如何优雅控制goroutine
文章目录
Goroutine
Processes and Threads
操作系统会为该应用程序创建一个进程。作为一个应用程序,它像一个为所有资源而运行的容器。这些资源包括内存地址空间、文件句柄、设备和线程。
线程是操作系统调度的一种执行路径,用于在处理器执行我们在函数中编写的代码。一个进程从一个线程开始,即主线程,当该线程终止时,进程终止。这是因为主线程是应用程序的原点。然后,主线程可以依次启动更多的线程,而这些线程可以启动更多的线程。
无论线程属于哪个进程,操作系统都会安排线程在可用处理器上运行。每个操作系统都有自己的算法来做出这些决定。
Goroutines and Parallelism
Go 语言层面支持的 go 关键字,可以快速的让一个函数创建为 goroutine,我们可以认为 main 函数就是作为 goroutine 执行的。操作系统调度线程在可用处理器上运行,Go运行时调度 goroutines 在绑定到单个操作系统线程的逻辑处理器中运行(P)。即使使用这个单一的逻辑处理器和操作系统线程,也可以调度数十万 goroutine 以惊人的效率和性能并发运行。
Concurrency is not Parallelism.
并发不是并行。并行是指两个或多个线程同时在不同的处理器执行代码。如果将运行时配置为使用多个逻辑处理器,则调度程序将在这些逻辑处理器之间分配 goroutine,这将导致 goroutine 在不同的操作系统线程上运行。但是,要获得真正的并行性,您需要在具有多个物理处理器的计算机上运行程序。否则,goroutines 将针对单个物理处理器并发运行,即使 Go 运行时使用多个逻辑处理器。
goroutine的使用
goroutine的使用遵循3个原则
- 将并发交给调用者,调用者决定后台执行还是前台执行.
- 管控goroutine生命周期.
- 搞清楚goroutine什么时候退出,能获取到goroutine退出的事件.
- 能控制goroutine什么时候退出,利用channel或者context.
Keep yourself busy or do the work yourself
空的 select 语句将永远阻塞。
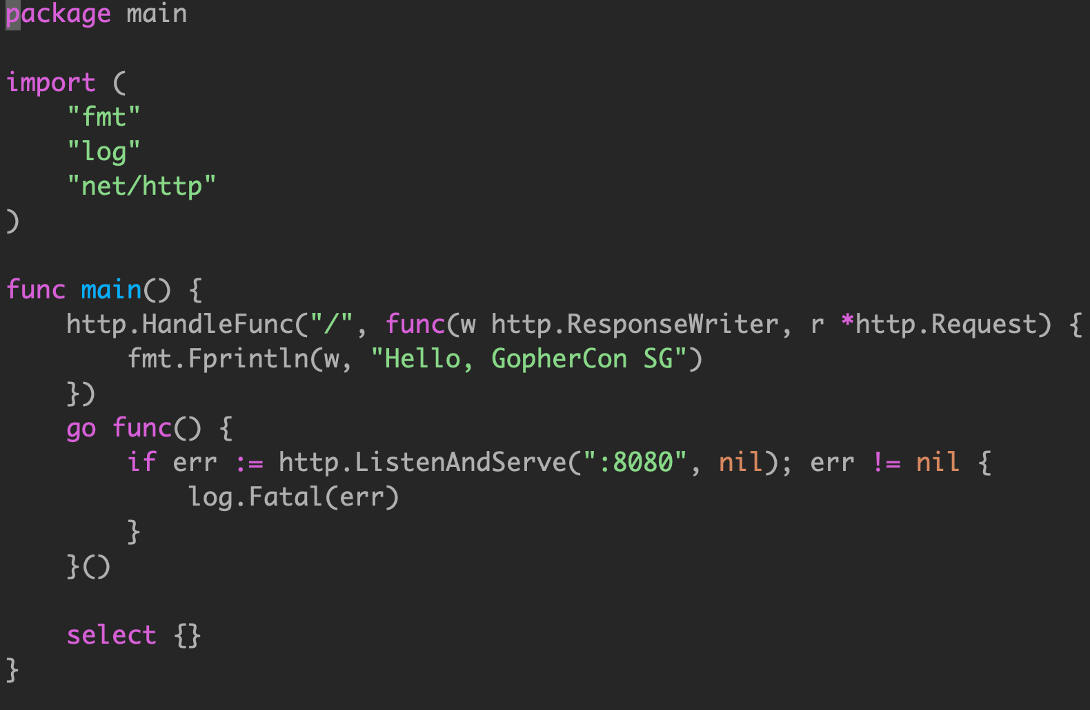
如果你的 goroutine 在从另一个 goroutine 获得结果之前无法取得进展,那么通常情况下,你自己去做这项工作比委托它( go func() )更简单。
这通常消除了将结果从 goroutine 返回到其启动器所需的大量状态跟踪和 chan 操作。
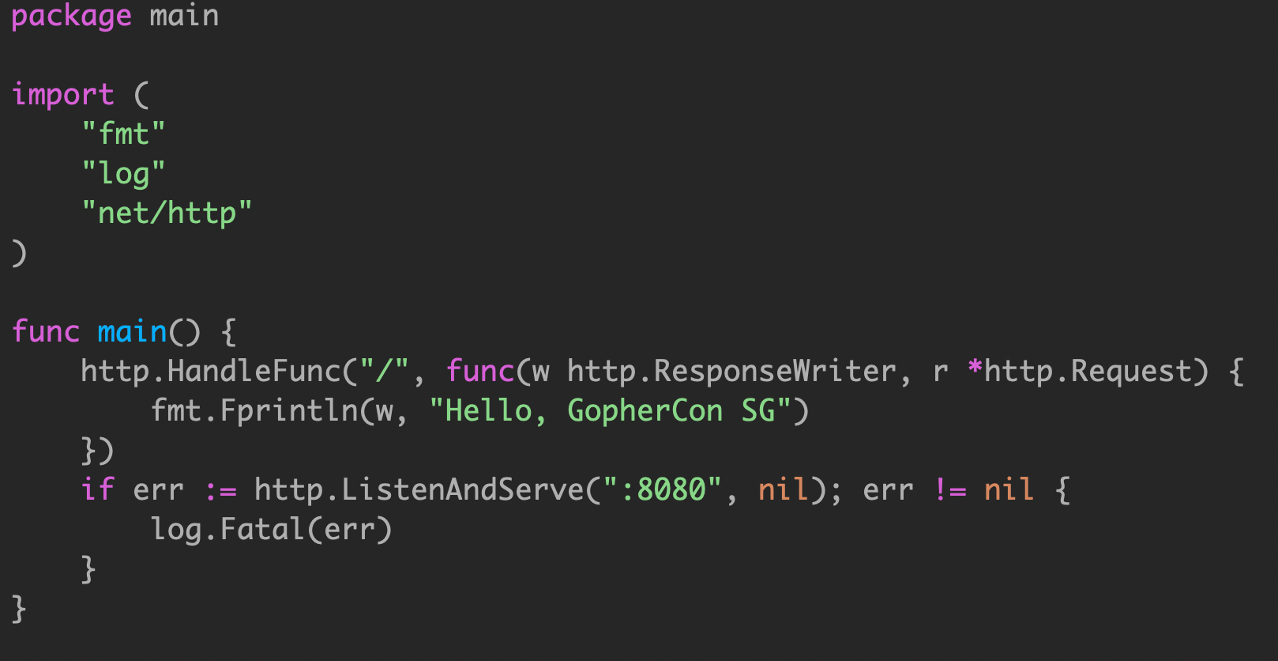
log.Fatal直接调用os.exit(),会导致defer无法执行.
