大端模式和小端模式转化及网络字节序
文章目录
转载:http://blog.csdn.net/szchtx/article/details/42834391
一、定义
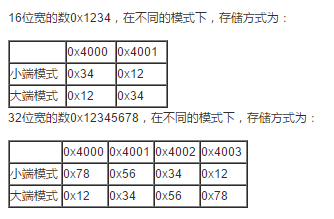
大端模式(Big Endian)
数据的高字节,保存在内存的低地址中;数据的低字节,保存在内存的高地址中。
最直观的字节序
只需要把内存地址从左到右按照由低到高的顺序写出
把值按照通常的高位到低位的顺序写出
两者对照,一个字节一个字节的填充进去
小端模式(Little Endian)
数据的高字节,保存在内存的高地址中;数据的低字节,保存在内存的低地址中。
最符合人的思维的字节序,从人的第一观感来说:
低位值小,就应该放在内存地址小的地方,也即内存地址低位
反之,高位值就应该放在内存地址大的地方,也即内存地址高位
二、判断大端模式和小端模式
使用联合,通过判断首个成员的值,确定是大端还是小端模式:
|
|
三、大端模式和小端模式转换
对32位的数,即4个字节,大端转换成小端:
|
|
上述代码中,将低8位(0~8位)左移24位,变成了高8位(24~32位),8~16位左移8位变成了(16~24位)。将原高8位和高16位右移,变成了新的低8位和低16位。
这种方法效率采用了移位运算,效率很高。而且该方法亦可用于小端模式转成大端模式。
有了32位的转换方法,对64位,即8个字节的转换同理。不过直接写移位运算未免麻烦,可以直接使用上述函数:
|
|
四、网络字节序
网络上传输的数据都是字节流,对于一个多字节数值,在进行网络传输的时候,先传递哪个字节?也就是说,当接收端收到第一个字节的时候,它将这个字节作为高位字节还是低位字节处理,是一个比较有意义的问题。
UDP/TCP/IP协议规定:把接收到的第一个字节当作高位字节看待,这就要求发送端发送的第一个字节是高位字节;而在发送端发送数据时,发送的第一个字节是该数值在内存中的起始地址处对应的那个字节,也就是说,该数值在内存中的起始地址处对应的那个字节就是要发送的第一个高位字节(即:高位字节存放在低地址处);由此可见,多字节数值在发送之前,在内存中应该是以大端法存放的。
网络字节序是大端字节序; 比如,我们经过网络发送整型数值0x12345678时,在80X86平台中,它是以小端发存放的,在发送之前需要使用系统提供的字节序转换函数htonl()将其转换成大端法存放的数值。
常见的网络字节转换函数有:
|
|
文章作者 Forz
上次更新 2017-06-25