系统设计中如何进行估算
文章目录
前言
在日常工作中,经常会遇到一些大促场景,需要评估系统的资源是否充足,是否需要增加资源,增加多少。
想要做到“准确”的估算,需要对数字有一定的感觉。
2 的次幂
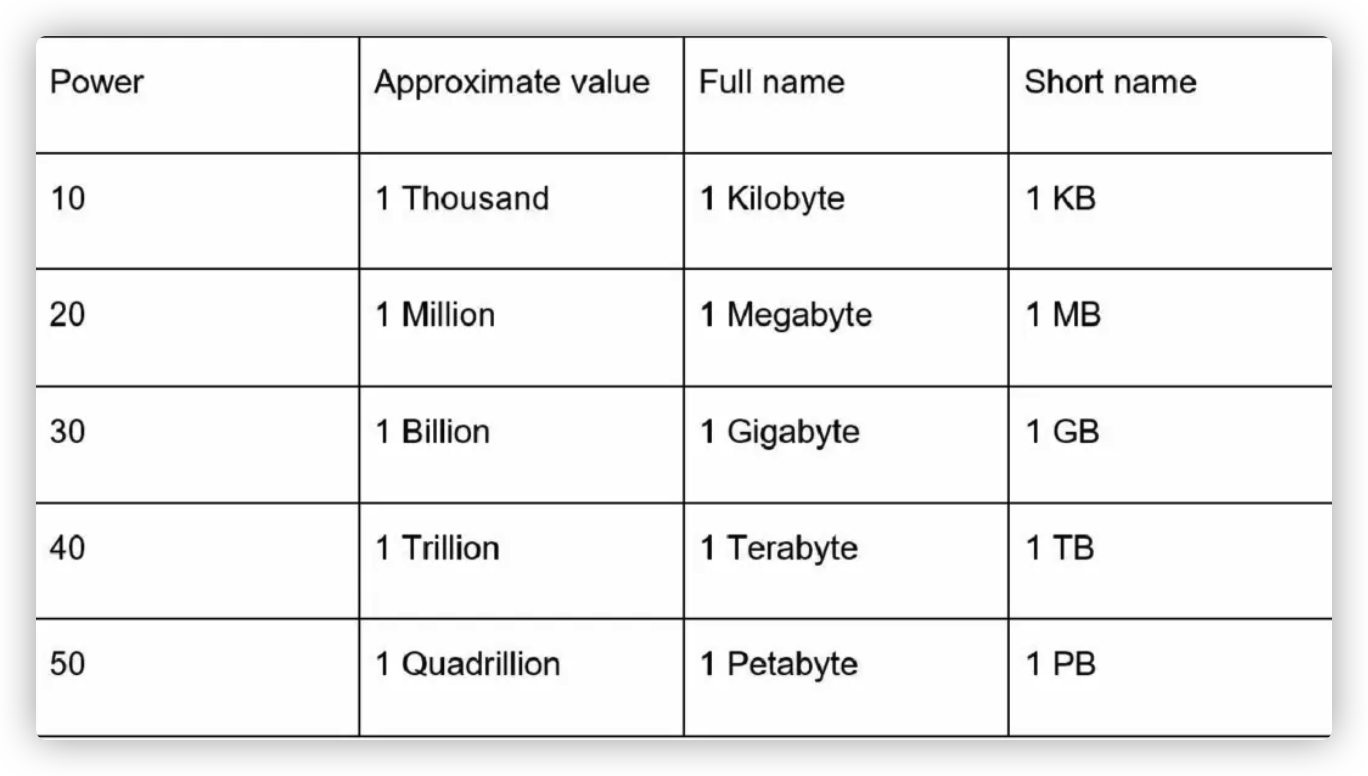
英语里面常讲 1 个 Million,1 个 Billion,分别是百万、十亿的意思。可以看到,以 3 个 0 为一组,层层递进。

延迟数字
这里有一张表格反映了一些计算机的典型操作的耗时,配套的还有一个可视化网站,这个其实见得比较多了。
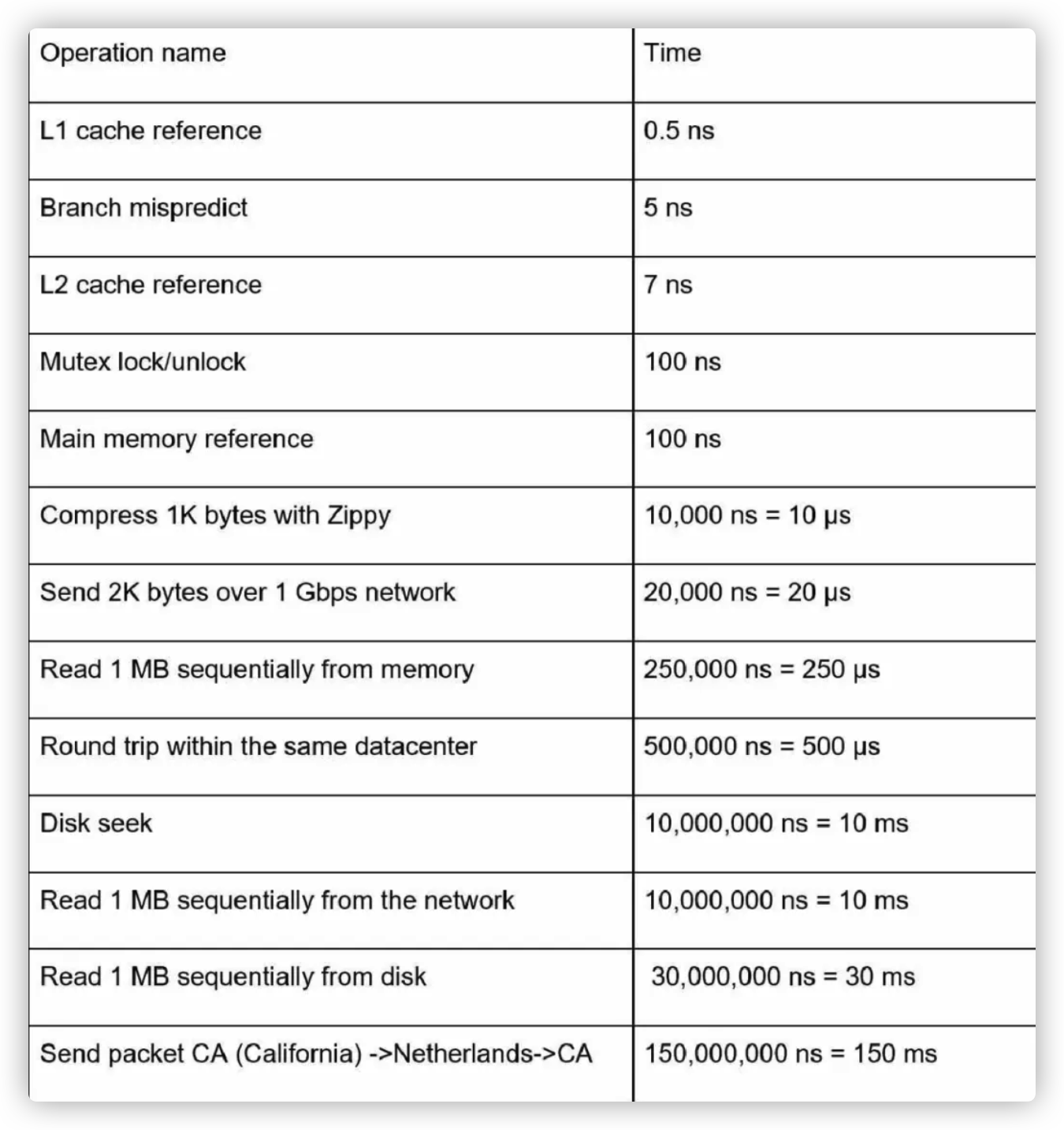
图形化的网页上可以选择年份,数据也更准确。
从中可以得出一些明显的结论:
- 内存比磁盘快。
- 避免 disk seek。
- 数据中心常常位于不同的区域,在它们之间传送数据比较耗时。
- 从磁盘顺序读数据比从网络顺序读数据慢。
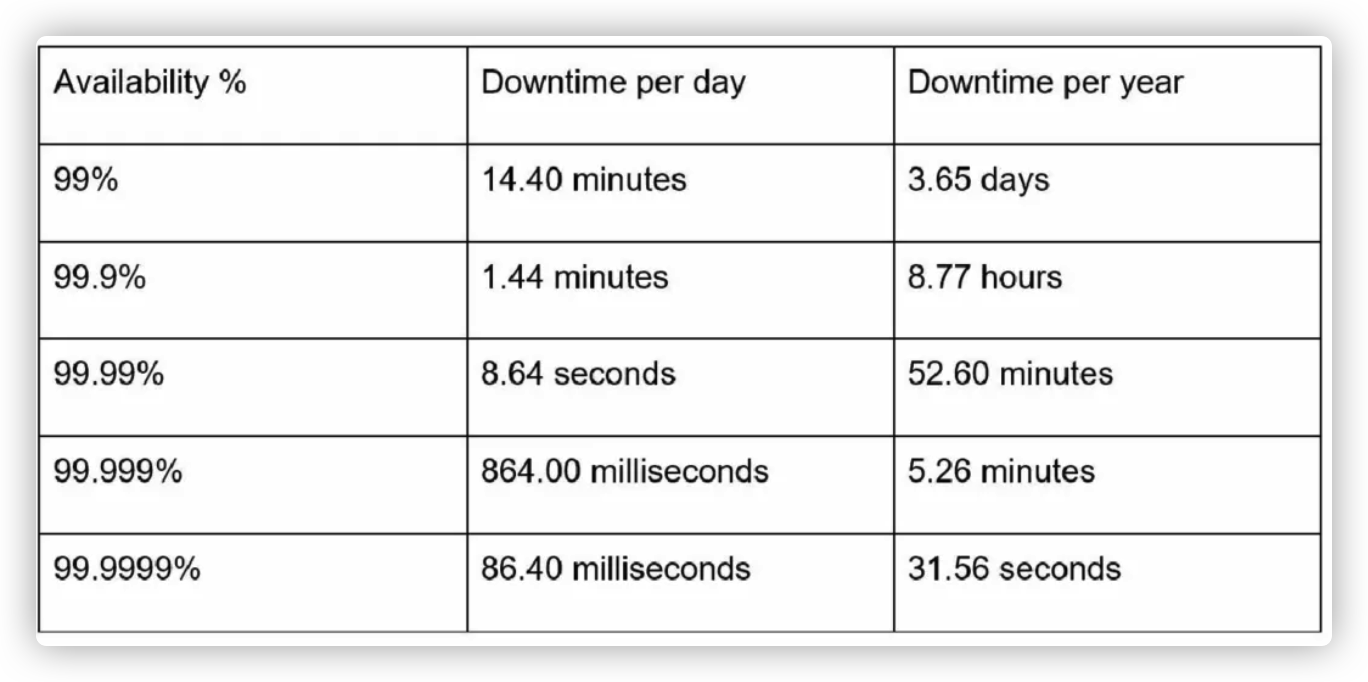
可用性数字
工作中,我们常用几个 9 来形容一个系统的可用性。100% 表示一个系统永远不会挂,实际中的系统可用性指标大多处于 99% -100% 之间。
像一些云厂商,如 Amazon,Microsoft,Google 承诺的可用性是 3 个 9,即 99.9% 或以上,描述的是可用时间。
