Map
Go 内建的 map 类型不是线程安全的,所以 Go 1.9 中增加了一个线程安全的 map,也就是 sync.Map。但是,我们一定要记住,这个 sync.Map 并不是用来替换内建的 map 类型的,它只能被应用在一些特殊的场景里。
那这些特殊的场景是啥呢?官方的文档中指出,在以下两个场景中使用 sync.Map,会比使用 map+RWMutex 的方式,性能要好得多:
- 只会增长的缓存系统中,一个 key 只写入一次而被读很多次;
- 多个 goroutine 为不相交的键集读、写和重写键值对.
这两个场景说得都比较笼统,而且,这些场景中还包含了一些特殊的情况。所以,官方建议你针对自己的场景做性能评测,如果确实能够显著提高性能,再使用 sync.Map。
sync.Map 的实现有几个优化点,这里先列出来,我们后面慢慢分析。
- 空间换时间。通过冗余的两个数据结构(只读的 read 字段、可写的 dirty),来减少加锁对性能的影响。对只读字段(read)的操作不需要加锁。
- 优先从 read 字段读取、更新、删除,因为对 read 字段的读取不需要锁。
- 动态调整。miss 次数多了之后,将 dirty 数据提升为 read,避免总是从 dirty 中加锁读取。
- double-checking。加锁之后先还要再检查 read 字段,确定真的不存在才操作 dirty 字段。
- 延迟删除。删除一个键值只是打标记,只有在提升 dirty 字段为 read 字段的时候才清理删除的数据。
通过引入两个map将读写分离到不同的map,其中read map提供并发读和已存元素原子写,而dirty map则负责读写。 这样read map就可以在不加锁的情况下进行并发读取,当read map中没有读取到值时,再加锁进行后续读取,并累加未命中数,当未命中数大于等于dirty map长度,将dirty map上升为read map。虽然引入了两个map,但是底层数据存储的是指针,指向的是同一份值。
下面我们介绍sync.Map的重点代码,以便理解它的实现思想。
Map
它的数据结构很简单,值包含四个字段:read、mu、dirty、misses。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
// Map is like a Go map[interface{}]interface{} but is safe for concurrent use
// by multiple goroutines without additional locking or coordination.
// Loads, stores, and deletes run in amortized constant time.
//
// The Map type is specialized. Most code should use a plain Go map instead,
// with separate locking or coordination, for better type safety and to make it
// easier to maintain other invariants along with the map content.
//
// The Map type is optimized for two common use cases: (1) when the entry for a given
// key is only ever written once but read many times, as in caches that only grow,
// or (2) when multiple goroutines read, write, and overwrite entries for disjoint
// sets of keys. In these two cases, use of a Map may significantly reduce lock
// contention compared to a Go map paired with a separate Mutex or RWMutex.
//
// The zero Map is empty and ready for use. A Map must not be copied after first use.
// Map 是一种并发安全的 map[interface{}]interface{},在多个 goroutine 中没有额外的锁条件
// 读取、存储和删除操作的时间复杂度平均为常量
//
// Map 类型非常特殊,大部分代码应该使用原始的 Go map。它具有单独的锁或协调以获得类型安全且更易维护。
//
// Map 类型针对两种常见的用例进行优化:
// 1. 给定 key 只会产生写一次但是却会多次读,类似于只增的缓存
// 2. 多个 goroutine 读、写以及覆盖不同的 key
// 这两种情况下,与单独使用 Mutex 或 RWMutex 的 map 相比,会显著降低竞争情况
//
// 零值 Map 为空且可以直接使用,Map 使用后不能复制
type Map struct {
// 当涉及到dirty数据的操作的时候,需要使用这个锁
mu Mutex
// read contains the portion of the map's contents that are safe for
// concurrent access (with or without mu held).
//
// The read field itself is always safe to load, but must only be stored with
// mu held.
//
// Entries stored in read may be updated concurrently without mu, but updating
// a previously-expunged entry requires that the entry be copied to the dirty
// map and unexpunged with mu held.
// 基本上你可以把它看成一个安全的只读的map
// 它包含的元素其实也是通过原子操作更新的,但是已删除的entry就需要加锁操作了
// 一个只读的数据结构,因为只读,所以不会有读写冲突。
// 所以从这个数据中读取总是安全的。
// 实际也会更新这个数据的entries,如果entry是未删除的(unexpunged), 并不需要加锁。如果entry已经被删除了,需要加锁,以便更新dirty数据。
// read 包含 map 内容的一部分,这些内容对于并发访问是安全的(有或不使用 mu)。
//
// read 字段 load 总是安全的,但是必须使用 mu 进行 store。
//
// 存储在 read 中的 entry 可以在没有 mu 的情况下并发更新,
// 但是更新已经删除的 entry 需要将 entry 复制到 dirty map 中,并使用 mu 进行删除。
read atomic.Value // readOnly
// dirty contains the portion of the map's contents that require mu to be
// held. To ensure that the dirty map can be promoted to the read map quickly,
// it also includes all of the non-expunged entries in the read map.
//
// Expunged entries are not stored in the dirty map. An expunged entry in the
// clean map must be unexpunged and added to the dirty map before a new value
// can be stored to it.
//
// If the dirty map is nil, the next write to the map will initialize it by
// making a shallow copy of the clean map, omitting stale entries.
// 包含需要加锁才能访问的元素
// 包括所有在read字段中但未被expunged(删除)的元素以及新加的元素
// dirty数据包含当前的map包含的entries,它包含最新的entries(包括read中未删除的数据,虽有冗余,但是提升dirty字段为read的时候非常快,不用一个一个的复制,而是直接将这个数据结构作为read字段的一部分),有些数据还可能没有移动到read字段中。
// 对于dirty的操作需要加锁,因为对它的操作可能会有读写竞争。
// 当dirty为空的时候, 比如初始化或者刚提升完,下一次的写操作会复制read字段中未删除的数据到这个数据中。
// dirty 含了需要 mu 的 map 内容的一部分。为了确保将 dirty map 快速地转为 read map,
// 它还包括了 read map 中所有未删除的 entry。
//
// 删除的 entry 不会存储在 dirty map 中。在 clean map 中,被删除的 entry 必须被删除并添加到 dirty 中,
// 然后才能将新的值存储为它
//
// 如果 dirty map 为 nil,则下一次的写行为会通过 clean map 的浅拷贝进行初始化
dirty map[interface{}]*entry
// misses counts the number of loads since the read map was last updated that
// needed to lock mu to determine whether the key was present.
//
// Once enough misses have occurred to cover the cost of copying the dirty
// map, the dirty map will be promoted to the read map (in the unamended
// state) and the next store to the map will make a new dirty copy.
// 记录从read中读取miss的次数,一旦miss数和dirty长度一样了,就会把dirty提升为read,并把dirty置空
// misses 的作用就是,当从read读取值没有读取到,从dirty中读取到了,自增加1. 当这种情况达到 m.misses < len(m.dirty)的时候,dirty的值就代替为read.m(read是readOnly),然后misses重置为0,dirty置为nil,重新开始计算值.
