如何控制Go服务在容器环境的内存占用
文章目录
现象
为什么个别 Go 业务服务,Memory 总是提示这么高,经常达到容器限额,以至于被动 OOM Kill,是不是有什么安全隐患?
发现个别业务服务内存占用挺高,触发告警,且通过 Grafana 发现在凌晨(没有什么流量)的情况下,内存占用量依然拉平,没有打算下降的样子,高峰更是不得了,像是个内存炸弹:
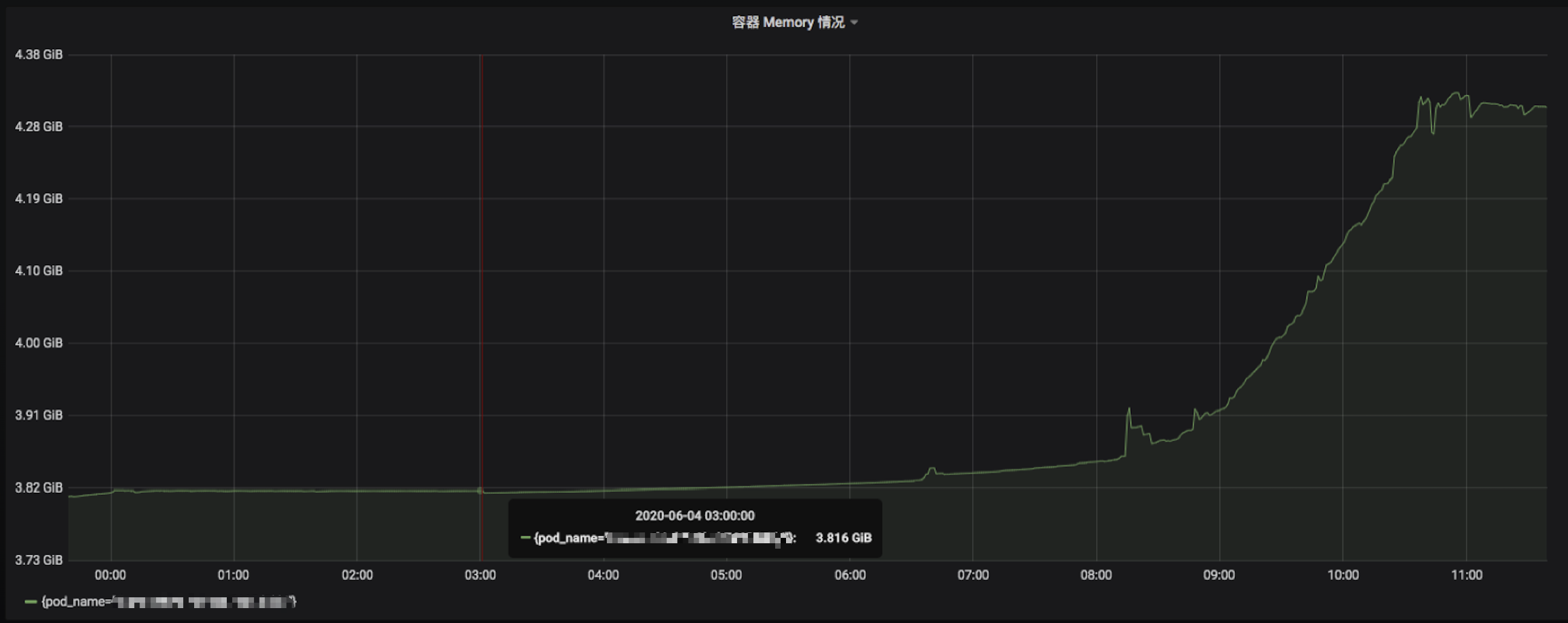
并且我所观测的这个服务,早年还只是 100MB。现在随着业务迭代和上升,目前已经稳步 4GB,容器限额 Limits 纷纷给它开道,但我想总不能是无休止的增加资源吧,这是一个大问题。
有的业务服务,业务量小,自然也就没有调整容器限额,因此得不到内存资源,又超过额度,就会进入疯狂的重启怪圈:

重启将近 300 次,非常不正常了,更不用提所接受到的告警通知。
容器的内存指标
容器 OOM 的判别标准是 container_memory_working_set_bytes(当前工作集)。
而 container_memory_working_set_bytes 是由 cadvisor 提供的,对应下述指标:

从结论上来讲,Memory 换算过来是 4GB+,石锤。接下来的问题就是 Memory 是怎么计算出来的呢,显然和 RSS 不对标。
一般系统内存过高的情况下,可以通过 free -m 查看当前系统的内存使用情况:
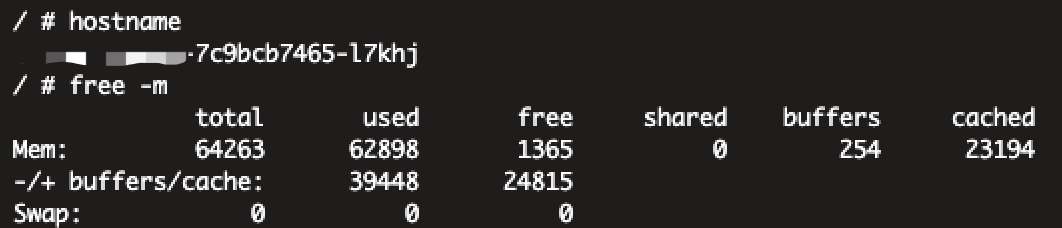
