前言
伪共享的非标准定义为:缓存系统中是以缓存行(cache line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
下面我们就来详细剖析伪共享产生的前因后果。首先,我们要了解什么是缓存系统。
局部性原理
1、时间局部性(Temporal Locality):如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。程序循环、堆栈等是产生时间局部性的原因。
2、空间局部性(Spatial Locality):在最近的将来将用到的信息很可能与正在使用的信息在空间地址上是临近的。
3、顺序局部性(Order Locality):在典型程序中,除转移类指令外,大部分指令是顺序进行的。顺序执行和非顺序执行的比例大致是5:1。此外,对大型数组访问也是顺序的。
指令的顺序执行、数组的连续存放等是产生顺序局部性的原因。
CPU缓存
现代处理器受内存延迟而不是内存容量的限制,处理器速度和内存访问时间之间的差距继续扩大。
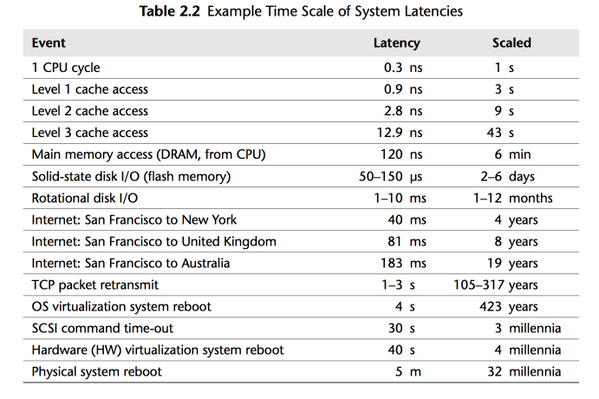
但是,就丢失处理器等待内存的处理器周期而言,物理内存仍与以往一样遥不可及,因为内存无法跟上 CPU 速度的提高。
因此,大多数现代处理器受内存延迟而不是容量的限制。
现代 CPU 针对批量传输和批量操作进行了优化。 在每个级别,操作的设置成本都会鼓励您进行大量工作。 一些例子包括
- 内存不是按字节加载,而是按高速缓存行的倍数加载,这就是为什么对齐变得不再像以前的计算机那样成为问题的原因。
- MMX 和 SSE 等向量指令允许一条指令同时针对多个数据项执行,前提是您的程序可以以这种形式表示。
CPU 缓存的百度百科定义为:
CPU 缓存(Cache Memory)是位于 CPU 与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。
高速缓存的出现主要是为了解决 CPU 运算速度与内存读写速度不匹配的矛盾,因为 CPU 运算速度要比内存读写速度快很多,这样会使 CPU 花费很长时间等待数据到来或把数据写入内存。