一些数字积累
- 某支付服务的支付峰值 60w QPS
- Go GC 打开写屏障需要花费 10-30us
- 内网中,一次网络请求的耗时是 ms 级别
- 万兆网卡,1.25GB/s 打满
- 4C8G 建 10w 到 20w 的连接没有问题
- 因为机械硬盘的机械结构,随机 I/O 与顺序的 I/O 性能可能相差几百倍。固态硬盘则只有十几倍到几十倍之间
- twitter 工程师认为,良好体验的网站平均响应时间应该在 500ms 左右,理想的时间是 200-300ms
- 平均 QPS:日平均用户请求除以 4w。日平均用户请求,一般来自产品的评估。峰值 QPS:平均 QPS 的 2~4 倍
实战
本章最后有一个实战的例子:评估 twitter 的 QPS 和存储容量。
先给出了一些预设:
- 300 个 million 的月活跃用户
- 50% 的用户每天都使用 twitter
- 用户平均每天发表 2 条 tweets
- 10% 的 tweets 包含多媒体
- 多媒体数据保存 5 年
下面是估算的过程:
先预估 QPS:
- DAU(每天的活跃用户数,Daily Active Users)为:300 million(总用户数) *50% = 150 million
- 发 tweets 的平均 QPS:150 million* 2 / 24 hour / 3600 second = ~3500
