前言
Go 的运行时能够直接接触到操作系统内核级的同步原语,note 和 mutex 分别是 Go 运行时实现的一次性通知机制和互斥锁机制, 其实现是操作系统特定的,这里讨论 darwin 和 linux 的分别基于 semaphore 和 futex 的实现,wasm 的实现我们放到其章节中专门讨论。
虽然 Go 受到 CSP 的影响提供了 channel 这一同步原语,但 channel 在某些情况下(比如天然需要共享内存的资源池) 使用共享内存的互斥锁这一同步原语在编程上会更加方便。但问题在于,由于调度器的存在,内核级的同步原语并不能直接暴露给用户态代码, 因此运行时还需要特殊设计的信号量机制来支持用户态的同步原语。
运行时通知机制 note
运行时的通知机制在 Linux 上直接基于 Futex(Fast userspace mutex),我们首先回顾它。
futex(快速用户区互斥的简称)是一个在Linux上实现锁定和构建高级抽象锁如信号量和POSIX互斥的基本工具
Futex 由一块能够被多个进程共享的内存空间(一个对齐后的整型变量)组成;这个整型变量的值能够通过汇编语言调用CPU提供的原子操作指令来增加或减少,并且一个进程可以等待直到那个值变成正数。Futex 的操作几乎全部在用户空间完成;只有当操作结果不一致从而需要仲裁时,才需要进入操作系统内核空间执行。这种机制允许使用 futex 的锁定原语有非常高的执行效率:由于绝大多数的操作并不需要在多个进程之间进行仲裁,所以绝大多数操作都可以在应用程序空间执行,而不需要使用(相对高代价的)内核系统调用。
结构
note 的结构本身并没有什么可说的,它自身只包含一个 uintptr 类型的标志。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// 休眠与唤醒一次性事件.
// 在任何调用 notesleep 或 notewakeup 之前,必须调用 noteclear 来初始化这个 note
// 且只能有一个线程调用 notewakeup 一次。一旦 notewakeup 被调用后,notesleep 会返回。
// 随后的 notesleep 调用则会立即返回。
// 随后的 noteclear 必须在前一个 notesleep 返回前调用,例如 notewakeup 调用后
// 直接调用 noteclear 是不允许的。
//
// notetsleep 类似于 notesleep 但会在给定数量的纳秒时间后唤醒,即使事件尚未发生。
// 如果一个 goroutine 使用 notetsleep 来提前唤醒,则必须等待调用 noteclear,直到可以确定
// 没有其他 goroutine 正在调用 notewakeup。
//
// notesleep/notetsleep 通常在 g0 上调用,notetsleepg 类似于 notetsleep 但会在用户 g 上调用。
type note struct {
// 基于 futex 的实现将其视为 uint32 key (linux)
// 而基于 sema 实现则将其视为 M*waitm。 (darwin)
// 以前作为 union 使用,但 union 会破坏精确 GC
key uintptr
}
|
注册通知
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
func notesleep(n *note) {
gp := getg()
if gp != gp.m.g0 {
throw("notesleep not on g0")
}
ns := int64(-1)
if *cgo_yield != nil {
// Sleep for an arbitrary-but-moderate interval to poll libc interceptors.
ns = 10e6
}
for atomic.Load(key32(&n.key)) == 0 {
gp.m.blocked = true
futexsleep(key32(&n.key), 0, ns)
if *cgo_yield != nil {
asmcgocall(*cgo_yield, nil)
}
gp.m.blocked = false
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
func notetsleep(n*note, ns int64) bool {
(...)
return notetsleep_internal(n, ns)
}
//go:nosplit
//go:nowritebarrier
func notetsleep_internal(n*note, ns int64) bool {
gp := getg()
if ns < 0 {
if *cgo_yield != nil {
// Sleep for an arbitrary-but-moderate interval to poll libc interceptors.
