致
// 连接被关闭
db.maxIdleClosed++
}
return false
}
|
即将打开 + 已打开的连接数不能超过最大打开的连接数限制。如果有连接请求,就从表中随便拿一个,拿出来的要从表中删掉,并把准备回池的连接直接发送给这个请求;没有连接请求的话就正常回池。
connectionOpener
connectionOpener:
- 用于处理连接请求 openerCh
- 如果没有设置 maxIdleClosed,则不会有 openerCh,也不会用到 connectionOpener
- 只在调用 maybeOpenNewConnections 时检查有无 connRequests,有则触发 connectionOpener
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
// This is the size of the connectionOpener request chan (DB.openerCh).
// This value should be larger than the maximum typical value
// used for db.maxOpen. If maxOpen is significantly larger than
// connectionRequestQueueSize then it is possible for ALL calls into the *DB
// to block until the connectionOpener can satisfy the backlog of requests.
var connectionRequestQueueSize = 1000000
// Runs in a separate goroutine, opens new connections when requested.
func (db *DB) connectionOpener(ctx context.Context) {
for {
select {
case <-ctx.Done():
return
case <-db.openerCh:
db.openNewConnection(ctx)
}
}
}
// Open one new connection
func (db *DB) openNewConnection() {
// 在发送到db.openerCh之前,maybeOpenNewConnections之前已经将numOpen++
// 如果新连接创建失败,或者已经被关闭,则在返回之前必须减1
ci, err := db.driver.Open(db.dsn)
// 创建连接的过程加了互斥锁
db.mu.Lock()
defer db.mu.Unlock()
if db.closed {
if err == nil {
ci.Close()
}
db.numOpen--
return
}
if err != nil {
db.numOpen--
db.putConnDBLocked(nil, err)
db.maybeOpenNewConnections()
return
}
dc := &driverConn{
db: db,
createdAt: nowFunc(),
ci: ci,
}
if db.putConnDBLocked(dc, err) {
db.addDepLocked(dc, dc)
} else {
db.numOpen--
ci.Close()
}
}
|
如果有连接请求,并且没有达到连接数的限制,告知 connectionOpener 打开新的连接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// Assumes db.mu is locked.
// If there are connRequests and the connection limit hasn't been reached,
// then tell the connectionOpener to open new connections.
func (db *DB) maybeOpenNewConnections() {
numRequests := len(db.connRequests)
if db.maxOpen > 0 {
numCanOpen := db.maxOpen - db.numOpen
if numRequests > numCanOpen { // 连接请求超过限制,即最大打开连接数 - 已打开的连接数
numRequests = numCanOpen // 以限制为准
}
}
for numRequests > 0 {
db.numOpen++ // optimistically
numRequests--
if db.closed {
return
}
db.openerCh <- struct{}{} // 告知 connectionOpener 打开新的连接,由 connectionOpener 执行打开连接的操作
}
}
|
也就是说,如果没有设置最大连接数,就不会有 connRequests,也不会触发 connectionOpener。调用 maybeOpenNewConnections 的时机包括:获取连接失败、连接被标记为 bad、关闭连接。因为正常情况下,打开的连接数是不变的,connRequests 只能等有连接释放的时候才能被满足。
connectionCleaner
以下逻辑实现连接的生命周期的管理,基本逻辑为:
定期遍历连接池中的每一个连接,检查其是存活时间是否超出了设定的maxLifetime,若超出则将它从池子中删除并关闭它
- 用于定期清理连接池中闲散连接
- 如果没有设置 maxLifetime 则不会启动
- 在将连接放回连接池、设置连接最大存活时间的时候执行检查,符合条件则启动
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
|
// SetConnMaxIdleTime sets the maximum amount of time a connection may be idle.
//
// Expired connections may be closed lazily before reuse.
//
// If d <= 0, connections are not closed due to a connection's idle time.
func (db *DB) SetConnMaxIdleTime(d time.Duration) {
if d < 0 {
d = 0
}
db.mu.Lock()
defer db.mu.Unlock()
// Wake cleaner up when idle time is shortened.
if d > 0 && d < db.maxIdleTime && db.cleanerCh != nil {
select {
case db.cleanerCh <- struct{}{}:
default:
}
}
db.maxIdleTime = d
db.startCleanerLocked()
}
// startCleanerLocked starts connectionCleaner if needed.
func (db *DB) startCleanerLocked() {
// 尽管每次putConnDBLocked的时候都会被调用,但注意它的条件db.cleanerCh == nil
// 这意味着其实db.connectionCleaner只会被启动一次
if db.maxLifetime > 0 && db.numOpen > 0 && db.cleanerCh == nil {
db.cleanerCh = make(chan struct{}, 1)
go db.connectionCleaner(db.maxLifetime)
}
}
// 清理过期连接的逻辑
func (db *DB) connectionCleaner(d time.Duration) {
const minInterval = time.Second
// 精度最高为秒级
if d < minInterval {
d = minInterval
}
t := time.NewTimer(d)
for {
// 这个写法很有意思
select {
case <-t.C:
case <-db.cleanerCh: // maxLifetime was changed or db was closed.
}
db.mu.Lock()
d = db.maxLifetime
if db.closed || db.numOpen == 0 || d <= 0 {
db.cleanerCh = nil
db.mu.Unlock()
return
}
expiredSince := nowFunc().Add(-d)
var closing []*driverConn
for i := 0; i < len(db.freeConn); i++ {
c := db.freeConn[i]
if c.createdAt.Before(expiredSince) {
closing = append(closing, c)
last := len(db.freeConn) - 1
// 数组中经典的删除元素的方法
db.freeConn[i] = db.freeConn[last]
db.freeConn[last] = nil
db.freeConn = db.freeConn[:last]
// 后退一步是为了可以检查刚刚置换过来的元素
i--
}
}
db.maxLifetimeClosed += int64(len(closing))
db.mu.Unlock()
for _, c := range closing {
c.Close()
}
if d < minInterval {
d = minInterval
}
t.Reset(d)
}
}
func (db *DB) connectionCleanerRunLocked() (closing []*driverConn) {
if db.maxLifetime > 0 {
expiredSince := nowFunc().Add(-db.maxLifetime)
for i := 0; i < len(db.freeConn); i++ {
c := db.freeConn[i]
if c.createdAt.Before(expiredSince) {
closing = append(closing, c)
last := len(db.freeConn) - 1
db.freeConn[i] = db.freeConn[last]
db.freeConn[last] = nil
db.freeConn = db.freeConn[:last]
i--
}
}
db.maxLifetimeClosed += int64(len(closing))
}
if db.maxIdleTime > 0 {
expiredSince := nowFunc().Add(-db.maxIdleTime)
var expiredCount int64
for i := 0; i < len(db.freeConn); i++ {
c := db.freeConn[i]
if db.maxIdleTime > 0 && c.returnedAt.Before(expiredSince) {
closing = append(closing, c)
expiredCount++
last := len(db.freeConn) - 1
db.freeConn[i] = db.freeConn[last]
db.freeConn[last] = nil
db.freeConn = db.freeConn[:last]
i--
}
}
db.maxIdleTimeClosed += expiredCount
}
return
}
|
connectionResetter
connectionResetter:
- 将连接放回连接池的时候检查,重置连接
- 连接池从逻辑上来说也是一个会话池,应当有类似重置会话的功能,避免把 bad connection 放回连接池
- 需要数据库驱动支持
CURD
数据库查询
我们了解了数据库连接与连接池。拿到了连接当然就是为了跟数据库交互。对于数据库交互,无怪乎两类操作,读和写。其中怎么读,怎么写,读和写的过程糅合一起就会遇到复杂的事务。本篇内容主要关注数据库的读写操作,后面再涉及事务的介绍。
源码分析
数据结构
一次Query查询会返回一个Rows对象,代表的是一个查询集合,里面是一行一行的记录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
type Rows struct {
dc *driverConn // owned; must call releaseConn when closed to release
releaseConn func(error)
rowsi driver.Rows
cancel func() // called when Rows is closed, may be nil.
closeStmt *driverStmt // if non-nil, statement to Close on close
// closemu prevents Rows from closing while there
// is an active streaming result. It is held for read during non-close operations
// and exclusively during close.
//
// closemu guards lasterr and closed.
closemu sync.RWMutex
closed bool
lasterr error // non-nil only if closed is true
// lastcols is only used in Scan, Next, and NextResultSet which are expected
// not to be called concurrently.
lastcols []driver.Value
}
|
Query
query方法逻辑很简单,通过db.conn方法返回一个新创建或者缓存的空闲连接。调用queryConn方法。
1
2
3
4
5
6
7
8
9
|
func (db *DB) query(ctx context.Context, query string, args []interface{}, strategy connReuseStrategy) (*Rows, error) {
ci, err := db.conn(ctx, strategy)
if err != nil {
return nil, err
}
// 执行查询
return db.queryConn(ctx, ci, ci.releaseConn, query, args)
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
// queryConn 执行查询
// The connection gets released by the releaseConn function.
func (db *DB) queryConn(ctx context.Context, dc *driverConn, releaseConn func(error), query string, args []interface{}) (*Rows, error) {
// 判断驱动是否实现了Queryer
if queryer, ok := dc.ci.(driver.Queryer); ok {
dargs, err := driverArgs(nil, args)
if err != nil {
releaseConn(err)
return nil, err
}
var rowsi driver.Rows
// 调用驱动的查询方法
withLock(dc, func() {
rowsi, err = ctxDriverQuery(ctx, queryer, query, dargs)
})
// 不带参数的返回
if err != driver.ErrSkip {
// 说明用户没有要求用Prepared Statement
if err != nil {
releaseConn(err)
return nil, err
}
// Note: ownership of dc passes to the *Rows, to be freed
// with releaseConn.
