atomic
原理
在现在的系统中,write 的地址基本上都是对齐的(aligned)。 比如,32 位的操作系统、CPU 以及编译器,write 的地址总是 4 的倍数,64 位的系统总是 8 的倍数(还记得 WaitGroup 针对 64 位系统和 32 位系统对 state1 的字段不同的处理吗)。对齐地址的写,不会导致其他人看到只写了一半的数据,因为它通过一个指令就可以实现对地址的操作。如果地址不是对齐的话,那么,处理器就需要分成两个指令去处理,如果执行了一个指令,其它人就会看到更新了一半的错误的数据,这被称做撕裂写(torn write) 。所以,你可以认为赋值操作是一个原子操作,这个“原子操作”可以认为是保证数据的完整性。
但是,对于现代的多处理多核的系统来说,由于 cache、指令重排,可见性等问题,我们对原子操作的意义有了更多的追求。在多核系统中,一个核对地址的值的更改,在更新到主内存中之前,是在多级缓存中存放的。这时,多个核看到的数据可能是不一样的,其它的核可能还没有看到更新的数据,还在使用旧的数据。
多处理器多核心系统为了处理这类问题,使用了一种叫做内存屏障(memory fence 或 memory barrier)的方式。一个写内存屏障会告诉处理器,必须要等到它管道中的未完成的操作(特别是写操作)都被刷新到内存中,再进行操作。此操作还会让相关的处理器的 CPU 缓存失效,以便让它们从主存中拉取最新的值。
atomic 包提供的方法会提供内存屏障的功能,所以,atomic 不仅仅可以保证赋值的数据完整性,还能保证数据的可见性,一旦一个核更新了该地址的值,其它处理器总是能读取到它的最新值。但是,需要注意的是,因为需要处理器之间保证数据的一致性,atomic 的操作也是会降低性能的。
原子操作
原子操作依赖硬件指令的支持,但同时还需要运行时调度器的配合。我们以 atomic.CompareAndSwapPointer 为例,介绍 sync/atomic 包提供的同步模式。
CompareAndSwapPointer 它在包中只有函数定义,没有函数体:
1
|
func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool)
|
其本身由运行时实现。
我们简单看过了两个属于公共包的方法 atomic.Value 和 atomic.CompareAndSwapPointer, 我们来看一下运行时实现:
1
2
3
4
5
6
7
8
9
10
11
|
//go:linkname sync_atomic_CompareAndSwapUintptr sync/atomic.CompareAndSwapUintptr
func sync_atomic_CompareAndSwapUintptr(ptr *uintptr, old, new uintptr) bool
//go:linkname sync_atomic_CompareAndSwapPointer sync/atomic.CompareAndSwapPointer
//go:nosplit
func sync_atomic_CompareAndSwapPointer(ptr *unsafe.Pointer, old, new unsafe.Pointer) bool {
if writeBarrier.enabled {
atomicwb(ptr, new)
}
return sync_atomic_CompareAndSwapUintptr((*uintptr)(noescape(unsafe.Pointer(ptr))), uintptr(old), uintptr(new))
}
|
可以看到 sync_atomic_CompareAndSwapUintptr 函数在运行时中也是没有方法本体的, 说明其实现由编译器完成。那么我们来看一下编译器究竟干了什么:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
package main
import (
"sync/atomic"
"unsafe"
)
func main() {
var p unsafe.Pointer
newP := 42
atomic.CompareAndSwapPointer(&p, nil, unsafe.Pointer(&newP))
v := (*int)(p)
println(*v)
}
|
编译结果:
1
2
3
4
5
6
7
8
9
|
TEXT sync/atomic.CompareAndSwapUintptr(SB) /usr/local/Cellar/go/1.11/libexec/src/sync/atomic/asm.s
asm.s:31 0x1001070 e91b0b0000 JMP runtime/internal/atomic.Casuintptr(SB)
:-1 0x1001075 cc INT $0x3
(...)
