自动dump库homles介绍
文章目录
背景
Go 项目做的比较大(主要说代码多,参与人多)之后,可能会遇到类似下面这样的问题:
- 程序老是半夜崩,崩了以后就重启了,我也醒不来,现场早就丢了,不知道怎么定位
- 这压测开压之后,随机出问题,可能两小时,也可能五小时以后才出问题,这我蹲点蹲出痔疮都不一定能等到崩溃的那个时间点啊
- 有些级联失败,最后留下现场并不能帮助我们准确地判断问题的根因,我们需要出问题时第一时间的现场
Go 内置的 pprof 虽然是问题定位的神器,但是没有办法让你恰好在出问题的那个时间点,把相应的现场保存下来进行分析。特别是一些随机出现的内存泄露、CPU 抖动,等你发现有泄露的时候,可能程序已经 OOM 被 kill 掉了。而 CPU 抖动,你可以蹲了一星期都不一定蹲得到。
这个问题最好的解决办法是 continuous profiling,不过这个理念需要公司的监控系统配合,在没有达到最终目标前,我们可以先向前迈一小步,看看怎么用比较低的成本来解决这个问题。
从现象上,可以将出问题的症状简单分个类:
- cpu 抖动:有可能是模块内有一些比较冷门的逻辑,触发概率比较低,比如半夜的定时脚本,触发了以后你还在睡觉,这时候要定位就比较闹心了。
- 内存使用抖动:有很多种情况会导致内存使用抖动,比如突然涌入了大量请求,导致本身创建了过多的对象。也可能是 goroutine 泄露。也可能是突然有锁冲突,也可能是突然有 IO 抖动。原因太多了,猜是没法猜出根因的。
- goroutine 数暴涨,可能是死锁,可能是数据生产完了 channel 没关闭,也可能是 IO 抖了什么的。
CPU 使用,内存占用和 goroutine 数,都可以用数值表示,所以不管是“暴涨”还是抖动,都可以用简单的规则来表示:
- xx 突然比正常情况下的平均值高出了 25%
- xx 超过了模块正常情况下的最高水位线
这两条规则可以描述大部分情况下的异常,规则一可以表示瞬时的,剧烈的抖动,之后可能迅速恢复了;规则二可以用来表示那些缓慢上升,但最终超出系统负荷的情况,例如 1s 泄露一兆内存,直至几小时后 OOM。
而与均值的 diff,在没有历史数据的情况下,就只能在程序内自行收集了,比如 goroutine 的数据,我们可以每 x 秒运行一次采集,在内存中保留最近 N 个周期的 goroutine 计数,并持续与之前记录的 goroutine 数据均值进行 diff:
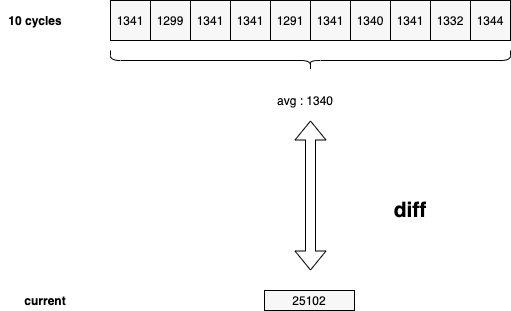
比如像图里的情况,前十个周期收集到的 goroutine 数在 1300 左右波动,而最新周期收集到的数据为 2w+,这显然是瞬时触发导致的异常情况,那么我们就可以在这个点自动地去做一些事情,比如:
- 把当前的 goroutine 栈 dump 下来
- 把当前的 cpu profile dump 下来
- 把当前的 off-cpu profile dump 下来
不怕死的话,也可以 dump 几秒的 trace
