如何保证服务的稳定性
文章目录
方法论
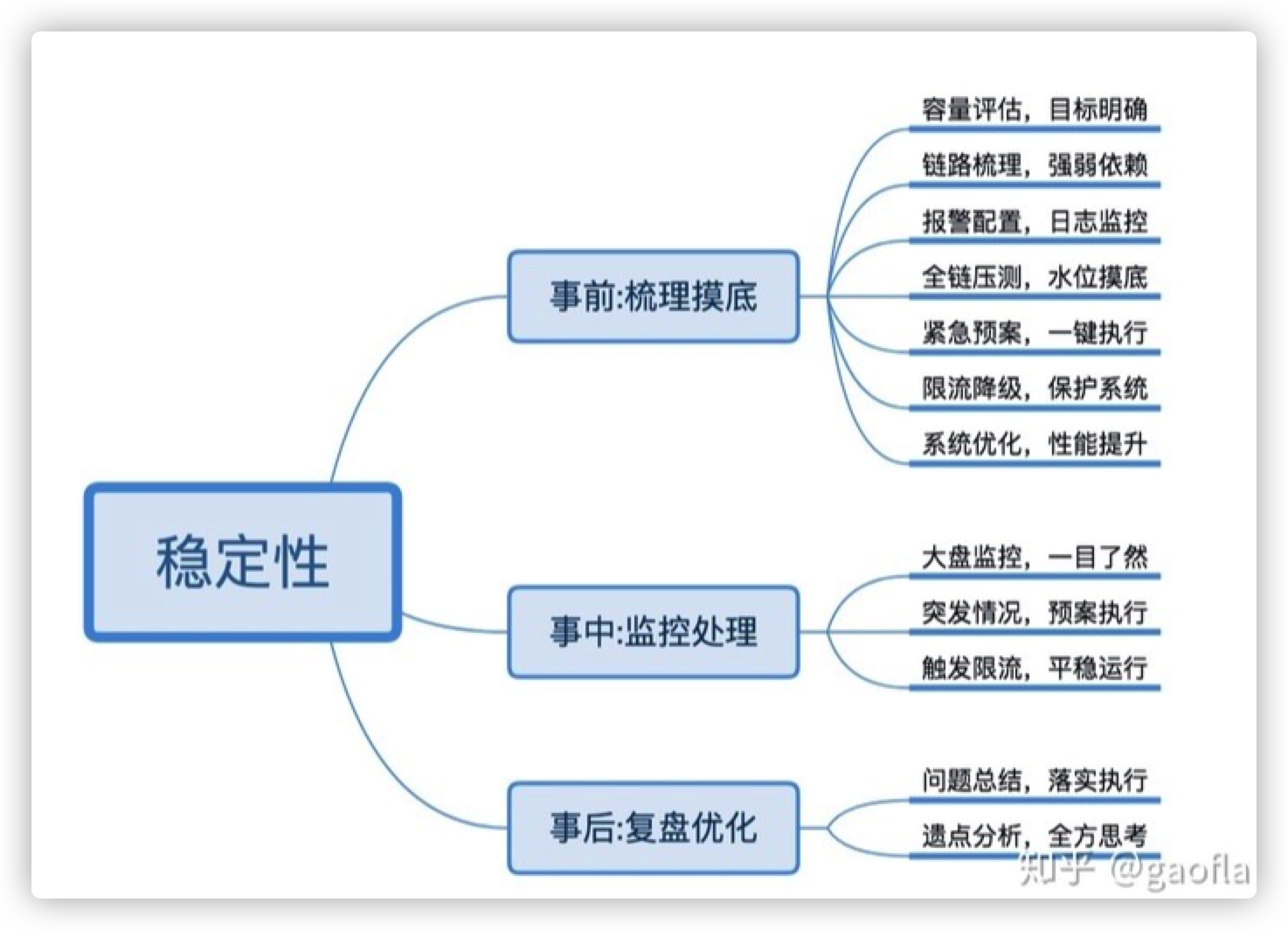
事前
容量评估:
- 根据过往情况评估业务系统性能指标、容量指标
- 国内做的好的某巨头公司(你们应该知道是哪家),大促期间的系统性能,监控数据都是会保留的,最近几个月的监控数据也是保留的
- 监控数据会为扩容需要加多少台机器提供一定参考
链路梳理:
- 当前业务的流程依赖哪些服务?