// misses 计算了从 read map 上一次更新开始的 load 数,需要 lock 以确定 key 是否存在。
//
// 一旦发生足够的 misses 足以囊括复制 dirty map 的成本,dirty map 将被提升为 read map(处于未修改状态)
// 并且 map 的下一次 store 将生成新的 dirty 副本。
misses int
}
|
在这个结构中,可以看到 read 和 dirty 分别对应两个 map,但 read 的结构比较特殊,是一个 atomic.Value 类型。
从 misses 的描述中可以大致看出 sync.Map 的思路是发生足够多的读时,就将 dirty map 复制一份到 read map 上。 从而实现在 read map 上的读操作不再需要昂贵的 Mutex 操作。
使用了两个map,一个叫read,一个叫dirty,两个map存储的都是指针,指向value数据本身,所以两个map是共享value数据的,更新value对两个map同时可见。
dirty可以进行增删查,当时都要进行加互斥锁。
read中存在的key,可以无锁的读,借助CAS进行无锁的更新、删除操作,但是不能新增key,相当于dirty的一个cache,由于value共享,所以能通过read对已存在的value进行更新。
read不能新增key,那么数据怎么来的呢?sync map中会记录miss cache的次数,当miss次数大于等于dirty元素个数时,就会把dirty变成read,原来的dirty清空。
为了方便dirty直接变成read,那么得保证read中存在的数据dirty必须有,所以在dirty是空的时候,如果要新增一个key,那么会把read中的元素复制到dirty中,然后写入新key。
然后删除操作也很有意思,使用的是延迟删除,优先看read中有没有,read中有,就把read中的对应entry指针中的p置为nil,作为一个标记。在read中标记为nil的,只有在dirty提升为read时才会被实际删除。
如果 dirty 字段非 nil 的话,map 的 read 字段和 dirty 字段会包含相同的非 expunged 的项,所以如果通过 read 字段更改了这个项的值,从 dirty 字段中也会读取到这个项的新值,因为本来它们指向的就是同一个地址。
dirty 包含重复项目的好处就是,一旦 miss 数达到阈值需要将 dirty 提升为 read 的话,只需简单地把 dirty 设置为 read 对象即可。不好的一点就是,当创建新的 dirty 对象的时候,需要逐条遍历 read,把非 expunged 的项复制到 dirty 对象中。
read和dirty
1
2
3
4
5
6
7
8
|
// readOnly is an immutable struct stored atomically in the Map.read field.
// 当dirty中包含read没有的数据时为true,比如新增一条数据
type readOnly struct {
m map[interface{}]*entry
// amended指明Map.dirty中有readOnly.m未包含的数据,所以如果从Map.read找不到数据的话,还要进一步到Map.dirty中查找。
// 如果Map.dirty有些数据不在Read中的时候,这个值为true
amended bool // true if the dirty map contains some key not in m.
}
|
readOnly.m和Map.dirty存储的值类型是*entry,它包含一个指针p, 指向用户存储的value值。read和dirty中存的实际是key=>值的指针的结构,会存在存了两份值的指针,但不是存了两份值.这样,在用空间换时间的情况下,如果map存的key很多,也不会消耗大量内存,会增加消耗的是指针定义读内存的占用,这比值的占用要小很多.
- read中的key是readOnly的(key的集合不会变,删除也只是打标记),value的操作全都可以原子完成,所以这个结构不用锁
- dirty是一个read的拷贝,用锁的操作在这做,如增加元素、删除元素等(dirty上删除是真删除)
read并不是只是读操作,也有原子写操作.在读操作的时候,是使用了atomic.Value的Load(),没有用锁,达到了在线程安全的情况下读性能的大大提高,同时也会把dirty中的对应的值给修改了,因为相同key的entry,在read和dirty中存的是entry的指针,两个指针没有变,指针的值改了,所以read和dirty 对应的entry同时改变。 为什么呢?因为当key不在map中,会进行map新建记录操作,相同的key既会在read中新建,也会在dirty中新建,新建的就是相应entry的指针: key=>*(entry)。这样,当进行update操作时,就直接修改read,而不需要再加锁操作dirty,性能好多了。
而将read中的值同步到dirty或对dirty进行读或写操作时,使用了互斥量锁Mutex. 写操作分为新增和更新.新增的时候,需要把这个值指针存到dirty.更新的时候,更新一个没有被标记过expunged的key,直接对read进行atomic.CompareAndSwapPointer操作就可以,如果之前expunged过,将key同步到dirty. 而在Store、Delete操作的时候,都要进行m.read.Load().(readOnly)操作.根据上文中推荐的文章进行的benchmark的结果,sync.Map的写、删除性能不尽如意,这个结果可以预料到.
- 当dirty不存在的时候,read就是全部map的数据
- 当dirty存在的时候,dirty才是正确的map数据
可以把read看成是一个cache,当cache miss到一定数量的时候,dirty中的数据会被提升到read中去。但是决定哪些数据应该过去实在太费时了,倒不如时间换空间,read中的数据我在dirty中也存一份,提升的时候直接整个赋值就好了~
read相当于cache层,dirty是更底层的数据层,当read多次没有命中数据时,达到条件,这个cache层命中率太低了,直接将整个read用dirty替换,然后dirty又重新为nil,不需要马上将read同步到dirty,而是下一次Store一个新的key的时候,再触发进行一次dirty的初始同步,并且初始同步在dirty的一个生存周期内,只会进行一次.
在进行Store和Load的时候,其实都是先操作read,如果read中存在并且对应值没有被expunged过,就执行返回了,如果read中不存在,或者对应值被expunged,就需要对dirty进行操作,将这个key同步到dirty中.
entry
read和dirty中的map存的元素值是entry,entry的field是p unsafe.Pointer,是指向具体存储值的指针,这个具体值是以interface{}值存在的,所以在Load取出值的时候,要自行做.(type)的转换.
假设read和dirty中的map存在name这个key,当read进行了atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i))操作后,改的是p这个指针所指的值的地址,而entry这个指针没有改变,read和dirty中的map存在name指的是同一个entry.所以,read中对p的写原子操作,如果dirty中有相同的key,也会同样被更改,因为他们的entry是同一个.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
// expunged is an arbitrary pointer that marks entries which have been deleted
// from the dirty map.
// expunged是用来标识此项已经删掉的指针
// 当map中的一个项目被删除了,只是把它的值标记为expunged,以后才有机会真正删除此项
var expunged = unsafe.Pointer(new(interface{}))
// An entry is a slot in the map corresponding to a particular key.
// entry代表一个值
// 只是简单的创建一个 entry
// entry 是一个对应于 map 中特殊 key 的 slot
type entry struct {
// p points to the interface{} value stored for the entry.
//
// If p == nil, the entry has been deleted and m.dirty == nil.
//
// If p == expunged, the entry has been deleted, m.dirty != nil, and the entry
// is missing from m.dirty.
//
// Otherwise, the entry is valid and recorded in m.read.m[key] and, if m.dirty
// != nil, in m.dirty[key].
//
// An entry can be deleted by atomic replacement with nil: when m.dirty is
// next created, it will atomically replace nil with expunged and leave
// m.dirty[key] unset.
//
// An entry's associated value can be updated by atomic replacement, provided
// p != expunged. If p == expunged, an entry's associated value can be updated
// only after first setting m.dirty[key] = e so that lookups using the dirty
// map find the entry.