Never start a goroutine without knowning when it will stop
main函数的端口监听
这个简单的应用程序在两个不同的端口上提供 http 流量,端口8080用于应用程序流量,端口8001用于访问 /debug/pprof 端点。
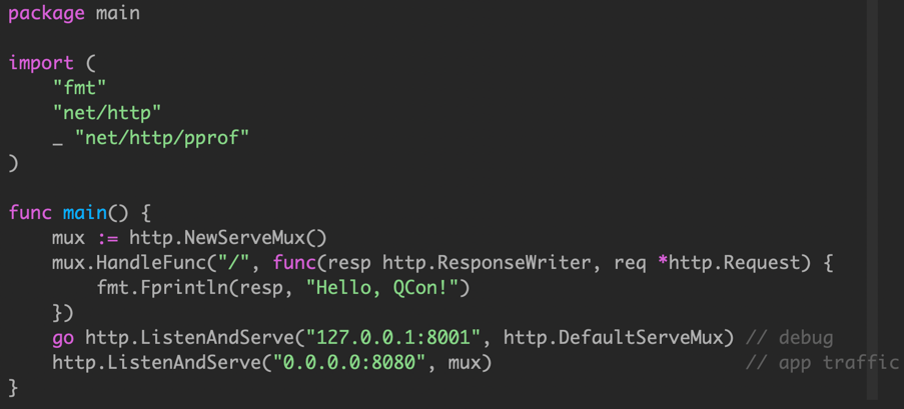
Any time you start a Goroutine you must ask yourself:
- When will it terminate?
- What could prevent it from terminating?
通过将 serveApp 和 serveDebug 处理程序分解为各自的函数,我们将它们与main.main 解耦,我们还遵循了上面的建议,并确保 serveApp 和 serveDebug 将它们的并发性留给调用者。
如果 serveApp 返回,则 main.main 将返回导致程序关闭,只能靠类似 supervisor 进程管理来重新启动。
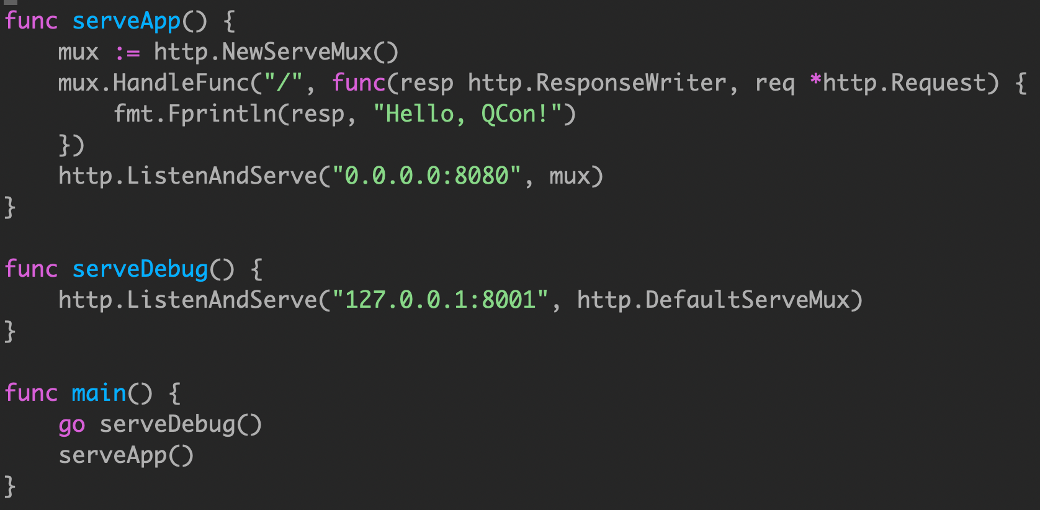
然而,serveDebug 是在一个单独的 goroutine 中运行的,如果它返回,那么所在的 goroutine 将退出,而程序的其余部分继续运行。由于 /debug 处理程序很久以前就停止工作了,所以其他同学会很不高兴地发现他们无法在需要时从您的应用程序中获取统计信息。
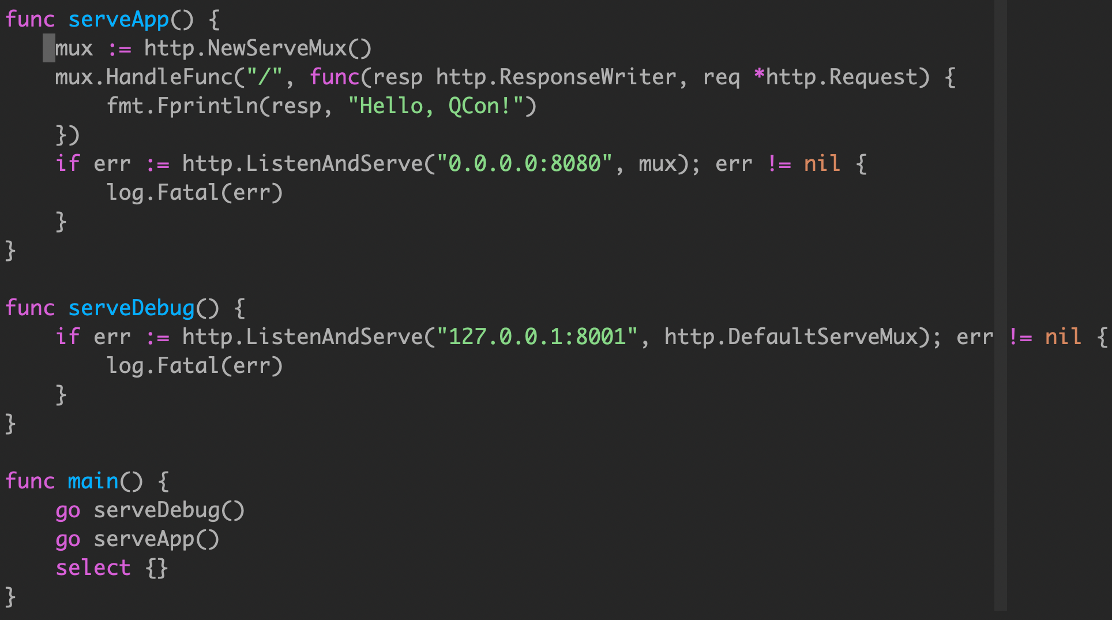
ListenAndServer 返回 nil error,最终 main.main 无法退出。
log.Fatal 调用了 os.Exit,会无条件终止程序;defers 不会被调用到。
Only use log.Fatal from main.main or init functions.
goroutine有两个原则:
- 调用者来决定是否需要后台执行.
