C++程序内存分配形式
文章目录
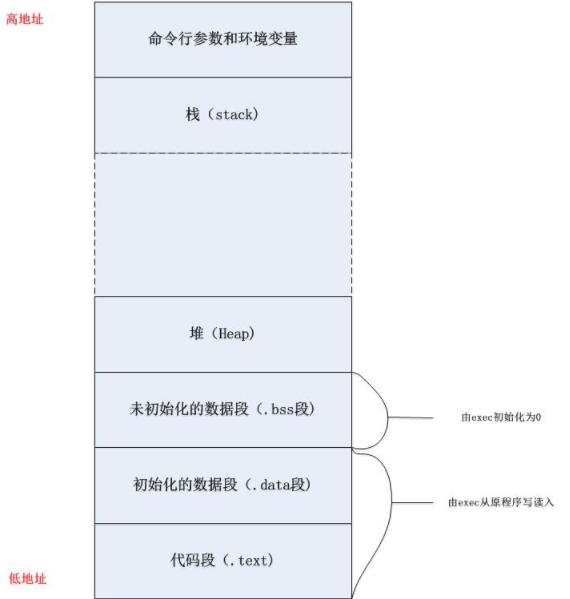
程序中内存分配方式
(1) 正文段 (.text)
程序代码就存储在text 段,这是由C P U执行的机器指令部分。通常,正文段是可共享的,所以即使是经常执行的程序(如文本编辑程序、C编译程序、s h e l l等)在存储器中也只需有一个副本,另外,正文段常常是只读的,以防止程序由于意外事故而修改其自身的指令。
当你在链接定位文件中将该符号放置在代码段后,那么该符号表示的值就是代码段大小,编译连接时,该符号所代表的值会自动代入到源程序中。
(2) 只读数据段 .rdata (常量区)
存储常量字符串,程序结束后由系统释放。(这里的常量不是const变量,而是文字常量如:char* p=”hello” 中的”hello”)
注意常量的存放区域,通常情况下,常量存放在程序区(程序区是只读的,因此任何修改常量的行为都是非法的),而不是数据区。有的系统,也将部分常量分配到静态数据区,比如字符串常量(有的系统也将其分配在程序区)。
但是要记住一点,常量所在的内存空间都是受系统保护的,不能修改。对常量空间的修改将造成访问内存出错,一般系统都会提示。常量的生命周期一直到程序执行结束为止。
(3) 初始化数据段data
通常是指用来存放程序中已初始化且不为0的全局变量和静态变量的一块内存区域。
在编译器进行编译的时候就为该变量分配的内存,即全局变量和静态变量(用static声明的变量),存放在这个区的数据程序全部执行结束后系统自动释放,声明周期贯穿于整个程序执行过程。
(3) 未初始化数据段bss
未初始化或被初始化为0的全局变量和静态变量放在BSS段,不占用磁盘空间,加载到内存后才分配空间。
(4) 栈stack
存放函数的形式参数和局部变量,由编译器分配和自动释放,函数执行完后,局部变量和形参占用的空间会自动被释放。效率比较高,但是分配的容量很有限。
(5) 堆heap
这部分存储空间完全由程序员自己负责管理,它的分配和释放都由程序员自己负责。这个区是唯一一个可以由程序员自己决定变量生存 期的区间。可以用malloc,new申请对内存,并通过free和delete释放空间。如果程序员自己在堆区申请了空间,又忘记将这片内存释放掉,就 会造成内存泄露的问题,导致后面一直无法访问这片存储区域。但程序退出后,系统自动回收资源。分配方式类似于链表。
.rdata,.data,.bss中数据的初始化时间 rdata和data段的值都是在编译的时候就确定了,并且将其编译进了可执行文件。
bss段是在运行的时候由编译器自动在代码段中加入一段代码,将bss段内所有变量初始化为0.
常量字符串的保存位置
字符串常量, 按保存区域的不同分为以下几种:
-
保存在栈区。
char name5[20] = "fengkewei"; char name1[] = "fengkewei"; -
保存在文字常量区
char *name = "fengkewei"; -
保存在全局区(静态区)
-
保存在堆区,即用malloc, alloc, realloc 分配内存分配的区域,可由程序员自身分配和释放
实例演示
首先看下下面这段:
|
|
下面是各字符串的首地址 它们都在文字常量区里 相同也就相同了 不同则是递增分配的( 文字常量区也是递增分配的)
|
|
可见name1[]是在一个不同的地方的 也就是说它就是在栈上
关于strcpy
char name4[20];
strcpy(name4, "fengkewei");
|
|
可见 每个数组元素的地址都在栈区 而它们的值保存的都是相应的字符。也就是说 这个strcpy()并没有调用文字常量区的”fengkewei”,而是直接把内容放在栈区name4[20]了.
程序中的数据存储
常量
对于整型常量和字符型常量,由于不需要写操作,编译器会将其直接编译在代码之中,因此不需要存储。
对于字符串常量,编译器将其放入只读数据端.rdata,同事对于相同的字符串常量,编译器会优化并只存储一次。
变量
全局变量
未初始化的,存储于.bss ; 初始化的,存储于.data
静态变量
和全局变量相同
自动变量
局部变量存储于stack ; 动态分配的内存,存储于heap,指向该内存的指针,存储于stack
寄存器变量
存储位置在CPU寄存器内。
栈和堆的区别
管理方式不同
对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生memory leak。
空间大小不同
一般来讲在32位系统下,堆内存可以达到4G的空间,从这个角度来看堆内存几乎是没有什么限制的。但是对于栈来讲,一般都是有一定的空间大小的,例如,在VC6下面,默认的栈空间大小是1M。
能否产生碎片不同
对于堆来讲,频繁的new/delete势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因 为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出,在他弹出之前,在他上面的后进的栈内容已经被弹出。
生长方向不同
对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
分配方式不同
堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。
分配效率不同
栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较 高。堆则是C/C++函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法在堆内 存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到 足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
文章作者 Forz
上次更新 2017-06-23