前言
我们已经知道:
- 全局变量可通过GoStub框架打桩
- 过程可通过GoStub框架打桩
- 函数可通过GoStub框架打桩
- interface可通过GoMock框架打桩
但还有两个问题比较棘手:
- 方法(成员函数)无法通过GoStub框架打桩,当产品代码的OO设计比较多时,打桩点可能离被测函数比较远,导致UT用例写起来比较痛
- 过程或函数通过GoStub框架打桩时,对产品代码有侵入性
下面我们举两个例子,阐述GoStub框架对产品代码的侵入性
例一:函数定义侵入
1
2
3
|
func Exec(cmd string, args ...string) (string, error) {
...
}
|
上面的函数Exec的定义为常规方式,但这时不能通过GoStub框架对函数Exec进行打桩,除非将函数Exec定义为非常规方式(侵入性):
1
2
3
|
var Exec = func(cmd string, args ...string) (string, error) {
...
}
|
例二:适配层侵入
产品代码中很多函数都会调用Golang的库函数或第三方的库函数,这些库函数的定义显然是常规方式,要想通过GoStub框架对这些函数打桩,一般会在适配层定义相关的变量(侵入性):
1
2
3
4
5
6
|
package adapter
var Stat = os.Stat
var Marshal = json.Marshal
var UnMarshal = json.Unmarshal
...
|
本文将介绍第四个框架Monkey的使用方法,目的是解决这两个棘手的问题,同时考虑将GoStub的优点集成到Monkey。
原理
monkey patch(猴子补丁)是一种在不改变原始源代码的情况下扩展或修改动态语言的运行时代码的方法。许多人认为猴子修补只限于Python等动态语言。但事实并非如此,我们可以在运行时来修改Go函数。主角就是github.com/bouk/monkey。
猴子补丁主要有以下几个用处:
- 在运行时替换方法、属性等
- 在不修改第三方代码的情况下增加原来不支持的功能
- 在运行时为内存中的对象增加patch而不是在磁盘的源代码中增加
- 增加钩子,在执行某个方法的同时执行一些其他的处理,如打印日志,实现AOP等。
调用函数的实现
看看下面的代码反编译之后的结果:
1
2
3
4
5
6
7
|
package main
func a() int { return 1 }
func main() {
print(a())
}
|
编译完成后通过Hopper查看,上面的代码将会展示下面的汇编代码:
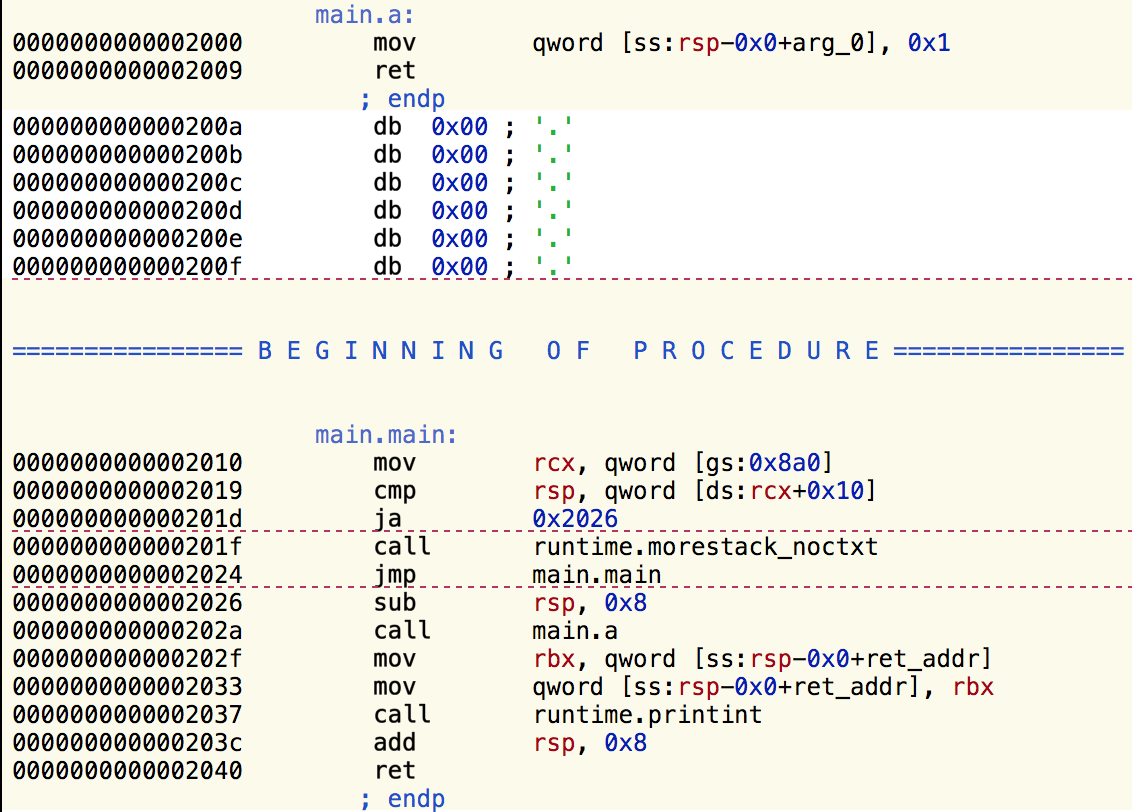
我将参考屏幕左侧显示的各种指令的地址。
我们的代码从过程main.main开始,指令 0x2010 到 0x2026 初始化了栈。你可以参考这些扩展阅读,下面的文章将会忽略那些代码。
0x202a 行调用了函数main.a,0x2000 行简单得把 0x1 压入栈返回。0x202f 到 0x2037 行把值传给了runtime.printint。
够简单了!现在咱们一起看看 Go 里面的函数值是如何实现的。
