排行榜方案设计
文章目录
业务分类
排行榜业务变化多样,从不同的角度思考,是不同的排行榜需求,但总结起来,主要分为以下几类:
实效性
从排行榜的实效性上划分,主要分为:
- 实时榜:基于当前一段时间内数据的实时更新,进行排行。例如:当前一小时内游戏热度实时榜,当前一小时内明星送花实时榜等
- 历史榜:基于历史一段周期内的数据,进行排行。例如:日榜(今天看昨天的),周榜(上一周的),月榜(上个月的),年榜(上一年的)
业务数据类型
从需要排行的数据类型上划分,主要分为:
- 单类型数据排行榜:是指需要排行的主体不需要区分类型,例如,所有用户积分排行,所有公贡献值排行,所有游戏热度排行等
- 多类型(复合类型)数据排行榜:是指需要排行的主体在排行中要求有类型上的区分,例如:竞技类游戏热度排行、体育类游戏热度排行、MOBA类游戏操作性排行、角色/回合/卡牌三类游戏热度排行等
展示唯度
从榜单的最终展示唯度上划分,主要分为:
- 单唯度:是指选择展示的排行榜就是基于一个唯度下的排行,例如前面提到的MOBA类游戏操作性排行榜,就仅展示所有MOBA类游戏按操作性的评分排行
- 多唯度:是指选择展示的排行榜还有多种唯度供用户选择,仍然以前面的MOBA类游戏为例,唯度除了操作性,还有音效评分排行,难易度评分排行,画面评分排行等。
展示数据量
从需要展示的数据量上划分,主要分为:
- topN数据:只要求展示topN条排行纪录,例如:最火MOBA游戏top20
- 全量数据:要求展示所有数据的排行,例如:所有用户的积分排行
在以上几种榜单中,往往还会有需要加入,当前用户自身的一些数据在排行榜中的位置。
基于MySQL
先看下数据库的结构,总共有 2 个表:用户表 和 用户积分表。
用户表存储了用户信息,以及用户的总积分(实时更新),也就是说总积分榜需要的数据可以直接从这里取到,不需要再去计算。
用户表内容:
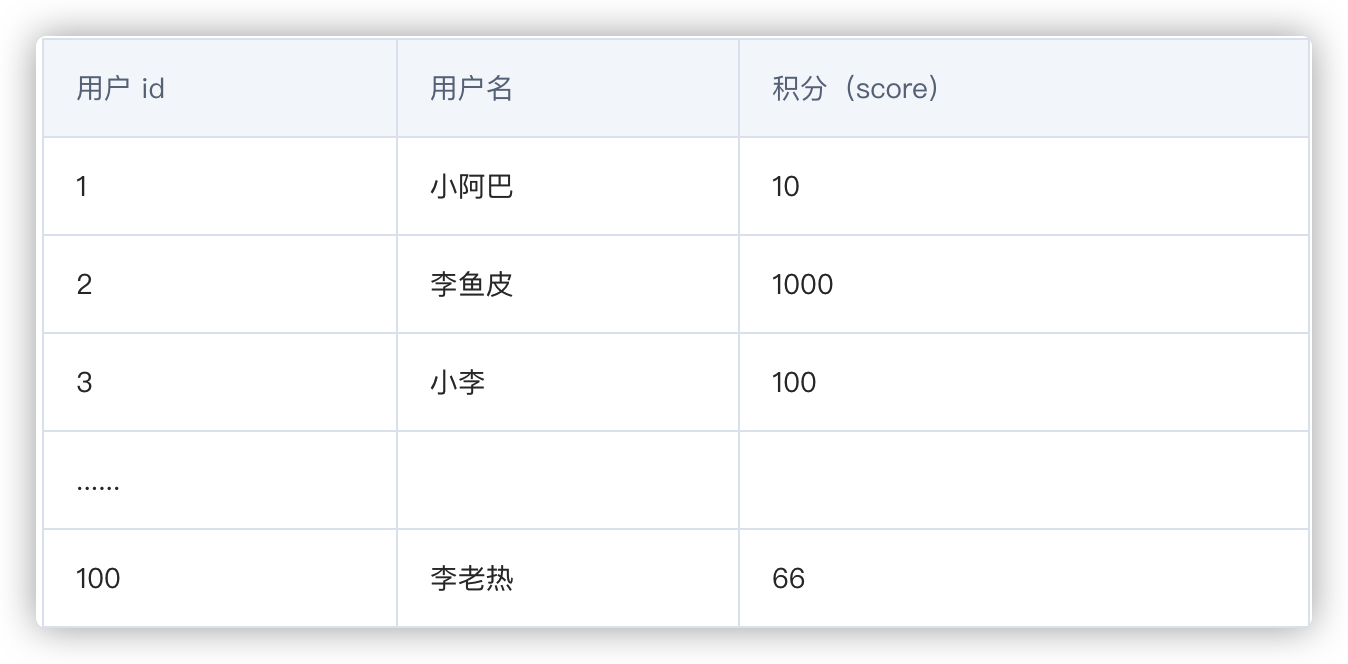
如果要取前 10 名,只需要把所有用户的信息先取出来,再排个序就好啦,写 SQL 语句查询的话就是:
|
|
然后如果要取自己的总排名,先用 SQL 语句查出用户的分数:
|
|
然后再用 SQL 语句统计分数大于该用户分数的数量:
|
|
最后只需要将该查询结果加 1,就是自己的排名啦~
亿级数据获取TopN
下面让我们加大难度,假如用户数再多一点点呢,比如说一亿个,怎么实时获取前 10 名呢?
