前言
sync.Pool 数据类型用来保存一组可独立访问的临时对象。请注意这里的“临时”这两个字,它说明了 sync.Pool 这个数据类型的特点,也就是说,它池化的对象会在未来的某个时候被毫无预兆地移除掉。而且,如果没有别的对象引用这个被移除的对象的话,这个被移除的对象就会被垃圾回收掉.
因为 Pool 可以有效地减少新对象的申请,从而提高程序性能,所以 Go 内部库也用到了 sync.Pool,比如 fmt 包,它会使用一个动态大小的 buffer 池做输出缓存,当大量的 goroutine 并发输出的时候,就会创建比较多的 buffer,并且在不需要的时候回收掉。
有两个知识点你需要记住:
- sync.Pool 本身就是线程安全的,多个 goroutine 可以并发地调用它的方法存取对象;
- sync.Pool 不可在使用之后再复制使用。
在Go中,sync.Pool提供了对象池的功能。它对外提供了三个方法:New、Get 和 Put。下面用一个简短的例子来说明一下Pool使用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
var pool *sync.Pool
type Person struct {
Name string
}
func init() {
pool = &sync.Pool{
New: func() interface{}{
fmt.Println("creating a new person")
return new(Person)
},
}
}
func main() {
person := pool.Get().(*Person)
fmt.Println("Get Pool Object:", person)
person.Name = "first"
pool.Put(person)
fmt.Println("Get Pool Object:",pool.Get().(*Person))
fmt.Println("Get Pool Object:",pool.Get().(*Person))
}
|
结果:
1
2
3
4
5
|
creating a new person
Get Pool Object: &{}
Get Pool Object: &{first}
creating a new person
Get Pool Object: &{}
|
这里我用了init方法初始化了一个pool,然后get了三次,put了一次到pool中,如果pool中没有对象,那么会调用New函数创建一个新的对象,否则会重put进去的对象中获取。
sync.Pool主要在两种场景使用:
- 进程中的 inuse_objects 数过多,gc mark 消耗大量 CPU
- 进程中的 inuse_objects 数过多,进程 RSS 占用过高
请求生命周期开始时,pool.Get,请求结束时,pool.Put。 在 fasthttp 中有大量应用
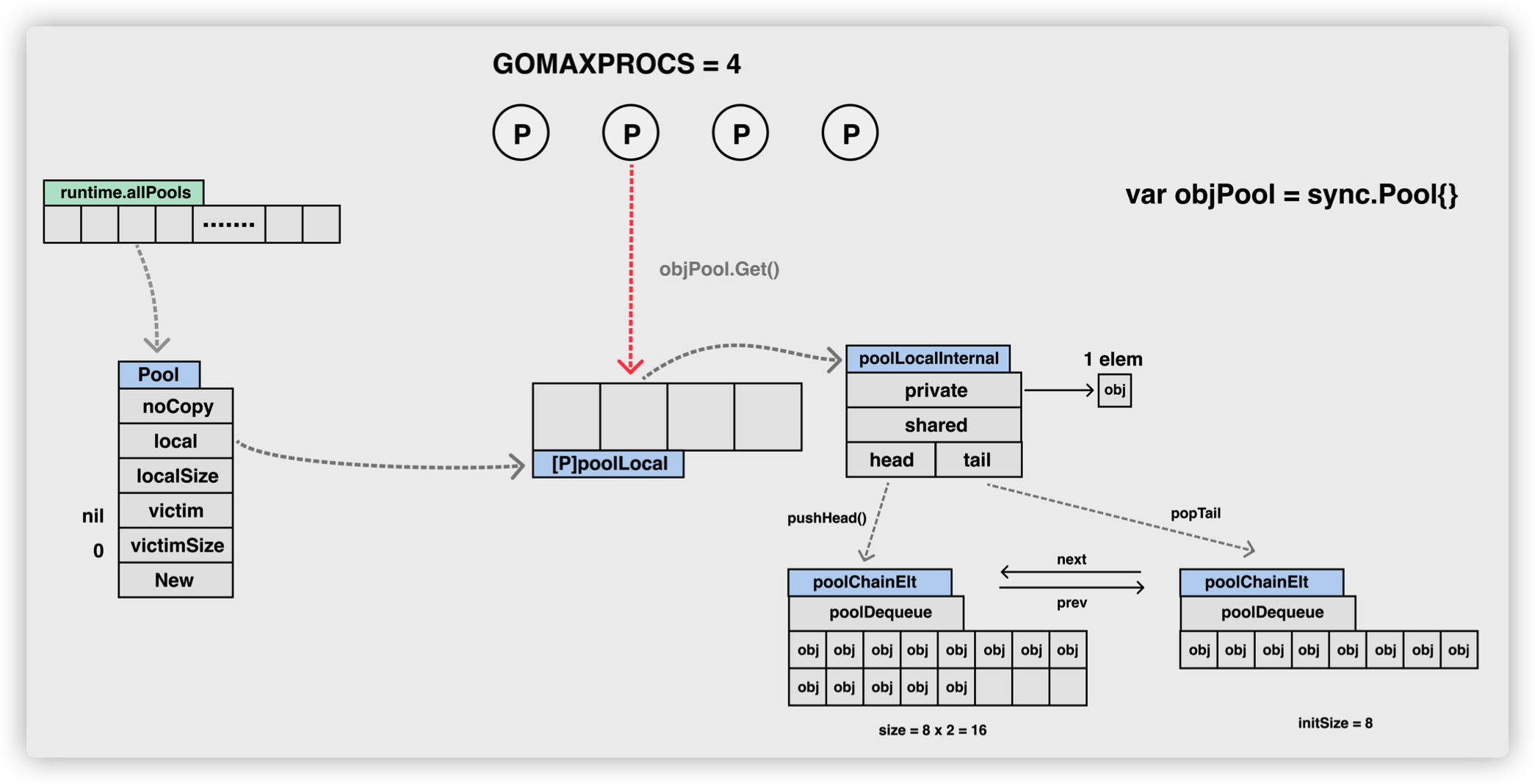
Pool
Pool 最重要的两个字段是 local 和 victim,因为它们两个主要用来存储空闲的元素。弄清楚这两个字段的处理逻辑,你就能完全掌握 sync.Pool 的实现了。下面我们来看看这两个字段的关系。
每次垃圾回收的时候,Pool 会把 victim 中的对象移除,然后把 local 的数据给 victim, 这样的话,local 就会被清空,而 victim 就像一个垃圾分拣站,里面的东西可能会被当做垃圾丢弃了,但是里面有用的东西也可能被捡回来重新使用。
victim 中的元素如果被 Get 取走,那么这个元素就很幸运,因为它又“活”过来了。但是,如果这个时候 Get 的并发不是很大,元素没有被 Get 取走,那么就会被移除掉,因为没有别人引用它的话,就会被垃圾回收掉。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
// A Pool is a set of temporary objects that may be individually saved and
// retrieved.