- goroutine的生命周期需要用户进行管理.
我们可以通过两个channel来进行管理.
- stop:控制内部,相互通知两个协程可以退出.
- done:知道对方什么时候退出.
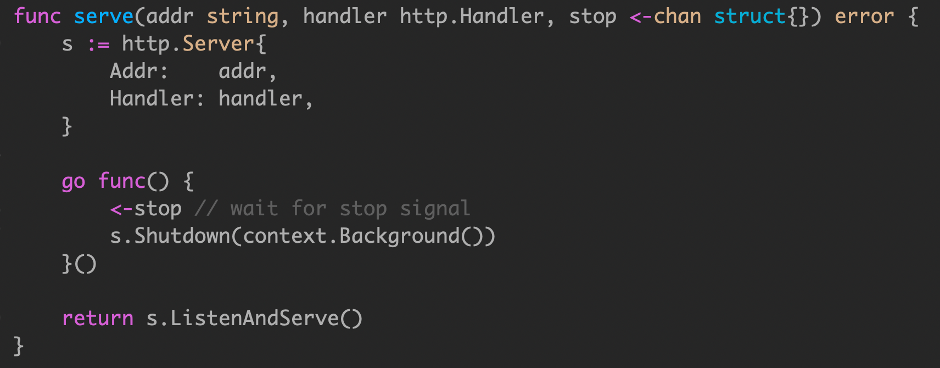
当我们向stop发送信号后,执行Shutdown,这时候ListenAndServe就会退出.
为什么在serve里面可以再开一个go func呢,因为Shutdown和ListenAndServe存在关联关系,只要shutdown执行,整个协程就会退出,两者生命周期存在关联.
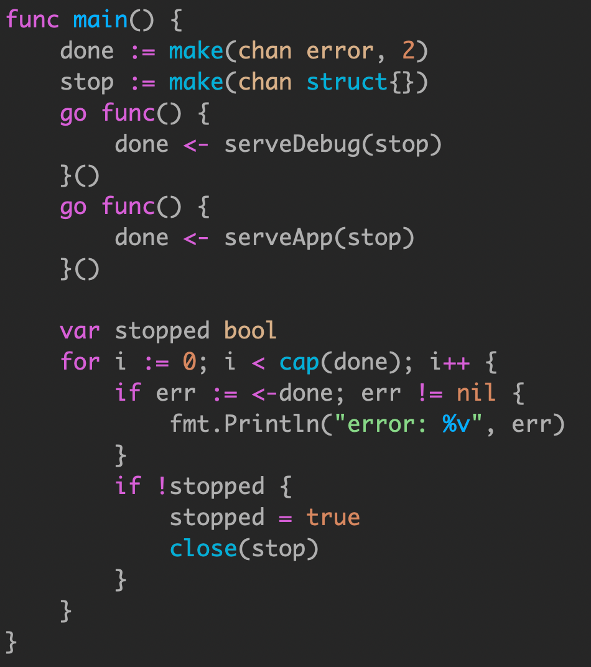
只要有一个协程退出,就会发送done信号,for循环会关闭stop channel,让另外一个协程安全退出.
我们for循环循环两次,就是在等待两个协程都退出,然后退出main函数.
channel为局部变量
在这个例子中,goroutine 泄漏可以在 code review 快速识别出来。不幸的是,生产代码中的 goroutine 泄漏通常更难找到。我无法说明 goroutine 泄漏可能发生的所有可能方式,您可能会遇到:
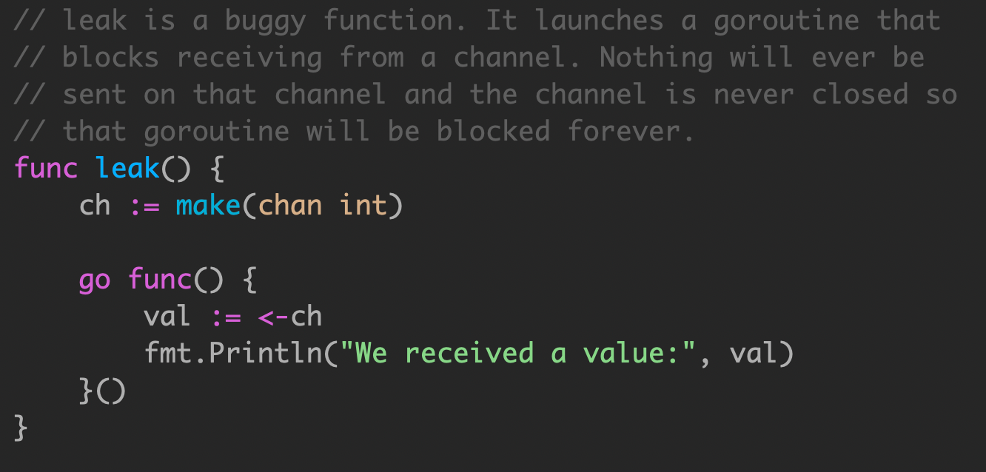
当leak执行完后,内部的go func()永远无法退出,因为ch是局部变量,没有任何办法在leak函数外发信号,让其退出.