// p 指向 interface{} 类型的值,用于保存 entry
//
// 如果 p == nil,则 entry 已被删除,且 m.dirty == nil
//
// 如果 p == expunged, 则 entry 已经被删除,m.dirty != nil ,则 entry 不在 m.dirty 中
//
// 否则,entry 仍然有效,且被记录在 m.read.m[key] ,但如果 m.dirty != nil,则在 m.dirty[key] 中
//
// 一个 entry 可以被原子替换为 nil 来删除:当 m.dirty 下一次创建时,它会自动将 nil 替换为 expunged 且
// 让 m.dirty[key] 成为未设置的状态。
//
// 与一个 entry 关联的值可以被原子替换式的更新,提供的 p != expunged。如果 p == expunged,
// 则与 entry 关联的值只能在 m.dirty[key] = e 设置后被更新,因此会使用 dirty map 来查找 entry。
p unsafe.Pointer // *interface{}
}
func newEntry(i interface{}) *entry {
return &entry{p: unsafe.Pointer(&i)}
}
|
p有三种值:
- nil: 表示为被删除,调用Delete()可以将read map中的元素置为nil
- expunged: 也是表示被删除,但是该键只在read而没有在dirty中,这种情况出现在将read复制到dirty中,即复制的过程会先将nil标记为expunged,然后不将其复制到dirty
- 其他: 表示存着真正的数据
Load
读取时,先去read读取;如果没有,就加锁,然后去dirty读取,同时调用missLocked(),再解锁。在missLocked中,会递增misses变量,如果misses>len(dirty),那么把dirty提升为read,清空原来的dirty。
- 如果 read map 中已经找到了该值,则不需要去访问 dirty map(慢)。
- 但如果没找到,且 dirty map 与 read map 没有差异,则也不需要去访问 dirty map。
- 如果 dirty map 和 read map 有差异,则我们需要锁住整个 Map,然后再读取一次 read map 来防止并发导致的上一次读取失误
- 如果锁住后,确实 read map 读取不到且 dirty map 和 read map 一致,则不需要去读 dirty map 了,直接解锁返回。
- 如果锁住后,read map 读不到,且 dirty map 与 read map 不一致,则该 key 可能在 dirty map 中,我们需要从 dirty map 中读取,并记录一次 miss(在 read map 中 miss)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
// Load returns the value stored in the map for a key, or nil if no
// value is present.
// The ok result indicates whether value was found in the map.
// Load 返回了存储在 map 中对应于 key 的值 value,如果不存在则返回 nil
// ok 表示了值能否在 map 中找到
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
// 首先从read处理
// 1.首先从m.read中得到只读readOnly,从它的map中查找,不需要加锁
// 拿到只读 read map
read, _ := m.read.Load().(readOnly)
// 从只读 map 中读 key 对应的 value
e, ok := read.m[key]
// 2. 如果没找到,并且m.dirty中有新数据,需要从m.dirty查找,这个时候需要加锁
if !ok && read.amended {
// 如果不存在并且dirty不为nil(有新的元素)
m.mu.Lock()
// Avoid reporting a spurious miss if m.dirty got promoted while we were
// blocked on m.mu. (If further loads of the same key will not miss, it's
// not worth copying the dirty map for this key.)
// 双检查,看看read中现在是否存在此key
// 双检查,避免加锁的时候m.dirty提升为m.read,这个时候m.read可能被替换了。
// 锁住后,再读一次 read map
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
// 如果m.read中还是不存在,并且m.dirty中有新数据
// 如果这时 read map 确实读不到,且 dirty map 与 read map 不一致
if !ok && read.amended {
//依然不存在,并且dirty不为nil
// 从dirty中读取
// 则从 dirty map 中读
e, ok = m.dirty[key]
// Regardless of whether the entry was present, record a miss: this key
// will take the slow path until the dirty map is promoted to the read
// map.
// 不管m.dirty中存不存在,都将misses计数加一
// missLocked()中满足条件后就会提升m.dirty
// 无论 entry 是否找到,记录一次 miss:该 key 会采取 slow path 进行读取,直到
// dirty map 被提升为 read map。
m.missLocked()
}
m.mu.Unlock()
}
// 如果 read map 或者 dirty map 中找不到 key,则确实没找到,返回 nil 和 false
if !ok {
return nil, false
}
//返回读取的对象,e既可能是从read中获得的,也可能是从dirty中获得的
// 如果找到了,则返回读到的值
return e.load()
}
// 元素不存在或者被删除,则直接返回
func (e *entry) load() (value interface{}, ok bool) {
// 读 entry 的值
p := atomic.LoadPointer(&e.p)
// 如果值为 nil 或者已经删除
if p == nil || p == expunged {
// 则读不到
return nil, false
}
// 否则读值
return *(*interface{})(p), true
}
|
在代码中,我们可以看到一个double check,检查read没有,上锁,再检查read中有没有,是因为有可能在第一次检查之后,上锁之前的间隙,dirty提升为read了,这时如果不double check,可能会导致一个存在的key却返回给调用方说不存在。 在下面的其他操作中,我们经常会看到这个double check。
1
2
|
if !ok && read.amended {
m.mu.Lock()
|
可以看到,如果我们查询的键值正好存在于m.read中,无须加锁,直接返回,理论上性能优异。即使不存在于m.read中,经过miss几次之后,m.dirty会被提升为m.read,又会从m.read中查找。所以对于更新/增加较少,加载存在的key很多的case,性能基本和无锁的map类似。
如果幸运的话,我们从 read 中读取到了这个 key 对应的值,那么就不需要加锁了,性能会非常好。但是,如果请求的 key 不存在或者是新加的,就需要加锁从 dirty 中读取。所以,读取不存在的 key 会因为加锁而导致性能下降,读取还没有提升的新值的情况下也会因为加锁性能下降。
其中,missLocked 增加 miss 的时候,如果 miss 数等于 dirty 长度,会将 dirty 提升为 read,并将 dirty 置空。
missLocked
当记录 miss 时,涉及 missLocked 操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// 此方法调用时,整个 map 是锁住的
func (m *Map) missLocked() {
// 增加一次 miss
m.misses++// misses计数加一
// 如果 miss 的次数小于 dirty map 的 key 数
// 则直接返回
if m.misses < len(m.dirty) {
// 如果没达到阈值(dirty字段的长度),返回
return
}
// 否则将 dirty map 同步到 read map 去
m.read.Store(readOnly{m: m.dirty})
//把dirty字段的内存提升为read字段
// 清空 dirty map
m.dirty = nil // 清空dirty
// miss 计数归零
m.misses = 0 // misses数重置为0
}
|
可以看出,miss 如果大于了 dirty 所存储的 key 数时,会将 dirty map 同步到 read map,并将自身清空,miss 计数归零。
上面的最后三行代码就是提升m.dirty的,很简单的将m.dirty作为readOnly的m字段,原子更新m.read。提升后m.dirty、m.misses重置,并且m.read.amended为false。
Store
我们先来看 Store 方法,它是用来设置一个键值对,或者更新一个键值对的。
这个方法是更新或者新增一个entry。
read和dirty的相同key指向同一个value
写入的时候,先看read中能否查到key,在read中存在的话,直接通过read中的entry来更新值;在read中不存在,那么就上锁,然后double check。这里需要留意,分几种情况:
- double check发现read中存在key,如果不是expunged,直接写入值。如果entry.p==expunged,那么就先把expunged替换成nil,并且把e复制到dirty中,再在read中写入值.
- read中不存在key,dirty中存在key,直接更新
- dirty中不存在key,如果此时dirty为空,那么需要将read复制到dirty中,最后再把新值写入到dirty中。复制的时候调用的是dirtyLocked(),在复制到dirty的时候,read中为nil的元素,会更新为expunged,并且不复制到dirty中
我们可以看到,在更新read中的数据时,使用的是tryStore,通过CAS来解决冲突,在CAS出现冲突后,如果发现数据被置为expunge,tryStore那么就不会写入数据,而是会返回false,在Store流程中,就是接着往下走,在dirty中写入。
再看下情况1的时候,为啥要那么做。double check的时候,在read中存在,那么就是说在加锁之前,有并发线程先写入了key,然后由Load触发了dirty提升为read,这时dirty可能为空,也可能不为空,但无论dirty状态如何,都是可以直接更新entry.p。如果是expunged的话,那么要先替换成nil,再复制entry到dirty中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
|
// unexpungeLocked ensures that the entry is not marked as expunged.