ns = 10e6
}
for atomic.Load(key32(&n.key)) == 0 {
gp.m.blocked = true
futexsleep(key32(&n.key), 0, ns)
if *cgo_yield != nil {
asmcgocall(*cgo_yield, nil)
}
gp.m.blocked = false
}
return true
}
if atomic.Load(key32(&n.key)) != 0 {
return true
}
deadline := nanotime() + ns
for {
if *cgo_yield != nil && ns > 10e6 {
ns = 10e6
}
gp.m.blocked = true
futexsleep(key32(&n.key), 0, ns)
if *cgo_yield != nil {
asmcgocall(*cgo_yield, nil)
}
gp.m.blocked = false
if atomic.Load(key32(&n.key)) != 0 {
break
}
now := nanotime()
if now >= deadline {
break
}
ns = deadline - now
}
return atomic.Load(key32(&n.key)) != 0
}
//go:nosplit
func futexsleep(addr *uint32, val uint32, ns int64) {
// Some Linux kernels have a bug where futex of
// FUTEX_WAIT returns an internal error code
// as an errno. Libpthread ignores the return value
// here, and so can we: as it says a few lines up,
// spurious wakeups are allowed.
if ns < 0 {
futex(unsafe.Pointer(addr), _FUTEX_WAIT_PRIVATE, val, nil, nil, 0)
return
}
var ts timespec
ts.setNsec(ns)
futex(unsafe.Pointer(addr), _FUTEX_WAIT_PRIVATE, val, unsafe.Pointer(&ts), nil, 0)
}
|
1
2
3
4
5
6
7
8
|
// 允许在用户 g 上调用
func notetsleepg(n *note, ns int64) bool {
(...)
entersyscallblock()
ok := notetsleep_internal(n, ns)
exitsyscall()
return ok
}
|
发送通知
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
func notewakeup(n*note) {
old := atomic.Xchg(key32(&n.key), 1)
if old != 0 {
print("notewakeup - double wakeup (", old, ")\n")
throw("notewakeup - double wakeup")
}
futexwakeup(key32(&n.key), 1)
}
func futexwakeup(addr*uint32, cnt uint32) {
// linux futex 系统调用
ret := futex(unsafe.Pointer(addr), _FUTEX_WAKE_PRIVATE, cnt, nil, nil, 0)
if ret >= 0 {
return
}
(...)
}
|
清除通知
note 通知被设计为调用前必须对其标志位进行复位,这就需要调用 noteclear:
1
2
3
4
5
6
7
8
9
|
// darwin, runtime/lock_sema.go
func noteclear(n *note) {
n.key = 0
}
// linux, runtime/lock_futex.go
func noteclear(n *note) {
n.key = 0
}
|
运行时互斥量机制 mutex
结构
运行时的 mutex 互斥锁与 note 原理几乎一致,结构上也只有一个 uintptr 类型的 key:
1
2
3
4
5
6
7
8
|
// 互斥锁。在无竞争的情况下,与自旋锁 spin lock(只是一些用户级指令)一样快,
// 但在争用路径 contention path 中,它们在内核中休眠。零值互斥锁为未加锁状态(无需初始化每个锁)。
type mutex struct {
// 基于 futex 的实现将其视为 uint32 key (linux)
// 而基于 sema 实现则将其视为 M* waitm。 (darwin)
// 以前作为 union 使用,但 union 会打破精确 GC
key uintptr
}
|
lock
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
const (
mutex_unlocked = 0
mutex_locked = 1
mutex_sleeping = 2
active_spin = 4
passive_spin = 1
)
//go:nosplit
func key32(p *uintptr)*uint32 {
return (*uint32)(unsafe.Pointer(p))
}
func lock(l*mutex) {
gp := getg()
(...)
gp.m.locks++
// 锁的推测抓取
v := atomic.Xchg(key32(&l.key), mutex_locked)
if v == mutex_unlocked {
return
}
// wait 可能是 MUTEX_LOCKED 或 MUTEX_SLEEPING
// 取决于是否有线程在此 mutex 上休眠。
// 如果我们没有将 l.key 从 MUTEX_SLEEPING 修改到其他值,
// 我们必须小心的在返回前将其修改回 MUTEX_SLEEPING,进而保证睡眠的
// 的线程能够获得唤醒调用
wait := v
// 在单处理器中,没有 spinning
// 在多处理器中,作为 ACTIVE_SPIN 尝试进行自旋
spin := 0
if ncpu > 1 {
spin = active_spin
}
for {
// 尝试加锁, spinning
for i := 0; i < spin; i++ {
for l.key == mutex_unlocked {
if atomic.Cas(key32(&l.key), mutex_unlocked, wait) {
return
}
}
procyield(active_spin_cnt) // 30
}
// Try for lock, rescheduling.
