TCP-BBR 算法
BBR(Bottleneck Bandwidth and Round-trip propagation time)是 Google 近年来提出的拥塞控制算法,诞生后大幅度提高了在高延迟等情况下网络传输的吞吐。从命名就可以看到带宽(Bandwidth)和往返时延(Round-trip time)关键字,在上述铺垫过程中,对应的就是 maxBW 和 minRTT。对于多变的网络环境 BBR 大胆的采用了以预期公式驱动,实时交替探测两个负载指标的办法,下文会对此详细解释。
算法核心解读
BBR 认为:既然网络多变,且最佳带宽和时延不好同时测量,那么就采取实时交替探测的方式。通过滑动窗口细粒度的交替收集一段时间内的每秒最大传输量和最小的 RTT,通过计算就可以获得目前最佳的 BDP。即BestBDP = BtlBw (bottleneck bandwidth) * RTprop (round-trip propagation time)
BtlBw
表示目前网络中的瓶颈带宽,也就是上节中的 maxBW,是网络设施传输的上限。BBR 会取得一段时间内滑动窗口的统计的最大 BtlBw 值作为参考。其测量方式简述为一段时间内的数据包总量除以他们所抵达花费的时间。
RTprop
表示抛开任何外在噪音,如 ack 重发耗时,网络抖动等等导致 RTT 偏高情况。即在滑动窗口统计中的 RTT 最小值作为参考,其测量方式为数据包发送和回复耗时。
inflight
这指的是,在 BBR 工作期间内,已经发送至网络但是还是没有收到答复的数据包。也就说真实的,在网络设备里正在传输的数据量,即负载。有了预期公式计算出的 BestBDP 指导将 RTprop 与 BtlBW 相乘,BBR 就可以得出当前时刻外界网络最佳的负载量与实际 inflight 的关系。有了这样的简单的数值比对,算法就可以控制发包的最佳量以进行拥塞控制。
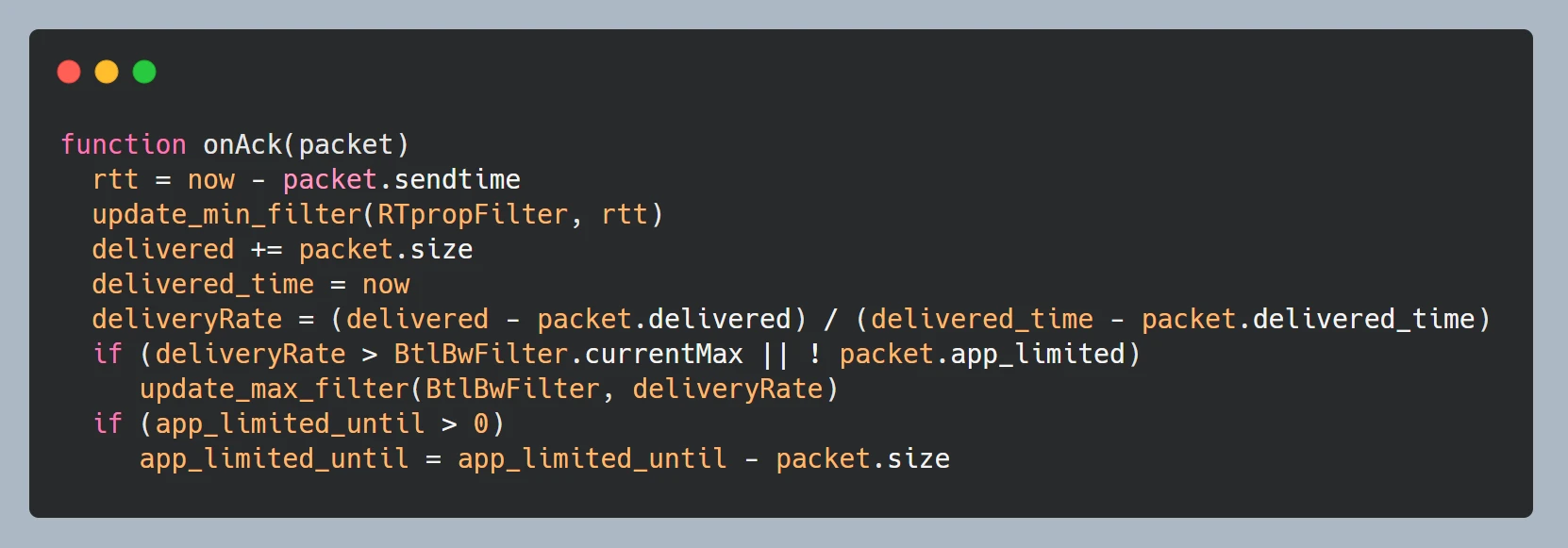
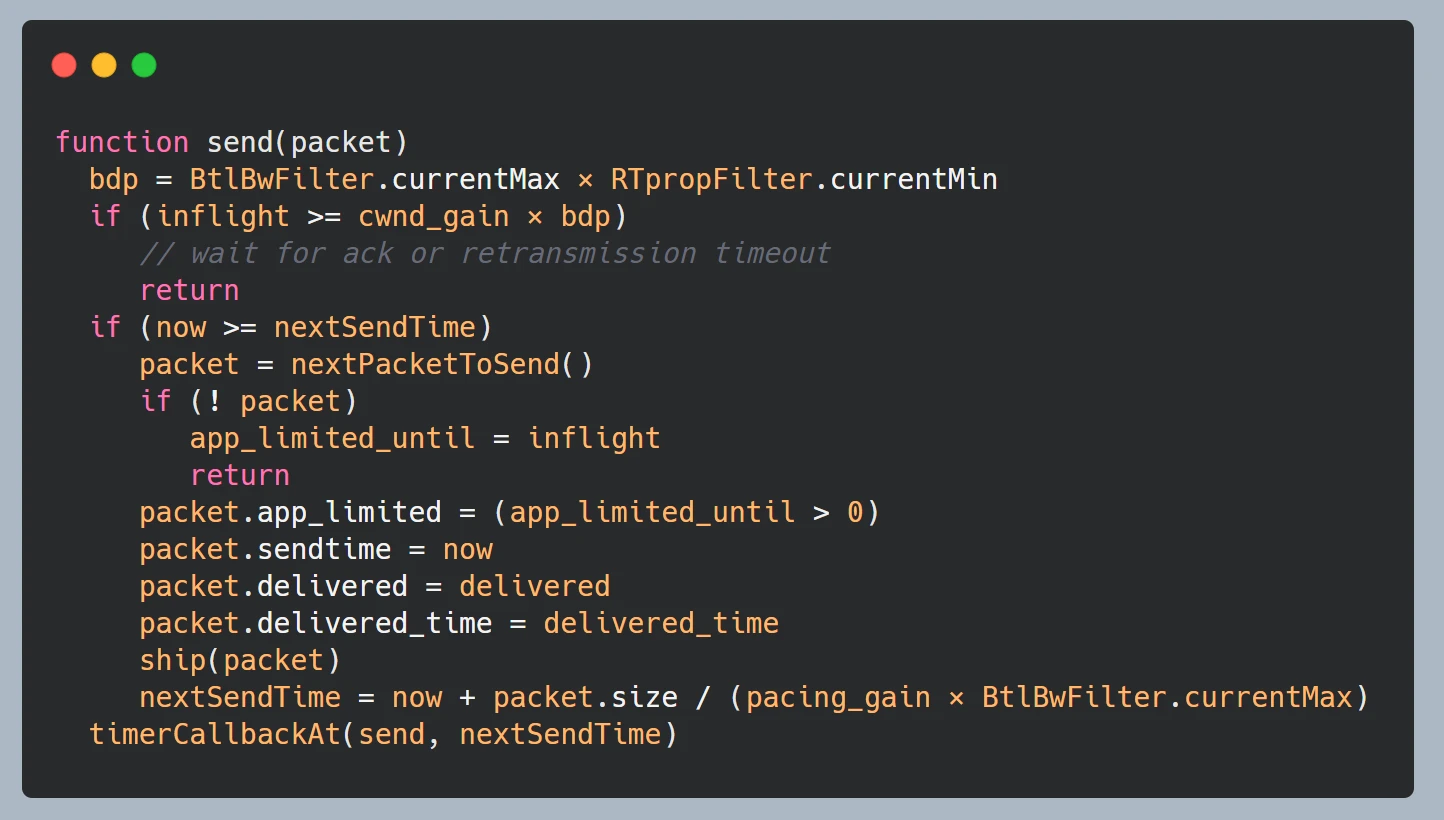
以下伪代码直观的体现了 BBR 算法在发包和收包时的处理逻辑。
收包 onAck
发包 send
算法组成
了解了核心的算法逻辑,接下来将简述其运作周期,进一步了解算法是如何充分利用未知网络设备传输能力的。算法运行状态主要分为启动阶段(Startup)、排空阶段(Drain)、带宽探测(ProbeBW)、时延探测(ProbeRTT)。同样,本文将不会阐述具体细节,具体细节可以参考文末的 reference。我们回到核心关注点,BBR 是如何探测以及适应当前网络设备传输能力的。
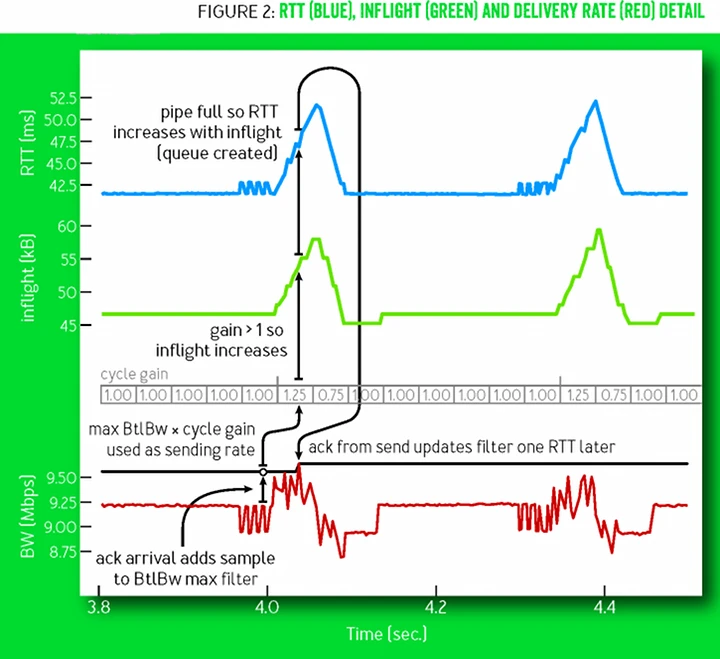
上图摘自 google BBR 论文,展示了在稳定网络传输节点下 BBR 算法中关键指标 RTT、BW、inflight 的变化图。其中灰色 cycle gain 数组,相当于滑动窗口。其中每个元素装载了带宽探测时的增益系数,通过与当前最大 BW 相乘可以实现增加/减少向网络中的数据发送,从而实现适应未知网络传输能力目的;同理,对于时延探测,简单来说 BBR 同样会周期性的发送小体量数据包收集最佳 RTT。
