引言
熔断器是当依赖的服务已经出现故障时,为了保证自身服务的正常运行不再访问依赖的服务,防止雪崩效应.Hystrix断路器的工作原理是:
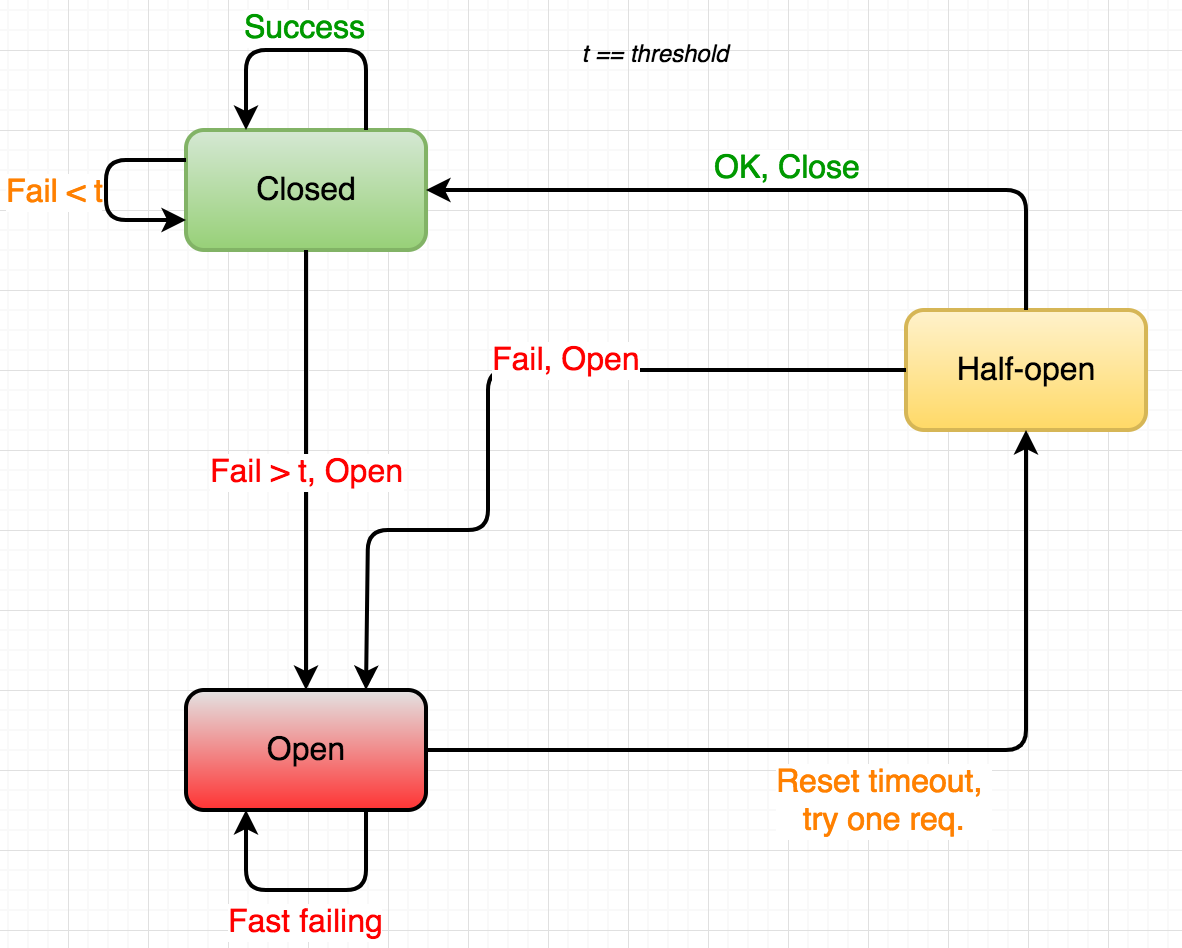
熔断器有三种状态:
- 关闭:在正常运行时,断路器是关闭的,允许请求(或电)通过。
- 打开:当检测到故障时(在一段时间内有n个失败的请求,请求时间过长,电流大幅增加),电路将打开,确保用户服务短路而不是等待失败的生产者服务。
- 半开:电路断路器定期地让一个请求通过。如果成功,电路可以再次闭合,否则,它将保持打开。
Hystrix有两个关键要点:
- Hystrix允许我们提供一个回退函数,它将被执行,而不是运行正常的请求。这允许我们提供一种回退行为。有时,我们不能没有错误的生产者的数据或服务,但正如通常情况下,我们的回退方法可以提供一个默认结果,一个结构良好的错误消息,或者可能调用一个备份服务。
- 停止级联失败。虽然回退行为非常有用,但是断路器模式中最重要的部分是我们要立即返回对调用服务的响应。这样做没有任何线程池充满待处理请求,没有超时,希望更少惹恼终端消费者。
入门指南
软件包hystrix是一个延迟和容错库,旨在隔离对远程系统,服务和第三方库的访问点,停止级联故障,并在不可避免发生故障的复杂分布式系统中实现弹性。
基于Netflix的同名Java项目。https://github.com/Netflix/Hystrix
作为Hystrix命令执行代码
定义依赖于外部系统的应用程序逻辑,并将函数传递给Go。当该系统运行正常时,这将是唯一执行的东西。
1
2
3
4
|
hystrix.Go("my_command", func() error {
// talk to other services
return nil
}, nil)
|
定义备用行为
如果您希望代码在服务中断期间执行,请将第二个函数传递给Go。理想情况下,此处的逻辑将使您的应用程序能够妥善处理不可用的外部服务。
这会在您的代码返回错误或由于各种运行状况检查而无法完成错误时触发,请参见 https://github.com/Netflix/Hystrix/wiki/How-it-Works
1
2
3
4
5
6
7
|
hystrix.Go("my_command", func() error {
// talk to other services
return nil
}, func(err error) error {
// do this when services are down
return nil
})
|
等待输出
调用Go就像启动goroutine一样,只不过您收到一条可以选择监视的错误通道。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
output := make(chan bool, 1)
errors := hystrix.Go("my_command", func() error {
// talk to other services
output <- true
return nil
}, nil)
select {
case out := <-output:
// success
case err := <-errors:
// failure
}
|
同步API
由于调用命令并立即等待其完成是一种常见的模式,因此可以通过Do函数使用同步API,该函数返回单个错误。
1
2
3
4
|
err := hystrix.Do("my_command", func() error {
// talk to other services
return nil
}, nil)
|
配置设置
在应用程序启动期间,您可以调用ConfigureCommand来调整每个命令的设置。
1
2
3
4
5
|
hystrix.ConfigureCommand("my_command", hystrix.CommandConfig{
Timeout: 1000,
MaxConcurrentRequests: 100,
ErrorPercentThreshold: 25,
})
|
你也可以使用 Configure, 其接受 map[string]CommandConfig.
启用Dashboard和metric
在您的main.go中,在端口上注册事件流HTTP处理程序,然后在goroutine中启动它。在为Hystrix仪表板配置了turbine以开始流事件后,您的命令将自动开始出现。