//
// If the entry was previously expunged, it must be added to the dirty map
// before m.mu is unlocked.
func (e *entry) unexpungeLocked() (wasExpunged bool) {
return atomic.CompareAndSwapPointer(&e.p, expunged, nil)
}
// Store sets the value for a key.
// Store 存储 key 对应的 value
func (m *Map) Store(key, value interface{}) {
// 如果m.read存在这个键,并且这个entry没有被标记删除,尝试直接存储。
// 因为m.dirty也指向这个entry,所以m.dirty也保持最新的entry。
// 获得 read map
read, _ := m.read.Load().(readOnly)
// 如果read字段包含这个项,说明是更新,cas更新项目的值即可
// 首先发生的是更新已经存在值的情况: 更新操作直接更新 read map 中的值,如果成功则不需要进行任何操作,如果没有成功才继续处理。
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
// read中不存在,或者cas更新失败,就需要加锁访问dirty了
// 如果`m.read`不存在或者已经被标记删除(设置为空标记)
m.mu.Lock()
// 经过刚才的一系列操作,read map 可能已经更新了
// 因此需要再读一次
read, _ = m.read.Load().(readOnly)
// 修改一个已经存在的值
// 读取 read map 中的值
// 如果读到了,则尝试更新 read map 的值,如果更新成功,则直接返回,否则还要继续处理(当且仅当要更新的值被标记为删除)
// 如果没读到,则还要继续处理(read map 中不存在)
// 双检查,看看read是否已经存在了
if e, ok := read.m[key]; ok {
// 这种情况下,本质上还分两种情况:
// 1. 可能因为是一个已经删除的值(之前的 tryStore 失败)
// 2. 可能先前仅保存在 dirty map 然后同步到了 read map(这是可能的,我们后面读 Load 时再来分析 dirty map 是如何同步到 read map 的)
// 对于第一种而言,我们需要重新将这个已经删除的值标记为没有删除,然后将这个值同步回 dirty map(删除操作只删除 dirty map,之后再说) 对于第二种状态,我们直接更新 read map,不需要打扰 dirty map。
//read中存在该key,e为值,也就是说可以确定该key是被标记清除了
// unexpungeLocked确保条目标记为未清除。
// 修改一个已经存在的值
if e.unexpungeLocked() {
// 此项目先前已经被删除了,通过将它的值设置为nil,标记为unexpunged
// 说明 entry 先前是被标记为删除了的,现在我们又要存储它,只能向 dirty map 进行更新了
// The entry was previously expunged, which implies that there is a
// non-nil dirty map and this entry is not in it.
// 更新 dirty map 的值即可
m.dirty[key] = e
//m.dirty中不存在这个value,所以加入m.dirty,因为read是只读,不能进行操作
}
// 更新
// 无论先前删除与否,都要更新 read map
e.storeLocked(&value)
} else if e, ok := m.dirty[key]; ok {
// 如果dirty中有此项
// 直接更新
// 此时read map没有该元素,但是dirty map有该元素,必须修改dirty map元素值为最新值
e.storeLocked(&value)
} else {
// 否则就是一个新的key
// 如果m.dirty中没有新的数据
// 如果 dirty map 里没有 read map 没有的值(两者相同)
// 如果 read map 和 dirty map 中存储的内容是相同的,那么我们这次存储新的数据 只会存储在 dirty map 中,因此会造成 read map 和 dirty map 的不一致。
if !read.amended {
// 首次添加一个新的值到 dirty map 中
// 确保已被分配并标记为 read map 是不完备的(dirty map 有 read map 没有的)
//从m.read中复制未删除的数据
//如果dirty为nil
// We're adding the first new key to the dirty map.
// Make sure it is allocated and mark the read-only map as incomplete.
// 需要创建dirty对象,并且标记read的amended为true,
// 说明有元素它不包含而dirty包含
m.dirtyLocked()
// 更新 amended,标记 read map 中缺少了值(标记为两者不同)
m.read.Store(readOnly{m: read.m, amended: true})
}
//将新值增加到dirty对象中
//m.dirty中没有新的数据,往m.dirty中增加第一个新键
//将这个entry加入到m.dirty中
// 不管 read map 和 dirty map 相同与否,正式保存新的值
m.dirty[key] = newEntry(value)
}
// 解锁,有人认为锁的范围有点大,假设read map数据很大,那么执行m.dirtyLocked()会耗费花时间较多,完全可以在操作dirty map时才加锁,这样的想法是不对的,因为m.dirtyLocked()中有写入操作
m.mu.Unlock()
}
|
tryStore
我们来看一下 tryStore。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
// tryStore 在 entry 还没有被删除的情况下存储其值
//
// 如果 entry 被删除了,则 tryStore 返回 false 且不修改 entry
func (e *entry) tryStore(i *interface{}) bool {
// 获取对应Key的元素,判断是否标识为删除,因为并发问题,这里也需要二次检查确认
// 读取 entry
p := atomic.LoadPointer(&e.p)
// 如果 entry 已经删除,则无法存储,返回
if p == expunged {
return false
}
for {
// cas尝试写入新元素值
// 交换 p 和 i 的值,如果成功则立即返回
if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) {
return true
}
// 判断是否标识为删除
p = atomic.LoadPointer(&e.p)
if p == expunged {
return false
}
}
}
|
从 tryStore 可以看出,在更新操作中只要没有发生 key 的删除情况,即值已经在 dirty map 中标记为删除, 更新操作一定只更新到 read map 中,不涉及与 dirty map 之间的数据同步。
dirtyLocked
read map 和 dirty map 相同的情况,首先调用 dirtyLocked()。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
//新加的元素需要放入到 dirty 中,如果 dirty 为 nil,那么需要从 read 字段中复制出来一个 dirty 对象
//从m.read中复制未删除的数据(如此做的原因在于删除的时候如果read map存在该元素且read的amended==false:直接将read中的元素置为nil。还有一种情况是read map和dirty map同时存在该元素:将read map中的元素置为nil,因为read map和dirty map 使用的均为元素地址,所以均被置为nil。)
func (m *Map) dirtyLocked() {
// 如果 dirty map 为空,则一切都很好,返回
if m.dirty != nil { // 如果dirty字段已经存在,不需要创建了
return
}
// 获得 read map
read, _ := m.read.Load().(readOnly)
// 创建一个与 read map 大小一样的 dirty map
m.dirty = make(map[interface{}]*entry, len(read.m))
// 依次将 read map 的值复制到 dirty map 中。
for k, e := range read.m {
if !e.tryExpungeLocked() {
// 把非punged的键值对复制到dirty中
m.dirty[k] = e
}
}
}
//尝试将已经删除的标记设置为nil标记
func (e *entry) tryExpungeLocked() (isExpunged bool) {
// 获取 entry 的值
p := atomic.LoadPointer(&e.p)
// 如果 entry 值是 nil
for p == nil {
// 将已经删除标记为nil的数据标记为expunged
// 检查是否被标记为已经删除
if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
// 成功交换,说明被标记为删除
return true
}
// 删除操作失败,说明 expunged 是 nil,则重新读取一下
p = atomic.LoadPointer(&e.p)
}
// 直到读到的 p不为 nil 时,则判断是否是标记为删除的对象
return p == expunged
}
// expunged是一个任意指针,用于标记已删除的条目
//来自dirty map
var expunged = unsafe.Pointer(new(interface{}))
// unexpungeLocked确保条目标记为未清除。
//如果该条目先前已被清除,则必须将其添加到dirty map中
//在m.mu解锁之前
func (e *entry) unexpungeLocked() (wasExpunged bool) {
return atomic.CompareAndSwapPointer(&e.p, expunged, nil)
}
// storeLocked无条件地将值存储到条目中。
//必须知道该条目不被删除。
func (e *entry) storeLocked(i *interface{}) {
atomic.StorePointer(&e.p, unsafe.Pointer(i))
}
|
Delete
sync.map 的第 3 个核心方法是 Delete 方法。在 Go 1.15 中欧长坤提供了一个 LoadAndDelete 的实现,所以 Delete 方法的核心改在了对 LoadAndDelete 中实现了。
删除元素,采用延迟删除,当read map存在元素时,将元素置为nil,只有在提升dirty的时候才清理删除的数,延迟删除可以避免后续获取删除的元素时候需要加锁。当read map不存在元素时,直接删除dirty map中的元素
同样,删除操作还是从m.read中开始,如果这个entry不存在于m.read中,并且m.dirty中有新数据,则加锁尝试从m.dirty中删除。注意,还是要双检查的。 从m.dirty中直接删除即可,就当它没存在过.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
// Delete deletes the value for a key.