其实 Top N 问题的核心在于保证空间和时间复杂度,先要考虑数据能存入内存运算,在怎样算得更快。
通常 Top N 问题有下列几种解决方案。
全部排序
直接对所有数据进行排序(快排等),缺点是需要将数据一次性加载到内存中。
局部淘汰
内存中维护一个大小为 N 的容器,再让剩余的数一个个进入容器,并淘汰容器内的最小值。最终容器内剩下的数就是前 N 名。优点是能节省内存,缺点是太慢了。
分治
把数据分为多个小组,小组内先分别选出前 N 名小组长,最后再让这些小组长同台竞技,选出最终的前 N 名。
哈希预处理
假如数据重复度很高,可以通过 hash 的方式,去掉很多重复数据。比如 1 亿个数据里,一半是 0,一半是 1,那么取前 10 名时,可以直接淘汰掉另一半为 0 的数据。
但是预处理本身也需要时间和空间,这就需要我们对数据的重复度有一个清晰的判断,否则自作聪明、适得其反。
小根堆
面试算法中的高频考点 —— 堆排序,可以先取前 N 个数组成小根堆,堆顶始终是最小值。 然后遍历后续数字,大于堆顶就替换掉堆顶并调整最小堆结构。该算法时间复杂度和空间复杂度(为 N,常数)都不错,所以必须要掌握。
但是具体选择哪种方案呢?还是要结合我们实际的项目和业务场景来分析。
实际解决
使用MySQL排名的主要当查询单表用户范围大于10w就不适合做排名,对相应的的score字段创建索引可以加速排序。如上文的分桶排名策略,首先统计规划合理的得分范围,比如将1000w用户记录平均依据得分直方图拆分到均匀的100张得分表中:
|
|
|
|
更新用户时,依据uid查询leaderboard表,查找用户得分,与当前得分进行比较更新leaderboard_bucke_$id表中记录,使用redis维护一个分桶用户数缓存比如每一分钟失效。
查询单用户排名时,使用 select count(uid) from leaderboard_bucke_$id where score>= $score and uid>= $uid order by score 即可查询得到相关用户的得分排名,累加相应比当前分桶高的分桶表用户数即得到用户排名。
MySQL的分表做不到Redis那么的迅速,但是保证用户分表用数户均匀恰当能够觉得可以满足你的排名需要。当前大多数数据库都支持分布式,所以其他数据库如MongoDB,PostgreSQL都是可以考虑作为排名存储用的数据库。
基于Redis
这个场景其实就是在考察你对于 Redis 的 sorted set 数据结构的掌握。
