服务隔离与多集群设计
文章目录
隔离
隔离,本质上是对系统或资源进行分割,从而实现当系统发生故障时能限定传播范围和影响范围,即发生故障后只有出问题的服务不可用,保证其他服务仍然可用。
服务隔离
- 动静分离、读写分离
轻重隔离
- 核心、快慢、热点
物理隔离
- 线程、进程、集群、机房
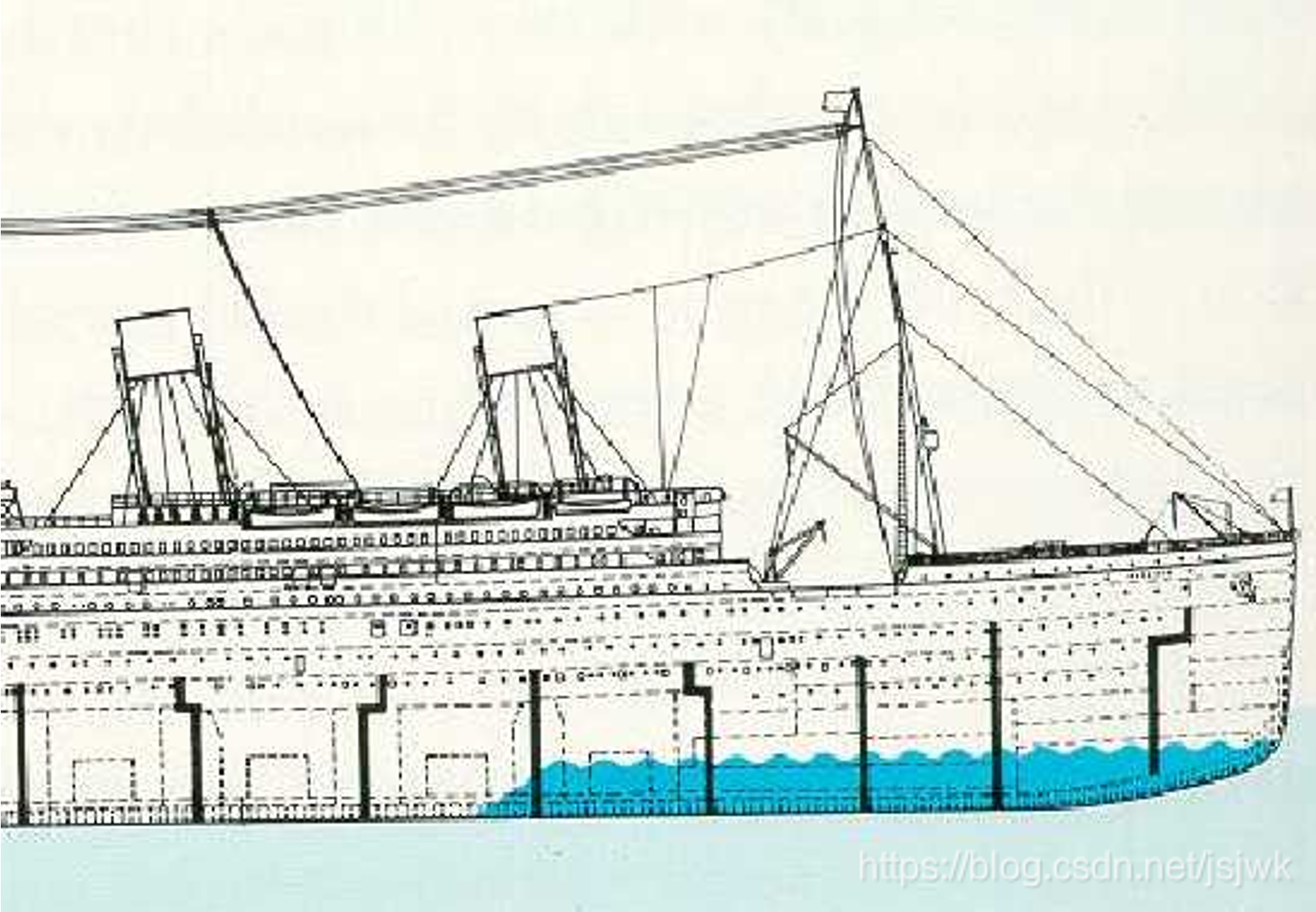
隔离 - 服务隔离
动静隔离:
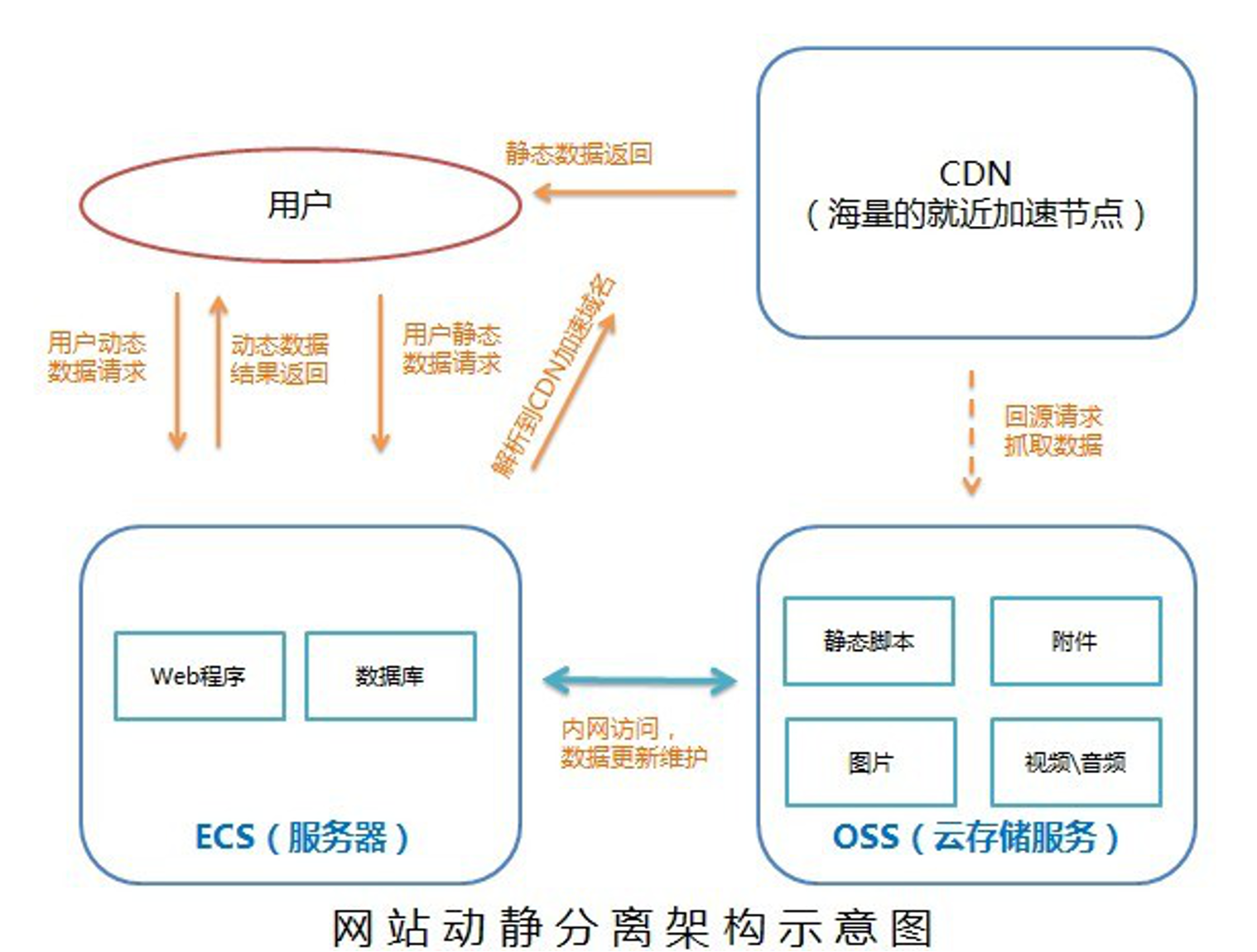
小到 CPU 的 cacheline false sharing、数据库 mysql 表设计中避免 bufferpool 频繁过期,隔离动静表,大到架构设计中的图片、静态资源等缓存加速。本质上都体现的一样的思路,即加速/缓存访问变换频次小的。比如 CDN 场景中,将静态资源和动态 API 分离,也是体现了隔离的思路:
- 降低应用服务器负载,静态文件访问负载全部通过CDN。