// 注意:这里将驱动返回的行信息rowsi在这里封装成了
// sql.Rows
rows := &Rows{
dc: dc,
releaseConn: releaseConn,
rowsi: rowsi,
}
rows.initContextClose(ctx)
return rows, nil
}
}
// 如果驱动没有实现Queryer接口或者用户指定要使用Prepared Statement(返回了driver.ErrSkip),则使用Prepared Statement来做查询
var si driver.Stmt
var err error
// 带参数的返回,创建prepare对象
withLock(dc, func() {
si, err = ctxDriverPrepare(ctx, dc.ci, query)
})
if err != nil {
releaseConn(err)
return nil, err
}
ds := driverStmt{dc, si}
// 执行语句
rowsi, err := rowsiFromStatement(ctx, ds, args...)
if err != nil {
withLock(dc, func() {
si.Close()
})
releaseConn(err)
return nil, err
}
// Note: ownership of ci passes to the *Rows, to be freed
// with releaseConn.
rows := &Rows{
dc: dc,
releaseConn: releaseConn,
rowsi: rowsi,
closeStmt: si, // close的时候,这个也需要关闭
}
rows.initContextClose(ctx)
return rows, nil
}
|
queryConn函数内容比较多。先判断驱动是否实现了Queryer,如果实现了即调用其Query方法。方法会针对sql查询语句做查询。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
func ctxDriverQuery(ctx context.Context, queryerCtx driver.QueryerContext, queryer driver.Queryer, query string, nvdargs []driver.NamedValue) (driver.Rows, error) {
if queryerCtx != nil {
return queryerCtx.QueryContext(ctx, query, nvdargs)
}
dargs, err := namedValueToValue(nvdargs)
if err != nil {
return nil, err
}
// 注意这里ctx的用法,根据ctx是否已被取消,提早返回
select {
default:
case <-ctx.Done():
return nil, ctx.Err()
}
// 从这里以后就会到驱动的代码了
return queryer.Query(query, dargs)
}
|
例如mysql的驱动如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
func (mc *mysqlConn) Query(query string, args []driver.Value) (driver.Rows, error) {
return mc.query(query, args)
}
func (mc *mysqlConn) query(query string, args []driver.Value) (*textRows, error) {
if mc.closed.IsSet() {
errLog.Print(ErrInvalidConn)
return nil, driver.ErrBadConn
}
if len(args) != 0 {
// 是否转义sql中的参数来防止sql注入
// 如果指定不转义的话会使用 prepared statement
if !mc.cfg.InterpolateParams {
return nil, driver.ErrSkip
}
// try client-side prepare to reduce roundtrip
prepared, err := mc.interpolateParams(query, args)
if err != nil {
return nil, err
}
query = prepared
}
// Send command
err := mc.writeCommandPacketStr(comQuery, query)
if err == nil {
// Read Result
var resLen int
resLen, err = mc.readResultSetHeaderPacket()
if err == nil {
rows := new(textRows)
rows.mc = mc
if resLen == 0 {
rows.rs.done = true
switch err := rows.NextResultSet(); err {
case nil, io.EOF:
return rows, nil
default:
return nil, err
}
}
// Columns
rows.rs.columns, err = mc.readColumns(resLen)
return rows, err
}
}
return nil, mc.markBadConn(err)
}
|
Query先检查参数是否为0,然后调用writeCommandPacketStr方法执行sql并通过readResultSetHeaderPacket读取数据库服务返回的结果。
如果参数不为0,会先判断是否是prepared语句。这里会返回一个driver.ErrSkip错误。把函数执行权再返回到queryConn函数中。然后再调用si, err = ctxDriverPrepare(ctx, dc.ci, query)创建Stmt对象.
在 database/sql 执行 QueryDC 逻辑时,会调用 ctxDriverPrepare 方法来进行 SQL Query 的预处理,我们来看看这段逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func ctxDriverPrepare(ctx context.Context, ci driver.Conn, query string) (driver.Stmt, error) {
if ciCtx, is := ci.(driver.ConnPrepareContext); is {
return ciCtx.PrepareContext(ctx, query)
}
si, err := ci.Prepare(query)
if err == nil {
select {
default:
case <-ctx.Done():
si.Close()
return nil, ctx.Err()
}
}
return si, err
}
|
在其中,ctxDriverPrepare 会调用 ci.Prepare(query) 来执行对应 SQL Driver 实现的 Prepare 或者 PrepareContext 方法来对 SQL 预处理,在 go-mysql-driver 中,对应的实现是这样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
func (mc *mysqlConn) PrepareContext(ctx context.Context, query string) (driver.Stmt, error) {
if err := mc.watchCancel(ctx); err != nil {
return nil, err
}
stmt, err := mc.Prepare(query)
mc.finish()
if err != nil {
return nil, err
}
select {
default:
case <-ctx.Done():
stmt.Close()
return nil, ctx.Err()
}
return stmt, nil
}
|
这一段的逻辑是 go-mysql-driver 会向 MySQL 发起 prepared statement 请求,获取到对应的 Stmt 后将其返回
在 stmt 中包含了对应的参数数量,stmt name 等信息。在这里,SQL 会将 ? 等参数占位符进行解析,并告知客户端需要传入的参数数量
接下来调用rowsiFromStatement执行查询:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
func rowsiFromStatement(ds driverStmt, args ...interface{}) (driver.Rows, error) {
ds.Lock()
want := ds.si.NumInput()
ds.Unlock()
// -1 means the driver doesn't know how to count the number of
// placeholders, so we won't sanity check input here and instead let the
// driver deal with errors.
if want != -1 && len(args) != want {
return nil, fmt.Errorf("sql: statement expects %d inputs; got %d", want, len(args))
}
dargs, err := driverArgs(&ds, args)
if err != nil {
return nil, err
}
ds.Lock()
rowsi, err := ds.si.Query(dargs)
ds.Unlock()
if err != nil {
return nil, err
}
return rowsi, nil
}
|
rowsiFromStatement方法会调用驱动的ds.si.Query(dargs)方法,执行最后的查询。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
func (stmt *mysqlStmt) Query(args []driver.Value) (driver.Rows, error) {
if stmt.mc.netConn == nil {
errLog.Print(ErrInvalidConn)
return nil, driver.ErrBadConn
}
// Send command
err := stmt.writeExecutePacket(args)
if err != nil {
return nil, err
}
mc := stmt.mc
// Read Result
resLen, err := mc.readResultSetHeaderPacket()
if err != nil {
return nil, err
}
rows := new(binaryRows)
if resLen > 0 {
rows.mc = mc
// Columns
// If not cached, read them and cache them
if stmt.columns == nil {
rows.columns, err = mc.readColumns(resLen)
stmt.columns = rows.columns
} else {
rows.columns = stmt.columns
err = mc.readUntilEOF()
}
}
return rows, err
}
|
调用 stmt和参数执行sql查询。查询完毕之后,返回到queryConn方法中,使用releaseConn释放查询的数据库连接。
Query返回的结果集是sql.Rows类型。它有一个Next方法,可以迭代数据库的游标,进而获取每一行的数据
Next
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
func (rs *Rows) Next() bool {
var doClose, ok bool
withLock(rs.closemu.RLocker(), func() {
doClose, ok = rs.nextLocked()
})
if doClose {
rs.Close()
}
return ok
}
func (rs *Rows) nextLocked() (doClose, ok bool) {
if rs.closed {
return false, false
}
// Lock the driver connection before calling the driver interface
// rowsi to prevent a Tx from rolling back the connection at the same time.
rs.dc.Lock()
defer rs.dc.Unlock()
if rs.lastcols == nil {
rs.lastcols = make([]driver.Value, len(rs.rowsi.Columns()))
}
// 从此进入驱动的代码
rs.lasterr = rs.rowsi.Next(rs.lastcols)
if rs.lasterr != nil {
// Close the connection if there is a driver error.
if rs.lasterr != io.EOF {
return true, false
}
nextResultSet, ok := rs.rowsi.(driver.RowsNextResultSet)
if !ok {
return true, false
}
// The driver is at the end of the current result set.
// Test to see if there is another result set after the current one.