可见,基于预期的负载控制算法,即同时集合负载因子和关键结果的计算,相比只关注一个指标的实现方式在高吞吐场景下具备一定的优越性。同时,基于滑动窗口细粒度的动态探测极值,使得测量结果更具时效性与说服力。
利特尔法则
应用层和传输层在应对负载时本质需求是相同的,那么关于应用层的核心预期公式的推导显然具有相似性,那就是最佳请求数TW(当前最佳处理任务数目) = TPS * latency。如下所示
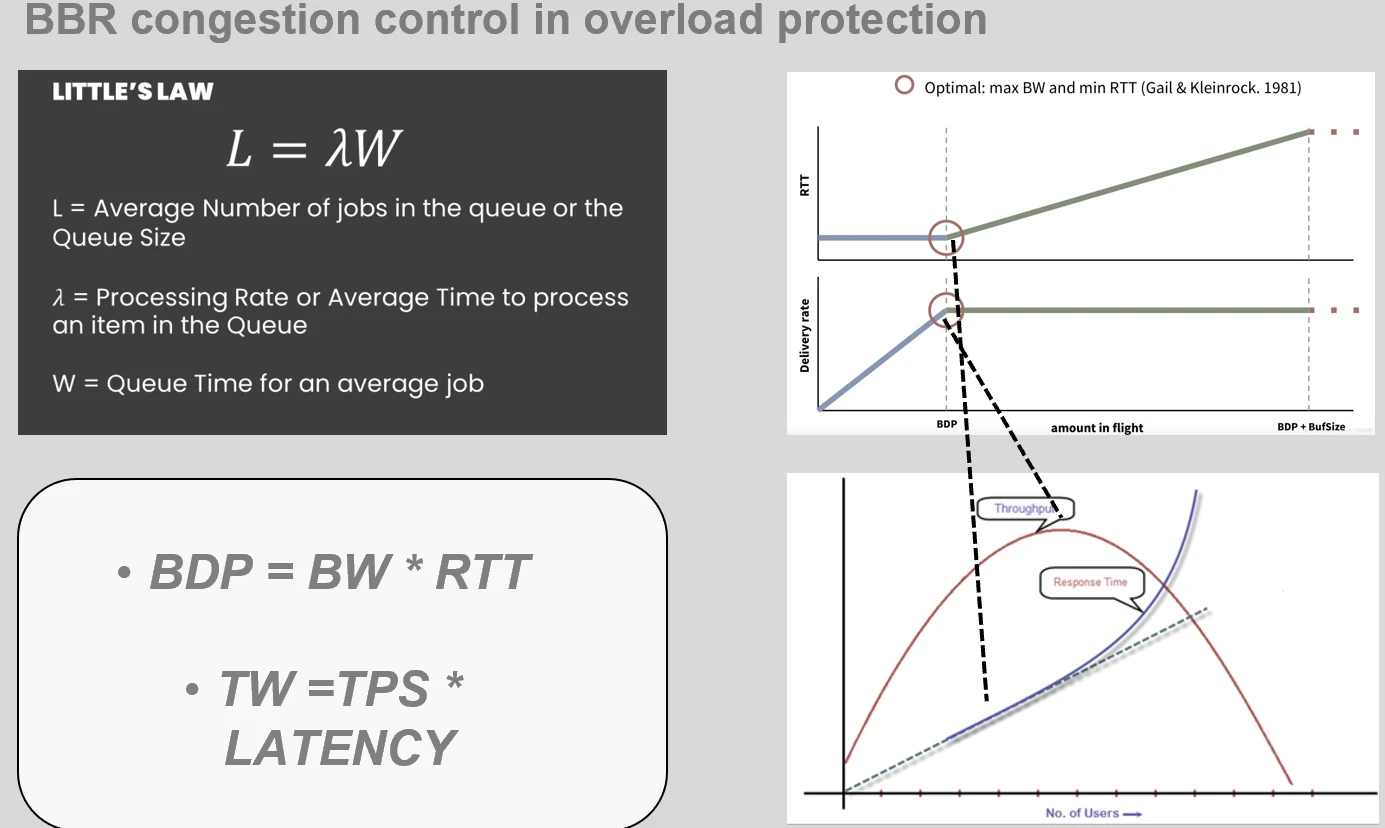
其实这个公式的依据是显赫有名的利特尔法则 little’s law,为通过对工业中平均生产数量和对应耗时提供了理论基础,以进一步衡量生产能力。
BBR自适应限流算法
我们已经具备充分的理论基础和传输层实现指导,下一步就是因地制宜的实施在应用层后台服务。在业内最初版目前所知是由阿里的 sentinel 组件引入,由 kratos 进行了进一步拓展。在此我们需要搞清楚两个关键问题,才能保证最大化吞吐的同时防止服务过载。
控制时机
BBR 作为数据发送方,需要面临的问题未知网络设施传输能力。由于网络设施的传输能力、拥塞状态对发送方是非直接可见的,所以才有了上文提到的 BBR 带宽探测。滑动窗口内通过 cycle gain 变化,来适应不同时刻的传输能力。
应用层作为请求处理方,无论是在容器网络和物理机上部署,计算资源是相对固定的。这意味着存在着最佳处理量上限,我们要保证的是在流量上升或者因为其他因素导致计算资源紧张时,通过计算出的最佳 TW 来限制入口流量。
控制信号
了解了控制时机,可就是当计算资源紧张时进行干预。那么该如何确定资源紧张信号呢?总的来说就是 CPU 利用率或者操作系统负载,或者内存、磁盘等资源。以入口流量特征来看(进程 RPC 调用下游服务按照业务需求进行组装、计算、返回),内存资源不足导致的 GC(依赖 CPU)、磁盘 I/O 吞吐下降、调度抢占等等因素,都会导致用户请求增加、序列化成本增加(CPU)进而时延上升恶性循环。所以在 sentinel 和 kratos 的实现中都选择了适用 CPU 作为资源信号限流,只不过前者使用的是 cpu load1,后者使用的是服务基于 cgroup 对 CPU 的实时采样使用率。
两者使用各有千秋,但我们认为,基于 load1 作为控制信号仍不够敏感。在 linux 下操作系统 load1 表示一分钟内 CPU 的平均负载值,对于流量洪峰等过载的发生干预有效性较慢。
具体方案
本部分屏蔽到绝大部分代码与设施细节,关注应用方式与过程中上线效果、遇到的问题以及优化。
CPU 利用率峰值信号
kratos 以是当前容器网络服务 CPU 利用率的 80%作为控制信号临界点,通过为此服务会开启独立的 goroutine 每隔 250ms 进行基于本服务的 cgroup(/sys/fs/cgroup/cpu/*)CPU 占用信息采集,以及系统总 cpu tick(proc/stat)占用采集。
对 CPU 占用率的计算本质是间隔内 本进程占用的 CPU 时间增量/系统的总 CPU 时间占用增量。显然 CPU 的变化是相当迅速的,会受到各种因素的影响来回抖动动。为此我们采用了滑动均值(算法原理参考)的办法进行降噪稳定。通过确定参考衰退率β(<1),使得最终结果等于:β*上次的CPU占用率 + (1-β)*本次的时机测得CPU占用率。如下所示:
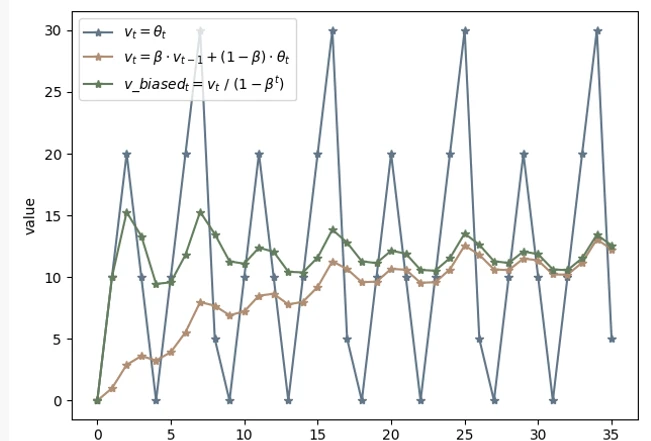
- 深蓝色折线代表了正常实际测量下 CPU 的变化折线图,可以看到抖动十分不稳定。
- 橘色公式折线表示了在滑动均值算法下趋于平稳变动的 CPU 变化图,但是能看到前提 CPU 数值较低。
- 绿色公式折线是在具体滑动均值算法作用下,对前期数据量不足导致 CPU 起点低的问题进行的偏差修正。
最终经过上述修正,我们得到线上具有参考使用价值的 CPU 占用率。
Pass&RT
pass 和 RT 分别表示处理完成请求数和对应请求所消耗的时间,即 TPS 和 Latency。相应的,我们的测量办法同样是通过滑动窗口对 pass 和 RT 进行统计,如下图。
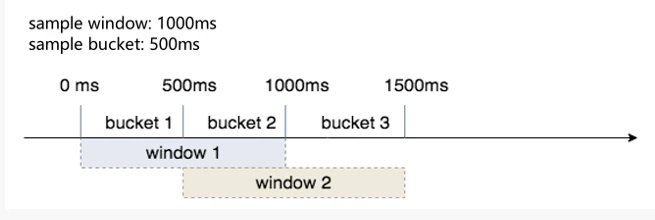
sample window 表示窗口采样周期,sample bucket 表示周期内的采样批次。假设现在采样窗口时间为 1000ms,bucket 采样批次时间持续 500ms,那么就表示在前 500ms 内完成的请求数和这些请求消耗的平均时延都会被原子(atomic)统计在 bucket1 中。同理,当第 501ms 会被统计在 bucket2 中,当第 1001ms 时会再次回到 bucket1,以此类推。可见当 bucket 足够多,以及统计间隔足够小时最能够得到真实的数据,更有效的应对秒内流量洪峰。
流量干预
当 CPU 利用率过载时,就需要通过预期公式进行干预了。我们会在服务运行期间持续统计当前服务的请求数,即 inflight,通过在滑动窗口内的所有 buckets 中比较得出最多请求完成数 maxPass,以及最小的耗时 minRT,相乘就得出了预期的最佳请求数 maxFlight。通过 inflight 与 maxFlight 对比,如果前者大于后者那么就已经过载,进而拒绝后续到来的请求防止服务过载。
线上效果与调优
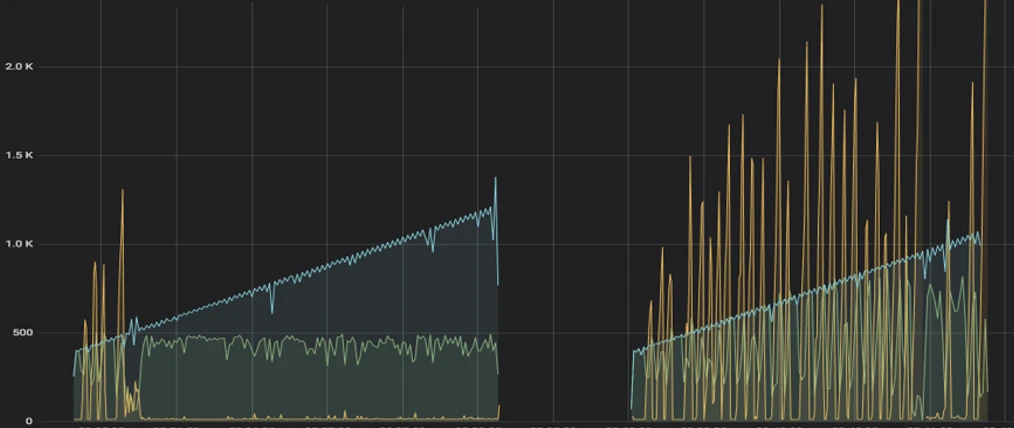
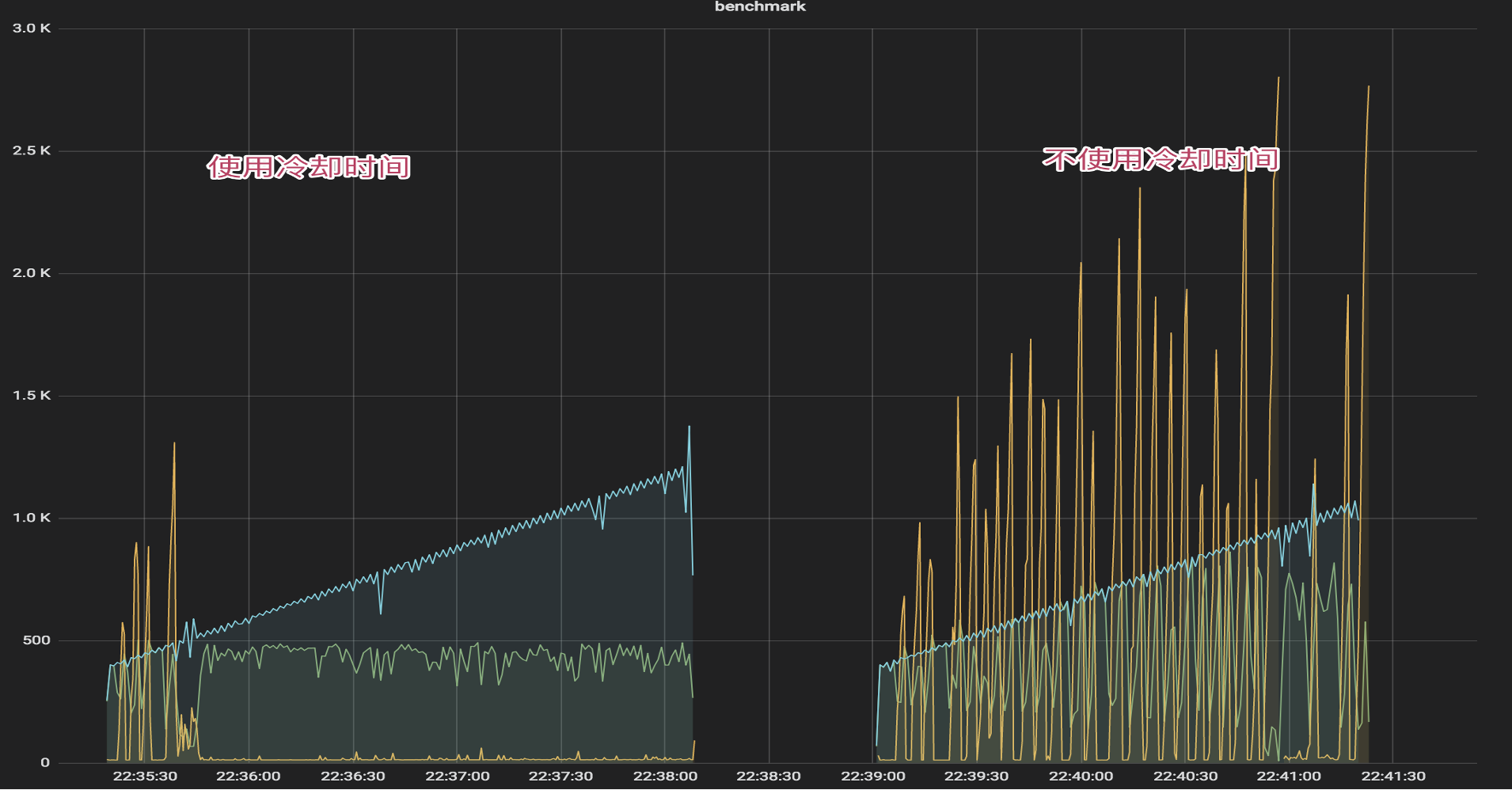
上图是在线上部署了基于 kratos 的自适应算法后的效果图,其中蓝色曲线代表了并发访问的用户数,深黄色代表对应请求的时延,浅绿色则表示成功处理的请求数。左侧为最终版,右侧为第一版。
不难看出,第一版时当算法控制后黄色的时延仍然很高,成功处理的请求数也并非稳定。产生这样结果的原因其实依然是 CPU 利用率很敏感且粒度很细,当 CPU 大于 80%利用率阈值时算法生效,当微量请求被拒绝时算法便停止了干预。最终的结果便是算法会因为流量的涌入与拒绝中频繁开启与关闭,导致结果不符合预期。
优化手段
为此我们简单加入了 1s 的冷却时间,也就是说算法开启后会持续至少 1s 的冷却时间,在此期间保持算法开启。当冷却时间过后会再次统计当前 CPU 利用率,并根据阈值对比进行持续或者关闭。最终测试结果如最终版左图所示,在流量持续涌入的情况下请求的成功处理数和时延都十分稳定。
BBR struct
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// BBR implements bbr-like limiter.