- 对象存储存储费用最低。
- 海量存储空间,无需考虑存储架构升级。
- 静态CDN带宽加速,延迟低。
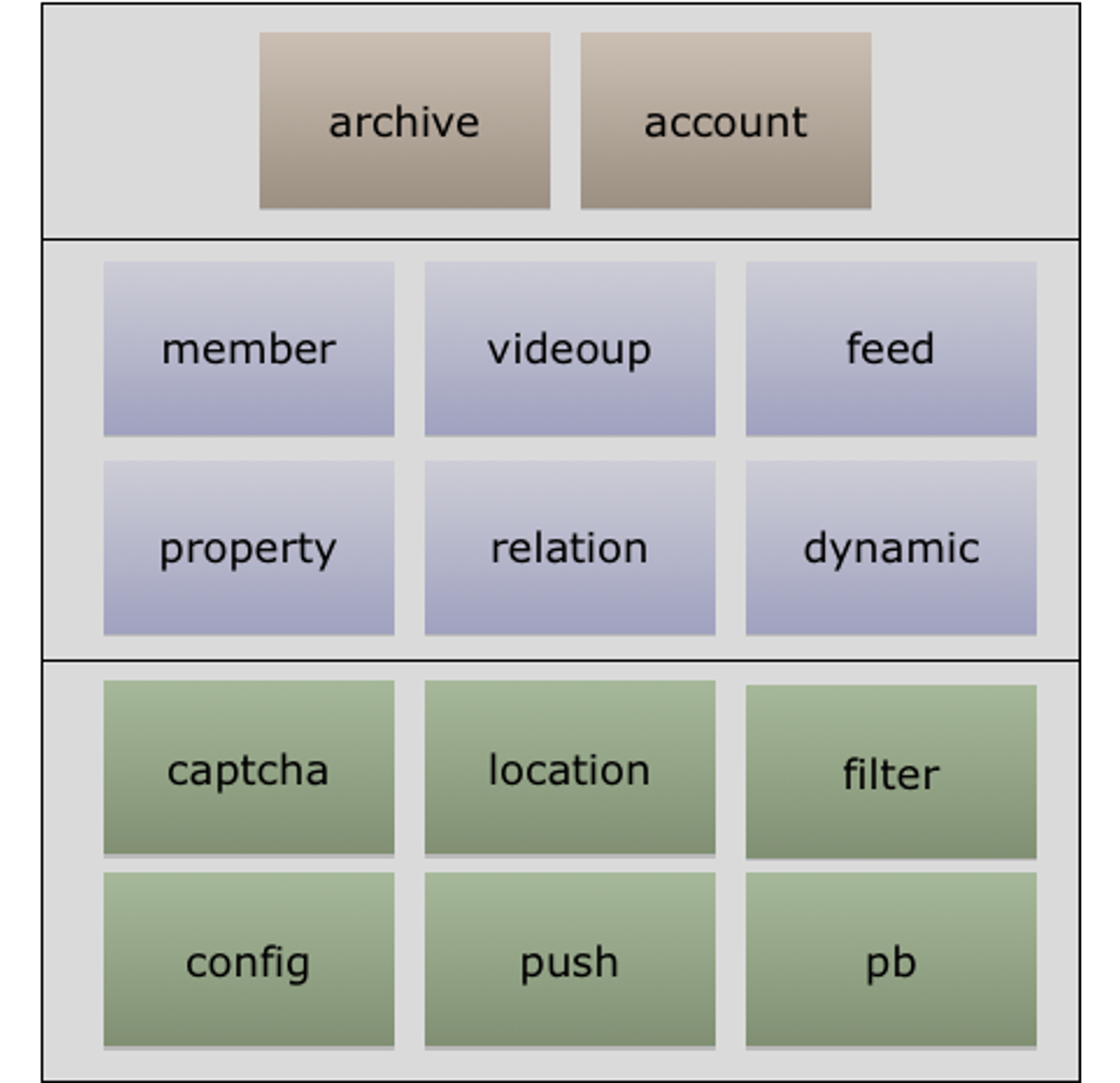
archive: 稿件表,存储稿件的名称、作者、分类、tag、状态等信息,表示稿件的基本信息。
在一个投稿流程中,一旦稿件创建改动的频率比较低。
archive_stat: 稿件统计表,表示稿件的播放、点赞、收藏、投币数量,比较高频的更新。
随着稿件获取流量,稿件被用户所消费,各类计数信息更新比较频繁。
MySQL BufferPool 是用于缓存 DataPage 的,DataPage 可以理解为缓存了表的行,那么如果频繁更新 DataPage 不断会置换,会导致命中率下降的问题,所以我们在表设计中,仍然可以沿用类似的思路,其主表基本更新,在上游 Cache 未命中,透穿到 MySQL,仍然有 BufferPool 的缓存。
- 读写分离:主从、Replicaset、CQRS。