// Only close Rows if there is no further result sets to read.
if !nextResultSet.HasNextResultSet() {
doClose = true
}
return doClose, false
}
return false, true
}
// mysql驱动的代码,位于rows.go中
func (rows *textRows) Next(dest []driver.Value) error {
if mc := rows.mc; mc != nil {
if err := mc.error(); err != nil {
return err
}
// Fetch next row from stream
// 这里会读取MySQL的查询结果
// 想了解MySQL的client与server间的交互协议的可以看这个函数
return rows.readRow(dest)
}
return io.EOF
}
|
Scan
执行Next之后,会将从mysql读到的行数据保存在Rows对象的一个私有字段里(lastcols),然后终于来到了Scan阶段
为Scan方法准备下一行结果,如果成功则返回true,而没有更多下一行或者错误发生时,则返回false
注意:每次调用Scan之前,必须先调用Next
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
func (rs *Rows) Scan(dest ...interface{}) error {
rs.closemu.RLock()
if rs.lasterr != nil && rs.lasterr != io.EOF {
rs.closemu.RUnlock()
return rs.lasterr
}
if rs.closed {
err := rs.lasterrOrErrLocked(errRowsClosed)
rs.closemu.RUnlock()
return err
}
rs.closemu.RUnlock()
if rs.lastcols == nil {
return errors.New("sql: Scan called without calling Next")
}
if len(dest) != len(rs.lastcols) {
return fmt.Errorf("sql: expected %d destination arguments in Scan, not %d", len(rs.lastcols), len(dest))
}
// 遍历这一行的每一个字段
for i, sv := range rs.lastcols {
// 转成Golang内部类型
// 对于数据库里的某个字段类型会被转成Golang里哪种类型
// 有疑问的可以看这个函数的实现
err := convertAssignRows(dest[i], sv, rs)
if err != nil {
return fmt.Errorf(`sql: Scan error on column index %d, name %q: %v`, i, rs.rowsi.Columns()[i], err)
}
}
return nil
}
|
Close
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
// Close closes the Rows, preventing further enumeration. If Next is called
// and returns false and there are no further result sets,
// the Rows are closed automatically and it will suffice to check the
// result of Err. Close is idempotent and does not affect the result of Err.
func (rs *Rows) Close() error {
return rs.close(nil)
}
func (rs *Rows) close(err error) error {
rs.closemu.Lock()
defer rs.closemu.Unlock()
if rs.closed {
return nil
}
rs.closed = true
if rs.lasterr == nil {
rs.lasterr = err
}
withLock(rs.dc, func() {
err = rs.rowsi.Close()
})
if fn := rowsCloseHook(); fn != nil {
fn(rs, &err)
}
if rs.cancel != nil {
rs.cancel()
}
if rs.closeStmt != nil {
rs.closeStmt.Close()
}
rs.releaseConn(err)
return err
}
|
读取数据
database/sql提供了Query和QueryRow方法进行查询数据库。对于Query方法的原理,正如前文介绍的主要分为三步:
- 从连接池中请求一个连接
- 执行查询的sql语句
- 将数据库连接的所属权传递给Result结果集
Query方法我们很熟悉了,它的内部调用了db.query方法,并且根据连接重连的状况选择是cachedOrNewConn模式还是alwaysNewConn模式。前者会从返回一个cached连接或者等待一个可用连接,甚至也可能建立一个新的连接;后者表示打开连接时的策略为每次建立一个新的连接。这就是所说的retry2次连接。
大概使用范式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
rows, err := db.Query("SELECT world FROM test.hello")
if err != nil{
log.Fatalln(err)
}
for rows.Next(){
var s string
err = rows.Scan(&s)
if err !=nil{
log.Fatalln(err)
}
log.Printf("found row containing %q", s)
}
rows.Close()
|
上述代码我们已经见过好多次了,想必大家都轻车熟路啦。rows.Next方法设计用来迭代。当它迭代到最后一行数据之后,会触发一个io.EOF的信号,即引发一个错误,同时go会自动调用rows.Close方法释放连接,然后返回false。此时循环将会结束退出。
通常你会正常迭代完数据然后退出循环。可是如果并没有正常的循环而因其他错误导致退出了循环。此时rows.Next处理结果集的过程并没有完成,归属于rows的连接不会被释放回到连接池。因此十分有必要正确的处理rows.Close事件。如果没有关闭rows连接,将导致大量的连接并且不会被其他函数重用,就像溢出了一样。最终将导致数据库无法使用。
那么如何阻止这样的行为呢?上述代码已经展示,无论循环是否完成或者因为其他原因退出,都显示的调用rows.Close方法,确保连接释放。又或者使用defer指令在函数退出的时候释放连接,即使连接已经释放了,rows.Close仍然可以调用多次,是无害的。
使用defer的时候需要注意,如果一个函数执行很长的逻辑,例如main函数,那么rows的连接释放就会也很长,好的实践方案是尽可能的越早释放连接。
rows.Next循环迭代的时候,因为触发了io.EOF而退出循环。为了检查是否是迭代正常退出还是异常退出,需要检查rows.Err。例如上面的代码应该改成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
rows, err := db.Query("SELECT world FROM test.hello")
if err != nil{
log.Fatalln(err)
}
defer rows.Close()
for rows.Next(){
var s string
err = rows.Scan(&s)
if err !=nil{
log.Fatalln(err)
}
log.Printf("found row containing %q", s)
}
rows.Close()
if err = rows.Err(); err != nil {
log.Fatal(err)
}
|
其中的几个部分很容易出错,可能会产生不良后果。
- 你应该总是检查rows.Next()循环结尾处的错误。如果循环中出现错误,则需要了解它。不要仅仅假设循环遍历,直到你已经处理了所有的行。
- 第二,只要有一个打开的结果集(由行代表),底层连接就很忙,不能用于任何其他查询。这意味着它在连接池中不可用。如果你使用rows.Next()遍历所有行,最终将读取最后一行,rows.Next()将遇到内部EOF错误,并为你调用rows.Close()。但是,如果由于某种原因退出该循环-提前返回,那么行不会关闭,并且连接保持打开状态。(如果rows.Next()由于错误而返回false,则会自动关闭)。这是一种简单耗尽资源的方法。
- rows.Close()是一种无害的操作,如果它已经关闭,所以你可以多次调用它。但是请注意,我们首先检查错误,如果没有错误,则调用rows.Close(),以避免运行时的panic。
- 你应该总是用延迟语句defer推迟rows.Close(),即使你也在循环结束时调用rows.Close(),这不是一个坏主意。
- 不要在循环中用defer推迟。延迟语句在函数退出之前不会执行,所以长时间运行的函数不应该使用它。如果你这样做,你会慢慢积累记忆。如果你在循环中反复查询和使用结果集,则在完成每个结果后应显示的调用rows.Close(),而不用延迟语句defer。
读取单条记录
Query方法是读取多行结果集,实际开发中,很多查询只需要单条记录,不需要再通过Next迭代。golang提供了QueryRow方法用于查询单条记录的结果集。
1
2
3
4
5
6
7
8
9
10
|
var s string
err = db.QueryRow("SELECT world FROM test.hello LIMIT 1").Scan(&s)
if err != nil{
if err == sql.ErrNoRows{
log.Println("There is not row")
}else {
log.Fatalln(err)
}
}
log.Println("found a row", s)
|
QueryRow方法的使用很简单,它要么返回sql.Row类型,要么返回一个error,如果是发送了错误,则会延迟到Scan调用结束后返回,如果没有错误,则Scan正常执行。只有当查询的结果为空的时候,会触发一个sql.ErrNoRows错误。
Scan在获取数据之前,会先调用Rows.Next来判断是否有记录,如果没有会返回ErrNowRows错误。其内部调用Rows.Scan方法获取数据。
如果结果集记录多于一条,则只返回第一条。并会调用Rows.Close来关闭。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
func (r *Row) Scan(dest ...interface{}) error {
if r.err != nil {
return r.err
}
// TODO(bradfitz): for now we need to defensively clone all
// []byte that the driver returned (not permitting
// *RawBytes in Rows.Scan), since we're about to close
// the Rows in our defer, when we return from this function.
// the contract with the driver.Next(...) interface is that it
// can return slices into read-only temporary memory that's
// only valid until the next Scan/Close. But the TODO is that
// for a lot of drivers, this copy will be unnecessary. We
// should provide an optional interface for drivers to
// implement to say, "don't worry, the []bytes that I return
// from Next will not be modified again." (for instance, if
// they were obtained from the network anyway) But for now we
// don't care.
defer r.rows.Close()
for _, dp := range dest {
if _, ok := dp.(*RawBytes); ok {
return errors.New("sql: RawBytes isn't allowed on Row.Scan")
}
}
if !r.rows.Next() {
if err := r.rows.Err(); err != nil {
return err
}
return ErrNoRows
}
err := r.rows.Scan(dest...)
if err != nil {
return err
}
// Make sure the query can be processed to completion with no errors.