在缓存中的数据是内存中的一小部分,但这一小部分是短时间内 CPU 即将访问的,当 CPU 调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。
CPU 和主内存之间有好几层缓存,因为即使直接访问主内存也是非常慢的。如果你正在多次对一块数据做相同的运算,那么在执行运算的时候把它加载到离 CPU 很近的地方就有意义了。
按照数据读取顺序和与 CPU 结合的紧密程度,CPU 缓存可以分为一级缓存,二级缓存,部分高端 CPU 还具有三级缓存。每一级缓存中所储存的全部数据都是下一级缓存的一部分,越靠近 CPU 的缓存越快也越小。所以 L1 缓存很小但很快(译注:L1 表示一级缓存),并且紧靠着在使用它的 CPU 内核。L2 大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。L3 在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。最后,你拥有一块主存,由全部插槽上的所有 CPU 核共享。拥有三级缓存的的 CPU,到三级缓存时能够达到 95% 的命中率,只有不到 5% 的数据需要从内存中查询。
多核机器的存储结构如下图所示:
L1D cache 又会被划分为多个cache line,每个 cache line = 64 bytes
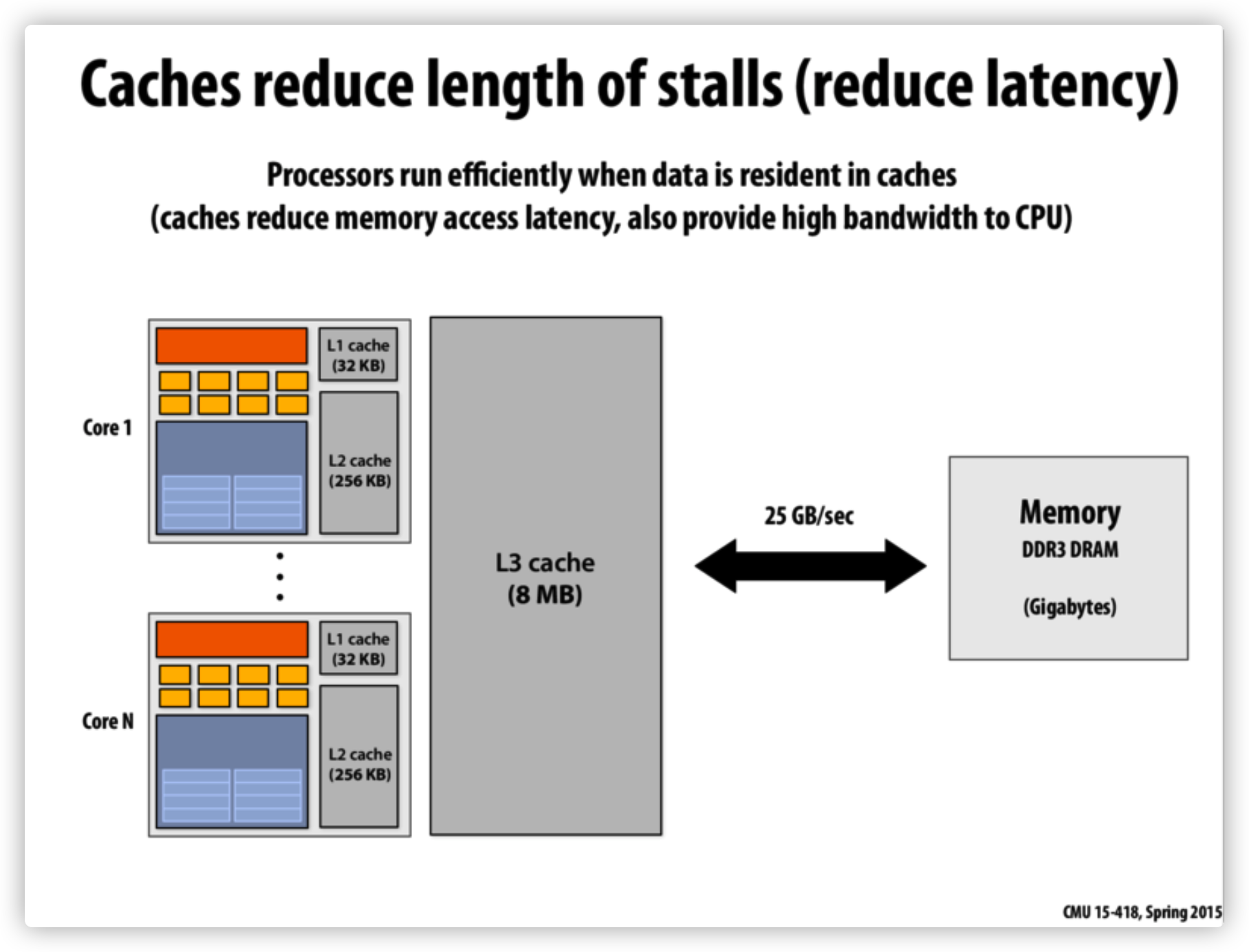
当 CPU 执行运算的时候,它先去 L1 查找所需的数据,再去 L2,然后是 L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要确保数据在 L1 缓存中。
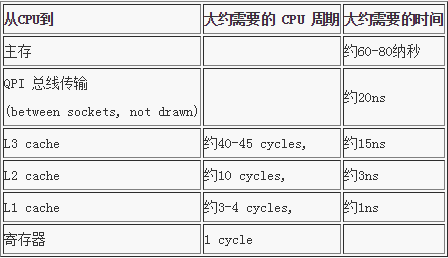
Martin Thompson 给出了一些缓存未命中的消耗数据,如下所示:
MESI 协议及 RFO 请求
从上一节中我们知道,每个核都有自己私有的 L1,、L2 缓存。那么多线程编程时, 另外一个核的线程想要访问当前核内 L1、L2 缓存行的数据, 该怎么办呢?