- 高峰期 QPS 一般认为是平均 QPS 的 2 倍:2 * 3500 = 7000 QPS
再来估算存储容量:
假设多媒体的平均大小为 1MB,那么每天的存储容量为:150 million *2* 10% *1MB = 30 TB。5 年的存储容量为 30 TB* 365 * 5 = 55 PB。
最后这两个的估算过程是这样的:
300 个 million *10%* 1MB,1 MB 其实就是 6 个 0,相当于 million 要进化 2 次:million -> billion -> trillion,即从 M -> G -> T,于是结果等于 300 T * 10% = 30 T。
30 TB *365* 5 = 30 TB *1825 = 30 TB* 10^3 *1.825,TB 进化一次变成 PB,于是等于 30* 1.825 PB = 55 PB。
Go map[int64]int64 写入 redis 占用多少内存
这是我最近在做的一个工作,将内存中的一个超大的 map[int64]int64 写入到 redis,map 里的元素个数是千万级的。设计方案的时候,需要对 redis 的容量做一个估算。
如果不了解 redis 的话,可能你的答案是用元素个数直接乘以 16B(key 和 value 各占 8B)。我们假设元素个数是 5kw,那估算结果就是:5kw *16B=50kk* 16B = 800MB。
答案是错的。
为了解决这个问题,需要深入地研究一下 redis 的数据结构。
整个 redis 数据库就是一个大的 map,它容纳了所有的 key,我们都知道 key 都是 string 类型,而 value 则有 string, list, set, hashmap, zset……等类型。
Redis 中的一个 k-v 对用一个 entry 项表示,其中每个 entry 包含 key、value、next 三个指针,共 24 字节。由于 redis 使用 jemalloc 分配内存,因此一个 entry 需要申请 32 字节的内存。这里的 key, value 指针分别指向一个 RedisObject:
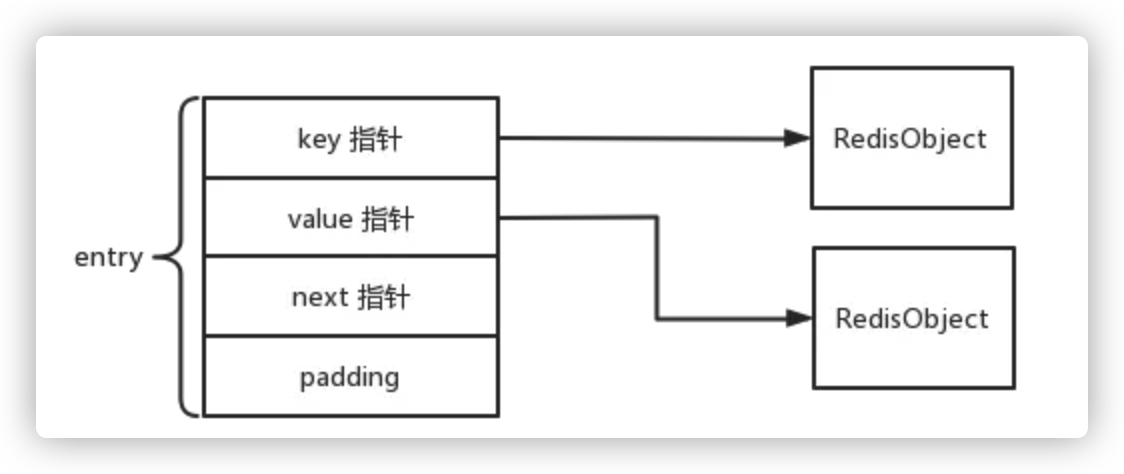
|
|
RedisObject 对应前面提到的各种数据类型,其中最简单的就是 redis 内部的字符串了。它有如下几种编码格式:
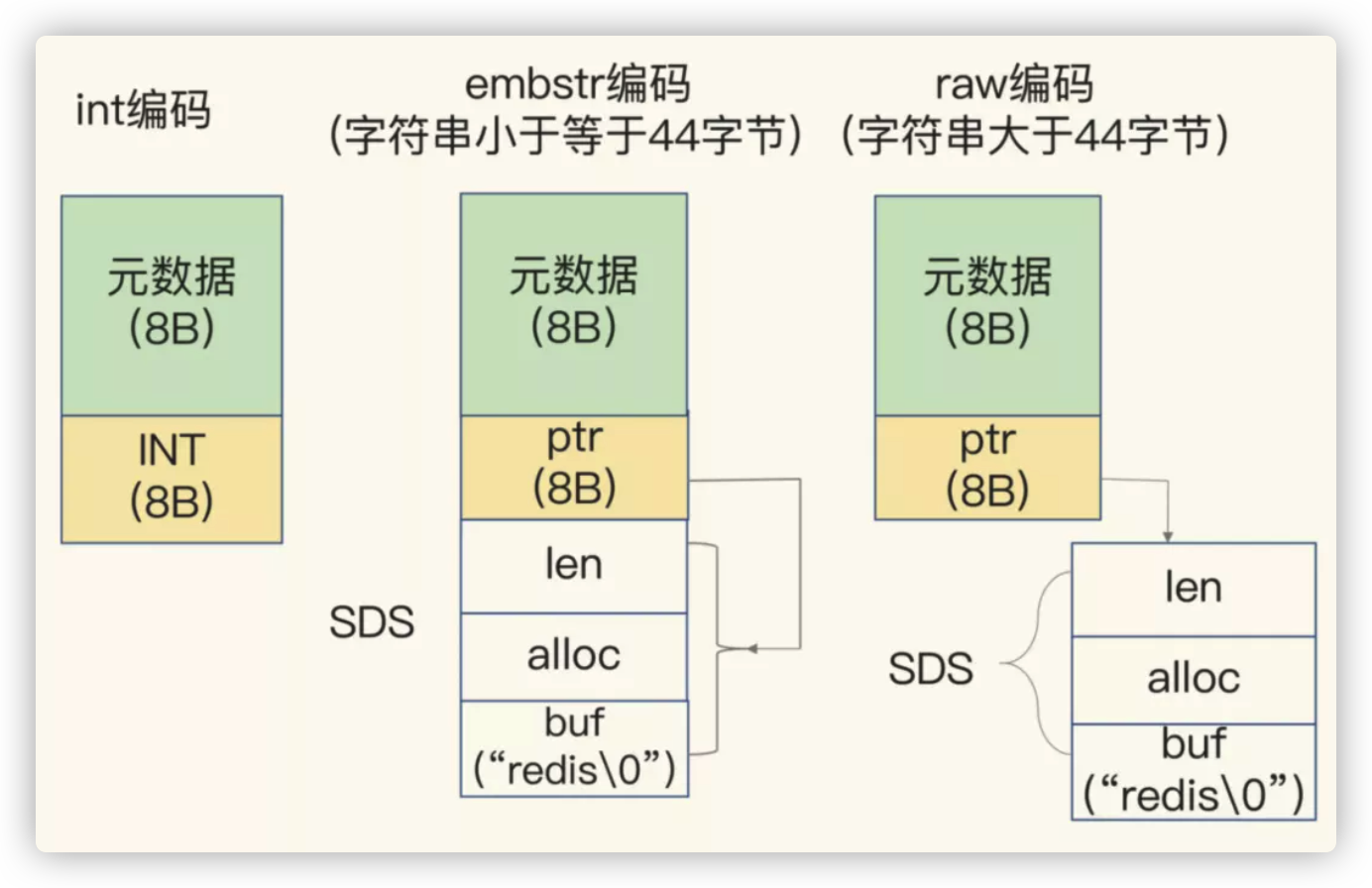
图中的元数据包括 type,encoding,lru, refcount,分别表示数据类型,编码类型,最近一次访问的时间戳,引用次数。
当字符串是一个整型时,直接放在 ptr 位置,不用再分配新的内存了,非常高效。