if err := r.rows.Close(); err != nil {
return err
}
return nil
}
|
你可以选择先检查错误再调用Scan方法,或者先调用Scan再检查错误。
1
2
3
4
5
6
|
var name string
err = db.QueryRow("select name from users where id = ?", 1).Scan(&name)
if err != nil {
log.Fatal(err)
}
fmt.Println(name)
|
如果id为1的不存在,err为sql.ErrNoRows,一般应用中不存在的情况都需要单独处理。此外,Query返回的错误都会延迟到Scan被调用,所以应该写成如下代码:
1
2
3
4
5
6
7
8
9
10
|
var name string
err = db.QueryRow("select name from users where id = ?", 1).Scan(&name)
if err != nil {
if err == sql.ErrNoRows {
// there were no rows, but otherwise no error occurred
} else {
log.Fatal(err)
}
}
fmt.Println(name)
|
把空结果当做Error处理是为了强行让程序员处理结果为空的情况
字段转换
结果集方法Scan可以把数据库取出的字段值赋值给指定的数据结构。它的参数是一个空接口的切片,这就意味着可以传入任何值。通常把需要赋值的目标变量的指针当成参数传入,它能将数据库取出的值赋值到指针值对象上。
1
2
|
var var1, var2 string
err = row.Scan(&var1, &var2)
|
在一些特殊案例中,如果你不想把值赋值给指定的目标变量,那么需要使用*sql.RawBytes类型。如何使用sql.RawBytes需要参考更细的官方文档。大多数情况下我们不必这么做。但是还是需要注意在db.QueryRow().Scan()中不能使用sql.RawBytes。
Scan还会帮我们自动推断除数据字段匹配目标变量。比如有个数据库字段的类型是VARCHAR,而他的值是一个数字串,例如"1"。如果我们定义目标变量是string,则scan赋值后目标变量是数字string。如果声明的目标变量是一个数字类型,那么scan会自动调用strconv.ParseInt()或者strconv.ParseInt()方法将字段转换成和声明的目标变量一致的类型。当然如果有些字段无法转换成功,则会返回错误。因此在调用scan后都需要检查错误。
1
2
|
var world int
err = stmt.QueryRow(1).Scan(&world)
|
此时scan会把字段转变成数字整型的赋值给world变量
1
2
|
var world string
err = stmt.QueryRow(1).Scan(&world)
|
此时scan取出的字段就是字串。同样的如果字段是int类型,声明的变量是string类型,scan也会自动将数字转换成字串赋值给目标变量。
但是scan仅支持为某一个变量赋值,不支持对结构体或map赋值,如:
1
2
3
4
5
6
7
8
9
10
11
|
type data struct {
id int
name string
weight int
}
rows, _ := db.Query("select * from test where id = ?", 2)
for rows.Next() {
line := data{}
err = rows.Scan(&line)
log.Println(line)
}
|
运行结果
SELECT * 这样做的习惯可不好,一般都是指定字段,这样在scan的时候也相对容易把握变量顺序和个数。scan必须指明所有字段并且顺序要符合查询时候的顺序,正确的做法应该是将line的每个变量分别赋值,而且要保证查询语句里的字段顺序和 struct的字段顺序是一致的,如果sql语句里简单的用*代替,在sql表字段不变,但顺序改变的时候就会出错。
1
|
rows.Scan(&line.id, &line.name, &line.weight)
|
空值处理
数据库有一个特殊的类型,NULL空值。可是NULL不能通过scan直接跟普遍变量赋值,甚至也不能将null赋值给nil。对于null必须指定特殊的类型,这些类型定义在database/sql库中。例如sql.NullFloat64。如果在标准库中找不到匹配的类型,可以尝试在驱动中寻找。下面是一个简单的例子:
1
2
3
4
5
6
7
8
9
10
|
var (
s1 string
s2 sql.NullString
i1 int
f1 float64
f2 float64
)
// 假设数据库的记录为 ["hello", NULL, 12345, "12345.6789", "not-a-float"]
err = rows.Scan(&s1, &s2, &i1, &f1, &f2) if err != nil {
log.Fatal(err) }
|
因为最后一个f2字段的值不是float,这会引发一个错误。
1
|
sql: Scan error on column index 4: converting string "not-a- oat" to a oat64: strconv.ParseFloat: parsing "not-a- oat": invalid syntax
|
如果忽略err,强行读取目标变量,可以看到最后一个值转换错误会处理,而不是抛出异常:
1
2
3
4
|
err = rows.Scan(&s1, &s2, &i1, &f1, &f2)
log.Printf("%q %#v %d %f %f", s1, s2, i1, f1, f2)
// 输出 "hello" sql.NullString{String:"", Valid:false} 12345 12345.678900 0.000000
|
可以看到,除了最后一个转换失败变成了零值之外,其他都正常的取出了值,尤其是null匹配了NullString类型的目标变量。
对于null的操作,通常仍然需要验证:
1
2
3
4
5
6
7
8
9
|
var world sql.NullString
err := db.QueryRow("SELECT world FROM hello WHERE id = ?", id).Scan(&world)
...
if world.Valid {
wrold.String
} else {
// 数据库的value是不是null的时候,输出 world的字符串值, 空字符串
world.String
}
|
对应的,如果world字段是一个int,那么声明的目标变量类似是sql.NullInt64,读取其值的方法为world.Int64。
但是有时候我们并不关心值是不是Null,我们只需要把他当一个空字符串来对待就行。这时候我们可以使用[]byte(null byte[]可以转化为空string)
1
2
3
4
|
var world []byte
err := db.QueryRow("SELECT world FROM hello WHERE id = ?", id).Scan(&world)
...
log.Println(string(real_name)) // 有值则取出字串值,null则转换成 空字串。
|
自动匹配字段
在执行查询的时候,我们定义了目标变量,同时查询的时候也写明了字段,如果不指名字段,或者字段的顺序和查询的不一样,都有可能出错。因此如果能够自动匹配查询的字段值,将会十分节省代码,同时也易于维护。
go提供了Columns方法用获取字段名,与大多数函数一样,读取失败将会返回一个err,因此需要检查错误。
1
2
3
4
|
cols, err := rows.Columns()
if err != nil{
log.Fatalln(er)
}
|
对于不定字段查询,我们可以定义一个map的key和value用来表示数据库一条记录的row的值。通过rows.Columns得到的col作为map的key值。下面是一个例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
func main() {
db, err := sql.Open("mysql", "root:@tcp(127.0.0.1:3306)/test?parseTime=true")
if err != nil{
log.Fatal(err)
}
defer db.Close()
rows, err := db.Query("SELECT * FROM user WHERE gid = 1")
if err != nil{
log.Fatalln(err)
}
defer rows.Close()
cols, err := rows.Columns()
if err != nil{
log.Fatalln(err)
}
fmt.Println(cols)
vals := make([][]byte, len(cols))
scans := make([]interface{}, len(cols))
for i := range vals{
scans[i] = &vals[i]
}
var results []map[string]string
for rows.Next(){
err = rows.Scan(scans...)
if err != nil{
log.Fatalln(err)
}
row := make(map[string]string)
for k, v := range vals{
key := cols[k]
row[key] = string(v)
}
results = append(results, row)
}
for k, v :=range results{
fmt.Println(k, v)
}
}
|
数据表user有三个字段,id(int),gid(int),real_name(varchar)。我们使用*取出所有的字段。使用rows.Columns()获取字段名,是一个string的数组。然后创建一个切片vals,用来存放所取出来的数据结果,类似是byte的切片。接下来还需要定义一个切片,这个切片用来scan,将数据库的值复制到给它。
完成这一步之后,vals则得到了scan复制给他的值,因为是byte的切片,因此在循环一次,将其转换成string即可。
转换后的row即我们取出的数据行值,最后组装到result切片中。
运行结果如下
1
2
3
4
|
[id gid real_name]
0 map[id:4 gid:1 real_name:瑟兰督依]
1 map[real_name:来格拉斯 id:5 gid:1]
2 map[id:15 gid:1 real_name:]
|
有一条记录的 real_name 值为空字串,因为其数据库存储的是NULL。
Exec
前面介绍了很多关于查询方面的内容,查询是读方便的内容,对于写,即插入更新和删除。这类操作与query不太一样,写的操作只关系是否写成功了。database/sql提供了Exec方法用于执行写的操作。
我们也见识到了,Eexc返回一个sql.Result类型,它有两个方法LastInsertId和RowsAffected。LastInsertId返回是一个数据库自增的id,这是一个int64类型的值。
Exec执行完毕之后,连接会立即释放回到连接池中,因此不需要像query那样再手动调用row的close方法。
使用Exec(),最好用一个准备好的statement来完成INSERT,UPDATE,DELETE或者其他不返回行的语句。下面的示例演示如何插入行并检查有关操作的元数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
stmt, err := db.Prepare("INSERT INTO users(name) VALUES(?)")
if err != nil {
log.Fatal(err)
}
res, err := stmt.Exec("Dolly")
if err != nil {
log.Fatal(err)
}
lastId, err := res.LastInsertId()
if err != nil {
log.Fatal(err)
}
rowCnt, err := res.RowsAffected()
if err != nil {
log.Fatal(err)
}
log.Printf("ID = %d, affected = %d\n", lastId, rowCnt)
|
执行该语句将生成一个sql.Result,该语句提供对statement元数据的访问:最后插入的ID和行数受到影响。
如果你不在乎结果怎么办?如果你只想执行一个语句并检查是否有错误,但忽略结果该怎么办?下面两个语句不会做同样的事情吗?