// It is inspired by sentinel.
// https://github.com/alibaba//wiki/%E7%B3%BB%E7%BB%9F%E8%87%AA%E9%80%82%E5%BA%94%E9%99%90%E6%B5%81
type BBR struct {
cpu cpuGetter
// passStat:请求处理成功的量(滑动窗口计数器)
passStat metric.RollingCounter
// rtStat:请求成功的响应耗时(滑动窗口计数器)
rtStat metric.RollingCounter
inFlight int64
winBucketPerSec int64
bucketDuration time.Duration
winSize int
conf *Config
// 对应于公式的 prevDrop
prevDrop atomic.Value
maxPASSCache atomic.Value
minRtCache atomic.Value
}
|
- cpu: cpu的指标函数,CPU的使用率, 这里为了减小误差,把数字扩大化,乘以1000,比如使用率60%,也就是0.6 cpu的值就为600
- passStat: 请求数的采样数据,使用滑动窗口进行统计
- rtStat: 响应时间的采样数据,同样使用滑动窗口进行统计
- inFlight: 当前系统中的请求数,数据得来方法是:中间件原理在处理前+1,处理handle之后不管成功失败都减去1
- bucketPerSecond: 一个 bucket 的时间
- bucketSize: 桶的数量
- prevDropTime: 上次触发限流时间
- maxPASSCache: 单个采样窗口中最大的请求数的缓存数据
- minRtCache: 单个采样窗口中最小的响应时间的缓存数据
公共接口: Limiter
Limter 公共接口 limiter.go 定义如下: 核心 Allow 方法,返回 error 不为 nil 表示需要限流,回调函数 func(info DoneInfo),传入的参数为 Doneifno,有点类似于 gPRC 的 balancer.picker 实现,在 RPC 返回成功时调用的回调方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
const (
// Success opertion type: success
Success Op = iota
// Ignore opertion type: ignore
Ignore
// Drop opertion type: drop
Drop
)
// DoneInfo done info.
type DoneInfo struct {
Err error
Op Op
}
// Limiter limit interface.
type Limiter interface {
//func(info DoneInfo) 调用参数为 Doneinfo,返回值无
Allow(ctx context.Context, opts ...AllowOption) (func(info DoneInfo), error)
}
|
全局变量:
1
2
3
4
5
6
7
8
9
10
11
12
|
var (
cpu int64
decay = 0.95
initTime = time.Now()
defaultConf = &Config{
Window: time.Second * 10,
WinBucket: 100,
CPUThreshold: 800,
}
)
type cpuGetter func() int64
|
在 limiter 中,也有分组的概念,比如针对后端某个 CGI 或 RPC 方法,应用不通的限速策略及规则,这里直接就使用了 container/group 来进行封装: 封装 group.Group 的指针成员,作为 bbr.Group:
1
2
3
4
5
|
// Group represents a class of BBRLimiter and forms a namespace in which
// units of BBRLimiter.
type Group struct {
group *group.Group
}
|
初始化 bbr.Group:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// NewGroup new a limiter group container, if conf nil use default conf.
func NewGroup(conf *Config)*Group {
if conf == nil {
// 使用默认 group 配置
conf = defaultConf
}
// 创建 group
group := group.NewGroup(func() interface{} {
return newLimiter(conf)
})
return &Group{
group: group,
}
}
|
通过 key 获取对应的 limter 配置(不存在则创建),获取到 limter 对象之后,直接调用 limiter.Allow() 就可以进行限速判定了:
1
2
3
4
5
|
// Get get a limiter by a specified key, if limiter not exists then make a new one.
func (g *Group) Get(key string) limit.Limiter {
limiter := g.group.Get(key)
return limiter.(limit.Limiter)
}
|
通过 newLimiter 方法创建一个 bbr.Limiter 并返回,注意看初始化的参数,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func newLimiter(conf *Config) limit.Limiter {
if conf == nil {
conf = defaultConf
}
size := conf.WinBucket
bucketDuration := conf.Window / time.Duration(conf.WinBucket)
//
passStat := metric.NewRollingCounter(metric.RollingCounterOpts{Size: size, BucketDuration: bucketDuration})
rtStat := metric.NewRollingCounter(metric.RollingCounterOpts{Size: size, BucketDuration: bucketDuration})
// 定义了 cpu 为 func,直接返回全局变量 cpu 的值(atomic 方式)
cpu := func() int64 {
return atomic.LoadInt64(&cpu)
}
limiter := &BBR{
cpu: cpu,
conf: conf,
passStat: passStat,
rtStat: rtStat,
winBucketPerSec: int64(time.Second) / (int64(conf.Window) / int64(conf.WinBucket)),
}
return limiter
}
|
CPU计算
在包初始化函数 init 中,启动了一个新的子协程来计算 CPU 的利用率数据,此外,计算出的 CPU 使用率是一个 Gauge,使用 atomic 包存储在全局变量 cpu int64 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
func init() {
go cpuproc()
}
// cpu = cpuᵗ⁻¹ * decay + cpuᵗ * (1 - decay)
func cpuproc() {
ticker := time.NewTicker(time.Millisecond * 250)
defer func() {
ticker.Stop()
if err := recover(); err != nil {
log.Error("rate.limit.cpuproc() err(%+v)", err)
// 在 recover 中重启 CPU 监控
go cpuproc()
}
}()
// EMA algorithm: https://blog.csdn.net/m0_38106113/article/details/81542863
for range ticker.C {
stat := &cpustat.Stat{}
cpustat.ReadStat(stat)
// 获取前一个周期的 cpu 数据
prevCpu := atomic.LoadInt64(&cpu)
//decay = 0.95
curCpu := int64(float64(prevCpu)*decay + float64(stat.Usage)*(1.0-decay))
// 保存新的校准后的 CPU 数据
atomic.StoreInt64(&cpu, curCpu)
}
}
|
CPU获取的是cgroup的cpu:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
|
package cpu
import (
"bufio"
"fmt"
"io"
"os"
"path"
"strconv"
"strings"
)
const cgroupRootDir = "/sys/fs/cgroup"
// cgroup Linux cgroup
type cgroup struct {
cgroupSet map[string]string
}
// CPUCFSQuotaUs cpu.cfs_quota_us
func (c *cgroup) CPUCFSQuotaUs() (int64, error) {
data, err := readFile(path.Join(c.cgroupSet["cpu"], "cpu.cfs_quota_us"))
if err != nil {
return 0, err
}
return strconv.ParseInt(data, 10, 64)
}
// CPUCFSPeriodUs cpu.cfs_period_us
func (c *cgroup) CPUCFSPeriodUs() (uint64, error) {
data, err := readFile(path.Join(c.cgroupSet["cpu"], "cpu.cfs_period_us"))
if err != nil {
return 0, err
}
return parseUint(data)
}
// CPUAcctUsage cpuacct.usage
func (c *cgroup) CPUAcctUsage() (uint64, error) {
data, err := readFile(path.Join(c.cgroupSet["cpuacct"], "cpuacct.usage"))
if err != nil {
return 0, err
}
return parseUint(data)
}
// CPUAcctUsagePerCPU cpuacct.usage_percpu
func (c *cgroup) CPUAcctUsagePerCPU() ([]uint64, error) {
data, err := readFile(path.Join(c.cgroupSet["cpuacct"], "cpuacct.usage_percpu"))
if err != nil {
return nil, err
}
var usage []uint64
for _, v := range strings.Fields(string(data)) {
var u uint64
if u, err = parseUint(v); err != nil {