container_memory_working_set_bytes 指标的组成实际上是 RSS + Cache。
Cache过高
Cache 高的情况,常见于进程有大量文件 IO,占用 Cache 可能就会比较高,猜测也与 Go 版本、Linux 内核版本的 Cache 释放、回收方式有较大关系。
而各业务模块常见功能,如:
- 批量图片解压缩。
- 批量二维码生成。
- 批量上传渲染后图片。
- 批量 PDF 生成。
- …
只要是涉及有大量文件 IO 的服务,基本上是这个问题的老常客了,写这类服务基本写一个中一个,因为这是一个混合问题,像其它单纯操作为主的业务服务就很 “正常”,不会出现内存居高不下。
我们肯定是希望知道 Cache 中有什么,为什么占用了那么大的空间,此时我们可以通过 Linux pmap 来查看该容器进程的内存映射情况:
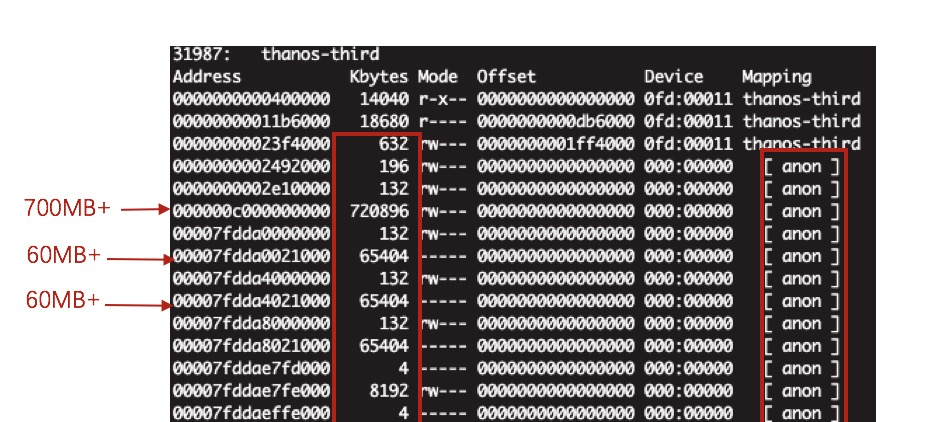
在上图中,我们发现了大量的 mapping 为 anon 的内存映射,最终 totals 确实达到了容器 Memory 相当的量,那么 anon 又是什么呢。实质上 anon 行表示在磁盘上没有对应的文件,也就是没有实际存在的载体,是 anonymous。
既然存在如此多的 anon,结合先前的考虑,我们知道出现这种情况的服务都是文件处理型服务,包含大量的批量生成图片、生成 PDF 等资源消耗型的任务,也就是会瞬间申请大量的内存,使得系统的空闲内存触及全局最低水位线(global wmark_min),而在触及全局最低水位线后,会尝试进行回收,实在不行才会触发 cgroup OOM 的行为。