解析一下 44 字节的原因:元数据和 ptr 共占 16 字节,加上 44 字节,再加上字符串末尾的 ‘\0’,共61 字节。因为字符串的长度只有 44,因此 len 和 alloc 各用 1 个字节就够了。再加上 1 个字节的 flags,刚好是 64 字节。超过了这个值,SDS 就需要单独再申请一块内存,导致访问的时候就多了一跳指针。
多提一句,redis 最大支持 512MB 大小的字符串。
回答本文的问题,恰好我们要写入 redis 的 map 中的 key 和 value 都是整数,因此直接将值写入 ptr 处即可。
于是 map 的一个 key 占用的内存大小为:32(entry)+16(key)+16(value)=64B。于是,5kw 个 key 占用的内存大小是 5kw*64B = 50 kk* 64B = 3200MB ≈ 3G。
假如我们在 key 前面加上了前缀,那就会生成 SDS,占用的内存会变大,访问效率也会变差。
总之,我们根据要写入 redis 中的字符串的长度可以很方便地估算占用内存的总大小。如果 key 和 value 恰好都是 int64 类型的,那么尽量不要在 key 前加前缀,这样可以直接使用 key 的个数乘以 64B 就能算出占用内存的大小。
转载
文章作者 Forz
上次更新 2022-02-20