//
// Any item stored in the Pool may be removed automatically at any time without
// notification. If the Pool holds the only reference when this happens, the
// item might be deallocated.
//
// A Pool is safe for use by multiple goroutines simultaneously.
//
// Pool's purpose is to cache allocated but unused items for later reuse,
// relieving pressure on the garbage collector. That is, it makes it easy to
// build efficient, thread-safe free lists. However, it is not suitable for all
// free lists.
//
// An appropriate use of a Pool is to manage a group of temporary items
// silently shared among and potentially reused by concurrent independent
// clients of a package. Pool provides a way to amortize allocation overhead
// across many clients.
//
// An example of good use of a Pool is in the fmt package, which maintains a
// dynamically-sized store of temporary output buffers. The store scales under
// load (when many goroutines are actively printing) and shrinks when
// quiescent.
//
// On the other hand, a free list maintained as part of a short-lived object is
// not a suitable use for a Pool, since the overhead does not amortize well in
// that scenario. It is more efficient to have such objects implement their own
// free list.
//
// A Pool must not be copied after first use.
type Pool struct {
// 用来标记,当前的 struct 是不能够被 copy 的
noCopy noCopy
// local字段存储的是一个poolLocal数组的指针,poolLocal数组大小是goroutine中P的数量,访问时,P的id对应poolLocal数组下标索引,所以Pool的最大个数runtime.GOMAXPROCS()
// 通过这样的设计,每个P都有了自己的本地空间,多个 goroutine 使用同一个 Pool 时,减少了竞争,提升了性能。
//有当前主要的空闲可用的元素都存放在 local 字段中,请求元素时也是优先从 local 字段中查找可用的元素。
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
// 上面数组的大小,即 P 的个数
localSize uintptr // size of the local array
// 同 local 和 localSize,只是在 gc 的过程中保留一次
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
// New函数是在创建pool的时候设置的,当pool没有缓存对象的时候,会调用New方法生成一个新的对象
New func() interface{}
}
|
使用 sync.Pool 只需要指定 sync.Pool 对象的创建方法 New, 则在使用 sync.Pool.Get 失败的情况下,会池的内部会选择性的创建一个新的值。 因此获取到的对象可能是刚被使用完毕放回池中的对象、亦或者是由 New 创建的新对象。
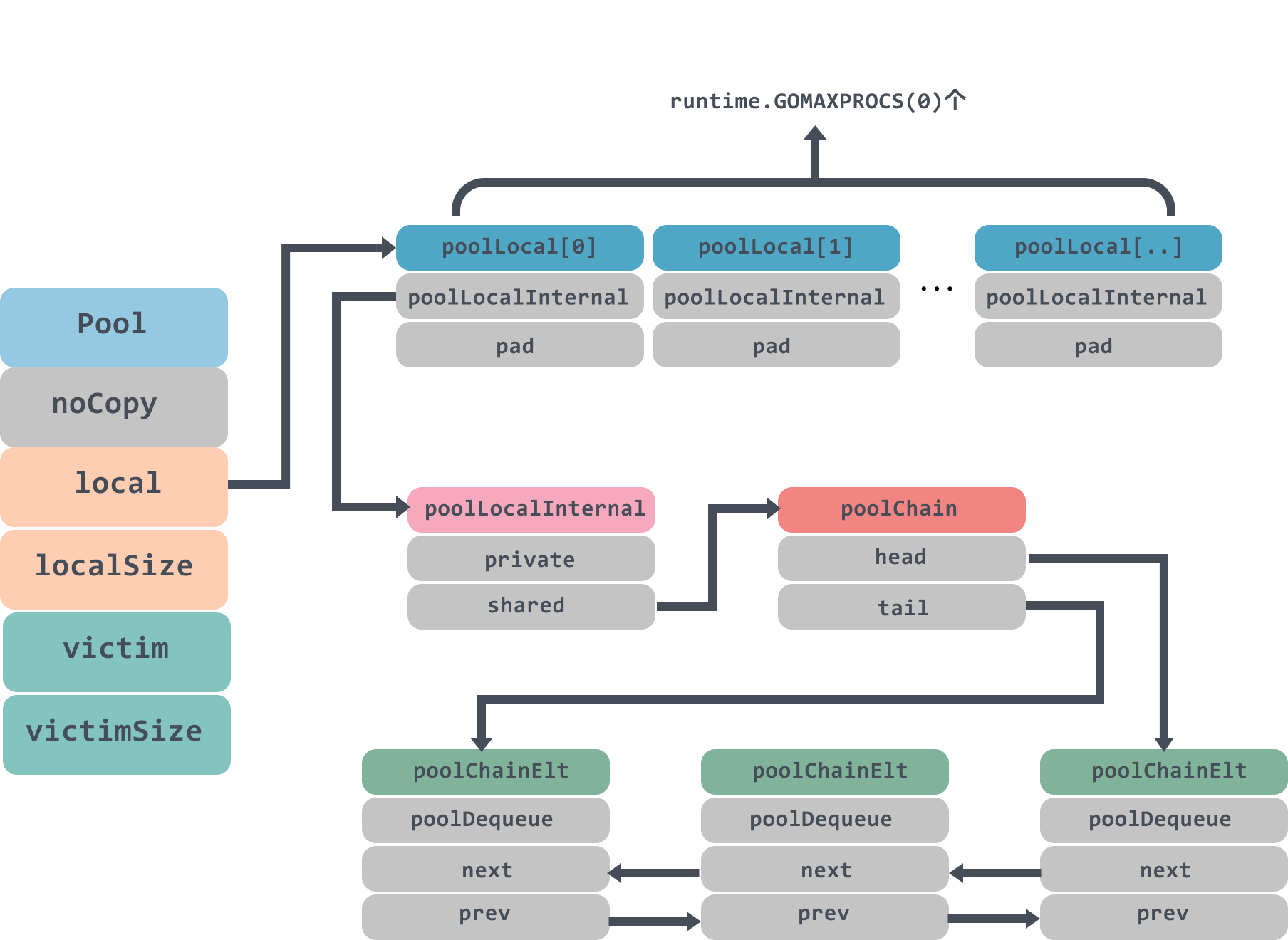
其内部本质上保存了一个 poolLocal 元素的数组,即 local,每个 poolLocal 都只被一个 P 拥有, 而 victim 则缓存了上一个垃圾回收周期的 local。
poolLocal是每个调度器(P)存Object的结构体
而 poolLocal 则由 private 和 shared 两个字段组成:
private是每个调度器私有的,shared是所有调度器公有的,每个调度器pop时的逻辑是: 先看private,没有再看自己的shared,再没有就去其他调度器的shared偷,再没有才是空.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
type poolLocal struct {
poolLocalInternal
// Prevents false sharing on widespread platforms with
// 128 mod (cache line size) = 0 .