1
2
3
|
hystrixStreamHandler := hystrix.NewStreamHandler()
hystrixStreamHandler.Start()
go http.ListenAndServe(net.JoinHostPort("", "81"), hystrixStreamHandler)
|
发送电路指标到Statsd
1
2
3
4
5
6
7
8
9
|
c, err := plugins.InitializeStatsdCollector(&plugins.StatsdCollectorConfig{
StatsdAddr: "localhost:8125",
Prefix: "myapp.hystrix",
})
if err != nil {
log.Fatalf("could not initialize statsd client: %v", err)
}
metricCollector.Registry.Register(c.NewStatsdCollector)
|
常问问题
如果我的运行功能出现panic怎么办?hystrix-go会触发fallback吗?
不可以。hystrix-go不会使用recover(),因此恐慌会像平常一样杀死进程。
Variables
1
2
3
4
5
6
7
8
|
var (
// ErrMaxConcurrency occurs when too many of the same named command are executed at the same time.
ErrMaxConcurrency = CircuitError{Message: "max concurrency"}
// ErrCircuitOpen returns when an execution attempt "short circuits". This happens due to the circuit being measured as unhealthy.
ErrCircuitOpen = CircuitError{Message: "circuit open"}
// ErrTimeout occurs when the provided function takes too long to execute.
ErrTimeout = CircuitError{Message: "timeout"}
)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
var (
// DefaultTimeout is how long to wait for command to complete, in milliseconds
DefaultTimeout = 1000
// DefaultMaxConcurrent is how many commands of the same type can run at the same time
DefaultMaxConcurrent = 10
// DefaultVolumeThreshold is the minimum number of requests needed before a circuit can be tripped due to health
DefaultVolumeThreshold = 20
// DefaultSleepWindow is how long, in milliseconds, to wait after a circuit opens before testing for recovery
DefaultSleepWindow = 5000
// DefaultErrorPercentThreshold causes circuits to open once the rolling measure of errors exceeds this percent of requests
DefaultErrorPercentThreshold = 50
// DefaultLogger is the default logger that will be used in the Hystrix package. By default prints nothing.