sorted set,见名知意,就是有序集合的意思。
在 Redis 中它大概是长这样的:
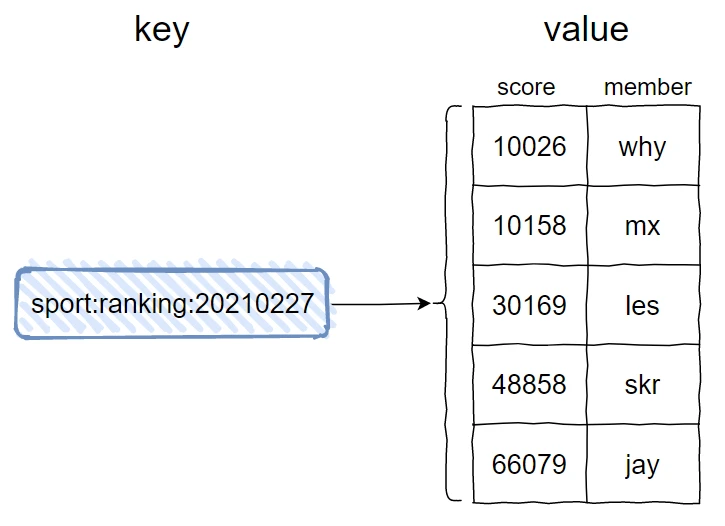
另一个需要注意的点是,虽然我的示意图中没有体现出来,但是在有序集合中,元素即 member 是不可以重复的,但是 score 是可以重复的。当多个元素具有相同的分数时,它们按照 lexicographically 进行排序。当分数一样的时候,按照字典序排序,所以上面的示意图 jay 在 why 之前。
我这里只讲几个需要用到的操作:
- 添加 member 命令格式:zadd key score member [score member …]
- 增加 member 的 score 命令格式:zincrby key increment member
- 获取 member 排名命令格式:zrank/zrevrank key member
- 返回指定排名范围内的 member 命令格式:zrange/zrevrange key start end [withscores]
比如我们把示意图中的数据添加到到有序集合里面去,语法是这样的:
|
|
意思是可以一次添加一对或者多对 score-member,比如下面这两个命令:
|
|
这个时候其实我们想要存储的是 User 对象,对象里面有这几个字段:昵称、头像图片链接、点赞数、步数。
你说,这个用 Redis 的啥数据结构来存?
可不就得用 Hash 结构了吗。
Hash 结构同样涉及到 key 和 value,那么它们分别是什么呢?
key 就是我们的有序集合的 key 后面再加上昵称,比如这样的:
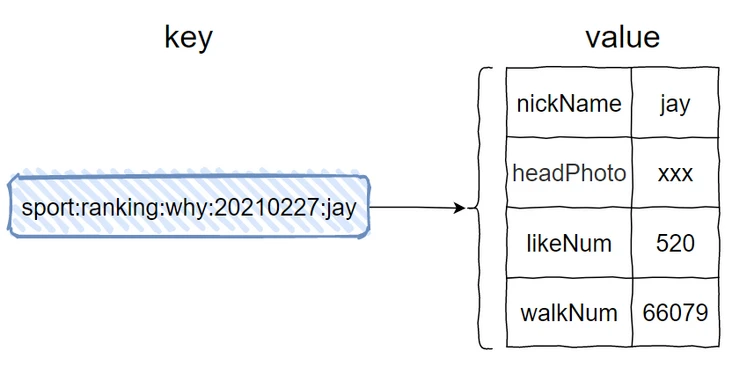
对应的命令是这样的:
|
|
执行完成之后,在 RDM 里面看起来是这样的:
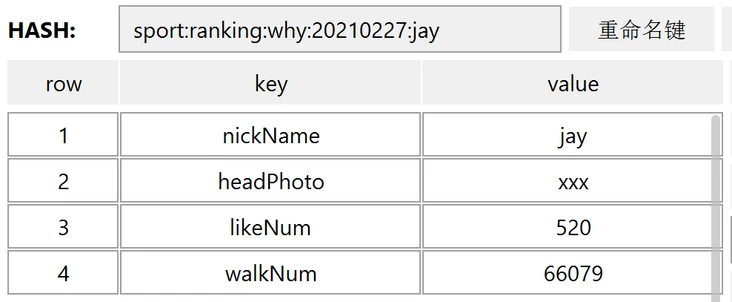
当后续有更多的赞的时候,需要调用更新命令更新 likeNum:
|
|
执行完成之后点赞数就会变成 1020:
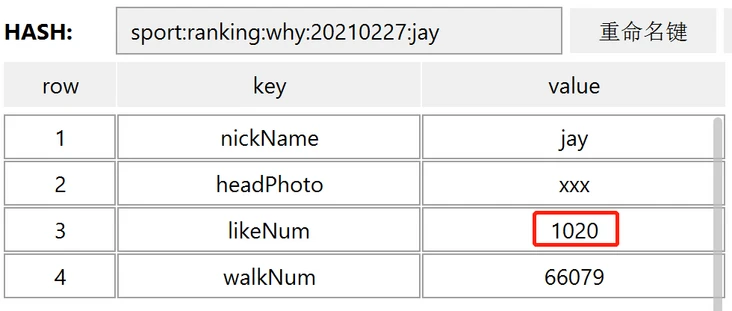
这样,排行榜上的所有字段我们都能获取到了,微信排行榜就说完了。
好友排行榜
微信步数排行榜有个问题,每个人看见的数据排行数据来源自己的微信好友,而微信好友各不相同,所以看到的排行榜也各不相同。
我们上面的场景更加类似于游戏排行榜,所有的人看到的全服排行榜都是一样的。