// Delete 删除 key 对应的 value
func (m *Map) Delete(key interface{}) {
m.LoadAndDelete(key)
}
// LoadAndDelete deletes the value for a key, returning the previous value if any.
// The loaded result reports whether the key was present.
func (m *Map) LoadAndDelete(key interface{}) (value interface{}, loaded bool) {
// 1. 从read map中查找,如果存在,则置为nil
// 获得 read map
read, _ := m.read.Load().(readOnly)
// 从 read map 中读取需要删除的 key
e, ok := read.m[key]
// 如果 read map 中没找到,且 read map 与 dirty map 不一致
// 说明要删除的值在 dirty map 中
if !ok && read.amended {
// 在 dirty map 中需要加锁
m.mu.Lock()
// 第二次检测
// 再次读 read map
read, _ = m.read.Load().(readOnly)
// 从 read map 中取值
e, ok = read.m[key]
// 没取到,read map 和 dirty map 不一致
// 2. 如果read map中不存在,但dirty map中存在,则直接从dirty map删除
if !ok && read.amended {
e, ok = m.dirty[key]
// 这一行长坤在1.15中实现的时候忘记加上了,导致在特殊的场景下有些key总是没有被回收
// 删除 dierty map 的值
delete(m.dirty, key)
// Regardless of whether the entry was present, record a miss: this key
// will take the slow path until the dirty map is promoted to the read
// map.
// miss数加1
m.missLocked()
}
m.mu.Unlock()
}
if ok {
return e.delete()
}
return nil, false
}
// 但是如果是从m.read中删除,并不会直接删除,而是打标记,因为read map和dirty map 使用的均为元素地址,所以均被置为nil
func (e *entry) delete() (value interface{}, ok bool) {
for {
// 读取 entry 的值
p := atomic.LoadPointer(&e.p)
// 已标记为删除
// 如果 p 等于 nil,或者 p 已经标记删除
if p == nil || p == expunged {
// 则不需要删除
return nil, false
}
// 原子操作,e.p标记为nil
// 否则,将 p 的值与 nil 进行原子换
if atomic.CompareAndSwapPointer(&e.p, p, nil) {
// 删除成功(本质只是解除引用,实际上是留给 GC 清理)
return *(*interface{})(p), true
}
}
}
|
从实现上来看,删除操作相对简单,当需要删除一个值时,移除 read map 中的值,本质上仅仅只是解除对变量的引用。 实际的回收是由 GC 进行处理。 如果 read map 中并未找到要删除的值,才会去尝试删除 dirty map 中的值。
如果 read 中不存在,那么就需要从 dirty 中寻找这个项目。最终,如果项目存在就删除(将它的值标记为 nil)。如果项目不为 nil 或者没有被标记为 expunged,那么还可以把它的值返回。
LoadOrStore
如果对应的元素存在,则返回该元素的值,如果不存在,则将元素写入到sync.Map。如果已加载值,则加载结果为true;如果已存储,则为false。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
// LoadOrStore 在 key 已经存在时,返回存在的值,否则存储当前给定的值
// loaded 为 true 表示 actual 读取成功,否则为 false 表示 value 存储成功
func (m *Map) LoadOrStore(key, value interface{}) (actual interface{}, loaded bool) {
// 不加锁的情况下读取read map
// 第一次检测
// 读 read map
read, _ := m.read.Load().(readOnly)
// 如果 read map 中已经读到
if e, ok := read.m[key]; ok {
// 如果元素存在(是否标识为删除由tryLoadOrStore执行处理),尝试获取该元素已存在的值或者将元素写入
// 尝试存储(可能 key 是一个已删除的 key)
actual, loaded, ok := e.tryLoadOrStore(value)
// 如果存储成功,则直接返回
if ok {
return actual, loaded
}
}
// 否则,涉及 dirty map,加锁
m.mu.Lock()
// 第二次检测
// 以下逻辑参看Store
// 再读一次 read map
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok {
// 如果 read map 中已经读到,则看该值是否被删除
if e.unexpungeLocked() {
// 没有被删除,则通过 dirty map 存
m.dirty[key] = e
}
actual, loaded, _ = e.tryLoadOrStore(value)
} else if e, ok := m.dirty[key]; ok {
// 如果 read map 没找到, dirty map 找到了
// 尝试 laod or store,并记录 miss
actual, loaded, _ = e.tryLoadOrStore(value)
m.missLocked()
} else {
// 否则就是存一个新的值
// 如果 read map 和 dirty map 相同,则开始标记不同
if !read.amended {
m.dirtyLocked()
m.read.Store(readOnly{m: read.m, amended: true})
}
// 存到 dirty map 中去
m.dirty[key] = newEntry(value)
actual, loaded = value, false
}
m.mu.Unlock()
// 返回存取状态
return actual, loaded
}
|
如果没有删除元素,tryLoadOrStore将自动加载或存储一个值。如果删除元素,tryLoadOrStore保持条目不变并返回ok= false。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
func (e *entry) tryLoadOrStore(i interface{}) (actual interface{}, loaded, ok bool) {
p := atomic.LoadPointer(&e.p)
// 元素标识删除,直接返回
if p == expunged {
return nil, false, false
}
// 存在该元素真实值,则直接返回原来的元素值
if p != nil {
return *(*interface{})(p), true, true
}
// 如果p为nil(此处的nil,并是不是指元素的值为nil,而是atomic.LoadPointer(&e.p)为nil,元素的nil在unsafe.Pointer是有值的),则更新该元素值
ic := i
for {
if atomic.CompareAndSwapPointer(&e.p, nil, unsafe.Pointer(&ic)) {
return i, false, true
}
p = atomic.LoadPointer(&e.p)
if p == expunged {
return nil, false, false
}
if p != nil {
return *(*interface{})(p), true, true
}
}
}
|
流程图
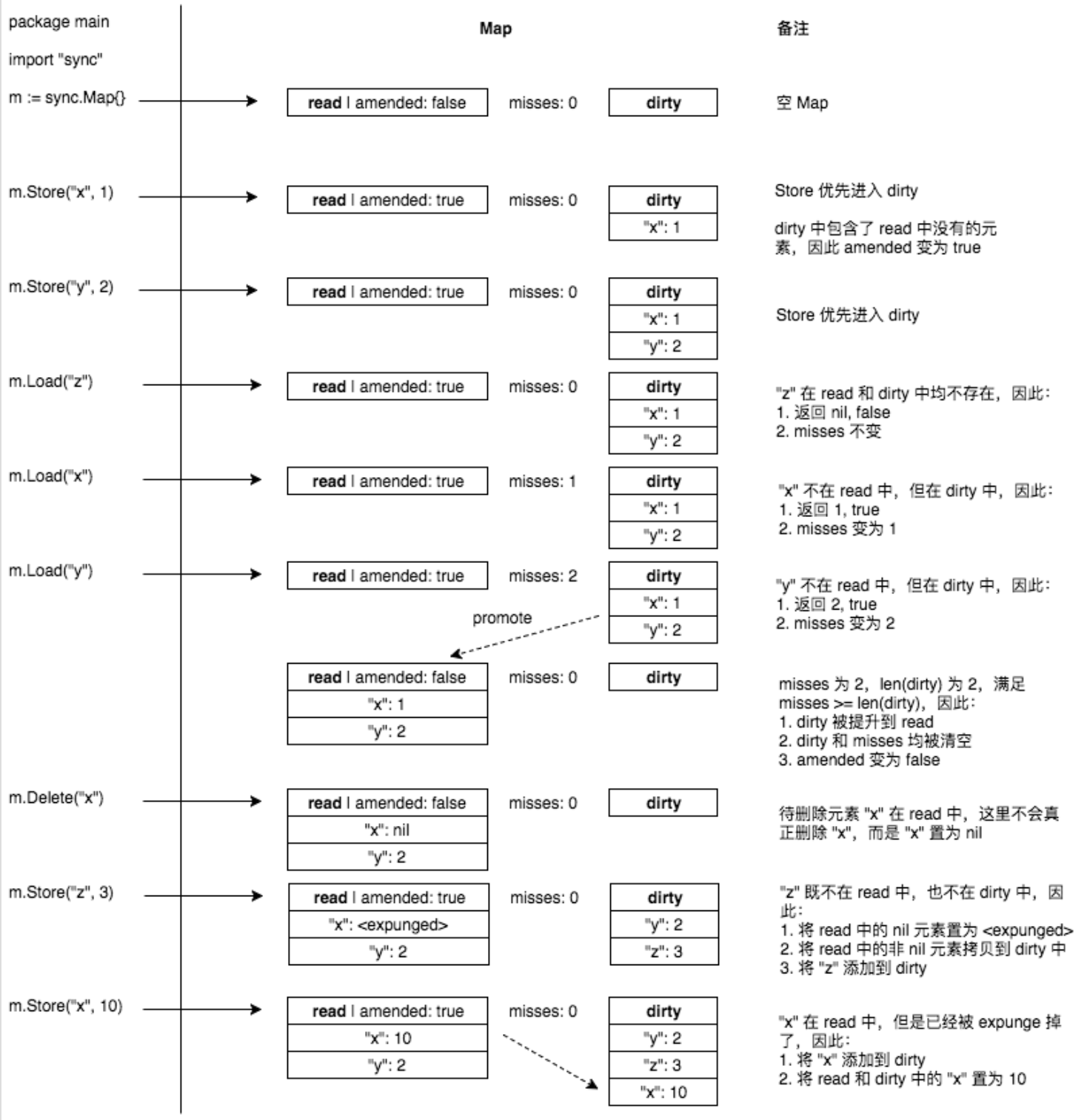
Range
因为for … range map是内建的语言特性,所以没有办法使用for range遍历sync.Map, 但是可以使用它的Range方法,通过回调的方式遍历。