DefaultLogger = NoopLogger{}
)
|
1
|
func Configure(cmds map[string]CommandConfig)
|
配置应用一组电路的设置
1
|
func ConfigureCommand(name string, config CommandConfig)
|
配置应用一个电路的设置
func Do
1
|
func Do(name string, run runFunc, fallback fallbackFunc) error
|
Do runs your function in a synchronous manner, blocking until either your function succeeds or an error is returned, including hystrix circuit errors
Do以同步方式运行您的函数,阻塞直到函数成功或返回错误(包括hystrix错误)为止
func DoC
1
|
func DoC(ctx context.Context, name string, run runFuncC, fallback fallbackFuncC) error
|
DoC以同步方式运行您的函数,阻塞直到函数成功或返回错误(包括hystrix错误)为止
func Flush
Flush会从内存中清除所有circuit电路和metric指标信息。
func GetCircuitSettings
1
|
func GetCircuitSettings() map[string]*Settings
|
func Go
1
|
func Go(name string, run runFunc, fallback fallbackFunc) chan error
|
Go在跟踪先前调用它的运行状况的同时运行您的函数。如果您的功能开始变慢或反复失败,我们将阻止对它的新调用,以便您给相关的服务时间进行维修。
如果要定义一些在停机期间执行的代码,请定义一个fallback备用功能。
func GoC
1
|
func GoC(ctx context.Context, name string, run runFuncC, fallback fallbackFuncC) chan error
|
GoC在跟踪先前调用它的运行状况的同时运行您的函数。如果您的功能开始变慢或反复失败,我们将阻止对它的新调用,以便您给相关的服务时间进行维修。
如果要定义一些在停机期间执行的代码,请定义一个fallback备用功能。
func SetLogger
1
|
func SetLogger(l logger)
|
SetLogger配置将使用的记录器。这仅适用于hystrix包。
type CircuitBreaker
1
2
3
4
|
type CircuitBreaker struct {
Name string
// contains filtered or unexported fields
}
|
为每个ExecutorPool创建CircuitBreaker,以跟踪是应尝试请求,还是在电路的运行状况太低时拒绝请求。
func GetCircuit
1
|
func GetCircuit(name string) (*CircuitBreaker, bool, error)
|
GetCircuit返回给定命令的电路以及此调用是否创建了该电路。
func (*CircuitBreaker) AllowRequest
1
|
func (circuit *CircuitBreaker) AllowRequest() bool
|
在执行命令之前检查AllowRequest,以确保电路状态和度量标准运行状况允许它。当电路是open时,此调用有时会返回true,以测量外部服务是否已恢复。
func (*CircuitBreaker) IsOpen
1
|
func (circuit *CircuitBreaker) IsOpen() bool
|
在执行任何命令之前,将调用IsOpen来检查是否应尝试执行该操作。open电路意味着它被禁用。
func (*CircuitBreaker) ReportEvent
1
|
func (circuit *CircuitBreaker) ReportEvent(eventTypes []string, start time.Time, runDuration time.Duration) error
|
ReportEvent记录命令度量标准,以跟踪最近的错误率并将数据公开给仪表板。
type CircuitError
1
2
3
|
type CircuitError struct {
Message string
}
|
CircuitError是对各种执行失败状态建模的错误,例如电路断开或超时。
func (CircuitError) Error
1
|
func (e CircuitError) Error() string
|
type CommandConfig
1
2
3
4
5
6
7
|
type CommandConfig struct {
Timeout int `json:"timeout"`
MaxConcurrentRequests int `json:"max_concurrent_requests"`
RequestVolumeThreshold int `json:"request_volume_threshold"`
SleepWindow int `json:"sleep_window"`
ErrorPercentThreshold int `json:"error_percent_threshold"`
}
|
CommandConfig用于在运行时调整电路设置
CommandConfig 几个字段的意义:
- Timeout: 执行command的超时时间。默认时间是1000毫秒
- MaxConcurrentRequests:command的最大并发量 默认值是10
- SleepWindow:当熔断器被打开后,SleepWindow的时间就是控制过多久后去尝试服务是否可用了。默认值是5000毫秒
- RequestVolumeThreshold: 一个统计窗口10秒内请求数量。达到这个请求数量后才去判断是否要开启熔断。默认值是20
- ErrorPercentThreshold:错误百分比,请求数量大于等于RequestVolumeThreshold并且错误率到达这个百分比后就会启动熔断 默认值是50
RequestVolumeThreshold与ErrorPercentThreshold通常组合使用
当然如果不配置他们,会使用默认值.