for i := 0; i < passive_spin; i++ {
for l.key == mutex_unlocked {
if atomic.Cas(key32(&l.key), mutex_unlocked, wait) {
return
}
}
osyield()
}
// Sleep.
v = atomic.Xchg(key32(&l.key), mutex_sleeping)
if v == mutex_unlocked {
return
}
wait = mutex_sleeping
futexsleep(key32(&l.key), mutex_sleeping, -1)
}
}
|
procyield 内部实现什么也不做,只是反复调用 PAUSE 指令 30 次。
1
2
3
4
5
6
7
|
TEXT runtime·procyield(SB),NOSPLIT,$0-0
MOVL cycles+0(FP), AX
again:
PAUSE
SUBL $1, AX
JNZ again
RET
|
osyield 则是系统调用 sched_yield 的封装:
1
2
3
4
|
TEXT runtime·osyield(SB),NOSPLIT,$0
MOVL $SYS_sched_yield, AX
SYSCALL
RET
|
unlock
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func unlock(l *mutex) {
v := atomic.Xchg(key32(&l.key), mutex_unlocked)
(...)
if v == mutex_sleeping {
futexwakeup(key32(&l.key), 1)
}
gp := getg()
gp.m.locks--
(...)
if gp.m.locks == 0 && gp.preempt { // restore the preemption request in case we've cleared it in newstack
gp.stackguard0 = stackPreempt
}
}
|
运行时信号量机制 semaphore
go中的semaphore作用和futex目标一样,提供sleep和wakeup原语,使其能够在其它同步原语中的竞争情况下使用。当一个goroutine需要休眠时,将其进行集中存放,当需要wakeup时,再将其取出,重新放入调度器中。
sync 包中 Mutex 的实现依赖运行时中关于 runtime_Semacquire 与 runtime_Semrelease 的实现。 他们对应于运行时的 sync_runtime_Semacquire 和 sync_runtime_Semrelease 函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
//go:linkname sync_runtime_Semacquire sync.runtime_Semacquire
// Semacquire等待*s > 0,然后原子递减它。
// 它是一个简单的睡眠原语,用于同步
// library and不应该直接使用。
func sync_runtime_Semacquire(addr *uint32) {
semacquire1(addr, false, semaBlockProfile, 0)
}
//go:linkname sync_runtime_Semrelease sync.runtime_Semrelease
// Semrelease会自动增加*s并通知一个被Semacquire阻塞的等待的goroutine
// 它是一个简单的唤醒原语,用于同步
// library and不应该直接使用。
// 如果handoff为true, 传递信号到队列头部的waiter