遍历获取sync.Map中所有的元素,使用的为快照方式,所以不一定是准确的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
// Range 为每个 key 顺序的调用 f。如果 f 返回 false,则 range 会停止迭代。
//
// Range 的时间复杂度可能会是 O(N) 即便是 f 返回 false。
func (m *Map) Range(f func(key, value interface{}) bool) {
// 第一检测
// 读取 read map
read, _ := m.read.Load().(readOnly)
// read.amended=true,说明dirty map包含所有有效的元素(含新加,不含被删除的),使用dirty map
// 如果 read map 和 dirty map 不一致,则需要进一步操作
if read.amended {
// 第二检测
m.mu.Lock()
// 再读一次,如果还是不一致,则将 dirty map 提升为 read map
read, _ = m.read.Load().(readOnly)
if read.amended {
// 使用dirty map并且升级为read map
read = readOnly{m: m.dirty}
m.read.Store(read)
m.dirty = nil
m.misses = 0
}
m.mu.Unlock()
}
// 一贯原则,使用read map作为读
// 在 read 变量中读(可能是 read map ,也可能是 dirty map 同步过来的 map)
for k, e := range read.m {
// 读 readOnly,load 会检查该值是否被标记为删除
v, ok := e.load()
// 如果已经删除,则跳过
// 被删除的不计入
if !ok {
continue
}
// 函数返回false,终止
// 如果 f 返回 false,则停止迭代
if !f(k, v) {
break
}
}
}
|
既然要 Range 整个 map,则需要考虑 dirty map 与 read map 不一致的问题,如果不一致,则直接将 dirty map 同步到 read map 中。
Range方法调用前可能会做一个m.dirty的提升,不过提升m.dirty不是一个耗时的操作。
补全Len
sync.Map没有提供获取元素个数的Len()方法,不过可以通过Range()实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func Len(sm sync.Map) int {
lengh := 0
f := func(key, value interface{}) bool {
lengh++
return true
}
one:=lengh
lengh=0
sm.Range(f)
if one != lengh {
one = lengh
lengh=0
sm.Range(f)
if one <lengh {
return lengh
}
}
return one
}
|
小结
我们来回顾一下 sync.Map 中 read map 和 dirty map 的同步过程:
- 当 Store 一个新值会发生:read map –> dirty map
- dirty map –> read map:当 read map 进行 Load 失败 len(dirty map) 次之后发生
因此,无论是存储还是读取,read map 中的值一定能在 dirty map 中找到。无论两者如何同步,sync.Map 通过 entry 指针操作, 保证数据永远只有一份,一旦 read map 中的值修改,dirty map 中保存的指针就能直接读到修改后的值。
当存储新值时,一定发生在 dirty map 中。当读取旧值时,如果 read map 读到则直接返回,如果没有读到,则尝试加锁去 dirty map 中取。 这也就是官方宣称的 sync.Map 适用于一次写入多次读取的情景。
sync.Map的适用场景
sync.Map 为了保证并发安全有一些性能损失,因此在非并发情况下,使用 map 相比使用 sync.Map 会有更好的性能。
总结一下,sync.Map像是一个不够完善的容器,比起已有的map主要存在以下不足:
- 低并发情况下的性能不足
- 冗余数据
- 缺少类型安全控制
- 有限的api。比如不支持len操作
它针对keys长时间没有变化且只有很少的稳态存储的,或者每一个Goroutine中有一个本地存储的key的并发循环使用做了优化。
对于不共享这些属性的使用场景,使用它同与使用sys.RWMutex保护的内置map相比可能有更差的性能表现,以及更差的类型安全。
经过了上面的分析可以得到,sync.Map并不适合同时存在大量读写的场景(这里的写是指新增和删除key, 修改key还是用的原子性操作),大量的写会导致read map读取不到数据从而加锁进行进一步读取,同时dirty map不断升级为read map。 从而导致整体性能较低,特别是针对cache场景.针对append-only以及大量读,少量写场景使用sync.Map则相对比较合适。
所以如我在前面理解的,如果我使用内置map显示出了数据竞争迹象同时map的key在整个应用程序的生命周期内不会经常变换,我可能会考虑使用sync.Map。对我来说,通俗的讲这个就是一个只有少量更新的高并发读取场景,或者只在一些突发情况下会发生大规模更新的场景。对我来说,通俗的讲这个就是一个只有少量更新的高并发读取场景,或者只在一些突发情况下会发生大规模更新的场景。
第一个benchmark显示了使用与sync.RWMutex一起的常规map与sync.Map之间写数据的比较:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
func nrand(n int) []int {
i := make([]int, n)
for ind := range i {
i[ind] = rand.Int()
}
return i
}
func BenchmarkStoreRegular(b *testing.B) {
nums := nrand(b.N)
rm := NewRegularIntMap()
b.ResetTimer()
for _, v := range nums {
rm.Store(v, v)
}
}
func BenchmarkStoreSync(b *testing.B) {
nums := nrand(b.N)
var sm sync.Map
b.ResetTimer()
for _, v := range nums {
sm.Store(v, v)
}
}
/*
BenchmarkStoreRegular-32 5000000 319 ns/op
BenchmarkStoreSync-32 1000000 1146 ns/op
*/
|
下面是删除操作的benchmark:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
func BenchmarkDeleteRegular(b *testing.B) {
nums := nrand(b.N)
rm := NewRegularIntMap()
for _, v := range nums {
rm.Store(v, v)
}
b.ResetTimer()
for _, v := range nums {
rm.Delete(v)
}
}
func BenchmarkDeleteSync(b *testing.B) {
nums := nrand(b.N)
var sm sync.Map
for _, v := range nums {
sm.Store(v, v)
}
b.ResetTimer()
for _, v := range nums {
sm.Delete(v)
}
}
/*
BenchmarkDeleteRegular-32 10000000 238 ns/op
BenchmarkDeleteSync-32 5000000 393 ns/op
*/
|
下面是读数据的benchmark,其中叫Found用例总是能够从map中读取到数据,叫NotFound的用例则几乎总是读取不到数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
func BenchmarkLoadRegularFound(b *testing.B) {
nums := nrand(b.N)
rm := NewRegularIntMap()
for _, v := range nums {
rm.Store(v, v)
}
currentResult := 0
b.ResetTimer()
for i := 0; i < b.N; i++ {
currentResult, _ = rm.Load(nums[i])
}
globalResult = currentResult
}