那么更进一步思考的是两个问题,一个是 cgroup 达到 Limits 前的尝试释放仍然不足以支撑所需申请的连续内存段,而另外一个问题就是为什么 Cache 并没有释放:
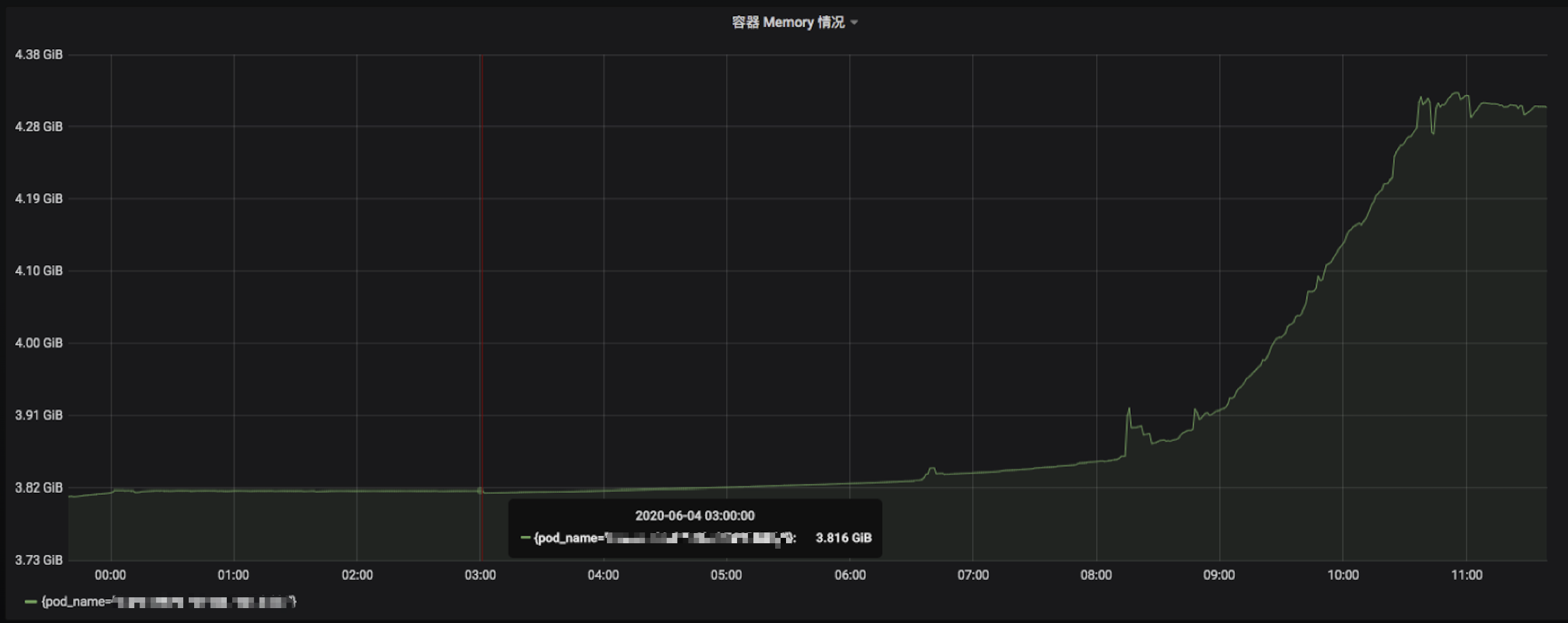
通过上图,可以肯定该服务在凌晨 00:00-06:00 是没有什么流量的,但是 container_memory_working_set_bytes 指标依旧稳定不变,排除 RSS 的原因,那配合指标的查看基本确定是该 cgroup 的 Cache 没有释放。
而 Cache 的占用高,主要考虑是由于其频繁操作文件导致,因为在 Linux 中,在第一次读取文件时会将一份放到系统 Cache,另外一份则放入进程内存中使用。关键点在于当进程运行完毕关闭后,系统 Cache 是不会马上回收的,需要经过系统的内存管理后再适时释放。
cache是操作系统内核的机制,同容器/业务/时间点无关,并不会说到了凌晨自动释放。
另外,如果压力降下来之后,只要系统未处于内存紧缺的状态,这部分cache是不会释放的。类似于拿内存换文件的io性能。毕竟【空闲】的内存放在那里,不用就浪费了。

可以看到,节点上真正意义上free的内存只有263M,但available的内存有13G.
available的内存包含了这里的free和部分buff/cache,当需要时,是可以随时用的.