超时控制
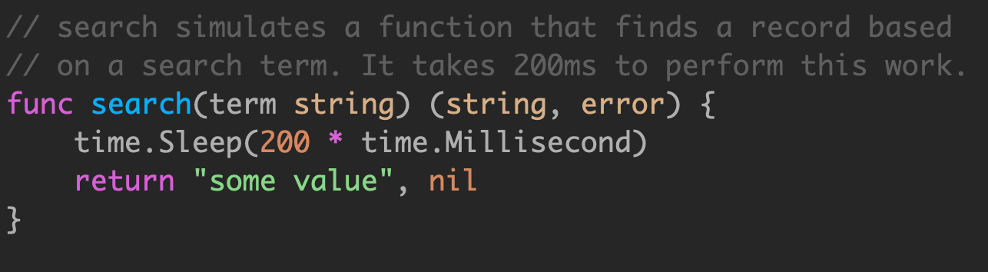
search 函数是一个模拟实现,用于模拟长时间运行的操作,如数据库查询或 rpc 调用。在本例中,硬编码为200ms。
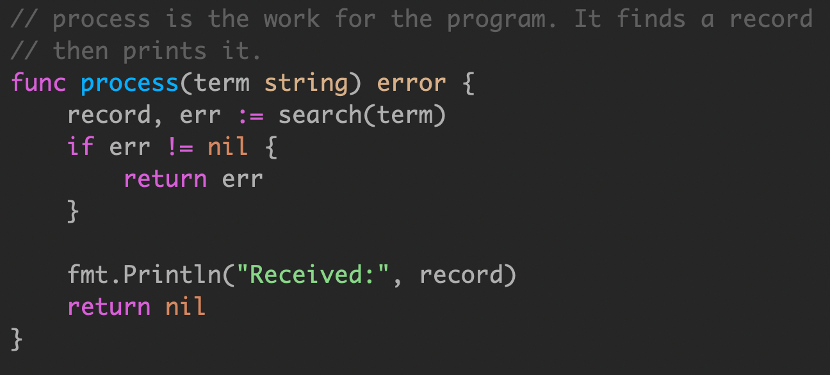
定义了一个名为 process 的函数,接受字符串参数,传递给 search。对于某些应用程序,顺序调用产生的延迟可能是不可接受的。
我们需要开协程进行处理,一定要做代码的超时控制.
我们利用go的context定义100ms超时,然后make一个channel.注意,并发执行search的行为是交给调用者process函数,当search执行完毕后,我们利用channel拿到执行结果.
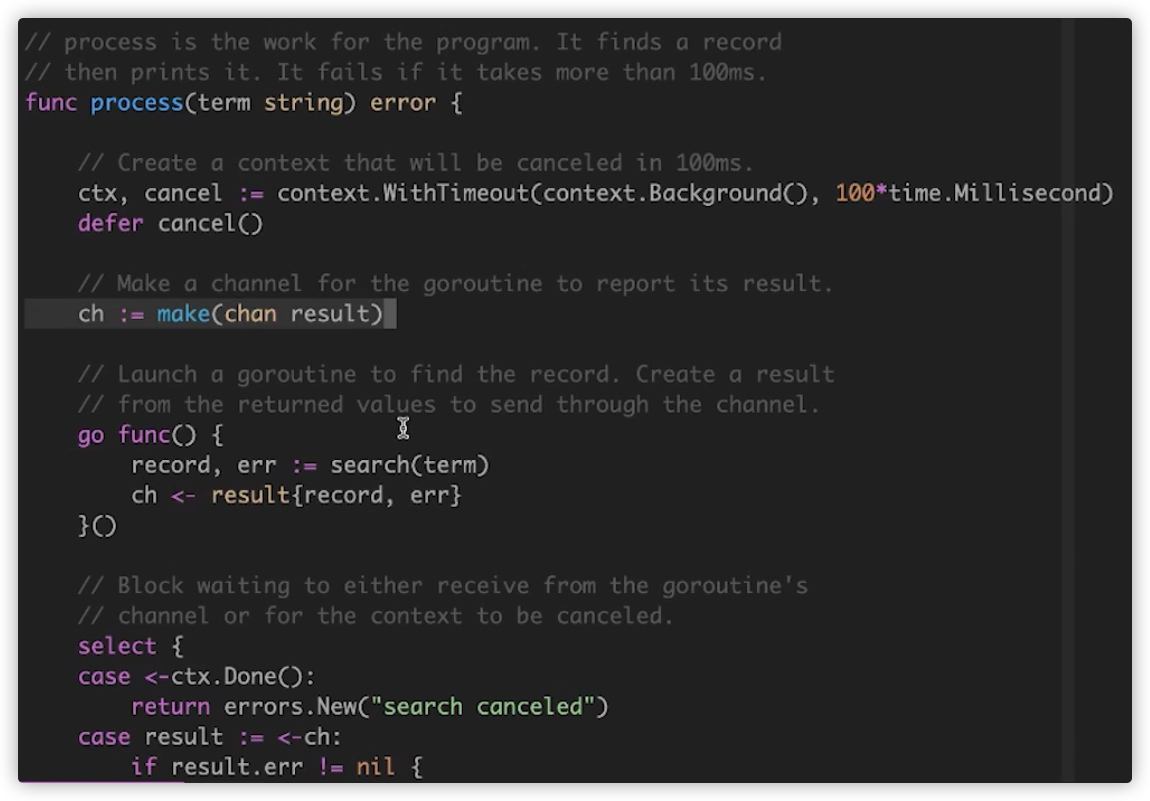
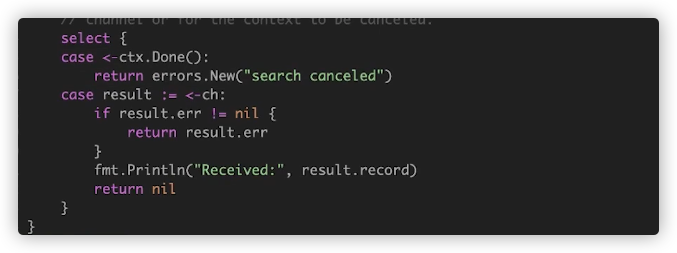
在调用者函数中,我们可以利用context处理超时,要不就ctx.Done完毕.要不就获取到结果.
但go func()中确实会阻塞很久,后续再进行优化.