隔离 - 轻重隔离
核心隔离:
业务按照 Level 进行资源池划分(L0/L1/L2)。
- 核心/非核心的故障域的差异隔离(机器资源、依赖资源)。
- 多集群,通过冗余资源来提升吞吐和容灾能力。
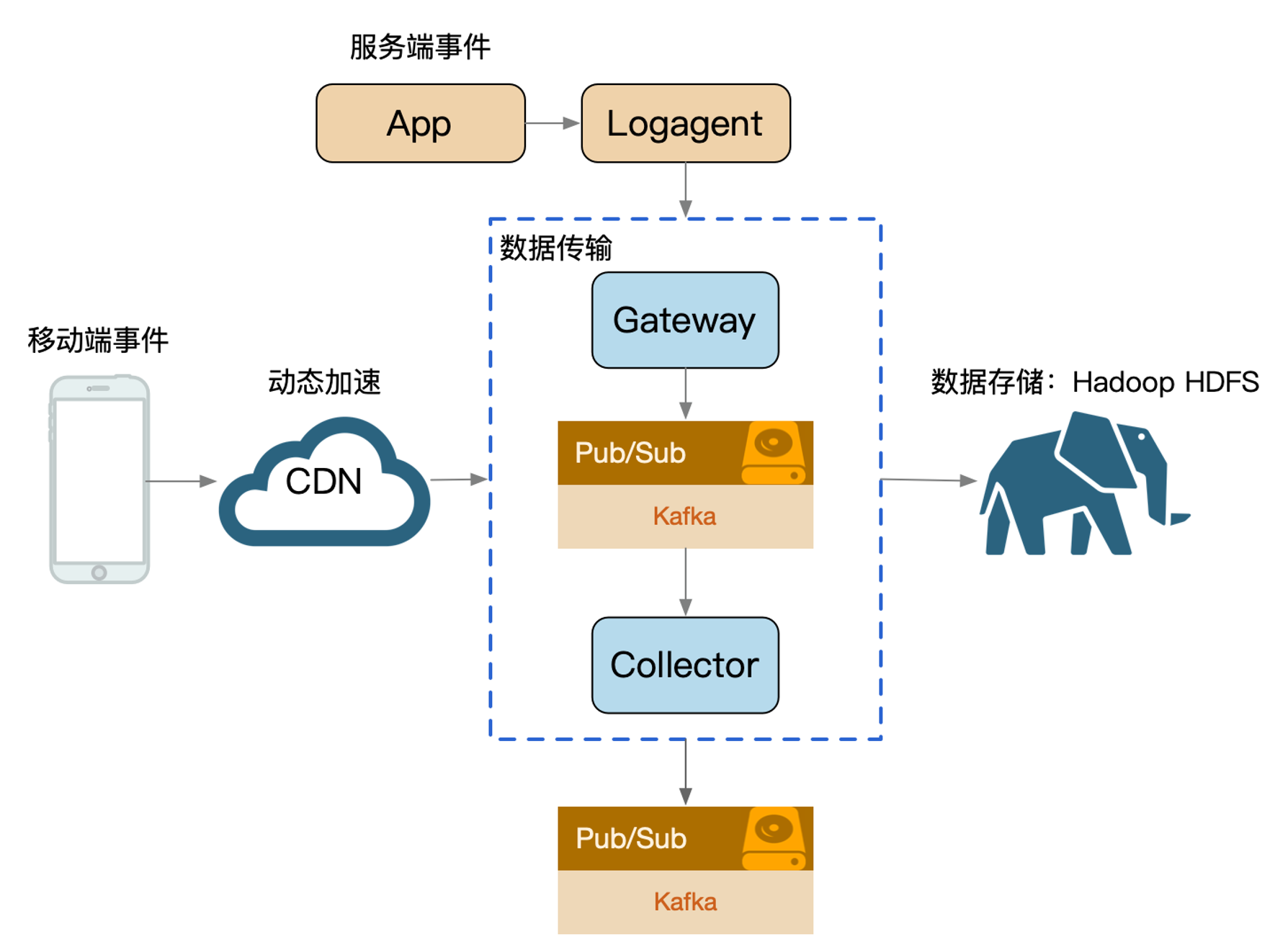
快慢隔离:
我们可以把服务的吞吐想象为一个池,当突然洪流进来时,池子需要一定时间才能排放完,这时候其他支流在池子里待的时间取决于前面的排放能力,耗时就会增高,对小请求产生影响。
日志传输体系的架构设计中,整个流都会投放到一个 kafka topic 中(早期设计目的: 更好的顺序IO),流内会区分不同的 logid,logid 会有不同的 sink 端,它们之前会出现差速,比如 HDFS 抖动吞吐下降,ES 正常水位,全局数据就会整体反压。
- 按照各种纬度隔离:sink、部门、业务、logid、重要性(S/A/B/C)。