有人说可以通过第 2 个核直接访问第 1 个核的缓存行,这是当然是可行的,但这种方法不够快。跨核访问需要通过 Memory Controller(内存控制器,是计算机系统内部控制内存并且通过内存控制器使内存与 CPU 之间交换数据的重要组成部分),典型的情况是第 2 个核经常访问第 1 个核的这条数据,那么每次都有跨核的消耗.。更糟的情况是,有可能第 2 个核与第 1 个核不在一个插槽内,况且 Memory Controller 的总线带宽是有限的,扛不住这么多数据传输。所以,CPU 设计者们更偏向于另一种办法: 如果第 2 个核需要这份数据,由第 1 个核直接把数据内容发过去,数据只需要传一次。
那么什么时候会发生缓存行的传输呢?答案很简单:当一个核需要读取另外一个核的脏缓存行时发生。但是前者怎么判断后者的缓存行已经被弄脏(写)了呢?
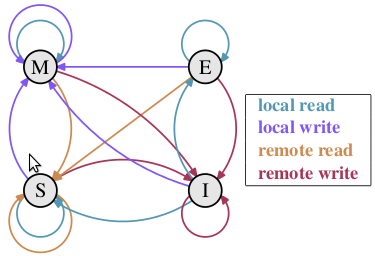
下面将详细地解答以上问题. 首先我们需要谈到一个协议—— MESI 协议。现在主流的处理器都是用它来保证缓存的相干性和内存的相干性。M、E、S 和 I 代表使用 MESI 协议时缓存行所处的四个状态:
- M(修改,Modified):本地处理器已经修改缓存行,即是脏行,它的内容与内存中的内容不一样,并且此 cache 只有本地一个拷贝(专有);
- E(专有,Exclusive):缓存行内容和内存中的一样,而且其它处理器都没有这行数据;
- S(共享,Shared):缓存行内容和内存中的一样, 有可能其它处理器也存在此缓存行的拷贝;
- I(无效,Invalid):缓存行失效, 不能使用。
下面说明这四个状态是如何转换的:
初始:一开始时,缓存行没有加载任何数据,所以它处于 I 状态。
本地写(Local Write):如果本地处理器写数据至处于 I 状态的缓存行,则缓存行的状态变成 M。
本地读(Local Read):如果本地处理器读取处于 I 状态的缓存行,很明显此缓存没有数据给它。此时分两种情况:(1)其它处理器的缓存里也没有此行数据,则从内存加载数据到此缓存行后,再将它设成 E 状态,表示只有我一家有这条数据,其它处理器都没有;(2)其它处理器的缓存有此行数据,则将此缓存行的状态设为 S 状态。(备注:如果处于M状态的缓存行,再由本地处理器写入/读出,状态是不会改变的)
远程读(Remote Read):假设我们有两个处理器 c1 和 c2,如果 c2 需要读另外一个处理器 c1 的缓存行内容,c1 需要把它缓存行的内容通过内存控制器 (Memory Controller) 发送给 c2,c2 接到后将相应的缓存行状态设为 S。在设置之前,内存也得从总线上得到这份数据并保存。
远程写(Remote Write):其实确切地说不是远程写,而是 c2 得到 c1 的数据后,不是为了读,而是为了写。也算是本地写,只是 c1 也拥有这份数据的拷贝,这该怎么办呢?c2 将发出一个 RFO (Request For Owner) 请求,它需要拥有这行数据的权限,其它处理器的相应缓存行设为 I,除了它自已,谁不能动这行数据。这保证了数据的安全,同时处理 RFO 请求以及设置I的过程将给写操作带来很大的性能消耗。
状态转换由下图做个补充:
我们从上节知道,写操作的代价很高,特别当需要发送 RFO 消息时。我们编写程序时,什么时候会发生 RFO 请求呢?有以下两种:
- 线程的工作从一个处理器移到另一个处理器, 它操作的所有缓存行都需要移到新的处理器上。此后如果再写缓存行,则此缓存行在不同核上有多个拷贝,需要发送 RFO 请求了。
- 两个不同的处理器确实都需要操作相同的缓存行
接下来,我们要了解什么是缓存行。
缓存行与伪共享
在文章开头提到过,缓存系统中是以缓存行(cache line)为单位存储的。缓存行通常是 64 字节(译注:本文基于 64 字节,其他长度的如 32 字节等不适本文讨论的重点),并且它有效地引用主内存中的一块地址。一个 Java 的 long 类型是 8 字节,因此在一个缓存行中可以存 8 个 long 类型的变量。所以,如果你访问一个 long 数组,当数组中的一个值被加载到缓存中,它会额外加载另外 7 个,以致你能非常快地遍历这个数组。事实上,你可以非常快速的遍历在连续的内存块中分配的任意数据结构。而如果你在数据结构中的项在内存中不是彼此相邻的(如链表),你将得不到免费缓存加载所带来的优势,并且在这些数据结构中的每一个项都可能会出现缓存未命中。
如果存在这样的场景,有多个线程操作不同的成员变量,但是相同的缓存行,这个时候会发生什么?。没错,伪共享(False Sharing)问题就发生了!有张 Disruptor 项目的经典示例图,如下:
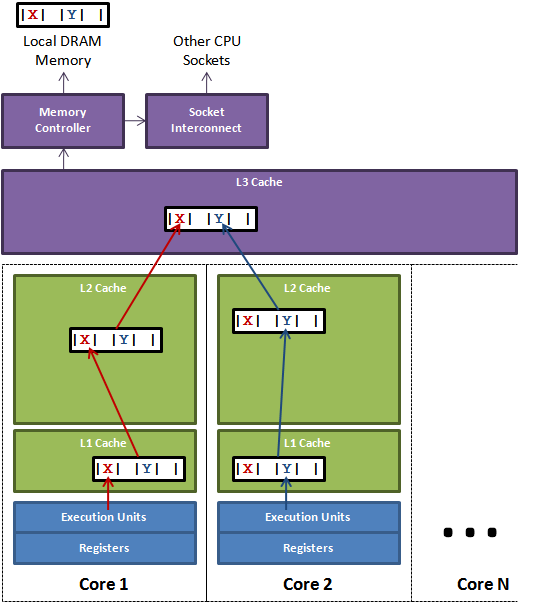
上图中,一个运行在处理器 core1上的线程想要更新变量 X 的值,同时另外一个运行在处理器 core2 上的线程想要更新变量 Y 的值。但是,这两个频繁改动的变量都处于同一条缓存行。两个线程就会轮番发送 RFO 消息,占得此缓存行的拥有权。当 core1 取得了拥有权开始更新 X,则 core2 对应的缓存行需要设为 I 状态。当 core2 取得了拥有权开始更新 Y,则 core1 对应的缓存行需要设为 I 状态(失效态)。轮番夺取拥有权不但带来大量的 RFO 消息,而且如果某个线程需要读此行数据时,L1 和 L2 缓存上都是失效数据,只有 L3 缓存上是同步好的数据。从前一篇我们知道,读 L3 的数据非常影响性能。更坏的情况是跨槽读取,L3 都要 miss,只能从内存上加载。
表面上 X 和 Y 都是被独立线程操作的,而且两操作之间也没有任何关系。只不过它们共享了一个缓存行,但所有竞争冲突都是来源于共享。
下面是在服务器上获取 L1 cache line size 的命令
1
|
getconf LEVEL1_DCACHE_LINESIZE
|
数组横着遍历,竖着遍历,哪种更快?
数组在内存中是按行储存的,按行遍历时可以由指向数组第一个数的指针一直往下走,就可以遍历完整个数组,而按列遍历则要获得指向每一列的第一行的元素的指针,然后每次将指针指下一行,但是指针的寻址很快,所以不会有明显的区别。
按行遍历比按列遍历效率高体现在哪里呢?
1、CPU高速缓存:(英语:CPU Cache,在本文中简称缓存)是用于减少处理器访问内存所需平均时间的部件。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。其容量远小于内存,但速度却可以接近处理器的频率。
当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。
缓存从内存中抓取一般都是整个数据块,所以它的物理内存是连续的,几乎都是同行不同列的,而如果内循环以列的方式进行遍历的话,将会使整个缓存块无法被利用,而不得不从内存中读取数据,而从内存读取速度是远远小于从缓存中读取数据的。
2、分页调度:物理内存是以页的方式进行划分的,当一个二维数组很大是如 int[128][1024],假设一页的内存为4096个字节,而每一行正好占据内存的一页,如果以列的形式进行遍历,就会发生128*1024次的页面调度,而如果以行遍历则只有128次页面调度,而页面调度是有时间消耗的,因而调度次数越多,遍历的时间就越长。
如何避免伪共享
在并发编程中,经常会有共享数据被多个goroutine同时访问, 所以如何有效的进行数据的设计,就是一个相当有技巧的操作。最常用的技巧就是Padding。现在大部分的CPU的cahceline是64字节,将变量补足为64字节可以保证它正好可以填充一个cacheline。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
package test
import (
"sync/atomic"
"testing"
)
type NoPad struct {
a uint64
b uint64
c uint64
}
func (np *NoPad) Increase() {
atomic.AddUint64(&np.a, 1)
atomic.AddUint64(&np.b, 1)
atomic.AddUint64(&np.c, 1)
}
type Pad struct {
a uint64
_p1 [8]uint64
b uint64
_p2 [8]uint64
c uint64
_p3 [8]uint64
}
func (p *Pad) Increase() {
atomic.AddUint64(&p.a, 1)
atomic.AddUint64(&p.b, 1)
atomic.AddUint64(&p.c, 1)
}
func BenchmarkPad_Increase(b *testing.B) {
pad := &Pad{}
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
pad.Increase()
}
})
}
func BenchmarkNoPad_Increase(b *testing.B) {
nopad := &NoPad{}
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
nopad.Increase()
}
})
}
|
运行结果:
1
2
3
4
5
|
go test -gcflags "-N -l" -bench .