type NoopLogger
1
|
type NoopLogger struct{}
|
NoopLogger不记录任何内容。
func (NoopLogger) Printf
1
|
func (l NoopLogger) Printf(format string, items ...interface{})
|
Printf什么也不做。
type Settings
1
2
3
4
5
6
7
|
type Settings struct {
Timeout time.Duration
MaxConcurrentRequests int
RequestVolumeThreshold uint64
SleepWindow time.Duration
ErrorPercentThreshold int
}
|
type StreamHandler
1
2
3
|
type StreamHandler struct {
// contains filtered or unexported fields
}
|
StreamHandler每秒向所有连接的HTTP客户端发布每个命令和每个池的度量。
func NewStreamHandler
1
|
func NewStreamHandler() *StreamHandler
|
NewStreamHandler返回一个server,该server能够通过HTTP公开仪表板指标。
func (*StreamHandler) ServeHTTP
1
|
func (sh *StreamHandler) ServeHTTP(rw http.ResponseWriter, req *http.Request)
|
func (*StreamHandler) Start
1
|
func (sh *StreamHandler) Start()
|
Start开始查看内存断路器的指标
func (*StreamHandler) Stop
1
|
func (sh *StreamHandler) Stop()
|
Stop关闭度量标准收集例程
执行:Do与Go
同步执行,直接调用Do方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
// Do runs your function in a synchronous manner, blocking until either your function succeeds
// or an error is returned, including hystrix circuit errors
func Do(name string, run runFunc, fallback fallbackFunc) error {
runC := func(ctx context.Context) error {
return run()
}
var fallbackC fallbackFuncC
if fallback != nil {
fallbackC = func(ctx context.Context, err error) error {
return fallback(err)
}
}
return DoC(context.Background(), name, runC, fallbackC)
}
// DoC runs your function in a synchronous manner, blocking until either your function succeeds
// or an error is returned, including hystrix circuit errors
func DoC(ctx context.Context, name string, run runFuncC, fallback fallbackFuncC) error {
done := make(chan struct{}, 1)
r := func(ctx context.Context) error {
err := run(ctx)
if err != nil {
return err
}
done <- struct{}{}
return nil
}
f := func(ctx context.Context, e error) error {
err := fallback(ctx, e)
if err != nil {
return err
}
done <- struct{}{}
return nil
}
var errChan chan error
if fallback == nil {
errChan = GoC(ctx, name, r, nil)
} else {
errChan = GoC(ctx, name, r, f)
}
select {
case <-done:
return nil
case err := <-errChan:
return err
}
}
|
异步执行Go方法,内部实现是启动了一个gorouting,如果想得到自定义方法的数据,需要你传channel来处理数据,或者输出。返回的error也是一个channel
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// Go runs your function while tracking the health of previous calls to it.
// If your function begins slowing down or failing repeatedly, we will block
// new calls to it for you to give the dependent service time to repair.
//
// Define a fallback function if you want to define some code to execute during outages.
func Go(name string, run runFunc, fallback fallbackFunc) chan error {
runC := func(ctx context.Context) error {
return run()
}
var fallbackC fallbackFuncC
if fallback != nil {
fallbackC = func(ctx context.Context, err error) error {