那么怎么保证我们每个人看到的各不相同呢?
如果每个用户都有在redis有一个自己的排行榜,一个用户的分数更新的时候就需要对所有好友的zset更新,这多大的代价啊,对吧?
当以用户为纬度做排行榜的时候,就会出现排行榜巨多的情况,导致维护成本升高。
每个用户看到的排行榜不一样,我们其实不用时时刻刻帮用户维护好排行榜。维护好了,用户还不一定来看,出力不讨好的节奏。所以还不如延迟到用户请求的阶段。
当用户请求查看排行榜的时候,再去根据用户的好友关系,循环获取好友的步数,生成排行榜。
七天排行榜
我们提供一个最近七天、上一周、上一月、上个季度、这一年排行榜啥的,又该怎么搞呢?
其实这还是在考察你对于 Redis 有序集合 API 的掌握程度。
- zinterstore/zunionstore其实就是交集/并集
- destination 将交集/并集的结果保存到这个键中
- numkeys 需要做交集/并集的集合的个数
- key [key …] 具体参与交集/并集的集合
- weights weight [weight …] 每个参与计算的集合的权重。在做交集/并集计算时,每个集合中的 member 会把自己的 score 乘以这个权重,默认为 1。
- aggregate sum|min|max 对于各个集合中的相同元素是 sum(求和)、min(取最小值)还是max(取最大值),默认为 sum。
拿最近七天举例:
|
|
可以看到我们一共有 7 天的数据:
而且需要注意的是 20210222 这一天是没有 jay 的数据的。
现在我们要求出最近 7 天的排行榜,就用下面这行命令,命令有点复杂,但是对着命令格式看,还是很清晰的:
|
|
这条命令后面的 weights 和 aggregate 都是可以不用写的,有默认值,我这里为了不隐藏数据,都写了出来。
执行完成后,可以看到多了一个 key,里面放的就是最近 7 天的数据汇总:
上面用的是并集,如果我们的要求是对最近 7 天,每天都上传运动数据的人进行排序,就用交集来算。
命令和上面的一致,只是把 zunionstore 修改为 zinterstore 即可。
另外为了有对比,合并之后的队列名称也修改一下,命令如下:
|
|
从执行结果可以看出来,由于 jay 同学在 20210222 这一天没有上传运动数据,所以取交集的时候没有他了:
知道最近 7 天的做法了,我们又有每一天数据,上一周、上一月、上个季度、这一年排行榜啥的不都是这个套路吗?