手动清理Cache
在发现是系统内存占用高后,就会有读者会提到,为什么不 “手动清理 Cache”,因为 Cache 高的话,可以通过 drop_caches 的方式来清理:
1.清理 page cache:
|
|
2.清理 dentries 和 inodes:
|
|
3.清理 page cache、dentries 和 inodes:
|
|
但新问题又出现了,因为我们的命题是在容器中,在 Kubernetes 中,若执行 drop_caches 相关命令,将会对 Node 节点上的所有其他应用程序产生影响,尤其是那些占用大量 IO 并由于缓冲区高速缓存而获得更好性能的应用程序,可能会产生 “负面” 后果。
我想这并不是一个好办法。
Linux内核参数调整
memcg 是 Linux 内核中管理 cgroup 内存的模块,但实际上在 Linux 3.10.x 的低内核版本中存在不少实现上的 BUG,其中最具代表性的是 memory cgroup 中 kmem accounting 相关的问题(在低版本中属于 alpha 特性):
-
slab 泄露:具体可详见该文章 SLUB: Unable to allocate memory on node -1 中的介绍和说明。
-
memory cgroup 泄露:在删除容器后没有回收完全,而 Linux 内核对 memory cgroup 的总数限制是 65535 个,若频繁创建删除开启了 kmem 的 cgroup,就会导致无法再创建新的 memory cgroup。
当然,为什么出现问题后绝大多数是由 Kubernetes、Docker 的相关使用者发现的呢(从 issues 时间上来看),这与云原生的兴起,这类问题与内部容器化的机制相互影响,最终开发者 “发现” 了这类应用频繁出现 OOM,于是开始进行排查。
调整内核参数
关闭 kmem accounting:
|
|
也可以通过 kubelet 的 nokmem Build Tags 来编译解决:
|
|
但需要注意,kubelet 版本需要在 v1.14 及以上。
升级内核版本
升级 Linux 内核至 kernel-3.10.0-1075.el7 及以上就可以修复这个问题,详细可见 slab leak causing a crash when using kmem control group,其在发行版中 CentOS 7.8 已经发布。
RSS过高
RSS过高原因有服务创建大量对象,内存泄露,goroutine泄露等,此处不再赘述,主要讲容器环境对服务的影响.
madvise 策略变更
在 Linux 系统中,在 Go Runtime 中通过系统调用 madvise(addr, length, advise) 方法,能够告诉内核如何处理从 addr 开始的 length 字节。
重点之一就是 ”如何处理“,在 Linux 下 Go 语言中目前支持两种策略,分别是:
- MADV_FREE:内核会在进程的页表中将这些页标记为“未分配”,从而进程的 RSS 就会变小。OS 后续可以将对应的物理页分配给其他进程。
- MADV_DONTNEED:内核只会在页表中将这些进程页面标记为可回收,在需要的时候才回收这些页面。
Go 语言官方恰好就在 2019 年的 Go1.12 做了如下调整。
Go1.12 以前,Go Runtime 在 Linux 上默认使用的是 MADV_DONTNEED 策略。
|
|
从整体效果来看,进程 RSS 可以下降的比较快,但从性能效率上来看差点。
Go1.12-Go1.15,当前 Linux 内核版本 >=4.5 时,Go Runtime 在 Linux 上默认使用了性能更为高效的 MADV_FREE 策略。
|
|
从整体效果来看,进程RSS 不会立刻下降,要等到系统有内存压力了才会释放占用,RSS 才会下降。
故事往往不是那么的美好,显然在 Go1.12 起针对 madvise 的 MADV_FREE 策略的调整非常 “片面”。
结合社区里所遇到的案例可得知,该次调整带来了许多问题:
- 引发用户体验的问题:Go issues 上总是出现以为内存泄露,但其实只是未满足条件,内存没有马上释放的案例。
- 混淆统计信息和监控工具的情况:在 Grafana 等监控上,发现容器进程内存较高,释放很慢,告警了,很慌。
- 导致与内存使用有关联的个别管理系统集成不良:例如 Kubernetes HPA ,或者自定义了扩缩容策略这类模式,难以评估。
- 挤压同主机上的其他应用资源:并不是所有的 Go 程序都一定独立跑在单一主机中,自然就会导致同一台主机上的其他应用受到挤压,这是难以评估的。
Go1.16 修改内容如下:
|
|
直接指定回了 debug.madvdontneed = 1,简单粗暴。
参考
文章作者 Forz
上次更新 2021-06-07