return fallback(err)
}
}
return GoC(context.Background(), name, runC, fallbackC)
}
|
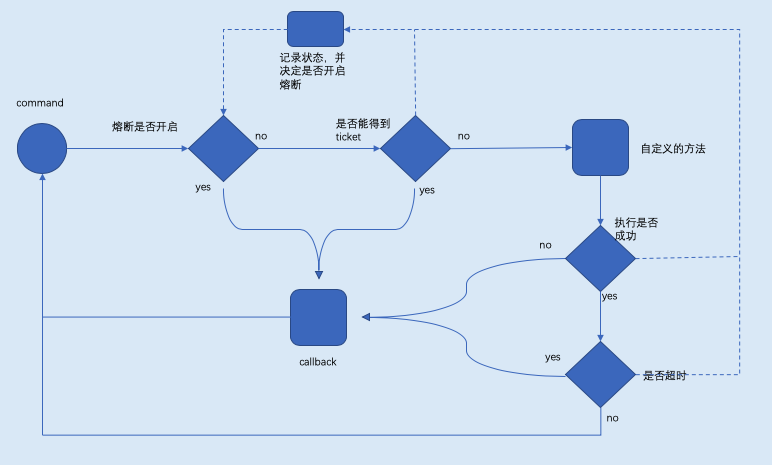
大概的执行流程图
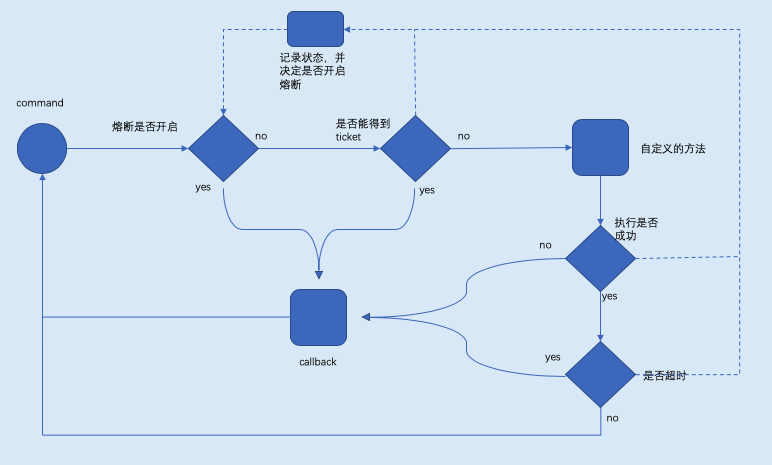
其实方法Do和Go方法内部都是调用了hystrix.GoC方法,只是Do方法处理了异步的过程,稍后讨论
配置:CommandConfig
1
2
3
4
5
6
7
8
|
// CommandConfig is used to tune circuit settings at runtime
type CommandConfig struct {
Timeout int `json:"timeout"`// 超时时间定义
MaxConcurrentRequests int `json:"max_concurrent_requests"`// 最大并发请求数
RequestVolumeThreshold int `json:"request_volume_threshold"`// 跳闸的最小请求数(不健康的断路器)
SleepWindow int `json:"sleep_window"`// 跳闸之后可以重试的时间
ErrorPercentThreshold int `json:"error_percent_threshold"`// 请求出错比
}
|
CommandConfig 几个字段的意义:
- Timeout: 执行command的超时时间。默认时间是1000毫秒
- MaxConcurrentRequests:command的最大并发量 默认值是10
- SleepWindow:当熔断器被打开后,SleepWindow的时间就是控制过多久后去尝试服务是否可用了。默认值是5000毫秒
- RequestVolumeThreshold: 一个统计窗口10秒内请求数量。达到这个请求数量后才去判断是否要开启熔断。默认值是20
- ErrorPercentThreshold:错误百分比,请求数量大于等于RequestVolumeThreshold并且错误率到达这个百分比后就会启动熔断 默认值是50
RequestVolumeThreshold与ErrorPercentThreshold通常组合使用
当然如果不配置他们,会使用默认值.
断路器:CircuitBreaker
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// CircuitBreaker is created for each ExecutorPool to track whether requests
// should be attempted, or rejected if the Health of the circuit is too low.
type CircuitBreaker struct { // 断路器-定义
Name string // 名字
open bool // 开启与否,关闭"open"=true,开启"open" = false
forceOpen bool // 强制开启
mutex *sync.RWMutex // 读写锁(unblock reading, block writer)
openedOrLastTestedTime int64 // 断路器被打开或者最近一次尝试的时间,尝试指断路器打开之后,系统探测是否可以发送请求。
executorPool *executorPool // 执行池
metrics *metricExchange // 监控断路器
}
var (
circuitBreakersMutex *sync.RWMutex // 断路器锁
circuitBreakers map[string]*CircuitBreaker // 注册断路器,所有的断路器都保存在这里
)
func init() {
circuitBreakersMutex = &sync.RWMutex{} // 初始化断路器锁
circuitBreakers = make(map[string]*CircuitBreaker) // 初始化断路器
}
|
获取断路器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// GetCircuit returns the circuit for the given command and whether this call created it.
func GetCircuit(name string) (*CircuitBreaker, bool, error) {
circuitBreakersMutex.RLock()
_, ok := circuitBreakers[name]
if !ok {
circuitBreakersMutex.RUnlock()
circuitBreakersMutex.Lock()
defer circuitBreakersMutex.Unlock() // 注意这里同时加了两次锁且第二把锁是互斥锁,其中一个goroutine hold住并且赋值,锁释放。其他goroutine从内存中获取断路器
if cb, ok := circuitBreakers[name]; ok { // double check,防止其他的goroutine修改了全局变量circuitBreakers
return cb, false, nil
}
circuitBreakers[name] = newCircuitBreaker(name)
} else {
defer circuitBreakersMutex.RUnlock()
}
return circuitBreakers[name], !ok, nil
}
|
监控:metricExchange
每一次断路器逻辑的执行都会上报执行过程中的状态:
断路器–>执行–>上报执行状态信息–>保存到相应的Buckets
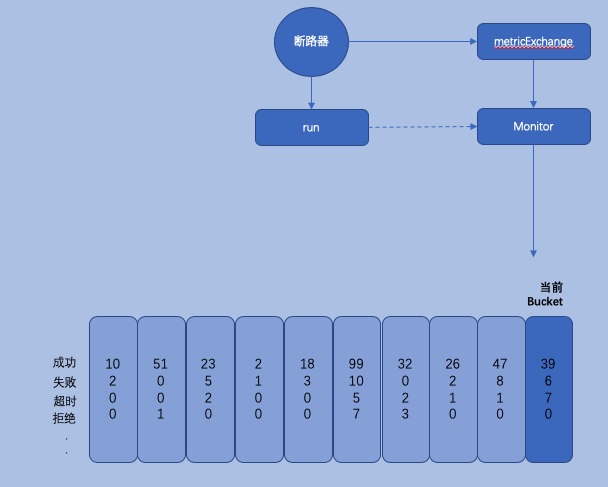
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// ReportEvent records command metrics for tracking recent error rates and exposing data to the dashboard.