// poolLocal里面有一个pad数组用来占位用,防止在 cache line 上分配多个 poolLocalInternal从而造成false sharing
// pad是防止伪共享
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
// Local per-P Pool appendix.
// 当前调度器的内部资源
type poolLocalInternal struct {
// private,代表一个缓存的元素,而且只能由相应的一个 P 存取。因为一个 P 同时只能执行一个 goroutine,所以不会有并发的问题。
// 当前调度器的私有资源
private interface{} // Can be used only by the respective P.
// shared,可以由任意的 P 访问,但是只有本地的 P 才能 pushHead/popHead,其它 P 可以 popTail,相当于只有一个本地的 P 作为生产者(Producer),多个 P 作为消费者(Consumer),它是使用一个 local-free 的 queue 列表实现的。
// 所有调度器的公有资源
shared poolChain // Local P can pushHead/popHead; any P can popTail.
}
|
从前面结构体的字段不难猜测,private 是一个仅用于当前 P 进行读写的字段(即没有并发读写的问题), 而 shared 则遵循字面意思,可以在多个 P 之间进行共享读写,是一个 poolChain 链式队列结构, 我们先记住这个结构在局部 P 上可以进行 pushHead 和 popHead 操作(队头读写), 在所有 P 上都可以进行 popTail (队尾出队)操作,之后再来详细看它的实现细节。
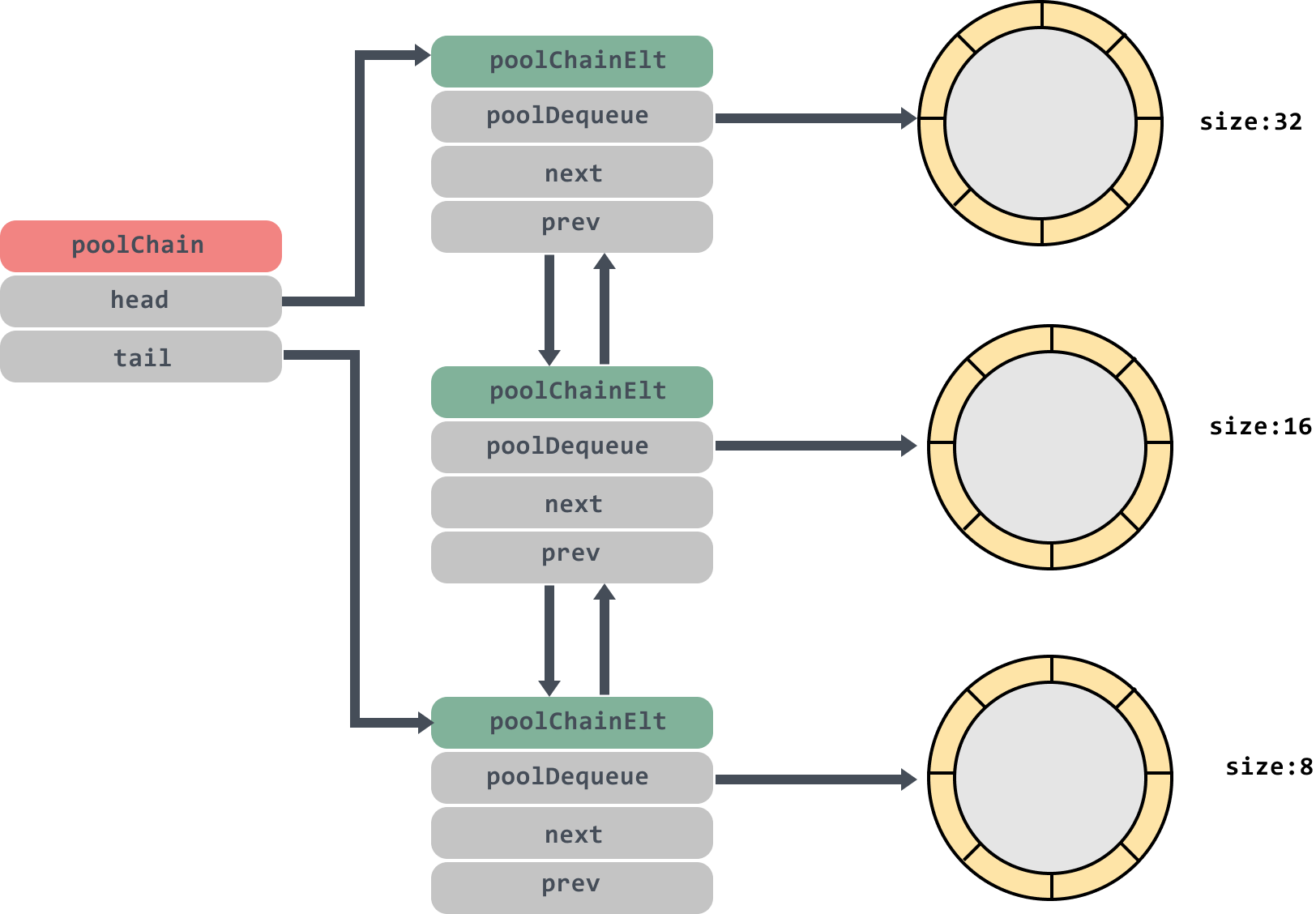
PoolChain
poolChain是一个双端队列,里面的head和tail分别指向队列头尾;poolDequeue里面存放真正的数据,是一个单生产者、多消费者的固定大小的无锁的环状队列,headTail是环状队列的首位位置的指针,可以通过位运算解析出首尾的位置.
poolChain 实际上是多个生产者消费者模型的链表。 对于一个局部 P 而言,充当了多个队头的单一生产者,它可以安全的 在整个链表中所串联的队列的队头进行操作。 而其他的多个 P 而言,则充当了多个队尾的消费者, 可以在所串联的队列的队尾进行消费(偷取)。
popHead 操作发生在从本地 shared 队列中消费并获取对象(消费者)。 pushHead 操作发生在向本地 shared 队列中放置对象(生产者)。 popTail 操作则发生在从其他 P 的 shared 队列中偷取的过程。
这个双端队列的模型大概是这个样子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// poolChain is a dynamically-sized version of poolDequeue.