TEXT runtime/internal/atomic.Casuintptr(SB) /usr/local/Cellar/go/1.11/libexec/src/runtime/internal/atomic/asm_amd64.s
asm_amd64.s:44 0x1001b90 e9dbffffff JMP runtime/internal/atomic.Cas64(SB)
:-1 0x1001b95 cc INT $0x3
(...)
|
可以看到 atomic.CompareAndSwapUintptr 本质上转到了 runtime/internal/atomic.Cas64,我们来看一下它的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// bool runtime∕internal∕atomic·Cas64(uint64 *val, uint64 old, uint64 new)
// Atomically:
// if(*val == *old){
// *val = new;
// return 1;
// } else {
// return 0;
// }
TEXT runtime∕internal∕atomic·Cas64(SB), NOSPLIT, $0-25
MOVQ ptr+0(FP), BX
MOVQ old+8(FP), AX
MOVQ new+16(FP), CX
LOCK
CMPXCHGQ CX, 0(BX)
SETEQ ret+24(FP)
RET
|
可以看到,实现的本质是使用 CPU 的 LOCK+CMPXCHGQ 指令:首先将 ptr 的值放入 BX,将假设的旧值放入 AX, 要比较的新值放入 CX。然后 LOCK CMPXCHGQ 与累加器 AX 比较并交换 CX 和 BX。
因此原子操作本质上均为使用 CPU 指令进行实现(理所当然)。由于原子操作的方式比较单一,很容易举一反三, 其他操作不再穷举。
原子值
原子值需要运行时的支持,在原子值进行修改时,Goroutine 不应该被抢占,因此需要锁定 MP 之间的绑定关系:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
//go:linkname sync_runtime_procPin sync.runtime_procPin
//go:nosplit
func sync_runtime_procPin() int {
return procPin()
}
//go:nosplit
func procPin() int {
_g_:= getg()
mp :=_g_.m
mp.locks++
return int(mp.p.ptr().id)
}
//go:linkname sync_atomic_runtime_procUnpin sync/atomic.runtime_procUnpin
//go:nosplit
func sync_atomic_runtime_procUnpin() {
procUnpin()
}
//go:nosplit
func procUnpin() {
_g_:= getg()
_g_.m.locks--
}
|
原子值 atomic.Value 提供了一种具备原子存取的结构。其自身的结构非常简单, 只包含一个存放数据的 interface{}:
1
2
3
|
type Value struct {
v interface{}
}
|
它仅仅只是对要存储的值进行了一层封装。要对这个值进行原子的读取,依赖 Load 方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// LoadPointer atomically loads *addr.
func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer)
func (v *Value) Load() (x interface{}) {
// 获得 interface 结构的指针
// 在 go 中,interface 的内存布局有类型指针和数据指针两部分表示
vp := (*ifaceWords)(unsafe.Pointer(v))
// 获得存储值的类型指针
typ := LoadPointer(&vp.typ)
if typ == nil || uintptr(typ) == ^uintptr(0) {
return nil
}
// 获得存储值的实际数据
data := LoadPointer(&vp.data)
// 将复制得到的 typ 和 data 给到 x
xp := (*ifaceWords)(unsafe.Pointer(&x))
xp.typ = typ
xp.data = data
return
}
// ifaceWords 定义了 interface{} 的内部表示。
type ifaceWords struct {
typ unsafe.Pointer
data unsafe.Pointer
}
|
从这个 Load 方法实际上使用了 Go 运行时类型系统中的 interface{} 这一类型本质上由 两段内容组成,一个是类型 typ 区域,另一个是实际数据 data 区域。 这个 Load 方法的实现,本质上就是将内部存储的类型和数据都复制一份并返回。
再来看 Store。存储的思路与读取其实是类似的,但由于类型系统的两段式表示(typ 和 data) 的存在,存储操作比读取操作的实现要更加小心,要考虑当两个不同的 Goroutine 对两段值进行写入时, 如何才能避免写竞争:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
// StorePointer atomically stores val into *addr.