goos: darwin
goarch: amd64
BenchmarkPad_Increase-4 30000000 56.4 ns/op
BenchmarkNoPad_Increase-4 20000000 91.4 ns/op
|
可能每次运行的结果不相同,但是基本上Padding后的数据结构要比没有padding的数据结构要好的多。
Java中知名的高性能的disruptor库中的设计中也采用了padding的方式避免伪共享。
你可以使用intel-go/cpuid获取CPU的cacheline的大小, 官方库x/sys/cpu也提供了一个CacheLinePad struct用来padding,你只需要在你的struct定义的第一行增加_ CacheLinePad这么一行即可:
1
2
3
4
5
|
var X86 struct {
_ CacheLinePad
HasAES bool // AES hardware implementation (AES NI)
HasADX bool // Multi-precision add-carry instruction extensions
......
|
测试代码
一个完整的测试, 相关讨论#25203:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
|
package test
import (
"runtime"
"sync"
"testing"
)
type foo struct {
x, y, z int64
}
type foo64Start struct {
_[64]byte
x, y, z int64
}
type foo64StartEnd struct {
_ [64]byte
x, y, z int64
_[64]byte
}
type foo128Start struct {
_ [128]byte
x, y, z int64
}
type foo128StartEnd struct {
_[128]byte
x, y, z int64
_ [128]byte
}
type foo64StartEndAligned struct {
_[64]byte
x, y, z int64
_ [64 - 24]byte
}
type foo128StartEndAligned struct {
_[128]byte
x, y, z int64
_ [128 - 24]byte
}
const iter = (1 << 16)
func BenchmarkFalseSharing(b *testing.B) {
var wg sync.WaitGroup
b.Run("NoPad", func(b*testing.B) {
arr := make([]foo, runtime.GOMAXPROCS(0))
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arr {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[i].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run("Pad64Start", func(b *testing.B) {
arr := make([]foo64Start, runtime.GOMAXPROCS(0))
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arr {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[i].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run("Pad64StartEnd", func(b*testing.B) {
arr := make([]foo64StartEnd, runtime.GOMAXPROCS(0))
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arr {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[i].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run("Pad128Start", func(b *testing.B) {
arr := make([]foo128Start, runtime.GOMAXPROCS(0))
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arr {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[i].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run("Pad128StartEnd", func(b*testing.B) {
arr := make([]foo128StartEnd, runtime.GOMAXPROCS(0))
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arr {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[i].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run("Pad64StartEndAligned", func(b *testing.B) {
arr := make([]foo64StartEndAligned, runtime.GOMAXPROCS(0))
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arr {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[i].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run("Pad128StartEndAligned", func(b*testing.B) {
arr := make([]foo128StartEndAligned, runtime.GOMAXPROCS(0))
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arr {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[i].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
}
func BenchmarkTrueSharing(b *testing.B) {
var wg sync.WaitGroup
b.Run("<64", func(b*testing.B) {
arr := make([]foo, runtime.GOMAXPROCS(0)*iter)
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arrChan {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[(i*iter)+j].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run(">64", func(b*testing.B) {
arr := make([]foo64Start, runtime.GOMAXPROCS(0)*iter)
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arrChan {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[(i*iter)+j].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run(">128", func(b*testing.B) {
arr := make([]foo128Start, runtime.GOMAXPROCS(0)*iter)
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arrChan {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[(i*iter)+j].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
}
|
参考
cacheline 对 Go 程序的影响
伪共享(false sharing),并发编程无声的性能杀手
二维数组按行和按列遍历效率哪个高?