return nil, err
}
// fix possible_cpu:https://www.ibm.com/support/knowledgecenter/en/linuxonibm/com.ibm.linux.z.lgdd/lgdd_r_posscpusparm.html
if u != 0 {
usage = append(usage, u)
}
}
return usage, nil
}
// CPUSetCPUs cpuset.cpus
func (c *cgroup) CPUSetCPUs() ([]uint64, error) {
data, err := readFile(path.Join(c.cgroupSet["cpuset"], "cpuset.cpus"))
if err != nil {
return nil, err
}
cpus, err := ParseUintList(data)
if err != nil {
return nil, err
}
var sets []uint64
for k := range cpus {
sets = append(sets, uint64(k))
}
return sets, nil
}
// CurrentcGroup get current process cgroup
func currentcGroup() (*cgroup, error) {
pid := os.Getpid()
cgroupFile := fmt.Sprintf("/proc/%d/cgroup", pid)
cgroupSet := make(map[string]string)
fp, err := os.Open(cgroupFile)
if err != nil {
return nil, err
}
defer fp.Close()
buf := bufio.NewReader(fp)
for {
line, err := buf.ReadString('\n')
if err != nil {
if err == io.EOF {
break
}
return nil, err
}
col := strings.Split(strings.TrimSpace(line), ":")
if len(col) != 3 {
return nil, fmt.Errorf("invalid cgroup format %s", line)
}
dir := col[2]
// When dir is not equal to /, it must be in docker
if dir != "/" {
cgroupSet[col[1]] = path.Join(cgroupRootDir, col[1])
if strings.Contains(col[1], ",") {
for _, k := range strings.Split(col[1], ",") {
cgroupSet[k] = path.Join(cgroupRootDir, k)
}
}
} else {
cgroupSet[col[1]] = path.Join(cgroupRootDir, col[1], col[2])
if strings.Contains(col[1], ",") {
for _, k := range strings.Split(col[1], ",") {
cgroupSet[k] = path.Join(cgroupRootDir, k, col[2])
}
}
}
}
return &cgroup{cgroupSet: cgroupSet}, nil
}
|
Allow 方法
先看看 Allow 方法的实现,在每次的服务端请求中都会调用此方法,注意下面节点:
- passStat 及 rtStat 的数据上报的逻辑
- rt–请求成功的响应耗时的计算方法
rt 的计算方法比较巧妙:
- 初始化全局变量
initTime = time.Now()
- 请求开始前计算
stime := time.Since(initTime)
- Allow 返回一个函数对象
func(info limit.DoneInfo),在函数对象中计算 rt := int64((time.Since(initTime) - stime) / time.Millisecond) 这样就成功的避免每次需要保存前一个周期计时点了,不过引入的成本就是需要取两次当前最新的时间戳。
值得细品的是返回的这个函数对象,通过对这个函数对象的延迟调用,可以实现一些在 “某某事情(接口调用、请求执行)完成后再执行的” 功能,在 golang 中可以算是通用的解决方式了。比如,在 Warden 的服务端实现中,默认加载了 bbr.Limiter 作为服务端过载保护的手段,实现的 Limiter 拦截器代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// Limit is a server interceptor that detects and rejects overloaded traffic.
func (b *RateLimiter) Limit() grpc.UnaryServerInterceptor {
return func(ctx context.Context, req interface{}, args*grpc.UnaryServerInfo, handler grpc.UnaryHandler) (resp interface{}, err error) {
uri := args.FullMethod
limiter := b.group.Get(uri)
done, err := limiter.Allow(ctx)
if err != nil {
_metricServerBBR.Inc(uri)
return
}
defer func() {
done(limit.DoneInfo{Op: limit.Success})
b.printStats(uri, limiter)
}()
resp, err = handler(ctx, req)
return
}
}
|
注意上面代码中的 done, err := limiter.Allow(ctx),就是调用了 bbr.Limiter 实现的 Allow() 方法,然后在 defer func() {......} 中巧妙的调用了 done 方法。注意 defer 的调用位置在 resp, err = handler(ctx, req) 之后,这代表,在真正的 RPC 方法执行完之后才调用 defer 中的逻辑:done(limit.DoneInfo{Op: limit.Success}),这里就调用了函数对象里面的实现逻辑:
- 计算 rt 的值
- 向 rtStat 滑动窗口计数器中累加 rt 及次数
- 当前正在处理请求数 inFlight 减 1
- 根据 do.Op 取值,若为 limit.Success,则向滑动窗口计数器 passStat 累加计数
- 返回
代码片段如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func(do limit.DoneInfo) {
// 获取执行过程的耗时
rt := int64((time.Since(initTime) - stime) / time.Millisecond)
// 向 RollingCounter 中添加 rt(这是把 RollingCounter 当做累加器使用)
l.rtStat.Add(rt)
atomic.AddInt64(&l.inFlight, -1)
switch do.Op {
case limit.Success:
l.passStat.Add(1)
return
default:
return
}
}
|
完整的 Allow 实现代码如下,注意是在 shouldDrop 方法是基于 bbr 的限流算法来判断是否应该丢弃请求:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
// Allow checks all inbound traffic.
// Once overload is detected, it raises ecode.LimitExceed error.
func (l *BBR) Allow(ctx context.Context, opts ...limit.AllowOption) (func(info limit.DoneInfo), error) {
allowOpts := limit.DefaultAllowOpts()
for _, opt := range opts {
opt.Apply(&allowOpts)
}
// shouldDrop 判断是否需要限流,如果true表示限流 之后重点讲
if l.shouldDrop() {
return nil, ecode.LimitExceed
}
atomic.AddInt64(&l.inFlight, 1) // 之前说的,正在处理数+1
stime := time.Since(initTime) // 现在时间减去程序初始化时间 表示程序开始执行时刻
return func(do limit.DoneInfo) { // allow返回函数 在中间件(拦截器)中handle执行完成后调用
rt := int64((time.Since(initTime) - stime) / time.Millisecond) // 执行完handle的时间减去stime 表示 程序执行的总时间 单位ms
l.rtStat.Add(rt) // 把处理时间放进采样数据window
atomic.AddInt64(&l.inFlight, -1) // 正在处理数-1 便是处理完成
switch do.Op {
case limit.Success:
l.passStat.Add(1) // 成功了,把通过数的采样数据window加1
return
default:
return
}
}, nil
}
// Stats contains the metrics’s snapshot of bbr. type Stat struct { Cpu int64 InFlight int64 MaxInFlight int64 MinRt int64 MaxPass int64 }
// Config contains configs of bbr limiter. type Config struct { Enabled bool Window time.Duration WinBucket int Rule string Debug bool CPUThreshold int64 }
|
滑动窗口
在自适应限流保护中,采集到的指标的时效性非常强,系统只需要采集最近一小段时间内的 qps、rt 即可,对于较老的数据,会自动丢弃。为了实现这个效果,kratos 使用了滑动窗口来保存采样数据。
单元节点: Bucket
Bucket 提供了 Append 方法,用于向 Points 中添加数据,Points 是 float64 类型的 slice,主要存放单个指标的值,如延迟,错误次数等等
1
2
3
4
5
|
type Bucket struct {
Points []float64 // 单个节点中的统计数据(数组)
Count int64 // 总数
next *Bucket // 链表实现
}
|
Bucket 提供了两种数值添加的接口:Append 和 Add,这两个方法会被上层 Window 的方法调用:
Append 是在 Bucket 的 Points 数组中直接追加数据:
1
2
3
4
5
|
// Append appends the given value to the bucket.
func (b *Bucket) Append(val float64) {
b.Points = append(b.Points, val)
b.Count++
}
|
Add 是在 Bucket 的 Points 数组中的指定 index 位置累加值:
1
2
3
4
5
6
|
// Add adds the given value to the point.