看下面的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
package main
import (
"fmt"
"unsafe"
)
func a() int { return 1 }
func main() {
f := a
fmt.Printf("0x%x\n", *(*uintptr)(unsafe.Pointer(&f)))
}
|
在第11行把a赋值给了f,这就意味着调用f()将会调用a。接下来用unsafe包读取出存在f里面的值。如果你是有 C 语言背景的程序员你可能会认为简单得把指向函数a的指针打印出来将会得到 0x2000(就是上面汇编里面看到的地址)。当我运行上面的代码得到了 0x102c38,这个地址相差了十万八千里!反编译后,这是第11行的代码:

这里引用了main.a.f,我们看看那个位置,可以发现:

啊哈!main.a.f在 0x102c38 并且包含值 0x2000,它正好是main.a的地址。看起来f并不是指向函数的指针,而是指向函数的指针的指针。让我们修改代码证实:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
package main
import (
"fmt"
"unsafe"
)
func a() int { return 1 }
func main() {
f := a
fmt.Printf("0x%x\n", **(**uintptr)(unsafe.Pointer(&f)))
}
|
和我们期望的一样,将会打印 0x2000。在这里我们也能找到一些线索。Go 语言的函数值包含了额外的信息,这是闭包和绑定实例实现的方式。
1
2
3
4
|
type funcval struct {
fn uintptr
// variable-size, fn-specific data here
}
|
接下来看看调用函数值的实现。把代码改成下面这样,给f赋值之后调用它。
1
2
3
4
5
6
7
8
|
package main
func a() int { return 1 }
func main() {
f := a
f()
}
|
反编译后可以得到下面的结果:

main.a.f加载到寄存器rdx里,然后把rdx寄存器指向的地址存入rbx里,最后调用。函数的地址值总是会加载到rdx寄存器里面,当代码调用的时候可以用来加载一些可能会用到的额外信息。这里的额外信息是指向绑定的实例和匿名函数闭包的指针。如果你想了解更多我建议你深入研究一下反编译代码!
运行时替换函数
让我们用新的知识实现 Go 语言里面的猴子补丁。
我们是想实现的是让下面的代码打印出来2:
1
2
3
4
5
6
7
8
9
|
package main
func a() int { return 1 }
func b() int { return 2 }
func main() {
replace(a, b)
print(a())
}
|
如何实现replace?我们需要修改函数a,让它跳转到b的代码,跳过执行它自己的代码。实际上,我们需要通过这种方法来实现替换,加载函数b到寄存器rdx,然后执行时跳转到rdx上面。
1
2
|
mov rdx, main.b.f ; 48 C7 C2 ?? ?? ?? ??