func BenchmarkLoadRegularNotFound(b *testing.B) {
nums := nrand(b.N)
rm := NewRegularIntMap()
for _, v := range nums {
rm.Store(v, v)
}
currentResult := 0
b.ResetTimer()
for i := 0; i < b.N; i++ {
currentResult, _ = rm.Load(i)
}
globalResult = currentResult
}
func BenchmarkLoadSyncFound(b *testing.B) {
nums := nrand(b.N)
var sm sync.Map
for _, v := range nums {
sm.Store(v, v)
}
currentResult := 0
b.ResetTimer()
for i := 0; i < b.N; i++ {
r, ok := sm.Load(nums[i])
if ok {
currentResult = r.(int)
}
}
globalResult = currentResult
}
func BenchmarkLoadSyncNotFound(b *testing.B) {
nums := nrand(b.N)
var sm sync.Map
for _, v := range nums {
sm.Store(v, v)
}
currentResult := 0
b.ResetTimer()
for i := 0; i < b.N; i++ {
r, ok := sm.Load(i)
if ok {
currentResult = r.(int)
}
}
globalResult = currentResult
}
/*
BenchmarkLoadRegularFound-32 10000000 180 ns/op
BenchmarkLoadRegularNotFound-32 20000000 107 ns/op
BenchmarkLoadSyncFound-32 10000000 200 ns/op
BenchmarkLoadSyncNotFound-32 20000000 291 ns/op
*/
|
正如你所看到的,这些benchmark中的所有用例中使用sync.RWMutex保护的常规map的性能都远胜于sync.Map。并且到目前为止,我们还没有将benchmark引入到多个goroutines中。让我们继续讨论这个问题,让我们看看夸核扩展成为一个因子后设计的benchmark性能如何。
让我们来使用Digital Ocean上的一个32核的虚拟机看看趋势是怎么样的。
对于这个benchmark,我想在当前的理想场景下测量基于两种map的实现的性能。在这个场景下,我将构建存储一组随机数据的两中map,并且我将在每个benchmark中使用不同的GOMAXPROCS并且创建与GOMAXPROCS数量相同的goroutines来执行。
再次,我将运行这些测试来模拟一个高读取场景,所以在benchmark时钟开始之前map内容就已经被构建并固定了。在这篇的文章的下一次更新中,我可能会创建一个benchmark来模拟固定数量的写入,但是现在让我们考虑这个有点人造的但是理想的用例。
接下来是我将如何定义这些并发的benmarks,但是首先概要的说明下代码:
这些benchmarks实际是一些被其他函数调用的函数,在调用函数中我们写死了workerCount。这样我们就能为每个benchmark配置GOMAXPROCS和workers的数量。
确保我们不会遇到Go编译器的优化,我们捕获了Load方法的输出。我们并不关心Load的结果,只是确保编译器不会因为我们未使用输出结果而将代码判断为死代码并将这段代码移除。
代码的主要部分将启动一个goroutine作为worker,它将通过使用b.N值来尽可能的的迭代满足Go benchmark的条件。随着每个goroutines的运行,我们执行我们的Load操作,最后使用sync.WaitGroup来通知goroutine的结束。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
|
func benchmarkRegularStableKeys(b *testing.B, workerCount int) {
runtime.GOMAXPROCS(workerCount)
rm := NewRegularIntMap()
populateMap(b.N, rm)
var wg sync.WaitGroup
wg.Add(workerCount)
// Holds our final results, to prevent compiler optimizations.
globalResultChan = make(chan int, workerCount)
b.ResetTimer()
for wc := 0; wc < workerCount; wc++ {
go func(n int) {
currentResult := 0
for i := 0; i < n; i++ {
currentResult, _ = rm.Load(5)
}
globalResultChan <- currentResult
wg.Done()
}(b.N)
}
wg.Wait()
}
func benchmarkSyncStableKeys(b *testing.B, workerCount int) {
runtime.GOMAXPROCS(workerCount)
var sm sync.Map
populateSyncMap(b.N, &sm)
var wg sync.WaitGroup
wg.Add(workerCount)
// Holds our final results, to prevent compiler optimizations.
globalResultChan = make(chan int, workerCount)
b.ResetTimer()
for wc := 0; wc < workerCount; wc++ {
go func(n int) {
currentResult := 0
for i := 0; i < n; i++ {
r, ok := sm.Load(5)
if ok {
currentResult = r.(int)
}
}
globalResultChan <- currentResult
wg.Done()
}(b.N)
}
wg.Wait()
}
func benchmarkRegularStableKeysFound(b *testing.B, workerCount int) {
runtime.GOMAXPROCS(workerCount)
rm := NewRegularIntMap()
values := populateMap(b.N, rm)
var wg sync.WaitGroup
wg.Add(workerCount)
// Holds our final results, to prevent compiler optimizations.
globalResultChan = make(chan int, workerCount)
b.ResetTimer()
for wc := 0; wc < workerCount; wc++ {
go func(n int) {
currentResult := 0
for i := 0; i < n; i++ {
currentResult, _ = rm.Load(values[i])
}
globalResultChan <- currentResult
wg.Done()
}(b.N)
}
wg.Wait()
}
func benchmarkSyncStableKeysFound(b *testing.B, workerCount int) {
runtime.GOMAXPROCS(workerCount)
var sm sync.Map
values := populateSyncMap(b.N, &sm)
var wg sync.WaitGroup
wg.Add(workerCount)
// Holds our final results, to prevent compiler optimizations.
globalResultChan = make(chan int, workerCount)
b.ResetTimer()
for wc := 0; wc < workerCount; wc++ {
go func(n int) {
currentResult := 0
for i := 0; i < n; i++ {
r, ok := sm.Load(values[i])
if ok {
currentResult = r.(int)
}
}
globalResultChan <- currentResult
wg.Done()
}(b.N)
}
wg.Wait()
}
/*
// These tests do a lookup using a literal value.