多维度排序
一些需求中经常要我们实现一个排行榜,数据量少的话可以使用 RDB 数据库排序,数据量大可以自己实现算法或者使用 NoSQL 数据库排序,NoSQL 数据库中最方便的可能就是利用 Redis 的 zset 来实现了。 例如要实现一个玩家成就点数的排行榜:
|
|
其中 B 和 C 的分数是一样的,这时我们可能想让先达到对应分数的人排在前面,相当于增加了一个排序维度。这时直接用 score 就不能实现了,需要做一些转换,这里分享几个我会用到的方法。
假设我们需要一个三个维度的排序,第一维度是具体的数值,第二个维度是一个是否标志位,第三个维度是时间戳。其中氪金的(0否1是)和时间早的排序靠前。 以下是原始数据:
|
|
利用 key 排序
如果后两个维度初始化后就不再变化的话,可以利用 Redis 的排序特性,将不变的维度写到 key 里,这样 score 相同时会用 key 来进行排序。
|
|
以上就是第一种方法了,实现起来非常简单。
score 存储格式
在介绍下两种方法前先来看看 zset 的 score 是怎么存储的,能保留多少精度,直接看跳表 node 的结构。
|
|
我们可以看到 score 是用 double 存储的,它是一个 IEEE 754 标准的 double 浮点数。

一个 64 位浮点数存储时分为3段
- S:符号位,第一段,占1位,0表示正数,1表示负数。
- Exp:指数字,第二段,占11位,移码方式表示正负数,排除全0和全1表示零和无穷大的特殊情况,指数部分是−1022~+1023加上1023,指数值的大小从1~2046
- Fraction:有效数字,占52位,定点数,小数点放在尾数最前面
实际数字 = (-1)^S *Fraction* 2^Exp (二进制计算)
double 存储的有效数据是第三段的52位,超出会损失精度,由于标准规定小数点是在有效数字最前面,所以实际可以存储 53 位数字。比如有个数字是 111___(53个1),有效数字位存储的是 .11___(52个1),计算时会在个位补1,得到1.11___(53个1),最大值为 2^53 = 9007199254740991,大概 log(2^53) = 15.95 位。
redis的zset中的score值为double类型,精度只有16位,事实上在存储9999999999999999 16位整数的时候,会变为17位的10000000000000000,超过17位会变为科学计数法1e+17。
可以看到只要保证有效数字小于等于9007199254740991就不会损失精度。
好了,现在有了理论基础,接下来看看我们可以怎么实现。
十进制分段
可以直接拆分十进制数,为了方便,还可以用小数划分维度,比如将分数放在整数位,标志位和时间戳放在小数位。不过浮点数的存储会有误差,通常不建议这样存储.