jmp [rdx] ; FF 22
|
我在汇编代码旁边附上了相应的机器码(你可以用这种在线汇编工具来模拟测试)。编写一个生成上面汇编代码的函数就很简单了,类似于下面这样:
1
2
3
4
5
6
7
8
9
10
11
|
func assembleJump(f func() int) []byte {
funcVal := *(*uintptr)(unsafe.Pointer(&f))
return []byte{
0x48, 0xC7, 0xC2,
byte(funcval >> 0),
byte(funcval >> 8),
byte(funcval >> 16),
byte(funcval >> 24), // MOV rdx, funcVal
0xFF, 0x22, // JMP [rdx]
}
}
|
这样就能把a的函数体指向b了!下面的代码尝试复制机器代码到函数体上。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
package main
import (
"syscall"
"unsafe"
)
func a() int { return 1 }
func b() int { return 2 }
func rawMemoryAccess(b uintptr) []byte {
return (*(*[0xFF]byte)(unsafe.Pointer(b)))[:]
}
func assembleJump(f func() int) []byte {
funcVal := *(*uintptr)(unsafe.Pointer(&f))
return []byte{
0x48, 0xC7, 0xC2,
byte(funcVal >> 0),
byte(funcVal >> 8),
byte(funcVal >> 16),
byte(funcVal >> 24), // MOV rdx, funcVal
0xFF, 0x22, // JMP [rdx]
}
}
func replace(orig, replacement func() int) {
bytes := assembleJump(replacement)
functionLocation := **(**uintptr)(unsafe.Pointer(&orig))
window := rawMemoryAccess(functionLocation)
copy(window, bytes)
}
func main() {
replace(a, b)
print(a())
}
|
运行上面的代码并不会工作,结果会是 segementation fault 段错误。这是因为加载后的二进制文件默认不允许修改。我们可以使用系统调用mprotect来关掉这个保护,这个最终版的代码终于可以像期望的那样,通过调用替换后的函数来打印出来 2。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
package main
import (
"syscall"
"unsafe"
)
func a() int { return 1 }
func b() int { return 2 }
func getPage(p uintptr) []byte {
return (*(*[0xFFFFFF]byte)(unsafe.Pointer(p & ^uintptr(syscall.Getpagesize()-1))))[:syscall.Getpagesize()]
}
func rawMemoryAccess(b uintptr) []byte {
return (*(*[0xFF]byte)(unsafe.Pointer(b)))[:]
}
func assembleJump(f func() int) []byte {
funcVal := *(*uintptr)(unsafe.Pointer(&f))
return []byte{
0x48, 0xC7, 0xC2,
byte(funcVal >> 0),
byte(funcVal >> 8),
byte(funcVal >> 16),
byte(funcVal >> 24), // MOV rdx, funcVal
0xFF, 0x22, // JMP rdx
}
}
func replace(orig, replacement func() int) {
bytes := assembleJump(replacement)
functionLocation := **(**uintptr)(unsafe.Pointer(&orig))
window := rawMemoryAccess(functionLocation)
page := getPage(functionLocation)
syscall.Mprotect(page, syscall.PROT_READ|syscall.PROT_WRITE|syscall.PROT_EXEC)
copy(window, bytes)
}
func main() {
replace(a, b)
print(a())
}
|
使用场景
Monkey框架的使用场景很多,依次为:
- 基本场景:为一个函数打桩
- 基本场景:为一个过程打桩
- 基本场景:为一个方法打桩
- 复合场景:由任意相同或不同的基本场景组合而成
- 特殊场景:桩中桩的一个案例
函数打桩
Exec是infra层的一个操作函数,实现很简单,代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// infra/os-encap/exec.go
func Exec(cmd string, args ...string) (string, error) {
cmdpath, err := exec.LookPath(cmd)
if err != nil {
fmt.Errorf("exec.LookPath err: %v, cmd: %s", err, cmd)
return "", infra.ErrExecLookPathFailed