//
// This is implemented as a doubly-linked list queue of poolDequeues
// where each dequeue is double the size of the previous one. Once a
// dequeue fills up, this allocates a new one and only ever pushes to
// the latest dequeue. Pops happen from the other end of the list and
// once a dequeue is exhausted, it gets removed from the list.
type poolChain struct {
// head is the poolDequeue to push to. This is only accessed
// by the producer, so doesn't need to be synchronized.
// 头指针,只能单一producer操作(push, pop)
head *poolChainElt
// tail is the poolDequeue to popTail from. This is accessed
// by consumers, so reads and writes must be atomic.
// 尾指针,可以被多个consumer pop,必须是原子操作
tail *poolChainElt
}
|
从 poolChainElt 的结构我们可以看出,这是一个双向队列,包含 next 和 prev 指针:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
type poolChainElt struct {
poolDequeue
// next and prev link to the adjacent poolChainElts in this
// poolChain.
//
// next is written atomically by the producer and read
// atomically by the consumer. It only transitions from nil to
// non-nil.
//
// prev is written atomically by the consumer and read
// atomically by the producer. It only transitions from
// non-nil to nil.
next, prev *poolChainElt
}
|
1
2
3
4
5
6
|
func storePoolChainElt(pp **poolChainElt, v *poolChainElt) {
atomic.StorePointer((*unsafe.Pointer)(unsafe.Pointer(pp)), unsafe.Pointer(v))
}
func loadPoolChainElt(pp **poolChainElt) *poolChainElt {
return (*poolChainElt)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(pp))))
}
|
pushHead
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
func (c *poolChain) pushHead(val interface{}) {
d := c.head
// 如果head为nil,说明队列现在是空的,那么新建一个节点,将head和tail都指向这个节点
// 如果链表空,则创建一个新的链表
if d == nil {
// Initialize the chain.
// 固定长度为 8,必须为 2 的指数
const initSize = 8 // Must be a power of 2
d = new(poolChainElt)
d.vals = make([]eface, initSize)
c.head = d
// 设置尾指针
storePoolChainElt(&c.tail, d)
}
// 将val push到head的环形队列中,如果push成功了,可以返回了
if d.pushHead(val) {
return
}
// The current dequeue is full. Allocate a new one of twice
// the size.
// 如果没push成功,则说明head的环形队列满了,就再创建一个两倍head大小的节点[最大(1 << 32) / 4],
newSize := len(d.vals) * 2
if newSize >= dequeueLimit {
// Can't make it any bigger.
newSize = dequeueLimit
}
// 创建一个新的poolChainElt并在链表头部插入
d2 := &poolChainElt{prev: d}
d2.vals = make([]eface, newSize)
// 将新节点作为head,并且处理好新head和旧head的next,prev关系
c.head = d2
storePoolChainElt(&d.next, d2)
// 将val push到head的环形队列中
d2.pushHead(val)
}
|
popHead
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func (c *poolChain) popHead() (interface{}, bool) {
// 先在head环形队列中popHead试试
d := c.head
for d != nil {
// 能取到就返回,取不到说明队列空了
// d 是一个 poolDequeue,如果 d.popHead 是并发安全的,
// 那么这里取 val 也是并发安全的。若 d.popHead 失败,则
// 说明需要重新尝试。这个过程会持续到整个链表为空。
if val, ok := d.popHead(); ok {
return val, ok
}
// There may still be unconsumed elements in the
// previous dequeue, so try backing up.
// 如果空了,当前节点就没用了,就删掉当前节点,去prev节点并且把prev节点作为新head再取一值递归下去,
d = loadPoolChainElt(&d.prev)
}
return nil, false
}
|
popTail
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
func (c *poolChain) popTail() (interface{}, bool) {
d := loadPoolChainElt(&c.tail)
// 如果tail为nil,说明队列是空的,直接返回
if d == nil {
return nil, false
}
// 如果tail非nil,就取取试试,有东西就返回
for {
// It's important that we load the next pointer
// *before* popping the tail. In general, d may be
// transiently empty, but if next is non-nil before
// the pop and the pop fails, then d is permanently
// empty, which is the only condition under which it's
// safe to drop d from the chain.
d2 := loadPoolChainElt(&d.next)
// 尝试从当前poolChainElt的队列尾部取,成功则直接返回
if val, ok := d.popTail(); ok {
return val, ok
}
// 如果没取出来东西,那么说明tail节点没存东西了,递归去prev节点环形队列中popTail,并且把prev节点作为tail,能取到就返回,取不到就是空了
if d2 == nil {
// This is the only dequeue. It's empty right
// now, but could be pushed to in the future.
// d2为空表明链表只有一个节点,而从该节点取对象已失败,则返回
return nil, false
}
// The tail of the chain has been drained, so move on
// to the next dequeue. Try to drop it from the chain
// so the next pop doesn't have to look at the empty
// dequeue again.
if atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&c.tail)), unsafe.Pointer(d), unsafe.Pointer(d2)) {
// We won the race. Clear the prev pointer so
// the garbage collector can collect the empty
// dequeue and so popHead doesn't back up
// further than necessary.
storePoolChainElt(&d2.prev, nil)
}
d = d2
}
}
|
poolDequeue
poolDequeue 是一个无锁、固定大小的单生产端多消费端的环形队列,单一 producer 可以在头部 push 和 pop(可能和传统队列头部只能 push 的定义不同),多 consumer 可以在尾部 pop.
eface 数组存储了实际的对象,其 eface 依赖运行时对 interface{} 的实现,即一个 interface{} 由 typ 和 val 两段数据组成
poolDequeue里面的环状队列大小是固定的,当环状队列满了的时候会创建一个size是原来两倍大小的环状队列。最大扩展到 dequeueLimit = (1 << 32) / 4 = (1 << 30),之后就不会扩展了.
为什么vals长度必须是2的幂?这是因为go的内存管理策略是将内存分为2的幂大小的链表,申请2的幂大小的内存可以有效减小分配内存的开销
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
// poolDequeue is a lock-free fixed-size single-producer,
// multi-consumer queue. The single producer can both push and pop
// from the head, and consumers can pop from the tail.
//
// It has the added feature that it nils out unused slots to avoid
// unnecessary retention of objects. This is important for sync.Pool,
// but not typically a property considered in the literature.
type poolDequeue struct {
// headTail packs together a 32-bit head index and a 32-bit
// tail index. Both are indexes into vals modulo len(vals)-1.