Incomplete Work
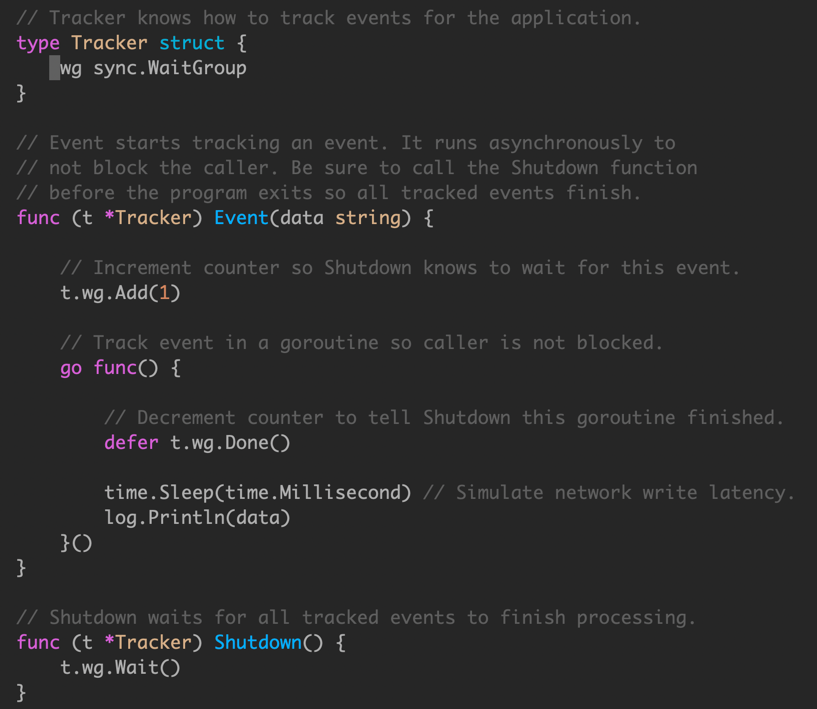
我们使用服务端埋点来跟踪记录一些事件。
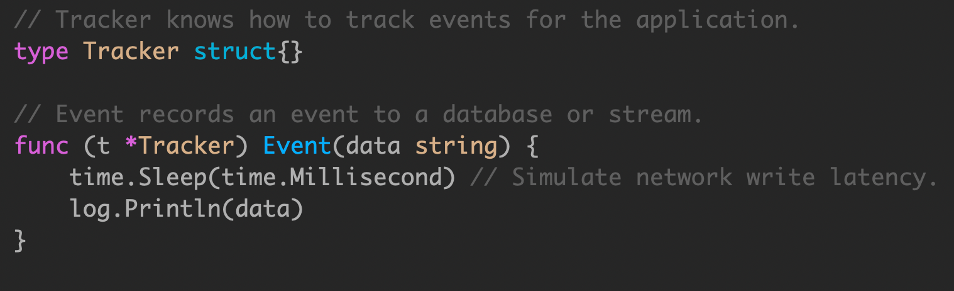
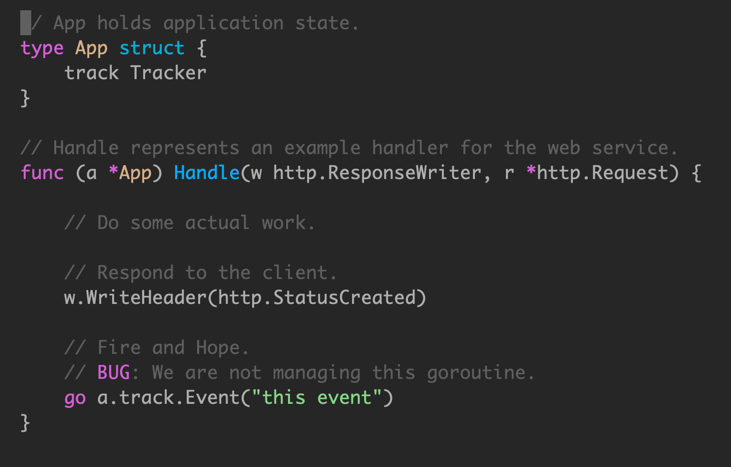
无法保证创建的 goroutine 生命周期管理,会导致最场景的问题,就是在服务关闭时候,有一些事件丢失。
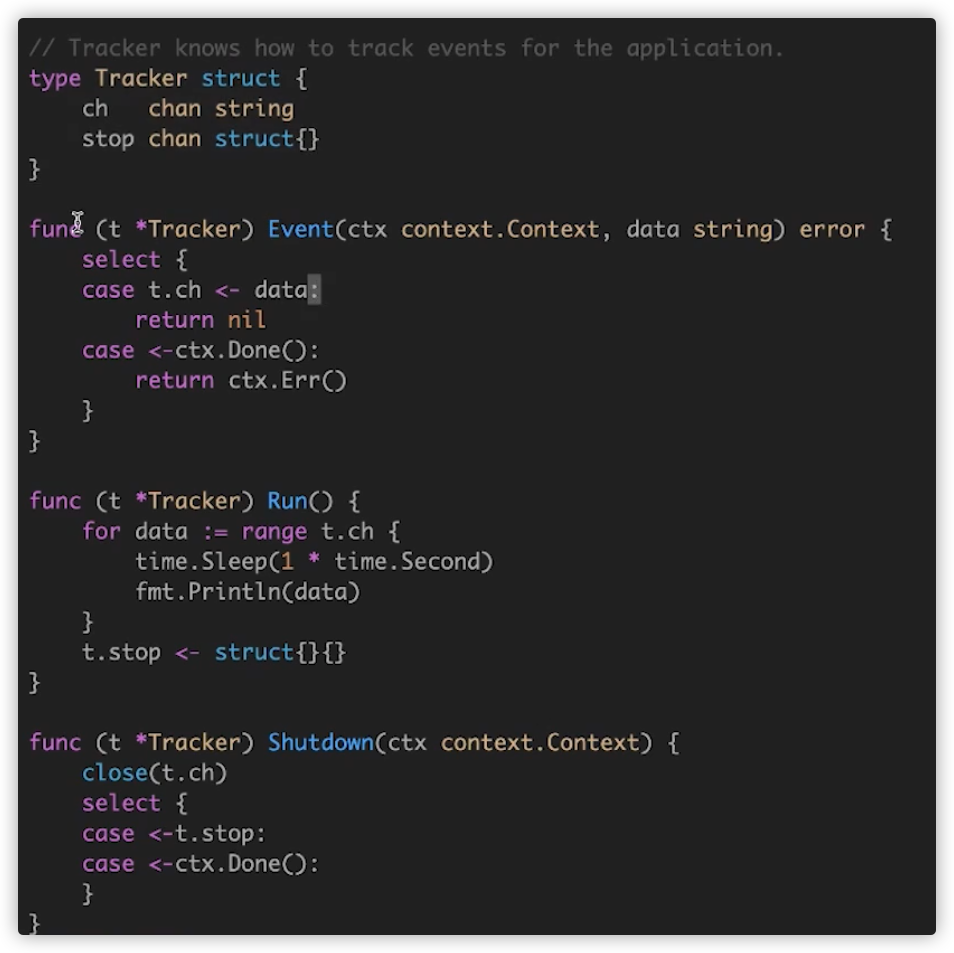
使用 sync.WaitGroup 来追踪每一个创建的 goroutine。
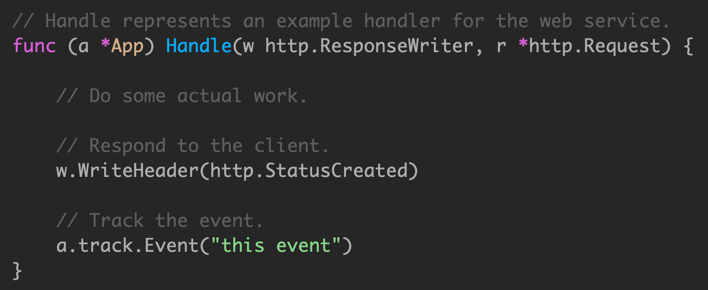
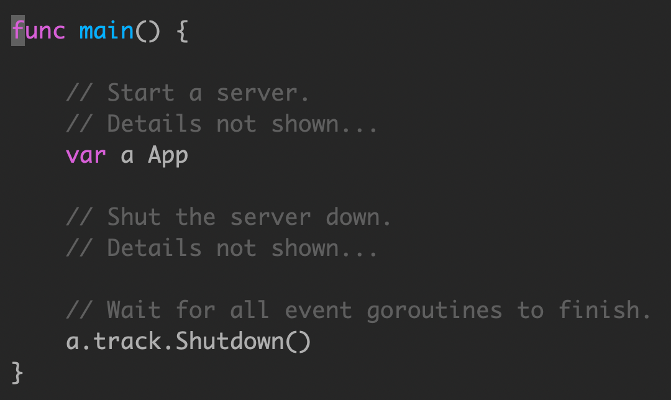
shutdown还会有一个问题,如果event阻塞时间太久,会导致无法执行.我们需要加入超时限制.