}
var output []byte
output, err = exec.Command(cmdpath, args...).CombinedOutput()
if err != nil {
fmt.Errorf("exec.Command.CombinedOutput err: %v, cmd: %s", err, cmd)
return "", infra.ErrExecCombinedOutputFailed
}
fmt.Println("CMD[", cmdpath, "]ARGS[", args, "]OUT[", string(output), "]")
return string(output), nil
}
|
Exec函数的实现中调用了库函数exec.LoopPath和exec.Command,因此Exec函数的返回值和运行时的底层环境密切相关。在UT中,如果被测函数调用了Exec函数,则应根据用例的场景对Exec函数打桩。
Monkey的API非常简单和直接,我们直接看打桩代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import (
"testing"
. "github.com/smartystreets/goconvey/convey"
. "github.com/bouk/monkey"
"infra/osencap"
)
const any = "any"
func TestExec(t *testing.T) {
Convey("test has digit", t, func() {
Convey("for succ", func() {
outputExpect := "xxx-vethName100-yyy"
guard := Patch(osencap.Exec, func(_ string, _ ...string) (string, error) {
return outputExpect, nil
})
defer guard.Unpatch()
output, err := osencap.Exec(any, any)
So(output, ShouldEqual, outputExpect)
So(err, ShouldBeNil)
})
})
}
|
Patch是Monkey提供给用户用于函数打桩的API:
- 第一个参数是目标函数的函数名
- 第二个参数是桩函数的函数名,习惯用法是匿名函数或闭包
- 返回值是一个PatchGuard对象指针,主要用于在测试结束时删除当前的补丁
过程打桩
当一个函数没有返回值时,该函数我们一般称为过程。很多时候,我们将资源清理类函数定义为过程。
我们对过程DestroyResource的打桩代码为:
1
2
3
4
|
guard := Patch(DestroyResource, func(_ string) {
})
defer guard.Unpatch()
|
方法打桩
当微服务有多个实例时,先通过Etcd选举一个Master实例,然后Master实例为所有实例较均匀的分配任务,并将任务分配结果Set到Etcd,最后Master和Node实例Watch到任务列表,并过滤出自身需要处理的任务列表。
我们用类Etcd的方法Get来模拟获取任务列表的功能,入参为instanceId:
1
2
3
4
5
6
7
8
|
type Etcd struct {
}
func (e *Etcd) Get(instanceId string) []string {
taskList := make([]string, 0)
...
return taskList
|
我们对Get方法的打桩代码如下:
1
2
3
4
5
|
var e *Etcd
guard := PatchInstanceMethod(reflect.TypeOf(e), "Get", func(_ *Etcd, _ string) []string {
return []string{"task1", "task5", "task8"}
})
defer guard.Unpatch()
|
PatchInstanceMethod API是Monkey提供给用户用于方法打桩的API:
- 在使用前,先要定义一个目标类的指针变量x
- 第一个参数是reflect.TypeOf(x)
- 第二个参数是字符串形式的函数名
- 返回值是一个PatchGuard对象指针,主要用于在测试结束时删除当前的补丁
场景组合
假设Px为用于函数、过程或方法打桩的API调用,则任意相同或不同基本场景组合的打桩过程形式化表达为:
1
2
3
4
5
|
Px1
defer UnpatchAll()
Px2
...
Pxn
|
该测试执行完后,函数UnpatchAll将删除所有的补丁。
桩中桩
在某些特殊场景下(比如反序列化),函数或方法既有返回值,又有出参。出参一般为指针类型,包括具体的指针类型(比如*int)和抽象的指针类型(一般为interface{})。我们常用的库函数json.Unmarshal就属于这种情况。
笔者在实践中遇到的出参类型大多是具体的指针类型,其指针变量指向的内存不管在传入前确定还是在传入后确定,都将影响后面的代码逻辑。
下面呈现桩中桩的一个案例,以便大家灵活使用Monkey框架。
何谓桩中桩?
interface中声明了一个方法,既有返回值,又有出参。在测试中,先通过GoMock框架打桩多态到mock方法,然后又通过Monkey框架跳转到补丁方法,最终修改出参并返回。在这个过程中,mock方法可以看作一个桩,补丁方法又可以看作mock方法的一个桩,即补丁方法是一个桩中桩。
定义一个具体类型Movie:
1
2
3
4
5
|
type Movie struct {
Name string
Type string
Score int
}
|
定义一个interface类型Repository:
1
2
3
4
|
type Repository interface {
Retrieve(key string, movie *Movie) error
...