//
// tail = index of oldest data in queue
// head = index of next slot to fill
//
// Slots in the range [tail, head) are owned by consumers.
// A consumer continues to own a slot outside this range until
// it nils the slot, at which point ownership passes to the
// producer.
//
// The head index is stored in the most-significant bits so
// that we can atomically add to it and the overflow is
// harmless.
headTail uint64
// vals is a ring buffer of interface{} values stored in this
// dequeue. The size of this must be a power of 2.
//
// vals[i].typ is nil if the slot is empty and non-nil
// otherwise. A slot is still in use until *both* the tail
// index has moved beyond it and typ has been set to nil. This
// is set to nil atomically by the consumer and read
// atomically by the producer.
vals []eface
}
// 存储元素的结构体,类型指针和值指针
// Pool 底层用 eface 来存储单个 Object, 包括 typ 指针: Object 的类型,val 指针: Object 的值
type eface struct {
typ, val unsafe.Pointer
}
// dequeueLimit is the maximum size of a poolDequeue.
//
// This must be at most (1<<dequeueBits)/2 because detecting fullness
// depends on wrapping around the ring buffer without wrapping around
// the index. We divide by 4 so this fits in an int on 32-bit.
// 为什么dequeueLimit是(1 << 32) / 4 = 1 << 30 ?
// dequeueLimit 必须是2的幂(上边解释过)
// head和tail都是32位,最大是1 << 31,如果都用的话,head和tail就是无符号整型,无符号整型使用的时候会有很多上溢的错误,这类错误是不容易检测的,所以相比之下还不如用31位有符号整型,有错就报出来
const dequeueLimit = (1 << dequeueBits) / 4
// dequeueNil is used in poolDeqeue to represent interface{}(nil).
// Since we use nil to represent empty slots, we need a sentinel value
// to represent nil.
type dequeueNil *struct{}
|
headTail 字段的前 32 位 表示了下一个需要被填充的对象槽的索引,而后 32 位则表示了队列中最先被插入的数据的索引
headTail:
1
2
3
4
5
6
|
[hhhhhhhh hhhhhhhh hhhhhhhh hhhhhhhh tttttttt tttttttt tttttttt tttttttt]
1. headTail表示下标,高32位表示头下标,低32位表示尾下标,poolDequeue定义了,head tail的pack和unpack函数方便转化,
实际用的时候都会mod ( len(vals) - 1 ) 来防止溢出
2. head和tail永远只用32位表示,溢出后会从0开始,这也满足循环队列的设计
3. 队列为空的条件 tail == head
4. 队列满的条件 (tail+uint32(len(d.vals)))&(1<<dequeueBits-1) == head tail加上队列长度和head相等(实际上就是队列已有的空间都有值了,满了)
|
正如前面所说 poolDequeue 是一个单生产者、多消费者的固定长度的环状队列, popHead、pushHead 由局部的 P 操作队首,而 popTail 由其他并行的 P 操作队尾。 其中 headTail 字段的前 32 位表示了下一个需要被填充的对象槽的索引, 而后 32 位则表示了队列中最先被插入的数据的索引。
通过 pack和unpack方法来实现对head和tail的读写:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
const dequeueBits = 32
// 将headTail分解为head和tail
func (d *poolDequeue) unpack(ptrs uint64) (head, tail uint32) {
const mask = 1<<dequeueBits - 1
head = uint32((ptrs >> dequeueBits) & mask)
tail = uint32(ptrs & mask)
return
}
// 将head和tail组合成headTail
func (d *poolDequeue) pack(head, tail uint32) uint64 {
const mask = 1<<dequeueBits - 1
return (uint64(head) << dequeueBits) |
uint64(tail&mask)
}
|
从 poolChain 的实现中我们可以看到,每个 poolDequeue 的 vals 长度为 8。 但由于是循环队列,实现中并不关心队列的长度,只要首尾元素的索引相等,则说明队列已满。 因此通过 CAS 原语实现单一生产者的对队头的读 popHead 和写 pushHead:
popHead
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
// popHead removes and returns the element at the head of the queue.
// It returns false if the queue is empty. It must only be called by a
// single producer.
// 获取并删除队首元素
func (d *poolDequeue) popHead() (interface{}, bool) {
var slot *eface
for {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
if tail == head {
// Queue is empty.
// 队列为空,获取对象失败
return nil, false
}
// Confirm tail and decrement head. We do this before
// reading the value to take back ownership of this
// slot.
// 因为head是下一个对象存储的位置,因此从队列头部获取对象需先将head-1
head--
ptrs2 := d.pack(head, tail)
if atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2) {
// We successfully took back slot.
slot = &d.vals[head&uint32(len(d.vals)-1)]
break
}
}
val := *(*interface{})(unsafe.Pointer(slot))
if val == dequeueNil(nil) {
val = nil
}
// Zero the slot. Unlike popTail, this isn't racing with
// pushHead, so we don't need to be careful here.
// 重置slot
*slot = eface{}
return val, true
}
|
pushHead
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
// pushHead adds val at the head of the queue. It returns false if the
// queue is full. It must only be called by a single producer.
// 添加元素到队首
func (d *poolDequeue) pushHead(val interface{}) bool {
ptrs := atomic.LoadUint64(&d.headTail)
// 解析出head、tail的索引
head, tail := d.unpack(ptrs)
if (tail+uint32(len(d.vals)))&(1<<dequeueBits-1) == head {
// 队列已满,插入失败
// Queue is full.
return false
}
// 找到head的槽位
slot := &d.vals[head&uint32(len(d.vals)-1)]
// Check if the head slot has been released by popTail.
// 此处可能与 popTail 发生竞争,参见 popTail
// 检测这个槽位有没被popTail释放
typ := atomic.LoadPointer(&slot.typ)
if typ != nil {
// Another goroutine is still cleaning up the tail, so
// the queue is actually still full.
return false
}
// The head slot is free, so we own it.
if val == nil {
val = dequeueNil(nil)
}
*(*interface{})(unsafe.Pointer(slot)) = val
// Increment head. This passes ownership of slot to popTail
// and acts as a store barrier for writing the slot.
atomic.AddUint64(&d.headTail, 1<<dequeueBits)
return true
}
|
popTail
多个消费者读的处理手段非常巧妙,通过 interface{} 的 typ 和 val 两段式 结构的读写先后顺序,在 popTail 和 pushHead 之间消除了竞争
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
// popTail removes and returns the element at the tail of the queue.
// It returns false if the queue is empty. It may be called by any
// number of consumers.
// 获取并删除队尾元素
func (d *poolDequeue) popTail() (interface{}, bool) {
var slot *eface
for {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
if tail == head {
// Queue is empty.