func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer)
func (v *Value) Store(x interface{}) {
if x == nil {
panic("sync/atomic: store of nil value into Value")
}
// Value 存储值的指针和要存储的 x 的指针
vp := (*ifaceWords)(unsafe.Pointer(v))
xp := (*ifaceWords)(unsafe.Pointer(&x))
for {
typ := LoadPointer(&vp.typ)
// v 还未被写入过任何数据
if typ == nil {
// 禁止抢占当前 Goroutine 来确保存储顺利完成
runtime_procPin()
// 先存一个标志位,宣告正在有人操作此值
if !CompareAndSwapPointer(&vp.typ, nil, unsafe.Pointer(^uintptr(0))) {
// 如果没有成功,取消不可抢占,下次再试
runtime_procUnpin()
continue
}
// 如果标志位设置成功,说明其他人都不会向 interface{} 中写入数据
StorePointer(&vp.data, xp.data)
StorePointer(&vp.typ, xp.typ)
// 存储成功,再标志位可抢占,直接返回
runtime_procUnpin()
return
}
// 有其他 Goroutine 正在对 v 进行写操作
if uintptr(typ) == ^uintptr(0) {
continue
}
// 如果本次存入的类型与前次存储的类型不同
if typ != xp.typ {
panic("sync/atomic: store of inconsistently typed value into Value")
}
// 类型已经写入,直接保存数据
StorePointer(&vp.data, xp.data)
return
}
}
|
可以看到 atomic.Value 的存取通过 unsafe.Pointer(^uintptr(0)) 作为第一次存取的标志位, 当 atomic.Value 第一次写入数据时,会将当前 Goroutine 设置为不可抢占, 并将要存储类型进行标记,再存入实际的数据与类型。当存储完毕后,即可解除不可抢占,返回。
在不可抢占期间,且有并发的 Goroutine 再此存储时,如果标记没有被类型替换掉, 则说明第一次存储还未完成,形成 CompareAndSwap 循环进行等待。
真正的赋值,无论是第一次,还是后续的 data 赋值,在 Store 内,只涉及到指针的原子操作,不涉及到数据拷贝;
如果 p.Store( /* */ ) 传入的不是指针,而是一个结构体呢?编译器识别到这种情况,编译期间就会多生成一段代码,用 runtime.convT2E 函数把结构体赋值转化成 eface (注意,这里会涉及到结构体数据的拷贝);然后再调用 Value.Store 方法,所以就 Store 方法而言,行为还是不变;
再思考一个问题:既然是指针的操作,为什么还要有个 for 循环,还要有个 CompareAndSwapPointer ?这是因为 ifaceWords 是两个字段的结构体,初始赋值的时候,要赋值类型和数据指针两部分。atomic.Value 是服务所有类型,此类需求的,通用封装。
应用:COW模式

cfg 作为包级全局对象,在这个例子中被多个 goroutine 同时访问,因此这里存在 data race,会看到不连续的内存输出。
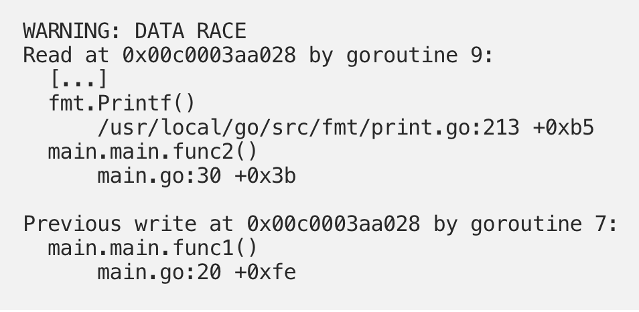
我们想到使用 Go 同步语义解决:
- Mutex:锁粒度很大,不适合读多写少场景
- RWMutex:适合读多写少场景,性能依旧不够.
- Atomic:性能最好.