func (circuit *CircuitBreaker) ReportEvent(eventTypes []string, start time.Time, runDuration time.Duration) error {
if len(eventTypes) == 0 {
return fmt.Errorf("no event types sent for metrics")
}
circuit.mutex.RLock()
o := circuit.open
circuit.mutex.RUnlock()
if eventTypes[0] == "success" && o {
circuit.setClose()
}
var concurrencyInUse float64
if circuit.executorPool.Max > 0 {
concurrencyInUse = float64(circuit.executorPool.ActiveCount()) / float64(circuit.executorPool.Max)
}
select {
case circuit.metrics.Updates <- &commandExecution{
Types: eventTypes,
Start: start,
RunDuration: runDuration,
ConcurrencyInUse: concurrencyInUse,
}:
default:
return CircuitError{Message: fmt.Sprintf("metrics channel (%v) is at capacity", circuit.Name)}
}
return nil
}
|
circuit.metrics.Updates 这个信道就是处理上报信息的,上报执行状态信息的结构是metricExchange,结构体很简单只有4个字段:
- Updates:有buffer的commandExecution通道,默认的数量是2000个,所有的状态信息都在他里面
- metricCollectors:保存的具体的这个command执行过程中的各种信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
type metricExchange struct {
Name string
Updates chan *commandExecution
Mutex *sync.RWMutex
metricCollectors []metricCollector.MetricCollector
}
type commandExecution struct {
Types []string `json:"types"`
Start time.Time `json:"start_time"`
RunDuration time.Duration `json:"run_duration"`
ConcurrencyInUse float64 `json:"concurrency_inuse"`
}
|
在执行newMetricExchange的时候会启动一个协程 go m.Monitor()去监控Updates的数据,然后上报给metricCollectors 保存执行的信息数据比如前面提到的调用次数,失败次数,被拒绝次数等等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
func newMetricExchange(name string) *metricExchange {
m := &metricExchange{}
m.Name = name
m.Updates = make(chan *commandExecution, 2000)
m.Mutex = &sync.RWMutex{}
m.metricCollectors = metricCollector.Registry.InitializeMetricCollectors(name)
m.Reset()
go m.Monitor()
return m
}
func (m *metricExchange) Monitor() {
for update := range m.Updates {
// we only grab a read lock to make sure Reset() isn't changing the numbers.
m.Mutex.RLock()
totalDuration := time.Since(update.Start)
wg := &sync.WaitGroup{}
for _, collector := range m.metricCollectors {
wg.Add(1)
go m.IncrementMetrics(wg, collector, update, totalDuration)
}
wg.Wait()
m.Mutex.RUnlock()
}
}
|
更新调用的是go m.IncrementMetrics(wg, collector, update, totalDuration),里面判断了他的状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func (m *metricExchange) IncrementMetrics(wg *sync.WaitGroup, collector metricCollector.MetricCollector, update *commandExecution, totalDuration time.Duration) {
// granular metrics
r := metricCollector.MetricResult{
Attempts: 1,
TotalDuration: totalDuration,
RunDuration: update.RunDuration,
ConcurrencyInUse: update.ConcurrencyInUse,
}
switch update.Types[0] {
case "success":
r.Successes = 1
case "failure":
r.Failures = 1
r.Errors = 1
case "rejected":
r.Rejects = 1
r.Errors = 1
// ...
}
// ...
collector.Update(r)
wg.Done()
}
|
底层控制器:MetricCollector
每一个Command都会有一个默认统计控制器,当然也可以添加多个自定义的控制器。
默认的统计控制器DefaultMetricCollector保存着熔断器的所有状态,调用次数,失败次数,被拒绝次数等等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
// DefaultMetricCollector holds information about the circuit state.
// This implementation of MetricCollector is the canonical source of information about the circuit.
// It is used for for all internal hystrix operations
// including circuit health checks and metrics sent to the hystrix dashboard.
//
// Metric Collectors do not need Mutexes as they are updated by circuits within a locked context.
type DefaultMetricCollector struct {
mutex *sync.RWMutex
numRequests *rolling.Number
errors *rolling.Number
successes *rolling.Number
failures *rolling.Number
rejects *rolling.Number
shortCircuits *rolling.Number
timeouts *rolling.Number
contextCanceled *rolling.Number
contextDeadlineExceeded *rolling.Number
fallbackSuccesses *rolling.Number
fallbackFailures *rolling.Number
totalDuration *rolling.Timing
runDuration *rolling.Timing
}
|
最主要的还是要看一下rolling.Number,rolling.Number才是状态最终保存的地方
Number保存了10秒内的Buckets数据信息,每一个Bucket的统计时长为1秒
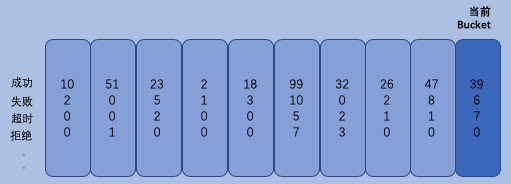
1
2
3
4
5
6
7
8
9
10
|
// Number tracks a numberBucket over a bounded number of
// time buckets. Currently the buckets are one second long and only the last 10 seconds are kept.