将 wg.Wait() 操作托管到其他 goroutine,owner goroutine 使用 context 处理超时。
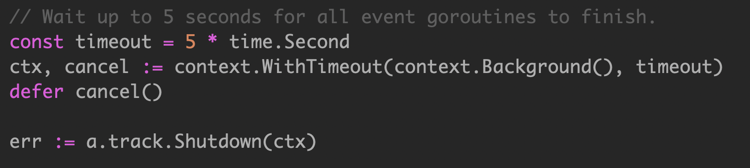
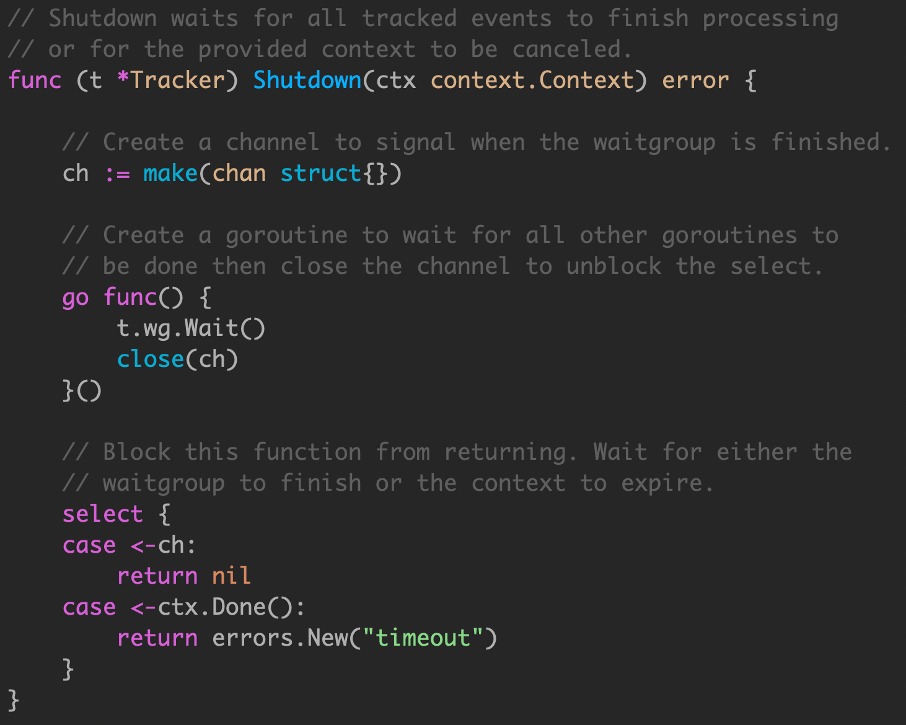
但是这个 demo,大量创建goroutine 来处理任务,代价高。
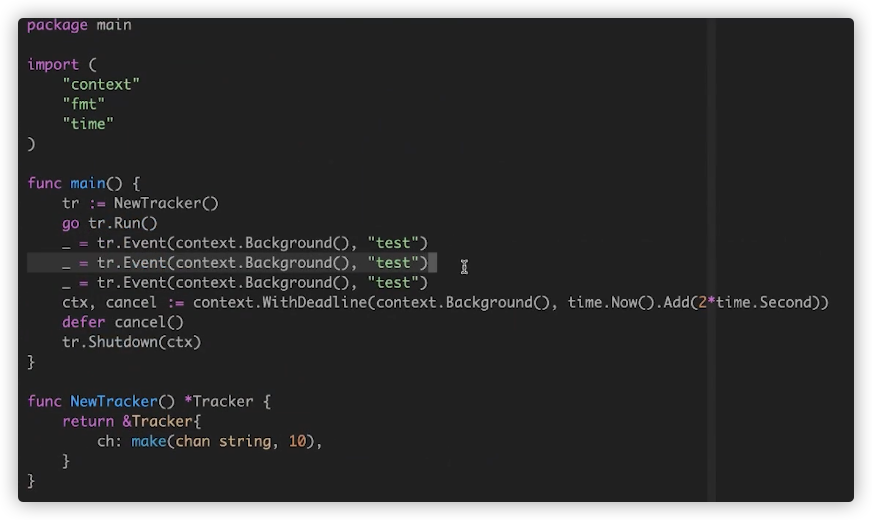
在Event函数中加入context,做超时控制.
在Event函数中,不直接进行埋点处理,而是将data发送到t.ch,由Run方法进行埋点.在main函数中调用Run.
如果调用shutdown,会关闭t.ch.Run函数发送发送stop信号,shutdown继续执行.
Leave concurrency to the caller
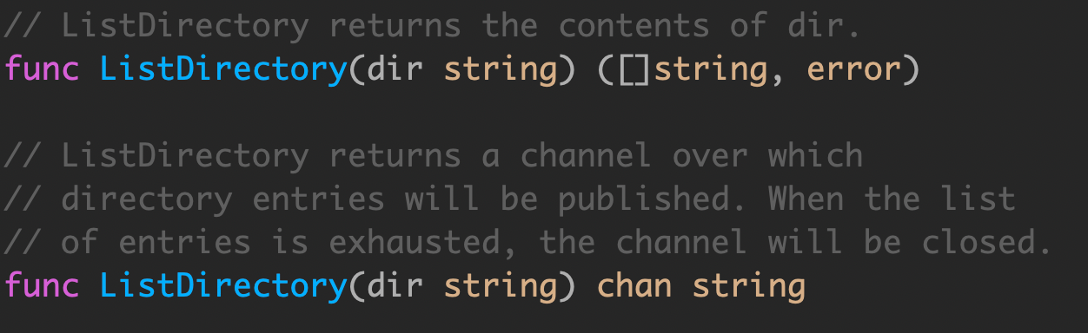
这两个 API 有什么区别?