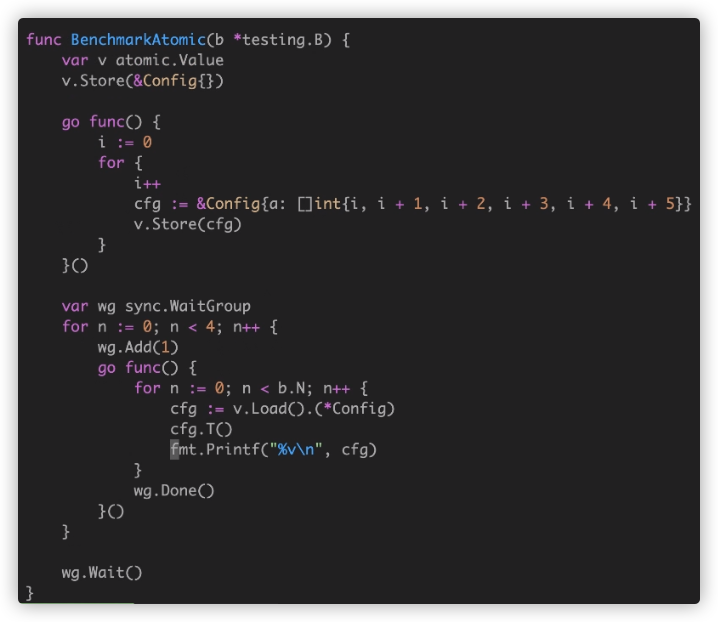
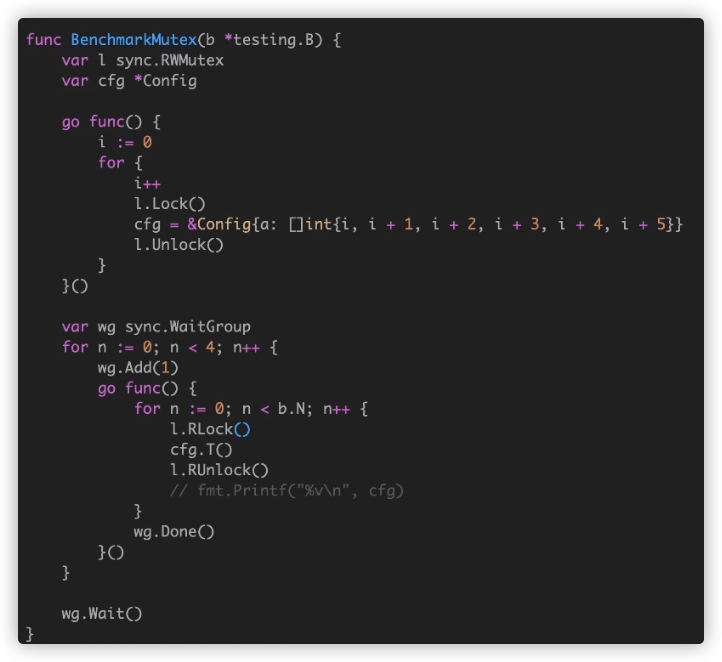
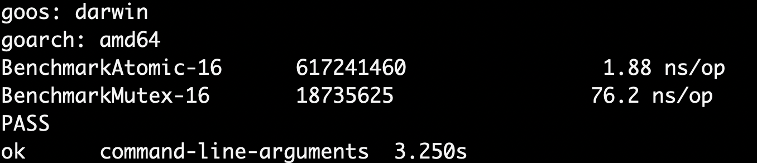
Benchmark 是出结果真相的真理,即便我们知道可能 Mutex vs Atomic 的情况里,Mutex 相对更重。因为涉及到更多的 goroutine 之间的上下文切换 pack blocking goroutine,以及唤醒 goroutine。
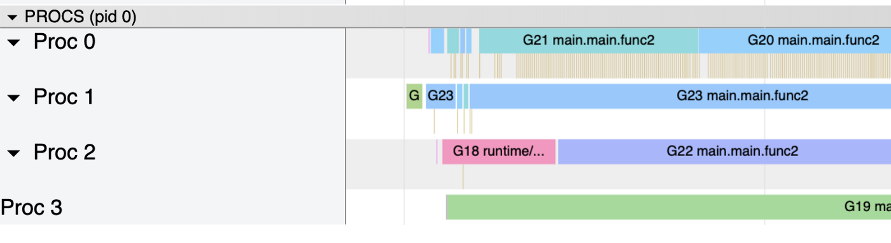
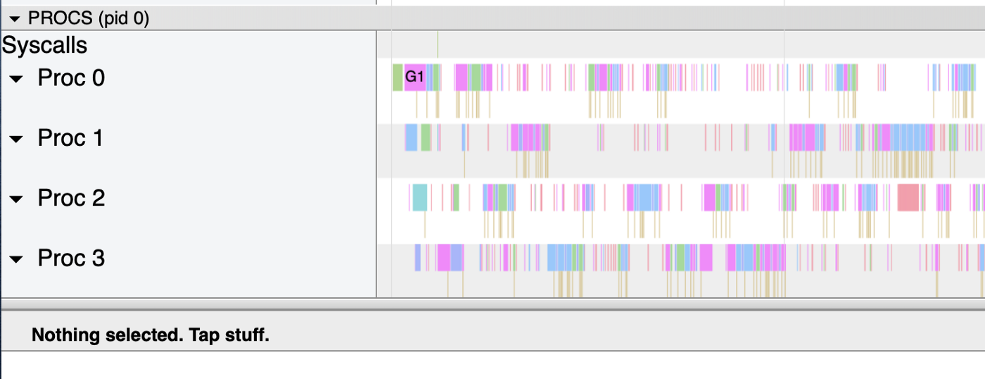
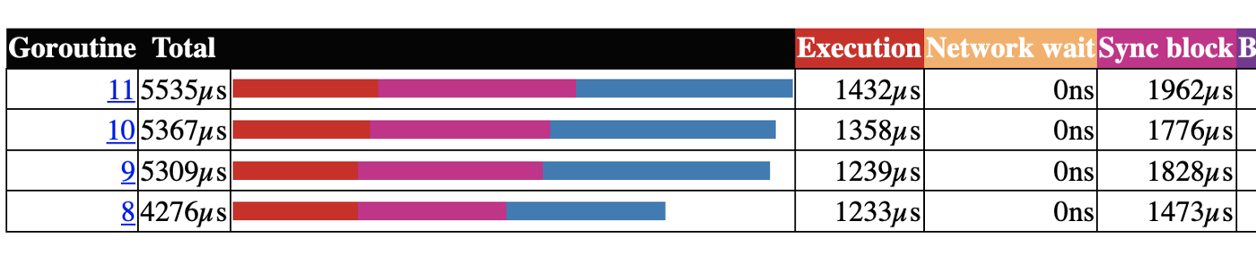
配置中心
Copy-On-Write 思路在微服务降级或者 local cache 场景中经常使用。写时复制指的是,写操作时候复制全量老数据到一个新的对象中,携带上本次新写的数据,之后利用原子替换(atomic.Value),更新调用者的变量。来完成无锁访问共享数据。
因为COW策略会将原始数据复制一份,写入性能很低,适合读极多写少的场景.
看如下代码,我们定期(每10s)利用loadconfig读取配置,然后存入config.在使用的时候,利用load读出来,再进行处理.


参考
https://colobu.com/2017/07/11/dive-into-sync-Map
https://segmentfault.com/a/1190000015242373
https://pathbox.github.io/2018/04/05/understand-sync.Map-in-Goalng/
http://www.qiuxiaobing.cn/%E7%BC%96%E7%A8%8B%E8%AF%AD%E8%A8%80/2018/03/09/go-sync-map.html
http://www.gogodjzhu.com/index.php/code/basic/397/
http://russellluo.com/2017/06/go-sync-map-diagram.html
5.4 条件变量
5.5 同步组
Go 标准库源码分析 - sync 包的Pool
5.7 并发安全散列表
6.1 上下文 Context
go context剖析之源码分析
5.3 原子操作