- 哪些服务是强依赖,哪些是弱依赖?
- 外部弱依赖出故障时,是否能够不影响本服务?
- P0 级别的服务,不应该依赖 P2 级的服务
监控:
- runtime.Memstats(prometheus client 中自带)
- 接口 p99,依赖方延迟(包括数据库)
- 内存 RSS 用量
- CPU 用量
- 连接数,tcp_retrans
- 业务日志,业务指标监控
- Panic 日志监控
- etc
报警:
- Goroutine 数量超限报警
- p99 超 SLA 报警
- 内存 RSS 超水位线报警,OOM 报警
- CPU 用量报警
- 业务指标异常报警
- Panic 报警
- Supervisor 的 stderr 日志中的 fatal 报警
- etc
全链路压测:
- 流量入口 :流量染色,染色标识透传
- 压测日志:shadow 目录
- 数据库:shadow 表(在 sql 中可以使用 /comment/ 透传给 mysql 中间件压测信息)
- 缓存 : 同数据库
- 第三方服务 : 压测流量来时要降级
- MQ 消息 :下游不消费压测消息
- 大数据生态 :不采集压测相关的任何数据
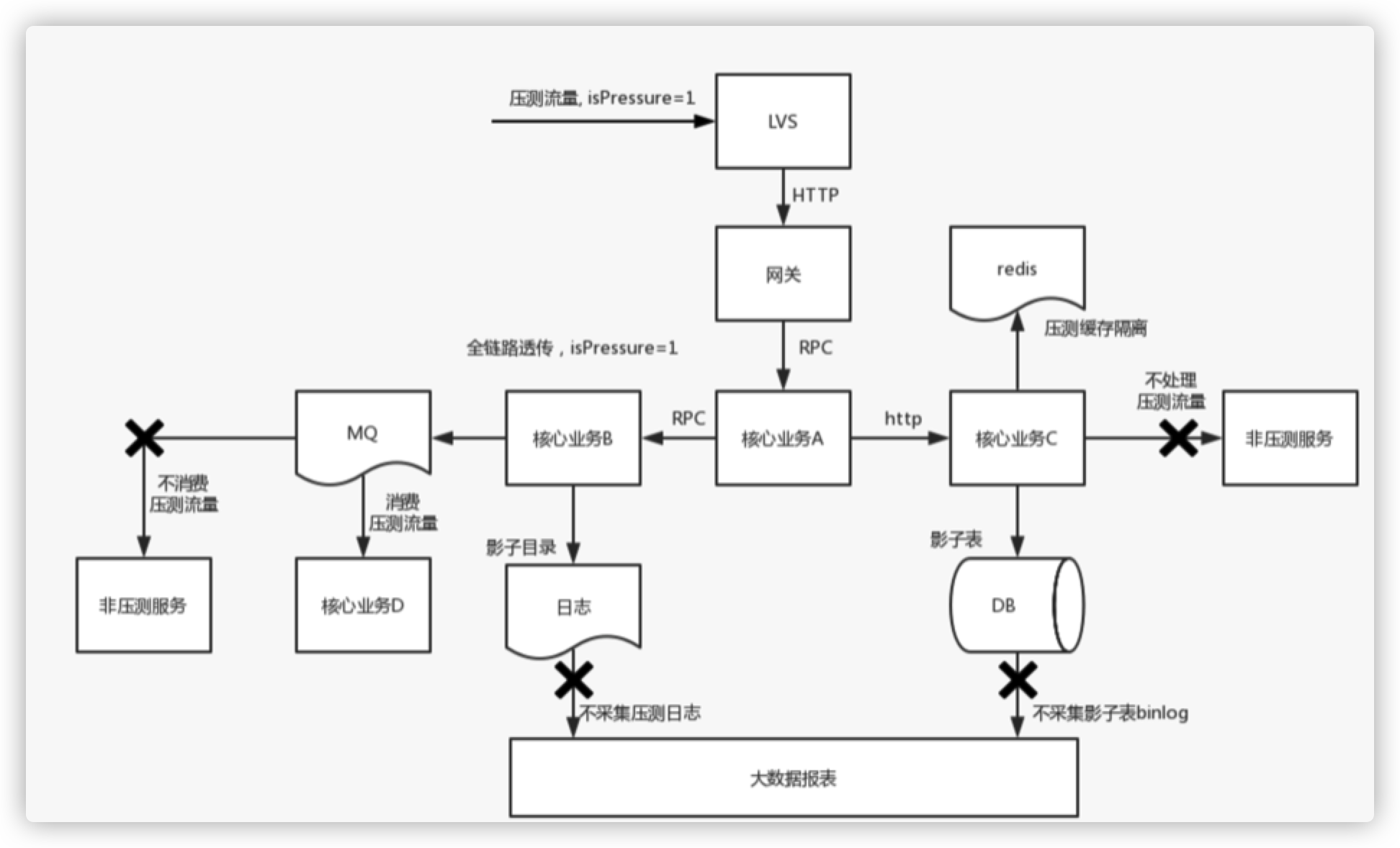
- 压测数据不要污染生产数据
- 模拟真实用户行为
- 逐步加压
- 全链路关键系统上都应有人对压测跟进 * 常态化
- 需要有压测大盘与压测报告
- 对压测中体现出的问题要复盘和改进
预案系统
- 大促期间会将很多边缘服务进行降级
- 影响性能的不重要功能会被关闭
- 开关实在太多,人为管理难以为继(预案一键管理系统)
巡检系统
- 机器配置不一致?
- 十万台规模的机器,配置下发都成功了吗?
- 每一个预案都正确执行成功了吗?
- 其实就是在每台机器上都可以执行一个脚本,脚本可以检查:
- 下发的配置项
- 接口的返回值
- 文件/日志的内容
系统优化
- 节省 CPU:
- 节省更多的机器
- 节省内存:
- 节省更多的机器
- 在线/离线任务混部:
- 节省更多的机器
- 提高集群资源利用率:
- 节省更多的机器
事中
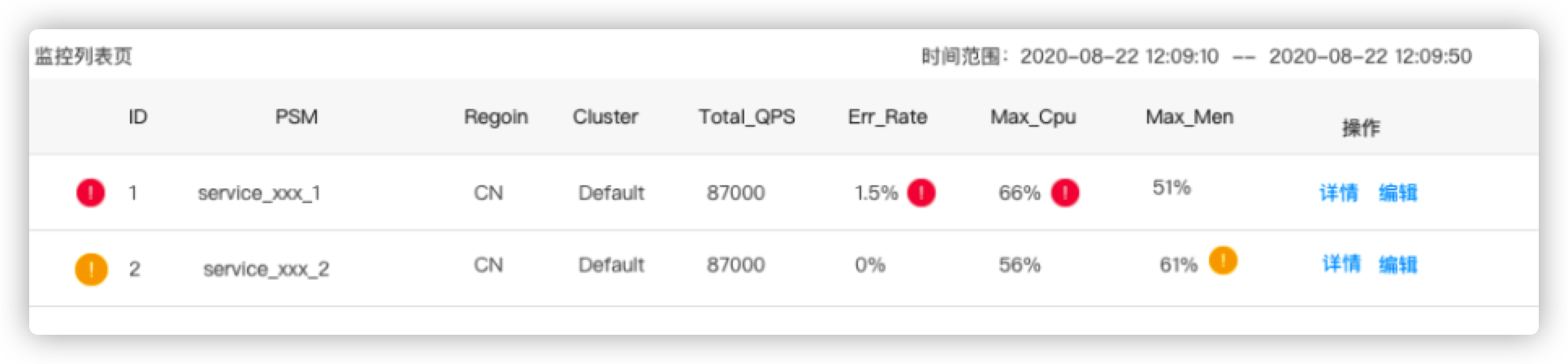