文件保存下来,模块挂掉也就无所谓了。之后在喝茶的时候,发现线上曾经出现过崩溃,那再去线上机器把文件捞下来,一边喝茶一边分析,还是比较悠哉的。
这里面稍微麻烦一些的是 CPU 和内存使用量的采集,现在的应用可能跑在物理机上,也可能跑在 docker 中,因此在获取用量时,需要我们自己去做一些定制。物理机中的数据采集,可以使用 gopsutil,docker 中的数据采集,可以参考少量 cgroups 中的实现。
实现
Go 的采样工具
Go的pprof工具集,提供了Go程序内部多种性能指标的采样能力,我们常会用到的性能采样指标有这些:
- profile:CPU采样
- heap:堆中活跃对象的内存分配情况的采样
- goroutine:当前所有goroutine的堆栈信息
- allocs: 会采样自程序启动所有对象的内存分配信息(包括已经被GC回收的内存)
- threadcreate:采样导致创建新系统线程的堆栈信息
怎么获取采样信息
网上最常见的例子是在服务端开启端口让客户端通过HTTP访问指定的路由进行各种信息的采样
|
|
|
|
这种方法的弊端就是
- 需要客户端主动请求特定路由进行采样,没法在资源出现尖刺的第一时间进行采样。
- 会注册多个/debug/pprof类的路由,相当于对 Web 服务有部分侵入。
- 对于非 Web 服务,还需在服务所在的节点上单独开 HTTP 端口,起 Web 服务注册 debug 路由才能进行采集,对原服务侵入性更大。
Runtime pprof
除了上面通过HTTP访问指定路由进行采样外,还有一种主要的方法是使用runtime.pprof 提供的Lookup方法完成各资源维度的信息采样。
|
|
CPU的采样方式runtime/pprof提供了单独的方法在开关时间段内对 CPU 进行采样
|
|
这种方式是操作简单,把采样信息可以直接写到文件里,不需要额外开端口,再手动通过HTTP进行采样,但是弊端也很明显–不停的采样会影响性能。固定时间间隔的采样(比如每隔五分钟执行一次采样)不够有针对性,有可能采样的时候资源并不紧张。
也可以获取某一特定指标:
|
|
非容器环境获取服务器指标
我们先来讨论普通的宿主机和虚拟机情况下怎么获取这些指标,容器环境放在下一节来说。
获取Go进程的资源使用情况使用gopstuil库即可完成,它我们屏蔽了各个系统之间的差异,帮助我们方便地获取各种系统和硬件信息。gopsutil将不同的功能划分到不同的子包中,它提供的模块主要有:
- cpu:系统CPU 相关模块;
- disk:系统磁盘相关模块;
- docker:docker 相关模块;
- mem:内存相关模块;
- net:网络相关;
- process:进程相关模块;
- winservices:Windows 服务相关模块。
我们这里只用到了它的process子包,获取进程相关的信息。
声明:process 模块需要 import "github.com/shirou/gopsutil/process"后引入到项目,后面演示的代码会用到的os等模块会统一省略import相关的信息和错误处理,在此提前说明。
创建进程对象