// 队列为空,直接返回
return nil, false
}
// Confirm head and tail (for our speculative check
// above) and increment tail. If this succeeds, then
// we own the slot at tail.
// tail+1,表明尾部的对象已被获取
ptrs2 := d.pack(head, tail+1)
if atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2) {
// Success.
slot = &d.vals[tail&uint32(len(d.vals)-1)]
break
}
}
// We now own slot.
val := *(*interface{})(unsafe.Pointer(slot))
if val == dequeueNil(nil) {
val = nil
}
// Tell pushHead that we're done with this slot. Zeroing the
// slot is also important so we don't leave behind references
// that could keep this object live longer than necessary.
//
// We write to val first and then publish that we're done with
// this slot by atomically writing to typ.
// 注意:此处可能与 pushHead 发生竞争,解决方案是:
// 1. 让 pushHead 先读取 typ 的值,如果 typ 值不为 nil,则说明 popTail 尚未清理完 slot
// 2. 让 popTail 先清理掉 val 中的内容,在清理掉 typ,从而确保不会与 pushHead 对 slot 的写行为发生竞争
// 将slot置空
slot.val = nil
atomic.StorePointer(&slot.typ, nil)
// At this point pushHead owns the slot.
return val, true
}
|
Get
我们来看看 Get 方法的具体实现原理。
当从池中获取对象时,会先从 per-P 的 poolLocal slice 中选取一个 poolLocal,选择策略遵循:
- 尝试从当前P的private取,成功则直接返回
- private获取失败,则从当前P的share链表的头部节点取,成功则返回
- 从头部节点的队头获取成功,则直接返回
- 从头部节点获取失败,则从下一节点获取,直至获取成功或遍历完所有节点
- 当前P的share获取失败,则从其他P的share获取,成功则返回
- 遍历其他P的share链表直至获取对象成功,返回
- 从其他P的share链表的尾部的队尾获取对象,若成功则直接返回
- 若尾部节点的队尾获取对象失败,则表明该节点为空,删除该节点并遍历下一节点,直至获取对象成功或遍历完所有节点
- 其他P的share获取失败,则尝试从victim cache获取,成功则返回
- 优先尝试从private获取,成功则返回
- 若从private获取失败,则遍历victim的poolLocal,尝试从每一个poolLocal的链表尾部获取对象,成功则返回
- vitcim获取失败,则创建一个新对象返回
首先,从本地的 private 字段中获取可用元素,因为没有锁, 获取元素的过程会非常快,如果没有获取到,就尝试从本地的 shared 获取一个,如果还没有,会使用 getSlow 方法去其它的 shared 中“偷”一个。最后,如果没有获取到,就尝试使用 New 函数创建一个新的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
// Get selects an arbitrary item from the Pool, removes it from the
// Pool, and returns it to the caller.
// Get may choose to ignore the pool and treat it as empty.
// Callers should not assume any relation between values passed to Put and
// the values returned by Get.
//
// If Get would otherwise return nil and p.New is non-nil, Get returns
// the result of calling p.New.
// Get 从 Pool 中选择一个任意的对象,将其移出 Pool, 并返回给调用方。
// Get 可能会返回一个非零值对象(被其他人使用过),因此调用方不应假设
// 返回的对象具有任何形式的状态。
func (p *Pool) Get() interface{} {
if race.Enabled {
race.Disable()
}
// 把当前goroutine固定在当前的P上
// 获取一个 poolLocal
l, pid := p.pin()
// 优先从local的private字段取,快速
// 先从 private 获取对象
x := l.private
l.private = nil
if x == nil {
// Try to pop the head of the local shard. We prefer
// the head over the tail for temporal locality of
// reuse.
// 从当前的local.shared弹出一个,注意是从head读取并移除
// 尝试从 localPool 的 shared 队列队头读取,
// 因为队头的内存局部性比队尾更好。
x, _ = l.shared.popHead()
if x == nil {
// 当前P的private和share都取不到,则去其他P的share读取
x = p.getSlow(pid)
}
}
runtime_procUnpin()
if race.Enabled {
race.Enable()
if x != nil {
race.Acquire(poolRaceAddr(x))
}
}
// 如果没有获取到,尝试使用New函数生成一个新的
// 如果 getSlow 还是获取不到,则 New 一个
if x == nil && p.New != nil {
x = p.New()
}
return x
}
|
其实我们不难看出:
- private 只保存了一个对象;
- 第一次从 shared 中取对象时,还未涉及跨 P 读写,因此 popHead 是可用的;
- 当 shared 读取不到对象时,说明当前局部 P 所持有的 localPool 不包含任何对象,这时尝试从其他的 localPool 进行偷取。
- 实在是偷不到,才考虑新创建一个对象。
pin
pin 方法会将此 goroutine 固定在当前的 P 上,避免查找元素期间被其它的 P 执行。固定的好处就是查找元素期间直接得到跟这个 P 相关的 local。有一点需要注意的是,pin 方法在执行的时候,如果跟这个 P 相关的 local 还没有创建,或者运行时 P 的数量被修改了的话,就会新创建 local。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
// pin pins the current goroutine to P, disables preemption and
// returns poolLocal pool for the P and the P's id.
// Caller must call runtime_procUnpin() when done with the pool.
// 将当前goroutine和P绑定,禁止抢占,并返回对应的poolLocal和P的id
// 调用方在调用完成后必须调用runtime_procUnpin方法取消抢占
func (p *Pool) pin() (*poolLocal, int) {
// 返回当前 P.id
pid := runtime_procPin()
// In pinSlow we store to local and then to localSize, here we load in opposite order.
// Since we've disabled preemption, GC cannot happen in between.
// Thus here we must observe local at least as large localSize.
// We can observe a newer/larger local, it is fine (we must observe its zero-initialized-ness).