压测监控
- 压测期间显示关键链路上的服务的核心指标:CPU,mem,latency,连接数等
- 有问题自动突出显示
- 核心链路服务返回大量错误时自动终止
限流
熔断
过载保护
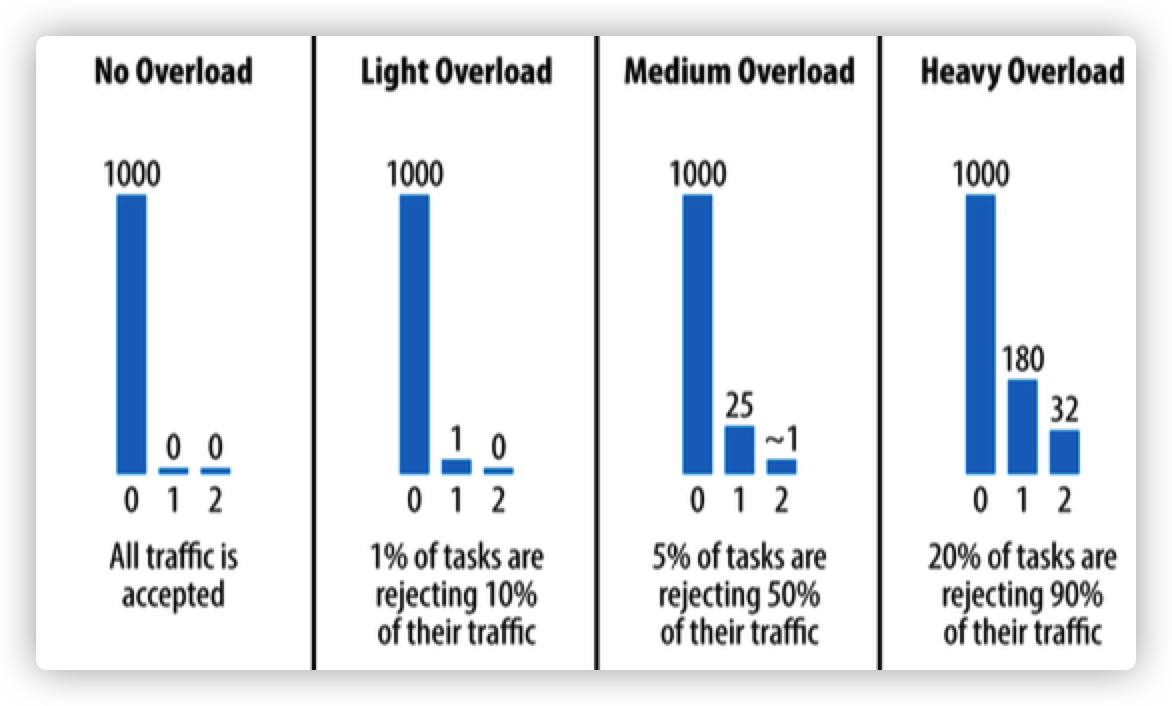
重试策略
- 一次请求最多重试三次
- 每个 client 重试和请求的比例要低于 10%
- 通过请求次数与重试次数建立如右边的直方图,来帮助后续请求判断系统整体负载
- 若过载,返回 overload 错误码
事后
稳定性复盘
- 压测中哪些系统有性能问题
- 记录 TODO,排期尽快修复
- 如果是紧急事件,是否可以通过业务开关进行临时绕过
- 将可以绕过的问题记录在预案平台中
其它稳定性保障机制
异地多活
流量回放
混沌工程
红蓝攻防演练
- 攻击方:
- 在线
- 实时
- 无差别
- 突袭
- 防御方:
- 自适应容灾
- 防抖
断网演练
单元化架构/set 化架构/bulkheads 模式
- 把业务系统划分成多个可扩展的逻辑分区(SET)