1
2
|
_, err := db.Exec("DELETE FROM users") // OK
_, err := db.Query("DELETE FROM users") // BAD
|
虽然用_忽略了返回值,但文件描述符(磁盘io或网络io)需要手动关闭,GC并不会自动处理
答案是否定的。他们不做同样的事情,你不应该使用Query()。Query()将返回一个sql.Rows,它保留数据库连接,直到sql.Rows关闭。由于可能有未读数据(例如更多的数据行),所以不能使用连接。在上面的示例中,连接将永远不会被释放。垃圾回收器最终会关闭底层的net.Conn,但这可能需要很长时间。此外,database/sql包将继续跟踪池中的连接,希望在某个时候释放它,以便可以再次使用连接。因此,这种反模式是耗尽资源的好方法(例如连接数太多)。
总结
目前,我们大致了解了数据库的CURD操作。对于读的操作,需要定义目标变量才能scan数据记录。scan会智能的帮我们转换一些数据,取决于定义的目标变量类型。对于null的处理,可以使用database/sql或驱动提供的类型声明,也可以使用[]byte将其转换成空字串。除了读数据之外,对于写的操作,database/sql也提供了Exec方法,并且对于sql.Result提供了LastInsertId和RowsAffected方法用于获取写后的结果。
在实际应用中,与数据库交互,往往写的sql语句还带有参数,这类sql可以称之为prepare语句。prepare语句有很多好处,可以防止sql注入,可以批量执行等。但是prepare的连接管理有其自己的机制,也有其使用上的陷阱,关于prepare的使用,我们将会在以后讨论。
Prepare
prepare
前面我们已经学习了sql的基本curd操作。总体而言,有两类操作Query和Exec。前者返回数据库记录,后者返回数据库影响或插入相关的结果。上面两种操作,多数是针对单次操作的查询。如果需要批量插入一堆数据,就可以使用Prepared语句。golang处理prepared语句有其独特的行为,了解其底层的实现,对于用好它十分重要。
所谓prepared,即带有占位符的sql语句,客户端将该语句和参数发给mysql服务器。mysql服务器编译成一个prepared语句,这个语句可以根据不同的参数多次调用。prepared语句执行的方式如下:
- 准备prepare语句
- 执行prepared语句和参数
- 关闭prepared语句
之所以会出现prepare语句方式,主要因为这样有下面的两个好处:
- 避免通过引号组装拼接sql语句。避免sql注入带来的安全风险
- 可以多次执行的sql语句。
这里需要注意一点的是,Prepared Statement 存在 Session 限制,一般情况下一个 Prepared Statement 仅存活于它被创建的 Session 。当连接断开,者在其余情况下 Session 失效的时候,Prepared Statement 会自动被销毁。
参数占位符语法
预处理语句中的占位符参数的语法是特定于数据库的。例如,比较MySql,PostgreSQL,Oracle:
1
2
3
4
|
MySQL PostgreSQL Oracle
===== ========== ======
WHERE col = ? WHERE col = $1 WHERE col = :col
VALUES(?, ?, ?) VALUES($1, $2, $3) VALUES(:val1, :val2, :val3)
|
db.Query
我们可以使用Query方式查询记录,Query函数提供了两种选择,第一种情况下参数是拼接好的sql,另外一种情况,第一参数是带有占位符的sql,第二个参数为sql的实际参数。
1
2
3
|
rows, err := db.Query("SELECT * FROM user WHERE gid = 1")
rows, err := db.Query("SELECT * FROM user WHERE gid = ?", 1)
|
上面两种方式都能获取数据,那么他们的底层实现是一样的么?实际上,上面两种方式的底层通信不完全一样。一种是plaintext方式,另外一种是prepared方式。
db.Prepare
在数据库级别,将准备好的语句绑定到单个数据库连接。典型的流程是:客户端向服务器发送带有占位符的SQL语句以进行准备,服务器使用语句ID进行响应,然后客户端通过发送其ID和参数来执行该语句。
然而在Golang中,连接不会直接暴露给database/sql包的用户。你不准备连接上语句。你准备好在一个db或tx。并且database/sql具有一些便捷的行为,如自动重试。由于这些原因,准备好的语句和连接(存在于驱动级别)之间的潜在关联被隐藏在代码中。
下面是它的工作原理:
- 准备一个语句时,它会在池中的连接上准备好。
- Stmt对象记住使用哪个连接。
- 当你执行Stmt时,它试图使用Stmt对象记住的那个连接(后面我们将这里的连接称为原始连接)。如果它不可用,因为它关闭或忙于做其他事情,它从池中获取另一个连接,并在另一个连接上重新准备与数据库的语句。
因为在原始连接繁忙时将根据需要重新准备语句,所以数据库的高并发使用可能会使很多连接繁忙,从而创建大量预准备语句。这可能导致语句的明显泄漏,正在准备和重新准备的语句比您想象的更频繁,甚至在语句数量上遇到服务器端限制。
从query查询可以看到,对于占位符的prepare语句,go内部会自动创建一个 stmt对象。其实我们也可以自定义stmt语句,使用方式如下:
1
2
3
4
5
6
7
8
9
10
|
stmt, err := db.Prepare("SELECT * FROM user WHERE gid = ?")
if err != nil {
log.Fatalln(err)
}
defer stmt.Close()
rows, err := stmt.Query(1)
if err != nil{
log.Fatalln(err)
}
|
即通过Prepare方法创建一个stmt对象,然后执行stmt对象的Query(Exec)方法得到sql.Rows结果集。最后关闭stmt.Close。这个过程就和之前所说的prepare三步骤匹配了。
创建stmt的prepare方式是golang的一个设计,其目的是Prepare once, execute many times。为了批量执行sql语句。但是通常会造成所谓的三次网络请求( three network round-trips)。即preparing executing和closing三次请求。
对于大多数数据库,prepread的过程都是,先发送一个带占位符的sql语句到服务器,服务器返回一个statement id,然后再把这个id和参数发送给服务器执行,最后再发送关闭statement命令。
golang的实现了连接池,处理prepare方式也需要特别注意。调用Prepare方法返回stmt的时候,golang会在某个空闲的连接上进行prepare语句,然后就把连接释放回到连接池,可是golang会记住这个连接,当需要执行参数的时候,就再次找到之前记住的连接进行执行,等到stmt.Close调用的时候,再释放该连接。
在执行参数的时候,如果记住的连接正处于忙碌阶段,此时golang将会从新选一个新的空闲连接进行prepare(re-prepare)。当然,即使是重新reprepare,同样也会遇到刚才的问题。那么将会一而再再而三的进行reprepare。直到找到空闲连接进行查询的时候。
这种情况将会导致leak连接的情况,尤其是高并发的情景。将会导致大量的prepare过程。因此使用stmt的情况需要仔细考虑应用场景,通常在应用程序中。多次执行同一个sql语句的情况并不多,因此减少prepare语句的使用。
之前有一个疑问,是不是所有sql语句都不能带占位符,因为这是prepare语句。只要看了一遍database/sql和驱动的源码才恍然大悟,对于query(prepare, args)的方式,正如我们前面所分析的,database/sql会使用si, err = ctxDriverPrepare(ctx, dc.ci, query)创建stmt的,然后就立即执行prepare和参数,最后关闭stmt。整个过程都是同一个连接上完成,因此不存在reprepare的情况。当然也无法使用所谓的创建一次,执行多次的方式。
对于prepare的使用方式,目前需要注意的大致就是:
-
单次查询不需要使用prepared,每次使用stmt语句都是三次网络请求次数,prepared execute close
-
不要循环中创建prepare语句
-
注意关闭 stmt
如果不是批量的操作,是没必要使用db.Papare方法的,否则即多了Stmt创建和关闭的性能开销,又多写了两行代码,有点得不偿失。如果是批量的操作,那么毋庸置疑,肯定是db.Papare拿到Stmt,再由Stmt去执行sql,这样保证批量操作只进行一次预处理。
尽管会有reprepare过程,这些操作依然是database/sql帮我们所做的,与连接retry2次一样,开发者无需担心。
对于Qeruy操作如此,同理Exec操作也一样。
源码分析
Stmt
数据结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
// Stmt is a prepared statement.
// A Stmt is safe for concurrent use by multiple goroutines.
//
// If a Stmt is prepared on a Tx or Conn, it will be bound to a single
// underlying connection forever. If the Tx or Conn closes, the Stmt will
// become unusable and all operations will return an error.
// If a Stmt is prepared on a DB, it will remain usable for the lifetime of the
// DB. When the Stmt needs to execute on a new underlying connection, it will
// prepare itself on the new connection automatically.
type Stmt struct {
// Immutable:
db *DB // where we came from
query string // that created the Stmt
stickyErr error // if non-nil, this error is returned for all operations
closemu sync.RWMutex // held exclusively during close, for read otherwise.
// If Stmt is prepared on a Tx or Conn then cg is present and will
// only ever grab a connection from cg.
// If cg is nil then the Stmt must grab an arbitrary connection
// from db and determine if it must prepare the stmt again by
// inspecting css.
cg stmtConnGrabber
cgds *driverStmt
// parentStmt is set when a transaction-specific statement
// is requested from an identical statement prepared on the same
// conn. parentStmt is used to track the dependency of this statement
// on its originating ("parent") statement so that parentStmt may
// be closed by the user without them having to know whether or not
// any transactions are still using it.
parentStmt *Stmt
mu sync.Mutex // protects the rest of the fields
closed bool
// css is a list of underlying driver statement interfaces
// that are valid on particular connections. This is only
// used if cg == nil and one is found that has idle
// connections. If cg != nil, cgds is always used.
css []connStmt
// lastNumClosed is copied from db.numClosed when Stmt is created
// without tx and closed connections in css are removed.
lastNumClosed uint64
}
|
1
2
3
4
5
6
|
// connStmt is a prepared statement on a particular connection.
type connStmt struct {
dc *driverConn
ds *driverStmt
}
|
准备阶段
准备阶段,分别可以从DB、Conn和Tx上发起Prepare,先分析在DB上的Prepare
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
// Prepare creates a prepared statement for later queries or executions.