业务日志也属于某个 logid,日志等级就可以作为隔离通道。
热点隔离:
何为热点?热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行缓存。比如:
- 小表广播: 从 remotecache 提升为 localcache,app 定时更新,甚至可以让运营平台支持广播刷新 localcache。atomic.Value
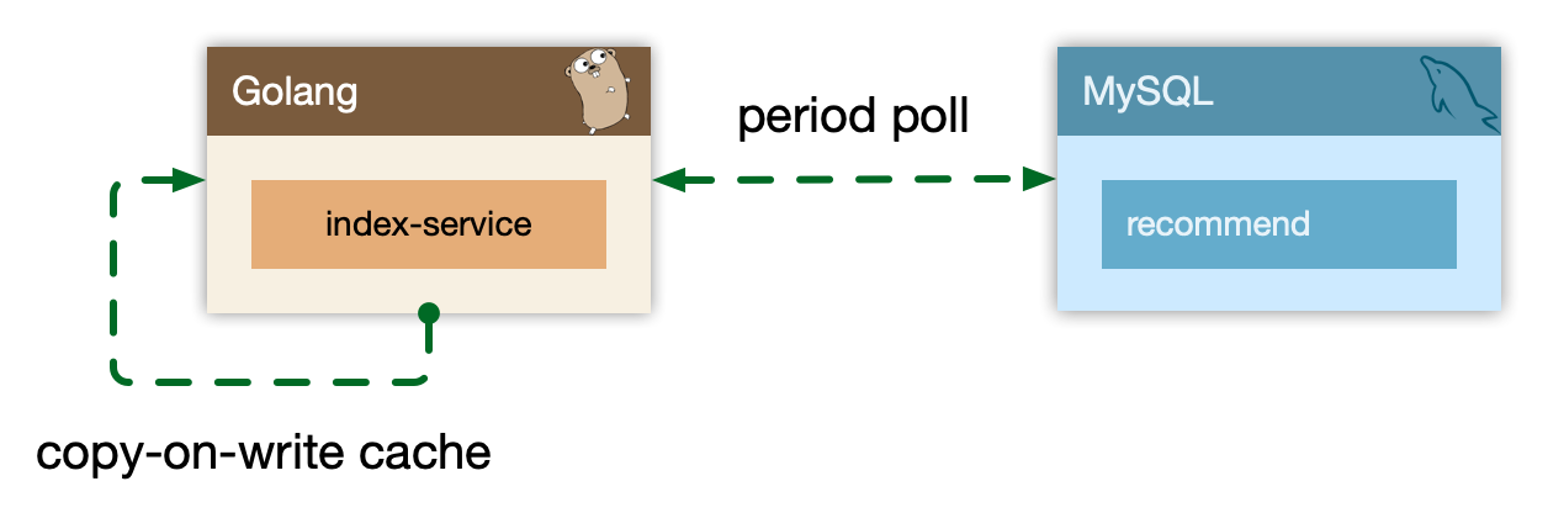
- 主动预热: 比如直播房间页高在线情况下bypass 监控主动防御。
隔离 - 物理隔离
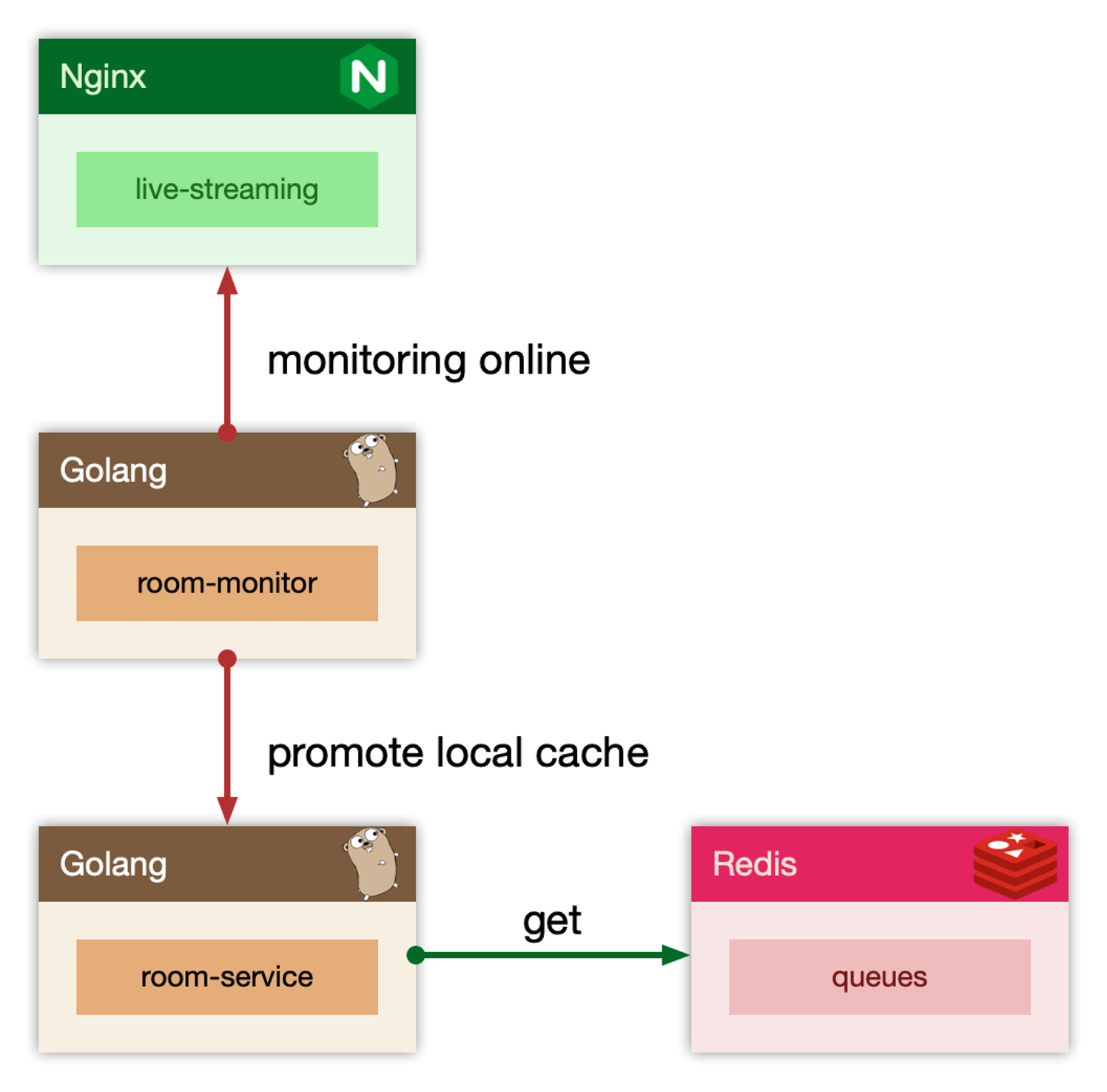
线程隔离:
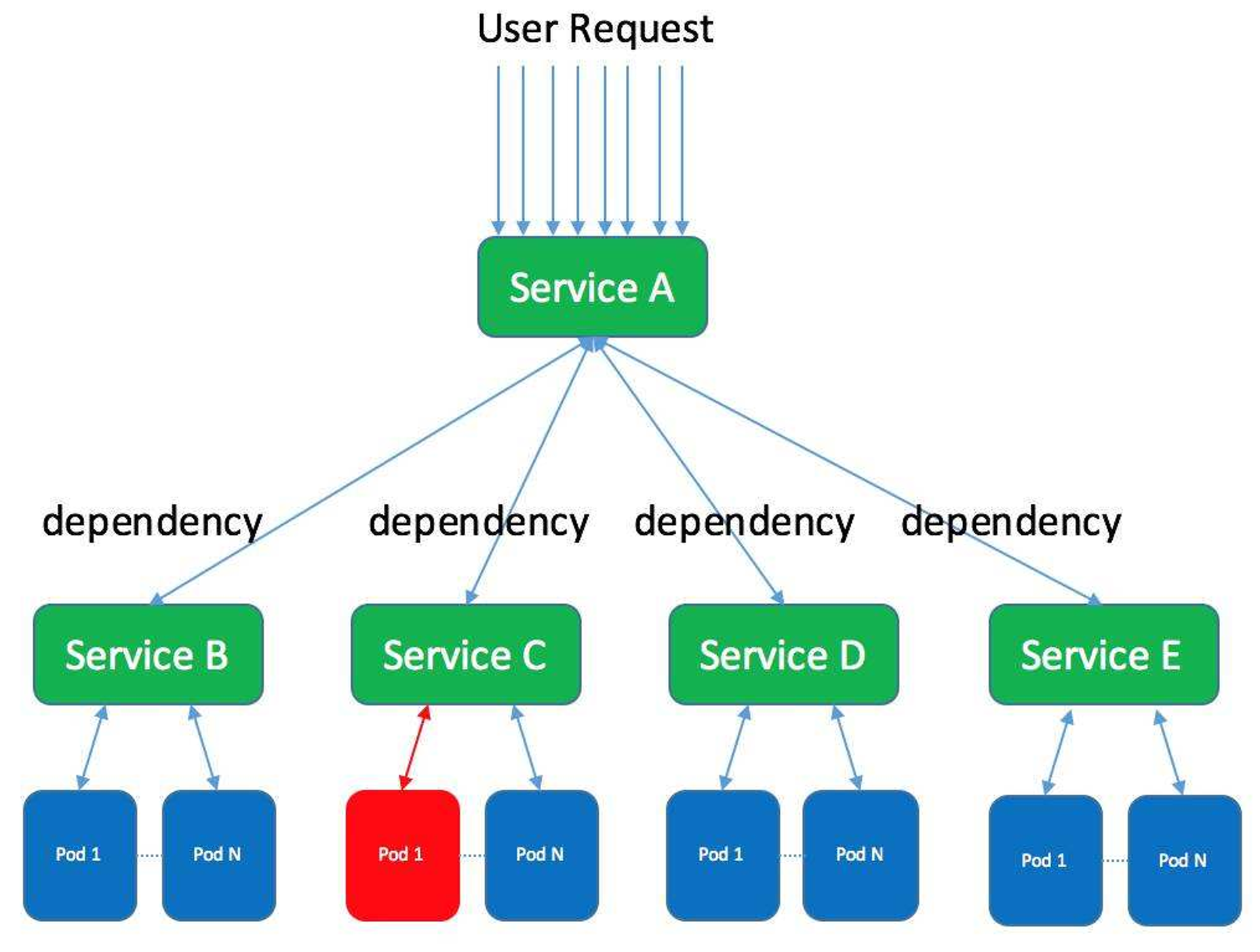
主要通过线程池进行隔离,也是实现服务隔离的基础。把业务进行分类并交给不同的线程池进行处理,当某个线程池处理一种业务请求发生问题时,不会讲故障扩散和影响到其他线程池,保证服务可用。