- SET是全功能的,可独立提供服务
- 控制数据和流量在SET间的分配
- 有些公司将SET称为LDC(logicaldatacenter)
- SET体量过大->直接拆成两个
- SET部署到异地->异地多活

支付宝架构
- GZone:不可拆分的数据,比如 配置
- RZone:按用户维度拆分的关键 业务系统,比如可以分 10000 个 zone,1 亿用户的话,每个 zone 服务 1w 个用户
- CZone:GZone只有一份,有些 RZone 访问 GZone 要跨机房, 因此会针对 city 做 GZone 的读 快照
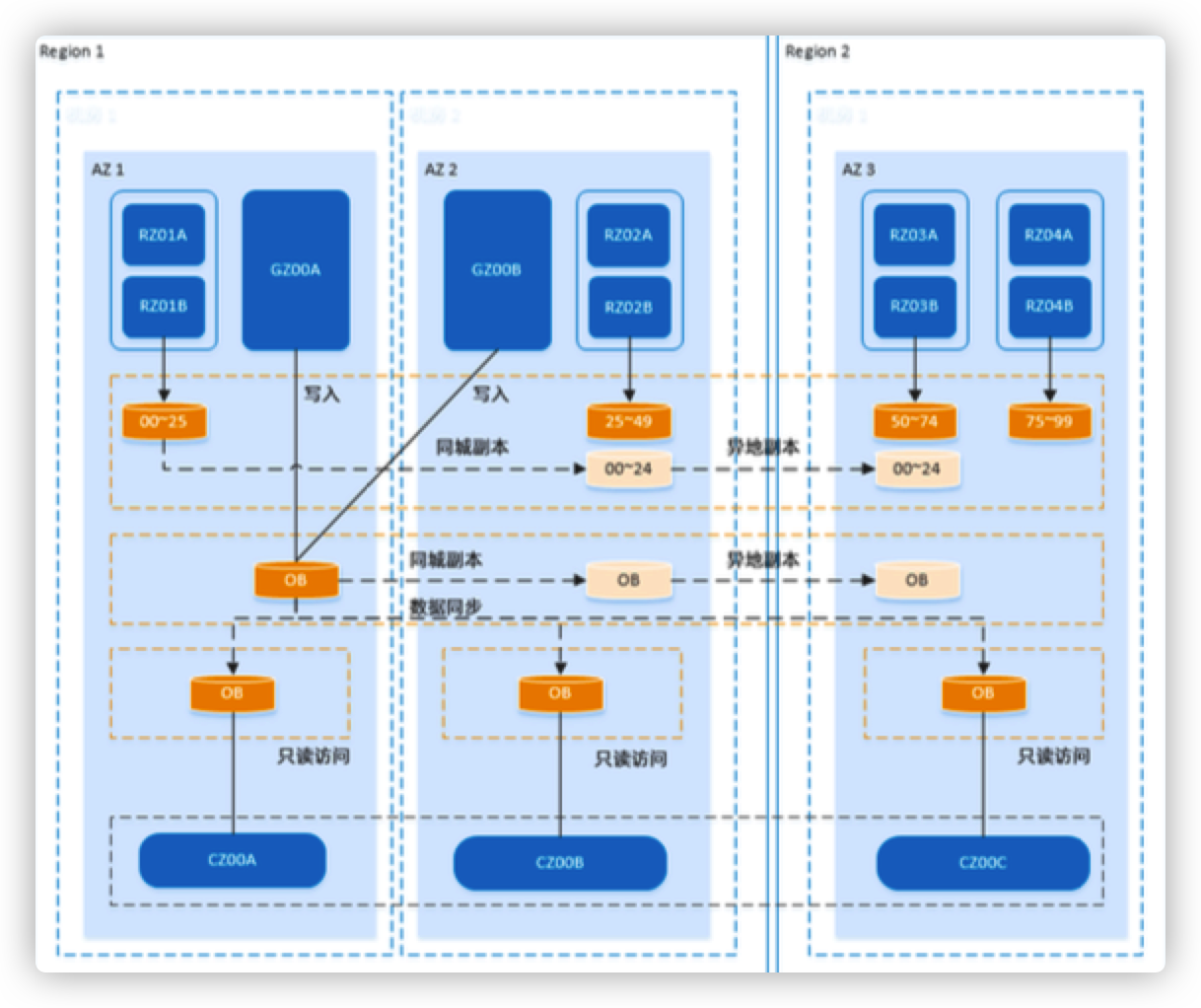
要不要做单元化
- 除了单元化能给我们带来的好处,也不能完全不考虑成本
- 单元化与全链路压测一样,需要很多系统改造支持
大公司的机制保障
- 大公司的 n 个 9 是通过机制来保障的
- 只要不违反红线,一般也不会造成太大的线上事故
- 红线举例,某公司的三板斧:可监控,可灰度,可回滚
文章作者 Forz
上次更新 2021-09-18