// Multiple queries or executions may be run concurrently from the
// returned statement.
// The caller must call the statement's Close method
// when the statement is no longer needed.
func (db *DB) Prepare(query string) (*Stmt, error) {
return db.PrepareContext(context.Background(), query)
}
// PrepareContext creates a prepared statement for later queries or executions.
// Multiple queries or executions may be run concurrently from the
// returned statement.
// The caller must call the statement's Close method
// when the statement is no longer needed.
//
// The provided context is used for the preparation of the statement, not for the
// execution of the statement.
func (db *DB) PrepareContext(ctx context.Context, query string) (*Stmt, error) {
var stmt *Stmt
var err error
for i := 0; i < maxBadConnRetries; i++ {
// 从连接池中尝试获取连接
stmt, err = db.prepare(ctx, query, cachedOrNewConn)
if err != driver.ErrBadConn {
break
}
}
if err == driver.ErrBadConn {
return db.prepare(ctx, query, alwaysNewConn)
}
return stmt, err
}
func (db *DB) prepare(ctx context.Context, query string, strategy connReuseStrategy) (*Stmt, error) {
// TODO: check if db.driver supports an optional
// driver.Preparer interface and call that instead, if so,
// otherwise we make a prepared statement that's bound
// to a connection, and to execute this prepared statement
// we either need to use this connection (if it's free), else
// get a new connection + re-prepare + execute on that one.
// 先从池子中获取一个连接
dc, err := db.conn(ctx, strategy)
if err != nil {
return nil, err
}
var si driver.Stmt
withLock(dc, func() {
// 这里是调用驱动来向server发起Prepare命令
si, err = dc.prepareLocked(ctx, query)
})
if err != nil {
db.putConn(dc, err)
return nil, err
}
stmt := &Stmt{
db: db,
query: query,
css: []connStmt{{dc, si}},
lastNumClosed: atomic.LoadUint64(&db.numClosed),
}
// 记住这个stmt是在哪个conn上Prepare的,便于后续exec时再继续用
db.addDep(stmt, stmt)
db.putConn(dc, nil)
return stmt, nil
}
|
执行阶段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
func (s *Stmt) ExecContext(ctx context.Context, args ...interface{}) (Result, error) {
s.closemu.RLock()
defer s.closemu.RUnlock()
var res Result
strategy := cachedOrNewConn
for i := 0; i < maxBadConnRetries+1; i++ {
if i == maxBadConnRetries {
strategy = alwaysNewConn
}
// 这里是尝试取回当时进行Prepare的连接以待继续操作
dc, releaseConn, ds, err := s.connStmt(ctx, strategy)
if err != nil {
if err == driver.ErrBadConn {
continue
}
return nil, err
}
// 从驱动读取执行结果
res, err = resultFromStatement(ctx, dc.ci, ds, args...)
releaseConn(err)
if err != driver.ErrBadConn {
return res, err
}
}
return nil, driver.ErrBadConn
}
|
Stmt在执行Exec和Query等方法时,会先执行connStmt方法
拿到type connStmt struct中的driverConn和driver.Stmt,再由resultFromStatement方法去做具体的数据库操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
func (s *Stmt) connStmt(ctx context.Context, strategy connReuseStrategy) (dc *driverConn, releaseConn func(error), ds *driverStmt, err error) {
if err = s.stickyErr; err != nil {
return
}
s.mu.Lock()
if s.closed {
s.mu.Unlock()
err = errors.New("sql: statement is closed")
return
}
// In a transaction or connection, we always use the connection that the
// stmt was created on.
// 在Tx或者Conn上Prepare的情况
if s.cg != nil {
s.mu.Unlock()
dc, releaseConn, err = s.cg.grabConn(ctx) // blocks, waiting for the connection.
if err != nil {
return
}
return dc, releaseConn, s.cgds, nil
}
s.removeClosedStmtLocked()
s.mu.Unlock()
// 以下是在DB上Prepare时的处理逻辑
// 直接从池子里遍历取连接,
// 然后判断这个连接是不是之前prepare过,
// 若prepare过,则直接返回这个连接即可,
// 若没有,则直接重新prepare后再返回
dc, err = s.db.conn(ctx, strategy)
if err != nil {
return nil, nil, nil, err
}
s.mu.Lock()
for _, v := range s.css {
// css是type connStmt的一个slice:css []connStm
if v.dc == dc {
s.mu.Unlock()
return dc, dc.releaseConn, v.ds, nil
}
}
s.mu.Unlock()
// No luck; we need to prepare the statement on this connection
withLock(dc, func() {
ds, err = s.prepareOnConnLocked(ctx, dc)
})
if err != nil {
dc.releaseConn(err)
return nil, nil, nil, err
}
return dc, dc.releaseConn, ds, nil
}
|
关闭阶段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// Close closes the statement.
func (s *Stmt) Close() error {
s.closemu.Lock()
defer s.closemu.Unlock()
if s.stickyErr != nil {
return s.stickyErr
}
s.mu.Lock()
if s.closed {
s.mu.Unlock()
return nil
}
s.closed = true
txds := s.cgds
s.cgds = nil
s.mu.Unlock()
if s.cg == nil {
return s.db.removeDep(s, s)
}
if s.parentStmt != nil {
// If parentStmt is set, we must not close s.txds since it's stored
// in the css array of the parentStmt.
return s.db.removeDep(s.parentStmt, s)
}
// txds是驱动端的stmt,最终调了驱动端的Close来关闭
return txds.Close()
}
|
总结
目前我们学习database/sql提供两类查询操作,Query和Exec方法。他们都可以使用plaintext和preprea方式查询。对于后者,可以有效的避免数据库注入。而prepare方式又可以有显示的声明stmt对象,也有隐藏的方式。显示的创建stmt会有3次网络请求,创建->执行->关闭,再批量操作可以考虑这种做法,另外一种方式创建prepare后就执行,因此不会因为reprepare导致高并发下的leak连接问题。
具体使用那种方式,还得基于应用场景,安全过滤和连接管理等考虑。至此,关于查询和执行操作已经介绍了很多。关系型数据库的另外一个特性就是关系和事务处理。下一节,我们将会讨论database/sql的数据库事务功能。
Transaction
事务处理是数据的重要特性。尤其是对于一些支付系统,事务保证性对业务逻辑会有重要影响。golang的mysql驱动也封装好了事务相关的操作。我们已经学习了db的Query和Exec方法处理查询和修改数据库。
tx对象
一般查询使用的是db对象的方法,事务则是使用另外一个对象。sql.Tx对象。使用db的Begin方法可以创建tx对象。tx对象也有数据库交互的Query,Exec和Prepare方法。用法和db的相关用法类似。查询或修改的操作完毕之后,需要调用tx对象的Commit提交或者Rollback方法回滚。
一旦创建了tx对象,事务处理都依赖与tx对象,这个对象会从连接池中取出一个空闲的连接,接下来的sql执行都基于这个连接,直到commit或者rollback调用之后,才会把连接释放到连接池。
在事务处理的时候,不能使用db的查询方法,虽然后者可以获取数据,可是这不属于同一个事务处理,将不会接受commit和rollback的改变,一个简单的事务例子如下:
1
2
3
4
|
tx, err := db.Begin()
tx.Exec(query1)
tx.Exec(query2)
tx.commit()
|
在tx中使用db是错误的:
1
2
3
4
|
tx, err := db.Begin()
db.Exec(query1)
tx.Exec(query2)
tx.commit()
|
上述代码在调用db的Eexc方法的时候,tx会绑定连接到事务中,db则是额外的一个连接,两者不是同一个事务。需要注意,Begin和Commit方法,与sql语句中的BEGIN或COMMIT语句没有关系。
事务与连接
创建Tx对象的时候,会从连接池中取出连接,然后调用相关的Exec方法的时候,连接仍然会绑定在改事务处理中。在实际的事务处理中,go可能创建不同的连接,但是那些其他连接都不属于该事务。例如上面例子中db创建的连接和tx的连接就不是一回事。
事务的连接生命周期从Beigin函数调用起,直到Commit和Rollback函数的调用结束。事务也提供了prepare语句的使用方式,但是需要使用Tx.Stmt方法创建。prepare设计的初衷是多次执行,对于事务,有可能需要多次执行同一个sql。然而无论是正常的prepare和事务处理,prepare对于连接的管理都有点小复杂。因此尽量避免在事务中使用prepare方式。例如下面例子就容易导致错误:
1
2
3
4
5
|
tx, _ := db.Begin()
defer tx.Rollback()
stmt, _ tx.Prepare("INSERT ...")