// skipframes是跟踪过程中要省略的帧数,从这里开始计算
// runtime_Semrelease's caller.
func sync_runtime_Semrelease(addr *uint32, handoff bool, skipframes int) {
semrelease1(addr, handoff, skipframes)
}
|
可以看到他们均为运行时中的 semacquire1 和 semrelease1 函数。
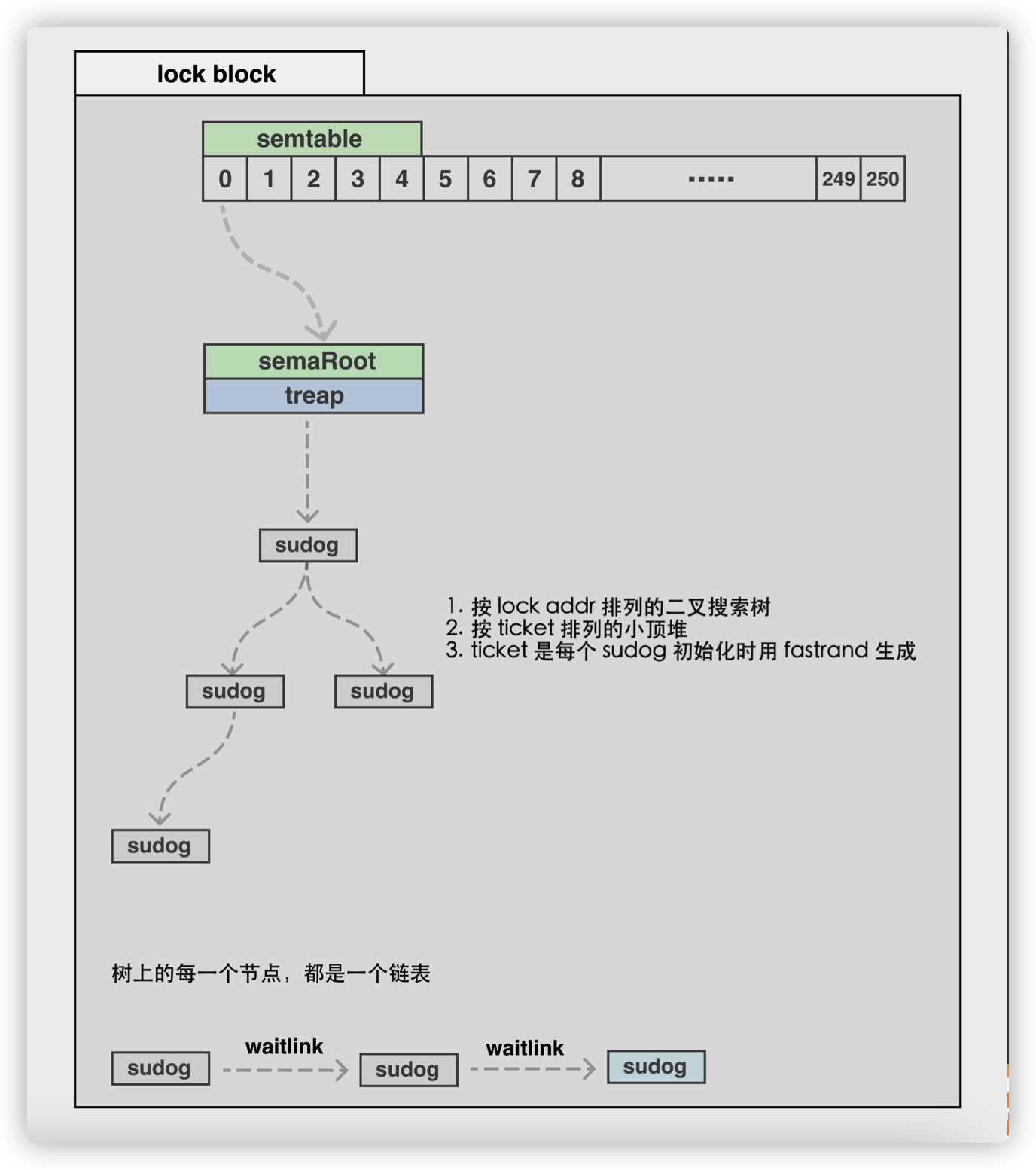
sudog 缓存
sudog 是运行时用来存放处于阻塞状态的 goroutine 的一个上层抽象,是用来实现用户态信号量的主要机制之一。 例如当一个 goroutine 因为等待 channel 的数据需要进行阻塞时,sudog 会将 goroutine 及其用于等待数据的位置进行记录, 并进而串联成一个等待队列,或二叉平衡树。
1
2
3
4
5
6
7
8
9
10
11
|
sudog
+---------+
| g | ---> goroutine
+---------+
| next | ---> 下一个 g
+---------+
| prev | ---> 上一个 g
+---------+
| elem | ---> 发送的元素,可能指向其他 goroutine 的执行栈
+---------+
| ... |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
// sudog represents a g in a wait list, such as for sending/receiving
// on a channel.
//
// sudog is necessary because the g ↔ synchronization object relation
// is many-to-many. A g can be on many wait lists, so there may be
// many sudogs for one g; and many gs may be waiting on the same
// synchronization object, so there may be many sudogs for one object.
//
// sudogs are allocated from a special pool. Use acquireSudog and
// releaseSudog to allocate and free them.
type sudog struct {
// The following fields are protected by the hchan.lock of the
// channel this sudog is blocking on. shrinkstack depends on
// this for sudogs involved in channel ops.
// 由 sudog 阻塞的通道的 hchan.lock 进行保护
g *g
next *sudog
prev *sudog
// 数据元素(可能指向栈)
elem unsafe.Pointer // data element (may point to stack)
// The following fields are never accessed concurrently.
// For channels, waitlink is only accessed by g.
// For semaphores, all fields (including the ones above)
// are only accessed when holding a semaRoot lock.