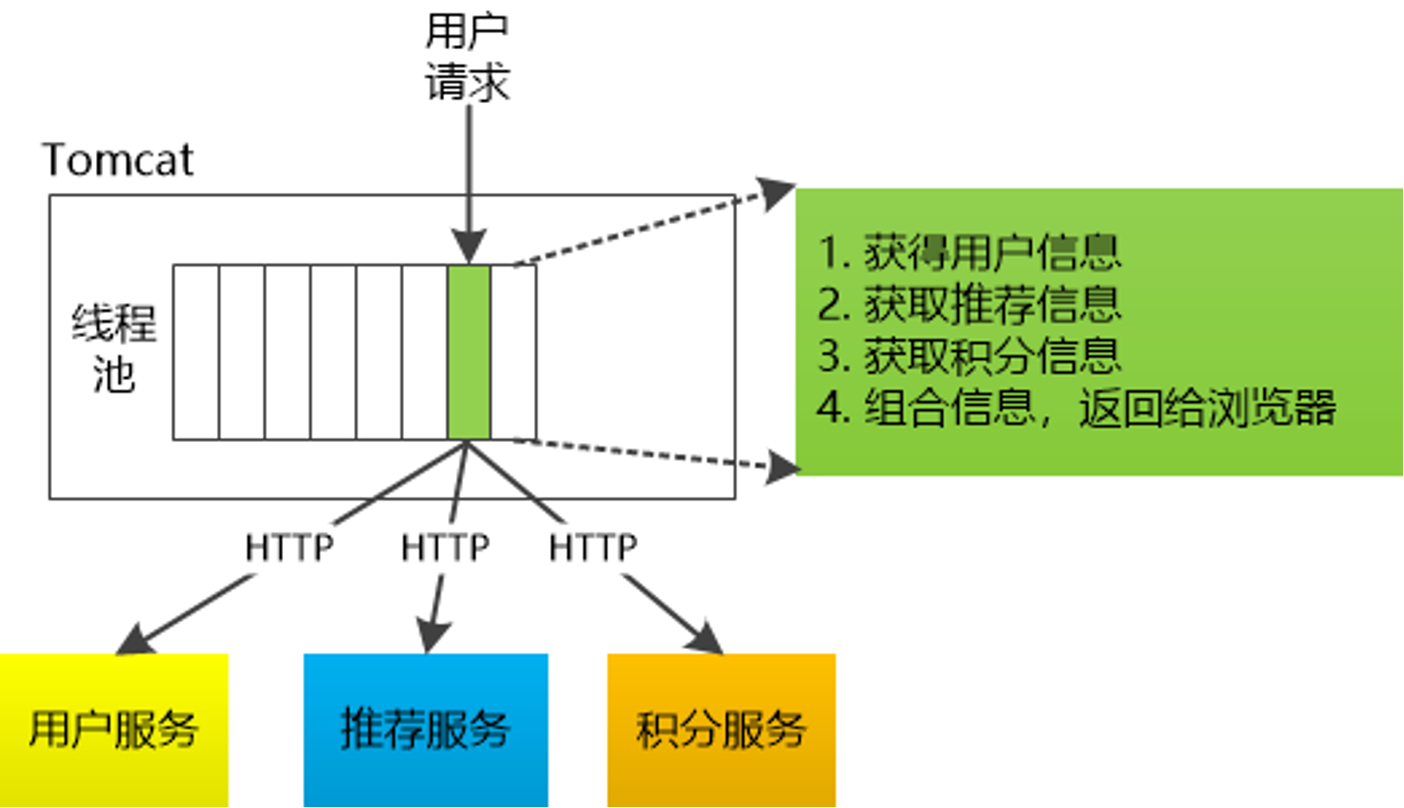
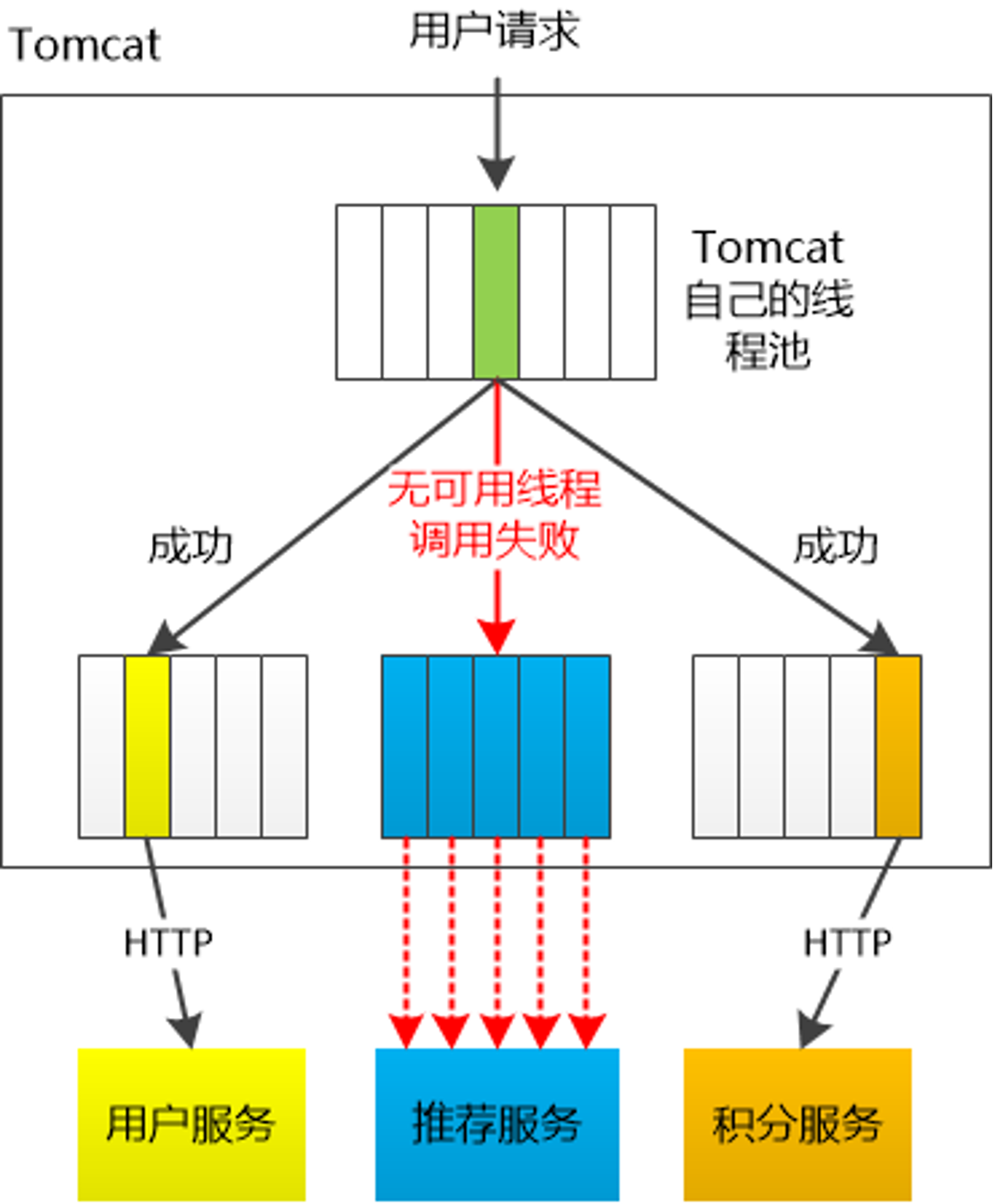
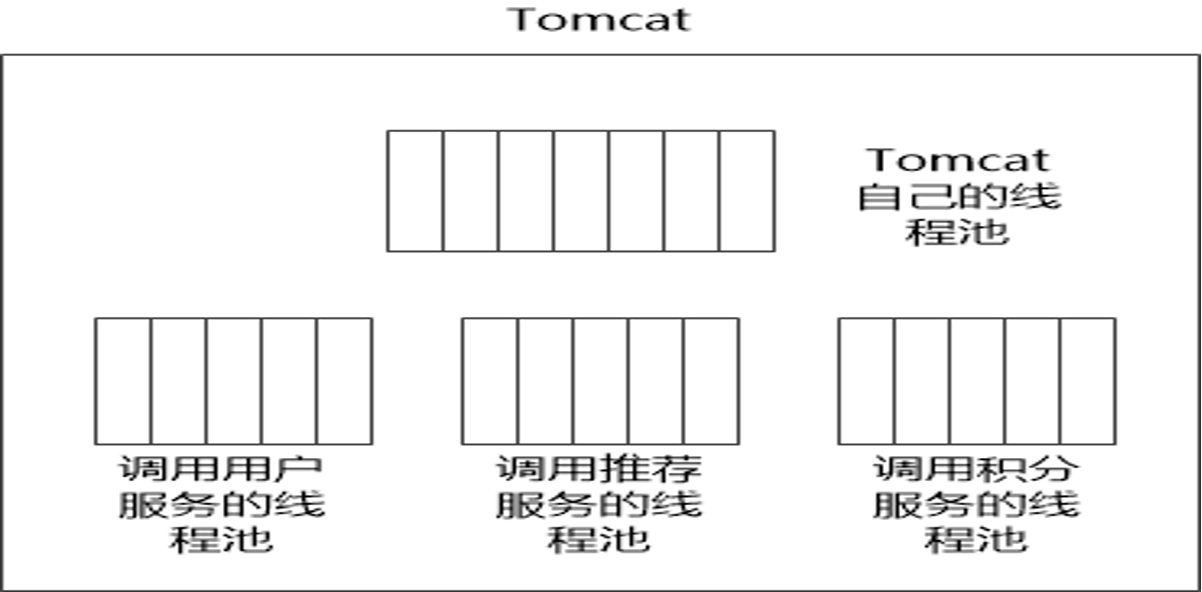
对于 Go 来说,所有 IO 都是 Nonblocking,且托管给了 Runtime,只会阻塞Goroutine,不阻塞 M,我们只需要考虑 Goroutine 总量的控制,不需要线程模型语言的线程隔离。
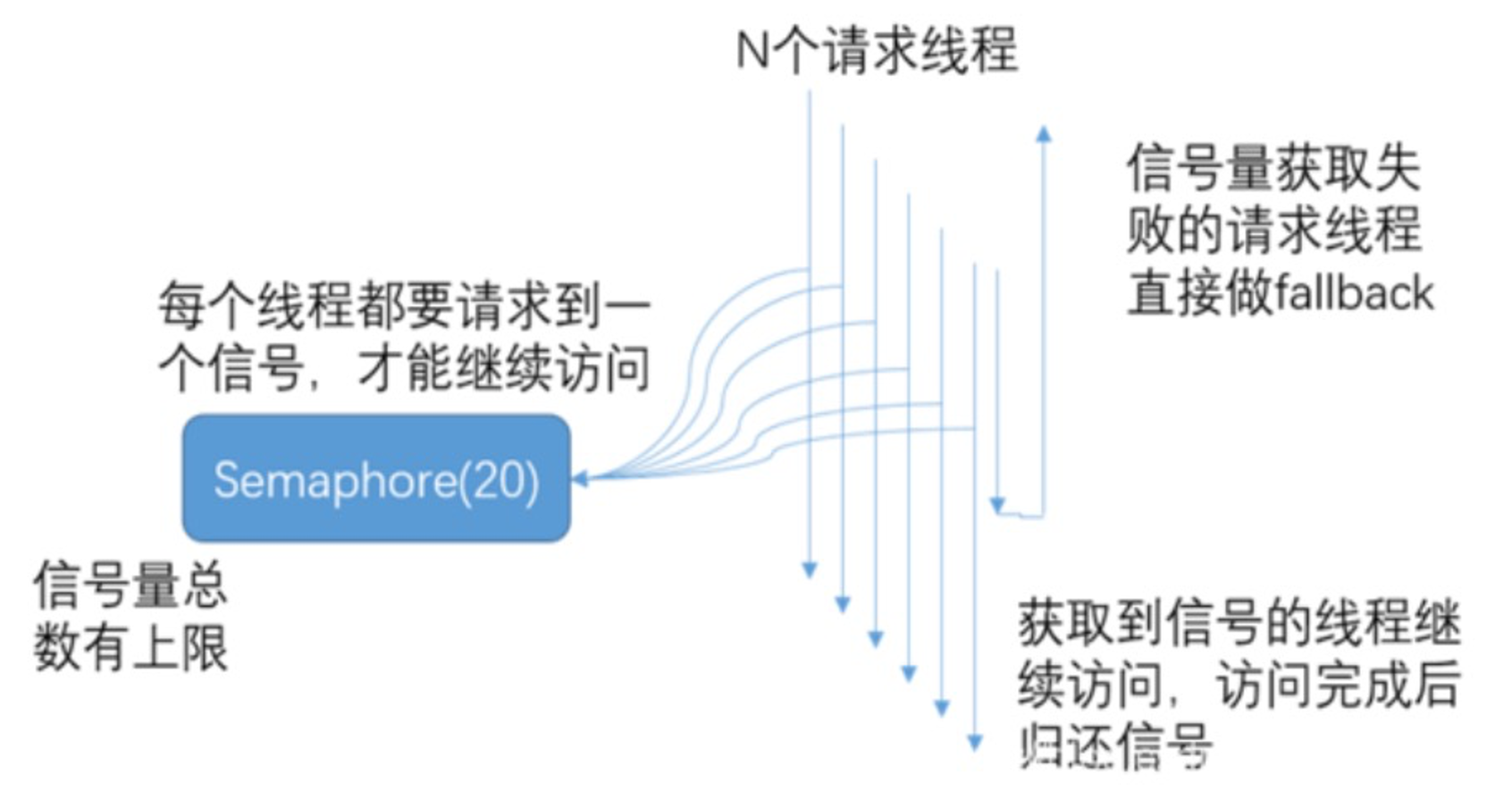
当信号量达到 maxConcurrentRequests 后,再请求会触发 fallback。
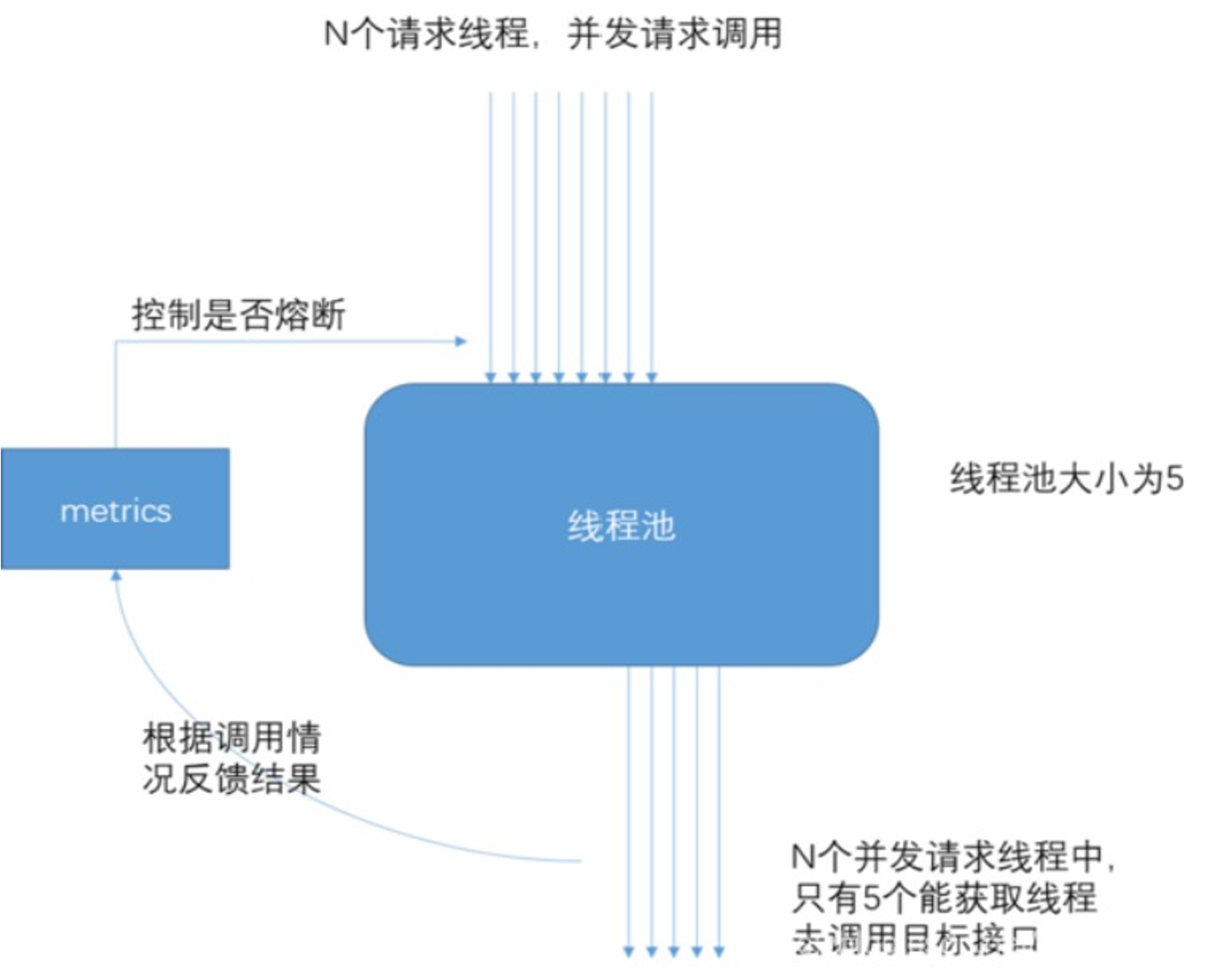
当线程池到达 maxSize 后,再请求会触发 fallback 接口进行熔断。
Java 除了线程池隔离,也有基于信号量的做法。