defer stmt.Close()
tx.Commit()
|
因为stmt.Close使用defer语句,即函数退出的时候再清理stmt,可是实际执行过程的时候,tx.Commit就已经释放了连接。当函数退出的时候,再执行stmt.Close的时候,连接可能有被使用了。
你不应该在SQL代码中混合BEGIN和COMMIT相关的函数(如Begin()和Commit()的SQL语句),可能会导致悲剧:
- Tx对象可以保持打开状态,从池中保留连接而不返回。
- 数据库的状态可能与代表它的Golang变量的状态不同步。
- 你可能会认为你是在事务内部的单个连接上执行查询,实际上Golang已经为你创建了几个连接,而且一些语句不是事务的一部分。
当你在事务中工作时,你应该注意不要对Db变量进行调用。应当使用db.Begin()创建的Tx变量进行所有调用。Db不在一个事务中,只有Tx是。如果你进一步调用db.Exec()或类似的函数,那么这些调用将发生在事务范围之外,是在其他的连接上。
如果你需要处理修改连接状态的多个语句,即使你不希望事务本身,也需要一个Tx。例如:
- 创建仅在一个连接中可见的临时表。
- 设置变量,如MySql’s SET @var := somevalue语法。
- 更改连接选项,如字符集或超时。
如果你需要执行任何这些操作,则需要把你的作业(也可以说Tx操作语句)绑定到单个连接,而在Golang中执行此操作的唯一方法是使用Tx。
事务并发
对于sql.Tx对象,因为事务过程只有一个连接,事务内的操作都是顺序执行的,在开始下一个数据库交互之前,必须先完成上一个数据库交互。例如下面的例子:
1
2
3
4
5
6
7
|
rows, _ := db.Query("SELECT id FROM user")
for rows.Next() {
var mid, did int
rows.Scan(&mid)
db.QueryRow("SELECT id FROM detail_user WHERE master = ?", mid).Scan(&did)
}
|
调用了Query方法之后,在Next方法中取结果的时候,rows是维护了一个连接,再次调用QueryRow的时候,db会再从连接池取出一个新的连接。rows和db的连接两者可以并存,并且相互不影响。
可是,这样逻辑在事务处理中将会失效:
1
2
3
4
5
6
|
rows, _ := tx.Query("SELECT id FROM user")
for rows.Next() {
var mid, did int
rows.Scan(&mid)
tx.QueryRow("SELECT id FROM detail_user WHERE master = ?", mid).Scan(&did)
}
|
tx执行了Query方法后,连接转移到rows上,在Next方法中,tx.QueryRow将尝试获取该连接进行数据库操作。因为还没有调用rows.Close,因此底层的连接属于busy状态,tx是无法再进行查询的。上面的例子看起来有点傻,毕竟涉及这样的操作,使用query的join语句就能规避这个问题。例子只是为了说明tx的使用问题。
事务中的准备语句
在Tx中创建的准备语句仅限于它,因此早期关于重新准备的注意事项不适用。当你对Tx对象进行操作时,你的操作直接映射到它下面唯一的一个连接上。
这也意味着在Tx内创建的准备语句不能与之分开使用。同样,在DB中创建的准备语句不能在事务中使用,因为它们将被绑定到不同的连接。
要在Tx中使用事务外的预处理语句,可以使用Tx.Stmt(),它将从事务外部准备一个新的特定于事务的语句。它通过采用现有的预处理语句,设置与事务的连接,并在执行时重新准备所有语句。这个行为及其实现是不可取的,甚至在databse/sql源代码中有一个TODO来改进它;我们建议不要使用这个。
在处理事务中的预处理语句时,必须小心谨慎。请考虑下面的示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
tx, err := db.Begin()
if err != nil {
log.Fatal(err)
}
defer tx.Rollback()
stmt, err := tx.Prepare("INSERT INTO foo VALUES (?)")
if err != nil {
log.Fatal(err)
}
defer stmt.Close() // danger!
for i := 0; i < 10; i++ {
_, err = stmt.Exec(i)
if err != nil {
log.Fatal(err)
}
}
err = tx.Commit()
if err != nil {
log.Fatal(err)
}
// stmt.Close() runs here!
|
之前Golang1.4关闭*sql.Tx将与之关联的连接返还到池中,但是,在预处理语句结束后,延迟调用时在那之后发生的,这可能导致并发访问底层的连接,使连接状态不一致。如果使用Golang1.4或更高的版本,则应确保在提交事务或回滚之前声明始终关闭。
源码分析
下面分析下对数据库事务的支持。同prepared statement一样,在数据库层面事务也只能在一个连接上进行,但在底层实现上,Tx的实现与prepared statement有明显不同,它底层从始至终只使用了一个连接。不过,我不太明白prepared statement为啥没有这样实现。
开启事务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
func (db *DB) BeginTx(ctx context.Context, opts *TxOptions) (*Tx, error) {
var tx *Tx
var err error
for i := 0; i < maxBadConnRetries; i++ {
tx, err = db.begin(ctx, opts, cachedOrNewConn)
if err != driver.ErrBadConn {
break
}
}
if err == driver.ErrBadConn {
return db.begin(ctx, opts, alwaysNewConn)
}
return tx, err
}
func (db *DB) begin(ctx context.Context, opts *TxOptions, strategy connReuseStrategy) (tx *Tx, err error) {
// 依然是先从池子中取出一个空闲连接
dc, err := db.conn(ctx, strategy)
if err != nil {
return nil, err
}
return db.beginDC(ctx, dc, dc.releaseConn, opts)
}
func (db *DB) beginDC(ctx context.Context, dc *driverConn, release func(error), opts *TxOptions) (tx *Tx, err error) {
var txi driver.Tx
withLock(dc, func() {
// 调用driver来开启事务
txi, err = ctxDriverBegin(ctx, opts, dc.ci)
})
if err != nil {
release(err)
return nil, err
}
// Schedule the transaction to rollback when the context is cancelled.
// The cancel function in Tx will be called after done is set to true.
ctx, cancel := context.WithCancel(ctx)
// 注意返回的tx对象记了启动事务的连接dc
// 后续所有的操作都会在这一个dc上进行
tx = &Tx{
db: db,
dc: dc,
releaseConn: release,
txi: txi,
cancel: cancel,
ctx: ctx,
}
go tx.awaitDone()
return tx, nil
}
|
执行阶段,exec和query过程类似,下面只分析exec的过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
func (tx *Tx) QueryContext(ctx context.Context, query string, args ...interface{}) (*Rows, error) {
// 取出之前保存在tx上的连接dc
dc, release, err := tx.grabConn(ctx)
if err != nil {
return nil, err
}
// 其实就是db.queryDC的逻辑
// 现在知道为什么tx上要记一个db对象了
return tx.db.queryDC(ctx, tx.ctx, dc, release, query, args)
}
func (tx *Tx) grabConn(ctx context.Context) (*driverConn, releaseConn, error) {
select {
default:
case <-ctx.Done():
return nil, nil, ctx.Err()
}
// closeme.RLock must come before the check for isDone to prevent the Tx from
// closing while a query is executing.
// 这个读写锁的目的是保证当tx被关闭时已经没有任何其它的查询在进行了
// 注意到一般每一个资源对象都有这样一个锁,比如Row、Stmt
tx.closemu.RLock()
if tx.isDone() {
tx.closemu.RUnlock()
return nil, nil, ErrTxDone
}
if hookTxGrabConn != nil { // test hook
hookTxGrabConn()
}
// 返回的是tx上记的那个dc
return tx.dc, tx.closemuRUnlockRelease, nil
}
|
总结
database/sql提供了事务处理的功能。通过Tx对象实现。db.Begin会创建tx对象,后者的Exec和Query执行事务的数据库操作,最后在tx的Commit和Rollback中完成数据库事务的提交和回滚,同时释放连接。
tx事务环境中,只有一个数据库连接,事务内的Eexc都是依次执行的,事务中也可以使用db进行查询,但是db查询的过程会新建连接,这个连接的操作不属于该事务。
关于database/sql和mysql的驱动,我们已经分三部分内容介绍了。下一节,将会对之前的内容进行梳理总结,包括错误处理和注意事项的补充。
错误处理
几乎所有使用database/sql类型的操作都会返回一个错误作为最后一个值。你应该总是检查这些错误,千万不要忽视它们。有几个地方错误行为是特殊情况,还有一些额外的东西可能需要知道。
遍历结果集的错误
请思考下面的代码:
1
2
3
4
5
6
|
for rows.Next() {
// ...
}
if err = rows.Err(); err != nil {
// handle the error here
}
|
来自rows.Err()的错误可能是rows.Next()循环中各种错误的结果。除了正常完成循环之外,循环可能会退出,因此你总是需要检查循环是否正常终止。异常终止自动调用rows.Close(),尽管多次调用它是无害的。
关闭结果集的错误
如上所述,如果你过早的退出循环,则应该总是显式的关闭sql.Rows。如果循环正常退出或通过错误,它会自动关闭,但你可能会错误的执行此操作:
1
2
3
4
5
6
7
8
9
10
|
for rows.Next() {
// ...
break; // whoops, rows is not closed! memory leak...
}
// do the usual "if err = rows.Err()" [omitted here]...
// it's always safe to [re?]close here:
if err = rows.Close(); err != nil {
// but what should we do if there's an error?
log.Println(err)
}
|
rows.Close()返回的错误是一般规则的唯一例外,最好是捕获并检查所有数据库操作中的错误。如果rows.Close()返回错误,那么你应该怎么做。记录错误信息或panic可能是唯一明智的事情,如果这不明智,那么也许你应该忽略错误。
QueryRow()的错误
思考下面的代码来获取一行数据:
1
2
3
4
5
6
|
var name string
err = db.QueryRow("select name from users where id = ?", 1).Scan(&name)
if err != nil {
log.Fatal(err)
}
fmt.Println(name)
|
如果没有id = 1的用户怎么办?那么结果中不会有行,而.Scan()不会将值扫描到name中。那会怎么样?