// 给 []float64 指定位置累加值
func (b*Bucket) Add(offset int, val float64) {
b.Points[offset] += val
b.Count++
}
|
Bucket 的遍历方式:
1
2
3
4
5
|
// Next returns the next bucket.
// 遍历链表用(返回当前 node 的下一个 node)
func (b *Bucket) Next()*Bucket {
return b.next
}
|
bucket 提供了 iterator 的封装,用于滑动窗口的遍历。遍历的目的是为了对窗口的数据做提取和计算;比如,计算截至当前时间滑动窗口的请求失败率,就需要遍历从窗口 start 位置到目前时间的所有 Bucket 的错误总数/请求总数。
环形数组: Window
Window 的结构,就是 Bucket 组成的 slice:
1
2
3
4
|
type Window struct {
window []Bucket // 滑动窗口实现
size int
}
|
Window 的初始化逻辑,这里有个细节是将 Bucket 初始化为环形数组(RingQueue):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// NewWindow creates a new Window based on WindowOpts.
// 初始化滑动窗口
func NewWindow(opts WindowOpts) *Window {
buckets := make([]Bucket, opts.Size)
for offset := range buckets {
// 初始化每个 bucket
buckets[offset] = Bucket{Points: make([]float64, 0)}
nextOffset := offset + 1
if nextOffset == opts.Size {
// 构建一个 queue(环)
nextOffset = 0
}
// 初始化为一个链表(首尾相接)
buckets[offset].next = &buckets[nextOffset]
}
return &Window{window: buckets, size: opts.Size}
}
|
同样的,Window 的数值添加方法也只是对 Bucket 提供接口的进一步封装:
Window 的 Append 方法:向指定的偏移 offset(位于 offset 位置的 Bucket)添加值
1
2
3
4
5
|
// Append appends the given value to the bucket where index equals the given offset.
func (w *Window) Append(offset int, val float64) {
// 调用了 Bucket 的 Append 方法
w.window[offset].Append(val)
}
|
Window 的 Add 方法:向指定的偏移 offset 的 0 号位置累加值(和 Append 有稍许不同)
1
2
3
4
5
6
7
8
9
10
|
// Add adds the given value to the latest point within bucket where index equals the given offset.
func (w*Window) Add(offset int, val float64) {
if w.window[offset].Count == 0 {
// 如果 bucket 是空的(没有统计值),直接 Append
w.window[offset].Append(val)
return
}
// bucket 非空,在 Point[] 的 0 号位置累加值
w.window[offset].Add(0, val)
}
|
Window 的迭代器生成
1
2
3
4
5
6
7
8
|
// 需要提供传入的 offset 和 count
func (w *Window) Iterator(offset int, count int) Iterator {
// 构建 window 的 Iterator(迭代器),方便统计和遍历
return Iterator{
count: count,
cur: &w.window[offset],
}
}
|
迭代器的结构如下:
1
2
3
4
5
6
|
// Iterator iterates the buckets within the window.
type Iterator struct {
count int // 遍历完成的条件(i.count != i.iteratedCount)
iteratedCount int
cur *Bucket // 当前迭代器的位置
}
|
下面 Next 方法,定义了遍历器的退出条件:遍历完 count 个 Bucket(窗口)后完成,其中 iteratedCount 是计数器
1
2
3
4
5
|
// 这里很重要,Iter 的迭代规则是,移动 count 的次数 == 当前移动次数
// Next returns true util all of the buckets has been iterated.
func (i *Iterator) Next() bool {
return i.count != i.iteratedCount
}
|
Bucket 方法,获取当前的 Bucket,并且把指针指向下一个 Bucket
1
2
3
4
5
6
7
8
9
10
|
// Bucket gets current bucket.
func (i *Iterator) Bucket() Bucket {
if !(i.Next()) {
panic(fmt.Errorf("stat/metric: iteration out of range iteratedCount: %d count: %d", i.iteratedCount, i.count))
}
bucket :=*i.cur
i.iteratedCount++ // 累加计数器
i.cur = i.cur.Next()
return bucket
}
|
滑动窗口: RollingPolicy
在项目中,如何在滑动窗口中加入时间跨度,用来实现滑动窗口结构的实例化?答案就是 Rolling 结构。如下图,一个 Bucket 代表 500ms,一个滑动窗口占据 2 个 Bucket。这是一个非常精妙的数据结构,表现在以下几点:
- 采集到的指标的时效性非常强,系统只需要采集最近一小段时间内关注的 Metrics 即可,对于较老的数据,会自动丢弃
- 如下图展示的的滑动窗口。整个滑动窗口用来保存最近 1s 的采样数据,每个小的桶用来保存 500ms 的采样数据。当时间流动之后,过期的桶会自动被新桶的数据覆盖掉,在图中,在 1000-1500ms 时,Bucket-1 的数据因为过期而被丢弃,之后 Bucket-3 的数据填到了窗口的头部。(由于在实现上滑动窗口被构造为一个环,所以 Bucket-3 的位置实际上在第 0 号位,即 Bucket-1 的位置)
- 由于滑动窗口以时间为 key,外部接口调用 Add 方法添加新的指标时,会根据时间跨度将不同(相近)时间戳的指标汇总到一个 “窗口” 中,从而可以使得统计结果更加趋于平滑,不会受到单次统计波动的影响
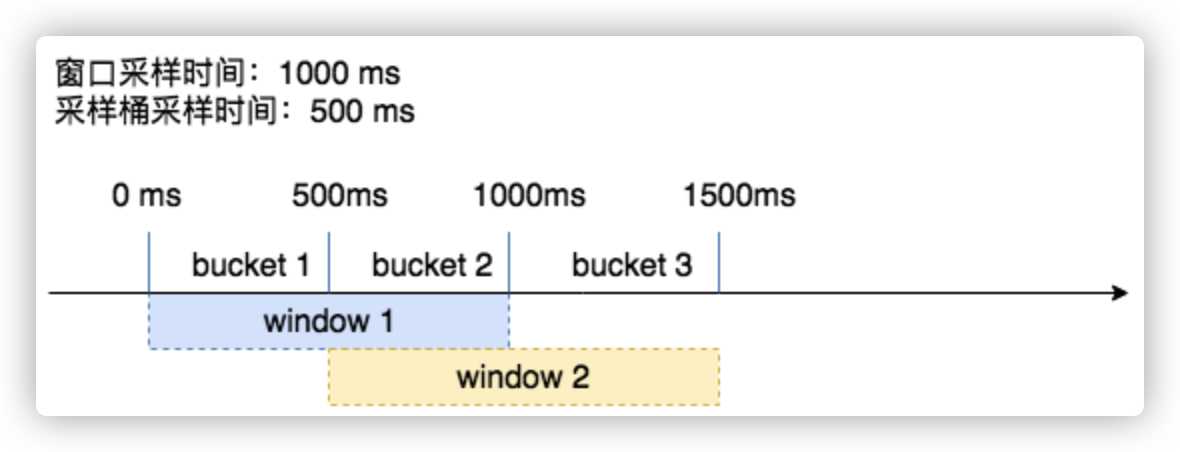
Rolling_policy 中,封装了滑动窗口,加入了互斥锁、单位时间跨度(单个桶)、最后一次更新时间等,使其成为外部可调用的结构体,如下:
1
2
3
4
5
6
7
8
9
|
type RollingPolicy struct {
mu sync.RWMutex //(子协程)并发的 add 操作必须加锁!
size int // 滑动窗口的 size
window *Window // 滑动窗口
offset int
bucketDuration time.Duration // 一个桶代表多长时间
lastAppendTime time.Time // 滑动窗口的 START 位置
}
|
通过,time.Now()- 当前时间、bucketDuration 以及 lastAppendTime 这几项时间因素的关联,是的 RollingPolicy.window 具有了基于时间的滑动窗口的概念。
RollingPolicy 中有 3 个核心方法,分别为 timespan、add 和 Reduce。
下面 timespan() 方法就是计算:当前调用此方法的时刻,距离上一次写入(lastAppendTime)滑过了几个 Bucket
1
2
3
4
5
6
7
8
|
func (r *RollingPolicy) timespan() int {
v := int(time.Since(r.lastAppendTime) / r.bucketDuration)
if v > -1 { // maybe time backwards
return v
}
// 时间调整了
return r.size
}
|
RollingPolicy 的添加数据方法,分别调用了 window 的 Append 和 Add 方法:
1
2
3
4
5
6
7
8
9
|
// Append appends the given points to the window.
func (r *RollingPolicy) Append(val float64) {
r.add(r.window.Append, val)
}
// Add adds the given value to the latest point within bucket.