|
|
需求
等级排行,大家都是30级,谁先到30级谁第一。需要设计一个 【分数 = 等级 + 时间】 ,谁分数大谁第一,最后再根据分数能解析出来等级即可。
设计
- 分数 = 等级 + 时间 (当前系统时间戳)
- 分数是 64位的长整型 Long (有符号)
设计方式一
- long 分数,二进制用高 32位存 等级,低32位存时间(秒精度),那么数据看起是这样
- A 玩家, 10 + 1111111111(时间戳)
- 后来 B 玩家也到 10 级, 10 + 2222222222(时间戳)
- 这样排序,最终还是 B 玩家 会排到第一名,不能达到目的。
设计方式二
- long 整数长度总共有 19位,923XXX…….,时间戳 毫秒精度 是 13位,所以只需 14 ~ 19 位存 等级,其他13位存时间。接下来看怎么存。
- 等级偏移: Math.power(10, 14) = 10000000000000000(14位)
- 这里有一个最大时间 MAX_TIME = 9999999999999 (13位)
- A 玩家,(10 * 等级偏移) + MAX_TIME - 11111111111111( 时间戳),最终分数 10888888888888888
- B 玩家,(10 * 等级偏移) + MAX_TIME - 22222222222222( 时间戳),最终分数 10777777777777777
- 最终排序,A 玩家依然是第一。通过分数可以解析出真实 【等级 = 分数 / 等级偏移,取整】
劣势
- 如果有三个,四个排序条件怎么办,这种情况还是推荐使用数据库,就别考虑 Redis了 。Redis 优势在于可以做到实时排行
方式二 14 ~ 19位,那么等级最大数据就只能是 919999,超过这个数就会溢出。可以把时间戳降低到秒级别,可以支持更大数字
最大时间的取值:
- 如果排行榜是临时的(超过某个时间就不存在或不保证数据的准确性), 那最大时间直接取排行榜的截止有效时间就可,这种方式时间信息占用的位数较少. (推荐)
- 如果排行榜一直存在就取一个固定值, 2050年? 这种时间占用位数较多, 但是可以降低时间精度缓解一点压力, 精确到秒? 或者占用几位小数(最好自己测一下精度有没有影响)
二进制分段
第二种方法,可以利用二进制 64 位 long 分段存储各个维度。
首先时间戳如果全存储就太长了,可以通过一些计算缩小一些,先忽略毫秒,然后和一个大数计算差值。
|
|
这样时间就缩小到了300000000以内。
接下来进行划分,首位标志位不用,剩下63位,然后我划分高33位存分数,1位存标志位,最后29位存时间戳,存储结构是这样的:
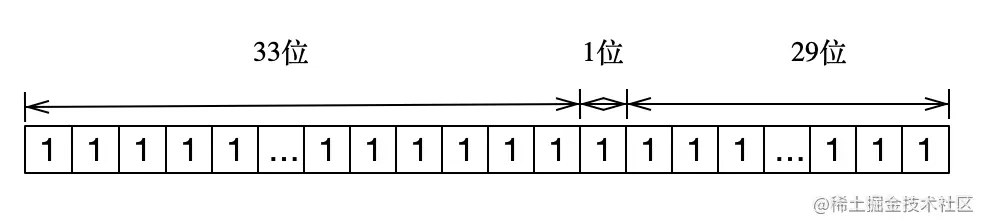
如果要不损失精度,第一段可存储位数 = 53 - 1 - 29 = 23。
第一段最大值 = 2^33 = 8589934591,不损失精度 = 2^23 = 8388607。 第三段最大值 = 2^29 = 536870911。
使用时可以适当缩短第三段时间戳的长度,或者不追求时间戳一定精确的话,第一段分数可以超出不损失精度的长度,也只会损失一点时间戳的精度而已。
然后就可以用下面的方法计算 score 了,因为是二进制,可以全用位运算。
|
|
增加高位分数的话直接把低维度设为0,计算出分数后调用 ZINCRBY 就行了。
改变低位维度值的话就不能调用 ZINCRBY 了,需要调用ZADD,我们用自旋加 CAS 更新,防止覆盖掉新更新的值。
亿级数据排行榜