// 在 pinSlow 中会存储 localSize 后再存储 local,因此这里反过来读取
// 因为我们已经禁用了抢占,这时不会发生 GC
// 因此,我们必须观察 local 和 localSize 是否对应
// 观察到一个全新或很大的的 local 是正常行为
s := atomic.LoadUintptr(&p.localSize) // load-acquire
l := p.local // load-consume
// 因为可能存在动态的 P(运行时调整 P 的个数)procresize/GOMAXPROCS
// 如果 P.id 没有越界,则直接返回
if uintptr(pid) < s {
// 对应的poolLocal已创建,调用indexLocal取出对应的poolLocal返回
return indexLocal(l, pid), pid
}
// 没有结果时,涉及全局加锁
// 例如重新分配数组内存,添加到全局列表
return p.pinSlow()
}
|
pin() 首先会调用运行时实现获得当前 P 的 id,将 P 设置为禁止抢占,达到固定当前 goroutine 的目的。 然后检查 pid 与 p.localSize 的值来确保从 p.local 中取值不会发生越界。 如果不会发生,则调用 indexLocal() 完成取值。否则还需要继续调用 pinSlow()。
1
2
3
4
5
|
func indexLocal(l unsafe.Pointer, i int) *poolLocal {
// 简单的通过 p.local 的头指针与索引来第 i 个 pooLocal
lp := unsafe.Pointer(uintptr(l) + uintptr(i)*unsafe.Sizeof(poolLocal{}))
return (*poolLocal)(lp)
}
|
在这个过程中我们可以看到在运行时调整 P 的大小的代价。如果此时 P 被调大,而没有对应的 poolLocal 时, 必须在取之前创建好,从而必须依赖全局加锁,这对于以性能著称的池化概念是比较致命的。
既然需要对全局进行加锁,pinSlow() 会首先取消 P 的禁止抢占,这是因为使用 mutex 时 P 必须为可抢占的状态。 然后使用 allPoolsMu 进行加锁。 当完成加锁后,再重新固定 P ,取其 pid。注意,因为中途可能已经被其他的线程调用,因此这时候需要再次对 pid 进行检查。 如果 pid 在 p.local 大小范围内,则不再此时创建,直接返回。
如果 p.local 为空,则将 p 扔给 allPools 并在垃圾回收阶段回收所有 Pool 实例。 最后再完成对 p.local 的创建(彻底丢弃旧数组):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
var (
allPoolsMu Mutex
// allPools 是一组 pool 的集合,具有非空主缓存。
// 有两种形式来保护它的读写:1. allPoolsMu 锁; 2. STW.
allPools []*Pool
)
// 对应的poolLocal不存在,则创建
func (p *Pool) pinSlow() (*poolLocal, int) {
// Retry under the mutex.
// Can not lock the mutex while pinned.
// 这时取消 P 的禁止抢占,因为使用 mutex 时候 P 必须可抢占
// 加锁期间须先取消抢占
runtime_procUnpin()
// 加锁
allPoolsMu.Lock()
defer allPoolsMu.Unlock()
// 当锁住后,再次固定 P 取其 id
pid := runtime_procPin()
// poolCleanup won't be called while we are pinned.
// 并再次检查是否符合条件,因为可能中途已被其他线程调用
// 当再次固定 P 时 poolCleanup 不会被调用
s := p.localSize
l := p.local
// 第二次检测,因为在加锁过程中可能别的goroutine调用创建了poolLocal
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
// 如果数组为空,新建
// 将其添加到 allPools,垃圾回收器从这里获取所有 Pool 实例
if p.local == nil {
allPools = append(allPools, p)
}
// 根据 P 数量创建 slice,如果 GOMAXPROCS 在 GC 间发生变化
// 我们重新分配此数组并丢弃旧的
// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
// 将底层数组起始指针保存到 p.local,并设置 p.localSize
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
atomic.StoreUintptr(&p.localSize, uintptr(size)) // store-release
// 返回所需的 pollLocal
return &local[pid], pid
}
|
getSlow
终于,我们获取到了 poolLocal,现在回到我们 Get 的取值过程。在取对象的过程中,我们仍然会面临 既不能从 private 取、也不能从 shared 中取得尴尬境地。这时候就来到了 getSlow()。
试想,如果我们在本地的 P 中取不到值,是不是可以考虑从别人那里偷一点过来?总会比创建一个新的要快。 因此,我们再次固定 P,并取得当前的 P.id 来从其他 P 中偷值,那么我们需要先获取到其他 P 对应的 poolLocal。假设 size 为数组的大小,local 为 p.local,那么尝试遍历其他所有 P
它首先要遍历所有的 local,尝试从它们的 shared 弹出一个元素。如果还没找到一个,那么,就开始对 victim 下手了。
在 vintim 中查询可用元素的逻辑还是一样的,先从对应的 victim 的 private 查找,如果查不到,就再从其它 victim 的 shared 中查找。
下面的代码是 getSlow 方法的主要逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
func (p *Pool) getSlow(pid int) interface{} {
// See the comment in pin regarding ordering of the loads.
size := atomic.LoadUintptr(&p.localSize) // load-acquire
locals := p.local // load-consume
// Try to steal one element from other procs.
// 尝试从其他P获取对象,成功则直接返回
for i := 0; i < int(size); i++ {
// 获取目标 poolLocal, 引入 pid 保证不是自身
l := indexLocal(locals, (pid+i+1)%int(size))
// 从其他的 P 中固定的 localPool 的 share 队列的队尾偷一个缓存对象
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// Try the victim cache. We do this after attempting to steal
// from all primary caches because we want objects in the
// victim cache to age out if at all possible.
// 如果其它proc也没有可用元素,那么尝试从vintim中获取
// 当 local 失败后,尝试再尝试从上一个垃圾回收周期遗留下来的 victim。
// 如果 pid 比 victim 遗留的 localPool 还大,则说明从根据此 pid 从
// victim 获取 localPool 会发生越界(同时也表明此时 P 的数量已经发生变化)
// 这时无法继续读取,直接返回 nil
// 尝试从victim cache中获取对象
size = atomic.LoadUintptr(&p.victimSize)
if uintptr(pid) >= size {
return nil
}
// 获取 localPool,并优先读取 private
locals = p.victim
l := indexLocal(locals, pid)
// 同样的逻辑,先从vintim中的local private获取
if x := l.private; x != nil {
l.private = nil
return x
}
for i := 0; i < int(size); i++ {
// 从vintim其它proc尝试偷取
l := indexLocal(locals, (pid+i)%int(size))
// 从其他的 P 中固定的 localPool 的 share 队列的队尾偷一个缓存对象
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// Mark the victim cache as empty for future gets don't bother
// with it.