func (r *RollingPolicy) Add(val float64) {
r.add(r.window.Add, val)
}
|
add 方法:通过计算出当前时间 time.Now() 与 lastAppendTime 的跨度差,在环形滑动窗口中获取正确的位置,然后调用传入的 f 进行插入操作。请注意,跨度超过了 Window 的 End 位置需要从 Start 位置重新计算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
func (r *RollingPolicy) add(f func(offset int, val float64), val float64) {
r.mu.Lock()
// 计算时间跨度(跨过了几个 bucket)
timespan := r.timespan()
if timespan > 0 {
// 当 timespan>0 时,表示有跨度
// 更新当前 append 时间
r.lastAppendTime = r.lastAppendTime.Add(time.Duration(timespan* int(r.bucketDuration)))
offset := r.offset
// reset the expired buckets
s := offset + 1 //s 指向下一个位置
if timespan > r.size {
// 如果跨度超过了 window 的大小,timespan 最大为 window 的 size
timespan = r.size
}
e, e1 := s+timespan, 0 // e: reset offset must start from offset+1
if e > r.size {
e1 = e - r.size
e = r.size
}
for i := s; i < e; i++ {
// 清理 offset1---> s+timespan 的之间的 bucket
r.window.ResetBucket(i)
offset = i
}
for i := 0; i < e1; i++ {
// 如果超过一个跨度,那么说明时间跨度在两个区间上
r.window.ResetBucket(i)
offset = i
}
r.offset = offset
}
// 添加到 offset 位置
//(当 timespan==0 时,说明,当前时间未出现 span,直接操作 r.offset 位置即可)
f(r.offset, val)
r.mu.Unlock()
}
|
Reduce 方法,非常有意思,它的传入参数是 reduce.go 中定义的求值操作,如 Sum、Avg、Min、Max 和 Couter。 该方法的作用是,在 timespan 这个区间进行遍历,计算遍历的起始位置 offset 和长度 count,会调用上面这个几个方法之一(对遍历的这些 Bucket)进行计算,最终得到 val。比如,求当前时间 time.Now() 到 lastAppendTime 之间,滑动窗口的 Sum 累加值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// Reduce applies the reduction function to all buckets within the window.
func (r *RollingPolicy) Reduce(f func(Iterator) float64) (val float64) {
r.mu.RLock()
timespan := r.timespan()
if count := r.size - timespan; count > 0 {
offset := r.offset + timespan + 1
if offset >= r.size {
offset = offset - r.size
}
// 计算得到遍历的开始位置 offset 和遍历长度 count
//f 的参数,就是 Iterator 的结果
val = f(r.window.Iterator(offset, count))
}
r.mu.RUnlock()
return val
}
|
计数器: RollingCounter
RollingCounter 就是基于滑动窗口的计数器。是 RollingPolicy 的上一层封装:
1
2
3
4
5
6
7
8
9
10
11
12
|
type rollingCounter struct {
policy *RollingPolicy
}
type RollingCounter interface {
Metric // with prometheus
Aggregation
Timespan() int
// Reduce applies the reduction function to all buckets within the window.
Reduce(func(Iterator) float64) float64
}
|
RollingCounter 的 Add 方法,限制了计数器累加值不能为负数:
1
2
3
4
5
6
7
|
func (r *rollingCounter) Add(val int64) {
// 计数器不能为负数
if val < 0 {
panic(fmt.Errorf("stat/metric: cannot decrease in value. val: %d", val))
}
r.policy.Add(float64(val))
}
|
瞬时统计: RollingGauge
RollingGauge 是基于滑动窗口的瞬时数据统计器。它和 RollingCounter 的最大不同是向 Bucket 的 Points 数组,追加数据(Points 数组的每个 index 代表了一种维度的 gauge)。RollingGauge 的结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
|
type rollingGauge struct {
policy *RollingPolicy
}
// RollingGauge represents a ring window based on time duration.
// e.g. [[1, 2], [1, 2, 3], [1,2, 3, 4]]
type RollingGauge interface {
Metric
Aggregation
// Reduce applies the reduction function to all buckets within the window.
Reduce(func(Iterator) float64) float64
}
|
RollingGauge 调用了 Window 的 Append 方法来完成存值:
1
2
3
4
5
6
7
|
func (r *rollingGauge) Add(val int64) {
r.policy.Append(float64(val))
}
// Append appends the given points to the window.
func (r *RollingPolicy) Append(val float64) {
r.add(r.window.Append, val)
}
|
MaxPass && MinRT
MaxPass 表示最近 5s 内,单个采样窗口(window)中最大的请求数。换言之,就是找出当前时间戳的滑动窗口的所有桶中,最大的请求计数器的值(单个桶):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
// 单个采样窗口的最大的请求数, 默认的采样窗口是10s, 采样bucket数量100
func (l *BBR) maxPASS() int64 {
rawMaxPass := atomic.LoadInt64(&l.rawMaxPASS)
if rawMaxPass > 0 && l.passStat.Timespan() < 1 {
// 当前的时间跨度未超过一个单位
return rawMaxPass
}