type Number struct {
Buckets map[int64]*numberBucket
Mutex *sync.RWMutex
}
type numberBucket struct {
Value float64
}
|
字典字段Buckets map[int64]*numberBucket 中的Key保存的是当前时间
可能你会好奇Number是如何保证只保存10秒内的数据的。每一次对熔断器的状态进行修改时,Number都要先得到当前的时间(秒级)的Bucket不存在则创建。
1
2
3
4
5
6
7
8
9
10
11
12
|
func (r *Number) getCurrentBucket() *numberBucket {
now := time.Now().Unix()
var bucket *numberBucket
var ok bool
if bucket, ok = r.Buckets[now]; !ok {
bucket = &numberBucket{}
r.Buckets[now] = bucket
}
return bucket
}
|
修改完后去掉10秒外的数据
1
2
3
4
5
6
7
8
9
10
|
func (r *Number) removeOldBuckets() {
now := time.Now().Unix() - 10
for timestamp := range r.Buckets {
// TODO: configurable rolling window
if timestamp <= now {
delete(r.Buckets, timestamp)
}
}
}
|
比如Increment方法,先得到Bucket再删除旧的数据
1
2
3
4
5
6
7
8
9
10
11
12
|
func (r *Number) Increment(i float64) {
if i == 0 {
return
}
r.Mutex.Lock()
defer r.Mutex.Unlock()
b := r.getCurrentBucket()
b.Value += i
r.removeOldBuckets()
}
|
统计控制器是最基层和最重要的一个实现,上层所有的执行判断都是基于他的数据进行逻辑处理的
执行池:executorPool
hystrix-go对流量控制的代码是很简单的。用了一个简单的令牌算法,能得到令牌的就可以执行后继的工作,执行完后要返还令牌。得不到令牌就拒绝,拒绝后调用用户设置的callback方法,如果没有设置就不执行。
结构体executorPool就是hystrix-go执行池的具体实现。字段Max就是每秒最大的并发值。
1
2
3
4
5
6
|
type executorPool struct { // 执行池
Name string // 名字
Metrics *poolMetrics // 执行池监控
Max int // 最大的并发请求数量
Tickets chan *struct{} // 票证
}
|
在创建executorPool的时候,会根据Max值来创建令牌。Max值如果没有设置会使用默认值10
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
//开启新的执行池
func newExecutorPool(name string) *executorPool {
p := &executorPool{}
p.Name = name//名字
p.Metrics = newPoolMetrics(name)
p.Max = getSettings(name).MaxConcurrentRequests// 从配置中获取最大的并发请求数量,如果配置中没有,则从默认配置中获取
p.Tickets = make(chan *struct{}, p.Max)// 初始化buffer chan
for i := 0; i < p.Max; i++ {
p.Tickets <- &struct{}{}
}
return p
}
//上报状态
func (p *executorPool) Return(ticket *struct{}) {
if ticket == nil {
return
}
p.Metrics.Updates <- poolMetricsUpdate{
activeCount: p.ActiveCount(),
}
p.Tickets <- ticket
}
func (p *executorPool) ActiveCount() int {
return p.Max - len(p.Tickets)
}
|
注意一下字段 Metrics 他用于统计执行数量,比如:执行的总数量,最大的并发数.这个数量也可以显露出,供可视化程序直观的表现出来。
1
2
3
4
5
6
7
8
9
10
11
|
type poolMetrics struct {
Mutex *sync.RWMutex
Updates chan poolMetricsUpdate
Name string
MaxActiveRequests *rolling.Number
Executed *rolling.Number
}
type poolMetricsUpdate struct {
activeCount int
}
|
令牌使用完后是需要返还的,返回的时候才会做上面所说的统计工作。
执行实体:GoC
hystrix在执行一次command会调用GoC方法,就是在判断断路器是否已打开,得到Ticket得不到就限流,执行我们自己的的方法,判断context是否Done或者执行是否超时.每次执行结果都要上报执行状态,最后要返还Ticket
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
|
// GoC runs your function while tracking the health of previous calls to it.
// If your function begins slowing down or failing repeatedly, we will block
// new calls to it for you to give the dependent service time to repair.