// Regular Map backed by RWMutex
BenchmarkRegularStableKeys1-32 50000000 30.5 ns/op
BenchmarkRegularStableKeys2-32 10000000 157 ns/op
BenchmarkRegularStableKeys4-32 5000000 377 ns/op
BenchmarkRegularStableKeys8-32 2000000 701 ns/op
BenchmarkRegularStableKeys16-32 1000000 1446 ns/op
BenchmarkRegularStableKeys32-32 500000 2825 ns/op
BenchmarkRegularStableKeys64-32 200000 5699 ns/op
// Sync Map
BenchmarkSyncStableKeys1-32 20000000 89.3 ns/op
BenchmarkSyncStableKeys2-32 20000000 101 ns/op
BenchmarkSyncStableKeys4-32 5000000 247 ns/op
BenchmarkSyncStableKeys8-32 5000000 330 ns/op
BenchmarkSyncStableKeys16-32 5000000 295 ns/op
BenchmarkSyncStableKeys32-32 5000000 269 ns/op
BenchmarkSyncStableKeys64-32 5000000 249 ns/op
// These tests do a lookup of keys already defined in the map per iteration.
// Regular Map backed by RWMutex
BenchmarkRegularStableKeysFound1-32 20000000 114 ns/op
BenchmarkRegularStableKeysFound2-32 10000000 203 ns/op
BenchmarkRegularStableKeysFound4-32 3000000 460 ns/op
BenchmarkRegularStableKeysFound8-32 2000000 976 ns/op
BenchmarkRegularStableKeysFound16-32 1000000 1895 ns/op
BenchmarkRegularStableKeysFound32-32 300000 3620 ns/op
BenchmarkRegularStableKeysFound64-32 200000 6762 ns/op
// Sync Map
BenchmarkSyncStableKeysFound1-32 5000000 357 ns/op
BenchmarkSyncStableKeysFound2-32 3000000 446 ns/op
BenchmarkSyncStableKeysFound4-32 3000000 501 ns/op
BenchmarkSyncStableKeysFound8-32 3000000 576 ns/op
BenchmarkSyncStableKeysFound16-32 2000000 566 ns/op
BenchmarkSyncStableKeysFound32-32 3000000 527 ns/op
BenchmarkSyncStableKeysFound64-32 2000000 873 ns/op
*/
|
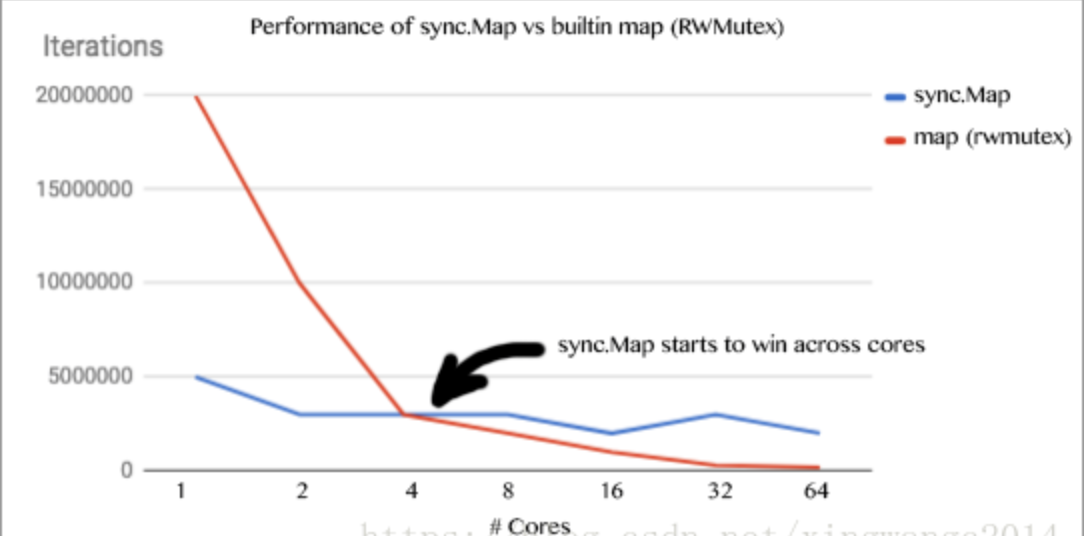
正如你所看到的,在使用sync.RWMutex保护的常规map上我们有很好的性能表现。事情一直沿着很好的方向在发展,但是到我们开始使用4核时情况就变了。在4核时,不仅数据竞争开始变成问题,就连我们夸核的扩展因子也是一个问题了。如果你是看的红线,当我们的CPU到8核的时候,你就可以忘了这根线了。在这个点上使用RWMutex我们有太多的读竞争,以至于到32核时性能受到很大影响。
蓝线表现的是sync.Map则展示了一个可预测的行为,因为我们持续的在扩展我们的核数。至此,我可以说基于我的初步测试和分析我们知道了sync.Map的发光点在哪儿。这个理想场景就是为它而建的。
警告:不要拷贝sync.Map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
package main
import (
"math/rand"
"sync"
)
func main() {
var m sync.Map
for i := 0; i < 64; i++ {
key := rand.Intn(128)
m.Store(key, key)
}
n := m
go func() {
for {
key := rand.Intn(128)
m.Store(key, key)
}
}()
for {
n.Range(func(key, value interface{}) bool {
return key == value
})
}
}
|
上述代码会报panic,原因在于创建完成的 sync.Map 是线程安全的,但是经过拷贝之后,两个 sync.Map 里面存储的是同一个 map(就是那个原生的,线程不安全的 map), mutex 无法起到保护作用,就线程不安全了。
但是如果真的要拷贝这个 sync.Map 应该怎么办呢? 那就只能再创建一个,然后 Range 老的 Map 一个个把 KV 拷进去了。
参考
https://colobu.com/2017/07/11/dive-into-sync-Map
https://segmentfault.com/a/1190000015242373
https://pathbox.github.io/2018/04/05/understand-sync.Map-in-Goalng/
http://www.qiuxiaobing.cn/%E7%BC%96%E7%A8%8B%E8%AF%AD%E8%A8%80/2018/03/09/go-sync-map.html
http://www.gogodjzhu.com/index.php/code/basic/397/
http://russellluo.com/2017/06/go-sync-map-diagram.html
5.4 条件变量
5.5 同步组
Go 标准库源码分析 - sync 包的Pool
5.7 并发安全散列表
6.1 上下文 Context
go context剖析之源码分析
5.3 原子操作