数据结构:unordered_map、unordered_set
文章目录
hashtable的数据结构
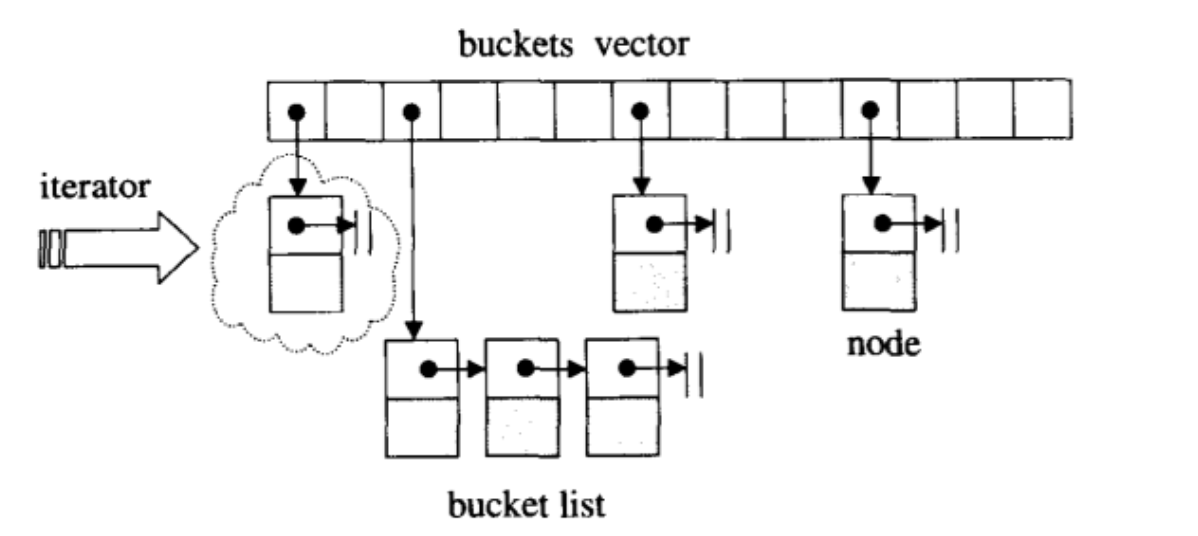
bucket所维护的linked list,并不采用STL的list或slist,而是自行维护上述的hashtable node。至于buckets聚合体,则以vector完成,以便有动态扩充能力。
虽然开链法(separate chaining)并不要求表格大小必须为质数,但STL仍然以质数来设计表格大小,并且先将28个质数(逐渐呈现大约两倍的关系)计算好,以备随时访问.
由于整个hash table由vector和linked-list组合而成,因此,复制和整体删除,都需要特别注意内存的释放问题。
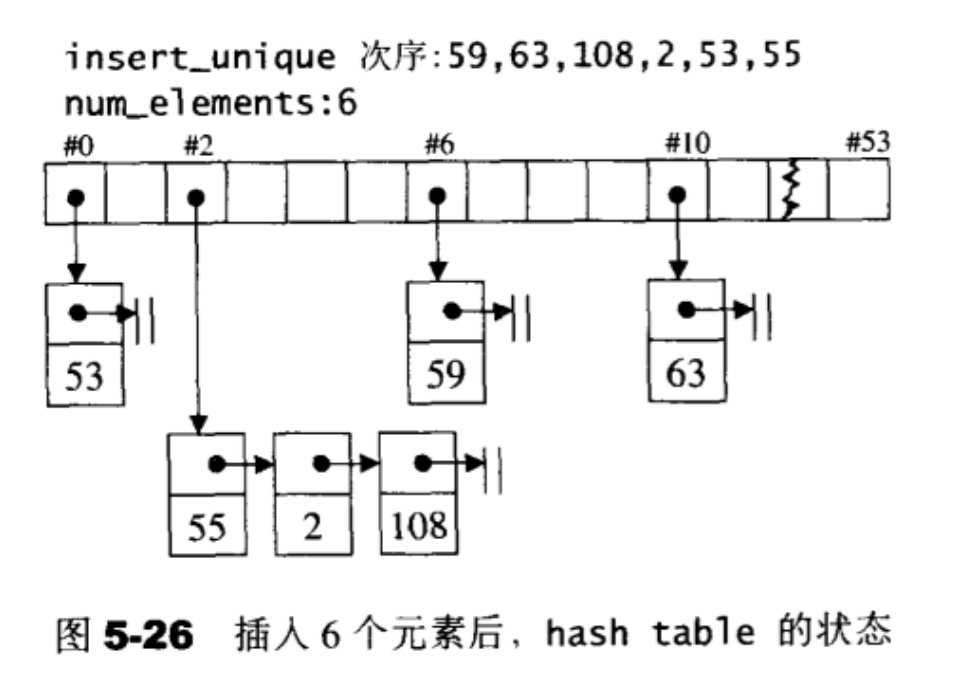
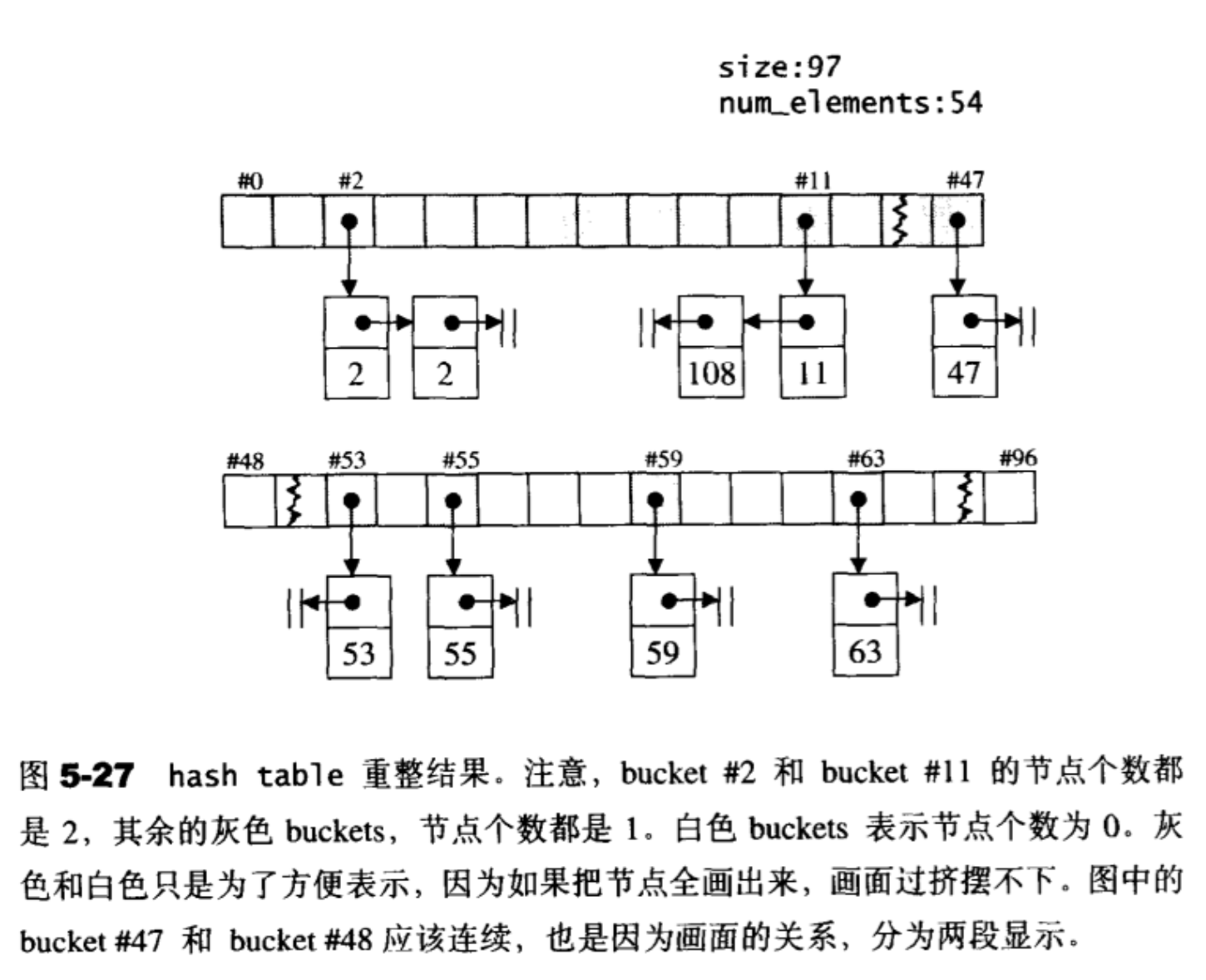
举例展示表格重整过程。一开始我保留50个节点,由于最接近的STL质数为53,所以buckets vector保留的是53个buckets,每个buckets (指针,指向一个hash table节点)的初值为0。接下来,循序加入6个元素:53,55,2,108,59,63,于是hashtable变成图5-26所示的样子。

hashtable的迭代器
hast table迭代器必须永远维系着与整个“buckets vector”的关系,并记录目前所指的节点。其前进操作是首先尝试从目前所指的节点出发,前进一个位置(节点),由于节点被安置于list内,所以利用节点的next指针即可轻易达成前进操作.如果目前节点正巧是list的尾端,就跳至下一个bucket身上,那正是指向下一个list的头部节点。