进程隔离:
容器化(docker),容器编排引擎(k8s)。我们15年在 KVM 上部署服务;16年使用 Docker Swarm;17年迁移到 Kubernetes,到年底在线应用就全托管了,之后很快在线应用弹性公有云上线;20年离线 Yarn 和 在线 K8s 做了在离线混部(错峰使用),之后计划弹性公有云配合自建 IDC 做到离线的混合云架构。
集群隔离:
回顾 gRPC,我们介绍过多集群方案,即逻辑上是一个应用,物理上部署多套应用,通过 cluster 区分。
多活建设完毕后,我们应用可以划分为: region.zone.cluster.appid
隔离 - Case Stduy
- 早期转码集群被超大视频攻击,导致转码大量延迟。
- 快慢隔离:划分3套worker,一套大视频,一套中视频,一套小视频.
- 入口Nginx(SLB)故障,影响全机房流量入口故障。
- 物理隔离
- 缩略图服务,被大图实时缩略吃完所有 CPU,导致正常的小图缩略被丢弃,大量503。
- 快慢隔离
- 数据库实例 cgroup 未隔离,导致大 SQL 引起的集体故障。
- 物理隔离
- INFO 日志量过大,导致异常 ERROR 日志采集延迟。
多集群
L0 服务,类似像我们账号,之前是一套大集群,一旦故障影响返回巨大,所以我们从几个角度考虑多集群的必要性:
- 从单一集群考虑,多个节点保证可用性,我们通常使用 N+2 的方式来冗余节点。
- 从单一集群故障带来的影响面角度考虑冗余多套集群。
- 单个机房内的机房故障导致的问题。
我们利用 paas 平台,给某个 appid 服务建立多套集群(物理上相当于两套资源,逻辑上维护 cluster 的概念),对于不同集群服务启动后,从环境变量里可以获取当下服务的 cluster,在服务发现注册的时候,带入这些元信息。当然,不同集群可以隔离使用不同的缓存资源等。
- 多套冗余的集群对应多套独占的缓存,带来更好的性能和冗余能力。