Golang定义了一个特殊的错误常量,称为sql.ErrNoRows,当结果为空时,它将从QueryRow()返回。这在大多数情况下需要作为特殊情况来处理。空的结果通常不被应用程序代码认为是错误的,如果不检查错误是不是这个特殊常量,那么会导致你意想不到的应用程序代码错误。
来自查询的错误被推迟到调用Scan(),然后从中返回。上面的代码可以更好地写成这样:
1
2
3
4
5
6
7
8
9
10
|
var name string
err = db.QueryRow("select name from users where id = ?", 1).Scan(&name)
if err != nil {
if err == sql.ErrNoRows {
// there were no rows, but otherwise no error occurred
} else {
log.Fatal(err)
}
}
fmt.Println(name)
|
有人可能会问为什么一个空的结果集被认为是一个错误。空集没有什么错误。原因是QueryRow()方法需要使用这种特殊情况才能让调用者区分是否QueryRow()实际上找到一行;没有它,Scan(0)不会做任何事情,你可能不会意识到你的变量毕竟没有从数据库中获取任何值。
当你使用QueryRow()时,你应该只会遇到此错误。如果你在别处遇到这个错误,你就做错了什么。
识别特定的数据库错误
像下面这样编写代码是很有诱惑力的:
1
2
3
4
5
6
|
rows, err := db.Query("SELECT someval FROM sometable")
// err contains:
// ERROR 1045 (28000): Access denied for user 'foo'@'::1' (using password: NO)
if strings.Contains(err.Error(), "Access denied") {
// Handle the permission-denied error
}
|
这不是最好的方法。例如,字符串值可能会取决于服务器使用什么语言发送错误消息。比较错误编号以确定具体错误是啥要好得多。
但是,驱动的机制不同,因为这不是database/sql本身的一部分。在本教程重点介绍的MySql驱动中,你可以编写以下代码:
1
2
3
4
5
|
if driverErr, ok := err.(*mysql.MySQLError); ok { // Now the error number is accessible directly
if driverErr.Number == 1045 {
// Handle the permission-denied error
}
}
|
再次,这里的MySQLError类型由此特定驱动程序提供,并且驱动程序之间的.Number字段可能不同。然而,该值是从MySql的错误消息中提取的,因此是特定于数据库的,而不是特定于驱动的。
这段代码还是很丑相对于1045,一个魔术数字是一种代码气味。一些驱动(虽然不是MySql的驱动程序,因为这里的主题的原因)提供错误标识符的列表。例如Postgres pg驱动程序在error.go中。还有一个由VividCortex维护的MySql错误号的外部包。使用这样的列表,上面的代码写的更漂亮:
1
2
3
4
5
|
if driverErr, ok := err.(*mysql.MySQLError); ok {
if driverErr.Number == mysqlerr.ER_ACCESS_DENIED_ERROR {
// Handle the permission-denied error
}
}
|
处理连接错误
如果与数据库的连接被丢弃,杀死或发生错误该怎么办?
当发生这种情况时,你不需要实现任何逻辑来重试失败的语句。作为database/sql连接池的一部分,处理失败的连接是内置的。如果你执行查询或其他语句,底层连接失败,则Golang将重新打开一个新的连接(或从连接池中获取另一个连接),并重试10次。
然而,可能会产生一些意想不到的后果。当某些类型错误可能会发生其他错误条件。这也可能是驱动程序特定的。MySql驱动程序发生的一个例子是使用KILL取消不需要的语句(例如长时间运行的查询)会导致语句被重试10次。
惊喜,反模式和限制
虽然database/sql很简单,但一旦你习惯了它,你可能会对它支持的用例的微妙之处感到惊讶。这是Golang的核心库通用的。
资源枯竭
如果你不按预期使用database/sql,你一定会为自己造成麻烦,通常是通过消耗一些资源或阻止它们被有效的重用:
- 打开和关闭数据库可能会导致资源耗尽。
- 没有读取所有行或使用rows.Close()保留来自池的连接。
- 对于不返回行的语句,使用Query()将从池中预留一个连接。
- 没有意识到预处理语句如何工作会导致大量额外的数据库活动。
巨大的uint64值
这里有一个令人吃惊的错误。如果设置了高位,就不能将大的无符号整数作为参数传递给语句:
1
|
_, err := db.Exec("INSERT INTO users(id) VALUES", math.MaxUint64) // Error
|
这将抛出一个错误。如果你使用uint64值要小心,因为它们可能开始小而且无错误的工作,但会随着时间的推移而增加,并开始抛出错误。
连接状态不匹配
有些事情可以改变连接状态,这可能导致的问题有两个原因:
- 某些连接状态,比如你是否处于事务中,应该通过Golang类型来处理。
- 你可能假设你的查询在单个连接上运行。
例如,使用USE语句设置当前数据库对于很多人来说是一个典型的事情。但是在Golang中,它只会影响你运行的连接。除非你处于事务中,否则你认为在该连接上执行的其他语句实际上可能在从池中获取的不同的连接上运行,因此它们不会看到这些更改的影响。
此外,在更改连接后,它将返回到池,并可能会污染其他代码的状态。这就是为什么你不应该直接将BEGIN或COMMIT语句作为SQL命令发出的原因之一。
数据库特定的语法
database/sql API提供了面向行的数据库抽象,但是具体的数据库和驱动程序可能会在行为或语法上有差异,例如预处理语句占位符。
多个结果集
Golang驱动程序不以任何方式支持单个查询中的多个结果集,尽管有一个支持大容量操作(如批量复制)的功能请求似乎没有任何计划。
这意味着,除了别的以外,返回多个结果集的存储过程将无法正常工作。
调用存储过程
调用存储过程是特定于驱动程序的,但在MySql驱动程序中,目前无法完成。看来你可以调用一个简单的过程来返回一个单一的结果集,通过执行如下的操作:
1
|
err := db.QueryRow("CALL mydb.myprocedure").Scan(&result) // Error
|
事实上这行不通。你将收到以下错误1312:PROCEDURE mydb.myprocedure无法返回给定上下文中的结果集。这是因为MySql希望将连接设置为多语句模式,即使单个结果,并且驱动程序当前没有执行此操作(尽管看到这个问题)。
多个声明支持
database/sql没有显式的拥有多个语句支持,这意味着这个行为是后端依赖的:
1
|
_, err := db.Exec("DELETE FROM tbl1; DELETE FROM tbl2") // Error/unpredictable result
|
服务器可以解释它想要的,它可以包括返回的错误,只执行第一个语句,或执行两者。
同样,在事务中没有办法批处理语句。事务中的每个语句必须连续执行,并且结果中的资源(如行或行)必须被扫描或关闭,以便底层连接可供下一个语句使用。这与通常不在事务中工作时的行为不同。在这种情况下,完全可以执行查询,循环遍历行,并在循环中对数据库进行查询(这将发生在一个新的连接上):
1
2
3
4
5
6
|
rows, err := db.Query("select * from tbl1") // Uses connection 1
for rows.Next() {
err = rows.Scan(&myvariable)
// The following line will NOT use connection 1, which is already in-use
db.Query("select * from tbl2 where id = ?", myvariable)
}
|
但是事务只绑定到一个连接,所以事务不可能做到这一点:
1
2
3
4
5
6
7
|
tx, err := db.Begin()
rows, err := tx.Query("select * from tbl1") // Uses tx's connection
for rows.Next() {
err = rows.Scan(&myvariable)
// ERROR! tx's connection is already busy!
tx.Query("select * from tbl2 where id = ?", myvariable)
}
|
不过,Golang不会阻止你去尝试。因此,如果你试图在第一个释放资源并自行清理之前尝试执行另一个语句,可能会导致一个损坏的连接。这也意味着事务中的每个语句都会产生一组单独的网络往返数据库。
连接的有效性
连接失效会有什么问题?
- 如果连接是客户端主动关闭的,那会在write packets 的时候返回一个 ErrBadConn,连接池会在重试次数内,获取新的连接
- 如果连接时数据库服务器主动关闭的,那客户端对此是不知道的,拿到连接后,write packets 是不会报错的,但是连接的,但是在读服务器的 response 包的时候会有一个 unexpected EOF 错误。但是在读失败的时候一般是不能返回ErrBadConn的,因为客户端拿到新的连接会重新执行语句,可能会导致插入语句的 duplicate err。
解决思路 1:设置 maxLifetime
- DB 会定期清理连接池中过期的连接
- 如果没有设置maxLifetime,表示连接池中的连接可以一直复用,如果服务器关闭了这一条连接,连接池是不知道的,返回给客户端的就会是一条已经关闭的连接。
- 获取数据库服务器的 wait_timeout,然后设置 maxLifetime 比这个数值小 10 s 左右
解决思路 2:检查连接的有效性
- mysql 推荐的在获取连接、放回连接池、定期检查
- sql 包在 1.10 版本加了一个 connectionResetter 相关的逻辑,在连接放回连接池前校验,但需要数据库 driver 的支持。
- mysql driver 包会发送新的请求之前,校验 tcp 连接的有效性,同样也没有 release。
参考
https://www.jianshu.com/p/bc8120bec94e
http://go-database-sql.org/index.html
Gorm 源码分析(一) database/sql
Database/sql 源码学习