// 通过 Reduce 方法来获取最大的 Pass 值
// 遍历100个采样bucket, 找到采样bucket中最大的请求数
rawMaxPass = int64(l.passStat.Reduce(func(iterator metric.Iterator) float64 {
var result = 1.0
for i := 1; iterator.Next() && i < l.conf.WinBucket; i++ {
bucket := iterator.Bucket()
count := 0.0
for _, p := range bucket.Points {
// 叠加 bucket.Points,注意 Points 的类型是 Points []float64
count += p
}
result = math.Max(result, count)
}
return result
}))
if rawMaxPass == 0 {
rawMaxPass = 1
}
// 存储在 rawMaxPASS 中并返回
atomic.StoreInt64(&l.rawMaxPASS, rawMaxPass)
return rawMaxPass
}
|
MinRt 表示最近 5s 内,单个采样窗口中最小的响应时间。windows 表示一秒内采样窗口的数量,默认配置中是 5s 50 个采样,那么 windows 的值为 10。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
// 单个采样窗口中最小的响应时间
func (l *BBR) minRT() int64 {
rawMinRT := atomic.LoadInt64(&l.rawMinRt)
if rawMinRT > 0 && l.rtStat.Timespan() < 1 {
return rawMinRT
}
// 遍历100个采样bucket, 找到采样bucket中最小的响应时间
rawMinRT = int64(math.Ceil(l.rtStat.Reduce(func(iterator metric.Iterator) float64 {
var result = math.MaxFloat64
for i := 1; iterator.Next() && i < l.conf.WinBucket; i++ {
bucket := iterator.Bucket()
if len(bucket.Points) == 0 {
continue
}
total := 0.0
for _, p := range bucket.Points {
total += p
}
avg := total / float64(bucket.Count)
result = math.Min(result, avg)
}
return result
})))
if rawMinRT <= 0 {
rawMinRT = 1
}
atomic.StoreInt64(&l.rawMinRt, rawMinRT)
return rawMinRT
}
|
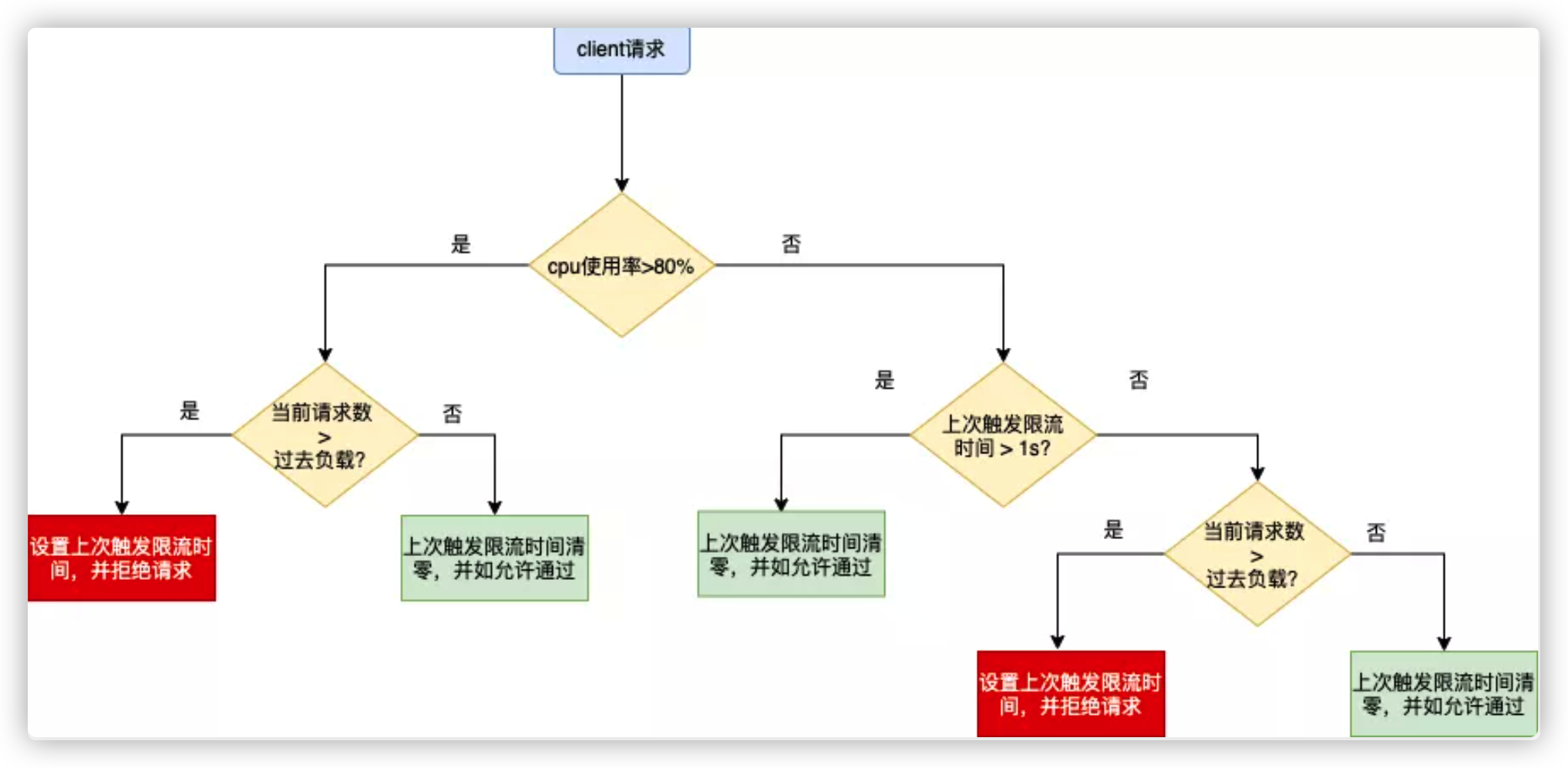
判断规则
我们使用 CPU 的滑动均值(CPU > 800)作为启发阈值,一旦触发进入到过载保护阶段,算法为:(pass* rt) < inflight
判断是否丢弃当前请求的算法如下:
1
|
cpu > 800 AND (Now - PrevDrop) < 1s AND maxFlight < InFlight
|
(Now - PrevDrop) < 1s 表示当前处于冷却时间内,限流效果生效后,CPU 会在临界值(800)附近抖动,如果不使用冷却时间,那么一个短时间的 CPU 下降就可能导致大量请求被放行,严重时会打满 CPU。
在冷却时间后,重新判断阈值(CPU > 800 ),是否持续进入过载保护。
maxInFlight()方法代表过去的负载
1
2
3
|
func (l *BBR) maxFlight() int64 {
return int64(math.Floor(float64(l.maxPASS()*l.minRT()*l.winBucketPerSec)/1000.0 + 0.5))
}
|
l.maxPass() * bucketPerSecond/1000 为每毫秒处理的请求数
- l.maxPass() 表示在采样周期内,单个采样窗口的最大的请求数
- l.minRT(): 表示在采样周期内,单个采样窗口中最小的响应时间
- T ≈ QPS* Avg(RT)
- +0.5为向上取整
- l.winBucketPerSec: 每秒内的采样桶数量,其计算方式:int64(time.Second)/(int64(conf.Window)/int64(conf.WinBucket)), conf.Window默认值10s, conf.WinBucket默认值100. 简化下公式: 1/(10/100) = 10, 所以每秒内的采样桶数就是10
shouldDrop
shouldDrop 代码实现了前文的公式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
func (l *BBR) shouldDrop() bool {
// 判断目前cpu的使用率是否达到设置的CPU的限制, 默认值800
if l.cpu() < l.conf.CPUThreshold {
// 如果上一次舍弃请求的时间是0, 那么说明没有限流的需求, 直接返回
prevDrop, _ := l.prevDrop.Load().(time.Duration)
if prevDrop == 0 {
return false
}
// 如果上一次请求的时间与当前的请求时间小于1s, 那么说明有限流的需求
if time.Since(initTime)-prevDrop <= time.Second {
if atomic.LoadInt32(&l.prevDropHit) == 0 {
atomic.StoreInt32(&l.prevDropHit, 1)
}
// 增加正在处理的请求的数量
inFlight := atomic.LoadInt64(&l.inFlight)
// 判断正在处理的请求数是否达到系统的最大的请求数量
return inFlight > 1 && inFlight > l.maxFlight()
}
// 清空当前的prevDrop
l.prevDrop.Store(time.Duration(0))
return false
}
// 增加正在处理的请求的数量
inFlight := atomic.LoadInt64(&l.inFlight)
// 判断正在处理的请求数是否达到系统的最大的请求数量
drop := inFlight > 1 && inFlight > l.maxFlight()
if drop {
prevDrop, _ := l.prevDrop.Load().(time.Duration)
// 如果判断达到了最大请求数量, 并且当前有限流需求
if prevDrop != 0 {
return drop
}
l.prevDrop.Store(time.Since(initTime))
}
return drop
}
|
流程图
压测报告
场景1,请求以每秒增加1个的速度不停上升,压测效果如下:
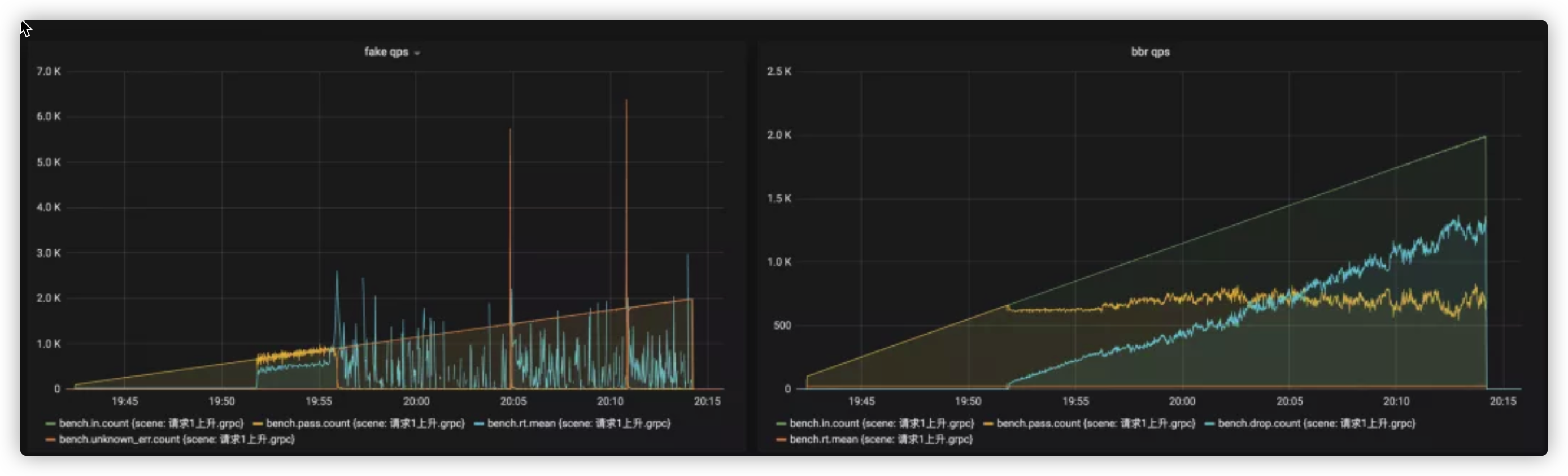
左测是没有限流的压测效果,右侧是带限流的压测效果。可以看到,没有限流的场景里,系统在 700qps 时开始抖动,在 1k qps 时被拖垮,几乎没有新的请求能被放行,然而在使用限流之后,系统请求能够稳定在 600 qps 左右,rt 没有暴增,服务也没有被打垮,可见,限流有效的保护了服务。
参考
Kratos 源码分析 - BBR限流源码实现
从kratos分析BBR限流源码实现
限流器系列(3)–自适应限流
Kratos 源码分析:理解 Kratos 的数据统计类型 Metrics(二)
Kratos 源码分析:理解 Kratos 的数据统计类型 Metrics(一)
Sentinel系统自适应限流【原理源码】
深入理解云原生下自适应限流技术原理与应用