当用户足够多时,我们需要对排行榜的score依据你的系统用户已有的排名得分数据进行直方图统计,统计出每个score用户数量,然后对score进行合理范围拆分,比如score在0~100万范围,根据直方图统计后 0~10w, 10w~25w, 25w~30w,… ,50w~100w ,10个区间能将一千万用户拆成100w用户一个分桶范围,将对应得分用户分别储存在响应范围的分桶sorted set中。排名时简单缓存每个分桶sorted set的用户总数。对于查询top 排名时,只要查看最高分区桶sorted set排名即可, 对于查询个体用户的排名,需要外加一份用户得分记录存储于MySQL等数据库中,用于查询到单用户的得分,然后依据得分查找到得分存储在相应redis sorted set分桶排名,然后把高于当前分桶范围的分桶用户相加得到相关用户的排名。
更新用户得分时,首先需要查询到原有得分,然后如果用户的现在的得分比较如果得分分布的sorted set分桶已经不是原来的分桶,这是需要删除原桶用户记录,然后在新桶sorted set入录得分记录。
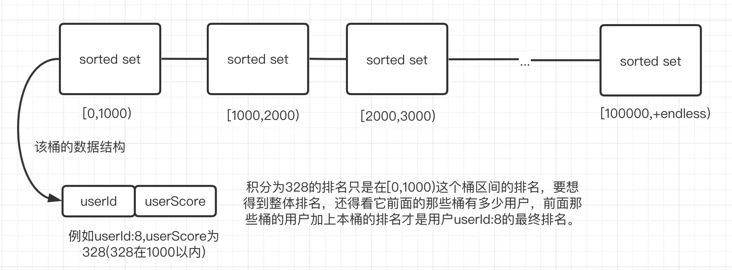
这种方案就能轻松应对亿级用户的游戏排行榜了,我这里是以积分排行榜来设计的,其它的类似。这里每个桶按照承载百万用户,然后分了100个桶,如果积分分布均匀的话,那就可以轻松应对了。当然你可能会说,有很多新手比如玩了几次这个游戏就没玩了,在[0,1000)区间这个桶内有很多用户。是的,这里我们实行之前,会有个预估。大一点的公司会有数据分析工程师来对游戏用户做个合理的预估,通过一系列高数、概率论的知识把这个分桶区间预估的尽可能准。
对于查询top排名时,只要查看最高分区桶sorted set排名即可。
对于查询个体用户的排名,根据用户的积分判断看在哪个桶里,计算本桶该用户的排名与高于当前分桶范围的分桶用户相加得到相关用户的排名。
定时刷新
虽然我们将排行榜数据存入zset中了, 但这个只是提高了我们的访问效率, 并不能完全保证数据的准确性. 可能会因为各种原因(并发, 网络异常)导致缓存数据不准确, 因此需要定时刷新缓存数据.
然后缓存刷新策略大概有一下几种:
- 全量刷新: 把所有缓存数据都重新计算一遍, 比如每天刷一遍
- 增量刷新: 把一定时间内变化的缓存数据刷新, 每个小时刷一次
- 根据数据变化频率动态刷新: 类似redis持久化策略. 一定时间内变化的频率到达一个阈值就刷新.
具体采取哪种策略也是看具体的需求, 对数据的准确性实时性需求、性能需求等. 可以同时结合多种策略. 以及时间间隔也取决于产品需求和刷新耗时.
大概就是使用一个定时任务, 查询数据库最近一段时间内积分变化的用户, 对这些用户的积分进行重算, 刷新缓存.
还有就是到了缓存过期的时候, 就别再刷了. 除非打算这个排行榜一直存在缓存中.
缓存击穿
缓存肯定是要设置过期时间的, 过期时间肯定是在缓存数据不经常访问的时候. 那如果缓存过期后用户访问排行榜, 这个时候就需要从数据库中查询相关数据, 重新计算排行榜前n位(没必要全部重算), 显然重算排行榜是一个比较费事费力的操作.
但是假如这个时候是大量用户并发访问, 然后查询排行榜缓存, 发现没有数据, 于是都去查询数据库重算. 这个时候数据库压力就会很大, 很容易挂掉. 即缓存击穿.
然后解决方式大概有几种
- 不设置过期时间, 不过期就不会失效.
- 加锁, 重新加载缓存的时候加锁, 防止所有的请求都去数据库查询重算.
然后结合具体场景, 这里加载缓存时不一定时缓存过期了, 可能还没构建缓存, 就有大量用户访问该排行榜. 并且该排行榜缓存没有必要一直存在, 浪费空间.
参考
文章作者 Forz
上次更新 2022-01-14