// 下面的字段永远不会并发的被访问。对于 channel waitlink 只会被 g 访问
// 对于 semaphores,所有的字段(包括上面的)只会在持有 semaRoot 锁时被访问
acquiretime int64
releasetime int64
ticket uint32
// isSelect indicates g is participating in a select, so
// g.selectDone must be CAS'd to win the wake-up race.
// isSelect 表示 g 正在参与一个 select,因此 g.selectDone 必须以 CAS 的方式来避免唤醒时候的 data race。
isSelect bool
// success indicates whether communication over channel c
// succeeded. It is true if the goroutine was awoken because a
// value was delivered over channel c, and false if awoken
// because c was closed.
success bool
// semaRoot 二叉树
parent *sudog // semaRoot binary tree
// g.waiting 列表或 semaRoot
waitlink *sudog // g.waiting list or semaRoot
waittail *sudog // semaRoot
c *hchan // channel
}
|
这些信息是从一个全局缓存池或 per-P 的缓存池进行分配(per-P 优先),当使用完毕后又再次归还给缓存池。 其遵循策略:
- 优先从 per-P 缓存中获取,如果 per-P 缓存为空,则从全局池抓取一半;
- 优先归还到 per-P 缓存,如果 per-P 缓存已满,则将 per-P 缓存的一半归还到全局池。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
//go:nosplit
func acquireSudog() *sudog {
// Delicate dance: 信号量的实现调用acquireSudog,然后acquireSudog调用new(sudog)
// new调用malloc, malloc调用垃圾收集器,垃圾收集器在stopTheWorld调用信号量
// 通过在new(sudog)周围执行acquirem/releasem来打破循环
// acquirem/releasem在new(sudog)期间增加m.locks,防止垃圾收集器被调用。
// 获取当前 g 所在的 m
mp := acquirem() // 获取当前 g 所在的 m
pp := mp.p.ptr()
// 检查 per-P sudogcache 池是否存在可复用的 sudog
if len(pp.sudogcache) == 0 {
lock(&sched.sudoglock)
// 从中央缓存抓取一半
for len(pp.sudogcache) < cap(pp.sudogcache)/2 && sched.sudogcache != nil {
s := sched.sudogcache
sched.sudogcache = s.next
s.next = nil
pp.sudogcache = append(pp.sudogcache, s)
}
unlock(&sched.sudoglock)
// 中央缓存也没有,新分配
if len(pp.sudogcache) == 0 {
pp.sudogcache = append(pp.sudogcache, new(sudog))
}
}
// 取缓存中最后一个
n := len(pp.sudogcache)
s := pp.sudogcache[n-1]
// 将刚取出的在缓存中移除
pp.sudogcache[n-1] = nil
pp.sudogcache = pp.sudogcache[:n-1]
(...)
releasem(mp)
return s
}
//go:nosplit
func releaseSudog(s*sudog) {
(...)
mp := acquirem() // 避免在释放时重新调度到其他的 p 上
pp := mp.p.ptr()
// p 的 sudogcache 已存满,将一半放回到中央缓存中
if len(pp.sudogcache) == cap(pp.sudogcache) {
var first, last *sudog
for len(pp.sudogcache) > cap(pp.sudogcache)/2 {
n := len(pp.sudogcache)
p := pp.sudogcache[n-1]
pp.sudogcache[n-1] = nil
pp.sudogcache = pp.sudogcache[:n-1]
// 构建 sudog 链表
if first == nil {
first = p
} else {
last.next = p
}
last = p
}
lock(&sched.sudoglock)
last.next = sched.sudogcache
sched.sudogcache = first
unlock(&sched.sudoglock)
}
// 将释放的 s 添加到 sudogcache
pp.sudogcache = append(pp.sudogcache, s)
releasem(mp)
}
|
基于 goroutine 抽象的信号量
运行时的信号量需要在 Go 运行时调度器的基础之上提供一个 sleep 和 wakeup 原语,从而向用户态代码屏蔽内部调度器的存在。 例如,当用户态代码使用互斥锁发生竞争时,能够让用户态代码依附的 goroutine 进行 sleep,并在可用时候被 wakeup,并被重新调度。