}
|
桩中桩的一个测试用例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
func TestDemo(t *testing.T) {
Convey("test demo", t, func() {
Convey("retrieve movie", func() {
ctrl := NewController(t)
defer ctrl.Finish()
mockRepo := mock_db.NewMockRepository(ctrl)
mockRepo.EXPECT().Retrieve(Any(), Any()).Return(nil)
Patch(redisrepo.GetInstance, func() Repository {
return mockRepo
})
defer UnpatchAll()
PatchInstanceMethod(reflect.TypeOf(mockRepo), "Retrieve", func(_ *mock_db.MockRepository, name string, movie *Movie) error {
movie = &Movie{Name: name, Type: "Love", Score: 95}
return nil
})
repo := redisrepo.GetInstance()
var movie *Movie
err := repo.Retrieve("Titanic", movie)
So(err, ShouldBeNil)
So(movie.Name, ShouldEqual, "Titanic")
So(movie.Type, ShouldEqual, "Love")
So(movie.Score, ShouldEqual, 95)
})
...
})
}
|
我们先通过Monkey框架的Patch API将mock对象注入,然后通过Monkey框架的PatchInstanceMethod API将mock方法跳转到补丁方法,间接完成对指针变量movie的内存分配及赋值,并返回nil。
取消patch
有时候在我们不仅要mock函数,而且在patch方法里还需要调用原来的函数。这时候需要使用monkey库提供的 PatchGuard结构体。关键在于,调用原来的函数之前先调用一次Unpatch,恢复到mock之前的情况;然后在调用了原函数之后,调用一次Restore。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
package main
import (
"fmt"
"strings"
"github.com/bouk/monkey"
)
func main() {
var guard *monkey.PatchGuard
guard = monkey.Patch(fmt.Println, func(a ...interface{}) (int, error) {
s := make([]interface{}, len(a))
for i, v := range a {
s[i] = strings.Replace(fmt.Sprint(v), "hell", "*bleep*", -1)
}
// 取消patch
guard.Unpatch()
defer guard.Restore()
// 使用默认的fmt.Println
return fmt.Println(s...)
})
fmt.Println("what the hell?") // what the *bleep*?
fmt.Println("what the hell?") // what the *bleep*?
}
|
Monkey的缺陷及解决方案
inline函数
Golang中虽然没有inline关键字,但仍存在inline函数,一个函数是否是inline函数由编译器决定。inline函数的特点是简单短小,在源代码的层次看有函数的结构,而在编译后却不具备函数的性质。inline函数不是在调用时发生控制转移,而是在编译时将函数体嵌入到每一个调用处,所以inline函数在调用时没有地址。
inline函数没有地址的特性导致了Monkey框架的第一个缺陷:对inline函数打桩无效。
模拟一个简单的inline函数:
1
2
3
|
func IsEqual(a, b string) bool {
return a == b
}
|
对HasDigit函数进行打桩测试:
1
2
3
4
5
6
7
8
9
10
11
12
|
func TestIsEqual(t *testing.T) {
Convey("test is equal", t, func() {
Convey("for patch true", func() {
guard := Patch(IsEqual, func(_, _ string) bool {
return true
})
defer guard.Unpatch()
ok := IsEqual("hello", "world")
So(ok, ShouldBeTrue)
})
})
}
|
在命令行运行这个测试,结果不符合期望:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
$ go test -v func_test.go -test.run TestIsEqual
=== RUN TestIsEqual
test is equal
for patch true ✘
Failures:
* /Users/zhangxiaolong/Desktop/D/go-workspace/src/test/monkey/func_test.go
Line 67:
Expected: true
Actual: false
1 total assertion
--- FAIL: TestIsEqual (0.00s)
FAIL
exit status 1
FAIL command-line-arguments 0.006s
|
解决方案:通过命令行参数-gcflags=-l禁止inline