process模块的NewProcess会返回一个持有指定PID的Process对象,方法会检查PID是否存在,如果不存在会返回错误,通过Process对象上定义的其他方法我们可以获取关于进程的各种信息。
|
|
进程的CPU使用率
进程的CPU使用率需要通过计算指定时间内的进程的CPU使用时间变化计算出来
|
|
上面返回的是占所有CPU时间的比例,如果想更直观的看占比,可以算一下占单个核心的比例。
|
|
内存使用率
|
|
容器环境获取容器指标
上面获取进程资源占比的方法只有在虚拟机和物理机环境下才能准确。类似Docker这样的Linux容器是靠着Linux的Namespace和Cgroups技术实现的进程隔离和资源限制,是不行的。
现在的服务很多公司是K8s集群部署,所以如果是在Docker中获取Go进程的资源使用情况需要根据Cgroups分配给容器的资源上限进行计算才准确。
在Linux中,Cgroups给用户暴露出来的操作接口是文件系统,它以文件和目录的方式组织在操作系统的/sys/fs/cgroup路径下,在 /sys/fs/cgroup下面有很多诸cpuset、cpu、 memory这样的子目录,每个子目录都代表系统当前可以被Cgroups进行限制的资源种类。
针对我们监控Go进程内存和CPU指标的需求,我们只要知道cpu.cfs_period_us、cpu.cfs_quota_us 和memory.limit_in_bytes 就行。前两个参数需要组合使用,可以用来限制进程在长度为cfs_period的一段时间内,只能被分配到总量为cfs_quota的CPU时间, 可以简单的理解为容器能使用的核心数 = cfs_quota / cfs_period。
所以在容器里获取Go进程CPU的占比的方法,需要做一些调整,利用我们上面给出的公式计算出容器能使用的最大核心数。
|
|
然后再把通过p.Percent获取到的进程占用机器所有CPU时间的比例除以计算出的核心数即可算出Go进程在容器里对CPU的占比。
|
|
而容器的能使用的最大内存数,自然就是在memory.limit_in_bytes里指定的啦,所以Go进程在容器中占用的内存比例需要通过下面这种方法获取
|
|
上面进程内存信息里的RSS叫常驻内存,是在RAM里分配给进程,允许进程访问的内存量。而读取容器资源用的readUint,是containerd组织在cgroups实现里给出的方法。
|
|
适合采样的时间点
经过了上面的分析,现在看来只要让Go进程在自己占用资源突增或者超过一定的阈值时再用pprof对程序Runtime进行采样,才是最合适的,那么接下来我们就要想一下,到底以什么样的规则,才能判断出当前周期是适合采样的时段呢。
判断采样时间点的规则
CPU 使用,内存占用和 goroutine 数,都可以用数值表示,所以无论是使用率慢慢上升直到超过阈值,还是突增之后迅速回落,都可以用简单的规则来表示,比如:
cpu/mem/goroutine数 突然比正常情况下的平均值高出了一定的比例,比如说资源占用率突增25%就是出现了资源尖刺。cpu/mem/goroutine数 超过了程序正常运行情况下的阈值,比如说80%就定义为服务资源紧张。 这两条规则可以描述大部分情况下的异常,第一个规则可以表示瞬时的,剧烈的抖动,之后可能迅速恢复正常的情况。
规则二可以用来表示那些缓慢上升,但最终超出阈值的情况,例如下图中内存使用率一直在慢慢上升,直到超过了设置的80%的阈值。
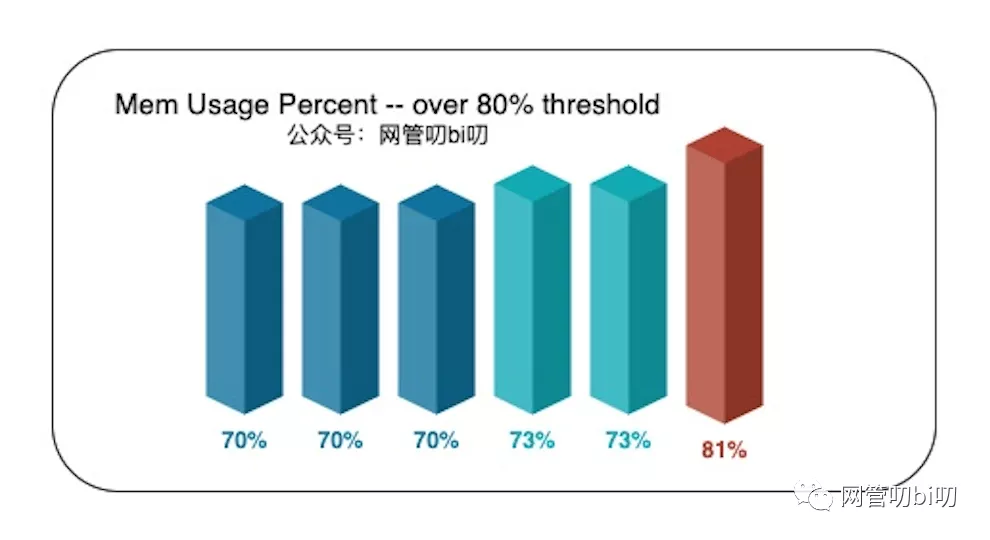
而规则一判断资源突增,需要与历史均值对比才行。在没有历史数据的情况下,就只能在程序内自行收集了,比如进程的内存使用率,我们可以以每 10 秒为一个周期,运行一次采集,在内存中保留最近 5 ~ 10 个周期的内存使用率,并持续与之前记录的内存使用率均值进行比较:
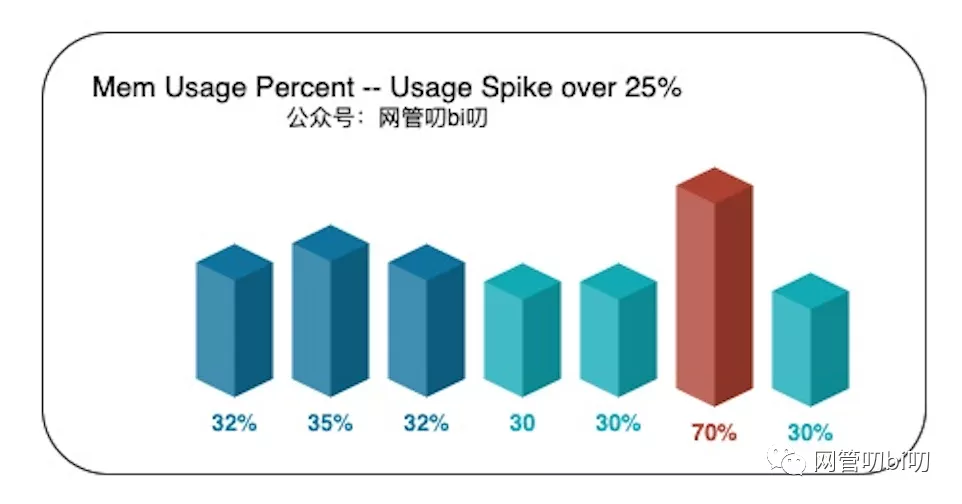
比如像上图里的情况,前五个周期收集到的内存占用率在 35% 左右波动,而最新周期收集到的数据为70%,这显然是瞬时突增导致的异常情况,那么我们就可以在这个时间点,自动让程序调用 pprof 把 mem 信息采样到文件里,后续无论服务是否已重启都能把采样信息拿下来分析。
而关于怎么让Go程序获取本进程的CPU、Mem使用量在系统中的占比,我们在之前的文章 学会这几招让 Go 程序自己监控自己 已经跟大家分享过了,只需要编码实现在上面描述的两个采样时机进行性能采样即可。
holmes
社区里其实已经有开源库实现了类似的功能,比如曹大在蚂蚁的时候设计的Holmes.
使用起来也比较方便,比如下面是一个对内存使用率突增 25% 和超过阈值 80% 这两种情况下让程序自动进行Mem信息采样的例子。如果你公司里的基建还没有到把持续采样做到统一平台里的水平的话,Holmes 是一个比较好的选择,能快速解决问题,比较适合中小型的业务快速发展的团队。
简单的看一个 Web 服务接入 Holmes 分析内存占用率的例子。
|
|
- WithCollectInterval(“2s”) 指定 2s 为区间监控进程的资源占用率, 线上建议设置大于10s的采样区间。
- WithMemDump(3, 25, 80) 指定进程的mem占用率超过3%后(线上建议设置成30),如果有25%突增,或者总占用率超过80%后进行采样
通过采样能获取到了内存资源突增时的程序调用栈,
[1: 1073741824]表示有一个对象消耗了1GB的内存,通过调用栈分析我们也能快速找到找到造成资源占用的代码位置。
|
|
关于这个库更详细的使用介绍可以直接看仓库提供的Get Started 教程 https://github.com/mosn/holmes
解决问题
OOM 类问题
RPC decode 未做防御性编程,导致 OOM
应用侧的编解码可能是非官方实现(如 node 之类的无官方 SDK 的项目),在一些私有协议 decode 工程中会读诸如 list len 之类的字段,如果外部编码实现有问题,发生了字节错位,就可能会读出一个很大的值。
非标准 app —-encode——-> 我们的应用 decode —–> Boom!