-
将目录读取到一个 slice 中,然后返回整个切片,或者如果出现错误,则返回错误。这是同步调用的,ListDirectory 的调用方会阻塞,直到读取所有目录条目。根据目录的大小,这可能需要很长时间,并且可能会分配大量内存来构建目录条目名称的 slice。
-
ListDirectory 返回一个 chan string,将通过该 chan 传递目录。当通道关闭时,这表示不再有目录。由于在 ListDirectory 返回后发生通道的填充,ListDirectory 可能内部启动 goroutine 来填充通道。
ListDirectory chan 版本还有两个问题:
-
通过使用一个关闭的通道作为不再需要处理的项目的信号,ListDirectory 无法告诉调用者通过通道返回的项目集不完整,因为中途遇到了错误。调用方无法区分空目录与完全从目录读取的错误之间的区别。这两种方法都会导致从 ListDirectory 返回的通道会立即关闭。
-
调用者必须继续从通道读取,直到它关闭,因为这是调用者知道开始填充通道的 goroutine 已经停止的唯一方法。这对 ListDirectory 的使用是一个严重的限制,调用者必须花时间从通道读取数据,即使它可能已经收到了它想要的答案。对于大中型目录,它可能在内存使用方面更为高效,但这种方法并不比原始的基于 slice 的方法快。

filepath.WalkDir 也是类似的模型,如果函数启动 goroutine,则必须向调用方提供显式停止该goroutine 的方法。通常,将异步执行函数的决定权交给该函数的调用方通常更容易。
如何控制goroutine的数量
用什么方法控制goroutine的数量? 要在每一次执行go之前判断goroutine的数量,如果数量超了,就要阻塞go的执行。第一时间想到的就是使用通道。每次执行的go之前向通道写入值,直到通道满的时候就阻塞了,如下:
|
|
这样每次同时运行的goroutine就被限制为10个了。但是新的问题出现了,因为并不是所有的goroutine都执行完了,在main函数退出之后,还有一些goroutine没有执行完就被强制结束了。这个时候我们就需要用到sync.WaitGroup。使用WaitGroup等待所有的goroutine退出。如下:
|
|
综上所述,我们封装一下,代码如下:
|
|
来段测试代码:
|
|
如何限制goroutine的同时执行数量
由于channel的阻塞机制,通过设置缓冲channel的缓冲大小来控制同时执行的协程数量。
|
|
控制Goroutine的执行顺序
单核情况下的Goroutine执行顺序
单核情况下的Goroutine的执行顺序并不是顺序执行,而是以一种非常奇怪的顺序执行:在只有一个CPU工作的时候,永远是最后一个先执行 剩下的按顺序执行.
示例代码:
|
|
执行的结果是先打印出b,再打印出a
一般情况下在同一个goroutine中创建的多个任务中最后创建那个任务最可能先被执行。原因的话就要看go的实现细节了:简单说同一goroutine中2个任务被创建后 理论上会按顺序 被放在同一个任务队列,但实际上最后那个任务会被放在专一的next(下一个要被执行的任务的意思)的位置,所以优先级最高,最可能先被执行。剩下的任务如果go运行时调度器发现有空闲的core,就会把任务偷走点,让别的core执行,这样才能充分利用多核,提高并发能力。
以下为goroutine任务放入队列的函数源码:
|
|
控制多核情况下的Goroutine执行顺序
编写一个程序,开启 N 个线程A,B,C…,这N个线程的输出分别为 A、B、C…,每个线程将自己的输出在屏幕上打印 M 遍,要求输出的结果必须按顺序显示。如:ABC…ABC…ABC… 其中 N <= 1000, M <= 1000
注意:输出要在各自的线程中输出,不能在主线程中输出
利用 Channel 做信号量的解法
使用信号量的话,这个题的解题思路就很简单:
- 创建 N 个Goroutine 执行输出操作。
- 每个 Goroutine 的具体操作可用以下伪代码来表示:
|
|
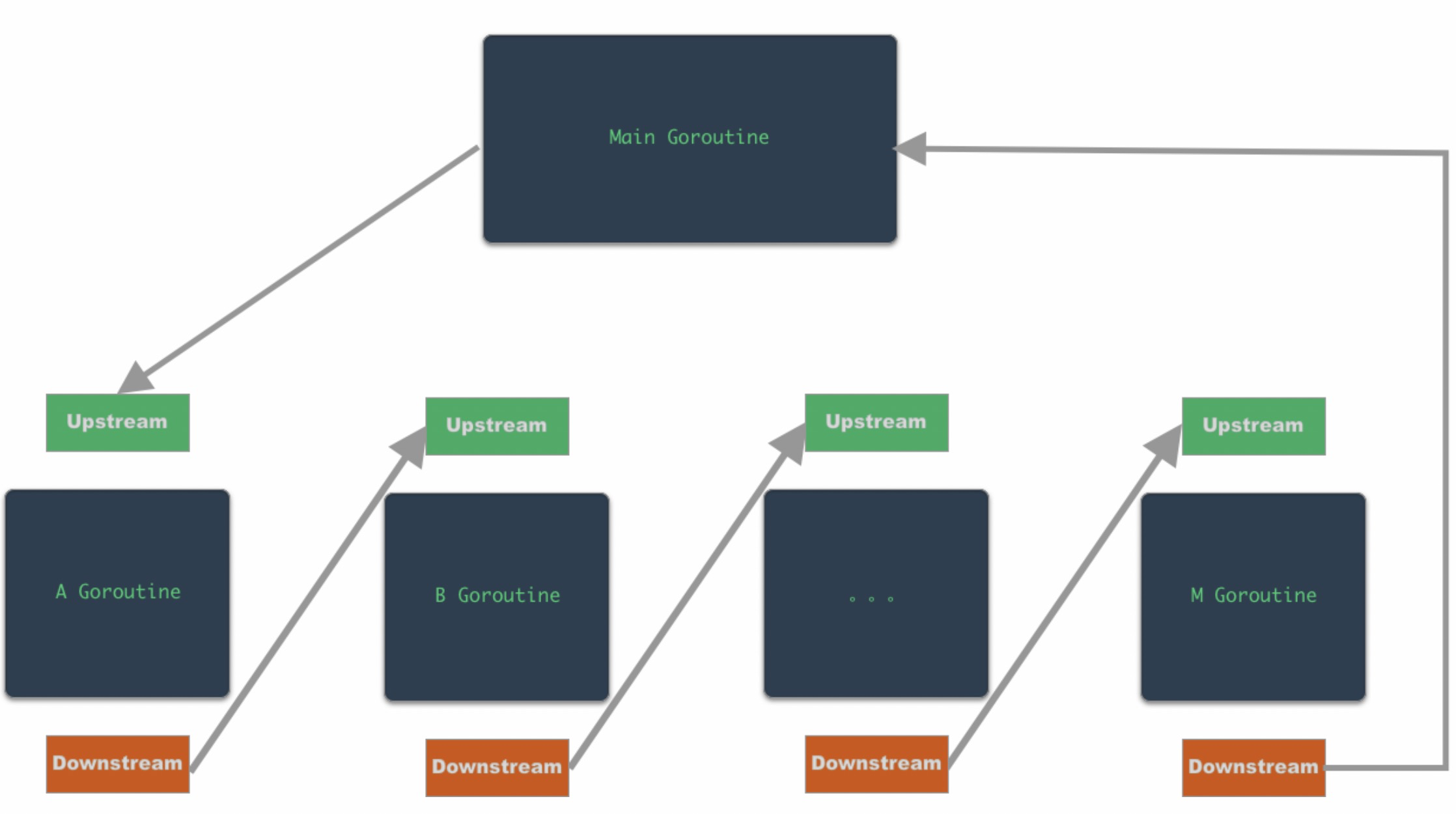
其中Upstream 和 Downstream 都表示信号量,A Goroutine 的 Downstream 是 B Goroutine 的 Upstream,依此类推,所有 Goroutine 会形成一个链式的关系。
可以使用下图来表示:
|
|
FanIn 的方式
根据题目要求来看,在主线程中输出结果,有些不符合要求,但有个答案的实现很有意思,我就也放上来了
通过将多个输入 channel 多路复用到单个处理 channel 的方式,一个函数能够从多个输入 channel 中读取数据并处理。当所有的输出 channel 都关闭的时候,单个处理 channel 也会关闭。这就叫做扇入。
理解了扇入的概念后,上述问题的答案也呼之欲出了。我们可以为A,B,C,…这N个 Goroutine 创建N个 channel。然后通过一个 FanIn 函数将N个 channel 的输出输入到一个 channel 中。具体代码如下:
|
|
如何退出一个Goroutine
需求分析 (3个原因)
产生这个需求,通常有以下的原因:
- 这个 goroutine 的运行超出了太多预计的时间,以致后续的计算不再有意义
- 这个 goroutine 阻塞在某个 read/write channel 变得没有响应
- 这个 goroutine 阻塞在某个系统调用,外部调用或业务逻辑的死循环
这种时候很自然地就会产生“主动外部 kill goroutine”的需求 (正如手动结束掉一个无响应的进程那样)。
然而 goroutine 被设计为不可以从外部无条件地结束掉,只能通过 channel 来与它通信。也就是说,每一个 goroutine 都需要承担自己退出的责任。(A goroutine cannot be programmatically killed. It can only commit a cooperative suicide.)
Goroutine控制分类
以下我们分可响应 (1 & 2) 和不可响应 (3) 两种情况分开讨论
处理仍可响应 channel 的 goroutine (1 & 2)
最直接的方法是关闭与这个 goroutine 通信的 channel close(ch)。如果这个 goroutine 此时阻塞在 read 上,那么阻塞会失效,并在第二个返回值中返回 false (此时可以检测并退出);如果阻塞在 write 上,那么会 panic,这时合理的做法是在 goroutine 的顶层 recover 并退出。
更健壮的设计一般会把 data channel (用于传递业务逻辑的数据) 和 signal channel (用于管理 goroutine 的状态) 分开。不会让 goroutine 直接读写 data channel,而是通过 select-default 或 select-timeout 来避免完全阻塞,同时周期性地在 signal channel 检查是否有结束的请求。
以上的方法可以处理前两种情况。
处理无法响应 channel 的 goroutine (3)
对于第三种情况,程序员能做的就是:
- 尽量使用 Non-blocking IO (正如 go runtime 那样)
- 尽量使用阻塞粒度较小的 sys calls (对外部调用也一样)
- 业务逻辑总是考虑退出机制,编码时避免潜在的死循环
- 在合适的地方插入响应 channel 的代码,保持一定频率的 channel 响应能力
关于 blocking syscall,需要注意的是 Go runtime 会启动新的 OS 线程去调度剩下的 goroutines,如果不能及时从阻塞中恢复并持续有新的 blocking goroutine 的话,OS 线程数量会线性地增长,这是一种非常不理想的情况.
通过channel通知退出
这个最主要的goroutine退出方式。goroutine虽然不能强制结束另外一个goroutine,但是它是它可以通过channel通知另外一个goroutine你的表演该结束了。常用的方法到处都可以看到,这里也不详细说明了,直接上一个示例:
下面的示例中起了一个goroutine执行cancelByChannel,但是在起它之前还通过time.After返回了一个time.Time类型的channel,该channel上在定时超时时会发送一个当前时间数据。
cancelByChannel每隔1s会检查这个channel上是否有数据接收,如果有数据则退出goroutine,如果没有信号接收就在连接上发送一条数据。所以下面这段代码在运行10s发送10条消息后将退出。
程序起起来后,另开一个终端执行nc localhost:8000(Linux上)或nc localhost 8000(mac 上)可以看到程序执行情况。
|
|
通过context通知goroutine退出
通过channel通知goroutine退出还有一个更好的方法就是使用context。它本质还是接收一个channel数据,只是是通过ctx.Done()获取。
|
|
这种形式的协程关闭和自己写的区别在于自己写的话自己要记录下协程的数量,关闭的chan等等
总结
由于Goroutine被设计为只能自己退出,而不能强制退出。在实际使用中,我们可能会因为某些原因被block在Goroutines里面,或由于设计缺陷导致一些Goroutines执行很长的时间。只是基于一些其他语言的经验,我们可能会期望有一种外部机制能够强制结束一个Goroutines。但是这就是Go和Goroutine,它的目的就是要提供一种轻量的,简单的并发方式。保证它这个特性的基础也决定了我们不能用外部方式强制关闭一个Goroutines(额外post译文或博文说明这个问题,此文不深入展开)。所以当你遇到这种情况的时候,你可能需要考虑你的设计是不是足够的Go style,或者你对一些外部依赖是否足够了解了。
参考: https://blog.csdn.net/xingwangc2014/article/details/78998727 https://gulu-dev.com/post/2016-02-02-kill-goroutine https://blog.csdn.net/soekchl521/article/details/72420535
文章作者 Forz
上次更新 2018-12-14