//
// Define a fallback function if you want to define some code to execute during outages.
func GoC(ctx context.Context, name string, run runFuncC, fallback fallbackFuncC) chan error {
cmd := &command{// command执行者
run: run, //run
fallback: fallback,//fallback
start: time.Now(), //开始时间
errChan: make(chan error, 1), //错误
finished: make(chan bool, 1), //是否完成
}
// dont have methods with explicit params and returns
// let data come in and out naturally, like with any closure
// explicit error return to give place for us to kill switch the operation (fallback)
//得到断路器,不存在则创建
circuit, _, err := GetCircuit(name)
if err != nil {
cmd.errChan <- err
return cmd.errChan
}
cmd.circuit = circuit
ticketCond := sync.NewCond(cmd)// cond条件
ticketChecked := false
// When the caller extracts error from returned errChan, it's assumed that
// the ticket's been returned to executorPool. Therefore, returnTicket() can
// not run after cmd.errorWithFallback().
// 返还ticket
returnTicket := func() {
cmd.Lock()
// Avoid releasing before a ticket is acquired.
for !ticketChecked {
ticketCond.Wait()// 相当于select{}
}
cmd.circuit.executorPool.Return(cmd.ticket)// 将ticket放回池子中
cmd.Unlock()
}
// Shared by the following two goroutines. It ensures only the faster
// goroutine runs errWithFallback() and reportAllEvent().
// 上报执行状态
returnOnce := &sync.Once{}// 确保被multi goroutine执行一次
reportAllEvent := func() {// events采集,后续dashboard使用
err := cmd.circuit.ReportEvent(cmd.events, cmd.start, cmd.runDuration)
if err != nil {
log.Printf(err.Error())
}
}
// g1, 检测断路器不允许通过,尝试fallback,将中途遇到的event上报。
go func() {
defer func() { cmd.finished <- true }()
// Circuits get opened when recent executions have shown to have a high error rate.
// Rejecting new executions allows backends to recover, and the circuit will allow
// new traffic when it feels a healthly state has returned.
// 查看断路器是否已打开
if !cmd.circuit.AllowRequest() {
cmd.Lock()
// It's safe for another goroutine to go ahead releasing a nil ticket.
ticketChecked = true
ticketCond.Signal()
cmd.Unlock()
returnOnce.Do(func() {
returnTicket()
cmd.errorWithFallback(ctx, ErrCircuitOpen)
reportAllEvent()
})
return
}
// As backends falter, requests take longer but don't always fail.
//
// When requests slow down but the incoming rate of requests stays the same, you have to
// run more at a time to keep up. By controlling concurrency during these situations, you can
// shed load which accumulates due to the increasing ratio of active commands to incoming requests.
cmd.Lock()
// 获取ticket 如果得不到就限流
select {
case cmd.ticket = <-circuit.executorPool.Tickets:// 从池子中取出ticket
ticketChecked = true
ticketCond.Signal()// 通知cond.Wait()
cmd.Unlock()
default:
ticketChecked = true
ticketCond.Signal()
cmd.Unlock()
returnOnce.Do(func() {
returnTicket()
cmd.errorWithFallback(ctx, ErrMaxConcurrency)// 并发过高
reportAllEvent()
})
return
}
// 执行我们自已的方法,并上报执行信息
runStart := time.Now()
runErr := run(ctx)
returnOnce.Do(func() {
defer reportAllEvent()
cmd.runDuration = time.Since(runStart)// 运行时间
returnTicket()// 把ticket返回去
if runErr != nil {
cmd.errorWithFallback(ctx, runErr)
return
}
cmd.reportEvent("success")// 执行成功
})
}()
// 等待context是否被结束,或执行者超时,并上报
go func() {
timer := time.NewTimer(getSettings(name).Timeout)
defer timer.Stop()
select {
case <-cmd.finished:// 结束select
// returnOnce has been executed in another goroutine
case <-ctx.Done():// 处理ctx错误
returnOnce.Do(func() {
returnTicket()
cmd.errorWithFallback(ctx, ctx.Err())
reportAllEvent()
})
return
case <-timer.C:// 处理超时
returnOnce.Do(func() {
returnTicket()
cmd.errorWithFallback(ctx, ErrTimeout)
reportAllEvent()
})
return
}
}()
return cmd.errChan// 错误返回至上层
}
|
可视化:StreamHandler
代码中StreamHandler就是把所有断路器的状态以流的方式不断的推送到dashboard. 这部分代码我就不用说了,很简单。
需要在你的服务端加3行代码,启动我们的流服务:
1
2
3
|
hystrixStreamHandler := hystrix.NewStreamHandler()
hystrixStreamHandler.Start()
go http.ListenAndServe(net.JoinHostPort("", "81"), hystrixStreamHandler)
|
如果是集群可以使用Turbine进行监控
参考:
https://www.cnblogs.com/li-peng/p/11050563.html
https://www.zybuluo.com/aliasliyu4/note/1248898