- 尽量避免业务隔离使用或者 sharding 带来的 cache hit 影响(按照业务划分集群资源)。
- 业务隔离集群带来的问题是 cache hit ratio 下降,不同业务形态数据正交,我们推而求其次整个集群全部连接。
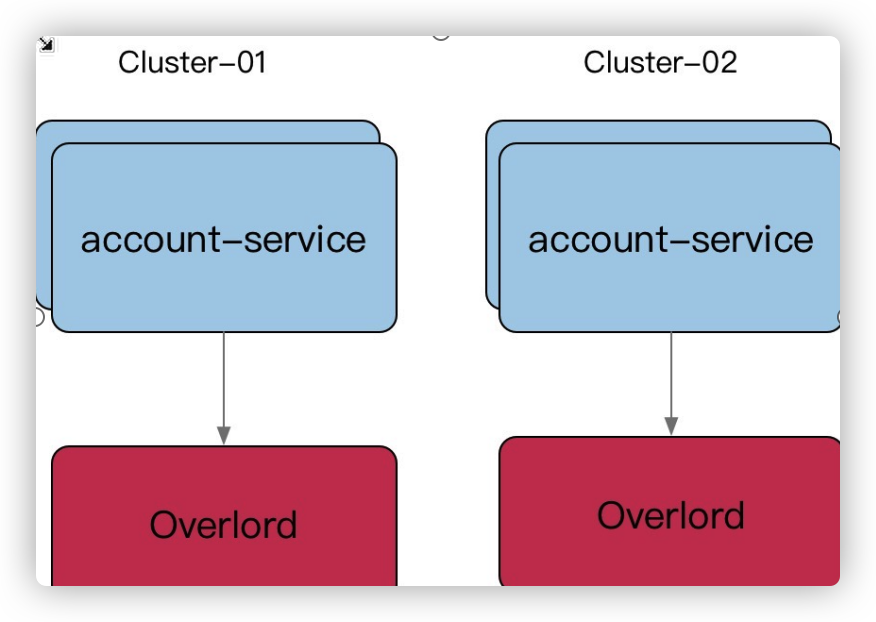
统一为一套逻辑集群(物理上多套资源池),即 gRPC 客户端默认忽略服务发现中的 cluster 信息,按照全部节点,全部连接。能不能找到一种算法从全集群中选取一批节点(子集),利用划分子集限制连接池大小。
- 长连接导致的内存和 CPU 开销,HealthCheck 可以高达30%。
- 短连接极大的资源成本和延迟。
合适的子集大小和选择算法
- 通常20-100个后端,部分场景需要大子集,比如大批量读写操作。
- 后端平均分给客户端。
- 客户端重启,保持重新均衡,同时对后端重启保持透明,同时连接的变动最小。

文章作者 Forz
上次更新 2021-11-11