// 如果victim中都没有,则把这个victim标记为空,以后的查找可以快速跳过了
// 将 victim 缓存置空,从而确保之后的 get 操作不再读取此处的值
// 清空 victim cache。下次就不用再从这里找了
atomic.StoreUintptr(&p.victimSize, 0)
return nil
}
|
我们来证明一下此处确实不会发生取到自身的情况,不妨设:pid = (pid+i+1)%size 则 pid+i+1 = a*size+pid。 即:a*size = i+1,其中 a 为整数。由于 i<size,于是 a*size = i+1 < size+1,则: (a-1)*size < 1 ==> size < 1 / (a-1),由于 size 为非负整数,这是不可能的。
Put
Put 的过程则相对简单,只需要将对象放回到池中。 与 Get 取出一样,放回遵循策略:
- 尝试将对象存储在当前P的private,成功则直接返回
- 存入private失败,则尝试存入当前P的share链表的头部节点的队头,成功则返回
- 若链表头部节点的队列已满存入失败,则创建一个新节点,节点队列大小为原来的两倍,将对象存入新节点, 并将该节点设置为新的头部节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
// Put adds x to the pool.
func (p *Pool) Put(x interface{}) {
// 如果存入对象为nil直接返回
if x == nil {
return
}
if race.Enabled {
if fastrand()%4 == 0 {
// Randomly drop x on floor.
return
}
race.ReleaseMerge(poolRaceAddr(x))
race.Disable()
}
// 获得一个 localPool
l, _ := p.pin()
// 优先放入 private
if l.private == nil {
l.private = x
x = nil
}
// 如果不能放入 private 则放入 shared
if x != nil {
l.shared.pushHead(x)
}
runtime_procUnpin()
if race.Enabled {
race.Enable()
}
}
|
runtime_procUnpin & runtime_procPin
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
//go:linkname sync_runtime_procPin sync.runtime_procPin
//go:nosplit
func sync_runtime_procPin() int {
return procPin()
}
//go:linkname sync_runtime_procUnpin sync.runtime_procUnpin
//go:nosplit
func sync_runtime_procUnpin() {
procUnpin()
}
//go:nosplit
func procPin() int {
_g_ := getg()
mp := _g_.m
mp.locks++
return int(mp.p.ptr().id)
}
//go:nosplit
func procUnpin() {
_g_ := getg()
_g_.m.locks--
}
|
PoolCleanup
sync.Pool 的垃圾回收发生在运行时 GC 开始之前。
在 src/sync/pool.go 中:
1
2
3
4
5
6
7
|
// 将缓存清理函数注册到运行时 GC 时间段
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
// 由运行时实现
func runtime_registerPoolCleanup(cleanup func())
|
在 src/runtime/mgc.go 中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// 开始 GC
func gcStart(trigger gcTrigger) {
...
clearpools()
...
}
// 实现缓存清理
func clearpools() {
// clear sync.Pools
if poolcleanup != nil {
poolcleanup()
}
...
}
var poolcleanup func()
// 利用编译器标志将 sync 包中的清理注册到运行时
//go:linkname sync_runtime_registerPoolCleanup sync.runtime_registerPoolCleanup
func sync_runtime_registerPoolCleanup(f func()) {
poolcleanup = f
}
|
再来看实际的清理函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
var (
allPoolsMu Mutex
// allPools is the set of pools that have non-empty primary
// caches. Protected by either 1) allPoolsMu and pinning or 2)
// STW.
allPools []*Pool
// oldPools is the set of pools that may have non-empty victim
// caches. Protected by STW.
// oldPools 是一组 pool 的集合,具有非空 victim 缓存。由 STW 保护
oldPools []*Pool
)
func poolCleanup() {
// 该函数会注册到运行时 GC 阶段(前),此时为 STW 状态,不需要加锁
// 它必须不处理分配且不调用任何运行时函数。
// 由于此时是 STW,不存在用户态代码能尝试读取 localPool,进而所有的 P 都已固定(与 goroutine 绑定)
// 从所有的 oldPools 中删除 victim
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// 将主缓存移动到 victim 缓存
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// 具有非空主缓存的池现在具有非空的 victim 缓存,并且没有任何 pool 具有主缓存。
oldPools, allPools = allPools, nil
}
|
注意,即便是最后 p.local 已经被置换到 oldPools 的 p.victim,其中的缓存对象仍然有可能被偷取放回到 allPools 中,从而延缓了 victim 中缓存对象被回收的速度。
小结
至此,我们完整分析了 sync.Pool 的所有代码。总结:
1
2
3
4
5
6
7
8
9
|
goroutine goroutine goroutine
| | |
P P P
| | |
private private private
| | |
[ poolLocal poolLocal poolLocal ] sync.Pool
| | |
shared shared shared
|
一个 goroutine 固定在 P 上,从当前 P 对应的 private 取值, shared 字段作为一个优化过的链式无锁变长队列,当在 private 取不到值的情况下, 从对应的 shared 队列的队首取,若还是取不到,则尝试从其他 P 的 shared 队列队尾中偷取。 若偷不到,则尝试从上一个 GC 周期遗留的 victim 缓存中取,否则调用 New 创建一个新的对象。
对于回收而言,池中所有临时对象在一次 GC 后会被放入 victim 缓存中, 而前一个周期被放入 victim 的缓存则会被清理掉。
对于调用方而言,当 Get 到临时对象后,便脱离了池本身不受控制。 用方有责任将使用完的对象放回池中。
本文中介绍的 sync.Pool 实现为 Go 1.13 优化过后的版本,相较于之前的版本,主要有以下几点优化:
- 引入了 victim (二级)缓存,每次 GC 周期不再清理所有的缓存对象,而是将 locals 中的对象暂时放入 victim ,从而延迟到下一个 GC 周期进行回收;
- 在下一个周期到来前,victim 中的缓存对象可能会被偷取,在 Put 操作后又重新回到 locals 中,这个过程发生在从其他 P 的 shared 队列中偷取不到、以及 New 一个新对象之前,进而是在牺牲了 New 新对象的速度的情况下换取的;
- poolLocal 不再使用 Mutex 这类昂贵的锁来保证并发安全,取而代之的是使用了 CAS 算法优化实现的 poolChain 变长无锁双向链式队列。
这种两级缓存的优化的优势在于:
- 显著降低了 GC 发生前清理当前周期中产生的大量缓存对象的影响:因为回收被推迟到了下个 GC 周期;
- 显著降低了 GC 发生后 New 对象的成本:因为密集的缓存对象读写可能从上个周期中未清理的对象中偷取。
参考
https://colobu.com/2017/07/11/dive-into-sync-Map
https://segmentfault.com/a/1190000015242373
https://pathbox.github.io/2018/04/05/understand-sync.Map-in-Goalng/
http://www.qiuxiaobing.cn/%E7%BC%96%E7%A8%8B%E8%AF%AD%E8%A8%80/2018/03/09/go-sync-map.html
http://www.gogodjzhu.com/index.php/code/basic/397/
http://russellluo.com/2017/06/go-sync-map-diagram.html
5.4 条件变量
5.5 同步组
Go 标准库源码分析 - sync 包的Pool
5.7 并发安全散列表
6.1 上下文 Context
go context剖析之源码分析
5.3 原子操作
多图详解Go的sync.Pool源码