请注意,hashtable的迭代器没有后退操作(operator—-()),hashtable也没有定义所谓的逆向迭代器(reverse iterator)。
unordered_set
unordered_set,以hashtable为底层机制.由于unordered_set所供应的操作接口,hashtable都提供了,所以几乎所有的unordered_set操作行为,都只是转调用hashtable的操作行为而已。
运用set,为的是能够快速搜寻元素。这一点,不论其底层是RB-tree或是hash table,都可以达成任务。但是请注意,RB-tree有自动排序功能而hashtable没有,反应出来的结果就是,set的元素有自动排序功能而unordered_set没有。set的元素不像map那样可以同时拥有实值和键值,set元素的键值就是实值,实值就是键值。这一点在unordered_set中也是一样的。
unordered_set的使用方式,与set完全相同。
unordered_map
unordered_map,以hashtable为底层机制.由于unordered_map所供应的操作接口,hashtable都提供了,所以几乎所有的unordered_map操作行为,都只是转调用hashtable的操作行为而已。
运用map,为的是能够根据键值快速搜寻元素。这一点,不论其底层是RB-tree或是hashtable,都可以达成任务。但是请注意,RB-tree有自动排序功能而hashtable没有,反应出来的结果就是,map的元素有自动排序功能而unordered_map没有。
map的特性是,每一个元素都同时拥有一个实值和一个键值。这一点在unordered_map中也是一样的。unordered_map的使用方式,和map完全相同。
文章作者 Forz
上次更新 2017-09-03