在命令行增加参数-gcflags=-l重新运行测试,结果符合期望:
1
2
3
4
5
6
7
8
9
10
11
12
|
go test -gcflags=-l -v func_test.go -test.run TestIsEqual
=== RUN TestIsEqual
test is equal
for patch true ✔
1 total assertion
--- PASS: TestIsEqual (0.00s)
PASS
ok command-line-arguments 0.007s
|
方法名首字母小写
这一年多,Golang的版本在快速演进,上个月已经发布了go1.9版本。然而,一些团队可能一直还在用go1.6版本,并有计划在近期升级到go1.7或以上版本。
Monkey框架的实现中大量使用了反射机制,尤其是方法的补丁实现函数PatchInstanceMethod。但是,go1.6版本和更高版本(比如go1.7)的反射机制有些差异:在go1.6版本中反射机制会导出所有方法(不论首字母是大写还是小写),而在更高版本中反射机制仅会导出首字母大写的方法。
反射机制的这种差异导致了Monkey框架的第二个缺陷:在go1.6版本中可以成功打桩的首字母小写的方法,当go版本升级后Monkey框架会显式触发panic,表示unknown method:
1
2
3
4
|
m, ok := target.MethodByName(methodName)
if !ok {
panic(fmt.Sprintf("unknown method %s", methodName))
}
|
说明:反射机制的差异并不波及Patch函数的实现,所以go版本升级前后首字母小写的函数名的打桩不受影响。
正交设计四原则告诉我们,要向稳定的方向依赖。首字母小写的方法或函数不是public的,仅在包内可见,不是一个稳定的依赖方向。如果在UT测试中对首字母小写的方法或函数打桩的话,会导致重构的成本比较大。
解决方案:不管现在团队使用的go版本是哪一个,都不要对首字母小写的方法或函数打桩,不但可以确保测试用例在go版本升级前后的稳定性,而且能有效降低重构的成本。
API不够简洁优雅
在讨论Monkey的API之前,我们先回顾一下GoStub框架的API。
GoStub框架的API既包括函数API,也包括方法API。由于Monkey框架的API只涉及函数API,所以在这里我们只回顾GoStub框架的函数API。
我们先看GoStub框架的第一个函数API:
1
|
func Stub(varToStub interface{}, stubVal interface{}) *Stubs
|
这个API我们一般用于对全局变量打桩:
1
2
|
stubs := Stub(&num, 150)
defer stubs.Reset()
|
然而,这个API也可以用于函数打桩:
1
2
3
4
|
stubs := Stub(&osencap.Exec, func(_ string, _ ...string) (string, error) {
return "xxx-vethName100-yyy", nil
})
defer stubs.Reset()
|
GoStub框架的Stub API对函数的打桩方法是不是和Monkey框架的API的使用方法很像?这是毋庸置疑的,这样的API才是原生的API,StubFunc API是专门针对函数或过程打桩的改进版:
1
|
func StubFunc(funcVarToStub interface{}, stubVal ...interface{}) *Stubs
|
StubFunc替代Stub对函数的打桩示例:
1
2
|
stubs := StubFunc(&osencap.Exec,"xxx-vethName100-yyy", nil)
defer stubs.Reset()
|
是不是简洁优雅了很多?
说明:一般情况下,Golang的桩函数都关注的是返回值,所以这种封装很适用。但在特殊场景下,即桩函数在关注返回值的同时也关注出参,这时就要用原生的API。
为了应对多次调用桩函数而呈现不同行为的复杂情况,笔者二次开发了GoStub框架,提供了下面的API:
1
2
3
4
5
6
7
|
type Values []interface{}
type Output struct {
StubVals Values
Times int
}
func (s *Stubs) StubFuncSeq(funcVarToStub interface{}, outputs []Output) *Stubs
|
只有原生的API导致了Monkey框架的第三个缺陷:API不够简洁优雅,同时不支持多次调用桩函数(方法)而呈现不同行为的复杂情况。
解决方案:笔者计划二次开发Monkey框架,增加下面四个API:
1
2
3
4
|
func PatchFunc(target interface{}, stubVal ...interface{}) *PatchGuard
func PatchInstanceMethodFunc(target reflect.Type, methodName string, stubVal ...interface{}) *PatchGuard
func PatchFuncSeq(target interface{}, outputs []Output) *PatchGuard
func PatchInstanceMethodFuncSeq(target reflect.Type, methodName string, outputs []Output) *PatchGuard
|
小结
至此,我们已经知道:
- 全局变量可通过GoStub框架打桩
- 过程可通过Monkey框架打桩
- 函数可通过Monkey框架打桩
- 方法可通过Monkey框架打桩
- interface可通过GoMock框架打桩
我们在产品代码中,尽量不要使用全局变量.
参考:
https://www.jianshu.com/p/2f675d5e334e
https://blog.cyeam.com/golang/2018/08/07/monkey-patch