因此 sleep 和 wakeup 原语的本质是,当一个 goroutine 需要休眠时,将其进行集中存放,当需要 wakeup 时,再将其取出,重新放入调度器中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// semaRoot拥有一个具有不同地址(s.elem)的sudog平衡树。
// 每个sudog都可以依次(通过s.waitlink)指向一个列表,在相同地址上等待的其他sudog。
// 对具有相同地址的sudog内部列表进行的操作全部为O(1)。顶层semaRoot列表的扫描为O(log n),
// 其中,n是阻止goroutines的不同地址的数量,通过他们散列到给定的semaRoot。
type semaRoot struct {
lock mutex
// waiters的平衡树的根节点
treap *sudog
// waiters的数量,读取的时候无所
nwait uint32
}
var semtable [251]struct {
root semaRoot
pad [cpu.CacheLinePadSize - unsafe.Sizeof(semaRoot{})]byte
}
func semroot(addr*uint32) *semaRoot {
// 对信号量的地址取 hash(x) = (x >> 3) % size
return &semtable[(uintptr(unsafe.Pointer(addr))>>3)%semTabSize].root
}
|
其实现中使用分布式散列表结构,根据信号量的实际地址的散列值将其打散到 251 个 treap 树中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags, skipframes int) {
// 快速路径:*addr -= 1
if cansemacquire(addr) {
return
}
// 增加等待计数
// 再试一次 cansemacquire 如果成功则直接返回
// 将自己作为等待者入队
// 休眠
// (等待器描述符由出队信号产生出队行为)
s := acquireSudog()
root := semroot(addr)
(...)
s.ticket = 0
(...)
for {
lock(&root.lock)
// 把我们添加到 nwait 进而避免 semrelease 中的快速路径
atomic.Xadd(&root.nwait, 1)
// 避免虚假唤醒
if cansemacquire(addr) { // atomic *addr -= 1
atomic.Xadd(&root.nwait, -1)
unlock(&root.lock)
break
}
// 任何在 cansemacquire 之后的 semrelease 都知道我们在等待(因为设置了 nwait),因此休眠
// treap.insert(addr, s), addr 保存到 s.elem 中, s 保存到 root 中,
root.queue(addr, s, lifo) // lifo == true: list 中已经有 addr 了
// 将当前goroutine置于等待状态并解锁锁。
// 通过调用goready(gp),可以使goroutine再次可运行。
goparkunlock(&root.lock, waitReasonSemacquire, traceEvGoBlockSync, 4+skipframes)
if s.ticket != 0 || cansemacquire(addr) { // atomic *addr -= 1
break
}
}
(...)
// 归还sudog
releaseSudog(s)
}
func semrelease1(addr *uint32, handoff bool, skipframes int) {
root := semroot(addr)
atomic.Xadd(addr, 1)
// 快速路径: 没有人在此 root 等待
// 必须发生在 xadd 之后,避免虚假唤醒
if atomic.Load(&root.nwait) == 0 {
return
}
// 搜索一个等待着然后将其唤醒
lock(&root.lock)
if atomic.Load(&root.nwait) == 0 {
unlock(&root.lock)
return
}
s, t0 := root.dequeue(addr) // 查找第一个出现的 addr
if s != nil {
atomic.Xadd(&root.nwait, -1)
}
unlock(&root.lock)
if s != nil { // 可能会很慢,因此先解锁
(...)
if handoff && cansemacquire(addr) { // atomic *addr -= 1
s.ticket = 1
}
readyWithTime(s, 5) // goready(s.g, 5) // 标记 runnable,等待被重新调度
}
}
|
这一对 semacquire 和 semrelease 理解上可能不太直观。 首先,我们必须意识到这两个函数一定是在两个不同的 M(线程)上得到执行,否则不会出现并发,我们不妨设为 M1 和 M2。 当 M1 上的 G1 执行到 semacquire1 时,如果快速路径成功,则说明 G1 抢到锁,能够继续执行。但一旦失败且在慢速路径下 依然抢不到锁,则会进入 goparkunlock,将当前的 G1 放到等待队列中,进而让 M1 切换并执行其他 G。 当 M2 上的 G2 开始调用 semrelease1 时,只是单纯的将等待队列的 G1 重新放到调度队列中,而当 G1 重新被调度时(假设运气好又在 M1 上被调度),代码仍然会从 goparkunlock 之后开始执行,并再次尝试竞争信号量,如果成功,则会归还 sudog。
参考
6.8 同步原语