decoder 实现都是需要考虑这种情况的,类似这样。如果对请求方的数据完全信任,碰到对方的 bug 或者恶意攻击,可能导致自己的服务 OOM。
在线上实际发现了一例内存瞬间飚升的 case,收到报警后,我们可以看到:
|
|
1: 1330208768 [1: 1330208768] 表示 inuse_objects : inuse_space [alloc_objects : alloc_space],这里可以看到一个对象就直接用掉了 1GB 内存,显然不是正常情况,查看代码后,发现有未进行大小判断而完全信任用户输入数据包的 decode 代码。
修复起来很简单,像前面提到的 async-h1 一样加个判断就可以了。
tls 开启后线上进程占用内存上涨,直至 OOM
线上需要做全链路加密,所以有开启 tls 的需求,但开启之后发现内存一路暴涨,直至 OOM,工具可以打印如下堆栈:
|
|
查阅老版本的 Go 代码,发现其 TLS 的 write buffer 会随着写出的数据包大小增加而逐渐扩容,其扩容逻辑比较简单:
|
|
初始为 1024,后续不够用每次扩容为两倍。但是阅读 tls 的代码后得知,这个写出的数据包大小最大实际上只有 16KB + 额外的一个小 header 大小左右,但老版本的实现会导致比较多的空间浪费,因为最终会扩容到 32KB。
这段比较浪费空间的逻辑在 Go1.12 之后已经进行了优化:
|
|
变成了需要多少,分配多少的朴实逻辑。所以会比老版本在这个问题上有不少缓解,不过在我们的场景下,新版本的代码依然没法满足需求,所以还需要进一步优化,这就是后话了。
goroutine 暴涨类问题
本地 app GC hang 死,导致 goroutine 卡 channel send 在我们的程序中有一段和本地进程通信的逻辑,write goroutine 会向一个 channel 中写数据,按常理来讲,同物理机的两个进程通过网络通信成本比较低,类似下面的代码按说不太可能出问题:
|
|
看起来问题不大,但是线上经常都有和这个 channel send 相关的抖动,我们通过工具拿到的现场:
|
|
当前憋了 5w 个 goroutine,有 4w 个卡在 channel send 上,这个 channel 的对面还是一条本地连接,令人难以接受。
但是要考虑到,线上的业务系统是 Java,Java 发生 FGÇ 的时候可不是闹着玩的。对往本地连接的 write buffer 写数据一定不会卡的假设是有问题的。
既然出问题了,说明在这里对我们的程序进行保护是必要的,修改起来也很简单,给 channel send 加一个超时就可以了。
应用逻辑死锁,导致连接不可用,大量 goroutine 阻塞在 lock 上
大多数网络程序里,我们需要在发送应用层心跳,以保证在一些异常情况(比如拔网线)下,能够把那些无效连接从连接池里剔除掉。
对于我们的场景来说,客户端向外创建的连接,如果一直没有请求,那么每隔一段时间会向外发送一个应用心跳请求,如果心跳连续失败(超时) N 次,那么将该连接进行关闭。
在这个场景下会涉及到两把锁:
- 对连接进行操作的锁 conn lock
- 记录心跳请求的 request map lock
心跳成功的流程:收到心跳响应包,获取 conn lock -> 获取 request map lock 心跳失败的流程:timer 超时,获取 request map lock -> 需要关闭连接 -> 获取 conn lock
可以看出来,心跳的成功和失败流程并发时,获取锁的流程符合死锁的一般定义:持有锁、非抢占、循环等待。
这个 bug 比较难触发,因为心跳失败要失败 N 次才会关闭连接,而正好在最后一次发生了心跳成功和失败并发才会触发上述的死锁,线上可以通过 goroutine 短时间的上涨发现这个问题,goroutine 的现场也是可以看得到的。简单分析就可以发现这个死锁问题(因为后续的流程都会卡在其中一把锁上)。
知道原因解决起来就不麻烦了,涉及到一些具体的业务逻辑,这里就不赘述了。
CPU 尖刺问题
应用逻辑导致死循环问题
国际化业务涉及到冬夏令时的切换,从夏令时切换到冬令时,会将时钟向前拔一个月,但天级日志轮转时,会根据轮转前的时间计算 24 小时后的时间,并按与 24:00 的差值来进行 time.Sleep,这时会发现整个应用的 CPU 飚高。自动采样结果发现一直在循环计算时间和重命名文件。
list 一下相关的函数,能很快地发现执行死循环的代码位置。这里就不截真实代码了,随便举个例子:
|
|
参考
文章作者 Forz
上次更新 2021-06-08